MPICH サンプルプログラム
0 並列計算について 0.1 並列プログラミングライブラリのメッセージパッシングモデル 並列プログラムにはメモリモデルで分類すると,共有メモリモデルと分散メモリモデルの2 つに分 けられる.それぞれ次のような特徴がある. ・ 共有メモリモデル 複数のプロセスやスレッドが事項する主体となり,互いに通信や同期を取りながら計算が継続される. スレッド間の実行順序をプログラマが保証してやらないと,思った結果が得られない. 共有メモリモデルは,pthread や OpenMP などで記述する. ・ メッセージパッシングモデル 複数のプロセスがメモリ空間を独立に持ちながら計算が実行されている.そこで,プロセス間でデ ータ通信の必要が生じた場合には送る側(sender)と受け取る側(receiver)の間に通信のチャネルを開く. このとき,双方の受信の準備ができたことを同時に確認できるので同期を記述する必要はない. メッセージパッシングモデルは,HPF や,PVM,MPI などがある.0.2 HPF(High Performance Fortran)によるプログラミング
HPF は,構成のコンピューティング用に開発されたプログラミング言語である.Fortran 言語に最 小限の指示文を付加することにより,分散メモリ並列システムで簡単に高い性能を得ることを目視し ている. 分散メモリシステム上の並列化において,最も重要となるのは処理対象データの分散メモリ上への 配置を行うデータマッピング,および計算処理の各要素プロセッサへの分配を行う計算マッピングで ある.HPF の本質的な考え方は,データアクセスの局所性を高めるためのデータ分割をユーザが明示 的に指示し,それ以外の仕事を処理系(コンパイラ)に任せようというものである.HPF プログラミン グの考え方は,以下のようなものである. (1) 並列化方針の決定 ・プログラム全体の構造把握,並列化可能ループの同定,負荷集中ループの把握 (2) データ悪説の抽出 ・並列化すべき主要ループを選択し,主要配列のデータ分配配置の決定 ・各ループの並列に必要な通信を見積もり,主要配列以外のデータ分配配置の決定 ・主要ループ以外の並列化 (3) データマッピングの指示文の挿入 ・プロセッサ配列の宣言および指示文の挿入 (4) ループの並列化 ・コンパイラが自動的に並列化を判定できないループについて指示文の挿入 (5) その他の最適化 冗長通信の削除,通信効率の向上 0.3 スレッド スレッドを用いて並列処理を行うときは,マルチスレッドを用いる.マルチプロセッサでは複数の プロセスを並列に動作させることができるため,システム全体の処理能力を高めることができる.し
MPICH サンプルプログラム かし,異なったプロセス間でデータを共有するためには,プロセス間通信や特殊な共有メモリ領域を 利用する必要がある.このためマルチプロセッサマシンの利点を最大に引き出すことができない.こ の問題はマルチスレッドを用いることで解決できる.マルチスレッドとは,1つのプロセスの中に複 数のスレッドが動作することをいい,マルチスレッドを用いると,同一プロセス中の複数のプログラ ムコードを同時に実行できる.スレッドは互いに独立して動作するため,スレッドで同期を取る必要 がない限り,他のスレッドで何をしているか気にする必要がない.スレッドによるプログラミングで は,同期を取るのが難しく,実行順序なども気にしなければならない.
0.4 PVM(Parallel Virtual Machine)
PVM では,プログラマは問題を別々のプログラムに分解し,それぞれのプログラムを C で書いて, ネットワーク内のコンピュータで走るようにコンパイルする必要がある.プログラムの実行前に,ま ず問題に対して使うコンピュータの集合を定義しなければならず,その集合が仮想並列マシンを構成 する.設定方法は,利用できるコンピュータ名のリストを PVM がリードするホストファイル中に作 ることである.または,PVM の制御コマンドを用いて手動で設定する. プロセス数がプロセッサ数より多いことがある.PVM では,プロセッサ数に無関係に任意のプロセ スを生成でき,プロセスはプロセッサに自動的に割り当てられる PVM のプログラムは 1 個のマスタプログラムが最初に実行され,そのマスタプロセスから残りが生 み出されるマスター−スレーブ型に構成される.実行するときにプロセスが最初にしなければならな いことの一つにPVM への「登録」がある. 0.5 PVM と MPI の違い MPI は,PVM を始めとする主要メッセージ通信ライブラリの開発を行った研究者と,並列計算機 ベンダのほとんどが開発に参加している.また,出来上がった使用が,数多くの有用な機能を持ち, 多くの並列計算やLAN 環境で高い性能を実現できる.MPI は PVM の機能を包含した形となってい る.しかしMPI にはない PVM の特徴として,動的なプロセス管理,資源管理,異種機種間での通信 サポートの3 つがある. プロセス管理では,アプリケーションの中からプロセスを生成したり,停止 したりできる.資源管理は,利用可能なノードのグループを管理する機能である.このグループに含 まれるノードを動的に増減したり,調べたりすることができる.異機種間での通信サポートでは,複 数の異なるアーキテクチャのマシン間の通信を,幅広いアーキテクチャについてサポートしている. 1 MPI プログラムの枠組み すべてのMPI プログラムに共通する枠組みを以下に示す. ・ MPI ヘッダフィルの読み込み ・ MPI の初期化 (..MPI を使う並列処理..) ・ MPI の処理の終了 最初に MPI ライブラリを使うためのヘッダファイルを読み込む必要がある.ヘッダファイルには,MPI 独自の定義済み定数や変数の宣言が入っている. 次に,MPI ライブラリを利用するために必要な準備(初期化)を,関数 MPI_Init を呼び出すことで行 う.MPI_Init は,他のすべての MPI 関数の呼び出しに先立って呼び出す必要がある. そして,プログラムの事項を終了する前に,MPI ライブラリの利用の後始末(終了処理)を,関数 MPI_Finarize を呼び出すことで行う.プログラムでは,以下のようになる.
#include "mpi.h" /* ヘッダファイルの読み込み */ void main(int argc, char* argv[]){
int error;
error = MPI_Init(&argc, &argv); /* MPI ライブラリ使用の初期化 */ /*
* MPI による並列処理を行う */
error = MPI_Finalize(); /* MPI ライブラリ使用の終了処理 */ } C 言語の場合,MPI のどの関数についても,最初の MPI の 3 文字は常に大文字で,次の単語の先頭も大 文字で,次の単語の先頭も大文字で,以降はすべて小文字である. 2 MPI プログラムの実行 MPI プログラムを実行する際の注意事項!! ・ LAN で接続された PC は同じドメインまたはワークグループに存在していなければならない.ま た,ユーザ名とパスワードを登録しておく. ・ 実行ファイルは各PC で同じ場所で事項させる(メインマシンの C:¥tmp に実行ファイルを保存 したら,他のマシンでもC:¥tmp に実行ファイルを保存する.) 実行はコマンドプロンプトより実行する.C:¥tmp¥Keisan フォルダに存在する example.exe を 3 台の マシンで並列計算を行う場合,以下のコマンドを入力する. C:>cd c:¥tmp¥Keisan C:¥tmp¥Keisan>mpirun –np 3 example.exe 実行はmpirun コマンドを使用し,-np でマシン台数を設定し,その後実行ファイルを指定する.もし, 引数を指定したいときは実行ファイルの後に引数を指定し実行する 実行すると,初回のみユーザ名とパスワードを聞かれる.ドメイン/ユーザ名と書かれているが,ユーザ 名のみ指定すればよい. 以下,MPI ライブラリを使用した並列計算プログラムの簡単なサンプルを示す. 3 送受信を行うサンプルプログラム 3.1 目的 各プロセス間でデータの送受信を行う. 3.2 処理 データの送受信には,大きく分けて,以下の事項を指定する必要がある. 1) メッセージバッファ 2) 通信相手 3) コンテクスト メッセージバッファの指定は,送信の際には送るべきデータの所在を示し,受信の際には受け取っ たデータをどこに置けば良いかを示す.MPI ではバッファの先頭アドレス(ポインタ),データの個 数,単位データ型である. 通信相手は,プロセスを指定できればよいので,プロセスグループとランクの対を指定する.
MPICH サンプルプログラム 通信コンテクストとは,通信で転送されるデータが何に関するものかを示すもので,整数値の「タ グ」と「コミュニケータ」である.
MPI で最も基本的な送信関数は MPI_Send であり,以下の引数を持つ. MPI_Send(buffer, count, datatype, destination, tag, communicator) /* *buffer バッファの先頭アドレス *count データの個数 *datatype 単位データ型 *destination あて先のプロセスランク *tag タグ *communicator コミュニケータ */ 同様に最も基本的な受信関数はMPI_Recv であり,以下の引数を持つ. MPI_Recv(buffer, count, datatype, destination, tag, communicator, status) /* *buffer バッファの先頭アドレス *count データの個数 *datatype 単位データ型 *destination あて先のプロセスランク *tag タグ *communicator コミュニケータ *status 受信したメッセージに関する情報 */ ここで,タグは送信側と受信側で一致していなければならない.
次にサンプルプログラムの説明を行う.このプログラムは,各マシンである値をdest で設定したラ ンクを持つマシンに送信し,dest で設定された rank を持つマシンは source で指定した rank を持つ マシンよりデータを受信する.
3.3 サンプル
#include <stdio.h> #include <string.h> #include "mpi.h"
int main(int argc, char* argv[]){ int my_rank; /* カレントプログラムのランク */ int p; /* プロセスの数 */ int source; /* 送信プロセスのランク */ int dest; /* 受信プロセスのランク */ int tag=0; /* メッセージのタグ */ int message = 0; /* 送信データ */ MPI_Status status; /* 受信の戻りステータス*/
MPI_Init(&argc, &argv); /* MPIのスタートアップ */
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); /* カレントプロセスのランクを求める */ MPI_Comm_size(MPI_COMM_WORLD, &p); /* プロセスの数を求める */
if(my_rank != 0){ /* ランクが0でないとき(スレーブの処理) */ message = my_rank+1; /* 送信データの設定 */
dest=0;
printf( "Greetings from process %d!\n", my_rank); printf("send message = %d\n",message);
MPI_Send(&message, 1, MPI_INT, dest, tag, MPI_COMM_WORLD); /* データを送信 */ }else{ /* ランクが0のとき(マスタの処理) */
for(source =1; source<p; source++){ /* データを受信 */
MPI_Recv(&message, 1, MPI_INT, source, tag, MPI_COMM_WORLD, &status); printf( "Greetings from process %d!\n", my_rank);
printf("receve message = %d\n", message); } 1 2 1 1 2 2 図1 送受信の例
rank0 rank1 rank2
マシン データの流れ
MPICH サンプルプログラム } MPI_Finalize(); /* MPIライブラリ使用の終了処理 */ getchar(); return 1; } 3.4 結果 出力結果を以下に示す.出力結果は,各ランク(マシン)ごとに出力されている. C:¥tmp¥Keisan>mpirun -np 3 greetings.exe
Greetings from process 1! //rank=1 のマシンの出力結果 send message = 2
Greetings from process 2! //rank=2 のマシンの出力結果 send message = 3
Greetings from process 0! //rank=0 のマシンの出力結果 receive message = 2
Greetings from process 0! receive message = 3 4 シフト通信を行うサンプルプログラム 4.1 目的 各プロセスが他のプロセスにメッセージを送信し,それと並行してさらに別のプロセスからメッセ ージを受信する. 4.2 処理 単純なシフトとして,rank0 からn-1 までのn個のプロセスが存在するとき,rank i (0≦i≦n-1)の プロセスからi+1 のプロセスへのメッセージ渡しがあげられる.各プロセスが自分の持っているデー タを隣に送ると同時に,反対側の隣のプロセスからデータを受け取る.このサンプルでは最大ランク を持つプロセスがランク0 のプロセスにメッセージを送ることで,環状の通信パターンになっている. シフトのように送信と受信を1 回ずつ並行して行う処理には,MPI_Sendrecv()関数を用いるのがよい.
MPI_Sendrecv(sendbuf, sCount, sType, destination, sTag, recvbuf, rCount, rType, source, rTag, comm, status)
/* *sendbuf 送信データ *sCount 送信データ数 *sType 送信データの型 *destination 送信先ランク *sTag 送信タグ *recvbuf 受信データ *rCount 受信データ数 *rType 受信データの型 *source 受信元のランク *rTag 受信タグ
*comm コミュニケータ *status 状態 */ Sendrecv 関数は,comm で指定したプロセスグループ中の全プロセスが参加して環状のシフト通信 を行う.通信相手は隣のプロセスである.(図 2) は じ め に MPI_Comm_rank に よ り , コ ー ド を 実 行 す る プ ロ セ ス の ラ ン ク を 取 得 し , MPI_Comm_size により,MPI_COMM_WORLD に含まれるプロセス数を求める.これらの値を元に, 送信先プロセスのランクを dest に,受信しようとするメッセージの発信者のランクを source に求め る.そして,MPI_Sendrecv により,送信と受信をまとめて起動する.アドレス sendbuf にある int がたの値を1 つのランク dest のプロセスに送ると同時に,ランク source のプロセスが発信したメッ セージを,recvbuf を先頭とする int 型変数 1 つ分のバッファに受信する.
4.3 プログラム
#include <stdio.h> #include "mpi.h"
int main(int argc, char* argv[]){ /*
* dest 送信先アドレス * source 受信元アドレス */
int myrank, size, dest, source; int sendbuf, recvbuf;
MPI_Status status; /* 受信状態をあらわす */ MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); MPI_Comm_size(MPI_COMM_WORLD, &size); /* 送受信データを設定 */ sendbuf = myrank; recvbuf = -1; dest = myrank+1;/* 送信先ランクを設定 */ source = myrank-1;/* 受信先ランクを設定 */ 図2 シフトの例 rank0 rank1 rank2
1 2 3 3 1 1 2 2 3 r s r s r s マシン データの流れ r:受信 s:送信
MPICH サンプルプログラム if(myrank == size-1){/* 送信先ランクを設定 */ dest = 0; }else if(myrank == 0){/* 受信先ランクを設定 */ source = size - 1; } /* シフトを行う */
MPI_Sendrecv(&sendbuf, 1, MPI_INT, dest, 0, &recvbuf,1,MPI_INT, source, 0, MPI_COMM_WORLD, &status);
printf("shift: sendbuf=%d recvbuf%d\n", sendbuf, recvbuf); MPI_Finalize();
return 1; }
4.4 結果
C:¥tmp¥Keisan>mpirun -np 3 shift.exe shift: sendbuf=2 recvbuf1
shift: sendbuf=0 recvbuf2 shift: sendbuf=1 recvbuf0
5 ブロードキャストを行うサンプルプログラム 5.1 目的 ブロードキャストは,ある1 つのプロセスから,複数のプロセスすべてに対して同じメッセージを 送るというパターンの通信である. 5.2 処理 MPI_COMM_WORLD に属するすべてのプロセスに同じデータを配る場合を扱う.ブロードキャス トの範囲をより小さなプロセスグループに絞る方法もある. rank1 のプロセスが他のすべてのプロセスに同じデータを配っている.例では 3 つのプロセスから なるプロセスグループがあって,その中の1 つが他の 2 つのプロセスにメッセージを送っている.ブ ロードキャストの結果,このグループのプロセスはすべて同じデータを持つようになっている.ブロ ードキャストのためのMPI 関数は MPI_Bcast である.
MPI_Bcast(message, count, datatype, root, comm) /* *sendbuf 送受信データ *count 送受信データ数 *datatype 送受信データ型 *root 送信元ランク *comm. コミュニケータ */
ランクroot プロセスの message 中のデータのコピーをコミュニケータ comm の中の全プロセスに 送る.bcast では message が入出力パラメータはとされる.root ランクのプロセスでは入力,他のプ ロセスでは出力である.ブロードキャストの通信例を図3 に示す.
5.3 プログラム
#include <stdio.h> #include "mpi.h"
#define MAX 10;
int main(int argc, char* argv[]){
const int max = 10;
int sendbuf[max]; /* 送受信データ */
int rank, size,root=1; /* ランク,プロセスのサイズ,データ送信元のランク */ MPI_Status status; /* 送受信結果 */
MPI_Init(&argc, &argv); /* 並列計算開始 */
MPI_Comm_rank(MPI_COMM_WORLD, &rank); /* ランクを求める */ MPI_Comm_size(MPI_COMM_WORLD, &size); /* サイズを求める */ printf("rank:%d size:%d\n", rank, size);
/* 送信データ設定 */ for(int i=0; i<max; i++){
if(rank == 1)sendbuf[i] = i; else sendbuf[i]=0;
}
for(int i=0; i<max; i++){ printf("%d ",sendbuf[i]); }
printf("\n");
/* ブロードキャストを行う */
MPI_Bcast(&sendbuf, max, MPI_INT, 1, MPI_COMM_WORLD); printf("Bcast 呼び出し\n");
/* 受信データ表示 */ for(int i=0; i<max; i++){
printf("%d ",sendbuf[i]); }
図3 ブロードキャストの例 rank0 rank1 rank2
1 2 3
1 2 3 1 2 3 1 2 3
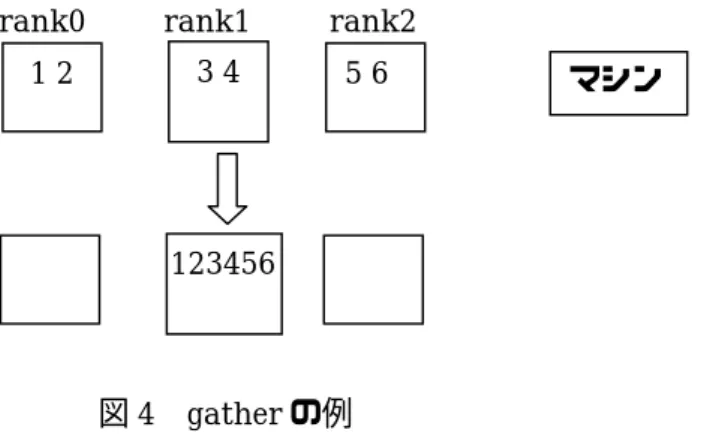
MPICH サンプルプログラム printf("\n"); /* 並列計算終了 */ MPI_Finalize(); return 1; } 5.4 出力結果 C:¥tmp¥Keisan>mpirun -np 3 bcast.exe rank:0 size:3 0 0 0 0 0 0 0 0 0 0 Bcast 呼び出し 0 1 2 3 4 5 6 7 8 9 rank:1 size:3 0 1 2 3 4 5 6 7 8 9 Bcast 呼び出し 0 1 2 3 4 5 6 7 8 9 rank:2 size:3 0 0 0 0 0 0 0 0 0 0 Bcast 呼び出し 0 1 2 3 4 5 6 7 8 9 6 gather を行うサンプルプログラム 6.1 目的 各ノードが持っている値を1 つのノードに集める.このノードをルートという.ルートノードは, そのランクを引数として,渡すことで指定する. 6.2 処理 データを1 箇所に集める関数は MPI では MPI_Gather が提供されている. MPI_Garher(sendbuf, sCount, sType, recvbuf, rCount, rType, root, comm) /* * sendbuf 送信データ * sCount 送信データ個数 * sType 送信データの型 * recvbuf 受信データ * rCount 受信データ個数 * rType 受信データの型 * root ルートノード * comm. コミュニケータ */ MPI_Gather はコミュニケータにおける各プロセスの送信データを集め,ランクの順に root プロセス の受信データにプロセスランクの順にストアする.仕上がって,データはプロセス0 が最初に,次意 プロセス1,プロセス 2 のようになる.各プロセスの sendbuf で参照されるデータは sCount 個の要 素を持ち,それぞれの型はsType である.rCount と rType は sCount と sType と同じである.それ
らは,各プロセスからの要素の数と要素の型を指定するが,受け取るデータの総量については指定し ない.recv パラメータはルートプロセスでのみ意味を持つ.パラメータ root と comm はコミュニケ ータcomm の全プロセスにおいて同一でなければならない.ほとんどのケースで,sCount と sType は全プロセスで同じである. コミュニケータにおける各プロセスの送信データで参照されるデータを集め,ランクの順に,root プロセス 6.3 プログラム #include <stdio.h> #include "mpi.h"
int main(int argc, char* argv[]){ const int smax = 5;
const int rmax = 15; /* 送信,受信データ */
int sendbuf[smax], recvbuf[rmax]; /* プロセスのランク,プロセス数 */ int rank, size;
/* */ int root=0; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); /* 送信データ設定 */
for(int i=0; i<smax; i++){ sendbuf[i] = i+2*10*rank; }
/* 受信データ初期化 */ for(int i=0; i<rmax; i++){
recvbuf[i] = 0; }
図4 gather の例 rank0 rank1 rank2
1 2 3 4 5 6
123456
MPICH サンプルプログラム
printf("rank:%d root %d\n",rank,root); for(int i=0; i<smax; i++){
printf("%d ", sendbuf[i]); }
printf("\n");
/* allgatherを行う */
/* 受信データのサイズは各ランクから受信するデータの数である(全受信データ数ではない) */ MPI_Gather(sendbuf, smax, MPI_INT, recvbuf, smax, MPI_INT, root, MPI_COMM_WORLD);
/* 受信結果を出力 */ if(rank == root){
printf("gather\n");
for(int i=0; i<rmax; i++){ printf("%d ",recvbuf[i]); } } MPI_Finalize(); return 1; } 6.4 結果 C:¥tmp¥Keisan>mpirun -np 3 gather.exe rank:1 root 0 20 21 22 23 24 rank:2 root 0 40 41 42 43 44 rank:0 root 0 0 1 2 3 4 gather 0 1 2 3 4 20 21 22 23 24 40 41 42 43 44
7 scatter を行うサンプルプログラム 7.1 目的 1 つのノード(これもルートと呼ぶ)が持っているデータを各ノードに配る.ブロードキャストと の違いは,ノードごとに配るデータが異なることである.典型的には,ルートが持っている配列を分 割して,その断片を各ノードに配る処理に使う. 7.2 処理 scatter として以下の MPI 関数が提供されている.
scatter(sendbuf, sCount, sType, recvbuf, rCount, rType, root, comm) /* * sendbuf 送信データ * sCount 送信データ個数 * sType 送信データの型 * recvbuf 受信データ * rCount 受信データ個数 * rType 受信データの型 * root ルートノード(送信元ノード) * comm. コミュニティ */ root プロセス上の送信データを p 個のセグメントに分割する.各セグメントは,データ型 sType を持つsCount 個のデータからなる.最初のセグメントはプロセス 0 に,次のセグメントは,プロセ ス1 に,など,ランクの順に送られる.send パラメータはルートプロセスのみで意味を持つ.ほとん どの場合,sCount は rCount とおなじであり,sType は rType と同じである.
7.3 プログラム
#include <stdio.h> #include "mpi.h"
int main (int argc, char* argv[]){
const int max = 30; const int maxR = max/3;
図5 scatter の例 rank0 rank1 rank2
1 2 3 4 5 6
マシン 123456
MPICH サンプルプログラム
/* 送信受信データ,プロセスのランク,プロセス数,データを集めるランク */ int sendbuf[max], recvbuf[maxR], rank, size, root=1;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); /* データ初期化 */
if(rank == root){
for(int i=0; i<max; i++){ sendbuf[i] = i; }
for(int i=0; i<max; i++){ printf("%d ",sendbuf[i]); }
printf("\n"); }
/* scatterを行う */
MPI_Scatter(sendbuf, maxR, MPI_INT, recvbuf, maxR, MPI_INT, root, MPI_COMM_WORLD); MPI_Finalize();
printf("rank:%d\n",rank); for(int i=0; i<maxR; i++){
printf("%d ",recvbuf[i]); } printf("\n"); return 1; } 7.4 出力結果 C:¥tmp¥Keisan>mpirun -np 3 scatter.exe rank:0 0 1 2 3 4 5 6 7 8 9 rank:2 20 21 22 23 24 25 26 27 28 29 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 rank:1 10 11 12 13 14 15 16 17 18 19
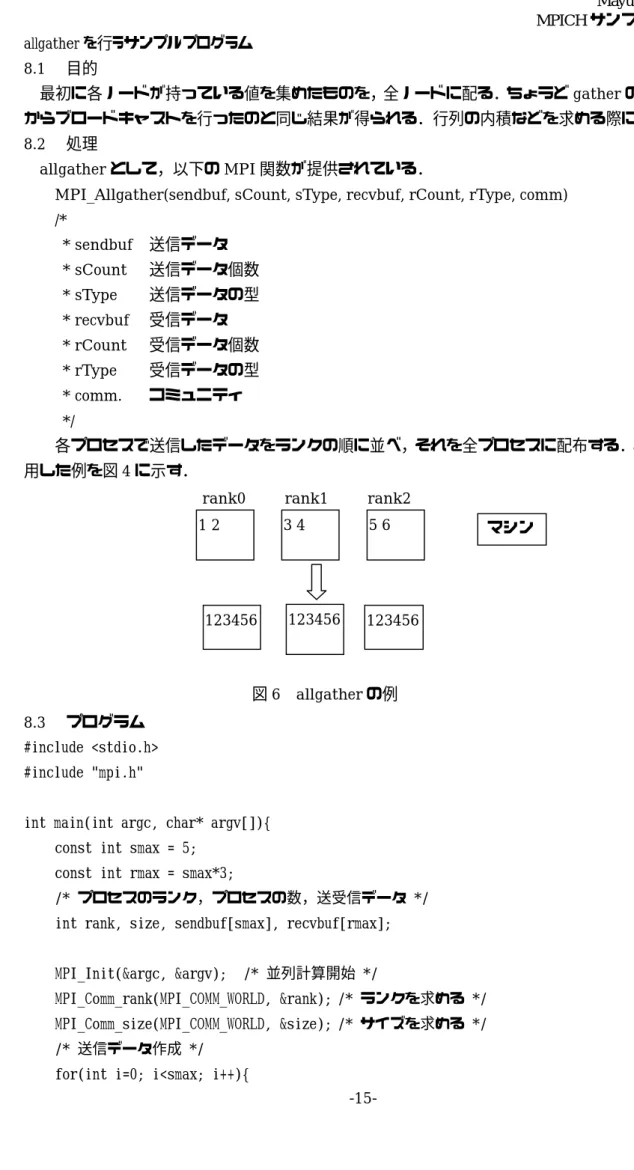
8 allgather を行うサンプルプログラム 8.1 目的 最初に各ノードが持っている値を集めたものを,全ノードに配る.ちょうどgather の直後にルート からブロードキャストを行ったのと同じ結果が得られる.行列の内積などを求める際に使用される. 8.2 処理 allgather として,以下の MPI 関数が提供されている.
MPI_Allgather(sendbuf, sCount, sType, recvbuf, rCount, rType, comm) /* * sendbuf 送信データ * sCount 送信データ個数 * sType 送信データの型 * recvbuf 受信データ * rCount 受信データ個数 * rType 受信データの型 * comm. コミュニティ */ 各プロセスで送信したデータをランクの順に並べ,それを全プロセスに配布する.allgather を使 用した例を図4 に示す. 8.3 プログラム #include <stdio.h> #include "mpi.h"
int main(int argc, char* argv[]){ const int smax = 5;
const int rmax = smax*3;
/* プロセスのランク,プロセスの数,送受信データ */ int rank, size, sendbuf[smax], recvbuf[rmax];
MPI_Init(&argc, &argv); /* 並列計算開始 */
MPI_Comm_rank(MPI_COMM_WORLD, &rank); /* ランクを求める */ MPI_Comm_size(MPI_COMM_WORLD, &size); /* サイズを求める */ /* 送信データ作成 */
for(int i=0; i<smax; i++){
図6 allgather の例 rank0 rank1 rank2
123456 123456 123456
マシン 1 2 3 4 5 6
MPICH サンプルプログラム
sendbuf[i] = i+rank*10; }
printf("rank:%d\n",rank); for(int i=0; i<smax; i++){
printf("%d ",sendbuf[i]); }
printf("\n");
/* allgatherを行う */
/* 1プロセスで受信する受信データは送信データのsmaxだけ受信する */
MPI_Allgather(sendbuf, smax, MPI_INT, recvbuf, smax, MPI_INT, MPI_COMM_WORLD); /* 受信データ表示 */
for(int i=0; i<rmax; i++){ printf("%d ",recvbuf[i]); } printf("\n"); MPI_Finalize(); /* 並列計算終了 */ return 1; } 8.4 出力結果 C:¥tmp¥Keisan>mpirun -np 3 allgather.exe rank:0 0 1 2 3 4 0 1 2 3 4 10 11 12 13 14 20 21 22 23 24 rank:2 20 21 22 23 24 0 1 2 3 4 10 11 12 13 14 20 21 22 23 24 rank:1 10 11 12 13 14 0 1 2 3 4 10 11 12 13 14 20 21 22 23 24
9 alltoall を行うサンプルプログラム 9.1 目的 すべてのノードからすべてのノードに対して,あて先ノードごとに違う値を配る.各ノードをルー トとして scatter を繰り返しても同様の結果が得られるが,MPI_Alltoall を使用するほうが効率がよ い.転置行列を作成する場合に効率がよい.alltoall は,各プロセスに同量のデータを送るので ,一 見したところ使い道がないように思える. 9.2 処理 alltoall は以下の MPI 関数が提供されている.
alltoall(sendbuf, sCount, sType, recvbuf, rCount, rType, comm) /* * sendbuf 送信データ * sCount 送信データ個数 * sType 送信データの型 * recvbuf 受信データ * rCount 受信データ個数 * rType 受信データの型 * comm. コミュニティ */
プロセス q 上への働きは sCount 個の sType 型の要素を各プロセスへ送ることである.sCount 個の最初のブロックはプロセス0 へ,第 2 のブロックはプロセス 1 へ送られる.プロセス q はまた, すべてのプロセスから rCount 個の rType 型の要素を受け取る.プロセス 0 からの要素は recfvbuf の先頭に受け取る.プロセス1 からの要素はプロセス 0 からの要素の直後に受け取る.
9.3 プログラム
#include "mpi.h" #include <stdio.h> #include <stdlib.h>
int main(int argc, char* argv[]){
int sendbuf[10]; /* メッセージの保存場所 */ int recvbuf[10]; /* メッセージの保存場所 */ int my_rank; /* カレントプログラムのランク */ int numprocs; /* プロセス数 */ int tag=0; /* メッセージのタグ */ 図7 alltoall の例 rank0 rank1 rank2
1 4 7 2 5 8 3 6 9
マシン 1 2 3 4 5 6 7 8 9
MPICH サンプルプログラム MPI_Status status; /* 受信の戻りステータス*/ MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); /* カレントプロセスのランクを取得 */ MPI_Comm_size(MPI_COMM_WORLD, &numprocs); /* プロセス数を取得 */ printf("myrank:%d \n", my_rank); /* 送信データ設定 */
for(int i=0; i<numprocs; i++){ sendbuf[i]=my_rank*10+i;
printf("sendbuf[%d]=%d \n", i, sendbuf[i]); }
/* alltoallを行う */
MPI_Alltoall(sendbuf, 1, MPI_INT, recvbuf, 1, MPI_INT, MPI_COMM_WORLD); /* 受信データ出力 */
for(int i=0; i<numprocs; i++){ printf("%d ", recvbuf[i]); } printf("\n"); MPI_Finalize(); getchar(); return 0; } 9.4 出力結果 C:¥tmp¥Keisan>mpirun -np 3 matrix.exe Mpd needs an account to launch processes with: account (domain¥user): arakawa
password: myrank:1 sendbuf=2 sendbuf=2 1 2 3 myrank:2 sendbuf=3 sendbuf=3 1 2 3 myrank:0 sendbuf=1 sendbuf=1 1 2 3
10 reduce を行うサンプルプログラム 10.1 目的 各プロセスが持っているデータの総和がルートプロセスに得られる.各プロセスが配列上にデータ を持っている場合には,配列の各要素ごとの総和が得られる. 10.2 処理 和を求めるために,MPI では以下の関数が提供されている.
MPI_Reduce(sendbuf, recvbuf, count, datatype, operator, root, comm) /* * sendbuf 送信データ * recvbuf 受信データ * count 送信データ数 * datatype データ型 * operator 計算オプション * root ルートノード * comm. コミュニケータ */ sendbuf で参照されるメモリ中の複数のオペランドを,演算 operator を用いて結合し,結果をプロ セスroot の recvbuf にストアする.sendbuf,recvbuf はともにデータ型 datatype により,count 個 のメモリロケーションを参照する.MPI_Reduce はコミュニケータ個 mm の中のすべてのプロセスに 呼ばれ,count,datatype,operator および root は同じでなければならない. パラメータoperator は表 1 に示す定義済みの値のうちの一つが取れる. 表1 MPI の定義済みの操作 操作名 意味 MPI_MAX 最大値 MPI_MIN 最小値 MPI_SUM 和 MPI_PROD 積 MPI_LAND 論理積 MPI_BAND ビット論理積 MPI_LOR 論理和 MPI_BOR ビット論理和 MPI_LXOR 排他的論理和 MPI_BXOR ビット排他的論理和 MPI_MAXLOC 最大値と位置 MPI_MINLOC 最小値と位置 総和を求めるパターンを図4
MPICH サンプルプログラム
10.3 プログラム
#include <stdio.h> #include "mpi.h"
int main(int argc, char* argv[]){
const int max = 10; const int rmax = max*3;
int rank, size, root =1; /* プロセスのランク,プロセス数,データを集めるランク */ int sendbuf[max], recvbuf[rmax]; /* 送信・受信データ */
MPI_Comm comm = MPI_COMM_WORLD; /* コミュニケータ */ /* 並列処理 */ MPI_Init(&argc, &argv); MPI_Comm_rank(comm, &rank); MPI_Comm_size(comm, &size); printf("rank:%d root:%d\nsendbuf\n",rank,root); /* 送信データ設定 */
for(int i=0; i<max; i++){ sendbuf[i] = i + 10*rank; }
for(int i=0; i<max; i++){ printf("%d ",sendbuf[i]); }
printf("\n");
/* 受信データ初期化 */ for(int i=0; i<rmax; i++){
recvbuf[i] = 0; }
printf("reduce-sum\n");
/* 第3引数には送信データの個数を送信する */
MPI_Reduce(sendbuf, recvbuf, max, MPI_INT, MPI_SUM, root, comm); /* ランクがrootのとき */
if(rank==root){
図8 reduce の例 rank0 rank1 rank2
12 15 18
マシン 1 2 3 4 5 6 7 8 9
printf("recvbuf\n"); /* 出力結果表示 */
for(int i=0; i<max; i++){ printf("%d ",recvbuf[i]); } printf("\n"); } printf("end mpi\n"); /* 並列計算終了 */ MPI_Finalize(); return 1; } 10.4 出力結果 C:¥tmp¥Keisan>mpirun -np 3 reduce.exe rank:2 root:1 sendbuf 20 21 22 23 24 25 26 27 28 29 reduce-sum end mpi rank:1 root:1 sendbuf 10 11 12 13 14 15 16 17 18 19 reduce-sum recvbuf 30 33 36 39 42 45 48 51 54 57 end mpi rank:0 root:1 sendbuf 0 1 2 3 4 5 6 7 8 9 reduce-sum end mpi