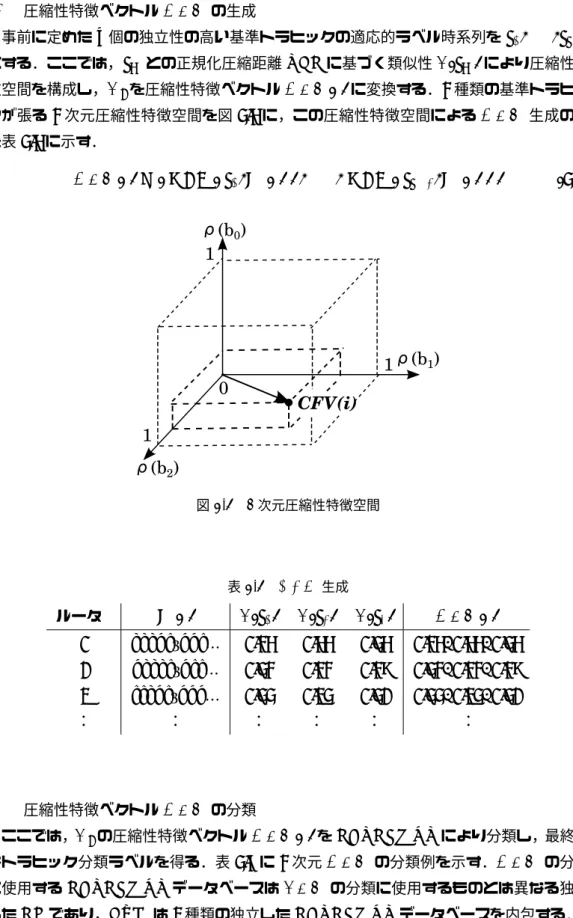
時系列圧縮性による機械化方式に関する研究
大関 潮
電気通信大学 大学院情報システム学研究科 博士(工学)の学位申請論文
2015 年 3 月
時系列圧縮性による機械化方式に関する研究
博士論文審査委員会
主査 古賀 久志 准教授
委員 多田 好克
教授
委員 南 泰浩 教授
委員 森田 啓義 教授
委員 大坐畠 智 教授
委員 渡辺 俊典 名誉教授
大関 潮
2015 年 3 月
Using Time Series Compressibility
Ushio Ozeki
Abstract
In order to grasp network usages, network administrators observe visually the time series graphs of aggregate traffic. They judge the normality or the abnormality of network by comparing observed traffic patterns with the patterns in their empirical domain knowledge, and simultaneously learn new empirical knowledge about traffic patterns. Automatic monitoring methods are also built on their empirical knowledge acquired from this visual monitoring, so that the empirical knowledge about traffic patterns is undoubtedly the fundamental knowledge of network monitoring. Hence, the visual monitoring has been widely performed since the early days of the Internet, and will continue to be significant hereafter.
However, it is very difficult to maintain the empirical knowledge because it is up- dated through daily monitoring tasks. In addition, since the visual monitoring must be conducted manually, the administrators are imposed significant burdens. Nev- ertheless, there is almost no mechanical way to help them to acquire and maintain the empirical knowledge. Existing automatic monitoring methods only detect the anomaly traffic emitted from computer viruses or P2P applications, etc. Therefore, in this research, we aim to solve these difficult problems by the automation of the visual monitoring.
The proposed method automates the visual monitoring as the man-machine-system based on the interactions between the administrators and the system. In the proposed method, a monitoring process repeats the following two steps alternately, which aids to acquire and maintain the empirical knowledge.
1)The system classifies observed traffic patterns, grasps the state of the network by comparing the result to the classifications assumed by the administrators, and notifies the state to them.
2)Driven by the notification, the administrators inspect the causes of the differ- ences between the notification and their assumptions, and let the system learn
In this process, their empirical knowledge is accumulated in the system as the traffic classification examples via their supervisions. As the result, their empirical knowledge can be completely preserved in the system without sinking into oblivion. In addition, the system informs the administrators of unregistered patterns, and prompts them to examine these new patterns. After inspecting the network based on the notification, they acquire new empirical knowledge. Therefore, the proposed method aids them to acquire and maintain the empirical knowledge.
The proposed method has following two adaption abilities which enable to monitor various networks for various purposes.
a)The ability to adapt autonomously to the traffic patterns which widely vary depending upon the observation points and times.
b)The ability to adapt to the traffic classification criterions which varies de- pending on monitoring purposes, supported by the supervision from the ad- ministrators.
In the proposed method, the system represents observed traffic as the label series generated adaptively to the distribution of the data, and transforms it into the com- pressibility feature vectors using the compressibility feature space spanned by the base traffic time series. This process realizes the ability a). Next, the system learns the classification examples instructed by the administrators, and based on these ex- amples, classifies observed traffic represented as the compressibility feature vectors, which realizes the ability b). In this paper, we conduct the monitoring experiments using various traffic data generated by network simulator, and show that the proposed method achieves the research goals.
時系列圧縮性による機械化方式に関する研究
大関 潮
概要
利用者がネットワークをどの様に使用しているのかを知るため,ネットワーク管理者
(以下,管理者と略記)は観測されたトラヒック時系列のグラフを日常的に目視している.
そして,グラフに描かれるトラヒックパターンと過去に経験したパターンを比較する事に より,ネットワークの正常性や異常性を把握するとともに,トラヒックパターンに関する 新たな経験知識も獲得する.目視モニタリングから得られる経験知識は自動モニタリング 手法の設計にも必要であり,まさしくモニタリングの基盤的知識である.それ故に目視モ ニタリングはインターネットの初期から広く利用されており,今後も非常に重要である.
しかし,管理者の経験知識は日々のモニタリング作業で更新されるため,維持管理が非 常に困難である.更に,目視モニタリングの大半は人の作業であるため,管理者の負担は 大きい.それにもかかわらず,モニタリング基盤である経験知識の獲得と維持管理につい て管理者を支援する機械的手段は殆ど存在しない.現状の自動モニタリング手法は,ウイ ルスやP2P等による既知の異常トラヒックの検出手法であり,経験知識の獲得を対象と しない.よって,本研究は目視モニタリングの機械化によりこれらの困難な問題の解決を 目指す.
提案手法は目視モニタリングを管理者とシステムの相互作用に基づくマンマシンシステ ムとして機械化する.特に,1回のモニタリングを次の2ステップで構成し,それらを交 互に繰り返す事により経験知識の獲得と維持管理について管理者を支援する.
1)システムは観測されたトラヒックパターンを分類し,その分類結果を管理者が 想定する分類結果と比較する事によりネットワークの状態を把握し,管理者に通知 する.
2)システムからの通知をきっかけに,管理者は分類結果が想定と一致しないトラ ヒックについてネットワークを調査し,判明した正しい分類結果をシステムに学習 させ,以降の自動状態把握に反映させる.
この過程において,管理者の経験知識は管理者が教示した分類事例としてシステムに蓄積 される.その結果として,管理者の経験知識は忘却の恐れなくシステムに完全に保存され る.また,システムは事例データベースにない新パターンを管理者に通知し調査を促す.
そして,この通知に基づいてネットワークを調査する事で,管理者は新たな経験知識を獲
適応能力を持つ.
a)観測する地点や時点により多様に変化するトラヒックに対し自律的に適応する 能力.
b)モニタリング目的に応じて多様に変化するトラヒック分類基準に対し管理者の 教示により適応する能力.
提案手法では,まず,システムは観測されたトラヒック時系列を観測データの分布に対し て適応的なラベル時系列として表現し,基準トラヒックが張る圧縮性特徴空間によりパラ メータフリーで低次元の圧縮性特徴ベクトルへと変換する.これにより,上のa)を実現 する.次に,システムは管理者から教示されたトラヒック分類事例を基準として学習し,
蓄積された事例に基づいて圧縮性特徴ベクトルとして表現されたトラヒックを分類する.
これにより,上のb)を実現する.シミュレーション生成した多様なトラヒックを用いた 実験により,提案手法が研究目標を達成する事を示す.
第1章 序論 1
1.1 研究の背景と目的 . . . 1
1.2 目的達成へのアプローチ . . . 2
1.3 本論文の構成 . . . 4
第2章 ネットワークモニタリングの現状 5 2.1 トラヒックデータ . . . 5
2.2 管理者の目視モニタリング. . . 7
2.3 自動モニタリング . . . 8
2.3.1 集約トラヒックの変動分析 . . . 9
2.3.2 ホストの振る舞い分析 . . . 14
2.4 モニタリングの課題と解決へのアプローチ . . . 18
2.4.1 自動モニタリング手法と管理者の目視モニタリングの比較 . . . 18
2.4.2 課題と解決へのアプローチ . . . 19
第3章 関連するパターン認識技術 21 3.1 圧縮性によるパターン表現. . . 21
3.1.1 コルモゴロフ複雑性 . . . 21
3.1.2 コルモゴロフ複雑性に基づく文字列間の類似度. . . 22
3.1.3 圧縮性特徴空間 . . . 23
3.2 学習機能付き事例データベース . . . 24
第4章 時系列圧縮性による適応的トラヒックパターン分類方式 26 4.1 適応的トラヒックパターン分類方式 . . . 26
4.2 分類方式の詳細. . . 28
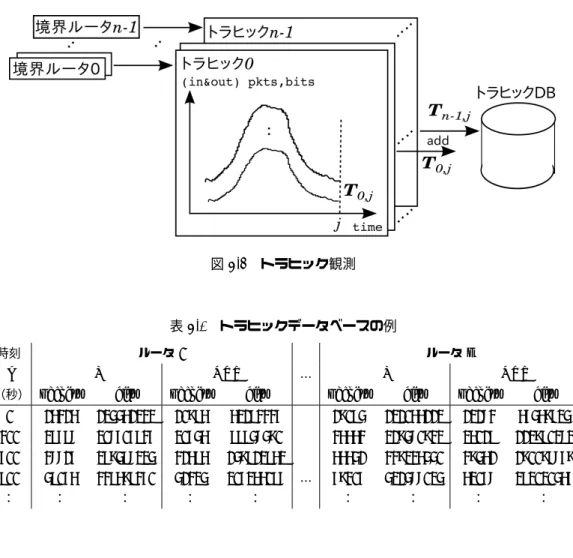
4.2.1 トラヒック観測 . . . 28
4.2.2 トラヒック時系列の適応的ラベル時系列表現 . . . 29
4.2.3 圧縮性による適応的ラベル時系列の分類 . . . 31
4.3 実験. . . 33
4.3.3 実験結果のまとめ . . . 47
4.4 分類方式の結論. . . 48
第5章 時系列圧縮性によるポリシー指向ネットワークモニタリング方式 49 5.1 モニタリングの機械化のための検討 . . . 49
5.1.1 目視モニタリングの分析 . . . 49
5.1.2 技術要件 . . . 53
5.1.3 機械化要件のまとめ . . . 54
5.2 モニタリング方式の概要 . . . 54
5.2.1 提案方式におけるモニタリング手順の概要 . . . 54
5.2.2 技術要件への適合性 . . . 56
5.3 モニタリング方式の詳細 . . . 57
5.3.1 トラヒック観測 . . . 57
5.3.2 ポリシー定義 . . . 58
5.3.3 状態把握 . . . 58
5.3.4 使用イメージ . . . 62
5.4 実験. . . 63
5.4.1 20週間分のトラヒックデータ生成 . . . 63
5.4.2 モニタリング実験 . . . 64
5.4.3 実験結果のまとめ . . . 71
5.5 基準トラヒック選択のガイドライン . . . 72
5.5.1 初期基準 . . . 73
5.5.2 追加基準 . . . 73
5.6 エキスパートシステムとの関連性 . . . 73
5.7 モニタリング方式の結論 . . . 74
第6章 本論文の結論 75 6.1 むすび . . . 75
6.2 今後の課題 . . . 75
参考文献 79
関連論文の印刷公表の方法及び時期 80
謝辞 81
1.1 目視モニタリングをマンマシンシステム化する提案モニタリング手法 . . 3
2.1 ネットワーク環境 . . . 6
2.2 SNMPによるトラヒック観測 . . . 6
2.3 集約トラヒックの時系列グラフ . . . 7
2.4 フラッシュクラウドの例 . . . 8
2.5 主成分分析,フーリエ解析,指数移動平均による2乗予測残差. . . 13
2.6 グラフレット . . . 16
3.1 NCDによる3次元圧縮性特徴空間の例 . . . 24
3.2 DANDELIONによる事例の適応的分類. . . 25
4.1 CTFIのブロックダイアグラム . . . 27
4.2 ネットワーク環境 . . . 27
4.3 トラヒック観測. . . 29
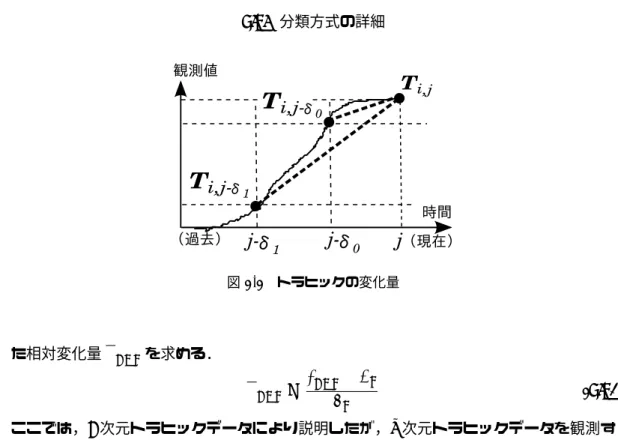
4.4 トラヒックの変化量 . . . 30
4.5 3次元圧縮性特徴空間 . . . 32
4.6 マイクロフローの多重化によるトラヒック表現 . . . 34
4.7 集合住宅向けブロードバンド(RBB: Residentail broad band) . . . 35
4.8 企業(CRP: Corporate user) . . . 35
4.9 サーバファーム(SVF: Server farm) . . . 36
4.10 トラヒック変動パターン . . . 36
4.11 トラヒックフローモデル . . . 38
4.12 類似した3種類のトラヒック変動パターン . . . 39
4.13 bpsトラヒック . . . 40
4.14 ppsトラヒック . . . 40
4.15 パケットサイズ分布(月曜日) . . . 41
4.16 平均パケットサイズ(月曜日) . . . 41
5.1 ネットワーク環境 . . . 50
5.4 組織種別によるポリシーの形成 . . . 51
5.5 組織種別によるポリシーにおける異常検出の例 . . . 51
5.6 異常検出のための学習 . . . 52
5.7 異常パターンの蓄積 . . . 52
5.8 平日と休日の区別を目的とするモニタリング . . . 53
5.9 システム概要 . . . 55
5.10 モニタリング目的に合わせた事例データベースの形成 . . . 56
5.11 ネットワーク環境 . . . 57
5.12 短期特徴ベクトルT F V . . . 59
5.13 適応的ラベル時系列への変換 . . . 59
5.14 CF V の分類 . . . 60
5.15 管理者による正しい分類結果の教示 . . . 61
5.16 管理者とシステムの相互作用に基づくモニタリング. . . 62
5.17 生成トラヒック(Bps) . . . 63
5.18 トラヒックパターンクラスタ . . . 64
5.19 安定状態における正答率 . . . 68
5.20 安定状態におけるトラヒックパターンクラスタ . . . 68
5.21 新旧トラヒックパターン . . . 69
5.22 パターンが変化した場合の正答率 . . . 69
5.23 不適切なポリシーによる正答率 . . . 70
5.24 平日と休日を区別するポリシーにおける正答率 . . . 71
5.25 4次元圧縮性特徴空間による安定パターンのモニタリング . . . 73
4.1 トラヒックデータベースの例 . . . 29
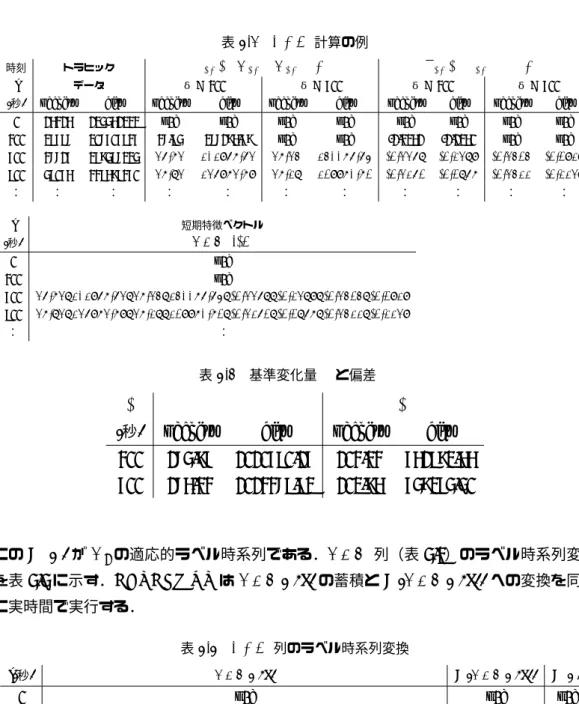
4.2 T F V 計算の例. . . 31
4.3 基準変化量µと偏差σ . . . 31
4.4 T F V 列のラベル時系列変換 . . . 31
4.5 CF V 生成 . . . 32
4.6 CF V の分類 . . . 33
4.7 アプリケーションレイヤの入出力スループット比(RBB,CRPは入力に 対する出力の比率,SVFは出力に対する入力の比率) . . . 37
4.8 入出力スループット比(Smallスケール)(RBB,CRPは入力に対する出 力の比率,SVFは出力に対する入力の比率) . . . 38
4.9 平滑化区間(単位:分) . . . 42
4.10 DANDELIONの類似度減衰率(T F V =tanα, CF V =tanβ)(単位:度) 42 4.11 18系列のSmall scaleトラヒック . . . 43
4.12 分類結果 . . . 43
4.13 正答率 . . . 43
4.14 パラメータ . . . 43
4.15 パターンa(27系列) . . . 44
4.16 パターンb(45系列) . . . 44
4.17 基準トラヒック. . . 45
4.18 トラヒック変化後の正答率(%) . . . 45
4.19 ラベル学習とパラメータ再探索の同時実施 . . . 46
4.20 ラベル学習の単独実施 . . . 46
4.21 パラメータ再探索の単独実施 . . . 47
5.1 ポリシー . . . 58
5.2 トラヒック分類結果(ルータ,所属クラスタ) . . . 60
5.3 状態通知 . . . 61
5.4 手動補正 . . . 61
5.5 事例DBへの登録内容 . . . 61
出力に対する入力の比) . . . 65
5.8 基準トラヒック. . . 66
5.9 平滑化区間(単位:分) . . . 66
5.10 実験パラメータ. . . 66
5.11 最小ラベル数とT F V の類似度減衰率 . . . 67
5.12 CF V の類似度減衰率と平均正答率(%) . . . 67
5.13 平日と休日を区別するポリシーに対するパラメータ. . . 71
序論
1.1 研究の背景と目的
ユーザがネットワークをどの様に利用しているのかを知ることは,ネットワークの設計 や運用管理にとって非常に重要である.例えば,利用のピーク時間帯や異常発生の有無は 設備設計やサービスの品質管理に必要な情報である.そのため,管理者はトラヒック量の 時系列グラフを日常的に目視する事でネットワークを監視している.例えば,単位時間あ たりのトラヒック量や変動パターンが平常時と同一である事から,管理者はネットワーク は概ね正常であると判断する.この管理者の目視モニタリングは,バックボーンから企業 や大学等のインターネットの端点までの広範囲のネットワークにおいて,一般的に実施さ れている基盤的モニタリング手法である.
インターネットの前身である研究ネットワークARPANETの誕生直後からモニタリン グは実施されている[1].モニタリングの最初期には,インターネットの利用者が極めて 限定的である事も相まって,今日的な手法は殆ど用いられていない.しかし,利用者が増 加するにつれ,トラヒックに一定の変動パターンが生じる様になる.そして,すぐにそれ らのパターンを利用した目視モニタリングが実施される様になった.そして,モニタリン グにおける発生イベントと観測されたトラヒックパターンが関連付けられ,管理者の経験 知識として蓄積される様になった.経験知識の蓄積が進むにつれて,ネットワークの状態 把握が可能なトラヒックパターンの経験知識,特に状態把握にとって重要な正常パターン の経験知識の価値が強く認識され,目視モニタリングが定型的モニタリング手法として管 理者の間に浸透した.更に,蓄積された経験知識から数理モデルとして定式化可能なパ ターンが見出され,トラヒックデータの機械処理による自動モニタリング手法が開発され ている.例えば,P.Barfordらは,正常なトラヒックパターンを周波数解析によりモデル 化し,事前に定めた正常モデルからの外れ値を異常として検出する手法を提案している [2].つまり,目視モニタリングから得られる正常なトラヒックパターンに関する経験知識 は自動モニタリング手法の重要な基盤としての役割を果たしている.
しかし,目視モニタリングでは,管理者の経験知識は日々のモニタリング作業で更新さ
れる.そのため,目視モニタリングには,管理者の経験知識の維持管理が非常に困難であ るという問題がある.更に,大半が人の作業であるため,特に多数のトラヒックを内包す る大規模ネットワークの管理者の負担は大きい.そこで,本研究では,目視モニタリング の機械化によりこれらの困難な問題の解決を目指す.
本研究の目的は,トラヒックパターンに関する経験知識の獲得と維持管理の機械化によ る支援である.トラヒックパターンの経験知識はモニタリングの重要基盤であるため,本 研究は自動モニタリング手法を含めたモニタリング全体に貢献できる.
1.2 目的達成へのアプローチ
目視モニタリングは,管理者が経験知識に基づいて想定するトラヒックパターンと観測 されたトラヒックパターンの比較によるネットワークの状態把握行為であり,観測トラ ヒックを多次元変動パターンに基づいて分類する必要がある.また,インターネットトラ ヒックは観測する地点や時点により多様に変化するため,時々刻々と変化するトラヒック に自律的に適応するパターン分類能力が要求される.目視モニタリングは,トラヒック分 類基準がトラヒックデータに含まれないモニタリング目的に応じて変化する複雑なシステ ムである.そのため,この手法を完全に自動化する事は極めて困難であるが,特定のモニ タリング目的のみを対象とした自動化では汎用性に欠ける.そこで,目視モニタリングを マンマシンシステム化する事により,高い汎用性と自動化度を持つ新しい機械化されたモ ニタリング手法を提案する.
従来の自動モニタリング手法には,下記の2タイプがある.
i) トラヒック量の変動パターン分析 ii) 個別ホストの振る舞い分析
i)の例は,正常トラヒックを周波数解析によりモデル化し,そのモデルからの外れ値を異 常として検出する手法である[2].ii)の例は,全パケットを検査し,異常アプリケーショ ンが持つ特徴的なビットパターンを検出する手法である[3].つまり,従来手法の目的は 事前に定めた異常パターンの検出であり,検出基盤であるトラヒックパターンに関する 経験知識の獲得は含まれていない.例えば,i)とii)の従来手法は正常パターンや異常パ ターンに関する経験知識を必要とするが,それらの重要な経験知識は管理者が獲得する事 を期待している.一方で,提案手法の目的は,モニタリングの基盤であるトラヒックパ ターンに関する経験知識の獲得と維持管理であり,従来手法とは目的が大きく異なる.
そのため,提案手法は,管理者が正しい分類結果をシステムに学習させるマンマシンシ ステムとして目視モニタリングを機械化する.具体的には,システムは学習した事例に基 づくトラヒック分類結果と,蓄積された経験知識に基づいて管理者が想定する分類結果を 比較する事で,ネットワークの状態を評価し,管理者に通知する.そして,管理者はその 通知をきっかけにネットワークを調査し,正しい分類結果を経験知識として獲得し,シス
テムに学習させる(図1.1).この手法には次の2つの能力が要求される.
図1.1 目視モニタリングをマンマシンシステム化する提案モニタリング手法
1) トラヒックのモデル化や人の介在を殆ど必要とせずに,複雑に変化するトラヒック パターンを適応的に分類する能力
2) 蓄積されたトラヒックパターンに関する経験知識に基づいてネットワークの状態を 把握する能力
尚,上の要件1)と2)はそれぞれ図1.1の1)と2)に対応している.本研究では,提案モ ニタリング手法を実現するため,まず,要件1)を満たすトラヒックパターン分類手法を 開発し,次に,その分類手法を用いたマンマシンシステム化により要件2)を満たすモニ タリング手法を開発する.要件1)が定める自律適応的なトラヒックパターン分類能力は 次の2ステップで実現する.
a) 観測データ全体の分布に対して適応的なベクトル量子化を教師なしで学習し,観測 トラヒック時系列をラベル時系列として表現する
b) 事前に定めた基準トラヒックとの圧縮性に基づく類似性を特徴量として,観測トラ ヒック時系列を分類する
要件2)が定める蓄積された経験知識に基づく状態把握は,次の2ステップで実現する.
c) 蓄積された経験知識に基づいて管理者が事前に定めた分類結果と,自動分類結果の 比較によりネットワークの状態を把握する
d) 管理者が教示したトラヒックパターン分類事例を学習し,自動トラヒック分類に反 映させる
上述したa),b),c),d)はそれぞれ図1.1のa),b),c),d)に対応している.
1.3 本論文の構成
ここで本論文の構成を述べる.第2章では,モニタリングで使用するトラヒックデータ について説明した後で,従来のモニタリング手法について分析し,モニタリングの課題と 解決へのアプローチを明確にする.管理者の目視モニタリングの詳細もここで説明する.
第3章では,本研究で使用する圧縮性によるパターン表現と学習機能付き事例データベー スについて説明する.まず,コルモゴロフ複雑性に基づいてデータ圧縮とパターン認識の 関連性を述べた後で,多様なデータの取扱いが可能な汎用性の高いフレームワークである 圧縮性特徴空間について説明する.第4章以降で本研究の内容について説明する.第4 章では,提案モニタリング手法で使用する時系列圧縮性による適応的トラヒックパターン 分類手法(図1.1の 1)トラヒック分類 )を説明する.第5章では,4章で述べたトラ ヒック分類手法を用いて目視モニタリングをマンマシンシステム化する提案モニタリング 手法(図1.1)を提案する.尚,4章と5章では,シミュレーション生成した多様なトラ ヒックデータを用いた実験により,トラヒックパターンの変化に対する提案手法の自律適 応的なパターン分類能力とモニタリング能力を示す.第6章では,本研究の成果を総括し た結論と,今後の課題について述べる.
ネットワークモニタリングの現状
グラフ化されたトラヒックデータを管理者が目視によりモニタリングする手法は,企業 や大学等のインターネットの端点から通信事業者等のバックボーンまでの非常に広範囲の ネットワークで実施されている基盤的なネットワークモニタリング手法である.ネット ワークモニタリング手法はこの管理者の目視モニタリングと,トラヒックデータの機械処 理による自動モニタリングに大別される.そこで,本章ではこれらの手法を比較する事 で,現状のモニタリングの問題と解決へのアプローチについて論じる.はじめにトラヒッ クデータについて述べ,その後でモニタリング手法について説明する.
2.1 トラヒックデータ
トラヒックデータには下記の3タイプがある.
(1)パケットキャプチャデータ (2)フローデータ
(3)集約トラヒック
パケットキャプチャデータやフローデータは個別ホストの通信データを含むため,プライ バシー保護の観点からその保管や取扱いには注意が必要である.特に通信の秘密が法律に より定められた通信事業者にはこれらのデータの利用に対する制約が多い.日本国内向け には通信事業者の団体がガイドラインを一般に公開している[4, 5].下記で上の3種類の データについて説明する.
(1) パケットキャプチャデータ
パケットキャプチャデータは通信パケットをそのまま全て記録したデータであり,ペイ ロードを含めた全通信データであるためそのデータ量は非常に大きく,トラヒック観測の コストも高い.tcpdump[6]やWireshark[7]等のツールにより取得される.
(2) フローデータ
通信パケットのヘッダ部分に相当するデータであり,下記の5つ組は使用頻度が高い.
( 送信元アドレス,送信ポート番号,宛先アドレス,宛先ポート番号,プロトコル) パケットキャプチャデータ程ではないが,全パケットが記録対象であるため,やはりデー タ量が大きく,トラヒック観測のコストは高い.Cisco社のNetFlow[8]やInMon社の
sFlow[9]等の通信機器のモニタリング機能や,ntop[10]等のツールによって取得される.
またこのデータはパケットキャプチャデータからも取り出せる.WIDEプロジェクトは バックボーンネットワークで取得したフローデータを匿名化した上で公開している[11].
(3) 集約トラヒック
集約トラヒックは多数のフローが集約されたものであり,境界ルータ(図2.1)のデータ 転送量(パケット数やビット数)として表現される.集約トラヒックは利用者数や利用方 法等のネットワークの状態を反映するため,多くのモニタリング手法において利用されて いる.集約トラヒックの観測にはSNMP(Simple Network Management Protocol)[12]
とMIB(Management Information Base)[13, 14]が一般的に利用されている.SNMPは データの要求と返答のプロトコルを,MIBは観測項目を定義している.SNMPとMIB によるトラヒック観測はSNMPマネージャが対象ルータに対して一定間隔でデータを 要求し,ルータ内のSNMPエージェントがその要求に返答する事により実施される(図 2.2).SNMPとMIBは低コストのトラヒック観測とネットワーク機器の集中管理を実現 しており,非常に多くのネットワーク機器で利用できる.また,このデータはパケット キャプチャデータやフローデータの集計によっても得る事ができる.
図2.1 ネットワーク環境
図2.2 SNMPによるトラヒック観測
2.2 管理者の目視モニタリング
管 理 者 の 目 視 モ ニ タ リ ン グ と は ,集 約 ト ラ ヒ ッ ク の 時 系 列 グ ラ フ( 図 2.3)を MRTG(Multi Router Traffic Grapher)[15]等のツールにより作成し,管理者がそのグラ フをモニタリングする手法である.この手法では,一般的に集約トラヒックとして境界 ルータを通過したパケット数やビット数の時系列グラフが利用される.管理者は時系列グ ラフとして描かれる集約トラヒックをモニタリングし,過去のモニタリングによって蓄積 された経験知識を基準として,現在の集約トラヒックの変動パターンからネットワークの 状態を把握する.
まず,企業や大学等におけるモニタリングを想定し,図2.3が示すトラヒックを用いて 目視モニタリングを説明する.図のパターン(a),(b)はそれぞれ平日と休日に頻繁に観測 されるパターンであり,これらのパターンが観測された時には問題は発生していなかっ た.そのため,管理者は(a)を平日の正常パターン,(b)を利用者が少ない休日の正常パ ターンである事を経験知識として学習し,平日に(a)が,休日に(b)が観測される事を ネットワークの正常性の1つの基準として認識する.この知識の下で既知の正常パターン
(a),(b)と異なるパターン(c)や(d)が観測された場合,管理者は原因を調査し,しばしば
次の様な調査結果を得る.
(c) ある部門の夜間バッチによるサイズが大きなデータのダウンロードが原因であり,
このパターンは異常行為ではなく今後も時折発生する正常パターンである
(d) あるホストが発生する過大トラヒックが原因の異常パターンであり,トラヒックの 遮断が必要
管理者はこれらの事例から新たな正常パターン(c)や異常パターン(d)を発見し,それら を経験知識として蓄積し,後の状態把握に応用する.
図2.3 集約トラヒックの時系列グラフ
次に,より複雑な例を紹介する.異常トラヒックの特性分析[16]から抜粋した米国ウィ スコンシン大学のトラヒックを図2.4に示す.Linuxのダウンロードサーバが設置されて いる”CSキャンパス”のトラヒックが新バージョンLinuxのリリース日から大きく増加し ている.この図の特徴はリリース日を境とした”CSキャンパス”と”その他のキャンパス”
のトラヒックの差の拡大であり,サーバへのアクセス集中によりトラヒックパターンが大 きく変化するフラッシュクラウドの発生を示している.この事例から得られるフラッシュ クラウドによるパターン変化も経験知識として蓄積され,以降の状態把握に応用される.
また,バックボーンネットワークにおけるモニタリング報告[17]においても,まずグラ フの目視によりトラヒック変動パターンや平日と休日の差異等の重要な基礎的特性が導か れ,その知識が後の詳細分析に応用されている.更に,インターネット初期のモニタリン
グ報告[18, 19, 20, 21]において,既に変動パターン分析から同様の知識が獲得されてお
り,この手法がインターネットの誕生初期から利用されている事が分かる.例えば,イン ターネットの前身であるARPANET初期のモニタリング報告[18]では,月曜日のトラ ヒック量が他の日と比べて多いという知識が獲得されている.
図2.4 フラッシュクラウドの例
管理者は上述した様な日々のモニタリングによりトラヒックパターンの経験知識を獲得 してゆく.よって,熟練した管理者は観測されたトラヒックパターンから多様な分析が可 能である.目視モニタリングにおいて,管理者は,
• 集約トラヒックの時系列グラフを目視によりモニタリングし,ネットワークの状態 を把握する
• また,必要があれば調査を実施し,新たな知識を獲得する
という仕事を繰り返している.つまり,この手法は経験知識の獲得と応用からなるネット ワークの状態把握行為であり,末端からバックボーンまでの広範囲のネットワークにおい て,インターネットの誕生初期から実施されている基盤的なモニタリング手法である.
2.3 自動モニタリング
従来の自動モニタリング手法の多くは異常検知手法であり,下記の2タイプがある.
• 集約トラヒックの変動分析
• 個別ホストの振る舞い分析
以下でこれらの手法について説明する.
2.3.1 集約トラヒックの変動分析
集約トラヒックの変動分析による異常検知手法は,ウィルスやDoS/DDoS(Denial of Service/Distributed Denial of Service)攻撃が形成するトラヒックスパイクを異常な短 期急変動として検出する.このタイプには,主に下記の2種類の手法がある.
(1) 信号処理による手法 (2) 機械学習による手法
以下でこれらの手法について説明する.
(1) 信号処理による手法
この手法は信号処理分野における時系列解析や周波数解析の応用により,過去の観測 データから正常トラヒックのモデルを作成し,そのモデルから乖離したトラヒックを異常 として検出する手法である.時系列解析と周波数解析の応用について下記で説明する.
(i) 時系列解析の応用
ここでは,集約トラヒック分析の初期におけるロバストなノンパラメトリックモデルに よる手法から始め,近年のパラメトリックモデルによる手法を説明する.前者は1次元モ デルのみであり,後者には1次元モデルと多次元モデルがある.
(a)ノンパラメトリックモデルによる手法
(a.1)観測データから適応的にモデルを構成する手法.集約トラヒックの変動分析の初
期の研究において,Maxionは観測された正常トラヒックから適応的にモデルデータを作 成し,そのモデルからの外れ値として異常を検出する手法を提案している[22].モデル データは過去の観測データから平滑化によりノイズを除去した時系列データと各時点にお ける許容変動域から構成され,平滑化された最新の観測データとの指数移動平均に基づい て逐次更新される.観測データの平滑化は,分析対象のパラメトリックなモデルを必要と しない探索的データ分析(EDA:Exploratory Data Analysis)の一部の技法や,メディア ンフィルタ,最小二乗直線による区間近似等により実施される.そして許容変動域も過去 の変動幅に対して同様の平滑化を適用して作成される.この研究では2週間分の観測デー タからモデルデータが作成され,ネットワークバックアップによる高トラヒックが異常と して検出されている.その後,このバックアップは異常行為ではない事が判明し,更に継 続的に発生したため,正常性の基準であるモデルデータにその高トラヒックが反映され,
異常検出数が大きく減少する事が示されている.
(b)パラメトリックモデルによる手法 (b.1)1次元モデル
下記の手法は集約トラヒックをデータ転送量の1次元時系列として取り扱う.
(b.1.1)Holt-Winters法によるモデル化手法.BrutlagはHolt-Winters法により正 常トラヒックをモデル化し,そのモデルからの外れ値として異常を検出する手法を提案 している[23].Holt-Winters法は時系列データを相互に関係する3つの成分(定常成分,
直線成分,周期成分)に分解してモデル化する時系列解析手法であり,各成分はその関連 成分を含む指数移動平均により定められる.これらの定常成分,直線成分,周期成分はそ れぞれ,時系列データにおける短時間の変動パターン,長期的な増加減少の傾向,周期的 変動パターンを表現する.これらの3つの成分の例として,1時間程度,35時間程度,24 時間程度の期間が取り上げられている.信頼区間は最新の誤差と過去の予測誤差の指数移 動平均から逐次定められる.この研究では単一の集約トラヒックを10日間程度モニタリ ングし,通常とは異なる変動パターンが異常として検出されている.
(b.1.2)回帰分析によるモデル化手法.Krishnamurthyらは,回帰分析により正常ト ラヒックをモデル化し,そのモデルからの外れ値として異常を検出する手法を提案して いる[24].通常の集約トラヒックは境界ルータ毎にデータ転送量を集計して作成される が,この手法では,宛先IPアドレスのハッシュにより膨大なフローデータを少数の集約 トラヒックに集約してモニタリングしている.このハッシュを応用した集約により,バッ クボーンの様な大規模な上流ネットワークにおいて,多数の下流ネットワークを効率的 にモニタリングできる.この研究では,5 種類の回帰モデル(単純移動平均,重み付き 移動平均,指数移動平均,周期成分を考慮しないHolt-Winters法,自己回帰和分移動平 均(ARIMA:AutoRegressive Integrated Moving Average))を適用した結果が比較され,
ハッシュによる集約トラヒックは厳密なフローデータと同等の検出精度を達成している.
回帰モデルのパラメータ決定には残差平方和が小さい値を求めるMulti-pass Grid Search という単純なヒューリティクスが利用されている.
この手法ではハッシュ値の衝突率と分布の一様性が理論的に保障されるユニバーサル ハッシュ[25]が利用されている.ユニバーサルハッシュでは,衝突率の条件を満たすハッ シュ関数の集合を事前に定め,その中から関数をランダムに選択してハッシュ値を計算す る.この研究では,4つのキー(宛先IPアドレス)に対するハッシュ値の衝突率とその 分布の一様性が条件として定められた4-universalハッシュが利用されている.
(b.2)多次元モデル
下記の手法は集約トラヒックを複数の観測項目に基づく多次元時系列として取り扱う.
(b.2.1)局所変化量によるモデル化手法.Cabreraらは,全観測項目の局所的な変化量 が一定の閾値を越えないトラヒックとして正常トラヒックをモデル化し,DDoS攻撃の前 兆を検出する手法を提案している[26].事前に正常トラヒックから定めた閾値との単純な 比較により攻撃の前兆を検出するため,攻撃データにグレンジャー因果性テストを適用 し,攻撃の先行指標となる複数の観測項目を事前に選定している.そして,それらの観測 項目の局所的な変化量と閾値の比較により,DDoS攻撃の前兆が高率で検出されている.
グレンジャー因果性テストは時系列xk(先行指標の候補)が,別の時系列ykの予測に 寄与するか否かを統計的に検定する手法である.この研究では,ykは攻撃の結果として急
変動が発生する観測項目の時系列であり,被攻撃側で観測される.xkはykの急変動の前 に異変が発生する時系列であり,攻撃側で観測される.グレンジャー因果性テストはこの xkを明らかにするために実施される.グレンジャー因果性テストは次の様に実施される.
まず,前兆と攻撃間の遅延をpとし,ykの回帰式の残差をxkの回帰式として表現する.
yk+1=
∑p
i=1
αiyk−i+1+r0,k, r0,k=
∑p
i=1
βixk−i+1+r1,k
この研究では,yk にはARモデルが,r0,kにはMAモデルが適用されている.ここで,
xkがykの予測に寄与しないときは,βi= 0であるため,”r0,k =r1,k”という帰無仮説が 成立する.よって,この仮説を検定する.ここで,残差r0,k, r1,k を用いてF分布に従う 統計量f を定める.そして,観測データのf を事前に定めた棄却値と比較し,帰無仮説を 検定する.つまり,f が棄却値より大きければxkはykの先行指標であると結論できる.
f が大きいほど予測に寄与する可能性が高いため,観測項目の重要性も評価できる.
(b.2.2)多次元的な局所変動パターンによりモデル化する手法.Thottanらは,異常な 局所変動パターンを含まないトラヒックとして正常トラヒックをモデル化し,そのモデル からの外れ値として異常を検出する手法を提案している[27].彼らは,異常時に観測され る各変数の局所変動は相互に関連しており,それらの異常な局所変動は共通の重ね合わせ パターンを持つ事を見出した.この重ね合わせパターンとは,各変数の局所変動が多数の 変数の局所変動の線形結合として表現される事を意味する.例えば,変数iの局所変動の 大きさはψi = ai,0ψ0+ai,1ψ1+· · ·+ai,n−1ψn−1と表現される.そして,全ての係数 ai,j から重ね合わせの表現行列Aが定められる.このAの固有ベクトルは共通の重ね合 わせパターンを持つ種々の異常を生成する局所変動パターンであるとみなせる.よって,
事前に定めたAの固有ベクトルを含む観測トラヒックの局所変動を異常として検出する.
Aは固有値λが0≤λ≤1を満たす対称行列として構成される.そのため,観測され た局所変動ψが特定の固有ベクトルを含む場合,f(ψ) =<ψ,Aψ>はその固有ベクトル に対応する固有値よりも大きくなる.そこで,下限となる固有値λmin を事前に選択し,
f(ψ) > λmin となるψ を異常として検出する.局所変動ψは事前に定めたARモデル を観測トラヒックに適用する事により計測される[28].この手法により,特徴空間におい て異なるクラスタを形成するファイルサーバ障害やアクセス障害等の複数の異なる異常が 統合的に検出されている.
(ii) 周波数解析の応用
集約トラヒックは時間により周波数の分布が変化する非定常信号であるため,モデル化 には入力信号を時間領域の情報を保持した周波数成分に分割できるウェーブレット解析が 主に利用されている.P.Barfordらは,ウェーブレット解析により抽出した周波数成分の 局所的な分散値が一定の閾値を越えないトラヒックとして正常トラヒックをモデル化し,
そのモデルからの外れ値を異常として検出する手法を提案している[2].まず,抽出した 多数の周波数成分を用いて,観測トラヒックの低域,中域,高域の3つの周波数成分を合
成する.そして,それらの局所的な分散の重み付き合計が事前に定めた閾値を越えるトラ ヒックを異常として検出する.この研究では,継続時間が短いDoS攻撃が中域と高域の 周波数成分から高精度で検出されている.また,継続時間が長いフラッシュクラウドの様 な異常も低域の周波数成分から検出可能である.
(2) 機械学習による手法
この手法は,集約トラヒックをその特徴に基づいて分類する手法であり,機械的基準に 基づく教師なし学習と,管理者が分類基準を教示する教師あり学習の2種類の手法があ る.また,この手法では,集約トラヒックは複数の観測項目に基づく多次元データとして 取り扱われる.以下でそれぞれについて説明する.
(i) 教師なし学習
A.Lakhinaらは,主成分分析(PCA:Pricipal Component Analysis)により,観測トラ ヒックを主成分だけで近似できる正常パターンと,近似誤差が閾値を越える異常パターン に分類する手法を提案している[29].この研究では,事前の予備実験により,第1から第 4までの主成分は偏差が大きい異常な局所変動を含まない事が確認されている.そこで,
基底をそれら4つの主成分に変換する主軸変換により,観測データyから,主成分による 近似データyˆとその残差y˜を得る.
y=yˆ+y˜
そして,近似の2乗予測誤差(SPE: Squared Prediction Error)∥y˜∥2が事前に定めた閾値 を越えるトラヒックを異常パターンとして検出する.この閾値として,Jacksonらが主成 分分析による外れ値検出のための境界として提案しているQ-統計量[30]が利用されてい る.この手法により,バックボーンネットワークで観測された多数の独立組織のトラヒッ クを含む集約トラヒックから,それらの個別組織で発生した大きな局所変動がオンライン かつ高精度で検出されている.また,この手法は観測データから主成分(共通の特徴)を 除いた残差のみを分析するため,正常トラヒックの知識を要求しない.
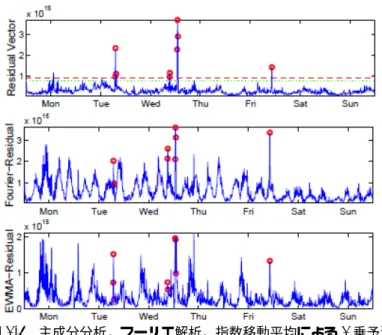
ここで,主成分分析,フーリエ解析,指数移動平均による近似の2乗予測誤差を文献 [29]から抜粋する(図2.5).図の丸印は検出対象の異常を表す.図の最上段にある主成分 分析の場合,その2乗予測誤差は周期変動成分を殆ど含まず,正常値は一定の閾値(図の 点線)を越えない値として異常値から明確に区別できる.しかし,図の中段及び下段の フーリエ解析と指数移動平均の場合,それらの2乗予測誤差の周期変動は大きく,正常値 と異常値が共に小さな値から大きな値までの広範囲に分布しているため,それらを明確に 区別できる一定の閾値が存在しない.以上から,主成分分析による近似は,フーリエ解析 や指数移動平均による近似よりも,閾値による異常検出に適している.
(ii) 教師あり学習
(a)サポートベクトルマシンによる手法
図2.5 主成分分析,フーリエ解析,指数移動平均による2乗予測残差
Yuらは,サポートベクトルマシン(SVM:Support Vector Machine)により,観測トラ ヒックを局所変化量に基づいて正常パターンと多数の異常パターンに分類する手法を提案 している[31].サポートベクトルマシンは,2種類の入力データを分割する最適境界を人 の教示に基づいて形成する教師あり学習アルゴリズムである.この手法は,多数のSVM の組み合わせにより多クラス分類を実現しており,単一SVMにより異常を検出する第1 段階と,第1段階で検出された異常の種別を多数のSVMにより判別する第 2段階から 構成される.尚,利用するSVMには事前に正常パターンと異常パターンを学習させてお く.第1段階では,単一SVMにより,観測トラヒックを正常パターンと異常パターンの 2クラスに分類し,異常トラヒックを検出する.第2段階では,入力パターンを特定種別 とそれ以外の2クラスに分類する多数のSVMにより,第1段階で検出した異常パターン の種別を判別する.具体的には,各SVMは識別対象パターンと入力パターンの適合度を 分離境界からの距離として評価し,それらの評価結果に基づいて判別関数により最適な種 別を決定する.また,正常パターンと学習済みの異常パターンのどちらにも所属しないト ラヒックは未知の異常として識別される.この手法により,TCP-SYN flooding等の複 数の異なる攻撃がその種別と共に高精度で検出されている.
(b)ニューラルネットワークによる手法
Manikopoulosらは,ニューラルネットワーク(Neural Network)により,観測トラヒッ クを局所変化量の分布に基づいて正常パターンと異常パターンに分類する手法を提案して いる[32].ニューラルネットは,人の教示に基づいて非線形写像を形成する教師あり学習 アルゴリズムであり,層状に連結された多数のニューロンのネットワークから構成され る.この手法は,観測トラヒックと正常トラヒックの統計的比較に基づいてネットワーク
の特徴ベクトルを求める第1段階と,ニューラルネットにより特徴ベクトルを分類する第 2段階から構成される.第1段階では,まず,観測トラヒックと正常トラヒックの局所変 化量の確率分布をコルモゴロフ・スミルノフ統計量(Kolmogorov-Smirnov Statistic)に 基づいて比較し,それらの類似度を求める.そして,全ての観測項目に対する類似度か らネットワークの特徴ベクトルを構成する.尚,正常トラヒックの確率分布は事前に定 めておく.第2段階では,観測トラヒックの特徴ベクトルをバックプロパゲーション型
(BP:Back Propagation)のニューラルネットに入力し,観測トラヒックと正常トラヒッ
クの類似度を評価する.正常トラヒックに近いトラヒックが正常パターンに,その他は異 常パターンに分類される.このとき,ニューラルネットには事前に正常トラヒックの特徴 ベクトルを学習させておく.上述した様に,ニューラルネットを特徴ベクトルの分類に特 化させる事で,計算量や学習データ量を削減できる.この手法により,UDP-flooding等 のDoS攻撃がオンラインで高精度に検出されている.また,この手法はモバイル機器か ら構成される変化に富んだワイヤレス・アドホックネットワークにも適用可能である.
(c)ベイジアンネットワークによる手法
C.S.Hoodらは,ベイジアンネットワーク(Bayesian Network)により,観測トラヒッ クを事前に定めた条件付き確率分布を用いて正常パターンと異常パターンに分類する手法 を提案している[33].ベイジアンネットワークは,事象間の因果関係を非循環有向グラフ (DAG:Directed Acyclic Graph)として,その因果関係の強さを条件付き確率として定め る推論アルゴリズムである.この手法は,ARモデルのパラメータから観測トラヒックの 特徴量を求める第1段階と,観測トラヒックが異常トラヒックである確率をベイジアン ネットワークにより求める第2段階から構成される.第1段階では,観測トラヒック時系 列にARモデルを適用し,そのパラメータを用いて観測トラヒックの特徴量f を定める.
第2段階では,事前に定めた正常トラヒックの特徴量の確率分布に対してベイズの定理を 適用し,観測トラヒックの異常性を特徴量f を条件とする確率として評価する.
P r(N etwork=abnormal|F eature=f)
そして,この条件付き確率が0.5を超える観測トラヒックを異常パターン,その他を正常 パターンに分類する.この手法により,ファイルサーバの障害が事前に検出されている.
2.3.2 ホストの振る舞い分析
ホストの振る舞い分析による異常検知手法は,フローデータやパケットキャプチャデー タの分析により,主に不正アクセスやP2Pアプリケーションを異常として検出する手法 である.このタイプには,主に下記の2種類の手法がある.
(1) パターンマッチによる手法 (2) 機械学習による手法
以下でこれらの手法について説明する.
(1) パターンマッチによる手法
このタイプの手法は,ホストの振る舞いの特徴を接続パターンやパケットの文字列パ ターンにより表現し,事前に定めたサンプルデータとのパターンマッチにより異常アプリ ケーションを検出する手法である.
(i) ホスト間の接続パターンによる手法 (a)接続パターンの確率分布による手法.
L.T.Herberleinらは,ホストの振る舞い分析の初期において,ホストベース侵入検知を
ネットワークに拡張した手法を提案している[34].この手法は,ホスト間の接続パターン を4つ組(送信ホスト,受信ホスト,利用サービス,接続ID)により表現し,正常トラ ヒックにおける発生確率が低い観測トラヒックの4つ組を異常アプリケーションとして検 出する.事前に正常トラヒックにおける四つ組のデータ転送量の確率分布を定めておき,
その分布に基づいて観測された四つ組のデータ転送量の発生確率を求め,その値が小さい 4つ組を異常として検出する.この4つ組のデータは詳細な情報をもたらすが,データ量 が多いため分析に必要な計算量が多い.そのため,集約により総量が削減されたデータを 併用し,計算量を削減する.具体的には,単一項目(送信ホスト),2つ組(送信ホスト,
受信ホスト),3つ組(送信ホスト,受信ホスト,利用サービス),4つ組の4種類のデータ を用いて階層的に異常を検出する.まず,最も集約された単一項目のデータが分析され,
異常が検出された場合にのみ,より詳細なデータが利用される.この手法により,ネット ワークゲームやユーザ情報探索プログラム等の異常アプリケーションがオンラインで検出 されている.
(b)接続パターンのグラフ表現による手法.
T.Karagiannisらは,ホスト間の接続パターンをグラフにより表現し,事前に定めたパ
ターンとの比較により異常アプリケーションを識別する手法を提案している[35].この手 法は,主に四つ組(送信ホスト,受信ホスト,送信ポート,受信ポート)を集約したグ ラフをシグネチャとして利用し,トラヒック発生源のアプリケーションを識別する(図 2.6,[35]より抜粋).この図の(a)から(l)までのグラフはグラフレットと呼ばれ,各グラ フレットは対応するアプリケーションの送信ポートや受信ポートの使用法を表している.
(a)から(j)までのグラフレットはそれぞれ四つ組を,(k)と(l)のグラフレットはプロト コルを加えた五つ組を使用している.アプリケーションの識別にはグラフレット以外の情 報も利用される.その情報とは,二つ組(送信ホスト,受信ホスト)を受信ホストと人気 度(通信相手先数)によりグループ化したコミュニティや,送信ポート数の分布,管理者 のヒューリティクスである.例えば,同一コミュニティにおける特定受信ホストがサーバ であれば,その近隣ホストもサーバであると推定でき,更に使用した送信ポート数が1又 は2の場合にはそのホストはWebサーバである可能性が高い.この手法では,コミュニ ティ(ソーシャルレベル),使用された送信ポート数の分布(ファンクショナルレベル),
グラフレット(アプリケーションレベル)の順に観測トラヒックが分析され,各レベルの 分析にはそれ以前のレベルで得られた情報が応用される.そして最後に,アプリケーショ ン毎の受信ポート数やパケットサイズの分布等のヒューリティクスが適用され,トラヒッ ク発生源のアプリケーションが識別される.この手法により,P2Pやウイルス等の異常 アプリケーションが高精度で検出されている.
図2.6 グラフレット
(ii) パケットの文字列パターンによる手法
M.Roeschは,ホストの振る舞いの特徴をペイロードを含むパケットの文字列パターン
により表現し,事前に定めたパターンを含む異常パケットを検出する手法を提案している [3].この手法は,文字列データをパケットから抽出するパケットデコーダ,抽出された文 字列データを事前に定めたパターンと比較する検出エンジン,検出結果の記録や警報発信 を行うロギング/警報システムの3種類のサブシステムから構成される.このシステム 構成は多様なネットワークにおけるパケットモニタリングに必要な高速性や柔軟性,保守 を容易にする簡潔性を実現している.パケットデコーダはイーサネットのみならずSLIP やPPPを含む種々のリンク層における多様なTCP/IPパケットからの効率的なデータ 抽出が可能である.また,検出エンジンは多数のパケットデータに対して,送受信ホスト のIPアドレスや使用ポート番号のみならず,ペイロードの文字列パターンを含めた柔軟 なパターン定義に基づくパターンマッチを実現している.例えば,文字列”/cgi-bin/phf”
をペイロードに含む,CGIサービスを探査する異常パケットの検出が可能である.
(2) 機械学習による手法
このタイプの手法は,フローデータを特徴に基づいて分類する事により,異常アプリ ケーションを検出する手法であり,教師なし学習による手法と,教師あり学習による手法 がある.それぞれについて下記で述べる.
(i) 教師なし学習
(a)K-MeansとDBSCANによる手法
J.Ermanらは,フローデータを教師なしで分類する異常アプリケーションの検出手法
において,K-MeansとDBSCANの結果を比較している[36].この手法はフローの特徴 を合計パケット数,平均パケットサイズ,平均ペイロードサイズ,合計バイト数,パケッ トの平均到着間隔の5つ組で表現する.そして,この特徴量に基づいて全てのフローを クラスタリングし,各クラスタのアプリケーションを識別する事で異常アプリケーション を検出する.この研究では,ポート番号やパケットペイロードにより,事前にトラヒック 発生源のアプリケーションが識別された8千から1万6千件程度のサンプルフローデー タをクラスタリングしている.DBSCANによりノイズとして除外される外れ値は全て 誤りとして判別される.そのため,平均検出精度はこのノイズを含めた場合はK-Means が有利であるが,除外した場合はDBSCANが有利である.計算時間はK-Meansが約1
分,DBSCANが約3分と高速であった.また,確率モデルに基づくAutoClassによる
クラスタリング結果も評価されている.AutoClassはノイズを含めた場合はK-Meansや
DBSCANよりも10%から20%ほど精度が高く,クラスタ数が自動で決定される利点を
持つが,計算時間は大幅に長く,約4.5時間を要した.
(b)MSTによる手法
G.Dewaele らは,ホストの振る舞いの特徴をホストの接続パターンにより表現し,
MST(Minimum Spanning Tree)により教師なしで分類する事により,異常アプリケー
ションを検出する手法を提案している[37].この手法は,送信ホストの接続パターンを,
受信ホスト数や使用ポート数,受信ホストのIPアドレスの分布,平均送信パケット数や パケットサイズ分布等による9次元特徴量として表現する.そして,ホストをこの特徴 量に基づいてMSTでクラスラリングした後,各クラスタのアプリケーションをポート番 号や他の検出ツール,ヒューリティクスにより判別し,異常アプリケーションを実行した ホストを検出する.この手法により,使用ポート番号を多様に変化させる検出が困難なタ イプのP2Pアプリケーションが,使用ポート数が非常に多いホストのクラスタとして検 出されている.この研究で使用しているデータは,1日あたり15分のサンプリングデー タであり,サイズは平均約400MB,30万から60万個のIPアドレスと,50万から100 万件のフローを含んでいる.このデータを分析する場合,特徴量の計算に1日あたり2,3 分,MSTによるクラスタリングにも同程度の時間を要する.生成されたクラスタとMST による追加トラヒックの分類は実時間で実行可能である.
(ii) 教師あり学習
H.Kim らは,フローデータを教師あり学習機械で分類する異常アプリケーション
の 検 出 手 法 に お い て ,SVM(Support Vector Machine), Neural Network, k-Nearest
Neighbors(k-NN)等の多くのアルゴリズムの結果を比較している [38].この研究では,
特徴選択手法CFS(Colleration-based Filter)を使用し,相関性に基づいてフローデータ から選択したプロトコル,ポート番号,TCPフラグ,パケットサイズ等のデータ項目に より特徴ベクトルを構成している.SVMが95%程度と最も良好な検出精度であり,次 にNeural Network,3番目がk-Nearest Neighborsであった.しかし,Neural Network は学習データが一定以上に増加すると計算時間が非常に長くなり,計測が不可能になっ た.k-Nearest Neighborsは学習データが少ない場合にはSVMよりも高速であるが,学 習データの増加に対する計算時間の増加が急激であり,1万件以上の学習データを用いた 場合,結局はSVMよりも低速になった.よって,この研究では,SVMがフローデータ の分類に最も適した教師あり学習機械であった.
2.4 モニタリングの課題と解決へのアプローチ
ここでは,従来のモニタリング手法の課題を明らかにし,解決へのアプローチを示す.
そのために,まず,自動モニタリング手法と管理者の目視モニタリングを比較し,次に,
それらの従来手法の課題と解決へのアプローチを示す.
2.4.1 自動モニタリング手法と管理者の目視モニタリングの比較
ここでは、従来の自動モニタリング手法と管理者の目視モニタリングを比較する.下記 で,集約トラヒックの変動分析とホストの振る舞い分析それぞれについて述べる.
(1) 集約トラヒックの変動分析
集約トラヒックの変動を分析する従来手法を管理者の目視モニタリングと比較する.こ のタイプの従来手法は管理者が正常トラヒックに関する十分な経験知識を持つ事を前提 とする.例えば,時間周波数解析[2],時系列解析[23, 24, 26, 27]や教師あり機械学習
[31, 32, 33]による手法は正常トラヒックのモデルから外れた観測データを異常として検
出する.よって,これらの手法には,正常トラヒックについての経験知識やそれに基づく 想定が必要である.
観測データから適応的にモデルを構成する手法[22]では,システムは全てのトラヒック を単一の正常モデルに自動的に集約する.しかし,複数の正常なトラヒックパターンがあ る場合,システムは自動的にそれらを単一モデルに集約してしまうため,正常パターンを 正しく識別できなくなる.よって,その様な場合,管理者は意図的にシステムに複数のモ デルを構築させる必要がある.例えば,この研究においても,管理者はパターンが異なる
平日と休日の正常トラヒックに対して独立したモデルを構築させる必要がある.つまり,
この手法を適切に利用するためには,やはり管理者には正常トラヒックについての経験知 識が要求される.また,教師なし機械学習(主成分分析)[29]による手法では,トラヒッ クの主成分が正常である事が前提であり,観測データから主成分を除いた非主成分から局 所的な異常変動を検出する.従って,この手法を適切に利用するためには,トラヒックの 主成分が正常である事を確かめる必要があり,やはり管理者には正常トラヒックについて の経験知識が要求される.
これらの手法に対し,目視モニタリングは上述した手法が前提とするトラヒックの正常 性に関する知識を含むトラヒックパターンに関する経験知識の獲得と維持管理を担ってい る.よって,このタイプの従来手法に対して,管理者の目視モニタリングは非常に重要な 基盤的役割を果たしている.
(2) ホストの振る舞い分析
個別ホストの振る舞いの分析手法について考察する.このタイプの手法は不正アクセス やP2P等の異常アプリケーションを検出する.しかし,それらのアプリケーションが発 生させた異常トラヒックを評価するためには,やはり正常なトラヒックパターンの経験知 識が必要である.例えば,P2P アプリケーションが異常として検出された場合,観測さ れた集約トラヒックが正常パターンから大きく乖離している場合とそうでない場合とでは P2Pが集約トラヒックに与えた影響の重大性は異なる.更に,観測された集約トラヒック が正常パターンとは大きく異なる事が経験知識から検出できれば,そのP2Pアプリケー ションの活動時間帯も判別できる.よって,このタイプの従来手法においてもトラヒック パターンの経験知識は必要であり,管理者の目視モニタリングは重要な基盤的役割を果た している.
2.4.2 課題と解決へのアプローチ
ここでは、自動モニタリング手法と管理者の目視モニタリングの比較に基づき,これら の従来手法の課題を提起し,解決へのアプローチを示す.従来の自動モニタリング手法は トラヒックパターンに関する経験知識を前提としてモデル化された限定的な異常トラヒッ クの検出手法であるが,当然ながら,ある手法の前提知識をその手法自身により獲得する 事は非常に困難である.つまり,従来のモニタリング手法では,モニタリングの重要基盤 であるトラヒックパターンの経験知識の獲得と維持管理を実施する事が非常に困難であ り,それらを管理者が実施する事を期待している.しかし,目視モニタリングから得られ る経験知識は主に管理者個人の知識として蓄積され,日々のモニタリング作業で更新され る.そのため,経験知識の維持管理が非常に困難である.例えば,管理者個人に蓄積され た経験知識は忘却による消失が避けられず,他の管理者との共有も困難である.また,目 視モニタリングは頻繁に実施されるがグラフ作成を除くほぼ全ての作業が人手に依るた