CUDAを用いたGROMACSの高速化
6
0
0
全文
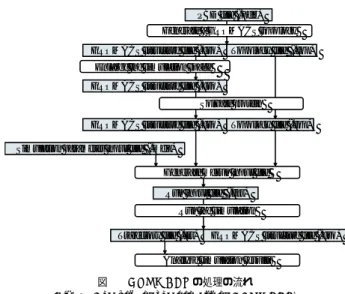
(2) Vol.2010-MPS-79 No.10 2010/7/12. 情報処理学会研究報告 IPSJ SIG Technical Report PBD file (.pdb) Generate a GROMACS topology GROMACS structure file (.gro). Topology file (.top). Enlarge the simulation space GROMACS structure file (.gro) Solvate protein GROMACS structure file (.gro). (2). データの読み込み. (3). 各種制限. (4). QM/MM(Quantum Mechanics / Molecular Mechanics)法の適用. (5). (必要時)PPPM(Particle-Particle Particle-Mesh)法の適用. (6). シミュレーション方法の選択と実行. • 分子動力学法. Topology file (.top). • Polak-Ribiere による共役勾配法. Simulation parameter input file (.mdp). • ニュートン法. Generate mdrun input file. • 準ニュートン法. Run input file (.tpr). • 最急降下法. Run the simulation Trajectory file (.trr). (7). GROMACS structure file (.gro). 原子へ変換. このうち手順 6 のシミュレーション方法の選択と実行において,構成原子全てに対して逐. Analyze simulation results. 次解析を行う.そのため,計算時間を必要とする.この計算時間の短縮のために,MPI10). 図 1 GROMACS の処理の流れ Fig. 1 The flow of the process of GROMACS.. を用いた並列計算が実装されている.また,OpenMM を用いることで,GROMACS のシ ミュレーション計算を GPU により並列化することが出来る.. の拡張命令を用いたアセンブリ言語のルーチンが実装されているため,高いパフォーマンス. 2.2 OpenMM を用いた GROMACS の高速化. を得ることが出来る.トポロジーやパラメータが,テキスト形式のファイルに保存されてい. OpenMM は,高性能コンピュータ・アーキテクチャで分子動力学シミュレーションを実. るため,その利点としては,読み書きが容易であることが挙げられる.書き込まれたファイ. 行するための API である11) .OpenMM を用いることで CUDA を利用した GROMACS. ルは検証される.もし,書き込みミスがある場合,エラーメッセージが発行される.また,. のシミュレーション実行による並列処理化が可能である.ただし,GROMACS で実行出来. GROMACS の起動は,コマンドラインから可能であるという利点がある.. る全てのシミュレーション環境に対応しているわけではなく,次のようないくつかの制約が ある.積分器は,ニュートンの運動方程式の馬跳びアルゴリズム(md)12) ,精密な馬跳び統. シミュレーションの流れは次の通りである.. (1). 構造ファイルの作成(pdv2gmx). 計的力学積分器(sd)12) ,Brownian または Langevin のオイラー積分器 (bd)12) のいずれ. (2). ボックスの大きさの変更(editconf). かである.束縛法は,無し(none),水素原子の結合を束縛(h-bonds),全ての結合を束. (3). 水分子を混入(genbox). 縛(all-bonds)のいずれかとなる.静電相互作用の計算方法は,cut-off12) ,Reaction-Field. (4). シミュレーション実行用設定ファイルの作成(grompp). 法12) ,Ewald 法13) ,PME 法14) を適用可能である.温度や圧力によるカップリングは無し. (5). シミュレーションの実行(mdrun). (6). シミュレーション結果の解析(g ). (no).. GROMACS-OpennMM は,以下の関数で構成されている. • openmm init(). 括弧内はコマンド名である.. • openmm take one step(). 図 1 は,処理の流れ図である.このうち最も計算時間がかかるのが処理 5 のシミュレー. • openmm copy state(). ションの実行である.処理 5 の流れは次の通りである.. (1). • openmm cleanup(). 初期化. 2. c 2010 Information Processing Society of Japan °.
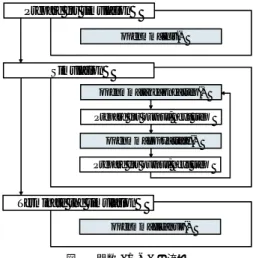
(3) Vol.2010-MPS-79 No.10 2010/7/12. 情報処理学会研究報告 IPSJ SIG Technical Report. 表 1 GROMACS-OpenMM 実行時間 Table 1 The execution time of GROMACS-OpenMM. Prepare for simulation openmm_init() 原子数. Simulation 計測時間. openmm_take_one_step(). villin 9,389 CPU GPU 0m 0m 49.747s 43.086s. lysozyme 23,207 CPU GPU 5m 3m 59.755s 26.864s. dppc 121,856 CPU GPU 39m 89m 41.242s 50.128s. poly 12,000 CPU GPU 1m 1m 2.390s 2.533s. Prepare for output, next step openmm_copy_state(). ている gmxbench-3.015) を利用している.. Prepare for output, next step. villin は,NMR(Nuclear Magnetic Resonance)により構造決定されている 36 アミノ Terminate the simulation. 酸残基からなる Villin headpiece サブドメインを切頂八面体の単位胞を用いて 3000 個の水 分子と一緒にシミュレーションを実行したものである.積分器は md,束縛法は h-bonds,. openmm_cleanup(). 静電相互作用は cut-off であり,ステップ数は 5000 である.また,原子数は 9389 個である. 図 2 関数 do md の流れ Fig. 2 The flow of function do md.. lysozyme は,大きな lysozyme タンパク(pdb entry 2LZM)に SPC (Simple Point Charge)モデルの水分子と一緒にシミュレーションを実行したものである.積分器は md,. 図 2 は,これらの関数の関係図である.. 束縛法は all-bonds,静電相互作用は cut-off であり,ステップ数は 5000 である.また,原. openmm init() は,分子動力学シミュレーションを始める前に 1 度だけ呼ばれる初期化関. 子数は 23207 個である.. 数である.この関数では,GROMACS が作成した GROMACS データ構造でかかれたデー. poly は,異方性 united atom でモデル化した 6000 ユニットの polyethylene 分子につい. タが読み込まれ,そのデータは,OpenMM データ構造の OpenMM データに書き換えられ. てシミュレーションを実行したものである.積分器は md,束縛法は all-bonds,静電相互. る.このデータには,シミュレーション方法の詳細やパラメータが記録されている.また,. 作用は cut-off であり,ステップ数は 5000 である.また,原子数は 12000 個である.. 使用する GPU 情報の読み込みや,その情報をもとに並列実行環境の整備,GPU 側のメモ. dppc は,脂質 dipalmitoylphosphosphatidylcholine(DPPC)1024 分子と脂質一分子あ. リ確保等,GPU 使用のための準備もこの関数内で行われる.. たり 23 個の水分子からなる脂質二重層配置されたリン脂質膜に対して,SPC モデルの水. openmm take one step() は,分子動力学シミュレーションを 1 ステップ分進める関数で. 分子を作用させるシミュレーションである.積分器は md,束縛法は無し,静電相互作用は. ある.この関数内で CUDA による実行関数が呼び出され並列計算が行われる.呼び出され. cut-off であり,ステップ数は 5000 である.また,原子数は 121856 個である.. る関数の種類は,openmm init() で作成された OpenMM データ内の値により異なる.. 計測環境は,CPU は Quad-Core AMD Opteron(TM) Processer 2382,メモリは 7.9GB,. openmm copy state() は,原子の位置や速度等の最新の状態が保存されている OpenMM. OS は fedora 10,GPU は Tesla C1060 であり Tesla C1060 のプロセッサコア周波数は 1.296. データを GROMACS データにコピーする関数である.GROMACS 側で出力や解析等を行. Ghz,メモリは 4GB である.ソフトウェアのバージョンは,CUDA は 2.3,GROMACS. うために呼び出される.. は 4.0.7,OpenMM は 1.1.1,GROMACS-OpenMM は 1.1 である. 表 1 の 1 行目は,実行したシミュレーションの種類を示している.CPU とは,CPU の. openmm cleanup() は,シミュレーション終了時に 1 度だけ呼ばれる終了関数である. openmm init() で作成した OpenMM データの削除を行う.. みで実行した場合の実行時間であり,GPU とは,GROMACS-OpenMM を使用した場合. GROMACS-OpenMM の性能を調べるために実験を行う.実験の対象は,villin,lsozyme,. の実行時間である.実行時間における m とは minutes の略で分のこと,h とは hour で時. poly,dppc である.各シミュレーションは,GROMACS の開発グループにより公開され. 間のことである.CPU と GROMACS-OpenMM の実行時間を比較すると,GROMACS-. 3. c 2010 Information Processing Society of Japan °.
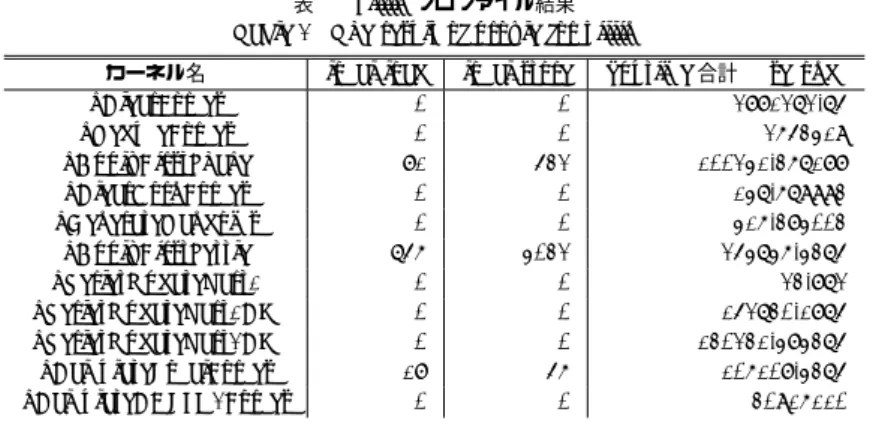
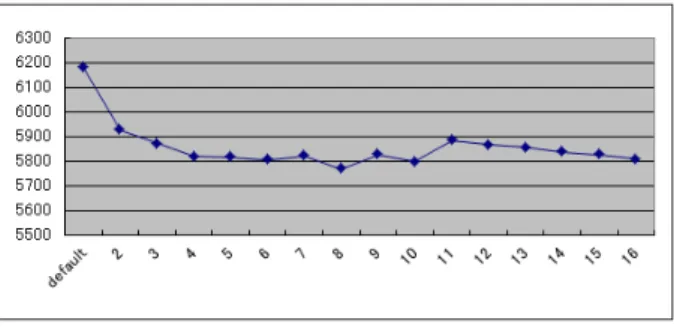
(4) Vol.2010-MPS-79 No.10 2010/7/12. 情報処理学会研究報告 IPSJ SIG Technical Report 表 2 villin プロファイル結果 Table 2 The result of profile for villin カーネル名. kClearForces kReduceForces kApplyFirstShake kClearBornForces kGenerateRandoms kApplyFirstSettle kVerletUpdatePart1 kVerletUpdatePart1CM kVerletUpdatePart2CM kCalculateLocalForces kCalculateCDLJN2Forces. local load 0 0 81 0 0 756 0 0 0 18 0. local store 0 0 532 0 0 4032 0 0 0 56 0. 理に弱いという特徴があるため,ループアンローリングを行うことにより,ループの終了判 定回数が減り,分岐処理が削減されることで実行時間が短くなる可能性がある.. gputime 合計 (µsecond) 2881272.75 2653419 100241.367188 147.679993 416.384003 254746.4375 23.872 152730.1875 130231.484375 106108.4375 30916110. また,プロファイルの結果から,カーネル kApplyFirstSettle は,ローカルメモリへの ロード,ストア回数ともに他のカーネルと比べると多いことが分かる.CUDA において, カーネルを実行する際,スレッド当たりのレジスタ数が,ストリーム・プロセッサ当たり のレジスタ数/ブロック内のスレッド数より多い時は,カーネルを実行することが出来ない. それを回避する為に,CUDA のコンパイラでは,1 スレッドが使用するレジスタの上限を 決めるオプションがある.上限を超える場合,溢れたレジスタ分をローカルメモリで補う.. GROMACS-OpenMM では,1スレッド当たりのレジスタの使用上限を 32 に固定してコ ンパイルされている.これは,レジスタの数が GPU によって異なるため,任意の GPU で カーネルが起動可能とするために,小さい値に固定されていると考えられる.1 スレッド当. OpenMM を使用した場合,CPU と比べて villin は約 1.15 倍,lysozyme は 1.74 倍早くなっ. たりのレジスタ数が 32 となっているため,カーネル関数にてレジスタ不足となりローカル. ている.しかし,dppc は 0.44 倍,poly は 0.99 倍となり遅くなっており,シミュレーショ. メモリを使用している関数がいくつか存在する.カーネル kApplyFirstSettle はそのひとつ. ン内容によっては遅くなるものがある.Quad-Core AMD Opteron(TM) Processer 2382. である.しかしながら,ローカルメモリへのアクセスは,レジスタと比べ 100 倍以上アク. は,24.00Gflops であり,Tesla C1060 は最大 933Gflops であるので,約 39 倍の速度向上. セスが低速である.よって,カーネル kApplyFirstSettle のローカルメモリへのアクセスを. が見込まれるはずである.よって,現在の高速化は不十分と考えられ,改良する必要がある.. 減らす必要があると考えられる.カーネル kApplyFirstSettle は,1 ステップ進める度に必 ず 1 度呼ばれる.このカーネルは,196byte のローカルメモリを使用している.まず,この. 3. 高速化の検討. 使用量を削減することで,ローカルメモリへのアクセス回数が軽減されると考えられる.. 本実験では,2 章で挙げたシミュレーション villin に着目する.まず,シミュレーション. 4. 実. villin に対して CUDA Profiler を使用する.CUDA Profiler とは,NVIDIA 社が提供する. 験. プロファイリングツールであり,各メモリ転送にかかった時間や各カーネルにおけるレジ. 3 章で考察したカーネルについて実験を行う.. スタやメモリの使用状況等を自動的にプロファイリングするツールである.プロファイリ. 4.1 節ではカーネル kCalculateCDLJN2Forces についての実験,4.2 節ではカーネル kAp-. ングの結果が,表 2 である.表 2 の 1 行目の local load はローカルメモリへのロード回数,. plyFirstSettle についての実験を述べる. 4.1 カーネル kCalculateCDLJN2Forces. local store はローカルメモリへのストア回数のことである.gputime とは,GPU が実行し た時間のことを指す.その合計とは,シミュレーション villin 実行時,呼び出し回数の異な. カーネル kCalculateCDLJN2Forces 内の 2 重ループについて,内側ループをループアン. る各カーネルの gputime の合計のことである.. ローリングを行う.17 回以上はアンロールの際にエラーが出たため,アンローリング回数. このプロファイリング結果から,カーネル kCalculateCDLJN2Forces が全てのカーネル. は 2-16 回である.各アンロール回数に変更し,GROMACS-OpenMM をコンパイルし,得. の実行時間の総計の約 83% を占めており,実行時間も長いことが分かる.よって,カーネ. た結果をグラフ化したものが図 3 と図 4 である.図 3 は,gputime の平均値のグラフであ. ル kCalculateCDLJN2Forces は改善される余地があると考えられる.カーネル kCalculate-. り,図 4 は,命令回数のグラフである.. CDLJN2Forces は,1 ステップ進める度に必ず 1 度呼ばれており,また,2 重ループが使用. ループアンローリングの結果,命令回数の減少が見られ,それに伴い実行時間も短縮され. されている.内側ループは,ループ回数を 32 回に固定して実行している.GPU は分岐処. ている.アンローリング回数が 8 の時が最も gputime 平均値が短縮されており,約 1.07 倍. 4. c 2010 Information Processing Society of Japan °.
(5) Vol.2010-MPS-79 No.10 2010/7/12. 情報処理学会研究報告 IPSJ SIG Technical Report. 表 3 変数削除による実行時間の変化 Table 3 The change of the execution time from deleting parameter. 変更前 段階 1 段階 2 段階 3 段階 4 段階 5 段階 6 段階 7. lmem(byte) 196 160 160 160 160 160 160 160. local load 756 483 483 483 483 483 483 483. local store 4032 3024 3024 3024 3024 3024 3024 3024. gputime 平均値 (µsecond) 50.9492875 44.9394875 44.9461125 44.93571875 44.959875 44.95637813 44.94621563 44.9659. 図 3 ループアンローリング結果(実行時間) Fig. 3 The result of Loop Unrolling(execute time).. • 段階 3. float 型変数 yb0 の削除. • 段階 4. float 型変数 zb0 の削除. • 段階 5. float 型変数 xc0 の削除. • 段階 6. float 型変数 yc0 の削除 • 段階 7. float 型変数 zc0 の削除. float3 型とは CUDA で定義されているベクトル型であり,メンバが float 型 x,float 型. y,float 型 z の構造体である.表 3 は段階ごとに計測した実行時間を表す.lmem は使用し ているローカルメモリの大きさ,local load はローカルメモリへのロード回数,local store はローカルメモリへのストア回数である.段階ごとにカーネル kApplyFirstSettle を変更し, 図 4 ループアンローリング結果(命令回数) Fig. 4 The result of Loop Unrolling(number of instruction).. GROMACS-OpenMM をコンパイル,CUDA Profiler を用いて各項目について測定する. 構造体である float3 型変数 center を削除した時点で各項目に減少が見られ,実行時間は. 短縮されている.また,シミュレーション villin の実行時間は,35.531 秒となり,1.21 倍. 約 1.14 倍短縮することが出来ている.大きな構造体ほど,ローカルメモリに置かれる可能. 短縮されている.これは,ループアンローリングを行うことで,ループの終了判定回数が減. 性が高くなるが,float3 型という比較的小さな構造体でも,ローカルメモリに置かれている. り,分岐処理が削減され,命令回数が減り,実行時間が短縮したと考えられる.アンローリ. と考えられる.また,変数 center 以外の変数を削除しても大きな変化は見られない.これ. ング数 8 が最も早くなったのは,32 の約数であるためと考えられる.同じ 32 の約数でも 4. らは,単なるスカラ変数であるため,ローカルメモリを使用していないと考えられる.. では,アンロール回数が少なく分岐命令の削減は十分ではなく,16 ではループ内の命令回. 次に,共有メモリに変数の値を退避させることによる変数の削除を行う.共有メモリは同. 数が多すぎるため,アンロール回数 8 回ほどの性能が出なかったと考えられる.. 一ブロック内で共有することが出来る,大きさが 16KB のメモリ境域である.1 つのブロック. 4.2 カーネル kApplyFirstSettle. は,最大 512 のスレッドを持つことが出来る.つまり,最大スレッド数を使用した場合,1 ス. まず,不要な変数の削除を行う.不要な変数とは,意味のない計算をし,その結果を格納. レッドあたり 31.25byte を個別に使用することが可能である.カーネル kApplyFirstSettele. している変数を指す.次のような段階を踏んで,変数の削除を行う.. 内では,使用されている変数の型は int 型または float 型である.よって,4byte である int. • 段階 1. float3 型変数 center の削除. 型または float 型の変数 7 個を共有メモリに退避させることが出来る.ここで考慮すべきこ. • 段階 2. float 型変数 xb0 の削除. とは,バンク競合の回避である.共有メモリは 5 のように 16 のバンクが分かれている.複. 5. c 2010 Information Processing Society of Japan °.
(6) Vol.2010-MPS-79 No.10 2010/7/12. 情報処理学会研究報告 IPSJ SIG Technical Report. 行時間の総計の約 83% を占めるカーネル kCalculateCDLJN2Forces に対して,ループア ンローリングを施し,シミュレーション villin は 1.21 倍の速度向上が見られた.ローカル メモリへのアクセス回数の多いカーネル kApplyFirstSettle に対して,ローカルメモリ使用 削減の為に使用変数の削減を行った.その結果,カーネル kApplyFirstSettle は 1.41 倍の 速度向上が見られた.ローカルメモリ使用削減に,共有メモリの使用は有効であるが,高速 化には,ローカルメモリへのロード回数の削減が望ましい.. 参. 図 5 バンク競合 Fig. 5 bank confliction.. lmem(byte) 160 152. local load 483 504. local store 3024 2688. 文. 献. 1) David B. Kirk, Wen-mei W. Hwu: Programming Massively Parallel Processors: A Hands-on Approach , Morgan Kaufmann (2010). 2) GROMACS:http://www.gromacs.org/ (2010-06-07 確認). 3) OpenMM Oerverview:https://simtk.org/home/openmm (2010-06-07 確認). 4) Herbert Goldstein, Charles P. Poole, John L. Safko:Classical Mechanics, Pearson Education (US); 3rd International edition 版 (2001). 5) Liu, D.C. and Nocedal, J.:On the limited memory BFGS method for large scale optimization, Math. Programming, Vol.45, No.3, pp.503–528 (1989). 6) Scales, L. E. : Introduction to non-linear optimization, Springer-Verlag New York (1985). 7) Bernard R. Brooks, Robert E. Bruccoleri, Barry D. Olafson, David J. States, S. Swaminathan, Martin Karplus:CHARMM: A program for macromolecular energy, minimization, and dynamics calculations,J. Comp. Chem., 4, pp187–217 (1983). 8) AMD 3DNow!(TM) Technology Manual (2000). 9) IntelR 64 and IA-32 Architectures Software Developer’s Manual Volume 1: Basic Architecture (2010). 10) Peter Pacheco:Parallel Programming with MPI,Morgan Kaufmann (1996). 11) Kyle Beauchamp,Christopher Bruns,Peter Eastman ,Mark Friedrichs,Joy P. Ku,Vijay Pande,Randy Ra-dmer,Michael Sherman,Users Manual and Theory Guide (2010). 12) GROMACS:GROMACS USER MANUAL Versi-on4.0 (2009). 13) Tom Darden, Darrin York, Lee Pedersen:Particle me-sh Ewald: An N・log(N) method for Ewald sums in large systems,J. Chem. Phys. 98 pp10089–10092(1993) 14) Ulrich Essmann,Lalith Perera,Max L. Berkowitz,Tom Darden,Hsing Lee,Lee G. Pedersen:A smooth particle mesh Ewald method,J. Chem. Phys. 103 pp8577– 8593 (1995) 15) gmxbench-3.0:ftp://ftp.gromacs.org/pub/benchmarks/g-mxbench-3.0.tar.gz (201006-07 確認).. 表 4 変数退避による実行時間の変化 Table 4 The change of the execution time from evacuating parameter. 段階 7 変数退避後. 考. gputime 平均値 (µsecond) 44.9659 48.112823. 数のスレッドが,同時に同じバンクにアクセスすることをバンク競合と呼ぶ.バンク競合が 生じた場合,あるスレッドがメモリアクセスした時,そのスレッドがメモリアクセスを終了 するまで,他方のスレッドは待ち状態となり,速度低下の一因となる.バンク競合を避ける ためには,退避させる変数の個数とバンクの数 16 が互いに素である必要があり,7 はその 条件を満たす.そこで,7 個の変数を退避させることにする.退避させる変数は,参照回数 の多いものから順に選ぶ.退避させた後,GROMACS-OpenMM をコンパイルし,CUDA. Profiler を用いて各項目について測定した結果が表 4 である.なお,変数の退避は,段階 7 の後に行っている. ローカルメモリの使用量は 8byte,ローカルメモリへのストア回数は 336 回,それぞれ減 少している.しかしながら,ローカルメモリへのロード回数は,21 回増加しており,gputime の平均値も 1.07 倍増加している.このことから,ローカルメモリの使用に関する高速化に は,ローカルメモリへのロード回数を減らすことが望ましいと考えられる.. 5. ま と め 本研究では,GROMACS-OpenMM の改良を行った.シミュレーション villin に対して. CUDA Profiler でプロファイリングを行い,改善点を調べ,実験を行った.カーネルの実. 6. c 2010 Information Processing Society of Japan °.
(7)
図
+2

関連したドキュメント
高層ビルにおいて、ビルの屋上に生活用水 のためのタンクを設置し、タンクに水を貯
2Tは、、王人公のイメージをより鮮明にするため、視点をそこ C木の棒を杖にして、とぼと
基本波を用いる近似はピクセル単位の時間放射能曲線に対しては用いることができる
本節では本研究で実際にスレッドのトレースを行うた めに用いた Linux ftrace 及び ftrace を利用する Android Systrace について説明する.. 2.1
原稿は A4 判 (ヨコ約 210mm,タテ約 297mm) の 用紙を用い,プリンターまたはタイプライターによって印 字したものを原則とする.
実際, クラス C の多様体については, ここでは 詳細には述べないが, 代数 reduction をはじめ類似のいくつかの方法を 組み合わせてその構造を組織的に研究することができる
※ 硬化時 間につ いては 使用材 料によ って異 なるの で使用 材料の 特性を 十分熟 知する こと
および皮膚性状の変化がみられる患者においては,コ.. 動性クリーゼ補助診断に利用できると述べている。本 症 例 に お け る ChE/Alb 比 は 入 院 時 に 2.4 と 低 値
