Factored Translation Models
を用いた
事後並べ替えによる日英翻訳
小林 和也
2014 年 2 月 6 日 奈良先端科学技術大学院大学 情報科学研究科 情報科学専攻本論文は奈良先端科学技術大学院大学情報科学研究科に 修士 (工学) 授与の要件として提出した修士論文である。 小林 和也 審査委員: 松本 裕治 教授 (主指導教員) 中村 哲 教授 (副指導教員) 新保 仁 准教授 (副指導教員) Kevin Duh 助教 (副指導教員)
小林 和也
内容梗概 統計的機械翻訳システムの翻訳精度は,翻訳を行う言語ペアによって大きく変 化する.日本語と英語のような文構造が大きく異なる言語間の翻訳を行う場合, 長距離の語順の並べ替えを考慮する必要がある.しかし,現在の統計的機械翻訳 システムは並べ替えモデルと計算量の問題から,文構造の異なる言語間の翻訳を 不得手としている. 本研究では,日英翻訳における語順の並べ替えの問題を解決するために事後並 べ替えと呼ばれる手法に注目し,単語の表層以外の情報を考慮する手法を提案す る.提案手法では,Factored translation models を用いて単語の表層と品詞,クラ スタの情報を考慮した翻訳を行う.キーワード
統計的機械翻訳,事後並べ替え,Factored Translation Models,日英翻訳
∗奈良先端科学技術大学院大学 情報科学研究科 情報科学専攻 修士論文, NAIST-IS-MT1251045,
2014 年 2 月 6 日.
Kazuya Kobayashi
Abstract
Translation quality using statistical machine translation systems strongly depends on language pair. When translating between Japanese and English, we need to consider long distance reorderings. Current statistical machine translation systems do not work well because of the low flexibility of standard reordering models and the limits of computational complexity.
In this thesis, we focus a method called ”post-ordering” to mitigate reordering prob-lem in Japanese to English translation and propose a method using additional infor-mation beyond word surface forms. We use ”Factored Translation Models” to use additional information such as POS-tag and word class.
Keywords:
Statistical Machine Translation, Post-ordering, Factored Translation Models, Japanese to English Translation
∗Master’s Thesis, Department of Information Science, Graduate School of Information Science,
Nara Institute of Science and Technology, NAIST-IS-MT1251045, February 6, 2014.
謝 辞
本研究を行うにあたり,多くの方々にご協力いただきました.皆様に心より感 謝いたします. 主指導教員である自然言語処理学研究室の松本裕治教授には,勉強会や研究会 において多くのコメントや助言をいただきました.副指導教員である知能コミュ ニケーション研究室中村哲教授には,ゼミナールや修士論文の発表において有益 なコメントをいただきました.新保仁准教授には,研究会において的確な質問を いただきました.Kevin Duh 助教には,研究の全体において非常に多くの助言をい ただきました.また,研究の進め方やプレゼンテーションの方法など多くのこと を学ばさせていただきました.知能コミュニケーション研究室の Graham Neubig 助教にも,研究を進める中で多くの助言をいただきました. 最後に,自然言語処理学研究室の先輩,後輩,そして同期の方々には,研究のみ でなく日頃の生活においても非常にお世話になりました.個性のある方々の集まっ た研究室で,多くの刺激を受けながら楽しく 2 年間を過ごすことが出来ました.目 次
謝 辞 v 第 1 章 緒言 1 1.1 統計的機械翻訳とは . . . . 1 1.2 文構造の違いによる問題点 . . . . 2 1.3 本研究の目的 . . . . 2 1.4 本論文の構成 . . . . 3 第 2 章 フレーズベース統計的機械翻訳 5 2.1 言語モデル . . . . 5 2.2 翻訳モデル . . . . 5 2.2.1 IBM モデル 1 . . . . 6 2.2.2 IBM モデル 2 . . . . 7 2.2.3 IBM モデル 3 . . . . 7 2.2.4 IBM モデル 4,5 . . . . 8 2.3 フレーズベースモデル . . . . 8 2.4 並べ替えモデル . . . . 9 2.5 ディストーションリミット . . . . 9第 3 章 Factored Translation Models 11 第 4 章 並べ替えに関する関連研究 13 第 5 章 事後並べ替え 15 5.1 Head Finalization . . . . 16
5.2 2段階の翻訳 . . . 16
第 6 章 Factored Translation Models を用いた事後並べ替え 19 6.1 日本語から HFE への翻訳 . . . 20
第 7 章 事後並べ替えにおける factor の影響の評価実験 21 7.1 データセット . . . 21 7.2 使用したツール . . . 21 7.3 評価指標 . . . 21 7.4 実験結果と考察 . . . 22 7.4.1 日本語から HFE への翻訳における factor の影響 . . . 22 7.4.2 HFE から英語への翻訳における factor の影響 . . . . 23 7.4.3 ディストーションリミットによる翻訳への影響 . . . . 24 第 8 章 結言 27 参考文献 29 viii
図 目 次
2.1 並べ替えモデルの操作 . . . 10
3.1 factored translation models による翻訳の流れの一例 . . . . 11
4.1 事前並べ替えと事後並べ替えの流れ . . . 14
5.1 事後並べ替えの流れ . . . . 15
5.2 XML 形式の Enju の出力 . . . . 17
5.3 Head Finalization:太線は統語主辞を表す . . . . 17
6.1 Factored Translation Models を考慮した事後並べ替えにおける翻訳 の流れ . . . 20
表 目 次
7.1 各手法に対する評価指標の数値 . . . 23 7.2 日本語から HFE への翻訳における評価値 . . . 24 7.3 HFE から英語の翻訳における評価値 . . . . 24 7.4 最適な factor を考慮した際の翻訳精度 . . . 25 7.5 ディストーションリミットによる翻訳への影響 . . . 26第
1
章
緒言
1.1
統計的機械翻訳とは
機械翻訳とは,計算機を用いて,ある言語から別の言語に自動的に翻訳を行う 技術である.近年の計算機の性能の向上や対訳コーパスの充実,学習アルゴリズ ムの発達といった要因により,現在では統計的機械翻訳が主流となっている.統 計的機械翻訳では,最適な翻訳を生成するための確率モデルのパラメータを対訳 コーパスから学習する.統計的機械翻訳の基本的なモデルは noisy channel model で表現される.翻訳する前の言語(原言語)と翻訳された後の言語(目的言語) をそれぞれ f ,e とおくと,原言語のある文 f = ( f1, f2,··· , fm) が目的言語の文e = (e1, e2,··· ,en) に翻訳される確率は P(e|f) となる.これをベイズの定理を用い
て書きなおすと,
P(e|f) = P(e)P(f|e)
P(f) (1.1) と表すことができる.式 (1.1) の分母は e に依存しないため,式 (1.1) を最大化す る ˆe は以下のように求めることができる. ˆe = argmax e P(e)P(f|e) (1.2) ここで,P(e) は言語モデル,P(f|e) は翻訳モデルと呼ばれる.言語モデルは e の言 語らしさを表すモデルで,目的言語のコーパスを用いて学習する.一方の翻訳モ デルは e が f に翻訳される確率を表すモデルで,対訳コーパスを用いて学習する.
noisy channel model の問題点として,言語モデルと翻訳モデルに対する重み付 けが行えないことと他の素性を考慮するためのモデルの拡張が行えないことが挙 げられる.これらの問題点を解決する手法として,Och ら [14] によって提案され た対数線形モデルがある.対数線形モデルでは,言語モデルや翻訳モデルなどの 素性が M 個あり,それらの素性が関数 hm(e, f) で表されるとき,P(e|f) を以下の ように表す. P(e|f) = exp[∑ M m=1λmhm(e, f)]
∑e’exp[∑Mm=1λmhm(e’, f)]
ここで,λ は各素性関数の重みを表す.式 (1.3) の分母は e に依存しないため,式 (1.3) を最大化する ˆe は以下のように求めることができる. ˆe = argmax e P(e|f) (1.4) = argmax e M
∑
m=1 λmhm(e, f) (1.5)1.2
文構造の違いによる問題点
統計的機械翻訳の翻訳精度は,翻訳を行う言語ペアによって大きく変化する. 例えば,英語から日本語への翻訳精度は,フランス語への翻訳精度よりも低くな る.この翻訳精度の違いの主な要因として,言語間の文構造の違いが挙げられる. 英語やフランス語は,”John hit a ball.”のように主語−動詞−目的語という語順の SVO 言語であるのに対し,日本語は”ジョンはボールを打った。”のように主語− 目的語−動詞という語順の SOV 言語である. 英語と日本語のように文構造が異なる言語間の翻訳を行う場合,長距離の語順 の並べ替えを考慮しなければならない.もし,出力する単語数が n 個で並べ替え の距離を制限しない場合,有りうる単語列の候補は n! 個となり,探索空間は非常 に大きくなるため,全ての単語列の候補を考慮するのは計算量の問題から不可能 である. 現在の統計的機械翻訳システムの並べ替えモデルは長距離の語順の並べ替えを 解決するには充分ではない.さらに,長距離の語順の並べ替えを考慮する場合, 上に述べたように,翻訳候補の増加に伴って計算量が増加する.以上の 2 点より, 現在の統計的機械翻訳システムは長距離の語順の並べ替えが必要となる言語間の 翻訳を不得手としている.1.3
本研究の目的
文構造が異なる言語間での翻訳における長距離の語順の並べ替えの問題を解決 するために,事前並び替えと事後並び替えと呼ばれる手法が提案されてきた.こ れらの手法は単語の翻訳と語順の並べ替えを別々に行うことで翻訳精度を向上さ せている.事前並べ替えでは,前処理として原言語を目的言語の語順に並べ替え たあとに翻訳を行う.翻訳を行う前に原言語の語順を目的言語に近づけることで, 翻訳中の語順の並べ替えの距離を少なくしている.一方の事後並べ替えは,翻訳 を行ったあとに語順の並べ替えを行う手法である. 21.4
本論文の構成
2 章において,フレーズベース統計的機械翻訳で考慮されるモデルを解説する. 3 章では品詞などの情報を考慮するための factored translation models について解説 する.4 章では,文構造の異なる言語間における翻訳に対して,単語の翻訳と並べ 替えを別々に扱った手法を紹介する.5 章では,本研究で用いる並べ替え手法であ る事後並べ替えについて解説する.6 章では,事後並べ替えに factored translation models を組み合わせた手法を提案する.7 章では,実験を通して提案手法の性能 の評価を行う.8 章で,本論文の総括を行う. 3
第
2
章
フレーズベース統計的機械
翻訳
Koehn ら [11] によって提案されたフレーズベース統計的機械翻訳は,Och ら [16] によって提案された単語ベース統計的機械翻訳を拡張したものであり,現在 の統計的機械翻訳の主流となっている.本節ではフレーズベース統計的機械翻訳 で考慮されるモデルについて説明する.2.1
言語モデル
式 (1.1) や式 (1.3) における統計的機械翻訳システムの言語モデルには一般的に n-gram モデルが用いられる.単語列 w1, w2, ..., wlが与えられたとき,この単語列 の生起確率は以下のように表すことができる. P(w1w2...wl) = P(w1)P(w2|w1)...P(wl|w1w2...wl−1) (2.1) 式 (2.1) を推定するために,以前に生起した単語列を全て保持しておくことは現 実的では無い.n-gram モデルでは,wiの生起確率の推定を直前の n− 1 単語の頻 度を用いて行う.例えば,3-gram の生起確率は以下のように表すことができる. P(wi|wi−1wi−2) = C(wi−2wi−1wi) C(wi−2wi−1) (2.2) ここで,C(x) はコーパス中の x の出現回数を表す.式 (2.2) は未知語を含む 3-gram の確率は 0 になる等の問題があるため,Kneser-Ney スムージング [8] や Witten-Bell スムージング [19] などのスムージング手法を用いてモデルの推定を行う.2.2
翻訳モデル
式 (1.1) や式 (1.3) における翻訳モデルとして代表的なものとして IBM モデル [2] がある.IBM モデルは,目的言語の文 e が与えられたとき,原言語の文 f とアラインメント a の条件付き確率を用いて,P(f|e) を推定する. P(f|e) =
∑
a P(f, a|e) (2.3) f と e の長さがそれぞれ m,l とし,原言語のそれぞれの単語は1 つの目的言語の 単語に対応するか,いずれの単語にも対応しないとすると,a は a1a2...amという m 個の系列で表される.例えば,もし fjが eiに対応するならば,aj= i となり, fjが e のいずれの単語にも対応しないならば,aj= 0 となる.このとき,P(f, a|e) は以下のように書き表すことができる. P(f, a|e) = P(m|e) M∏
j=1 P(aj| f1j−1, a1j−1, m, e)P( fj| f1j−1, a1j−1, m, e) (2.4) ここで,fijは文 f の i 番目の単語から j 番目までの単語までの単語列を表す.IBM モデルはモデル 1 からモデル 5 までの 5 種類があり,モデル 1 が最も単純なモデ ルであり,モデル 5 が最も複雑なモデルである.それぞれのモデルについて以下 の節で説明する.2.2.1
IBM
モデル
1
IBM モデル 1 では以下の 3 つの条件を仮定して,式 (2.4) を単純化する. • P(m|e) は m と e に依存しない. • P(aj|a1j−1, f1j−1, m, e) は l にのみ依存し,(l + 1)−1である. • P( fj| f1j−1, a1j−1, m, e) は fjと eaj にのみ依存し, f ( fj|eaj) = P( fj| f j−1 1 , a j−1 1 , m, e) (2.5) と表す.式 (2.5) は eaj が与えられたときの fjの翻訳確率と呼ぶ. 上記の仮定の下で,P(f, a|e) は以下のように表すことができる. P(f, a|e) = ε (l + 1)m m∏
j=1 t( fj|eaj) (2.6) 6a1=0 am=0j=1 = ε (l + 1)m l
∑
i=0 m∏
j=1 t( fj|eaj) (2.7)2.2.2
IBM
モデル
2
モデル 2 では,P(aj|a1j−1, f1j−1, m, l) が l だけでなく, j と aj,m にも依存する と仮定し,以下のアライメント確率を導入する. a(aj| j,m,l) = P(aj|a1j−1, f1j−1, m, l) (2.8) 式 (2.7) と式 (2.8) を用いて,P(f|e) は以下のように表すことができる. P(f|e) = ε l∑
a1=0 ···∑
l am=0 m∏
j=1 t( fj|eaj)a(aj| j,m,l) = ε l∑
i=0 m∏
j=1 t( fj|eaj)a(aj| j,m,l) (2.9) モデル 1 はモデル 2 の a(i| j,m,l) を (l + 1)−1とした特殊なケースとみなすことが できるため,モデル 1 で得られた解を初期値として用いてモデル 2 のパラメータ の推定を行うことができる.2.2.3
IBM
モデル
3
モデル 1,2 では原言語の単語は 1 つの目的言語の単語に対応するか,いずれの 単語にも対応しないかであるとしていた.モデル 3 ではこれを拡張するため,原 言語の単語が複数の目的言語の単語に対応するケースを考慮する.目的言語の単 語 eiがいくつの原言語の単語に対応するかをモデル化する確率分布 n(ϕ|e) を導 入し,これを繁殖モデル(fertility model)と呼ぶ.原言語の単語が目的言語のい ずれの単語にも対応しない場合,ϕ = 0 となる.また,新たに単語が挿入される ケースに対応するために,ヌルトークンの挿入確率 p1を導入する.モデル 3 は ヌルトークンを挿入したあとに,単語のアラインメントが取られる.このため, 7モデル 2 で用いたアライメント確率 a(aj| j,m,l) に替わって,ディストーション確 率 d( j|i,l.m) を導入する.モデル 3 では山登り法によって n(ϕ|e) と p1,t( fj|eaj), d( j|i,l.m) を推定する.
2.2.4
IBM
モデル
4
,
5
翻訳のプロセスにおいて,大きなフレーズはまとまって移動する傾向にある. 原言語において隣り合う単語は目的言語においても隣り合う可能性が高い.しか し,モデル 3 で導入したディストーション確率はこのような問題をうまく扱うこ とができない.この問題を解決するために,モデル 4 では単語の対応の位置は直 前の単語に依存するとする.また単語を分類したクラスの情報も考慮して,単語 のアライメントを推定する. モデル 3 と 4 では目的言語の複数の単語が同じ位置に割り当てられる可能性が 存在する.モデル 5 ではこのような問題に対処するために単語を割り当てること のできる位置に制限を加える.2.3
フレーズベースモデル
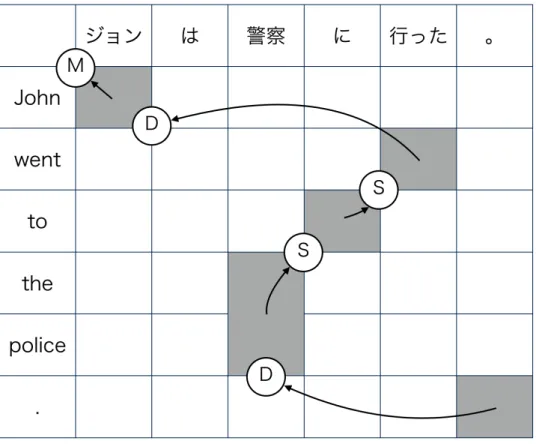
これまで言語モデルや翻訳モデルなどのモデルを単語単位で考えてきたが,フ レーズベース統計的機械翻訳システムではそれぞれのモデルをフレーズ単位で考 える.フレーズベースモデルにおけるフレーズとは,言語学的な意味としてのフ レーズではなく,翻訳に適した単語列という意味で用いられる. 翻訳を単語単位ではなくフレーズ単位で行う利点として以下の 4 点が挙げら れる. • 1 対多のアライメントを取るのが容易である. • 単語列を翻訳することで,翻訳の曖昧性を解消できる. • 大量の訓練データを利用できる場合,より長いフレーズを学習できる. • 繁殖モデルや単語の挿入,削除などを考慮する必要がなくなる. 8原 言 語 の フ レ ー ズ 列 ¯f = ( ¯f1, ¯f2,··· , ¯fm) と 目 的 言 語 の フ レ ー ズ 列 ¯e = ( ¯e1, ¯e2,··· , ¯en),フレーズのアラインメント a = (a1, a2, ..., an) が与えられたとき, このモデルは並べ替えの操作の系列 o = (o1, o2, ..., on) の確率を以下のように推定 する. P(o|¯e, ¯f) = n
∏
i=1P(oi|¯ei, ¯fai, ai−1, ai) (2.10) oiは以下の 3 種類に分類される.それぞれの操作を図 (2.1) に示す.
• monotone(M):2 つのフレーズの位置が連続している場合 • swap(S):2 つのフレーズの位置が入れ替わる場合
• discontinuous(D):上記 2 つに当てはまらない場合
デコードの際は,o をそれぞれの操作についての素性関数に区別する.
• fm=∑ni=1log p(oi= M|...)
• fs=∑ni=1log p(oi= S|...)
• fd=∑ni=1log p(oi= D|...)
2.5
ディストーションリミット
文構造の異なる言語間において翻訳を行う場合,長距離の並べ替えが必要とな る.日英翻訳の場合,日本語の動詞は文末にあるが,英語の動詞は主語の直後に あるため,多くの単語を越える移動が必要となる.しかし,出力文の文長が n で 並べ替えの距離を制限しない場合,翻訳候補は n! 個となり探索空間が非常に大き くなる.そこで,ディストーションリミットを導入し,次に翻訳する単語を選択 できる範囲を制限する.これにより,計算量は縮小されるが,文全体の単語の並 べ替えは考慮できなくなる. 9図 2.1: 並べ替えモデルの操作
第
3
章
Factored Translation Models
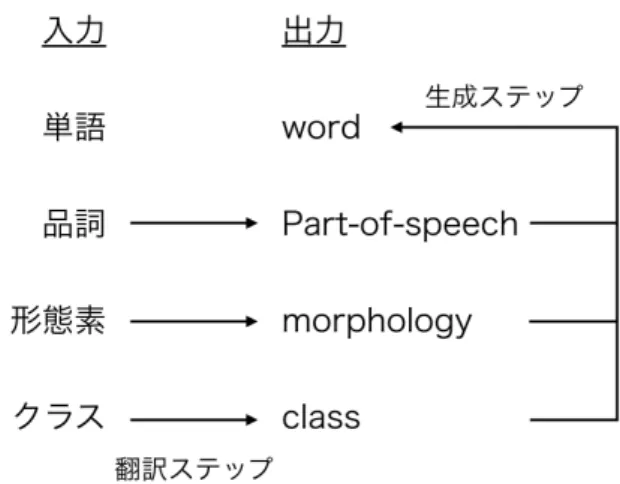
Koehn ら [9] が提案した factored translation models は品詞や形態素などの単語 レベルでの情報を統合するモデルである.また,先に挙げた品詞や形態素などの 情報を factor と呼ぶ. 単語の表層の情報のみを考慮する統計的機械翻訳システムでは形態論をうまく 扱うことができない.例えば,翻訳モデルにおいて house と houses は全く別々の 単語として扱われ,訓練データにおける house は houses の翻訳に対して影響を与 えない.これは英語やアラビア語,ドイツ語などの形態論の豊富な言語において 大きな問題となる.そこで,factored translation models では,図 3.1 のように翻訳 ステップと生成ステップの 2 段階で翻訳を行う.まず見出し語と形態論の情報を 別々に翻訳する.その後に,翻訳した情報を組み合わせることで最終的な表層の 単語を生成する.
Factored translation models はフレーズベースモデルと同様に言語モデルや翻訳 モデル,翻訳ステップ,生成ステップなどの構成要素の組み合わせである.それ ぞれの構成要素は対数線形モデルに組み込むことができる素性関数で定義するこ とができる.
第
4
章
並べ替えに関する関連研究
翻訳における並べ替えの問題の改善策として,単語の翻訳と並べ替えを別々に 行う手法が提案されてきた.図 4.1 に示すように,単語の翻訳と並べ替えの順序 によって事前並べ替えと事後並べ替えに分類される. Collins ら [3] は独英翻訳に対して事前並べ替えを適用し,翻訳精度の改善を図っ た.Collins らの手法ではまず原言語であるドイツ語の文に対して解析を行い,次 に解析によって得られた句や節に対して並べ替え規則を適用することによって, ドイツ語の文を英語の語順へと並べ替える. Katz-Brown ら [7] は 2 種類の事前並べ替えの規則を適用して日英翻訳を行った. Katz-Brown らの手法では,日本語の助詞”は”に着目して並べ替え規則を適用する 手法と,日本語の依存構造木に対して並べ替え規則を適用する手法を用いて事前 並べ替えを行った. Isozaki ら [6] は,日本語が主辞後続言語であることに着目した並べ替え規則を 提案した.Isozaki らの手法では英語に対して解析を行い,統語主辞を句や節の後 ろに移動させる規則を適用することで英語を日本語の語順に並べ替えた. 事前並べ替えでは翻訳精度が改善しない言語対に対する手法として,原言語を 翻訳したあとに単語の並べ替えを行う事後並べ替えと呼ばれる手法が提案されて きた.Sudoh ら [18] は日英翻訳に対する事後並べ替えを提案した.Sudoh らは, 日本語から日本語語順の英語への翻訳で単語の翻訳を行い,その後に日本語語順 の英語から英語への翻訳によって語順の並べ替えを行うことで日英翻訳を行った. また,日本語語順の英語は Isozaki らの提案した並べ替え規則 [6] を用いて生成 した.図 4.1: 事前並べ替えと事後並べ替えの流れ
第
5
章
事後並べ替え
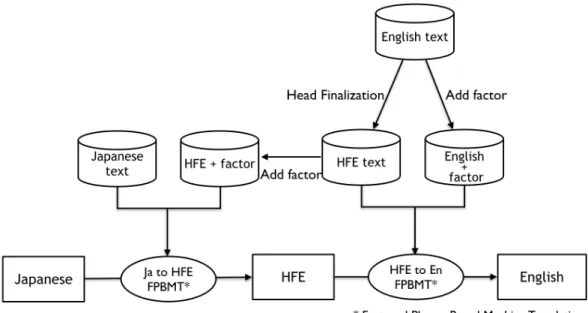
英語の日本語語順へと並べ替えはいくつかの単純な規則で高精度に実現できる. これは,日本語が典型的な主辞後続言語(head-final language)であるため,統語 主辞を対応するフレーズや節の最後尾に移動させればよいからである.Isozaki ら は日本語のこのような特徴に着目した並べ替え規則を提案して英日翻訳の事前並 べ替えを行った.一方,日英翻訳では日本語を英語語順に並べ替える規則を提案 するのは簡単ではないため,事前並べ替えによる翻訳精度の向上は難しい. そこで,Sudoh らは単語の翻訳を行った後に語順の並べ替えを行う事後並べ替 え [18] を提案した.Sudoh らの提案した事後並べ替えによる翻訳の流れを図 5.1 に示す.事後並べ替えでは,日英翻訳を単語の翻訳と並べ替えの 2 つのステップ に分割して行う.まず,英語に対して Isozaki らの提案した並べ替え規則 [6] を適 用し,日本語語順の英語 (Head-Final English:HFE) を生成する.そして,日本語 と HFE の言語対と HFE と英語の言語対を用いて 2 つの翻訳モデルを学習し,そ れらの翻訳モデルを用いて日本語から HFE への翻訳と HFE から英語への 2 段階 の翻訳を行うことで英文を出力する. 図 5.1: 事後並べ替えの流れ5.1
Head Finalization
本節では,英語を Head-Fianl English に並べ替える Head Finalization の規則 [6] について説明する.本研究では,英語における統語主辞を出力するための解析器 として Enju1[12] を用いた.図 5.2 に Enju の出力の例を示す.Enju はそれぞれの ノードについて最大 2 つのノードを子として出力する.片方が統語主辞で,もう 片方が従属部である.Head Finalization は英語に対して以下の 4 つの規則を適用 して並べ替えを行う.Head Finalization を適用した例を図 5.3 に示す. 1. 統語主辞はその従属部の後ろに置く.ただし,並列句は除く. 2. 複数形の名詞は単数形に置き換える. 3. 前置詞”a”,”an”,”the”を取り除く. 4. 日本語の助詞の”は”や”を”に相当する擬似単語を挿入する. • va0:文の主辞動詞の主語. • va1:その他の動詞の主語. • va2:動詞の目的語. 規則 2∼4 は英語と日本語の単語の対応を取りやすくするための規則である.
5.2
2段階の翻訳
事後並べ替えでは,図 5.1 に示すように,2 段階の翻訳を行うことで日本語を 英語へと翻訳する.事後並べ替えにおける最初の翻訳である日本語から HFE へ の翻訳では,原言語に日本語のコーパス,目的言語に HFE のコーパスを用いて 統計的機械翻訳システムを構築する.HFE のコーパスは英語のコーパスに対して Head Finalization を適用したものを使用する.日本語から HFE への翻訳の大きな 目的はフレーズの翻訳であり,長距離の語順の並べ替えは行わない.よって,デ コードの際は短い距離の単語の移動のみを許すか,単語の移動を全く許さないよ うにディストーションリミットを設定する. HFE から英語への翻訳では,HFE と英語のコーパスを用いて統計的機械翻訳シ ステムを構築する.HFE から英語への翻訳では単語の長距離の並べ替えが大きな 目的である.よって,長距離の並べ替えが行えるようにディストーションリミッ トを設定しデコードを行う.また,HFE に挿入された擬似単語の削除や前置詞の 挿入などもこの翻訳で行われる. 1http://www.nactem.ac.uk/tsujii/enju/index.html 16図 5.3: Head Finalization:太線は統語主辞を表す
第
6
章
Factored Translation Models
を用いた事後並べ替え
事後並べ替えにおける翻訳で単語以外の情報を考慮するため,factored translation models[9] を用いる.
f を出力文,e を入力文としたとき,本来の統計的機械翻訳は翻訳確率 P( f|e)
を翻訳モデル P( fword|eword) と言語モデル P( fword) から最適な f を出力する.f を
出力文,e を入力文としたとき,本来の統計的機械翻訳は最適な f を出力する翻訳 確率 P( f|e) を翻訳モデル P( fword|eword) と言語モデル P( fword) から推定する.本
研究では factor translation models を用いて,出力側の factor を考慮した翻訳モデ ル P( fword, ff actor1, ff actor2,···|eword) とそれぞれの factor の言語モデル P( ff actor)
を考慮し,翻訳確率 P( f|e) を推定する.Factor を考慮することで,翻訳における 情報量や制限を増やしている.これによって,日本語の”前に”などの複数の翻訳 候補を持つ単語の翻訳をうまく扱うことができる. 本研究では,品詞とクラスタの 2 種類の factor を考慮する.品詞については Enju の出力を用いる.一方のクラスタは,訓練データに対して Brown Clustering[1] を 適用したものを用いる.Brown Clustering のクラスタ数は 50 と 1,000 の 2 種類で 分類を行う.50 クラスタでの分類は Enju の出力する品詞が約 50 個であるため, 品詞による分類と Brown Clustering による分類の違いの影響を評価するために用 いる.1,000 クラスタでの分類は品詞と単語の間の粒度の分類による翻訳への影 響を評価するために用いる. 提案手法における翻訳の流れを図 6.1 に示す.まず,英語の訓練データに対し て head finalization を適用し,HFE の訓練データを生成する.次に,英語と HFE の訓練データに対して,Enju の出力の品詞と Brown Clustering で分類したクラス タを付与する.その後,日本語の訓練データと factor の付与された HFE の訓練 データを用いて日本語から HFE への翻訳システム,HFE の訓練データと factor の 付与された英語の訓練データを用いて HFE から英語への翻訳システムをそれぞ れ学習する.そして,それぞれの翻訳システムを用いて日本語から HFE と HFE から英語への翻訳を行う.
図 6.1: Factored Translation Models を考慮した事後並べ替えにおける翻訳の流れ
6.1
日本語から
HFE
への翻訳
日本語から HFE への翻訳では,目的言語である HFE のそれぞれの factor の言語 モデル P( fword) と P( f品詞),P( fクラスタ) と日本語の単語と HFE の factor の組み合わ
せによる翻訳モデル P( fword, f品詞, fクラスタ|eword) を学習する.ここで,HFE のク
ラスタは英文の訓練データではなく,HFE の訓練データに対して Brown Clustering を適用したものを用いる.また,実験におけるディストーションリミットは 6 と する.
6.2
HFE
から英語への翻訳
HFE から英語への翻訳では,日本語から HFE への翻訳の際と同様に,目的言 語である英語のそれぞれの factor の言語モデルと HFE と英語の factor の組み合わ せによる翻訳モデルを学習する.また,ディストーションリミットは 12 として 実験を行う.
第
7
章
事後並べ替えにおける
factor
の影響の評価実験
7.1
データセット
実験には Wikipedia 日英関連文書対訳コーパスを対訳コーパスとして用いる. Wikipedia 日英関連文書コーパスは京都に関連する Wikipedia の記事を使用した 対訳コーパスである.今回の実験では,訓練データに 318,443 文,パラメータの チューニングデータに 1,166 文,テストデータに 1,160 文をそれぞれ用いた.7.2
使用したツール
単語アラインメントの獲得には GIZA++[15]1を用い,IBM モデル 4 までを学 習したモデルを使用した.言語モデルの学習には SRILM2を用いた.言語モデル は単語の表層は 5-gram,factor は 7-gram までとした.パラメータのチューニング には MERT[13],デコーダには Moses3を用いた.7.3
評価指標
翻訳精度の評価指標には BLEU[17] と RIBES[5] を用いた.BLEU は n-gram の 適合率と短い出力文へのペナルティによって計算される評価尺度で,現在の機械 翻訳の評価尺度として広く使われている.BLEU のスコアは式 (7.1) で計算される. BLEU = BP× exp( N
∑
n=1 wnlogPn) (7.1) 1https://code.google.com/p/giza-pp/ 2http://www.speech.sri.com/projects/srilm/download.html 3http://www.statmt.org/moses/ここで,BP は短い出力文に対してペナルティを与える項である.wnは n-gram に
対する重み,logPnは n-gram の適合率を表す.また N = 4 として評価を行う.
RIBES は,Kendall のτと unigram の適合率によって計算される評価尺度で,語 順の評価を行う際に用いられる.RIBES のスコアは式 (7.2) で計算される.
RIBES = τ+ 1
2 × P
α (7.2)
ここで,τは Kendall のτを,P は unigram の適合率,α は unigram 適合率の重み を表す.
7.4
実験結果と考察
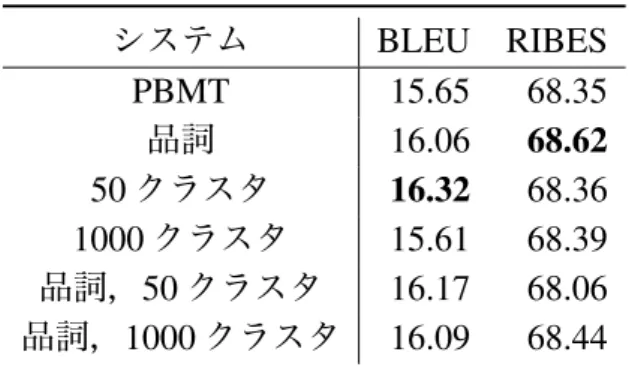
実験結果を表 7.1 に示す.事後並べ替えの有無にかかわらず factor を考慮する ことで BLEU スコアが上昇している.また,RIBES に関しても事後並べ替えの有 無にかかわらずスコアが上昇している.このことから,翻訳の際に単語の表層以 上の情報を考慮して情報量を増やすことで,翻訳精度が改善することが分かる. 事後並べ替えにおけるそれぞれの factor の影響について見ると,品詞と 1000 ク ラスタを考慮した場合に BLEU と RIBES のスコアが最も高くなっている.Factor 毎の影響の違いを見ると,品詞よりも 50 クラスタを考慮することで翻訳精度が 向上していることが分かる.これは Brown Clustering がデータに沿った分類を行 なっているため,品詞による分類と比較して,よりデータの傾向に沿ったモデル が学習され,翻訳精度の向上につながったと考えられる.7.4.1
日本語から
HFE
への翻訳における
factor
の影響
単語の翻訳に有効な factor を調査するために日本語から HFE への翻訳を行い,翻 訳精度を比較した.正解データには英語のテストデータに対して Head Finalization を適用したものを用いた.実験結果を表 7.2 に示す.これを見ると,50 クラスタ を考慮した際に,BLEU が最も高くなっている.このことから,事後並べ替えの 前半で単語の翻訳をうまく行えていることが全体での翻訳精度の高さにつながっ ていると考えられる. 22PBMT + 50 クラスタ 12 17.36 65.25 PBMT + 1000 クラスタ 17.56 65.88 PBMT + 品詞,50 クラスタ 17.41 65.23 PBMT + 品詞,1000 クラスタ 17.47 65.50 事後並べ替え 16.22 65.73 事後並べ替え + 品詞 16.22 65.77 事後並べ替え + 50 クラスタ 6 12 16.69 65.39 事後並べ替え + 1000 クラスタ 16.16 65.89 事後並べ替え + 品詞,50 クラスタ 16.55 65.45 事後並べ替え + 品詞,1000 クラスタ 16.79 65.99 表 7.1: 各手法に対する評価指標の数値
7.4.2
HFE
から英語への翻訳における
factor
の影響
単語の並べ替えに有効な factor を調査するために,factor 毎の HFE から英語への 翻訳の精度を比較した.本実験では英語のテストデータに対して Head Finalization を適用したデータを入力文として使用し,HFE から英語への翻訳を行った.この 結果を表 7.3 に示す.表 7.2 と異なり,クラスタを考慮すると BLEU と RIBES の 両方のスコアが上昇し,品詞と 1,000 クラスタの両方を考慮したときに BLEU が 最も高くなっている.また,1,000 クラスタを考慮した際の BLEU スコアが,50 クラスタを考慮した際の BLEU スコアよりも高くなっていることから,事後並べ 替えの後半の翻訳ではより細かい粒度の情報を考慮することが翻訳精度の改善に つながると言える. 表 7.2 と表 7.3 より,事後並べ替えの前半の翻訳では 50 クラスタ,後半の翻訳 では品詞と 1000 クラスタが有効であることが分かった.特に品詞と 1,000 クラ スタの組み合わせは事後並べ替えの前半と後半のそれぞれに有効であることが分 かった.それぞれの翻訳の際に最も有効な fator を考慮した場合の翻訳精度を表 7.4 に示す.これを見ると,それぞれの翻訳の際に最も BLEU スコアが高くなる factor を考慮した場合に,翻訳全体の BLEU スコアが最も高くなることが分かる. 23
システム BLEU RIBES PBMT 15.65 68.35 品詞 16.06 68.62 50 クラスタ 16.32 68.36 1000 クラスタ 15.61 68.39 品詞,50 クラスタ 16.17 68.06 品詞,1000 クラスタ 16.09 68.44 表 7.2: 日本語から HFE への翻訳における評価値 システム BLEU RIBES PBMT 59.69 82.31 品詞 58.85 81.85 50 クラスタ 60.09 82.27 1000 クラスタ 60.74 83.36 品詞,50 クラスタ 60.08 82.58 品詞,1000 クラスタ 60.99 83.16 表 7.3: HFE から英語の翻訳における評価値
7.4.3
ディストーションリミットによる翻訳への影響
ディストーションリミットによる翻訳への影響を調査した結果を表 7.5 に示す. 表 7.5 より,事後並べ替えにおける factored translation models は日本語から HFE への翻訳におけるディストーションリミットによって翻訳への影響が異なってい ることが分かる.BLEU に関しては,日本語から HFE への翻訳におけるディス トーションリミットを大きく設定することでスコアが高くなった.これは,ディ ストーションリミットを大きくすることで,日本語から HFE の翻訳の際に単語の アラインメントがうまく学習できていることが影響していると考えられる.一方 の RIBES は,日本語から HFE への翻訳におけるディストーションリミットを小 さくしたほうがスコアが高くなった.これは,ディストーションリミットを小さ くすることで,日本語から HFE への翻訳における出力文が日本語の語順に近く なり,HFE から英語への翻訳システムの学習に用いた HFE のデータの傾向に近 づくことで,並べ替えモデルが有効に働いたためだと考えられる. また,事後並べ替えにおけるそれぞれの factor の影響については,ディストー 24+ 50 クラスタ 16.69 65.39 + 1,000 クラスタ 6 12 16.16 65.89 + 品詞,50 クラスタ 16.55 65.45 + 品詞,1,000 クラスタ 16.79 65.99 + 50 クラスタ & + 品詞,1,000 クラスタ 17.16 65.69 表 7.4: 最適な factor を考慮した際の翻訳精度 ションリミットの設定にかかわらず,品詞と 1,000 クラスタを考慮した場合が最 も BLEU が高くなった.RIBES に関しては,ディストーションリミットを小さく 設定した際は,品詞と 1,000 クラスタを考慮した場合が最も高くなったのに対し て,ディストーションリミットを大きく設定した際は,1,000 クラスタのみを考 慮した場合が最も高くなった. 25
ディストーションリミット BLEU RIBES 日本語 → HFE HFE → 英語 事後並べ替え 16.22 65.73 事後並べ替え + 品詞 16.22 65.77 事後並べ替え + 50 クラスタ 6 12 16.69 65.39 事後並べ替え + 1,000 クラスタ 16.16 65.89 事後並べ替え + 品詞,50 クラスタ 16.55 65.45 事後並べ替え + 品詞,1,000 クラスタ 16.79 65.99 事後並べ替え 16.32 64.64 事後並べ替え + 品詞 17.16 64.64 事後並べ替え + 50 クラスタ 20 12 16.62 63.84 事後並べ替え + 1,000 クラスタ 17.01 65.36 事後並べ替え + 品詞,50 クラスタ 16.84 64.39 事後並べ替え + 品詞,1,000 クラスタ 17.43 65.25 表 7.5: ディストーションリミットによる翻訳への影響 26
第
8
章
結言
本研究では日英翻訳に対する事後並べ替えに factored translation models を用い て単語の品詞とクラスタを翻訳における追加の情報として考慮する手法を提案し た.実験から,追加の情報を考慮することによって並べ替えの精度が向上するこ とが確認できた.また,factored translation models は BLEU による n-garm の適合 率と RIBES による語順の適合率に対して異なる影響を持つことが分かった.
今後の課題として,考慮する factor の調査を行う必要があると考えている.本 研究で行った実験から,50 クラスタよりも 1,000 クラスタを考慮することによっ て翻訳精度が向上したことが確認できた.これによって,クラスタの粒度の違い によって翻訳精度に影響を及ぼすことが分かった.また,今回はクラスタリング の手法として brown clustering を用いたが,deep learning などのより多くの情報を 考慮できるクラスタリングの手法を用いることで,より訓練データの傾向を捉え た factor を利用でき,並べ替えの改善につながると考えられる. また,原言語の factor を考慮することによって,日本語から HFE への翻訳にお ける精度の改善が期待できる.原言語側の factor の情報は,日本語の助詞などの, 単語の表層は一致しているが意味の異なる単語の翻訳において有効であると考え られる.これによって,日本語から HFE への単語の翻訳の精度が向上すると考え られる.
参考文献
[1] Peter F Brown, Peter V Desouza, Robert L Mercer, Vincent J Della Pietra, and Jenifer C Lai. Class-based n-gram models of natural language. Computational
linguistics, Vol. 18, No. 4, pp. 467–479, 1992.
[2] Peter F Brown, Vincent J Della Pietra, Stephen A Della Pietra, and Robert L Mercer. The mathematics of statistical machine translation: Parameter estima-tion. Computational linguistics, Vol. 19, No. 2, pp. 263–311, 1993.
[3] Michael Collins, Philipp Koehn, and Ivona Kuˇcerov´a. Clause restructuring for statistical machine translation. pp. 531–540, 2005.
[4] Michel Galley and Christopher D Manning. A simple and effective hierarchical phrase reordering model. In Proceedings of the Conference on Empirical
Meth-ods in Natural Language Processing, pp. 848–856, 2008.
[5] Hideki Isozaki, Tsutomu Hirao, Kevin Duh, Katsuhito Sudoh, and Hajime Tsukada. Automatic evaluation of translation quality for distant language pairs. In Proceedings of the 2010 Conference on Empirical Methods in Natural
Lan-guage Processing, pp. 944–952, 2010.
[6] Hideki Isozaki, Katsuhito Sudoh, Hajime Tsukada, and Kevin Duh. Head fi-nalization: A simple reordering rule for sov languages. In Proceedings of the
Joint Fifth Workshop on Statistical Machine Translation and MetricsMATR, pp.
244–251, 2010.
[7] Jason Katz-Brown and Michael Collins. Syntactic Reordering in Preprocess-ing for Japanese to English Translation: MIT System Description for NTCIR-7 Patent Translation Task. Proceedings of NTCIR-7 Workshop Meeting, 2008. [8] Reinhard Kneser and Hermann Ney. Improved backing-off for m-gram language
modeling. In Acoustics, Speech, and Signal Processing, 1995. ICASSP-95., 1995
[9] Philipp Koehn and Hieu Hoang. Factored translation models. EMNLP-CoNLL, pp. 868–876, 2007.
[10] Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, et al. Moses: Open source toolkit for statistical machine translation. pp. 177–180, 2007.
[11] Philipp Koehn, Franz Josef Och, and Daniel Marcu. Statistical phrase-based translation. In Proceedings of the 2003 Conference of the North American
Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1, pp. 48–54, 2003.
[12] Yusuke Miyao and Jun’ichi Tsujii. Feature forest models for probabilistic hpsg parsing. Computational Linguistics, Vol. 34, No. 1, pp. 35–80, 2008.
[13] Franz Josef Och. Minimum error rate training in statistical machine translation. In Proceedings of the 41st Annual Meeting on Association for Computational
Linguistics-Volume 1, pp. 160–167, 2003.
[14] Franz Josef Och and Hermann Ney. Discriminative training and maximum en-tropy models for statistical machine translation. In Proceedings of the 40th
An-nual Meeting on Association for Computational Linguistics, pp. 295–302, 2002.
[15] Franz Josef Och and Hermann Ney. A systematic comparison of various statis-tical alignment models. Computational linguistics, Vol. 29, No. 1, pp. 19–51, 2003.
[16] Franz Josef Och, Christoph Tillmann, Hermann Ney, et al. Improved alignment models for statistical machine translation. In Proc. of the Joint SIGDAT Conf.
on Empirical Methods in Natural Language Processing and Very Large Corpora,
pp. 20–28, 1999.
[17] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th
an-nual meeting on association for computational linguistics, pp. 311–318, 2002.
[18] Katsuhito Sudoh, Xianchao Wu, Kevin Duh, Hajime Tsukada, and Masaaki Na-gata. Post-ordering in statistical machine translation. In Proc. MT Summit, 2011.