社団法人 電子情報通信学会
THE INSTITUTE OF ELECTRONICS,
INFORMATION AND COMMUNICATION ENGINEERS
信学技報
TECHNICAL REPORT OF IEICE.
Web
からの関係情報の抽出
辻下
卓見
†森
純一郎
††石塚
満
†††
東京大学工学部
〒 113–8656 東京都文京区本郷 7–3–1
††
東京大学大学院情報理工学系研究科
〒 113–8656 東京都文京区本郷 7–3–1
E-mail:
†{
tjstkm,jmori,ishizuka
}
@mi.ci.i.u-tokyo.ac.jp
あらまし 近年の Web における情報の爆発的な増加を受けて,Web から有用な情報や構造を抽出する Web マイニン
グに関する研究が盛んに行われてきている.本研究では,Web マイニングの一手法として,エンティティとエンティ
ティの間の関係をあらわすような情報を Web 上からキーワードとして自動的に抽出する手法を提案する.提案手法で
は同じ関係を持ったエンティティペアは同様の文脈で Web 上に表れるとの仮定に基づき,エンティティペアの出現文
脈を重要語でモデル化する.エンティティペアモデルをクラスタリングすることで,生成されたクラスターから関係
情報を抽出する.提案手法を用いた実験では政治家と地名のエンティティペアに対して適切な関係情報が抽出できる
ことを検証した.
キーワード 情報抽出,Web マイニング, 検索エンジン,エンティティペアモデル,クラスタリング
Extracting Relationships among Named Entities from the Web
Tsujishita TAKUMI
†, Junichiro MORI
††, and Mitsuru ISHIZUKA
†††
Faculty of Engineering, University of Tokyo
Hongo 7–3–1, Bunkyo-ku, Tokyo, 113–8656 Japan
††
Graduate School of Information Science and Technology, University of Tokyo
Hongo 7–3–1, Bunkyo-ku,
Tokyo, 113–8656 Japan
E-mail:
†{
tjstkm,jmori,ishizuka
}
@mi.ci.i.u-tokyo.ac.jp
Abstract
With the currently huge amount of information on the Web, Web mining methods that obtain useful
information and structures from the Web have been gained interest. We propose a novel Web mining method that
automatically extracts relational information among named entities from the Web. The basic idea is to cluster
similar pairs of named entities based on their contextual similarity on a Web document. Relational information
among named entityes is obtained from the result of clustering process. Our experiments conducting on entity pairs
of politicians and places achives clustering of the entity pairs with high recall and precision, and find appropriate
relational information among the entities.
Key words
Information Extraction, Web Mining, Search engine, Entity pair model, Clustering
1.
は じ め に
近年のWebにおける情報の爆発的な増加を受けて,Webか ら有用な情報や構造を抽出するWebマイニングに関する研究が 盛んに行われてきている.特に,検索エンジンを利用したWeb マイニング手法が注目されている.基本的な考え方は,検索エ ンジンにおけるヒット件数や検索結果のページを用いてある語 やフレーズがどの程度Web上で用いられているかの統計情報 を取得し有用な情報を抽出するというものである.検索エンジ ンを用いたWebマイニング手法は,Web全体を巨大なコーパ スと見なした言語処理であり,Webマイニングのみならず自然 言語処理やセマンティックWebなどさまざまな分野から多様 な応用が研究されてきている. 検索エンジンを用いたWebマイニングの一例として,エン ティティの自動抽出があげられる.エンティティ抽出とは,あ るWebページに出現する人名,地名や組織名などのエンティ ティをWeb上における出現パターンや頻度を元に自動で抽出 するものである[1]∼[4].また,人と人,組織と組織といったエ ンティティ間の関係,ネットワークをWebから抽出する研究 も行われている.松尾らは,氏名のWeb上における共起情報 から研究者間の関係をWebから自動的に抽出する手法を提案 している[5]. また,同様の手法で金らは企業間の関係をWeb から抽出する手法を提案している[6] 近年の社会ネットワー クへの関心の増大から,Web上における共起情報を用いてエンティティ同士の関係を抽出する手法は大きく着目されており, 他にもさまざまな研究がなされてきている[7]∼[10]. エンティティとエンティティのつながりが得られたときに, 興味深いことは,その関係に関するさらなる情報である.松尾 らは研究者間の関係を抽出する際に,その関係が共著,同所属 など研究上でどのような関係にあるのかを判別している.企業 間の関係抽出において金らは提携や訴訟などの関係を同定して いる.このように,関係を自動抽出する際に単に関係の強さだ けでなく,その関係の背後にある情報も含めて抽出することで, 関係構造だけでは浮かび上がってこない多様な意味づけと解釈 を社会ネットワークに与えることできる. 関係に関する情報はセマンティックWebにおいても重要であ る.セマンティックWebの語彙を表現するための枠組みである
RDF(Resource Description Framework)のメタデータのモ
デルは、トリプルと呼ばれる主語(subject)述語(predicate) 目的語(object)の三つの要素でリソースに関する関係情報を 記述する文からなる.トリプルは主語と目的語をノードとし述 語をラベルとしたエッジで結ぶことでネットワーク構造として も表現される.例えば,主語と目的語をそれぞれ,人と組織と いったエンティティすると,述語は「所属している」「社員であ る」といったエンティティ間のある関係をあらわす情報である. 以上のように,社会ネットワーク,セマンティックWebと いった現在のWebの流れにおいて,対象間の関係に関する情 報は,その重要性が増してきている.本研究では,人と組織, 人と地名,人と人といった,あるエンティティとエンティティ の間の関係をあらわすような情報を関係情報として,それらの 情報をWeb上からキーワードとして自動的に抽出する手法を 提案する.エンティティ間の関係を表す情報とは,例えば政治 家と地名というエンティテペアであれば,その政治家が元首, 出身,選出など地名とどのような関係にあるかをあらわすもの である.提案手法では同じ関係を持ったエンティティペアは同 様の文脈でWeb上に表れるとの仮定に基づき,エンティティ ペアをクラスタリングすることで関係情報を抽出することを行 う.抽出された関係情報は社会ネットワーク,セマンティック Webにおけるメタデータの自動生成,さらに情報検索や質問応 答などへの応用が考えられる. 以下,2章ではWebからの関係情報抽出の手法を述べる.3 章では実験について述べ,4章では評価を行う.5章において 提案手法の有効性と限界について議論を行い,最後に6章にお いてまとめを行う.
2.
Web
からの関係情報の抽出
関 係 情 報 の 抽 出 は 情 報 抽 出 タ ス ク の 一 つ と し て , MUC(Message Understanding Conference)に お け る Tem-plate Relation TaskやACE(Automatic Content Extraction) meetingsにおけるRelation Detection and Characterization などで扱われてきた.これらのタスクで対象とする関係とは 人物や組織などのエンティティ(注 1)間における所属,役割,位
(注 1):ACE における固有表現抽出タスクでは Person, Organization,
Fa-置,Part-Whole, 社会的関係を指すものであり,例えば,ACE
の関係抽出タスクにおいては場所の関係を表すlocated, near,
part-wholeや社会的関係を表すbusiness, familyや雇用関係を
表すexecutive, staffなどの関係が定義されている.例えば「日 本の小泉純一郎首相は...」という記述に対しては,PERSON エンティティである「小泉純一郎」とGPEエンティティ(注 2) で ある「日本」との関係である「首相」がエンティティ間の関係 を表すことになる. 2. 1 提案手法のアイデア あるエンティティとエンティティの関係情報をWebからどの ように抽出できるだろうか.ここで,例として,政治家 (PER-SON)と地名(GRE)という二つのエンティティ間にある関係 を抽出することを考えてみよう.政治家と地名での間には,そ の地名の出身,選挙区から選出された,その地名の首長,元首 などさまざまな関係が存在する.これらの関係はエンティティ とともにWeb上の文書に表れているはずである.エンティティ 間の関係を情報抽出する際の単純な方法として,エンティティ のペアがWebページ上で表れる箇所を調べて,関係を表すよ うな情報を見つけるといったものが考えられる. 表1は,”小泉純一郎AND日本”,”森善朗AND日本”,” 小泉純一郎AND 神奈川”,”森善朗AND石川”という4つ の検索クエリーそれぞれに対して得られた検索結果の上位ペー ジの文書から検索クエリーの近傍に出現する重要語を抽出した 結果である.ここで,得られた重要語群は,検索クエリーであ る政治家と地名のエンティティペアが出現する文脈をbag of wordsで単純に表したものとみなせる.なお,重要語の抽出に はtf idfを用いてスコアリングを行った. ”小泉純一郎AND日本”と”森善朗AND 日本”という検 索クエリーは,どちらも”首相”または”総理大臣”といった関 係を含む政治家と地名のエンティティペアであるが,それぞれ のエンティティペアに対して得られた重要語の中で共通してい る語を見てみると”首相”,”総理”,”内閣”といった関係を表 す語が共通して含まれていることがわかる.また,”小泉純一 郎AND神奈川”と”森善朗AND石川”は,どちらも政治家 と選挙区という関連を持つエンティティペアであるが,こちら も重要語として”選挙”,”首相”,”候補”,”議員”といった関 係を表すような語が共通して含まれている.一方,”小泉純一 郎AND日本”と”小泉純一郎AND 神奈川”に対するそれぞ れの重要語を見比べると,同一人物であるにもかかわらず”日 本”と”神奈川”という,クエリーにおける地名の違いにより, 異なる重要語が表れていることがわかる. 以上のことから,Webからのエンティティ間のの関係情報の 抽出において,「Web上に出現する文脈が類似しているエンティ ティのペアは類似した関係を持っている」という仮説を考える ことができる.文脈の類似性が意味的な類似性に寄与するとい う同様の仮説は従来研究においても指摘されいている[11]. こ
cility, Location, GPE, Vehicle, Weaponのエンティティが定義されてい る.
(注 2):GPE は Geo political entity であり地名を政治的な意味として用いら れるものである.
表 1 ”小泉純一郎 AND 日本”,” 森善朗 AND 日本”,” 小泉純一郎 AND 神奈川”,
”森善朗 AND 石川” の各検索結果の上位ページから tf idf によって得られた重要語
Table 1 Keyword list obtained from the search results with a search query: ”Junichiro Koizumi AND JAPAN”, “Yoshiro Mori AND JAPAN”, “Junichiro Mori AND Kanagawa”, and “Yoshiro Mori AND Ishikawa”
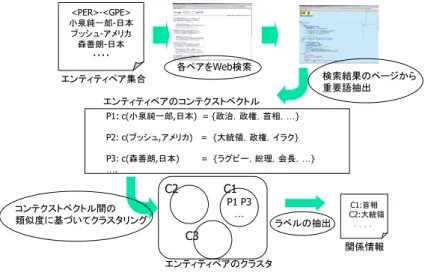
クエリー tf idfによって抽出された重要語 小泉純一郎 AND 日本 病理 藤原首相 小泉 光文社 政治 宰相 参拝 ページ, 総理 バックス 野郎, 商品 内閣 国民 改革大臣 ワルシャワ アメリカ 靖国 靖国神社 再生 社会 森善朗 AND 日本 ラグビー首相 会長 招致 大臣 協会 科学政権 総理 館長 サッカー アフリカ 世界 宇宙 競技 ページ スポーツ 失言 関連 メディア 毛利 弘之 敦子内閣 理事 小泉純一郎 AND 神奈川 選挙 首相 横須賀 候補 つよし 議員 斉藤 自民党 三浦 小泉 民主党 衆議院 ページ 関連強敵 政治 公認 自由民主党 一家 総裁 出馬 補選 地元 同志 森善朗 AND 石川 一川 保夫首相 選挙 自民 奥田 候補 小松 議員 自民党 祐士 能美 加賀 金沢 西村 ページ 新進 回答 松任 公明党 当選 委員 民主 政治 県議 比例 支配 衆院 開票 の仮説に基づいて,類似した文脈で表れるエンティティのペア をまとめ,同じ関係を持つエンティティペアが共通して持つ重 要語を関係を表す情報として抽出するというのが提案手法の基 本的なアイデアである.この時,個別のエンティティのペアを 対象に処理を行うのではなく,ペアの集合を扱うことにより得 られる大局的な情報を用いる点が提案手法の重要な点である. 以下では,このアイデアに基づくWebからの関係情報抽出 の手法について具体的に述べていく. 2. 2 提案手法の詳細 本研究で提案するWebからの関係情報抽出の手順は以下の 通りである. (1) エンティティペアの集合を取得 (2) 各エンティティペアの文脈モデルを取得 (3) エンティティペア間の文脈モデルの類似度を計算 (4) 類似度に基づきエンティティペアをクラスタリング (5) 各クラスタから関係情報となるラベルを抽出 図1は提案手法の手順を図示したものである.まず,関係抽 出の対象とするエンティティのペア集合を取得する.例えば,人
物(PERSON)と組織(ORGANIZATION)や人物(PERSON)
と地名(GPE)などのエンティティのペアである.次に各エン ティティペアを検索エンジンのクエリーとして検索をおこな い,エンティティペアを含むWebページを取得する.取得し たWebページの中でエンティティペアの出現する周囲の語を 用いて,ペアの文脈ベクトルを作成する.各エンティティペア について文脈ベクトルを作成し,文脈ベクトル間の類似度に基 づいてクラスタリングを行う.クラスタリングの結果生成され た各クラスターからラベルを抽出し,最終的にそのラベルをク ラスターに属するエンティティペアの関係情報とする.先の仮 説に基づけば,類似した文脈で表れるエンティティのペアは同 一のクラスターに属し,そのクラスターの各ペアは同様の関係 を持っているはずである. 以下では,各手順の詳細について説明を行う. 2. 3 エンティティペア集合の取得 関係抽出の対象とするエンティティのペアの集合は人物と組 織,人物と地名のような同一種類のペアの集合とする.これは 提案手法のアイデアに基づき,同一種類のエンティティペア集 合から,同様の関係を持つエンティティペアをまとめていき関 係を取り出すという処理を行うためである.そのためには,ま ず対象とするエンティティの判別を行う必要がある. エンティティの判別・抽出は自然言語処理の固有表現抽出タ スクにおいて研究がなされたきた.近年では,固有表現抽出技 術の精度が実用レベルまで向上してきており,抽出ツールを用 いることで対象の文書から高い精度でエンティティの自動抽出 を行うことが可能である.IREXプロジェクトの固有表現抽出 タスクでは,8種類の表現,組織名,政府組織名,人名,地名, 固有物名,日付表現,時間表現,金額表現,割合表現を定義し ており,対応するツール[12]を利用することで文書集合から人 物,地名,組織などのエンティティを抽出することができる. エンティティの判別はメタデータの自動アノテーションを目 的にセマンティックWebの分野でも研究がなされており[1]∼ [4],これらのエンティティ判別技術とともに,”同じ文に出現 している”,”同じページに出現している”,”検索エンジンで で一定件数以上ヒットする”などの条件により関係抽出の対象 とする人物と組織,人物と地名,人物と人物,組織と組織など といったエンティティのペアの集合を事前に作成しておく. 2. 4 エンティティペアモデルの取得 エンティティペアを同士を類似度に基づきクラスタリングす るために,エンティティペア集合の各ペアがWeb上に出現す る文脈を何らかのモデルで表現する必要がある.Raghavanら は,テキストに出現する人名,地名や組織名といったエンティ ティを表現するためにentity languageモデルというものを提 案している[13].このモデルは,エンティティが出現する周辺 語の統計的な分布によってエンティティを表現するものである. ここでは,このモデルをエンティティのペアに適用する.つま り,エンティティペアがある距離内で共起している時に,その 間の語およびエンティティの前後の語を用いてエンティティペ アの文脈を表現する. エンティティペアモデルを作成するために,エンティティ集 合の各ペアを検索エンジンのクエリーとして検索を行う.例え ば,人物と組織のエンティティペアを対象とする場合は,人物
<PER>-<GPE> 小泉純一郎-日本 ブッシュ-アメリカ 森善朗-日本 ・・・・ P1: c(小泉純一郎,日本) = {政治,政権,首相,…} P2: c(ブッシュ,アメリカ) = {大統領,政権,イラク} P3: c(森善朗,日本) = {ラグビー,総理,会長,…} …. P1 P3 … エンティティペア集合 エンティティペアのコンテクストベクトル 各ペアをWeb検索 検索結果のページから 重要語抽出 エンティティペアのクラスタ コンテクストベクトル間の 類似度に基づいてクラスタリング ラベルの抽出 関係情報 C1 C2 C3 C1:首相 C2:大統領 .... 図 1 Webからの関係情報抽出手法の概要図
Fig. 1 Extraction of relational information among named entities from the Web
名と組織名をAND検索する.この時,検索ヒット件数が,あ らかじめ定めた閾値以下のエンティティペアはWeb上におい て出現が少ないと見なして処理から除くようにする. 検索結果から上位のWebページを取得し,各Webページか らエンティティペアがある語数以内で共起する箇所を抽出し, エンティティの間の語およびエンティティの前後の語をエンティ ティペアの文脈として取得する.語の品詞としては名詞,未知 語を使用する.また,ストップワードとして低頻度および高頻 度の語は除くようにする. エンティティペアe1− e2を含む文脈から取得した各語tに対 して,tf idf (Term Frequency-Inverse Document Frequency) を用いて次の式で重み付けを行う. tf idf (t) = tf (t)· idf(t) ここで,tf (t)はe1− e2を含むすべての文脈における語tの 出現頻度,idf (t)は全エンティティペアの文脈ベクトルの作成 に用いたWebページの内,どれぐらいのWebページに語tが 出現するかの尺度である.以上により,エンティティペアモデ ルは,ペアをなすエンティティe1,e2の文脈ベクトルC(e1, e2) として以下のように表される. C(e1, e2) ={t1, t2, ..., tk, ...} ここで,文脈ベクトルの要素となる語tkはtf idf (tk)により重 み付けがなされている. 2. 5 エンティティペア間のクラスタリングとラベル抽出 各エンティティペアの文脈ベクトルを用いて,ペアのクラス タリングを行う.クラスタリングを行う際のエンティティペア 間の類似度は文脈ベクトルCi同士の内積 cos(Ci, Cj) = CiCj |Ci||Cj| によって求める.クラスタリングの手法は,生成すべきクラス ター数が事前にわからないため階層化クラスタリングを用いる. エンティティペアをクラスタリング後,クラスター内のエン ティティペアの文脈ベクトルに多く含まれているような語を, そのクラスターのラベルとして抽出する.その際に,文脈ベク トル作成の時と同様にtf idfを用いてラベルの重要度を決定す る.ただし,この時のtfはクラスターにおける語の出現頻度を 用いる.これは各クラスターに特徴的な語を,そのクラスター に属するエンティティペアの関係情報となるラベルとして抽出 していることに相当する.
3.
実
験
提案手法を用いて,実際にWebから関係情報の抽出実験を 行った.実験に用いたエンティティペアは,人物(PERSON) と地名(GPE)を対象とした.特に政治家と関連する地名のペ アを使用し,”首相”や”議員”のように地名に対して人物が政 治的な立場,役割,関わりをもったエンティティペアのデータ を作成した.対象としたエンティティペアの総数は143であり, 各ペアに対して正解データとして関係のラベル付けを行った. その関係の内訳は首相が22,大統領が17,知事が47,市長が 13,議員が44ペアであった. 各エンティティペアをWeb検索(注 3) し,上位100件のWeb ページを用いて文脈ベクトルを作成した.各Webページから エンティティペアが含まれる文脈を取得する際に,2つのパラ メータを用意した.一つはエンティティ間の語数n,もう一つ はエンティティの前後の語数mである.文脈ベクトルの作成 において,エンティティペアが語数n以内で共起する箇所を対 象に,エンティティペアに挟まれるすべての語とエンティティ の前後のm語を用いた.2章において示した表1は,実験で用 いたエンティティペアとその文脈ベクトル要素である語の例を 示している. クラスタリングには最長距離法を用い,生成するクラスター の数は事前に付与した正解ラベルの数である5つとした.表2 は,nを30,mを10とした時に各クラスターから抽出された ラベルを示しており,関係情報として重要度の高い順に左から 並んでいる. (注 3):検索エンジンには google を使用した表 2 エンティティペアのクラスターから抽出した関係情報 Table 2 Relational Information obtained from a cluster of entity pairs
クラスター ラベル (手動判別) クラスターから抽出した関係情報 1 市長 市長 知事 府知事 委員 市民 会長 県知事 開催 日本共産党 都知事 2 大統領 大統領 政権 政治 世界 経済 関連 戦争 選挙 記事 ページ 3 首相 首相 政権 政治 選挙 記事 大統領 病理 戦争 重体 ページ 4 知事 県知事 知事 ページ 会長 市長 関連 県政 委員 サイト 泉田 5 議員 選挙 議員 自民 自民党 比例 衆院 民主党 衆議院 民主 当選 表 3 文脈ベクトルに使用する語とクラスタリングの性能
Table 3 Clustering performance in relation to the number of POS in a contextual vector
文脈ベクトルに使用する語 Precision Recall F尺度 エンティティペアの前後 10 語および間 30 語まで 0.992 0.995 0.994 エンティティペアの前後 5 語および間 10 語まで 0.88 0.85 0.86 エンティティペアを含むページ全体 0.76 0.677 0.716
4.
評
価
まず,クラスタリングの結果についてPrecisionとRecallを 用いた評価を行う.生成された各クラスタごとに,手動判別した クラスターのラベルと一致するクラスター内のエンティティペ アを正解とし,クラスタclにおける正解ペアの数をNcorrect,cl, 不正解であったペアの数をNincorrect,clとする.また,関係r ついて正解であったペアの数をNcorrect,r,関係rの正解ラベル がついてるペアの数をNtrue,rとする.この時,クラスタリン グの結果のPrecision(P )とRecall(R)を以下のように求める. P = Σcl Ncorrect,cl Ncorrectmcl+ Nincorrect,cl , R = Σr Ncorrect,r Ntrue,r また,P とRからF尺度も同時に求める. 図2はエンティティペアの文脈ベクトル作成時に用いる語数 のパラメータであるnとmを変化させた時のクラスタリング 結果のF尺度を表している.エンティティペア間の語数の上 限であるnは30語,エンティティペアの両端の語数mは10 語とした時にもっともクラスタリング結果のF値が高いこと がわかる.この時,表3に示すようにクラスタリングの結果 はPrecisionおよびRecallともに99%を示している.文脈ベク トル作成に使用する語数の幅を増減させるとF値は減少する. ページ全体を対象とした場合は,エンティティペアの文脈とあ まり関係のない語が含まれるようになるためクラスタリング結 果の精度は大きく落ち込む.エンティティペアの文脈を適切に モデル化するには,使用する近傍の語数が大きく影響している ことがわかる. つぎに表2を見ると,関係情報となる抽出されたラベルにつ いて,各クラスターから抽出された重要度の高いラベルと正解 ラベルはよく一致していることがわかる.しかし,抽出したラ ベルには関係情報とは関連のない一般的な語や他のクラスター のラベルが含まれているなどしているため,ラベルの重要度計 算については今後改良を行う必要がある.また,ラベルの評価 に関して概念距離や意味的な類似度を用いることで適切な関係 情報が抽出できているかを定量的に評価を行えるようにする必 要がある. 0 0.2 0.4 0.6 0.8 1 1.2 5 10 15 20 25 30 35 40 45 averaged F measurewindow size (the number of POS)
window size between entities window size at sides of entities
図 2 文脈ベクトルに用いる語数とクラスターの F 尺度の関係
Fig. 2 The number of POS in a contextual vector vs. F measure of Clustering results
表 4 文脈ベクトルのスコアリングとクラスタリングの性能
Table 4 Clustering performance in relation to scoring methods of a contextual vector
文脈ベクトルのスコアリング手法 Precision Recall F尺度
tf idf 0.88 0.85 0.86
共起 0.338 0.225 0.27
表 5 文脈ベクトル間の類似尺度とクラスタリングの性能
Table 5 Clustering performance in relation to similarity measures between contextual vectors
クラスタリングの距離尺度 Precision Recall F尺度 cosine 0.88 0.85 0.86 ユークリッド 0.426 0.365 0.393
5.
議
論
提案手法には,検討すべきいくつかの項目が存在する.ここ では,文脈ベクトルのスコアリングとベクトル間の類似尺度に ついて考えてみる. 現在のところ,エンティティペアの文脈ベクトルはtf idf に より語がスコア付けされている.しかしながら,語のスコアリングは他にもさまざまな指標が考えられる.tf idfと並んで,重 要語の抽出によく使われる指標として語の共起情報がある[10]. 表4はエンティティペアと文脈中の語の共起を用いて文脈ベク トルの語をスコアリングした時と,tf idf を用いた時のクラス タリング結果の性能を比較したものである(ただし,nとmは それぞれ10語,5語とし,類似尺度には内積を用いた).スコア リングに共起を用いた場合は,クラスタリング結果の性能が非 常に悪くなっている.エンティティペアと語の共起を考慮した ことにより,各エンティティペアに特徴的な語に対して偏って スコアが付けが行われたためである.文脈ベクトルの作成にお いては,エンティティペアの文脈を表す適切な一般語をよく拾 うtf idfと非常に特徴的な語を拾う共起情報を組みあせたスコ アリングを今後検討する必要がある. 次に,エンティティペアのクラスタリングを行う際に用いて 類似尺度について検討を行う.表5は類似尺度にユークリッド 距離を用いた時と,内積を用いた時のクラスタリング結果の性 能を比較したものである(ただし,nとmはそれぞれ10語,5 語とし,文脈ベクトルのスコアリングにはtf idf を用いた).内 積と比べると類似尺度にユークリッド距離を用いたものはクラ スタリング結果性能が悪くなっている.内積,ユークリッド距 離のほかにも類似尺度にはさまざまな指標が存在するため[13], 今後はクラスタリングおよび関係情報抽出のための適切な類似 尺度の検討をおこなう. この他にも,エンティティペアモデルの作成に使用するWeb ページ数や生成するクラスター数の決定などの検討を行い.手 法の改善を行っていく予定である.
6.
関 連 研 究
本研究の提案手法は,トレーニングデータを必要としない非 教師なしの手法である.一方,関係抽出タスクにおける従来の 手法の多くは,新聞記事集合のような定型的な文書集合を対象 にし,事前にタグ付けされた大規模な関係データやブートラッ ピングを用いた教師付き学習のアプローチである[14], [15].し かし,教師付き学習のためには学習に用いるための十分なト レーニングデータの準備に大きな手間を要する.さらに,あら かじめタグ付けをする関係を定めてしまうことにより,抽出さ れる関係を限定しまうこととなる. Hasegawaらは提案手法と同様にエンティティペアが出現す る文脈をクラスタリングすることによって新聞記事集合からエ ンティティ間の関係を抽出する手法を提案している[16].一方, 本研究の提案手法はWebを対象とした関係情報抽出を対象と しているため単純な比較はできない.しかしながら,大きな違 いの一つとして,Web上の不均質で非定型的な文書集合からエ ンティティペアモデルを取得するために検索エンジンを使用し たWebマイニング手法を用いていることは,提案手法の特徴 である. Webから関係情報を抽出するという新たなWebマイニングの 手法である本提案は,従来のWebマイニング手法[1], [3], [5], [7]. と統合することでより多様で質の高い情報抽出を行うことがで きるだろう.7.
ま と め
本研究では,Webからの関係情報の抽出手法を提案した. Web上において出現する文脈が類似しているエンティティペ アは類似した関係を持っているという提案手法の基本的な考え 方である.この仮定の基づいて,Webから取得したエンティ ティペアモデルのクラスタリングを行い,クラスターからエン ティティ間の関係を抽出するのが提案手法の特徴である.今後 は,議論で述べたように手法の改善を行うとともに,多様なエ ンティティペアの種類に対して適用を行っていく. 文 献[1] P. Cimiano, G. Ladwig, and S. Staab, “Gimme’ the con-text: Context-driven automatic semantic annotation with cpankow,” Proc. of the 14th World Wide Web Conference, 2005.
[2] P. Cimiano, S.Handschuh, and S. Staab, “Towards the self-annotating web,” Proc. of the 13th World Wide Web Con-ference, 2004.
[3] O. Etzioni, M. Cafarella, D. Downey, S. Kok, A. Popescu, T. Shaked, S. Soderland, D. Weld, and A. Yates, “Web-scale information extraction in knowitall(preliminary re-sults,” Proc. of the 13th World Wide Web Conference, pp.100-109, 2004.
[4] O. Etzioni, M. Cafarella, D. Downey, A. Popescu, T. Shaked, S. Soderland, D. Weld, and A. Yates, “Meth-ods for domain-independent information extraction from the web: An experimental comparison,” Proc. of the AAAI Conference, 2004. [5] 松尾豊,友部博教,橋田浩一,中島秀之,石塚満,“Web 上の 情報からの人間関係ネットワークの抽出,”人工知能誌,vol.20, no.1,pp.46–56,2005. [6] 金英子,松尾豊,石塚満,“Web 上の情報を用いた企業間関係 の抽出,”知識ベースシステム研究会, SIG-KBS,2005.
[7] P. Mika, “Flink:semantic web technology for the extraction and analysis of social networks,” Journal of Web Semantics, vol.3, no.2, 2005.
[8] A. Culotta, R. Bekkerman, and A. McCallum, “Extracting social networks and contact information from email and the web,” Proc. of CEAS, 2004.
[9] 原田昌紀,佐藤進也,風間一洋,“Web 上の key person の発見
と関係の可視化,”情処学研報, DBS-130/FI-71,2003.
[10] 森純一郎,松尾豊,石塚満,“Web からの人物に関するキーワー
ド抽出,”人工知能誌,vol.20,no.5,pp.337–345,2005. [11] G.A. Miller, and W.G. Charles, “Contextual correlates of
semantic similarity,” Language and Cognitive Processes, vol.6, no.1, pp.1-28, 1991.
[12] 工藤拓,松本裕治,“段階適用による日本語係り受け解析,”情処
学論,vol.43,no.6,pp.1834-1842,2002.
[13] H. Raghavan, J. Allan, and A. McCallum, “An exploration of entity models, collective classification and relation de-scription,” Proc. of LinkKDD, 2004.
[14] E. Agichtein, and L. Gravano, “Extracting relations from large plain-text collections,” Proc. of the 5th ACM Interna-tional Conference on Digital Libraries (ACMDL00), pp.85-94, 2000.
[15] D. Zelenko, C. Aone, and A. Richardella, “Kernel methods for relation extraction,” Proc. of the Conference on Em-pirical Methods in Natural Language Processing, pp.71-78, 2002.
[16] T. Hasegawa, S. Sekine, and R. Grishman, “Discovering re-lations among named entities from large corpora,” Proc. of the Annual Meeting of Association of Computational Lin-guistics (ACL 04), 2004.