Development of Preschool Children Subsystem for ASR and Q&A in a Real-Environment Speech-Oriented Guidance Task
4
0
0
全文
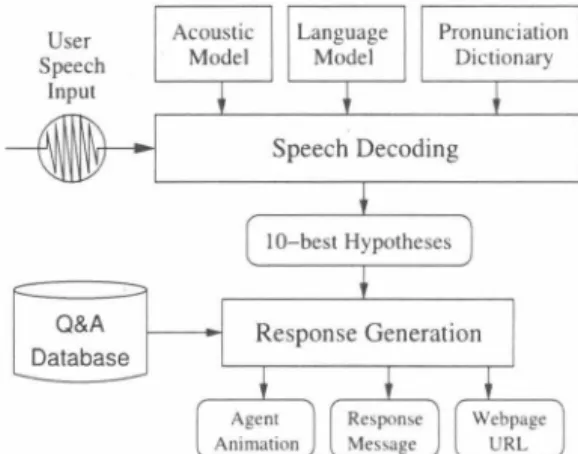
(2) AM Construction LM Construction ASR Engir】E Acoustic恥10del Acoustic Features Language Model. HTK 3.2 [14] SRILM 1.5.0 [15] Julius 3.5 [16] PTM [17], 2,000 states, 8,256 Gaussians 12 MFCCムMFCC. Ó. E LR 2-gram, RL 3-gram,Kneser-Ney. 2.1. Preschool Children Data. The preschool children speech data is remarkably di仔erent from the speech data of lower grade and higher grade school children. In a preliminary evaluation experiment the recognition perfor mance was 76.9% for higher grade school children and 75.2% for lower grade school children, but only 45.5% for preschool children even when employing an acoustic model train巴d on collected data of each corresponding speaker group. Different pronunciation of words which appear randomly, a lower speak ing rate and differences in sentence construction and word us age are the three most pr巴valent characteristics. There are also differences among preschool children, since they usually grow up in a different environment (di仔"erent parents).. 3. Baseline System The m勾or components of the speech-oriented guidance system are a speech recognizer and a response generation module as shown in Figure 1. The acoustic model is a context-dependent phonetic-tied mixture (PTM) model. The initial model is con structed from the JNAS database [13] and then r巴trained with all available children speech data (cf. Table 1). The baseline lan guage model has been built from one million sentences of text data collected from the web, transcriptions of about 17,000 chiト dren utterances and about 6,000 questions devised by humans The vocabulary size is about 42k and the pronunciation dictio nary contains only one possible phoneme sequence per word Other experimental conditions are uniform. They are given in Table 2.. 4. System Optimization The baseline system has been built using relatively few data af ter the system has been installed in a public place. In the follow-. 2 3 4 5 6. (Preschool) (Lower Grade) (Higher Grade) (Pre)+(Lower) (Pre)+(Lower)+(High) (Preschool/Std). I Ik 51k 17k 62k 79k l lk. 7 8. (Pre/Std)+(Select) (Pre)+(Select). 21k 21k. y 日 二 、 一 日 -4,‘ Fi 円 万 K一 一. Table 2: Experimental Conditions.. Ba犯lin巴. C =5 一. Figure 1: Th巴 speech-oriented guidance system and its m勾or components. Mode印刷. 4 = 1 一 r j ia. 円百I I 0I. K L = L r 一 ツ 石 一 E 一 一 H u 司 j e 一 U= = 一品作. Table 3: Different Acoustic Models, Training Data Size and Recognition Performance. Word correctness (Corr.) and word accuracy (Acc.) in percent. 54.0. 49.0. 51.2 37.8 52.5 51.4. 44.2 28.6 45.9 44.9. 55.2. 49.8. 57.6. 51.9. 56.7. 50.3. ing it is shown how the system performance can be optimized for preschool children, when two years of real-environment children speech data b巴come available. 4.1. Acoustic ModeIing. Several acoustic models built by retraining the baseline model on different children speech data sets are considered. The re sult 凶given in Table 3. The best performance is naturally ob tained for the matched case (1), i.e. when training the initial model with preschool children data. When employing data from lower grade (2) or higher grade school children (3) the recog nition performance degrades by about 5% and 20% absolute, respectively. Adding lower (4) and higher (5) grade data to the preschool children data has also negative e仔ects. Training with preschool children data when using standardized transcriptions (6) improves the performance slightly in comparison to when using speech sound conform transcriptions. This is also natural, since the referenc巴 transcriptions were also normalized w.r.t. standard pronunciation. Instead of employing the whole children speech data p∞l for training, selection of speech data acoustically cJose to preschool children data is conducted 】n advance. For data selec tion a previously proposed greedy ML algorithm for utterance based selection of task-speci自c data is employed. The method has been successfully applied for a building a task-spec泊c acoustic models in supervised and unsupervised manner [18, 19]. The a1gorithm starts with the whole children speech data pool and successively tests each utterance for del巴tion. A train ing utterance is removed from the data p∞1, if its independent deletion improves the retrained model's likelihood for a sep arate data set of preschool children data. When iterating th巴 selection algorithm two times, 16% or about 10k utterances of the data pool (Iower and higher grade children data, 62k utter ances) are selected. Combining the selected and the preschool children data, performance improves to 51.9% (7), which is 23% higher than when using only preschool children data (6) and 5-7% higher than when employing the whole children speech data pool (5) for training 4.2. Language ModeIing. The baseline language model is trained on web data and tran scriptions of several thousand children utterances. The perfor mance of this model is compared to five language models which are trained on transcriptions of children utterances only. Acous tic model (7) from the previous section is employed for this. O UF n p j A吐 A斗 司14.
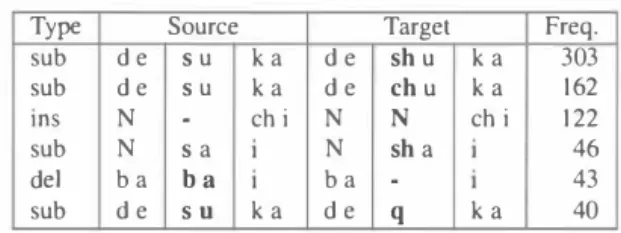
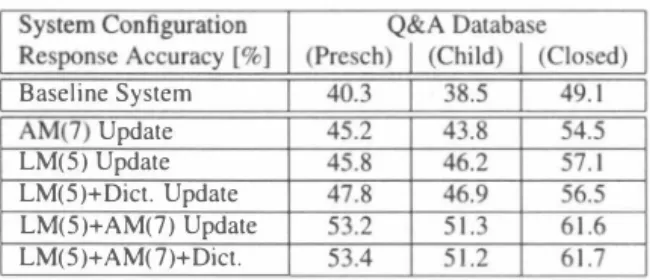
(3) Table 5: Examples for pronunciation mapping rules. Table 4・Performanc巴 for language models train巴d on different data sets when using acoustic model (7).. |ID I |1 I 2 I. Type sub sub. ModellData Web-based Model. 10S. (P陀) (P印)+(Lo岬) (P陀)+(Low)+(High) (Pre/Std) (Pre/Std)+(Lo岬). sub del sub. de de N N ba de. Source su ka su ka . ch i 1 sa ba s u. ka. de de N N ba de. Target sh u ka ka ch u N ch i sh a. .. q. ka. Fr巴q. 303 162 122 46 43 40. Table 6: Application of pronunciation conversion rules ranked by absolute or relative appearance frequency. Acoustic model (0) and language model (5) are employed for evaluation.. investigation. From Table 4 it is clear, that the transcription based language models (2)ー(6) perform better than the web based baseline model (1). It has a positive effect when adding lower grade (3) and higher grade school children data (4) to the preschool children data (2) for model training. The rea son is likely to be the fact, that in contrast to the lower and higher grade data, the preschool children speech transcripts con tain non-standard words. Consequently, a language model (5) trained on normalized preschool children data transcripts was examined finally which yielded the best performance. Here, adding lower grade (6) data to (5) did not improve the perfor mance further.. unfamiliar with the Japanese writing system, only phoneme se quences are shown. The source part of each mapping is compared with every word entry in the pronunciation dictionary. For each rule and word matching one extra pronunciation variant is added to the pronunciation dictionary. The effect of applying only the k highest ranked conversion rules is investigated in the following experiment. Conversion rules may be rank巴d either by their ab solute or relative appearance frequency. For performance evalu ation, acoustic model (0) and language model (5) are employed. The result is shown in Table 6. When ranking the pronunciation rules by their absolute (re卜 ative) appearance frequency, a peak in performance seems to be reached after 400 (600) pronunciation mappings have been applied. There is an absolute improvement of up to 3.5% in comparison to when using only a standard pronunciation dic tionary showing the eff,巴ctiveness of pronunciation modeling However, there was no significant increase in performance by editing the pronunciation dictionary when employing acoustic models (6,7). This is due to the fact that the preschool chil dren's idiosyncratic way of pronouncing words has already been “learned " by the acoustic model, since normalized utt巴rance transcriptions hav巴 been employed during their training. 4.3. Pronunciation恥fodeling. The purpose of pronunciation modeling is to be able to recog nize the normalized form of words although their pronuncia tion has been altered by the preschool children in an idiosyn cratic way. For example, preschool children pronounce 'Take maru' as 'Tachimaru', 'Takebaru' or 'Takemau'. Nevertheless, all three pronunciation variants should be recognized as 'Take maru'. Therefore, it is proposed to add these pronunciation vari ants for the word 'Takem訂正in the pronunciation dictionary used during recognition. In order to understand the idea of the proposed approach in more detail, the reader should be aware, that in the Japanese lan guage there is a one-to-one coπespondence between graphemes and speech sounds, i.e. a bijective mapping between Japanese characters and phoneme pairs can be established. Except a few Japanese characters for th巴 'N' sound and the自ve vowels 'a', 'i', 'u', 'e', '0', each character of the Hiragana/Katakana writ ing system is pronounced as a consonant followed by a vowel. Hiragana/Katakana are the Japanese “alphabets " by which any Japanese word can be written as it is spoken. (Besides from these “alphabetsヘthe Japanese language uses Chinese charac ter, the so-called Kanji to remove meaning ambiguities). In this paper pronunciation modeling is considered at the Hira gana/Katak加a level. The preschool children training data is transcribed in two ways. 4.4. Response Accuracy. Since the application consid巴red in this paper is a guidance sys tem, it is imperative to evaluate the system's response accu racy in order to see whether an improvement in speech recogni tion accuracy transfers to a increase in response accuracy. Re sponse generation is based on a question imd answer data base (QADB), which contains Q&A pairs for approx. 300 responses. The questions are taken from the transcripts of the collect巴d speech data, the corresponding answers are assigned manually by humans. Three QADBs ar巴 considered here: (Presch) based on the collect巴d preschool children data, (Child) built from all available children data and (Closed) which contains only the Q&A pairs co汀esponding to the transcription of the test data The evaluation result is shown in Table 7. Updating either the language or the acoustic model has equally high positive effects. 1. Transcription of how words were actually pronounced 2. Transcription of each word's standard pronunciation Context-sensitive pronunciation mappings are obtained from the forced alignment of the transcriptions (1) and (2) There a問substitution (3→3 characters), deletion (3→2 characters) and insertion (2→3 characters) rules. After dis carding rules with an absolute occurrence frequency of one, there were 1,295 substitution, 57 insertion and 35 deletion rules Extra substitution rules have been derived for word begin and end by ignoring either the left or the right context, respectively Several examples are given in Table 5. Since readers may b巴. ド. げ 幻 1.
(4) [5] S. Lee, A. Potamianos, and S. Narayanan, “'Analysis of Children's Speech: Duration, Pitch and Formants," in Proc. of Eurospeech, 1997, pp. 473-476.. Table 7: Response accuracy for different combinations of acoustic mod巴1,language model and pronunciation dictionary目. l. [6] Q. Li and M.J. Russel, “Why is Automatic Recognition of Children's Speech Difl白cult?," in Proc. of Eurospeech, 2∞1, pp. 2671-2674.. Baseline System. I AM(7) Update. [7] A. Potamianos, S. Narayanan, and S. Lee,“Automatic Sp巴巴:ch Recognition for Children:' in Proc. of Eurospeech, 1997, pp. 2371-2374.. LM(5) Update LM(5)+Dict. Update LM(5)+AM(7) Update LM(5)+AM(7)+Dict.. [8] A. Hagen, B. Pellom, S.Y. Vuuren, and R. Cole, “Ad vances in Children's Sp巴ech Recognition with an Interac tive Literacy Tutor," in HLT/NAACL, 2004.. in improving the system's response accuracy. When updating both models,the absolute improvement of their independent up date seem to add up. Editing the pronunciation dictior】ary has a positive effect, but it is 1巴ss promising than optimizing the acoustic model by training with normalized utterance transcrip tions and selecting additional training utt巴rances from lower and higher grade school children data. There were no further im provements when updating acoustic model and pronunciation dictionary at the same time. [9] D. Elenius and M. Blomberg, “Adaptation and Normal ization Experiments in Spee氾h Recognition for 4 to 8 Year Old Children," in Proc. of Eurospeech, 2∞5, pp. 27492752 [10] J. Gustafson and K. Sjölander,吋0】ce Transforrnation for Improving Children's Speech Recognition in a Publicly Available Dialogue System," in Proceedings of rhe In temational Conference on Spoken Language Processing,. 2002, pp. 297-300. [11] R. Nisimura, Y. Nisihara, R. Tsurumi, A. Lee, H. Saruwatari, and K. Shikano, “Takemaru-kun: Speech oriented Information System for Real World Research Platform," in Intemational Workshop on Language Un derstanding and Agents for Real '"伽ld Interaction, 2∞3, pp. 70-78.. 5. Conclusion In this paper automatic speech recognition and response gener ation for a real-environment speech-oriented guidance system has been investigated. For improving speech recognition accu racy of preschool children, acoustic, language and pronuncia tion modeling are considered. For language modeling, a model trained on the normalized transcriptions of more than ten thou sand preschool chiIdren utterances yielded the highest perfor mance. A previously proposed method for selective training of the acoustic model was applied successfully for augmenting the existing preschool children training data with an appropriate subs巴t of the school children data. Context-dependent pronunci ation modeling applied at the Japan巴s巴 'syllable' level was less promising. Finally, the response accuracy of the system was evaluat巴d. Improvements in r巴cognition accuracy transferred in the same degree to an improvement in respons巴 accuracy. In the end a response accuracy of mor巴 than 60% was achieved. [12] R. Nisimura, A. Lee, M. Yamada, and K. Shikano, “Op erating a public spoken guidance system in real environ ment," in Proc. of Eurospeech, 2∞5,pp. 845-848 [13] K. Ito, M. Yamamoto, K. Takeda, T. Takezawa, T. Mat suoka, T. Kobayashi,K. Shikano, and S. Itahashi,“JNAS: Japanese Speech Corpus for Large Vocabulary Continu ous Speech Recognition Research," The Joumal of the Acoustical Society of Japan, vol. 20, pp. 199-206, 1999 [14]“HTK. Speech. Recognition. http://htk.eng.cam.ac.uk/:. Toolkit,. [15] A. Stolcke,“SRILM・An Extensible Language Modeling Toolkit," in Proc. of ICSLP, 2∞2, pp. 901-904.. 6. Acknowledgments. [16]“Julius, an Open-Source Large Vocabulary CSR Engine -. A part of this work is supported by the MEXT e-Society pr句巴ct, Japan.. http://julius.sourceforge.jp/: [17] A. Lee,T. Kawahara,K. Takeda, and K. Shikano,“A New Phonetic Tied-Mixture Model for Efficient Decoding," in. 7. References. Intemational Conference on Acousrics, Speech, and Sig・. [1] s. Narayanan and A. Potamianos, “Creating Conversa tional Interfaces for Children," IEEE Trans. on Speech and Audio Processing, vol. 10, no. 2, pp. 65-78, 2002. nal Processing,. 2∞0, pp. 1269-1272.. [18] T. Cincarek, T. Toda, H. Saruwatari, and K. Shikano, “Selective EM Training of Acoustic Models based on Sufficient Statistics of Single Utterances," in Automatic Speech Recognirion and Understanding "ゐrkshop, 2005, pp. 168-173. [2] D. Giuliani and M. Gerosa,“Investigatir】g Recognition of Children's Spe配h," in Intemational Conference on Acoustics, Speech, and Siglwl Processing, 2003, vol. 2, pp. 137-140.. [19] T. Cincarek, T. Toda, H. Saruwatari, and K. Shikano, “Acoustic modeling for spoken dialogue systems bas巴d on unsupervised selective training," in Proc. of ICSLP, 2∞6, pp. I 722-1725.. [3] G. Stemmer, C. Hacker, S. Steidl, and E. Nöth, “Acous tic Normalization of Children Speech," in Proc. of Eu rospeech, 2003,pp. 1313-1316 [4] S.M. D' Arcy, L.P. Wong, and M.J. Russel, “Recognition of Read and Spontaneous Children's Speech Using Two New Corpora," in Proceedings of the Intemational Con ference on Spoken Language Processing, 2004. 1472. - 148 -.
(5)
図
関連したドキュメント
A tendency toward dependence was seen in 15.9% of the total population of students, and was higher for 2nd and 3rd grade junior high school students and among girls. Children with
Information gathering from the mothers by the students was a basic learning tool for their future partaking in community health promotion activity. To be able to conduct
Regres- sion analyses of the sequence data for thermophilic, mesophilic and psychrophilic bacteria revealed good linear relationships between OGT and the dinucleotide com- positions
The aims of this study were to explore the trends in research on support for the siblings of children with diseases/disabilities and discuss future challenges related to this topic.
The classical Ehresmann-Bruhat order describes the possible degenerations of a pair of flags in a linear space V under linear transformations of V ; or equivalently, it describes
We construct a Lax pair for the E 6 (1) q-Painlev´ e system from first principles by employing the general theory of semi-classical orthogonal polynomial systems characterised
This implies that a real function is realized by a stable map if and only if it is continuous, thus further leads to an admissible representation of the space of continuous
First we use explicit lower bounds for the proportion of cyclic matrices in GL n (q) (obtained in [9, 14, 20]) to determine a lower bound for the maximum size ω(GL n (q)) of a set
