GPUを用いたレイトレーシングの高速化
4
0
0
全文
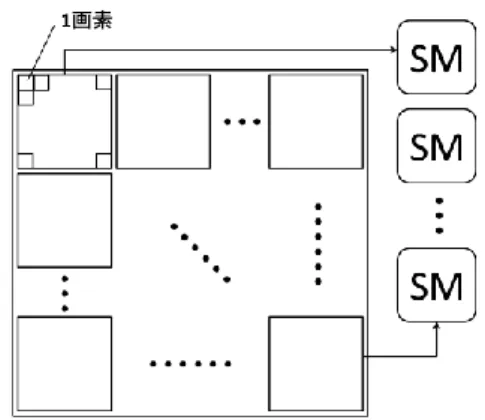
(2) 図3. 画面のブロック分割による並列実行. リーンを 64*64 ブロックに分割し、各ブロックは 8*8 の 画素で構成される。このとき 1 ブロック内には 64 スレッ ドがあるため、ワープが 2 つ存在することになる。. 図 2 ストリーミング・マルチプロセッサ(SM) SM は 32 個のスレッドをグループ化したワープを単位 として、スレッドのスケジューリングを行う。SM にはワ ープ・スケジューラとディスパッチ・ユニットがそれぞ れ 2 個ずつあるため、2 クロックで 2 ワープを実行するこ とができる。各ワープ・スケジューラは、1 つのワープを 選択し、1 命令で 16 スレッドを実行する。ディスパッチ 先となるのは、16 個の SP、16 個のロード・ストアユニ ット、4 個の SFU のいずれかのグループとなる。Geforce GTX 580 には 16 個の SM があるため、最大 512 個の SP を並列動作させることができる。. 3.GPU 上での並列処理方式 図 4 に作成した処理系の構成を示す。本プログラムは CPU 側と GPU 側の 2 つの処理から成り立っている。. 2.2 ストリーミング・マルチプロセッサによる画 面分割 レイトレーシングは実行処理時間が膨大であるが、そ の多くは交差判定処理に費やされている。つまり、交差 判定の高速化が必要不可欠である。そのためには、交差 判定の回数をアルゴリズムの改良により減らす、あるい は交差判定そのものを高速化することが必要である。こ こでは交差判定を高速化するために GPU を用いた画面分 割による並列化を行う。 レイトレーシングでは、スクリーン上のある画素の輝 度値を求める処理が、他の画素の輝度値を求める処理に 依存していないので、各画素の輝度値を独立に計算でき る。そのため、GPU を用いた画面分割による並列化と相 性が良い。 本研究では 512*512 の解像度のスクリーンを用いる。 SM による画面分割では、図 3 に示すようにスクリーンを 複数のブロックに分割し、各ブロックをそれぞれ SM に 割り当てる。各 SM ではブロック内のスレッドを 32 個単 位のワープに分割する。1 つのブロックは 1 つの SM で処 理され、1 つのスレッドは 1 つの SP で処理される。例え ば、ブロック数 64*64、スレッド数 8*8 の場合は、スク. 図4. モジュールの構成. まず、CPU 側でレイトレーシングの実験用のシーンデ ータである SPD(Standard Procedural Databases)ファ イルを読み込む。SPD とはレイトレーシングの実験用の シーンデータであり、視点ベクトル、スクリーンの背景 色、照明、物体素材の性質、球、三角形などの定義が含 まれている。本実験で用いた 4 つのシーンデータ(図 5~ 図 8)のポリゴン数とサイズを表1に示す。 CPU 側でブロック数とスレッド数を指定し、SPD 情報 を GPU 側に転送する。 GPU 側では受け取ったブロック、スレッド情報を元にス クリーンを SM 数分のブロックに分割する。次に、各ブロ ックをワープ単位の 32 スレッドに分割する。.
(3) 表 1 SPD シーンデータ. この時 1 スレッドはスクリーンの画素 1 つの処理を行う。 各スレッドでは 1 画素分のレイトレーシング結果を得る ために、光線の方向探索、交差判定、反射、屈折、及び 輝度計算を行い、スクリーンにレイトレーシング結果を 書き込む。 CPU 側でスクリーン情報を受信し、その結果を ppm 形 式のファイルに変換することで画像を得る。 GPU のメモリは外部のグローバルメモリ、GPU 内の L2 キャッシュ、SM 内の L1 キャッシュ/共有メモリの 3 つの階層から構成されている。本研究ではスクリーンを グローバルメモリ上に確保している。 SPD 情報は最初グローバルメモリに転送される。各 SP による 1 画素分のレイトレーシング計算では、SPD 情報 全体を必要とするので、SPD 情報は L2 キャッシュを介し て、L1 キャッシュに転送される。. 実験は以下に示す 5 通りのブロック数とスレッド数で行 った。 ・ブロック数 256*256、スレッド数 2*2 ・ブロック数 128*128、スレッド数 4*4 ・ブロック数 64*64、スレッド数 8*8 ・ブロック数 32*32、スレッド数 16*16 ・ブロック数 16*16、スレッド数 32*32 CPU1 個 ( 4 コ ア ) の 実 験 環 境 は 、 OS : Windows7 Ultimate 、 プ ロ セ ッ サ : Intel(R) Core(TM) i7-2600K CPU @3.4GHz、メモリ容量:8.00GB である。 GPU を用いた画面分割の並列化の実験環境は、CPU1 個の環境に、GPU:Geforce GTX580、グラフィッククロ ック:772MHz、メモリクロック:2004MHz、メモリ容 量:3.00GB、並列処理環境:CUDA を加えたものである。. 4.2. GPU による性能向上の評価. CPU1 個の実行時間は図 5 の teapot が 126.1(秒)、図 6 の tetra が 66.3(秒)、図 7 の mount が 195.2(秒) 、図 8 の nurbs が 30.9(秒)である。並列実行環境での実行時間と、CPU1 個に対する速度向上比を表 2 に示す。. 表2. 実行時間と速度向上比. 4. 実験結果と考察 4.1. 実験環境. 図 5~図 8 に示す 4 種類のシーンデータ(teapot, tetra, mount, nurbs)に対して、GPU を用いた画面分割による 並列化を行った。各シーンデータに対して、ブロック数 とスレッド数を変化させて画面分割を行い、最適な分割 パターンを検討した。. 図5. teapot. 図6. 図7. mount. 図 8 nurbs. tetra. 図9. 速度向上比.
(4) 図 9 は teapot, tetra, mount, nurbs の 4 つのシーンの速 度向上比を表したものである。このグラフからどのシー ンも共通して、ブロック数が 64*64、32*32、16*16 の場 合は速度向上比が大きく、特にブロック数が 64*64、スレ ッド数が 8*8 の場合が最も高速であることが確認できる。 これは、ブロック数 64*64、32*32、16*16 の場合、ワー プ内のスレッド数が 32 の倍数になるので、各 SP が常に 動作することができるため、速度向上比が大きくなって いる。また、ブロック数が少なくなるほど、速度向上比 が減少している。これはブロック数が少なくなると 1 ブ ロック内に含まれるスレッド数が増加し、スレッドあた りの使用レジスタ数が減少したためである。SM は 16 個 が並列に動作しているので、64*64 の場合が、他の場合に 比べて、使用効率が良い。 また、ブロック数が 256*256、128*128 の場合は速度 向上があまり得られていない。これは、1ブロック内の スレッド数が 32 よりも小さいので、各 SP に均等に処理 を割り当てることができず、速度向上比が大幅に低下し ている。 表 2 の実行時間は、表 1 の SPD シーンデータのサイズ と相関が認められる。1 画素のレイトレーシング計算で SPD 全体を参照するので、SPD のサイズに比例した時間 がかかっている。また、サイズがほぼ同じ tetra, nurbs で はポリゴン数に比例した時間がかかっていると考えられ る。. 4.3. GTX480 と GTX580 の比較. 我々はすでに GTX480 での実験を行なっているので[3]、 ここでは GTX480 と GTX580 の比較評価を行う。表 3 に GTX580 と GTX480 の主な仕様を示す。また、表 4 にブ ロック数 64*64、スレッド数 8*8 の場合のそれぞれの GPU で の 実 行 時 間 を 示 す 。 ま た 、 速 度 向 上 比 は GTX480/GTX580 で求めた。. 表3. GTX580 と GTX480 の仕様. GTX580 は GTX480 と比べて 1.13~1.35 倍の速度向上 が得られた。GTX580 では SM16 個が同時動作し、64*64 のブロックが全ての SM に均等に負荷分散されているの で、GTX480 よりも高速であると考えられる。. 5. おわりに. 本論文では、GPU を用いたリアルタイムレイトレーシ ングの速度向上の評価を行った。レイトレーシングの各 画素の輝度値を求める処理が、他の画素の計算と独立で あることを用いて、画面を均等にブロック分割し、各ブ ロックを各ストリーミング・マルチプロセッサで並列実 行した。 実験では Geforce GTX 580 を用い、SPD の 4 つのシー ンデータ(teapot, tetra, mount, nurbs)に対して、ブロ ック数とスレッド数を変化させて実行時間を測定した。 その結果、ブロック数 64*64、スレッド数 8*8 のときに、 mount で最大 109 倍の速度向上が得られており、他のシ ーンデータにおいても、80 倍~90 倍の速度向上が得られ た。また、GTX580 は SM16 個が同時動作するので、 GTX480 と比べて 1.13~1.35 倍の速度向上が得られた。 現在、新たなシーンデータで動作させられるように球 の反射アルゴリズムを作成中である。 本研究の最終目標は、レイトレーシング法での画像生 成を 100ms 以下で実現することであり、現在の 10 倍以 上の速度向上を達成することが必要である。今後の課題 として、共有メモリの有効活用、インタリーブ分割によ る画面分割の実現、適応型空間分割による交差判定回数 の削減などがあげられる。. 参考文献 [1] Patrickomatic.com:http://patrickomatic.com/c-raytracer [2] 上野謙二郎, 孟林, 山崎勝弘:GPU を用いたリアルタ イムレイトレーシングの検討, 情報処理学会第 74 回 全国大会, 1ZB-1, 2012. [3] 孟林, 上野謙二郎, 山崎勝弘:GPU を用いたリアルタ イムレイトレーシングの並列化, 第 11 回情報科学技 術フォーラム, FIT2012, 2C-1, 2012. [4] 吉谷崇史, 山崎勝弘:適応型空間分割による並列レイ トレーシング法, 情報処理学会第 54 回全国大会, 4Q6, 1997.. 表4. GTX480 と GTX580 での実行時間(秒). [5] 千葉則茂, 土井章男:3 次元 CG の基礎と応用[新訂 版], サイエンス社, 2004..
(5)
図

関連したドキュメント
試験体は図 図 図 図- -- -1 11 1 に示す疲労試験と同型のものを使用し、高 力ボルトで締め付けを行った試験体とストップホールの
機械物理研究室では,光などの自然現象を 活用した高速・知的情報処理の創成を目指 した研究に取り組んでいます。応用物理学 会の「光
この論文の構成は次のようになっている。第2章では銅酸化物超伝導体に対する今までの研
私はその様なことは初耳であるし,すでに昨年度入学の時,夜尿症に入用の持物を用
水道水又は飲用に適する水の使用、飲用に適する水を使
本節では本研究で実際にスレッドのトレースを行うた めに用いた Linux ftrace 及び ftrace を利用する Android Systrace について説明する.. 2.1
※ 硬化時 間につ いては 使用材 料によ って異 なるの で使用 材料の 特性を 十分熟 知する こと
「系統情報の公開」に関する留意事項
