析の詳細について―
著者
周 振, 吉本 啓
雑誌名
国際文化研究(オンライン版)
巻
26
ページ
89-104
発行年
2020-03-31
URL
http://hdl.handle.net/10097/00127390
1 .はじめに 電子化された文章に対して言語分析情報を付加(タグ付け)したコーパスは様々な形で言語の 研究に利用されている。かつてはテクストを単語ごとに分けて品詞情報だけをタグ付けしたもの が多かったが、現在は品詞情報だけでなく構文情報も付加したコーパス(ツリーバンク)が増え つつある。これにより、コーパス利用の効率は飛躍的に高まった。しかし、中国語に関しては、 文系の言語研究者が簡単に利用できるツリーバンクはこれまでどこにも存在しなかった。さらに、 ツリーバンクそのものにも限界がある。通常のツリーバンクでは表層的な統語情報が示されるだ けである。複文が現れた場合、明示的に示されていない動詞の取る主語や目的語を捉えることは 困難である。このような背景の中、筆者たちは、言語分析情報の付加(アノテーション)を意味 のレベルまで進め、統語情報(ツリー)と意味情報(述語論理式)が両方提供できる中国語コー パスを開発している。その作業は二つの段階に分けられる。即ち、 1 ) 分析データとして選ばれ た中国語のテクストに対し統語情報を付与すること(統語解析)、および 2 ) スコープ制御理論 (Scope Control Theory; SCT Butler 2010) を実装したシステムで 1 )の結果を処理することに
よる自動的な文の論理意味表示の獲得(意味解析)である。本論文は、統語解析の詳細について 説明しようとするものである。
統語・意味情報付き中国語コーパスの構築
―統語解析の詳細について―
周 振・吉本 啓
要 旨 電子化された文章に対して言語分析情報を付加したコーパスは言語研究にとって有用であ る。しかし、中国語の場合、文系の言語研究者が気軽に利用できるツリーバンクはこれまで 存在しなかった。このような背景の中、筆者たちは新しい中国語コーパスの開発に取り組ん でいる。このコーパスは、従来の形態素情報と統語情報だけではなく、深層的な意味情報も 同時に付加している。本論文は、統語・意味情報付き中国語コーパスを開発する際に、本研 究が使用するアノテーション方式(統語解析の部分)について説明する。統語解析を行うた めに使用する解析規約の詳細を紹介し、その特徴を考察する。また、中国語の実情および意 味処理の要請から本研究が当解析規約に対して行った修正についても論じていく。 【キーワード:コーパス 統語解析 依存関係 同一指示 中国語】2 .現存の中国語コーパスに見られる不足 中国語のコーパスは、現時点では、ある程度存在してはいるが、主にデータの質および使いや すさの面において問題がある。本節では、データの量が確保できしかも一般に公開されている典 型的な三つの中国語コーパスを例にして、上述の二点を具体的に見ていく。 北京大学の CCL コーパスは、新聞、雑誌、小説などを含む4.77億字の膨大な中国語データベー スを提供している。しかしながら、CCL コーパスにおいてはその中に収納される中国語の文に 対して、言語学的に有用な情報の付与は一切行われていない。そのため、利用者は、検索に際し てキーワードにしか頼ることができず、コーパスの中から自分のほしいデータを抽出することは 非常に困難である。 一方、台湾の中央研究院の Sinica コーパスには、 1 千万語相当の中国語データが含まれてい る。コーパスの中に収納される文は、全て語ごとにセグメントされ、しかもその一つ一つに品詞 ラベルも与えられている。品詞の分類は十分だとは言えないものの(例えば、“ 的 ” に対しては、 構造助詞および文末助詞という二つの品詞にしか分けていない)、このような形態素解析という 作業が徹底的に行われているために、CCL コーパスに比べて、Sinica コーパスは一段と使いやす くなっている。しかし、これだけではまだ十分ではない。形態素解析のような一次元的アノテー ションは、自然言語の持っている多次元の曖昧性を十分に排除することができないのである。そ のため、精度の高い検索が難しく、利用者の求める言語データへのアクセスは依然困難なままで ある。 以上述べたデータの質に関する問題を相当克服しているのは、ペンシルバニア大学の開発した 中国語版のペンツリーバンク (Penn Chinese Treebank; CTB) である。バージョン9.0には、約 2 百万語の中国語データが収納されている。CTB は、中国語の文に対して、語の品詞情報だけ でなく、語と語がどのような係り受け関係で文を構築するのかが分かる統語解析情報(ツリー) も付与されている。これにより、語や句・節の構造を手掛かりとするより柔軟な二次元の検索が 可能になった。しかし、CTB は元々自然言語処理(例えば、構文解析器の訓練と評価)を目的 としてデザインされたものである。そもそも開発目的の違いがあったため、CTB は、従来中国 語学の研究者から関心を集めてきた中国語の各構文に対しては、極めて初歩的な解析しか与えて いない。また、CTB 式のアノテーションは統率・束縛理論 (GB; Chomsky 1981, Chomsky 1982) に従っているため、全ての品詞カテゴリーに対して句レベルの投射が厳しく規定されている。そ の結果、CTB 式のツリーは内部構造が複雑で階層が多く、精度の高い検索を行うためには複雑 な検索式の作成が求められる。このように、特定の言語学理論に関する知識や自然言語処理の技 術を持たない普通のユーザーにとっては、CTB は極めて使いづらい。さらに、CTB にはデータ の質の面においても問題が残っている。CTB のような通常のツリーバンクでは表層的な統語構 造が示されるだけである。コントロール構文や主題化構文や関係節構文などの複雑な構文が現れ た場合、文の基本をなす格名詞句と動詞との依存関係をつきとめることは非常な困難を伴う。
3 .ペン通時コーパス式の解析規約
本研究は、統語解析を行う際に、基本的にはペン通時コーパス (Penn Historical Corpora; PHC) 式の解析規約 (Santorini 2010) に従う。当解析スキームは、ペンツリーバンク (Penn Treebank; PTB) 式の解析スキーム(中国語版の場合は、Xue and Xia 2000)を修正したもので あり、文の統語構造をラベル付きの括弧(ツリーのもう一種類の表出形式であり、具体例とその 説明は第4節を参照)で表示する。ラベルには単語レベルの品詞タグ(例えば、普通名詞は N、 形容詞は ADJ)と句レベルのカテゴリー(例えば、名詞句は NP、形容詞句は ADJP)の二種類 がある。文の全ての末端要素(即ち、語や句読点)は、単語レベルのラベルによってタグ付けさ れているが、必ずしも句レベルのカテゴリーを持つ(即ち、句へ投射する)必要はない。 また、実用性重視という原則を貫き、同解析スキームは特定の言語理論に依拠していない。 GB 理論に拘ったペンツリーバンク式のものと異なり、PHC 式の解析規約では、中間レベルの構 造(N´や ADJ´など)は、いかなる場合も明示的にタグ付けされることはない。その最大の理 由は、これによりツリーの構造がシンプルなままに保てることにある。さらに、PHC 式の解析 規約においては、言語学者たちがこれまで使い続けてきた幾つかの句の構造が廃止されている。 その典型的な例は動詞句 (VP) である。PHC 式の解析規約は、VP の境界を決めることはほぼ不 可能に近いと考え、アノテーションの一貫性を保つために、VP の使用を認めていないのである。 PHC 式の解析スキームは、高い適用性を持ち、言語ごとに必要なある程度の修正を施した上で、 これまで多くの言語(英語、フランス語、アイスランド語、ポルトガル語、ギリシア語、日本語 など)に適用されてきた。 4 .解析規約の詳細 PHC 式の解析スキームを応用し実際に中国語の無制約の文(1)に対して統語解析を行うと、 ( 2 )が得られる。 ( 1 ) 嗯, 所以 张三 不 想 买 那 一 款 新 车 。 うん だから 張三 ない たい 買う あの 一 モデル 新しい 車 うん、だから張三はあの新車を買いたくない。 ( 2 ) (IP-MAT (INTJ 嗯) (PU ,) (CONJ 所以) (NP-SBJ (NPR 张三)) (NEG 不) (AX 想) (VB 买)
(NP-OB1 (D 那) (NUMCLP (CARD 一) (NUMCL 款)) (ADJ 新) (N 车)) (PU 。)) ( 2 )はラベル付きの括弧からなっており、( 1 )の統語構造を表示するものである。これは、 ツリーの本体で、ツリーのテクスト版と考えてよい。「(NP-SBJ (NPR 张三))」は、“ 张三 ” は NPR(固有名詞)という品詞タグを持っており、NP-SBJ(主語名詞句)によって直接支配され ている(あるいは、NP-SBJ を投射している)ということを表す。このように、左に行けば行く ほど文の構成要素の階層が徐々に高くなっていき、一番右に位置するのは “ 张三 ” や “ 车 ” など の語(末端要素)で、一番左にあるのは主節(あるいは、文)を示す IP-MAT となる。この手 法を使うことによって、「語→句→節→文」という文の内部の統語構造に関するシステマティッ クな表現と編集が実現できる。(2)を左から右まで大ざっぱに説明してみると以下の通りになる。 つまり、IP-MAT の下には、INTJ(間投詞)、PU(補助記号)、CONJ(接続詞)、NP-SBJ、NEG(否 定辞)、AX(助動詞)、VB(動詞)、NP-OB1(直接目的語名詞句)および PU の九つの要素が並 んでいる。また、NP-SBJ は NPR から、NP-OB1は D(限定詞)、NUMCLP(数助詞句)、ADJ(形 容詞)および N(名詞)からなっている。さらに、NUMCLP は、CARD(数詞)と NUMCL(数 助詞)によって構築されることになる。 4.1 節の内部構造 中間レベルの I´や VP は存在しないので、節(IP と CP)は常に VB と節レベルの構成要素を 直接支配する。動詞の他、中国語の場合、形容詞 (ADJ) もそのまま述語になれるため、節に直 接支配されることが許される。また、他にも極少数の単語レベルの要素が節に直接支配される形 で現れることができる。それは、( 2 )に見られる INTJ、CONJ、NEG および AX の他に、ア スペクト助詞 (AS) とモーダル助動詞 (MD) がある。以上のいずれの品詞タグも、句を投射し ても常に二分木(二股)にならないという点において、共通している。 4.2 句の内部構造 句のヘッド(主要部)は各句によって直接支配されるため、中間レベルの構造が示されていな い。( 2 )では、名詞句のヘッドである N の “ 车 ” は、NP-OB1によって直接支配されている。こ のように、原則として、ヘッド(N や ADJ)は句レベルのカテゴリー(NP や ADJP)と一致し なければならないが、二つの例外がある。それは、( 2 )の NP-SBJ の構造が示すように、ヘッ ドが一般的なカテゴリーのラベルよりもある意味では特殊なラベルを持っているか、またはヘッ
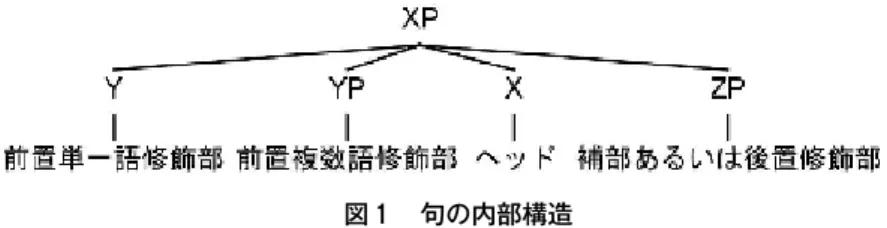
ドが省略されたか、のどちらかの場合である。 以上のように、ヘッドは通常句を投射するが、これにも二つの例外がある。まずは、4.1節で 述べたように、INTJ、CONJ、NEG、AX、AS、MD、VB および述語になった ADJ は常に句を 投射しない。さらに、( 2 )における NP-SBJ の内部構造の示す通り、単一の単語からなる前置 修飾部(当例の場合は D と ADJ)も句を投射しない。これは、単一の単語からなる前置修飾部 の投射する句の可能性は予測できる(D は DP、ADJ だけでは ADJP を投射することしかできな い)ため、枝分かれのない投射を減少することによって句の内部構造を単純化するためである。 これに対して、複数の単語から構築される前置修飾部は、相当する句を投射する。例えば、( 2 ) では、NUMCL の “ 款 ” は CARD の “ 一 ” を取り NUMCLP を投射してから N を修飾している。 一方、補部・修飾部が後置する場合は、いずれも相当する句を投射する必要がある。以上を踏ま えて、句(IP と CP は節として扱われるため両者を除く)の内部構造を図 1 に一般化することが できる。 中間レベルの構造は存在しないので、従来のいわゆる指定部および付加部は修飾部に統合さ れ、しかも修飾部も補部も常にヘッドと同じレベルにある。 4.3 機能情報 ラベルには、形式と機能を示すものがある。単語レベルの品詞タグは決して機能を示すもの を持つことはないが、句レベルのカテゴリーは形式と機能を示すものを両方持つことができる。 例えば、( 2 )における NP-OB1の場合、NP は句のタイプが名詞句であることを表すと同時に、 OB1はこの名詞句の機能を直接目的語に限定している。 節レベルの構成要素(即ち、IP または CP によって直接支配されるもの)の中、NP は常に機 能タグを持つことになる。( 2 )では、IP-MAT によって直接支配される二つの NP は、それぞ れ SBJ および OB1によってマークされている。一方、助詞句 (PP) に対しては、機能タグを一 切付与していない。しかしながら、本研究は、中国語の実情および意味処理の観点から解析規約 のこの部分に対してある程度の修正も加える(6.1節を参照)。また、すべての節は機能タグによっ てタイプ分けがなされている(IP-MAT の他、IP-ADV(副詞節)や CP-REL(関係節)などが ある)。
5 .ペン通時コーパス式の解析規約のメリット PHC 式の解析スキームは、特定の言語理論に偏っていない。従って、これに基づいて構築で きたツリーバンクは、異なる研究背景を持つ言語学者たちにとっては、従来のものに比べて比較 的に使いやすくなっていると思われる。そして、実用性重視とはいえ、これは決してコーパスの 質が落ちたというわけではない。図 1 が示しているように、PHC 式の解析規約に基づいて構築 したツリーは、句の内部構造が常にシンプルで共通性が保てる。また、一部の句・節の統語情報 に関しては、一貫して機能タグを通して明示的且つ豊富に表示を行う。これらは、ツリーバンク のデータを使用して更なる処理を行うために役に立っている。本研究は、ツリーバンクのデータ を意味処理システムの入力として使っているが、句の内部構造がシンプルで共通性を持つこと は、意味処理の段階で句の構成要素を規則正しく見つけ出すことに貢献している。さらに、句・ 節に関する統語情報をアクセスしやすい形で豊富に提供できるため、従来の述語 ‐ 項関係に止 まらない、より複雑な意味情報の抽出も可能となる。 以下、動詞句の例を挙げて、具体的に見ていくことにする。( 3 )は動詞句の一例であり、( 4 ) はペンツリーバンク (PTB) 式の解析スキーム(本研究で採用するペン通時コーパス (PHC) 式 の解析スキームと異なり、PTB は VP を使用している)を使ってそれを解析した結果である。 ( 3 ) 晚上 做 作业 夜 する 宿題 夜に宿題をする ( 4 ) (VP (NP (N 晚上)) (VP (VB 做) (NP (N 作业)))) VP 内部の階層から、一番目の NP“ 晚上 ” は動詞 “ 做 ” の修飾部(PHC の場合、付加部は修飾部 になる)であり、二番目の NP“ 作业 ” はその補部であるという情報が得られる。これらの統語 情報に基づいて、意味処理の結果を次のように導くことができる(述語論理式の紹介および意味 処理の詳細については、本論文では割愛する)。 ( 5 ) ∃ x1 x2 e3 (晚上(x2) ∧ 作业(x1) ∧ 做(e3, _, x1) ∧ link(e3) = x2) 本研究で使用されている( 5 )のような述語論理式は、Davidson (1967) に従い、述語が常に少 なくとも一つの暗黙のイベント変項によってエンコードされている(( 5 )の場合は、e3)。この イベント変項は、個体変項と同じように、定量化されており、さらに修飾されることも可能であ
る(( 5 )の場合、e3は関数 link の入力として使われている)。 “ 作业 ” は “ 做 ” の補部であるという情報が( 4 )によって提供されているため、( 5 )では、 個体変項 x1が述語 “ 做 ” の後ろに続くその項のリストの中に入れられている。これに対して、そ の付加部に当たる x2“ 晚上 ” は、link という関数によって、イベント変項 e3“ 做作业 ” につながっ てはいるが、述語 “ 做 ” の項のリストには入っていない。一方、PHC 式の解析規約は、中間レ ベルの構造が明示的に表示されず VP も使用していないため、補部と修飾部を区別するためのヒ ントがなくなってしまう。この弱点を克服するために、4.3節で紹介したように、PHC 式の解析 規約においては節に直接支配される NP の機能情報が必須である。PHC 式の解析規約に従って ( 3 )を解析した結果は次の(6)である。 ( 6 ) (FRAG (NP-TMP (N 晚上)) (VB 做) (NP-OB1 (N 作业))) ( 6 )では、二つの NP にそれぞれ TMP と OB1が付けてある。これにより、“ 晚上 ” は時間名詞 句であり、“ 作业 ” は直接目的語名詞句であるという情報が伝わる。 ( 7 ) ∃ x1 t2 e3 (作业(x1) ∧ 晚上(t2) ∧ 做(e3, _, x1) ∧ tmp(e3) ⊑ t2) ( 7 )は( 6 )に基づく意味処理の結果である。( 5 )に比べて、( 7 )はより精度が高い。( 5 ) から得られる情報は、“ 晚上 ” が何らかの関係で e3の “ 做作业 ” に関連しているということに止 まるが、( 7 )はその関係が何であるかについても明らかにしている。つまり、e3の行う時間が t2に包含されているのである。意味処理の要請から考えると、ここで大事なのは、名詞句が動詞 の必須項である(即ち、名詞句が動詞によって下位範畴化される)か否かということを判断する ための手掛かりを統語解析の段階で残しておくことである。句の異なる文法的役割を区別するた めに、ペンツリーバンク式の解析スキームは句の階層構造をいろいろ作っていたが、PHC 式の 解析スキームは、階層構造の代りに、句に明示的な機能タグを付与する方法を採用している。両 者は理論上どちらも統語情報の表出を詳細に行うが、以上見られたように、情報付与の利便性と 一貫性および精密性から見ると、後者のほうが優れている。 6 .ペン通時コーパス式の解析規約に対する修正 PHC 式の解析スキームは多くのメリットを持っている。それにもかかわらず、それ自体はあ くまでも統語解析のために設計されたものである。本研究のように、それに従って解析した中国 語のツリーをさらに意味処理という目的に利用する際に、十分な統語情報を意味処理システムに
提供できないこともある。本節では、本研究が意味処理の要請および中国語の実情から PHC 式 の解析規約に対して行った主な修正をめぐって説明する。 6.1 助詞句に対する機能情報の付与 5.2節で見たように、PHC 式の解析スキームは機能情報ぬきでは成り立たない。しかし、ペン 通時コーパス式の解析規約においては、PP に関する機能タグの付与は求められていない。その 一つの理由としては、英語の場合、補部の PP と修飾部の PP に関する区別が非常に難しいこと があるということが挙げられる。PP に機能情報を与えずに済むのであれば、その判断を回避で きるのである。そのもう一つの理由は、開発者は助詞句に関する機能情報は既に助詞の中に含ま れると考えているからである。 確かに、英語の場合、PP に対して補部と修飾部の区別が極めて困難なケースが多数存在し、 英語自体も多様な助詞(前置詞)を持っているため、このような考え方はある程度納得できると 言える。しかし、中国語の場合はどうだろう。まず、中国語には、英語のような PP に関する補 部と修飾部との区別をめぐる問題はほとんど存在しない1。しかも、助詞と一言で言っても、情 況は遥かに複雑である。以下の三つの例を考えよう。 ( 8 ) 在 公司 工作 で 会社 仕事する 会社で仕事をする ( 9 ) 把 药 喝 了 助詞 薬 飲む 完了 薬を飲んだ (10) 连 内幕 都 知道 さえ 内幕 “ 连 ” と呼応 知る 内幕さえも知っている ( 8 )の “ 在 ” は、“ 公司 ” と一緒に前置詞句を作り動詞 “ 工作 ” を修飾している。これに対して、 ( 9 )の “ 把 ” が取る “ 药 ” は動詞 “ 喝 ” の直接目的語である2。最後に、(10)では、通常動詞の 後ろに現れるべき “ 内幕 ” は、助詞 “ 连 ” によって繰り上げられ、動詞 “ 知道 ” の前に来ている。 しかも、“ 把 ” と違って、“ 连 ” は、直接目的語の他、主語などの前にも現れることができる(例 えば、“ 这件事连张三都知道。(この件は張さんさえ知っている。)”)ので、取り立て助詞として 扱うべきだと考えられる。このように、同じ助詞と言っても、三者は全く異なる統語的な振る舞 いを見せている。統語解析を行う際に、PHC 式の解析規約にそのまま従うと、意味処理の段階
で三者の区別ができなくなり、その結果、精度の高い述語論理式が得られなくなってしまう。従っ て、本研究は解析規約のこの部分に対して修正を行い、( 8 )、( 9 )と(10)の統語解析をそれ ぞれ以下のように付与する3。 (11) (FRAG (PP (P 在) (NP (N 公司))) (VB 工作)) (12) (FRAG (PP (P 把) (NP (N 药))) (NP-OB1 * 把 *) (VB 喝) (AS 了)) (13) (FRAG (PP (P 连) (NP (N 内幕))) (NP-OB1 *) (ADVP (ADV 都)) (VB 知道)) (11)における PP は、これ以上のアノテーションは行われていない。一方、(12)と(13)の PP に対しては、各自付加的なアノテーションをしている。即ち、PP の直後に NP を追加しその NP に機能タグを与えることによって、PP に関する機能情報を明示している。(12)では、“ 把 ” は動詞の直接目的語を示す格助詞的な使い方なので、右側の NP に OB1を付け加えた上で、NP-OB1の端末要素として「* 把 *」を補足している。これは “ 把 ” が取る NP は述語の直接目的語の 位置に移動したという意味である。これに対して、(13)では、NP-OB1の終端要素は * だけとなっ ている。これは(12)に見られる移動を示すものではなく、NP が “ 连 ” を経由し述語にかかっ ていることおよび両者の間の統語関係が直接目的語と述語との関係になっていることを意味す る。タイプの違う PP に異なるアノテーションをそれぞれ付与することによって、意味処理の段 階で三者の区別ができるようになる。( 8 )、( 9 )と(10)の意味処理の結果はそれぞれ次の通 りである。 (14) ∃ x1 e2 (公司(x1) ∧ 工作(e2) ∧ 在(e2) = x1) (15) ∃ x1 e2 (药(x1) ∧ 吃 _ 了(e2, _, x1))
(16) ∃ x1 e2 (都(e2) ∧ 内幕(x1) ∧ 知道(e2) ∧ arg1_ 连(e2) = x1) (14)は、x1“ 公司 ” が “ 在 ” を経由して e2“ 工作 ” につながるという意味表示である。一方、 “ 把 ” 構文は「処置文」とも呼ばれるように、通常の文とは異なる意味的な特徴が見られる。と はいえ、ここでは通常の論理式として表される中核的な意味のみを扱うことにし、“ 把 ” 構文の 持つ残りの意味については、ディスコース意味論や語用論の課題とする。この前提の下で考えれ ば、“ 把 ” は “ 药 ” に関する格の情報(統語レベルの情報)以外は特に意味レベルの情報を持っ ていない。そのため、(15)では、“ 把 ” は意味処理の結果から消え、x1“ 药 ” は “ 吃 ” の直接目 的語項の位置に入れられている(主語が現れていないので、主語項の位置が空白を示す「_」に なっている)。これに対して、(16)は、述語 “ 知道 ” の直接目的語項に x1が現れるわけではない が、式の最後の部分において複合的な述語「arg1_ 连」が作られ、結果として、x1が直接目的語 であることと “ 连 ” の支配下にあることが示されている。以上のように細部までの相違が捉えら れるのは、統語解析の段階で三者にそれぞれ異なった解析を付与したためである。 6.2 節レベルのスコープアノテーション 精度の高い述語論理式を得るには、まだ課題が残っている。それは、文を構築する要素の間の コントロール関係(同一指示関係)の同定である。従属節を伴う複文を対象とする文解析におい ては、従属節の主語が現れていない例もたくさんある。従属節の述語に関する完全な述語論理式 を得るために、明示的に現れていない従属節の主語と同一指示関係を持つ要素を主節などから見 付け出して両者を同定する作業が不可欠である。本節では、上述の問題を扱うために、本研究の 施した処置について、論じていきたい。 一般的には、依存関係の表示および述語 ‐ 項関係の再構成に必要なため、主語または目的語 が動詞の必須格として求められるにもかかわらず、文中で表現されていない場合、ゼロ代名詞の 追加を行ってそれらを明示する必要がある。ゼロ代名詞は、一般に純粋な代名詞類の性質を持つ pro (small pro) および代名詞類の性質と照応形の性質を合わせ持つ PRO (big pro) に分類され る。従来コントロール構文に対するゼロ代名詞のタギングは、直接 PRO を付け加えることが主 流だった。例えば、目的語コントロール構文(中国語学で言う兼語文)の(17)と主語コントロー ル構文の(18)に対して、(19)と(20)に示すように、ペンツリーバンク式の解析スキームでは、 従属節の IP に対して主語 PRO(即ち、「(NP-SBJ *PRO*)」)のアノテーションを行っている(比 較と説明の便宜上中間レベルの階層と VP は示さないが、NP に機能情報を与えることにする)。 (17) 张三 今晚 请 我 吃饭 。 張三 今晩 招待する 私 食事する 張三は今晩私を御馳走する。
(18) 张三 帮 我 叫 医生 。 張三 手伝う 私 呼ぶ お医者さん 張三は私のために医者を呼ぶ。 (19) (IP (NP-SBJ (NPR 张三)) (NP-TMP (N 今晚)) (VB 请) (NP-OB1 (PRO 我)) (IP (NP-SBJ *PRO*) (VB 吃饭)) (PU 。)) (20) (IP (NP-SBJ (NPR 张三)) (VB 帮) (NP-OB1 (PRO 我)) (IP (NP-SBJ *PRO*) (VB 叫) (NP-OB1 (N 医生))) (PU 。)) このようなコントロール構文の解析の仕方はある意味で論理的であるが、従属節の動詞に関 するより精度の高い述語論理式を目指し、PRO の値を確定しようとする際に問題が出てしまう。 即ち、PRO で表せる統語情報は「PRO と同一指示関係を持つものが前方で既に現れた」という ことに止まり、PRO を実際にコントロールしている対象(主節の主語なのかそれとも目的語な のか)の同定まではできないのである。一方、PHC 式の解析規約の場合、pro のアノテーショ ンはなされているが、PRO に対してはそのアノテーションが行われていない。その理由は、や はり実用面からのものである。即ち、pro と PRO は相補分布を成し一方から他方が導かれると いう関係にあるため、一方 (pro) を明示的に表記さえすれば、ディフォールトとしてもう一方 (PRO) が捉えられるということになる。しかし、PRO は pro との相補分布からディフォールト
的に自動追加されるからといって、その値を同定することまでは依然できていない。
コントロールのタイプは主節の動詞によって決まることが多い(例えば、(17)と(18)が示 すように、“ 请 ” は目的語コントロールを、“ 帮 ” は主語コントロールを構築することが一般的で ある)が、状況がさらに複雑な場合もある。
(21) 张三 帮 我 一起 做 作业 。 張三 手伝う 私 一緒に する 宿題 張三は私の宿題を手伝う。(張三は手伝ってくれて私と一緒に宿題をする。) (22) 张三 帮 我 做 作业 。 張三 手伝う/代わりにする 私 する 宿題 張三は私の宿題を手伝う。/ 張三は私の代わりに宿題をしてくれる。 (21)と(22)は、(18)と同じく、“ 帮 ” を主節動詞とする文である。しかしながら、(18)に おける “ 帮 ” はその意味の可能性が単一であるのに対して、(22)は語彙レベルの曖昧性が見ら れる(即ち、“ 帮 ” がどちらの意味を取るか決められない)。一方、(21)は(22)と比べてほと んど変わらないが、“ 一起 ” が入っているため、“ 帮 ” の取る意味が限定される。このような違い が三者のコントロールの状況にも相違をもたらしている。(18)は主語コントロールであるのに 対して、(21)は部分コントロール (partial control) になっている(即ち、従属節の PRO =“ 张 三 ”+“ 我 ”)。さらに、(22)は “ 帮 ” の取る意味によって、この二種類のコントロールのどちら にもなれる。 以上から分かるように、コントロールのタイプを決めるには、主節の動詞が何かに止まらず、 動詞の取る意味まで把握する必要がある。また、これは一般的な話でもあるが、場合によっては (例えば、(22)が文脈に入っていない場合)、文の語彙レベルの曖昧性を除去できないこともあ る。動詞の意味による(21)と(22)の違いを論理意味表示のレベルで区別する必要があるか否 かはそもそも検討の余地があるが、もし(18)も含めて三者の “ 帮 ” の部分に対して緩めの意味 解釈を共通して与えるならば、(23)のように単純化することができる。
(23) 帮(e1, 张三 , λ x Verb(e2, x, y), 我)
つまり、従属節の動詞の動作主に相当する主語項を無理に埋めず、それをラムダ化した式を入れ ておくことである。これは一種の不完全指定 (underspecification) であり、これ以上詳しいこと は語彙情報や語用論により与えられることになる。 (21)と(22)のような例はともかくとして、ここでは、統語レベルの情報(本研究の採用す るアノテーション方式の許す範囲内のもの)を用いてコントロール構文の処理を試みることにす る。SCT では、スコープの階層 (scope hierarchy) という概念を導入している。PHC 式の解析 規約に従って構築したツリーは比較的フラットなために、節レベルにおける各要素間のスコープ 関係は基本的には自由だと考えられる。とはいうものの、複数の要素が存在する場合は、必要に 応じてある程度の調整を加えることも可能である。例えば、節の述語が常により狭いスコープを 取るように設定したり、SBJ によってマークされる要素をより高いスコープの階層に移動したり
することができる。更に、スコープの階層関係に関するより精密的な調整を可能にするために、 HIGH および LOW という二つの機能タグも導入されている。以上を踏まえて、本研究における 節レベルの要素に関するスコープの階層を降順で以下の(24)のように規定する。なお、同じ階 層の要素が二つ以上存在する場合、そのスコープの階層は自然言語の語順で決まることになる。 (24) ① TPC(主題)、VOC(呼格)と HIGH によってマークされる要素 ② SBJ(主格)によってマークされる要素 ③ IP-PPL(分詞節) ④ MD(モダリティー) ⑤ NEG(否定) ⑥ HIGH と LOW によってマークされていない要素 ⑦ LOW によってマークされる要素 ⑧ 述語 ⑨ CP-THT(THAT 節)や IP-INF(不定詞節) ここで言っておきたいのは、(24)に示す階層は最終的なものではなく、一種の暫定的なディ フォールトに過ぎないということである。節レベルの要素のスコープ関係は実に複雑なものであ り、その傾向をある程度解明するためには、コーパスレベルの量のデータを考察する必要がある。 コーパスを構築すると同時に、このような考察を行っていくためには、暫定的な階層を設定した 上で取りあえずアノテーションを進めていくことが効率的だと考えられる。つまり、自分が暫定 的に設定した階層を修正していくためには、この階層に合わないデータを見つけ出す必要がある が、このようなデータを一気に抽出できるようにアノテーションを行う際に何らかの手掛かりを 残すことが(できれば、正しく修正してもらうことも)望ましい。本研究の場合、節レベルのス コープのアノテーションを行っており、暫定の階層に合わない文には必ず HIGH または LOW と いう印が残してある。それだけでなく、HIGH または LOW によってその階層が修正された文は いわば学習データにもなるため、構文解析器の訓練と同様に、節レベルの要素のスコープを自動 的に解析してくれるようなツールの開発も可能になる。 (24)に加えて、本研究は、意味処理システムにおいて、不定詞節 (IP-INF)、分詞節 (IP-PPL) および副詞節 (IP-ADV) に対して、(25)のようなディフォールト的解釈も付与する。
(25)IP-PPL / IP-INF / IP-ADV:
それによって直接支配される主語項が文中に明示的に表示されていない場合、それと姉妹 の関係を持つ要素からなるスコープの階層において、それよりも高い階層にあり、しかも もっとも近い距離を保つ制御項が、それが直接支配する主語項となる。
ここの制御項というのは、主節の主語や目的語など従属節の主語をコントロール可能なものの ことを言う。(24)と(25)により、明示的に現れていない従属節の主語を実際にコントロール している対象の同定は、意味処理を行うことによってできるようになる。(17)と(18)の統語 解析は、それぞれ(26)と(27)のように付与する。 (26) (IP-MAT (NP-SBJ (NPR 张三)) (NP-TMP (N 今晚)) (VB 请) (NP-OB2 (PRO 我)) (IP-INF (VB 吃饭)) (PU 。)) (27) (IP-MAT (NP-SBJ (NPR 张三)) (VB 帮) (NP-OB2 (PRO 我)) (IP-PPL (VB 叫) (NP-OB1 (N 医生))) (PU 。)) (26)と(27)では、PRO のタギングが行われていない。その代りに、従属節の二つの IP が それぞれ IP-INF および IP-PPL とされているが、これは必ずしもそうでなければならないとい うわけではない。語彙レベルの情報に頼らず本研究の枠組みの中でコントロールの問題を取り扱 うためには、統語解析の段階で従属節の IP を区別すること(即ち、IP に異なる機能タグを付与 すること)が望ましい。IP に与える機能タグについては、今の段階では、取りあえず英語の解 析規約を参考にしこれらを INF と PPL にしているが、どちらを INF(あるいは PPL)にするか は英語のような形式上の根拠(中国語の動詞は形態の変化が見られない)がない限り基本的には 自由だと考えられる。なお、中国語の実情に合わせて IP により適切な機能タグを付与するため には、今後更なる検討が必要である。 また、本研究では、“ 请 ” や “ 帮 ” のような IP-INF か IP-PPL を項として取る動詞を二重目的 語他動詞として扱う。“ 给(あげる)” のような典型的な二重目的語他動詞の場合、その受益者 と対象がそれぞれ間接目的語と直接目的語として扱われるのが一般的だということを考えれば、 “ 请 ” や “ 帮 ” の場合も同じく、その受益者である “ 我 ” を間接目的語 (NP-OB2)と、その対象 である IP-INF や IP-PPL を直接目的語と見なすほうが適切だと考えられる。(24)で規定したス コープの階層に、(26)と(27)における IP-MAT によって直接支配される各要素を当てはめる と、そのスコープ階層はそれぞれ以下の(28)と(29)のようになる。
(28) [NP-SBJ (张三) [NP-TMP (今晚) [NP-OB2 (我) [VB (请) [IP-INF (吃饭)]]]]] (29) [NP-SBJ (张三) [IP-PPL (叫医生) [NP-OB2 (我) [VB (帮)]]]]
IP-PPL / IP-INF に与えたディフォールトの解釈(25)により、(28)では、NP-OB2が IP-INF よりも高いスコープの階層にあり、しかもそれともっとも近いので、その主語項になるのに対し て、(29)では、IP-PPL よりも高いスコープの階層を持ちしかもそれにもっとも接近しているの は NP-SBJ となるので、これが IP-PPL の主語になる。このように、節レベルのスコープアノテー ションおよび従属節に対するディフォールト的解釈の付与を行うことによって、要素間の同一指 示関係が捉えられるようになる。(26)と(27)を入力とする意味処理の結果は、(30)と(31) の通りである。 (30) ∃ x4 t1 e2 e3 (x4 = 我 ∧ 今晚(t1) ∧
请(e3, 张三 , 吃饭(e2, x4), x4) ∧ tmp(e3) ⊆ t1) (31) ∃ x4 x1 e2 e3 (x4 = 我 ∧ 医生(x1) ∧ 帮(e3, 张三 , 叫(e2, 张三 , x1), x4)) (30)では、個体変項 x4“ 我 ” は述語 “ 吃饭 ” の主語項であると同時に、述語 “ 请 ” の間接目的語 項でもある。これに対して、(31)では、個体定項 “ 张三 ” は述語 “ 叫 ” と述語 “ 帮 ” の両方の主 語項になっている。 もちろん、節レベルのスコープアノテーションはその限界がある。もし、(21)と(22)の違 いを論理意味表示のレベルで区別しようとするのであれば、語彙レベルの情報も求められる。そ れにもかかわらず、コントロールだけではなく、否定や量化詞の作用域に関する問題を処理する ためにも、やはり節レベルのスコープアノテーションが不可欠だと考えられる。 7 .終わりに 統語・意味情報付き中国語コーパスを開発する際に、本研究が使用するアノテーション方式
(統語解析の部分)の詳細について述べてきた。従来句の複雑な内部階層を作ることによって表 出される統語情報は、本研究の採用する PHC 式の解析規約では、明示的な機能タグによって示 されている。このような統語情報の表出法は、情報付与の利便性と一貫性および精密性に勝って おり、中国語のような機能語に乏しい言語にとっては最適だと考えられる。また、中国語の実情 および意味処理の要請から、本研究は、PHC 式の解析規約に対する部分的な修正も行った。そ の結果、文の統語・意味解析を従来の方法ではなかなか手が届かない領域まで進めた。 参考文献
Butler, Alastair. (2010) The Semantics of Grammatical Dependencies. Bingley: Emerald. Chomsky, Noam. (1981) Lectures on Government and Binding. Dordrecht: Foris.
Chomsky, Noam. (1982) Some Concepts and Consequences of the Theory of Government and Binding. Cambridge, M. A.: MIT Press.
Davidson, Donald. (1967) The Logical Form of Action Sentences. In N. Rescher (ed.), The Logic of Decision and Action, 81-95. Pittsburgh: University of Pittsburgh Press.
Santorini, Beatrice. (2010) Annotation Manual for the Penn Historical Corpora and the PCEEC (Release 2). Tech. rep., Department of Computer and Information Science, University of Pennsylvania.
Xue, Nianwen, and Xia Fei. (2000) The Bracketing Guidelines for the Penn Chinese Treebank (3.0). Tech. rep., Institute for Research in Cognitive Science, University of Pennsylvania.
注 1 “ 住在上海(上海に住む)” のような例の場合、“ 在 ” を助詞(前置詞)として扱うのであれば、“ 在上海住 (上海に住む)” との類似性を捉える必要もあり、助詞句 “ 在上海 ” が動詞 “ 住 ” によって下位範疇化されている (“ 住 ” の補部である)という考え方も一理あると思われる。 2 “ 把 ” が助詞かそれとも動詞かに関する議論は今でも続いているが、“ 把 ” を助詞とするのであれば、目的格 を示す格助詞と考えるのが適切だと考えられる。 3 (10)における “ 连 ” と “ 都 ” の呼応に関する情報は語彙レベルのものだと考えられる。通常の統語コーパス には語彙レベルの情報が含まれないということもあり、現段階では、本研究はこれらの情報のアノテーション を行っていない。 (周振 東北大学大学院国際文化研究科 GSICS フェロー) (吉本啓 東北大学高度教養教育・学生支援機構 教授)