MapReduceにおける通信データ量を考慮したReduceタスク割り当て手法
8
0
0
全文
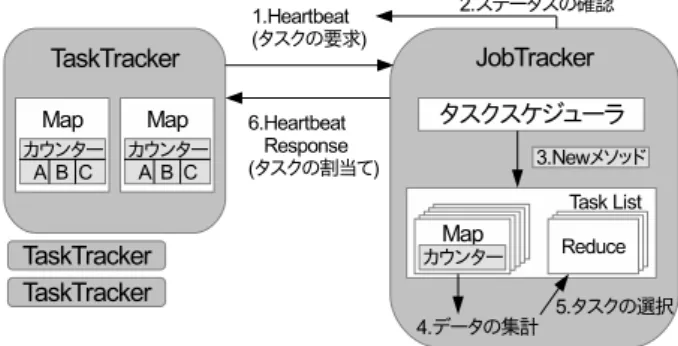
(2) Vol.2014-ARC-210 No.11 Vol.2014-OS-129 No.11 2014/5/15. 情報処理学会研究報告 IPSJ SIG Technical Report. 行われる.タスクに必要な入力データがタスクを処理する. 2. 研究背景 インターネット利用者の増加や,環境モニタリング,ライ フログなどの普及により,蓄積データは増加の一途を辿っ ている.これらの大規模データを高速に処理するためには, 複数台の計算機を協調動作させ,並列に処理することが有 効である.並列分散処理には通信処理や同期処理などが必 要になるが,これらを行うための機能を提供し,アプリケー ション作成の負荷を軽減するためのシステム [1][2][3] が提 案されている.Hadoop は,このような並列分散処理を容 易に行うための環境を提供するシステムのひとつである.. 2.1 Hadoop Hadoop は,Apache Software Foundation によって開発 されている,分散型コンピューティングのためのオープ ンソースソフトウェアである.Hadoop は大別して,高ス ループットでのアクセスを可能とする分散ファイルシステ ム Hadoop Distributed File System と,並列分散処理フ レームワーク Hadoop MapReduce から構成される.. Hadoop MapReduce は,大規模データを処理するために Google が開発した並列分散処理フレームワーク MapReduce を基に実装したものである.MapReduce では,フ レームワークによって,分散処理に必要な処理の割り当 てや,ノード間の通信,障害への対応などの機能が提供さ れるため,ユーザーは容易に並列分散処理を実現できる.. MapReduce は多くの企業で利用されており,また,データ ベース [7][8],画像処理 [9],計算科学アプリケーション [10], 機械学習 [11] など様々な分野での応用が研究されている.. MapReduce は,データ処理を独立に実行可能な複数の タスクに分割し,各ノードに分散させることで並列に処理 を行う.タスクは,データの読み込み,整理を行い,中間 データを出力する Map タスクと,その中間データを集約 し最終的な結果を出力する Reduce タスクに分割される. 中間データは各 Reduce タスクに対応するパーティション というグループに分割される.Reduce タスクは入力とな るパーティションをコピーし,それを処理する.タスクは. 1 台のホストノードによって,スレーブノードに割り当て られる.スレーブノードは,割り当てられたタスクに必要 な入力データを,他のノードからコピーをする.このとき のノード間で送受信されるデータ量が大きくなれば,処理 時間も増加するため,通信データ量を小さく抑えるための タスクスケジューリングが必要となる.. 2.2 タスクスケジューリング 既存の Hadoop における Map タスクのスケジューリン グでは,データのコピーにかかる時間を抑えるため,入力 データのネットワーク位置を考慮したスケジューリングが. ⓒ 2014 Information Processing Society of Japan. ノードに存在している場合をノードローカル,データが同 一ラック内の他のノードに存在している場合をラックロー カル,それ以外のノードに存在している場合をノンロー カルと呼ぶ.ノードローカルでない場合,他のノードから ネットワークを介したデータのコピーが必要となる.Map タスクのスケジューリングでは,ノードにタスクを割り当 てる際に,ノードローカル,ラックローカル,ノンローカ ルの順にタスクを探索し,割り当てを行う.これにより, 入力データがノードに近いタスクから優先的に割り当てら れ,データのコピーにかかる時間を抑えることができる. また,Map タスクのスケジューリングをより効率よく行う ための研究として,スケジューラが配置するタスクをノー ドの Map タスク数や入力データのレプリケーション構造 に基づいて選択する手法 [12],ノードローカルなタスクを 配置できない場合にノンローカルなタスクを配置するかを 判断する手法 [13],CPU の I/O 待ち率が高い場合に動的 に Map スロット数を増加させるスロットスケジューリン グ手法 [14][15] などが提案されている. 一方,Hadoop における Reduce タスクのスケジューリ ングでは,Map タスクのような入力データの位置を考慮し たスケジューリングは行われておらず,タスクを要求した ノードに無条件で割り当てを行う.Reduce タスクは Map タスクによって出力されたデータを入力とする.処理の内 容や処理するデータによっては,ノード間で Map タスク が出力するデータに偏りが生じ,割り当てる Reduce タス クが適切でないとネットワークトラフィックが増加し,処 理時間が長くなる場合がある. このような問題に対処するために,ネットワーク距離と パーティションデータ量から,Reduce タスクの最も通信 コストの小さくなる重心ノードを求め,割り当てを行う手 法 CoGRS[16] が提案されている.CoGRS では,ノード がタスクを要求した際に,未実行の全ての Reduce タスク の重心ノードを求める.重心ノードはパーティションをコ ピーするノード間のネットワーク距離とコピーするデータ 量から算出される.そして,タスクを要求したノードが重 心ノードとなる Reduce タスクを割り当てる.タスクを要 求したノードが重心ノードとなる Reduce タスクが存在し ない場合,重心ノードとなる全てのノードの進捗状況を確 認し,すぐにタスクを実行できないノードが重心ノードと なる Reduce タスクの中から割り当てを行う.このとき, タスクを要求したノードと重心ノードとのネットワーク距 離が最も近いものが選択される. 提案手法では,Reduce タスクのスケジューリングにお いて,各ノードが格納するパーティションデータ量から, タスクを割り当てた際に必要となる通信データ量を算出 し,クラスタ全体で最も通信データ量が少なくなるように. Reduce タスクの割り当てを行う.. 2.
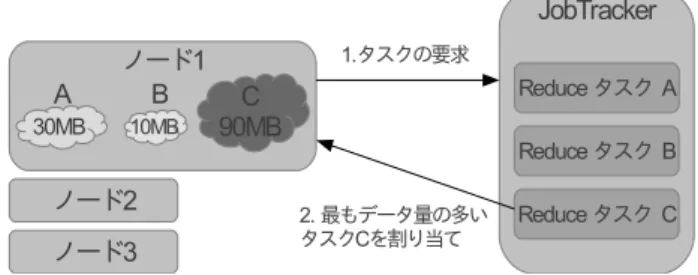
(3) Vol.2014-ARC-210 No.11 Vol.2014-OS-129 No.11 2014/5/15. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 2. 最大格納データ割り当て概略図. 図 1 Hadoop におけるタスクスケジューリング. ドがデータをあまり格納していないパーティションを入力. 3. 通信データ量を考慮した Reduce タスク割 り当て手法. とする Reduce タスクが割り当てられることを防ぐことが できるため,通信データ量の削減を期待できる.また,1 つの Map タスクの出力が1つの Reduce タスクのみの入. Hadoop におけるタスクスケジューリングの流れを図 1. 力となるような処理では,Map タスクを実行したノードが. に示す.Hadoop でのタスクの割り当ては,ホストノード. Reduce タスクに必要なパーティションを全て格納するた. となる JobTracker とスレーブノードとなる TaskTracker. め,ノードローカルなタスクの割り当てが行える.. との Heartbeat 通信を利用して行われる.TaskTracker は タスクの実行が可能であることを Heartbeat 通信を用い. 3.2 最少通信データ量割り当て. て JobTracker に通知する.JobTracker は TaskTracker の. 最大格納データ量割り当てでは,タスクを割り当てる際. ステータスを確認すると,タスクリストの中からタスクを. に他のノードのパーティションのデータ量を考慮してい. 選択し,HeartbeatResponse によって割り当てを行う.タ. ないため,タスク要求したノードが格納しているパーティ. スクの入力となるデータが他のノードにある場合,ネット. ションのデータ量が,他のノードと比べて少ない場合でも. ワークを介したデータのコピーが必要となる.Reduce タ. Reduce タスクを割り当ててしまい,通信データ量が多く. スクの入力データは,Map タスクで出力された中間デー. なる可能性がある.この問題を解決するため,クラスタ全. タを各 Reduce タスクに対応するパーティションというグ. 体で必要となる通信データ量が最少となるよう割り当てを. ループに分けられたものである.各パーティションのデー. 行う最少通信データ量割り当てを提案する.. タサイズが均一である保証はなく,入力データや処理に よって偏りが生じる場合がある. 既存の Hadoop における Reduce タスクの割り当ては,. 最小通信データ量割り当ての概要を図 3 に示す.最少通 信データ量割り当てでは,全ての Reduce タスクをノード にどのように割り当てるかを考える.タスクをノードに割. タスクを要求する TaskTracker に未実行のタスクのリスト. り当てた場合のデータのコピーに必要となる通信データ量. の先頭からタスクを1つ取り出し,無条件に割り当てると. を算出し,全てのノードとタスクの割り当ての組み合わせ. いうものである.この手法では,ノード間での多くのデー. の中で,最も通信データ量が少ない組み合わせを求め,そ. タの送受信が必要となるタスクの割り当てが行われ,効率. の結果に基づいてタスクの割り当てを行う.図 3 の例では,. が低下する可能性がある.本章では,Reduce タスクが入. ノードが 3 台あり,それぞれがパーティション A,B,C の. 力に必要とするデータのコピーにかかる通信データ量を削. データを格納している.各ノードに 1 つの Reduce タスク. 減するための2つの手法について述べる.. が割り当てられるものとし,通信データ量が最小となるタ スクの割り当ての組み合わせを考える.ノード 1 に Reduce. 3.1 最大格納データ量割り当て. タスク A を割り当てた場合の通信データ量は,ノード 2,. 最大格納データ量割り当ての概要を図 2 に示す.最大格. ノード 3 が格納するパーティション A のデータ量の合計で. 納データ量割り当てでは,タスクを要求したノードが格納. ある.タスク A,B,C の割り当ての組み合わせで必要と. しているパーティションのデータ量を考慮し,最もデータ. なる通信データ量の合計を算出し,最少となる組み合わせ. 量の多いパーティションを入力とする Reduce タスクを割. を求める.その結果,ノード 1 にタスク B,ノード 2 にタ. り当てる.図 2 の例だと,Reduce タスク A,B,C があり,. スク A,ノード 3 にタスク C を割り当てることが最適な組. ノード 1 はパーティション A のデータを 30MB,B のデー. み合わせとなり,タスクを要求したノードに対応するタス. タ 10MB,C のデータを 90MB 格納しており,最もデータ. クを割り当てる.. 量の多い C のタスクが割り当てられる.これにより,ノー. ⓒ 2014 Information Processing Society of Japan. 3.
(4) Vol.2014-ARC-210 No.11 Vol.2014-OS-129 No.11 2014/5/15. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 3 最小通信データ量割り当て概略図. 4. 実装 提案手法を,Hadoop-1.2.1 に実装した.提案手法のタス. 図 4 提案手法におけるタスクの割り当て. Map タスクの進捗情報から,ノードが格納するパーティ ション毎のデータ量を集計し,各手法を用いて,割り当 てるタスクを選択し,JobTracker に返す.JobTracker は. ク割り当ての流れを図 4 に示す.各ノードのパーティショ. 返された Reduce タスクを HeartbeatResponse に格納し,. ン毎のデータ量を取得するため,Map タスクにカウンター. TaskTracker に渡すことでタスクの割り当てを行う.. を追加した.また,タスクスケジューラの Reduce タスク. ノードが格納するパーティション毎のデータ量を取得す. スケジューリング機能部分に変更を加え,各割り当て手法. るため,Map タスクに,中間データをファイルに出力す. を実装した.提案手法のタスク割り当ての流れと,各手法. る際にパーティション毎のデータ量を保持するカウンター. の実装について述べる.. を追加した.カウンターはタスクの進捗情報として,Map タスクから TaskTracker に渡され,Heartbeat 通信により. 4.1 Reduce タスク割り当ての流れ JobTracker から TaskTracker への Reduce タスクの割. JobTracker に渡される.タスクの進捗情報には,どのノー ドが実行しているか,処理は完了しているか等の情報が含. り当ての流れは以下のようになる.. まれており,これにより JobTracker は,各 Map タスクを. ( 1 ) TaskTracker が Heartbeat 通信を用いて JobTracker に. 実行したノードと出力されたパーティション毎のデータ量. タスクを要求する. を知ることができる.. ( 2 ) JobTracker は,TaskTracker のステータスを確認し, タスクスケジューラを呼び出す. 4.2 最大格納データ量割り当ての実装. ( 3 ) タスクスケジューラは Reduce タスクを割り当てるか. 最大格納データ量割り当てでは,まず全ての Map タスク. どうかを判断し,新たに実装した各手法のメソッドを. の進捗情報から,タスクを要求したノードが格納している. 呼び出す. パーティション毎のデータ量を集計する.各パーティショ. ( 4 ) 全 Map タスクの進捗情報から,ノードが格納するパー ティション毎のデータ量を集計する. ( 5 ) 集計したデータから,各手法を用いて Reduce タスク を選択し,JobTracker へ返す. ( 6 ) JobTracker はタスクを HeartbeatResponse に格納し, TaskTracker へ割り当てる Hadoop MapReduce では,TaskTracker は RPC で JobTracker の Heartbeat メソッドを呼び出す.TaskTracker. ンのデータ量を比較していき,未実行の Reduce タスクの リストの中で,タスク要求先のノードが最もデータを多く 格納しているパーティションを入力とする Reduce タスク を求める.そして JobTracker に,当該 Reduce タスクを返 す.必要な計算は最大値を求めるだけであり,計算量は未 実行の Reduce タスクの数に依存する.処理が進むにつれ て Reduce タスクは各ノードへ割り当てられていくため, 未実行の Reduce タスクは減っていき,計算量も減少して. はタスクが実行可能かどうかを acceptNewTasks というフ. いく.通常,Reduce タスクの数は TaskTracker の数以下. ラグを用いて通知する.JobTracker はこのフラグを確認. に設定されるため,計算量は少ない.. し,実行可能ならタスクスケジューラを呼び出す.タスクス ケジューラは,実行中のジョブを表すクラス JobInProgress のメソッドを呼び出し,実行するべきタスクがあるか,Map. 4.3 最少通信データ量割り当ての実装 最少通信データ量割り当てでは,ジョブの初期化時に,. タスクが一定数 (デフォルトで 5%) 終了しているかを確認. 全てのノードとタスクの組み合わせ方の情報を持つ組み. した後,findTaskFromList メソッドの変わりに,新たに実. 合わせリストを作成しておく.タスクの選択では,まず,. 装した各手法のメソッドを呼び出す.各メソッドは,全. 全ての Map タスクの進捗情報から,全てのノードが格納. ⓒ 2014 Information Processing Society of Japan. 4.
(5) Vol.2014-ARC-210 No.11 Vol.2014-OS-129 No.11 2014/5/15. 情報処理学会研究報告 IPSJ SIG Technical Report. Hadoop. 表 1 評価環境 hadoop-1.2.1. OS. Debian 3.11.10-1. CPU. Intel(R) Xeon(R) CPU E31260L @ 2.40GHz. メモリ. 8GB. ノード数. 10. ネットワーク. 1Gbps Ethernet. 表 2. 入力データとタスク数. プログラム. 入力データサイズ. Map タスク数. Reduce タスク数. terasort. 5.3GB. 90. 7. wordcount. 5.3GB. 90. 7. pagerank(stage1). 600MB(300 万ページ). 90. 7. pagerank(stage2). (stage1 の出力). 7. 7. Reduce タスクの割り当ては,通常全 Map タスクの 5%が 終了した段階から開始される.これは,Reduce タスクが それぞれの Map タスクが処理を終えたらすぐにデータの コピーを開始するためである.そのため,Map タスクの 処理が進むにつれて各ノードの格納データ量が増加してい 図 5. 最少通信データ量割り当ての計算アルゴリズム. き,通信データ量が最少となる組み合わせが変わる場合が ある.よって,TaskTracker がタスクを要求する度に,そ. しているパーティション毎のデータ量を集計する.集計し. の時点でタスクを実行可能なノードと未実行の Reduce タ. たデータから,ノードに Reduce タスクを割り当てた際に. スクの中で,最も通信データ量の少なくなる組み合わせを. 必要となる通信データ量の表を作成する.次に,初期化時. 計算し,最適なタスクを割り当てる.計算量は,ノード数. に作成しておいた組み合わせリストをもとに,各組み合わ. を N,Reduce タスク数を R としたときの組み合わせの数. せで必要となる通信データ量を計算する.全ての組み合わ. N PR. せを調べ,通信データ量が最少となるノードとタスクの組. に大きくなる.また,組み合わせを網羅するためのリスト. み合わせを求める.その結果に基づき,タスクを要求した. を作成する際にも多くの時間がかかる.. ノードに割り当てるタスクを JobTracker へ返す. ノード数3,Reduce タスク数3の場合の計算アルゴリ ズムを図 5 に示す.まず,全てのノードとタスクの割り当 ての組み合わせを網羅するため,3 P3 の順列の要素を求め,. に依存するため,ノードとタスクの数によっては非常. 5. 評価 Hadoop に付属している terasort ,wordcount プログ ラムと Intel の提供する Hadoop のベンチマークである. 組み合わせリストを生成する.タスクの選択では,全ての. HiBench[17] の中の PageRank プログラムを使用し,各手. ノードが格納しているパーティション毎のデータ量を集. 法での通信データ量について評価を行った.評価環境を表. 計し,格納データ量表を作成する.格納データ量表から,. 1 に示す.JobTracker ノード 1 台と TaskTracker ノード 9. ノードにタスクを割り当てたときにデータのコピーに必要. 台の計 10 台のクラスタ上で評価を行った.terasort プログ. となる通信データ量表を作成する.例えば,ノード N0 に. ラムは,1つの MAP タスクは1つのパーティションにし. タスク P0 を割り当てたときに必要となる通信データ量は,. か出力せず,各ノードの格納するパーティション毎のデー. その他のノード N1 ,N2 が格納している P0 のデータ量の. タ量に偏りが生じる.wordcount プログラムは,1つの. 合計となる.次に,初期化時に作成しておいた組み合わせ. MAP タスクがほぼ全てのパーティションへ出力し,ノー. リストをもとに,各組み合わせで必要となる通信データ量. ド間でのデータの偏りがほとんど起こらない.PageRank. を計算する.組み合わせが [0,1,2] の場合は,タスク P0 を. プログラムは,Web ページのランク付けをするプログラム. ノード N0 に,タスク P1 をノード N1 に,タスク P2 をノー. であり,Web ページのリンク関係と現在のランクを算出. ド N2 に割り当てたときに必要となる通信データ量である.. する stage1 と,ページ毎にリンク先のランクとリンク数. 全ての組み合わせを調べ,組み合わせ [2,1,0] が通信データ. からランクを計算する stage2 の 2 つの処理を行う.stage1. 量が最少となる割り当てとなるため,これを選択する.. の Map タスクは全てのパーティションへデータを出力. 通信データ量が最少となるノードとタスクの組み合わ. し,ノード間の格納データの偏りはほとんど起こらない.. せの計算は,TaskTracker がタスクを要求する度に行う.. stage1 の Reduce タスクの出力が stege2 の Map タスクの. ⓒ 2014 Information Processing Society of Japan. 5.
(6) Vol.2014-ARC-210 No.11 Vol.2014-OS-129 No.11 2014/5/15. 情報処理学会研究報告 IPSJ SIG Technical Report 1.3. 1.3. Original MaxPartition MinNetworkTraffic Min Max. 1.2. 1.2. 1.1. 1.1. Transferred data size. Transferred data size. Original MaxPartition MinNetworkTraffic Min Max. 1. 0.9. 0.8. 1. 0.9. 0.8. 0.7. 0.7. 0.6. 0.6. 0.5. 0.5. 1. 2. 3. 4. 5. 1. 2. Number of trials. 図 6. terasort での通信データ量. 1.3. 4. 図 7. 5. wordcount での通信データ量. 1.3. Original MaxPartition MinNetworkTraffic Min Max. 1.2. Original MaxPartition MinNetworkTraffic Min Max. 1.2. 1.1. 1.1. Transferred data size. Transferred data size. 3. Number of trials. 1. 0.9. 0.8. 1. 0.9. 0.8. 0.7. 0.7. 0.6. 0.6. 0.5. 0.5. 1. 2. 3. 4. 5. 1. Number of trials. 図 8 pagerank stage1 での通信データ量. 2. 3. 4. 5. Number of trials. 図 9. pagerank stage2 での通信データ量. 入力となる.stage2 では,Map タスクと Reduce タスク. データ量を求めたものを,それぞれ Min,Max とした.縦. の数が等しく,1 つの Map タスクの出力が 1 つの Reduce. 軸は Original の通信データ量を 1 としたとき通信データ. タスクの入力となる.. 量,横軸は試行回数 5 回のそれぞれの結果となっている.. 本評価での入力データとタスク数を表 2 に示す.tera-. 表 3 に平均通信データ量を示す.terasort プログラムで. sort,wordcount プログラムの入力には約 5.3GB のログデー. は Min と Max で通信データ量に約 1.13GB の差がある.. タを用いた.PageRank プログラムの入力には,HiBench. Original と比べて,最大データ格納割り当てでは平均 8%,. の付属ツールで生成したページ数 300 万のデータセット使. 最大 11%,最少通信データ量割り当てでは,平均 13%,最. 用した.データ量とノードへの分散を考慮して,Map タス. 大 18%の通信データ量が削減している.wordcount および. ク数は TaskTracker 数の 10 倍の 90 とした.通常,Reduce. pagerank stage1 では,通信データ量の最小値と最大値の. タスクの数は TaskTracker の数以下に設定されるが,本実. 差がほとんどなく,各手法において通信データ量は同じと. 験では 7 とした.. なった.pagerank の stage2 では,2 つの提案手法ともに 通信データ量は 0 となり 2.79 GB 削減している.terasort. 5.1 通信データ量の評価結果. ,pagerank の stage2 では,各ノードが格納するパーティ. 各評価プログラムを実行したときの通信データ量を測定. ション毎のデータ量に偏りが起こり,割り当てる Reduce. した.測定結果を図 6-図 9 に示す.Original は Hadoop の. タスクによって通信データ量が大きく変動するため,各手. タスク割り当てを,MaxPartition は最大格納データ量割. 法が有効に働いたと考えられる.特に pagerank stage2 の. り当てを,MinNetworkTraffic は最少通信データ量割り当. ような 1 つの Map タスクの出力が1つの Reduce タスク. てを表す.全ての Map タスクの出力が完了した後の,最. のみの入力になる場合には,通信データ量を 100%削減で. 終的なパーティションのデータ量から,最少と最大の通信. き,効果が大きい.一方,wordcount,pagerank の stage1. ⓒ 2014 Information Processing Society of Japan. 6.
(7) Vol.2014-ARC-210 No.11 Vol.2014-OS-129 No.11 2014/5/15. 情報処理学会研究報告 IPSJ SIG Technical Report 平均通信データ量 (GB). 1.3. Original. MaxPartition. MinNetworkTraffic. Min. Max. terasort. 5.34. 4.91. 4.64. 4.50. 5.63. wordcount. 8.85. 8.82. 8.81. 8.76. 8.89. pagerank(stage1). 1.30. 1.30. 1.30. 1.28. 1.30. pagerank(stage2). 2.79. 0.00. 0.00. 0.00. 3.16. 表 4. terasort の平均処理時間 (秒). Reduce タスク数. Original. MaxPartition. MinNetworkTraffic. 4. 61.317. 59.166. 58.165. 5. 56.188. 56.160. 55.177. 6. 47.150. 46.143. 45.000. 7. 47.153. 45.143. 44.037. 8. 42.147. 41.226. 41.043. 9. 41.140. 39.141. 48.905. 10. 44.148. 42.149. 60.871. MinNetworkTraffic MaxPartition Original. 1.2. Execution time. 表 3 プログラム. 1.1. 1. 0.9. 0.8 4. 5. 6. 7. 8. 9. 10. Number of ReduceTasks. 図 10. terasort の処理時間. では,各ノードが格納するパーティション毎のデータ量に. 多いパーティションに対応する Reduce タスクを割り当て. 偏りがほとんどなく,どのノードにどのタスクを割り当て. る.最少通信データ量割り当てでは,クラスタ全体でパー. ても通信データ量はほとんど変わらないため,両手法とも. ティションのコピーに必要となる通信データ量を考慮し,. に効果は少なかった.. 通信データ量が最少となるノードと Reduce タスクの組み 合わせを求めて,Reduce タスクを割り当てる.両手法と. 5.2 処理時間の評価結果. もに,各ノードが格納するパーティション毎のデータ量に. TaskTracker 数を 10 台とし,Reduce タスクの数を 4 か. 偏りがある場合には,通信データ量および処理時間を削減. ら 10 に変化させて terasort プログラムを実行し,各手. できる.最大通信データ量割り当ては,ノード数,タスク. 法での処理時間を測定した.測定結果を表 4 および図 10. 数に関わらず通信データ量および処理時間を削減できるが,. に示す.グラフの縦軸は Original の処理時間を 1 とした. 最少通信データ量割り当てと比べて削減量が小さい.最少. ときの割合,横軸は,Reduce タスクの数となっている.. 通信データ量では,組み合わせの候補が少ないときは,通. MaxPartition は全ての場合で Original より処理時間が削. 信データ量および処理時間を大きく削減できる.しかし,. 減している.MinNetworkTraffic においても Reduce タス. 組み合わせの候補数が増加するにつれて計算量が大きく. クの数が 4 から 8 の時は処理時間が削減しており,3 つの. なり,組み合わせ候補と最小値の計算時間が増加してしま. 手法の中で最も処理時間が短くなっている.このことか. う.組み合わせ候補のリストを格納するためのメモリ領域. ら,通信データ量が削減されたことで,パーティションの. も大きくなる.また,今回は1つのラックのみの実験環境. コピーにかかる時間が短縮され,処理時間の削減に繋がっ. であった.実際の環境ではノード数がもっと多く,複数の. ていることが分かる.そして,クラスタ全体の通信データ. ラックで分けられていることもあるため,ネットワークの. を考慮したことで,削減率の高まった MinNetworkTraffic. 距離等の影響も考慮する必要がある.. が最も処理時間が短くなった.しかし,MinNetworkTraffic では,Reduce タスクの数が 9 以上になると処理時間が大 きく増加している.このときの,組み合わせの候補の数は 10 P9 =3628800. となり,候補の生成時間および最小値の計. 参考文献 [1] [2]. 算時間が長くなったことが原因だと考えられる.よって, 組み合わせ候補数が少ない場合は最少通信データ量割り当 てを使用し,候補数が多いときは最大格納データ量割り当. [3]. て,もしくは別の最少通信データ量の近似解を求めるよう な手法を使用するのが良いと考えられる.. 6. おわりに. [4] [5]. 本論文では,MapReduce における通信データ量を考慮 した Reduce タスク割り当て手法について述べた.最大格 納データ量割り当てでは,タスクを要求したノードが格納 するパーティションのデータ量を考慮し,最もデータ量の. ⓒ 2014 Information Processing Society of Japan. [6]. OpenMPI. http://www.mcs.anl.gov/research/projects/mpi 原 健太朗, 田浦 健次朗, 近山 隆. DMI:計算資源の動的 な参加/脱退をサポートする大規模分散共有メモリイン ターフェース.情報処理学科論文誌,Vol. 3, No. 1, pp. 1-40 (2010). 三添匠, 小鍛治翔太, 芝公仁. プロセスを分散実行するため のシステムコール制御手法, 情報処理学会研究報告. [ハイ パフォーマンスコンピューティング] 2011- HPC-132(33), 1-7, 2011-11-21 Hadoop. http://hadoop.apache.org/ Dean, J. and Ghemawat, S. 2004. MapReduce: Simplified data processing on large clusters. In Proceedings of Operating Systems Design and Implementation(OSDI). San Francisco, CA. 137-150. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google file system. In 19th Symposium on Operating Systems Principles, pages 29-43, Lake George,. 7.
(8) 情報処理学会研究報告 IPSJ SIG Technical Report. [7] [8] [9]. [10]. [11] [12]. [13]. [14]. [15]. [16]. [17] [18]. Vol.2014-ARC-210 No.11 Vol.2014-OS-129 No.11 2014/5/15. New York, 2003. Hbase. http://hbase.apache.org/ Hive. http://hive.apache.org/ 塚本 勢児, 布広 永示. Hadoop を用いた衛星画像データ解 析処理の高速化の研究. 研究報告システムソフトウェアと オペレーティング・システム(OS)2014-OS-128, 9, 1-6, 2014-02-27 滝澤 真一朗, 松田 元彦, 丸山 直也. MapReduce による計 算科学アプリケーションのワークフロー実行支援. ハイパ フォーマンスコンピューティングと計算科学シンポジウ ム論文集, 2014, 1-9 (2013-12-31) Mahout. http://mahout.apache.org/ Ibrahim, S., Jin, H., Lu, L., He, B. Antoniu, G. and Wu,S. Maestro: Replica-Aware Map Scheduling for MapReduce, 12th IEEE/ACM Internatinal Symposium on Cluster, I Cloud and Grid Computing, Ottawa, Canada(2012). Zhang, X., Feng Y., Feng, S, Fan, J. and Ming, Z. An effective data locality aware task scheduling method for MapReduce framework in heterogeneous environments International Conference on Cloud and Service Computing (CSC), (2011) Kurazumi, S., Tsumura, T., Saito, S., Matsuo, H. Dynamic Processing Slots Scheduling for I/O Intensive Jobs of Hadoop MapReduce , ICNC ’12 Proceedings of the 2012 Third International Conference on Networking and Computing , Pages 288-292 , DOI: 10.1109/ICNC.2012.53 藏澄汐里 , 津邑公暁 , 齋藤彰一 , 松尾啓志. Hadoop MapReduce におけるリソース使用状態を考慮したスロッ トスケジューリング. 研究報告ハイパフォーマンスコン ピューティング(HPC),2013-HPC-142(32),1-8 M. Hammoud, M.S. Rehman, and M.F. Sakr. Center-ofgravity reduce task scheduling to lower mapreduce network traffic. In 2012 IEEE 5th International Conference on Cloud Computing (CLOUD) , pp. 49 58, June 2012. HiBench. https://github.com/intel-hadoop/HiBench Tom White: Hadoop 第 3 版 ,オライリー・ジャパン , July 2013.. ⓒ 2014 Information Processing Society of Japan. 8.
(9)
図


関連したドキュメント
入力用フォーム(調査票)を開くためには、登録した Gmail アドレスに届いたメールを受信 し、本文中の URL
主人が部曲を殴打して死亡させた場合には徒一年に処する。故意に殺害した 場合 (1) には一等を加重する。(部曲に)落ち度 (2)
問についてだが︑この間いに直接に答える前に確認しなけれ
仮定2.癌の進行が信頼を持ってモニターできる
の点を 明 らか にす るに は処 理 後の 細菌 内DNA合... に存 在す る
BC107 は、電源を入れて自動的に GPS 信号を受信します。GPS
特に、その応用として、 Donaldson不変量とSeiberg-Witten不変量が等しいというWittenの予想を代数
を受けている保税蔵置場の名称及び所在地を、同法第 61 条の5第1項の承
