最先端の自動並列化コンパイラ技術
10
0
0
全文
(2) 動並列化コンパイラでは,プログラムの実行時間の多く. ると,. はループで消費されるということから,ループの並列化. • 異なる能力のプロセッサが,要求される性能に合わせ. を中心に研究開発が行われていた. 2). .このようなループ. を対象とした並列処理では,1980 年代に我が国のコン パイラが世界をリードした自動ベクトル化コンパイラ. 1). が思い出される.この国産ベクトル化コンパイラとベク. 集積するプロセッサ数を変えるだけで,短期間で開発 できる.. • クロック周波数もチップ内プロセッサ単位でローカル に上げやすい.. トルスーパーコンピュータハードウェアの優位性が高か. • アプリケーションにより,一時的に利用されないプロ. ったことから,マルチプロセッサ用の自動並列化コンパ. セッサには電力を供給しないなど低消費電力化が可. イラ. 能.. 1)∼ 3). では米国が 1980 年代中旬から製品開発を行. っていたのに対し,我が国では 1990 年代中旬以降と開. という利点もあり,今後の携帯電話,ゲーム,PDA ,. 発が大幅に遅れた.. ディジタルテレビ等多くの SoC(System on Chip)分野. 現在,スーパーコンピュータのような超高性能コン. でも採用されていくと考えられる.. ピュータでは,地球シミュレータに代表されるベクト. このためマルチプロセッサ用の自動並列化コンパイラ. ルプロセッサを並列接続したベクトル型マルチプロセッ. の開発は,SoC 分野からスーパーコンピュータ分野,さ. サシステム,あるいは図 -1 の Power4 のような汎用プ. らにはそれらの情報システムを利用する多くの科学技術. ロセッサを並列接続した図 -2(b)の IBM pSeries690 の. 分野の研究開発競争力強化のために有用である.. ようなスカラ型マルチプロセッサ,またスカラ型マルチ. このような背景の下,マルチプロセッサシステム用. プロセッサをノードとしそれを多数接続した米国 ASCI. 自動並列化コンパイラ技術を世界最先端に高めるため,. (Accelerated Strategic Computing Initiative)マシンの. 2000 年 9 月より政府ミレニアムプロジェクト IT21 の. ように,すべてがマルチプロセッサ化されている.. 一環としてアドバンスト並列化コンパイラプロジェクト. また,高性能コンピュータだけでなく,図 -2(a)に. が 3 年度計画で開始された.このプロジェクトは,経. 示すような 4 プロセッサ程度のデスクトップワークス. 済産業省ミレニアムプロジェクト官民共同研究開発プロ. テーション,大学研究室単位で購入可能なエントリレベ. ジェクトとして,新規産業創出型産業科学技術研究開発. ルサーバなど多くのコンピュータがマルチプロセッサ方. 制度(産技制度)に基づき,新エネルギー・産業技術総. 式に移行している.さらには,図 -1 の Power4 は,1 チ. 合開発機構(NEDO)からアドバンスト並列化コンパイ. ップ上に 2 つのプロセッサコアと共有 L2 キャッシュを. ラ技術研究体が委託を受け行われた.なお,この研究体. 集積したチップマルチプロセッサで,今後の高性能プロ. は(財)日本情報処理開発協会(JIPDEC),早稲田大学,. セッサの多くはこのようなチップマルチプロセッサにな. 産業技術総合研究所で構成され,参加企業の日立,富士. ると考えられている.. 通からの研究者は JIPDEC に出向するかたちで共同体に. このようなチップマルチプロセッサ方式が採用され. 加わり,再委託の電気通信大学,東京工業大学,東邦大. (a). Tendler, J. M., Dodson, J. S., Fields, J. S. Jr., Le, H. and Sinharoy, B. : POWER4 System Microarchitecture, IBM Journal of Research and Development, Vol46, No. 1 (2002). 図 -1 チップマルチプロセッサ IBM Power4. (b). (a) 4 プロセッサ・ワークステーション Sun Ultra 80 (b) 32 プロセッサ・ハイエンドサーバ IBM pSeries690 図 -2 共有メモリ型マルチプロセッサ・システム. IPSJ Magazine Vol.44 No.4 Apr. 2003. 385.
(3) 学のメンバとともに研究開発を行っている.. ケジューリングすなわち割当ておよび実行順序の決定,. 次章では,このアドバンスト並列化コンパイラプロ. プロセッサ間データ転送の最小化あるいはキャッシュ・. ジェクトで研究開発された最先端の自動並列化コンパ. 分散共有メモリの有効利用を目指したデータ分割配置. イラ技術を,従来の基本的な技術も織り交ぜながら解説. (データ分散)を行う.最後にそのプログラムのスケジ. する.. ューリング結果およびデータ分散結果を実現する並列プ ログラムの生成を行う.生成されたプログラムは,OS の管理の下,ターゲットマシン上で実行される.. 最先端の自動並列化技術. 通常のコンパイラでは,生成される並列プログラム は機械語で記述されるが,本アドバンスト並列化コン. 自動並列化コンパイラは,ユーザが記述した通常の逐. パイラ(以下 APC)プロジェクトでは生成される並列. 次型プログラム中から並列性を抽出するため,最初に,. プログラムがどの共有メモリ型マルチプロセッサシ ステム上でも動作するように,共有メモリ型マルチプ. (1)データの定義・使用関係による実行順序制約を解析 するデータ依存解析. 1)∼ 3). ロセッサシステム用の標準並列化言語拡張 OpenMP (http://www.openmp.org)で記述されたプログラムを. (2)条件分岐などの制御の流れを解析し,どの条件分岐. 生成する.OpenMP は,Fortran, C, C++ 等に対する拡. がどの命令集合の実行を確定するかという制御依存解. 張で,並列実行可能部分の指定および同期等をコンパイ. 析. ラに対する指示文の形(この指示文は,対応コンパイラ. 1). (3)依存によりそのままでは並列化できないプログラム. 以外ではコメント文として認識される)で記述する.す. 部分を,同じ計算を行う並列性のある表現へと変換す. なわち,APC プロジェクトで開発するコンパイラは参. るプログラムリストラクチャリング. 加企業開発のマルチプロセッサ以外でも処理を高速化で. 1)∼ 3). きることを目指し,図 -3 のように逐次 FORTRAN プログ を行う.次に,並列実行可能な部分のプロセッサへのス. ��� ���������� ������������� ��������. ラムから,OpenMP 並列化指示文を持つ FORTRAN プロ. ��������� ���� ������������ � ����� ������������ � ��� ������������. ���� ���������� ��������. ������ ������� �������. � ���������������� � �����������. ���������� ��������������� � ������������ �������� � ������ ������������. ���������� � ������ ���������� � ������� ����������. ������ ���� ����������. ����������� ��������� � ������ ����� � ������ ����� � ������������ �������. �������� ������������� ������ ������ ������� ������������� ��������� ���������� ��� ��������� � ��������� ������� ����. ����������������� ��������� ��������� �� �������� ����������. ������� ����. ��� ����� � ��� �� ������� ��� �� ������� ������� ������ � �������. ��� ��� ����� ��. ��� ������. ��� ����������. ������� �� ������ ������ �������� �������� 図 -3 APC コンパイラの構成. 386. 44 巻 4 号 情報処理 2003 年 4 月.
(4) グラムを生成し,ターゲットマルチプロセッサ用のコン. に,配列データをプライベート化し並列化可能とする. パイラで機械語プログラムに翻訳し実行するという方式. 方式). をとっている.また,一部のエキスパートユーザ向け. (i)ユニモジュラー変換(ループリバーサル,パーミュ. に,実行プロファイルを利用したプログラムチューニン. テーション,スキューイング等を線形変換で統一的に. グツールも用意している.. 扱う方式). この APC コンパイラは,現在のループ並列化の限界 を超えるため,早稲田大学で提案されたマルチグレイン. など各種のプログラムリストラクチャリングを行い並列. 並列化. 性を高めようとしている.しかし,このループ並列化は. 1),6),7). の実現を目指している.. 長期にわたるさまざまな研究のためすでに成熟期に達し. ループ並列化. ており,今後大幅な性能向上は難しいといわれている.. ここで,ループ並列化とは,現在市販されているマル. そこで,マルチグレイン並列化ではこのループ並列化に. チプロセッサシステム用のコンパイラが採用している並. 加え,より大きい並列化単位であるサブルーティンおよ. 列処理方式で,ループのイタレーション(繰り返し)間. びループ間の粗粒度並列性,あるいは基本ブロックと呼. のデータ依存を解析して各イタレーションを独立に処. ばれる算術代入を行うステートメントが連続して並んで. 理してよいと判断できる場合には,各イタレーション. いるプログラム部分内のステートメント間近細粒度並列. を別々のプロセッサに割り当てて並列処理する方式で. 性を階層的に引き出し,プログラム全域の並列性を使用. ある. しようとする方式である.. 1)∼ 5). .このループ並列化を効果的に行うために,. 現在各社から販売されている商用並列化コンパイラ, 4). および米国イリノイ大学で開発されている Polaris ,. Parafrase2 ,あるいはスタンフォード大学で開発されて 5). いる SUIF のような研究コンパイラは,. マルチグレイン並列化. 単一プログラム中のサブルーティン,ループ,基本ブ ロック間の並列性を利用する粗粒度並列処理は,マクロ データフロー処理とも呼ばれ. 1),6),7). ,APC コンパイ. (a)ステートメントの実行順序の変更. ラのコアの 1 つとなる早稲田大学 OSCAR マルチグレイ. (b)ループディストリビューション(単一ループを少数. ン Fortran 並列化コンパイラで初めて実現された. 1). .. のステートメントを含む複数のループへ分割し,ベク. OSCAR コ ン パ イ ラ で は, 粗 粒 度 タ ス ク( マ ク ロ タ. トル化したり,ループ並列性を高める方式). ス ク )と し て, 単 一 の FORTRAN プ ロ グ ラ ム よ り RB. (c)ノードスプリッティング/スカラエクスパンション. (Repetition Block),SB(Subroutine Block),BPA(Block. (データのコピーあるいはスカラ変数の配列変数への. of Pseudo Assignment Statements)の 3 種類のマクロ. 拡張を行うことにより逆依存,出力依存と呼ばれる見. タスクを生成する.RB は各階層での最外側ナチュラル. た目上のデータ依存を削除し,並列化を可能とする方. ループであり,SB はサブルーティン,BPA はスケジュ. 式). ーリングオーバーヘッドあるいは並列性を考慮し融合あ. (d)ループインターチェンジ(ネストされたループの外. るいは分割された基本ブロックである. 1). 側と内側を入れ替え,より大きな並列性を引き出した. 次にマクロタスク間の制御フロー. り,キャッシュアクセスを最適化する方式). 解析し,図 -4(a)のようなマクロフローグラフ(MFG). (e)ループアンローリング(ループの複数イタレーショ. とデータ依存を. を生成する.MFG では, 各ノードがマクロタスク(MT) ,. ンを展開し,より大きな並列性を抽出したり,ループ. 点線のエッジが制御フロー,実線のエッジがデータ. 制御あるいはキャッシュプリフェッチオーバーヘッド. 依存,ノード内の小円が条件分岐文を表している.ま. を削減する方式). た,MT7 のループ(RB)は,内部で階層的に MT および. (f)ループフュージョン(複数の別々なループを 1 つの. MFG を定義できることを示している.. 1),6). ループへ融合し,ループ制御オーバーヘッドを軽減し. 次に,マクロタスク間制御依存. およびデータ依. たり,データローカリティを高める方式). 存を統合的に解析し各マクロタスクが最も早く実行で 1). (g)ストリップマイニング(1 重ループをネストされた. きる条件(最早実行可能条件) すなわちマクロタスク. 多重ループへと変換し,キャッシュ等限られた容量の. 間の並列性を検出する.この並列性をグラフ表現したの. メモリの有効利用,階層的なループ並列化を可能とす. が図 -4(b)に示すマクロタスクグラフ(MTG)である.. る方式). MTG でも,ノードは MT ,実線のエッジがデータ依存,. (h)アレイプライベタゼーション(ループ内テンポラリ. ノード内の小円が条件分岐文を表す.ただし点線のエッ. ー配列による見た目上のデータ依存を削除するため. ジは拡張された制御依存を表し,矢印のついたエッジは IPSJ Magazine Vol.44 No.4 Apr. 2003. 387.
(5) 元の MFG における分岐先,実線の円弧は AND 関係,点. タスク MT1_3 および並列化できないループであるマク. 線の円弧は OR 関係を表している.たとえば,MT6 への. ロタスク MT1_4 内では,階層的にマクロタスクグラフ. エッジは,MT2 中の条件分岐が MT4 の方向に分岐する. MTG1_3 ,MTG1_4 を生成し,各グラフの並列度を推. か,MT3 の実行が終了したとき,MT6 の実行が可能に. 定後,その並列度に合ったスレッドグループを生成し階. なることを示している.. 層的に並列処理している.この例の場合,これらのマク. 次にコンパイラは,MTG 上の MT をプロセッサグル. ロタスクグラフは条件分岐を含んでいるため,ダイナミ. ープへスタティックに割当てを行う(スタティックスケ. ックスケジューリングが適用される.図中では,マクロ. ジューリング)か,実行時に割当てを行うためのダイナ. タスクグラフ MTG1_3 に対しては,1 つのスレッドに. ミックスケジューリングプログラムを Dynamic CP アル. スケジューリングを任せる集中型ダイナミックスケジュ. ゴリズムを用いて生成し,これを並列化プログラム中. ーリングを適用する場合が示されており,マクロタスク. に埋め込む.これは,従来のマルチプロセッサのよう. グラフ MTG1_4 に対しては 4 スレッドを 2 スレッドず. に OS あるいはランタイムライブラリに粗粒度タスクの. つの 2 グループに分け,各スレッドグループがスケジ. 生成,スケジューリングを依頼すると数千から数万ク. ューリングを行う分散型ダイナミックスケジューリング. ロックという大きなオーバーヘッドが生じてしまう可能. の場合が示されている.. 性があり,これを避けるためである.このような並列化. APC コンパイラは,この例のように多重にネストさ. プログラムを OpenMP を用いて生成するために,APC. れたプログラムに対しても,各階層のマクロタスクグラ. コンパイラでは図 -5 に示すワンタイムシングルレベル. フの並列度をループ並列性も含め推定し,各階層ごとに. スレッド生成法. その並列度に見合ったスレッドグループ数を自動的に設. 6),7). を開発した.図 -5 は,サブルー. 7). ティン,逐次ループ等ネスト構造を持つプログラムを. 定し,フレキシブルな階層的並列処理を可能とする. 8 スレッドで階層的に並列処理する場合に,ワンタイム. さらに,このような粗粒度並列性を抽出する際には,. シングルレベルスレッド生成法を用いて生成される並. サブルーティン間にわたるデータ依存を正確に解析す. 列化プログラムのイメージを表している.この例では,. ることが重要となる.APC プロジェクトではこのイン. 第 1 階層のマクロタスクグラフがデータ依存エッジの. タープロシージャ解析の高度化に関する研究開発も行っ. みを持っているため,第 1 階層の 4 つのマクロタスク. た.APC コンパイラは,図 -6 に示すようにサブルーテ. をコンパイラがスタティックスケジューリングを適用. ィンにわたる定数の伝搬を行い,必要に応じクローンと. し,各 4 スレッドからなる 2 つのスレッドグループに. 呼ぶサブルーティンのコピーを作成し,その結果不要と. 割り当てている.また,サブルーティンであるマクロ. なる条件分岐文等を削除しプロシージャ間のデータ依存. (a)A Macro Flow Graph. (b)A Macro Task Graph. 図 -4 マクロタスクフローグラフからの最早実行可能条件解析によるマクロタスクグラフの生成. 388. 44 巻 4 号 情報処理 2003 年 4 月. ..
(6) を正しく解析できるようにしている. 7). .これにより粗粒. 実現する実用的な手法を開発し,図 -7 に示すようなパ. 度タスク間の並列性をより多く引き出せるとともに,ル. イプライン化された並列コードを OpenMP を用いて生. ープボディ中にサブルーティンコールを含むループの並. 成することに成功した. 列化もより高精度に行うことができるようになった. 7). .. 7). .. メモリ利用最適化技術. また APC では,不完全ネストループより並列性を引 き出すとともに,データローカリティを高め,さらにイ. 実際のマルチプロセッサシステム上で効果的な並列処. タレーション間同期オーバーヘッドを減らす手法として. 理を実現するためには,並列性の抽出のみならず,メモ. スタンフォード大 SUIF グループにより提案されたがコ. リアクセスオーバーヘッドをいかに抑えるかが重要な課. ンパイラには実装できなかった Affine Partitioning を. 題となる.これはプロセッサの動作速度向上に対しメモ. 8). ����������� ���������� ����. ����� �� ��������� ������ ���� ��� ������������ ���������� �������� ���������� �������� �������. ��� ����� ����������� ���������� ����. �����. ����� �����. ����� ��. ����� ��. ��. �������. ��. ��. ��. ���� ����. ����� ����� ����� �����. ����� ����� �����. ��. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. �����. ����� ��� ��������. ��� �����. ������ ������. ������ ������. ��� �����. ��. ���� ����. �����. �����. ��. �����. �����. �����. ��. 図 -5 OpenMP を用いた階層的マルチグレイン並列化のための並列コード生成方式. �������� �������� ��������� ����� ���� ������ ���� ������. ���� ������������ ���� ������. ���������� ������ �� ����� ���� ���� ���� ���� �� ����� ���� ���� ���� ����� ���������� ������������ ���� ���� ���������� ������ ���� ����. 図 6 定数伝搬・クローニングを用いたインター プロシージャ解析. �� �����. �� � � �� ���� ���������� �� � � ������ ����� ��� ��� ����� �������������� �����. �� �����. �� �. 図 7 Affine Partitioning を用いたパイプライン並列化 IPSJ Magazine Vol.44 No.4 Apr. 2003. 389.
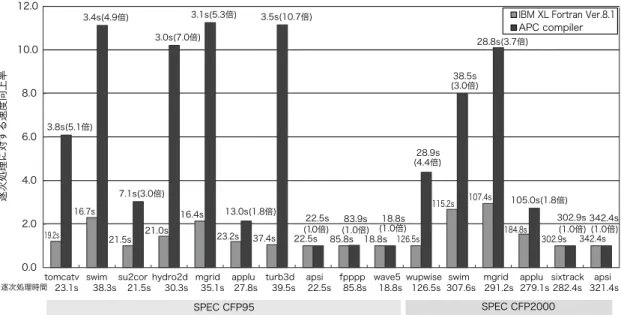
(7) リのアクセス速度向上が追いついていないために生じる もので,主記憶共有型マルチプロセッサではキャッシュ. APC コンパイラの性能. の有効利用が,また分散共有メモリ型マルチプロセッサ では近接分散共有メモリの有効利用が性能に大きく影響. ここでは,前章までで述べたコンパイラ技術を統合. する.. した APC コンパイラを市販の主記憶共有メモリ型マル. このため APC コンパイラでは,主記憶共有型マルチ. チプロセッサシステム上で性能評価した結果について述. プロセッサ用の分散キャッシュメモリの有効利用を目指. べる.. したデータローカライゼーション技術と,分散共有メモ. APC コ ン パ イ ラ は 図 -3 に 示 し た よ う に, 逐 次 型. リ型マルチプロセッサのためのファーストタッチ制御方. FORTRAN プログラムを入力すると OpenMP 指示文を. 式を開発した.データローカライゼーションは,マクロ. 用いて並列化された FORTRAN プログラムを生成する.. タスクグラフ上でデータ依存が存在する複数のループに. 今回評価に使用したマシンは,Power4 チップを搭載し. わたりイタレーション間のデータ依存を解析し(インタ. た IBM pSeries690 16 プロセッサ・ハイエンドサーバ,. ーループデータ依存解析) ,プロセッサ間データ転送が. IBM RS6000 604e high-node 8 プロセッサ・ミッドレ. 最小になり,さらにデータがキャッシュに収まるように. ンジサーバ,Sun Ultra 80 4 プロセッサデスクトップワ. ループとデータを分割(ループ整合分割)する. .さら. ークステーションである.これらのマシンを使用するに. に一度キャッシュ上に載せたデータを複数のループにわ. あたって,使用するコンパイラは,pSeries690 では最. たり使用できるように,前のループが終了してから次の. 新の IBM コンパイラ XL Fortran Ver.8.1 ,RS6000 では. ループを実行するという通常の実行順序ではなく,前の. APC プロジェクト開始時のコンパイラ XL Fortran Ver.. ループの一部(整合分割により生成された小ループ)を. 7.1 ,Ultra 80 では Sun Forte 6 update 2 を用いた.評. 実行すると同一のデータにアクセスする他のループの一. 価においては,SPEC CFP95 および SPEC CFP2000 のう. 部,またそれにデータ依存する他のループの一部を実行. ちの全 FORTRAN77 プログラム 16 本に対し APC コンパ. するという方式で,キャッシュ上のデータを長期間有効. イラを適用し,生成された OpenMP コードを上述の各. 利用できるようにしている.さらに,プログラム中の配. 社コンパイラを用いてコンパイルして実行した.本アド. 列サイズがキャッシュサイズの整数倍あるいは整数分の. バンスト並列化コンパイラプロジェクトにおいてはプロ. 1 の場合,配列間でラインコンフリクトが頻発すること. ジェクトの基本計画としてプロジェクト開始当時のルー. がある.これを避けるため,本データローカライゼーシ. プ並列化コンパイラの性能を概ね 2 倍上回るという数. ョン手法では配列サイズを拡張する配列間パディングを. 値目標を与えられており,この性能評価を客観的に行う. 行い,ローカライゼーション後のラインコンフリクトを. ために性能評価を担当するグループがプロジェクト内に. 最小化する方式も開発している. 設置されている.コンパイラ開発プロジェクトで数値目. 6). 7). .. また,分散共有メモリ型マルチプロセッサ用の自動デ. 標を持った研究開発は世界でも例がなく,2 倍をどのよ. ータ分散では,SGI 社 Origin2000 の OS が,最初に当該. うに評価するかが問題になるが,本プロジェクトにおい. データを触ったプロセッサ上のメモリにデータを割り付. ては使用可能なプロセッサ数までのプロセッサを用いた. けるファーストタッチ方式を採用していることから,こ. 際の商用コンパイラの最高性能と APC コンパイラの最. れを利用しコンパイラが望むデータ分散を実現する方. 高性能を比較する方式をとることとした.これはループ. 式を開発した.これは,プログラム中で最も処理時間を. 並列性のみを使っている商用コンパイラに比べ,APC コ. 消費するループ(メインループ)で要求されるデータ分. ンパイラはより大きな並列性およびメモリアクセスオー. 散に合わせ,コンパイラがその分散を実現するダミーの. バーヘッドの軽減が可能であるためプロセッサ数ととも. ループ(ファーストタッチ制御ループ)を生成し,メイ. に性能が向上する場合が多いのに対して,商用コンパイ. ンループ内での遠隔分散共有メモリへのアクセスを最. ラでは,プロセッサを増やすと逆に性能が低下してしま. 小化する.この方式を用いると,配列へのアクセスパタ. う場合があり,たとえば同じ 16 プロセッサ同士の性能. ーンが実行時まで分からないため人手でもデータ分散が. を比較すると APC コンパイラの性能が非常によく見え. 難しかった配列の間接参照(配列添え字中に他の配列が. てしまうためである.. 現れるようなメモリ参照)を伴うプログラムに対しても. このように各マシンが持つ最大プロセッサ数までの最. 最適なデータ分散を実現できる.これにより,SGI 社コ. 高性能を,逐次処理に対するスピードアップ率として表. ンパイラに対し,32 プロセッサ Origin2000 上で NAS. 示したのが,図 -8 から図 -10 である.. Parallel Benchmarks CG プログラムを 6.6 倍高速に実行. 図 -8 は,16 プロセッサ pSeries690 上での性能であ. できることを確かめている.. り,各バー 2 本の組のうち,左側が XL Fortran Ver.8.1. 390. 44 巻 4 号 情報処理 2003 年 4 月.
(8) 12.0. 3.1s(5.3倍). 3.4s(4.9倍). 10.0. 逐次処理に対する速度向上率. IBM XL Fortran Ver.8.1 APC compiler. 3.5s(10.7倍). 3.0s(7.0倍). 28.8s(3.7倍) 38.5s (3.0倍). 8.0. 6.0. 3.8s(5.1倍) 28.9s (4.4倍). 4.0. 2.0. 0.0. 7.1s(3.0倍) 16.7s 19.2s. 21.0s. 21.5s. 23.2s. 107.4s. 115.2s. 13.0s(1.8倍). 16.4s. 105.0s(1.8倍). 22.5s 18.8s 83.9s (10倍) . (1.0倍) (1.0倍) 22.5s 85.8s 18.8s 126.5s. 37.4s. tomcatv swim su2cor hydro2d mgrid applu turb3d 38.3s 21.5s 30.3s 35.1s 27.8s 39.5s. 逐次処理時間 23.1s. 184.8s. 302.9s 342.4s (1.0倍) (1.0倍) 302.9s 342.4s. apsi fpppp wave5 wupwise swim mgrid applu sixtrack apsi 22.5s 85.8s 18.8s 126.5s 307.6s 291.2s 279.1s 282.4s 321.4s. SPEC CFP2000. SPEC CFP95. *各バーの数字はIBM社製最新コンパイラXL Fortran Ver.8.1と,開発したAPCコンパイラによる各プログラムの処理時間[s:秒]を示す. APCコンパイラによる処理時間横のカッコ内は,IBMコンパイラに比べAPCコンパイラが何倍処理速度を向上できるかを示している.. 図 -8 IBM ハイエンドサーバ pSeries690 16 プロセッサ上での APC コンパイラの性能 12.0. IBM XL Fortran Ver.7.1 APC compiler 109s (2.0倍). 10.0. 逐次処理に対する速度向上率. 115s(3.7倍). 8.0. 89s (4.1倍). 859s(1.5倍). 90s(6.2倍). 6.0 218s. 333s(5.2倍). 97s (2.1倍). 1755s. 191s(2.6倍). 4.0. 2.0. 1115s(1.6倍). 87s(2.2倍). 1328s(2.9倍). 1328s. 193s 200s. 364s. 426s 487s. 0.0. tomcatv swim su2cor hydro2d mgrid 1044s 492s 988s 592s 逐次処理時間: 637s. 555s. applu 705s. turb3d 555s. 280s 529s 501s (1.0倍) (1.0倍) (1.0倍) 529s 1741s 501s 280s. apsi 280s. 3803s. 3859s 1842s (1.0倍) (1.0倍) 1842s 3859s. fpppp wave5 wupwise swim mgrid applu sixtrack apsi 501s 529s 1741s 7896s 5520s 6051s 1842s 3859s. SPEC CFP2000. SPEC CFP95. *各バーの数字はIBM社製最新コンパイラXL Fortran Ver.7.1と,開発したAPCコンパイラによる各プログラムの処理時間[s:秒]を示す. APCコンパイラによる処理時間横のカッコ内は,IBMコンパイラに比べAPCコンパイラが何倍処理速度を向上できるかを示している.. 図 -9 IBM RS6000 604e high node 8 プロセッサ上での APC コンパイラの性能 10.0. Sun Forte6 Update2 APC compiler. 21s(5.4倍). 9.0. 逐次処理に対する速度向上率. 8.0 7.0. 19s(5.1倍). 6.0 31s(2.5倍) 21s(1.1倍). 5.0. 22s. 3.0 115s. 2.0 1.0 0.0. 30s (1.0倍) 31s 77s. 92s (1.4倍) 133s. 97s. tomcatv swim. 逐次処理時間: 121s. 198s. su2cor hydro2d mgrid. 70s. 141s. 97s. 216s(4.0倍). 56s(3.5倍). 4.0. applu. 172s. 194s. turb3d. 201s. 387s 58s (1.0倍) (1.0倍) 58s. apsi. 58s. 387s. fpppp. 387s. 98s (1.0倍) 98s. 870s. 878s 569s 763s 1313s 962s (1.0倍) (1.2倍) (1.0倍) (1.0倍) (1.1倍)579s 1094s 1046s 763s 1313s. wave5 wupwise swim. 98s. 881s. SPEC CFP95. 1139s. mgrid. 846s. applu. 1453s. sixtrack. 763s. apsi. 1313s. SPEC CFP2000. *各バーの数字はSun社製最新コンパイラ Forte 6 Update 2と,開発したAPCコンパイラによる各プログラムの処理時間[s:秒]を示す. APCコンパイラによる処理時間横のカッコ内は,IBMコンパイラに比べAPCコンパイラが何倍処理速度を向上できるかを示している.. 図 -10 4 プロセッサ Sun Ultra 80 ワークステーション上での APC コンパイラの性能 IPSJ Magazine Vol.44 No.4 Apr. 2003. 391.
(9) ループ並列化コンパイラを用いたときのスピードアッ. 野でマルチグレイン並列化という新しい技術の優位性を. プ率であり,右側が APC コンパイラを用いたときのス. 示すには,参加メンバが所有しているコンパイラ技術を. ピードアップ率である.図中プログラム名の下に書かれ. フル活用した短期間での開発実証が必須と考えたためで. ている数値は逐次処理時間 [ s ] を表しており,各バー上. ある.. の数字は並列処理時の処理時間 [ s ] を,またカッコ内の. プロジェクトを通じ,従来例を見ない数値目標は大. 数字は APC コンパイラによる XL Fortran コンパイラに. きなプレッシャーであったが,最新の 16 プロセッササ. 対する速度向上率を示している.この図を見ると分かる. ーバ上で,そのマシン用の最新コンパイラと比べ,平均. ように,APC コンパイラは SPEC CFP95 turb3d プログ. 3.5 倍の速度向上を達成できたことは,開発者としても. ラムに対し,pSeries690 上で 10.7 倍の高速化を達成で. 予想しなかった好成績である.これは,同一のハードウ. きることが分かる.また 16 プログラムの平均速度向上. ェア上で,APC コンパイラを一度通すだけで自動的に. 率を計算すると算術平均で 3.5 倍という数値が得られて. 性能向上を得られることを意味しており,この技術をさ. おり,最新のマシンおよび最新の市販コンパイラに対し. らに磨けばマルチプロセッサを使用する各種アプリケー. て,プロジェクトの目標を大幅に上回る性能を得ること. ションユーザの方の計算速度向上およびプログラム開発. ができた.. 期間の短縮が可能になると考えている.. ま た, 図 -9 は 8 プ ロ セ ッ サ IBM RS6000 上 で の 性. また,このコンパイラは高性能コンピュータの利用. 能を表している.プロセッサ数が少ないこともあり,. 者のみならず,今後のチップマルチプロセッサの性能. pSeries690 と比べ性能向上率は小さいが,最大で 6.2. 向上,価格性能比向上,アプリケーション開発期間の短. 倍,平均で 2.4 倍の性能を得ることができた.これら. 縮にも役立つものと期待できる.特に,ゲーム,携帯電. の IBM マシンで最大性能が得られた turb3d では,クロ. 話,PDA などの SoC 分野ではハードウェア・ソフトウ. ーニングを伴うインタープロシージャ解析,ワンタイム. ェアの開発期間短縮,価格性能比の向上,アプリケーシ. シングルレベルスレッド生成を用いたマルチグレイン並. ョンソフトウェアの質が市場を分ける重要な要素となる. 列化が有効に働き上記のような性能が得られている.ま. ため,自動並列化コンパイラが今後この分野の競争力強. た,tomcatv ,swim 等のプログラムではデータローカ. 化のために役立つものと考えている.. ライゼーションを用いたキャッシュ最適化が有効に働 き,良好な速度向上が得られた. 図 -10 は上記 2 マシンと比べ価格の低い 4 プロセッ サ主記憶共有型ワークステーション上での性能を表し ている.このマシンは,上記 2 マシンに比べメモリ性. 謝辞 本稿執筆にあたり,種々ご協力いただきまし. た経済産業省,新エネルギー・産業技術総合開発機構 (NEDO),IT21 評価助言委員会,アドバンスト並列化コ ンパイラプロジェクトの皆様に感謝いたします.. 能が低いため,キャッシュ最適化が性能に大きく影響す る.このマシン上では,レベル 2 キャッシュがダイレ クトマップ方式であるためパディングによるラインコン フリクト除去を併用したキャッシュ最適化がきわめて有 効で,SPEC CFP95 swim では 4 プロセッサで逐次処理 に比べ 9.3 倍の速度向上,Forte コンパイラに比べ 5.4 倍の速度向上を得ることができた.また全 16 プログラ ムに対する速度向上の平均でも 2.0 倍という数値を得ら れている. 以上のように,APC コンパイラは複数の機種の主記 憶共有メモリ型マルチプロセッサに対してきわめて高い 性能を示すことが確かめられた.. 自動並列化コンパイラの現状および今後 アドバンスト並列化コンパイラプロジェクトは 2003 年 3 月に実質 2 年半の研究開発を終了する.このよう な短い研究開発期間を選んだのは,競争の激しいこの分. 392. 44 巻 4 号 情報処理 2003 年 4 月. 参考文献 1)笠原博徳 : 並列処理技術,コロナ社 (1991). 2)Banerjee, U.: Loop Parallelization, Kluwer Academic Pub. (1994). 3)Wolfe, M.: High Performance Compilers for Parallel Computing , Addison Wesley (1996). 4)Eigenmann, R., Hoeflinger, J. and Padua, D.: On the Automatic Parallelization of the Perfect Benchmarks, IEEE Trans. on Parallel and Distributed Systems, Vol.9, No.1 (1998). 5)Hall, M. W., Anderson, J. M., Amarasinghe, S. P., Murphy, B. R., Liaos.-W., Bugnion, E. and Lam, M. S.: Maximizing Multiprocessor Performance with the SUIF Compiler, IEEE Computer (1996). 6)Kasahara, H., Obata, M., Ishizaka, K., Kimura, K., Kaminaga, H., Nakano, H., Nagasawa, K., Murai, A., Itagaki, H. and Shirako, J.: Multigrain Automatic Parallelization in Japanese Millenium Project IT21 Advanced Parallelizing Compiler, Proc. of IEEE PARELEC, Warsaw, Poland (Sep. 23, 2002). 7)APC2003: アドバンスト並列化コンパイラ国際シンポジウム資料, (財)日本情報処理開発協会 (JIPDEC), 早稲田大学理工学部 (Mar. 20, 2003). 8 )Lim , A. W. and Lam. , M. S.: Cache Optimizations with Affine Partitioning, Proceedings of the Tenth SIAM Conference on Parallel Processing for Scientific Computing (2001). (平成 15 年 3 月 5 日受付).
(10)
(11)
図

関連したドキュメント
An easy-to-use procedure is presented for improving the ε-constraint method for computing the efficient frontier of the portfolio selection problem endowed with additional cardinality
It is suggested by our method that most of the quadratic algebras for all St¨ ackel equivalence classes of 3D second order quantum superintegrable systems on conformally flat
[18] , On nontrivial solutions of some homogeneous boundary value problems for the multidi- mensional hyperbolic Euler-Poisson-Darboux equation in an unbounded domain,
Since the boundary integral equation is Fredholm, the solvability theorem follows from the uniqueness theorem, which is ensured for the Neumann problem in the case of the
The rationality of the square root expression consisting of a product of repunits multi- plied by twice the base of one of the repunits depends on the characteristics of the
Next, we prove bounds for the dimensions of p-adic MLV-spaces in Section 3, assuming results in Section 4, and make a conjecture about a special element in the motivic Galois group
Transirico, “Second order elliptic equations in weighted Sobolev spaces on unbounded domains,” Rendiconti della Accademia Nazionale delle Scienze detta dei XL.. Memorie di
We study the classical invariant theory of the B´ ezoutiant R(A, B) of a pair of binary forms A, B.. We also describe a ‘generic reduc- tion formula’ which recovers B from R(A, B)
