広域分散ファイルシステムGfarm上でのMapReduceを用いた大規模分散データ処理
7
0
0
全文
(2) Vol.2010-HPC-126 No.4 2010/8/3. 情報処理学会研究報告 IPSJ SIG Technical Report. の際に入力データを HDFS へインポートしたり,計算結果をエクスポートする作業が必要と. 2.1 Hadoop. なる.これは利便性が悪いだけではなく,ストレージの無駄遣いとなる.本研究では一つの. Google は Google file system, MapReduce, BigTable などの様々な分散処理技術を発表. ファイルシステムでデータを管理し,様々なアプリケーションを実行するために,分散ファ. したが,それらの技術をオープンソースで開発を進めているのが Apache Hadoop プロジェ. イルシステム Gfarm9) を使用することを提案する.Gfarm は POSIX 準拠の API を持った. クトである.Hadoop には様々なサブプロジェクトがあり,Google の Google file system,. 14). 広域分散ファイルシステムである.Gfarm はその並列入出力 API だけでなく FUSE. MapReduce, Big table6) にそれぞれ HDSF, Hadoop MapReduce, HBase1) が対応する.. を. 使って Linux クライアントからマウント可能で,既存のプログラムから完全に透過的にアク. また,最近では周辺のサブプロジェクトの開発も進んでおり,MapRedue のプログラムを書. セスできる.また,MPI-IO による MPI プログラムからのアクセスも可能である.Gfarm. くよりも簡単にデータ処理を記述できるメタ言語実行環境として Pig4) や Hive3) が注目さ. を HDFS の代わりに使うことで,無駄なデータの移動やコピーを減らし,ストレージの管. れている.Pig や Hive はそれぞれ独自の記法で記述したプログラムを MapReduce のジョ. 理を Gfarm に一元化することができる.. ブに変換して実行する.MapReduce プログラムを直接記述するよりも自由度や性能面で劣. 本研究では Hadoop MapReduce から直接 Gfarm 上のファイルへアクセス可能にするた. るが,プログラマの負担を減らす事ができるという大きなメリットを持つ.. めの Hadoop-Gfarm プラグインの設計し,実装した.本稿では,実装したプラグインの設. 3. 分散ファイルシステム. 計について述べ,実環境において評価を行なった. 本稿の構成を次に示す.まずは研究の背景として 2 章では MapReudce の説明をし,3 章で. この章では HDFS と Gfarm のアーキテクチャについて述べる.いづれもマスタースレー. HDFS と Gfarm の特徴について述べる.4 章では本研究において実装した Hadoop-Gfarm. ブ型の分散ファイルシステムで,ファイルシステムのメタデータを管理するマスターサーバ. プラグインの説明をし,5 章で性能の評価を行う.6 章で関連研究と比較を行い,7 章で全. と,実際のデータへのアクセスを提供するスレーブサーバを持つ.データの書き込み,読み. 体をまとめを行う.. 込みなどはスレーブサーバへ直接行われるため,ノード数に対してスケーラブルな性能を持 つ.また,複製を作成し分散配置することにより信頼性を確保することができる.次節では. 2. MapReduce MapReduce. 7). 各ファイルシステムの特徴について述べる.. とは Google によって 2004 年に提案された大規模データを並列分散処理. 3.1 HDFS. するためのフレームワークである.MapReduce のプログラミングモデルでは処理を Map,. HDFS は大きいファイルのストリーミング型のデータアクセスに特化しており,書き込. Shuffle,Reduce の各フェーズに分解する.Map では key/value のペアを入力データとして. みを一度だけ行い,読み込みを何度も行うデータ処理のパターンに向いている.ファイルは. 受け取り,ユーザー定義の map 関数を実行し,中間 key/value を生成する.Shuffule フェー. ブロック(デフォルトでは 64MB)に分割され,各スレーブノードに分散して配置される.. ズでは,中間 key/value を受け取り同じ key に対して value のリストを生成し,ソートして. これらの特徴は MapReduce プログラムを実行することを想定されており,MapReduce の. Reduce に渡す.Reduce フェーズでは,key と対応する value のリストを受け取り,ユー. プログラムには適している.しかし,MapReduce プログラムでは必要にならないが,他の. ザー定義の reduce 処理を行い,最終出力となる key/value データを生成する.各 Map タ. アプリケーションでは必要になる機能に関して足りない部分がある.HDFS は複数のライ. スク,Reduce タスクは副作用がなく,完全に並列して計算可能である.ジョブマスタがこ. ターからの書き込みやファイルの任意の位置の修正などをサポートしていない.FUSE で. の一連の MapReduce ジョブを管理し,ワーカーが実際の Map タスクと Reduce タスクを. マウントすることは可能だが,マウントしたとしてもこれらの操作はサポートしておらず,. 実行する.ジョブを実行すると,ジョブマスタが入力データを自動的に 16MB から 64MB. 既存のソフトウェアから HDFS 上のファイルを処理することは出来ない.以上の理由によ. 程度に分割し,タスクを生成し,各ワーカノードに割り当てる.タスクの割り当ての際に. り,汎用的なファイルシステムとして用いることは難しい.. 入力データの近くに割り当てることによってネットワークのデータ転送量を抑え,効率的な. 3.2 Gfarm file system. I/O を実現している.. Gfarm はより広範囲なアプリケーションへの適応,日常的な利用を可能にすることを目. 2. c 2010 Information Processing Society of Japan ⃝.
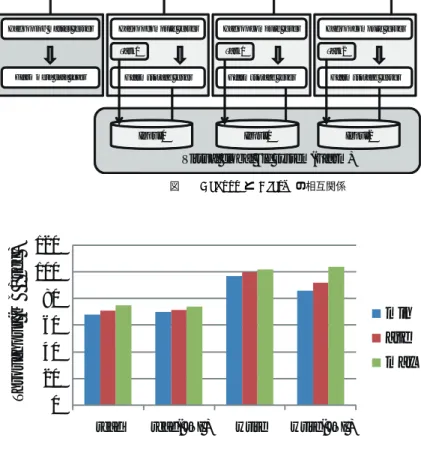
(3) Vol.2010-HPC-126 No.4 2010/8/3. 情報処理学会研究報告 IPSJ SIG Technical Report. 標として,NFS の代用となりうる,POSIX 標準 API をサポートする頑強で信頼性のある. getFileBlockLocations() 関数を使用して,Gfarm のメタデータサーバに各タスクのデータ. 広域分散ファイルシステムである.HDFS とは違って,一つのファイルはブロック分割さ. の位置を取得し,データに近い計算サーバに優先してタスクを割り当てる.Gfarm はファイ. れず一台のスレーブノードに格納される.MapReduce プログラムにおいてスケーラブルな. ルがブロック分割されてないが,MapReduce プログラムを実行する際はこちらが設定ファ. 性能を達成するには,ファイルがノードに分散されて配置されている必要がある.ファイル. イルで指定したサイズで入力データの分割も自動的に行われ,Map タスクの粒度がファイ. を分割することがユーザーの負担になるという意見もあるだろうが,実際は大きいデータ. ルサイズと同じになることはない.スケジューリングの方法は HDFS の場合とまったく同. セットは複数ファイルに分かれてることが多いため,ユーザの負担は小さい.FUSE で通常. じ方法で行われる.. のファイルシステムへマウントすることが可能で,既存のソフトウェアから完全に透過に利. Hadoop-Gfarm ではこれらの関数を JNI(Java Native Interface) を使って実装し,Hadoop. 用できる.また,MPI-IO による MPI プログラムからの並列 I/O もサポートしている.. から Gfarm のクライアントライブラリを直接利用している.Java と C++のデータのやり 取りの際にはコピーが発生しないように直接バッファに参照されるメモリ領域の開始アドレ. 4. Hadoop-Gfarm プラグイン. スを渡している.まず,JNI の shim layer に関するオーバーヘッドの評価を性能評価を実. Hadoop MapReduce プログラムから Gfarm 上のファイルにアクセスするには FUSE. 施した.表 1 に使用したマシンの性能を示す.結果を図 3 に示す.read と write が Gfarm. を使ってアクセスすることも可能である.しかし,その場合,FUSE のオーバーヘッド. の C 言語の API を直接使用した場合の結果で,read( JNI ) と write( JNI ) はその API. の影響を受けることと,Hadoop MapReduce によるデータの位置を考慮したスケジュー. を Java のコードから JNI を通して使用した場合の結果である.書き込み読み込み共に大き. リングができないため,本研究において Hadoop から Gfarm 上のファイルへ直接アクセ. な性能の差は見られず,プラグインを実装するにあたって JNI のオーバーヘッドは小さい. スするための Hadaop-Gfarm プラグインを開発した.Hadoop は元々バックエンドの分. ことが確認できた.. 散ファイルシステムを HDFS 以外でも利用できるように抽象化された FileSystem API. 5. 性 能 評 価. (org.apache.hadoop.fs.FileSystem) を備えており,Hadoop-Gfarm プラグインでもこのファ イルシステム API を継承して Gfarm 用に実装している.同様の実装として KFS8) や S313). HDFS と Gfarm の比較をするために,マイクロベンチマークによる読み込み,書き込み. などもこの API を使用して Hadoop MapReduce プログラムから直接アクセス可能となっ. の性能評価,grep と sort の MapReduce アプリケーションによる評価を行った.表 1 に実. ている.図 1 に Hadoop-Gfarm のソフトウェアスタックを示す.Hadoop-Gfarm プラグイ. 験に使用したマシンの性能を示す.今回の評価では 15 ノードまで使用し,15 ノードの際は. ンは JNI(Java Native Interface) の shim layer であり,Hadoop や Gfarm のソースコー. 一つはマスターとスレーブを兼ねており,それ以外の場合は別にマスターノードを使用して. ドに変更を加えることなく Hadoop MapReduce のアプリケーションを実行できる.また. いる.また,どちらのファイルシステムも複製の作成が可能ではあるが今回は全て複製なし. Hive や Pig は Hadoop MapReduce の上位のレイヤーなので,これらのプログラムも実行. で評価を行った.. 5.1 書き込み性能. 可能である. この FileSystem API が含む関数は,通常の POSIX ライクの read(), write(), open(),. Hadoop 付属の TestDFSIO ベンチマークを使って書き込みの性能を計測した.各ノード. mkdir() などのファイルシステム操作である.さらに Hadoop がデータの位置を知るため の関数 getFileBlockLocations() も含んでおり,HDFS 以外のファイルシステムでもこの関. CPU Memmory OS Disk Hadoop Version Gfarm Version. 数を実装することで Hadoop のジョブを管理するマスターサーバがデータが実際に保存さ れているホスト名を知ることができ,データの位置を考慮したスケジューリングが可能とな る.図 2 に Hadoop と Gfarm の関係を示す.スレーブには Hadoop の計算サーバと Gfarm のストレージサーバ両方を起動する.ジョブが実行されると,Haodop のジョブマスタが. 3. 表 1 マシン性能 2.33GHz Quadcore Xeon E5410 (2 sockets) 32GB Linux 2.6.18-6-amd64 SMP Hitachi HUA72101 1TB 0.20.2 2.30. c 2010 Information Processing Society of Japan ⃝.
(4) Vol.2010-HPC-126 No.4 2010/8/3. 情報処理学会研究報告 IPSJ SIG Technical Report. Hadoop MapReduce applicaons. Hadoop job master server. Hadoop compute server. Hadoop compute sever. Hadoop compute server. Task0. Task1. Task2. Gfarm storage sever. Gfarm meta data sever. Gfarm storage sever. Gfarm storage server. File system API Input0. HDFS client library. Input1. Input2. Virtual global file system(Gfarm). Gfarm JNI shim layer. 図 2 Hadoop と Gfarm の相互関係. HDFS servers 図1. Throughput (MB / sec ). Gfarm client library Gfarm servers Hadoop-Gfarm ソフトウェアスタック. 毎異なるファイルを同時に書き込んで,各ノード書き込みに要した時間を合計してスルー プットを計算している.メモリサイズが 32GB あるため,それよりも大きいサイズである. 120 100 80 min. 60. ave. 40. max. 20 0 read. 50GB を各ノードで書き込んでいる.図 4 に 1 ノードから 15 ノードまでノード数を変えて 書き込んだ結果を示す.どちらもノード数に対して線形にスケールしているが,Gfarm が. read( JNI ). write. write( JNI ). 図 3 JNI の shim layer に関するオーバーヘッドの評価. HDFS より 30% 近く高い性能を示している. 5.2 読み込み性能. 配置した場合の性能を計測した.図 5 では Gfarm w/ affinity がデータの配置を考慮した. 書き込み性能の評価と同様に TestDFSIO ベンチマークを使用して性能を計測した.本評. 場合,Gfarm w/o affinity はデータの位置を考慮していない場合の結果を示す.HDFS と. 価ではプログラムに一部変更を加えた.TestDFSIO の読み込みベンチマークではデータの. Gfarm はほぼ同等の性能を示している.また,Gfarm においてデータの位置を考慮した場. 配置を考慮せずにデータを読み込む.しかし,実際の MapReduce プログラムではデータ. 合と考慮しない場合でも,ほとんど性能差は見られなかった.しかし,データの位置を考慮. の配置を考慮出来るように修正した.このプログラムでは各ノードに 5GB のファイルが生. していない場合はネットワークのトラフィックが高くなっており,ノード数がさらに多い環. 成されている状態で,各ノードで異なるのファイルを同時に読み込んでいる.生成した後,. 境ではネットワークがボトルネックとなると考えられる.また,今回の読み込みでは各ノー. メモリから追い出してから読み込みを行っている.また,読み込みにおいてタスクをデータ. ドが一つの別々のファイルを最後まで読み込むため,どのようにタスクを配置してもディス. の近くに配置することの性能への影響を調べるためにデータの位置を考慮せずにタスクを. クアクセスの衝突が起こることはない.しかし,通常の MapReduce アプリケーションでは. 4. c 2010 Information Processing Society of Japan ⃝.
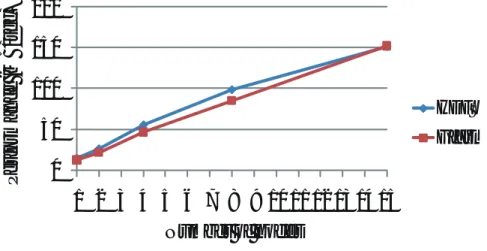
(5) Vol.2010-HPC-126 No.4 2010/8/3. 1400 1200 1000 800 600 400 200 0. Aggregate Throughput (MB/sec). Aggregate throughput (MB/sec). 情報処理学会研究報告 IPSJ SIG Technical Report. HDFS Gfarm. 1000 800 600 HDFS. 400. Gfarm w/ affinity. 200. Gfarm w/o affinity. 0 1 3 5 7 9 11 13 15. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15. Number of nodes. Number of nodes 図5 図4. 読み込み性能. 書き込み性能. 5.4 sort ソート性能の評価には Terasort プログラム10) を使用した.Terasort プログラムは Ter-. 入力データを分割して読み込むので,データの位置がわからない場合はスケジューリングに 偏りが起こり,性能低下が起こると考えられる.. agen プログラムによって生成されたテキストを key によってソートし,そのまま出力する. 5.3 grep. プログラムである.出力ファイルは別々のファイルへ書き出されるが,ファイルの順序は保. Hadoop 付属の Teragen プログラムを使用して生成したデータに対して grep を行った.. たれている.つまり,出力ファイル N の全ての key が出力ファイル N+1 のどの key より. 生成されたデータは key が 10byte, value が 90byte のテキストである.このデータに対し. も小さいことを保証している.Hadoop MapReduce では自動的に shuffle フェーズでソー. て”AAA”の文字列で grep を行った.map タスクではテキストを検索し,マッチしたテキ. トを行うため,map タスク,reduce タスクは何もせずに値をそのまま出力するだけである.. ストを key,数字の 1 を value として出力する.reduce タスクでは map の出力の value を. 実行結果を図図 7 に示す.縦軸は入力データサイズに対する平均秒間処理バイト数である.. 合計し,出現回数をカウントしている.また,combiner として reduce と同じ関数を使用. ソートアプリケーションにおいても HDFS と Gfarm は同等の性能を示した.. し,map タスク側で結果をまとめることでデータの転送量を減少させている.データを生. 6. 関 連 研 究. 成してから grep を行う前に,データをメモリから読み込まないようにメモリをクリアして から評価を行った.結果を図 6 に示す.縦軸は入力データサイズに対する平均秒間処理バ. 6.1 Cloudstore. イト数である.Gfarm と HDFS はほぼ同程度の性能を示した.Gfarm においてデータの. Cloudstore8) は Hadoop の利用を想定して作られたファイルシステムで,C++で実装さ. 配置の考慮がある場合 (Gfarm w/ affinity) と無い場合 (Gfarm w/o affinity) を比較した. れており,POSIX ライクの API を持ち,MapReduce 以外のアプリケーションからも利用可. 結果,15 ノードでは約 5 倍の性能差が見られた.Hadoop のスケジューリングでは,ファ. 能である.Hadoop-Gfarm と同様に Java Native Interface を使って Hadoop MapReduce. イルの位置がわからない場合は1ファイル全て処理してから次のファイルを処理していくた. アプリケーションから Cloudstore 上のファイルへのアクセスを提供している.しかし,セ. め,1 つのファイルに対して読み込みが衝突し,効率が低下していた.. キュリティやファイルのパーミッションなどの機能は備えていない.. 5. c 2010 Information Processing Society of Japan ⃝.
(6) Vol.2010-HPC-126 No.4 2010/8/3. 400. Performance (MB/sec). Performance (MB/sec). 情報処理学会研究報告 IPSJ SIG Technical Report. 300 200. HDFS. 100. Gfarm w/ affinity Gfarm w/o affinity. 0 1. 3. 5. 7. 9 11 13 15. 200 150 100 HDFS 50. Gfarm. 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15. Number of nodes. Number of nodes 図6. grep 性能 図 7 ソート性能. 6.2 Hadoop-PVFS PVFS11) は並列アプリケーションによる高速な I/O を提供するために設計された並列ファ. 望である.. 15) イルシステムである. では,16 台までの環境で HDFS と PVFS が同等の性能を達成した. 本稿の残された課題としては,より大規模な広域環境での性能評価やより多様なアプリ. ことを示している.また,PVFS 自体は複製の作成をサポートしていないが,Hadoop-PVFS. ケーションによる評価,複製がある場合の評価など,実環境に近い状態での性能評価が挙げ. 側で複製の作成をサポートしている.しかし,PVFS はファイルをストライピングするた. られる. 謝辞 本研究の一部は,情報爆発時代に向けた新しい IT 基盤技術の研究,文部科学省科. め,ネットワークへの負荷が多くなり,台数を増やした場合にスケールしない可能性がある.. MapReduce のようにタスクを分散してデータの近くに配置する仕組みを持った並列アプリ. 学研究費補助金「特定領域研究」(課題番号 21013005) および文部科学省次世代 IT 基盤構. ケーションにおいては,ストライピングはローカリティを有効に使うことが出来ないため適. 築のための研究開発「e-サイエンス実現のためのシステム統合・連携ソフトウェアの研究開. していない.. 発」,研究コミュニティ形成のための資源連携技術に関する研究 (データ共有技術に関する 研究) による.. 7. ま と め. 参. 本稿では HDFS の代わりに Gfarm を使用することを提案し,それを実現するための. 1) 2) 3) 4) 5). Hadoop-Gfarm プラグインを設計,実装し,HDFS と Gfarm の性能比較を行った.最大 15 ノードまでの環境において Gfarm は HDFS よりも約 30%高い書き込み性能,同等の読 み込み性能を示し,grep や sort の MapReduce アプリケーションにおいても同等の性能を 示した.機能面では,POSIX 準拠で汎用的なファイルシステムとして利用できる Gfarm が 有利であり,Hadoop MapReduce のファイルシステムとして Gfarm を使用することは有. 6. 考. 文. 献. Apache: HBase, http://hbase.apache.org/. Apache: HDFS Architecture, http://hadoop.apache.org. Apache: Hive, http://wiki.apache.org/hadoop/Hive. Apache: Pig, http://wiki.apache.org/hadoop/pig. Ben Langmead, Michael C Schatz, Jimmy Lin, Mihai Pop and Steven L Salzberg: Searching for SNPs with cloud computing, Genome Biol 2009, 10:R134 (2009).. c 2010 Information Processing Society of Japan ⃝.
(7) Vol.2010-HPC-126 No.4 2010/8/3. 情報処理学会研究報告 IPSJ SIG Technical Report. 6) Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber: Bigtable: A Distributed Storage System for Structured Data, OSDI’06 (2006). 7) Jeffrey Dean, Sanjay Ghemawat: MapReduce: Simplified Data Processing on Large Clusters, OSDI04 (2004). 8) Kosmos: CloudStore, http://kosmosfs.sourceforge.net. 9) Osamu Tatebe, Noriyuki Soda, Youhei Morita, Satoshi Matsuoka, Satoshi Sekiguchi: Gfarm v2: A Grid file system, Proceedings of CHEP 04 (2004). 10) Owen O Malley and Arun C. Murthy: Winning a 60 Second Dash with a Yellow Elephant (2009). 11) Philip H. Carns, Iii, Robert B. Ross, and Rajeev Thakur: Pvfs: a parallel file system for linux clusters, In ALS 00: Proceedings of the 4th annual Linux Showcase and Conference (2000). 12) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung: The Google File System, 19th ACM Symposium on Operating Systems Principles (2003). 13) Services, A.W.: S3, https://s3.amazonaws.com/. 14) Szeredi, M.: Filesystem in USEr space, http://sourceforge.net/projects/avf (2003). 15) Wittawat Tantisiriroj, Swapnil Patil, and Garth Gibson: Data-intensive file systems for internet services: A rose by any other, CMU-PDL-08-114 (2008).. 7. c 2010 Information Processing Society of Japan ⃝.
(8)
図

関連したドキュメント
られてきている力:,その距離としての性質につ
停止等の対象となっているが、 「青」区分として、観光目的の新規入国が条件付きで認めら
トルコ石がいつの頃から人々の装飾品とし て利用され始めたのかはよく分かっていない が、考古資料をみると、古代中国では
システムであって、当該管理監督のための資源配分がなされ、適切に運用されるものをいう。ただ し、第 82 条において読み替えて準用する第 2 章から第
創業当時、日本では機械のオイル漏れを 防ぐために革製パッキンが使われていま
あれば、その逸脱に対しては N400 が惹起され、 ELAN や P600 は惹起しないと 考えられる。もし、シカの認可処理に統語的処理と意味的処理の両方が関わっ
Google マップ上で誰もがその情報を閲覧することが可能となる。Google マイマップは、Google マップの情報を基に作成されるため、Google
また自分で育てようとした母親達にとっても、女性が働く職場が限られていた当時の
