大規模推測における最適なランキングと選択の方法:ベイズ流階層混合モデリングの応用
14
0
0
全文
(2) 方法として広く用いられているようになって. であり, この混合構造を適切にモデル化するた. いる (佐藤 他, 2018). 一方で, スクリーニング. めに, null/nonnull の混合分布モデルを用いた. を行った後の詳細な評価を行う研究には, コス. ベイズ流の方法が発展してきた (Efron, 2004,. ト・リソースの制約があることも多く, 検定に. 2008, 2010; Efron & Tibshirani, 2002; Efron et. よる有意性の評価よりも, 少数の特に重要な要. al., 2001; Storey, 2002, 2003). ベイズ流の方法. 因に絞り込みを行うことが有用なストラテジー. においては, モデルの著しい誤特定が推測に与. となることも多い. このようなケースでは, 重. える影響は大きく, 効果サイズの分布の真の構. 要度・優先順位に基づくランキングと選択が,. 造がそのような混合分布の構造になっている. ひとつの目的に適った方法となる. 最適なラ. 場合に, それを無視した単純な構造のモデルを. ンキング・選択の方法は, 特に, ベイズ, 経験ベ. 用いた解析を行うと, R 値によるランキングの. イズ法の枠組みにおいて, 古くから広く研究さ. 正確性も大きく損なわれる可能性がある. そこ. れており, 多くの有用なアプローチが提案され. で, 本研究では, このような大規模推測におけ. ている (Gelman & Price, 1999; Henderson &. る, より有効な実践的枠組みとして, ベイズ流. Newton, 2016; Laird & Louis, 1989; Lin et al.,. 階層混合モデリングを用いた R 値によるランキ. 2006; Noma & Matsui, 2013a, c; Noma et al.,. ングと選択の方法を議論する. 特に, 分布モデ. 2010; Shen & Louis, 1998; Wright et al., 2003).. ルの誤特定を避け, 柔軟なモデル化を可能とす. この中でも, 特に, 近年, Henderson & Newton. るために, Laird (1978), Laird & Louis (1991). (2016) によって提案された R 値 (r-value) は,. によるノンパラメトリック最尤法をもとにし. P 値, Q 値に類する, 正確なランキングと選択. たセミパラメトリック階層混合モデル (Noma. を行うための新たな指標であり, 前述のような. & Matsui, 2013b, c) を用いた経験ベイズ推測. 大規模データの解析において, 正確な推測を行. 手法を用いることを提案する. 加えて, M. D.. うためのひとつの有用な統計指標となることが. Anderson Cancer Center で行われた乳がんの. 期待される.. 臨床研究 (Hatzis et al., 2011) を事例として,. 一方で, Henderson & Newton (2016) で扱わ. 提案する方法の有用性の評価を行う.. れている解析事例では, 単純な共役モデルなど のみが扱われており, 前述の医学・生物学にお. 2.. Henderson-Newton による一致性の基 準と最適なランキング, 選択の方法. ける事例でも, 共役モデルによる 2 型糖尿病の ゲノムデータの解析例が議論されている. しか. 大規模推測において, 効果サイズの大きさに. しながら, Efron (2008, 2010) で議論されてい. 基づく正確なランキングと選択の方法を与える. るように, ゲノム・オミックス研究など, これら. ために, Henderson & Newton (2016) は, 後述. の大規模推測が対象とする多くの研究では, 対. する一致性 (agreement) の基準を最大化する. 象となるユニットのうち, 大多数のものが「効. 閾値関数の族を与えている. いま, ランキング. 果サイズがゼロ (null)」であり, 相対的に少数の. を行う推測の対象となるユニットが m 個存在. ものが「効果サイズが非ゼロ (nonnull)」である. するものとして, 実数値をとるこれらのユニッ. という構造が想定される. むしろ, 前述の多重. トごとのランキングの基準となるパラメータ. 検定の方法論の研究では, この少数の nonnull. を θi (i = 1, 2, . . . , m), ランキングに用いられ. であるユニットを正確に選択することが目的. る適当な統計量を Yi (i = 1, 2, . . . , m) とする.. — 106 —.
(3) 2 段階の階層ベイズモデルとして, Yi の確率密. ラメータ θi が上位 α の割合に含まれることの. 度関数を p(y|θi , ηi ), θ1 , . . . , θm は交換可能で. 同時確率を最大化する基準であり, I∗ がそれを. あるとし, その事前分布を F (θ), ηi をモデル中. 達成する閾値関数の族となる.. の局外パラメータとする. 4 節で議論する乳が. この最適な閾値関数族は, 以下のように与え. んの臨床研究を例とすると, Affymetrix U133A. られる. θi の事後分布の裾野確率 Vα (Yi , ηi ) =. GeneChip (Affymetrix, Santa Clara, Califor-. Pr(θi ≥ θα |Yi , ηi ) に対して, 次の制約を任意の. nia) によって, 22283(= m) 種類のプローブに. α について満たす λα が存在するとする.. おいて遺伝子発現データが測定されており, 化 学療法による腫瘍の縮小 (あり, なし) をアウ トカム, 遺伝子発現データを説明変数とした単 変量ロジスティック回帰モデルにおける回帰係 数 (対数オッズ比) が θi となる. Yi はその最尤. Pr(Vα (Yi , ηi ) ≥ λα ) = α このとき, Henderson & Newton (2016) は, 次 の閾値関数の族が, この一致性の基準を達成す るものとなることを示した.. 推定量などとなる. ここでは, 特に, θi の絶対. t∗α (η) = inf{y : Vα (y, η) ≥ λα }. 値が大きな遺伝子が, 化学療法への個々人の反. この閾値関数から計算される閾値は, 一定の正. 応性に関連する遺伝子の候補として関心の対象. 則条件のもとで, 次式により α のスケールに逆. となり, 後続の詳細な評価のために, θi の大き. 算することができる.. さに基づく正確なランキングを行うことが目的 となる.. r(Yi , ηi ) = inf{α : Vα (Yi , ηi ) ≥ λα } Henderson & Newton (2016) は, ランキングの. Henderson & Newton (2016) は, まず, 正確 なランキングを与えるための基準として, 閾値 関数の族 I = {tα : α ∈ (0, 1)} を定義した. こ. こで tα は, Yi ≥ tα (ηi ) である場合, および, そ. の場合に限り, ユニット i が上位 α の割合にラ. 基準の変数として, この指標を R 値と定義して いる. ユニット i が, Vα (Yi , ηi ) によるランキン グによって上位 α の位置にあるとき, R 値にお いても上位 α の位置にあることになる. R 値 によるランキングおよび選択は, ベイズ決定理. ンクインすることを規定する閾値関数 tα (η) で. 論の観点からも, 上位 α の割合のユニットの誤. ある. つまり, 任意の α ∈ (0, 1) に対して, サ. 分類損失関数に基づくベイズルール, あるいは,. イズ制約 (size constraint) Pr(Yi ≥ tα (ηi )) = α. 制約付きベイズルールとして導かれている.. における最適な関数族を, Henderson & Newton. 3.. が存在する. この制約のもとで, 閾値関数族 I. (2016) は, 不等式 Pr(Yi ≥. 階層混合モデリングによるベイズ推測 前節で述べた通り, R 値は θi の事後分布から. t∗α (ηi ), θi. 定義される指標であるため, R 値によるランキ. ≥ θα ) ≥. ング・選択においては, 事後分布そのものがそ. Pr(Yi ≥ tα (ηi ), θi ≥ θα ) を満たす I∗ = {t∗α } として定義している. ただ. し θα は, 事前分布の上側 α クォンタイルであ り, Pr(θi ≥ θα ) = α である. 先述の一致性の. 基準とは, 任意の α に対して, 上記の i 番目の ユニットが上位 α の割合に含まれることと, パ. の正確性に影響を与えることは明らかである. すなわち, 効果サイズの分布に対応する事前分 布 F (θ) のモデルの妥当性が結果に大きな影 響を与えることとなる. Henderson & Newton. (2016) で議論されている事例では, F (θ) が共. — 107 —.
(4) 役分布などの単純な事前分布モデルであること. つユニットの θi の分布を表しており, 一般的. を前提としている. しかしながら, Efron (2008,. に, 0 以外の領域に値をとる確率分布となる.. 2010) で議論されているように, ゲノム・オミッ. Efron (2008) では, π0 ≥ 0.90 と想定されるよ. クス研究などの応用では, これらの大規模推測. うな事例を扱っているが, そのようなケースで,. が対象とする多くの研究において, 対象となる. この混合分布の構造を無視して, 事前分布に単. m 個のユニットのうち, 大多数のものが「効. 純な正規分布モデルなどを用いて経験ベイズ推. 果サイズがゼロ」であり, 相対的に少数のもの. 測を行うと, 大部分を占める null なユニットの. が「効果サイズが非ゼロ」であると想定される.. 影響によって, 事前分布は 0 の周辺に強く縮小. 従来の多重検定手法では, この混合構造を適切. した分布になってしまう可能性が高い. その事. にモデル化するために, null/nonnull の混合分. 前分布を推測に用いてしまうと, 個々のユニッ. 布モデルが広く用いられてきた (Efron, 2004,. トの事後分布も 0 の周辺に過剰に縮小推定され. 2008, 2010; Efron & Tibshirani, 2002; Efron et. てしまうリスクがある. これによって, 事後分. al., 2001; Storey, 2002, 2003).. 布に基づくランキング・選択も不正確なものに. 本研究では, 以下のセミパラメトリック階層. なる可能性が生じる. また, 特に関心がある効. 混合モデル (Noma & Matsui, 2013b, c) を用. 果サイズが上位のユニットについては, この過. いる. ここでは, 一般性を失うことなく, 4 節. 小推定の影響は大きく, 効果サイズの推定自体. の事例に合わせて, Yi を対数オッズ比, 対数ハ. に大幅な過小推定のバイアスが入ることにな. ザード比などの要約指標の推定量として, その. る. 上記の階層混合モデルを用いることによっ. 分布モデルを正規分布であることにするが, 以. て, より正確なランキング・推測を行うことが. 降の議論は, 2 項分布やポアソン分布などの場. 可能になることが期待できる.. 合にも同様に適用することができる.. Yi ∼ N(θi , σi2 ). また, nonnull の分布 F1 (θ) については, パラ. (3.1). メトリックモデルを用いることも可能である が, 分布形の誤特定のリスクを回避するため,. θi ∼ π0 F0 (θ) + π1 F1 (θ). ここでは, ノンパラメトリックモデルによっ. (i = 1, . . . , m). てモデル化を行うことを考える. 本研究では,. ここで, σi2 は既知として扱い, その適当な推. Laird (1978) によるノンパラメトリック最尤法. 定値などで置き換えるものとする (前節にお. の近似計算法として, smoothing-by-roughening. ける ηi に対応). θi の事前分布は, null の分. (SBR) 法 (Laird & Louis, 1991; Shen & Louis,. 布 F0 (θ) と nonnull の分布 F1 (θ) の混合分布. 1999) を用いる. SBR 法による F1 (θ) のモデル. であるとして, それぞれのコンポネントの比率. として, 以下の a を実現値とする離散分布を仮. は, π0 , π1 であるとする (π0 + π1 = 1). Efron. 定する.. (2008, 2010) などによる混合分布モデルによる. a = (a1 , a2 , . . . , aL ),. 枠組みでは, null のコンポネントの分布 F0 (θ). a1 < a2 < … < aL ,. は, 検定における帰無仮説のもとでの効果サイ ズの分布に対応し, ここでは, 0 にのみ値をと. al ̸= 0 (l = 1, 2, . . . , L).. る一点分布 δ0 (θ) とする. 一方, nonnull のコ. ここで, a は θi の実現値が存在する範囲を十分. ンポネント F1 (θ) は, 非ゼロの効果サイズを持. にカバーすると考えられる領域に密に配置した. — 108 —.
(5) 等間隔のグリッドである. Lは十分大きい数に 設定することが望ましい (Shen & Louis (1999) では, L > 200 とすることが推奨されている). このとき,. Vα (Yi , σi2 ) = Pr(θi ≥ θα |Yi , σi2 ) を用いて, r(Yi , σi2 ) = inf{α : Vα (Yi , σi2 ) ≥ λα } と逆算することができる. 加えて, Efron (2008,. 2010), Storey (2002, 2003) の混合分布モデル. Pr(θi = aj ) = pj (j = 1, 2, . . . , L). の枠組みによって, 階層混合モデルに基づく R. と し た 分 布 モ デ ル が SBR の モ デ ル で あ る. 値によるランキングに対して, null のユニット. (p1 + p2 + · · · + pL = 1). グリッドを密に. がどの程度, 誤って選択されているかについて,. 配置することによって, 任意の確率分布を離散. FDR の推定を行うことも可能となる. いま, 上. 分布で近似することを目的としたノンパラメ. 位K 位までのユニットの添え字集合をG とする. トリックモデルとなっている. 経験ベイズ法を. と, そのユニットの集合における FDR の推定. 行う際には, この事前分布を EM アルゴリズム. 量は,. (Dempster et al., 1977) で推定すればよい. ア. FDR =. ルゴリズムの詳細については, 付録に記載する. 事後分布も同じく null/nonnull ともに, 0 お よび a に値をとる離散分布となる. まず, i番 目のユニットが, それぞれのコンポネントに属. i∈G. となる (McLachlan et al., 2006).. 4.. する事後確率は, 以下のように表される.. Pr(i ∈ Ξ0 |Yi ) = π0 ϕ. (. yi σi. ). (. yi σi. 1 ∑ Pr(i ∈ Ξ0 |Yi ) K. 事例解析:乳がんの臨床研究への応用. Hatzis et al. (2011) は, 浸潤性乳がんにお ける患者の術前化学療法に対する治療反応性. ). の予測を目的として, M. D. Anderson Cancer. π0 ϕ ( ) ∑L l + l=1 π1 pl ϕ yiσ−a i. Center で行われた前向きの多施設研究である. 浸潤性乳がんと診断された患者に対して, 腫. Pr(i ∈ Ξ1 |Yi ) = 1 − Pr(i ∈ Ξ0 |Yi ). 瘍組織における遺伝子発現解析を Affymetrix. ここで, Ξ0 , Ξ1 はそれぞれ null, nonnull のコン. U133A GeneChip によって行っている. プロー. ポネントに属するユニットの添え字集合であ. ブの数は, 22283(= m) であり, 腫瘍縮小につ. る. Null のコンポネントは, 0 にのみ値をとる. いてのアウトカムには, RCB (residual cancer. 一点分布となるが, nonnull のコンポネントは,. burden) による基準が用いられている. ここで. 事前分布と同じく a を実現値とする離散分布. は, 完全奏功または RCB-I を「反応あり」とし,. となり,. RCB-II/III を「反応なし」とする. それぞれ86 pj ϕ. Pr(θi = aj │ Yi ) = ∑ L. l=1. (. yi −aj σi. pl ϕ. (. ). yi −al σi. 人, 215人の患者がこれに該当した. この腫瘍縮 小についてのアウトカムを結果変数とし, それ. ). ぞれの遺伝子発現データを説明変数とした単変. となる. ただし, ϕ(·) は標準正規分布の密度. 量ロジスティック回帰モデルにおける対数オッ. 関数である. この事後分布を用いて, 事後平. ズ比の最尤推定量 Yi とその分散の推定値 σi2. 均, 信用区間 (経験ベイズ法の場合には信頼. によって, 3 節のモデル (3.1) の尤度モデルを. 区間) などの推測を行うことができる. また,. 定義する. SBR モデルのグリッドは,. R 値の計算は, この事後分布全体に対しての. a = (−2.50, −2.49, . . . , −0.01, 0.01, . . . , 2.50). — 109 —.
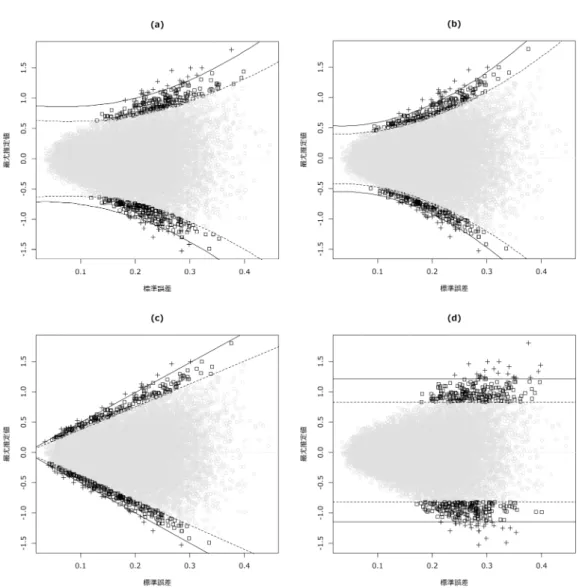
(6) に配置することとした. EM アルゴリズムに. はそれぞれ対数オッズ比の最尤推定値および標. よって, 事前分布の推定を行ったところ, non-. 準誤差を表している. また実線および点線は,. null コンポネント F1 (θ) の推定結果は, 図 1 の. 各指標においてそれぞれ対数オッズ比の絶対値. ようになった. π ˆ0 = 0.436, π ˆ1 = 0.564 であり,. が上位0.1%および1.0%と判定される境界を表. 相応数の治療反応性に関連する遺伝子が存在. している. 以降, 本段落では, 図 2 の結果とそ. することが示唆された. また効果サイズについ. の解釈について記す. それぞれの指標により,. ても, オッズ比が 2 倍以上となる遺伝子が存在. 上位にランクインする遺伝子は大きく異なる. θi. することが示唆されており (e がオッズ比とな. ことがわかる. これまでの研究によって, 最尤. る), かなり関連の強い遺伝子が一定の割合で存. 推定値によるランキングは, 相対的にサンプル. 在すると考えられる. ここでは, 特に, この分布. サイズが小さい設定では, 個々のユニットごと. の裾野領域に存在するであろう, 効果サイズが. の推定値のばらつきが大きく, 標準誤差が大き. 最も大きな遺伝子を正確にランキングし, スク. な遺伝子が, 偶然の誤差で上位にランクインす. リーニングすることが目的となる.. る傾向にあることが知られており (Henderson. & Newton, 2016; Laird & Louis, 1989; Noma et al., 2010), 今回の事例でも, 標準誤差が大き なものが上位にランクインしている. また, P 値によるランキングでは, 検定統計量が最尤推 定値と標準誤差の比によって構成されるため, 単純に, その比の絶対値の大きさによって決定 する. あくまでも「対数オッズ比が 0 」という 帰無仮説に対しての検定の有意性の指標によ るランキングとなるため, 必ずしもオッズ比の 大きさによって選択を行う際の最適なランキ ングになるわけではない (Noma et al., 2010). 一方, R 値によるランキングは, 2 節での一致 性の基準から最適なランキングを与えるため,. (a), (b) で与えられているランキングは, 事前. 図 1 : 効果サイズの分布 F1 (θ) の SBR 推定値. 分布によって効果サイズの分布が正しく特定さ 図 2 に, (a) 階層混合モデル (3.1) による R 値, (b) 階層モデル (3.1) の事前分布に自然共 役な正規分布を仮定したモデルによる R 値, (c) 上述した単変量ロジスティック回帰モデルの回 帰係数 (対数オッズ比) の検定による P 値, (d) 同じく上述した単変量ロジスティック回帰モデ ルの対数オッズ比の最尤推定値によるランキン グの結果を示している. 図中の各点は, それぞ れのプローブに対応しており, 縦軸および横軸. れていれば, 経験ベイズ法により, 正確なラン キングを与えてくれることが期待できる. R 値 によるランキングは, 事前分布の型により, (a),. (b) で一定の相違があることがわかる. ベイズ モデルによる推測の縮小効果によって, いずれ も, 最尤推定値が単純に大きな遺伝子でも, 標 準誤差が大きなものについては, 順位は下がる. 正規分布モデルは, 効果サイズが 0 の null な遺 伝子 (最尤推定の結果からは, 半数近く存在す. — 110 —.
(7) 図 2 : それぞれの指標において上位0.1%, 1.0%と判定された遺伝子:(a) 階層混合モデルに基づく R 値, (b) 正 規分布モデルに基づく R 値, (c) 単変量ロジスティック回帰による対数オッズ比の検定の P 値, (d) 対数 オッズ比の最尤推定値 (上位0.1%は+, 上位1.0%は □ でプロットされている).. る) と nonnull な遺伝子の対数オッズ比を, ひ. 実際に, 階層混合モデルと正規分布モデルで,. とつの正規分布に従う交換可能なパラメータと. 上位にランクインした遺伝子の推測結果を, 表. 仮定して推定をしているので, null の方向へよ. 1 , 2 にそれぞれ示す. 以降, 本段落では, 表 1 ,. り強く縮小効果がかかり, 標準誤差が大きなユ. 2 の結果とその解釈について記す. 医学的・生. ニットの順位が相対的に下がる傾向が認められ. 物学的に, 特に関心が持たれるのは, 上位の比. る. 一方で, この混合構造をモデル化している. 較的少数の遺伝子となるが, やはりモデル化の. 階層混合モデルによるランキングでは, 縮小効. 方法の違いによって, R 値のランキングにも一. 果がやや弱まり, 対数オッズ比の推定値の絶対. 定の違いが認められることがわかる. 図 1 に. 値が大きなものが上位にランクインしやすい傾. 示した上位0.1%の遺伝子が, 概ねこれらのリス. 向がある.. トと重複することとなるが, 階層混合モデルの. — 111 —.
(8) probe. 221864 at 221934 s at 200718 s at 209747 at 218937 at 203538 at 203073 at 217892 s at 203792 x at 208865 at 214109 at 200711 s at 218483 s at. 順位. 1 2 3 4 5 6 7 8 9 10 11 12 13. 5.93×10−5 5.93×10−5 9.45×10−5 1.45×10−4 2.13×10−4 3.03×10−4 3.03×10−4 4.18×10−4 4.18×10−4 4.18×10−4 5.60×10−4 5.60×10−4 5.60×10−4. R値 1.46 1.28 1.50 1.13 1.80 1.14 1.50 1.09 1.07 1.35 1.10 1.20 1.29. (0.94, (0.80, (0.91, (0.71, (1.06, (0.69, (0.87, (0.67, (0.66, (0.77, (0.66, (0.69, (0.74,. 1.98) 1.75) 2.09) 1.54) 2.54) 1.60) 2.13) 1.51) 1.49) 1.93) 1.53) 1.71) 1.84). 最尤推定値 (95% CI). 4.57×10−8 1.19×10−7 6.59×10−7 9.37×10−8 1.64×10−6 8.53×10−7 3.24×10−6 3.51×10−7 3.46×10−7 4.86×10−6 8.04×10−7 3.37×10−6 4.46×10−6. P値 0.80 0.79 0.77 0.79 0.72 0.76 0.73 0.77 0.77 0.73 0.76 0.74 0.73. (0.48, (0.46, (0.34, (0.47, (0.14, (0.41, (0.16, (0.43, (0.43, (0.17, (0.41, (0.23, (0.18,. 0.96) 0.95) 0.95) 0.95) 0.94) 0.94) 0.94) 0.94) 0.94) 0.94) 0.94) 0.94) 0.94). 階層混合モデル. 0.46 0.46 0.40 0.48 0.34 0.43 0.36 0.45 0.45 0.37 0.44 0.39 0.38. (0.16, (0.17, (0.09, (0.21, (0.02, (0.15, (0.05, (0.18, (0.19, (0.06, (0.16, (0.10, (0.08,. 0.75) 0.74) 0.70) 0.75) 0.66) 0.71) 0.67) 0.72) 0.72) 0.67) 0.71) 0.68) 0.68). 正規分布モデル. 事後平均 (95% CI). 表 1: 階層混合モデルに基づく R 値によるランキングでの上位遺伝子. 2.91×10−5 2.71×10−5 1.03×10−4 7.95×10−5 3.25×10−4 2.82×10−4 3.55×10−4 3.13×10−4 2.81×10−4 3.17×10−4 2.93×10−4 2.91×10−4 3.06×10−4. FDR. . . — 112 —.
(9) probe. 221864 at 209747 at 221934 s at 205201 at 203792 x at 217892 s at 208517 x at 214109 at 203538 at 212638 s at 222125 s at 222275 at 214053 at. 順位. 1 2 3 4 5 6 7 8 9 10 11 12 13. 5.25×10−5 5.25×10−5 1.02×10−4 1.58×10−4 1.95×10−4 2.40×10−4 2.95×10−4 3.61×10−4 3.61×10−4 4.41×10−4 5.37×10−4 5.37×10−4 6.51×10−4. R値 1.46 1.13 1.28 0.97 1.07 1.09 1.06 1.10 1.15 0.80 0.97 1.09 0.74. (0.94, (0.71, (0.80, (0.61, (0.66, (0.67, (0.65, (0.66, (0.69, (0.50, (0.58, (0.65, (0.47,. 1.98) 1.54) 1.75) 1.32) 1.49) 1.51) 1.48) 1.53) 1.60) 1.11) 1.35) 1.53) 1.01). 最尤推定値 (95% CI). 4.57×10−8 9.37×10−8 1.19×10−7 1.06×10−7 3.46×10−7 3.51×10−7 6.48×10−7 8.04×10−7 8.53×10−7 3.02×10−7 1.13×10−6 1.22×10−6 1.16×10−7. P値 0.80 0.79 0.79 0.76 0.77 0.77 0.76 0.76 0.76 0.70 0.74 0.75 0.67. (0.48, (0.47, (0.46, (0.45, (0.43, (0.43, (0.42, (0.41, (0.41, (0.40, (0.40, (0.39, (0.39,. 0.96) 0.95) 0.95) 0.93) 0.94) 0.94) 0.94) 0.94) 0.94) 0.90) 0.93) 0.94) 0.88). 階層混合モデル. 0.46 0.48 0.46 0.48 0.45 0.45 0.44 0.44 0.43 0.46 0.44 0.43 0.46. (0.165, (0.207, (0.175, (0.229, (0.186, (0.182, (0.172, (0.161, (0.151, (0.226, (0.176, (0.151, (0.246,. 0.752) 0.746) 0.742) 0.731) 0.724) 0.724) 0.714) 0.711) 0.710) 0.690) 0.699) 0.704) 0.679). 正規分布モデル. 事後平均 (95% CI). 表 2: 正規分布モデルに基づく R 値によるランキングでの上位遺伝子. . . . . — 113 —.
(10) ほうが, 標準誤差に対するペナルティが相対的. 医学・生物学に限らず, スポーツ科学などの事. に弱く, 対数オッズ比の絶対値が大きな遺伝子. 例なども含まれており, 階層混合モデルによる. が特に上位に挙がっている. しかしながら, 縮. アプローチが必ずしも有効でないケースも多く. 小効果は機能しており, 最尤推定値と標準誤差. あると思われるが, 4 節で示した乳がんの臨床. の大きさのトレードオフによってランキング. 研究のように, ゲノム・オミックスデータなど. は決まっている. また, 最尤推定値や P 値によ. を用いた大規模データの解析などでは, このモ. るランキングとも, まったく異なる遺伝子が上. デリングのストラテジーは有効であると思われ. 位にランクインしている. 加えて, 対数オッズ. る. 混合モデルを用いることで, 上位のユニッ. 比の点推定値に対応する事後平均を比較して. トの選択における FDR の情報を付与すること. みると, より明確な違いを見て取ることができ. も可能であり, 実践的なデータ解析には明確な. る. 正規分布モデルでは, 事前分布が過度に縮. 利点があると思われる. 本稿では, R 値による. 小される傾向にあり, 事後平均の値が null の方. ランキングの方法にフォーカスして議論を行っ. 向により強く縮小されている. 階層混合モデル. たが, この他にも Laird & Louis (1989), Lin et. では, 少なくとも, null/nonnull の混合分布の. al. (2006), Noma et al. (2010) などでは, 順位. 構造がモデル化されているため, 縮小の程度は. 統計量の事後平均など, さまざまな基準に基づ. より控えめである. 経験ベイズ推定量の最適性. くランキングの方法が提案されている. Noma. は, 交換可能な事前分布が, 真のパラメータの. et al. (2010) によるシミュレーション実験で. 分布に一致しているときに担保されるため, 真. は, 事後分布の裾野確率を用いたランキング法. の構造により近いモデルのほうが, より正確な. は, 上位のユニットの選択確率は高いが, 誤っ. 推定値を与える. 区間推定に関しても同様で,. て下位のユニットをランダム誤差によって上位. 両者の経験ベイズ信頼区間は明確に異なる. 加. にピックアップしてしまうリスクが高く, 相対. えて, 3 節で述べた通り, 階層混合モデルによ. 的に不安定なランキング手法であることが示. る解析では, 上位遺伝子の FDR の推定値の情. されている. Henderson & Newton (2016) も,. 報を付与することができるため, 後続の研究の. これらの利用可能な手法間の比較などは十分. ための選択を行う際に, 偽陽性の誤分類の情報. に行っておらず, R 値によるランキングそのも. を, 参考情報として付与することができる. 今. のの実践的な有用性については, 今後の研究に. 回の事例では, 腫瘍縮小と関連の強い遺伝子の. よって, より詳細な評価を行う必要があるとい. 数が相対的に大きく, 上位数十位までの遺伝子. えるであろう. また, 本稿では, Henderson &. には, 偽陽性のものが混入するリスクは低いと. Newton (2016) の議論の枠組みのもと, 片方向. 解釈してよいであろう.. の R 値について議論を行ったが, オッズ比など の指標の絶対値の順位を対象とした両方向の指. 5.. まとめ. 標にも, これらの方法は同様に適用することが. 本稿では, 大規模データ解析において, 新た に提案されたランキングの指標である R 値を. できると予想される. これらの問題は, 今後の 重要な課題として, 稿を改めて議論したい.. 用いた解析に対して, ベイズ流階層混合モデル を応用することについて議論した. Henderson. A. EM アルゴリズム. & Newton (2016) が扱っている解析事例には,. — 114 —. 3 節における階層混合モデルの事前分布の.
(11) 超パラメータの最尤推定値は, 以下の EM アル. plete data via the EM algorithm. Journal. ゴリズムによって求めることができる. ν 回目. of the Royal Statistical Society, Series B,. (ν) (ν) の反復計算における更新値をπ0 , π1 , p(ν) ( ) (ν) (ν) p1 , . . . , pL とする.. 39, 1–38.. (ν). τ0,i. =. Efron, B. (2004). Large-scale simultaneous hy-. ( ) (ν) π0 ϕ σyii ( ) ∑ ) ( = (ν) (ν) (ν) L l π0 ϕ σyii + l=1 π1 pl ϕ yiσ−a i. とすると, M-step における更新式は,. pothesis testing: The choice of a null hypothesis. Journal of the American Statistical Association, 99, 96–104. Efron, B. (2008). Microarrays, empirical Bayes and the two-groups model. Statistical Sci-. m. (ν+1) π0. 1 ∑ (ν) = τ0,i , m. ence, 23, 1–22.. i=1. (ν+1). π1. (ν+1). pj. Efron, B. (2010). Large-Scale Inference: Em-. (ν+1). =1 − π0 , ) ( ) / ( m 1 − τ (ν) p(ν) ϕ yi −aj ∑ 0,i j σi ( ) = ∑L p(ν) ϕ yi −al i=1 l=1 l σi {m } ) ∑( (ν) 1 − τ0,i. pirical Bayes Methods for Estimation, Testing, and Prediction. Cambridge University Press. Efron, B. & Tibshirani, R. (2002). Empirical Bayes methods and false discovery rates. i=1. for microarrays.. となる (j = 1, 2, . . . , L). π0 , π1 の初期値には,. Genetic Epidemiology,. 23, 70–86.. Storey (2002) の推定方法などによる推定値を. Efron, B., Tibshirani, R., Storey, J. D. &. 用いることができる. p の初期値は, 離散一様. Tusher, V. (2001). Empirical Bayes analy-. 分布などを用いればよい (Shen & Louis, 1999).. sis of a microarray experiment. Journal of the American Statistical Association, 96,. 謝辞. 1151–1160.. 本研究は, 独立行政法人科学技術振興機構. Gelman, A. & Price, P. N. (1999). All maps. CREST (課題番号 JPMJCR1412), 国立研究開. of parameter estimates are misleading.. 発法人日本医療研究開発機構革新的がん医療実. Statistics in Medicine, 18, 3221–3234.. 用化研究事業 (課題番号 17CK0106266) の助成. Hatzis, C., Pusztai, L., Valero, V., et al.. を受けた.. (2011).. A genomic predictor of re-. sponse and survival following taxane参考文献. anthracycline chemotherapy for invasive. Benjamini, Y. & Hochberg, Y. (1995). Con-. breast cancer. Journal of the American. trolling the false discovery rate: A prac-. Medical Association, 305, 1873–1881.. tical and powerful approach to multiple. Henderson, N. C. & Newton, M. A. (2016).. testing. Journal of the Royal Statistical. Making the cut: Improved ranking and. Society, Series B, 57, 289–300.. selection for large-scale inference. Jour-. Dempster, A. P., Laird, N. M. & Rubin, D. B. (1977). Maximum likelihood from incom-. — 115 —. nal of the Royal Statistical Society, Series B, 78, 781–804..
(12) Laird, N. (1978). Nonparametric maximum. Noma, H., Matsui, S., Omori, T. & Sato, T.. likelihood estimation of a mixing distribu-. (2010).. tion. Journal of the American Statistical. methods using hierarchical mixture mod-. Association, 73, 805–811.. els in microarray studies.. Laird, N. M. & Louis, T. A. (1989). Empirical Bayes ranking methods. Journal of. Bayesian ranking and selection Biostatistics,. 11, 281–289. 佐藤孝明・榊 佳之・松原謙一 (監修) (2018). プレシジョン・メディシン:ビッグデータ. Educational Statistics, 14, 29–46.. の構築・分析から臨床応用・課題まで. エ. Laird, N. M. & Louis, T. A. (1991). Smooth-. ヌ・ティー・エス.. ing the non-parametric estimate of a prior distribution by roughening: A computa-. Shen, W. & Louis, T. A. (1998). Triple-goal. tional study. Computational Statistics &. estimates in two-stage hierarchical mod-. Data Analysis, 12, 27–37.. els. Journal of the Royal Statistical Society, Series B, 60, 455–471.. Lin, R., Louis, T. A., Paddock, S. M. & Ridgeway, G. (2006). Loss function based. Shen, W. & Louis, T. A. (1999). Empirical. ranking in two-stage, hierarchical models.. Bayes estimation via the smoothing by. Bayesian Analysis, 1, 915–946.. roughening approach. Journal of Computational and Graphical Statistics, 8, 800–. McLachlan, G. J., Bean, R. W. & Jones, L.. 823.. B-T. (2006). A simple implementation of a normal mixture approach to differential. Storey, J. D. (2002). A direct approach to false. gene expression in multiclass microarrays.. discovery rates. Journal of the Royal Sta-. Bioinformatics, 22, 1608–1615.. tistical Society, Series B, 64, 479–498. Bayesian. Storey, J. D. (2003). The positive false dis-. ranking and selection methods in microar-. covery rate: A Bayesian interpretation. ray studies.. and the q-value. Annals of Statistics, 31,. Noma, H. & Matsui, S. (2013a).. In Statistical Diagnostics. 2013–2035.. for Cancer: Analyzing High-Dimensional Data (Emmert-Streib, F. & Dehmer, M.. Wright, D. L., Stern, H. S. & Cressie, N. (2003). Loss functions for estimation of. (Eds.)), Wiley-VCH, 57–74. Noma, H. & Matsui, S. (2013b). An empirical. extrema with an application to disease. Bayes optimal discovery procedure based. mapping. Canadian Journal of Statistics,. on semiparametric hierarchical mixture. 31, 251–266.. models. Computational and Mathematical (2019年 7 月23日受付, 2020年 8 月28日採択). Methods in Medicine, 2013, 568480. Noma, H. & Matsui, S. (2013c). Empirical Bayes ranking and selection methods via semiparametric hierarchical mixture models in microarray studies.. Statistics in. Medicine, 32, 1904–1916.. — 116 —.
(13) OPTIMAL RANKING AND SELECTION FOR LARGE-SCALE INFERENCE: APPLICATION OF BAYESIAN HIERARCHICAL MIXTURE MODELING Naohiro Kato∗ , Hisashi Noma∗∗ and Kengo Nagashima∗∗∗ ∗. Department of Statistics, Radiation Effects Research Foundation, 5-2 Hijiyama Park, Minami-ku, Hiroshima 732-0815, Japan. ∗∗. Department of Data Science, The Institute of Statistical Mathematics, 10-3 Midori-cho, Tachikawa, Tokyo 190-8562, Japan ∗∗∗. Research Center for Medical and Health Data Science, The Institute of Statistical Mathematics,. 10-3 Midori-cho, Tachikawa, Tokyo 190-8562, Japan. Identifying the most relevant or interesting units is a common task in large-scale statistical inference. Recently, Henderson & Newton (2016; Journal of the Royal Statistical Society, Series B, 78, 781–804) proposed a new ranking measure named r-value to achieve optimal ranking in Bayesian inference. The r-value depends on the assumed Bayes model and its ranking accuracy can be violated by model misspecification. In medical and biological studies, large-scale candidate variables often consist of a mixture of null (the effect sizes are zero; non-interesting units) and nonnull (the effect sizes are non-zero; interesting units) components, e.g., for genome-wide association studies. In this article, to provide accurate ranking outputs, we propose to apply the Bayesian hierarchical mixture modeling for the ranking and selection inferences. We also propose to use a semiparametric approach using Laird’s nonparametric maximum likelihood estimation in empirical Bayes inference. Using the mixture modeling, we can estimate false discovery rate (FDR) for the selected highly ranked units. We assess the effectiveness of the proposed method via an application to a breast cancer clinical study. Key words:. r-value, Empirical Bayes, False discovery rate, Genomics and omics studies, Non-. parametric maximum likelihood. — 117 —.
(14) .
(15)
図
関連したドキュメント
Economic and vital statistics were the Society’s staples but in the 1920s a new kind of statistician appeared with new interests and in 1933-4 the Society responded by establishing
適合 ・ 不適合 適 合:設置する 不適合:設置しない. 措置の方法:接続箱
[r]
EC における電気通信規制の法と政策(‑!‑...
日本における社会的インパクト投資市場規模は、約718億円と推計された。2016年度の337億円か
経験からモジュール化には、ポンプの選択が鍵を握ると考えて、フレキシブルに組合せ が可能なポンプの構想を図 4.15
(2号機) 段階的な 取り出し
(2号機) 段階的な 取り出し
