EMC CLARiX ストレージ・システムでの Oracle の実装
ベスト・プラクティスのプランニング
USホワイトペーパー翻訳版
要約
このホワイト・ペーパーでは、EMC® CLARiX® CXまたはCX3 UltraScale™シリーズのファイバ・チ ャネル・ストレージ・システムを使用してOracleデータベースを実装するときに考慮するべき問題に ついて説明します。また、Oracleの一般的な推奨事項とCLARiXシステム特有のパフォーマンス特性 を対比させ、OracleでCLARiXストレージ・システムを使用する際の一般的な推奨事項について取り 上げています。
2008年5月
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 2
Copyright © 2004, 2008 EMC Corporation. All rights reserved.
EMC Corporationは、この資料に記載される情報が、発効日時点で正確であると見なします。こ
の情報は、予告なく変更されることがあります。
この資料に記載される情報は、「現状有姿」の条件で提供されています。EMC Corporationは、
この資料に記載される情報に関する、どのような内容についても表明保証条項を設けず、特に、
商品性や特定の目的に対する適応性に対する黙示の保証はいたしません。
この資料に記載される、いかなるEMCソフトウェアの使用、複製、頒布も、当該ソフトウェ ア・ライセンスが必要です。
最新のEMC製品名については、EMC.comでEMC Corporationの商標を参照してください。
他のすべての名称ならびに製品についての商標は、それぞれの所有者の商標または登録商標です。
パーツ番号H796.3-J
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 3
目次 Tベスト・プラクティスのプランニング ... 0
エグゼクティブ・サマリー ... 5
概要 ... 5
対象読者... 5
用語... 5
このホワイト・ペーパーについて ... 7
Oralce の CLARiX ストレージ認定 ... 7
CLARiX ストレージに対する Oracle データベース設計に関する考慮事項 ... 8
「魔法の弾丸」シンドロームに対応... 8
データベースの論理レイアウトおよびパフォーマンス... 8
Oracle OFAおよび特殊領域とテーブル... 9
パフォーマンスへのアプリケーションの種類の影響... 10
標準のOLTPアプリケーションの特徴... 10
標準DSSアプリケーションの特徴... 11
シーケンシャルまたはランダムI/O... 12
I/Oプロファイルの決定... 12
一時パターンおよびピーク・アクティビティ... 12
Oracle I/O構造... 13
データ・テーブルのI/O... 13
REDOログのI/O... 14
アーカイブのI/O... 14
データベース・ブロック・サイズ(DB_BLOCK_SIZE)... 14
REDOログ... 15
REDOログに関する考慮事項... 15
インスタンス・パラメータ... 19
インスタンス・パラメータの例... 20
データベースのバックアップ... 20
コールド・バックアップ... 21
ホット・バックアップ... 21
SnapViewでのホット・バックアップ... 22
SnapViewでの他に影響しないバックアップ... 22
パフォーマンスに関するその他の考慮事項... 24
ホストOSおよびHBAに関する考慮事項... 24
最大I/Oサイズ... 24
配置... 25
ファイル・システムまたはrawパーティション... 25
rawパーティション... 26
ファイル・システム... 26
ホスト・ベースのスクリプト作成(Plaid)... 27
OracleのSAME... 27
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 4
ホスト・ベースのストライピングのガイドライン... 27
metaLUNの使用... 28
純粋なmetaLUNおよびラウンドロビン・ロギング... 28
metaLUNおよび従来のログ・デバイスのハイブリッド使用... 29
CLARiXキャッシュ... 30
キャッシュ・ページ・サイズ... 30
キャッシュ対象のLUN... 30
スピンドルおよびストライプ... 30
ストライプ・エレメント・サイズ... 31
RAIDレベルとパフォーマンス... 31
RAID 6を使用する状況... 31
RAID 5を使用する状況... 32
RAID 1/0を使用する状況... 32
RAID 1を使用する状況... 32
RAID 0を使用する状況... 33
RAIDレベルと冗長性... 33
ディスク... 33
結論 ... 33
関連資料... 35
付録A:REDOログ ... 36
コンシステンシの必要性... 36
パフォーマンスの利用... 36
最適化の推進:バッファ結合... 37
付録 B : DB チューニングの基本ステップ ... 38
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 5
エグゼクティブ・サマリー
Oracleのパフォーマンスに関する問題は設計フェーズにあります。これは、アプリケーションお
よび論理インフラストラクチャの設計がパフォーマンスにとって非常に重要だからです。これら の問題が解決済みと考えられる場合、ストレージ・パフォーマンスの最適化において重要視され るのは、オブジェクト・モデルの競合です。オブジェクト・レベルで分析するには、データベー ス設計に関する知識が必要です。そして、競合しているオブジェクトを、ストレージ・サブシス テム上の別々の物理ディスク・ドライブに配置することで、最適化が実現されます。
Oracleデータベースの設計によって、REDOログなど、既知のI/Oパターンを備えたコンポーネン トがいくつか生成されます。これらのパターンをRAIDやディスク構成で利用すると、通常は、
競合するテーブル上でスピンドルが共有されることがなくなります。所定のOracleのインスタン ス・パラメータが、EMC® CLARiX®ストレージの特性と連携して動作するように設定する必要 があります。
概要
業界トップの RDBMS(リレーショナル・データベース管理システム)である Oracleは、堅牢で、
かつ可用性に優れたデータ・エンジンです。可用性、堅牢性、およびパフォーマンスを実現する
ために、Oracleは、データベース・テーブルのストレージへの実装に関して、一般的な推奨事項
を示しています。これらの推奨事項は、すべての実装およびストレージ・システムに適用される わけではありません。このホワイト・ペーパーでは、OracleデータベースをCLARiX CXおよび CX3 UltraScale™シリーズのファイバ・チャネル・ストレージ・システムに実装する最適な方法 について説明します。なお、このホワイト・ペーパーは、Oracle 10g以降導入されたOracle ASM(自動ストレージ管理)モデルへの展開を計画している方は対象にしていません。
このホワイト・ペーパーは3つのセクションに分かれています。
• 「OracleのCLARiXストレージ認定」
• 「CLARiXストレージ向けのOracleデータベース設計に関する考慮事項」
• 「パフォーマンスに関するその他の考慮事項」
Oracle ASM導入に関する実装のガイダンスについては、ホワイト・ペーパー「EMC CLARiiON SnapView and MirrorView for Oracle Database 10g Automatic Storage Management – Best Practices Planning」を参照してください。
対象読者
このホワイト・ペーパーは、CLARiXストレージを使用したOracle RDBMSの実装に興味をお持 ちのデータベース管理者(DBA)またはCLARiXシステム・エンジニアを対象にしています。
また、読者はRDBMSの基本的な機能および用語に関する一般的な知識を持っているほか、
Oracle固有の用語とテクノロジーについて精通している必要があります。
用語
アトミック:アトミック変更は、1つの個別の手順で発生します。したがって、システム障害が 発生した場合、状態はまったく変更されないか、またはすべてが更新されるかのどちらかです。
アトミック・トランザクションでは部分的に変更された状態はあり得ません。
自動ストレージ管理(ASM):Oracle Database 10gの機能。データベース管理者に、すべてのサ ーバおよびストレージ・プラットフォームで一貫したシンプルなストレージ管理インタフェース
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 6
を提供します。ASMは、Oracleデータベース・ファイル専用の垂直統合型ファイル・システム およびボリューム・マネージャとして、非同期I/Oのパフォーマンスにおけるファイル・システ ムの管理を容易にします。
チェックポイント:RDBMSが、実行されていないすべてのアイテムをREDOログで処理し、新 しいブックマーク(システム・コントロール番号)でテーブルを更新するプロセス。
結合:ファイル・システム・レベルで小さなI/Oを大きなI/Oにバンドルすること。データのロ ーカル性がある場合(たとえば、ファイル・システム内でブロック同士が近接している場合)に 実行できます。
エレベータ・アルゴリズム:ディスク・ドライブが、アクセス要求を最も効率よく処理できるよ うに並べ替える方式。
OPS(Oracleパラレル・サーバ):Oracle 7で導入されたOracleクラスタリング・テクノロジ ーの名前。Oracleサーバ・エンジン・インスタンスは、通常、サーバ・ホストから実行し、一連 のOSファイルまたはrawパーティションへのアクセスのみを所有します。拡張およびHAサポ ートの両方を提供するために、Oracle RDBMSソフトウェアは、複数のOracleエンジン・インス タンスが連携し、これらのOSファイルまたはrawパーティション上の一連の同じデータへのア プリケーション・アクセスをサポートするよう拡張されました。
RAC(リアル・アプリケーション・クラスタ):Oracle 9i以降、Real Oracleアプリケーションの 拡張と高可用性をサポートするRDBMSテクノロジーを表すために、OPS(Oracleパラレル・サ ーバ)がRACという名前に変更されました。
REDOログ/オンライン・ログ/トランザクション・ログ:REDOログは、高パフォーマンスを実現
するための、Oracleの最も重要なツールです。これは、意図された変更をデータベースに記録す るためのスクラッチ・パッドで、Oracleエンジンが次のジョブに移行する間、DBWRの書き込み のキューに配置できます。この特殊な領域は、シーケンシャルI/O用に最適化された、高速かつ 信頼性の高いストレージに実装する必要があります。
リザーブキャパシティ:通常の運用時よりも優れたパフォーマンスを実現できる可能性があると いう概念。たとえば、レスポンス・タイムのターゲットが10ミリ秒の場合、通常の運用ではス トレージ・システムで8ミリ秒のレスポンス・タイムを実現します。したがって、需要がピー クに達している期間は、システムでは引き続き10ミリ秒のパフォーマンスが実現できます。
ストライプ/ストライプ・エレメント:RAIDアルゴリズムでは、多数のディスクにストレージの シーケンシャル・チャンクを分散させることで速度と信頼性を実現します。I/Oが次のディスク にジャンプする前に書き込まれたブロック数が、ストライプ・エレメントのサイズです。また、
グループ×ストライプ・エレメント・サイズ内のディスク数=RAIDストライプのサイズです。ス トライプ・サイズの方がさまざまな計算でよく使用されますが、ストライプ・エレメントも同様 に重要です。
SGA(システム・グローバル・エリア):Oracleデータベース・エンジンが存在するメモリ領域。
Oracleは、最近使用されたデータに高速にアクセスし、レイジー書き込み(キューにコミットさ
れているがディスクにはまだ書き込まれていない書き込み)を行うために、この領域でDBWRバ ッファなどのバッファを管理します。Oracleでは大量のメモリと独自のバッファリングを使用す るため、OSのチューニングが重要です。
システム・コントロール番号:前回のチェックポイント後に行われた変更を特定する際に使用す るグローバル・ブックマーク。
ライト・アサイド・サイズ:512 バイトのブロックで測定される最大サイズ。RAID エンジンは、
このサイズまでの要求に対してキャッシュI/Oを書き込みます。このサイズよりも大きな要求は
EMC CLARiXストレージ・システムでのOracleの実装
ディスクに直接書き込まれます。詳細については、ホワイト・ペーパー「EMC CLARiiON Best Practices for Fibre Channel Storage」を参照してください。
このホワイト・ペーパーについて
このホワイト・ペーパーを参照として使用しやすいように、注意が必要な段落には以下のように 注記されています。
推奨:概念については、付録を参照してください。
また、このホワイトペーパーで扱うトピック固有の用語については、「用語」セクションで説明 しています。なお、「用語」セクションで定義されている用語は、最初は太字で記されています。
付録では、次のトピックについてより詳しく説明します。
• OracleREDOログ・プロセス
• Oracleの基本的なチューニング手順
• パフォーマンスに関するその他の考慮事項
Oralce の CLARiX ストレージ認定
Oracleは、Oracleソフトウェアとストレージ・テクノロジーの互換性を保証するために、OSCP
(Oracle Storage Compatibility Program)というパートナー・プログラムを策定しました。このプ ログラムは、ネットワーク接続のファイル・サーバ、リモート・ミラーリング・テクノロジー、
およびスナップショット・テクノロジーのいずれかのストレージ・ソリューションとOracleの互 換性を検証するものです。テスト・キットを提供するのはOralceですが、実際にテストを実施す るのはパートナーで、そのテスト結果をOracleが検証します。テストには、さまざまな障害発生 シナリオにおける動作の正確性が重点的に盛り込まれており、EMCは、2007年1月までこのプ ログラムに参加していました。
Oracleは、これらのストレージ・システム・テクノロジーは業界から受け入れられており、スト
レージ・システム・ベンダーにより提供される新世代のシステムにおいてもこれ以上検証の必要 がないところまで成熟していると信じています。CLARiX製品ラインはOSCPプログラムによっ て検証されてきました。そのテスト方式は、CLARiXの新製品リリース前のCLARiX検証テスト に取り入れられているため、新世代のCLARiXストレージ・システムが新しい要件に対応し続け ているということがお客様にも保証されています。
さらに、EMCは、CLARiXストレージ・システムをクラスタリング・ソリューションおよびバ
ックアップ・ツールでの使用を認定しています。どちらの使用においても、EMC E-Lab™によっ て、Oracle 11g、Oracle 10g、Oracle9i RAC(Real Application Clusters)とOCFS(Oracleクラス タ・ファイル・システム)でさまざまなオペレーティング・システムの使用が認定されています。
これらの認定により、EMCとOracleのテクノロジーが確実に連携し、お客様側で問題が発生し たとしても完全にサポートされることが保証されます。
http://www.emc.com/products/interoperability/index.htm
EMCには、Oracleと緊密に連携するパートナー・エンジニア・グループがあります。EMCエンジ ニアは、新しいバージョンのOracleソフトウェアを、CLARiXストレージ・システムに接続され ているさまざまな種類のサーバ上でテストします。これらのラボでは、SnapView™や
MirrorView®などのCLARiX機能を最新のOralceソフトウェアに統合する方法について開発してい ます。
ベスト・プラクティスのプランニング 7
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 8
CLARiX ストレージに対する Oracle データベース設計に関
する考慮事項
ストレージ・システムのOracleデータベース・ファイルを設定するには、データベースの論理的 なデータ・レイアウト、およびデータの使用パターンについて具体的によく理解する必要があり ます。たとえば、次の点について考えます。
• データベースの論理レイアウトおよびパフォーマンス
• アプリケーションおよびパフォーマンス
• Oracle I/O構造
• REDOログ
• Oracleインスタンス・パラメータ
• バックアップ
このセクションでは、これらの考慮事項について順番に説明します。
「魔法の弾丸」シンドロームに対応
このホワイト・ペーパーで取り上げるアプローチについて、非技術系スタッフは次のような疑問 を持つ可能性があります。「このホワイト・ペーパーで扱っているのはストレージ・システムに 関する推奨事項なのに、なぜ、データベース設計について考えなければならないのか?」ストレ ージ・システムは、データベースのパフォーマンスの問題を解消する「魔法の弾丸(特効薬)」
として考えられています。そうは言っても、結局のところ、重要なのは設計なのです。
「付録:DBチューニングの基本ステップ」には、Oracleが推奨するチューニング手順が記載され ています。手順8では、ストレージ・システムをチューニングしています。ソフトウェア・レイ ヤーのチューニングの重要性に関する疑問はすべて、Oracle独自の推奨事項によって解消されま す。
チューニング・プロセスは、レスポンス・タイムが悪い、というユーザーの不満の声があが ってから開始するものではありません。通常、最も効果的なチューニング・テクノロジーの いくつかは、不満が出てから使用するのでは遅すぎます。この時点で、アプリケーションの 設計を完全に変更するつもりがなければ、メモリを割り当て直し、I/Oをチューニングしても、
ほんのわずかしかパフォーマンスは向上しません。1 …また、ハードウェアを追加してもシ ステムのパフォーマンスが向上することはありません。設計が不十分なシステムでは、ハー ドウェアをいくら割り当てたとしても、パフォーマンスは良くならないのです。2
そこで、まず最初に、アプリケーション設計がストレージ・システムのパフォーマンスにどのよ うな影響を与えるか、ということについて説明します。
データベースの論理レイアウトおよびパフォーマンス
使用率の高いテーブルが、I/O要件を処理できるストレージ上に確実に配置されるようにする必 要があります。重要なのはスキーマ、つまり、どのテーブルが一斉にアクセスされるかを把握す ることです。これにより、ディスク上の物理レイアウトが決まるからです。
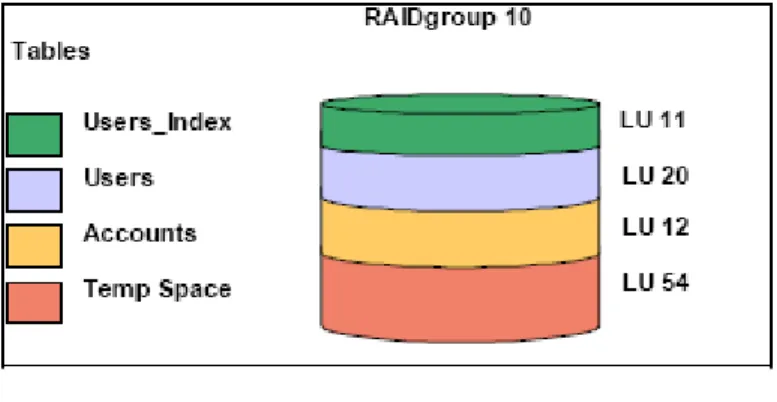
図1では、具体例を簡単な形で示しています。4つのテーブルが一連のスピンドルを共有してお り、これらすべてのテーブルがサンプルSQLステートメントで幅広く使用されているため、デ ィスク競合が発生しています。
1 Oracle8i Tuning Release 8.1.5、パーツ番号A67775-01。
2 Oracle9i Database Performance Planning Release 2 (9.2)、パーツ番号A96532-01。
EMC CLARiXストレージ・システムでのOracleの実装
SQL:SELECT FirstName, LastName, Acctnum, Balance FROM Users INNER JOIN Accounts ON (Users.Acctnum = Accounts.Acctnum) WHERE Balance > 0 ORDER BY Balance
図1:ディスク競合の例
データベース・レイアウトで重要なのは、I/Oのインタラクションがファイル・レベルではなく テーブル・レベルであるという点です。したがって、テーブルとインデックスの関係を理解する ことが大事です。物理メディアにテーブルを配置する場合、一般的には、同時にアクセスするオ ブジェクトは別々の物理スピンドルに配置する必要があります。図1では、1つのクエリーが2 つのテーブルで構成されています。両方のテーブルを同じディスクに置くと、読み取り要求によ って、ディスク・ヘッドがディスク上の2か所のロケール間をシークするようになります。
CLARiX RAIDドライバはディスクのエレベータ・アルゴリズムを利用して、できるだけ効率的
にディスク・アクセスを実行できるようにしますが、やはり、こうした競合は避けることをお勧 めします。
もちろん、例外もあります。テーブルおよびインデックスが小さく、頻繁に参照され、さらに、
SGA(システム・グローバル・エリア)とサーバ・メモリが十分に確保されている場合は、イン デックスがメモリにキャッシュされるので、ディスク・アクセスが問題になることはありません。
推奨:同時にアクセスされるオブジェクトは、異なる物理ドライブに配置されないようにす る必要があります。ここで説明するオブジェクトには、インデックス、テーブル、TEMPテ ーブル、RBS(ロールバック・セグメント)、およびログが含まれます。
もちろん、例外もあります。テーブルおよびインデックスが小さく、頻繁に参照され、さらに、
SGA(システム・グローバル・エリア)とサーバ・メモリが十分に確保されている場合は、イン デックスがメモリにキャッシュされ、ディスク・アクセスが問題になることはありません。
Oracle OFA および特殊領域とテーブル
Oracleには、OFA(Optimal Flexible Architecture)というガイドラインがあり、これにはできる限 り従う必要があります。ディスク上の大量のデータを整理する目的は、デバイスのボトルネック とパフォーマンスの低下を避けることです。
OFAでは、以下のコンポーネントを切り離すことを推奨しています。
• DATAテーブル
• INDXテーブル(インデックス)、DATAに対応
• RBS(ロールバック・セグメント)
ベスト・プラクティスのプランニング 9
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 10
• REDOログ
• TEMP
• SYSTEM
• SYSAUX(10gの新機能)
• フラッシュ・リカバリ領域(10gの新機能)
ただし、このガイドラインは、使用されているストレージの種類に合わせて調整されます。スト ライプ構成(ホストまたはアレイ・ベースのストライピング)の場合は、次の例外が適用されま す。
• ソートの大部分がメモリ内で実行される場合、RBSとTEMPは共存できる。
(SORT_AREA_SIZEを最適化し、ロールバックおよび一時セグメントへの継続的な同時書
き込みがないことを確認します。)
• 環境のほとんどで、SYSTEMとRBSまたはTEMPを共有できる。
• インデックスとテーブルが共存できる場合がある。ここでは、インデックスとテーブルが(テ ーブル・スキャン時のように)同時にアクセスされると仮定します。ただし、OLTP 環境では、
インデックスがメモリ内に保持されない場合、結果としてパフォーマンスが許容範囲外まで 低下する可能性があります。
パフォーマンスへのアプリケーションの種類の影響
アプリケーションは、OLTP(オンライン・トランザクション処理)とDSS(意思決定支援シス テム)の2つのカテゴリに大きく分けられます。これらのカテゴリによって、ストレージに便利 にアプローチできるようになりますが、市販のRDBMSには両カテゴリのアプリケーションが含 まれています。問題はどちらのI/Oタイプに合わせて最適化するか、ということです。
このホワイト・ペーパーでは、OLTPまたは DSSのワークロードに基づいた推奨事項を示します。
ご使用のアプリケーションが、どちらのI/Oタイプにより適しているかを判断するには、次のガ イドラインを参考にしてください。
標準の OLTP アプリケーションの特徴
ユーザーの観点から見た場合のOLTPアプリケーションの特徴を次に示します。
• トランザクションあたりの読み取り/更新に対するデータ量(テキスト・フィールドのページ など)が少ない
• トランザクション(ユーザー・トランザクション)あたりのレスポンス・タイムが短い(通 常は秒単位)
• ユーザー接続数が多い(10~1,000)
• データベースのデータが最新でなければならない。したがって、可用性が重要
代表的なOLTPアプリケーションには、受注管理、アカウント更新、保険、行政関連のフォーム があります。
OLTP I/Oの標準のプロファイル
ストレージ・システムの観点から見た場合のOLTPアプリケーションのI/Oプロファイルを次に 示します。
• I/Oサイズが小さい(通常は8 KB未満)
• I/Oアクセス(データ・テーブルおよびインデックス)がほぼランダム
• ワークロードにおけるランダム書き込みの割合が30%を超える
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 11
• 定期チェックポイントによって、ディスク上のDBを周期的な書き込みバーストと同期させる
• REDOログ・デバイスが、集中的なシーケンシャル書き込みのアクティビティによって非常
にアクティブになり得る
• たまに発生するバックアップ・ワークロードが(通常はシーケンシャルでI/Oサイズが大き い)、実際のアプリケーション・プロファイルとまったく異なる
パフォーマンスの影響
OLTPワークロードは、高速アクセス時間/低レーテンシーのドライブからメリットを得られます。
これにより、ランダム読み取りだけでなく、キャッシュからのランダム書き込みのフラッシュが 高速になり、ストレージ・システムでより多くのロードを処理できます。ランダム性が高いため、
ストライプRAIDソリューションが必須となります。RAID 5よりもRAID 1/0の方がディスクに対 する書き込みロードが少ないため、OLTPに適しています。また、より迅速にキャッシュからの ランダム書き込みをフラッシュできます。読み取りについても、ほぼ同じことが言えます。(10 ページの「シーケンシャルまたはランダムI/O」セクションを参照。)
標準 DSS アプリケーションの特徴
エンド・ユーザーの観点から見た場合のDSSアプリケーションの特徴を次に示します。
• データの更新がまったく(またはほとんど)ない
• 大量のデータ(10~100行のレポート)を取得するためのクエリーが複雑で、多数の異なる タイプやレコードが関連している
• クエリーの経過時間の単位は複雑さに応じて異なる(分~時間)
• データの古さは時間または日数で測定され、更新はバッチ・ジョブとして適用される
• 出力データには、ソートまたはグループ化されたデータ量総計(合計)が含まれる
• 取得データのファイルが大きい(地理データベースなど)ことがある
DSS I/Oの標準のプロファイル
ストレージ・システムの観点から見た場合のDSSアプリケーションのI/Oプロファイルを次に示 します。
• I/Oサイズが大きい(通常は16~512 KB)
• データ/インデックスを読み取る複数のシーケンシャル・ストリーム
• クエリーの実行中、重要な書き込みアクティビティが、一時DBストレージに対して実行さ れる
• 定期的なバッチ更新のワークロードが、実際のアプリケーションのワークロードと異なる
• ログ・デバイスおよびチェックポイントはバッチ更新中にのみ関連する
パフォーマンスの影響
広帯域幅を実現するにはストライプRAIDタイプが必要です。ドライブのシーケンシャル・アク セスを最大化する必要があるため、同時アクセス・テーブルを切り離すことが重要です。また、
強制フラッシュによってRAID 5ストライプ(MR3)書き込みを行えなくなる場合があるため、
キャッシュ管理も大切です。RAID 5はDSSにとってかなり効果的です。
ソート・アクティビティのため、高速で、かつ大きなTEMP領域(ストライプRAIDを使用)が 必要です。
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 12
シーケンシャルまたはランダム I/O
データベース・アクセス・パターンの中には、OLTPまたはDSSにきちんと適応しないものがあ ります。この場合、ストレージ・システム・パフォーマンスに影響する主な特性は、I/Oアクセ スのランダム性になります。ランダム書き込み動作は、特にRAID 5では、シーケンシャル書き 込みよりもキャッシュ・リソースに対してより大きなストレスをもたらします。ランダム読み取 りは、各テーブルのスピンドル、つまりRAID 1/0またはより大きなRAID 5グループからメリッ トを得られます。どちらにおいても、高速ドライブが役に立ちますが、ランダム・アクセス・パ ターンの方がその効果がはっきり現れます。
シーケンシャルI/Oは、ランダムI/Oほどキャッシュに対するストレスは大きくありません。デ ィスク・オペレーションを効率よく行うためにシーケンシャル要求を大きな転送にバンドルでき るからです。実際のところ、シーケンシャル書き込みの処理は、RAID 1/0よりRAID 5の方がう まく行えます。シーケンシャル読み取りについては、いずれのRAIDタイプでも効果的にプリフ ェッチできます。
ランダム更新の例を次に示します。
• クライアント・アカウント・バランスの更新
• インベントリ・トラッキング
• アカウンティング
シーケンシャルI/Oの例を次に示します。
• ユーザーの追加など、テーブルへのあらゆるタイプの累積的追加
• 後の分析で使用するリアルタイム・データの追加
• ファイルのバックアップ
アクセス・パターンのランダム性によって、テーブルにインデックスを設定するかどうかなどの Oracleの設計や、テーブルに導入するRAIDタイプが決まります。
I/O プロファイルの決定
DBAが既存のデータベースのデータを新しいシステムに移行する必要があるとします。このよう な場合は、実験に基づいた分析を行うことができます。現在のストレージがCLARiXシステムの 場合、I/Oを特徴づけるツールとして最適なのはNavisphere®Analyzerです。Symmetrix®環境では Workload Analyzerが最適です。
Oracle 10gよりも前のバージョンでは、utlbstat/utlestatスクリプト3を使用して、長いテーブル・
スキャンまたは短いテーブル・スキャンがレポートされているreport.txtと呼ばれるファイルを出 力できます。また、Oracle 10g以降では、AWR(Automatic Workload Repository)を使って、デー タベース・エンジンのより包括的なパフォーマンス統計を収集できます。
一時パターンおよびピーク・アクティビティ
毎日の受領書や週間レポートなど、トランザクション・バッチ処理を計画します。これにより、
サービスでスパイクを引き起こすことがあります。このスパイクは、ファイル・システム・レベ ルおよびグローバルの両方で発生します。したがって、データベース・バッファやストレージ・
システム・キャッシュなどのグローバル・リソースには、スパイクに対応するためのリザーブ容 量が必要です。
3 開始する場合は、$ORACLE_HOME/rdbms/admin/utlbstat.sql。終了する場合は、utlestat.sql。
EMC CLARiXストレージ・システムでのOracleの実装
また、ピーク・アクティビティも、予期可能なイベントによって引き起こされます。計画対象の イベントには、食事時間、スケジュールされたイベント、金曜日、給料日、祝日など多忙が予想 される日などが含まれます。
Oracle I/O 構造
このホワイト・ペーパーで説明するパフォーマンス上のトレードオフについては、OracleのI/O 構造が分かっていればよく理解できます。
Oracleの構造は、データベース・エンジンの書き込み先である一連のバッファを使用します。こ
れらのバッファはSGA(システム・グローバル・エリア)に存在し、このSGAはホストの
RAMに存在します。Oracleは、このバッファを頻繁に使用してI/Oを最適化します。これにより、
良好なパフォーマンスを得るには、RDBMSホストにRAMおよび仮想メモリが大量に必要であ るという重要な事実が浮き彫りになっています。
Oracleのプロセスはこれらのバッファ上で動作し、rawパーティションまたはファイル・システ
ムのいずれかで実装されているファイルの読み取りおよび書き込みを行います(図2)。
図2:Oracle I/Oの構造
Oracleでは、分割統治法を使用してストレージのアクセスを並列化します。データベースには、
さまざまな機能に対して、メモリ内の個別のSGAバッファ、そのバッファをディスクにフラッ シュするための個別のプロセス、およびI/Oを行う個別のテーブルまたはファイルが用意されて います。さらに、各プロセス・タイプの複数インスタンスを実装するほか、非同期I/Oを使用す ることで、同時性を実現できます。
最高速度でI/Oを実行するためのリソースを、Oracleプロセスに必ず確保するようにしてくださ い。
データ・テーブルの I/O
データベース上で変更または要求が行われると、Oralceは、そのバッファを手段として使用し、
読み取りおよび書き込みのパフォーマンスを最適化します。たとえば、先行読み取りを実行し、
必要になるであろうデータをデータ・バッファに配置します。また、メモリ内データ・バッファ でデータが置かれている場所で、ライト・バックも使用します。トランザクションは継続され、
ベスト・プラクティスのプランニング 13
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 14
ディスクI/Oの完了を待たずに次のトランザクションに進みます4。DBWRプロセスは、バッファ で示されている読み取り、書き込み、および先行読み取り動作を実行します。
DBWR I/Oの特性(大/小ブロック、ランダム、またはシーケンシャル)の大部分は、アプリケー
ションによって決まります(「パフォーマンスへのアプリケーションの種類の影響」セクション を参照)。
REDO ログの I/O
REDOログ(トランザクション・ログまたはオンライン・ログとも呼ばれます)は、要するに、
データベースの更新タスクを実行するために用意されているOralceの手段で、Oracleが行おうと している変更が記録されます。テーブルへの実際の変更は、後から行われます。簡単な変更メモ を作成する方が実際に変更を行うよりも速いため、次のタスクに進む前に、ログ・エントリが作 成され、そのログはディスクに確実に書き込まれます。変更テーブル・ページの書き込みは、後 でDBWRがバックグラウンドのバルク・ダーティー・ページのフラッシュとして行います。その 際、データベース・トランザクションのコミットを妨ぐことはありません。
REDOログのI/Oはシーケンシャルで、かつ同期的です。つまり、それぞれのオペレーションが、
他のオペレーションが開始する前に完了していなければなりません。REDOログは、512バイト の倍数単位の小さなチャンクで書き込まれます。なお、このログはデータベースに対する変更を トラッキングするため、読み取り専用のアプリケーションではREDOログは使用されません。
LGWRプロセスは、REDOログ・オペレーションを実行します。通常、オンラインREDOログ・
ファイルはいっぱいになるまで、つまり、LGWRが他のREDOログ・ファイルに切り替わるまで 書き込まれます。ARCHIVELOGモードが設定されている場合、いっぱいになったREDOログ・
ファイルは、定義されている場所にアーカイブされます。アーカイブされたREDOログ・ファイ ルは、現在のREDOログ・ファイルがいっぱいになったときに再利用できます。ARCHIVELOG モードが設定されていない場合、いっぱいになったこのログ・ファイルは再利用可能な状態に設 定されます。再利用されたら、前のREDOログ・レコードのコンテンツは上書きされ、失われま す。再利用されるのを待機しているログ・ファイルには、オフラインのタグが設定されます。
REDOログ・サブシステムのパフォーマンスは、そのサブセクションを保証するため重要です
(「REDOログ」を参照)。
アーカイブの I/O
ARCHプロセスはオプションの機能で、現在オフラインになっているREDOログをバックアップ します。前回のデータベース同期以降に書き込まれたREDOログのバックアップ(チェックポイ ントとして知られています)を使用すると、致命的な障害が発生した場合にデータベースを再構 築できます。これは、データベースのリモート・コピーまたはオフラインのバックアップを同期 する際にも使用できます。詳細については、「REDOログ」セクションを参照してください。
データベース・ブロック・サイズ(DB_BLOCK_SIZE)
DB_BLOCK_SIZEの値はOracle I/Oの効率性にとっては非常に重要で、これにより、データベー スが行う変更の増分単位が決まります。通常は、このパラメータは、OLTPアプリケーションの 場合は小さな値が、DSSアプリケーションの場合はできる限り大きな値が設定されます。その目 的は、変更が少ない場合は、データの交換がほとんど行われないようにすることです。大きなオ
4 Oracleがライト・バックを使用してデータベースの整合性を維持する方法については、「REDO
ログ」セクションを参照してください。
EMC CLARiXストレージ・システムでのOracleの実装
ペレーションの場合は、I/O を大きくして数を減らすようにするとより効率的です。これにより、
ストレージ・システムに対するより大きな要求に、大きなブロックを結合できます。
推奨:CLARiXのキャッシュ・ページ・サイズは、OracleのDB_BLOCK_SIZEと同じ値に設 定する必要があります。OracleとCLARiXでは、DB_BLOCK_SIZEをファイル・システム・
ブロック・サイズと同じ値にすることを推奨しています。
OSのページ・サイズがファイル・システムのブロック・サイズよりも小さい場合、またはファ イル・システムが使用されていない場合、慎重なDBAであればDB_BLOCK_SIZEをOSのペー ジ・サイズに設定するでしょう。ファイル・システムのブロック・サイズが大きいのに対して
Oracleのブロック・サイズが小さいと、データが必要以上に取得されるため、ファイル・システ
ムのリソースが無駄になります。
しかし、Oracleのブロック・サイズが大きすぎると、意図しないプリフェッチが行われてしまう
可能性があります。このプリフェッチは、ファイル・システム(使用されている場合)またはス トレージ・システム・レベルで発生します。たとえば、データベース・ブロック・サイズがファ イル・システム・ブロック・サイズの2倍の場合、このデータベースでは、ファイル・システム から2つの要求が必要となります。これにより、不必要なプリフェッチがファイル・システムで 発生し、ストレージ・システム・リソースが無駄になります。
REDO ログ
前述したように、REDOログはOracleのスクラッチ・パッドのことで、そこではOracleが行おう としている変更が記録されます。REDOログを実装する場合は、ログ自体のストレージとアーカ イブ・ストレージの2つの側面から考えていく必要があります。
REDO ログに関する考慮事項
Oracleではアトミック性を確保する必要があるため、REDOログは同期的に書き込まれます。つ まり、物理メディアへの書き込みオペレーションが完了するまで、データベースの処理はどの書 き込みからも続行されません。これは、REDOログのコンテンツがデータベースのリカバリに非 常に重要だからです。このコンテンツでは、整合性および安全性が確保されていなければなりま せん。
ライトスルー・ファイル・システム
ファイル・システムのライト・キャッシュをバイパスできない場合は、ファイル・システムを使 用してREDOログ・ファイルを保持するべきではありません5。処理を続行するには、その前に REDOログの書き込みを永続的に保存する必要があります。
ライトスルー・ストレージ・システム
障害発生時におけるライト・キャッシュのデータの一貫性がライト・キャッシュ・スキームによ って保証されない限り、ストレージ・システムではライト・キャッシュを使用するべきではあり ません。障害発生時こそが、まさにライト・キャッシュ・データをディスクに格納する最適な状 況です6。システムによっては、発生した障害が致命的でなくてもログを保護できないことがあ ります。たとえば、LSI「E」シリーズやHP StorageWorks EVAなどのシステムでは、キャッシュ
5 サーバに致命的な障害が発生した場合、物理メディアにコミットされているとOracleが見なし たデータが失われることがあります。
6 障害が発生した場合、すべてのCLARiXおよびSymmetrixアレイでディスク上にキャッシュが格 納されます。
ベスト・プラクティスのプランニング 15
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 16
に対してミラーされていない書き込みを行うことが可能です。この場合、LUNトレスパスがデー タベース破損につながることがあります。
OFAおよびREDOログのデバイス
ログ書き込みプロセスでは512バイトの倍数のブロック単位でシーケンシャル書き込みが行われ るため、ログLUNにとってライト・キャッシュは非常に効果的です。OFAでは、他のI/Oで使 用されていないドライブにオンライン・ログを置くことを提案していますが、ストレージ・シス
テムがCLARiXファイバ・チャネル・システムの場合、これは現実的ではありません。なぜでし
ょう?
• ライト・キャッシュによって、ホスト書き込みがディスク・アクセスから切り離されます。
重要なのは、このライト・キャッシュはキャッシュが書き込みでいっぱいになるのを防ぐた めに、ログ書き込みをすばやくフラッシュできるという点です。
• ログ書き込みはシーケンシャルです。シーケンシャル書き込みでは、ライト・キャッシュは 最適な速度でフラッシュできます。したがって、共有RAID 5グループでもOracle LGWRの 速度に対応できます。
• ドライブが大きくなるほど、Oracleログ(数ギガビット)のみに使用される、複数のスピン ドルを受け入れ可能なユーザーが少なくなります。
FLARE® 24に導入されたNQM(Navisphere QoS Manager)を使用すると、一連の個別のスピンド ルをREDOログのサービスI/O専用にする必要がなくなります。同じRAIDグループから複数の LUNを作成できるので、スピンドルに必要以上の容量があっても無駄にはなりません。また、
NQMによって、指定したサービス・レベルをREDOログLUN上で維持できます。これにより、同 じRAIDグループ内の他のLUNに他のアプリケーションがアクセスしていても、必要なパフォー マンスのレベルをデータベースから確保できます。共有RAIDグループのLUNは、スピンドルが 過負荷にならないように、帯域幅およびスループットの要件が制限されているアプリケーション に割り当てることを推奨します。NQMの使用については、ホワイト・ペーパー「Using
Navisphere QoS Manager in Oracle Database Deployments」を参照してください。このホワイト・ペ ーパーはPowerlink®から入手できます。
REDOログ・アーカイブを使用するかどうかは、Oralceの{NO}ARCHIVELOG設定によって決ま ります。本番環境では、通常は、ARCHIVELOGモードが設定されています。REDOログ・アー カイブは、REDOログよりもはるかに大きなブロックでシーケンシャルに書き込まれます。大き なI/Oサイズは古い(FCシリーズ)ストレージ・システムのファクタで、これによりライト・
キャッシュ帯域幅が制限されます。これらの古いシステムで実行されている書き込み集中型デー タベースは、アーカイブ書き込みのライト・キャッシュをバイパスすることによってメリットを 得られます。(CXおよびCX3シリーズのシステムは格段に優れた帯域幅を提供しているため、
この処理は通常は必要ありません。)
アーカイブ書き込み用キャッシュをバイパスする
CLARiXライト・キャッシュ・アーキテクチャの柔軟性を利用することで、通常はアーカイブ・
ログ・アクティビティでいっぱいのキャッシュ・ページを解放できます。これらの書き込みがキ ャッシュをバイパスできると、より多くのページが本番I/O用に解放されます。これを制御する には、CLARiXのライト・アサイド設定を使用します。アーカイブLUNのライト・アサイド・サ イズは、ログのバックアップで使用されるI/Oよりも小さいサイズに設定します7。たとえば、ア ーカイブ・プロセスが512 KBの書き込みを実行する場合、ライト・アサイド・サイズは1,023ブ
ロック(511.5 KB)に設定します。また、アーカイブLUNのライト・キャッシュをオフにするこ
ともできます。
7 ライト・アサイドの詳細については、ホワイト・ペーパー「EMC CLARiiON Best Practices for Fibre Channel Storage」を参照してください。
EMC CLARiXストレージ・システムでのOracleの実装
オフライン・ログがオンラインになる前にログ・アーカイブ・プロセスを確実に完了させるには、
キャッシュされていない書き込みが効率的に実行されるようにします。この手法には複数の方法 でアプローチできます。
最初のアプローチでは、アーカイブLUN上のRAIDストライプに合わせてI/Oを割り当てる必要 があります。この場合、アーカイブ・デバイスは、非常に効率的なストライプ書き込み(修正 RAID 3つまりMR3)を実行するRAID 5になります。MR3の調整および最適化については、ホ ワイト・ペーパー「EMC CLARiiON Best Practices for Fibre Channel Storage」を参照してください。
2番目のアプローチは、ファイル・システムによって調整済みの書き込みが排除されているか、
またはアーカイブ・プロセスとファイル・システムの組み合わせによって十分なサイズのI/Oが 排除され、パリティ・ストライプがいっぱいになっていることが前提となっています。この場合、
アーカイブは、ミラーされたストレージ、つまりRAID 1またはRAID 1/0のいずれかに配置され ている必要があります。ディスク・アクティビティは、最適化されたRAID 5のアクティビティ よりも大きくなるにもかかわらず、効率的です。アーカイブ・プロセスに対するI/Oが非常に小 さい場合は、ライト・アサイド・パラメータでキャッシュをバイパスするよりも、ライト・キャ ッシュをオフにする方がよいでしょう。
複数ログ・デバイスの使用
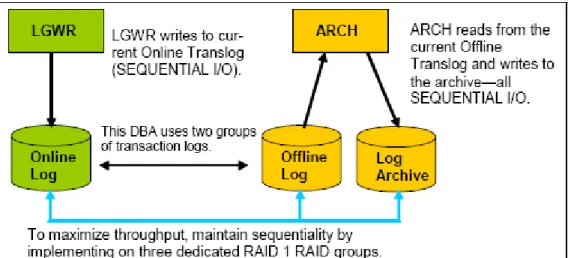
大規模システムの多くが複数のログを使用しています。これらのログは、通常、LGWRプロセス からアクセスされた順に番号が付けられており、また、グループに分けられています(図3)。
理想的には、ログ・グループは、アクティブ・ログ用および非アクティブ・ログ用の2つの専用 RAIDグループに置かれます。なお、非アクティブ・ログ用のグループはアーカイブされていま す。
図 3:複数ログのレイアウト
オンライン・ログへの書き込み、オフライン・ログからの読み取り、アーカイブへの書き込みの 3つのログ・オペレーションすべてが、シーケンシャルI/Oであることに注意してください。
RAIDグループをこれらのデバイス専用にすると、ディスクの能力を最大限に使用して、シーケ ンシャルI/Oが実行されます。その結果、ログやアーカイブへの書き込みはキャッシュから即座 にフラッシュされるので、データベース書き込みの際の余分なオーバーヘッドを回避できます。
書き込みの負荷が高いシステムでこの手法を利用すると、書き込みパフォーマンス全体を向上さ せるのに役立ちます(図4)。
ベスト・プラクティスのプランニング 17
EMC CLARiXストレージ・システムでのOracleの実装
図4:ARCHIVELOGモードがアクティブの場合のOracleログI/O構成
推奨:大規模なシステム(40を超える数のドライブを使用中)で、書き込みの負荷が大きい(す べてのホスト・トラフィックの30%以上)場合には、オンライン、オフライン、アーカイブ・
ログのデバイスは別のドライブ・セットに展開する必要があります。ディスク・グループがス トライプRAIDである限り、パフォーマンスに重要な影響を与えるような他のデータとアーカ イブ・ドライブを共有しても問題ありません。
OFAを小規模システムに適応させる
Oracleデータベースは、サイズもI/O要件も適度に設定することが可能です。ドライブ数が少な
いシステムでは、REDOログのデータが、他のファイルと共存しなければならないことがありま す。この場合、ストレージ・システムがREDOログを効果的にキャッシュできることが重要です。
REDOログ書き込みはライト・キャッシュにヒットするため、REDOログ・オペレーションはキ ャッシュ速度で実行されます。Oracleが小規模展開されている場合、このロードのみがライト・
キャッシュに負荷をかけているとは考えにくいのですが、ストレージ・システムが、他の書き込 み集中型プロセスと共有されている場合は、キャッシュが飽和状態になることを予測できなけれ ばなりません。キャッシュが飽和状態になると、強制的にフラッシュされ、すべてのI/Oの速度 が遅くなるほか、REDOログのパフォーマンスが低下します。キャッシュが飽和状態であること を検出するには、Navisphere Analyzerでシステムをモニターするのが最適です。
Oracleを小規模なストレージ・システム(20ドライブ未満)で効果的に展開するには、できるだ
け多くのドライブをRDBMSファイルで使用できるように(これにより、ファイルを共有する必 要が生じても)、ディスク・グループを区分化します。このケースに適しているのは、アクセス が少ないホスト(部門ファイル・サーバなど)およびデータベース間でドライブを共有できる metaLUNです。
たとえば、metaLUNを使用しなければ、20のディスクを備えたシステムには、通常、4つの RAIDグループが含まれることになり、通常の展開方式(5ディスク・グループ)では、LUNが アクセスできるディスク数は最大で5つです。metaLUNを使用すると、各ディスク・グループが 区分化され、グループごとに1つのLUNがホストのmetaLUNに割り当てられます。metaLUNで はそれぞれ最大20のドライブを使用でき、I/Oバーストに対応します。
ベスト・プラクティスのプランニング 18
EMC CLARiXストレージ・システムでのOracleの実装
共有環境でREDOログをアーカイブするには、ストレージ・システム・キャッシュのダーティ ー・ページをモニターする必要があります。ログおよびデータ・テーブルがディスクを共有して いる場合、アーカイブ・ログへの書き込みによって強制フラッシュが発生すると、ドライブに対 する他の要求が影響を受けます。強制フラッシュを行わなくてもアーカイブ・プロセスに対応で きるだけのドライブがある場合、ホストは、これらのドライブにコンカレントI/Oを移動できま す。また、アーカイブ・デバイスに対してライト・アサイドを使用するかライト・キャッシュを 完全にオフにすると、本番I/Oのキャッシュ・ページが解放されます。
推奨:小規模なシステム(ドライブの数が20より少ない)の場合、もっともビジーなテーブ ルをできるだけ多くのドライブに広げて、バーストを吸収する必要があります。ライト・キャ ッシュはドライブ・アクセスをバッファするので、データをログ・デバイスと共有しても問題 ありません。metaLUNを使用して、ディスク・ドライブを最大限に使用できるようにしてくだ さい。
インスタンス・パラメータ
Oracleデータベース・インスタンスには、ストレージとの対話を制御するためのパラメータがあ
ります(表1)。データベースを設定する場合は、ストレージ構成を考慮してください。これら のパラメータは、ストレージに逆らって動作するのではなく、ストレージとともに動作します。
たとえば、表2では、例で使用されているRAIDグループのストライプ・サイズに合わせてパラ メータが調整されています。
これらのパラメータは、通常は、$ORACLE_HOME/dbs/init.oraまたはinit.oraファイルにありま す。Oracleインスタンス・パラメータが含まれるSQLPLUSプロンプト(8iシステムの場合は svrmgrプロンプト)レポートから、show parametersコマンドを使用してください。
表1:重要なOracle設定とデフォルト値
パラメータ 設定単位 標準の デフォ ルト
説明および推奨事項
DB_BLOCK_SIZE バイト 2048
ファイル・システムのブロック・サイズと同 じで、かつOSのページ・サイズ以上8。
DB_BLOCK_CHECKPOINT
_ WRITE_BATCH DB_BLOCK_SIZE 8
チェックポイントの書き込みの書き込みチャ ンク・サイズ。CLARiX LUNストライプ・エ レメント・サイズからCLARiXストライプ・
サイズまでの値を設定。ただし、OSの最大 I/Oサイズを超えないようにする。
DB_FILE_MULTIBLOCK_
READ_COUNT DB_BLOCK_SIZE 8
テーブルおよびインデックス完全スキャン用 の読み取りチャンク・サイズ。CLARiX LUN ストライプ・エレメント・サイズから
CLARiXストライプ・サイズまでの値を設
定。ただし、OSの最大I/Oサイズを超えない ようにする。
8 DB_BLOCK_SIZEの詳細については、14ページの「アーカイブのI/O
」を参照してください。
ベスト・プラクティスのプランニング 19
EMC CLARiXストレージ・システムでのOracleの実装 HASH_MULTIBLOCK_IO_
COUNT DB_BLOCK_SIZE 8
ハッシュ結合のI/Oチャンク・サイズ。
CLARiX LUNストライプ・エレメント・サイ ズからCLARiXストライプ・サイズまでの値 を設定。ただし、OSの最大I/Oサイズを超え ないようにする。
USE_DIRECT_IO ブール値 N/A ファイル・システムをバイパスできる場所
(使用できる場合)。
パラメータのサイズ設定(CLARiXストライプ・エレメント・サイズからストライプ・サイズま で)は、アプリケーションの種類に多少依存します。OLTPの場合は、ストライプ・エレメン ト・サイズを使用します。DSSの場合は、ストライプ・サイズを使用します。また、metaLUN を使用する場合は、metaLUNのストライプ・エレメント・サイズではなく、べースLUNのスト ライプ・エレメント・サイズを参考にします。
インスタンス・パラメータの例
表2は、インスタンス・パラメータの設定を示しています。この表で示すインスタンス・パラメ ータは、次の構成に基づいています。
• Windows 2000ホストで、NTFSファイル・システムにテーブルを展開(ファイル・システム では4 KBブロック・サイズを使用)
• データLUNの場合は64 KB(128ブロック)ストライプ・エレメント・サイズ 表 2:OLTP構成のインスタンス・パラメータ
パラメータ 値 コメント
DB_BLOCK_SIZE 4096 ファイル・システムのブロック・サイズ。
DB_BLOCK_CHECKPOINT_
WRITE_BATCH
16 16*4096 = 64 KB、べースLUNストライプ・エレメン ト・サイズ。
DB_FILE_MULTIBLOCK_READ_
COUNT
16 16*4096 = 64 KB、べースLUNストライプ・エレメン ト・サイズ。
HASH_MULTIBLOCK_IO_COUNT 16 16*4096 = 64 KB、べースLUNストライプ・エレメン ト・サイズ。
USE_DIRECT_I/O 未使用
推奨:Oracleの先行読み取りサイズおよび書き込みクラスタ・サイズが、基本のLUN RAID
ストライプ・サイズまたはストライプ・エレメント・サイズと必ず対応ようにしてくださ い。
データベースのバックアップ
データベースのバックアップは2通りの方法で実行できます。1つはコールド・バックアップと いい、データベースをシャットダウンしてバックアップを行います。もう1つはホット・バック アップで、データベースを実行したままバックアップ・モードでバックアップを行います。両オ ペレーションともストレージ・サブシステムの設計に影響するので重要です。したがって、この 両方について検討していきます。システムを設計する場合は、バックアップによって発生する時 間およびI/Oロードを考慮し、ホット・バックアップ中に十分なパフォーマンスが確保されるよ うにします。
ベスト・プラクティスのプランニング 20
EMC CLARiXストレージ・システムでのOracleの実装
ベスト・プラクティスのプランニング 21
Oracleバックアップの詳細については、Oracleドキュメント「User-Managed Backup and Recovery Guide」を参照してください。
コールド・バックアップ
コールド・バックアップでは、データベースがシャットダウンされます。これと並行して、デー タベースを構成するOracleデータベース・ファイルをバックアップ・メディアにコピーできます。
Oracle RMANは使用できません。Oracle RMANでは、データベースを実行しておく必要がある からです。
データベースが停止するため、パフォーマンスの要件を予測することができます。たとえば、バ ックアップ対象のLUNの数に気をつけたり、読み取りアクセス用の総帯域幅を計算したりしま す。この総帯域幅をストレージ・システム自体、バックアップ・ホスト、およびメディアの最大 帯域幅と比較して、どこがボトルネックになっているかを特定します。読み取りアクセスのブロ ックは大きくなければなりません。また、このアクセスはシーケンシャルに実行される必要があ ります。
ホット・バックアップ
DBAは、I/Oを停止せずにデータベースをバックアップする方法を見つけることが重要です。
Oracleでは、ホット・バックアップ・モードを使用できます。このホット・バックアップの詳細 については、「関連資料」セクションで紹介するホワイト・ペーパー「Oracle 9i with SnapView in SAN Environments」または「Oracle 10g with SnapView in SAN Environments」を参照してください。
以下にその特徴を簡単に示します。
• データベースはログ可能モードで動作している必要がある。
• ホット・バックアップ・モードが開始される。
• データベースにチェックポイントが設定され、SCN(System Change Number)が凍結される。
• データベースへの変更が許可されている間にバックアップが完了し、REDOログのレコード が変更される。
• バックアップが完了すると、データベースはホット・バックアップ・モードでなくなり、
REDOログが通常のログ・モードに戻る。SCNの凍結が解除され、コミットされた変更すべ てがデータベースに正しく反映される。
• ホット・バックアップ期間中に生成されたREDOログが、データベース・バックアップ・フ ァイルとともに収集、アーカイブ、および保存される。また、制御ファイルのバックアッ プ・コピーが、REDOログのアーカイブの完了後に作成される。
バックアップ期間中は、データベースのこの部分に対するブックキーピングがさらに必要となる ため、データベースに対するアクティビティが多くなるとREDOログが急速に拡大します。デー タベースがホット・バックアップ・モードのままの場合、トランザクションのレスポンス・タイ ムに悪影響を与えます。
データベースによるI/Oオペレーションはホット・バックアップ中も行われています。したがっ て、コールド・バックアップに比べると、パフォーマンス要件を予測することが難しくなってい ます。バックアップ・プロセスにおける読み取りのシーケンシャル処理はデータベース・アクテ ィビティによって分割され、本番アプリケーションとバックアップ・プロセスの両方のI/Oが影 響を受けます。データベースを設計するときはパフォーマンス・ヘッドルームを十分に考慮する 必要があります。または、ホット・バックアップは、それほど処理が多くないときに実行するよ うにします。