潜在ランク理論に基づくコンピュータ適応型テスト
のアルゴリズムに関する研究
著者
秋山 實
学位授与機関
Tohoku University
学位授与番号
11301甲第15963号
URL
http://hdl.handle.net/10097/57685
博士学位論文
潜在ランク理論に基づく
コンピュータ適応型テストの
アルゴリズムに関する研究
秋 山 實
平成 25 年度
東北大学
Abstract
There is a desire to significantly reduce the time of testing without compromising the accuracy of the test. One solution is to employ computerized adaptive testing. If we administer computerized adaptive testing using whole items of conventional tests as an item bank, the accuracy will be the same as that obtained by a conventional test under the condition that the number of attempted items is less than half. Computerized adaptive testing requires an item bank, and this can be obtained by analyzing the answer data of a test based on a test theory. Most computerized adaptive test systems are based on item response theory. However, item response theory cannot be applied to small sample size data. Therefore, I focused on latent rank theory, which can estimate the parameters of small sample size data.
This study proposes algorithms of computerized adaptive testing based on the latent rank theory and verifies its validity. The target performance of the algorithms, using the item bank of 50 or fewer items in size, is the number of answered items to be less than 50% of the item bank and 10% or less of error.
In the latent rank theory, the measure of the ability of the examinees is an ordinal scale of a discrete value called the rank (hereinafter referred to as a rank scale). A rank membership profile is a vector representing the probability distribution of ability of examinees in the rank scale. In addition, an item reference profile is an item characteristic vector corresponding to the item characteristic curve in the item response theory. Computerized adaptive testing consists of initial setting, item selection, ability estimation, and termination condition.
In this study, I applied the algorithms of computerized adaptive testing based on the item response theory to the algorithms of that based on the latent rank theory. The statistic, which is the key in the algorithms of computerized adaptive testing based on the item response theory, is item information.
Therefore, I initially defined information in the latent rank theory, corresponding to that in the item response theory. In the item response theory, item information for two-parameter logistic model is Ij(θi) = aj2pijqij,
where aj is the slope of the item characteristic curve in θi. In the case of
the latent rank theory, item reference profile corresponds to item characteristic curve of the item response theory. However, because the scale of the latent rank theory is ordinal, it is not possible to obtain the difference. Therefore, I defined the discrimination power by the difference between the correct answer probabilities of rank adjacent to the examinee ability rank of the item reference profile. I defined Ij (Ri) = δRi,j2pijqij for the
item information using this definition of discrimination power. In addition, there was an assumption of additivity in the item response theory; the test information is defined as Itest = ΣIj(Ri). I proposed new algorithms for three
components of computerized adaptive testing using these definitions.
In this paper, I have proposed a maximum information criterion for item selection, weighted maximum likelihood estimation method for ability estimation, and standard error reduction criterion for the termination condition. Computerized adaptive testing based on the latent rank theory, which is constituted by proposed algorithms, was evaluated by means of Monte Carlo simulation. Simulation results indicated that the estimation error rate was 6.5% (in the case of rank 5 for 150 items) and 6.4% (in the case of rank 3 for 50 items). Moreover, in the case of rank 2, using item
bank with item numbers 20, 30, 40, and 50 showed that the number of answered items was below 50%, and the estimation error rate was below 10%.
目次
第1 章 序論 1 第1 節 研究の背景 1 第2 節 問題の所在と研究の目的 2 第3 節 本論文の構成 3 第2 章 潜在ランク理論 5 第1 節 はじめに 5 第2 節 潜在ランク理論のモデル 6 第3 節 アイテムに関する特性パラメータの推定 9 第4 節 受験者能力に関する特性パラメータの推定 11 第5 節 モデル適合度指標 14 第6 節 小さいサンプルサイズの場合のモデル適合度 15 第7 節 おわりに 16 第3 章 項目応答理論に基づくコンピュータ適応型テスト 18 第1 節 はじめに 18 第2 節 初期設定 20 第3 節 アイテム選択 20 第4 節 能力推定 21 第5 節 終了判定 24 第6 節 おわりに 25 第4 章 潜在ランク理論に基づくコンピュータ適応型テスト 26 第1 節 はじめに 26 第2 節 初期設定 26 第3 節 アイテム選択 27 第4 節 能力推定 28 第5 節 終了判定 29第6 節 おわりに 30 第5 章 新しいアルゴリズムの提案 31 第1 節 はじめに 31 第2 節 正答確率 32 第3 節 識別力ベクトルの定義 32 第4 節 情報量の定義 33 第5 節 アイテム選択 33 第6 節 能力推定 34 第7 節 終了判定 36 第8 節 おわりに 37 第6 章 新しいアルゴリズムの評価 38 第1 節 はじめに 38 第2 節 シミュレーションの方法 39 第3 節 使用する回答データ 41 第4 節 先行研究との比較 48 第5 節 提案アルゴリズムの評価 51 第6 節 おわりに 58 第6 章 結論 60 参考文献 62 謝辞 64
第 1 章 序論
第1節 研究の背景
近年,eラーニングが普及し,多くのeラーニングのソフトウェアはオンラインテスト,いわ ゆるCBT(Computer Based Testing)の機能を持っており,比較的手軽にオンラインテス トができるようになってきた.CBT の長所は,1)自動採点ができ,採点に手間と時間がかか らないこと,2)受験者はテストを受験した直後にその結果を知ることができること,3)テスト アイテム(以下,単にアイテムという)を再利用することでテストの準備が省力化できること,4) マルチメディアを使い,「紙と鉛筆」による従来のテストでは実現できなかった聴解スキルを 測るアイテムなどを実現できること,などがあげられる.このように CBT は,従来の「紙と鉛 筆」によるテストに比べ多くの長所を有している.しかし,CBT も「紙と鉛筆」による従来のテ ストも全員が同じ問題を解くことには変わりはなく,メディアと配信方法の技術は進歩したが テストの本質的な部分では大きな進歩はない. eラーニングの普及と歩調を合わせて,インストラクショナル・デザイン(Instructional Design, ID)の概念やアプローチが普及してきている.ID に則ったコース設計をする場合, コースを教授項目の依存関係で構造化し,教授項目ごとにモジュール化する.このモジュ ールには,1)学習を始める前にその学習モジュールの内容を既に学習しているか否か確 認するテストを設け,学習していれば,そのモジュールをスキップする,2)学習モジュール の学習が終わった後にその学習モジュールの内容を習得できているか確認するテストを設 け,学習できていなければ,学習をやり直しさせる,ことでステップバイステップの学習を実 現する.このような確認テストは学習モジュールの学習項目を網羅したテストアイテムで構 成される.テストの信頼度を確保するためにはテストアイテムを増やす必要がある.しかし,
学習モジュールの学習時間に比べ,このようなテストに割ける時間は多くないので,テスト アイテムを省かざるを得ない場合もあり,学習者が学習を進めていくうちに学習上のつまず きが生じてしまうという望ましくない結果を招くことになりかねない. 一般的にも教育の過程で学習者の理解度を測りながら教授活動を進めていくことは行 われているが,その手段としてテストは古くから行われており,今後も無くなることはないで あろうし,テストを短時間で実施したいという要求は存在し続けると思われる. このような「短時間で,かつ,ある程度の信頼度でテストを実施したい」という要求に応え うる有力な解決策の一つとしてコンピュータ適応型テスト(Computerized Adaptive Test, CAT)がある.CAT は,リニアテスト(受験者全員に同じ問題を解かせる従来型のテスト)に 比べ,半分以下の問題数でリニアテストと同程度の精度で能力を測定できるといわれてい る.しかし,CAT を実施するにはあらかじめアイテムの特性パラメータを推定しておく必要 がある.そのようなアイテム群をアイテムバンクと呼ぶ.アイテムバンクを構築するには,あ らかじめ,能力を測定する受験者とは別の受験者にテストを受験させ,その結果を分析して アイテムの特性パラメータを推定する.この時,適用するテスト理論・モデルに応じた,特性 パラメータを推定するために必要十分な数の受験者に受験させることが必要である.
第2節 問題の所在と研究の目的
現在,多くのCAT は項目応答理論(Item Response Theory)に基づいている.特性パ ラメータを推定するために必要なサンプルサイズは,1 パラメータロジスティックモデルで 20 問・200 名程度,2 パラメータロジスティックモデルで 30 問・600 人程度,3 パラメータロ ジスティックモデルで30問・2,000名程度と言われている.このような予備テスト(または,そ れに代わる過去のテスト)の回答データを得るためには時間とコストがかかるため,ある程 度の規模で行うテストを除き,手軽に CAT を実施することは難しい状況にある.また,この ような大きさのサンプルが得られない場合,テスト理論のモデルへの適合度が十分に得ら れず,たとえ特性パラメータが推定できたとしても,CAT を適切に機能させるために必要な アイテムバンクを構成することはできない. CATは,項目応答理論に基づくものに限定されているわけではなく,受験者の回答とア
イテムの特性パラメータから受験者の能力を推定することができれば,どのようなテスト理論 に基づくものであっても実現することができる.潜在ランク理論(Latent Rank Theory,潜 在ランク理論; Shojima,2007a)は,潜在変数に離散値の順序尺度(以降,ランク尺度と呼 ぶ)を仮定するノンパラメトリックなテスト理論である.この潜在ランク理論の特長の一つは, サンプルサイズが小さくても特性パラメータの推定ができることである(秋山,2012).このこ とから,「短時間である程度の精度でテストを実施したい」という要求が実現できる可能性が ある. 本研究の目的は,従来のテストをそのまま CAT のアイテムバンクにしてテストを実施す るというシナリオを前提にして,「アイテム数50 以下のテストの結果を使ってパラメータを推 定し,構築したアイテムバンクで誤差 10%以下,受験アイテム数が元のテストの 50%以下 の実用的な性能を実現できる潜在ランク理論に基づくコンピュータ適応型テストのアルゴリ ズムを提案し,その有効性を検証する」ことである. なお,本研究では潜在ランク理論の二値モデルを対象とする.以降はすべて二値モデ ルについて述べている.
第3節 本論文の構成
最後に,本論文の構成を示す.第2 章では,本研究で採用する新しいテスト理論である 潜在ランク理論の基礎的事項について述べるとともに,その特長の一つである小さいサン プルサイズでもパラメータを推定できることを実際の受験データを分析した結果によって示 す.第3 章では,現在主流となっている項目応答理論に基づく CAT のアルゴリズムを第 4 章以降の導入として説明する.第4 章では,潜在ランク理論に基づく CAT の先行研究を紹 介する.第5 章では,潜在ランク理論に基づく CAT の新しいアルゴリズムを項目応答理論 に基づくCAT のアルゴリズムの考え方を潜在ランク理論において適用するため,新しいア イテム指標を提案し,これを使用してアイテム情報量,テスト情報量を定義し,アイテム選択, 能力推定,終了判定の3 つのアルゴリズムを新たに提案する.第 6 章では,先行研究のア ルゴリズムと提案したアルゴリズムの比較を構成要素毎にシミュレーションによって行い,評 価する.また,アイテム数が10 から 50,ランク数が 2 から 5 のアイテムバンク 40 種類それぞれについて,終了条件の受験アイテム数を変えながらシミュレーションを行い,本研究で 提案したアルゴリズムによるCAT の推定誤差が基準を満たす範囲を明らかにする.第 6 章 では,本論文について総括する.
第 2 章 潜在ランク理論
第1節 はじめに
潜在ランク理論(Shojima, 2007a)は,新しいテスト理論である.受験者の能力を潜在ラ ンクという離散値の順序尺度(以後,ランク尺度と呼ぶ)で表すことから潜在ランク理論と名 付けられているが,提案された当初は,ニューラルテスト理論(Neural Test Theory, NTT) と名付けられた.特性パラメータを推定する際に自己組織化マップ(Self-Organizing Map, SOM; Kohonen, 1995)や生成ポトグラフィックマッピング(Generative topographic Mapping, GTM; Bishop,Svensen and Williams, 1998)というニューラルネットワークの 一種のメカニズムを利用していたことに由来している.本章では,潜在ランク理論の概要, モデル,特性パラメータの推定について述べ,特長の一つである小さいサンプルサイズで も特性パラメータの推定ができることを「日本語を読むための語彙量テスト」(松下,2012) の回答データをEXAMETRIKA(Shojima, 2012)で分析することにより示す(秋山,2013).
第2節 潜在ランク理論のモデル
潜在ランク理論のモデルは,潜在変数に一次元の順序変数を仮定したノンパラメトリック なモデルである.したがって,数学的な表現によってモデルを与えることはできない.項目 応答理論におけるモデルは,例えば,2 パラメータロジスティックモデルでは,能力 θiの受 験者i がアイテム j を受験したときの正答確率Pj(θi)として, (2.1) で与えられる. ここで,aj,bjはアイテムjの識別力パラメータと項目困難度パラメータであり,Dはロジス ティック関数で累積正規分布関数を近似する際の誤差補正用の定数である. 潜在ランク理論のモデルは,ノンパラメトリックなモデルであり,数式で定義されるわけで はないが,項目応答理論のモデルのようにある受験者があるアイテムを受験したときの正 答確率によってモデルを与えるとしたら, (2.2) と表すことができる.ここで IRPj Riはアイテム j の特性を示すアイテム参照プロファイル(Item Reference Profile, IRP)ベクトルの受験者 i の能力ランクRiに相当する要素である.
IRP ベクトルは Q 次元のベクトルである.Q はモデルのランク数であり,2 から 20 程度の範 囲で目的やモデル適合度によって選択する.
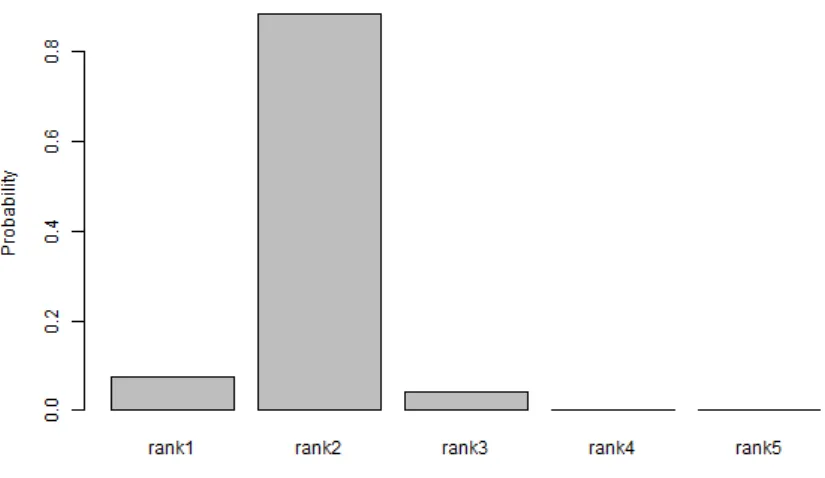
能力ランクRiは,受験者の能力確率分布の中で最も高い確率となるランクであり,ランク
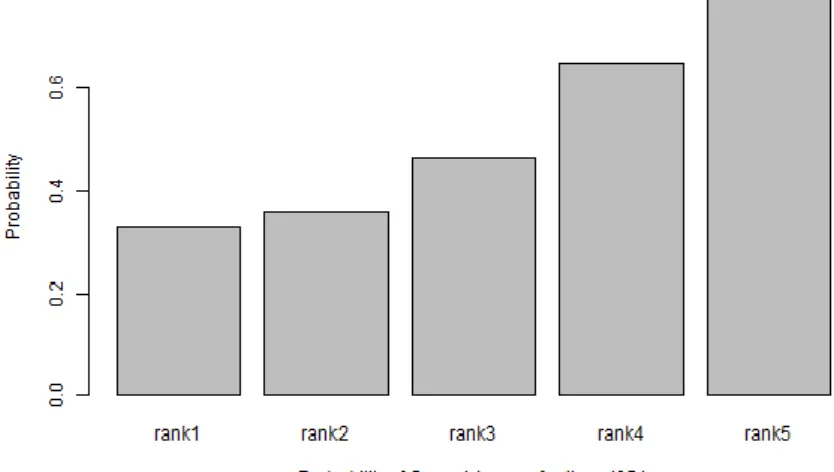
メンバーシッププロファイル(Rank Membership Profile, RMP)の最大の要素である. RMP は,モデルのランク数 Q と同じ次元のベクトルである.RMP を横軸に能力ランク,縦 軸に確率をとって棒グラフで図示したのが図 2.1 である.基本的には単峰性の形状をして いるが,受験者の能力特性によっては双峰性のグラフになる場合もある.RMP ベクトルの 各要素の和は1 である.また,図 2.1 の場合,能力ランクは 2 である. IRPjの各要素はその対応するランクの能力を持つ受験者がこのアイテムを受験した場 合の正答確率を表している.横軸に能力ランク,縦軸に正答確率をとって棒グラフで表した
のが図2.2 である.基本的には単調増加する形状をしている.ただし,横軸の能力ランクは 順序尺度であり,ランクの間隔は不定である.項目応答理論の項目応答曲線(Item Characteristic Curve, ICC)は,ある能力 θ を持つ受験者がこのアイテムを受験した場合 の正答確率を表しているのに対して,潜在ランク理論のIRP ベクトルは,ある能力ランク R を持つ受験者がこの項目を受験した場合の正答確率を表している.項目応答理論の ICC に対して項目特性ベクトル(Item Characteristic Vector, ICV)と考えることができる.
なお,式(2.2)は,潜在ランク理論のモデルを与えるものではなく,SOM や GTM のメカ ニズムを用いてIRP ベクトルを推定した後に結果として得られるものである.
図2.2 IRP の例:「日本語を読むための語彙量テスト」のアイテム I051 潜在ランク理論のアイテムの特性については,IRP 指標が項目応答理論の項目困難度 や識別力,当て推量を表す特性パラメータに対応する指標として項目難易度,項目識別度, 項目単調度が提案されている(熊谷,2007).IRP 指標の例として某大学の英語語彙・語句 テストのアイテムI154 の場合を図 2.3 に示す. 項目識別度α は,隣接するランクで最も正答確率の差 a が大きいときの小さい方のラン クであり,図2.3 では 4 である.a は 0.124 である. 項目難易度β は,正答率が初めて基準値を超えるランクである.ただし,ランクが 1 や Q の場合0.5 未満でも β は 1,Q とする.図 2.3 では β は 5 である.その時の正答確率を b と する.項目応答理論ではICC において正答確率が 0.5 の時の θ の値を項目困難度 b とし ていることから,潜在ランク理論でもこの基準値を0.5 とするのが一般的である.図 2.3 では b は 0.488 である. 項目単調度γ は,隣り合うランクのペアで正答率の差がマイナスになる割合であり,この 例では2 / 4 = 0.5 である.減少部分の総和を c としている.この場合,c = 0.050 + 0.014 = 0.064 である. これらのアイテム指標の中で識別力と困難度を表す指標は潜在ランク理論に基づく CAT のアルゴリズムで使う統計量の候補として考えられるが,予備的なシミュレーションの 結果では良い結果を示さなかったので,本研究では後述する新たな指標を提案する.
図2.3 IRP 指標の例:某大学の英語語彙・語句テストのアイテム I154
第3節 アイテム特性パラメータの推定
潜在ランク理論の特性パラメータは,SOM や GTM のメカニズムを利用して推定するこ とは先に述べた.荘島(植野・荘島,2010)は,SOM はサンプルデータが 1,000 程度以下 の場合,GTM はそれ以上の場合に適用すると目安を示している.本研究では,小さなサ ンプルデータを扱うので SOM のメカニズムを使ってアイテムの特性パラメータを教師なし 学習をさせることにより推定する.その手順を以下に述べる(植野・荘島, 2010). 受験者i の(i = 1,…,N)のアイテム j(j=1,…,n)に対する回答ベクトルをuij とする.本研 究では2 値モデルを扱っているので,正答の場合 1,誤答の場合は 0 である.SOM には 入力層と競合層があり,SOM の競合層の出力は Q 個ある.Q は潜在ランク理論のモデル のランク数である.入力層はn 個のアイテムに対応して n 個の入力がある.全ての入力層 は競合層に結合されるので,それを結ぶノードを考える.このノードはn 行×Q 列のマトリク スを構成するので,ランク参照マトリクス(Rank Reference Matrix, RRM)と呼び,V={vjq}で表す.以下,SOM に受験者数 N の入力ベクトルuijをT 回繰り返し学習させることでV
の推定値を得る手順を示す.V(t,h)は第t 番目の繰り返しの h 番目のデータを入力すること
T ≧ N # 学習を N 回以上繰り返す FOR k = 1 TO n DO #V を初期化 FOR q = 1 TO Q DO Vkq(1,0) = q / (Q + 1) ENDFOR ENDFOR FOR t = 1 TO T DO # 教師なし学習 U(t-1)を受験者(行ベクトル)でランダムに並び替える IF t > 1 DO U(t) をU(t-1)で置換える FOR h = 1 TO N DO uh(t)の勝者ランクRw(t,h)を選択する V(t,h) = V(t,h-1) +1n h(t) (uh(t)1’Q – V(t,h-1)) ENDFOR ENDFOR (2.3) のようになる.(# 以降行端まではコメントである) ここで,勝者ランクは, (2.4) であり,uh(t)に最も近いランクを選択する.d(t,h,q)は,最小二乗距離 dLS(t,h,q),最尤距離 dML(t,h,q),最大事後距離dMAP(t,h,q)などがあり, (2.5) (2.6) (2.7) と定義されている. h(t)は近傍関数と呼ばれる関数で,
(2.8) と定義されている.ここで,1n は長さ n の単位列ベクトル,1’Q は長さ Q の単位行ベクトル である.h(t)は勝者ランクとの距離に関する単調減少関数で,その減少する度合いは距離 が増加するほど大きくなる.このようにして得られた V マトリクスの行ベクトルが IRP ベクト ルである.
第4節 受験者能力に関する特性パラメータの推定
潜在ランク理論においてアイテムの特性パラメータが既知のテストの回答から受験者の 能力を推定する方法としては,最尤推定法(Maximum Likelihood method, ML; 荘島, 2007b)と MAP(Maximum expectation A Preori; 荘島,2008)が提案されている.これ を著者がプログラムとして実装したものを紹介する. ML 法で受験者の能力ランクを推定するには,以下のように求める.テストを構成するア イテムのIRP の各要素を vjq(j=0…n,q=1,…,Q),受験者 i の能力ランクを Ri,受験者i のアイテム j,…,n に対する回答の正誤を uij,とし,各ランクで uijが発生する確率(尤度) は, (2.9) である.尤度を最大にするw が受験者の能力ランクであるから, (2.10) として求まる.なお,RMP ベクトルについては,RMP ベクトルの各要素は各ランクの尤度 と全体の尤度の比で求めることができるので,(2.11) となる. ML 推定のアルゴリズムを疑似コードで表すと, LH_max = 0.0 w = 1 FOR q TO Q DO LH = 1.0 FOR j TO n DO IF uij == 0 THEN DO LH = LH * (1 - vqj) ELSE DO LH = LH * vqj ENDIF ENDFOR IF LH > LH_max THEN DO LH_max = LH w = q ENDIF ENDFOR RETURN w (2.12) となる. また,MAP 法については,受験者能力の事後分布の最大を求めることにより能力ランク を推定するが,ベイズの定理により,事後分布は,尤度に受験者の能力ランクの事前分布 を重み付けとして得られるので,ML 法の式 2.9 に事前分布p(q)を乗じた,
(2.13) で与えられる.事前分布が一様分布であれば,ML 法と同じ結果を得る.事前分布は潜在 ランク理論の場合,RMP ベクトルで与えられるので,前回推定値RMPi(n-1)を使えば, (2.14) となる.尤度を最大にするw が受験者の能力ランクであるから, (2.15) で求めることができる.なお,RMP ベクトルについては,その各要素は, (2.16) で得られる. 疑似コードでアルゴリズムを示すと, LH_max = 0.0 w = 1 FOR q TO Q DO LH = 1.0 FOR j TO n DO IF uij == 0 THEN DO LH = LH * (1 - vqj) * RMPq(n-1) ELSE DO LH = LH * vqj * RMPq(n-1) ENDIF IF LH > LH_max THEN DO LH_max = LH (2.17)
w = q ENDIF ENDFOR RETURN w となる.ここでRMP(n-1) は前回推定値である.
第5節 モデル適合度指標
前節で述べたように潜在ランク理論の特性パラメータは,EXMETRIKA を用いて SOM のメカニズムで推定することができる.推定されたパラメータがどの程度モデルに適 合しているかを検査する必要がある.十分なモデル適合度が得られなかった場合,潜在ラ ンク理論に基づくCAT が正しく受験者の能力を推定できない可能性があるからである.適 切な適合度指標が得られない場合,1)個々のアイテムや受験者のモデル適合度指標をみ て適合度の悪いアイテムや受験者を除外する,2)ランク数を減す,などして適切なモデル 適合度が得られるようにする必要がある. 現時点では,潜在ランク理論のモデル適合度の指標は,潜在ランク理論に最適化した, あるいは,広く認知された指標はなく,構造方程式モデリング(Structural Equating Modeling, SEM)のモデル適合度指標(豊田,2008)を用いている.EXAMETRIKAで は,Χ2値,自由度Fおよびp値 ,それらを基に様々な補正を加えたSEMの枠組みの適合度指標である標準適合度指標(Normed Fit Index, NFI),相対度適合指標(Relative Fit Index, RNI),増分適合度指標(Increment Fit Index, IFI),タッカー・ルイス指標 (Tucker-Lewis Index, TLI),比較適合度指標(Comparative Fix Index, CFI),近似誤 差平均平方根(Root Mean Square Error of Approximation, RMSEA),赤池情報量基 準(Akaike Information Criterion, AIC),調整赤池情報量基準(Consistent Akaike Information Criterion, CAIC),ベイズ情報量基準(Bayes Information Criterion, BIC)を算出している(図2.4参照).これらのモデル適合度指標のうち,NFIとRFIは,本研 究の対象である小さいサンプルサイズのテストデータに関しては,経験的にランク数やサン プルサイズの変化に最も敏感に変化する指標である.潜在ランク理論モデルに関してはそ
れぞれ同じ傾向を示すので,以降はRFIを使用する.RFIは, RFI = 1 - F / Fi (2.18) で定義され,値が大きければ大きいほどモデル適合が良いとされている.Fは目的のモデ ルの自由度,Fiは独立モデルの自由度である.本研究では,回答データの分析の経験か ら,適合度は0.7以上であれば良好としている. 図2.4 EXAMETRIKA で算出されるモデル適合度指標:EXAMETRIKA5.3 に添付 されているEXAMPLE1 を分析した結果
第6節 小さいサンプルサイズのモデル適合度
項目応答理論に比べて潜在ランク理論が優位な点は,小さいサンプルサイズのデータ であっても,モデルのランク数を小さくすることによって,特性パラメータを推定できる点で ある.その理由は,潜在ランク理論が項目応答理論よりモデルの制約が少ないこと,ランク 数を小さくすることで推定するパラメータが減ること,などが考えられる.項目応答理論では, 受験者の能力分布が正規分布に従うという制約があるが,潜在ランク理論のモデルでは, 個々のアイテムが独立であるという制約だけである.本節では,小さいサンプルサイズのデ ータであっても特性パラメータを推定できることを実データにより検証した手順と結果を示 す(秋山,2013). 最初に,「日本語を読むための語彙量テスト」(松下, 2012)の 182 名のデータからラン ダムに160 名,80 名,40 名の受験者を抽出した.次に,それぞれのサンプルデータのサブセット(150 アイテム-160 名,150 アイテム-80 名,150 アイテム-40 名)から 100 ア イテム,50 アイテムを抽出して 9 通りの回答データを作成した.「日本語を読むための語彙 量テスト」は,使用頻度順に1,000 語毎に 15 グループに分け 10 アイテムずつ,15,000 語 までの150 アイテムで構成されているので,グループ毎にランダムに抽出することで,回答 データの特性への影響をできるだけ少なくするよう配慮した. 次に,EXAMETRIKAで分析可能なすべてのランク(ランク数2から20まで)について, 上記の9 通りの回答データを分析した.その結果,RFI が 0.7 以上のランクは,図 2.5 に示 すように広い範囲であった.「日本語を読むための語彙量テスト」の各アイテムは良い特性 を持ったアイテムが多く,このような結果が得られたと考えられるので,この結果は上限に 近いと考えた方が良いと思われる.モデル適合が良いのはどの範囲かという問いに対して 一般的な回答は今のところない.この結果は一例に過ぎないが,大まかな傾向を知ること ができる. 図2.5 ランク数とモデル適合度指標 RFI
第7節 おわりに
本章では,本論文の基礎である潜在ランク理論について,その尺度が離散値の順序尺 度であること,特性パラメータはモデルのランク数と同じ次元を持つベクトルとして表されること,IRP は項目応答理論の ICC に相当するアイテム特性ベクトルであること,RMP は受 験者の能力確率分布ベクトルとみることができること,などを述べた.その特長の一つであ るサンプルサイズが小さい場合であっても特性パラメータを適切に推定できることを示し た.
第 3 章 項目応答理論に基づく
コンピュータ適応型テスト
第1節 はじめに
本章では,コンピュータ適応型テスト(Computerized Adaptive Test,CAT)について 述べる.CAT は,コンピュータテスト(Computer Based Test, CBT)の特徴に加え,1) 個々の受験者の能力を推定しながら,次に出題するアイテムを受験者の能力を推定するの に適したアイテムを選択して出題するため,受験するアイテム数がリニアテストに比べて大 幅に少ない,2) 個々の受験者の能力や受験行動が異なるので,出題するアイテムも異な り,チーティングが行われにくい,3) 出題するアイテムを選択する過程でアイテムを使用す る頻度を制限することができる,などの特長がある一方で,1) 測定したい範囲をカバーす る十分な数のアイテムが必要である,2) 「紙と鉛筆」があれば実施できる従来のテストに比 べ,ネットワークに接続されたパソコン,タブレットやスマートフォンなどの機器がなくては実 施できないという面も持っている.
本章では,主流となっている項目応答理論(Item Response Theory)に基づく CAT に ついて,その代表的なアルゴリズムを例に用いて紹介する.
CAT のフローチャートを図 3.1 に示す.この図には,初期設定,アイテム選択,能力推 定,終了判定の4 つの CAT 特有の処理が示されている.その他に CBT と共通の処理とし て問題を提示する「出題」と受験者の回答を受け取って採点する「採点」の部分がある.
図3.1 CAT のフローチャート フローチャートに従って,CAT の動きを説明する. 1) CAT を受験開始すると,まず,「初期設定」で初期能力値や必要ならアイテムの 制約をかけるなどしてアイテムバンクから使用可能なアイテムを未出題アイテム リストにセットし,回答リストをクリアする 2) 次に「アイテム選択」では,「初期設定」で設定された初期の能力値,または,「能 力推定」で推定された暫定的な推定値を基に,未出題アイテムリストから,何らか の統計値を最大化,あるいは,最小化するようなアイテムを選択し,未出題アイ テムリストから選択したアイテムを削除する 3) 選択されたアイテムが「出題」され,受験者の回答が「採点」される.この部分は CBT と共通の部分である 4) 「能力推定」では,回答リストに最新の回答の採点結果とアイテム ID を追加し, 既回答のアイテムの特性値とそれに対する正誤パターンを用いて最尤推定法等 のアルゴリズムで受験者の能力値を推定する 5) 「終了判定」では,最新の能力推定値や前回の推定値,標準誤差やその変化値
などを調べて,能力推定プロセスを終了させるかどうかを判定する 6) 終了と判定されなければ 2) に戻って 5) までの処理を繰り返す 以上のCAT の能力推定プロセスは,アルゴリズムの基礎としてどのようなテスト理論を 採用するかには依存しない.
第2節 初期設定
初期設定は,CAT を受験開始した時点では,受験者の能力がわからない場合が多いの で,以下のようなアルゴリズムで設定する場合が多い. (ア) 一律に固定値,例えば,最も頻度が高い能力値である θ = 0.0 とする. (イ) 最初に出題するアイテムがどの受験者でも同じになるのを避けるため, ある範囲(例えば-0.5 から+0.5 までの範囲)でランダムに θ を設定する. (ウ) 能力測定の範囲をカバーする数問の固定アイテム(初期テストレット)を 出題し,得られた推定値を初期値として用いる. 初期テストレットを使う場合は,テストレットとCAT の 2 段階方式とも見えるが,テストレット で初期値を推定して能力の初期値を設定するという意味では,テストレットの部分は初期設 定の範疇とみることができる.テストレットは効率が悪い面もあるが,アイテムの内容のバラ ンスをとる場合には有効な手段である.第3節 アイテム選択
アイテム選択は,CAT の構成要素の中でも CAT の性能を左右する部分である.能力を 推定する過程で,推定中の暫定的な受験者能力を基に,真値に近い能力値を推定するよ う次に出題するアイテムを選択する.真値に収束せず何らかの極値に収束する場合もあり, どのような統計量に着目するかが重要である.アイテム情報量を最大化する,暫定推定能 力値におけるテスト情報量を最大化する,能力確率分布の事後期待値を最大化する,など 様々なものが提案され,利用されている. 項目応答理論に基づくCAT のアイテム選択アルゴリズムの一例として,情報量最大化 基準(Maximum Information criteria,MI)がある.もっともポピュラーなアルゴリズムで,多くのCAT で使用されている.このアルゴリズムは,受験者能力 θiの暫定推定値における
アイテムの情報量Ij(θi),
(3.1)
が最大になるようなアイテムを次に出題すべきアイテムとして選択する(2 パラメータロジス ティックモデルの場合).
van der Linden(1998)は,選択候補のアイテム j を受験者がそれに正答した場合と誤 答した場合のそれぞれの場合に推定される能力値における情報量で重み付けした事後期 待値が最も大きいアイテムikを未出題リストRkから選択するアルゴリズム,情報量重み付け
事後期待値最大化基準(Maximum Expected Posterior Weighted Information criterion, MEPWI)を提案した.選択されるアイテム ikは, (3.2) で示される.このアルゴリズムは,MI に比べるとアイテム選択の処理の中で能力推定を 1 アイテムあたり2 回行っており,未出題アイテムが多い受験直後やアイテムバンクを構成す るアイテム数が多い場合などでは格段に計算量が多く,特に受験者が多い場合にはCAT システムのレスポンスが悪くなると思われる.
第4節 能力推定
能力推定は,CAT 推定精度を左右する部分である.能力推定アルゴリズムは,既に出 題したアイテムの特性とそれらのアイテムに対する回答の採点結果を用いて受験者の能力 を推定する.第 2 章ではリニアテストの場合について,潜在ランク理論の ML 推定法, MAP 推定法について述べた.CAT では,受験者が回答する都度,1アイテムずつ推定す るアイテムが増加するので,推定誤差は徐々に少なくなってくる.しかし,能力推定の方法 や特性は,固定長の従来方式のテストもCAT も同じである.以下,項目応答理論に基づくCAT に使われる 2 パラメータロジスティックモデルの場合 のML 推定法,MAP 推定法,WML 推定法について具体的に説明する(村木, 2012).
ML 推定法は,受験者 i が n 個のアイテムを受験したときの回答パタ ーン uij=(uij(1),…,uij(n))が発生する確率(尤度),
(3.3) が最も大きいθi を求める方法である.式 3.3 は対数をとって θi を求めてもよいので, (3.4) と表すことができる.θ iの最大値は,式3.4 の1階微分した式 (3.5) が0 となる点として求めればよい.2 パラメータロジスティックモデルの場合,第 1 次偏導関 数は, (3.6) であるから,ニュートン・ラプソン法で解くことができる.ニュートン・ラプソン法に基づくt+1 回目の反復推定の更新式は, (3.7) であり,第2 次偏導関数は, (3.8) と簡潔になり,ニュートン・ラプソン法で尤度の最大値を与えるθi を求めることができる.
MAP 推定法は,受験者能力 θi の事後確率分布を最大にする θi を求める方法である. 受験者の能力の事後確率分布は尤度関数と事前確率分布の積, (3.9) で表される.この事後確率分布を最大にするθiは,対数尤度関数の第1 次偏導関数を 0 と して, (3.10) を満たすθiを求めればよい.θiの事前分布を正規分布と仮定すれば, (3.11) となり第1 次偏導関数は, (3.12) と簡潔になり,第2 次偏導関数も (3.13) と簡潔な式となる.そこでニュートン・ラプソン法に基づくt+1 回目の反復推定の更新式は, (3.14) となり,θiのMAP 推定値を求めることができる.MAP 推定法の事前確率分布は重み付け と解釈することができ,ML 推定法の事前確率分布による重み付け推定法ともいえる. WML 推定法(Warm, 1989)は, MAP 推定法の重みをテスト情報量の平方, (3.15) に代えたものとみなすことができる.Ij(θ)はアイテム情報関数であり,2 パラメータロジスティ ックモデルの場合,
(3.16) である.なお,ajはアイテム識別力である.
第5節 終了判定
終了判定は,受験者の能力を推定する過程で変化する統計量そのもの,あるいは,その 変化量を目安として,その値が一定値以下(または以上)になった時にテストの終了を判定 するアルゴリズムを用いる.終了を判定する適切な統計量がない場合や受験者の受験時 間を一定の時間内に収めたい場合,受験アイテム数の上限を指定し,上限に達した場合に 終了と判定する方法をとる場合もあり,現実的な方法である. 項目応答理論に基づく CAT で用いられている代表的なアルゴリズムは,標準誤差基準 (Standard Error criterion, SE)や標準誤差低減量基準(Standard Error Reduction criterion, SER)である. 2 パラメータロジスティックモデルの場合アイテム情報量は, (3.17) で表され,式2.1 をpijに,qij = 1 - pijをqijに代入すれば, (3.18) となる.アイテムk まで受験したときの標準誤差SE は, (3.19) で求められ,これがあらかじめ定めた閾値に達したとき終了と判定する.これが標準誤差基 準である.SE の変化量が一定値以下になった時に終了するのが,標準誤差低減量基準 である.第6節 おわりに
本章では,項目応答理論に基づくCAT の動作フローと4つの構成要素について具体例 を挙げて説明した.本章で述べたCAT の構成や動作は項目応答理論に限らず,ほとんど のテスト理論に基づくCAT にも当てはめることができる.
第 4 章 潜在ランク理論に基づく
コンピュータ適応型テスト
第1節 はじめに
本章では,潜在ランク理論(Latent Rank Theory, LRT; Shojima, 2007a)に基づくコ ンピュータ適応型テスト(Computerized Adaptive Test, CAT)のアルゴリズムについて, シミュレーションによって評価され,実地においても試行された唯一の先行研究である木 村・永岡(2012)の CAT(以降,KN-CAT と呼ぶ)について説明する. KN-CAT で用いられているアイテムバンクは,日本実用英語検定協会の 2007 年第 1 回から2008 年第 1 回までの 4 回分の準 1 級から 3 級の文法語彙問題のうち,多肢選択形 式の問題を選んで使用している.そのアイテムを3 次にわたって予備テストを行い,受験し た延べ2,867 人の受験データを分析し,ラッシュモデルの適合度指標を用いて取捨選択さ れた263 アイテムで構築されている.
第2節 初期設定
KN-CAT の初期設定は,受験者の能力の初期値をテストレットによって設定している. 能力ランクの中央の5 つのランクについて,アイテム指標 β がランクに等しいアイテムの中 からランダムにアイテムを選択し,5 アイテムのテストレットを構成している.受験者の RMP の初期値はこのテストレットを受験させて得た推定値を設定する. このアルゴリズムは,1) 中央の 5 つのランクからテストレット用に選択されるアイテムはア イテム指標β が選択するランクに等しいものが先に選ばれるので,CAT の能力推定プロセスに使うために温存しておきたい識別力の高いアイテムがテストレットに使われてしまう可 能性があること,2) それらのアイテムの露出度がほかのアイテムより高くなる可能性がある こと,3) テストレットに使用されるアイテムには,アイテム選択アルゴリズムが適用されず,ラ ンダムに選択されるため,テストレット方式を採用しない場合より効率が悪くなる可能性があ ること,などの懸念がある. 木村ほか(2012)は「実際の能力が初期能力推定値からずれていた場合,その後の項目 選択と能力推定が不適切に行われてしまうことが attenuation paradox(Load & Nivick, 1968)として知られている.この点を考慮して,LRT-CAT の場合,最初の出題は 1 問では なく,潜在ランクの中央付近の問題を複数問出題するテストレット形式とすることを提案す る.」と述べているが,潜在ランク理論に基づくCAT において attenuation paradox が確 認されているわけではない.特に,小規模なアイテムバンクの場合は経験的にモデルのラ ンク数が小さく,attenuation paradox は確認できないのではないかと考える.
第3節 アイテム選択
木村ほか(2012)は,熊谷(2010)の IRP 指標の項目識別力 a を拡張し,アイテム j の識 別力をランク尺度の全域にわたって表すλijを導入した.このλijは, (4.1) と定義されている.ここでIRPjq は候補のアイテム j の IRP ベクトル,RMPiq は推定中の 受験者のRMP ベクトルである.式 4.1 は,IRP の差分の項が同じなのでまとめると, (4.2) となる.λijは,IRP ベクトルの隣り合う要素,つまりランクの正答確率の差を識別力とみなし, 隣り合うRMPベクトルの要素の算術平均をそれに重みとしてかけたものQ-1個の和をその アイテムの受験者能力における識別力とするものであると解釈できる. λijを用いるアイテム選択アルゴリズム(以後,λ アルゴリズムと呼ぶ)について木村ほか(2012)は,「アイテムバンクに蓄えられた項目数が多くなると,計算負荷がサーバーにか かり過ぎるので,本研究ではIRP 指標 β が受験者 i の暫定の潜在ランクの推定値±1 の項 目に限定してλ の値を計算し,その中で最小となる項目を選択する」としているが,乗算回 数は1 アイテムあたり Q-1 回であり,計算量は非常に少ない.一方,小規模なアイテムバン クの場合,β によって選択するアイテムを絞り込むと未出題アイテムリストにアイテムが残っ ているにも関わらず,出題できるアイテムがなくなり途中でテストを終了する事態になりかね ない. 木村ほか(2012)の λ の定義の不便な点は,RMP ベクトルや IRP ベクトルが Q 個の要 素を持つのに対し,λ をベクトルの要素の和としてみた場合,そのベクトルは Q-1 個の要素 しかないことである.もし,Q 個の要素があれば,能力ランク Riの受験者i に対するアイテム j の識別力を求めることも可能であり,それを使ったアイテム選択アルゴリズムが成り立つは ずである. また,λ アルゴリズムについて木村ほか(2012)は「これは項目応答理論の項目選択ルー ルについて論じているVan der Linden(1998)の中に出てくる Maximum Expected Posterior Weighted Information という方法に相当すると考えられる」と述べているが, 選択候補のアイテムについて正答した場合,誤答した場合のテスト情報量を重みとして使う Linden のアルゴリズムとは異なる.
第4節 能力推定
KN-CAT の能力推定アルゴリズムについて木村ほか(2012)は,CAT の能力推定法に ついて具体的に述べていない.ただし,初期テストレットの能力推定には,最尤推定法 (Maximum Likelihood estimation, ML; Shojima, 2007)の記述が引用されている. 一方,シミュレーション条件として「(3) 推定方法:SOM」と記しているので,木村ほかの誤 解があると思われる.KN-CAT では,本論文の著者が実装した潜在ランク理論版最尤推定 法(Maximum Likelihood estimation LRT version, ML-LRT)を採用していることは事 実であり,その詳細については第2 章第 4 節で既に述べた.(式 2.9 から式 2.12 までを参 照)
第5節 終了判定
KN-CAT の終了判定アルゴリズムは,RMP の変化と受験アイテム数の二つを条件とし て使用している.潜在ランク理論に基づくCAT の場合,能力の推定過程では RMP のある ランクの正答率が増加し,最終的には1 に近づくので,その変化の値が予め設定した閾値 より小さくなったとき終了と判定する.図4.1にその様子を示す.受験者が1アイテムずつ回 答するごとに暫定推定値であるRMP が変化し,6 アイテム以降徐々に能力ランク 3 の確率 が高くなって1.0 に近づいているのが分かる. 図4.1 潜在ランク理論に基づく CAT の能力推定過程における RMP の変化の例 k-1 アイテム目に推定した RMP と k アイテム目に推定した RMP の差ベクトルの要素の うち,絶対値が最も大きい値をμq(k)とし,これが0.05 未満になり,かつ,指定アイテム数受 験したとき終了する.しきい値μq(k)は,(4.3) で与えられる.これはシミュレーションで使用された終了条件で,実際のテストでは,上記 の条件で実施したシミュレーションの結果に基づいて,最大受験アイテム数と最小受験アイ テム数を設定し,受験アイテム数のみを終了判定に使用している.
第6節 おわりに
KN-CAT は,シミュレーションで性能を評価した上で実地のテストに使用された最初のも のである.木村ほか(2012)で報告されたシミュレーションの結果では,推定された能力ラン クが真値と一致したケースは59.2%,真値±1 と 1 ランク外れて推定されたケースが 36.4% と報告されている.推定された約4 割の受験者の能力ランクが 1 以上ずれているという結果 である.第 5 章 新しいアルゴリズムの提案
第1節 はじめに
本章では,潜在ランク理論(Latent Rank Theory, LRT; Shojima, 2007a)に基づくコン ピュータ適応型テスト(Computerized Adaptive Test, CAT)の新しいアルゴリズムを提案 する.新しいアルゴリズムを考案するためのアプローチとして,項目応答理論(Item Response Theory, IRT)の考え方を潜在ランク理論に適用する方法を採用した.潜在ラン ク理論は,離散的な項目応答理論で,項目応答理論の近似モデルであると捉えるのである. このアプローチでは,まず,アルゴリズムに使用する統計量として,情報量に相当する統計 量を定義する.そのためにアイテムの特性を表す識別力を定義する.その後,情報量に着 目したアルゴリズムをアイテム選択,能力推定,終了判定の3つの構成要素のアルゴリズム をそれぞれ提案する. アイテム選択については,項目応答理論の情報量最大化基準(Maximum
Information criterion, MI)の考え方を潜在ランク理論に適用した潜在ランク理論版情報 量最大化基準(Maximum Information criterion LRT version, MI-LRT)を提案する. 能力推定については,項目応答理論の重み付き最尤推定法(Weighted Maximum Likelihood estimation, WML)の考え方を潜在ランク理論に適用し,新たに定義したテス ト情報量を重みとして採用した潜在ランク理論版重み付き最尤推定法(Weighted
Maximum Likelihood estimation LRT version, WML-LRT)を提案する.終了判定に ついては,項目応答理論の標準誤差低減量基準(Standard Error Reduction criterion, SER)の考え方を潜在ランク理論に適用し,新たに定義したテスト情報量を使って標準誤
差を求め,その変化値を終了判定に使用する潜在ランク理論版標準誤差低減量基準 (Standard Error Reduction criterion LRT version, SER-LRT)を提案する.
なお,初期設定に関しては,KN-CAT の初期テストレット方式は採用せず,単に受験者 の能力確率分布を一様分布とする方式を採用した.すなわち,モデルのランク数をQ とす ると,初期のRMP の各要素は 1 / Q とする方式である.これは KN-CAT の初期テストレッ トの能力推定時の初期値と同じである.
第2節 正答確率
RMPi,能力ランクRiの受験者i がアイテム特性 IRPjを持つアイテムj を受験したときの 正答確率は,第2 章の式 2.2 で IRP ベクトルの Riの要素として示したが,この他にも正答 確率を定義することは可能である.それは,IRP と RMP の要素同士の積の和を正答確率 とする, (5.1) である.受験者の能力を推定中のCAT のプロセスでは暫定的な RMP は各ランクの確率 が大きく,それを反映した正答確率となる特徴があり,CAT のアルゴリズムの中で正答確率 を計算する場合に有効である.一方,式2.2 の正答確率は,確定した能力ランクの受験者 の正答確率を計算する場合に有効で,モンテカルロシミュレーションで回答を生成する場 合などに用いる.第3節 識別力ベクトルの定義
項目応答理論のアイテムの識別力は,項目特性曲線の傾きであるが,潜在ランク理論の 尺度は順序尺度であるため,隣接する各ランクの間隔は不定であり,傾きを計算することは 意味がない.そこで隣り合うランクの正答確率の差を識別力に相当すると考える.しかし, 2 つあるので,平均値によって識別力を定義する.正答確率の差であるので幾何平均ではなく算術平均をとる.さらに,各ランクにおける識別力を要素とした識別 力ベクトルδ を定義する.モデルのランク数を Q としたとき,RMPiで表される能力を持つ受 験者i に対するアイテム特性 IRPjを持つアイテムj の識別力ベクトルの各要素を (5.2) ただし, (5.3) と定義する.それぞれの要素は,能力ランクqの受験者に対するアイテムjの識別力を意味 する.
第4節 情報量の定義
項目応答理論のアイテム情報量は2 パラメータロジスティックモデルの場合,式3.1 で定 義される.潜在ランク理論でも同様に,RMPiで表される能力を持ち,能力ランクRiを持つ 受験者i に対するアイテム特性IRPjを持つアイテムj の情報量を前節で定義したアイテム 識別力ベクトルδijを使って, (5.4) と定義する.テスト情報量についても項目応答理論と同様に,n 個のアイテムからなるテスト のテスト情報量Itestは,テストを構成するアイテム1 からアイテム n までのアイテム情報量の 総和として, (5.5) と定義する.第5節 アイテム選択
本研究では,項目応答理論のアイテム選択アルゴリズムから情報量最大化基準報量最大化基準(Maximum Information criterion LRT version, MI-LRT)を提案す る.
MI-LRT アルゴリズムは,k 番目に出題するアイテムとして 1 から k-1 アイテムまでの受 験結果で推定した受験者i の能力ランクRi(k-1)とIRPi(k-1)から求めたIj(Ri(k-1))を最大にする
アイテム, (5.6) を選択する.なお,pij(k-1)は式5.2で与えられている正答確率である.MI-LRTアルゴリズム を疑似コードで表現すると, MI-LRT(RMP, 未出題アイテムリスト) Info_max = 0.0 Item_selected = “N/A” WHILE 未出題アイテムリストにアイテムあり DO 未出題リストからアイテム j を一つ取り出す Info = δjRi2pijqij # 式 5.4
IF info > info_max THEN DO Info_max = info Item_selected = アイテム j ENDIF ENDWHILE RETURN Item_selected (5.7) となる.
第6節 能力推定
本研究では,ML 法の尤度にテスト情報関数の平方を重み付けした Warm の重み付け 最尤度推定法(Weited maximum likelihood estimation method, WML )の考え方を潜 在ランク理論に適用し,先に述べたテスト情報量を使って再定義した重み付け最尤度推定法(Weighted maximum likelihood estimation method LRT version, WML-LRT)を 提案する.
第2 章で紹介した最大事後分布法(Maximum A Posteriori, MAP)の重みを事後分布 ではなく,テスト情報量の平方に置き換えた ものが WML である(村木, 2011). WML-LRT では,式 5.5 で定義したテスト情報量を使い,各ランクの尤度, (5.8) を求め,最大の尤度となるランクを受験者の能力ランク, (5.9) を得る. また,受験者のRMP ベクトルの各要素は, (5.10) で与えられる. WML-LRT の推定手順を疑似コードで示すと, LHtotal = 0.0 w = 1 FOR q TO Q DO LHq_max = 0.0 LHq = 1.0 FOR j TO n DO IF uij == 0 THEN DO LHq = LHq * (1 - vqj) ELSE DO LHq = LHq * vqj (5.11)
ENDIF ENDFOR LHq = LHq * SQRT[ Itest(n)(q)] IF LHq > LH_max THEN DO LHq_max = LHq w = q ENDIF LHtotal = LHtotal + LHq ENDFOR FOR q TO Q DO RMPq = LHq / LHtotal ENDFOR RETURN w, RMP となる.
第7節 終了判定
本研究では,項目応答理論の標準誤差低減量基準(Standard Error Reduction criterion, SER)の考え方を潜在ランク理論に適用し,先に述べたテスト情報量による標準 誤差を使って再定義した潜在ランク理論版標準誤差低減量基準(Standard Error Reduction criterion LRT version, SER-LRT)を提案する.
潜在ランク理論における標準誤差を項目応答理論の標準誤差に倣って (5.12) と仮定する.これを終了判定に使用する.SER は,k 番目のアイテム受験時の SE が k-1 番目のアイテム受験時からどれほど減少したか,その低減量がしきい値 ε を下回った時終 了と判定する.すなわち, SER(k) = SE(k) – SE(k-1) < ε (5.13)
を満たしたとき能力推定の過程を終了させる.
第8節 おわりに
潜在ランク理論におけるアイテムの識別力を新たに提案した.これを基にして潜在ランク 理論に基づくCAT のアルゴリズムに使用する統計量として項目応答理論におけるアイテム 情報量に相当する統計量のアイテム情報量を,さらに,それに基づいたテスト情報量を定 義した. 提案したアルゴリズムは,MI-LRT,WML-LRT,SER-LRT のいずれもアイテム情報量, あるいはテスト情報量に基礎を置いたアルゴリズムであるが,この情報量は CAT のアルゴ リズムを記述するうえでの便宜上のものであり,必ずしもその名の意味するものではない. LRT-CAT のアルゴリズムが項目応答理論に基づく CAT 同様に機能するならば,定義した アイテム情報量もそれに近いものになっている可能性があるといえるであろう.第 6 章 新しいアルゴリズムの評価
第1節 はじめに
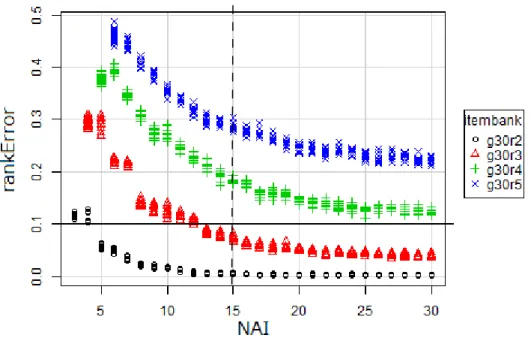
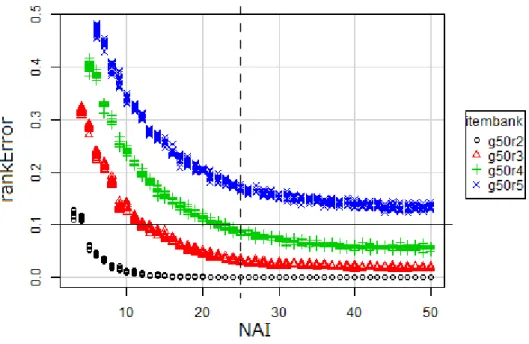
本章では,第5 章で提案したアルゴリズムを検証し評価する.その手段としてモンテカル ロシミュレーションを用いる.モンテカルロシミュレーションは乱数を使ったシミュレーション 全般を指す.本研究では,潜在ランク理論のモデルに適合する理想的なアイテムバンクを 構築するために,受験者の回答データとしてガットマン尺度のような回答パターンを使用し, これをEXAMETRIKA(Shojima, 2012)で分析して CAT のシミュレーションを行う.リニ アテストの受験結果から推定した能力ランクを真値と仮定し,CAT の推定誤差を計算する. 潜在ランク理論では,推定された能力ランクと真値の能力ランクを用いて誤差を計算する際 に,真値との差を計算することができない.能力ランクは順序尺度であり,その差は不定だ からである.そこで,N 回同じ条件で CAT のシミュレーションを行い,ランク誤差(Rank Error)を真値と不一致の試行の数Neとすると, rankError = Ne / N (6.1) と定義し,評価に用いる.なお,N は 100 とした. モンテカルロシミュレーションの目的は,シミュレーションを実施したアルゴリズムの性能 を一般化して評価することである.アルゴリズムの評価にはアイテムバンクの特性による影 響をできる限り受けないよう排除するため,使用するアイテムバンクと受験者集団の特性は 理想的な特性を持った受験者集団とアイテムバンクを使用することが望ましい. 評価の基準は,推定誤差と受験アイテム数である.推定誤差と受験アイテム数はトレード オフの関係にあり,本研究では,目的を記述する際に基準値として推定誤差 10%以下,受 験アイテム数が元のリニアテストの50%以下と示した.これによってアルゴリズムを評価する.評価に際しては,まず,先行研究のKN-CAT を比較対象とし,本研究で提案するアルゴリ ズムを構成要素毎に入れ替えてモンテカルロシミュレーションを行い,提案したアルゴリズ ムの効果を確認する.次に,提案したアイテム選択と能力推定のアルゴリズムの組み合わ せでランク数と受験アイテム数を変化させてモンテカルロシミュレーションを行い,評価基 準をクリアできる限界を明らかにする.
第2節 シミュレーションの方法
本研究で使用するシミュレーションは,著者が作成した潜在ランク理論に基づく CAT の シミュレータLRT-CAT_sim(秋山, 2013)を使ってモンテカルロシミュレーションを行う. LRT-CAT_sim のシミュレーションの内容を疑似コードで表すと, LRT-CAT_sim( Test=g50, # g150 / g50 / g40 / g30 / g20 / g10 # j150 / j50 / j40 / j30 / j20 / j10 繰り返し回数=100, 初期設定=一様分布, # テストレット / 一様分布 アイテム選択=MI-LRT, # MI-LRT / LAMBDA 能力推定=WML-LRT, # ML-LRT / WML-LRT 終了判定=SER-LRT, # SER-LRT / dRMP 閾値 = 0.000014, # 0.00014 / 0.004 最小受験アイテム数 = 25, 最大受験アイテム数 = 75) Itembank=テストを分析して得た IRP データ Examinees=テストを分析して得た RMP データ WHILE Examinees = NOT NULL DO Examinees から受験者を 一人取り出す FOR i = 1 TO 繰り返し回数 DO Answereditems = NULLAnswerlist = NULL Itemlist=Itembank FOR q=1 TO Q DO RMPq0 = 1/Q ENDFOR IF 初期設定 == テストレット THEN DO テストレットを作成 Itemlist からテストレットに使用したアイテムを削除 Answerlist = 回答生成(‘RD’, Q, テストレット) Answereditems = テストレット RMP = 能力推定(テストレット,Answerlist, Examinee) ENDIF Ne=0 終了判定=FALSE WHILE 終了判定==FALSE DO
Item = 項目選択(Itemlist, Examinee, RMP k-1)
Itemlist = Itemlist – Item
Answer = 回答生成(能力ランク, Item) Answereditems = Answereditems + Item Answerlist = Answerlist + Answer
RMP(k)=能力推定(Answereditems, Answerlist,受験者, RMP(k-1)) ENDWHILE 推定ランク = max(RMPqk) IF 推定ランク <> 真のランク THEN DO Ne = Ne +1 ENDIF 受験アイテム数を保存 ENDFOR
ランク誤差 = Ne / 繰り返し数 ランク誤差を保存 ENDWHILE RETURN ランク誤差の平均と標準偏差,受験アイテム数 (6.2) となる. モンテカルロシミュレーションではモデルを表す式 2.2 により得た正答確率が区間[0.0, 1.0]の一様乱数より大きい場合正答,小さい場合誤答として回答を生成するが,ランク誤差 を求めるため N 回繰り返しシミュレーションを実行する.アイテム選択,能力推定,終了判 定の各アルゴリズムは,第4 章,第 5 章で述べたものの中から指定されたものを実行する. 回答生成の部分を疑似コードで表すと, 回答生成(能力ランク, Item)
IF Item の IRP(能力ランク) > 乱数[0.0, 1.0] THEN DO RETURN 1 ELSE DO RETURN 0 ENDIF (6.3) となる.
第3節 使用する回答データ
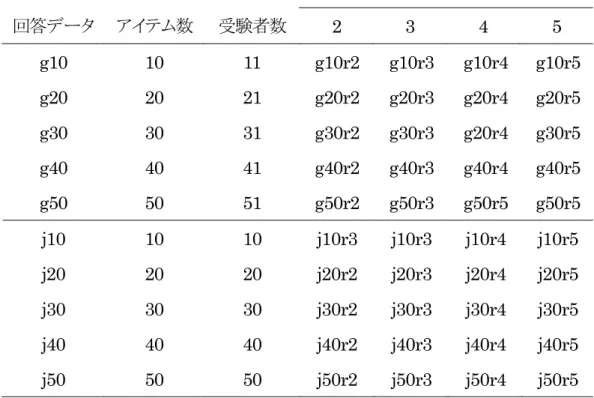
シミュレーションで使用する回答データは,2種類である.一つは,純粋にアルゴリズムを 評価するためのアイテムバンクを作るために用いる.アイテムを正答数の多い順に左から 右に並べ,かつ,受験者を素点の高い順に上から下に並べた場合に1 の部分が左上を頂 点にした直角二等辺三角形状になるガットマン尺度のような回答データ(図6.1参照)を使う. このような回答データは現実には発生することは極めてまれである.これを EXAMETRIKA で分析してアイテムの IRP と受験者の RMP を得て,潜在ランク理論に 基づくCAT のモンテカルロシミュレーションに用いる.なお,これらのアイテムがガットマン尺度に適合するということではなく,局所独立の制約 は成立していると仮定している.このような回答パターンにすることで一意に理想に近い特 性のIRP を持つアイテムバンクと理想に近い特性の RMP を持つ受験者集団のデータが 得られる.なお,Item02 の Examinee09,Examinee10 と Item09,Item10 の
Examinee02 で 1,0 が逆転しているのは,EXAMETRIKA で分析する際に全て正答,全 て誤答のアイテムや受験者が分析の対象外になるので,これを避けるために回答データ のパターンをあえて崩している. 回答データのサイズは,目標とするテストのサイズである50 アイテム 51 名のほか,限界 を確認するため,ガットマン尺度のような回答パターンから生成した40 アイテム 41 名,30 アイテム31 名,20 アイテム 21 名,10 アイテム 11 名とした.一方,先行研究の KN-CAT と比較するため,項目応答理論が適用できる下限に近く,先行研究に近いサンプルサイズ のデータとして150 アイテム 151 名を用意した. ランク数は,2 から 5 までとした.潜在ランク理論に基づく CAT は,小さいサンプルデー タの場合,ランク数を小さくすることで推定するパラメータの数が少なくなり,SOM によるパ ラメータの推定が適切にでき,誤差や受験アイテム数が所期の範囲で動作するからであ る. 以上,理想に近い特性を持つアイテムバンクと受験者集団について述べた.150アイテ ムでランク数5のアイテムバンクをg150r5,50アイテムから10アイテムでランク数5のアイテ ムバンクをそれぞれg50r5,g40r5,g30r5,g20r5,g10r5と呼ぶ. g10r5のIRPをグラフ 化したものを例として図6.2に示す.単調増加制約,事後分布を一様分布として分析した. 図6.1 ガットマン尺度のような回答データの例:10 アイテム 11 名の受験者の例
図6.2 g10r5のIRPのグラフ:EXAMETRIKAの分析結果 シミュレーションで使用する回答データのもう一方は,実地に行ったテストの回答データ である.使用したテストは「日本語を読むための語彙量テスト」(松下,2012)で、「日本語を 読むための語彙データベース」(松下,2003)の15,000語を使用頻度によって15レベルに 分け,それぞれのレベルの1,000語ごとに10語を語種のバランスを考慮して抽出し作成さ れた150アイテムからなるテストである.このテストを多様なレベル・背景の263名の学習者 が受験した.松下(2012)によれば,ラッシュ分析の結果、信頼できるテストであることが確認 されている(Rasch reliability estimate = .93).その代表的なアイテムの内容とIRPを表 6.1に示す.表の右の列が問題文と選択肢で,左肩の番号は,ハイフンの左が15レベルに 分けたレベルで,ハイフンの右は各レベル10アイテムずつある同じレベルのアイテムの連 番になっている.右の列がEXAMETRIKAで分析したときに出力されるIRPのグラフであ る.左のアイテムの内容と右のIRPは番号とアイテムIDがずれているが,同じアイテムのも のである.レベルの低いアイテムは困難度が低く正答確率は1に近い.多くのアイテムのグ ラフが右肩上がりになっており,アイテムの識別力が高いことがわかる. 回答データのサイズは,理想に近い特性を持つアイテムバンクと受験者集団の場合と同 様に,目標とするテストのサイズである50アイテム50名のほか,限界を確認するため,素点 および正答数で並び替えた上でデータを間引いて生成した「日本語を読むための語彙量 テスト」のサブセットを50アイテム50名,40アイテム40名,30アイテム30名,20アイテム20 名,10アイテム10名とした.一方,先行研究のKN-CATと比較するため,項目応答理論が 適用できる下限に近く,先行研究に近いサンプルサイズのデータとして150アイテム150名