GPUによるソフトウェアOpenFlowスイッチのフロー検索高速化
7
0
0
全文
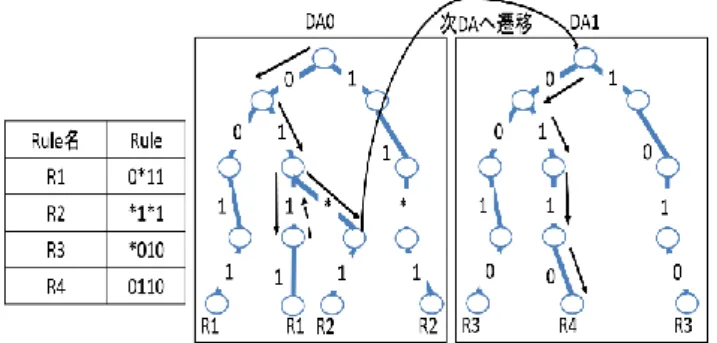
(2) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2015-OS-132 No.15 2015/2/27. 図 3 Double Array を用いたテーブル管理 図 1 H-Trie を用いたフロー検索 ックトラック動作によりマッチング回数が増加するためフ ロー検索性能の低下が起こる.そこで H-Trie 内の*で分岐 する場合に 0 側と 1 側の両方の部分木に予めエントリを追 加することでバックトラックをなくし検索を高速化する SP-Trie が提案された.評価の結果 SP-Trie は高速にフロー 検索をすることは可能であるが空間効率が悪いため OpenFlow スイッチのフロー検索アルゴリズムとしてその まま利用することは難しい.そこで H-Trie と SP-Trie を組 み合わせた手法が提案されている.この手法では木の上半 分に SP-Trie の手法を用い,下半分は H-Trie の手法を用い 図 2 H-Trie と SP-Trie の組み合わせ手法によるフロー検索. ることでバックトラックを葉付近の短い距離のみに抑えて いる.0111 にマッチするルールの検索を例に H-Trie と. のデータ転送などの GPU に対するアクセス処理は master. SP-Trie の組み合わせ手法を用いたフロー検索を図 2 に示. スレッドのみが行う.その他の OpenFlow スイッチに到着. す.図 1 と比較してマッチング回数の削減が行われている. したパケットを RX キューから取り出し,その中からフロ. ことがわかる.図 2 を用いて 0111 を探索する方法を示す.. ー検索に必要な情報だけを抽出することや,GPU でのフロ. まず先頭ビットである 0 のビットマッチングを行う.完全. ー検索処理が完了した後に TX キューにフロー検索結果の. 一致可能でワイルドカードによる一致が不可能であること. 適用済みパケットを格納する処理は worker スレッドが行. がわかるので完全一致する 0 で遷移する.次のビットであ. う.このように GPU へアクセスする担当のスレッドを決め. る 1 も同様にマッチングを行い遷移する.3 ビット目の 1. ることで,複数 CPU スレッドが GPU へアクセスすること. の時,完全一致とワイルドカードによる一致の両方が可能. により発生するオーバーヘッドを削減することが可能であ. であるため現在のノード位置とビット位置をスタックへ保. る.しかし PacketShader のフロー検索では線形探索を含む. 存し完全一致する 1 で遷移する.最後のビットである 1 の. ため,フローテーブル内にビットマスクを持つエントリ数. マッチングを行う際,完全一致もワイルドカードによる一. が増大するに従い,性能が低下するという問題がある.. 致も不可能であるためスタックに格納したノード位置とビ. 2.2 H-Trie と SP-Trie の組み合わせ手法. ット位置に戻る.再度最後のビットをワイルドカードによ. 文献 [2]では,エントリ内のフィールドの各ビットをそ. る一致で遷移を行った結果,全ビットの探索が完了し,ス. れぞれ一つのフィールドと考え,ビットマスクを含むフロ. タックが空となったのでフロー検索を終了する.. ー検索の問題を L 次元の Packet Classification として扱って. 2.3 Double Array によるトライ木の実装. いる.L は検索を行うヘッダのビット長である.フローテ. ワイルドカード展開を行うことで検索の高速化を行う. ーブルを 0,1,*の三種類の文字列を扱うパトリシア木とし. ことができるがメモリ空間量が増加するという問題がある.. て考える手法を H-Trie と呼ぶ.0111 の該当するルールの検. そこでトライ木の実装には Double Array [3]を用いている.. 索を例に H-Trie を用いたフロー検索を図 1 に示す.矢印は. 木のノードをポインタで相互参照する基本的な実装では各. マッチング処理を行い,ノードの移動をしていることを示. ノ ー ド の 子 の 数 だ けメ モ リを 確 保 す る 必 要 が ある が ,. す.完全一致により遷移可能なノードとワイルドカード一. Double Array を用いた実装では BASE と CHECK の 2 つの. 致により遷移可能なノードの両方候補がある際には現在の. 配列により状態遷移を保持し,配列の要素数を少なくする. ノードの位置を記憶し,完全一致するノードへ移動する.. ことでメモリ効率を抑えることが可能である.. 途中で検索に失敗した際には記憶したノードへ戻りワイル. Double Array を用いて検索を行う際には,まず遷移状態. ドカード一致により遷移可能なノードへ移動する.このバ. を表す index を 1 とし,マッチング処理を検索対象の先頭. ⓒ2015 Information Processing Society of Japan. 2.
(3) 情報処理学会研究報告 IPSJ SIG Technical Report. 図 4 パケット処理アーキテクチャ. Vol.2015-OS-132 No.15 2015/2/27. 図 5 empty-list を用いた Double Array. から 1 ビットずつ各ビットが対応するラベルを用いて行う.. わせた手法を用いることで検索の高速化を図るが,メモリ. C[B[index] + ラベル]==index を満たす時に遷移成功とし,. 空間量を削減するために利用する Double Array は挿入する. 全ビットに対して遷移が完了した際の BASE 値の値に-1 を. エントリ数が膨大になると構築時間に非実用的な時間を要. かけた値を検索対象にマッチするエントリ ID として得る.. するため OpenFlow スイッチとして利用することが難しい.. 例として図 3 の Double Array を用いて 010 がマッチするエ. そこで本研究では Double Array 構築時間の短縮とフロー検. ントリの検索手順を示す.まず,現在の状態遷移を表す. 索の高速化を行う.. index を 1 とし検索対象の先頭ビットである 0 に紐づくラベ. 3.1 Double Array 構築時間の削減. ル 1 を取得する.この時の BASE 値は B[1]から 4 が得られ,. 本研究では Double Array 構築時に Double Array を複数個. C[4+1]が 1 であり現在の index と同じ値であるため遷移可. 用意しそれぞれの Double Array に対して CPU スレッドを割. 能であることがわかる.遷移が可能であるため index の値. り当てることでエントリの挿入を並列化する.CPU による. は B[1] + 1 より 5 となり,検索対象の全ビットに対して繰. 並列化の実装には OpenMP を用いる.また各 Double Array. り返し処理を行う.全ビットに対して検索が終了した際の. が保持するエントリ数を削減することで Double Array 構築. index の値は 4 となる.この時の BASE 値は B[4]から-1 が. 時間の短縮を行う.Double Array に挿入するエントリ数が. 得られ,これに-1 を掛けた 1 が検索対象にマッチするエン. 増加するにつれ構築時間を要するのはエントリ挿入時の衝. トリ ID となる.. 突 処 理 に お い て , 遷移 可 能な 空 ノ ー ド を 決 定 する ま で. Double Array へのエントリ挿入時に既に挿入されている. BASE 値のインクリメントを繰り返するためである.そこ. エントリと衝突することがある.例えば図 3 の Double. で文献 [5]では効率的に空きノードを管理する empty-list が. Array に対して新たに 110 というエントリを追加する場合,. 提案されている.empty-list は空ノードの CHECK 値に次の. 先頭ビットである 1 を挿入しようとした際に挿入先の. 空ノードのインデックスを持つ単方向連結リストである.. CHECK 値に既に値が設定されているため衝突が発生する.. empty-list を用いることで空ノードの位置を効率的に見つ. この場合には衝突した index の Base 値である B[1]を新しく. けることができるため衝突処理時の BASE 値再設定を高速. 決めなおす必要がある.そのため Double Array の保持する. 化することが可能になる.図 5 に衝突処理発生時に. エントリ数が増加するに従い衝突処理を実施する回数が増. empty-list を使用して**1 を Double Array へ挿入する際の方. え,Double Array 構築に非実用的な時間を要するという問. 法を示す.まず,現在の遷移状態を表す index を 1 とし,. 題がある.また,アルゴリズムの点から同一 Double Array. 空ノードの先頭インデックスを表す e_head を 5 とする.. に対して複数エントリを同時に挿入できないため並列化に. Double Array へ挿入するエントリの先頭ビットからラベル. よる高速化が難しい.. 値 3 を得る.遷移先ノードである B[index]+N(*)=B[1]+3=4. 3. 提案手法. のノードの CHECK 値は既に使用されており,衝突が発生 するため現在のノードの BASE 値である B[1]を再設定する. 従来の OpenFlow スイッチのパケット処理アーキテクチ. 必要がある.この時,e_head から順に BASE 値が条件を満. ャを図 4 に示す.Network Interface Card (NIC)に到着したパ. たすか確認し,満たす場合には現在のノードから遷移して. ケットは Direct Memory Access (DMA)でホストメモリにコ. いるラベル値と挿入しようとしているラベル値の中から最. ピーされる.その後 CPU スレッドは検索対象のパケットヘ. 小 の ラ ベ ル 値 minlabel を 取 得 し , BASE[1] に e_head –. ッダをホストメモリから取り出し,処理ルールを決定する. minlabel = 4 を再設定する.繰り返し,挿入するエントリの. ためにフローテーブルに対して線形探索を行う.. 全ビットに対して同様に処理を繰り返す.. 本研究では従来 CPU が行っていたフロー検索を GPU へ. 3.2 フロー検索の高速化. オフロードすることでフロー検索の高速化を行う.この時. 本研究では従来 CPU が行っていたフロー検索を GPU へ. のフロー検索アルゴリズムには H-Trie と SP-Trie を組み合. オフロードすることでフロー検索の高速化を行う.この時. ⓒ2015 Information Processing Society of Japan. 3.
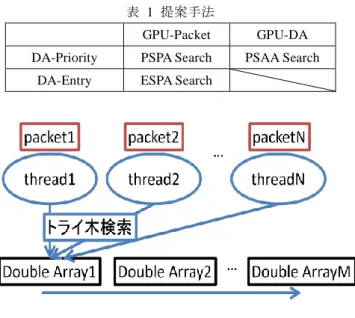
(4) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2015-OS-132 No.15 2015/2/27. 表 1 提案手法 GPU-Packet. GPU-DA. DA-Priority. PSPA Search. PSAA Search. DA-Entry. ESPA Search. 図 7 PSAA Search アーキテクチャ. 図 6 PSPA Search アーキテクチャ のフロー検索アルゴリズムには H-Trie と SP-Trie を組み合 わせた手法を用いる.この時,分割した Double Array への エントリ挿入方法としてフローエントリが持つ優先度を基 に挿入する方法と先頭 L ビットが同じエントリを類似する エントリと考え,同一の Double Array へ挿入する方法があ 図 8 ESPA 類似エントリの集約. る.L はワイルドカード展開したビット長を示す.この時 挿入先の Double Array は先頭 L ビットをインデックスとし て決定する.また,GPU スレッドの割り当て方は分割した. かし,同一 Double Array 内では検索時に優先度の高いエン. 各 Double Array へ割り当てる方法と検索対象の各パケット. トリが先に見つかるとは限らないため Double Array 内の検. ヘッダへ割り当てる方法がある.Double Array の構築方法. 索は遷移可能なノードがなくなるまで検索する必要がある.. と GPU スレッドの割り当て方法がそれぞれ 2 種類ずつある. 3.2.2 PSAA Search 分割した Double Array ごとに GPU スレッドを割り当て,. ので,組み合わせると 4 種類ある.しかしこのうち,類似 するエントリを集約した Double Array に対して GPU スレッ. Double Array に対してフローテーブル内のエントリを順不. ドを割り当てる方法は,検索対象のパケットヘッダにマッ. 同で挿入 する. 本手法 を Priority-based table Splitting &. チするエントリが挿入されている Double Array が予め先頭. Array-based thread Assignment (PSAA) Search と呼ぶ.図 7. L ビットよりわかるためその他の Double Array にスレッド. に本手法のアーキテクチャを示す.本手法ではスレッドブ. を割り当てるのは有効でないため除外する.そこで,表 1. ロックを複数個作成し検索対象のパケットヘッダを均等に. に示す残りの 3 種類を実装する.. 分割することでフロー検索の並列化を図る.GPU スレッド. 3.2.1. を Double Array 毎に割り当てることで検索対象にマッチす. PSPA Search. パケットヘッダごとに GPU スレッドを割り当て,分割し. るエントリを並列に探索することが可能となり,また同時. た Double Array に対してエントリが持つ優先度で集約する.. にスレッドブロックごとにパケットヘッダも割り当てるこ. 本手法を Priority-based table Splitting & Packet-based thread. とでパケットヘッダに対する検索の並列も可能となる.. Assignment (PSPA) Search と呼ぶ.図 6 に本手法のアーキテ. 3.2.3 ESPA Search. クチャを示す.分割した Double Array へエントリを挿入す. パケットヘッダごとに GPU スレッドを割り当て,分割し. る際にはあらかじめフローテーブルの優先度が降順になる. た Double Array に対して類似エントリを集約する.本手法. ようにソートしておき,Double Array の個数で均等に分割. を. し,挿入する.これによって優先度を持った Double Array. Assignment (ESPA) Search と呼ぶ.図 8 に類似したエント. を構築することができ,フロー検索時には各 GPU スレッド. リの集約例を示す.フローエントリ内のワイルドカードを. は優先度の高い Double Array から順に検索することで優先. 展開する先頭 N ビットまでを Double Array のインデックス. 度の高いエントリを先に見つけた次第,残りの Double. として使用する.これにより,実際に Double Array へ挿入. Array の探索を行う必要がなくなるのでマッチするエント. するビットは残りのビット長だけになる.0111 というエン. リが見つかったところで検索を終了することができる.し. トリを挿入する際にはまずワイルドカード展開を行う先頭. ⓒ2015 Information Processing Society of Japan. Entry-based. table. Splitting. &. Packet-based. thread. 4.
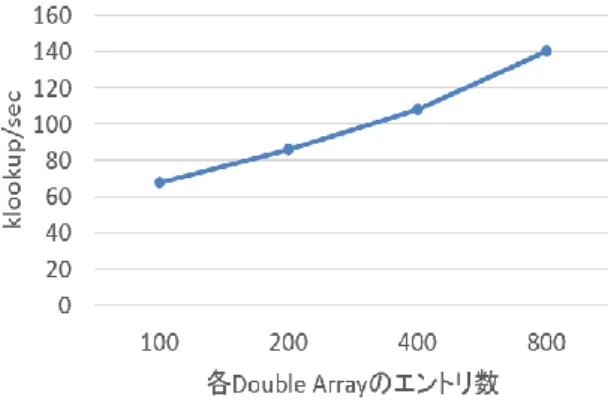
(5) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2015-OS-132 No.15 2015/2/27. 表 2 実装・評価環境 CPU. Intel(R) Core(TM) i7-4900. GPU. GeForce GTX 760. Memory. DDR3 32GB. OS. Scientific Linux 6.6 x86_64. CUDA Toolkit. 6.5. 2 ビット 01 から Double Array のインデックス 1 を決定する. その後,実際に Double Array へ挿入するのは残りの 11 の 2 ビットだけで良い.これにより Double Array 構築時に発生. 図 9 スレッドブロックサイズと検索性能. する衝突処理の削減やフロー検索時のマッチング回数の削 減が可能となる.本手法を用いて Double Array を構築する. の各エントリはビット長が 32 ビットであるランダムな値. 際には PSPA Search や PSAA Search で行っていたような均. にビットマスクを適用したものとする.展開するワイルド. 等にフローテーブルを分割し,Double Array に挿入するこ. カードは各エントリの先頭から 4 ビット長とする.これは. とは出来ない.そのため,各 Double Array の構築を担当す. GPU が Double Array や検索対象のパケットヘッダを保存す. るスレッドがフローテーブルの中から該当するフローを選. るのに利用することのできるグローバルメモリのサイズが. 択する必要がある.まず,集約化のために各エントリが挿. 1535Mbytes であり展開することが可能なワイルドカード. 入される先の Double Array を管理した配列を作成する.こ. のビット長の最大が 4 ビットとなったためである.また,. の時,フローテーブルの上から順に各エントリの挿入先. 手法によっては Double Array に挿入されるエントリ数や. Double Array を決定するのではエントリ数が増加した際に. GPU のスレッドブロックサイズによって性能が異なるた. 線形に集約するための時間が掛かってしまうため,集約化. め,最初に各手法において最も性能が高くなる際のパラメ. の作業を並列に行う.CPU スレッドによる集約化の際には. ータを調査した.. フローテーブルを実行するスレッド数だけ均等に分割し,. 4.1 スレッドブロックサイズと検索性能の関係. 挿入先 Double Array の決定作業を行う.. 4. 評価. まず,スレッドブロックサイズがフロー検索性能に影響 を与える手法において最も高い性能を出すことが可能なス レッドブロックサイズを調査した.該当する手法である. 本稿で提案した 3 つの手法に加え,GPU を用いた並列化. PSPA Search と ESPA Search のスレッドブロックサイズと検. の有効性を確認するため PSPA Search が行うフロー検索を. 索性能の関係を図 9 に示す.グラフの横軸が GPU で実行. 8 スレッド CPU により並列化した手法を加えた 4 つを実装. される際のスレッドブロックサイズで,縦軸がフロー検索. した.実装には NVIDIA が提供する Compute Unified Device. 速度である.. Architecture (CUDA) [6]を使用する.GPU は従来画像処理な. 評価結果から PSPA Search と ESPA Search において最も高. どの計算を行うのに利用されプロセッサを多く持った構造. い性能を実現するスレッドブロックサイズは 32 であるこ. で大量のデータを複数のプロセッサで並列処理することが. とがわかる.従来スレッドブロックサイズを大きくし実行. 可能である [7].実装は表 2 に示す環境で行い,GPU とし. されるスレッド数を増やすことでメモリへアクセスする際. ては,NVIDIA 製の GeForce GTX 760 を利用した.このグ. のレイテンシ軽減を図るが,この結果からメモリレイテン. ラフィックスカードは 6 個の Stream Multiprocessors(SMs). シの影響があまりないことがわかる.これは GPU スレッド. を持ち各 SM は 192 個の Stream Processors(SPs),計 1152 コ. が検索時に保持するパケットヘッダのサイズがレジスタに. アを持つ.SPs で実行される全てのスレッドは同一プログ. 保存するのに十分サイズが小さいためであると考えられる.. ラムを実行しカーネル関数と呼ばれる.各 SM は Single. よって以降のこれらの手法の評価においてはこのスレッド. Instruction Multiple Thread(SIMT)と呼ばれるアーキテクチ. ブロックサイズを利用する.. ャで実行され,各スレッドは独自の動作を行う.32 スレッ. 4.2 各 Double Array のエントリ数と検索性能. ドずつのグループとして管理される SM はワープと呼ばれ. PSPA Search においてフローテーブル内のエントリ数が. 各ワープ内のスレッドは同一コードを実行する.SM 内で. 20000 の時の各 Double Array のエントリ数と検索性能の評. SP の個数以上のスレッド数を生成することでメモリアク. 価結果を図 10 に示す.グラフの横軸が Double Array を複. セスの遅延を抑えた処理が可能になる.評価実験はビット. 数個に分割した際にそれぞれに挿入されるエントリ数で,. マスクが 100 種類である場合に対してエントリ数を変化さ. 縦軸がフロー検索速度である.. せ,提案手法のフロー検索性能の評価を表 1 の環境で行っ た.ビットマスクはランダムに生成し,フローテーブル内. ⓒ2015 Information Processing Society of Japan. この結果より,Double Array あたりのエントリ数を削減 することでのバックトラックの削減は複数個の Double. 5.
(6) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2015-OS-132 No.15 2015/2/27. 図 10 各 Double Array のエントリ数と検索性能 図 11 エントリ数とフロー検索性能の関係 表 3 Double Array 構築時間 4.4 エントリ数とフロー検索性能. 手法. 構築時間 (sec). 従来手法. 3407.8. Double Array 200 分割 PSPA. 8.4. 時のエントリ数とフロー検索性能の評価結果を図 11 に示. Double Array 100 分割 PSPA. 15.5. す.グラフの横軸がエントリ数,縦軸がフロー検索速度で. Double Array 50 分割 PSPA. 29.6. ある.グラフより ESPA Search が最も高い性能を得られた. Double Array 25 分割 PSPA. 67.8. がこれは他の手法と比較して実際にマッチングに利用され. Double Array 16 (=24) 分割 ESPA. 44.3. るビット長が短かったためであると考えられる.. ワイルドカード展開するビットが先頭から 4 ビット長の. 一方,各パケットヘッダのマッチするエントリを並列に Array でマッチング処理を行う回数に比べて影響が小さい. 検索することを目的として実装した PSAA Search は他の手. ことがわかる.そのため複数個の Double Array を用いてフ. 法と比較して著しく性能が低下した.これは Double Array. ロー検索を行う際にはなるべく検索する Double Array の個. 毎に割り当てた GPU スレッドのほとんどが検索失敗の状. 数を少なくすることが性能向上に必要であると考えられる.. 態で待機状態となり,並列の有効性を活かしきれていない. 以上の結果から,PSPA Search において最も高い性能を実 現するときの Double Array 内のエントリ数は 800 であるこ とがわかるため以降の本手法の評価においてはこの値を用 いる. 4.3 Double Array 構築時間 既存の一つの Double Array へエントリを挿入する手法と 本研究で提案する Double Array 分割手法の構築時間の測定 を行った.挿入するフローエントリ数の合計は 20000 とし, 提案手法の並列化には CPU 8 スレッドを用いた.測定結果 を表 3 に示す.評価の結果,提案手法を用いることで従来 手法と比較し大幅に Double Array の構築時間が削減された. これは各 Double Array に挿入されるエントリ数が減少した ことに加え,CPU スレッドによりそれぞれの Double Array が並列に構築されたためであると考えられる. この実験結果から,各 Double Array に挿入されるエント リ数が増加するにつれ,線形に構築時間が増加することが 見てとれる.また,Double Array を PSPA Search で構築する ときと ESPA Search で構築するときの構築時間を比較する と ESPA のほうが Double Array あたりのエントリ数が多い ときでも構築時間が短くなった.これは ESPA では PSPA と比較して実際に Double Array へ挿入されるビット長が短 いためであると考えられる.. ⓒ2015 Information Processing Society of Japan. ためであると考えられる.. 5. 考察 Double Array 構築において表 3 より提案手法を用いるこ とで既存手法と比べ大幅に構築時間を削減したことがわか る.これは各 Double Array へ挿入するエントリ数を削減し たことで衝突処理を削減し,分割した Double Array をそれ ぞ れ 並 列 に 構 築 し たた め と考 え ら れ る . こ の こと か ら Double Array あたりのエントリ数が少なくなるにつれて構 築時間が短縮されるが,フロー検索性能が低下してしまう ことが図 10 からわかる.これは Double Array あたりに挿 入されるエントリ数が減少することで,エントリを見つけ るまでに複数個の Double Array を検索するためにメモリア クセス回数が増えるためであると考えられる.0110 の検索 を例に Double Array に挿入されるエントリ数に差がある時 のマッチング回数の違いを図 12,図 13 を用いて示す.図 12 はテーブルを 2 つに分割して,エントリを 2 つの Double Array のそれぞれへ挿入する場合を示す.図 13 はテーブル 内の全エントリを 1 つの Double Array へ挿入する場合を示 す.これらの図から複数の Double Array へエントリを分割 して挿入した際により多くのマッチング処理を行うため検 索性能が低下することがわかる.また,PSPA と比較し ESPA に基づいて Double Array の挿入を行う際には Double Array. 6.
(7) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2015-OS-132 No.15 2015/2/27. 築アルゴリズムの観点からも並列化が困難であった.そこ で本研究では Double Array を複数個に分割し効率的な挿入 アルゴリズムを検討し,構築を並列化することで構築時間 を実用の範囲内で抑えることができた.同時に,分割した Double Array に対して類似するエントリを集約する方法で は実際にフロー検索時に行うマッチング回数を減らすこと が出来たため他の検索アルゴリズムと比較して高い性能を 得た.これにより,OpenFlow スイッチのフロー検索アルゴ リズムとして利用する可能性が開けたと考えられる. 図 12 2 つの Double Array からのエントリ検索. また,大量のパケット処理を行う必要がある環境を想定 し,パケット処理エンジンに GPU を用いることで検索の並 列化を行った.その結果 CPU を用いて並列にフロー検索を 行うよりも高速な検索性能が実現された.これは GPU の高 い並列性能を活かすことが出来た結果であると考えられる が,本実装ではフロー検索において GPU の苦手とする条件 分岐を 1 ビット毎のマッチングで行ったため,GPU スレッ ドの実行率が低下している面はあると考えられる.今後は, GPU で行う条件分岐を削減することで更なるフロー性能 の向上が期待できる.. 参考文献 図 13 1 つの Double Array からのエントリ検索 あたりのエントリ数は増加するが挿入するビット数の削減 が可能であるため構築時間が短い. フロー検索性能において図 11 の評価結果より ESPA Search が最も高い性能を実現可能なことがわかる.これは 他の手法と比較してワイルドカードを展開するビット長の マッチング処理が不要になるのに加え,展開したビット長 を Double Array のインデックスとして利用することで予め マッチするエントリを保持する Double Array の特定が可能 であるため,マッチング回数が削減されたためであると考 えられる.その結果,PSPA Search と比較して約 1.5 倍高い 性能を実現することが出来た.また PSPA Search を GPU 実 装したことで同一アルゴリズムを用いた CPU 実装よりも 約 2 倍のフロー検索性能が得られた.しかし,本環境にお いて GPU が得意とする計算処理が主となる行列計算を CPU と GPU で実行すると GPU が CPU の約 15 倍高速に実 行が完了した.それと比較し今回の GPU を利用したことで 得られた CPU との性能差はメモリアクセスや条件分岐の 処理が多いために小さくなったと考えられる.. [1] P. Gupta and N. McKeown. "Algorithms for packet classification," IEEE Network, Vol. 15, No. 2, pp. 24-32, 2001. [2] 日比智也, 中島佳宏, 高橋宏和 , 尾花和昭, “ソフトウェア OpenFlow スイッチにおける Bitmask 対応の高速なフロー検索 手法の検討,” 情報処理学会研究報告 Vol.2014-OS-128 No.12, 2014. [3] J. Aoe. "An Efficient Digital Search Algorithm by Using a Double-Array Structure," IEEE Transaction on Software Engineering, Vol. 15, No. 9, pp. 1066-1077, 1989. [4] S. Han, K. Jang, K. Park, and S. Moon. "PacketShader: a GPU-accelerated software router," In Proceedings of the ACM SIGCOMM 2010 conference (SIGCOMM '10), pp. 195-206, 2010. [5] K. Morita, A. Tanaka, M. Fuketa and J. Aoe, "Implementation of update algorithms for a double-array structure," IEEE International Conference on e-Systems and e-Man for Cybernetics in Cyberspace, Vol. 1, pp. 494-499, 2001 [6] NVIDIA Corporation, "About CUDA," [Online]. Available: https://developer.nvidia.com/about-cuda. [7] OpenFlow Reference System, "OpenFlow Switch Specification, Version 1.1.0," [Online]. Available: http://archive.openflow.org/documents/openflow-spec-v1.1.0.pdf. [8] OPEN NETWORK FOUNDATION, "Software-Defined Networking: The New Norm for Networks," [Online]. Available: https://www.opennetworking.org/images/stories/downloads/sdn-res ources/white-papers/wp-sdn-newnorm.pdf. [9] NVIDIA Corporation, "WHAT IS GPU ACCELERATED COMPUTING?," [Online]. Available: http://www.nvidia.com/object/what-is-gpu-computing.html.. 6. まとめ OpenFlow スイッチのフロー検索高速化のために,トライ 木による検索アルゴリズムの GPU による並列化を行った. 既存の手法ではトライ木の実装に用いる Double Array への エントリ挿入時に発生する衝突処理のために,Double Array の構築自体に非実用的な時間が必要であり,用いている構. ⓒ2015 Information Processing Society of Japan. 7.
(8)
図


+2
関連したドキュメント
うのも、それは現物を直接に示すことによってしか説明できないタイプの概念である上に、その現物というのが、
以上のことから,心情の発現の機能を「創造的感性」による宗獅勺感情の表現であると
突然そのようなところに現れたことに驚いたので す。しかも、密教儀礼であればマンダラ制作儀礼
実際, クラス C の多様体については, ここでは 詳細には述べないが, 代数 reduction をはじめ類似のいくつかの方法を 組み合わせてその構造を組織的に研究することができる
および皮膚性状の変化がみられる患者においては,コ.. 動性クリーゼ補助診断に利用できると述べている。本 症 例 に お け る ChE/Alb 比 は 入 院 時 に 2.4 と 低 値
共通点が多い 2 。そのようなことを考えあわせ ると、リードの因果論は結局、・ヒュームの因果
評価 ○当該機器の機能が求められる際の区画の浸水深は,同じ区 画内に設置されているホウ酸水注入系設備の最も低い機能
評価 ○当該機器の機能が求められる際の区画の浸水深は,同じ区 画内に設置されているホウ酸水注入系設備の最も低い機能
