DOI: http://doi.org/10.14947/psychono.36.40
刺激の効果を侮るなかれ
―ランダム刺激効果を含んだ線形混合モデルの重要性と落とし穴―
村 山 航
a,baレディング大学,b高知工科大学
Stimulus effect matters:
The importance and cautionary notes of linear mixed-effects model
with random stimulus effects
Kou Murayama
aUniversity of Reading, UK, bKochi University of Technology, Japan
When researchers analyze data from an experiment with multiple experimental stimuli, they tend to aggregate responses to the experimental stimuli before performing a statistical test (e.g., t-test, analysis of variance). This com-mon practice, however, ignores sampling errors of experimental stimuli, resulting in a substantial increase in Type-1 error rate. This article reviews the relevant literature and provides conceptual explanations about the mechanisms underlying the inflation of Type-1 error rate. The article also illustrates how linear mixed-effects model with ran-dom-stimulus effects can address the issue, with the emphasis on the correct model specification when using linear mixed-effects model.
Keywords: random stimulus effects, mixed-effects model, multilevel model, hierarchical linear model
次のような単純な実験を考えてみよう。あなたは何ら かの理由で,ネガティブな写真とニュートラルな写真と で,人の評定スピードに差があるのではないかと考え た。そこで,代表的な写真刺激である International Af-fective Picture System (IAPS; Lang, Bradley, & Cuthbert, 1997) からネガティブな写真とニュートラルな写真を6 枚ずつランダムに選び,その合計12枚に関して,写真 がどれくらい自然にみえるかを被験者に評定してもらっ た。被験者は20人であり,それぞれが12枚すべての写 真を評定した。写真の平均評定時間に,ネガティブ写真 とニュートラル写真の間で差があるかを調べるのがメイ ンの目的である。さて,仮説を検証するためにどのよう な分析をするだろうか。多くの人は次のように答えるの ではないだろうか。まず,被験者ごとにネガティブ写真 とニュートラル写真の評定時間の平均を出す。そして, 20人から得られた20組(ニュートラルvs. ネガティブ) の平均値を対応のあるt検定にかけて,有意かどうかを 調べる,と。 まっとうな,問題のない分析手続きに感じられる。し かし実はこの方法,タイプ1エラーを増大させてしまう のである。しかもおそらく皆さんが想像するよりもはる かに大きく。つまり,ネガティブ写真とニュートラル写 真の間に評定時間の差が本当はなかったとしても,有意 な結果が出る可能性が 5%よりもずっと高いのである。 なぜなのか不思議に思った方は,ぜひ読み進めていただ きたい。本稿の目的は,この理由をランダム刺激効果 (random stimulus effect/random item effect) という観点か
ら説明し,この問題を解消するための方法として,ラン ダム刺激効果を含んだ線形混合モデルの有用性と注意点 を論じることである。なお,本稿では限られたスペース で概念的な理解を優先させるため,数学的には厳密でな い説明も含まれている点,あらかじめ了承してもらいた い(より厳密な議論を知りたい方は,参考文献をあたっ て欲しい)。
Copyright 2018. The Japanese Psychonomic Society. All rights reserved. Corresponding address: Department of Psychology,
Univer-sity of Reading, Earley Gate, Whiteknights, Reading RG6 6AL, UK.
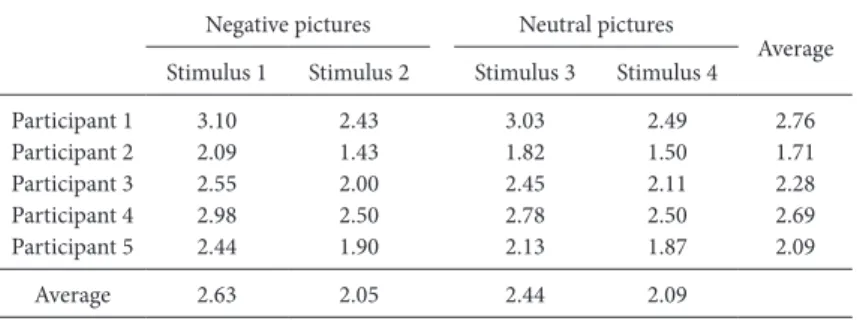
ランダム刺激効果 Table 1は,上記のデザインの実験データを示したもの である。スペースの都合上,刺激の数と被験者の数は減 らしてある。通常の手続きにしたがって,被験者ごとに 評定時間の平均値を出すと,当然ながら評定時間には個 人差があることがわかる。全体として評定が早い被験 者,遅い被験者,といった具合である。この評定時間の (厳密には真値の)個人差をランダム被験者効果 (ran-dom participant effects) と呼ぶ。冒頭で論じた,平均値の t検定は,この被験者の個人差をもとに検定しており, ランダム被験者効果を考慮した検定だということができ る。つまり,得られた平均値差が,被験者をランダムに 抽出したことによる標本誤差によって説明できてしまう かどうかを調べるのが,このt検定の目的である。言い 換えれば,このt検定の結果は被験者母集団に一般化す ることが可能になる。これは通常の統計の授業で習うこ とである. この実験データを別の角度から眺めてみよう。被験者 ごとの平均値を出せたように,刺激ごとの平均値を出せ ることに気づく。そして,当然ではあるが,評定時間に は刺激間差があることがわかる。写真が自然に見えるか どうかの評定は,写真の内容によって難しさが違うだろ うから,評定時間の刺激間差があるのは,当然である。 と同時に,先ほどの分析では,この刺激間差を考慮して いなかったことに気づく。この評定時間の(真値の)刺 激間差をランダム刺激効果と呼ぶ。実はこのランダム刺 激効果を考慮した t検定も実施可能である。具体的に は,刺激ごとの平均値を使って,刺激を単位とした(つ まり12組の刺激があれば,N=12の)対応のないt検定 を行えばよい。この分析は,得られたネガティブ写真と ニュートラル写真の違いが,写真をランダムに抽出した ことによる標本誤差によって説明できるかを調べるもの である。したがって,この結果は,刺激母集団に一般化 することが可能になる。得られた評定スピードの違い が,今回の刺激特有のものではなく,ニュートラル写 真・ネガティブ写真全般に当てはまるかを検討できるの である。心理学の研究のほとんどは,刺激特有の効果で はなく,それを超えた,刺激母集団やその刺激母集団を 代表する構成概念(この場合だと感情価)の効果を調べ ることが目的であるので,この一般化は多くの場合,非 常に重要である。しかし,通常の分析方法(被験者を単 位としたt検定)は,刺激間の違いを一切考慮に入れて いないので,この刺激母集団への一般化ができない。 ランダム刺激効果を考慮しないことによる タイプ1エラーの増大 通常の分析方法が,ランダム刺激効果を考慮に入れて いないことはわかってもらえただろう。では,それの何 が問題なのか。これまでの議論で明らかなのは,結果を 刺激母集団に一般化できないことである。しかし,これ と関連した大きな統計的な帰結がある。それがタイプ1 エラーの増大である。Table 2は著者が被験者数と刺激数 を系統的に変えたうえで,シミュレーションを行い,通 常のランダム刺激効果を考慮しないt検定(α=5%)に よって生じるタイプ1エラーを計算したものである。つ まり,実際は条件間差がないにもかかわらず,通常のt 検定が(誤って)有意であると判断する割合をシミュ レーションで求めた。シミュレーションのためには,当 然こうしたランダム効果の大きさをあらかじめ決める必 要があるが,これは例示のため便宜的に決めた(Table 1 の注を参照のこと)。ただし,経験上決して非現実的で はない(むしろ控えめな)設定にしておいたことは付記 しておく。 結果をみて驚くのが,そのタイプ1エラーの率が全体 的に非常に大きいことである。タイプ 1エラーは通常 Table 1.
Illustration of how the data described in the text can be structured. Values represent reaction time (s) to rate pictures. The average values are rounded.
Negative pictures Neutral pictures
Average Stimulus 1 Stimulus 2 Stimulus 3 Stimulus 4
Participant 1 3.10 2.43 3.03 2.49 2.76 Participant 2 2.09 1.43 1.82 1.50 1.71 Participant 3 2.55 2.00 2.45 2.11 2.28 Participant 4 2.98 2.50 2.78 2.50 2.69 Participant 5 2.44 1.90 2.13 1.87 2.09 Average 2.63 2.05 2.44 2.09
5%であるべきであり,たとえば10%を超えればかなり 大きいという印象を持つが,シミュレーションの結果 は,それをはるかに超えたものである。また,項目数が 少ないほど,そして被験者数が多いほどタイプ1エラー が高いこともわかる。被験者数が多いほど,タイプ1エ ラーが高くなるというのは面白い。近年では,心理学の 知見の再現性の問題(友永・三浦・針生,2016)で, False-positiveな知見を減らすためにサンプルサイズを増 やすことが強く奨励されているが,被験者数を増やすと 皮肉にもFalse-positiveな結果が得られる可能性が増えて しまうのである。近年では,再現性の問題で80人程度 のサンプルサイズを求められることも少なくないが,そ の場合のタイプ1エラー率はこのシミュレーションの場 合,最大で何と53%である。被験者をもっと集めると, さらにこの値は高くなる。おそらく幾多の論文で多くの 研究者が実施していると思われる,通常のt検定による 分析には,実は想像もつかないほど高いタイプ1エラー の危険性があるのである。 なぜこのようなことが起きるのだろうか。刺激の母集 団を想定し(ネガティブ写真母集団・ニュートラル写真 母集団), そこでは評定スピードの平均値にまったく条件 間差がないと仮定しよう(帰無仮説)。各々の刺激(写 真)が評定スピードに関して固有の(真の)値を持つと 考えたとき,母集団でその平均値を算出した場合,ネガ ティブ写真母集団における評定スピードの平均値と, ニュートラル写真母集団における評定スピードの平均値 がまったく同じだという意味である。さて,理想的には この母集団にあるすべての刺激を実験で使えればいい が,実際の実験では不可能である。そこで,私たちが通 常行っているのは,そこから刺激を選択し(たとえば今 回の例では 6枚ずつ), それを実験に使用することであ る。この刺激の選択過程はランダムでないことも多い が,ここではランダムに選択するとみなす(強引に見え るが,被験者が母集団からランダムサンプリングされて いないのに,検定ではランダムサンプリングと見なすこ とを,心理学者はいつも行っている)。ここで,このサ ンプルされた6枚ずつの写真の刺激固有の評定スピード の平均値を条件ごとに算出したとき,条件間で平均値に 差があるだろうか。刺激母集団においては平均値の条件 間差がないのだから,サンプルされた刺激においても, 平均値の条件間差は小さいと考えられる。しかし,平均 値の条件間差がぴったり0であるかと問われると,そう でないと考えるのが自然だろう。刺激のサンプリングに ともなう標本誤差があるからである。この「0に近いか もしれないけれど,ぴったり0ではない」というのがポ イントである。この刺激固有の評定スピードの違いに よって生じる小さな条件間差は,同じ刺激セットを使っ ている限り,被験者間で同一の値である。ここで,たと えば20人に対してこの刺激を使った実験を行い,通常 のt検定による分析を行うと,この「0に近いかもしれ ないけれど,ぴったり0ではない」(そして被験者間で 同一の)小さな効果を検出してしまう可能性がある。し かし,実際は帰無仮説が正しいのだから,ここで有意な 効果が得られたとしてもそれはタイプ1エラーである。 ここまでくると,なぜ被験者数が多いほど,タイプ1 エラーが増大するかもわかるだろう。被験者が多ければ 多いほど,この刺激のサンプリング誤差によって生じた 小さな効果を皮肉にもより検出しやすくなってしまうか らである。また,なぜ項目数が少ないほど,タイプ1エ ラーが増大するかもわかる。項目数が少ないと,刺激の サンプリングに伴う標本誤差が大きいため,刺激固有の 効果による条件間差が0よりも大きく離れてしまう可能 性が高くなるためである。 2点,付記しておきたい。まず,確認のために注意し ておきたいのは,このタイプ1エラーは,あくまで効果 を刺激母集団に一般化する目的のもとで生じるというこ とである。もし,今回の実験の目的が「ネガティブ写真 とニュートラル写真全般の間で評定スピードに差があ る」ことを調べるのではなく,「今回選んだ0 0 0 0 0 6枚のネガ ティブ写真と6枚のニュートラル写真の間で評定スピー ドに差がある」ことを調べるのであるならば,通常のt 検定でも問題はない。2条件の間に小さな効果があると いうのは,たとえそれが刺激の標本誤差で偶然生じたも のだとしても,この12枚の写真に限って言えば,正し いことだからである(つまり,もし結果が有意になった Table 2.
Empirical type 1 error rates when by-participant paired-sample t test is applied to participants x stimulus data.
k=5 k=10 k=20 k=40 N=10 0.15 0.12 0.09 0.07 N=20 0.26 0.19 0.14 0.10 N=40 0.40 0.30 0.22 0.15 N=80 0.53 0.45 0.35 0.23 Note. N=Total number of participants. k=Total number of stimuli per condition. The number of replication=10,000 per cell. In this simulation, the variance ratio of random partici-pant intercept, random participartici-pant slope, random item inter-cept, and residuals is set to 1 : 1 : 1 : 4 according to Judd et al. (2012). Random participant intercept and random participant
として,この同じ刺激を使っている限り,知見は再現さ れる)。しかし,繰り返しになるが,通常の心理学の実 験で,実験で選んだ刺激特有の効果を調べたいようなこ とは,ほぼないといってよいだろう。 2点目として,この問題は今回扱ったデザインに特有 のものではないという点である。たとえば,今回の実験 が被験者間デザインであっても同じ問題が生じる。理解 のよい読者なら,この問題は条件間で同じ刺激を使って いれば問題ないと考えるかもしれない。たとえば,若者 群と老人群で,同じセットの語彙決定課題の反応潜時を 比較するような場合である。また,刺激を条件間でカウ ンターバランスするような状況も考えられる。こうした 場合,条件間で刺激が同じであるので,刺激数が有限で あっても,刺激固有の効果の平均値差は完全に0になる かもしれない。しかし,そのような場合であっても,ラ ンダム刺激効果が条件ごとに違う可能性がありうる(全 体としてどのような単語で反応が早いかは,若者と老人 で違うと考えられるだろう)。この条件とランダム刺激 効果の交互作用が存在するならば,やはり同じようにタ イプ1エラーの増加は起きる。さらに,この問題は2条 件間の比較に限らない。t検定は分散分析や回帰分析の 特殊例だと考えられる。そう考えると,条件が3つ以上 あるとき,もしくは被験者内の回帰分析を行うとき(た とえば語彙の出現頻度と,被験者の語彙決定課題の反応 時間に関係があるかを調べるような場合など)も,同じ 問題が当てはまることは容易に想像つくだろう。 ランダム刺激効果を含んだ 線形混合モデルによる解決 ランダム刺激効果を無視した分析によるタイプ 1エ ラーの増加は実は決して新しい発見でも何でもない。心 理言語学 (psycholinguistics) の分野で,Clark (1973) がす でに指摘していたことである。実際,長年に渡って,心 理言語学の分野ではランダム刺激効果の問題は広く認識 されている。しかし,実験心理学や他の社会科学の分野 では,この点が認知されていたとは言いがたい。冒頭の ような例で,多くの心理学者は,通常のt検定をするこ とに違和感を覚えないのではないだろうか。心理学にお いて,この問題が脚光を浴びたのは,Baayen, Davidson, & Bates (2008) が,この問題を改めて取り上げ,ランダ ム刺激効果を含んだ線形混合モデルが解決策になること を(そのこと自体は以前よりわかっていた),心理学の 読者にわかりやすい形で論じたことが大きいと思われ る。BatesはRで線形混合モデルを実施するlme4ライブ ラリの開発者であり,この論文と lme4ライブラリの開 発によって,線形混合モデル普及の大きなきっかけを 作った。その後,Judd, Westfall, & Kenny (2012) が社会心 理学研究の文脈で,また著者もメタ認知研究の文脈で, 同じトピックを論じている (Murayama, Sakaki, Yan, & Smith, 2014)。日本では,下木戸 (2007) が Baayen et al. (2008) の論文を先取りする形でこのトピックを議論し
ており,その先見の明は注目に値する。
では,ランダム刺激効果を含んだ線形混合モデル
(linear mixed effects model) とはどのようなものか。近年 では線形混合モデルも普及してきたため,その名前を 知っている人は多いだろう。ただしポイントは「ランダ ム刺激効果を含んだ」線形混合モデルだという点であ る。線形混合モデル自体は一般的な統計モデルであり, 線形混合モデルを使うこと=タイプ 1エラー増加を防 ぐ,というわけではない。線形混合モデルというと,そ れだけで分散分析よりも進んでいてすごいという印象を 受けるかもしれないが,重要なのは線形混合モデルの枠 組みでどのようにモデルを定める(specify)かという点 である (Barr, Levy, Scheepers, & Tily, 2013)。線形混合モデ ルを使っている論文が必ずしも進んでいる分析をしてい るわけではない。モデルの定め方によっては,通常の分 散分析と機能的に等しいことをやっているのにすぎない ことも多い(このポイントは近年やはり同じように流 行っているベイジアンモデリングにも当てはまる)。 上記の点を意識しつつ,限られた紙幅で,著者流に説 明を試みてみたい(なおBaayen et al., 2008は線形混合モ デルのイントロダクションとしても非常によく書けてい る。Barr et al., 2013も深い理解には必読である)。Table 1 のデータをTable 3のように並べ替える。これをロング フォーマットと呼ぶこともある。Table 3はデータ数を減 らしてあるが,冒頭の実験例を用いるなら,実際は 12 ×20=240行のデータとなる。ここで条件間差を調べる ために条件を独立変数とした回帰分析をこのデータに対 して行ったと考えよう。これはこのロングフォーマット のデータに対応のないt検定を実施することと数学的に 等価である。ほとんどの読者はこの分析がおかしいと思 うだろう。20人のデータにもかかわらず,データを240 個に「水増し」して分析を行っているからである。なぜ この分析が駄目なのかというと,240個のデータは独立 ではなく,各被験者の中の12個のデータが似ているか らである。図をみても,1人目の被験者の評定時間は比 較的長く,2人目は全体的に低いことがわかるだろう。 つまり,各被験者に12個のデータがネストされている クラスタ構造(階層構造)のデータであるにかかわらず, それを無視した分析を行っているのが問題である。この
「水増し」の分析ではサンプル数がみため増えるため, タイプ1 エラーが増大するのは簡単に想像がつくだろ う。この水増しの問題を解決する方法は,被験者の効果 というものをランダム効果として回帰モデルに組み込む ことである。このように通常の回帰モデルに,クラスタ 化の効果をランダム効果として組み込んだものが線形混 合モデルである。なお,従属変数として記憶成績のよう にカテゴリ変数を扱うときには,一般化(generalized) 線形混合モデルと呼ばれる。ランダム効果の詳細な説明 は省略するが(日本語だと豊田,1994の解説がわかりや すい), たとえばランダム被験者効果であるならば,その 効果は被験者間のばらつき(分散)で表現され,それが 大きいほど個人差が大きいことを意味する。 ここで被験者の効果といったとき,2種類が考えられ る。評定スピードの平均値の個人差,そして,平均値の 条件間差の個人差(条件の効果の個人差)である。実際, データをみると,最初の人は次の人よりも条件のわずか ながら効果が小さいようにみえる。前者は被験者のラン ダム切片 (random intercept), 後者は被験者のランダム傾 き (random slope; 傾きとはこの場合条件間差だと思って もらうとよい) と呼ばれることもある。ランダム傾き は,条件の効果にどれくらい個人差があるか,逆にいう と効果がどれくらい一般的なのか(個人差が小さいと効 果が一般的だと考えられる)を示しているものだとも考 えられる(南風原,2002)。線形混合モデルでは,この2 つのランダム効果(さらに正確にはこの2つのランダム 効果の共分散)を組み込んだ分析を行うことができる。 実は,このように被験者のランダム効果を考慮するこ とは,伝統的な手法でも暗黙に行っていることである。 このデータを,被験者ごとに平均値を出して,対応のあ るt検定(もしくは分散分析)をするという,分析方法 を思い出してみよう。実は,上で述べた線形混合モデル と,この対応のあるt検定は機能的に同一である。実際 のt値やp値もほとんど変わらない。したがって,タイ プ1エラーの上昇も生じてしまう。唯一違うのは,線形 混合モデルでは,条件の個人差(効果の一般性)が明示 的に推定されるのに対して,通常の方法ではそれが推定 されず,それによって検定の自由度が少し異なってくる ことくらいである。上で書いたように,線形混合モデル はフルデータ(試行・刺激レベルのデータ)を使ってい て,ランダム効果を明示的に推定していて,通常の分析 よりもだいぶ進んでいるように思えるが,モデルによっ ては伝統的な方法の衣装を変えて行っているのに過ぎな いのである(Barr et al., 2013)。また,線形混合モデルを 使っていると,被験者のランダム切片だけを満足してし まい,ランダム傾きを含めずに分析する例も多く見受け られる。これは多くの場合誤った分析であり,普通のt 検定(上で述べたように,この分析はランダム切片とラ ンダム傾きの両方を暗黙に想定している)よりも劣るの である。線形混合モデルがt検定よりも劣ると聞くと驚 くだろうが,モデルの定め方によってはそうなってしま う。意外な落とし穴である。実際,近年ではこの被験者 のランダム傾きを入れずに分析をしPsychological Science 誌に載った論文が,誤った分析だと指摘を受けて,撤回 されている (Fischer, Hahn, DeBruine, & Jones, 2015)。
さて,今回の実験例で,線形混合モデルが真価を発揮 するのは,ランダム刺激効果をさらに組み込んだ場合で ある。Table 3をみると,データは被験者ごとにクラスタ 化されているだけでなく,刺激(写真)ごとにもクラス タ化されていることが分かる。つまり,240個のデータ は独立ではなく,同じ刺激であった場合の評定スピード が似ている。実際,1つ目の刺激の評定時間は他の刺激 に比べて比較的長い。先ほど,今回のデータは被験者に ネストされていると書いたが,実際は,被験者と刺激の 両方がクロスしているのである。データがクロスしてい ることは,データが Table 1のように記述できることか らも明らかであろう。ということは,被験者のランダム 効果だけでなく,前述の線形混合モデルに,刺激のラン Table 3.
A long format of the data presented in Figure 1. Negative picture condition and neutral picture condition are coded as −1 and 1, respectively. RT=Reaction time (s).
ID Stimulus Condi tion RT
1 1 −1 3.10 1 2 −1 2.43 1 3 1 3.03 1 4 1 2.49 2 1 −1 2.09 2 2 −1 1.43 2 3 1 1.82 2 4 1 1.50 3 1 −1 2.55 3 2 −1 2.00 3 3 1 2.45 3 4 1 2.11 4 1 −1 2.98 4 2 −1 2.50 4 3 1 2.78 4 4 1 2.50 5 1 −1 2.44 5 2 −1 1.90 5 3 1 2.13 5 4 1 1.87
ダム効果をさらに組み込むのはどうだろうか。線形混合 モデルを用いると,このようにいくつものランダム効果 を柔軟にモデル化することができる。基本はあくまでフ ルデータを用いた回帰分析だが,そこにデータ間の依存 性を説明するランダム効果を柔軟に取り入れられるのが 線形混合モデルの本質である。このモデルによって,被 験者と刺激のランダム効果を同時に推定することが可能 になり,結果の刺激への一般化が可能になる。そして重 要なことに,あれだけ大きかったタイプ1エラーの増大 も,ほぼ完全に消失する(サンプルサイズが小さいとき には,自由度に関する少し複雑な問題があるのだが,興 味ある人は参考文献を読んで欲しい)。先ほど,今回の データでは被験者を単位としたt検定と,刺激を単位と したt検定の両方が実施できることを指摘したが,どち らのアプローチにしろ,最初に評定値の平均を算出して 片方の要因をつぶしているので,被験者と刺激のランダ ム効果の両方を同時に考慮することが不可能だったこと を思い出して欲しい。 まとめと補足 本稿の内容をまとめると以下の通りである。(1)刺激 の効果を無視して,通常の t検定や分散分析を行うと, タイプ1エラーが上昇する,(2)その上昇は被験者が多 く,もしくは項目が少ないほど高くなり,その値は50% を優に超えることも珍しくない,(3)ランダム刺激効果 を含んだ線形混合モデルを用いるとこの問題を解決する ことができる,(4)ただし,ランダム刺激効果を明示的 に含まなければ,線形混合モデルを使っても問題は解決 しない。 繰り返しになるが,特に文脈によっては意外に忘れら れやすいのが(4)の点である。この原因の一つが,心 理学における線形混合モデルの発展の歴史のように思わ れる。心理学において,線形混合モデルは階層線形モデ ル(hierarchical linear model) や マ ル チ レ ベ ル モ デ ル (multilevel model)の文脈で使われることが多かった (Goldstein, 2003; Raudenbush & Bryk, 2002)。これらのモ
デルは数学的に等価であるが,階層線形モデルやマルチ レベルモデルの文脈では,その名の通り階層構造のデー タを扱うことが多い。また,社会調査で発展したモデル ということもあり,独立変数がカテゴリ変数でなく,連 続量であることも多い。この階層線形モデルに慣れてし まうと,実際のデータが階層構造ではなくクロス構造で あっても,ついそれを無視してしまい,階層構造を仮定 した分析を行いがちである (Murayama et al., 2014)。た とえば,30人の被験者に20個の商品について好みと刺 激の複雑さを評定してもらったとしよう。好みと(主観 的な)刺激の複雑さに関係があるだろうか。階層線形モ デルに慣れた人ならば,商品(レベル1)が被験者(レ ベル2)にネストされていると考えて,好みを複雑さか ら予測する分析することも多いのではないだろうか。し かし,これまで述べてきたように,このような分析は, たとえ階層線形モデル・マルチレベルモデルという先進 的な感じのするラベルがついていても,クロスの構造を 無視しているのだから,タイプ1エラーの増大を免れ得 ない(加えると,この分析は,欠損値がなければ,被験 者ごとに個人内の回帰分析を行い,30個の回帰係数をt 検定にかけるという素朴な手法とほぼ機能的に等価であ る)。意外に知られていないことだが,階層線形モデル やマルチレベルモデルでも,クロスしたデータを扱い, 2種類以上のランダム効果をモデルに取り入れることが 可能であり,それはクロス分類モデル(cross-classified model) と呼ばれる。したがって,ここの例においては, クロス分類モデルを使う必要がある。 なお,本稿ではランダム刺激効果に関して,統計的な 解決方法を示したが,実際は実験のデザインによっても ランダム刺激効果の影響を最小限にする方法も可能であ る。もっとも単純でかつ効果的な方法は,実際に実験で 使う刺激よりもずっと多くの刺激を集め,被験者ごとに 刺激をランダムにサンプリングして,異なる刺激を呈示 することである(もちろん刺激が多少オーバーラップし ても構わない)。被験者ごとに刺激が違うので,ランダ ム刺激効果の影響を最小化することができる。もしくは 刺激のセットをいくつも作り,被験者ごとにどれかの セットに割り当てるのも1つの手であろう。 最後に,今回指摘した問題は,実験心理学だけに限っ たものではないことを指摘しておきたい。たとえば脳イ メージングの研究では,被験者ごとの脳データに一般線 形モデル(回帰モデル)を当てはめ,その回帰係数を被 験者間で(t検定などを用いて)検定することが一般的 である。先に述べた,被験者ごとに回帰分析を適用する アプローチとほぼ同じである。刺激の効果は一切に考慮 しない。ここで,被験者ごとに同じ刺激セットを用いて いるのなら,本稿で述べた問題点がそのまま当てはま る。したがって,現在出版されている脳イメージング研 究には,刺激のランダム効果によって生じたFalse-posi-tiveの結果が私たちが考えているよりもずっと多く含ま れているかもしれない(もちろんこの推論は,帰無仮説 がどれだけ正しいかという私たちが知りようのないベー スレートに依存するので,確定的なことは言えない)。 筆者はこの点を学会などで指摘していたが (Murayama,
2015), ちょうど昨年この問題を指摘し,それを解決する 手法を提案した論文が出版された(Westfall, Nichols, & Yarkoni, 2017)。また,筆者は近年,縦断調査研究などで 幅広く用いられる潜在曲線モデル (latent growth-curve model; McArdle & Anderson, 1990) にも,ランダム時点効 果(random time effect)というものが存在し,それが同 じようなタイプ1エラー増大の問題を引き起こしている こ と を示 している (Usami & Murayama, under review)。 読者の皆さんも,自分がよく扱うデータやデータ分析の 方法を,今回の論文をもとに考え直してみると,意外に 似たようなことがあったりするかもしれない。
引用文献
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random Mixed-effects for subjects and items. Journal of Memory and Language, 59, 390–412. doi: 10.1016/j.jml.2007.12.005
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Ran-dom effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68, 255– 278.
Clark, H. H. (1973). The language-as-fixed-effect fallacy: A critique of language statistics in psychological research. Journal of Verbal Learning & Verbal Behavior, 12, 335–359. doi: http://dx.doi.org/10.1016/S0022-5371(73)80014-3 Fisher, C. I., Hahn, A. C., DeBruine, L. M., & Jones, B. C.
(2015). Women’s preference for attractive makeup tracks changes in their salivary testosterone. Psychological Science, 26, 1958–1964.
Goldstein, H. I. (2003). Multilevel statistical model (3rd ed.). London: Edward Arnold.
南風原朝和(2002).心理統計学の基礎――統合的理解 のために―― 有斐閣
Judd, C. M., Westfall, J., & Kenny, D. A. (2012). Treating stim-uli as a random factor in social psychology: A new and comprehensive solution to a pervasive but largely ignored problem. Journal of Personality and Social Psychology, 103,
54–69.
Lang, P. J., Bradley, M. M., & Cuthbert, B. N. (1997). Interna-tional Affective Picture System (IAPS): Technical manual and affective ratings. Gainesville: NIMH Center for the Study of Emotion and Attention.
McArdle, J. J., & Anderson, E. (1990). Latent variable growth models for research on aging. In J. E. Birren & K. W. Schaie (Eds.), Handbook of the psychology of aging (3rd ed.). (pp. 21–44). San Diego: Academic Press.
Murayama, K. (2015). Time-specific random effect and Type-1 error inflation in longitudinal intra-individual data analy-sis: A mixed-effects model perspective. Presented at Net-work on Intrapersonal Research in Education (NIRE), Seminar 3: Intensive longitudinal data and statistical meth-ods. Helsinki.
Murayama, K., Sakaki, M., Yan, V. X., & Smith, G. M. (2014). Type I error inflation in the traditional by-participant anal-ysis to metamemory accuracy: A generalized mixed-effects model perspective. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40, 1287–1306. http:// dx.doi.org/10.1037/a0036914
Raudenbush, S. W., & Bryk, A. (2002). Hierarchical linear models: Applications and data analysis methods (2nd ed.). Newbury Park, CA: Sage.
下木戸隆司 (2007).言語刺激を固定要因と見なす誤り をめぐって 心理学評論,50, 135–150. 友永雅己・三浦麻子・針生悦子(2016)心理学の再現可 能性: 我々はどこから来たのか 我々は何者か 我々 はどこへ行くのか――特集号の刊行に寄せて―― 心 理学評論,59, 1–2. 豊田秀樹(1994).違いを見抜く統計学――実験計画と 分散分析入門―― 講談社
Usami, S., & Murayama, K. (under review). Random time ef-fects in growth curve modeling: Type-1 error inflation and a possible solution with mixed-effects models.
Westfall, J., Nichols, T. E., & Yarkoni, T. (2017). Fixing the stimulus-as-fixed-effect fallacy in task fMRI [version 2; ref-erees: 1 approved, 2 approved with reservations]. Wellcome Open Research, 1: 23 doi: 10.12688/wellcomeopenres. 10298.2