修 士 論 文
組み合わせ分割照合法による 日本語署名照合の高精度化
平成 25 年度修了
三重大学大学院工学研究科 博士前期課程 情報工学専攻
上平 裕太
はじめに
本人を確認することは,クレジットカードの利用や入退室管理など生活の様々な場面で 必要であり,個人情報の保護や不正アクセス防止のためにも重要な問題である.身体的特 徴や行動的特徴を用いた認証は,盗難,紛失,忘却等の心配が少なく,他人による代行が 困難であることから,今後の発展や改良が見込まれている.その中でも署名照合は,デー タ取得に対する拒絶感や抵抗感が少ないことと,行動的特徴であるため本人の意志確認を 伴う等のメリットがあり,数多くの研究がされている.署名照合方式には,オンライン署 名照合とオフライン署名照合がある.オンライン署名照合は,ペンとタブレットなどの入 力装置を用いて取得したペンの座標位置,筆圧,筆速などの筆記運動情報を利用する手法 である.オフライン署名照合は,すでに書かれた署名から得られる筆跡など形態情報を 利用する手法である.近年では,オンライン情報の取得環境が整ったこと,筆速,筆圧な ど,より多くの情報を取得できることから,オンライン署名照合が実用化されつつある.
これまでに,オンライン署名照合に関する多くの研究が行われてきたが,そのほとんどが 筆跡を時間関数と捉えて DP ( Dynamic Programming )マッチングや隠れマルコフモデル
( HMM )によって照合する手法である.しかし,登録署名数の削減や,更なる照合精度の
向上などの課題が残されている.照合精度を向上する観点からは,多くの登録署名テンプ
レートを用いることによって署名の変動を十分に学習する必要があるが,実環境における
利用条件では,多くの登録署名を取得することは利用者に負担がかかり現実的でない.一
方,少数の登録署名による不十分な学習では,単一の照合手法に高い照合精度を期待する
ことが困難である.これらの問題を解決するために本論文では,オフライン特徴とオンラ
イン特徴に基づく組み合わせ分割照合法と呼ばれる新しい署名照合手法を提案する.オフ
ライン特徴による照合では,フルネームの署名画像とその部分画像である姓と名から 3 つ
の異なる特徴ベクトルを抽出し,各特徴ベクトルごとにマハラノビス距離を計算する.オ
ンライン特徴による照合では,フルネーム署名の時系列データとその部分データである
姓と名の時系列データに DP マッチングを適用する.最終的な照合は, 3 つのマハラノビ
ス距離と DP マッチングにより得られる 3 つの相違度を入力とする SVM (Support Vector
ii
と FAR(False Acceptance Rate) が等しい時の EER ( Equal Error Rate )は 3.35% となった.
この結果は,単独手法により得られる最も低い結果 6.45% と比べ, 3.10% 低く,組み合わ せ分割照合法が日本語署名照合の精度を大きく改善することが示された.
今後の課題としては,波形解析や HMM などによるさらに異なる署名照合との組み合
わせや,分割方法の検討,日本語署名以外への応用などが考えられる.
目次
はじめに i
第 1 章 序論 1
1.1 研究の背景 . . . . 1
1.2 署名照合 . . . . 2
1.2.1 偽筆 . . . . 2
1.2.2 オフライン情報とオンライン情報 . . . . 3
1.2.3 従来研究 . . . . 3
1.3 本研究の目的 . . . . 4
1.4 本論文の構成 . . . . 5
第 2 章 照合の流れと提案手法 6 2.1 照合手順 . . . . 6
2.2 時系列点座標データの取得 . . . . 7
2.3 濃度こう配特徴をマハラノビス距離で分類を行う署名照合 . . . . 7
2.3.1 画像生成 . . . . 7
2.3.2 画像の自動分割 . . . . 7
2.3.3 特徴抽出 . . . . 9
2.3.4 照合 . . . . 10
2.4 DP マッチングを用いる署名照合 . . . . 12
2.4.1 データの正規化 . . . . 12
2.4.2 筆速データの作成 . . . . 12
2.4.3 DP マッチング . . . . 12
2.4.4 分類 . . . . 13
2.5 SVM ( Support Vector Machine ) . . . . 14
2.5.1 カーネルトリック . . . . 15
目次 iv
2.5.3 分類 . . . . 15
第 3 章 実験 16 3.1 実験データ . . . . 16
3.2 等価誤り率の定義 . . . . 18
3.3 実験 1 . . . . 20
3.3.1 実験条件 . . . . 20
3.3.2 結果 . . . . 21
3.3.3 考察 . . . . 21
3.4 実験 2 . . . . 22
3.4.1 実験条件 . . . . 22
3.4.2 結果 . . . . 22
3.4.3 考察 . . . . 23
3.5 実験 3 . . . . 24
3.5.1 実験条件 . . . . 24
3.5.2 結果 . . . . 24
3.5.3 考察 . . . . 25
3.6 実験 4 . . . . 27
3.6.1 実験条件 . . . . 27
3.6.2 結果 . . . . 27
3.6.3 考察 . . . . 28
第 4 章 結論 29 4.1 まとめと今後の課題 . . . . 29
付録 A 文字単位画像の利用 30 A.1 実験データ . . . . 31
A.1.1 実験データ 1 . . . . 31
A.1.2 実験データ 2 . . . . 31
A.2 実験条件 . . . . 33
A.3 結果 . . . . 33
A.3.1 実験データ1を用いた場合 . . . . 33
A.3.2 実験データ2を用いた場合 . . . . 33
A.4 考察 . . . . 34
付録 B 署名データリスト 36
付録 C プログラムソースリスト 38
付録 D 発表資料 39
謝辞 40
参考文献 41
1
第 1 章
序論
1.1 研究の背景
本人かどうか確認することは,クレジットカードの利用,特定場所の入退室など社会生 活のいたるところで必要であり,個人情報の保護や犯罪防止のためにも,重要な問題であ る.本人認証手法として,以下のものがある.
• 本人が持つ知識による認証:パスワード,暗証番号
• 本人の所有物による認証: IC カード,印鑑
• 本人の身体的特徴や行動的特徴による認証:署名,指紋,音声
本人しか知り得ない,本人しか所有していないものによる認証は,他人に盗まれたり,
なくしたりすることにより,他人に悪用される危険性がある.それらに比べ,本人の身体 的特徴や行動的特徴を用いた認証(バイオメトリクス)は,盗難,紛失,忘れる等の心配 が非常少なく,他人による代行が困難であることから,近年特に注目されている.
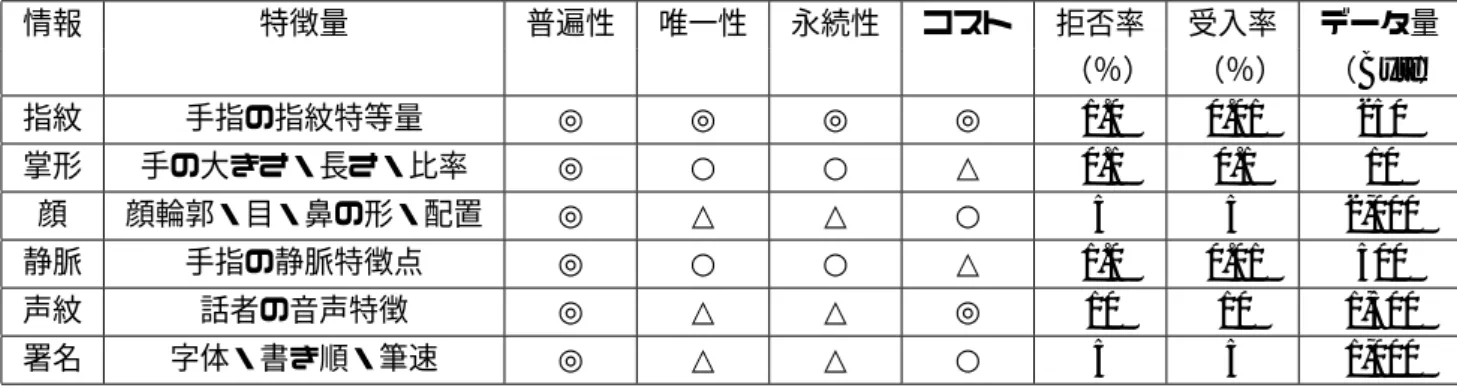
バイオメトリクスは大きく二つに分類できる.一つは指紋,虹彩,顔,静脈などの身体 的特徴であり,もう一つは声紋,署名などの行動的特徴である.主なバイオメトリクスと その特徴を表 1.1 に示す [1] .ここで普遍性とは誰もが持っている特徴であること,唯一 性とは本人以外は同じ特徴を持たないこと,永続性とは時間の経過とともに変化しないこ とである.また,拒否率とは本人を間違って拒否する誤りであり,受入率とは他人を間 違って受け入れる誤りである.表を見ると,指紋を用いた認証が良いように思われるが,
犯罪捜査などに利用されていることから,登録において心理的な抵抗感があると言える [2] .
このように,バイオメトリクスにはそれぞれ一長一短があり,要求されるセキュリティ
レベルや利用方法に応じた選択が必要となる.本研究で取り上げる署名は,以下のような
特徴がある.
表 1.1: バイオメトリクスの比較
情報 特徴量 普遍性 唯一性 永続性 コスト 拒否率 受入率 データ量
(%) (%) ( Byte ) 指紋 手指の指紋特等量 ◎ ◎ ◎ ◎ 1.0 0.01 250 掌形 手の大きさ・長さ・比率 ◎ ○ ○ △ 0.1 0.1 10
顔 顔輪郭・目・鼻の形・配置 ◎ △ △ ○ 5 5 2,000 静脈 手指の静脈特徴点 ◎ ○ ○ △ 1.0 0.01 500 声紋 話者の音声特徴 ◎ △ △ ◎ 10 10 1,500 署名 字体・書き順・筆速 ◎ △ △ ○ 5 5 1,000
• クレジットカード利用時など,従来より社会的に受け入れられている個人認証方法 であり,他のバイオメトリクスに比べて利用者の受容性が高い.
• 行動的特徴による個人認証であるため,本人の意志確認を伴う.
• 永続性の高い身体的特徴の登録データとは違い,署名は万が一,流出や漏洩が生じ ても登録データそのものを変更することが可能である.
• 電子文書への貼り付けが可能である.
このような特徴を持つことから,署名による個人認証はバイオメトリクスの中でも重要な 技術の一つである [3] .
1.2 署名照合
署名照合とは,文字どおりある人が手で書いた署名が,本当にその人自身が書いたもの であるかどうかを確認することによってその筆記者を特定の人物として受け入れるか,あ るいはそうでないとして拒否するかを判断することである.
署名照合とは別に,書かれた文字や文書に依存しない筆者識別や筆跡鑑定技術があり,
脅迫状や遺言状などにおける筆者の特定に用いられている.
1.2.1 偽筆
署名照合の精度評価を行うためには本人の筆記した署名以外に,偽筆と呼ばれる署名が 必要となる.偽筆は本人以外の人物が筆記した署名である.偽筆は以下の 4 つに分類する ことが出来る [4] .
• ランダム偽筆 (Random Forgery) 本人署名についてなんら情報が与えられていな
1.2 署名照合 3 一般には,取得が容易な他人の本人署名をランダム偽筆として用いることが多い [5] .
• 単純偽筆 (Simple Forgery) なりすまし者が本人の名前等は知っているが,署名の
形状は知らない状況で筆記した署名.単純に文字認識を行えば,同じ署名として認 められる可能性はあるが,署名形状と名前に関連がない場合はランダム偽筆と同じ である.
• 模写偽筆 (Simulated Forgery) 本人署名を上からなぞることにより作成した偽筆
である.署名形状は本人署名に非常に似ている.従って,オフライン署名認証では 判別の難しい署名である.
• 訓練偽筆 (Skilled Forgery) 本人署名の形状や書き順,筆記方法等の情報を入手し
たなりすまし者がオンライン情報を含め真似るための練習を行った後に筆記する署 名であり,オンライン署名認証においては最も脅威となる署名である.
1.2.2 オフライン情報とオンライン情報
署名照合方式には,オフライン署名照合とオンライン署名照合がある.
オフライン署名照合とは,すでに書かれた署名から得られる筆跡など形態情報を利用す るものである.
一方,オンライン署名照合とは,タブレットなどの専用機器より取得できる筆順,筆圧,
筆速など署名をしているときの筆記運動情報を利用するものである.この場合,専用機 器としてタブレットや電子ペンが必要になる.最近ではタブレット PC , PDA ( Personal
Digital Assistant ) ,スマートフォンなど,ペン入力がさまざまな場面で利用可能となって
きている.また,オフライン情報よりも得られる情報が多く,筆速やペンの傾きなどは,
他人が容易に真似ることが困難であると考えられる.
現実においてどちらの情報が利用できるかは状況次第であるが,オンライン情報の取得 環境が整いつつあることと,得られる情報の多さより,本研究ではオンライン署名照合を 研究対象とする.
1.2.3 従来研究
オンライン署名照合に関して,署名文化のある欧米で研究が盛んに行われている [4, 6] .
しかしそのほとんどが,筆跡の動的情報であるペンの座標,筆速,筆圧,傾きなどの時系
列データに対して DP ( Dynamic Programming )マッチングを行う手法 [7] ,セグメント
ごとの曲率や向きなどの局所的特徴の時系列を隠れマルコフモデル( HMM )により照合
を行う手法 [8] など,筆跡を時間関数と捉えて照合するものが主流である [3] .最近では,
ユーザ共通の Fusion モデルにより複数の距離を組み合わせることで照合を行う手法 [9]
が提案されている.この手法では,アルファベットベースの署名を含む公開オンライン署 名データベースの MYCT と BIOMET を用いて性能評価を行なっている. MCYT をデー タセットとして性能評価を行った場合,登録署名数が 5 個の時に等価誤り率 3.73% の精度 を得ている.また, BIOMET をデータセットとして性能評価を行った場合,登録署名数 が 5 個の時に等価誤り率 4.55% の精度を得ている.また日本語署名を対象にした研究も 数多く発表されている [10] .文献 [11] では,筆跡の動的情報であるペンの座標,筆圧,傾 きの時系列データを用いる手法が提案されている.この手法では 8 氏名から採取した 293 個の真筆, 540 個の偽筆を実験データとし,登録署名数を 7 〜 11 個として性能評価を行っ た結果,本人拒否率 2.4% ,他人受け入れ率 1.3% の精度を得ている.文献 [12] では,動的 情報の時間変化を離散ウェーブレット変換によりサブバンド分解した信号を特徴とし,適 応信号処理技術を応用して照合する手法が提案されている.この手法では 4 氏名から採取 した 98 個の真筆, 200 個の偽筆を実験データとし,登録署名数を 5 個として性能評価を 行った結果,等価誤り率約 5% の精度を得ている.
1.3 本研究の目的
これまでに,オンライン署名照合に関する多くの研究が行われてきたが,そのほとんど
が筆跡を時間関数と捉えて DP ( Dynamic Programming )マッチングや隠れマルコフモデ
ル( HMM )によって照合する手法である [7, 11, 8] .しかし,登録署名数の削減や,更な
る照合精度の向上などの課題が残されている.照合精度を向上する観点からは,多くの登
録署名テンプレートを用いることによって署名の変動を十分に学習する必要があるが,実
環境における利用条件では,多くの登録署名を取得することは利用者に負担がかかり現実
的でない.一方,少数の登録署名による不十分な学習では,単一の照合手法に高い照合精
度を期待することが困難である.これらの問題を解決するために本論文では,オフライン
特徴とオンライン特徴に基づく組み合わせ分割照合法と呼ばれる新しい署名照合手法を提
案する.オフライン特徴による照合では,フルネームの署名画像とその部分画像である姓
と名から 3 つの異なる特徴ベクトルを抽出し,各特徴ベクトルごとにマハラノビス距離
を計算する.オンライン特徴による照合では,フルネーム署名の時系列データとその部
分データである姓と名の時系列データに DP マッチングを適用する.最終的な照合は, 3
つのマハラノビス距離と DP マッチングにより得られる 3 つの相違度を入力とする SVM
(Support Vector Machine) により行われる.
1.4 本論文の構成 5
1.4 本論文の構成
本論文の二章では,本研究における署名照合手法の流れと,各処理の詳細について述べ
る.さらに第三章では,提案手法の照合実験を実験署名データ,条件とともに結果と考察
を述べる.最後に第四章で,本研究のまとめと今後の課題について述べる.
第 2 章
照合の流れと提案手法
本章では,本研究で提案する組み合わせ分割照合法について述べる.
2.1 照合手順
提案手法による署名照合処理の流れ図を図 2.1 に示す.タブレット PC より得られた入 力署名から時系列点座標データを取得する.得られた時系列点座標データから筆速を輝度 値に反映させたフルネーム署名画像を生成し,その画像を分割することにより部分画像
(姓と名)を取得する.得られた画像ごとに濃度勾配特徴を抽出し,マハラノビス距離を 算出する.次に,フルネームの時系列点座標データを部分データ(姓と名)に分割し,各 署名データから DP マッチングを用いる署名照合により相違度を算出する.そして得られ た 6 つの出力値を特徴ベクトルとし, SVM により照合分類する.各手法や処理の詳細に ついては,続く節にて述べる.
図 2.1: 提案手法の流れ
2.2 時系列点座標データの取得 7
2.2 時系列点座標データの取得
タブレット PC を用いて 600 × 300 画素の枠内に書かれた署名の時系列点座標データ には文字の位置である x, y 座標データ,経過時間を表す時刻データが保存されている.
2.3 濃度こう配特徴をマハラノビス距離で分類を行う署名 照合
濃度こう配特徴を用いる署名照合は画像生成,特徴抽出,照合の各ステップから構成さ れている [13].
2.3.1 画像生成
時系列点座標と筆速データを用いて,筆速を反映した署名画像を生成する.各点での輝 度値を,筆速の速い点ほど輝度値を高く,遅い点ほど輝度値を低くすることで,筆速を反 映した署名画像を生成する.
まず始めに,時系列データの正規化,平滑化を含む前処理を行う.各点の筆速は,次点 までのタブレットセンサー上の距離と次点までにかかった時間(秒)との商により求めら れる.
輝度値 P i は次式で求める.
P i = v i − v min
v max − v min × P max (2.1)
ここで v i は筆速, v min は筆速の最小値, v max は最大値 P max は輝度値の最大値で ある.
本実験では,予備実験の結果から, P max を 250 , v min を 0 , v max を 50,000 とした.
最後に, 4 近傍膨張処理を行って,ストロークに一定の幅を持たせる.
出力画像の真筆,偽筆の例を図 2.2 に示す.
2.3.2 画像の自動分割
画像の自動分割処理は,フルネームの署名画像を姓と名に自動的に分割を行う.分割は 以下のような手順で行われる :
1. フルネーム署名画像を外接枠で切り取り, 792 × 144(pixel) の画像サイズに正規化
する.正規化画像の例を Fig . 2.3 に示す.
(a) genuine
(b) forgery
図 2.2: 生成画像の例
Example of generated image
2. 各署名者の学習データに対して姓と名の間の中点の x 座標を計算し,その平均を分 割点の初期値とする.
3. 入力データを分割点を通る垂線により姓と名に分割する.分割する時に,文字と垂 線が重なる場合は,左右 60pixel 範囲内で最も縦方向に黒画素が少ない点を分割点 として分割を行う.
4. 生成された姓と名の各画像を,外接枠で切り取り, 396 × 144(pixel) の画像サイズ に正規化する.
図 2.4 に正規化された分割画像の例を示す.
図 2.3: 正規化署名画像例
Example of normalized signature image
2.3 濃度こう配特徴をマハラノビス距離で分類を行う署名照合 9
(a) Last name (b) First name
図 2.4: 分割画像例
Example of segmented image
2.3.3 特徴抽出
特徴抽出処理では,生成した画像から濃度こう配特徴の抽出を行う.濃度こう配特徴と は,各画素における濃度こう配の方向別のヒストグラム特徴である [14, 15] .本研究では,
フルネーム,姓,名の各画像をブロック化して 576 次元の特徴ベクトルを抽出して照合を 行った.以下に,濃度こう配特徴の抽出手順を示す.
1. 入力画像を 2.3.2 に述べた方法で自動分割し,位置・大きさの正規化を行う.
2. フルネーム,姓,名の正規化画像に対して,全画素に 2 × 2 の平均値フィルタ処理 を 5 回行うことで,実数値をとる濃淡画像を得る.
3. 濃度値画像の濃度値の平均が 0 ,最大値が 1 となるように画像を正準化する(図 2.8 ) .
4. 正準化画像に対して Roberts フィルタを適用し,各画素ごとにこう配の向きと強 度を算出する.こう配の強度 f (x, y) ,向き θ (x, y) はそれぞれ以下の式で求めら れる.
f (x, y) =
√
(∆u) 2 + (∆v) 2 (2.2)
θ (x, y) = tan − 1 ∆v
∆u (2.3)
∆u = g (x + 1, y + 1) − g (x, y) (2.4)
∆v = g (x + 1, y) − g (x, y + 1) (2.5)
ここで, g (x, y) は (x, y) における濃度値である.
5. 得られたこう配の方向を π/16 刻みの 32 方向に量子化する.
6. 各画像の外接枠を 17( 横 ) × 7( 縦 ) のブロックに分割し(図 2.10 参照 ) ,各領域内で 量子化した方向別にエッジ強度の値を加算して局所方向ヒストグラムを得る.ブ ロック分割数や方向量子化数は,文献 [14] を基に実験により決定した値である.
7. 各ブロックにおいて, 32 方向ヒストグラムのこう配強度を 1 次元加重フィルタ [1
4 6 4 1] によって平滑化した後に,水平右方向から一方向おき(π /8 刻み)にサン
プリングして向きを 16 方向に削減する .
8. 各方向毎に, 17 × 7 ブロックのこう配強度を 2 次元加重平均フィルタによって平 滑化した後に,奇数行かつ奇数列にあるブロックのこう配強度をサンプリングして ブロック数を 9 × 4 に削減する.
図 2.2(a) の真筆の例に対し,抽出した濃度こう配を擬似カラー表現した画像を図 2.9 に
示す.この図では,こう配の向き,強度をそれぞれの色相,明度によって表現している.
2.3.4 照合
得られた特徴ベクトルに対して正則化マハラノビス距離の値を算出する.得られた値 が,しきい値 T 以下であれば真筆,さもなければ偽筆に分類する.マハラノビス距離は次 式で定義される.
g (X) = (X − M l ) T Σ − w 1 (X − M l ) (2.6) ここで X は入力署名の特徴ベクトル, M l はクラス l (署名者)の平均ベクトル, Σ w は 併合級内共分散行列である.級内共分散行列 Σ w のランクは(学習データ数 − クラス数)
を超えない.したがって,特徴ベクトルの次元数に対して学習データが少ないと, Σ w が 正則にならないので逆行列が存在しない.そこで, Σ w を次式によって正則化する.
(1 − α)Σ w + α trace { Σ w }
n I (2.7)
ここで trace { Σ } は行列 Σ のトレースであり, I は単位行列である.
2.3 濃度こう配特徴をマハラノビス距離で分類を行う署名照合 11
図 2.5: 入力画像 ↓
図 2.6: 正規化画像 ↓
図 2.7: 濃淡画像 ↓
図 2.8: 正準化画像 ↓
図 2.9: こう配画像
図 2.10: ブロック分割数
2.4 DP マッチングを用いる署名照合
DP マッチングを用いる署名照合の流れを以下に示す.
2.4.1 データの正規化
本人であっても署名の大きさや書き始めの位置は常に一定ではないので,差異を緩和す るため DP マッチングによる相違度を計算する前にサイズの正規化を行う.また署名の大 きさによる筆記時間のばらつきを抑えるために筆記時間の正規化も行う.
1. 学習データ,評価データ共に文字外接枠での筆跡サイズの正規化を行う.
2. それぞれの重心点を算出し,重心点を原点とする座標値に置き換える.
3. 評価データの筆記終了時間を登録データの時間 ( 秒 ) に合わせる.
2.4.2 筆速データの作成
各点の筆速データ v は,次点までのタブレットセンサー上の距離と次点までにかかった 時間 t( 秒 ) との商により求められるが,点ごとの筆速が観測誤差により変動するため,前 点,次点の筆速データの平滑化を行う.次式によって x 方向, y 方向の筆速を求める.
v xi =
√ (x i+1 − x i − 1 ) 2 t i+1 − t i − 1
, v yi =
√ (y i+1 − y i − 1 ) 2 t i+1 − t i − 1
(2.8)
2.4.3 DP マッチング
DP マッチングとは動的計画法を用いるパターンマッチング手法であり,長さが異なる 二つの系列データの類似性を比較する方法 [16] である.以下の漸化式で相違度 g(i, j) を
7 I 時~醐|本
1 7
2.4 DP マッチングを用いる署名照合 13 g (0, 0) = d (0, 0) = (x 0 − x ′ 0 ) 2 + (y 0 − y ′ 0 ) 2 + λ(v x0 − v ′ x0 ) 2 + λ(v y0 − v y0 ′ ) 2
+ µ(z 0 − z 0 ′ ) 2 + ν(t 0 − t ′ 0 ) 2 (2.9)
g (i, j) = min
g (i − 1, j) + d (i, j) i = 1 〜 n
g (i − 1, j − 1) + d (i, j) j = 1 〜 m g (i, j − 1) + d (i, j)
(2.10)
d (i, j) = (x i − x ′ j ) 2 + (y i − y ′ j ) 2 + λ(v xi − v xj ′ ) 2 + λ(v yi − v yj ′ ) 2
+ µ(z i − z ′ j ) 2 + ν(t i − t ′ j ) 2 (2.11) x i , y i , v xi , v yi , z i , t i , (x ′ j , y j ′ , v xj ′ , v ′ yj , z j ′ , t ′ j ) はそれぞれ評価用 ( 学習用 ) データの i また は j 番目の x, y, v x , v y , z, t 要素, λ, µ, ν は重み係数である.
また, z, z ′ はペンが非接触の場合に 0 ,接触している場合に 1 をとる. t, t ′ は署名開始 時点からの経過時間 ( 秒 ) である.
図 2.11: 1次元データの場合の例
2.4.4 分類
得られた相違度がしきい値 T 以下であれば真筆,しきい値 T 以上であれば偽筆に分類
する.本研究では評価データ 1 個に対し登録用データとの相違度を計算し,その中で最小
の相違度を用いて最近傍法による照合を行う.
2.5 SVM ( Support Vector Machine )
SVM ( Support Vector Machine )は, 2 クラスの分類を行う学習機械の一種で,与えら れた学習サンプルのなかで,サポートベクトルと呼ばれるクラス境界近傍に位置する学習 サンプルと識別面との距離であるマージンを最大化するように分離超平面を構築しクラス 分類を行う.従来パターンの認識手法と比べ,高い汎化能力を持ち, 2 次の凸計画問題と して定式化されるため学習の結果,最適解を得ることが出来るという特徴を持つ.
SVM の識別関数は以下の式で表される.
g(x) =
∑ d i=1
w i x i + b (2.12)
ここで w i は重みと呼ばれるパラメータで,ベクトル表示した w を重みベクトルと呼ぶ.
b はバイアス項と呼ばれるパラメータである.この識別器の g(x) = 0 を満たす点の集合
(識別面)は, d − 1 次元の超平面となる.
図 2.12 に SVM の概念図を示す. SVM は超空間内で 2 クラス分離する超平面の内,
マージンが最大となるような超平面を求め, w ・ x + b = 0 を最終的な分類決定境界とす
る.また w ・ x + b = 1 および w ・ x + b = − 1 上の訓練データをサポートベクトルと呼ぶ.
2.5 SVM ( Support Vector Machine ) 15
2.5.1 カーネルトリック
SVM で線形で分離が難しい際には,入力空間をより高次の特徴空間に写像し,そこで 線型分離を行う「カーネルトリック」という方法で非線型の問題にも適用が可能となる.
非線形な場合の高次元への写像の様子を図 2.13 に示す.
図 2.13: 非線形写像による高次元化
2.5.2 データのスケーリング
入力署名のそれぞれの署名照合を行い相違度や相関値を求める. SVM に入力する前に,
それぞれの出力の値を線形変換する.この線形変換は学習データにおける出力の範囲が -1
〜 1 となるような線形変換である.
評価用データは学習用データのスケーリングを行ったパラメータでスケーリングを 行う.
2.5.3 分類
得られた出力ベクトルに対する真偽の判定を SVM と学習用データによって学習する.
SVM のカーネルとして線形, 2 次多項式, 3 次多項式, 4 次多項式, RBF (ガウシアン
カーネル)を用いる.評価用データに対する SVM の出力がしきい値 T 以下(以上)なら
真筆(偽筆)とする.
第 3 章
実験
3.1 実験データ
2007 年度, 2008 年度の研究室の学生 31 人によって,タブレット PC を用いて実験に使 用する署名データを集めた.署名者がペンタブレットの使用に充分慣れ,自然な状態で筆 記できるように練習をした後に,データを取得した.また,署名者が署名する際に,過去 に登録した自筆は参照しないこととする.一方偽筆者は,同時期に書いた本人署名を参考 にして,偽筆を作成する.
本研究では,タブレット PC を用いて実験に使用する署名データを集めた.筆記者は 2007 年度, 2008 年度の研究室の研究生 31 人を対象としている.筆記者にはペンタブ レットの使用に充分慣れ,自然な状態で筆記出来るように練習してもらった後に,署名 データを取得した.これは,ペンタブレットでの筆記に慣れていないために生じる署名の 変動を小さくするためである.次に利用者自身が署名する際に,過去に登録した自筆の参 照を不可とする.一方偽筆者は利用者が登録するのと同時期に書いた本人署名(紙にボー ルペンで署名したもの)を参考にして偽筆を作成する.登録用データ,学習,評価用デー タの内訳を以下に示す.
登録用データ
• 真筆署名: 186 個( 31 人分× 6 個)
学習,評価用データ
• 真筆署名: 1116 個( 31 人分× 36 個)
• 偽筆署名: 1116 個( 31 人分× 36 個)
3.1 実験データ 17 に連続で 9 個署名する.二・三・四日目にはそれぞれ連続で 9 個の署名を取得して,一人 あたり計 42 個の署名を集めた.偽筆署名は, 1 個の対象署名に対して,偽筆者 4 人から 連続で 9 個の署名を取得することで,計 36 個集めた.それにより,真筆署名 1302 ( 42 個
/人 × 31 人)個,偽筆署名 1116 ( 36 個/人 × 31 人)個を集めた.個別手法の真筆学習
用データとして一日目の署名を最大 6 個用い,残りを評価用データとする.融合に用いる
SVM は評価用データを 2 分割し,一方を SVM の学習用データとし,もう一方を最終評
価用データとして平均し評価を行った.
3.2 等価誤り率の定義
署名照合には真筆署名を偽筆と誤って判定する割合を示す本人拒否率( FRR : False
Rejection Rate )と偽筆署名を真筆と誤って判定する割合を示す他人受入率( FAR : False
Acceptance Rate )の 2 つの誤り率がある.
FRR と FAR は次式によって定義される.
本人拒否率 FRR= b
a + b × 100(%) 他人受入率 FAR= c
c + d × 100(%) a :真筆に対して正しく真筆と判定した数 b :真筆に対して誤って偽筆と判定した数 c :偽筆に対して誤って真筆と判定した数 d :偽筆に対して正しく偽筆と判定した数
本人拒否率と他人受入率はトレードオフの関係にある(図 3.1 ) .本研究では照合のしき
い値 T を変化させて, FAR = FRR となったときの等価誤り率 (EER:Equal Error Rate) を
示す. EER は真筆と偽筆の事前確率の不均一や変化の影響を受けないため,署名照合の
性能評価に適している.
3.2 等価誤り率の定義 19
0 10 20 30 40 50 60 70 80 90
-3 -2 -1 0 1 2 3 4
Error Rate(%)
Threshold
FRR FAR
図 3.1: FAR と FRR のトレードオフの関係
/ / / /
/
/ ノ〆 〆
〆 〆J /
〆
/
〆
一一一一一一一f/ f / / /
/
/〆 / f
/ / / /
3.3 実験 1
フルネーム署名画像とその部分署名画像(姓・名)から濃度こう配特徴を抽出してマハ ラノビス距離を算出する( GDM ) .得られた 3 つのマハラノビス距離を特徴ベクトルとす る SVM により照合・分類することで EER が減少するかどうかの検証を行った.実験 1 の処理の流れを図 3.2 に示す.
図 3.2: 実験1の処理の流れ
3.3.1 実験条件
フルネーム,姓,名の署名画像に対して得られるマハラノビス距離を組み合わせ,登録 用の真筆署名として 3 個または 6 個を用いた場合の署名照合の性能評価を行った. SVM のカーネルとして線形,多項式 (2 次 ) ,多項式 (3 次 ) ,多項式 (4 次 ) , RBF( ガウシアン カーネル ) を用いて実験を行った . しきい値は全筆記者共通の値とし,しきい値を変動させ
FAR = FRR となるしきい値を求めた.
3.3 実験 1 21
表 3.1: 各画像ごとの等価誤り率 (%)
EER of individual images(%)
Number of training signatures GDM
Full name First name Last name
Three 11.34 15.95 13.08
Six 6.45 10.89 9.23
表 3.2: 3つのマハラノビス距離を組み合わせた時の等価誤り率 (%)( 学習データ数 :3,6 個 ) EER when combined three mahalanobis distances with three or six training
signatures/signer(%)
hhhhhhh Number of training signature hhhhhhh
Kernel GDM(Full name + First name + Last name) linear polynomial polynomial polynomial RBF
(deg 2) (deg 3) (deg 4)
Three 10.66 10.12 9.63 10.16 10.30
Six 6.09 6.72 6.45 6.72 5.72
3.3.2 結果
表 3.1 に各画像ごとの単独の照合結果を示す.登録用署名が 3 個, 6 個/署名者でフル ネーム,姓,名の画像から得られる 3 つのマハラノビス距離を SVM により組み合わせた 場合の照合実験の結果を表 3.2 に示す.
3.3.3 考察
学習署名が 3 個/署名者の場合,フルネーム,姓,名の画像から得られる 3 つのマハ ラノビス距離を SVM により組み合わせることで 9.63% の EER が得られ,フルネーム署 名画像のみを用いた時の EER 11.34% から約 1.71% EER が減少した.学習署名が 6 個/
利用者の場合,フルネーム,姓,名の画像から得られる 3 つのマハラノビス距離を SVM により組み合わせることで 5.72% の EER が得られ,フルネーム署名画像のみを用いた時
の 6.45% から約 0.73%EER が減少した.この結果は,フルネーム署名画像を姓と名に分
割し,各画像ごとのマハラノビス距離を SVM により組み合わせることが有効であること
を示している.これは,フルネームから抽出される特徴には署名全体の大局的な情報がよ
り多く反映される一方,姓と名から抽出される特徴には局所的な情報がより多く反映され
るため,相補性が高いからと考えられる.
3.4 実験 2
フルネーム署名とその部分署名(姓・名)の時系列点座標データの DP マッチングに よって相違度を算出する( DP ).得られた 3 つの相違度を特徴ベクトルとする SVM に よって照合・分類することで EER が減少するかどうかの検証を行った.実験 2 の処理の 流れを図 3.3 に示す.
図 3.3: 実験 2 の処理の流れ
3.4.1 実験条件
登録用の真筆署名として 3 個または 6 個用い署名照合の性能評価を行った. SVM の カーネルとしてを線形,多項式 (2 次 ) ,多項式 (3 次 ) ,多項式 (4 次 ) , RBF( ガウシアン カーネル ) を用いて実験を行った . しきい値は全筆記者共通の値とし,しきい値を変動させ
FAR = FRR となるしきい値を求めた.
3.4.2 結果
3.4 実験 2 23
表 3.3: 各系列データごとの等価誤り率 (%)
EER of individual images(%)
Number of training signatures DP
Full name First name Last name
Three 8.24 13.64 16.17
Six 7.84 11.96 14.07
表 3.4: 3つの相違度を組み合わせた時の等価誤り率 (%)( 学習データ数 :3,6 個 )
EER when combined three dissimilarities with three or six training signatures/signer(%)
hhhhhhh Number of training signature hhhhhhh
Kernel DP(Full name + First name + Last name) linear polynomial polynomial polynomial RBF
(deg 2) (deg 3) (deg 4)
Three 7.88 8.47 8.15 8.42 8.06
Six 6.90 7.52 7.53 6.90 6.76
た場合の照合実験の結果を表 3.4 に示す.
3.4.3 考察
学習署名が 3 個/署名者の場合,フルネーム,姓,名のデータから得られる 3 つの相 違度を SVM により組み合わせることで 7.88% の EER が得られ,フルネーム署名データ のみを用いた時の EER 8.24% から約 0.36%EER が減少した.学習署名が 6 個/署名者の 場合,フルネーム,姓,名のデータから得られる 3 つの相違度を SVM により組み合わせ
ることで 6.76% の EER が得られ,フルネーム署名データのみを用いた時の 7.84% から約
1.08%EER が減少した.実験 1 と同様に,署名データにおいてもフルネームから抽出され
る特徴には署名全体の大局的な情報がより多く反映される一方,姓と名から抽出される特
徴には局所的な情報がより多く反映されるため,相補性が高いからと考えられる.
3.5 実験 3
濃度こう配特徴を用いた署名照合( GDM ) (フルネーム,姓,名)で得られる 3 つのマ ハラノビス距離と DP マッチングによる署名照合( DP ) (フルネーム,姓,名)で得られ る 3 つの相違度を特徴ベクトルとする SVM によって照合・分類することで EER が減少 するかどうかの検証を行った.実験 3 の処理の流れを図 3.4 に示す.
図 3.4: 実験 3 の処理の流れ
3.5.1 実験条件
登録用の真筆署名として 3 個または 6 個用い署名照合の性能評価を行った. SVM の カーネルとして線形,多項式 (2 次 ) ,多項式 (3 次 ) ,多項式 (4 次 ) , RBF( ガウシアンカー ネル ) を用いて実験を行った . しきい値は全筆記者共通の値とし,しきい値を変動させて
FAR = FRR となるしきい値を求めた.
3.5.2 結果
FRR と FAR が等しくなる時の単独手法の EER を表 3.5 に示す.単独手法による EER
の最小値は,登録用署名数が 3 個の場合,フルネーム署名データから DP マッチングによ
り算出した相違度を用いて照合した場合で 8.24% , 6 個の場合,フルネーム署名画像から
3.5 実験 3 25
表 3.5: 各手法ごとの等価誤り率 (%)
EER of individual verification techniques(%)
Number of training signatures GDM DP
Full name First name Last name Full name First name Last name
3 11.34 13.08 15.95 8.24 14.07 16.17
6 6.45 9.23 10.89 7.84 11.96 13.67
表 3.6: 複数の特徴を組み合わせた時の等価誤り率 (%)( 学習データ数 :3 個 ) EER when combined some techniques with three training signatures/signer(%)
hhhhhhh
hhhhhhhh
Combination
Kernel linear polynomial polynomial polynomial RBF (deg 2) (deg 3) (deg 4)
GDM(Full name + First name + Last name) 10.66 10.12 9.63 10.16 10.30 DP(Full name + First name + Last name) 7.88 8.47 8.15 8.42 8.06
GDM(Full name) + DP(Full name) 7.54 8.60 8.64 8.87 7.48
GDM(Full name + First name + Last name)
6.27 6.54 6.41 6.54 6.54
+ DP(Full name)
GDM(Full name + First name + Last name)
5.59 5.82 5.46 6.18 6.54
+ DP(Full name + First name Last name)
表 3.7: 複数の特徴を組み合わせた時の等価誤り率 (%)( 学習データ数 :6 個 ) EER when combined some techniques with three training signatures/signer(%)
hhhhhhh
hhhhhhhh
Combination
Kernel linear polynomial polynomial polynomial RBF (deg 2) (deg 3) (deg 4) GDM(Full name + First name + Last name) 6.09 6.72 6.45 6.72 5.72
DP(Full name + First name + Last name) 6.90 7.52 7.53 6.90 6.76
GDM(Full name) + DP(Full name) 5.24 6.85 6.00 8.77 5.27
GDM(Full name + First name + Last name)
4.38 4.57 4.12 4.52 4.48
+ DP(Full name)
GDM(Full name + First name + Last name)
3.54 3.98 3.45 3.35 3.60
+ DP(Full name + First name Last name)
ム,姓,名の各署名データから得られる相違度の 6 つの特徴を様々な組み合わせ方で融合 した時の結果を,学習署名が 3 個/署名者の場合を表 3.6 に , 学習署名が 6 個/署名者の 場合を表 3.7 に示す.また登録用署名が 3 個/署名者の DET 曲線を図 3.5 に, 6 個/署名 者の DET 曲線を図 3.6 に示す. DET 曲線とは,分類におけるしきい値をパラメータとし て,他人受入れ率 FAR と本人拒否率 FRR をプロットしたグラフであり,原点に近いほど その照合精度が良い.
3.5.3 考察
学習署名が 3 個の場合, GDM( フルネーム + 姓 + 名 ) + DP( フルネーム + 姓 + 名 ) によ
り最小 EER 5.46% が得られ,単独手法の DP (フルネーム)の 8.24% から 2.78% EER が
0 5 10 15 20 25 30
0 5 10 15 20 25 30
False Rejection Rate(FRR)[%]
False Acceptance Rate(FAR)[%]
Proposed GDM(Full name) GDM(First name) GDM(Last name) DP(Full name) DP(First name) DP(Last name)
図 3.5: DET 曲線 ( 学習データ数 :3 個 )
DET curve when three signatures/user are used for training
0 5 10 15 20 25 30
0 5 10 15 20 25 30
False Rejection Rate(FRR)[%]
False Acceptance Rate(FAR)[%]
Proposed GDM(Full name) GDM(First name) GDM(Last name) DP(Full name) DP(First name) DP(Last name)
図 3.6: DET 曲線 ( 学習データ数 :6 個 )
DET curve when six signatures/user are used for training
減少した.学習署名が 6 個の場合, GDM ( フルネーム + 姓 + 名) + DP( フルネーム + 姓 + 名 ) により最小 EER 3.35% が得られ,単独手法の GDF (フルネーム ) の 6.45% から 3.10%
EER が減少した. GDM, DP 共に姓と名では特徴量が異なる照合結果の相補性が高い.ま た,フルネームから抽出される特徴には署名全体の大局的情報が反映される一方,姓と名 から抽出される特徴には局所的な情報がより多く反映されるため,同様に相補性があると 考えられる. GDM と DP を組み合わせた時に精度が向上した理由は,それぞれの手法で 特徴抽出や分類手法が大きく異なるため融合効果が大きくなったためと考えられる.
lヘ¥
¥ : !
¥
L日
¥ ¥ ¥
1 • ~
「弘
、
、' . c
、、。、ー一、、 '.~'. "'1,¥、、、
一 一一、、三、
句、¥ー
、、
、1町I 、
\ γ‘...,_~:....
、、"、¥
一 司一、白 、-;;むミ吉~-‘"R
: ' =.,
、
"
止
、
寸 、. 、
L 、
1、 -,~ .".~
¥, 、 、九ι ",
、、 目、. 、‑
三二でともと
=-"::;-~~
、ー』、、丸 .,、ー 、
』ι 一・ 一・ー ー、 ー
、
、『、 、、 ヘ 『
九一、→町 、 一一 、 』 、
ーヘ 、 一 一、ー
一」ー 」
官、、一一司Eニーごー』→
3.6 実験 4 27
3.6 実験 4
実験 1 において,署名者の登録署名数をさらに増加させた場合の実験を行う.
3.6.1 実験条件
フルネーム署名画像とその部分署名画像(姓・名)から濃度こう配特徴を抽出してマハ ラノビス距離を算出し, SVM に入力して照合・分類する手法を登録署名数をさらに増加 させ実験を行った.実験データには, 2007 年度の 19 人分の署名を用いた.署名者の学習 署名数を 3 個から 15 個まで変化させ, 2 分割交差検定によって評価した.実験データの 内訳を以下に示す.
登録用データ
• 真筆署名: 84 個( 19 人分× 15 個)
学習,評価用データ
• 真筆署名: 513 個( 19 人分× 27 個)
• 偽筆署名: 513 個( 19 人分× 27 個)
3.6.2 結果
表 3.8: 登録署名数を変化させた場合の等価誤り率 (%) EER with different number of training signatures
Number of training signatures Full name First name Last name Full name + First name + Last name
Three 12.87% 12.61% 18.30% 7.77%
Six 9.11% 10.28% 13.45% 4.93%
Nine 5.60% 6.77% 9.36% 3.93%
Twelve 5.43% 6.18% 9.61% 3.34%
Fifteen 5.43% 6.43% 8.27% 3.34%
登録署名数を 3 個から 15 個まで変化させた時の各照合手法の EER を表 3.8 と図 3.7 に
示す.
0 5 10 15 20
4 6 8 10 12 14
Equal Error Rate [%]
The number of training data per person Full name + First name + Last name
Full name First name Last name
図 3.7: EER と登録署名数の関係
EER vs. Number of training data
3.6.3 考察
実験結果より,登録署名数を 3 個から 9 個まで増やした場合,単独画像による照合の場 合でも, SVM により組み合わせる場合でも EER が大きく減少することがわかる.また,
登録署名数を 9 個から 12 個まで増やした場合,単独画像による照合でも, SVM により組 み合わせる場合でも EER はゆるやかに減少することがわかる.登録署名数を 12 個から 15 個に増やした場合,姓の画像を単独で用いる照合では EER が減少したが,その他の単 独画像による照合では EER は減少しないという結果となった.また, SVM により組み合 わせた場合では EER は減少しないという結果になった.
︑︑︑︑︑︑︑︑︑¥
︑
︑
︑︑︑
︑︑︑︑ ︑
︑︑︑屯︑一︑︑
︑ ︑ 川︑一ー︑︑︑︑.︑
喝︑
九︑九
︑
む