DOI: http://doi.org/10.14947/psychono.39.3
日本語音声の誤知覚における文脈効果
1藤 平 昌 代
a,*・小 島 治 幸
ba金沢大学大学院,b金沢大学
Context effects on Japanese voice misperceptions
Masayo Fujihira
a,* and Haruyuki Kojima
baGraduate School of Human and Socio-Environmental Studies, Kanazawa University bFaculty of Human Sciences, Kanazawa University
The McGurk effect occurs when inconsistencies between a person’s voice and facial movements cause misper-ceptions among listeners. In this study, we investigated whether these mispermisper-ceptions are affected by the context in which the stimuli are experienced. We used sentences with a target word that was either a meaningful (word sen-tence) or meaningless (non-word sensen-tence) three-syllable term. The speakers’ voices and facial movements during the second (target) syllable of the target word involved the sounds /ba/, /ga/, or /da/, which were combined indepen-dently. Participants reported what they heard during the combined voice-movement stimuli. Incongruity between target syllables in the word sentences and voices indicated a high error ratio with regard to the voices. In addition, congruency between target syllables in non-word sentences and voices also indicated a high error ratio for voices. When the sentences and facial movements were meaningful, many responses matched the facial movements shown, beyond the classic McGurk effect. Completing the Japanese sentences with misperceptions was caused by higher-lev-el cognitive processing in order to understand the sentence.
Keywords: speech perception, McGurk effect, word, context 日常会話におけるコミュニケーションは,多くの場合 音声言語のやり取りによって成立している。このため, 電話のような音声聴覚情報のみによるコミュニケーショ ンが可能である。しかし,通常の対面コミュニケーショ ンでは,私たちは聴覚情報のみでなく視覚情報も利用し ている。たとえば,発話者の表情などによって私たちは 発話者の感情や意図さえも理解することができる(de Gelder & Vroomen, 2000)。この事実は,聴覚情報に加え て視覚情報が私たちにさらなるコミュニケーション情報 をもたらしていることを示している。現実のコミュニ ケーションの中には,発話理解にとって最適ではない場 面が存在する。ノイズが加えられた発話音声に含まれる 標的語の識別では,聴覚情報単独よりも視覚情報が同時 に呈示された場合に識別度が上昇した(O’Neill, 1954;
Sumby & Pollack, 1954; Erber, 1969)。加えて,参加者の非 母語を用いた発話を復唱することを求める課題では,発 話の視覚情報はその復唱課題の成績を高めることがわ かっている(Reisberg, McLean, & Goldfield, 1987)。これ らの先行研究は,視覚を含む複数のモダリティによる情 報が,聴覚情報を主とする発話理解を容易にすることを 示している。一般的な日常会話では,発話理解に最適な 場面でなくとも,発話者自体の発話音声(聴覚情報)と そのときの口の形状(視覚情報)は常に対応関係にある。 しかし,その対応が崩れた場合,視覚情報が聴覚情報を 誤って補足することがある。このような現象として, McGurk 効 果 が 知 ら れ て い る(McGurk & MacDonald, 1976; MacDonald & McGurk, 1978)。
McGurk効果は,特定の単音節の聴覚情報が,異なる 音節を産出している話者の視覚情報によって誤って知覚
される現象である。この現象では典型的に,音節/ba/と
/ga/を用いて示され,発話音声/ba/と発話映像/ga/が同時 に呈示されると融合反応/da/に聞こえ,発話音声/ga/と Copyright 2020. The Japanese Psychonomic Society. All rights reserved.
1 発話撮影においてご協力いただいた話者の方々に謝
意を表します.
* Corresponding author. Graduate School of Human and Socio-Environmental Studies, Kanazawa University, Kakuma-machi, Kanazawa-shi, Ishikawa 920–1192, Japan. E-mail: [email protected]
発話映像/ba/が呈示されると複合反応/bga/に聞こえるこ とが示されている(McGurk & MacDonald, 1976)。この McGurk効果の発生には,唇を一度閉じてから発音する
「唇音」 (/ba/, /pa/など) と,唇を開けたまま発音する 「非
唇音」(/ga/, /ka/など)による音声と映像の組み合わせ が重要であることがわかっている(MacDonald & Mc-Gurk, 1978)。McGurk効果は/ba/や/ga/を含む様々な単音 節(Green, Kuhl, Mltzoff, & Stevens, 1991; Sekiyama & Toh-kura, 1991; Beauchamp, Nath, & Pasalar, 2010)で示されて きた。単音節に加えて,abaやagaといった2音節(Mun-hall, Gribble, Sacco, & Ward, 1996; Jones & Callan, 2003)の ように,McGurk効果を引き起こす音節に別の音節が付 属した際にも同様の効果が生じる。さらに,McGurk効 果を引き起こす音節を含む単語を単独で呈示した際に は,有意味単語のみならず無意味単語を用いても Mc-Gurk 効果が報告されている(Sams, Manninen, Surakka, Helin, & Kättö, 1998; Brancazio, 2004)。 こ れ ら の う ち, Brancazio (2004)は英語を,Sams et al. (1998)はフィン ランド語を用いて McGurk効果が生じることを示した。 フィンランド語は音節構造が日本語と似ており(堀, 1994),英語とは異なる。音節構造が異なる言語間で McGurk効果が生じたことから,McGurk効果は特定の言 語に限定されない現象であることが示唆される。した がって,日本語の単語を用いた場合でもMcGurk効果が 生じると考えられる。複数の言語で有意味単語と無意味 単語の両方でMcGurk効果が示されているため,日本語 でも同様に単語が有意味であるか無意味であるかにかか わらずMcGurk効果が生じることが予測される。 有意味単語のみに焦点を当てた研究においても,刺激 となる単語を構成する聴覚情報と視覚情報が不一致な場 合には,呈示された聴覚情報が異なる音声として知覚さ れることが示されてきた(Dodd, 1977; Dekle, Fowler, & Funnel, 1992)。Dekle et al. (1992)は,聴覚情報(/mail/), 視覚情報(/deal/),それら両情報を同時に呈示した時に 生じると予期されるMcGurk効果(/nail/)の何れもが有 意味単語である条件を設定した。参加者は,聴覚情報, 視覚情報,McGurk効果のリストの中から聞こえたと思 う単語を回答するように求められた。このとき参加者の 多くは,McGurk効果を報告した。 しかし,有意味単語を単独で用いた場合,このような 聴覚情報に対するMcGurk効果の促進が見られなかった 研究もある。Easton & Basala (1982)は,発話に関する 聴覚情報と視覚情報が矛盾している場合において,参加 者が視覚情報を正確に読み取ることができるかを調べ た。この実験は読唇の成績に注目しており,参加者は唇 の動きを回答する実験群と,聞こえた音声を回答する統 制群に分けられた。参加者は,発音が異なる2つの有意 味単語の聴覚情報と視覚情報(例えば/whirl/の発話音声 と/word/の発話映像)を用いて組み合わされた刺激を呈 示された。このとき,実験群では視覚情報に対する誤答 が増えたが,統制群では聴覚情報に対する誤答はほぼ生 じなかった。Easton & Basala (1982)は,統制群におけ
る従来のMcGurk効果と矛盾するように見える結果につ
いて,用いた刺激が単音節であるか単語であるかの違い によるものであると考えた。しかしながら Dekle et al. (1992)はEaston & Basala (1982)について,聴覚情報が
刺激として用いた有意味単語間で類似しており,矛盾し ているとはいえないため,従来のMcGurk効果とは異な る結果が見られたと指摘している。このことから,2つ の単語の聴覚情報が類似していても必ずしもMcGurk効 果は生じないこと,むしろ2つの単語の聴覚情報が異な りそれらの間で音声が選択可能な場合に,視覚情報が 誤った音声知覚を生じさせることが示唆される。 McGurk効果は文のような,文脈を付加した条件でも 生じる。Windman (2004)はドイツ語を用いて,文を呈 示した後に,聴覚情報と視覚情報が不一致である標的語 を呈示し,聞こえた音声を自由再生させた。聴覚情報と 視覚情報は,McGurk効果が生じた場合に有意味単語と なるように選ばれた。その結果,McGurk効果が生じる と標的語と文の意味との関連が高くなる場合に,McGurk 効果すなわち文脈に沿う反応が頻繁に生じた。しかし, McGurk効果が生じても標的語と文の意味との関連が低 い場合には,予測されたMcGurk効果とは異なる反応が
数多く生じた。Wright & Wareham (2005)は文脈として, 以下のような物語の映像を用いた。一人の女性が,自分 の後方を歩く男性に尾行されていると感じて走り出す。 走って逃げている途中で女性の靴が脱げ,男性はその靴 を拾って追いかける,というものである。この物語の最 後に,“He’s gonna shoot”という聴覚情報と,“He’s got your boot”という視覚情報を組み合わせた見物人の発話 場面が呈示された。このとき,見物人の発話の最後の単 語は“shoe”であるという反応が多く見られた。この結 果は,元の聴覚情報とは異なるだけでなく,文脈に依存 したMcGurk効果が生じることを示した。文脈を用いた McGurk効果の実験から,文脈の存在が聴覚情報に対す る誤知覚を促進することと,McGurk効果の強さは文脈 理解といった高次認知過程によって「調整」されうるこ とが示唆される。一方で,Sams et al. (1998)はフィンラ ンド語の文を用いた場合に,文脈に依存しない反応が多 く見られたことを報告している。Windmann (2004)は
Sams et al. (1998) の用いた刺激について,予期したMcGurk 効果が生じにくいような聴覚刺激と視覚刺激の組み合わ せであったと指摘している。このように研究によって McGurk効果への文脈の影響は必ずしも一貫した結果と はなっておらず,文脈処理がどのように音声に対する誤 知覚を調整するのかは明らかにされていない。McGurk 効果は,音声か映像のどちらか一方にのみ注目して回答 するように求められた場合(Massaro & Cohen, 1983)や, 音声と映像の呈示が時間的(Munhall et al., 1996),空間 的 (Jones & Munhall, 1997) に同調していない際にも見ら れる。このように,認知的操作が存在する場合にも生じ る現象であることが示されてきた。特定のモダリティへ の注目や,時空間的不一致にもかかわらずMcGurk効果 が生じることは,低次の感覚処理の結果ではなく,むし ろ総合的に情報を処理するような認知的処理の結果であ ると考えられる。しかし,これまでに認知的操作を行っ た研究の多くは単音節を刺激として用いてきた(Green et al., 1991; Rosenblum, Schmuckler, & Johnson, 1997)。単音 節の知覚は,あまり多くの認知処理を必要としないと考 えられる。その一方で文脈理解のような場面では,多く の認知処理が必要とされ,従来のMcGurk効果だけでは 説明できない反応が見られることが示唆される。 本研究では,McGurk効果を手段として用い,音声に 対する誤知覚に文脈が及ぼす影響を示すことを目的とし た。そのために,McGurk効果が生じることを想定した 音節(標的音節)を含む単語(標的語)を単文中に埋め 込み呈示する。単文の標的語以外の部分を文脈(文の意 味)と定義する。標的語には文脈に沿った有意味単語と 文脈に沿わない無意味単語を用いて,標的語と文脈の関 連性の高さを操作し,文脈依存の誤答と,非文脈依存の 誤答の生じ方を検討した。両単語条件間で誤答の内容に 差が見られなければ,音声の誤知覚は単語の有意味性と は無関係であり,低次の感覚レベルで生じることを意味 する。その一方で,有意味単語と無意味単語間で誤答の 内容に差があるならば,標的音節の知覚は単語の有意味 性の影響を受けることになり,音声に対する誤知覚が文 理解の処理にかかわる比較的高次の認知過程において生 じることを意味するであろう。単語の標的音節には,強 いMcGurk 効果が期待される音節の組み合わせである /ba/と/ga/, そしてそれらの融合反応とされる/da/を用い た。文脈に沿う単語の標的音節が/ba/と/ga/である場合 は,融合反応は非文脈依存すなわち古典的なMcGurk効 果による誤答であることを意味する。一方で文脈に沿う 単語の標的音節が/da/である場合は,融合反応は文脈依 存の誤答あるいは古典的なMcGurk効果による誤答であ ることを意味する。それら2種類の文の間で誤答の内容 が類似していれば,誤答は文脈に左右されず聴覚情報 (音声刺激)と視覚情報(映像刺激)の組み合わせによっ て画一的に生じるといえる。しかし誤答の内容が異なっ ていれば,誤答は文脈による調整を受けたと予測でき る。さらに,文脈に沿う単語の標的音節が/ba/である場 合は,複合反応が生じる音声映像組み合わせ(音声刺激 /ga/と映像刺激/ba/)において,文脈と映像刺激が一致 する。一方で文脈に沿う単語の標的音節が/ga/である場 合は,融合反応が生じる音声映像組み合わせ(音声刺激 /ba/と映像刺激/ga/)において,文脈と映像刺激が一致 する。前者で複合反応,後者で融合反応が生じた場合, 誤答は文脈にかかわらず生じるといえる。複合反応と融 合反応以外の誤答が生じれば,誤答は聴覚情報と視覚情 報の組み合わせによって画一的に生じるのではないこと を示す。このように,文脈とMcGurk効果が生じる音声 映像組み合わせの関係性を操作することで,音声に対す る誤知覚が文理解の処理にかかわる比較的高次の認知過 程を介するものであるか否かを検討する。 音声刺激と映像刺激の組み合わせには,文脈に沿う単 語の標的音節である/ba/, /ga/, /da/から作成可能なすべて の種類の組み合わせ(9種類)を用いた。これらの組み 合わせによって,音声刺激と映像刺激の両方が文脈に沿 う条件,音声刺激と映像刺激のどちらかが文脈に沿う条 件,音声刺激と映像刺激の両方が文脈に沿わない条件を 設定し,すべての文の間で同じ音声映像刺激の組み合わ せに対する誤答を比較することができる。 事 前 検 討 標的語が話者によって適切に発音されているかを確か めるために,音声刺激のみを呈示し,音声刺激の妥当性 に関する事前検討を行った。 参加者(1 回目) 20 名の大学生(男性 2 名,女性 18 名,年齢幅20–26歳,平均年齢21.45歳)が参加した。 刺激 McGurk効果の生起を評価するため,3音節の 標準的な日本語の名詞が用いられた(標的語)。そのた めにまず,第2音節に/ba/, /ga/, /da/(これらを標的音節
と呼ぶ)のいずれかを含む3音節の有意味単語を,各5 語ずつ選定した。各有意味単語は日本語コーパス(天 野・近藤,1999)における音声単語親密度の評定値が5 より高い名詞であり,親しみ深いものであったといえ る。すべての刺激文は,“第 1目的語+第2目的語+動 詞”(例えば,‘食器 を とだな に しまう’)の形 式を持つ単文とし,第 2目的語を標的語とした。これ を,有意味単語文と呼ぶことにする (Table 1 AからO)。
文内の標的語以外の部分は,標的語を含めて意味が通じ るように作成された。標的音節が/ba/である文を/Ba/文, /ga/の文を/Ga/文,/da/の文を/Da/文と呼ぶ。
続いて,有意味単語文を原文とし,その標的音節を /ba/, /ga/, /da/の中で変化させた文(有意味単語変形文) が作成された。変形文は原文ごとに2文用意された(例 えば,上記の例文に対して,‘食器 を とばな に しまう’と,‘食器 を とがな に しまう’)。変形 文の標的語のイントネーションは,原文と同一に保っ た。変形文は,原文の意味を失ったものであった。 また,有意味単語文の標的語ごとに,標的音節はその ままで第1と第3音節の子音を変化させた3音節の非単 語を 1 語ずつ用意した(例えば,‘食器 を のださ に しまう’; 有意味単語文中の‘とだな’を,‘のださ’ に置き換えた)。これらの無意味単語を有意味単語文の 標的語と入れ換えた文を,無意味単語文と呼ぶ(Table 1 aからo)。そして,無意味単語文を原文とし,その標的 音節のみを変化させた文(無意味単語変形文)を用意し た(例えば,上記の無意味単語文に対して,‘食器 を のばさ に しまう’と,‘食器 を のがさ に し まう’)。無意味単語文とその変形文の標的語のイント ネーションは,有意味単語文と同一になるように保たれ た。無意味単語文で用いられたすべての標的語は,一般 的な辞典(新村,1998)によって意味を持たないことを Table 1.
A list of word sentences and non-word sentences.
Note. A list of stimuli with alphabets A to O indicating word sentences and a to o indicating non-word sentences.
確かめられた。このようにして/ba/, /ga/, /da/のいずれか の標的音節を持つ15個の有意味単語から作られた原文 及び各2種類の変形文の合計45文と,無意味単語につい て同様に作成された45文を用意した。
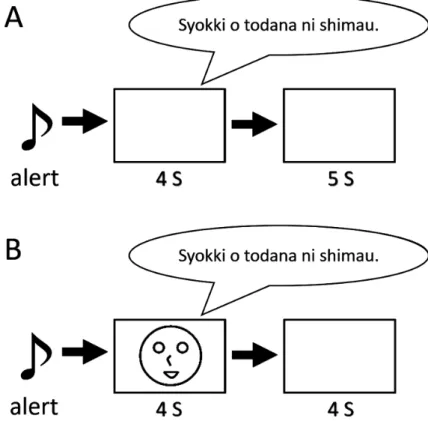
発話場面は,デジタルカメラ(Canon, Ixy Digital 25is) を用いて記録された。発話者は,北陸地方出身の日本語 母語話者2名であり,その一人は20歳男性で,もう一人 は22歳女性であった。発話者は,各音ともに明瞭かつ 自然な口の動きで,各文を1語あたり1 s程度,1文を3 s 程度で読み上げた。 記録された発話場面は,動画編集ソフト(Adobe, Pre-miere Pro CS3)を用いて音声と映像が切り離された。事 前検討では,音声のみを用いた。 手続き(1回目) テストは,減音された小実験室の 中で行われた。発話音声は,パソコン(Epson, Endeavor NJ1000)に接続されたスピーカー(Diamond Audio Tech-nology, EMC2.0-USB)から呈示された。スピーカーは参 加者の正面に置かれた。音圧レベルは発音が聞きやすい レベル(およそ67–73 dB程度)に保たれた。 各試行ではビープ音に続いて4 sの発話音声が呈示さ れ,その後回答用紙に記入するための5 sの空白時間が 設けられた (Figure 1A)。刺激の呈示順序は,Cedrus社の SuperLab4.0を用いて疑似ランダム化された。回答用紙は, 標的語以外の部分が記述されており,標的語部分は空欄 であった。参加者は呈示された発話音声を聞き,聞こえ た単語を空欄に書くよう教示を受けた。各参加者は,男 女どちらか1名の話者による音声刺激を呈示された。呈 示される話者は参加者間で無作為に割り当てられた。 刺激選別(1回目) 有意味単語文において,参加者 が一人でも誤答した場合には,再度その発話場面を撮影 し,刺激映像を作り直した。その他の文については,参 加者2名以上が誤答した場合に再撮影し作り直した。2 名の話者に共通して誤答が多かった標的語は,音声のみ では聞き取りづらい音節の組み合わせであると考えられ た。したがって,誤答が多かった標的語は音声知覚にお ける発話映像の影響を調べるためには不適当であるとし て,異なる標的語に差し替えられた。このような差し替 えが必要であった標的語はすべて無意味単語文または無 意味単語変形文の語であった。 参加者(2 回目) 15 名の大学生(男性 1 名,女性 14 名,年齢幅20–22歳,平均年齢21.27歳)が参加した。 手続き(2回目) 1回目の刺激選別を基に,再撮影し
た発話音声を呈示した。そのほかの手続きは,1回目の 手続きと同様であった。 刺激選別(2回目) 有意味単語文は全員が正しく聞 き取ることができた。また,無意味単語を含むそれ以外 の文のすべてについても,90%以上の参加者が正しく聞 き取り可能であることが確かめられた。Table 1に示した 文は,最終的に刺激として用意された文である。 方 法 実験参加者 45 名の大学生(男性 12 名,女性 33 名, 年齢幅18–23歳,平均年齢=20.44歳)が参加した。 刺激 事前検討で選別された音声と,それに付随する 映像を組み合わせて刺激を作成した。以下では,音声を 小文字で,映像を大文字で示す。発話場面は各刺激とも 4 sとし,発話の開始前と終了後に約0.5 s間の静止場面を 含んだ。各刺激文の発話は3 sになるように編集調整さ れた。そして刺激文の発話場面は,標的音節に関して, 音 声 と 映 像 が/ba/-/BA/, /ba/-/GA/, /ba/-/DA/, /ga/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/BA/, /da/-/GA/, /da/-/DA/になる ように組み合わされた。
手続き 発話映像は,小実験室内のLCDプロジェク
ター(NEC, NP50)によってスクリーン上に投影された。 発話音声は,パーソナルコンピュータ(Epson, Endeavor NJ1000)に接続されたスピーカー(Diamond Audio Tech-nology, EMC2.0-USB)によって呈示された。スピーカー はスクリーンの正面に設置された。参加者はスクリーン までの視距離3 mの位置に座り,スクリーン(視角垂直 8.7°×水平7.6°)に投影される話者の顔刺激を観察した。 実験は2, 3名ずつ集団で行われた。すべての参加者がス クリーンを観察しやすい位置に着席した。各試行では ビープ音に続き4 sの発話刺激を呈示した。その後4 sの 空白画面が続いた(Figure 1B)。参加者はあらかじめ回 答用紙を与えられ,呈示された発話刺激を視聴して,聞 こえた単語を空欄に書き込むように教示を受けた。各参 加者は,男女どちらか1名の話者による音声映像刺激を 呈示された。呈示される話者は参加者間で無作為に割り 当てられた。Table 1に示した30文それぞれについて9種 類の刺激が用意されたため,総刺激数は 270個であっ た。各刺激は実験中1度のみ呈示された。全刺激の呈示 順序は同じ文脈を持つ文が連続しないように疑似ランダ ム化 さ れ た。 実 験 は 3 セ ッ シ ョ ン に 分 け て 行 わ れ, 1セッションは90試行から成り立っていた。セッション
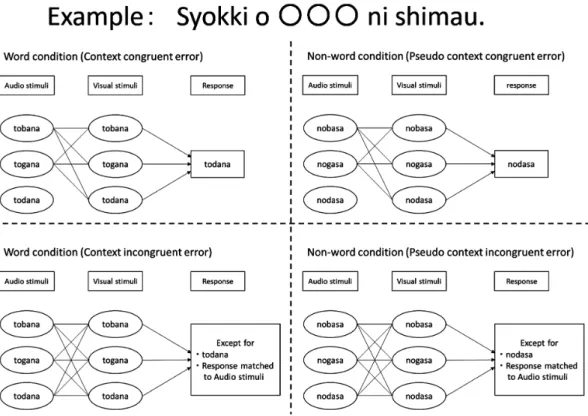
Figure 2. The expected responses in word and non-word conditions. Word conditions contain context congruent and incon-gruent errors. Non-word conditions contain pseudo context conincon-gruent and inconincon-gruent errors.
間には60 s間の休憩をはさんだ。 参加者の反応はすべて,正答か誤答のいずれかに振り 分けられた。音声刺激と一致している回答は正答,音声 刺激と一致しない回答は誤答であると定義した。誤答は 標的語条件(原文が有意味単語あるいは無意味単語)ご とに以下のように分類された。有意味単語条件から得ら れた誤答について,文の意味が成り立つように標的語を 誤って回答する反応は「文脈一致型誤答」,文の意味が 成り立たないように標的語を誤って回答する反応は「文 脈不一致型誤答」と名づけられた。無意味単語条件から 得られた誤答について,標的語の第1・第3音節は音声 刺激の通りに回答し,標的音節は有意味単語条件の「文 脈一致型誤答」と同様の音に誤っている反応を「疑似文 脈一致型誤答」,それ以外の誤りを「疑似文脈不一致型 誤答」と分類することにした(Figure 2)。 結 果 誤答率 分析は統計分析ソフト R (version 3.5.1 (2018-07-02)) を用いて行われた。標的語条件,文の種類,標的音節の 音声映像ごとに誤答の生じ方の傾向を検討するため,音 声刺激に対するすべての誤答を数えた。誤答数から各条 件に対する誤答率を実験参加者ごとに求め,全参加者の 平均誤答率を算出した。これら参加者の誤答率は比率を 表しており分散が一定ではない。このため分散は,逆正 弦変換を用いて一定になるよう処理された。標的語条件 (有意味単語,無意味単語)×文の種類 (Ba文,Ga文,Da 文)×標的音節の音声映像(/ba/-/BA/, /ba/-/GA/, /ba/-/DA/, /ga/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/BA/, /da/-/GA/, /da/-/DA/)の 3 要因の分散分析を行った(Table 2)。す べての要因は被験者内要因であった。 Mendozaの多標本球面性検定を行った結果,文の種類 の主効果,標的音節の音声映像の主効果,標的語条件と 標的音節の音声映像の交互作用,文の種類と標的音節の 音声映像の交互作用,標的語条件と文の種類と標的音節 の音声映像の交互作用には球面性が認められなかった。 このため,Greenhouse–Geisserのεによる自由度の調整を 行った。また,分散分析におけるすべての多重比較につ いて,Shaffer法による修正が行われた。 上記3要因の分散分析を行った結果,標的語条件の主 効果は有意ではなかったが,文の種類の主効果が有意で あり (F(1.76, 77.58)=10.11, p<.001, η2=.19),Ba文はGa 文とDa文よりも誤答率が高かった (ps<.05)。また,標 的音節の音声映像の主効果が有意であった (F(2.38, 104.91)=31.07, p<.001, η2=.41)。 多 重 比 較 の 結 果, /ba/-/GA/, /ba/-/DA/, /ga/-/BA/, /da/-/BA/は,/ba/-/BA/, Table 2.
Error ratios to audio-visual stimuli by word condition (word or non-word) and the type of sentence (Ba sentence, Ga sentence or Da sentence).
Note. For both audio and visual stimuli, the target word has /ba/, /ga/ or /da/ at the 2nd syllable.
/ga/-/GA/, /ga/-/DA/, /da/-/GA/, /da/-/DA/と比べて有意に 誤 答 率 が 高 か っ た(ps<.001)。 ま た,/ba/-/GA/は /ba/-/DA/よりも誤答率が高かった(p<.005)。これらの 結果から,音声刺激と映像刺激が唇音(/ba/)と非唇音 (/ga/, /da/)の間で不一致になる組み合わせは,音声刺 激と映像刺激が唇音同士,または非唇音同士の組み合わ せと比べて誤答率が高かったことがわかる。さらに,唇 音と非唇音の組み合わせの中でも,McGurk & MacDon-ald (1976) で融合反応が生じるとされた典型的な組み合 わせ(/ba/-/GA/)は,より誤答率が高かった。 交互作用については,標的語条件と文の種類ごとに, 誤答が生じる標的音節の音声映像が異なるかを検討する ために,二次の交互作用である標的音節の音声映像の 単純・単純主効果に焦点を当てる。標的語条件×文の 種類×標的音節の音声映像の交互作用が有意であった (F(6.96, 306.21)=10.49, p<.001, η2=.19)。まず有意味単 語について下位検定を行った結果,すべての文の種類 で,有意味単語文の標的音節と音声刺激が一致せず, 音声刺激と映像刺激が唇音と非唇音の組み合わせであ る刺激は,すべての唇音同士,非唇音同士の組み合わ せによる刺激よりも誤答率が高くなることがわかった。 以下に,文の種類ごとに詳細を示す。Ba文における標 的音節の音声映像の単純・単純主効果が有意であった (F(3.64, 160.34)=32.31, p<.001, η2=.42)。/ga/-/BA/, /da/-/BA/ は,/ba/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/GA/, /da/-/DA/と 比べて誤答率が高かった(ps<.001)。Ga文における標 的音節の音声映像の単純・単純主効果も有意であった (F(3.87, 170.36)=22.97, p<.001, η2=.34)。/ba/-/GA/, /ba/-/DA/, /da/-/BA/は,/ba/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/GA/, /da/-/DA/よりも誤答率が高かった(ps<.05)。 Da文における標的音節の音声映像の単純・単純主効果も 有意であった(F(3.26, 143.52)=26.08, p<.001, η2=.37)。 /ba/-/GA/, /ba/-/DA/, /ga/-/BA/は,/ba/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/GA/, /da/-/DA/よりも誤答率が高かった (ps<.005)。 次に無意味単語について下位検定を行った結果,無意 味単語では有意味単語と異なり,無意味単語文の標的音 節と音声刺激が一致し,音声刺激と映像刺激が唇音と非 唇音の組み合わせである刺激は,すべての唇音同士,非 唇音同士の組み合わせによる刺激よりも誤答率が高くな ることがわかった。以下に,文の種類ごとに詳細を示す。 Ba文における標的音節の音声映像の単純・単純主効果 が有意であった (F(2.81, 123.68)=21.50, p<.001, η2=.33)。 /ba/-/GA/, /ba/-/DA/は,/ba/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/GA/, /da/-/DA/よりも誤答率が高かった(ps<.001)。
Ga文における標的音節の音声映像の単純・単純主効果も 有意であった(F(2.43, 106.74)=18.77, p<.001, η2=.30)。 /ga/-/BA/は,/ba/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/GA/, /da/-/DA/よりも誤答率が高かった (ps<.005)。Da文にお ける標的音節の音声映像の単純・単純主効果も有意であっ た(F(3.12, 137.20)=14.86, p<.001, η2=.25)。/da/-/BA/は, /ba/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/GA/, /da/-/DA/よりも 誤答率が高かった(ps<.005)。
文脈依存性
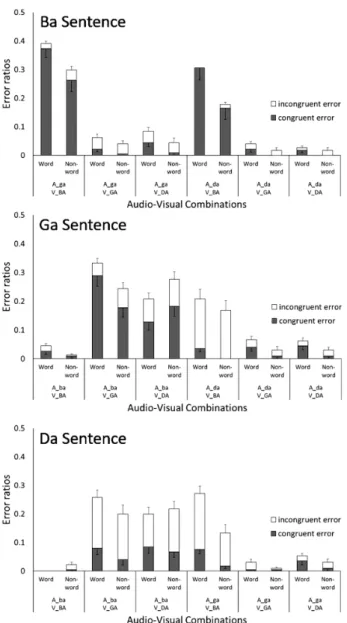
ここまでで,有意味単語と無意味単語で誤答の生じ方 に違いがあることが示された。Table 2から,原文の標的 音節と音声刺激として呈示された標的音節が一致する組 Figure 3. Error ratios of Ba, Ga and Da sentences that
match the target syllable in the word or non-word sen-tence and audio stimuli (Excerpt from Table 2). Error bars represent standard errors.
み合わせを抜粋した(Figure 3)。有意味単語では原文と なる有意味単語文中の標的音節と,音声刺激として呈示 された標的音節が一致すると誤答が生じにくくなり,無 意味単語ではそれらが一致してもなお誤答が生じた。こ のことは,音声映像刺激が唇音と非唇音の組み合わせの 場合に顕著であった。用いた文の種類によって誤答が生 じやすい条件が異なることは,文脈によって誤答の内容 が異なることを示唆する。したがって,文脈依存の誤答 (文脈一致型誤答,疑似文脈一致型誤答)と非文脈依存 の誤答(文脈不一致型誤答,疑似文脈不一致型誤答)に 焦点を当て,それらの出現割合を調べた。これら文脈依 存の誤答は,有意味単語文及び無意味単語文において, 標的音節と呈示された音声刺激が一致する場合は出現し ないことから,以下の標的音節の音声映像刺激に対する 反応は分析から除外された。それは,Ba文では/ba/-/BA/, /ba/-/GA/, /ba/-/DA/, Ga文では/ga/-/BA/, /ga/-/GA/, /ga/-/DA/, Da 文では/da/-/BA/, /da/-/GA/, /da/-/DA/の各刺激に対す る結果である。
Figure 4. Error ratios to audio-visual stimuli based on each type of sentence (Ba sentence, Ga sentence, or Da sentence) ac-cording to word condition (word or non-word) and context congruencies among the misperceptions (congruent or incon-gruent). In the non-word condition, incongruent and congruent refer to pseudo context errors. Error bars represent stan-dard errors.
標的語条件(有意味単語,無意味単語)×標的音節の 音声映像 (/ba/-/BA/, /ba/-/GA/, /ba/-/DA/, /ga/-/BA/, /ga/-/GA/, /ga/-/DA/, /da/-/BA/, /da/-/GA/, /da/-/DA/) の2要因の分散 分析を,文の種類 (Ba文,Ga文,Da文),誤答の文脈依 存性(文脈依存,非文脈依存)ごとに行った(Figure 4)。 すべての要因は被験者内要因であった。数値の逆正弦変 換処理,多標本球面性検定,自由度調整,多重比較の手 法はすべて,これまでと同様であった。以下の分析では すべて,標的音節の音声映像の主効果,標的語条件と標 的音節の音声映像の交互作用に球面性が認められなかっ たため,前述の修正を行った。 まず,すべての文の種類に共通する事項について記 す。文脈一致型,疑似文脈一致型誤答について,標的語 条件の主効果が有意であり(Fs≧4.72, ps<.05, η2s≧.10), 有意味単語では無意味単語より原文の標的語と同じ単語 を回答する割合が高かった。また,標的音節の音声映像 の主効果が有意であった(Fs≧10.12, ps<.001, η2s≧.19)。 原文の標的語と呈示された映像刺激の標的語が一致し, 音声映像刺激が唇音と非唇音の組み合わせである場合は, 音声映像刺激が唇音同士,非唇音同士の組み合わせより も,原文の標的語と同じ単語を回答する割合が高かった (ps<.05)。文脈不一致型,疑似文脈不一致型誤答につい ても,すべての文の種類について標的音節の音声映像の 主効果が有意となった(Fs≧3.32, ps<.05, η2s≧.07)が, 下位検定を行ったところ一貫した結果は得られなかった。 次に,特定の文の種類にのみ該当する事項について記 す。文脈一致型,疑似文脈一致型誤答について,Ba文 とGa文では,標的語条件と標的音節の音声映像の交互 作用が有意であった(Fs≧6.16, ps<.005, η2s=.12)。Ba文 とGa文の原文の標的語と映像刺激の標的語が一致して おり,音声刺激が唇音と非唇音の組み合わせ(Ba文に おける/ga/-/BA/と/da/-/BA/, Ga文における/ba-/GA/)は, 有意味単語の方が無意味単語よりも原文の標的語と同じ 単語を回答する割合が高かった (ps<.05)。Ba文とGa文 の有意味単語条件では,上記の組み合わせは,それ以外 の組み合わせよりも文脈一致型誤答の割合が高かった (ps<.05)。この結果は,Ba文とGa文の無意味単語条件 における疑似文脈一致型誤答でも同様であった (ps<.05)。 文脈不一致型,疑似文脈不一致型誤答について,Da文の み標的語条件と標的音節の音声映像の交互作用が有意で あった (F(2.78, 122.15)=3.58, p<.05, η2=.08)。Da文の有 意味単語条件では,原文の標的語と映像刺激の標的語が 一致しており,音声映像刺激が唇音と非唇音の組み合わ せは,音声映像刺激が唇音同士,非唇音同士の組み合わ せよりも文脈不一致型誤答の割合が高かった(ps<.05)。 この結果は,Da文の無意味単語条件における疑似文脈 不一致型誤答でも同様であった(ps<.001)。 考 察 本研究では,日本語を母語とする参加者において日本 語の文刺激を用い,McGurk効果にみられる音声誤知覚 が発話文脈の影響をうけるかどうかを調べた。標的語に は有意味単語と無意味単語を用いて,標的語と文脈の関 連性の高さを操作した。 本実験は集団で行われたが,各集団は2, 3名と少人数 であり,集団の全員がはっきりと話者の音声や顔を視聴 することができた。Paré, Richler, ten Hove, & Munhall (2003) によって,参加者は発話観察の際に話者の顔の中で目や 口以外の部分にほぼ視線を向けないことと,McGurk効 果は話者の顔の中に参加者の視線が向けられる限り減少 しないことが示されている。このことは,話者の目や口 といった主要な顔部分の情報が明瞭に録画されている限 り,その顔のどこかを参加者が観察することがMcGurk 効果の出現にとって重要であることを意味する。そし て,視線の方向や観察の厳密な位置は影響しないことが 示唆される。また,Jordan & Sergeant (2000)によって, 観察距離が10 m以下である場合は,McGurk効果の出現 率はその観察距離の影響を受けないことが示されてい る。Siddig, Sun, Parker, & Hines (2019) は,VRを用いて仮 想上の観察距離を変更しても,McGurk効果の出現率に 違いが見られないことを示した。このため,本研究の結 果は観察条件の多少の違いによって影響を受けない結果 であると考えられる。 誤答率の分散分析において,標的音節の音声映像要因 の主効果が見られ,唇音と非唇音の組み合わせは唇音同 士および非唇音同士の組み合わせと比べて誤答率が高い ことが示された。音声刺激と映像刺激が不一致である組 み合わせにおいて音声刺激に対する誤知覚が多く見られ たことは,McGurk & MacDonald (1976)の示した結果と 同様である。本実験は,この古典的な現象が文中でも生 じることを示した。しかしながら,本実験における音声 刺激に対する誤知覚は Brancazio (2004)による英語や Sams et al. (1998)によるフィンランド語において行われ た同様の研究における効果よりも小さかった。これは, 日本人の McGurk効果は欧米人のMcGurk効果よりも弱 いという報告(Sekiyama & Tohkura, 1991, 1993; Sekiyama, 1997)と一致する結果である。
また,有意味単語と無意味単語の両方で誤答が生じた が,その誤答の内容が異なることが明らかになった。有 意味単語では,音声刺激が標的語を除く文部分から予想
される有意味単語と一致する場合は音声刺激のみで文が 完成される。しかし無意味単語では,音声刺激を標的語 以外の文部分からは予想できず,標的語それ自体が無意 味であるため音声刺激によって文が完成されない。この ため,音声刺激が有意味単語文である場合は音声刺激そ のままの反応が見られるが,音声刺激が有意味単語変形 文,無意味単語文,無意味単語変形文である場合は,視 覚情報を利用して文の完成を試みるため,McGurk効果 と同様の音声誤知覚反応が生じると考えられる。これら のことから,単語が有意味であるか無意味であるかと, 音声刺激と予想される標的語とが一致するか否かの組み 合わせに従って誤答の生じ方が異なることがわかる。 結果の文脈依存性の検討において,文中の音声誤知覚 が,従来のMcGurk効果と異なることがわかった。まず Ba文の有意味単語条件において,原文の標的語と映像刺 激の標的語が一致する場合 (/ga/-/BA/, /da/-/BA/)に,文 脈一致型誤答が多く見られた。単音節のMcGurk効果で は,/ga/-/BA/の組み合わせは典型的に/bga/という複合反
応を引き起こすとされている(McGurk & MacDonald, 1976)。日本語には/bga/という音声がないため,そのよう に聞き取ることは難しいと考えられる。実際に文中の単 語を用いた本実験では,文脈すなわち映像刺激に一致し た/ba/という誤答が多く生じた。本実験で用いた/ga/-/BA/ 刺激において,古典的な単音節刺激と比べて,映像刺激 (/BA/) の影響を受けた音声誤知覚反応 (/ba/) が増加した ことは,聞き手が標的語の音声刺激を文の意味が通るよ うに知覚したことを示している。次にGa文の有意味単語 条件においても,原文の標的語と映像刺激の標的語が一 致する場合(/ba/-/GA/)に,文脈に一致した誤答が多く 見られた。単音節のMcGurk効果では,/ba/-/GA/の組み 合わせは典型的には/da/という融合反応を引き起こす。 しかし本実験では/ga/反応が見られた。これも有意味単 語において映像刺激に影響されて文脈に一致した誤答が 生じたことを示している。また,有意味単語の/ba/-/GA/ と無意味単語の/ba/-/GA/は標的音節に関する音声刺激 と映像刺激の組み合わせが同一であるので,古典的な McGurk効果が生じるならば,両条件間で同様の誤答傾 向を示すはずである。しかし,有意味単語と無意味単語 の間で誤答傾向が異なっていたことから,音声知覚が文 脈によって変化したことが示された。 本実験で得られた文脈依存の誤答は,すべての文の種 類に共通するものではなかった。Da文ではBa文やGa文 と比べて特定の条件に突出した文脈一致型誤答が見られ ないとともに,すべての唇音と非唇音の組み合わせで文 脈不一致型誤答が多く見られた。/ga/, /da/は共に非唇音 であるが,その調音位置が異なり,/ga/は軟口蓋音,/da/ は歯茎音に相当する。古典的なMcGurk効果は/ba/と/ga/, /pa/と/ka/など,(両)唇音と軟口蓋音を組み合わせて示 されてきた。このことは,McGurk効果が生じるために は適切な調音位置を持つ音節同士を組み合わせる必要が あることを示している。原文で用いられている音節に よって誤答の生じ方に違いが見られたことから,文中の McGurk効果は現在呈示されている単語のみならず,文 脈から予想される単語の調音位置からも影響を受けると 考えられる。さらにBa文とGa文では共に有意味単語に おいて,原文の標的語と映像刺激の標的語が一致し,音 声刺激と映像刺激が唇音と非唇音の組み合わせの場合に 文脈一致型誤答の割合が高かった。その中でも,Ba文 の/ga/-/BA/, /da/-/BA/では文脈一致型誤答の割合に差が 見られなかったが,Ga文の/ba/-/GA/は/ba/-/DA/よりも 文脈一致型誤答の割合が高かった。このように有意味単 語文において映像刺激の調音位置によって文脈一致型誤 答の現れ方が異なることは,音声刺激よりも映像刺激と 文脈情報との組み合わせによって標的語を判断していた ことを示す。
音声知覚モデルである運動理論 (Liberman & Mattingly, 1985)では,発話されている音素を特定しようとすると きに,発話情報に関する動きを考慮すると提唱されてい る。後に運動理論は音声知覚における脳活動の分野に取 り入れられた。そして特定の音節を聞く際に運動前野が 活性化することと,その運動前野内の活動部位は聞いた 音節を実際に発話した場合に活性化する部位と一致する こ と を示 し た(Pulvermüller et al., 2006; Meister, Wilson, Deblieck, Wu, & Iacoboni, 2007)。運動前野には,自らが 動作するときにも他者の同じ動作を観察するときにも活 性化するミラーニューロンが存在することが示されてお り(Rizzolatti & Craighero, 2004),発話知覚においても, 他者の口の動きを観察することで自らが発話する場合と 同じ脳部位の活性化が生じていることが示唆される。映 像刺激が有意味単語文と一致するとき,この活性化に よって得られた回答は意味の通る文である。意味の通る 文は馴染み深いため,古典的なMcGurk効果よりもより 強い影響を持ち,映像刺激優位の誤答が生まれたと考え られる。これまで,McGurk効果は非常に早い発話処理 レベルで自動的に生じるとし,認知的処理の介入に対し て非常に強固であることが示されてきた(Massaro & Cohen, 1983; Summerfield & McGrath, 1984)。しかし前段 落でも述べたように,本実験の結果は古典的なMcGurk 効果とは異なる様相も示しており,古典的なMcGurk効 果の生起メカニズムでは説明しきれない。むしろ,低次
の発話処理と高次の認知処理の相互作用の存在が示唆さ れる。 本実験の結果は,日本語と似た音節構造を持つフィン ランド語の単語を用いた実験 (Sams et al., 1998) とは異 なり,有意味単語に特有の誤答を示した。これは Mc-Gurk効果における言語特異性を示唆するが,それぞれ が用いた刺激特性の違いにも注意したい。本実験で用い られた文刺激は,音声刺激も映像刺激も意味の通る条 件,音声刺激または映像刺激のどちらかが意味の通る条 件,そして音声刺激も映像刺激も意味の通らない条件を 網羅した。一方でSams et al. (1998)で用いられた文刺激 は,音声刺激は文の意味が通じるが,映像刺激は文の意 味が通らない条件と,音声刺激も映像刺激も文の意味が 通らない条件に限られた。音声単語認知モデルであるコ ホート・モデル(Marslen-Wilson, 1987)では,単語が聴 覚的に入力されると,語頭部分に含まれる音素に適合す る単語候補が活性化される。活性化された単語候補は, 入力された音声や前後の文脈などによって逐次的に照合 処理が行われ,最終的に一つの単語が特定され,認知さ れる。コホート・モデルでは,単語を特定し,その特定 に確信を持つ時点をユニークネス・ポイントと呼ぶ。本 実験と Sams et al. (1998)の刺激と結果の関係をコホー ト・モデルを用いて比較する。Sams et al. (1998)のよう に,音声刺激のみ意味が通る場合と音声刺激と映像刺激 の両方の意味が通らない場合は,音声刺激に基づいて単 語候補の照合処理が行われ,ユニークネス・ポイントが 定まったと考えられる。音声刺激のみ意味が通る場合 は,文脈の関与が存在してもしなくても,音声刺激に基 づいた単語決定は意味の通る文を回答したことを意味す る。また,音声刺激と映像刺激の両方の意味が通らない 場合は,McGurk効果が生じると文の意味が通じるよう に設定されていた。それにもかかわらず文脈の関与が見 られなかったことは,意味の通らない映像刺激は,同じ く意味の通らない音声刺激のユニークネス・ポイントの 調整に関与しないことを示唆する。しかし,本実験のよ うに音声刺激の意味は通らないが,映像刺激の意味が通 る情報が与えられた場合には,音声刺激単独ではなく, 映像刺激の情報を利用して単語候補の照合処理が行わ れ,ユニークネス・ポイントが定まったと考えられる。 このように映像刺激の情報(有意味性)も,それだけで は無意味な音声刺激のユニークネス・ポイントを調整す るために使用される。この調整こそが文脈処理であり, 古典的なMcGurk効果とは異なるレベルの認知的処理が 語彙選択に関与し,その結果として選択された単語音声 が(誤)知覚されるのだと考えられる。そして,いわゆ る読唇術(リップリーディング)は,映像情報のみによ るこのような文脈推定処理によって連続的に語彙選択を 行う高度な認知処理によるのであろうと推測される。 本研究において見られた古典的なMcGurk効果とは異 なる回答の産出理由は,音声映像が不一致な刺激におけ る発話知覚の先行研究からも説明され得る。音声映像が 不一致な刺激は,知覚的な曖昧性を生む(Rosenblum & Saldaña, 1992; Massaro & Ferguson, 1993)。このように音 素的に曖昧な刺激に対しては,単語が完成するような音 素を当てはめるGanong効果が生じることが知られてい る(Ganong, 1980)。これは,音素の知覚に高次の言語 的処理が働いていることを示唆する。本実験の有意味単 語条件の Ga文における/ba/-/GA/も/ba/-/DA/も音声刺激 と映像刺激が不一致であり,曖昧性を持つ刺激であっ た。しかしそれが映像刺激によって誤答の内容が異なっ たことは,参加者が単純に文を補完するように音声を知 覚したのではなく,音声刺激と映像刺激を統合させたう えで最もそれらしい(文脈に合いそうな)音声を知覚し たということを表している。また,発話知覚研究におい て高次の言語的・認知的処理が音素の知覚的符号化を変 化させることを示したTRACEモデルが提唱されている (McClelland & Elman, 1986; McClelland, 1991)。TRACEモ デルに本実験の結果をあてはめると,音声映像が不一致 な音節がある単語では,その音節以外の部分によって トップダウン的に単語全体の知覚が補足されていると考 えられる。現段階ではこの補足の効果,つまり文脈の効 果が早期の知覚的な処理の段階で作用するのか,知覚し たものを統合しようとする段階で作用するのかは明らか になっていない。本実験の結果では,標的語の映像刺激 が有意味であるときに文脈の効果が見られた。標的語の 第3音節が呈示されるまでは映像刺激自体が有意味であ るかは判断できない。したがって,文脈の効果は映像刺 激による単語の処理が進んだ段階,すなわち知覚したも のを統合する段階で作用することが示唆される。 本研究は,有意味単語では原文と音声刺激が一致しな い場合に,一方で無意味単語では原文と音声刺激が一致 する場合に,音声刺激に対する誤答が増えることを示し た。このことから,単語が有意味であるか否かと音声刺 激が意味の通る文となるか否かの組み合わせによって, McGurk効果を典型とする音声誤知覚の現れ方が変化す ることが明らかとなった。文脈依存の誤答は,原文と映 像刺激が意味の通る文であり,音声刺激と映像刺激が唇 音と非唇音の組み合わせである場合に多く見られた。映 像刺激が意味の通る文であるとき,古典的なMcGurk効 果の範囲を超えて誤答が生じることが示された。誤知覚
によって刺激文を言語として完成させる現象は,文を理 解しようとする高次の認知的処理によってもたらされた と考えられる。 引用文献 天野成昭・近藤公久(編)(1999). NTTデータベースシ リーズ 日本語の語彙特性 第1巻 三省堂
Beauchamp, M. S., Nath, A. R., & Pasalar, S. (2010). fMRI-Guided transcranial magnetic stimulation reveals that the superior temporal sulcus is a cortical locus of the McGurk effect. Journal of Neuroscience, 30, 2414–2417.
Brancazio, L. (2004). Lexical influences in audiovisual speech perception. Journal of Experimental Psychology: Human
Per-ception and Performance, 30, 445–463.
de Gelder, B., & Vroomen, J. (2000) The perception of emo-tions by ear and by eye. Cognition and Emotion, 14, 289– 311.
Dekle, D. J., Fowler, C. A., & Funnell, M. G. (1992). Audiovi-sual integration in perception of real word. Perception and
Psychophysics, 51, 355–362.
Dodd, B. (1977). The role of vision in the perception of speech. Perception, 6, 31–40.
Easton, R. D., & Basala, M. (1982). Perceptual dominance dur-ing lipreaddur-ing. Perception and Psychophysics, 32, 562–570. Erber, N. P. (1969). Interaction of audition and vision in the
recognition of oral speech stimuli. Journal of Speech and
Hearing Research, 12, 423–425.
Ganong, W. F. (1980). Phonetic categorization in auditory word perception. Journal of Experimental Psychology:
Human Perception and Performance, 6, 110–125.
Green, K., Kuhl, P., Meltzoff, A., & Stevens, E. (1991). Integrat-ing speech information across talkers, gender, and sensory modality: Female faces and male voices in the McGurk effect. Perception & Psychophysics, 50, 524–536.
堀 誉子美 (1994).フィンランド語話者にとっての日 本語の音韻体系 横浜国立大学留学生センター紀要,
1, 64–83.
Jones, J. A., & Callen, D. E. (2003). Brain activity during au-diovisual speech perception: An fMRI study of the McGurk effect. Cognitive Neuroscience and Neuropsychology, 14, 1129–1133.
Jones, J. A., & Munhall, K. G. (1997). The effects of separating auditory and visual sources on audiovisual integration of speech. Canadian Acoustics, 25, 13–19.
Jordan, T., & Sergeant, P. (2000). Effects of distance on visual and audiovisual speech recognition. Language and Speech,
43, 107–124.
Liberman, A. M., & Mattingly, I. G. (1985). The motor theory of speech perception revised. Cognition, 21, 1–36.
MacDonald, J., & McGurk, H. (1978). Visual influences on speech perception processes. Perception & Psychophysics, 24, 253–257.
Marslen-Wilson, W. D. (1987). Functional parallelism in spo-ken word-recognition. Cognition, 25, 71–102.
Massaro, D. W., & Cohen, M. M. (1983). Evaluation and inte-gration of visual and auditory information in speech per-ception. Journal of Experimental Psychology: Human
Percep-tion and Performance, 9, 753–771.
Massaro, D. W., & Ferguson, E. L. (1993). Cognitive style and perception: The relationship between category width and speech perception, categorization, and discrimination.
American Journal of Psychology, 106, 25–49.
McClelland, J. L. (1991). Stochastic interactive processes and the effects of context on perception. Cognitive Psychology,
23, 1–44.
McClelland, J. L., & Elman, J. L. (1986). The trace model of speech perception. Cognitive Psychology, 18, 1–86.
McGurk, H., & MacDonald, J. (1976). Hearing lips and seeing voices, Nature, 264, 746–748.
Meister, I. G., Wilson, S. M., Deblieck, C., Wu, A. D., & Iaco-boni, M. (2007). The essential role of premotor cortex in speech perception. Current Biology, 17, 1692–1696. Munhall, K. G., Gribble, P., Sacco, L., & Ward, M. (1996).
Tem-poral constraints on the McGurk effect. Perception &
Psy-chophysics, 58, 351–362.
新村 出(編)(1998).広辞苑 第五版 岩波書店 O’Neill, J. J. (1954). Contributions of the visual components of
oral symbols to speech comprehension. Journal of Speech
and Hearing Disorders, 19, 429–439.
Paré, M., Richler, R. C., ten Hove, M., & Munhall, K. G. (2003). Gaze behavior in audiovisual speech perception: The influence of ocular fixations on the McGurk effect.
Per-ception & Psychophysics, 65, 553–567.
Pulvermüller, F., Huss, M., Kherif, F., Moscoso del Prado Martin, F., Hauk, O., & Shtyrov, Y. (2006). Motor cortex maps articulatory features of speech sounds. Proceedings
of the National Academy of Sciences of the United States of America, 103, 7865–7870.
Reisberg, D., McLean, J., & Goldfield, A. (1987). Easy to hear but hard to understand: A lip-reading advantage with intact auditory stimuli. In B. Dodd & R. Campbell
(Eds.),Hear-ing by eye: The psychology of lip read(Eds.),Hear-ing (pp. 97–114).
Hills-dale, NJ: Erlbaum.
Rizzolatti, G., & Craighero, L. (2004). The mirror-neuron sys-tem. Annual Review of Neuroscience, 27, 169–192.
Rosenblum, L. D., & Saldaña, H. M. (1992). Discrimination tests of visually influenced syllables. Perception &
Psycho-physics, 52, 461–473.
Rosenblum, L. D., Schmuckler, M. A., & Johnson, J. A. (1997). The McGurk effect in infants. Perception & Psychophysics,
59, 347–357.
Sams, M., Manninen, P., Surakka, V., Helin, P., & Kättö, R. (1998). McGurk effect in Finnish syllables, Isolated words, and words in sentences: Effects of word meaning and sen-tence context. Speech Communication, 26, 75–87.
Sekiyama, K. (1997). Cultural and linguistic factors in audiovi-sual speech processing: The McGurk effect in Chinese sub-jects. Perception & Psychophysics, 59, 73–80.
Sekiyama, K., & Tohkura, Y. (1991). McGurk effect in non-English listeners: Few visual effects for Japanese subjects
hearing Japanese syllables of high auditory intelligibility.
Journal of the Acoustical Society of America, 90, 1797–1805.
Sekiyama, K., & Tohkura, Y. (1993). Inter-language differeces in the influence of visual cues in speech perception. Journal
of Phonetics, 21, 427–444.
Siddig, A. B., Sun, P. W., Parker, M., & Hines, A. (2019). Per-ception dePer-ception: Audio-visual mismatch in virtual reality using McGurk effect. The 27th Irish Conference on Artificial
Intelligence and Cognitive Science, 1–12.
Sumby, W., & Pollack, I. (1954). Visual contribution to speech intelligibility in noise. Journal of the Acoustical Society of
America, 26, 212–215.
Summerfield, Q., & McGrath, M. (1984). Detection and reso-lution of audiovisual incompatibility in the perception of vowels. Quarterly Journal of Experimental Psychology
Sec-tion A, Human Experimental Psychology, 36, 51–74.
Windmann, S. (2004). Effects of sentence context and expecta-tion on the McGurk illusion. Journal of Memory and
Lan-guage, 50, 212–230.
Wright, D. B., & Wareham, G. (2005). Mixing sound and vision: The interaction of auditory and visual information for earwitnesses of a crime scene. Legal and Criminological
Psychology, 10, 103–108.