1.は じ め に
1・1 CNN(Convolutional Neural Network)
深層ニューラルネットワーク(DNN:Deep Neural Network)とはニューロンモデルを多層に接続したネッ トワークである.深層畳込みニューラルネットワーク (CNN:Convolutional Neural Network)とは二次元畳 込み層と DNN,ならびにプーリング層など多層に組み 合わせたニューラルネットワークの一種であり,特に画 像認識タスクにおいて優れた性能を発揮している. CNNのルーツは福島が提案したネオコグニトロンに 遡る [Fukushima 82].CNN のベースは LeCun らが 提案した LeNet-5 [Lecun 98] であり,畳込み層,プー リング層,フル結合層で構成されている.LeNet-5 は 5層で構成されており,手書き文字認識を実現した.
AlexNet [Krizhevsky 12]は ILSVRC’12 における画像 認識タスクコンペティションで他の特徴抽出法を引き離 して 1 位となり,今日のディープラーニング研究を活性 化した CNN である.AlexNet では 8 層の構造をもち, 2種類の CNN で構成され,学習に GPU を使い,学習 データとして ImageNet を使った点が特徴である.また 学習データの水増し(Augmentation)を使って認識精 度を上げている点も注目すべき技術である.GoogleNet [Szegedy 15]は ILSVRC’14 で優勝した Google 社が開 発した CNN である.22 層で構成され,特徴量を圧縮し つつ学習を行えるためにフル結合層を使わず Inception 演算を用いた点が特徴的である.現時点では Inception 演算のさまざまなバージョンが提案されており,層数も 100層を超えている.同年,VGG-16 [Simonyan 14] も 提案され,コンペティションで準優勝している.CNN の層数を増やすと認識精度が上がることが知られており [Donahue 14],VGG-16 では各畳込み層のカーネルサイ ズを小さく均一にして層数を増やしているのが特徴であ る.GoogleNet と比べて認識率の差はわずか 0.6 ポイン ト差であり,カーネルサイズが均一であり単純な畳込み 演算が繰り返される構造をもつため,ハードウェア化し やすい利点がある.ResNet [He 16] は層間の残差を学 習することで勾配消失問題を解決し,提案時は 152 層 で構成していた.また,彼らは学習を短期間で収束させ るためにバッチ正規化を用いたことも特筆すべき点であ る.ResNet をさらに発展させた DenseNet [Huang 16] は,ある畳込み層の出力をすべての後段の層に入力す る CNN である.現在は ResNet や DenseNet の改良版 が多数提案されている状況である.CNN は手書き文字 認識 [Lecun 98],顔認識 [Sankaradas 09],シーン判定 [Peemen 13],物体認識 [Farabet 10] などで広く用いら れており,今現在もさまざまな分野で基礎・応用研究が 進んでいる. 本稿では,CNN の学習はすでに行われているものと 仮定し,組込みシステムでディープラーニングの推論を 実現する方法を紹介する. 1・2 CNN の推論に求められる性能 推論時のインフラや計算デバイスに求められる性能 は,学習時とは大きく異なる.特に,組込みシステムで は,ネットワーク上のデータのトラフィック,処理の時 間的遅れ(レイテンシ),使用可能なメモリ量,消費電 力などに対する制約が要請される.例えば,Googleのデー タセンターにおける検索時間の要求は 7 ms,30 FPS の 動画処理では 33.3 ms である.その場合,推論のために データをクラウドなどへアップロードすることは時間的 遅延が大きくなってしまうため,エッジ,あるいはフォ グでの計算処理が必要となる.また,データ送受信の通 信コスト,信頼性の観点からもエッジにおける処理が望 ましい.データトラフィックの観点からは,推論のため に世の中に流通する全データをクラウドなどで集中管理 することは,非現実的であり,エッジ,あるいはフォグ でのコンピューティングが重要となると考えられる. したがって,組込みシステムでは消費電力の大きい
FPGA を用いたエッジ向け
ディープラーニングの研究開発動向
A Trand of the Deep Learning Research and Development for an FPGA
中原 啓貴
東京工業大学Hiroki Nakahara Tokyo Institute of Technology, Japan.
[email protected], http://www.hirokinakaharaoboe.net/
Keywords:
FPGA, deep learning, edge computing, binarized CNN. 「AI 計算資源」GPUではなく,搭載する計算ロジックを書き換えるこ とができる FPGA や専用チップのニーズが高まると考 えられる.Intel 社は,FPGA を主力製品とする Altera 社を買収し,CPU と FPGA を同一パッケージや同一 ダイに統合した製品の開発を行っており,Xilinx 社は 画像処理に特化した開発環境 reVISION を発表してい る.これらは FPGA で推論に特化した回路を想定して おり,学習までは対応していない.同様なツールはサー ドパーティーからも発表・リリース予定であり,例えば
TERADEEP社,DeePhi 社はすでに FPGA を採用した
推論アクセラレータをリリースしている. 本稿では,組込みシステムに適し,アルゴリズムの進 展に対応できるリコンフィギャラブルなデバイスである FPGAを紹介し,組込み向け GPU と比較して高性能か つ電力効率に優れたディープラーニングの推論を実現す る方法を述べる.
2.CNN の FPGA 実現
2・1 CNN ハードウェアの研究開発動向 [Nurvitadhi 16]では,ディープラーニングの推論デ バイスとして CPU,GPU,FPGA,ASIC をあげ,それ らの比較を行った.ディープラーニングの学習や推論に おいて,必ずしも倍精度計算は必要なく,8 ビット,4 ビッ ト,さらには 1 ビット(2 値化),2 ビット(3 値化)で の計算も可能との研究結果が相次いでおり,消費電力や 計算性能の観点から FPGA を用いたプロトタイプの研 究開発が進んでいる.興味深いのは,FPGA の 2 大ベン ダである Intel 社,Xilinx 社がともに 1 ∼ 2 ビットの研 究開発を進めていることであり,近い将来これらの低精 度が商用化される可能性は高い.通常,GPU や CPU で はニューラルネットワークの基本演算である積和演算を 8 ビットや 16 ビットの精度で行う.2 値化,すなわち 1 ビット精度でこれを行うと,最も電力・面積を必要とす る乗算回路を XNOR ゲートで実現できる.したがって, 大量の積和演算回路を 1 チップ上に集積することがで きる.もう一つの利点は,ニューラルネットワークの重 みと計算結果を格納するバッファ(メモリ)のサイズを 大幅に小さくできることである.ニューラルネットワー クの構成によってはすべてのバッファを 1 チップに格納 できるので,DRAM のようなオフチップは不要になる. 積和演算回路と各種メモリの距離に電力は比例する.2 値化によりすべてをオンチップに格納できれば DRAM に要する電力をバッファやレジスタファイルで必要な 電力に抑えることができる.したがって,2 値化は電力 削減にも貢献する.また,オンチップメモリで格納でき れば,演算器チップとオフチップの通信ボトルネックも 解消できる.したがって,低精度によるオンチップ化は 今後ますます研究開発が進むと見ている.学習時と推論 時で必ずしも同じデバイスを利用する必要はなく,むし ろそれぞれの用途に特化したデバイスとすることにより 高い計算性能や低電力を実現する試みもある.Google 社はディープラーニング用チップである TPU(Tensor Processing Unit)を開発し,すでに利用を開始してい ることを 2016 年 5 月に発表した.消費電力を従来のデ バイスに比べて 10 分の 1 程度に抑えつつ,Google 社の ディープラーニングフレームワークである TensorFlow との親和性を高め,開発者はハードウェアの違いを意 識せずに利用できる.また,韓国では KAIST(Korea Advanced Institute of Science and Technology)の Hoi-Jun Yoo らのグループが,ディープラーニングの推論用 の専用チップの開発を行っている2・2 Field Programmale Gate Array(FPGA)
図 1 に一般的な FPGA(Field Programmable Gate Array)の構成を示す.FPGA は LUT(Look-Up Table) と呼ばれる 6 ∼ 8 入力の小規模メモリをもち,メモリ の出力を書き換えることで任意の論理ゲートを実現でき る(図 2).図 3 に FPGA の配線構造を示す.任意の配 線を実現するため,スイッチブロックを LUT や配線間 にもち,トランジスタスイッチを切り換えることで接続 することができる.トランジスタスイッチには 1 ビッ トの記憶素子であるフリップフロップ(Flip-Flop)で 制御を行う.したがって,FPGA の構成を変えるには LUTとスイッチブロックの記憶素子(メモリ)を書き 換えればよい.これをビットストリームと呼ぶ.図 4 に 従来の FPGA の設計フローとシステム設計も含めた現 在の設計フローを示す.多くの場合,ハードウェア記述 言語(HDL:Hardware Description Language)を用
図 2 LUT(Look-Up Table)の構成例 図 1 FPGA(Field Programmable Gate Array)
いてクロック(同期式回路)を意識した RTL(Register Transfer Level) を 対 象 と し て 設 計 を 行 う. 次 に, FPGAのベンダが提供する CAD ツールで合成・配置 配線を行い,ビットストリームを生成する.最後に, FPGAにビットストリームを転送することで所望の回路 を実現できる.近年,より設計時間短縮を狙って FPGA ベンダは ARM などのプロセッサを内蔵した再構成可能 なシステムオンチップをリリースしており,高位合成・ コンパイラと組み合わせてシステム全体を同時に生成す るシステム(Xilinx 社 SDSoC,Intel 社 Intel SDK for OpenCL)を提供している(図 4)*1. FPGAは任意の回路を実現できるため,カスタムチッ プ(ASIC)と比較して柔軟性があり,開発期間も短く, 常に進化し続けるディープラーニング技術に対応でき る. GPUと比較して,任意のビット精度演算を実現でき るため,電力性能に優れている.組込みシステムでは特 に電力制約が厳しいため,FPGA に利点がある.ARM などのプロセッサと比較して FPGA は並列回路を実現 できるため高速である.したがって,低ビット精度で十 分であるディープラーニングの推論には FPGA を採用 するのが現時点では現実的だと考えられる.一方,8 ∼ 16ビットと比較的ビット精度が必要な学習には GPU, または ASIC が候補である.現時点ではディープラーニ ング技術が発展途上のため,短期間で対応できる FPGA が候補であるが,決定的な技術が出た場合は ASIC 化が 一般的な選択肢となり得る. 2・3 CNN の FPGA 実装に関する研究動向 多ビット精度 CNN に関してはさまざまな FPGA 実装 が提案されている.基本的なアーキテクチャは LeCun らの実装が最も古く [Farabet 09],応用事例まで実装し ている.高位合成を用いた短期間設計 [Zhang 15] が, また,各層ごとのカスタマイズ量子化による実装 [Qiu 16]も提案されている.著者らは枝刈りなどの CNN 圧 縮手法 [Han 16] をフル結合層に適用した実装を提案し た [Fujii 17].ハードウェアを実現する場合はカーネル サイズが固定である回路が最も実現しやすい.そのた め,これらの手法はすべて VGG がベースとなっている. VGGと ResNet に関する認識精度と推定(Inferrence) 時間にはトレードオフがあり,これらの比較が行われて いる [Canziani 17]. 近年,CNN の係数と重みを 2 値(−1 と 1)に限定 した 2 値化 CNN [Courbariaux 16, Rastegari 16] が提 案されている.入力と重みを 2 値にした場合,積和演 算を XNOR ゲートと加算器で実現できるため FPGA と 相性が良い.FPGA のトップベンダである Xilinx 社, Intel社もそれぞれ 2 値化 CNN を FPGA で実現してい る [Nurvitadhi 16, Umuroglu 17].高位合成を用いて 2 値化 CNN を FPGA で実現する手法 [Zhao 17],バッチ 正規化を組み合わせて認識精度を上げる手法 [Nakahara 16],バッチ正規化を最適化する手法とその回路実現が 提案されている [Nakahara 17].ただし,多ビット実現 と比較して認識精度が低下する問題が依然として残って おり,認識精度を維持する手法が求められている.
3.2 値 化 CNN
ここでは 2 値化 CNN を紹介する.まず,基本演算で ある人工ニューラルネットワークを述べ,CNN の基本 演算である二次元畳込み演算に拡張する.次に,2 値化 人工ニューラルネットワークについて述べ,認識精度の 劣化を防ぐバッチ正規化について述べる.最後に,著者 らが開発したバッチ正規化を整数バイアスとして定式化 する方法を述べる. 3・1 人工ニューラルネットワーク(Artificial Neural Network) nをビット精度とし,X =(x0, x1, …, xn−1)を入力変数, *1 著者の経験だが,これらのツールは C/C++を入力としている ものの,性能を出すにはハードウェアに向いた記述が必要であ る.残念ながら,高位合成でハードウェアを設計する方法論は 確立していないのが現状である.とはいうものの,HDL 記述せ ずにソフトウェアより数倍高速かつ低消費電力を容易に実現で きるのは魅力的である.現在,FPGA の学会では高位合成を使っ た設計事例が多数報告されており,その生産性(設計時間に対 する回路の性能)の高さから,近い将来,高位合成は設計論が 確立し一般的に普及するものと予想している. 図 3 FPGA の配線 図 4 システム設計も含めた FPGA の設計フローY=(y0, y1, …, yn−1)を中間変数,W=(w0, w1, …, wn−1)
を重み,fact(Y)を活性化関数,Z=(z0, z1, …, zn−1)を
出力変数とする.以降,本論文では整数を大文字,バイ ナリ値を小文字で記述する.図 5 に人工ニューラルネッ トワーク(AN:Artificial Neural Network)を示す.AN で行われる計算を以下に示す. Y= WiXi n Z= fact(Y) i=0 ANは与えられた入力 X に対し,重み W を掛け合 わせて総和 Y を求め,活性化 関数 factを通すことで ニューロンの刺激 Z を模擬する.ただし,X0=1 であ り,W0をバイアスという.活性化 関数はシグモイド関
数,tanh 関数,ReLU 関数 [Nair 10] などが用いられる.
ANを多層に接続したものをディープニューラルネット
ワーク(DNN:Deep Neural Network)という.
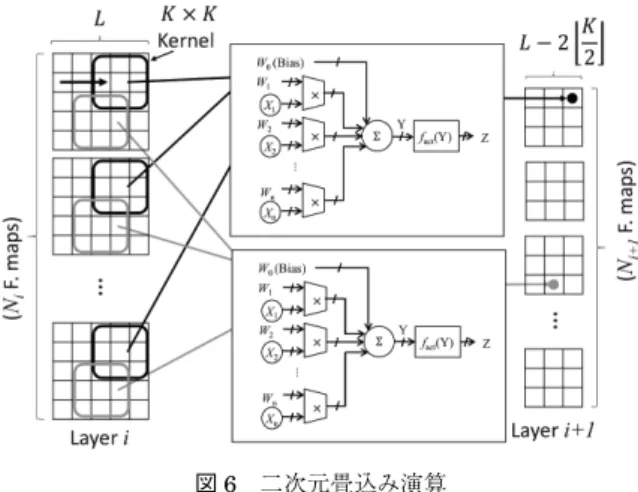
図 5 に示した AN の変数を二次元に並べたものを 特徴マップという.多層に並べた特徴マップに対す る畳込み演算を導入したものを畳込み DNN(CNN: Convolutional deep Neural Network)という.図 6 に
CNNで行われている二次元畳込み演算を示す.レイヤ i における Ni個の Li×Liサイズの入力特徴マップに対し てサイズ K2 iのカーネルをシフトしながら積和演算を行 い,活性化 関数を通してレイヤ i+1 の出力特徴マップ に出力する.この演算を Ni+1個の出力特徴マップだけ 繰り返す.出力特徴マップ i+1 の座標(x, y)における 二次元畳込みレイヤの演算は以下の式で表される. Zi+1, x, y=f(Ui+1, x, y Ui+1, x, y ) Ni+1-1 (Yk, x, y = k=0 + Xk, x+m, y+nWk, m, n) K-1 m=0 K-1 n=0 図 6 に示すように,二次元畳込み演算は AN 部と AN 部にデータを読み書きするメモリアクセス回路で構成で きる.したがって,AN 部のビット精度を落とすことが できれば,乗算器の面積とメモリアクセス時間を同時に 改善できる.本稿では入力と重みを両方とも 2 値化する ことで達成する. 全結合レイヤは上式の特徴マップサイズ,カーネルサ イズがそれぞれ 1 の場合であるといえる.上記の畳込み レイヤに加えて,CNN では移動不変性を得つつ畳込み 演算における計算量を削減するため,畳込み層間に非線 形な低画像化処理を挟むプーリングレイヤが挿入される ことが多い.本論文では多くの CNN で用いらている最 大値プーリング層を実装する.これは最大値を選択する 比較器で実現でき,二次元畳込み演算と比較して小規模 な回路で実現できる.2 値化 CNN では OR ゲートで実 現できるので,さらに小規模な回路で実現できる. 3・2 2 値 化 CNN 図 6 に示したように,CNN における畳込み演算は ANを二次元に拡張したものである.近年,重みと入力 値を 2 値(−1 と+1)に限定した 2 値化 CNN の一種 である BinaryNet [Courbariaux 16, Rastegari 16] が提 案されている.ここでは説明を簡略化するため,図 5 に 示した AN の 2 値化について述べる.2 値化 AN におけ る演算は以下の式で表される. wixi z= Sign(Y) Y= n i=0 ここで,Sign(Y)は中間変数 Y の符号を返す関数で あり Sign(Y)= -1(otherwise) (if Y 0)≧ 1 (1) である. 2値化 DCNN ではバイナリ化した入力と重みの積和
演算(Sum of Binaraized Weight)を行う*2.ここで,
入力 x と重み w は 2 値化されているが,中間変数 Y は 図 5 人工ニューラルネットワーク(Artificial Neural Network)
図 6 二次元畳込み演算
*2 ただし,レイヤ 1 の入力はカラー画像なので入力値は 8 ビッ ト整数である.
整数値であることに注意されたい.FPGA は直接−1 を 表現できないので論理値 0 を割り当てる.このとき,乗 算は XNOR ゲートで実現することができるため,整数 表現よりも乗算回路を大幅に削減できる.また,2 値化 ANでは入力と重みが 1 ビットとなるため,それらを読 み書きするメモリ帯域も圧縮できる. 3・3 バッチ正規化(Batch Normalization) 通常,学習時間の高速化と収束のため,CNN では学 習データをバッチと呼ばれるセットでまとめて逆伝搬さ せ,まとめて係数の更新を行うバッチ学習法が行われて いる [Sergey 15].このとき,バッチごとのデータの分 布の違いの影響で,学習の収束が遅くなったり,初期値 パラメータを慎重に決めなければならない問題が生じ る.この問題を解決する方法をバッチ正規化という. バッチ正規化は学習時にバッチごとの平均が 0,分散 が 1 になるように正規化パラメータγ,βを求める.γ お よびβはパラメータでそれぞれ正規化された値をスケー リングおよびシフトするためのものである.バッチ正規 化はバッチごとに平均が 0,分散が 1 になるように正規 化する.ただし,認識時には学習済みのパラメータを読 み出すだけでよい.したがってバッチ正規化を導入した 2値化 AN は z=Sign(Y ) wixi Y= n i=0 = + Y γ Y -µB β ε σ2 B+ (2) 図 7 にバッチ正規化を導入した 2 値化 AN を示す.す なわち,新たに乗算と加算,および正規化のためのパラ メータ変数が加わることになる.また,学習によっては これらのパラメータが極めて小さい値を取ることがある ので,浮動小数点精度の演算器が必要となる. 3・4 バッチ正規化フリー 2 値化 CNN バッチ正規化は認識精度を維持するために 2 値化 CNNでは必須であるが,図 7 が示すように,バッチご とに調整したパラメータが必要になってしまう.した がって,それらを演算するための乗算回路と加算器が余 分に必要になってしまう [Nakahara 16].また,これら の回路は浮動小数点精度が必要であることから,特に加 減算回路のオーバヘッドが無視できなくなる.著者らは バッチ正規化を導入した AN と等価な AN を解析的に求 め,CNN に拡張した [Nakahara 17].バッチ正規化と は中間変数 Y を正規化するので,式(2)に示したバッ チ正規化後の中間変数を Yとすると
- µB Y - = Y γ σ2 B + γ σ2 B+ ε ε と変形できる.これを用いれば,式(1)に示した 2 値 化活性化関数は
<-µB
- γ σ2 B+ Sign(Y)= -1(otherwise) if Y 1 ε となる.Y が中間関数であったことに注意すると,活性 関数の値が上式の値で決まるので 2 値化 CNN における 中間変数の値 Yは以下の式で書き直すことができる. Y -µB- γ σ2 B+ wixi = n i=0 β W + wixi = n i=1 w0-µB+
γ σ2 B+ + wixi = n i=1 β ε ε (3) したがって,上式からバッチ正規化を導入した 2 値化 CNNはバイアス値のみ整数値をもつ 2 値化 CNN と等 価であることが示された.これをバッチ正規化フリー 2 値化 AN と呼ぶことにする.バッチ正規化が整数化され たバイアス値で置き換えることができるため,回路が単 純となり,面積も小さくなる.もちろん,バッチ正規化 フリー AN は CNN に拡張することができる.ここで, 式(3)を注意深く観察すると,積和演算の項のインデッ クスが i=1 となっている.これは,学習時にバイアス 項(w0)が不要であることを示している.4.高位合成を用いた 2 値化 CNN の設計フロー
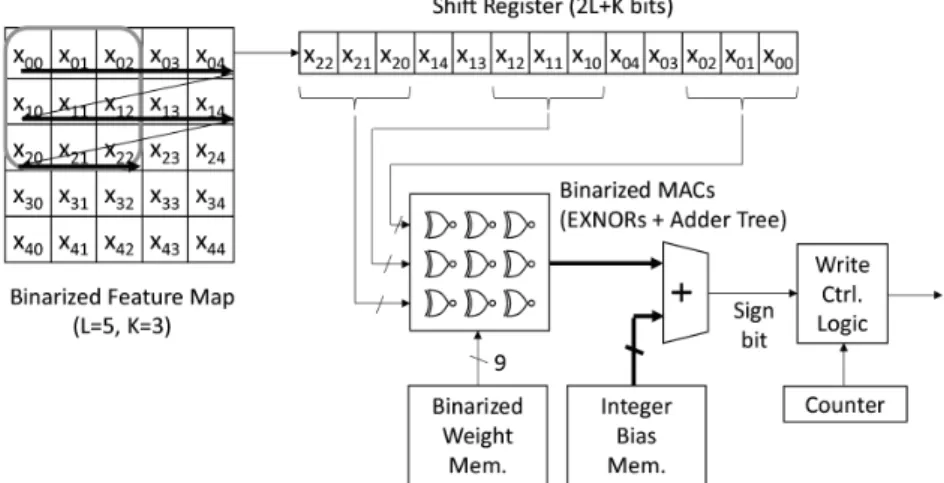
CNNは Python など抽象度の高い高位言語で設計す るのに対し,FPGA は Verilog など抽象度の低いハード ウェア記述言語で設計するため,CNN を FPGA で実現 する際に言語間の抽象度ギャップを埋めるために多大な 設計時間を要してしまう.現在,CNN のアルゴリズム・ 応用事例が加速度的に進歩しているため,FPGA 実装を 短期間で終わらせる必要がある.著者らはディープラー ニングフレームワークから C++記述を出力して高位合 図 7 バッチ正規化を適用した 2 値化 AN成による FPGA 実現を行うフローを提案している.まず, 高速かつ省面積な 2 値化 CNN を FPGA に実現する回路 について述べ,提案する設計フローについて述べる. 4・1 ストリーム処理を行う 2 値化二次元畳込み回路 図 8 にストリーム処理を行う 2 値化二次元畳込み回路 を示す.FPGA の利点としてカスタム演算に特化したパ イプライン処理を実現できることがあげられる.本稿で はスループットを上げるため,2 値化(つまり 1 ビット) シフトレジスタをバッファ回路としてメモリアクセス回 数を削減し,XNOR ゲートと加算器ツリーを用いた二 次元積和演算回路で二次元畳込みを行う.バッチ正規化 フリーにより,重みとバイアスのみを保持していればよ いので,FPGA の広帯域なオンチップメモリに格納する. これにより,オフチップ DRAM と比較して,高速アク セスを達成しつつ消費電力を削減できる.ストリーム処 理により,カーネルが特徴マップの境界を超えるときが あるので,出力に制御回路を付加する. さらにスループットを上げるため,処理中の入力層を 同時に読み出す 2 値化二次元畳込み回路を用いる.メモ リ帯域を確保するため,特徴マップの値も FPGA のオ ンチップメモリにすべて格納する.2 値化 CNN を用い ることでオンチップメモリに格納することができる.メ モリアクセス部分は既存の設計法とほぼ同じである [Qiu 16].既存手法と異なる点は,2 値化により重み,入出力, バイアスすべてを FPGA のオンチップメモリに格納した こと,バッチ正規化のためのパラメータを等価な多ビッ ト整数バイアスで置換したことである.また,FPGA な らではの実装として,Xilinx 社 FPGA の配線内部にあ る XOR 回路を利用してリソース効率を上げている.提 案回路は既存の DDR4SDRAM などの外部メモリを用い た設計に対し,メモリコントローラが不要であり,それ に伴う回路や電力を削減できることが特徴的である.ま た,メモリアクセスは内部メモリだけなので推論時間も 大幅に削減できる. 4・2 ディープラーニングフレームワークと高位合成を 組み合わせた設計フロー GUINNESS 図 9 に著者らが開発している FPGA 向け 2 値化ディー プラーニング設計環境 GUINNESS(GUI based neural
図 8 ストリーム処理を行う 2 値化二次元畳込み回路
network synthesizer)の設計フローを示す*3.GUINNESS
の設計フローは既存のディープラーニングフレームワー クである Chainer [Chainer] で学習した 2 値化 CNN を
直接 C++に変換し,FPGA の高位合成ツールを用いて
ビットストリームを直接生成して実行可能である.近年, Xilinx社から SDx シリーズ,Intel 社から Intel SDK
for OpenCLがそれぞれリリースされており,アクセラ レーションしたい部分を指示するだけで OS を含めたソ フトウェア部とハードウェア部を自動合成することがで きる.もちろん,高位合成を行うので入力言語は C++ ですべて記述できる.提案フローは FPGA になじみの ないアルゴリズム技術者が使うことができ,GPU と同 じ感覚で高速かつ低消費電力な CNN 回路を実現できる ため,アルゴリズム技術者は CNN の設計に注力できる.
5.実 験 結 果
5・1 実 装 環 境 CNNの一種である VGG11 を Chainer1.24.0 を用い て学習し,Xilinx 社 Zedboard 上に実装した.高位合成 ツールは Xilinx 社 Vivado HLS 2016.4 を用い,論理合 成は Vivado2016.4 を用いた.タイミング制約を 143.78 MHzとして論理合成した結果,タイミングが収束した. 各論文ごとに実装に用いた FPGA と CNN が異なる ので,面積効率と消費電力効率で比較を行った.表 1 に ほかの FPGA 実装との比較結果を示す.直近の実装結 果 [Zhao 17] と比較して認識精度が約 6%低下するもの の,5.00 倍高速であり,8.08 倍面積効率に優れており, 5.11 倍消費電力効率に優れていた. FPGA上に実装した 2 値化 CNN を CPU,GPU と比 較した.比較に用いた評価ボードは NVidia 社 Jetson TX1ボード(ARM Cortex-A57 と Maxwell GPU を搭 載)である.ベンチマークサイト [Nvidia] と同条件で ディープラーニングフレームワーク Caffe(バージョン 0.14)[Yangqing 14] を用いて VGG11 を CPU と GPU 上で動作させた.本実験ではレイテンシを測定するた め,バッチサイズを 1 とした.表 2 に比較結果を示す. ARM Cortex-A57と比較して 1 834.1 倍高速であり,消 費電力が 3 分の 1 であり,消費電力性能効率は 5 706.0 倍優れていた.Maxwell GPU と比較して 11.5 倍高速で あり,消費電力が 7 分の 1 であり,消費電力性能効率は 83.0 倍優れていた.したがって,ディープラーニングの 推論には FPGA が最も優れているといえる.6.ま と め
画像処理などディープラーニングの適用が進んでいる 一部の分野については,エッジ側での推論に係るハード ウェアの研究開発が進んでいる.実装の方向性として, 現状の CNN の枠組みを前提としてハードウェアを最適 化する方向と,専用化する部分に加えて GPU や FPGA を一部利用して柔軟性を残しておく方向がある.現状の ディープラーニングの研究が日進月歩である状況を考え ると,研究の現状を前提とするよりも,今後の発展部分 を採り入れる柔軟性を残しておく後者は,最高性能は劣 る可能性があるものの,適用分野の幅広さや息の長い開 発を見込むことができる.本稿では,柔軟性を実現する 方法として FPGA を紹介し,2 値化 CNN の実装方法と, 組込み GPU と比較したときの性能について紹介した. VGG11を用いた評価実験より,ディープラーニングの 推論には FPGA が有効な選択肢であるといえる. 謝 辞 本研究は,一部,日本学術振興会・科学研究費補助金(若 手(A):課題番号 15H05304),および科学技術振興機 構 ACCEL プロジェクト,NEDO 次世代人工知能・ロボッ ト中核技術開発/次世代人工知能技術分野プロジェクト による. *3 https://github.com/HirokiNakahara/GUINNESS で公 開中. 表 1 他の FPGA 実装との比較(VGG11 をバッチサイズ 1 で推論) 手法(Year) al.(2017) FINN(2017)Zhao et 著者ら FPGAボード(FPGA) (XC7Z020)Zedboard (XC7Z020)PYNQ board (XC7Z020)Zedboard
Clock〔MHz〕 143 166 143 LUT数 46 900 42 823 14 509 BRAM数 94 270 32 DSP数 3 32 1 誤認識率〔%〕 12.27% 19.9% 18.2% レイテンシ〔ms〕 5.94 2.24 2.37 FPS〔s-1〕 (168) (445) (422) Power〔W〕 4.7 2.5 2.3 FPS/W 35.7 178.0 182.6 FPS/LUT[×10− 4] 35.8 103.9 289.4 FPS/BRAM 1.8 1.6 13.1 表 2 他のプラットフォームとの比較 (VGG11 をバッチサイズ 1 で推論)
Platform CPU GPU FPGA
Device Cortex-A57ARM Maxwell GPU Zynq7020 Clock Freq. 1.9 GHz 998 MHz 143.78 MHz
Memory eMMC Flash16 GB LPDDR44 GB 4.9 MbBRAM レイテンシ〔ms〕 4210.0 27.23 2.37 FPS〔s− 1〕 (0.23) (36.7) (421.9)
Power〔W〕 7 17 2.3
◇ 参 考 文 献 ◇
[Canziani 17] Canziani, A., Paszke, A. and Culurciello, E.: An analysis of deep neural network models for practical applications, arXiv, 1605.07678v3(2017)
[Chainer] Chainer: A Powerful, Flexible, and Intuitive Framework for Neural Networks, http://chainer.org/ [Courbariaux 16] Courbariaux, M., Hubara, I., Soudry, D., Yaniv,
R. E. and Bengio, Y.: Binarized neural networks, Training deep neural networks with weights and activations constrained to +1 or −1, Computer Research Repository(CoRR),http:// arxiv.org/pdf/1602.02830v3.pdf(March 2016) [Donahue 14] Donahue, J., et al.: DeCAF: A deep convolutional
activation feature for generic visual recognition, Proc. ICML (2014)
[Farabet 09] Farabet, C., Poulet, C., Han, J. Y. and LeCun, Y.: CNP: An FPGA-based processor for convolutional networks,
Int’l Conf. on Field- Programmable Logic and Applications
(FPL),pp. 32-37(2009)
[Farabet 10] Farabet, C., Martini, B., Akselrod, P. Talay, S., LeCun, Y. and Culurciello, E.: Hardware accelerated convolutional neural networks for synthetic vision systems,
Int. Symp. on Circuits and Systems(ISCAS),pp. 257-260 (2010)
[Fujii 17] Fujii, T. Sato, S., Nakahara, H. and Motomura, M.: An FPGA realization of a deep convolutional neural network using a threshold neuron pruning, Int. Symp. on Applied
Reconfigurable Computing(ARC),pp. 268-280(2017) [Fukushima 82] Fukushima, K. and Miyake, S.: Neocognitron, A
new algorithm for pattern recognition tolent of deformations and shifts in position, Pattern Recognition, Vol. 15, pp. 455-469 (1982)
[Han 16] Han, S., et al.: Deep compression, compressing deep neural networkswith pruning, Trained quantization and HUFFMAN coding, ICLR(2016)
[He 16] He, K., Zhang, X., Ren, S. and Sun, J.: Deep residual learning for image recognition, IEEE Conf. on Computer
Vision and Pattern Recognition(CVPR)(2016)
[Huang 16] Huang, G., Liu, Z. and Weinberger, K. Q.: Densely connected convolutional networks, CoRR abs/1608.06993 (2016)
[Krizhevsky 12] Krizhevsky, A., Sutskever, I. and Hinton, G.: Imagenet classification with deep convolutional neural networks, Advances in Neural Information Processing
Systems, Vol. 25, pp. 1106-1114(2012)
[Lecun 98] Lecun, Y. Bottou, L. Bengio, Y. and Haffner, P.: Gradientbased learning applied to document recognition, Proc.
IEEE, Vol. 86, No. 11, pp. 2278-2324(1998)
[Nair 10] Nair, V. and Hinton, G. E.: Rectified linear units improve restricted Boltzmann machines, Int. Conf. on Machine
Learning(ICML),pp. 807-814(2010)
[Nakahara 16] Nakahara, H., Yonekawa, H., Sasao, T., Iwamoto, H. and Motomura, M.: A memory-based realization of a binarized deep convolutional neural network, Int. Conf. on
Field-Programmable Technology(FPT),pp. 273-276(2016) [Nakahara 17] Nakahara, H., Yonekawa, H., Iwamoto, H.
and Motomura, M.: A batch normalization free binarized convolutional deep neural network on an FPGA, ISFPGA, p. 290(2017)
[Nurvitadhi 16] Nurvitadhi, E., Sheffield, D., Sim, J., Mishra, A., Venkatesh, G. and Marr, D.: Accelerating binarized neural networks: Comparison of FPGA, CPU, GPU, and ASIC, FPT, pp. 1-8(2016)
[Nvidia] Nvidia Benchmarking, https://github.com/ charlyng/Embedded-Deep-Learning/tree/master/ Benchmark-Performance
[Peemen 13] Peemen, M., Setio, A. A. A., Mesman, B. and Corporaal, H.: Memory-centric accelerator design for convolutional neural networks, Int. Conf. on Computer Design (ICCD),pp. 13-19(2013)
[Qiu 16] Qiu, J., Wang, J., Yao, S., Guo, K., Li, B., Zhou, E., Yu, J., Tang, T., Xu, N., Song, S., Wang, Y. and Yang, H.: Going deeper with embedded FPGA platform for convolutional neural network, FPGA 2016, pp. 26-35(2016)
[Rastegari 16] Rastegari, M., Ordonez, V., Redmon, J. and Farhadi, A.: XNOR-Net: ImageNet classification using binary convolutional neural networks, ECCV, No. 4, pp. 525-542 (2016)
[Sankaradas 09] Sankaradas, M. Jakkula, V. Cadambi, S. Chakradhar, S. Durdanovic, I. Cosatto, E. and Graf, H. P.: A massively parallel coprocessor for convolutional neural networks, Int. Conf. on Applicationspecific Systems,
Architectures and Processors(ASAP),pp. 53-60(2009) [Sergey 15] Sergey, I. and Christian, S.: Batch normalization:
Accelerating deep network training by reducing internal covariate shift, Proc. 32nd Int. Conf. on Machine Learning,
Lille, JMLR: W&CP, Vol. 37, France (2015)
[Simonyan 14] Simonyan, K. and Zisserman, A.: Very deep convolutional networks for large-scale image recognition, arXiv, pp. 1409-1556(2014)
[Szegedy 15] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S. E., Anguelov, D., Erhan, D., Vanhoucke, V. and Rabinovich, A.: Going deeper with convolutions, CVPR, pp. 1-9(2015) [Umuroglu 17] Umuroglu, Y., Fraser, J. N., Gambardella,
G., Blott, M., Leong, P., Jahre, M. and Vissers, K.: FINN: A framework for fast, Scalable binarized neural network inference, ISFPGA(2017)
[Yangqing 14] Yangqing, J., Evan, S., Jeff, D., Sergey, K., Jonathan, L., Ross, G., Sergio, G. and Trevor, D.: Caffe: Convolutional architecture for fast feature embedding, arXiv preprint, arXiv.1408.5093(2014)
[Zhang 15] Zhang, C., Li, P., Sun, G., Guan, Y., Xiao, B. and Cong, J.: Optimizing FPGA-based accelerator design for deep convolutional neural networks, FPGA 2015, pp. 161-170 (2015)
[Zhao 17] Zhao, R., Song, W., Zhang, W., Xing, T., Lin, J.-H., Srivastava, M., Gupta, R. and Zhang, Z.: Accelerating binarized convolutional neural networks with software-programmable FPGAs, ISFPGA, pp. 15-24(2017)
2017年 11 月 6 日 受理