1
データ・ウェアハウスの未来をリードするGreenplum DB
2
ビッグデータ活用でビジネス変革を実現
企業向け次世代Hadoopソリューション Greenplum MR
18
Contents
徹底解説
EMCジャパン株式会社 東京都渋谷区代々木2-1-1 新宿マインズタワー 〒151-0053 http://japan.emc.com お問い合わせは http://japan.emc.com/contact/EMC2、EMC、Greenplum、Greenplum DatabaseおよびEMCロゴは、EMC Corporationの登録商標、または商標です。
これらの商標は、日本または諸外国で商標登録等により、適用法令で守られている場合があります。他のすべての名称ならびに製品についての商標は、それぞれの所有者の商標または商標登録です。
© Copyright 201 EMC Corporation. 不許複製
SG1038-1 02/12
Greenplum MR (旧Greenplum HD)が
「 ITpro EXPO AWARD 優秀賞 」
を受賞しました
第1版
バッチ処理・データ解析における汎用RDBMSの課題
Greenplum DBのアーキテクチャの話をする前に、これまでデータベース分野 でされてきた議論を、今、一度振り返ってみます。 データベースの分野では、これまで大きく2つのアーキテクチャが議論されて きました。 1つがシェアードエブリシングです。シェアードエブリシングというのは、1台 のサーバ・ストレージの中に、必要なデータを全て詰め込み、この1台のサーバ で、全てのデータベースの処理をしようというアプローチです。 シェアードエブリシング・アーキテクチャで、最も有名なのはOracleデータベー ス、IBM/DB2、あるいはMS SQL Server、PostgreSQL、MySQLのようなデータ ベースです。 一般的にデータベースといわれるものは、基本的にはシェアードエブリシング と考えてよいでしょう。 シェアードエブリシング・アーキテクチャはOLTPの処理には非常に向いていま すが、バッチ処理やデータウェアハウスの処理には不向きとされています。 何故かというと、OLTPのように、1件のデータを抜き出すというのではなくて、 全てのデータを一気にスキャンする、あるいはテーブルをJOINするなど、一気 にデータを読みだして処理をするところで、IOボトルネックが発生しやすいの です。1台のサーバで全てのデータを扱うため、CPU、メモリのボトルネックだ けでなく、プロセス自身のボトルネックも発生しやすいと言えます。 このシェアードエブリシング・アーキテクチャのシステムで大量データ処理の性 能を向上させるために何をするかというと、1台のサーバ・ストレージにできる だけ多くのハードウェア・リソースを追加していくことでした。 まず、CPUを10、20、30、40と増やしていくわけです。しかしながら、それで性 能が伸びるかというと、その保証はありません。次に、ストレージ・ボトルネッ クが発生し、性能がそのボトルネックに引っ張られてしまう。そのボトルネック を解消するために、ストレージを増設し強化する。増設したからといって、性能 が伸びるのかというと、次はまたCPUがボトルネックになってしまう。このよう なイタチごっこが、シェアードエブリシング・アーキテクチャが、データウェアハ ウス処理、バッチ処理に向いてないとされてきた理由です。シェアードナッシング・アーキテクチャ
この課題を解決するアーキテクチャとして、考え出されたのが、シェアードナッ シング・アーキテクチャです。 このシェアードナッシング・アーキテクチャというのは、一つのデータを分割 して複数のサーバに小分けにして処理をする、という考え方です。複数の小さ なサーバを水平方向に並べて、1台のサーバが処理しなければならないデータ の量を少なくすることで、ストレージの負荷を低くします。これによりIOボトル ネックを解消します。加えて、サーバのメモリ上に読み出したデータも少ないた め、CPUとメモリのボトルネックも解消できます。このような利点をもつものが シェアードナッシング・アーキテクチャです。 このシェアードナッシング・アーキテクチャは、特に新しいアーキテクチャであ りません。既に30年以上前からこの業界では使われてきたアーキテクチャであ り、古くはTeradataが、このアーキテクチャで実績を上げてきました。 しかしこのシェアードナッシング・アーキテクチャにはコストの課題がありま した。例えば、Teradataですと、サーバを並列に並べて、このお互いのサーバ がデータを通信するのですが、そのためのインタコネクトにバイネットという データウェアハウス向けの独自のテクノロジーが必要でした。バイネットは、専 用のハードウェアで動くもので、必然的にコストが上がっていくというのが課 題でした。 あるいは他社の例では、インタコネクトに加えてCPUも独自に開発をしていて、 そこがハードウェアを縛る原因になり、必ずコストが上がるような状況を招い ていました。 これらのような理由で、なかなかデータウェアハウス・システムのコストを下げ ることができない状況が続いていたのです。経済的に余裕のある企業がかな り大きな投資を行う。これがこれまでのデータウェアハウスのシステムでした。 Greenplum DBは、データウェアハウス分野のためのデータベースであり、当然 このシェアードナッシング・アーキテクチャを採用しています。しかしながら、そ れを構成するハードウェアは特別なものに縛られるということがありません。 サーバ同士を繋げるためのインタコネクトは通常のイーサネットスイッチを使う ことができます。 また、Greenplum DB自体はコモディティ化された普通のIAサーバ上で動作し ます。Linux OSが動けば、全てGreenplum DBの対象プラットフォームになりま す。Greenplum DBは、シェアードナッシング・アーキテクチャでありながら、特 定のハードウェアに縛られずに簡単にデータウェアハウス環境が構築できるの です。 Buffers Locks Control Blocks 集計が集中 ソートが集中 結合処理が集中 スキャンが集中 サーバ#1 シェアードエブリシング Buffers Locks Buffers Locks Buffers Locks Control Blocks Control Blocks Control Blocksサーバ#1 サーバ#2 サーバ#3 スキャン・結合・ソート・集計を並列化 シェアードナッシング
徹底解説その1
データ・ウェアハウスの未来をリードするGreenplum DB
図1: シェアードエブリシングとシェアードナッシング・アーキテクチャ Greenplum DBはデータウェアハウス、バッチ処理のための高速データベースです。構造化データを対象にしたビッグデータの分析を低コストで高速に実行する基 盤として利用できます。ここでは、Greenplum DBの先進機能、利用例を紹介しながらGreenplum DBのアーキテクチャを説明します。Greenplum DB
の特徴・アーキテクチャを理解する
Greenplum DBの位置づけ
次に、Greenplum DBがシステムの中のどこに位置付けられているのかを確認 してみましょう。 一番左は基幹系のデータベースです。日中にトランザクション処理をするため のデータベースで、OracleやIBM DB2、MySQLなどが使われています。これら のデータベースから日中のトランザクションを吸いだしてETLサーバを経由し て貯め込む先、そこにあるのがGreenplum DBです。ここに履歴、ヒストリカル データをどんどん貯め込み、分析をかけていくということになります。Greenplum DBはあくまでもデータベースですので、ユーザからはBIツールを 使ってアクセスすることになります。
BIツールとしては、Business Objectsや、MicroStrategy、JaspersoftやSASな ど、一般的に広く使われているツールが利用可能です。 BI、ETL製品への幅広い対応で基幹システム、分析システム連携を実現 基幹システム 分析&レポート ETL Extract Transform Load Oracle DataStage Infomatica SAS ETL Ab Initio PluralSoft Talend MicroStrategy Cognos SAS Jaspersoft Business Objects Pentaho Hyperion ACTUATE High Speed Loader IBM/DB2 MySQL Postgres SQL Server JDBC < > ODBC < > SQL/92 < >
Greenplum DBの3つの特徴
バッチ処理・データ解析のためのデータベースであるGreenplum DB。その特 徴を、3つご紹介します。 まず第1点目は、大規模に処理をパラレル化する、並列処理をさせるという、 シェアードナッシング・アーキテクチャである点です。シェアードナッシング・ アーキテクチャを採用することによって、百から千以上のCPUコアを同時に使 い、パラレルに、高速にデータ処理を行えるというのが第一点目の特徴です。 大規模並列処理と言っても、標準のSQLが使えます。SQLを知っている開発者、 ユーザであれば、Greenplum DBに標準のSQLを投げ込むだけで、ユーザは並列 処理を意識しなくてもGreenplum DBが自動的にパラレル処理を実現してくれ ます。 2点目は、特定のハードウェアに縛られないオープンアーキテクチャである点です。 Greenplum DBを構成する全てのコンポーネントは特定のハードウェアに縛ら れません。インタコネクト、ストレージ、サーバ、CPU、メモリ、OSに至るまで、 すべてのコンポーネントが特定のものに縛られていません。 従来、データウェアハウスを始めるということは、それ専用のデータウェアハウ ス・システムを新規に導入するということと同じでした。それに対しGreenplum DBは、コモディティのサーバ、スイッチ、ストレージをうまく活用してデータ ウェアハウスの環境を、構築し、運用することができる。これが2点目のポイン トです。 そして3点目が拡張性です。 Greenplum DBは、サーバを追加するだけで簡単に拡張できます。システムを止 めずに、オンラインでシステムにサーバを追加し、拡張することができますの で、CPUのパワーが足りなくなった場合にも、簡単に性能をアップさせることが できます。ストレージも同様です。この拡張性が3点目のポイントです。シェアードナッシング・アーキテクチャの実装により、
高速なバッチ処理・データ分析を実現
Greenplum DBを構成するコンポーネントは大きく3つあります。 上からマスターサーバ。2つ目がネットワーク・インタコネクト。3つ目がセグメ ントサーバです。 マスターサーバは、ユーザからのクエリの受付と、クエリ結果の返答を行いま す。ただしデータベース処理自身は行いません。データベース処理は、バックエ ンドにあるセグメントサーバに対して、分散して指示をします。 ユーザから「こういうクエリがきましたので、処理をしなさい」と命令を受け、 分散して処理をするのがセグメントサーバです。実際には、このセグメント サーバの台数によってデータベースの性能と、データベースの容量が決まります。 このマスターサーバと、セグメントサーバの間を繋げるのが、ネットワーク・イ ンタコネクトです。 マスターサーバと、セグメントサーバは、他社であれば専用のサーバが必要でし たが、Greenplum DBでは通常のインテル・アーキテクチャのサーバが活用でき ます。 OSはLinuxが一般的です。 このマスターサーバとセグメントサーバの間を取り持つ、ネットワーク・インタ コネクトにはイーサネットスイッチを使います。ここも、専用のものは必要あり ません。今であれば10Gbイーサネットスイッチを冗長化のために2台使う構成 が一般的です。よりコストを抑えたいということで1Gbイーサネットスイッチを 2台使用している事例もあります。シェアードナッシング・アーキテクチャ
による高速
DB
処理
SQLを解析し、セグメント サーバのための最適な 並列実行プランを作成 gNetソフトウェアインタ コネクトによるセグメン ト間の効率的なデータ 送受信 パラレルデータフローエ ンジンが、ハードサーバ 性能を最大活用 パラレルロードによる、 高速ローディング マスターサーバ クエリプランニング&ディスパッチ セグメントサーバ クエリの実行& データの格納 外部ソース ローディング、ストリーミング等 ネットワークインタコネクト SQL 大規模並列処理 ・ シェアードナッシングによる大規模並列処理 ・ パラレルエンジンが、数台から数百台のサーバによる並列処理を実現 ・ 広範囲のSQL対応(SQL-92, SQL-99, SQL-2003 OLAP) オープンアーキテクチャ ・ コモディティハードウェアで実現する大規模DB ・ ソフトウェアオンリーのアプローチにより、低価格かつ構成の高い柔軟性を実現 拡張性 ・ スモール・スタートが可能 ・ データ量の増加に伴うシステム拡張を 低コストで実現 ・ 数百ギガから数十ペタバイト規模までの リニアなスケーラビリティ 図2: Greenplum DBの位置づけ 図3: Greenplum DBの特徴4
5
世界最高速のデータロード性能
Greenplum DBは他製品と比べてさまざまな差別化ポイントがありますが、最 もわかりやすいポイントはデータロード性能です。データロード性能は他社製 品と比較して、圧倒的に高速です。 図4はGreenplum DBと、他社の4製品における、1時間当たりにローディングで きるデータの量を比較したグラフです。縦軸が1時間当たりでローディングでき るデータの量、TB/h、横軸が各製品です。 他製品が5TB、或いは2TBという性能に対して、Greenplum DBは10TBのデータ ローディングが可能です。他製品と比較して2倍、または5倍のローディング性 能があります。 また、Greenplum DBも他製品も1ラックから2ラック、3ラックと、ラックを増設 し拡張することができます。Greenplum DBの場合、2ラックにするとセグメン トサーバが増えて行き、リニアに性能が向上し、20TB/hのデータローディング が可能になります。対して他製品では性能が頭打ちになり、大きく変わりません。 2ラックでも3ラックでもローディング性能は5TBあるいは2TBのまま変わりま せん。 Greenplum DBは、2ラックでは20TB/h、3ラックにすると、30TB/hというよう に、ローディング性能がリニアに増加します。 リニアに性能を向上させることができることは、特にHadoopを利用している ユーザに非常に好評です。 Hadoopで扱うべきデータがどこまで増えるのか分からない状況で、性能を青 天井で向上させることができる仕組みが非常に評価されています。TB/h
10 0 20 30 40 Greenplum DBはラック数に比例してロード性能が向上0
2
4
6
8
10
12
TB/h
1ラック構成での比較世界最高速のデータロード性能を実現するGreenplum DB
のScatter/Gather Streaming 技術 活用例1
Greenplum DBが他製品と比較して何故これだけの性能差がでるのか?その 理由を、Greenplum DBの主要機能の紹介を通じて説明していきます。まず、 データローディングの機能について説明していきましょう。 Greenplum DBでは、様々なデータローディング手法があります。 その中で最も高速にデータをローディング出来るのが、この活用例1のロー ディング方法です。 図5では、マスターサーバ1台とセグメントサーバ2台という、非常に小さな Greenplum DBシステムを簡易的に表しています。このGreenplum DBシステム のインタコネクト部分に、ロードサーバ(NASやファイルサーバ)を直接接続し、 マスターサーバを経由しないでデータをローディングすることが可能です。ま た、このロードサーバ自身を水平方向に増やしていき、ローディング性能を増や していく、リニアにスケールさせることができます。 Oracleを利用しているユーザであれば、Oracleからファイルをロードサーバ上 に掃きだし、そこから直接インタコネクトを経由してセグメントサーバにデータ を流し込んでいく、ということも可能です。 他DB(Oracle等) セグメントサーバ ロードサーバ ロードサーバ セグメントサーバ マスターサーバデータロード:従来の処理方式
ここでは他製品の仕組みと比較しながらデータローディング性能の優位性に ついて更に説明します。従来のデータのローディング方式、これはOracle Exadata、Netezza、そして
Teradata、この3つのアーキテクチャに等しく当てはまるものです。 他製品ともに名称は違っても、2階層のサーバでシステムが構成されていると いう点ではGreenplum DBと同じです。 例えば、Greenplum DBでは、マスターサーバ、セグメントサーバと呼んでいます が、Oracleではデータベースサーバーとストレージサーバーと呼んでいます。 このストレージサーバーを並べることによって性能を上げています。これは Netezza、Teradataも同様です。 他製品におけるデータローディングは、全てのデータがマスターサーバを経由 して入っていきます。マスターサーバ上にローディングプロセスがあり、仮に ファイルサーバが2台、CSVのようなテキストファイルが2つあったとします。こ 図4: 世界最高速のロード性能
図5: Greenplum Scatter/Gather Streaming 活用例1
世界最高速のデータロード性能を実現する
Greenplum DB
の
Scatter/Gather Streaming
技術
れらのデータをローディングするとき、この図のようにマスターサーバを経由 しなければ全てのデータがセグメントサーバに入っていかないという事になり ます。 図6ではセグメントサーバは4台ですが、8台になったとしても、或いは12台に なったとしても、マスターサーバがボトルネックになってしまい、ローディング の性能は伸びません。 先ほどの1ラック、2ラック、3ラックと、システムを増強していたとしても、性能 が伸びないというのは、正にこの点に起因するわけです。 データソース マスタサーバ セグメントサーバ ローディング プロセス セグメントサーバ セグメントサーバ セグメントサーバ データソース
Greenplum DB の徹底した並列処理
これに対し、Greenplum DBのデータローディングでは、マスターサーバはデー タのやり取りをしません。 マスターサーバは、必須のコンポーネントであり、システム内には存在します が、データローディングの処理自体には関与しません。 ではどのようにデータをローディングしているのでしょうか。各セグメントサー バ上はデータを取りこむ、パラレルデータフローエンジンというものが存在し ます。従来製品の仕組みの説明でいうところの、ローディングプロセスを担っ ています。 データをデータソースから取りこむ処理を、他製品であれば1か所にしかない ところを、Greenplum DBでは各セグメントサーバ上に、ローディングプロセス を台数分持つわけです。 まず、各セグメントサーバは、データの内容などは特に考えず、図7の場合で言 えば、色や場所は特に考えないで、ブロック単位でデータソースからデータを 持ってきます。次に、セグメントサーバの1台1台が、マスターサーバが定める分 散ポリシーに応じて、データを分散するという処理を行います。実際には、こ の処理を全てのセグメントサーバが同時に行います。これによってローディン グ性能を向上させることができるのです。 ラックを増やすということは、当然セグメントサーバが増えることになり、デー タを引っ張ってきてデータを所定の位置に分散するという、この処理を行うエ ンジンであるセグメントサーバ分増えますので、ローディング性能がリニアにど んどん伸びていくのです。 セグメントサーバ データフロー エンジン セグメントサーバ データソース セグメントサーバ セグメントサーバ セグメントサーバ セグメントサーバ データソース パラレル データフロー エンジン パラレル データフロー エンジン パラレル データフロー エンジン パラレル データフロー エンジン データソース データソース パラレル データフロー エンジン パラレル データフロー エンジン パラレル データフロー エンジン パラレル セグメントサーバ セグメントサーバ 各セグメントサーバは、データの内容(この場合は色や場所)などは特に考えず、 ブロック単位でデータソースにデータを取りに行き、各々のデータのロード先にデータを振り分けます。 実際には、上記の処理をすべてのセグメントサーバが同時に行います。 この並列処理が高速なローディングを可能にしています。世界最高速のデータロード性能を実現するGreenplum DB
のScatter/Gather Streaming 技術 活用例2
活用例1でご紹介したのは、大量のデータを限られた時間に、できるだけ高速 に流し込むというローディング手法です。 それ以外にもGreenplum DBは、様々なデータのローディングが可能です。 2つ目のローディング手法としてご紹介するのは、ロードサーバを使用しない ローディング手法です。 ここでは、Oracleを例として説明します。 図8に示すとおり、OracleとIP通信ができる環境があれば、セグメントサーバが Oracleに対して直接コネクトし、データをローディングすることが可能です。 従って、Oracleから一度、ファイルサーバにファイルをダンプする必要なく、直 接データを抜き出すことが可能です。 このローディング手法は、一旦ロードサーバ(ファイルサーバ)に対してファイ ルをダンプして、そこからセグメントサーバにデータを流し込むというこの手間 を省けます。「なるべく最新のデータが欲しい」といった場合に、役に立つ仕組 みです。 このローディング手法は、ローディングのパフォーマンスが速いか遅いか は、データソース側の、この例であればOracleのシステムに依存します。直接 Oracleからデータを引っ張ってくることになるため、Oracle側のシステム規模 が小さいと、高いローディングの性能を出すことはできません。一方、Oracle側のサーバが非常に高スペックで、OracleとGreenplum DBの間の ネットワークも帯域が非常に太ければ、非常に速いローディングが期待できます。 ですからこの手法は、ニアリアルタイムなデータに対して分析をしたい場合に、 有効な手法です。
図6: 従来の処理方式
具体的な仕組みとしては、Greenplum DBの外部表という機能を使用してい ます。外部表というのは、Greenplum DBの中にまだ入っていない、セグメント サーバ上に置かれていないデータであるが、その外にあるデータをあたかも Greenplum DBのデータとして扱える機能です。 この外部表には、OSコマンドの結果をGreenplum DBのデータレコードとして 扱う機能があります。 例えばOracleからデータを抜き出す場合には、OSコマンドの中で、Oracleク ライアントのコマンドを叩き、Oracleクライアントが外部にあるOracleに対 して、SQL Plusでコネクションを張りデータを引き出してきて、その結果を Greenplum DBの中のデータレコードとして扱うことが可能です。 O Sコマンドとして発行できれば、何でも外部表データとして扱えるので、 Oracle以外のデータベースにも対応可能です。 DB2、SQL Serverであったり、 シェルのコマンドであったり、何かのアプリケーションの実行結果であったり、 様々なものをデータとして扱うことができます。 他DB(Oracle等) セグメントサーバ セグメントサーバ マスターサーバ
世界最高速のデータロード性能を実現するGreenplum DB
のScatter/Gather Streaming 技術 活用例3
ここまでは、高速にデータをロードする、あるいはニアリアルタイムなデータ をローディングする方法をご紹介しました。次は、データを書きだすお話しで す。当然、Greenplum DBは、マスターサーバを経由してデータを書きだすこと が可能ですが、ここもローディングと同じように、マスターサーバがボトルネッ クになる可能性があります。他製品が持っている、また違う箇所のボトルネッ ク、アンロード時のボトルネックになります。 Greenplum DBは、マスターサーバを経由してデータを書き出す以外に、セグメ ントサーバから直接ファイルサーバに対してデータを書き出すことも可能です。 それを示したのが図9です。 セグメントサーバから、マスターサーバを経由しないで、ダイレクトにデータを 書き出しています。 この書き出し先も、1台ではなく、2台、3台、4台と増設することができ、データ を受け取る側のサーバを増やすことによって、大量のデータのパラレルの高速 アンロードが可能です。 このパラレルなデータのロード、パラレルのデータのアンロード、この仕組は Hadoopとの連携に非常に有効に働きます。 ここでサポートしているファイルの形式は、CSVなどのテキストファイルです。 テキストファイルに対するデータの書き出しが可能です。 セグメントサーバ ロードサーバ ロードサーバ セグメントサーバ マスターサーバ世界最高速のデータロード性能を実現するGreenplum DB
のScatter/Gather Streaming 技術 活用例4
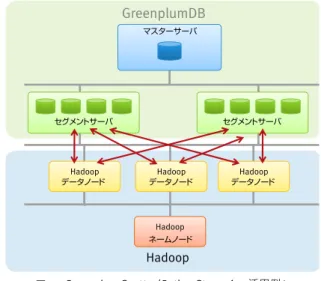
最新のデータのロード・アンドロードの技術として、Greenplum DB 4.1で搭載 された機能が、外部表のデータソースとしてHadoopをサポートしたことです。 Hadoopのデータをパラレルにローディングでき、パラレルにデータをアンロー ドすることもできます。 図10では、下がHadoopシステムです。Hadoop Hadoop Hadoop
Hadoop
Hadoop
GreenplumDB
セグメントサーバ データノード マスターサーバ セグメントサーバ データノード データノード ネームノード Hadoopは、Greenplum DBと似た2つのレイヤーから構成されています。 Hadoopは、親的役割をするネームノードと、水平方向にスケールさせて性能を あげていくデータノードの2つのレイヤーの組み合わせで構成されています。 HadoopのデータノードとGreenplum DBセグメントサーバが直接パラレルにや りとりすることによって、Greenplum DBのマスターサーバを経由せず、なおか つHadoopのネームノードも経由しないで、パラレルにデータのロードが可能で すし、アンロードも可能です。 Hadoopは、現在非常に注目されている技術ですので、他社製品も当然のよう にHadoopとの連携ができると言われています。 他社も「Hadoopとの連携ができるようになりました」と発表しています。 しかしながら、他製品は、マスターサーバを経由してHadoopとデータのロー ド・アンロードを行いますので、Hadoopと連携する際、Hadoopシステムから データを抜き出そうとすると、結局マスターサーバを経由します。同様にマス ターサーバを経由してデータが出ていくわけです。従って、データが大きくなれ ばなるほど、連携部分のボトルネックが顕著になります。 Greenplum DBはこの点を解決しています。Hadoopを外部表として使えるとい うようになったという、この機能がボトルネックを解消しているのです。 図8: Greenplum Scatter/Gather Streaming 活用例2図9: Greenplum Scatter/Gather Streaming 活用例3
図10: Greenplum Scatter/Gather Streaming 活用例4
例えばデータ量が50億件の非常に大規模なデータを、別の50億件のテーブル と突き合わせて、その突き合わせた結果の、非常に大きくなったテーブルをそ のまま集計も何もしないで、Hadoopに渡したい。このようにデータ量として は、数百ギガバイトになるようなものを、マスターサーバを経由させると当然ボ トルネックになります。そのような場合に使うのは、このアンロードの機能にな ります。
Greenplum DBにおけるマスターサーバの役割
ここで1つ疑問が生じたのではないでしょうか。Greenplum DBのマスターサー バは実際には何をやっているのでしょうか?マスターサーバはクエリの実行や JOIN処理などは行いません。それらの処理を行うのはセグメントサーバです。 Greenplum DBでは、セグメントサーバ同士が、自分以外のサーバが、どういっ たデータを持ってるかを知っています。従って、JOIN処理などにマスターサーバ が関わらないで、セグメントサーバ同士が通信をすることによって、処理を実行 していきます。 その処理に関する分散ポリシーを、各セグメントサーバに定義をすることは、マ スターサーバを経由してのみ可能です。 例えばテーブルを作るときに、「このテーブルはこういった分散をさせます」と いう指示をします。そうすると、その指示が各セグメントサーバ上に伝達され、 このテーブルに関しては「こういう分散ポリシーなんだ」ということを各セグ メントサーバが記憶します。その後は、例えばデータソースから直接データを 引っ張ってきたとしても、セグメントサーバは「マスターサーバから教わったこ の分散ポリシーに従って、分散すればいいのだ」と判断して処理を行います。 仮に「自分のところにあるべきデータじゃない」ということがわかった場合に は、他のセグメントサーバに渡せばいいということを知っていますので、直接他 のセグメントサーバにデータを渡します。 マスターサーバは必須であり、テーブルの定義、あるいは分散ポリシーを設定 するためには絶対に必要ですが、複雑な処理であったとしても、マスターサー バは実際のクエリ処理を、行わないで済むわけです。8
9
データレコードの分散処理
Greenplum DBが、データをどのように分散配置しているかを説明します。
Greenplum DBは、データレコードの分散配置の仕方をテーブル作成時に指定 します。具体的には CREATE TABLE 文の後ろに DISTRIBUTEDという句を追加し ます。DISTRIBUTED の後ろにカラムを指定しますと、データレコード1行づつ の指定されたカラムの値をハッシュ値にしてセグメントへのデータレコードの ハッシュ分散が行われます。図11は、Greenplum DBがハッシュ分散した時の仕 組みを表しています。DISTRIBUTED の後ろに RANDOMLY と指定すると、ハッ シュ分散は行わずにラウンドロビン方式でデータレコードを各セグメントへ分 散させてゆきます。 なお、分散配置の仕方が 2通りあると説明をしましたが、どちらの場合でもと ても重要なポイントは、テーブル作成後に指定された分散配置の仕方は各セグ メントにも通達されているという点です。ですので、各セグメントがクエリ処理 をする過程で他セグメントのデータレコードを参照する必要が出てきた場合で も、そのデータレコードの在処をマスターサーバに問い合わせません。各セグ メントサーバが分散配置の仕方を把握していますのでお互いに通信します。 B A B C C A A C C C C A A A B B データレコード マスターサーバ セグメントサーバ ハッシュ の指定 S2 S1 S3
クエリのパラレル処理
次にクエリのパラレル処理について説明します。Greenplum DBでは、各セグメ ントサーバへのクエリ処理は、マスターサーバからの指示を受けてパラレルに 行われます。 まず、クライアントは、クエリの投げ先としてマスターサーバを指定し、クエリ を投げます。次にクエリを受け付けたマスターサーバは、クエリの解析を行い、 各セグメントサーバへの実行プランを作成します。「パーティションスキャン をするか」、「シーケンシャルスキャンをするか」、などや「JOINでは入れ子JOIN をするか、ハッシュJOINするか」などの実行プランを考えるのがマスターサー バです。実行プランを作った後、実際にクエリの処理を始める時に、各セグメ ントサーバに対して、この実行プランを処理しなさいという指示を出します。 指示を受け取った各セグメントサーバは自分が持っているデータに対して、マス ターサーバから来た実行プランを実行します。全てのセグメントサーバは独立 して処理を実施しますが、データの配置によってはセグメント1台の中で処理が 終わらず、複数台のセグメントサーバと通信をしなければならない場合が生じ ます。ここが重要な点ですが、その場合もマスターサーバは介在せずセグメン トサーバ同士が直接会話してデータの交換をします。マスターサーバの介在を 必要としないためパラレリズムが維持されるわけです。 クエリ処理の結果は、セグメントサーバがそれぞれマスターサーバに対して返 して、そして最終的にクライアントに返っていく、これが通常のクエリ処理のフ ローです。 また、クエリの結果はアンロードすることも可能です。各セグメントサーバが実 施したクエリ処理の結果をアンロード先のサーバに対して出力したり、Hadoop に渡したりすることができます。 アンロードの仕組みは、出力先がファイルでも、Hadoopであったとしても、 Greenplum DBの外部表という機能を使っています。外部表ですからテーブル です。アンロード時は処理したクエリの結果を「こちらの外部表にINSERTして ください」というように指示します。このようにINSERTすると、実はその出力先 がHadoopであったり、あるいはファイルサーバ上のテキストファイルであった りするのです。Hadoopとの連携については、後の章で詳しく説明します。 クライアント クエリ実行プラン マスターサーバ セグメントサーバ セグメントサーバ セグメントサーバ セグメントサーバ 答 返 と 付 受 の リ エ ク ・ 成 作 の ン ラ プ 行 実 ・ の ン ラ プ 行 実 の へ ト ン メ グ セ ・ 配布と実行の指示 納 格 を タ ー デ ザ ー ユ ・ 答 返 と 付 受 の 示 指 の ら か タ ス マ ・ 行 実 の リ エ ク ・高度なパイプライン処理により高速化されたソーティング
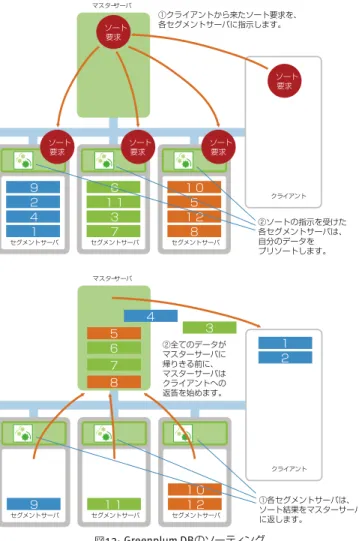
次にソーティングのお話をしましょう。 ソーティングのような複雑な処理は、結局セグメントサーバ上1台では処理し きれないので、マスターサーバがすべて処理するため、マスターサーバがボトル ネックになるのでは?と思われるかも知れません。 Greenplum DBは、マスターサーバがボトルネックになること無く、ソーティングを 非常に高速に実行できる仕組みを実現しています、その仕組みをご紹介します。 図13のマスターサーバ1台と、セグメントサーバ3台の構成で確認してみます。 まずクライアントからソートの要求が来たとします。次に、そのソートの要求は マスターサーバから、各セグメントサーバに対して指示が行きます。指示を受け たセグメントサーバは、まず自分たちの中に順番がバラバラな状態で持ってい るデータをプリソートします。その結果をマスターサーバに返していくわけで すが、実は全てのデータがマスターサーバに返りきる前に、マスターサーバはク複雑な検索・集計・分析を、短時間に処理するための先進機能
図11: データレコードのハッシュ分散 図12: クエリのパラレル処理 ライアントへの返答を始めます。 なぜこのような仕組みが可能なのでしょうか。 順を追って説明します。 まず、各セグメントサーバが、データのプリソートをした段階で、それぞれのセ グメントサーバが持っている一番小さなデータはわかります。そこから一番上 にあるデータを、それぞれのセグメントサーバが出し合います。この段階で、こ の全てのデータの中で一番小さなデータが何かということはわかります。この 図13の中では「1」が一番小さなデータということがわかり、それを返します。 そして次の一行が飛んでいきます。そして、この3行を比べてみて今回も一番左 のサーバのデータが一番小さいことがわかり、クライアントに返せます。 この仕組みを繋げていくと、パイプラインが途切れることなく、マスターサーバ を経由してクライアントに対してソーティングされたデータを返していくこと ができます。 セグメントサーバ セグメントサーバ セグメントサーバ マスターサーバ ソート 要求 ソート 要求 ソート要求 ソート要求 1 2 4 9 3 6 7 11 5 8 10 12 クライアント ②ソートの指示を受けた 各セグメントサーバは、 自分のデータを プリソートします。 ①クライアントから来たソート要求を、 各セグメントサーバに指示します。 ソート 要求 セグメントサーバ 1 2 4 9 セグメントサーバ 3 6 7 11 セグメントサーバ 5 8 10 12 マスターサーバ クライアント ①各セグメントサーバは、 ソート結果をマスターサーバ に返します。 ②全てのデータが マスターサーバに 帰りきる前に、 マスターサーバは クライアントへの 返答を始めます。 他製品の場合はどうでしょうか。プリソートされていない全てのデータを、一 回マスターサーバに持っていき、1台のマスターサーバでソーティングを行いま す。すべてのデータの読み出しと、すべてのソーティングを1台のデータベース のサーバの中で行うため、処理がパラレル化されず、ソーティング処理に非常 に時間がかかります。従ってソーティング処理を高速に行うためには、非常に CPUスペックが高く、大容量のメモリの積んだ非常に大きなサーバが必要にな るわけです。例えばCPUが64コア、メモリは1TBといった巨大なハードウェア・ リソースが必要となり、非常に高価なシステムになります。 これに対し、Greenplum DBは、ソーティング処理を効率良くパラレル化できる アーキテクチャを持っていますので、マスターサーバはボトルネックにはなりません。Greenplumのアプライアンス製品であるGreenplum DCAのマスターサー バが積んでいるCPUは、2CPU、トータル12コア。メモリは48GBです。この程度 のハードウェアスペックで充分なのです。
Greenplum Polymorphic Data Storage
が提供する豊富
な選択肢
先に紹介した機能以外にも、Greenplum DBには、データアクセスを高速化す るいくつかの仕組みがあります。 その仕組の一つであるデータの格納方式について説明します。 Greenplum DBでは、ローストアと、カラムストアという2つのデータの格納方式 を持っています。 ローストアというのはデータをロー方式、行単位で格納するという方式です。こ れは一般的なデータベース製品が使っている、非常に一般的なものです。 実は、この仕組みは、データウェアハウス処理でよくある集計処理には非常に 効率が悪いのです。何故でしょうか?例えば、このカラムのCのデータだけを 抜き出したいとします。ローストア方式の場合、ここの値だけを読みたいのに、 全てのカラムの全レコード読みながら、カラムCだけのデータを抜き出すこと をします。結果的に、非常に効率の悪いアクセスパターンになってしまうのです。 これに対してGreenplum DBが持っているカラムストアは、データをカラム単位 で格納していきます。 ですから、カラムCのデータだけ集計したい、例えばカラムCの「平均値を出し たい」あるいは「合計値を出したい」という場合でも、他のカラムに対するアク セスは一切行なわず、Cカラムだけ一気に足し合わせてアクセスをし、集計が できますので、IO負荷が非常に少なくて済むわけです。このように、集計処理 を非常に高速に実行できるというのがカラムストアのメリットです。 実は、このカラムストアというのは新しい技術ではありません。 古くはSybaseのデータウエアハウス・ソリューションである、SybaseIQが15年 前からこの仕組みを提供しています。ですが、カラムストア・データーベースの 課題というのは、逆にローストアを持っておらず、カラムストアしか無いという のが課題でした。 大半のデータベース、例えばOracleやDB2などはローストアを採用しています。 ローストアから持って来たデータをカラムストアに入れる、データベースのマイ グレーションすることはクエリの書き方をうまく調整しなければ、なかなかパ フォーマンスが出ません。 ローストアというのは、1件単位でデータを格納していきますので、インサート 処理は非常に高速です。逆にカラムストアは、集計処理は非常に速いのです が、インサート処理は苦手で遅いのです。インサート処理をカラムストア方式 に対してそのまま適応すると、非常に効率の悪いデータベータ処理になりま す。ここがカラムストアの課題でした。 Greenplum DBは、ローストアとカラムストアを、1つのテーブルの中で混合して 使うことが可能です。 テーブルをパーティショニングして、最新のデータに関しては、アップデートや インサートが多く発生し、複数カラムに対してアクセスが多くなるのでロースト アで格納する。それ以降の古いデータに関しては集計しかしないので、カラム ストアを使う。このようなことが可能です。これはGreenplum DBだけのテクノ ロジーです。 従来からあるローストアのテーブル カラムストアのテーブル 列A 列B 列C 列D 読み出す必要のない カラムの値もアクセス。 余分なIO負荷が発生 列A 列B 列C 列D 特定カラムの特定カラムの 値のみアクセスするため、 IO負荷を劇的に軽減 検索範囲 検索範囲テーブルパーティショニングによる 検索範囲の限定
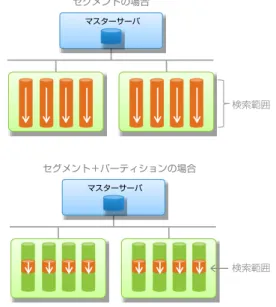
Greenplum DBのテーブルパーティショニングについて紹介しましょう。 データを、セグメントサーバにハッシュキーを使って分散配置をしていくという のは、先程説明しました。Greenplum DBは、更に各セグメントサーバの中で、 検索をする範囲を絞り込んでいくことができます。それが、テーブルパーティ ショニングになります。検索範囲を絞り込んでいくことで、ストレージへのIOを 減らし、レスポンスタイムを更に短くできます。 テーブルパーティショニングの種類としては、レンジ(範囲)パーティショニング、 リストパーティショニング、マルチレベルパーティショニングに対応しています。 1年間の集計処理を例にあげると、レンジパーティショニングでは2011年の1月 から12月の販売データを1カ月ごとに区切ることができるので、6月の売り上げ データだけを集計したい、合算値を出したいといった場合に、6月のデータだけ を読み出すことができます。 パーティショニングをしなければ、1月から12月のデータを全部読み出した(フ ルスキャン)上で6月分だけ抜き出して集計処理を行いますが、パーティショニ ングを行うと、1月から5月分および7月から12月分のデータを読まず、6月分の データだけを読み出せるので、フルスキャンを発生させること無く、非常に高 速なクエリ処理が可能になります。 また、レンジパーティショニングで区切ったテーブルを更にリストで分ける、あ るいは、レンジパーティショニングで分けたものを更にレンジパーティショニン グで分ける、といったことも可能です。 例えば、月単位で分けたテーブルを更に週単位で分ける、あるいは、リストで分け たものをリストで組み合わせる。これがマルチレベルパーティショニングです。Greenplum Polymorphic Data Storage
が提供する豊富な選択肢
図14: ローストア、カラムストア セグメントの場合 セグメント+パーティションの場合 検索範囲 マスターサーバ マスターサーバ 検索範囲
既存投資の保護とさらなる高速化へ – インデックス
Greenplum DBは、データベースですので当然インデックスにも対応しています。 広く一般的に使われているB-Treeインデックス、それ以外にビットマップ・イン デックスにも対応しています。B-Treeインデックスというのは、OLTP処理に強 いとされるインデックスです。ビットマップ・インデックスはDWH/BIシステムに 多い参照処理に効果的に機能します。この両方のインデックスに対応している ので、OLTP処理にもデータウェアハウス処理のどちらにも適したインデックス を使えます。Ze
b
ar
Root
Branch Branch Branch
Leaf Leaf Leaf Leaf Leaf Leaf
B
oo
k
ra
C
1
1 1
1
1
MALE
FEMALE
SAZAE TARAO WAKAME KATSUO MASUO FEMALE MALE FEMALE MALE MALE テーブル インデクス B-Treeインデクスの格納方式 Bitmapインデクスの格納方式ワークロード管理 - リソースキュー
続いて、ワークロード管理について紹介します。データウェアハウス・システム ですので、複数のユーザが同時にクエリを投げるということが当然ありえます。 この場合に、どのように優先順位付けをするかという機能がリソースキューを 使ったワークロード管理です。 Greenplum DBを使用する全てのユーザは、必ずどれかの一つのリソースキュー に紐付けられます。このリソースキューごとにCPUリソースの割り当てや同時に 実行可能なクエリの数を決めることができます。 例えば図17の場合、マネジメント層用のエグゼクティブキューと、レポート作成 の担当者用のレポートキュー、アナリスト用のアナリストキューの3つがありま す。このキューの太さ、これがCPUリソースの配分を表しています。マネジメント の方は、非常に太いキューを持っているので、多くのCPUリソースが割り当てら れており、アナリストと同じクエリを同時に投げたとしても、エグゼクティブは 非常に早くクエリの結果が得られます。一方アナリストは頻繁にクエリを発行 しているため、エグゼクティブに比べてCPUリソースが少し絞られており、クエ リ結果が帰ってくるのも少し遅いわけです。 加えて、いくつのクエリを同時に実行できるかも定義できます。 図17の場合、例えばアナリストは同時に4つのクエリしか実行できません。5つ 目のクエリを実行しようとしても、すでに4つのキューを使っているため、実行 中の4つのうちどれかが終わるまで待たされます。これに対してエグゼクティブ 用には、10のキューが設定されています。従って、5つ6つのクエリを実行して も、待たされずに処理されていきます。クエリが11個目になって、初めて待たさ れるというわけです。 この、クエリが実際に実行されるタイミング、CPUリソースの配分、加えてメモリ の配分を行えるのがワークロード管理、リソースキューという機能になります。 リソースキュー間でCPUや メモリ割当をプライオリティ付け エグゼクティブキュー レポートキュー アナリストグキュー アナリスト レポート作成 担当者 マネジメント 実行開始待ちのクエリ 実行中のクエリ リソースキュー間でCPUや メモリ割当をプライオリティ付け 同時に処理できるクエリ数か、 コストの総和をリソースキュー毎に設定 GreenplumDBの提供するワークロード管理機能の一つリソースキューによって、複数の利 用者やバッチ、システムの同時利用のために、受け付けたクエリの処理に関する優先順位付 けを行うことが可能です。 リソースキューは大きく4つの観点から優先順位付けを行います。 (1) 同時に処理されるクエリのコストの総和 クエリ毎のコストを確認し、処理中の複数クエリのコストの総和が、あらかじめ指定した閾 値を上回ることのないよう、制御します。 (2)同時に処理されるクエリ数 処理中のクエリ数を確認し、処理するクエリの数があらかじめ指定した閾値を上回ることが ないよう、制御します。 (3) CPUリソースの優先度 リソースキュー間でCPUリソースをどのように割り当てるかを制御します。 (4) メモリの優先度 リソースキュー間でメモリをどのように割り当てるかを制御します。 複数の利用者・バッチ処理・システムでの同時利用のための機能 図15: テーブルパーティショニングによる検索範囲の限定 図16: B-TreeインデクスとBitmapインデクス 図17: ワークロード管理 - リソースキュー12
13
動的なクエリ優先度付け
Greenplum DBでは、クエリごとにCPUリソースの動的な割り当てが可能です。 例えば、リソースキューについて、C P Uリソースの配分を最大限利用できる キューと、中くらい利用できるミディアムというキュー、配分が少ないローとい う3つのキューがあるとします。 まず1つ目のミディアムというキューのユーザは、まだ誰もシステム資源を使っ ていないためクエリを実行したときCPUリソースを100%使えます。仮に、この ミディアムのキューにもう一つクエリが来た場合には、リソース配分は、同じプ ライオリティですので、このように均等に配分されます。次にローのクエリが来 たとします。ミディアムよりプライオリティが低いので、CPUリソースの割り当て は限られます。少しだけCPUリソースをもらい、それに合わせて他の2つのクエ リの割り当ては均等に下がります。最後に4つ目のクエリとしてマックスのクエ リが来たとします。マックスは最大限CPUリソースが貰えます。それに伴い、ミ ディアムとローに関しては、割り当てが下がります。 これをマスターサーバが判断しながらダイナミックにCPUリソースの割り当て を変更していきます。Greenplum DBはこのような動的なリソース割り当てが可 能です。 また、この他にも特定のクエリを狙い撃ちでCPUリソースの割り当てを絞り込む ことも可能です。データウェアハウスの運用の中でまれにあるケースとして、アナ リストが1週間1つのクエリを回し続けているということがあります。非常に処理 が重たいクエリを実行してしまったため、1週間ずっとCPUを80%以上使ってし まい、他のユーザにCPUリソースが割り当てられないという状況に陥ってしまい、 今まではこれに対する術がありませんでした。手段としては、あくまでローにす るしかなく、ローでも割り当てられてしまいます。Greenplum DBは、この1週間実 行し続けられているクエリに対して、CPUリソースの割り当てを更に絞り込むこ とが可能です。まさに狙い撃ちをして、このユーザのこのクエリは徹底的に絞り 込み、それによって他のユーザに対するCPUリソースの割り当てを上げることが できます。これもGreenplum DBのリソース管理の機能の一つです。 リソースキュー Medium Max Low リソース使用量の合計Qry1 Qry2 Qry3
100% ? Qry4 リソースキュー Medium Max Low リソース使用量の合計
Qry1 Qry2 Qry3
100% ? ? Qry4 リソースキュー Medium Max Low リソース使用量の合計
Qry1 Qry2 Qry3
100% ? ? ? Qry4 ? 一つ目のミディアムユーザー は、まだ誰もリソースを使って いないため、クエリの実行にリ ソースを100%使えます。 ミディアムのキューにもう一つクエリ が来た場合は、同じプライオリティで すので、均等にリソース配分されます。 次にローとマックスのリソース が来ました。マックスは最大限 リソースが使えるので、それに 伴いミディアムとローの割り当 ては下がります。
Greenplum DBの高い可用性
次にご紹介するのは、可用性についてです。Greenplum DBでは、全てのコン ポーネントを冗長化できます。 マスターサーバは、ホット・スタンバイで構成します。ネットワーク部分は、アク ティブ・アクティブで2台以上のスイッチを使った冗長化をします。 次にセグメントサーバですが、セグメントサーバ間でデータをミラーリングす る、ミラーセグメントという機能があります。この機能により、例えばセグメン トサーバがダウンしてしまった場合に、その停止したサーバのミラーデータを 持っている他のセグメントサーバにフェイルオーバーし、サービスを止めること なく処理を継続できます。 加えて、当然マスターサーバであっても、セグメントサーバであっても、データ はR AIDで保護していますので、多段階でのデータの保護がなされていること になります。 マスターサーバ マスターサーバ セグメントサーバ セグメントサーバ セグメントサーバ セグメントサーバマスターサーバにおけるデータ保護
・サーバ障害に備えたトランザクションログの複製 ・ドライブ障害に備えたRAIDセグメントサーバにおけるデータ保護
・サーバ障害に備えたミラーセグメント ・ドライブ障害に備えたRAID 図18: 動的なクエリ優先度付け 図19: Greenplum DBの高い可用性Greenplum DB 4.2
の新機能
2011年12月にリリースされたGreenplum DBの最新バージョン4.2では、次のような機能拡張が行われており、クエリ・スピードの向上、リ ソースの利用率向上、システム管理機能の強化などが図られています。メモリ管理の最適化
最新バージョンでは、クエリの処理フェーズごとにメモリの割り当てが可能になり、クエリのスピードが向上しました。テーブル・パーティションのエンハンス
クエリプランナの拡張により、テーブル・パーティショニング時の性能が大幅に向上します。カラム単位の圧縮機能
カラム単位で圧縮アルゴリズムや圧縮レベルを選択可能になりました。 例えば普段はほとんど参照しないカラムは高圧縮に設定するなど、カラム毎に圧縮レベル の設定などが可能です。この機能をうまく活用することにより、ストレージの利用効率を 向上させることができます。Oracle関数への対応が拡張
最新バージョンでは、日付関数や文字列関数、算術関数など、20以上のOracle関数に対応しました。これにより、既存のクエリを極力書き 換えることなく、DBのマイグレーションやバッチ処理の最適化が可能となります。バックアップ機能の強化
Data Domain Boostに対応しました。これにより、 重複除外を行ってからバックアップができるよう になり、バックアップがより高速になります。
拡張機能のパッケージ化
PostGIS、pgcrypt、PL/Rなどの拡張機能が、新しいパッケージ・マネージャによりパッケージ化され、導入が容易になりました。システム管理ツールのエンハンス
従来のシステム管理ツールでは、各サーバ・リソースの利用率のモニタリングまででしたが、新しい管理ツールでは、Greenplumクラスタ全 体のモニタリングに加え、設定、スタート/停止などの操作も可能になりました。 カラム単位の圧縮機能 列A 列B 列C 列D 従来はテーブル 単位の圧縮 最新バージョンでは、カラム単位で 圧縮アルゴリズムや圧縮レベルを選択可能 マスターサーバ マスターサーバ セグメントサーバ セグメントサーバ セグメントサーバ セグメントサーバ 重複除外 重複除外 重複除外 重複除外 重複除外 重複除外 Data Domain DD Boostにより、重複除外プロセスの一部が 各マスターサーバ、セグメントサーバに分散され、 より高速あなバックアップが実現できます。Greenplum DBの適用範囲
ここでは、Greenplum DBがどのような分野に適用できるかをお話しします。 Greenplum DBはデータウェアハウス用の製品ですので、当然データウェアハウ スに適用できますが、それ以外にもデータベースの最適化という分野で多く利 用されてます。最適化の具体例としては、バッチ処理への適用です。 既存のシステムにおいて、データ量の増加にともないバッチ処理の長時間化 がシステムの課題となっているケースが多く見受けられます。既存のデータ ベース・システムに対してCPUやメモリーを追加しても性能が伸びない。また、 チューニングをいくら実施しても性能が伸びない。このような状況はよくある のではないでしょうか。 データ分析を業務に活用したいが、膨大 な初期投資が掛かるため、ROIが計れずに 着手できていない インフラ整備に費用がかかり、分析業務へ の投資が回らない Community Editionの発表 容量課金モデルでのライセンス S/W提供による柔軟なH/W構成 汎用的なオープンテクノロジーの活用 DWH/分析/BI環境のスモールスタート 既存運用に則ったシステム構築 大容量データでの分析を行いたいが、う まく回せる技術基盤がない 大容量データを扱うためのシステムコス トが膨大になってしまう 超並列処理(MPP)による高パフォーマン スのDB処理 高速データロード スケールアウト構成による拡張性 大容量データに適したアプライアンス 製品 予測不可能な将来のDWH環境 活用に 備えた、柔軟な拡張性をもったシステム 構成 Oracle等商用RDBのバッチ処理 時間が かかっており、オンライン処理に影響を及 ぼしている 商用RDB S/Wのコスト負荷 クエリ(大量データ検索など)のレスポンス が遅い 超並列処理(MPP)による高パフォーマンス のDB処理 高速データロード 容量課金モデルでのライセンス S/W提供による柔軟なH/W構成 汎用的なオープンテクノロジーの活用 汎用的インターフェースの採用 バッチ処理をGreenplum環境に切り出す ことによる既存DBシステムのシステム/ コスト最適化 高パフォーマンスの参照系DB 課題 Greenplum DBの特徴 Greenplum DBの活用 H W D 化 適 最 B D これはシェアードエブリシング・アーキテクチャにおいて多く見受けられる課題 です。バッチ処理の流れは、データのローディング、スキャン、テーブルの結合、 集計、最後にアンロードして返していく、というものです。シェアードエブリシ ング・アーキテクチャの場合、これら全ての処理が1台のサーバの中で処理され るため、全フェーズにおいてボトルネックが発生することが課題でした。 1.ロード 2.スキャン 3.結合 4.集約Σ
5.アンロード ノード#1 シェアード エブリシング アーキテクチャ ノード#1 ノード#1 ノード#1 ノード#1 シリアル処理のため、全フェーズにてボトルネックが発生 次にシェアードナッシング・アーキテクチャの場合を見てみましょう。 他社のシェアードナッシング・アーキテクチャが採用している仕組みの場合、ス キャン、結合、集約の各処理はパラレル化出来ていますが、データのロード、ア ンロードの部分はマスターサーバがボトルネックとなります。Σ
従来のMPP Greenplum DB 1.ロード 2.スキャン 3.結合 4.集約 5.アンロード ノード#1 ノード#1 ノード#1 ノード#1 ノード#2 ノード#2 ノード#2 ノード#1 ノード#3 ノード#3 ノード#3 ノード#1 ノード#1 ノード#1 ノード#2 ノード#2 ノード#2 ノード#3 ノード#3 ノード#3 ノード#1 ノード#2 ノード#3 ノード#1 ノード#2 ノード#3 ノード#n ノード#n ノード#n ノード#n ノード#n これに対してGreenplum DBは、ロードもアンロードもパラレル化できますので、 全フェーズにおいてパラレル処理が可能です。加えて、セグメントサーバの追加に より、パラレル度を容易に上げることができます。他製品と比べ、より大規模な 並列分散処理により高速にバッチ処理を実行することが可能なのです。 このすべてのフェーズにおけるパラレル化は、Hadoopの環境にも有効です。 Hadoopから、パラレルにデータを抜き出し、そのままスキャン、結合、集約、 アンロードまで、すべてパラレル処理をして、そのままHadoopにシームレスに データを戻す。このようなことが可能です。Σ
Greemplum DB Hadoop 処理 Hadoop 処理 1.ロード 2.スキャン 3.結合 4.集約 5.アンロード ノード#1 ノード#1 ノード#1 ノード#1 ノード#1 ノード#2 ノード#2 ノード#2 ノード#3 ノード#3 ノード#3 ノード#2 ノード#3 ノード#2 ノード#3 ノード#n ノード#n ノード#n ノード#n ノード#n ノード#1 ノード#2 ノード#3 ノード#n ノード#1 ノード#2 ノード#3 ノード#n 他システムとのパラレル連携を機能強化バッチ処理最適化の事例
バッチ処理にGreenplum DBを適用し、最適化に成功されたお客様事例をご紹 介します。このお客様は、他社のデータベース・システムでCRM/SFAを運用して いました。全国の営業が、自分の顧客の販売履歴を確認できるというシステム です。しかしながら、夜間のバッチ処理が終わらず、毎朝営業に、どの顧客に訪 問すべきかというデータを、必要なタイミングで渡せなくなりつつありました。 データ量が増加する一方で、営業のシステム利用頻度も増加しており、現状の 仕組みでは処理が追いつかなくなってきていたのです。そこで、他の製品・ソ リューションを検討され、様々な性能検証を交えて検討した結果、Greenplum DBが採用されました。性能検証では、ロード性能、クエリ性能、多重アクセス 性能、バッチ処理などを実施しました。 既存のデータベース・システムは残しつつ、そのデータベースの参照用キャッGreenplum DB
の利用イメージと、さまざまなニーズに応える提供形態
図20: Greenplum DBの適用範囲 図21: バッチ処理往年の課題 図22: バッチ処理フロー比較 図23: Greenplum DB 4.1によるバッチフロー シュとしてGreenplum DBをDWHデータベースとして適用したのですが、その結 果バッチ処理は20倍高速化され、データのロード性能は103倍向上しました。 それ以外にも、非定型のクエリで27倍の高速化が確認されて、性能としては申 し分なく、最後は他のDWHデータベース製品とのコスト比較になりましたが、 Greenplum DBは他製品と比べて数分の一で済み、そのコストパフォーマンス の高さが評価されて採用に至りました。 既存システムに対する負荷を、Greenplum DBを使いオフロードした結果、性能 面、コスト面でも高い効果が得られたという事例です。データベース機能別役割
図24は、データベースの機能を分類し、Greenplum DBが得意な適用範囲を示 した表です。 OLTPデータベース、キャッシュ用のデータベース、バッチ処理用データベース。 そしてデータウェアハウス用のデータベースがあります。 機能 OLTP 処理 参照系処理の高速化(キャッシュ) バッチ処理 ウェアハウスデータ 主なユーザー ••顧客顧客窓口 •顧客 •顧客窓口 •アナリスト -•マネジメント •アナリスト サービス •オンライン トランザクション •オンライン参照 •オンライン参照 •レポーティング (定型帳票/定型検索) •集計 •データマート作成 • レポーティング •データマイニング /非定型検索 アクセス・ プロファイル •複数ユーザによる 頻繁な検索と更新 •複数ユーザによる頻繁な検索 •バッチプロセスによるデータの集計 とテーブル作成 •複数ユーザによる 頻繁な検索と分析 ストアデータ 最新のデータ 直近 3ヶ月のデータ 集計対象データ 過去 3年間の長期データ 候補 DB OracleDB2 GreenplumDB GreenplumDB GreenplumDB適用範囲 Greenplum DBはOLTP系以外すべてに適用できます。図25でそれぞれ説明して いきます。 OLTP系処理には、既存のOracleやDB2が適しています。一方、参照系にかかる 負荷をオフロードしたい場合には、キャッシュ的な役割で、トランザクション・ データベース用のサーバの前にキャッシュサーバを置き、これにクライアントか らアクセスすることで、トランザクション・データベースに対する負荷を下げら れます。ここのキャッシュ用データベースとして、Greenplum DBを適用し、参 照系処理の性能を上げることができます。 次は、トランザクション用データベースのバックエンドにGreenplum DBを置い て、日中のトランザクション処理に関してはOracleなどで行い、夜間バッチ処理 はバッチ処理用のGreenplum DBにデータをロードして集計処理などを行い、 朝までにトランザクション・データベースにデータを戻す仕組みです。 最後はデータウェアハウスです。フロントのトランザクション・データベースか らGreenplum DBにデータをロードし、BIツール経由でユーザがクエリを発行し て分析やレポーティングを行うという一般的なデータウェアハウスの用途です。 このように、Greenplum DBはOLTP系以外の様々な用途で効果を発揮します。 トランザクション キャッシュ トランザクション バッチ データ ウェアハウス トランザクション OLTP処理 高速化(キャッシュ)参照系処理の バッチ処理 データウェアハウス トラン ザクション ザクショントラン ザクショントラン 図24: データベース機能別役割(1/2) 図25: データベース機能別役割(2/2)