交通シーンのエピソード記憶に基づく
安全予測モデルの構築
― 平成 27 年度(本報告) タカタ財団助成研究論文 ―
ISSN 2185-8950
研究実施メンバー
研究代表者
秋田県立大学 システム科学技術学部
准教授
間所
洋和
研究協力者
秋田県立大学 システム科学技術学部
寺田
裕樹
秋田県立大学 システム科学技術学部
佐藤
和人
秋田県立大学 システム科学技術学部
下井
信浩
報告書概要
本研究では,長期記憶と位相写像を扱う機械学習アルゴリズムを用いて,運転シーンのエ ピソード記憶化を試みた.提案手法は,安定性と可塑性を併せ持ち時系列データに対して追 加的に学習と記憶が行える適応共鳴理論,自己写像特性により空間的な位相関係を可視化す る自己組織化マップ,入力特徴と教示信号を対向させてラベル付けが行える対向伝搬ネット ワークから構成されており,運転時における走行シーン画像と運転者の顔画像を,コンテク スト情報として追加的に学習することにより,カテゴリマップとして学習データの関係性を 可視化する.ドライビングシミュレータを用いた予備実験では,視線と顔の向きを計測し, 運転者の顔から発せられる情報について比較した.また,ヒヤリハットと注意散漫状態を擬 似的に作成することにより,運転時の視線と顔向きに与える影響を定量化した.実車による 評価実験では,2 カメラ式のドライブレコーダを用いて取得した画像データセットから,運 転シーンのエピソード化を試みた.一般道や高速道路などの走行シーンに応じて,カテゴリ マップにより運転特性を可視化した.また,ヒヤリハット事象を含む独自のデータセットを 構築するとともに,カテゴリマップでのヒヤリハットの位置付けを表現した.カテゴリマッ プのみからヒヤリハットを含む特異的な事象をエピソードとして抽出するまでには至らなか ったものの,走行シーンや運転者に応じて,多様なカテゴリマップを形成する枠組みを提供 した.目 次
交通シーンのエピソード記憶に基づく安全予測モデルの構築 1 はじめに ... 1 2 画像特徴の抽出 ... 2 2.1 顕著性マップ... 2
2.1.1 ガウシアンピラミッド ... 3 2.1.2 特徴マップの生成 ... 4 2.1.3 顕著性マップの出力 ... 4 2.1.4 プロトオブジェクト ... 4 2.2 AKAZE 特徴量... 5
2.2.1 スケールスペース ... 5 2.2.2 特徴点の検出 ... 6 2.2.3 特徴量の記述 ... 6 2.3 顔検出... 6
2.3.1 Haar-Like 特徴 ... 7 2.3.2 AdaBoost ... 7 2.3.3 カスケード構造 ... 8 2.4 Gabor Wavelets... 8
3 カテゴリマップ構築法 ... 9 3.1 ネットワーク構成... 9
3.2 コードブックモジュール... 10
3.3 ラベリングモジュール... 11
3.4 マッピングモジュール... 12
4 DS を用いた予備実験 ... 14 4.1 計測環境... 14
4.2 実験条件... 15
4.3 運転の主観的評価
... 15
4.4 視線及び顔向きの分布特性... 16
4.5 注意散漫状態における運転特性... 17
5 実車画像を用いた評価実験 ... 18 5.1 実験装置... 18
5.2 実験条件... 18
5.3 特徴抽出結果... 19
5.4 分類粒度の検討... 21
5.5 カテゴリマップの生成結果... 21
5.6 ヒヤリハットデータによる結果... 23
6 まとめと今後の課題 ... 251
1 はじめに
人間は,交通環境に応じて安全知識を切り替え運転している.例えば,公園や学校の付近 では,歩行者の飛び出しや自転車などの行動に細心の注意を払っている.また,高速道路や 自動車専用バイパス道路では,高速に移動する周囲の車両や,変化の少ない景観に対して, 眠気に襲われないように注意しながら運転している.このように,安全を確保するための予 測モデルは,交通環境や交通シーンに応じて柔軟に切り替える必要がある.また我々は,過 去の経験や体験などの経験知に加えて,家族や知人などの体験談,テレビや新聞などのニュ ース,教習所や免許センターなどでの講習を通じた集合知[1]を得ることによって,安全知識 を高め,危険予測や状況判断を行っている.しかしながら,現在の工学的手法による予測モ デルでは,センシング情報から得られる履歴データから,統計情報や確率モデルを使って事 象を予測するのが限界である. 近年,研究が活発化している脳科学分野では,行動予測や意図理解に関する研究が盛んに 行われている.脳科学の知見によると,人間は,未来の出来事を予測するために記憶を蓄積 し,整理・編集していることが示されている[2].特に,未来予測には,対象シーンにおける 文脈(コンテクスト)と感情が出来事(エピソード)として結び付いたエピソード記憶[3] の寄与率が高いと言われている[4].エピソード記憶の工学的モデルは,前野[5]がロボット の心の作り方として,受動意識仮説に基づくモデルを提案しており,基本概念の提案に加え て,思考実験による結果が示されている. 本研究では,長期記憶と位相写像を扱うニューラルネットワークを用いて,エピソード記 憶を工学的に実現し,記憶に基づく安全予測モデルの構築を目指す.具体的には,時系列デ ータに対して安定性と可塑性を兼ね備えながら追加的に学習と記憶が行える適応共鳴理論 (Adaptive Resonance Theory: ART)[6],自己写像特性を用いて空間的な位相関係をマップ 表現する教師なしニューラルネットワークの自己組織化マップ(Self-Organizing Maps: SOM) [7],入力特徴と教示信号を対向させてラベル付けが行える対向伝搬ネットワーク(Counter Propagation Networks: CPN)[8]の 3 種類の機械学習アルゴリズムに着目し,交通シーンに 応じた安全予測モデルを構築するための記憶モデルとしてエピソード記憶を実現する.提案 モデルでは,運転者の視界方向と運転者の顔表情を撮影する視覚センサから得られた入力を, SOM により文脈情報としてのコンテクストマップと感情を対応付ける表情空間マップを構築 し,両マップの発火状態から,ART に形成される長期記憶を形成し,エピソード記憶へと展 開する. 現在,自動運転車の実現[9]に向けて,自動車メーカや大学,研究所,大手インターネット 関連サービス会社などが鎬を削りながら,活発な研究開発競争が繰り広げられている[10]. 自動運転のための車外センシングは,ステレオカメラやミリ波レーダ,レーザレンジファイ ンダなどを用いることにより,広範囲かつ高精度に計測することができる.また,専用の処 理装置を用いることにより,実時間でのセンシングと処理結果の利用ができる.このように, 車外センシングに関しては,日進月歩で性能が向上している.一方,車内センシングに関し ては,居眠り運転や脇見運転の検出[11,12],注意散漫状態の検出[13,14],表情からの状 態推定[15,16]などの研究が進められているものの人間をセンシング対象とする場合には, 個人差の影響への対応,再現性の確保,計測対象が時間の流れとともに変化することなど,2
車外センシングと比較して,解決しなればならない課題が多数残されている[17].また,現 状は,車外センシングと車内センシングは独立して実施されており,両者を有機的に結び付 けた研究事例は少ない.
本研究では,車外と車内の同時センシングに着目し,2 カメラ式のドライブレコーダ(Event Data Recorder: EDR)を用いて,運転シーンのエピソード記憶モデルの構築を目的とする. レーンの追跡や運転手の不注意を検出するために,運転者の視線に着目して,車外センシン グと同期させた研究[18,19]は報告されているものの,EDR のような簡易な計測装置を用い た車内外の同時センシングの研究は,これまで報告されていない.また,シーン画像からコ ンテクストを生成し理解する研究と顔画像から表情を認識する研究は,コンピュータビジョ ンの研究分野において個別に取り組まれているが,両者を同時に扱い,その発展形としてエ ピソード記憶へと結び付ける研究はこれまで報告されておらず,本研究が初の試みとなる. 本論文の構成は,2 章と 3 章において,特徴抽出と機械学習に基づく提案手法を示す.4 章 では,3 画面式のドライビングシミュレータ(Driving Simulator: DS)を用いて,ヒヤリハ ット遭遇時や注意散漫状態での顔計測について検討する.実車両による評価実験として,5 章では,提案手法を用いてカテゴリマップとしてエピソード記憶モデルのプロトタイプを示 すとともに,3 台の車両で夏と冬の 2 期間に撮影した EDR の映像の中から,ヒヤリハット事 例を抜き出して,カテゴリマップとして可視化して分析する.最後に,6 章において,本研 究の成果と今後の課題を述べる.
2
画像特徴の抽出
提案手法の全体構成を図 1 に示す.2 カメラ式のドライブレコーダを用いて,車外と車内 の映像を同時に取得する.車外に向けられたカメラは,顕著性マップを用いて視覚的顕著度 の高い領域に対して,局所特徴量を抽出する.局所特徴量の記述には,AKAZE を用いた.車 内向けのカメラは,Harr-like 特徴と Boosting を用いた Vila-Jones の手法を用いて顔領域 を検出し,Gabor wavelets を用いて特徴量を記述する. 2.1 顕著性マップ 人間は,視覚から得られる多種多様な情報を処理し,認識や理解,判断に結びつけている. しかしながら,目に映る全ての対象を瞬時に把握している訳ではなく,注目すべき対象のみ に,無意識に注意を引くような仕組みが備わっている.Itti ら[20]によって考案された顕著 図1: 提案手法の全体構成.3 性マップは,このような注視のメカニズムを工学的にモデル化した手法である. 顕著性マップの主な処理手順は,始めに入力画像からピラミッド画像を作成し,ガウシア ンフィルタにより特徴を抽出する.続いて,色相,輝度,方向の各成分の画像を作成し,中 心視野と周辺視の組み合わせにより,各成分の視覚的特徴を表す特徴マップ(Feature Maps: FM)を作成する.FM の線形和を取ることにより,顕著性マップが作成される.本研究では, 顕著性マップから顕著度の高い領域を用いるが,領域ではなく座標とする場合には,勝者総 取り方式の WTA(Winner Take All)が施される.
2.1.1 ガウシアンピラミッド 始めに,入力画像に対して 1/2 ずつスケールを変化させ,1/256 までのピラミッド画像を 作成し,ガウシアンフィルタを施す.これは低周波数成分だけを増幅させて高周波領域をカ ットする低域フィルタとして作用する.フィルタの範囲を大きくするほどフーリエ変換の幅 は狭くなるため,低周波領域が強調される.その後,原画像をこの画像に重ねて,ガウシア ンピラミッドを作成する.次にガウシアンピラミッドに対して,輝度成分,色相成分,方向 成分を抽出する.赤成分𝑅𝑅,緑成分𝐺𝐺,青成分𝐵𝐵としたとき,輝度成分𝐼𝐼は, 𝐼𝐼 =𝑅𝑅 + 𝐺𝐺 + 𝐵𝐵3 , (1) となる.色相成分では,𝑅𝑅𝐺𝐺𝐵𝐵成分に加えて,黄色成分𝑌𝑌を抽出する. 𝑌𝑌 =𝑅𝑅 + 𝐺𝐺2 −|𝑅𝑅 − 𝐺𝐺|2 − 𝐵𝐵, (2) ガボールフィルタ𝐺𝐺の方向成分𝑂𝑂の角度θは,0,45,90,135 deg の 4 方向に対して算出す る.画像上の座標 (𝑥𝑥, 𝑦𝑦)における𝐺𝐺は,正弦波とガウス関数の積[44]として,次式により定義 される. 𝐺𝐺(𝑥𝑥, 𝑦𝑦) = 𝑒𝑒𝑥𝑥𝑒𝑒 �−12 �𝑅𝑅𝜎𝜎𝑥𝑥2 𝑥𝑥2+ 𝑅𝑅𝑦𝑦2 𝜎𝜎𝑦𝑦2�� 𝑒𝑒𝑥𝑥𝑒𝑒 �𝑖𝑖 2𝜋𝜋𝑅𝑅𝑥𝑥 𝜆𝜆 �, (3) 𝑅𝑅𝑥𝑥 = 𝑥𝑥 cos 𝜃𝜃 + 𝑦𝑦 sin 𝜃𝜃, (4) 𝑅𝑅𝑦𝑦 = −𝑥𝑥 sin 𝜃𝜃 + 𝑦𝑦 cos 𝜃𝜃, (5) ここで,𝜆𝜆は波長の余弦成分,𝜎𝜎𝑥𝑥と𝜎𝜎𝑦𝑦は水平軸方向及び垂直軸方向のフィルタサイズを表す. 画像上の傾きを持った線分に対して𝐺𝐺を作用させると,線分の垂直な方向に積分値が最大とな り,傾きとその周波数成分が算出される.フィルタのサイズを𝑀𝑀×𝑁𝑁画素とすると,対象画像 のサンプル点𝑃𝑃(𝑥𝑥, 𝑦𝑦)のフィルタ出力𝑍𝑍(𝑥𝑥, 𝑦𝑦)は, 𝑍𝑍(𝑥𝑥, 𝑦𝑦) = � � 𝐺𝐺(𝑥𝑥 + 𝑖𝑖, 𝑦𝑦 + 𝑗𝑗)𝑃𝑃(𝑥𝑥 + 𝑖𝑖, 𝑦𝑦 + 𝑗𝑗), 𝑀𝑀 2 𝑖𝑖=−𝑀𝑀2 𝑁𝑁 2 𝑗𝑗=−𝑁𝑁2 (6) で表される.なお,𝑍𝑍(𝑥𝑥, 𝑦𝑦)は複素項を含むため,最終出力は次式となる. 𝑍𝑍 = �𝑅𝑅𝑚𝑚2+ 𝐼𝐼𝑚𝑚2. (7)
4 2.1.2 特徴マップの生成 ガウシアンピラミッドによって得られたスケールの異なる画像ペアから差分を算出し,そ れらを重ね合わせることで,注視位置を特定する.この操作は,視野の中心と周辺の特徴差 を抽出する処理になり,演算子⊝で表す.差分を取る際は,スケールの大きい側𝑐𝑐,小さい側 𝑠𝑠 が 個 別 に 扱 わ れ る . ス ケ ー ル の 各 番 号 を 𝑐𝑐, 𝑠𝑠(𝑐𝑐 < 𝑠𝑠) と す る と , 𝑐𝑐 = 2, 3, 4, 𝑠𝑠 = {𝑐𝑐 + 𝛿𝛿|𝛿𝛿 ∈ {3, 4}}となる.𝐼𝐼に対する差分は,次式で与えられる 𝐼𝐼(𝑐𝑐, 𝑠𝑠) = |𝐼𝐼(𝑐𝑐) ⊖ 𝐼𝐼(𝑠𝑠)|, (8) 色相成分は,𝑅𝑅と𝐺𝐺,𝐵𝐵と𝑌𝑌の差分を取る. 𝑅𝑅𝐺𝐺(𝑐𝑐, 𝑠𝑠) = ��𝑅𝑅(𝑐𝑐) − 𝐺𝐺(𝑐𝑐)� ⊖ �𝐺𝐺(𝑠𝑠) − 𝑅𝑅(𝑠𝑠)��, (9) 𝐵𝐵𝑌𝑌(𝑐𝑐, 𝑠𝑠) = ��𝐵𝐵(𝑐𝑐) − 𝑌𝑌(𝑐𝑐)� ⊖ �𝑌𝑌(𝑠𝑠) − 𝐵𝐵(𝑠𝑠)��. (10) 𝑂𝑂は,𝜃𝜃をパラメータとして差分を取る. 𝑂𝑂(𝑐𝑐, 𝑠𝑠, 𝜃𝜃) = |𝑂𝑂(𝑐𝑐, 𝜃𝜃) ⊖ 𝑂𝑂(𝑠𝑠, 𝜃𝜃)|. (11) 輝度成分が 6 枚,色相成分が 12 枚,方向成分が 24 枚の,合計 42 枚の FM が得られる. 2.1.3 顕著性マップの出力 各 FM に対して,マップ内での最大値𝑀𝑀を探索し,[0 … 𝑀𝑀]の範囲に正規化する.この際,𝑀𝑀以外 の極大値を全て抽出して,平均値𝑚𝑚を求め,全ての値に(𝑀𝑀 − 𝑚𝑚)2を乗算する. 輝度成分𝐼𝐼̅,色相成分𝐶𝐶̅,方向成分𝑂𝑂�の FM に対して個々に正規化し,マップの重ね合わせ処 理を行う.線形和を行う各マップの大きさは異なるため,差分の時と同様に小さい側を拡大 処理してピクセル毎に加算する.𝐼𝐼̅,𝐶𝐶̅,𝑂𝑂�の線形和は,次式で与えられる. 𝐼𝐼 = ⨁𝑐𝑐=24 ⨁𝑐𝑐=4𝑠𝑠=𝑐𝑐+3𝑁𝑁�𝐼𝐼(𝑐𝑐, 𝑠𝑠)�, (12) 𝐶𝐶̅ = ⨁𝑐𝑐=24 ⨁𝑐𝑐=4𝑠𝑠=𝑐𝑐+3�𝑁𝑁�𝑅𝑅𝐺𝐺(𝑐𝑐, 𝑠𝑠)� + 𝑁𝑁�𝐵𝐵𝑌𝑌(𝑐𝑐, 𝑠𝑠)��, (13) 𝑂𝑂� = � 𝑁𝑁 �⨁𝑐𝑐=24 ⨁𝑐𝑐=4𝑠𝑠=𝑐𝑐+3𝑁𝑁�𝑂𝑂(𝑜𝑜, 𝑐𝑐, 𝜃𝜃)��. 𝜃𝜃 (14) ここで,𝑁𝑁(∙)は正規化を表す.各成分に対して再度正規化し,全ての FM の線形和を取ること により,顕著性マップ𝑆𝑆が得られる. 𝑆𝑆 =1 3{𝑁𝑁(𝐼𝐼̅) + 𝑁𝑁(𝐶𝐶̅) + 𝑁𝑁(𝑂𝑂�)}. (15) 最後に,WTA により𝑆𝑆から顕著性の高い座標を注視点として取得するが,本研究では判別分析 に基づく大津法[21]により 2 値化した𝑆𝑆をマスク画像として,顕著度の高い領域を用いた. 2.1.4 プロトオブジェクト 本研究で用いた顕著性マップには,プロトオブジェクトの概念が導入されており,物体に 対して特異的に反応するメカニズムが組み込まれている[22].プロトオブジェクトは, Rensink ら[23,24,25]によって,事前注意段階における物体の候補に対応するために,コ ヒーレンス理論に基づいて考案された.コヒーレンス理論では,人間の視覚システムにおけ る顕著領域の検出は,2 段階に分けてモデル化されている.
5 1 段階目は,100ms 以内の並列かつ高速に作用する単純な事前注視である.2 段階目は,直 列に低速かつ複雑な注視である.このうち,事前注意の処理特性は,方向,エッジ,輝度成 分などの特定の低レベル特徴量を自動的に抽出している[26,27].この時,3 次元の方向成 分,エッジ成分,輝度成分がシーンの局所集合を構造情報として抽出され,プロトオブジェ クトとなる.同時に,プロトオブジェクトは,時間的制約を受けて,空間内の局所領域に凝 縮される.時系列に処理されていく中で,抽出されたプロトオブジェクトは,他のプロトオ ブジェクトの抽出に遷移する.また,置換の法則に基づく重ね合せを経て,網膜に新しい刺 激として置換される. プロトオブジェクトへの遷移と復帰は,連続的に処理される.また,少数のプロトオブジ ェクトを理解するエビデンスとして作用する.この過程で,複数のプロトオブジェクトと中 間レベルの因果関係とを低レベル情報として収集する.その後,フィードバックを介して, 高レベル層でのオブジェクトを決定する基礎として用いられる.プロトオブジェクトにより 抽出される領域は,短時間の干渉を受けても,顕著度の高い個体として維持することができ る.注目が外れた後,プロトオブジェクトの候補の集団に戻り,再び遷移と復帰を繰り返す. これらの位置は,視覚探索において,注意の持続効果の欠損を示し,微小時間の視覚記憶の 部位に表出する. 2.2 AKAZE 特徴量 シーンの大局的記述には,Gist 記述子[28]が著名であるが,屋外の自然風景を主な対象と しており記述粒度が粗いため,本研究で対象とするような運転シーンや標識等の物体の記述 には適していない.一般物体認識では,局所特徴量として,SIFT(Scale-invariant feature transform)記述子[29]が広く用いられている.一方,近年,SIFT の性能を上回る KAZE 記述 子[30]が提案され,応用が進んでいる.また,KAZE を高速化した AKAZE(Accelerated KAZE) 記述子[31]は,卓越した記述能力に加えて,実時間処置に適した特徴量として,評価と注目 が高まっている.
2.2.1 スケールスペース
AKAZE は,FED(Fast Explicit Diffusion)を用いて,異方性拡散を考慮した非線形スケ ールスペースを構築している.またスケールスペース演算の高速化のために,微細粒度のピ ラミッドフレームワークが組み込まれており,ロバストな特徴検出と記述が可能になってい る. 非線形となるスケールスペースは,オクターブ𝑂𝑂とサブレベル𝑆𝑆の連続性を利用して離散化 される.両者のサブレベルは,離散化のためのインデックスとなる𝑜𝑜と𝑠𝑠により特定される. これらのインデックスは,画素をパラメータとして,対応するスケールの𝜎𝜎𝑖𝑖に,次式により 写像される. 𝜎𝜎𝑖𝑖(𝑜𝑜, 𝑠𝑠) = 2𝑜𝑜+𝑠𝑠𝑆𝑆, 𝑂𝑂 ∈ [0 … 𝑂𝑂 − 1], 𝑠𝑠 ∈ [0 … 𝑆𝑆 − 1], 𝑖𝑖 ∈ [0 … 𝑀𝑀], (16) ここで,𝑀𝑀は非線形拡散フィルタによって処理された画素の総数を表す.ただし,非線形拡 散フィルタは,時間単位で作用することから,画素単位から時間単位へと変換するために,
6 以下の式を用いる. 𝑡𝑡𝑖𝑖 =12 𝜎𝜎𝑖𝑖2. (17) 加えて,入力画像に標準偏差𝜎𝜎0のガウシアンフィルタで畳み込みを行う.このとき,平滑化 された入力画像から,勾配ヒストグラムの 70%を閾値として,生成パラメータ𝜆𝜆を算出する. 2.2.2 特徴点の検出 非線形スケールスペースの各フィルタ画像𝐿𝐿𝑖𝑖に対して,ヘッセ行列を計算する.マルチス ケール微分演算子の組は,スケールを考慮して正規化される.この際,正規化のスケール尺 度は,非線形スケールスペース内の特定画像の𝑂𝑂が考慮される. 𝐿𝐿𝑖𝑖𝐻𝐻𝐻𝐻𝑠𝑠𝑠𝑠𝑖𝑖𝐻𝐻𝐻𝐻= 𝜎𝜎𝑖𝑖,𝐻𝐻𝑜𝑜𝑛𝑛𝑛𝑛2 �𝐿𝐿𝑖𝑖𝑥𝑥𝑥𝑥𝐿𝐿𝑖𝑖𝑦𝑦𝑦𝑦− 𝐿𝐿𝑖𝑖𝑥𝑥𝑦𝑦𝐿𝐿𝑖𝑖𝑥𝑥𝑦𝑦�, (18) ここで,ステップサイズを𝜎𝜎𝑖𝑖,𝐻𝐻𝑜𝑜𝑛𝑛𝑛𝑛として,Scharr フィルタ[32]を使用する.Scharr フィルタ は,Sobel フィルタや中心差分と比較して,回転に不変である[33].探索空間全体の最大値 を算出しておき,3×3 画素の探索ウィンドウから最大値を取得する.その後,最大値の候補 について,𝜎𝜎𝑖𝑖×𝜎𝜎𝑖𝑖のウィンドウについて𝑖𝑖 + 1から𝑖𝑖 − 1レベルの他のキーポイントに対して, 応答が最大となることを確認する.キーポイントの位置は,3×3 画素の画像近傍において, ヘッセの応答に,2 組の二次導関数を対応させ,最大値を探索する. 2.2.3 特徴量の記述 AKAZE では,非線形スケールスペースから勾配と輝度の情報を利用するために,M-LDB (Modified-Local Difference Binary)が用いられている.LDB は Yang ら[34]により提案さ れた記述子で,2×2,3×3,4×4 のパッチに分割されたグリッドを用いて特徴量を算出する. しかしながら,キーポイントの回転に対しては,計算コストが増大するという問題があった ため,M-LDB では,特徴検出時に使用した導関数を用いて,記述子を生成する操作の回数を 削減[35]している. 2.3 顔検出 本研究では,車内カメラの映像から運転手の顔を検出するために,Viola-Jones 法[36]を 用いた.画像中から任意の対象を検出する処理として,顔検出には様々な手法[37]が提案さ れているが,その中で Viola-Jones 法は,考案された 2001 年当時の一般的なコンピュータに おいて,実時間でビデオ映像に対して処理できる画期的な手法であった.その後,正面顔以 外の検出やオクリュージョンへの対応などの様々な改良が加えられており,顔検出において Viola-Jones 法はディファクトスタンダードになっている.現在では,スマートフォンやタ ブレッド型コンピュータにもアプリケーションとして実装されており,これらのデバイスで も実時間での検出処理が実行できている.Viola-Jones 法による高速処理のメカニズムは, Haar-Like 特徴による単純なパターン特徴と,AdaBoost により構築された識別器のカスケー ド接続による判定処理に由来する.以下では,各要素技術に関して,要点を簡潔に論述する.
7
2.3.1 Haar-Like 特徴
Haar-Like 特徴は,Haar 博士が考案した Harr wavelets[38]に基づく特徴量である.デジ タル画像に適用するためのフィルタ化は,Papageorgiou ら[39]によって基本的な枠組みが提 供された.Papageorgiou らの研究では顔と人物の検出を処理対象としており,判別器には SVM (Support Vector Machines)が用いられていたが,処理速度が課題となっていた.
Haar-Like 特徴では,任意のサイズの探索窓を設定し,その中に 2 種類の格子を配置する. 各格子の総和の差分をフィルタの出力とする,計算コストの小さい単純な特徴量である.探 索ウィンドウ内の格子の組み合わせにより,様々な特徴が得られるが,Viola-Jones 法による 顔検出では,3 種類の組み合わせが使われている.第一の組み合わせでは,ウィンドウ内に 2 個の格子を左右もしくは上下に配置する.この配置では,画像のエッジ成分に沿った特徴が 抽出される.第二の組み合わせでは,ウィンドウ内に 3 個の格子を配置する.同一種類の格 子が,もう一方の格子を挟みこむように置かれるため,挟み込まれた格子の幅に沿った水平 及び垂直方向の線分の特徴が抽出される.第三の組み合わせでは,ウィンドウ内に 4 個の格 子を対角に配置し,対角成分の特徴を抽出する. Viola らによる実装[36]では,探索窓のサイズを 24×24 pixel として,回転や拡大縮小を 加えることにより,初期特徴として 180,000 通りの Haar-Like 特徴量を得ている. 2.3.2 AdaBoost 個々の Haar-Like 特徴がフィルタとして,顔もしくは非顔を判別する識別器を構築するた めに,群学習の Boosting が用いられている.Boosting には様々な学習アルゴリズム[40]が 提案されているが,Freund ら[41]が考案した AdaBoost は,弱識別器の誤差量に応じて適応 的に学習を進めることができるため,高い識別性能に加えて,過剰適応を回避して汎化能力 に優れるという特徴を有している.AdaBoost の学習アルゴリズムを以下に示す. 𝑁𝑁枚の画像𝑥𝑥𝑖𝑖(𝑖𝑖 = 1, . . , 𝑁𝑁)と,各画像における正負サンプル𝑦𝑦𝑖𝑖が,学習データセットとして 与えられる.𝑦𝑦𝑖𝑖は,正サンプル,すなわち顔検出では顔の場合は𝑦𝑦𝑖𝑖 = 1,負サンプルの非顔の 場合は𝑦𝑦𝑖𝑖 = 0を取る.AdaBoost の弱識別器ℎ𝑗𝑗として,結合荷重𝑤𝑤(𝑡𝑡,𝑖𝑖)を𝑦𝑦𝑖𝑖の値に応じて以下の ように初期化する. 𝑤𝑤(1,𝑖𝑖) = �2𝐿𝐿 −1 (𝑦𝑦 𝑖𝑖 = 1), 2𝑀𝑀−1 (𝑦𝑦 𝑖𝑖 = 0). (19) ここで,𝐿𝐿と𝑀𝑀は正と負の場合のデータ数であり,𝑛𝑛とは以下の関係になる. 𝑁𝑁 = 𝐿𝐿 + 𝑀𝑀. (20) 𝑇𝑇個のℎ𝑗𝑗(𝑗𝑗 = 1, . . , 𝑇𝑇)に対して,𝑡𝑡番目の𝑤𝑤(𝑡𝑡,𝑖𝑖)を,次式により正規化する. 𝑤𝑤(𝑡𝑡,𝑖𝑖)=∑ 𝑤𝑤(𝑡𝑡,𝑖𝑖)𝑤𝑤 (𝑡𝑡,𝑗𝑗) 𝐻𝐻 𝑗𝑗=1 . (21) このとき,𝑤𝑤(𝑡𝑡)は確率分布となる.続いて,誤差𝜀𝜀𝑗𝑗を次式により算出し, 𝜀𝜀𝑗𝑗= � 𝑤𝑤𝑖𝑖�ℎ𝑗𝑗(𝑥𝑥𝑖𝑖− 𝑦𝑦𝑖𝑖� 𝑖𝑖 , (22) 𝜀𝜀𝑗𝑗が最小となるℎ𝑡𝑡を検出して,𝑤𝑤(𝑡𝑡,𝑖𝑖)を次式により更新する.
8 𝑤𝑤(𝑡𝑡+1,𝑖𝑖) = 𝑤𝑤(𝑡𝑡,𝑖𝑖)𝛽𝛽𝑡𝑡1−𝐻𝐻𝑖𝑖. (23) 𝛽𝛽𝑡𝑡 =1 − 𝜀𝜀𝜀𝜀𝑡𝑡 𝑡𝑡 . (24) ここで,𝑒𝑒𝑖𝑖は,𝑥𝑥𝑖𝑖が分類に成功した場合は 0,失敗した場合は 1 を取る.上記の処理を繰り返 し,最終的に𝑥𝑥に対する強識別器ℎ𝑥𝑥が得られる. ℎ𝑥𝑥 = �10 𝑜𝑜𝑡𝑡ℎ𝑒𝑒𝑒𝑒𝑤𝑤𝑖𝑖𝑠𝑠𝑒𝑒𝑖𝑖𝑖𝑖 ,� 𝛼𝛼𝑡𝑡ℎ𝑡𝑡(𝑥𝑥) ≥12 � 𝛼𝛼𝑡𝑡, 𝑇𝑇 𝑡𝑡=1 𝑇𝑇 𝑡𝑡=1 (25) 𝛼𝛼𝑡𝑡= log𝛽𝛽1 𝑡𝑡 . (26) 2.3.3 カスケード構造 学習データを𝑈𝑈個のグループに分割して,ℎ(𝑥𝑥,𝑢𝑢)(𝑢𝑢 = 1, . . , 𝑈𝑈)を生成し,順に顔・非顔を判定 する.任意の画像の位置が顔と判定されるには,𝑈𝑈個のℎ(𝑥𝑥,𝑢𝑢)が全て顔と判定しなければならな い.個々のℎ(𝑥𝑥,𝑢𝑢)は,真陽性が高くなるように学習させるが,投票方式ではなく全会一致方式を 取ることにより,偽陽性と偽陰性を回避できる.また,処理の実装では,ℎ(𝑥𝑥,𝑢𝑢)を一列に並べて 順に判定させるカスケード構造として,途中で非顔の判定が出た場合には,その地点で処理を 打ち切ることができる.早い段階で非顔として処理を打ち切ることにより,高速化が図れる. なお,Viola らの原著論文[36]では,カスケード構造を 38 層として実装されている. 2.4 Gabor Wavelets
網膜によって捕らえられた視覚情報は,外側膝状体(Lateral Geniculate Nucleus; LGN) を経由して後頭葉の一次視覚野(Primary Visual Cortex; Visual Area I; V1)に伝えられ る[42].V1 は,大きく分けて単純型細胞と複雑型細胞の 2 種類の視覚細胞から構成されてい る.LGN や V1 の単純型細胞には,受容野と呼ばれる特定の刺激に反応する視野範囲が存在す る.受容野は,特定の図形の大きさや長さ,傾き(方位),運動方向,色,周波数などに対し て選択的に反応する.これは反応選択性と呼ばれる.Hubel と Wiesel[43]が,麻酔下のネコ を用いた電気生理学実験から受容野に呈示された特定の方位を持つ線分に選択的に応答する ことを発見して以来,反応選択性の中でも方位選択性が注目されるようになった[44].反応 選択性の工学的モデルとしては,内部パラメータによって任意の特徴を強調できる Gabor Wavelets の情報表現が類似した特性を持つことが示されており,コンピュータビジョンや画 像処理などの様々な分野で応用されている. Gabor Wavelets は,平面上を一方向に伝わる平面波とガウス曲面とを積算したフィルタで ある.波長を𝜆𝜆,ガウス窓の水平軸方向及び垂直軸方向の大きさをそれぞれ𝜎𝜎𝑥𝑥,𝜎𝜎𝑦𝑦,平面波の 進行方向と x 軸とがなす角度を𝜃𝜃とすると,フィルタは次式で与えられる. 𝐺𝐺(𝑥𝑥, 𝑦𝑦) = 𝑒𝑒𝑥𝑥𝑒𝑒 �−12 �𝑅𝑅𝜎𝜎𝑥𝑥2 𝑥𝑥2+ 𝑅𝑅𝑦𝑦2 𝜎𝜎𝑦𝑦2�� 𝑒𝑒𝑥𝑥𝑒𝑒 �𝑖𝑖 2𝜋𝜋𝑅𝑅𝑥𝑥 𝜆𝜆 �, (27) �𝑅𝑅𝑅𝑅𝑥𝑥 = 𝑥𝑥cos 𝜃𝜃 + 𝑦𝑦sin 𝜃𝜃 , 𝑦𝑦= − 𝑥𝑥sin 𝜃𝜃 + 𝑦𝑦cos 𝜃𝜃 . (28)
9 オイラーの公式𝑒𝑒𝑥𝑥𝑒𝑒(𝑖𝑖𝜃𝜃) = cos 𝜃𝜃 + 𝑖𝑖 sin 𝜃𝜃を適用すると, 𝐺𝐺(𝑥𝑥, 𝑦𝑦) = 𝑒𝑒𝑥𝑥𝑒𝑒 �−12 �𝑅𝑅𝜎𝜎𝑥𝑥2 𝑥𝑥2+ 𝑅𝑅𝑦𝑦2 𝜎𝜎𝑦𝑦2�� cos � 2𝜋𝜋𝑅𝑅𝑥𝑥 𝜆𝜆 � +𝑖𝑖𝑒𝑒𝑥𝑥𝑒𝑒 �−12 �𝑅𝑅𝜎𝜎𝑥𝑥2 𝑥𝑥2+ 𝑅𝑅𝑦𝑦2 𝜎𝜎𝑦𝑦2�� sin � 2𝜋𝜋𝑅𝑅𝑥𝑥 𝜆𝜆 �, (29) となる.𝐺𝐺(𝑥𝑥, 𝑦𝑦)は複素項を含むため, 𝑍𝑍 = �𝑅𝑅𝑚𝑚2+ 𝐼𝐼𝑚𝑚2, (30) が最終出力となる.𝜎𝜎𝑥𝑥,𝜎𝜎𝑦𝑦の最適値については,それぞれが𝜆𝜆の関数であることから, �𝜎𝜎𝑥𝑥 = 𝑆𝑆𝑥𝑥𝜆𝜆, 𝜎𝜎𝑦𝑦= 𝑆𝑆𝑦𝑦𝜆𝜆, (31) となる.なお,𝑆𝑆𝑥𝑥及び𝑆𝑆𝑦𝑦は係数である.
3 カテゴリマップ構築法
3.1 ネットワーク構成 本研究では,適応的かつ追加的に系列データを学習し,カテゴリマップとして可視化する 手法として,適応的カテゴリ写像ネットワーク(Adaptive Mapping Networks: AMN)[45]を 用いた.AMN のネットワーク構造を図 2 に示す.AMN は,入力データをベクトル量子化するコ ードブックモジュール,カテゴリの候補となるラベルを適応的かつ追加的に生成するラベリ ングモジュール,そしてカテゴリの空間的な関係性をカテゴリマップとして可視化するマッ ピングモジュールの 3 モジュールから構成される.各モジュールは,SOM [7],ART [6],CPN [8]を基礎として構築している.SOM と ART は教師なし,CPN は教師ありを主体とした学習方 式であるが,カテゴリの候補ラベルを生成する独自のメカニズムにより,両モードでの学習 を実現している. 図2: 適応的カテゴリ写像ネットワークの全体構成.10 3.2 コードブックモジュール コードブックの作成には,k-means[47]が広く用いられている[46].一方,Vesanto らは, k-means を代表とする古典的クラスタリング法と比較して,SOM によるクラスタリングは優位 な性能を示すことを,実験的に検証している[48].また,寺島らは,k-means と比較して SOM がクラスタリングにおいて誤認識率が低下することを定量的に示している[49].よってコー ドブックを作成する本モジュールは,SOM を用いて構築した. 近傍と競合の概念により,教師なし学習による自己写像特性を通じて,SOM は特徴が類似 するデータの集合を形成する.SOM のネットワークは,入力層とマッピング層の 2 層から構 成される.入力層には,入力データの特徴次元数と同じ数のユニットが割り当てられる.入 力データを自己写像するマッピング層は,低次元空間に配置されたユニット群から構成され る. コードブックの作成では,クラスタリングによるベクトル量子化となるため,マッピング層 は 1 次元に配置した.入力データに対して,マッピング層のいずれかひとつのユニットが発 火するように学習が行われる. SOM の学習アルゴリズムを以下に示す.時刻𝑡𝑡において,入力層のユニット𝑖𝑖に提示されるデ ータを𝑥𝑥𝑖𝑖𝑐𝑐𝑛𝑛(𝑡𝑡),ユニット𝑖𝑖からマッピング層のユニット𝑗𝑗への結合荷重を𝑤𝑤𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)とする.ここ で,入力層とマッピング層の総ユニット数を𝐼𝐼,𝐽𝐽とする.学習に先立ち,𝑤𝑤𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)はランダム に初期化しておく.𝑥𝑥𝑖𝑖𝑐𝑐𝑛𝑛(𝑡𝑡)と𝑤𝑤𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)のユークリッド距離が最小となる勝者ユニットを探索し, そのインデックスを𝑐𝑐とする. 𝑐𝑐 = argmin 1≤j≤J �� �𝑥𝑥𝑖𝑖 𝑐𝑐𝑛𝑛(𝑡𝑡) − 𝑤𝑤 𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)� 2 𝐼𝐼 𝑖𝑖=1 . (32) 勝者ユニット𝑐𝑐を中心に,結合荷重を更新する範囲として,近傍サイズ𝑁𝑁𝑐𝑐(𝑡𝑡)を次式により算 出する. 𝑁𝑁𝑐𝑐(𝑡𝑡) = �𝜇𝜇 ∙ 𝐽𝐽 ∙ �1 −𝑂𝑂� + 0.5�𝑡𝑡 . (33) ここで,𝜇𝜇(0 < 𝜇𝜇 < 1.0)は近傍領域の初期サイズを規定するための係数,𝑂𝑂は学習回数である. 係数の 0.5 は,床関数において四捨五入となるように付した. 次に,𝑁𝑁𝑐𝑐(𝑡𝑡)の内部に位置する𝑤𝑤𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)を,入力データの特徴パターンに漸近するように,次 式により更新する. 𝑤𝑤𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡 + 1) = 𝑤𝑤 𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡) + 𝛼𝛼(𝑡𝑡) �𝑥𝑥𝑖𝑖𝑐𝑐𝑛𝑛(𝑡𝑡) − 𝑤𝑤𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)�. (34) ここで,𝛼𝛼(𝑡𝑡)は学習率係数であり,学習の進行と共にその値を減少させる.時刻𝑡𝑡における𝛼𝛼(𝑡𝑡) は,次式により与えられる. 𝛼𝛼(𝑡𝑡) = α(0) ∙ �1 − 𝑡𝑡 𝑂𝑂�. (35) 学習の初期段階では,𝛼𝛼(𝑡𝑡)を大きく取ることで,結合荷重の更新幅を大きくし,学習の進行 を加速させる.学習の後半は,係数が小さくなることで,学習が収束に向かう.
11 本モジュールにより𝐼𝐼次元の入力データは,マッピング層とユニット数と同じ次元の𝐽𝐽次元 に量子化される.モジュールの出力𝑦𝑦𝑖𝑖𝑐𝑐𝑛𝑛(𝑡𝑡)は,以下のように算出される. 𝑦𝑦𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡) = �� �𝑥𝑥𝑖𝑖𝑐𝑐𝑛𝑛(𝑡𝑡) ∙ 𝑤𝑤𝑖𝑖,𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)� 𝐼𝐼 𝑖𝑖=1 2 . (36) なお,本モジュールは,学習時はラベリングモジュールと接続しており,テストデータの 入力があった場合には,マッピングモジュールへと接続を切り替える.また,入力データを コードブック化せずに直接用いる場合は,前述の通り本モジュールはバイパスする. 3.3 ラベリングモジュール ラベリングモジュールは,カテゴリの候補となるラベルを生成する.本手法では,時系列 データに対して安定性と可塑性を保ちながら適応的かつ追加的にラベルを形成する教師なし ニューラルネットワークの ART を用いて本モジュールを構成する. ART には多数の派生形[50]が提案されているが,本研究では連続値が入力できる ART-2[6] を用いた.ART-2 のネットワークは,特徴表現層の F1 と,カテゴリ表現層の F2 から構成さ れる.F1 は,6 層のサブレイヤ𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛,𝑞𝑞𝑗𝑗𝑙𝑙𝑛𝑛,𝑢𝑢𝑗𝑗𝑙𝑙𝑛𝑛,𝑣𝑣𝑗𝑗𝑙𝑙𝑛𝑛,𝑤𝑤𝑗𝑗𝑙𝑙𝑛𝑛,ℎ𝑗𝑗𝑙𝑙𝑛𝑛から構成されており,入力デ ータが各サブレイヤを遷移することによって,短期記憶(Short Term Memory: STM)を実現 する.STM はノイズ除去と特徴強調を行う.F2 には,位相の強弱により長期記憶(Long Term Memory: LTM)としてカテゴリが形成される.LTM はユニット単位で生成され,独立したラベ ルが割り振られる. F2 のユニット𝑗𝑗は,F1 のサブレイヤ𝑒𝑒𝑖𝑖と接続されており,トップダウン結合荷重𝑍𝑍𝑘𝑘𝑗𝑗𝑙𝑙𝑛𝑛とボト ムアップ結合荷重𝑍𝑍𝑗𝑗𝑘𝑘𝑙𝑙𝑛𝑛を保持する.結合荷重は,以下の通り初期化される. 𝑍𝑍𝑘𝑘𝑗𝑗𝑙𝑙𝑛𝑛(0) = 0, (37) 𝑍𝑍𝑗𝑗𝑘𝑘𝑙𝑙𝑛𝑛(0) = 1 √𝐾𝐾. (38) ここで,𝐾𝐾は F2 層のユニット数である.次に,コードブックモジュールの出力𝑦𝑦𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)をラベ リングモジュールの入力として提示し,次式により各サブレイヤを伝搬させる. 𝑤𝑤𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) = 𝑦𝑦𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡) + 𝑎𝑎𝑢𝑢𝑗𝑗(𝑡𝑡 − 1), (39) ℎ𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) = 𝑤𝑤𝑗𝑗 𝑙𝑙𝑛𝑛(𝑡𝑡) 𝑒𝑒 + ‖𝑤𝑤‖, (40) 𝑣𝑣𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) = 𝑖𝑖 �ℎ𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡)� + 𝑏𝑏𝑖𝑖 �𝑞𝑞𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡 − 1)�, (41) 𝑢𝑢𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) = 𝑣𝑣𝑗𝑗 𝑙𝑙𝑛𝑛(𝑡𝑡) 𝑒𝑒 + ‖𝑣𝑣‖, (42) 𝑞𝑞𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) = 𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) 𝑒𝑒 + ‖𝑒𝑒‖, (43)
12 𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) = � 𝑢𝑢𝑖𝑖𝑙𝑙𝑛𝑛(𝑡𝑡) (𝑖𝑖𝑛𝑛𝑎𝑎𝑐𝑐𝑡𝑡𝑖𝑖𝑣𝑣𝑒𝑒), 𝑢𝑢𝑖𝑖𝑙𝑙𝑛𝑛(𝑡𝑡) + 𝑑𝑑𝑍𝑍𝐾𝐾𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) (𝑎𝑎𝑐𝑐𝑡𝑡𝑖𝑖𝑣𝑣𝑒𝑒), (44) 𝑖𝑖(𝑥𝑥) = �0 𝑖𝑖𝑖𝑖 0 ≤ 𝑥𝑥 < 𝜃𝜃, 𝑥𝑥 𝑖𝑖𝑖𝑖 𝑥𝑥 ≥ 𝜃𝜃. (45) ここで,𝑎𝑎と𝑏𝑏はフィードバックループ係数,𝑑𝑑は活性時にトップダウン結合荷重の影響を考 慮する係数である.𝜃𝜃は𝑣𝑣𝑗𝑗𝑙𝑙𝑛𝑛におけるノイズ除去を制御するパラメータである.また,𝑒𝑒は分母 がゼロになることを防ぐための係数である. 次に,最大活性化ユニットを探索し,そのインデックスを𝑐𝑐とする. 𝑐𝑐 = argmax 1≤k≤K �� 𝑒𝑒𝑗𝑗 𝑙𝑙𝑛𝑛(𝑡𝑡)𝑍𝑍 𝑗𝑗𝑘𝑘𝑙𝑙𝑛𝑛(𝑡𝑡) 𝑗𝑗 �, (46) 𝑐𝑐に対して,結合荷重を次式により更新する. 𝑍𝑍𝑐𝑐𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡 + 1) = 𝑍𝑍𝑐𝑐𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) + 𝛼𝛼 ∙ �𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) − 𝑍𝑍𝑐𝑐𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡)�, (47) 𝑍𝑍𝑗𝑗𝑐𝑐𝑙𝑙𝑛𝑛(𝑡𝑡 + 1) = 𝑍𝑍 𝑗𝑗𝑐𝑐𝑙𝑙𝑛𝑛(𝑡𝑡) + 𝛼𝛼 ∙ �𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) − 𝑍𝑍𝑗𝑗𝑐𝑐𝑙𝑙𝑛𝑛(𝑡𝑡)�. (48) ビジランスパラメータ𝜌𝜌を用いて,カテゴリへの帰属を判定する. 𝜌𝜌 < 𝑒𝑒 + ‖𝑒𝑒‖, (49) 𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) =𝑢𝑢𝑗𝑗 𝑙𝑙𝑛𝑛(𝑡𝑡) + 𝑠𝑠 ∙ 𝑒𝑒 𝑗𝑗𝑙𝑙𝑛𝑛(𝑡𝑡) 𝑒𝑒 + ‖𝑢𝑢‖ + ‖𝑠𝑠 ∙ 𝑒𝑒‖ . (50) ここで,𝑠𝑠は𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛から𝑒𝑒𝑗𝑗𝑙𝑙𝑛𝑛への伝搬係数,𝛼𝛼は学習率係数であり,両者間には𝑠𝑠 ∙ 𝛼𝛼 (1 − 𝛼𝛼) ≤ 1⁄ の 制約が与えられている. 式(49)が成立しない場合は,選択されたユニットをリセットして,次の活性化ユニットを 探索する.成立する場合は,F1 の変化率が小さくなるまで伝搬と結合荷重の更新を繰り返す. ここで,教師あり学習の場合は,教師信号をラベルとする.教師なし学習の場合は,インデ ックス𝑐𝑐をラベルとして保存する. 3.4 マッピングモジュール 本モジュールでは,学習結果としてカテゴリマップを生成する.本モジュールは,競合と 近傍の概念により,パターンを特定のカテゴリに分類する教師ありニューラルネットワーク である CPN を用いて構成する.CPN のネットワークは,入力層,マッピング層,及び Grossberg 層の 3 層で構成される.入力層とマッピング層は,コードブックモジュールで使用する SOM と同じであるが,Grossberg 層には教師信号が入力される.提案手法では,Grossberg 層に教 師信号を直接提示するのではなく,ラベリングモジュールを構成する ART-2 の F2 に割り振ら れるラベルを教師信号として用いる.このように,CPN と ART-2 を組み合わせることにより, ラベリング処理の自動化を実現している. 教師あり学習として AMN を用いる場合は,F2 のラベルには教師信号と 1 対 1 に対応付くラ
13 ベルが割り振られる.半教師あり学習の場合は,教師信号と対応付くラベルと,ART-2 が追 加的に生成した教師信号を持たないラベルが混在して写像される.教師なし学習の場合は, ART-2 が生成したラベルを用いて学習が行われる.このように,学習モードに応じてラベル 自体の意味は異なるが,本モジュールはラベルという中間的な表現形態を用いることで,い ずれの学習モードにおいても同じ動作で学習することができる. 学習結果はマッピング層のユニットにカテゴリマップとして表現される.カテゴリマップ には,類似度に基づきデータ間の空間関係が可視化される.本手法では,事前にカテゴリ数 の設定を必要とせずに,カテゴリマップを自動生成することができる.また,競合と近傍に 基づく学習プロセスを通じて,冗長なラベルは淘汰される. CPN の学習アルゴリズムを以下に示す.なお,カテゴリマップの可視化性を考慮して,マ ッピング層は 2 次元構造(𝐿𝐿 × 𝑀𝑀ユニット)とする.入力層と Grossberg 層は任意の構造を取 ることができるが,ここでは 1 次元(𝐽𝐽,𝐾𝐾ユニット)として説明する.時刻𝑡𝑡における入力層 ユニット𝑗𝑗から,マッピング層ユニット(𝑙𝑙, 𝑚𝑚)への結合荷重を𝑢𝑢𝑗𝑗,(𝑙𝑙,𝑛𝑛)𝑛𝑛𝑛𝑛 (𝑡𝑡)とする.時刻𝑡𝑡における Grossberg 層ユニット𝑘𝑘から,(𝑙𝑙, 𝑚𝑚)への結合荷重を𝑣𝑣(𝑙𝑙,𝑛𝑛),𝑘𝑘𝑛𝑛𝑛𝑛 (𝑡𝑡)とする.学習に先立ち,結合荷 重はランダムに初期化しておく. マッピングモジュールの入力には,コードブックモジュールの出力𝑦𝑦𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)が与えられる. 𝑦𝑦𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡)と𝑢𝑢𝑗𝑗,(𝑙𝑙,𝑛𝑛)𝑛𝑛𝑛𝑛 (𝑡𝑡)の間のユークリッド距離が最小となる勝者ユニットを探索し,そのインデ ックスを𝑐𝑐(𝑙𝑙, 𝑚𝑚)とする. 𝑐𝑐(𝑙𝑙, 𝑚𝑚) = argmin 1≤l≤L,1≤m≤M𝑑𝑑(𝑙𝑙,𝑛𝑛). (51) 𝑑𝑑(𝑙𝑙,𝑛𝑛)= �� �𝑦𝑦𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡) − 𝑢𝑢 𝑗𝑗,(𝑙𝑙,𝑛𝑛)𝑛𝑛𝑛𝑛 (𝑡𝑡)� 2 , 𝐽𝐽 𝑗𝑗=1 (52) 勝者ユニット𝑐𝑐(𝑙𝑙, 𝑚𝑚)の近傍領域𝑁𝑁𝑐𝑐(𝑙𝑙,𝑛𝑛)(𝑡𝑡)は,次式で与えられる. 𝑁𝑁𝑐𝑐(𝑙𝑙,𝑛𝑛)(𝑡𝑡) = �𝜇𝜇 ∙ (𝐿𝐿, 𝑀𝑀) ∙ �1 −𝑂𝑂� + 0.5�𝑡𝑡 . (53) ここで,𝜇𝜇(0 < 𝜇𝜇 < 1.0)は近傍領域の初期サイズを規定するための係数,𝑂𝑂は学習回数である. 𝑁𝑁𝑐𝑐(𝑙𝑙,𝑛𝑛)(𝑡𝑡)の内部の𝑢𝑢𝑗𝑗,(𝑙𝑙,𝑛𝑛)𝑛𝑛𝑛𝑛 (𝑡𝑡)は,Kohonen の学習アルゴリズムを用いて入力データに近づく ように更新される. 𝑢𝑢𝑗𝑗,(𝑙𝑙,𝑛𝑛)𝑛𝑛𝑛𝑛 (𝑡𝑡 + 1) = 𝑢𝑢𝑗𝑗,(𝑙𝑙,𝑛𝑛)(𝑡𝑡) + ∆𝑢𝑢, (54) ∆𝑢𝑢 = 𝛼𝛼(𝑡𝑡) �𝑦𝑦𝑗𝑗𝑐𝑐𝑛𝑛(𝑡𝑡) − 𝑢𝑢 𝑗𝑗,(𝑙𝑙,𝑛𝑛)𝑛𝑛𝑛𝑛 (𝑡𝑡)�. (55) また,𝑣𝑣(𝑙𝑙,𝑛𝑛),𝑘𝑘𝑛𝑛𝑛𝑛 (𝑡𝑡)は,Grossberg の学習アルゴリズムを用いた教師信号に近づくように更新さ れる. 𝑣𝑣(𝑙𝑙,𝑛𝑛),𝑘𝑘𝑛𝑛𝑛𝑛 (𝑡𝑡 + 1) = 𝑣𝑣(𝑙𝑙,𝑛𝑛),𝑘𝑘𝑛𝑛𝑛𝑛 (𝑡𝑡) + ∆𝑣𝑣, (56) ∆𝑣𝑣 = 𝛽𝛽(𝑡𝑡) �𝑇𝑇𝑘𝑘(𝑡𝑡) − 𝑣𝑣(𝑙𝑙,𝑛𝑛),𝑘𝑘𝑛𝑛𝑛𝑛 (𝑡𝑡)�. (57)
14 ここで,𝑇𝑇𝑘𝑘は前述の通り,ART-2 から与えられる教師信号である.𝛼𝛼(𝑡𝑡)と𝛽𝛽(𝑡𝑡)は,学習率係数 であり,学習の進行とともに減少する.時刻𝑡𝑡における学習率係数は次式により与えられる. �𝛼𝛼𝛽𝛽(𝑡𝑡)� = �(𝑡𝑡) 𝛼𝛼(0)𝛽𝛽(0)� ∙ �1 −𝑂𝑂�𝑡𝑡 , (58) 学習の初期の段階では,学習率係数を大きく取ることで,結合荷重を大きく更新し,学習の 進行を早めている.学習の後半は,学習率係数を小さくすることで,学習を収束に向かわせ ている. 最後に,Grossberg 層のユニット𝑘𝑘に対する𝑣𝑣(𝑙𝑙,𝑛𝑛),𝑘𝑘𝑛𝑛𝑛𝑛 (𝑡𝑡)の最大値として,次式によりカテゴリ 𝐿𝐿𝑘𝑘(𝑡𝑡)を探索する. 𝐿𝐿𝑘𝑘(𝑡𝑡) = argmax (1,1)≤(𝑙𝑙,𝑛𝑛)≤(𝐿𝐿,𝑀𝑀)𝑣𝑣(𝑙𝑙,𝑛𝑛),𝑘𝑘 𝑛𝑛𝑛𝑛 (𝑡𝑡). (59) 全てのユニットのカテゴリを決定することにより,カテゴリマップが生成される.学習によ り構築した判別器に対して,テストデータを入力する.テストデータと特徴パターンの類似 度,すわなちユークリッド距離が最小となるマッピング層のユニットが発火する.そのユニ ットに対応付くカテゴリが CPN の判定結果となる.
4 DS を用いた予備実験
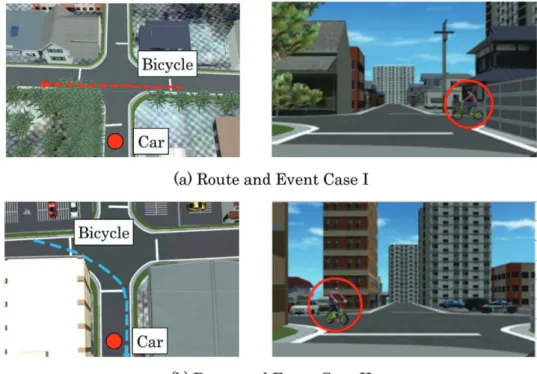
4.1 計測環境 EDR を用いた実車による評価実験に先立ち,運転シーンのエピソード記憶モデルを構築す るための予備検討を目的として,図 3 に示す DS を用いてヒヤリハット遭遇時における評価実 験を実施した.本 DS は 3 画面式で,6 軸モーションに対応して運転席が稼働するため,単画 面で固定座席式の DS より臨場感が高い.顔の計測には,RGB 映像に加えて,赤外線ドット照 射により深度情報が得られる ASUS 社の Xtion pro Live を用いた.また,Seeing Machines 社の眼球運動計測装置 faceLAB を用いて,視線情報を同時に取得した.実車による実験と異 なり,DS を用いることで高度な顔情報の計測が実現できる.また,ヒヤリハット事象を任意 に作成し提示することにより,ヒヤリハット遭遇時の顔情報における変化を抽出することが15 できる.本実験では,注意散漫状態におけるヒヤリハット遭遇時の身体情報の定量化につい ても併せて検討した. 4.2 実験条件 本評価では,図 4 に示す 2 種類のヒヤリハット事象を作成した.両事象とも,見通しの悪 い交差点で発生するヒヤリハットであり,自転車の飛び出しパターンによって,ケース I と ケース II に区分している.ケース I では,運転車両の進行方向を基準として,交差点の右か ら左に向かって直進する自転車が,自動車の前を横切る.ケース II では,交差点の左から自 転車が右に旋回しながら飛び出し,自動車の右横をすり抜けるように後方へと通り抜ける. なお,本ヒヤリハット事象に関する走行シナリオやシミュレーション環境の詳細に関しては, 我々の従来研究[51]における実験条件を踏襲している. 運転時には,注意散漫状態[52]を擬似的に作り出すために,末永らの研究[53]を参考にし て,1 桁同士の加減算を,3 秒に 1 問の間隔で,スピーカを通して出題した.被験者は口頭で 解答し,マイクロフォンを用いて音声情報として記録し,正答率を求めた. シミュレーション映像における走行環境の天候は晴れ,時間帯は視認性の高い昼間とした. 12 名の被験者からデータを取得した.被験者の内訳けは,男子学生 10 名,女子学生 2 名で, 順に被験者 A-L とした.本研究では,個人毎のエピソード記憶モデルを構築することを目的 としているため,チェックシートを用いて運転特性を評価し,その中から,任意の被験者に 的を絞り,評価を進めた. 4.3 運転の主観的評価 本実験では,一般社団法人・人間生活工学研究センターが提供している運転スタイルチェ ックシート(Driving Style Questionnaire: DSQ)[54]と運転負担感受性チェックシート
16
(Workload Sensitivity Questionnaire: WSQ)[55]を用いて,被験者の運転特性を事前に測 定した. DSQ では,運転に対する態度,志向,考え方などの運転スタイルを抽出し,定量的に把握 できる.質問は 18 問あり,(1)運転スキルへの自信,(2)運転に対する消極性,(3)せっかち な運転傾向,(4)几帳面な運転傾向,(5)信号に対する事前準備的な運転,(6)ステイタスシン ボルとしての車,(7)不安定な運転傾向,(8)心配性的傾向,(9)虚偽発見尺度の 9 項目の尺度 に分類され,各尺度に対して 4 段階で得点が与えられる.得点が高いほど,その尺度で表さ れる運転スタイルの傾向が強いと解釈できる. WSQ では,どのような種類の運転に対して負担を感じるのかを抽出し,定量的に把握でき る.質問は 38 問あり,(1)交通状況の把握,(2)道路環境把握,(3)運転への集中阻害,(4) 身体的活動度の低下,(5)運転ペース阻害,(6)身体的苦痛,(7)経路把握や探索,(8)車内環 境,(9)制御操作,(10)運転姿勢の 10 項目に分類され,各尺度に対して 5 段階で得点が与え られる.得点が高いほど,その尺度で表される運転負担を強く感じやすいと解釈できる. 両チェックシートの結果を図 5 に示す.この中で,被験者 C が,DSQ の(8)心配性的傾向と (9)虚偽発見の 2 項目において,被験者の平均と比較して突出した値を示していた.このため, 本研究では,被験者 C を対象として,評価と分析を進める. 4.4 視線及び顔向きの分布特性 ヒヤリハット遭遇時の被験者 C の視線及び顔向きについて,分布を散布図として可視化し た結果を図 6 に示す.交差点に進入した後,一時停止をして,右折が完了するまでの分布に なる.ヒヤリハット事象のケース I,ケース II の両結果とも,視線より顔向きが複雑に分布 していることが,本計測結果から読み取れる.見通しの悪い交差点であるため,左右に首を 振って確認する動作に加えて,ケース I では,自転車が右から左に大きく横切るため,それ に沿って大きく顔の向きが変化している.一方,ケース II では,交差点の左側から飛び出し てきた自転車が,交差点を横切るのではなく,車両と同じ道路に侵入するため,右側への顔 向きの変化が相対的に小さくなっている.その一方で,ケース II では上下方向への顔の動き が拡大している. このように DS では,運転者の顔から発せられる多様な情報を高度に計測できるが,実車で は FaceLAB のような装置を取り付けて,運転者の顔から発せられる情報を安定して計測する ことは困難である.しかしながら,本予備実験から,顔向きでも視線と同様に多様な情報が 図5: DSQ と WSQ の結果.
17 得られることを示唆する結果が得られた. 4.5 注意散漫状態における運転特性 顔向き変化が上下方向に大きく現れたケース II のヒヤリハットに対して,暗算タスクを課 していない通常の運転状態と課した注意散漫状態とで,顔向きの変化について時系列での特 徴追跡を試みた.本実験においても,上記の実験と同様に,被験者 C を評価対象として比較 した.図 7 に実験結果として,時系列データを示す.グラフの縦軸は,DS のディスプレイを 正規化した際の相対位置を示しており,画面の中心が 0,両端が±0.5となる.Y 軸のスケール は,上方向がプラス,下方向がマイナスを取る.X 軸のスケールは,左方向がプラス,右方 向がマイナスを取る. 顔向きは,被験者がディスプレイの中心よりやや下を向いているため,Y 軸の位置はマイ ナスを示している.暗算タスクが課されていない通常状態での,顔向きの時系列変化を図 7(a) に示す.ヒヤリハットに対して顔の動きが微小であることが,この結果から確認できる.一 図6: ヒヤリハット遭遇時の視線及び顔向きの分布(被験者 C). 図7: ヒヤリハット遭遇時の顔向きの時系列変化(被験者 C).
18 方,暗算タスクが課されている状態の図 7(b)の結果では,反応が少し遅れた後,大きくかつ 瞬時に顔の向きを変更している.この際,顔は左を向くと同時に,下方向に向くという不自 然な動作を示している.このような動作は 1 度きりの出来事であることが多く,再現性を得 ることは極めて困難であるが,実際に観測した運転行動であるため,本研究では,エピソー ドとして記録することを目的としている.
5
実車画像を用いた評価実験
5.1 実験装置本研究では,GARMIN 社製 EDR の GDR45DJ を用いた.カメラの外観を図 8 に示す.本 EDR は, 図 8(b)に示すバックカメラの GDR35D を接続することにより,2 カメラによる同時撮影が可能 となる.カメラの主な仕様を表 1 に示す.本カメラは対角視野が 132 度(水平視角 120 度) あり,運転シーンを広範囲に撮影することができる. 撮影した画像例を図 9 に示す.バックカメラは通常,車両後部に設置するが,本研究では 運転中の表情を撮影するために,ダッシュボード上に設置した.顔画像は,図 9(b)に示すよ うに,斜め下側からの撮影になる.なお,本 EDR には GPS が内蔵されており,取得した映像 には,走行経路としての位置情報が記録されており,メーカが提供する専用のツールを用い て,オンライン地図上で確認できる.更に,静止画に切り出した場合は,位置情報を含んだ ジオタグ画像やフォトナビゲーションとして利用できる. 5.2 実験条件 本研究では,3 台の車に EDR を取り付けて,データを取得した.データの取得期間は,夏 場の 7-8 月と冬場の 1-2 月の 2 シーズンに分けて実施した.研究代表者らの大学が所在する 表1: EDR の主な仕様. 図8: EDR の外観.
19 秋田県内でデータを取得したため,冬場には,雪道走行のデータが取得できた.また,日々 の運転からエピソードを得るために,通勤や通学路のデータを,繰り返し取得した. 2 カメラで同時に撮影した場合,本 EDR の本体では約 4 分程度の映像に切り出されて,avi 形式のファイルとして保存される.本実験では,このファイル単位でカテゴリマップを生成 し評価を行った.なお,映像データは 30 fps で取得したが,本実験では処理速度を考慮して 3 fps にダウンサンプリングした静止画像データを用いた. 5.3 特徴抽出結果 フロントカメラで取得した映像に対して,提案手法を用いて抽出した特徴量を図 10 に示す. 図 10(a)の原画像の全領域に対し,AKAZE で抽出した結果が図 10(b)となる.本運転シーンの 中で運転者が最も注視すると想定される道路標識のみならず,道路全体に渡って特徴点が分 布している.続いて,SM の抽出結果を図 10(c)に示す.2 値化後のマスク画像に対して,顕 著度の高い領域のみの AKAZE 特徴点の抽出結果を図 10(d)に示す.この図では,緑色の線が 顕著度の高い領域の輪郭となる.本画像では,標識や白線の一部の顕著度が高くなっている. 図9: EDR で撮影した画像例. 図10: フロントカメラで取得した画像に対する処理結果.
20 バックカメラで取得した映像から顔領域を検出した結果を図 11 に示す.図 11(a)は検出に 成功した例である.顔の向きや光の変化によっては検出に失敗することがある.通常の顔検 出と違って,自動車を運転中の顔検出は,運転者が運転席に着座してシートベルトで身体を 固定しているため,顔領域が大きく変動することはない.したがって,本手法では,フレー ム間で変位量を計算し,検出位置がフレーム間で大きく異なる場合は,顔検出に失敗したと 見做して,前フレームの関心領域を使って補正した.関心領域の抽出に成功した場合は緑枠, 失敗して補正した場合は赤枠で顔領域を示している. 抽出した画像特徴から,情報の圧縮と次元数の整列を目的としてコードブックを作成した. 図 13 に図 9 に対するコードブックを示す.SOM のマッピング層は 128 ユニットとした.AKAZE の特徴量は 61 次元だが,特徴点数は画像によって異なる.コードブック化により任意の次元 に統一することができる.粗視化後の GW の特徴量は 30×30 パッチの 900 次元であるが,コ ードブック化により,特徴量を大幅に縮減できる. 図11: Viola-Jones 法による顔領域の検出結果. 図12: GW の 4 方向成分(0,45,90,135 deg)の特徴量. 図13: SOM による作成したコードブック(128 次元).
21 5.4 分類粒度の検討 𝜌𝜌を 0.9950 から 0.0001 刻みで 0.9980 まで変更した場合に,生成された ART のラベルと CPN のカテゴリを図 14 に示す.𝜌𝜌の値が大きくなるにつれて,ART のラベル数,CPN のカテゴリ数 ともに増加している.ただし,後者に関しては,上下を示しながら増加している点が,前者 とは異なる.単純に𝜌𝜌が大きくなるにつれてカテゴリ数が増えるのではなく,CPN の写像空間 の中で適切に圧縮されていることが,この図から読み取れる. 分類粒度を決定する𝜌𝜌は,提案手法の中では最も影響度の高いメタパラメータである.本研 究では,ART のラベル数の増加に対して,CPN のカテゴリが安定して形成される 0.9965 から 0.9975 の範囲の中で,中央値となる𝜌𝜌=0.9970 を設定値とした. 5.5 カテゴリマップの生成結果 始めに,運転シーンと表情の画像を個別に AMN に入力して,カテゴリマップを作成した. カテゴリマップのサイズは,入力画像枚数に対して十分な写像空間を確保するために,50× 50=2500 ユニットとした.一般道を走行した際のデータセットによるカテゴリマップを図 15 に示す.カテゴリマップは色温度を使って表現しており,低温側の青色が前半のカテゴリ, 高温側の赤色が後半のカテゴリに対応している.色温度を用いることにより,各カテゴリの 分布に加えて,カテゴリ間の順序性が確認できる.なお,カテゴリ数に応じで離散化した色 温度のインデックスを,カテゴリマップの右側に縦棒として表示している.ART が生成した ラベルに対して,CPN の近傍と競合に基づく学習によりラベルが淘汰された場合には,その ラベルを間引きして色温度を与えている.図 15 に示す結果では,運転シーンは 14 カテゴリ, 表情は 9 カテゴリに分類された.色温度の分布から,前者は前半のカテゴリ,後者は後半の カテゴリが優位に分布している. 続いて,高速道路を走行した際のデータセットによるカテゴリマップを図 16 に示す.運転 シーンが 13 カテゴリ,表情が 8 カテゴリに分類された.一般道のデータセットと同様に,表 図14: ρと ART のラベル数及び CPN のカテゴリ数.
22 情より運転シーンのカテゴリ数が多くなっている.カテゴリの分布に関しては,運転シーン はマップの左右に分布する初期カテゴリの割合が高くなっているものの,表情シーンは全体 を通して均等に対応付いている. 両データセットに対して,運転シーンと顔画像の両方のデータを同時に入力した場合のカ テゴリマップを図 17 に示す.個別に入力する場合と比較して,コードブック化以降の ART と 図15: 一般道における運転シーンと表情のカテゴリマップ. 図16: 高速道路における運転シーンと表情のカテゴリマップ. 図17: 運転シーンと顔画像の両特徴を同時に入力した場合のカテゴリマップ.
23 CPN の入力の次元数が 2 倍になる.一般道では,8 カテゴリ,高速道路では 7 カテゴリに分類 された.前者は上位ラベル,後者は下位ラベルの割合か高くなっていることが,色温度の分 布から読み取れる.図 15 及び図 16 のカテゴリマップと比較した場合,顔表情よりも運転シ ーンの影響が強いことを示している.図 13 において示したように,コードブックの特徴量は, 後者より前者が変化に富んでおり,特徴差の違いによると考えられる. 図 17 (a)のカテゴリマップから,時系列順に発火ユニットのカテゴリを整列した結果を図 18 に示す.カテゴリマップの色温度に対応した結果を横棒で示しており,100,300,500, 700 フレーム目の画像を示している.またオンライン地図上に表示した走行経路を図の右側 に示す.本データセットの走行経路は,駐車場を出て,住宅街を走り抜け,大通りに出て, 幹線道路の大きな交差点で数分間の停止後,再び動き出すまでの映像になっている.高温度 色のラベルが対応付いている部分は,車が停止して,信号待ちの状態に対応付けられたカテ ゴリである.400-500 フレームの間で赤色で示す高温度のカテゴリが対応付いているのは, 車両が幹線道路に出て,交通量の多い中を走っているシーンである. 続いて,図 18 に,高速道路を走行している際の時系列順での分類結果を示す.シーンの変 化が少なく,単調な風景が続いているため,一般道の場合と比べてカテゴリの変化が少ない. 600 フレームを過ぎたところでトンネルに入ったため,新たなカテゴリが生成されている. 5.6 ヒヤリハットデータによる結果 3 台の車両でデータを取得している期間中に,2 回のヒヤリハットに遭遇した.1 回目は夏 場の夕暮れ時で,パチンコ店の駐車場から飛び出してきた高齢者が運転する軽自動車と接触 図18: 一般道路の走行における分類結果の時系列での展開結果. 図19: 高速道路の走行における分類結果の時系列での展開結果.
24 寸前になった.衝突は回避できたものの,タイヤが完全ロックする急ブレーキとなった.な お,この車両には ABS は搭載されていないため,タイヤロックという急制動になった.飛び 出した理由については事情を聴取していないので不明であるが,EDR を搭載した車両が南向 きに走行していたのに対して,軽自動車は西に向かって動き出しており,夕暮れ時の太陽が 眩しく,横から接近する車を見落としたと考えられる.EDR に内蔵されている加速度センサ には,図 20 に示すように,突出した値が示されていた. もう一例のヒヤリハットは,雪道を走行している際に,直角カーブの手前で減速したもの の,タイヤがスリップして,減速が十分にできずに,そのまま真っすぐ,道路ではない部分 に突き進んだ事象である.本車両には ABS が搭載しており,急ブレーキとともに作動したが, 雪道であったため,G センサには突出した値は現れていなかった. 夕暮れ時の走行におけるカテゴリマップを図 21(a)に示す.本データセットは,9 カテゴリ に分類された.中盤に生成されたカテゴリが,マップの下半分を占めている.前半に生成さ れたカテゴリは,複数の位置に分散している.最終段階で生成された 9 番目のカテゴリは, マップの右上に,独立した分布を示している.時系列順での分類結果を図 22 に示す.ヒヤリ ハットは 550 フレームから 560 フレームにかけて発生している.この範囲の発火位置を図 21(a)で白枠の円で囲んでいる.カテゴリ境界での発火分布となっており,カテゴリ変化が生 じている.しかしながら,本ヒヤリハットに対して新しいカテゴリが生成されたのではなく, 既存のカテゴリに遷移が戻っている. 雪道の走行シーンでのカテゴリマップを図 21(b)に示す.6 カテゴリと少ない分類数である ものの,全てのカテゴリは複数の領域に分散して分布している.これは,走行シーンの複雑 度が高いことを意味している.図 23 に示す時系列順での分類結果では,色温度の差の大きい カテゴリが複雑に入り組んでいることから,特徴変化の大きい結果になっている.ヒヤリハ ットは 390 フレームから 400 フレームにかけて発生しているが,こちらもカテゴリの変化は 図20: 加速度センサの出力(赤矢印の部分が急制動を取った位置). 図21: 夕暮れ時と雪道のカテゴリマップ (白枠の円はヒヤリハットに対して発火したユニット).