PowerPCプロセッサの特性を考慮した高速Javaバイトコードインタプリタの構成法
10
0
0
全文
(2) 2. 情報処理学会論文誌:プログラミング. Sep. 2002. 特に顕著である.原因は,1 命令の長さが一般に数バイ ト以下と短いことと,オペコードが基本的な操作ごと に割り当てられており,それらを処理するバイト コー ド ハンド ラ(以下単にハンド ラと呼ぶ)が短いコード 断片となることである. スーパスカラプロセッサではメモリアクセスがワー ド 単位で行われ,ワード 境界をまたぐ メモリアクセ スに対して内部で追加のメモリアクセスが行われる. そのため,1 ワード 未満のバイトコード やワード 境界 をまたぐバイトコード のフェッチで同一ワードを複数 回ロードし ,高頻度なロード が大きなボトルネック となる.我々はバイトコードをレジスタ( Bytecode. Cache Register または BCR )にキャッシュするこ とで,フェッチによる冗長なメモリアクセスを最小化 した.さらにワード 内の,バイトコードが始まる位置 ごとにカスタマイズしたハンド ラを用意し,それらで ステートマシンを構成することで,実行時チェックな しにバイトコード のワード 中の位置を決定できるよう. Fig. 1. 図 1 基本的なインタプ リタの構造 Structure of a basic bytecode interpreter.. にした.この手法を位置別ハンド ラと呼ぶ. ハンド ラにおけるディスパッチのための間接分岐に. 2.1 ベースインタプリタ. よるパイプラインストールも,スーパスカラプロセッ. 最も基本的なインタプ リタは,図 1 (b) に示すよう. サにおけるボトルネックとなる.プロセッサの分岐予. にデコード ループと呼ばれる短いコードの制御により,. 測機構でこれらの間接分岐の飛び先を予測することは. バイトコードのフェッチ,デコード,ディスパッチおよ. 困難である.この問題に対し,次の次のバイトコード. び実行を繰り返す.図 1 (c) に示すスレッデッド コー. のオペコード の候補となるバイトを投機的にデコード. ド 1),2) インタプリタは,デコードループを各ハンド ラ. する解決法が,VLIW プロセッサ向けに提案されてい. にインラインすることで,ハンド ラの処理完了後,次. 6). る .我々は,この手法のスーパスカラプロセッサ上. のハンド ラへ直接ジャンプする.. の実装法として位置別投機デコード を提案する.本手. 我々のベースインタプリタは,スレッデッドコード. 法では,Address Pool Register( APR )と呼ぶ. インタプリタに,実行中のバイトコードのオペランド. レジスタを 4 個用意し,オペコード の候補 3 個を投機. と次のバイトコード のオペコードを,同一のロード 命. 的にデコード することで,次のハンド ラのアドレスを. 令でロード する最適化を適用したものである.また,. ハンド ラの実行の最初で命令フェッチユニットに送り. 各ハンド ラを 64 バイト境界ごとにオペコード 順に配. パイプラインストールを減らす.. 置し,オペコード 0 のハンド ラを 16 K バイト境界に. 本稿では,PowerPC プロセッサ12) 向けの Java バイ. 整列することで,デコード を PowerPC の rlwimi 命. トコード インタプ リタの高速化手法を提案し,各々の. 令☆ 1 命令で処理する.この配置によりハンド ラ全体. 効果を最新の PowerPC プロセッサの 1 つである IBM. のサイズは 16 K バイトとなる.. POWER3 プロセッサ上でのベンチマーク結果を用い て示す.以下,2 章では我々が提案・評価したインタ. 2.2 スタックキャッシュ Java バイトコード など のスタック型仮想マシンの. プリタ高速化手法について述べ,3 章では提案した手. インタプ リタでは,スタックオペランド のプッシュ・. 法の移植性を考察する.4 章では各高速化手法を評価. ポップのために,メモリ上に配置されたオペランド ス. する.5 章では従来の研究について述べる.. タックを頻繁に操作する.したがって,数個のスタッ. 2. インタプリタ高速化手法 本章では,我々のベースインタプリタと,我々が提 案・評価した,PowerPC 向け Java バイトコード イン タプ リタを高速化する手法について述べる.. クオペランドをレジスタにキャッシュすれば実行速度 を向上できる.Java では,1 つのバイトコードで使用 ☆. ソースレジスタの内容を指定のビット数ローテートし ,結果の ビット列から一部分を取り出し,そのビット列でターゲットレジ スタの対応するビット列を置換する命令12) ..
(3) Vol. 43. No. SIG 8(PRO 15). 高速 Java バイトコード インタプ リタの構成法. 3. するスタックオペランドはほとんどの場合 2 個以下な. マイズされた部分は太斜体で記述されている.図 2 (c). ので,スタックトップのみ,もしくはスタックトップ. は各ステップ終了時の BCR の内容を示す.. と 2 番目をキャッシュすれば十分である.PowerPC プ. 位置別ハンド ラはソフトウェアパイプライン手法の. ロセッサでは,4 章で示すように,ライトスルー方式. 一種なので,分岐が起きるたびにソフトウェアパイプ. でスタックトップのみをキャッシュすればよい.1 個. ラインの再始動が必要で,その頻度が高い場合,その. のキャッシュで十分なのは,メモリロード のレ イテン. オーバヘッドにより実行速度が低下する可能性がある.. シが短く,それをインタプリタで必要な他の処理で隠. しかし,通常 Java プログラムの分岐頻度は 5∼7 命令. せるためである.ライトスルー方式で十分なのは,ア. に 1 回20) なので,本手法は一般的なプログラムに対. ウトオブオーダ実行によりストア命令がほかの命令の. して効果を期待できる.4 章に示す実行結果でも,多. 実行を妨げないためである.. くのベンチマークにおいて速度向上が得られた.. 2.3 位置別ハンド ラ ベースインタプリタは,各ハンド ラでバイトコード. 2.4 位置別投機デコード スレッデッドコード インタプ リタでは,ハンド ラは. のフェッチを行い,ワード 境界をまたぐ メモリロード. 間接分岐命令で次のバイトコードのハンド ラへジャン. のために 2 ワード をロード する場合が多い.. プする.Branch target buffer( BTB )などの分岐予. これらの無駄なメモリロードを減らすために,バイ. 測機構は分岐先アドレスの時間的な局所性を利用して. トコード 列をワードごとにレジスタ( BCR )にキャッ. いるので,次のバイトコードによって決まるハンド ラ. シュする.Java バイトコードでは 2 個の BCR を用意. のアドレスの予測は困難である.たとえば Java バイ. すれば十分である.しかし,バイトコード の先頭は必. トコード aload 0 と,その次に実行されるバイトコー. ずしもワード 境界にないので,バイトコードのレジス. ド の間には,時間的局所性がない.. タ内の位置を実行時に求める必要がある.この実行時. 一部のプロセッサは,分岐先アドレスを命令フェッ. チェックはハンド ラのクリティカルパス長を 2 倍以上. チユニットにセットすることで間接分岐実行時のパ. にする可能性があり現実的でない.Hoogerbugge らの. 8),12) イプラインストールを減らす機構を持っている.. 6). る.しかし,この方法は,実行時にレジスタシフトの. PowerPC プロセッサは,間接分岐実行の 4 サイクル 以上前13)に分岐先アドレスを特殊レジスタ( リンクレ ジスタもしくはカウントレジスタ)にセットすること. コストが必要になると同時に,バイトコードがワード. で,パイプラインストールをなくすことができる.イ. 境界を越えたかど うかの実行時チェックが必要である.. ンテル IA-64 プロセッサ8),9) も同様な機構を持ってい. 手法 のように,オペコード のレジスタ内の位置が一 定になるようにレジスタの内容をシフトする方法もあ. 我々の解決法では,各ハンド ラをワード 中のバイト. る.遅延分岐命令を持つプロセッサでは,遅延命令ス. 位置ごとの 4 通りにカスタマイズし,実行中のバイト. ロットを使用することで同等の効果を得られる6) .し. コード の位置に対応するハンド ラでバイトコードを処. かし,これらの機構を利用するためのレイテンシは多. 理する.各ハンド ラは図 2 (b) に示すステートマシン. くのハンド ラの実行サイクル数に対して長いので,ハ. により,実行時チェックなしに次のハンド ラを選択す. ンド ラがデコード 後に分岐先アドレスをセットすると. る.カスタマイズにより次の 5 つの処理を削減できる.. 十分な効果を得られない.. • バイトコードポインタの下位 2 ビットから,実行 中のバイトコード の位置を算出.. パイプ ライン化インタプ リタ手法の一部として実 装された投機的デコード 手法6),7)は,バイトコード の. • 2 つの BCR のど ちらに実行中のバイトコード の オペランドがあるかを判定.. をオーバラップさせることで,VLIW プロセッサにお. • オペランドを BCR から取り出すためのシフトカ ウントを,現在のバイト位置から算出.. が次の次のバイトコードをデコード することで,次の. • 次のオペコード を BCR から取り出すためのシフ トカウントを,現在のバイト位置から算出. • 次のワードをロード する必要があるかを,現在の バイト位置から判定.. フェッチ,デコード,ディスパッチ,実行の各ステージ いてこの問題を解決した.この手法では,各ハンド ラ バイトコード のハンド ラが,その次のハンド ラのアド レスを命令フェッチユニットに早くセットできるよう にする.可変長命令では,次のバイトコードをデコー ドしないとその次のバイトコード の位置を特定できな. 図 2 (d) はカスタマイズされたハンド ラの動作を示. いという問題があるが,いくつかの,次の次のバイト. す.灰色の矢印は図 2 (a) のバイトコード 列を実行し. コードのオペコードの候補を投機的にデコード するこ. たときの制御フローである.ハンド ラの処理でカスタ. とで解決している.投機デコード 結果はレジスタに保.
(4) 4. 情報処理学会論文誌:プログラミング. Fig. 2. Sep. 2002. 図 2 位置別ハンド ラを適用したハンド ラの動作 Operations in bytecode handlers with position-based handler customization.. 持し,可能ならば再利用して,複数の候補をデコード. い.また,我々のインタプリタはバイト位置ごとにカ. するオーバヘッド を減らしている.. スタマイズしたバイトコード ハンド ラを持つので,候. 最適な候補の数はバイトコード 命令セットに依存し, Java では 3 個である.実行頻度の高い Java バイト. 補と APR の対応を実行時に求める必要がない.. コード の命令長は 1∼3 バイトなので,次の命令の長. 同時に実装したインタプリタの動作を,図 3 (a) のバイ. 図 3 (b) に位置別ハンド ラと位置別投機デコード を. さを 1∼3 バイトと仮定した場合の候補 3 個をデコー. トコード 列を実行した場合の例で示す.図 3 (c) は各ス. ドすれば,高い頻度で投機デコードの効果を得られる.. テップ終了時の BCR と APR の内容を示す.灰色の背. 我々の手法は,Hoogerbrugge ら 6)と異なり,デコー. 景で示した処理は,バイトコード istore 1( 図 3 (a). ド 結果を保持するためのレジスタ( APR )を 4 個用. に灰色の背景で示した)を実行するするために必要な. 意し,候補のバイト位置と対応づけるので,デコード. 処理である.ステップ 1 では,BCR0 バイト位置 3 の. 結果の再利用のためにレジスタ間で移動する必要がな. デコード 結果を再利用するので,実際にハンド ラがデ.
(5) Vol. 43. No. SIG 8(PRO 15). Fig. 3. 高速 Java バイトコード インタプ リタの構成法. 5. 図 3 位置別投機デコード におけるハンド ラの動作 A sequence of operations in bytecode handlers for position-based speculative decoding.. コード するのは BCR1 のバイト位置 0 と 1 のみでよ. できる.バイトコードをキャッシュする C 言語のロー. い.ステップ 2 では,ハンド ラの先頭で次のバイト. カル変数は,ハンド ラ実行中はレジスタに載っていな. コード( istore 1 )のハンド ラのアドレ スを APR1. いと効果が少ない.switch 文を用いたインタプリタに. から取得しセットできる.. 適用するには,case ブロックをカスタマイズし,それ. 3. 移植性の考察. ぞれに個別の case ラベルを付ける.GNU C コンパイ. 本章は,我々の手法をほかのハード ウェアおよびソ. デッドコード インタプリタの場合は,アセンブラで記. フトウェア環境に移植する場合の問題点を考察する.. 3.1 位置別ハンド ラの移植性. ラ4) の拡張機能「 Labels as Values 」を用いたスレッ 述したインタプ リタと同様に実装する.. 64-bit プロセッサ用のインタプリタでは,汎用レジ. 本手法を実装するためには,BCR のために 2 個の. スタが 8 バイト幅なので,バイトコードを 8 バイトず. 汎用レジスタを予約する必要があり,インタプリタの. つキャッシュすれば最大の効果が得られる.この場合. 実装に必要な他のレジスタと合わせると,12 個程度. 8 通りのカスタマイズされたハンド ラが必要になる.. の汎用レジスタが必要となる.他のレジスタとは,た. また,BCR0 にキャッシュされたバイトコード 中に分. とえばスタックトップのキャッシュ,バイトコードポ. 岐命令が含まれる可能性が増えるので,BCR1 のロー. インタ,フレームポインタ,スタックポインタ,ロー. ドを遅らせた方がよい.しかし,コード サイズの増加. カル変数領域のベースポインタ,コンスタントプール. や,32-bit プロセッサとのバイナリ互換性を考慮する. へのポインタ,スレッド ローカルデータへのポインタ,. と,64-bit プロセッサでも 32-bit プロセッサ用の実装. 数個の作業用レジスタである.したがって,インテル. を用いる方が好ましいと考えられる.たとえば,我々. x86 プロセッサのようなレジスタが少ないプロセッサ. のインタプ リタの場合,8 通りのハンド ラでは 128 K. に移植した場合,本手法は効果が少ないと考えられる.. バイト必要となる.. 本手法は C 言語で記述されたインタプリタにも適用.
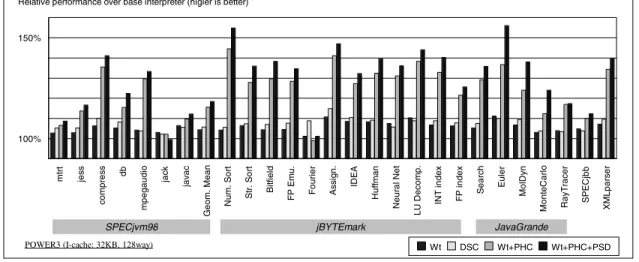
(6) 6. Sep. 2002. 情報処理学会論文誌:プログラミング 表1 Table 1. 3.2 位置別投機デコード の移植性 移植先プロセッサは,命令フェッチユニットに分岐 先アドレスをセットすることで,間接分岐時のパイプ. POWER3 17),19) , 400 MHz 32 Kbytes, 128-way set associative, 128 bytes/line 4 Kbyte 768 Mbytes AIX 4.3.3 IBM SDK Java edition 1.3.0 10). CPU I-Cache. ラインストールサイクルを減らす機構を備えている必 要がある.たとえば,PowerPC の mtlr 命令や mtctr 命令. 12). ,Intel Itanium プロセッサの mov br=gr,tag. 命令8),9) のような特殊命令,もしくは遅延分岐6)であ. ベンチマーク実行環境 Execution environment.. Page size Memory OS Java VM. る.セットした飛び先アドレスが反映されるまでのレ 表2 Table 2. イテンシは,ハンド ラの最小実行サイクル数を決定す るので,短いほど本手法の効果が大きい.また,飛び 先アドレスのセットに特殊命令を必要とするので,ハ ンド ラをアセンブラで記述するか,特殊命令を生成で. Interpreter Base Wt. Description ベースインタプ リタ. Base にライト スルー・スタックトップ キャッシングを適用したもの. きるようにコンパイラを変更する必要がある. インタプ リタは,APR のために 4 個の汎用レジス. DSC. タを予約する必要がある. 複数の候補をバイトコード 実行と並列にデコード す. Wt+PHC. るので,移植先プロセッサは,スーパスカラプロセッ サや VLIW プロセッサなど,命令レベル並列性( ILP ). 評価したインタプ リタ Evaluated interpreters.. Wt+PHC+PSD. を活用する必要がある.PowerPC プロセッサでは,投 機デコード とバイトコード 実行を同時に行うために,. Base にダ イナミック・キャッシング 3) を 適用し ,2 個までのスタックオペランド をキャッシュするもの Base に,ライトスルー・スタックトップ キャッシングと位置別ハンドラを適用した もの Base に,ライトスルー・スタックトップ キャッシング,位置別ハンド ラ,位置別投 機デコード を適用したもの. 整数演算命令を 1 サイクルあたり 2 命令以上実行でき る必要がある.また,位置別投機デコード を適用した ハンド ラの最小実行サイクル数は 4 サイクルで,典型. Table 3. 的なハンド ラの命令数は,投機デコード の 1∼3 命令. ベンチマーク. およびデコードループの 5 命令と合わせて 10∼16 命. SPECjvm. 令なので,1 サイクルあたりの発行命令数とリタイア. 表 3 評価したベンチマーク Evaluated application benchmarks. 概要. SPECjvm98 21) の各プログラムの実行時間 「 Geom. Mean 」は各ベンチマーク結果の幾 何平均.「 controls 」は 10 に変更した. 命令数は 4 以上が必要である.これらの条件を満たさ. jBYTEmark. Java 版 BYTEmark のインデックス値. ない場合は十分な効果を得られない可能性があり,投. JavaGrande. Java Grande Forum Benchmark Suite 15) の実行時間.Section 3 のみ測定. 機デコード する候補の数を減らすことなどが必要とな る可能性がある.. APR は,64-bit プロセッサの場合でも 4 個でよい. 8 通りのカスタマイズされたハンド ラを持つ場合,下. SPECjbb XMLparser. SPECjbb-2000 21) ベンチマークのスコア XMLparser for Java 11) で ,サンプ ル の XML ファイルをパースする時間. 位 2 ビットが同じ値のバイト位置に対応するハンドラ. る相対実行速度をグラフ化した.相対実行速度は値が. は,同じ APR を操作する.. 大きいほど 実行速度が速いように正規化した.. 4. 評. 価. 測定し たベンチマークの多くにおいて最も効果が あったのは位置別ハンド ラであった.このことから,. 我々は 2 章で述べた手法を表 3 のベンチマークで. バイトコード フェッチのための高頻度で冗長なメモリ. 評価した.実行環境は表 1 に示す.POWER3 は最新. ロードが,インタプリタの実行速度を制限する最大の. の PowerPC プロセッサの 1 つである.各手法の効果. 要因であることが確かめられた.. を個別に測定するために,IBM SDK for AIX,Java この JVM は 64-bit プロセッサ上でも 32-bit 互換モー. 4.1 スタックキャッシュ手法の評価 ライトスルー・スタックトップキャッシングの効果 を,キャッシュしているスタックオペランド の数に対. ドで動作し,32-bit プロセッサ用のインタプリタを用. 応するキャッシュ状態ごとにカスタマイズしたハンド. いる.JIT コンパイラは使用していない.. ラを用いるダイナミック・スタックキャッシング 3) の効. edition. 10). を変更し,表 2 のインタプリタを作成した.. 表 4 に測定結果と,ベースインタプリタに対する相. 果と比較して評価した.Wt および DSC インタプ リ. 対実行速度を示す.図 4 にベースインタプリタに対す. タの実行速度はそれぞれのスタックキャッシュ手法の.
(7) Vol. 43. No. SIG 8(PRO 15). Table 4. 高速 Java バイトコード インタプ リタの構成法. 7. 表 4 実行結果とベースインタプリタからの速度向上率( カッコ内) Benchmark results and the improvement over the base interpreter. Each cell shows: raw result (improvement over base).. SPECjvm98 (smaller is better). mtrt jess compress db mpegaudio jack javac Geom. Mean jBYTEmark Num. Sort (larger is better) Str. Sort Bitfield FP Emu. Fourier Assignment IDEA Huffman Neural Net LU Decomp. INT Index FP Index JavaGrande Search (smaller is better) Euler MolDyn MonteCarlo RayTracer SPECjbb (larger is better) XMLparser (smaller is better). Fig. 4. Base 10.060 4.307 30.679 2.734 31.556 5.810 2.688 7.822 6.492 6.746 6.777 6.607 3.121 6.466 4.847 6.559 5.997 6.500 6.321 4.955 200.1 429.1 233.7 127.9 385.4 684 6889. Wt 9.787 (102.8%) 4.182 (103.0%) 28.868 (106.3%) 2.597 (105.3%) 30.264 (104.3%) 5.641 (103.0%) 2.564 (106.4%) 7.491 (104.4%) 6.768 (104.3%) 7.179 (106.4%) 7.075 (104.4%) 6.903 (104.5%) 3.155 (101.1%) 7.162 (110.8%) 5.261 (108.5%) 7.110 (108.4%) 6.451 (107.6%) 7.174 (110.4%) 6.746 (106.7%) 5.266 (106.3%) 190.1 (105.3%) 386.0 (111.2%) 219.0 (106.7%) 124.1 (103.1%) 370.7 (104.0%) 717 (104.8%) 6427 (107.2%). DSC 9.550 (105.3%) 4.088 (105.4%) 28.900 (110.0%) 2.525 (108.3%) 30.417 (103.7%) 5.688 (102.1%) 2.546 (105.6%) 7.397 (105.7%) 6.851 (105.5%) 7.258 (107.4%) 7.258 (107.1%) 7.116 (108.8%) 3.396 (108.8%) 7.428 (114.9%) 5.353 (110.4%) 7.160 (109.2%) 6.343 (105.8%) 7.078 (108.9%) 6.880 (108.9%) 5.343 (107.8%) 186.3 (107.4%) 390.2 (110.0%) 213.5 (109.5%) 123.2 (103.8%) 372.6 (103.4%) 710 (103.8%) 6287 (109.6%). Wt+PHC 9.437 (106.6%) 3.790 (113.6%) 22.626 (135.6%) 2.367 (115.5%) 24.347 (129.6%) 5.685 (102.2%) 2.449 (109.8%) 6.766 (115.6%) 9.384 (144.5%) 8.631 (127.9%) 8.486 (129.7%) 8.486 (128.4%) 3.088 (98.9%) 9.125 (141.1%) 6.171 (127.3%) 8.690 (132.5%) 7.866 (131.2%) 8.998 (138.4%) 8.402 (132.9%) 6.023 (121.6%) 154.9 (129.2%) 313.9 (136.7%) 188.5 (124.0%) 113.8 (112.4%) 329.6 (116.9%) 752 (109.9%) 5128 (134.3%). Wt+PHC+PSD 9.254 (108.7%) 3.692 (116.7%) 21.737 (141.1%) 2.234 (122.4%) 23.662 (133.4%) 5.834 (99.6%) 2.396 (112.2%) 6.606 (118.4%) 10.060 (155.0%) 9.170 (135.9%) 8.894 (138.3%) 8.894 (134.6%) 3.155 (101.1%) 9.511 (147.1%) 6.412 (132.3%) 9.159 (139.6%) 8.166 (136.2%) 9.368 (139.2%) 9.863 (140.2%) 6.226 (125.7%) 147.3 (135.8%) 275.0 (156.0%) 169.2 (138.1%) 103.0 (124.1%) 328.4 (117.4%) 769 (112.4%) 4926 (139.8%). 図 4 ベースインタプ リタからの速度向上率 Performance improvement over the base interpreter.. 効果を示し ,前者では平均 5.9%の速度向上が得られ. 評価したベンチマークのほとんどで,そのようなバイ. た.後者の前者からの速度向上は平均 1.3%であった.. トコード の実行回数は全体の 30%以下であった.. 速度向上の差が少ない原因として,我々は以下の 2. 第 2 は,ハンド ラのクリティカルパス長が,バイト. つを考えている.第 1 は,スタックオペランドを 2 個. コード 実行パスと,インラインされたデコードループ. 必要とするバイトコードの実行頻度が低いことである.. の,長い方で決まることである.スタックキャッシュに.
(8) 8. 情報処理学会論文誌:プログラミング. Sep. 2002. オブオーダ実行を行うプロセッサでは,ライトスルー・ スタックトップキャッシングで十分である.. Wt+PHC インタプリタの実行速度が示すライトス ルー・スタックトップキャッシングと位置別ハンド ラ の組合せにより,平均 24.4%の実行速度向上が得られ た.ダ イナミック・キャッシングも 3 通りのカスタマ イズされたハンドラを必要とするので,コード サイズ の増加に対する速度向上効果の観点から,我々の手法 の組合せの方が優れている.. 4.2 位置別ハンド ラの評価 Wt インタプリタに対する Wt+PHC インタプリタ の速度向上は位置別ハンド ラの効果を示す.多くのベ ンチマークで 10%以上の速度向上が得られ,平均向上 率は 17.4%であった. 一方,いくつかのベンチマークでは実行速度が向上 しないか,または低下している.SPECjvm98 の jack のように頻繁に Java 例外をあげたり,jBYTEmark の Fourier のように頻繁にネイティブ メソッドを呼び 出したりするプログラムである.高頻度の BCR 再読 込のオーバヘッド のため実行速度が向上しない. 位置別ハンドラの問題点は,ハンド ラのサイズ増加 により命令キャッシュの利用効率が低下することであ る.しかし,全ハンド ラのサイズが 64 K バイトであ ることと,実行頻度の高いバイトコードは全体の半分 よりずっと少ない20) ことから,実行頻度の高いバイト コード ハンドラは,32 K バイトの命令キャッシュです べてキャッシュできると考えられる.POWER3 プロ セッサのパフォーマンスモニタによる測定結果では,. SPECjvm98 において,本手法適用後でも実行命令あ たりのキャッシュミスは 1%以下であった.. Fig. 5. 図 5 バイトコード iaload のハンド ラ The bytecode handlers for iaload bytecode.. 4.3 位置別投機デコード の評価 Wt+PHC インタプ リタに対する Wt+PHC+PSD インタプリタの速度向上は,位置別投機デコード の効 果を示す.多くのベンチマークで実行速度が向上し ,. よりバイトコード 実行パスがインラインされたデコー ドループより短くなっても実行速度は向上しない.図 5 に Java バイトコード iaload のハンドラを POWER3. 平均 4.6%,最大 14.1%の速度向上が得られた.. PowerPC プロセッサで最大の効果を得られるのは, デコードのための 1 サイクルがクリティカルパスから. プロセッサ上で実行した場合の例を示す.この例は,. なくなり,実行サイクル数が 5 サイクルから 4 サイク. 我々の JIT コンパイラ同様トラップ命令で Java 例外. ルになる場合である.JavaGrande の Euler のように,. を検出する最適化14)を適用している.Wt インタプリ. クリティカルパス長が 4 サイクル以下のハンド ラの実. タはスタックキャッシュにより実行サイクル数が 1 サ. 行頻度が高く,間接分岐のオーバヘッドがボトルネッ. イクル減っている.しかし,DSC インタプリタは,イ. クとなっていたプログラムで効果が高い.. ンラインされたデコードループ(灰色の背景)のため. 一方,本手法により SPECjvm98 の jack の実行速. に実行サイクル数が Wt インタプリタと変わらない.. 度が低下している.高頻度の Java 例外により,例外. 今 回 評 価し た 手 法で は 効 果の 差が 少な い ので ,. ハンド ラから実行を再開するために,頻繁に 3 個の候. PowerPC のようにロード のレ イテンシが短くアウト. 補すべてを投機デコード するオーバヘッドが原因と考.
(9) Vol. 43. No. SIG 8(PRO 15). 高速 Java バイトコード インタプ リタの構成法. えられる.. 9. さの予測から決定するので,デコード 結果の再利用に. 5. 関 連 研 究. レジスタ移動命令が必要となる.VLIW プロセッサで. スレッデッド コード 1),2)は,デコードループをイン. 処理できるので,実行時オーバヘッドがない.しかし,. は 2 個のレジスタ移動命令を未使用の実行ユニットで. ラインすることでディスパッチのためのサブルーチン. スーパスカラプロセッサでは,ハード ウェア資源の制. コールのオーバヘッドを減らす手法である.ハンド ラ. 約により実行速度が低下する可能性がある.. の終わりから,デコードループが次のハンド ラへジャ ンプするまでの短いパスで連続する間接分岐を避け,. 6. お わ り に. オーバヘッドを減らす.ILP を利用するプロセッサに. 本稿では,PowerPC プロセッサ用バイトコード イ. おける副次的効果は,デコードループの実行時オーバ. ンタプ リタを高速化する手法と,それらと従来手法. ヘッドを軽減することである.デコードループとバイ. との効果的な組合せを示した.また,これらの手法を. トコード 実行パスの間は依存がなく,バイトコード 実. 他のハード ウェアおよびソフトウェア環境に移植する. 行パスのほとんどは逐次実行される命令列なので,デ. 場合の問題点について議論した.そして,それぞれの. コードループを未使用の実行ユニットで実行でき,そ. 手法の実行速度向上への貢献を,主要な Java ベンチ. の実行サイクルを隠せる.. マークを用い IBM POWER3 プロセッサ上で評価し. スタックキャッシュは,スタックオペランド をプッ シュ・ポップするためのメモリ操作を減らす手法であ る.スタック型言語ではスタックトップ付近を操作す. た.本稿で述べたすべての手法を適用した場合,平均. 30.5%,最大 56%の速度向上が得られた. 謝辞 本稿をまとめる際に貴重な助言をいただいた,. る頻度が高いので,それらをレジスタにキャッシュし. 日本 IBM 東京基礎研究所ネットワークコンピューティ. て,データが使用可能になるまでのレイテンシを減ら. ングプラットフォームの河内谷清久仁研究員に深く感謝. す.ダ イナミック・キャッシング 3)は,キャッシュ状態. します.また,本稿に対して助言をいただいた,IBM. ごとにカスタマイズしたハンド ラでスタックへのメモ. T.J. Watson 研究所の David P. Grove 研究員およ. リ操作を最適化し,キャッシュ状態をハンド ラによる. び日本 IBM 東京基礎研究所ネットワークコンピュー. ステートマシンで効率良くトラックする手法である. しかし,アウトオブオーダ実行を行うプロセッサで はストールしたストア命令が後続命令の実行を妨げな いので,ストアの数を減らすことによる実行速度向上 の効果は少ない.ロード のレ イテンシが 1∼2 サイク ルの場合,ライトスルー方式でスタックトップデータ のみをキャッシュする簡単な実装でスタックキャッシュ の効果の大半を得ることができる.4 章で示した結果 でも,ほとんどのベンチマークにおいてダイナミック・ キャッシングを用いた場合との効果の差は非常に小さ い.バイトコード フェッチの冗長なメモリロードを減 らす方がより効果的であった. 投機デコードを行うパイプライン化インタプリタ6),7) は,バイトコード のフェッチ,デコード,デ ィスパッ チ,実行の各フェーズ間の依存をソフトウェアパイプ ライン手法により解消し,並行して実行する手法であ る.Hoogerbrugge らは VLIW プロセッサ用のインタ プリタで実装した.ハンド ラは,次の次のバイトコー ドのオペコード の候補数個を投機的にデコードし,正 しい候補が確定した時点でそのデコード 結果を選択す る.複数候補のデコード のオーバヘッドを減らすため に,可能ならばデコード 結果を再利用する. 彼らの実装は候補とレジスタの対応を次の命令の長. ティングプラットフォームの小野寺民也研究員に感謝 します.. 参 考 文 献 1) Bell, J.R.: Threaded Code, Comm. ACM, Vol.16, No.6, pp.370–372 (1973). 2) Dewar, R.B.: Indirect Threaded Code, Comm. ACM, Vol.18, No.6, pp.330–331 (1975). 3) Ertl, M.A.: Stack Caching for Interpreters, SIGPLAN ’95 Conference on Programming Language Design and Implementation (PLDI ), pp.315–327 (1995). 4) GNU Project: GCC Home Page. http://www.gnu.org/software/gcc/gcc.html 5) Gosling, J., Joy, B. and Steele, G.: The Java Language Specification, Addison-Wesley (1996). ISBN 0-201-63451-1. 6) Hoogerbrugge, J. and Augusteijn, L.: Pipelined Java Virtual Machine Interpreters, Lecture notes in computer science 1781 CC/ETAPS 2000, pp.35–49 (2000). 7) Hoogerbrugge, J., Augusteijn, L., Trum, J. and de Wiel, R.V.: A Code Compression System Based on Pipelined Interpreters, SOFTWARE — Practice and Experience, Vol.29, No.11, pp.1005–1023 (1999)..
(10) 10. Sep. 2002. 情報処理学会論文誌:プログラミング. 8) Intel Corp.: Intel IA-64 Architecture Software Developer’s Manual, Volume 3: Instruction Set Reference, Revision 1.1 (2000). Document Number: 246319-002. 9) Intel Corp.: Itanium Processor Microarchitecture Reference for Software Optimization (2000). Document Number: 245473-001. 10) International Business Machines, Inc.: IBM SDK, Java edition. http://www.ibm.com/java/ 11) International Business Machines, Inc.: XML Parser for Java. http://www.alphaworks.ibm.com/tech/xml4j 12) International Business Machines, Inc.: The PowerPC Architecture: A specification for a new family of RISC processors (1994). ISBN 1-55860-316-6. 13) International Business Machines, Inc.: The PowerPC Compiler Writer’s Guide (1996). Publication Number: SA14-2094-00. 14) Ishizaki, K., Kawahito, M., Yasue, T., Takeuchi, M., Ogasawara, T., Suganuma, T., Onodera, T., Komatsu, H. and Nakatani, T.: Design, Implementation, and Evaluation of Optimizations in a Just-In-Time Compiler, ACM 1999 Java Grande Conference, pp.119– 128 (1999). 15) Java Grande Forum: Java Grande Forum Benchmark Suite. http://www.epcc.ed.ac.uk/javagrande/ 16) Lindholm, T. and Yellin, F.: The Java Virtual Machine Specification, Addison-Wesley (1996). ISBN 0-201-63452-X. 17) O’Connel, F.P. and White, S.W.: POWER3: The next generation of PowerPC processors, IBM Journal of Research and Development, Vol.44, No.6, pp.873–884 (2000). 18) Paleczny, M., Vick, C. and Click, C.: The Java HotSpot Server Compiler, Java Virtual Machine Research and Technology Symposium (JVM ’01 ), pp.1–12 (2001). 19) Papermaster, M., Dinkjian, R., Mayfield, M., Lenk, P., Ciarfella, B., O’Cornnel, F.P. and DuPont, R.: POWER3: Next Generation 64bit PowerPC Processor Design (1998). http://www.ibm.com/servers/eserver/pseries/ hardware/whitepapers/power3wp.html 20) Radhakrishnan, R., Vijaykrishnan, N., John, L.K., Sivasubramaniam, A., Rubio, J. and Sabarinathan, J.: Java Runtime Systems: Characterization and Architectural Implications, IEEE Trans. Comput., Vol.50, No.2, pp.131–146 (2001). 21) Standard Performance Evaluation Corporation: SPEC JVM98 Benchmarks and SPECjbb-. 2000. http://www.spec.org/osg/jvm98/および http://www.spec.org/osg/jbb2000/ 22) Suganuma, T., Ogasawara, T., Takeuchi, M., Yasue, T., Kawahito, M., Ishizaki, K., Komatsu, H. and Nakatani, T.: Overview of the IBM Java Just-in-Time compiler, IBM System Journal, Vol.39, No.1, pp.175–193 (2000). 23) Suganuma, T., Yasue, T., Kawahito, M., Komatsu, H. and Nakatani, T.: A Dynamic Optimization Framework for a Java JustIn-Time Compiler, Object-Oriented Programming, System Languages, and Application (OOPSLA ’01 ), pp.180–194 (2001). 24) Sun Microsystems: The Java HotSpot Virtual Machine Technical White Paper (2001). http://java.sun.com/products/hotspot/ (平成 14 年 1 月 7 日受付) (平成 14 年 3 月 16 日採録) 緒方 一則( 正会員). 1967 年生.1990 年東京工業大学 工学部電気電子工学科卒業.同年, 日本 IBM(株)入社.現在,東京基 礎研究所において,Java 仮想マシン のインタプ リタの研究に従事. 小松 秀昭( 正会員). 1960 年生.1985 年早稲田大学大 学院理工学研究科電気工学専攻修了. 同年日本 IBM(株)東京基礎研究所 入社.コンパイラ,アーキテクチャ, 並列処理の研究に従事.博士(情報 科学) . 中谷登志男( 正会員). 1975 年早稲田大学理工学部数学 科卒業.同年日本 IBM(株)野洲工 場入社.1983 年から米国プ リンス トン大学大学院(コンピュータ・サ イエンス学科) .1985 年同大学から M.S.E. および M.A.,1987 年同大学から Ph.D. 同年 より,日本アイ・ビー・エム(株)東京基礎研究所に 移り,VLIW コンパイラ,HPF コンパイラ,JIT コ ンパイラ等のプロジェクトを担当.一貫して,プログ ラムを最適化して高速に実行させるための新しいソフ トウェア技術について研究開発している.現在,IBM. Distinguished Engineer,ネットワーク・コンピュ― ティング・プラットフォーム担当..
(11)
図



+2

関連したドキュメント
ü modeling strategies and solution methods for optimization problems that are defined by uncertain inputs.. ü proposed by Ben-Tal & Nemirovski
q-series, which are also called basic hypergeometric series, plays a very important role in many fields, such as affine root systems, Lie algebras and groups, number theory,
In the first part we prove a general theorem on the image of a language K under a substitution, in the second we apply this to the special case when K is the language of balanced
We recall here the de®nition of some basic elements of the (punctured) mapping class group, the Dehn twists, the semitwists and the braid twists, which play an important.. role in
Functional and neutral differential equations play an important role in many applications and have a long and rich history with a substantial contribution of Hungarian
The final-value problem for systems of partial differential equations play an important role in engineering areas, which aims to obtain the previous data of a physical field from
[Mag3] , Painlev´ e-type differential equations for the recurrence coefficients of semi- classical orthogonal polynomials, J. Zaslavsky , Asymptotic expansions of ratios of
In this diagram, there are the following objects: myFrame of the Frame class, myVal of the Validator class, factory of the VerifierFactory class, out of the PrintStream class,
