SIFT
ベクトル画像間の距離指標に対する極値解析の応用
Application of Extreme Value Analysis
to Distance Measure Evaluation between SIFT Vectors Images
深田健太
1∗鷲尾隆
1Kenta Fukata
1, Takashi Washio
11
大阪大学産業科学研究所高次推論方式
1
Department of Advanced Reasoning, Osaka University.
The Institute of Scientific and Industrial Research
Abstract: The needs of efficient image query is rapidly increasing under the development of broadband network and multimedia communication. The recent techniques in the image query extract thousands of points of interest (POI) from each image, and represent the feature of each POI by a Scale Invariant Feature Transform (SIFT) vector. The similarity among images is evaluated by the matching of SIFT vectors and used for the query. Crucial issues in the similarity evaluation are an appropriate formulation of the distance measure to evaluate the similarity between images and the establishment of an efficient computation method of the distance measure. In this report, we formulate the distance measure based on extreme value analysis and propose an efficent computaion method of the distance measure based on a k-NN query technique named ”SASH”.
1
はじめに
近年,ブロードバンドネットワークとマルチメディア の普及に伴い,画像検索のニーズが高まっている.現状 の多くの画像検索手法は,各画像中で興味深い点 (Point of Interest: POI))[3] あるいはその集合に着目して画 像同士の類似性を判断するという人間の視覚上の特徴 を利用する.代表的な方法では,1枚の画像から視点 の違いの影響を受け難く形状特徴の明確な画像上の点 を,その最適な縮尺率や回転角度の条件と共に POI と して数百∼数千個抽出し,周囲の各方向に関する画像 強度変化率からなる特徴ベクトルを計算する.このよう な特徴ベクトルを Scale Invariant Feature Transform (SIFT) ベクトルと呼び,標準的手法では各ベクトルが 128 次元要素からなる.つまり,画像検索の前処理と して,1枚の画像をこのような数百∼数千の SIFT ベ クトルの集合に変換する. 2 つの画像をマッチングするためには2つの SIFT ベ クトル集合同士のマッチングを行う必要があるため,一 方の集合内の各 SIFT ベクトルともう一方の集合内の 最近接 SIFT ベクトルまでの距離を計算し,それらの 集合間の距離に基づいて画像検索を行う.従来,この 画像距離を決定する指標として,ある画像内の全 SIFT ∗連絡先:大阪大学産業科学研究所 〒 567–0047 大阪府茨木市美穂ヶ丘 8-1 E-mail:[email protected] ベクトルに対して,最も小さいユークリッド距離を持 つ他の画像の SIFT ベクトルとの距離を用いてきた.し かし,この従来指標では,ある画像の一つのベクトル に関する他の画像の最近接ベクトルを探索することで 画像検索を行うため,画像全体をうまくマッチングす ることができない.そこで,この欠点を補うために我々 は平均値法や最小値法 [6] を提案した.これは画像間の 距離を測定するために,ある画像の SIFT ベクトル集合 Q 中の 1 つの SIFT ベクトル q と他の画像の全 SIFT ベ クトル集合 T の各ベクトルとの距離を測り,その最小 値 mindqT を計算し,それによって Q の各ベクトルに ついて得られる最小値の集合{mindqT|q ∈ Q}の平均 値や最小値を2画像間の距離とする指標である.平均 値法では,画像中であまり類似しない点に関する SIFT ベクトルを多く用いることになり,画像中の類似点の みに着目して類似性を判断する人間の感覚に合った効 果的な画像検索を行えない.また,最小値法では,統 計的に最小値の大小が著しく揺らぐことにより検索結 果に不自然なバラツキを生じる.そこで,画像間の類 似性を表すため,平均や最小値ではなく極値理論 [7][8] を応用することで,統計的誤差が少なく,効果的な画 像検索を行うことが可能な画像間距離指標を考案,検 討することを本研究の目的の一つとする. 一方,この画像間距離指標に基づいて効率的な画像 検索を行う手法として,k-d tree[4] とそれを発展させた人工知能学会研究会資料
SIG-DMSM-A701-03 (7/25)
Best-Bin-First(BBF) アルゴリズム [5] が存在する.k-d tree は探索空間の分割を行うことにより,query を行う 際に,その query の存在する空間と隣り合う空間のみ を探索し,計算量を減らす手法である.しかし,各事例 ベクトルが10次元を超えると,計算量が増大し,完全 探索より速度が劣る欠点がある.これに対して,BBF アルゴリズムは高次元ベクトルで表される事例につい て,より近い隣りの探索空間を優先的に探索し,効率 的に近い事象を見つけ出す近似探索手法である.これ は 1000 枚程度の画像数であれば効率的な検索を行う ことが可能であるが,より多くの画像のより高次元な SIFT ベクトルに対して検索を行うと,計算量の急激な 増大や似た距離に存在する SIFT ベクトル数の増加か ら,正確かつ高速な検索を実行することが困難になる. このことから,現状の SIFT ベクトルのマッチングに 基づく大量画像高速検索手法は不十分であると考えら れる. SIFT ベクトルマッチング問題は大規模次元大量ベ クトルデータに関する類似ベクトル検索問題である. 直接検索を用いると,画像の SIFT ベクトル本数を平 均 n 本とすると,O(n2) の計算時間複雑さとなる.こ の計算時間を短縮する方法として,M-tree[1] が存在す る.M-tree は類似した query の効果的な検索のために 使うことができるインデックス構造を有しており,高 次元ベクトル間の類似性評価において特に効果的な検 索を可能とする.そのため,次元の呪いに強い性質を 持つ.この計算時間複雑さはそれぞれの query につい て O(logn) であるため,全体で O(n log n) となり,そ の検索インデックス構造作成時 O(n log n),記憶容量 複雑さは O(n) である.これに対して近年 SASH 法 [2] と呼ばれる新しい検索手法が提案されており,その計 算時間複雑さは検索データ作成が O(n log n),検索時 O(log n),記憶容量複雑さは O(n) と前記手法と同様で ある.しかし,実際の計算速度や検索精度は SASH 法 が非常に優れていることが明らかになっている. 本研究では,ノイズを含む多数の高次元ベクトルで 表される画像間の適切な類似性距離を評価するために, 極値解析の利用を検討すると共に,SASH 法を用いた k-NN 類似 SIFT ベクトル検索に基づいた高速画像検索 方法について検討した.
2
関連先行研究
2.1
画像検索手法
本節では従来の画像検索手法 [3] の概要について述 べる. 2.1.1 SIFT ベクトル抽出 以下の 4STEP を行うことで,画像データ内で縮尺 や回転などに対して不変な場所を特定し,その場所の 特徴を表す SIFT ベクトルを作成する. 1. 縮尺率及び画像位置上の極値の発見 はじめに,適切な粒度の画像上の縮尺率や位置の 様々な組み合わせについて,ガウス関数差分を適 用し,縮尺率や位置の差異に対して不変である潜 在的に興味深い画像上の極値点を効率的に特定 する. 2. POI の特定 それぞれの極値点に対して,内挿補間によってよ り詳細な縮尺率と位置を推定する.そして,更 に,画像が表す物体形状の特徴が明確でない低コ ントラストな極値点や濃淡境界線上の極値点を除 いて,明確な対象形状を表す Point Of Interest (POI) を決定する. 3. 方向の割り当て 画像各所が歪みなどによって回転している可能性 を考慮し,画像強度が最も変化する方向を求め る.常にこの方向に次ステップで求める POI の 特徴ベクトルの座標系を統一することで,POI 付 近の画像回転歪の影響を受け難くする. 4. POI の SIFT ベクトル 各 POI について上記方向に合わせた座標系で周 囲4×4の格子点上のそれぞれ8方向に関する画 像強度の変化率から成る,128 次元 SIFT ベクト ルを求める. この処理を行うことにより,画像から位置や縮尺など に対して不変的で形状が明確な場所を見つけ出し,更 にその場所の回転を補正した SIFT ベクトルを特徴ベ クトルとして得る.一般に,SIFT ベクトルは各画像か ら数百∼数千本取り出される. 2.1.2 画像検索アルゴリズム 画像検索を行う際,はじめに検索対象とする各画像 から SIFT ベクトルを抽出し,データベースに貯蔵す る.新しいイメージを検索する際にはそのイメージか ら SIFT ベクトルを抽出し,画像間の SIFT ベクトル 集合のユークリッド距離に基づいて検索を行う.その 代表的な方法に,以下の2つがある. 1. Keypoint matching 対象画像から作られた SIFT ベクトル群の中から query 画像の SIFT ベクトルと最も近い SIFT ベ クトルを持つ画像を特定することで検索を行う. ここでは,SIFT ベクトル間のユークリッド距離 が最も小さいものを最も近い画像であると判定す る.ユークリッド距離は各ベクトル成分の差から 直接に計算する.2. Efficient nearest neighbor indexing 画像と画像をマッチングするためには2つの SIFT ベクトル集合同士のマッチングを行う必要がある ため,一方の集合内の各 SIFT ベクトルともう 一方の集合内の最近接 SIFT ベクトルまでの距 離を計算し,それらの集合間の平均距離に基づ いて画像検索を行う.128 次元のような,高次元 データにおける2つのベクトルの正確な nearest neighbor を測るアルゴリズムとしては,直接計 算法より高速なアルゴリズムは実用的に存在しな い.そこで,前述した高速な近似検索アルゴリズ ムである Best-Bin-First(BBF)[5] が用いられるこ とが多い.
2.2
SASH 法
SASH 法 [2] はランダムサンプリングを用いて SASH 構造を構築し,高速で近似的に高精度な k-nearest neigh-bor (k-NN) 類似事例検索を行う手法である. 2.2.1 SASH 構築 SASH 法は階層状にランダムにサンプリングされた ノードを展開し,それと同時にトップノードから順に 下のノードへリンクを張る処理を繰り返すことで,図 1に示すような SASH 構造を構築する.ただし,root ノードから辿れない孤児ノードを作らないために,root ノードを除いたノードは必ず親ノードを持つように構 成する.SASH の各レベルのノード数はトップの1個 から始めてレベルを降りる毎に2倍となり,最下レベ ルでは [n/2] 個となる. 図 1: SASH 構造 以下に SASH 構造を構築するアルゴリズムを述べる. SASH はその階層構造に沿って,SASH1(レベル1), SASH2(レベル2),・・・の順に再帰的に構築される. ここでは,SASH`−1が与えられたとき,SASH`を構 築する方法を示す. 1. `=2 のときは root ノードが親となり,root ノー ドはレベル 2 の全てのノードを子供に持つ.` ≠ 2 のとき,以下のステップを全て行う. 2. レベル ` のノード v 各々について,距離の評価指 標を用いて以下を行う.root ノードを選択し,そ れからリンクの貼られた次のレベルの子ノードの 中から v に近いものを p 個選ぶ.同様にここで選 択された p 個のノードからリンクが貼られた更に 次のレベルの子ノードから v に近いものを p 個 選ぶ,ということをレベル `-1 まで繰り返す.そ して,レベル `-1 で選択された p 個のノードを v の仮の親とする.そして,v の上述の `-1 レベル の仮の親にリンクを張る. 3. レベル `-1 の各ノードからリンクが張られたレベ ル ` のノードにエッジを張る.ただし,距離の指 標を用いて,レベル `-1 の各ノードから近い順に レベル ` の c 個のノードまでエッジを張る. 4. レベル ` の全てのノードが親を持てば次のレベル の SASH 構築を行う.親を持たないノードが存 在したとき,そのノードが持てる親の数 p を倍に して親を探索する.全ての子供が親を持つと,次 のレベルの SASH 構築を行う. 事例数が n のとき,SASH 構築の計算時間複雑さは o(nlog2n) に抑えられる.また,本研究においては下 位ノード1個当たりの親数を p=4 とし,親が持つこと ができる子供の最高数を c=16 とする. 2.2.2 SASH による高速近似 k-NN Query ある query(q) が与えられると,SASH 構築時と同様 にして,各レベル毎に事例 q に近い k 個の事例を探索 する.そして,探索された全ての事例の中から q に近 い k 個の事例を解として抽出する.このように SASH 法を用いて近似類似事例を探索する方法 [2] の計算時間 複雑さは o(log2n) となる.2.3
極値理論
2.3.1 極値分布 極値理論 [7][8] は標本または確率過程の極値(最大 値や最小値など)の漸近挙動を問題にする.統計学で は,限られたデータから大量データについて統計的に 期待される最大値や最小値を予測することが重要であ る.このとき,手持ちの限られたデータの最小値で大量 データに期待される最小値を代用するのは賢明ではな く,極値理論に基づきデータの外挿を行う必要がある. 例えば,ある画像の SIFT ベクトル集合 Q 中の 1 つの SIFT ベクトル q と他の画像の全 SIFT ベクトル集合 T の各ベクトルとの距離を測り,その最小値 mindqT を 計算すると図2のようなヒストグラムが得られる.た だし,横軸を mindqT,縦軸をその頻度とする.後に議 論するように,一般に SIFT ベクトル間のユークリッド距離の頻度分布は,距離のマイナス側にロングテー ルを有することが分かっている. 図 2: mindqT のヒストグラム例 ここで,この mindqTの数は限られているため,実際の 最小値を予測する際には分布関数を与える必要がある. このようなロングテールを表す確率分布を扱うには極 値理論の導入が必要である.これまでの確率標本の極 値統計量の漸近分布の研究より,3 つのタイプの極値分 布が存在することがわかっている.本稿では,その中で も標準的形式であるとされている Gumbel 分布につい て述べる.x→-∞にロングテールを有する Gumbel 分 布の確率分布関数 F(x),そしてその確率密度関数 f(x) は以下の式で表される. F (x) = 1 − exp[− exp{x − μ σ }] (1) f (x) = 1 σexp[ x − μ σ − exp{ x − μ σ }] (2) ここで,μは Gumbel 分布における代表値を,σは分 布の広がりを表す.この関数を利用して,標本データ からデータの外挿を行うことで,母集団の最小値や平 均値などの予測を行うことが可能となる. 2.3.2 パラメータ推定 本節では最も一般的に用いられている分布パラメー タ推定法の一つである最尤法について述べる.最尤法 で用いる尤度関数は以下のように定義される. L(θ) = N Y i=1 f (xi; θ) ここで,L は尤度,θ は確率密度関数のパラメータ集 合,f (xi; θ) は確率変数 x と確率密度関数のパラメー タ集合θを有する確率密度関数である.実際の計算で は,上式で示した尤度の対数(対数尤度)を最大化した 方が計算上扱い易い.N 個のデータ{xi|i = 1, ..., N } が与えられた時,データに関する対数尤度は以下のよ うに表すことができる. l(θ) = log L(θ) = N X i=1 log f (xi; θ) そこで,この式を最大化するようにθを決定する.Gum-bel 分布の場合,θ={μ, σ}である.上記の与えら れたデータについて対数尤度を最大化する Gumbel 分 布のパラメータは以下のように推定できる. σ = N P i=1 xiexp(xσi) N P i=1 exp(xi σ) − ¯x (3) µ = σ log{1 N N X i=1 exp(xi σ)} (4) ここで,¯x は xiのデータに亘る平均値である.このσ とμを Newton-Raphson 法を用いて計算することでパ ラメータの推定を行う.
3
提案手法
3.1
画像間距離指標
本節では,目的対象画像 T と検索画像 Q との距離 を定義する画像間距離指標を提案する。目的対象画像 とは検索対象となるデータベースに貯められた画像で あり、検索画像とは検索を行いたい新しい画像のこと である。はじめに,3.1.1,3.1.2 節において,これまで の我々の先行研究において提案した平均値法と最小値 法 [6] について述べる.その後,3.1.3,3.1.4 節において, 本論文で提案する極値理論を応用した手法であるロン グテール平均値法,全体理論最小上限値法,部分理論 最小上限値法を提案する. 3.1.1 平均値法 平均値法は目的対象画像の SIFT ベクトル集合 T と 検索画像の SIFT ベクトル集合 Q 間の距離を以下のよ うに定義する.ここで,T の SIFT ベクトル数を mT,Q の SIFT ベクトル数を mQとする.まず,T の各 SIFT ベクトル t と Q の各 SIFT ベクトル q のユークリッド 距離 dtqを計算する.そして,T の各 SIFT ベクトル t に対して,Q 内の SIFT ベクトルとの最小ユークリッ ド距離を mindtQとする.つまり,min dtQ= minq∈Qdtq である.同様に Q の各 SIFT ベクトル q から T の全 SIFT ベクトルへの最小ユークリッド距離 mindqT を 求める.mindtQ,mindqT はそれぞれ mT 個,mQ個 存在するため,その平均は ¯dT Q = P t∈T min dtQ mT , ¯dQT = P q∈Q min dqT mQ と計算できる.そして,その幾何平均を取っ た DT Q= q ¯ dT Q∗ ¯dQT を画像 T と画像 Q の距離の平 均値とする. 3.1.2 最小値法 目的対象画像の SIFT ベクトル集合 T の全 SIFT ベ クトルと検索画像の SIFT ベクトル集合 Q の全 SIFT ベクトルとのユークリッド距離を計算し,その中で最も
小さい値を画像 T と画像 Q の距離 DT Qとする手法が 最小値法である.具体的には,3.1.1 節と同様に mindqT を求め,さらに DT Q= min q∈Q(min dqT) とする. 3.1.3 ロングテール部平均値法 ある画像 T と画像 Q が類似した対象物を含んでい る場合には mindtQや mindqT の確率密度分布は 2.3.1 節の図2のようになると考えられる.これは類似した 対象物の存在によって,類似した SIFT ベクトルが両 方の画像で共有されるため,その部分が図のようなロ ングテールになるからである.そこで,視覚的に似て いると感じる部分であるこのロングテール部分に重点 を置いた距離指標を考える.そのために,以下の2つ を仮定する. 1. mindtQや mindqTの分布はロングテールを持ち, Gumbel 分布に従う. 2. Gumbel 分布のロングテール部分を µ − nσ 以下 の範囲とする. ただし,n は自然数であり,分布の広がりσを単位とし て,代表値μよりどの程度離れているかを表す係数であ る.このとき,Gumbel 分布でランダムに与えられた変 数が µ−nσ 以下の範囲に存在する理論確率を,パラメー タμ及びσの値に拘わらず計算できる.例えば n=4 であ れば F(x)=0.01815 となり,x≤ µ − 4σ の部分が全体の 1.185 %となる.ここで,仮定1より,{mindtQ|t ∈ Q }ないし{mindqT|q ∈ T }の中の何個がこの条件を満た すかを計算できる.つまり,n=4 であれば,mindtQや mindqTの数 mQ,mT の 1.815 %が x≤ µ − 4σ 以下(ロ ングテール部)となる個数であると考えられる.これよ り,ロングテール部と仮定される{mindtQ|mindtQ< µ − nσ, t ∈ T }や{mindqT|mindqT < µ − nσ, q ∈ Q} について,3.1.1 節と同様に平均値を計算し,幾何平均 をとることで画像間距離のロングテール部平均値 DT Q を計算できる. 3.1.4 理論最小上限値法 本提案手法は,mindtQ及び mindqTの確率密度分布 を Gumbel 分布と仮定し,そのパラメータσとμを推 定することで,mindtQや mindqT において期待され る理論的な最小値の上限を求め,その値を画像間距離 DT Qとするものである.具体的には,2.3.2 節の最尤 法により Gumbel 分布のパラメータσとμを推定する. パラメータσとμは式 (3),(4) によって推定できるが, 式 (3) は非線型方程式であるため,Newton-Raphson 法 を用いてσを推定し,それを式 (4) に代入してμを推 定する.そこで,式 (3) を用いて,以下のように f (σ) を定義する.また,f0(σ) は f(σ) を σ について微分し たものである. f (σ) = σPN i=1 exp(xi σ) − N P i=1 xiexp(xσi) + ¯x N P i=1 exp(xi σ) f0(σ) = PN i=1 exp(xi σ) − (¯x + σ) N P i=1 (xi σ2) exp(xσi) +PN i=1 (x2i σ2) exp(xσi) Newton-Raphson 法では,f(σ)=0 となる σ を求める. 初めに σ の適当な初期値 σ0を選び,次の漸化式によっ て,σ に収束する数列を得る. σ1= σ0− f (σ0) f0(σ0),・・・, σk+1= σk− f (σk) f0(σk) lim k→∞σk = σ (5) ここで,反復回数 k は実験により最適と考えられる値 を決定して用いるものとし,初期値 σ0は mindtQ や mindqT の分散とする. このようにして推定した Gumbel 分布のパラメータ σとμを用いて理論最小上限値を求める.Gumbel 分布 に従うデータが N 個あれば,Gumbel 分布の確率密度 関数 f(x) の区間積分が 1/N になる区間毎に1個のデー タが存在すると期待される.つまり x=-∞から分布関 数 F (x)=1/N を満たす x までが最も小さい xminの存 在が期待される区間といえる.そこで,この最小値の 存在が期待される上限値を理論最小上限値 xuminとす る.xuminは F (x)=1/N を x について解くことで以下 の式で与えられる. xu min= σ ln{− ln(1 − 1 N)} + µ (6) この xuminを画像間距離 DT Qとして用いる手法が理論 最小上限値法である. ただし,mindtQ,mindqT 各々について,その値域 部分の全体が Gumbel 分布であると仮定できるとは限 らない.つまり,mindtQ,mindqT の確率密度分布は 3.1.2 節の図2のようになると考えられるが,全値域に おいて Gumbel 分布に従うとは限らない.そこで,こ の確率分布の全値域部分が Gumbel 分布に従うと仮定 する方法と図2中のロングテール部のみが Gumbel 分 布に従うと仮定する方法の2種類を考える.mindtQ, mindqT の確率分布の全値域部分が Gumbel 分布に従 うと仮定する方法では,mindtQや mindqTの全ての値 を標本値として Gumbel 分布を推定する.つまり,標 本値として,{mindtQ|t ∈ Q}ないし{mindqT|q ∈ T } を式 (5) に代入することで Gumbel 分布のパラメータ σとμを得る.そしてσとμを式 (6) に代入すること で理論最小上限値 xuminを求める手法を全体理論最小 上限値法とする.また,mindtQ,mindqT の確率分布 のロングテール部のみが Gumbel 分布に従うと仮定す る方法では,ロングテール部として,3.1.3 節と同様に して x≤ µ − nσ 以下の部分を選ぶ.この際,式 (1) よ り F (µ − nσ) = 1 − exp{− exp(−n)} であるため,σ, µ の具体的値を必要とせずに,ロングテール部に含ま
れる mindtQ, mindqT の値を決定できる.このことか ら,ロングテール部と仮定される{mindtQ|mindtQ< µ − nσ, t ∈ T }や{mindqT|mindqT < µ − nσ, q ∈ Q} を標本値とし,その標本値を式 (5) に代入してσ,μ を得る.そして求めたσ,μを式 (6) に代入すること で理論最小上限値 xuminを求める手法を部分理論最小 上限値法とする.
3.2
SIFT ベクトル間最小距離の計算手法
前節で述べた各種画像間距離指標の評価には,mindtQ と mindqTの計算が必要である.画像検索を行う際,必 要とされる2画像間の距離計算回数が非常に多いため, 高速な画像検索手法開発において,mindtQと mindqT の計算の高速化は非常に重要である.しかし,この計 算を直接行うと,計算時間複雑さは O(|T ||Q|) であり, 画像数の増加に伴って計算時間が増加し,画像検索を 行う際,多くの計算時間を必要とする.そこで,我々 はこの計算を効率的に行う手法として SIFT ベクトル SASH 法を提案する.本節では,初めに一般的な距離 計算手法である全計算法について述べ,その後,提案 手法である SIFT ベクトル SASH 法について詳細に述 べる. 3.2.1 全計算法 目的対象画像の SIFT ベクトル集合 T と検索画像の SIFT ベクトル集合 Q が存在するとき,T の各 SIFT ベ クトル t と Q の各 SIFT ベクトル q のユークリッド距 離 dtqを全て計算する.このようにある画像の各 SIFT ベクトルと相手の画像の全 SIFT ベクトルとの距離を 全て計算し,SIFT ベクトル間最小距離を求める手法を 全計算法と呼ぶ. 3.2.2 SIFT ベクトル SASH 法SIFT ベクトル SASH 法は検索画像の SIFT ベクト ル集合 Q の各 SIFT ベクトルと目的対象画像の SIFT ベクトル集合 T の全 SIFT ベクトルとのユークリッド 距離を計算する際に,SASH を用いて,SIFT ベクトル の k-NN フィルタリングを行うことで計算量を減らす 手法である.その処理を図3に示す. 図 3: SIFT ベクトル SASH 法の概要図 初めに,目的対象画像の SIFT ベクトル集合 T の SASH 構築を行う.次に検索画像の SIFT ベクトル集合 Q の 各 SIFT ベクトル q 毎に,画像 T の SASH に対して, 2.2.2 節に説明した方法で query を行うことで近似 k-NN SIFT ベクトルの集合を得る.そして,q とその k-NN SIFT ベクトルとの間で,最も小さいユークリッ ド距離値を mindqT の近似値とする.必要に応じて Q の SASH 構築を行い,同様にして,T の各 SIFT ベク トルから Q の k-NN SIFT ベクトル集合を得て,その中 の最小ユークリッド距離 mindtQを得る.このようにし
て mindqT ないし mindtQを求める手法を SIFT ベク
トル SASH 法と呼ぶ.ただし,本研究では SASH に対 して query を行う際の k を,検索が最速となる k=1 又 はある程度の検索精度を確保可能な k = SIF T ベクトル数20 とする.
4
実験結果と考察
本評価実験では図4,5のような自転車や猫といっ た人間の目から見て特徴的な対象が含まれる8枚の写 真画像を用いた. 図 4: 画像1 図 5: 画像4 8 枚の画像の内,画像1,2,3が自転車,4,5,6 が猫であり,7,8は無関係な画像である.それらの 画像をそれぞれ SIFT ベクトルに変換し,3.1 節の様々 な方法で画像距離指標を定義し,検索画像の順位付け を行うことで,従来の距離指標と提案指標の有効性を 評価した.また,それと同時に,3.2 節の手法で画像距 離を計算し,それぞれの手法の計算時間や精度の比較 を行った.ただし,本稿ではスペースの都合上,必要最 小限の画像間の比較結果のみを示すが,他の画像間比 較でも同様の傾向を確認している.それぞれの画像に 対する SIFT ベクトル数は画像1:2483,画像2:4555, 画像3:3613,画像4:606,画像5:550,画像6:659,画 像7:3066,画像8:1350 であった.4.1
画像距離指標
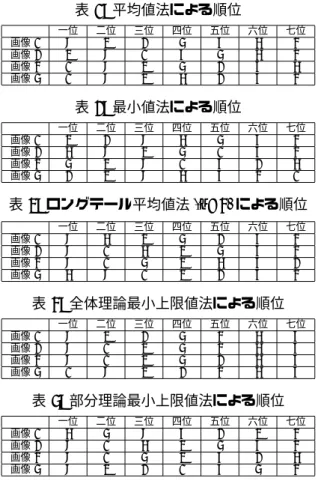
4節で述べた5種類の画像距離指標を使い,8 枚の画 像中 1 枚を検索画像とし,他の 7 枚をそれぞれ目的対 象画像として,1 位∼7 位まで目的対象画像の順位付け を行った結果が表1∼5である.ただし,ここではス ペースの都合上,検索画像として画像1,2,4,5 を用いたときの結果のみを示す.表 1: 平均値法による順位 一位 二位 三位 四位 五位 六位 七位 画像 1 8 3 2 5 7 6 4 画像 2 3 8 1 7 5 6 4 画像 4 1 8 3 5 2 7 6 画像 5 1 8 3 6 2 7 4 表 2: 最小値法による順位 一位 二位 三位 四位 五位 六位 七位 画像 1 3 2 8 6 5 7 4 画像 2 6 8 3 5 1 7 4 画像 4 5 3 8 1 7 2 6 画像 5 2 3 8 6 7 4 1 表 3: ロングテール平均値法 (n=4) による順位 一位 二位 三位 四位 五位 六位 七位 画像 1 8 6 3 5 2 7 4 画像 2 8 1 6 3 5 7 4 画像 4 8 1 5 3 6 7 2 画像 5 6 8 1 3 2 7 4 表 4: 全体理論最小上限値法による順位 一位 二位 三位 四位 五位 六位 七位 画像 1 8 3 2 5 4 6 7 画像 2 8 1 3 5 4 6 7 画像 4 8 1 3 5 2 6 7 画像 5 1 8 3 2 4 6 7 表 5: 部分理論最小上限値法による順位 一位 二位 三位 四位 五位 六位 七位 画像 1 6 5 8 7 2 3 4 画像 2 8 1 6 3 5 7 4 画像 4 8 1 5 3 7 2 6 画像 5 8 3 2 1 7 5 4 ここで,画像1∼3が自転車,4∼6が猫の画像である ため,例えば画像1の自転車が検索画像であれば画像 2や3が上位に順位付けされる指標が効果的な距離指 標であり,猫画像が検索画像のときも同様に考えられ る.初めに,表1, 2より,従来手法である平均値法と 最小値法の性能を考察する.表1を見ると,検索画像 が自転車の際は,他の自転車画像が上位となることか ら,効果的な検索がなされていると考えられる.しか し,猫画像に関しては検索がうまくできていない.こ れは,mindtQ又は mindqT の平均値を用いたため,ロ ングテールとならない,つまり画像中であまり類似し ない点も含めて距離を計算したためと考えられる.さ らに,画像1,2,3,8がどのような検索画像に対 しても上位となることからこの距離指標は効果的な検 索を行うことが困難であると考えられる.また,表2 において,画像1や画像4に関しては同様の画像が上 位となることから,最小値法により,ある程度効果的 な検索がなされていると考えられる.しかし,画像2 や5のように効果的な検索ができていない画像も存在 する.最小値法は mindqT の最小値のみを利用するた め,統計的誤差に弱く,そのため,このような結果が 得られると考えられる.このことから最小値法はある 程度よい結果を導くが,統計的誤差を受けやすい欠点 を持つことがわかる. 次に,提案指標であるロングテール平均値法,全体 理論最小上限値法,部分理論最小上限値法を距離指標 とした検索結果を考察する.表3を見ると,どの画像 においても似た画像が上位∼中位となることから,あ る程度効果的な検索ができていると考えられる.しか し,画像8が常に上位となり,画像4が常に下位とな る問題が挙げられる.そこで,これらの画像における mindqT のヒストグラムを作成し,その問題について 詳しく考察する.画像1を検索画像,画像8を目的対 象画像とした mindqT のヒストグラムは図6となる. 図 6: 画像1と画像8の mindqT のヒストグラム このようにあまり似ていない画像1と画像8(画像8 は車画像)であっても小さい mindqT がある程度存在 する場合があるため,ヒストグラムだけで完全に画像 距離を測ることは困難であり,この手法があまり効果 的に働かない場合が起こると考えられる.今回,ロン グテール範囲を決定する係数 n=4 とした結果を示した が,この n を小さくすると平均値法に近づき,n を大き くすると最小値法に近づく.また,全体理論最小上限 値法や部分理論最小上限値法を用いた画像検索順位結 果を見ると,あまり効果的な検索ができていない.こ れらの理由として,ヒストグラムを強引に Gumbel 分 布に当てはめたことによる誤差や,分布のパラメータ σやμの計算を行った際の近似による誤差などが考え られる.これらから,現段階では最小値法又はロング テール平均値法がある程度効果的な画像検索距離指標 であると言えるが,画像の性質を考慮したより効果的 な画像距離指標を考案する必要性があると考えられる.
4.2
画像検索時間
SIFT ベクトル変換や SASH 構築がすでになされた 画像 1 を目的対象画像に用い,SIFT ベクトル変換され た検索画像 2,4,7,8 との距離計算を行って類似性順 位付けを行った.その際,SIFT ベクトルを読み込む時 間と手法毎の距離計算に要した時間の合計を表6に示 す.ただし,単位は全て秒である.ここで SASH 法 1 表 6: 手法の検索時間比較 画像 2 画像 4 画像 7 画像 8 全計算法,av 16 2.02 11 4.77 全計算法,min 15.7 2.02 10.8 4.64 全計算法,tail 16.3 2.03 11 4.75 SASH 法 1,min 1.28 0.159 0.843 0.407 SASH 法 2,min 1.26 0.171 0.859 0.407 SASH 法 2,tail 1.25 0.188 0.874 0.406は SIFT ベクトル SASH 法 (k=1),SASH 法 2 は SIFT ベクトル SASH 法 (k=SIFT ベクトル数/20),av は平 均値法,min は最小値法,tail はロングテール平均値法 である.例えば右下の 0.406 という値は SIFT ベクト ル SASH 法 (k=SIFT ベクトル数/20) とロングテール 平均値法を用いると,画像 1 と画像 8 の距離計算時間 は 0.406 秒であったことを示す.これらの値は新しい ある検索画像 1 枚に対して,似た画像 1 枚を検索する 際に必要となる計算時間である.これより,全計算法 と比較して,SIFT ベクトル SASH 法を用いることで, どの画像においても,計算時間を10数分の1に短縮 可能であるといえる.また,距離指標の変更が計算時 間にほとんど影響を与えないことがわかる.
4.3
画像距離精度
3章の2つの手法を用いて各画像間の画像距離を計 算し,その距離に基づいて各画像同士の近さ順位付け を行った.全計算法によって導かれた距離が正しい画 像距離順位であると考え,その順位と SIFT ベクトル SASH 法により導かれた画像同士の近さ順位の差を調べ るため,以下のスピアマンの順位相関係数 ρ を用いた. ρ = 1 − 6 P D2 N (N2− 1) ここで,D は2つの順位間で同じ画像の順位の差,N は順位付け対象の検索画像数である.また画像 8 枚中 で1枚は目的対象画像に用いたため,N=7 である.各 画像1∼8を各々目的対象画像に用いた場合について, 全計算法と SIFT ベクトル SASH 法の順位相関係数 ρ を求め,それを全目的対象画像について平均を計算し たものが手法の精度と考えられる.全計算法と SIFT ベクトル SASH 法の順位相関値を表7にまとめる. 表 7: 手法の順位相関値SASH 法 1 SASH 法 2 SASH 法 1 SASH 法 2
min min tail tail
全計算法 min 1 1 全計算法 tail 0.9911 0.9955 これより最小値法を距離指標とした際には,全計算法 と SIFT ベクトル SASH 法の順位相関が 1 となる,つ まり SASH 法を用いて{mindtQ|t ∈ Q}の最小値を正 確に探索できていることがわかる.また,ロングテール 平均値法を距離指標とした際は,それらの相関係数が 0.99 以上であるため,SIFT ベクトル SASH 法を用い て,{mindtQ|t ∈ Q}の探索を正確にはできないが,十 分に精度のよい探索を行うことができるといえる.こ のことから,SIFT ベクトル SASH 法を用いることに より,高速で高精度な SIFT ベクトル間最小距離計算 を行えることがわかる.
5
おわりに
本研究において,2画像間の距離指標と高速画像間 距離計算手法を提案した.画像距離指標として,現状 では,最小値法又はロングテール平均値法がある程度 効果的といえる.また,SIFT ベクトル SASH 法を用い ることで,高精度を維持しつつ,十数倍の高速 SIFT ベ クトル間最小距離計算を可能とした.課題として,画 像の性質を考慮したより効果的な距離指標を開発する ことが挙げられる.また,本研究では画像2枚の距離 計算を行う方法を提案したが,大量の画像データが存 在するときに,効率的な画像検索を行うことができる 手法を考案する必要がある.参考文献
[1] P.Z.Paolo Ciaccia, Fausto Rabitti and M.Patella. M-tree HomePage, DEIS-CSITE-CNR, Univer-sity of Bologna,
http://www-db.deis.unibo.it/Mtree/, 2007. [2] Michael E.Houle,Jun Sakuma,Fast
Approx-imate Similarity Search in Extremely High-Dimensional Data Sets,Proceedings of the 21st International Conference on Data Engineering (ICDE’05),pp619-630(2005)
[3] David G.Lowe, Distinctive Image Features from Scale-Invariant Keypoints, International Journal of Computer Vision, 60, 2, pp.91-110(2004) [4] Friedman.J.H., Benteley.J.L, Finkel.R.A, An
al-gorithm for finding best matches in logarithmic expected time, ACM Transactions on Mathemat-ical Software, 3(3), pp.209-226(1977)
[5] Beis.J, Lowe.D.G, Shape indexing using approx-imate nearest-neighbour search in high demen-tional spaces, In Conference on Computer Vision and Pattern Recognition, pp1000-1006(1997) [6] 深田 健太, E.Houle, Michael, 鷲尾 隆,ノイズ
を含む高次元データにおける K-NN ベースクラス タリング手法,The Japanese Society for artifical Intelligence(JSAI) ,(2007)
[7] 高橋倫也, 志村隆彰,「特集 極値理論について」, 統計数理 (2004) 第 52 巻第 1 号 1-4 ,(2004) [8] 本城勇介, 篠田昌弘,統計的手法による作用モデ