2.2 3
次元非圧縮性熱流体計算プログラム
COSMOS
の測定評価
(株)豊田中央研究所 堀之内 成明
2.2.1
はじめに
自動車の設計・開発における熱流体
CAE (Computer-Aided Engineering)
は,日常的なものとして
様々な製品・部品を対象に用いられてきているが,実際には,非定常な乱流に加えて,熱,騒音,運動
(移動境界)
,反応などが連成するような現象も多く,これらに対して信頼性の高い結果を得るために
は,計算格子幅や,時間ステップ間隔を十分に小さくする必要が出てくるため,その結果として必然
的に計算規模が大きくなる.
このような大規模熱流体シミュレーションは,従来ではベクトル演算方式の計算機で行われること
が多く,プログラムもこの上で高速計算が可能となるようにチューニング,ならびにアルゴリズム開
発がなされてきた.本稿では,このようなプログラムを,ベクトル計算機での性能も維持しつつ,
「京」
をはじめとするマルチコアのスカラー型計算機においても高い実効性能を満たすことを目的として,
高速化に向けた改良を試みる.
2.2.2
プログラム概要
ここでは,
(株)豊田中央研究所で開発した非定常非圧縮性乱流計算プログラム
COSMOS
を対象に
チューニングを行う.このプログラムは,空力や空力騒音といった問題に適用するため,自動車まわ
りの高
Reynolds
数非定常流れを精度よく計算することを目的に開発された
[1]
.
2.2.2.1
プログラムの特徴
本プログラムは,以下の特徴を有する.
• Large Eddy Simulation (LES)
による非定常乱流の計算に関して,以下の独自技術を開発し,実
問題に適用し得る計算精度と実用性を両立させている.
– Grid-scale (GS)
成分計算の離散化スキームとして,質量,運動量のみならず,運動エネル
ギーまでをも高い精度で保存させ,数値粘性を用いなくても安定な計算を可能とする「改
良型コロケーション格子法
[2]
」
– Subgrid-scale (SGS)
成分の乱流モデルとして,様々な問題に対してモデル係数のチューニ
ングが不要で,かつダンピング関数を必要としない「混合時間スケール
SGS
モデル
[3]
」
•
計算格子には,計算精度に優れているというメリットから「境界適合型構造格子」を用いる.こ
れは,碁盤目状の格子を,対象となる物体の表面に沿わせ,且つ表面近くに格子点を集中させた
ものである.また,三角形(
2
次元の場合)やテトラ(
3
次元の場合)を用いる非構造格子に比
べて,プログラミングに際して間接参照(リストアクセス)の必要性が軽減でき,計算効率の
観点からも有利である.但し,車両などの複雑形状に対しては,格子生成に多くの工数やノウ
ハウを必要とするというデメリットもあり,そのような計算領域全体を一つの格子で覆うこと
自体が現実的には困難であったり,計算格子の歪みが大きくなり質が低下するといった課題も
ある.これを解決するために,局所的な形状に適合させた高品質な部分的構造格子(以下,部
分格子)をパッチワーク的に重ね合わせる「重合格子法」を採用している.車両形状に対する
重合格子の例を図
1
に示す.
•
非圧縮性流れの基礎方程式は,連続の式と
Navier-Stokes
方程式(運動方程式)であるが,
SMAC
法に準じて,これらから圧力に関する
Poisson
方程式を導いて解く.時間方向の離散化には,
Crank-Nicolson
法に基づく陰解法を採用しており,これから速度場に関する連立一次方程式が
導かれる.一方,圧力の
Poisson
方程式も,連立一次方程式を解くことに帰着される.本プロ
グラムの計算時間の
8
割程度は,これらの連立一次方程式を解くことに費やされるため,これ
らをいかに効率的に計算できるようにするかがキーとなる.この時,上述した重合格子法との
兼ね合いにより,単一格子での行列方程式計算よりも,アルゴリズムや配列の取り方などが,や
や複雑になり,この点も含めたチューニングが求められる.
図
1
自動車まわりの重合格子の例
2.2.2.2
連立一次方程式の数値解法
重合格子法の計算アルゴリズムは,領域分割法として提案されている
Schwarz
法の中でも,乗法的
Schwarz
法
(Multiplicative Schwarz algorithm)
の考え方に等しい(付録
p1
参照).その反復計算自体
も数値計算上の研究課題となり得るが,今回は,各部分格子の中で,離散化された連立一次方程式を,
係数行列がスパースな場合に用いられる手法の一つである
SOR (Successive Over Relaxation)
法で計
算する際の効率化を対象とする.
連立一次方程式の係数行列を
A
,解ベクトルを
x
,右辺ベクトルを
b
とする.すなわち,
Ax
= b
で
ある.また,反復法の第
k
ステップ目での近似解ベクトルを
x
(k)
と表すこととする.
SOR
法のベース
となる
Gauss-Seidel
法は,元の係数行列
A
を,
A
= L + D + U (L: A
の対角要素を除く下三角行列,
D:
A
の対角行列,
U: A
の対角要素を除く上三角行列
)
と分解した
(L
+ D + U)x = b
から,
(L
+ D) x = −Ux + b
(1)
とし,これに基づき,
(L
+ D) x
(k
+1)
= −Ux
(k)
+ b
(2)
x
(k
+1)
= − (L + D)
−1
U x
(k)
+ (L + D)
−1
b
(3)
として近似解ベクトルを更新(緩和)する手法である.式
(2)
から,近似解ベクトルを要素ごとに逐次
計算していく際に,下三角部分
L
にかかる要素は,常に最新の値が用いられていることがわかる.こ
のことから,プログラミング上は回帰参照が発生することになる.なお,実際のプログラムでは,式
(3)
に基づいて
x
(k
+1)
を計算するのではなく,
r
(k)
≡ b − Lx
(k
+1)
− (D + U) x
(k)
とおいた残差ベクトル
r
(k)
を用いて,
x
(k
+1)
= x
(k)
+ D
−1
r
(k)
(4)
のように計算する.さらに,この式
(4)
の右辺で,前の近似解ベクトル
x
(k)
に第
2
項を足し込むとき
に,加速係数(緩和係数とも言う)
ω
を掛け,
x
(k
+1)
= x
(k)
+ ωD
−1
r
(k)
(5)
とするのが
SOR
法である.
ω
は
0
< ω < 2
の範囲の値をとり,
ω = 1
の場合が
Gauss-Seidel
法という
ことになる.
Navier-Stokes
方程式,ならびに圧力の
Poisson
方程式を,それぞれ
2
次中心差分に相当するスキー
ムで空間的に離散化することで,連立一次方程式を得るわけだが,図
1
のように格子線の曲りや不等
間隔も許すため,計算空間(格子線座標
i
, j, k
の空間)で考えると,計算点から見て,斜め方向の点も
参照することとなる.
Navier-Stokes
方程式に関しては,対流項の
3
次風上差分(
QUICK
法)の可能
性を考慮し,
i
, j, k
の各方向に
5
点差分と,斜めの点を合わせて,全部で
27
点の差分,圧力
Poisson
方
程式に関しては全部で
19
点の差分となる.図
2
にその関係を示す.そして,この参照関係から,係数
行列の構造は図
3
のようになる.
図
2
格子点の参照関係
図
3
係数行列の形(イメージ)
さて,上記のような依存関係を含む手続きを正しく計算するために,ベクトル計算機向けのプログ
ラミングと同様に,マルチコアで並列計算においても回帰演算を回避する必要があり,本プログラム
ではマルチカラーオーダリングで実現している.オリジナル版では,ベクトル機で用いたものと同じ
1
次元化された配列を最小の色数となる
7
色でオーダリングする.圧力
Poisson
方程式に対するソー
スプログラムを付録
p2
に示す.
2.2.3
測定環境
今回は,円柱まわりの非圧縮性非定常流れの計算を性能評価用の例題とし,付録
p3
にある断面を示
すように,円柱のまわりのみと計算領域全体を覆う2種類の構造格子を重合させた計算格子を用いる.
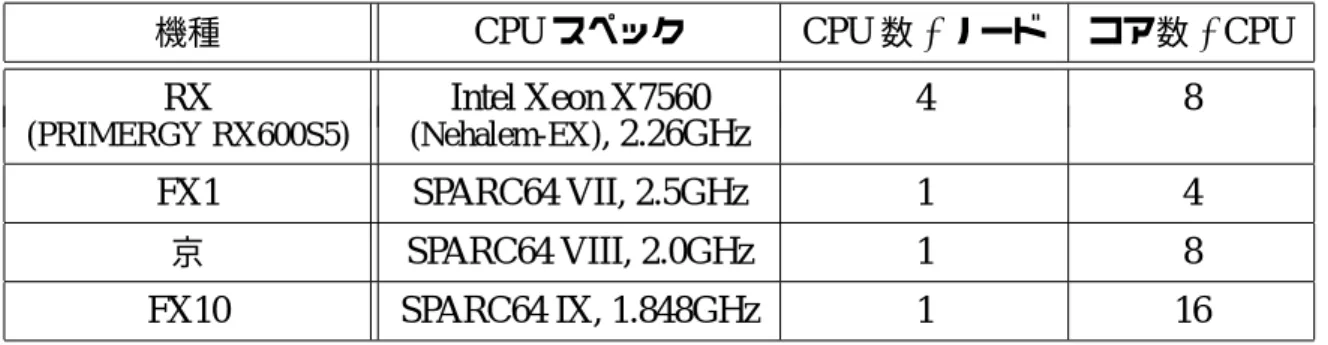
表
1
利用計算機の概要
機種
CPU
スペック
CPU
数
/
ノード
コア数
/ CPU
RX
Intel Xeon X7560
4
8
(PRIMERGY RX600S5)
(Nehalem-EX)
, 2.26GHz
FX1
SPARC64 VII, 2.5GHz
1
4
京
SPARC64 VIII, 2.0GHz
1
8
FX10
SPARC64 IX, 1.848GHz
1
16
測定に利用した計算機の一覧を表
1
に示す.
また,それぞれの計算機で測定する際のコンパイルオプションは次の通りである.
• RX: -Am -Kfast,parallel,ocl,vppocl,tl trt,prefetch -X9 -w -KXEON55 -Qt -Ectfiu -xdir=inline dir
-Karray subscript,array subscript rank
=2,array subscript elementlast=25
-Kprefetch iteration
=15,preex
• FX1: -Am -Kimpact,ocl,vppocl,tl trt -X9 -w -Qt -Ectfiu -xdir=$(MKDIR)/inline dir
-Kprefetch model
=FX1
-Karray subscript,array subscript rank
=2,array subscript elementlast=25
-Kprefetch iteration
=15,preex
•
京
,FX10: -Kfast,parallel,ocl,vppocl -Ntl trt -Nrt tune -X9
-Qt -xdir
=inline dir -W0,-zmpb=Swpl:message=detail
-Karray subscript,array subscript rank
=2,array subscript elementlast=25
-Kprefetch iteration
=15,preex
但し,
FX10
については,後述するチューニング実行時
(2.2.4.2
節
)
には,これに加えてオプション
(-Kprefetch stride,prefetch sequential
=soft)
が追加されている.
2.2.4
測定結果
2.2.4.1
オーダリングの違いに関する性能評価
オリジナル版のままでは,計算点に対するストライドアクセスが発生するために,キャッシュ利用
効率が低下することが予想された.そこで,計算空間座標
(i
, j, k)
に対して,各
2
色の組み合わせとす
る計
8
色でのオーダリングを行い(以下,改良版1)
,オリジナル版と比較した(但し,圧力
Poisson
方程式から得られる行列方程式のみ)
.後者のソースプログラムを付録
p4
に,
FX1
の
1
ノード
4Core
での比較結果,
PA
情報を
p5,p6
に示す.これによると,予想通り,改良版1の方がキャッシュアクセ
ス待ちを
7
割程度減らすことができ,プログラム全体で
8%
程度の実効速度向上につながった.
しかしながら,改良版1であっても,実効性能のピーク性能比は
4%
強にしか達しておらず,さら
なる性能向上が求められるため,次に,付録
p7
に示す改良を試みた(以下,改良版2)
.これは,計
算点から遠い参照点を別格子とし,すなわち
k
方向に交互にグルーピングする扱いとすることで,さ
らにキャッシュ利用効率を上げることを狙ったものである.ソースプログラムを付録
p8
に,社内計算
機での評価結果を付録
p9
に示す.コア数が少ない場合は,若干の効果は見られたが,残念ながら期待
したほどの結果とはならなかった.また,
FX1
,京,
FX10
でのプログラム全体の計算時間計測結果を
付録
p10
に示す.
2.2.4.2
コンパイルオプションによるチューニングの結果
前節でより良い性能を示した改良版においても,プロファイラの結果を見ていくと,浮動小数点演
算待ちや,ロード・ストア待ちが多く発生していることがわかる(付録
p11
)
.これらの改良のために,
以下のチューニングを行った.
1.
圧力
Poisson
方程式から得られる連立一次方程式の求解ルーチン
sor8p b h
(改良版2)に対し
て,ソフトウェアパイプラインによる命令スケジューリング(具体的な詳細は付録
p12
∼
p13
)
2. Navier-Stokes
方程式から得られる連立一次方程式の求解ルーチン
sor7v b
(オリジナル版)に
対して,配列
clp
に対するソフトウェアプリフェッチと,ストライドアクセスオプションの指定
(具体的な詳細は付録
p16
∼
p17
)
これらのチューニングの結果,付録
p14
∼
p15, p18
に示すように,それぞれの連立一次方程式の
SOR
法による求解部分において,
10
%∼
11
%の性能向上(該当サブルーチンのみでの実行時間の短縮)を
得ることができた.
2.2.5
まとめ
重合格子を用いた非定常乱流計算プログラムにおける連立一次方程式の反復ソルバーを対象に,マ
ルチコア計算機に対する性能評価,ならびに計算効率化のためのチューニングを行った.しかしなが
ら,ベクトル計算機との併用を前提にした配列構造やオーダリング(演算順序)の範囲内での性能向
上には限界があり,必ずしも,マルチコア本来の並列計算性能を十分に引き出せてはいないと考えら
れる.また,
SOR
法を用いたこの反復ソルバーのアルゴリズムをそのまま書き下すと,一つの計算点
に対して周辺の
19
点のデータを参照しながらの反復計算が必要となり,このままでは,どうしても
Byte
/Flops
(演算数に対するデータのロード・ストア数の割合)が大きくなってしまうことも,性能向
上が容易でない要因の一つと考えられる.
以上,今回の性能評価とチューニングから得られた知見から,さらに性能を向上させるためには,
•
反復解法レベルでの計算アルゴリズムの見直し
•
マルチコア計算機に特化した配列構造への書き換え
などの,より深い取組みが必要になってくると考えられる.今後の課題としたい.
参考文献
[1]
堀之内成明
,
稲垣昌英
,
加藤由博
,
自動車空力騒音のシミュレーション技術
,
応用数理
, 15 (2005),
60–64.
[2]
稲垣昌英
,
安倍賢一
,
コロケーション格子を用いた
LES
の計算精度改善に関する一考察
,
日本機械
学会論文集
, B
編
, 64, 623 (1998), 1981–1988.
[3]
稲垣昌英
,
近藤継男
,
長野靖尚
,
実用的な
LES
のための混合時間スケール
SGS
モデル
,
日本機械学
会論文集
, B
編
, 68, 673 (2002), 2572–2579.
3次元非圧縮性熱流体計算プログラムCOSMOSの
測定評価 (補足資料)
株式会社 豊田中央研究所
堀之内 成明
1
連立一次方程式の求解について
計算時間の大半(6割~8割)は連立一次方程式を解くことに費やされる.
z
次元数(
=格子点数): 数10万~数100万
z
規則非対称帯行列
z
各行の非零要素数: ~ 25
解法: 定常反復法 (SOR, Gauss-Seidel),
クリロフ部分空間法
(Bi-CGSTAB, ...)
z
重合格子の場合は,このような行列を格子ブロックごとに解くが, 反復の途中
で境界領域の格子点に対する補間を行う.
m m mx
b
A
Ω
r =
Ω
r
Ω
(1) 補間点をディリクレ境界とし,
を解く
[ ]
Ω
Γ
← x
Ι
′
x
r
mr
(2) 他の格子の最新の値から補間
格子
m=1
m m mx
b
A
Ω
r =
Ω
r
Ω
(1) 補間点をディリクレ境界とし,
を解く
[ ]
Ω
Γ
← x
Ι
′
x
r
mr
(2) 他の格子の最新の値から補間
格子
m=1
m m mx
b
A
Ω
r =
Ω
r
Ω
(1) 補間点をディリクレ境界とし,
を解く
[ ]
Ω
Γ
← x
Ι
′
x
r
mr
(2) 他の格子の最新の値から補間
格子
m=2
m m mx
b
A
Ω
r =
Ω
r
Ω
(1) 補間点をディリクレ境界とし,
を解く
[ ]
Ω
Γ
← x
Ι
′
x
r
mr
(2) 他の格子の最新の値から補間
格子
m=2
m m mx
b
A
Ω
r =
Ω
r
Ω
(1) 補間点をディリクレ境界とし,
を解く
[ ]
Ω
Γ
← x
Ι
′
x
r
mr
(2) 他の格子の最新の値から補間
格子
m= ...
m m mx
b
A
Ω
r =
Ω
r
Ω
(1) 補間点をディリクレ境界とし,
を解く
[ ]
Ω
Γ
← x
Ι
′
x
r
mr
(2) 他の格子の最新の値から補間
格子
m= ...
m m mx
b
A
Ω
r =
Ω
r
Ω
(1) 補間点をディリクレ境界とし,
を解く
[ ]
Ω
Γ
← x
Ι
′
x
r
mr
(2) 他の格子の内部の値から補間
格子
m=NVOL
(1),(2)の変化量が
小さくなるまで
繰り返し
他の格子の内部領域
Multiplicative(乗法的) Schwarz Method
常に最新の値
Gauss-Seidel like
Multiplicative(乗法的) Schwarz Method
常に最新の値
Gauss-Seidel like
2
7色オーダリングによるノード内並列化(オリジナル版)
SOR法を採用
(実際には緩和係数を1としているので,Gauss-Seidel法)
各格子ブロックごとにマルチカラーオーダリングによる自動並
列化で対応
z
ベクトル機でのオーダリングをそのまま流用 ⇒
7色飛び(1次元的)
配列のとり方も,それに合せて1次元並びになっている.
real*8 :: p0(n1max), bp(n1max)
real*8 :: clp(n1max,19)
do m=1,nvol
do ic=0,6
do n1=n1min(m)+ic,n1max(m),7
res=p0(n1 -iip1-1)*clp(n1,1)
$ +p0(n1-ijp1 -1)*clp(n1,2)
$ +p0(n1-
1) *clp(n1,3)
$ + ...
$ +p0(n1-ijp1) *clp(n1,9)
$ +p0(n1)
$ +p0(n1+ijp1) *clp(n1,11)
$ + ...
$ +p0(n1 +iip1+1)*clp(n1,19)
& -bp(n1)
p0(n1)=p0(n1)-res*omegap
enddo
enddo
enddo
オリジナルのベクトル機用コード
real*8 :: p0(n1max), bp(n1max)
real*8 :: fj_clp(19, n1max/7+1, 0:6)
do m=1,nvol
do ic=0,6
i=1
do n1=n1rs(m)+ic,n1re(m),7
res=p0(n1 -iip1-1)*fj_clp(1,i,ic)
$ +p0(n1-ijp1 -1)*fj_clp(2,i,ic)
$ +p0(n1-
1) *fj_clp(3,i,ic)
$ + ...
$ +p0(n1-ijp1) *fj_clp(9,i,ic)
$ +p0(n1)
$ +p0(n1+ijp1) *fj_clp(11,i,ic)
$ + ...
$ +p0(n1 +iip1+1)*fj_clp(19,i,ic)
& -bp(n1)
i=i+1
p0(n1)=p0(n1)-res*omegap
enddo
enddo
enddo
少し修正したコード(これで計測)
clpのみ色ごとに
連続アクセスとした
3
性能評価計算の概要
LESを用いた円柱まわりの非定常流れ場の計算
z
(実用計算を踏まえ)重合格子を使用
円柱まわり:
161x56x81=757,188点
背景:
121x61x81=620,248点
4
8色オーダリング(改良版1)の概要
I,j,k各方向に2色,計8色のオーダリングに変更.但し,配列の
構造(宣言)は基本的に変えていない.
real*8 :: p0(n1max), bp(n1max)
real*8 :: fj_clp0(19, m2max/7+1, nvol),
& fj_clp1(19, m2max/7+1, nvol),
& ...
& fj_clp7(19, m2max/7+1, nvol)
do m=1,nvol
do i=1,ico0max(m)
kk=(i-1)/ijp8aa
ij=-kk*ijp8aa+(i-1)
jj=ij/iip8a
ii=-jj*iip8a+ij
n1=(kk*2)*ijp1+(jj*2)*iip1+(ii*2)+n1rstr
res=p0(n1 -iip1-1)*fj_clp0(1,i,m)
$ +p0(n1-ijp1 -1)*fj_clp0(2,i,m)
$ +p0(n1-
1) *fj_clp0(3,i,m)
$ + ...
$ +p0(n1-ijp1) *fj_clp0(9,i,m)
$ +p0(n1)
$ +p0(n1+ijp1) *fj_clp0(11,i,m)
$ + ...
$ +p0(n1 +iip1+1)*fj_clp0(19,i,m)
& -bp(n1)
p0(n1)=p0(n1)-res*omegap
enddo
do i=1,ico1max(m)
...
enddo
...
enddo
(圧力
Poissonのみに適用)
色ごとのループ
5
評価結果の概要
csms_sor7(全体) - 時間 (sec) 0.0E+00 1.0E+02 2.0E+02 3.0E+02 4.0E+02 5.0E+02 6.0E+02 7.0E+02Process 0 Thread 0 Process 0 Thread 1 Process 0 Thread 2 Process 0 Thread 3 時間(sec) 整数ロー ドメモリアクセス待ち 浮動小数点ロードメモリアクセス待ち ストア待ち I/Oアクセス待ち 整数ロー ドキ ャッシュアクセス待ち 浮動小数点ロードキ ャッシュアクセス待ち 整数演算待ち 浮動小数点演算待ち 分岐命令待ち 命令フェッチ待ち uOPコミット その他の待ち 1命令コミット 整数レ ジスタ書き込み制約 浮動小数点レ ジスタ書き込み制約 2/3命令コミット(その他) 4命令コミット csms_sor8(全体) - 時間 (sec) 0.0E+00 1.0E+02 2.0E+02 3.0E+02 4.0E+02 5.0E+02 6.0E+02 7.0E+02
Process 0 Thread 0 Process 0 Thread 1 Process 0 Thread 2 Process 0 Thread 3 時間(sec) 整数ロー ドメモリアクセス待ち 浮動小数点ロードメモリアクセス待ち ストア待ち I/Oアクセス待ち 整数ロー ドキャッシュアクセス待ち 浮動小数点ロードキ ャッシュアクセス待ち 整数演算待ち 浮動小数点演算待ち 分岐命令待ち 命令フェッチ待ち uOPコミット その他の待ち 1命令コミット 整数レ ジスタ書き込み制約 浮動小数点レジスタ書き込み制約 2/3命令コミット(その他) 4命令コミット
JAXA殿FX1(1ノード4Core)での計測結果
z
スレッド並列:自動並列(VISIMPACT)
z
コンパイルオプション:
-Am -Kimpact,ocl,vppocl,tl_trt -X9 -w -Qt -Ectfiu -xdir=inline_dir
7色オーダリング
8色オーダリング
[sec]
[%]
sor7p_b_
31,883
318.83
49.1%
sor7v_b_
10,455
104.55
16.1%
sgs_
7,608
76.08
11.7%
corvcn_
4,036
40.36
6.2%
sor7p_
2,995
29.95
4.6%
全体
64,966
649.66
100.0%
プロファイラ
(count数)
ルーチン名
CPU時間
[sec]
[%]
sor8p_b_
28,331
283.31
47.7%
sor7v_b_
10,482
104.82
17.6%
sgs_
7,618
76.18
12.8%
corvcn_
4,018
40.18
6.8%
sgsbnd_
1,153
11.53
1.9%
全体
59,442
594.42
100.0%
プロファイラ
(count数)
ルーチン名
CPU時間
4174.03 Mips
1608.46 Mflops
5516.60 Mips
1742.24 Mflops
FPロードメモリアクセス待ち: 41%
FPロードキャッシュアクセス待ち: 23%
FP演算待ち: 10%
FPロードメモリアクセス待ち: 38% (-40sec)
FPロードキャッシュアクセス待ち: 13% (-74sec)
FP演算待ち: 12% (+9sec)
6
コスト上位ルーチン別のPA情報
圧力Poisson方程式のSOR計算
運動方程式の
SOR計算
SGS項算出
0.0E+00 5.0E+01 1.0E+02 1.5E+02 2.0E+02 2.5E+02 3.0E+02Process 0 Thread 0 Process 0 Thread 1 Process 0 Thread 2 Process 0 Thread 3 時間(sec) 0.0E+00 5.0E+01 1.0E+02 1.5E+02 2.0E+02 2.5E+02 3.0E+02 3.5E+02
Process 0 Thread 0 Process 0 Thread 1 Process 0 Thread 2 Process 0 Thread 3
7色オーダリング
8色オーダリング
0.0E+00 2.0E+01 4.0E+01 6.0E+01 8.0E+01 1.0E+02 1.2E+02Process 0 Thread 0 Process 0 Thread 1 Process 0 Thread 2 Process 0 Thread 3
0.0E+00 1.0E+01 2.0E+01 3.0E+01 4.0E+01 5.0E+01 6.0E+01 7.0E+01 8.0E+01 9.0E+01
Process 0 Thread 0 Process 0 Thread 1 Process 0 Thread 2 Process 0 Thread 3
FPロードメモリアクセス待ち: 70%
FP演算待ち: 33%
FPロードメモリアクセス待ち: 46%
FPロードメモリアクセス待ち: 43%
FPロードキャッシュアクセス待ち: 34%
7
更なる性能向上に向けた試み(改良版2)
1
3
2
4
2
4
3
4
4
5
7
6
8
6
8
7
8
8
5
7
6
8
6
8
7
8
8
は
を計算するときに参照される
数字は色分けの番号
全てを
一つの配列
p0に持つ
k方向を交互に
二つの配列
p1, p2に持つ
前回
今回
を計算するとき
は同じ配列をみる
は別の配列をみる
キャッシュに乗りやすい近くの点
キャッシュに乗りにくい遠くの点
p1
p2
8
ソースのイメージ
do m=1,nvol
do i=1,ico0max(m)
kk=(i-1)/ijp8aa
ij=-kk*ijp8aa+(i-1)
jj=ij/iip8a
ii=-jj*iip8a+ij
nn1=kk*ijp1+(jj*2)*iip1+(ii*2)+nn1rst
n1 =nn1+kk*ijp1+n1rsg
nn2=nn1-ijp1
res=p1(nn1-iip1-1,0,m)*fj_clp0(1,i,m)
$ +p1(nn2 -1,1,m)*fj_clp0(2,i,m)
$ +p1(nn1-
1,0,m)*fj_clp0(3,i,m)
$ + …
$ +p1(nn1-iip1 ,1,m)*fj_clp0(8,i,m)
$ +p1(nn2 ,1,m)*fj_clp0(9,i,m)
$ +p1(nn1 ,0,m)
$ +p1(nn1 ,1,m)*fj_clp0(11,i,m)
$ + …
$ +p1(nn1+ 1,0,m)*fj_clp0(17,i,m)
$ +p1(nn1 +1,1,m)*fj_clp0(18,i,m)
$ +p1(nn1+iip1+1,0,m)*fj_clp0(19,i,m)
& -bp(n1)
p1(nn1,0,m)=p1(nn1,0,m)-res*omegap
enddo
do i=1,ico1max(m)
...
enddo
...
enddo
real*8 :: p1(m2max,0:1,nvol)
real*8 :: p0(n1max), bp(n1max)
real*8 :: fj_clp0(19, m2max/7+1, nvol),
& fj_clp1(19, m2max/7+1, nvol),
& ...
& fj_clp7(19, m2max/7+1, nvol)
ここでは
p1,p2 を
p1(:,0:1,:) として
一つの配列にしてある
9
結果
結果的にはあまり速度向上はしなかった.
0 20 40 60 80 100 1202core 4core 8core 32core
前回 今回
圧力
Poisson
部のみの計算時間
[秒
]
但し,以下の社内計算機で評価
PRIMERGY RX600S5 x 11node
Intel Xeon X7560 (Nehalem-EX)
8core/chip, 4chip/node
測定結果
Copyright 2013 FUJITSU LIMITED
CSMS_SOR8最新版(改良版2)のFX1、京、FX10での測定結果
イタレーションは、step=50で測定
10
■
FX1、京、FX10 実行時間比較 (timeコマンドのreal)
Thread
実行時間
(秒)
スケール
Thread
実行時間
(秒)
スケール
Thread
実行時間
(秒)
スケール
1th
931.36
1.00
1th
997.14
1.00
1th 1187.14
1.00
4th
405.91
2.31
8th
144.59
6.90
16th
90.64
13.10
■
FX1比
Thread
FX1
Thread
京
Thread
FX10
1th
1.00
1th
0.93
1th
0.78
4th
1.00
8th
2.81
16th
4.48
(目安:FX1とのF演算ピーク性能比)
Thread
FX1
Thread
京
Thread
FX10
コア
1th
1.00
1th
1.59
1th
1.47
ノード
4th
1.00
8th
3.17
16th
5.87
FX10
csms_
sor8
csms_
sor8
FX1
京
高コストの
PA情報(FX10)
11
PA情報
スレッド0
step=50
FX10 (16スレッド)
Performance SIMD実行時間 (sec) 浮動小数点演算ピーク比 MFLOPS MIPS 浮動小数点演算数 (/有効総命令数)SIMD命令率 (/SIMD対象命令SIMD命令率 数) SIMD演算命令率 (/SIMD対象演算 命令数) SIMDロード命令率 (/SIMD対象ロード 命令数) SIMDストア命令率 (/SIMD対象ストア 命令数) sor7v_b T0 11.11 2.94% 434 458 4.82E+09 25.21% 31.41% 99.99% 0.00% 0.00% sgs T0 12.71 4.80% 710 1390 9.02E+09 0.00% 0.00% 0.00% 0.00% 0.00% sor8p_b_h T0 36.80 3.55% 525 1321 1.93E+10 10.65% 21.57% 99.98% 0.00% 0.00%
メモリスループットは
少し余裕がある。
L2ミス(dm)率が高い。
浮動小数点待ちが多く
命令スケジューリング
の余地があるか?
メモリスループットは少し余裕がある。
L2ミス(dm)率が高い。
演算待ちが多い。
①
②
③
Cache L1I ミス率 (/有効総命令数) L1D ミス率 (/ロード・ストア数) ロード・ストア数 L1D ミス数 L1D ミス dm率 (/L1D ミス数) L1D ミス hwpf 率 (/L1D ミス数) L1D ミス swpf 率 (/L1D ミス数) sor7v_b T0 0.05% 25.99% 2.81E+09 7.32E+08 52.05% 26.33% 21.62% sgs T0 0.00% 4.12% 6.45E+09 2.66E+08 70.90% 3.43% 25.67% sor8p_b_h T0 0.02% 6.24% 1.89E+10 1.18E+09 41.06% 58.93% 0.00%L2 ミス率 (/ロード・ストア数) L2 ミス数 L2 ミス dm 率 (/L2 ミス数) L2 ミス pf 率 (/L2 ミス数) メモリスループット (GB/sec) L2 スループット(GB/sec) µDTLB ミス率 (/ロード・ストア 数) mDTLB ミス率 (/ロード・ストア数) sor7v_b T0 9.62% 2.71E+08 23.17% 76.83% 3.61 8.43 0.00292% 0.00002% sgs T0 0.34% 2.20E+07 27.26% 72.74% 0.24 2.68 0.00083% 0.00001% sor8p_b_h T0 5.46% 1.03E+09 7.47% 92.53% 3.92 4.09 0.00424% 0.00001%
Loop1チューニング
「浮動小数点演算待ち」
と「整数演算待ち」が
多い。
ソフトウェアパイプライン
(SWP)による命令スケ
ジューリングがされてな
い。
-KSWPオプションは有効であったが、コンパイラがSWPしても効果
が無いと判断して、
SWPしていなかった。
そのため、最適化制御行(
OCL)で強制的にSWPしたところ、効果
が見られた。
高コスト③sor8p_b_hチューニングについて
12
チューニングソース
13
チューニング後のソース
DOループの前の66行目に !ocl swp を追加
62 *vocl loop,novrec(p1,div)
63 *voption indep(p1,div)
64 !cdir nodep(p1),nosync
65 !cdir on_adb(p1)
66
!ocl swp
<<< Loop-information Start >>>
<<< [PARALLELIZATION]
<<< Standard iteration count: 69
<<< [OPTIMIZATION]
<<< SIMD
<<< SOFTWARE PIPELINING
<<< Loop-information End >>>
67 1 pp v do i=1,ico0max(m)
68 1 p v kk=(i-1)/ijp8aa
69 1 p v ij=-kk*ijp8aa+(i-1)
70 1 p v jj=ij/iip8a
71 1 p v ii=-jj*iip8a+ij
72 1 p v k1 =kk*ijp1
73 1 p v nn1=k1+(jj*2)*iip1+(ii*2)+nn1rst
74 1 p v n1 =k1+nn1+n1rsg
75 1 p v nn2=nn1-ijp1
76 1 p v res=p1(nn1-iip1-1,0,m)*fj_clp0(1,i,m)
77 1 $ +p1(nn2 -1,1,m)*fj_clp0(2,i,m)
78 1 $ +p1(nn1-
1,0,m)*fj_clp0(3,i,m)
79 1 $ +p1(nn1 -1,1,m)*fj_clp0(4,i,m)
80 1 $ +p1(nn1+iip1-1,0,m)*fj_clp0(5,i,m)
81 1 $ +p1(nn2-iip1 ,1,m)*fj_clp0(6,i,m)
82 1 $ +p1(nn1-iip1 ,0,m)*fj_clp0(7,i,m)
83 1 $ +p1(nn1-iip1 ,1,m)*fj_clp0(8,i,m)
84 1 $ +p1(nn2 ,1,m)*fj_clp0(9,i,m)
85 1 $ +p1(nn1 ,0,m)
86 1 $ +p1(nn1 ,1,m)*fj_clp0(11,i,m)
87 1 $ +p1(nn2+iip1 ,1,m)*fj_clp0(12,i,m)
88 1 $ +p1(nn1+iip1 ,0,m)*fj_clp0(13,i,m)
89 1 $ +p1(nn1+iip1 ,1,m)*fj_clp0(14,i,m)
90 1 $ +p1(nn1-iip1+1,0,m)*fj_clp0(15,i,m)
91 1 $ +p1(nn2 +1,1,m)*fj_clp0(16,i,m)
92 1 $ +p1(nn1+ 1,0,m)*fj_clp0(17,i,m)
93 1 $ +p1(nn1 +1,1,m)*fj_clp0(18,i,m)
94 1 $ +p1(nn1+iip1+1,0,m)*fj_clp0(19,i,m)
95 1 & -bp(n1)
96 1 p v p1(nn1,0,m)=p1(nn1,0,m)-res*omegap
97 1 p v div(n1)=abs(res)
98 1 p v enddo
追加
Loop1チューニング
チューニングの結果、
「浮動小数点演算待ち」
と「整数演算待ち」の
コストが減った。
その結果として、
メモリスループットが
約68GB/secになった。
性能は約11%向上した。
高コスト③sor8p_b_hチューニング結果
(Loop1)
14
Cache L1I ミス率 (/有効総命令数) (/ロード・ストア数)L1D ミス率 ロード・ストア数 L1D ミス数 L1D ミス dm率(/L1D ミス数) L1D ミス hwpf 率 (/L1D ミス数) L1D ミス swpf 率 (/L1D ミス数) (/ロード・ストア数)L2 ミス率 L2 ミス数 L2 ミス dm 率(/L2 ミス数) L2 ミス pf 率(/L2 ミス数) メモリスループット (GB/sec) L2 スループット(GB/sec) オリジナル 0.06% 6.18% 2.39E+08 1.48E+07 42.23% 57.75% 0.03% 5.42% 1.30E+07 8.05% 91.95% 3.79 3.90 SWPL 0.06% 5.09% 2.94E+08 1.50E+07 38.24% 61.73% 0.03% 4.38% 1.29E+07 9.23% 90.77% 4.24 4.41Performance
実行時間 (sec) 浮動小数点演算ピーク比 MFLOPS MIPS 浮動小数点演算数 オリジナル 0.49 3.39% 501 1272 2.43E+08 SWPL 0.43 3.79% 561 1537 2.43E+08
メモリスループットが3.79 ⇒ 4.24 GB/secに改善。
16スレッドで、約68GB/sとなっており、
メモリスループットネックとなっている。
約11%
性能向上
高コスト③sor8p_b_hチューニング結果
(Loop1-8)
15
Loop1-8チューニング結果(16スレッド並列のスレッド0)
Loop1-8は、ほぼ同じ処理のループです。
Loop1-8の合計でもLoop1と同様に、
約
11%の性能改善とメモリースループット
ネックになっています。
実行時間 (sec) メモリ スループット (GB/sec) オリジナル 0.49 3.79 SWPL 0.43 4.24 オリジナル 0.48 3.83 SWPL 0.43 4.33 オリジナル 0.49 3.82 SWPL 0.43 4.28 オリジナル 0.48 3.83 SWPL 0.42 4.30 オリジナル 0.48 3.90 SWPL 0.44 4.28 オリジナル 0.47 3.96 SWPL 0.43 4.33 オリジナル 0.48 3.87 SWPL 0.43 4.35 オリジナル 0.47 3.88 SWPL 0.43 4.34 Loop7 Loop8 Loop1 Loop2 Loop3 Loop4 Loop5 Loop638 2 pp v do 100 n1=n1rs(m)+ic,n1re(m),7 40 2 p coef=omegav/clp(n1,10)
42 2 p v resu=u(n1 -iip1-1)*clp(n1,1) +u(n1-ijp1 -1)*clp(n1,2) 43 2 $ +u(n1- 1) *clp(n1,3) +u(n1+ijp1 -1)*clp(n1,4) 44 2 $ +u(n1 +iip1-1)*clp(n1,5) +u(n1-ijp1-iip1 )*clp(n1,6) 45 2 $ +u(n1-iip1) *clp(n1,7) +u(n1+ijp1-iip1 )*clp(n1,8) 46 2 $ +u(n1-ijp1) *clp(n1,9) +u(n1 ) *clp(n1,10) 47 2 $ +u(n1+ijp1) *clp(n1,11)+u(n1-ijp1+iip1 )*clp(n1,12) 48 2 $ +u(n1+iip1) *clp(n1,13)+u(n1+ijp1+iip1 )*clp(n1,14) 49 2 $ +u(n1 -iip1+1)*clp(n1,15)+u(n1-ijp1 +1)*clp(n1,16) 50 2 $ +u(n1+ 1) *clp(n1,17)+u(n1+ijp1 +1)*clp(n1,18) 51 2 $ +u(n1 +iip1+1)*clp(n1,19) 56 2 $ -bu(n1)
58 2 p v resv=v(n1 -iip1-1)*clp(n1,1) +v(n1-ijp1 -1)*clp(n1,2) 59 2 $ +v(n1- 1) *clp(n1,3) +v(n1+ijp1 -1)*clp(n1,4) 60 2 $ +v(n1 +iip1-1)*clp(n1,5) +v(n1-ijp1-iip1 )*clp(n1,6) 61 2 $ +v(n1-iip1) *clp(n1,7) +v(n1+ijp1-iip1 )*clp(n1,8) 62 2 $ +v(n1-ijp1) *clp(n1,9) +v(n1 ) *clp(n1,10) 63 2 $ +v(n1+ijp1) *clp(n1,11)+v(n1-ijp1+iip1 )*clp(n1,12) 64 2 $ +v(n1+iip1) *clp(n1,13)+v(n1+ijp1+iip1 )*clp(n1,14) 65 2 $ +v(n1 -iip1+1)*clp(n1,15)+v(n1-ijp1 +1)*clp(n1,16) 66 2 $ +v(n1+ 1) *clp(n1,17)+v(n1+ijp1 +1)*clp(n1,18) 67 2 $ +v(n1 +iip1+1)*clp(n1,19) 72 2 $ -bv(n1) : : 103 2 p 100 continue 106 1 110 continue
高コスト①のsor7v_b
-Karray_subscript, array_subscript_rank=2, array_subscript_elementlast=25
が既に指定されていて、
配列clp は次元移動により連続アクセス化
がされて
いました。
L2ミス(dm)率が高いため、配列clpのプリフェッチ(HWPF)が効果的でないの
ではないか?と言う観点で、HWPFを止めてSWPで検証しました。
また、コンパイラからは配列clp は
ストライドアクセスに見えるため、
ストライドアクセスオプションも
指定しました。
オプションは以下です。
-Kprefetch_stride
-Kprefetch_sequential=soft
高コスト①のチューニングについて
16
-Kprefetch_stride (使用手引書より抜粋)
ループ内で使用されるキャッシュのラインサイズよりも
大きなストライドでアクセスされる配列データに対して、
prefetch命令を使用したオブジェクトを生成します。
プリフェッチするアドレスが翻訳時に確定しないループ
を含みます。
sor7v_b ①
25 1 do 110 ic=0,6 <<< Loop-information Start >>> <<< [PARALLELIZATION]<<< Standard iteration count: 37 <<< [OPTIMIZATION] <<< SIMD <<< SOFTWARE PIPELINING <<< PREFETCH : 90 <<<
v: 54, bw2: 6, bw: 6, w: 18, bv: 6
<<< Loop-information End >>> 38 2 pp v do 100 n1=n1rs(m)+ic,n1re(m),7 40 2 p coef=omegav/clp(n1,10)42 2 p v resu=u(n1 -iip1-1)*clp(n1,1) +u(n1-ijp1 -1)*clp(n1,2) 43 2 $ +u(n1- 1) *clp(n1,3) +u(n1+ijp1 -1)*clp(n1,4) 44 2 $ +u(n1 +iip1-1)*clp(n1,5) +u(n1-ijp1-iip1 )*clp(n1,6) 45 2 $ +u(n1-iip1) *clp(n1,7) +u(n1+ijp1-iip1 )*clp(n1,8) 46 2 $ +u(n1-ijp1) *clp(n1,9) +u(n1 ) *clp(n1,10) 47 2 $ +u(n1+ijp1) *clp(n1,11)+u(n1-ijp1+iip1 )*clp(n1,12) 48 2 $ +u(n1+iip1) *clp(n1,13)+u(n1+ijp1+iip1 )*clp(n1,14) 49 2 $ +u(n1 -iip1+1)*clp(n1,15)+u(n1-ijp1 +1)*clp(n1,16) 50 2 $ +u(n1+ 1) *clp(n1,17)+u(n1+ijp1 +1)*clp(n1,18) 51 2 $ +u(n1 +iip1+1)*clp(n1,19) 56 2 $ -bu(n1) : 103 2 p 100 continue 106 1 110 continue
プリフェッチオプションはデフォルト
26 1 do 110 ic=0,6 <<< Loop-information Start >>> <<< [PARALLELIZATION]<<< Standard iteration count: 37 <<< [OPTIMIZATION] <<< SIMD <<< SOFTWARE PIPELINING <<< PREFETCH : 222 <<< u: 54, v: 54, bu: 6, w: 54, bw2: 6 <<< bw: 6,
clp: 36
, bv: 6 <<< Loop-information End >>> 39 2 pp v do 100 n1=n1rs(m)+ic,n1re(m),7 41 2 p coef=omegav/clp(n1,10)43 2 p v resu=u(n1 -iip1-1)*clp(n1,1) +u(n1-ijp1 -1)*clp(n1,2) 44 2 $ +u(n1- 1) *clp(n1,3) +u(n1+ijp1 -1)*clp(n1,4) 45 2 $ +u(n1 +iip1-1)*clp(n1,5) +u(n1-ijp1-iip1 )*clp(n1,6) 46 2 $ +u(n1-iip1) *clp(n1,7) +u(n1+ijp1-iip1 )*clp(n1,8) 47 2 $ +u(n1-ijp1) *clp(n1,9) +u(n1 ) *clp(n1,10) 48 2 $ +u(n1+ijp1) *clp(n1,11)+u(n1-ijp1+iip1 )*clp(n1,12) 49 2 $ +u(n1+iip1) *clp(n1,13)+u(n1+ijp1+iip1 )*clp(n1,14) 50 2 $ +u(n1 -iip1+1)*clp(n1,15)+u(n1-ijp1 +1)*clp(n1,16) 51 2 $ +u(n1+ 1) *clp(n1,17)+u(n1+ijp1 +1)*clp(n1,18) 52 2 $ +u(n1 +iip1+1)*clp(n1,19) 57 2 $ -bu(n1) : 104 2 p 100 continue 107 1 110 continue
-Kprefetch_stride
-Kprefetch_sequential=soft 指定
-Kprefetch_stride,
-Kprefetch_sequential=soft
により、配列 clp に対して、
prefetch命令が生成されて
いる。
17
Cache
L1I ミス率
(/有効総命令数)
L1D ミス率
(/ロード・ストア数)
ロード・ストア数
L1D ミス数 L1D
ミス dm率
(/L1D ミス数)
L1D ミス hwpf
率
(/L1D ミス数)
L1D ミス swpf 率
(/L1D ミス数)
L2 ミス率
(/ロード・ストア数)
L2 ミス数
L2 ミス dm 率
(/L2 ミス数)
L2 ミス pf 率
(/L2 ミス数)
メモリスループット
(GB/sec)
L2 スループット
(GB/sec)
Before T0
0.05%
25.99%
2.82E+08 7.32E+07
52.05%
26.33%
21.62%
9.62%
2.71E+07
23.15%
76.85%
3.63
8.42
OPT Tune T0
0.05%
26.91%
3.02E+08 8.14E+07
54.89%
0.01%
45.11%
9.97%
3.02E+07
3.38%
96.62%
4.40
10.37
SIMD
SIMD命令率
(/有効総命令数)
SIMD命令率
(/SIMD対象命令
数)
SIMD演算命令率
(/SIMD対象演算
命令数
)
SIMDロード命令率
(/SIMD対象ロード
命令数
)
SIMDストア命令率
(/SIMD対象ストア
命令数
)
Before T0
25.20%
31.41%
99.99%
0.00%
0.00%
OPT Tune T0
20.20%
31.41%
99.99%
0.00%
0.00%
Performance
実行時間
(sec)
浮動小数点演算
ピーク比
MFLOPS
MIPS
浮動小数点演算
数
Before T0
1.11
2.94%
434
458
4.82E+08
OPT Tune T0
1.00
3.25%
480
632
4.82E+08
sor7v_b ① (PA情報はstep=5)
L2ミスdm率が高く、
「浮動小数点ロードメモリアクセス待ち」が発生
↓
プリフェッチ生成により約
10%の性能向上
PA情報 [ sor7v_b ]
・オプションによるプリフェッチの生成をした。
⇒
L2のdmミス削減
0.0E+00 2.0E-01 4.0E-01 6.0E-01 8.0E-01 1.0E+00 1.2E+00Before T0 OPT Tune T0 [秒]