平成 27 年度修士論文
Twitter の実況ツイートを利用した
タイムライン上のネタバレ情報検知
情報理工学研究科 情報・通信工学専攻 コンピュータサイエンス コース
1431050 齊藤 令
指導教員 寺田 実 准教授
副指導教員 角田 博保 准教授
提出日 2016 年 3 月 14 日
1
概要
研究目的
Twitterでは,ユーザの増加により情報が氾濫し,ネタバレ情報が目に入りやすい環境になってい
る. 今放送している番組についてツイートする実況ツイートというものがあり,これにはネタバレ なツイートと非ネタバレなツイートが混在している. 実況ツイートを利用してネタバレ推定の分類 器を作成し, ネタバレなツイートの推定ができないか考えた. 本研究は, Twitterを対象として, ス ポーツやゲームの試合結果などのような積極的に発信されるネタバレ情報について着目する. この スポーツやゲームの試合に関する実況ツイートを利用してネタバレ判別分類器を作成し,ネタバレ 情報を含んだツイートの推定を試み, 提案手法の有効性を検証することが本研究の目的である.
方法
提案手法は,ハッシュタグのついた実況ツイートをツイート検索で収集し,教師用データとして 扱うためにネタバレか非ネタバレか区別するためのラベリングを行う. ツイートをURL除去,リプ ライ, 同じ文字を連続した記述の正規化等を行い,形態素解析しベクトル化しやすいように整形す る. BoW(Bag of Words)モデルにより単語ベクトルを生成し, LSI(Latent Semantic Indexing)に より単語ベクトルの次元削減を行う. 得られた単語ベクトルに, URLの有無, ユーザの興奮度, ツ イートの勢いの情報を加え,サポートベクトルマシンによる機械学習を行い,ネタバレツイートを 推定するための分類器を作成した.
結論
提案手法を用いて作成した分類器から得られた分類結果を取得し, Accuracy, AUC(Area Under the Curve), Precision, Recall, F値の評価値を算出し,分類器の性能評価を行った. 結果としてURL の有無,ユーザの興奮度,ツイートの勢いはネタバレ分類において有効であり,実況ツイートを利用 してネタバレ分類器が作成可能であることを示した. また,この3つの要素を追加することで単語 ベクトルを低次元にしたときでも分類できることがわかった. しかし,スコアやチーム名, 選手名 等の表記揺れに対応できなかったり,ネタバレと非ネタバレの誤認識などがあるので改善点がある.
2
目 次
第1章 序論 7
1.1 背景 . . . . 7
1.2 問題点 . . . . 7
1.3 着眼点 . . . . 8
1.4 研究目的. . . . 9
1.5 本論文の構成 . . . . 9
第2章 関連研究 10 2.1 ネタバレ防止ブラウザの実現[1] . . . . 10
2.1.1 ネタバレ検出方法. . . . 10
2.1.2 フィルタリングの視覚化 . . . . 10
2.1.3 本研究との比較 . . . . 11
2.2 Twitter上のネタバレ情報の検出[2] . . . . 11
2.2.1 本研究との比較 . . . . 11
2.3 Twitterのスポーツ実況ツイートからの要約 . . . . 12
2.3.1 良い実況者に着目した試合の要約[3] . . . . 12
2.3.2 チームに応じた試合の要約[4] . . . . 13
2.3.3 本研究との比較 . . . . 13
2.4 Twitter上のネタバレ情報の調査と分析 . . . . 13
2.4.1 ストーリーコンテンツに対するネタバレ[5]. . . . 13
2.4.2 本研究との関連 . . . . 14
2.4.3 直接的・間接的ネタバレの分析[6]. . . . 14
2.5 マイクロブログにおけるユーザの感情を表す単語の抽出 . . . . 15
第3章 提案手法 16 3.1 概要 . . . . 16
3.2 実況ツイートの収集 . . . . 16
3.3 ネタバレと非ネタバレのラベリング . . . . 16
3.4 形態素解析 . . . . 17
3.5 単語ベクトルの次元の削減 . . . . 17
3.6 追加要素. . . . 18
3.6.1 URLの有無 . . . . 19
3.6.2 ユーザの興奮度 . . . . 19
3.6.3 ツイートの勢い . . . . 19
3.7 分類器の評価方法 . . . . 19
3.7.1 ホールドアウト検証 . . . . 19
3
3.7.2 K分割交差検証 . . . . 20
3.8 分類器の評価指標 . . . . 20
3.8.1 Accuracy(正答率). . . . 22
3.8.2 Precision(適合率) . . . . 22
3.8.3 Recall(再現率) . . . . 22
3.8.4 F1-score(F値) . . . . 23
3.8.5 AUC(Area Under the Curve) . . . . 23
第4章 予備実験 24 4.1 データセット . . . . 24
4.2 結果 . . . . 24
4.2.1 ホールドアウト検証の実験結果 . . . . 24
4.2.2 交差検証の実験結果 . . . . 26
4.3 結論 . . . . 26
第5章 実装 27 5.1 開発環境. . . . 27
5.2 分類器の作成 . . . . 27
5.2.1 データセット . . . . 27
5.2.2 ツイートのベクトル化 . . . . 27
5.2.3 機械学習. . . . 30
第6章 評価実験 31 6.1 次元削減を行わない機械学習. . . . 31
6.2 出現頻度での単語ベクトルの除去 . . . . 31
6.3 LSIによる次元の削減 . . . . 32
6.4 追加要素. . . . 34
6.4.1 URLの有無 . . . . 34
6.4.2 ユーザの興奮度 . . . . 34
6.4.3 ツイートの勢い . . . . 34
6.4.4 全ての追加要素 . . . . 34
第7章 考察 41 7.1 LSIによる単語ベクトルの削減 . . . . 41
7.2 追加要素. . . . 41
7.2.1 URLの有無 . . . . 41
7.2.2 ユーザの興奮度 . . . . 41
7.2.3 ツイートの勢い . . . . 42
7.3 分類器の誤判定の解析 . . . . 42
7.3.1 ネタバレを非ネタバレと誤答した場合 . . . . 42
7.3.2 非ネタバレをネタバレと誤答した場合 . . . . 43
7.3.3 関連研究[2]との比較. . . . 44
4
第8章 結論 45
8.1 まとめ . . . . 45
8.2 今後の課題 . . . . 45
8.2.1 表記揺れの対応 . . . . 45
8.2.2 ネタバレ度のスコアリング. . . . 45
8.2.3 他のパラメータの付加 . . . . 45
8.2.4 他のスポーツでの検証 . . . . 46
8.2.5 教師なし学習での検証 . . . . 46
謝辞 47
参考文献 49
付録 49
5
図 目 次
1.1 ハッシュタグを用いた実況ツイートの例 . . . . 8
2.1 イベントストリームにおけるツイート例 . . . . 12
2.2 20番組において放送される世帯平均数 . . . . 14
3.1 高度な検索の画面 . . . . 17
3.2 時間毎のツイート数と出来事. . . . 20
3.3 システムの概略図 . . . . 21
3.4 ホールドアウト検証の概略図. . . . 21
3.5 交差検証のデータ分割に関する概略図. . . . 22
3.6 ROC曲線とAUC. . . . 23
4.1 野球とテニスの分類結果とROC曲線 . . . . 25
4.2 テニスと駅伝の分類結果とROC曲線 . . . . 25
4.3 野球と駅伝の分類結果とROC曲線 . . . . 25
5.1 ツイートの前処理例 . . . . 29
6.1 交差検証結果(単語ベクトルのみ) . . . . 39
6.2 交差検証結果(+URL) . . . . 39
6.3 交差検証結果(+興奮度) . . . . 40
6.4 交差検証結果(+ツイートの勢い) . . . . 40
6.5 交差検証結果(+all). . . . 40
6
表 目 次
2.1 関連研究[2]の結果 . . . . 12
3.1 ネタバレと非ネタバレの分類例 . . . . 18
3.2 事実と予測の関係 . . . . 20
4.1 ホールドアウト検証の予備実験結果1 . . . . 24
4.2 ホールドアウト検証の予備実験結果2 . . . . 26
4.3 交差検証の予備実験結果 . . . . 26
5.1 連続した記述の正規化例 . . . . 28
6.1 出現頻度に関する検証結果 . . . . 32
6.2 ホールドアウト検証結果1(単語ベクトルのみ) . . . . 33
6.3 ホールドアウト検証結果2(単語ベクトルのみ) . . . . 33
6.4 交差検証結果(単語ベクトルのみ) . . . . 33
6.5 ホールドアウト検証結果(+URL) . . . . 35
6.6 ホールドアウト検証結果2(+URL) . . . . 35
6.7 交差検証結果(+URL) . . . . 35
6.8 ホールドアウト検証結果1(+興奮度) . . . . 36
6.9 ホールドアウト検証結果2(+興奮度) . . . . 36
6.10 交差検証結果(+興奮度) . . . . 36
6.11 ホールドアウト検証結果1(+勢い). . . . 37
6.12 ホールドアウト検証結果2(+勢い). . . . 37
6.13 交差検証結果(+勢い) . . . . 37
6.14 ホールドアウト検証結果1(+all) . . . . 38
6.15 ホールドアウト検証結果2(+all) . . . . 38
6.16 交差検証結果(+all). . . . 38
7.1 スコア速報に関する誤答例と正答例 . . . . 42
7.2 端的なツイートの誤答例とユーザの興奮度が高いツイートの正答例 . . . . 43
7.3 非ネタバレをネタバレと誤答した例 . . . . 43
8.1 実際に分類された例(True Positive) . . . . 49
8.2 実際に分類された例(True Negative) . . . . 50
8.3 実際に分類された例(False Positive). . . . 51
8.4 実際に分類された例(False Negative) . . . . 52
7
第 1 章 序論
1.1 背景
SNSは他ユーザとの交流や今話題の情報を入手するために日夜利用されている. 利用者は非常に 多く,現代人にとってSNSは欠かせないものとなっている. その中でもTwitter1は,ユーザが親し い他ユーザをフォローすることで他ユーザとコミュニケーションを図ったり,自分の興味のある情 報を積極的に発信するユーザをフォローすることで興味のある情報を入手しやすくする等といった 使い方が一般的である. また, Twitterは即時性・速報性が高く,今流行りの話題や情報を直ちに入 手することができる.
しかし, 興味のある情報だからといって必ずしも今必要な情報とは限らない. 例えば,楽しみに していたコンテンツの結果を知ってしまう「ネタバレ」が挙げられる. ネタバレ情報は結果やそれ に至る過程を知ってしまうとそのコンテンツの面白さを減衰させてしまうことがあり,これからそ のコンテンツを楽しもうとしているユーザにとって大きなストレスとなり,コンテンツの魅力を台 無しにしてしまう恐れがある.
Twitterを利用するユーザの増加により情報が氾濫し,ネタバレ情報が目に入りやすい環境になっ
ている. Twitterでは,タイムラインに現れたネタバレを偶然遭遇してしまうことが多い.
1.2 問題点
ネタバレ情報に遭遇してしまったときのデメリットはコンテンツの面白さを減衰させることと, ネタバレによって与えるユーザのストレスにあること本章第1節で述べた.
ネタバレの被害に遭う要因として, 放送時間の違いというのが挙げられる. 例えば, ドラマやア ニメ等では地域間で放送時間が違い,スポーツでは生放送と録画放送で放送時間が違う. どちらの 例でも後続の放送で楽しむユーザにとって,先方の放送の情報は脅威となる.
上記からネタバレを防ぐことは非常に意義があると考えられる. ユーザがネタバレ情報を見ない ようにするためには, Twitterのタイムラインをなるべく見ないようにする, またはなるべく情報 収集しないといった対策がある. しかし, Twitterはコミュニケーションツールとして日常的に使 用するので,この対策は困難である.
ユーザが今放送している番組についてツイートする「実況」というものがある. Twitterでは,番 組に関連するハッシュタグをツイートに付加して「実況」を行うのが一般的である. このような番 組に関連するハッシュタグを付加してリアルタイムに投稿されたツイート(図1.1)を「実況ツイー ト」と呼ぶ. 実況ツイートは, 放送中に起こったこと, 放送を視聴してユーザ自身が思ったこと考 えたこと等がほとんどである. 中には放送中のキャプチャ画像やニュース記事等を付加したツイー トも存在する. このようにネタバレになりうるツイートが存在するため,後続の放送で楽しむユー ザは番組に関連するハッシュタグをミュートにすることである程度ネタバレを防ぐことができる.
1https://twitter.com/
第1章 序論 8
しかし,中にはハッシュタグを付けずに実況する人もいるため, 完全にネタバレを防ぐことはでき ない.
図1.1: ハッシュタグを用いた実況ツイートの例
1.3 着眼点
本研究では,実況ツイートに着目した. 前述の通り実況ツイートにはネタバレなツイートと非ネ タバレなツイートが混在している. 実況ツイートを利用して,分類器を作成すれば,放送外のコンテ ンツに関係したツイートやハッシュタグが付加されてない実況ツイートのフィルタリングにも応用 できるのではないかと考えた. さらに,そこに第3章で述べるURLの有無やツイートの勢い,ユー ザの興奮度といったパラメータを付加して分類器を作成すれば,分類器を良化させることができる のではないかと考えた.
第1章 序論 9
1.4 研究目的
スポーツやゲームの試合等のネタバレを実況ツイートから除去することを目的とする.
スポーツの試合結果や将棋,囲碁などのゲームの対戦結果は,多くの人にとってその速報性が重要 であるので,公式サイトやニュースサイトでも積極的に発信し, ユーザもその経過や結果から様々 な感想や考察等を積極的に発信する. 勝敗やスコア等で結果がはっきりしているため,ネタバレと 非ネタバレの区別がはっきりしている.
テレビ番組や小説, 映画などといったコンテンツでは,ネタバレ情報が公式サイトやニュースサ イトなどで積極的に公開されることはなく,ユーザのレビューやブログ等で発信される程度である.
また, 人によって解釈が異なることもあり, どのようなツイートがネタバレになるのか一概には言 えない.
本研究の目的は, Twitterを対象として, スポーツやゲームの試合結果などのような積極的に発 信されるネタバレ情報について着目し,実況ツイートを利用してネタバレ判別分類器を作成し, 実 況ツイートの中にあるネタバレ情報を含んだツイート(以下「ネタバレツイート」と呼ぶ)の推定 を試み,提案手法の有効性を検証する.
1.5 本論文の構成
本論文の構成を簡潔に説明する. 第1章では,序論として本研究の背景,問題点,着目点,研究目 的について述べた. 第2章では,関連研究について述べる. 第3章では,本研究の提案手法について 述べる. 第4章では,単語ベクトルを2次元に削減した場合でも2クラス分類ができるか確かめる 予備実験について述べる. 第5章では, 本研究でシステムの実装方法について述べる. 第6章では, 実験の結果について述べる. 第7章では,実験から得られた結果について考察する. 第8章では,結 論と今後の課題について述べる.
10
第 2 章 関連研究
ネタバレを遮断することを目的をした研究は過去にも幾つか行われており, Twitterの実況ツイー トを利用した研究も幾つか行われている.
2.1 ネタバレ防止ブラウザの実現 [1]
2.1.1 ネタバレ検出方法
中村の研究[1]は,ブラウザベースでフィルタリングを行いネタバレ情報を遮断する研究である.
ネタバレ情報の抽出は, オブジェクト名リストと正規表現辞書を利用している. オブジェクト名リ ストには,主に固有名詞が入っておりチーム名及び選手名(正式名称やニックネームなど)から構成 されている. 正規表現辞書には, スポーツ等の試合に関する汎用性の高い単語や英数字, オブジェ クト名リストのオブジェクトをマッチさせる正規表現が格納されている. このことからネタバレ情 報の検出はルールベースによるもので比較的シンプルなものとなっている.
2.1.2 フィルタリングの視覚化
この研究ではフィルタリングの視覚化に取り組み,ユーザへフィードバック方法について検討し ている. 以下の4つのフィードバック方法を提案している.
非表示手法
ネタバレと判断された部分を非表示にする手法である. ネタバレ部分のみがページから抜け 落ちるためユーザは閲覧中に気になることはない. しかし,何がネタバレと判断されたかユー ザは判断することができない.
黒塗り手法
ネタバレと判断された部分の背景とテキストを黒塗りにする手法である. この手法ではどこ がフィルタリングされているかユーザが把握できるが, 黒塗りされた部分が気になってしま う可能性がある.
曖昧記述変換手法
ネタバレ情報が明確に記述されている部分をぼかしたような記述にする手法である. 例えば,
「日本代表が勝利した」を変換すると,「日本代表が勝利したかもしれないし敗北したかも」,
「日本代表が勝利?敗北?」のようになる.
木の葉を隠すなら森の中手法(木の葉手法)
ネタバレと予想された部分を結果が反転したもの,類似したもの等をページ内に挿入する手 法である. どれが本当の情報なのかわからなくなるかわりに,ページ内がゴミだらけになって しまいユーザにストレスを与えさせる可能性がある.
第2章 関連研究 11
2.1.3 本研究との比較
この研究とは,スポーツを対象にネタバレをフィルタリングする点で共通している. 本研究では, ルールベースではなく機械学習により分類器を作成し,ネタバレツイートの推定を行う. 機械学習 により作成した分類器の性能評価が本研究の目的である.
2.2 Twitter 上のネタバレ情報の検出 [2]
Sungho Jeonらの研究[2]は, Twitter上でネタバレ情報を検出するにあたって重要な以下の4つ の要素を提唱し,これらの要素を元にSVMで機械学習したモデルを使い,既存の機械学習モデル と比べた研究と比較した研究である. この研究ではデータセットとして,リアリティ番組12回分の ツイート合計176426件を使用している. このツイートを手動でネタバレと非ネタバレのラベリン グを行い,ネタバレと判断されたツイートは5618件であった.
頻出人名
頻出人名はそのコンテンツに出ている人物である可能性が高い. この人物に関するツイート 全てがネタバレ情報を持っているとは限らないが,ネタバレ情報を持っている可能性があり 危険である.
頻出動詞
頻出動詞は今現在起こってることについて書かれている可能性が高い. 特に頻出人名と頻出 動詞の組み合わせは登場人物が今行っていることについて書かれている可能性が非常に高く ネタバレの可能性が高い.
URLつきツイート
URLつきツイートはニュースサイトや画像などのURLがついたツイートのことである. ニュー スサイトのURLがついたツイートはそのURLがコンテンツの結果を表すサイトである可能 性が高い. 画像や動画のURLでもそのコンテンツの過程・結果を表すものである可能性が ある. 中には関係のないURLつきツイートもあるが,ネタバレであるかは中身を見るまで未 知数である. システムがリンク先まで判別するのは困難なので, ここでは最初から除去して いる.
ツイートの時制
ツイートの時制はどの時制でツイートされているかである. 例えば,英語では現在形,過去形, 未来形等といった時制が存在する. 現在時制では今起きていることについて, 過去時制では コンテンツの結果について述べられることが予想される. 未来時制では仮定法で使われるこ とが多く,ユーザの予想や願望といった情報が多くなる. なので,未来時制ではネタバレ情報 は含まない.
結果は以下の表2.1の通りである. 結果を見ると,動詞を追加したときとURLの有無を追加した ときのF値が大幅に良化している. これらはネタバレ検知において有効であることが言える.
2.2.1 本研究との比較
SVMと実況ツイートを用いて学習を行う点で共通している. 本研究では,スポーツやゲームに関 する実況ツイートを対象にし,対象言語は日本語である. 上記の4つの要素を元にSVMで機械学
第2章 関連研究 12
表 2.1: 関連研究[2]の結果
Step Entered feature Recall Precision F-score
1 頻出名詞 0.3084 0.8291 0.4496
2 +動詞 0.5653 0.8611 0.6826
3 +URL 0.7699 0.7957 0.7825
4 +時制 0.7697 0.7987 0.7839
習した結果, F値が良化したため, これらの要素はネタバレ検知で重要であると考えられる. しか し,この研究では英語のツイートのみを扱っているため,日本語では別の要素が重要になる可能性 がある.
2.3 Twitter のスポーツ実況ツイートからの要約
2.3.1 良い実況者に着目した試合の要約 [3]
久保らの研究[3]は, 試合の内容が鮮明にわかるツイートをするユーザに着目し, そのユーザの ツイートを用いて試合の要約を行う研究である. 図2.1はイベントストリームにおけるツイート例 である. ユーザBは2つのサブイベントで試合で起きたことが鮮明にわかるツイートをしており, ユーザBが良い実況者ということになる. 逆にユーザAは単なる感想を述べているだけなので,悪 い実況者ということになる.
図2.1: イベントストリームにおけるツイート例
試合(イベント)中に起きたサブイベントを取得するためにバースト検出を用いている. ツイー
トが集中した時間帯に何らかのサブイベントが起きたとし,このときのツイートを解析する. この 研究では,動作の主体である名前と専門用語の組み合わせで多くのサブイベントが説明できるとし ている. 例えば,野球であれば「(選手名)ホームラン!」「(選手名)タイムリー!」等,サッカーで あれば「(選手名)にレッドカード」「(選手名)のシュート!」等である. つまり,動作の主体である 名前と専門用語の組み合わせの共起回数が多ければ,サブイベントをより詳しく説明しているとし, ツイートにスコアをつける. またこのようなツイートを迅速に行うユーザに対して高いユーザのス
第2章 関連研究 13
コアをつける. ツイートのスコアとユーザのスコアから良いツイートを選び, 要約を自動で生成し ている. また,動作の主体となる名前と専門用語はあらかじめ辞書リストを用意して, ルールベー スで解決している.
2.3.2 チームに応じた試合の要約 [4]
小林らの研究[4]は,ユーザの属性(応援しているチーム)に応じた試合の要約を行う研究である.
ハッシュタグが付加されたツイートを利用し,ユーザの属性を決定する. チームAに関するハッ シュタグが付いたツイートは,チームAを関連している(応援している)ツイートと考えられる. こ のチームAに関するハッシュタグのついたツイートを形態素解析し,得られた自立語にチームAの 属性を付与することで単語に属性を付与している. 試合時間内の実況ツイートを解析し,単語の属 性を評価し, 属性評価辞書を作成する. この辞書を用いることでハッシュタグが付加されていない ツイートでも属性を判別することが可能でユーザの属性を決定している. 区間ごとにツイート数の 平均と分散を利用し,ツイートがバーストした時間帯を属性別に見つけ出す. バーストした時間帯 のツイートから要約を生成している.
2.3.3 本研究との比較
どちらもツイートが急激に増えた時間帯を利用して要約を生成している. このことからツイート が急激に増えたところで試合展開に変化があったと推定でき,ネタバレツイートが集中すると考え られる. 本研究でも, ツイートがバーストしたことを分類器に学習させたいと考えている. ツイー トの分速を計測し, パラメータに加えることで分類器の良化を図る.
2.4 Twitter 上のネタバレ情報の調査と分析
2.4.1 ストーリーコンテンツに対するネタバレ [5]
田島らの研究[5]では, まず, アニメやドラマといったTV番組は地域間の放送時間差があるた めネタバレを防ぐ必要があると主張している. 図2.2は20個のTV番組についての地域世帯数の 平均と経過日数を表したグラフである. 横軸は最速放送からの経過日数,縦軸が平均世帯数である.
図2.2の通り最速放送を見ることができない世帯は非常に多い. スポーツでは, 昼や夕方の試合は 仕事等によって観れない人が多く, 録画放送等で視聴する人も多い. このことからTwitter上のネ タバレを防ぐ重要性は高い.
この研究ではストーリーコンテンツにおけるネタバレを「正体」「生死」「勝敗」等といったカテ ゴリ毎に分類し, SVMで機械学習し,カテゴリ別にネタバレを推定を行った. ネタバレ判定手法に 以下の3つの方法を提案している.
ベースライン手法
ツイートを形態素解析して,単語ベクトルを作成する手法である. 名詞,動詞,形容詞,連体詞,副 詞の5つの品詞を利用して単語ベクトルを生成する. この際,名詞以外の品詞は原型を使用して学 習させる.
第2章 関連研究 14
図2.2: 20番組において放送される世帯平均数
正規化手法
視聴者が感動等を表す際に用いる「!!!!!」「wwwww」のような連続した記述をすべて「!」
「w」のような1文字に置換し,学習させる手法である.
人物名の一般化手法
ストーリーコンテンツにおける主人公やヒロイン等の登場人物名は,コンテンツによって大きく 異なる. 人物名を一般化させることで新しいストーリーコンテンツのネタバレを推定できると唱え, 登場人物を一般的な語に置き換えて学習させる. ここでは,ストーリーの進行において影響力が高 い人物を「主要人物」,影響力がない人物を「モブ」と置き換えている.
2.4.2 本研究との関連
この研究では,アニメやドラマの「勝敗」に関するネタバレ検出に「!!!!!」「wwwww」のよ うな連続した文字を1文字に置換すると良い結果が得られた. 実況ツイートはこのような記述を 使ったツイートが頻繁に現れるので,正規化する手法は表記揺れを防ぐという意味で有効だと思わ れる. 本研究ではスポーツ等の試合を扱う. スポーツはスコアや勝敗の結果がひと目でわかりやす いため,勝敗に関するネタバレが大多数になると思われる. 本研究でも, 連続した記述を単一文字 に変換し,表記揺れをできるだけ防ぐことで分類器の良化に繋がると考えられる.
2.4.3 直接的・間接的ネタバレの分析 [6]
白鳥らの研究[6]では,直接的ネタバレと間接的なネタバレの2種類に人力で分けて,双方の特徴 や傾向を分析している. 直接的ネタバレと間接的ネタバレは以下のように定義される.
第2章 関連研究 15
直接的ネタバレ
試合の結果や経過,スコアが直接伝わってしまうものである. 例えば,「日本代表勝利!」「日 本,本田のゴールで先制!」「日本2-1アメリカ」等のようなものである.
間接的ネタバレ
直接単語や記述からは結果は伝わらないが,文脈や時間的な要素等から試合の結果や経過,ス コアが読み取れてしまうものである. 例えば,試合終了後に「やったぜ。」「うれしい」といっ た喜びを表すような言葉があると試合に勝利したことがわかる. また,「残念」「悔しい」と いった悲しみを表すような言葉があると試合に敗北したことがわかる. また, 直接的ネタバ レと間接的ネタバレの数は直接的ネタバレのほうが多いようである.
このように直接的ネタバレと間接的ネタバレは特徴が大きく異なる. 双方のネタバレツイートを 形態素解析を行い,品詞別に傾向を見ると. 名詞では,試合に出場した選手名, 国名, 得失点に関す るものが双方共に多い. 形容詞では,「良い」「悪い」等の評価に関するものが直接的ネタバレに多 く,「悔しい」「ほしい」等の自分の感情や展望に関するものが間接的ネタバレに多いということ がわかった.
この研究では,ネタバレを人力で分類して特徴を調べている. 本研究では, サポートベクトルマ シンを用いて分類器を作成しネタバレを分類する. 分類器が分類したツイートを解析し, その特徴 を探る.
2.5 マイクロブログにおけるユーザの感情を表す単語の抽出
Samuel Brodyらの研究[7]は,マイクロブログにおいて単語内に同じ文字が連続しているものを
利用して投稿者の強い感情を表す単語を抽出する研究である. 実況ツイートでは,「ホーーームラ ン!!!」「きたああああああああ」「お兄様すげえええええ」等といった書き込みはよく見るので, 連続した文字を検知し,元の言葉に直す必要がある.
本研究では, 連続した記述を単一文字に置換し, できるだけ元の言葉に近づけている. またこの ような連続した記述の量をスコアリングし,機械学習の際にパラメータとして加えている.
16
第 3 章 提案手法
3.1 概要
ネタバレツイートを分類するためのサポートベクトルマシン(SVM)による分類器を作成し, 分 類器を用いてネタバレツイートの推定を行う.
実況ツイートを検索し収集する. 実況ツイートをネタバレと非ネタバレに人力でラベリングを行 う. 次に,実況ツイートを形態素に分解し, Bag of Wordsモデルで単語ベクトルを作る. 得られた 単語ベクトルは高次元ベクトルであるため,後述の次元削減を行い,簡略化する. そこに,後述の追 加要素をパラメータとして加える. このようにベクトル化された実況ツイートをSVMで機械学習 を行う. 得られた分類器はホールドアウト検証とK分割交差検証(K-fold cross-validation)を用い て評価を行う.
3.2 実況ツイートの収集
実況ツイートは, twitterのハッシュタグ検索を用いて自分で収集する. twitterの高度な検索1を 用いることで過去のツイートについても検索することが可能である. 高度な検索は図3.1のよう なものになっている. ここでは,単語(ORやNOT検索,特定フレーズ,ハッシュタグ,特定言語),
ユーザ名(特定アカウントのツイートまたはリプライ),地域,日付(特定の日付の前後,特定の区間)
を指定して検索することができる. また,ハッシュタグクラウド2やツイポーート/twport3等といっ た外部Webサービスを用いることで簡単にツイートを収集することもできる.
3.3 ネタバレと非ネタバレのラベリング
実況ツイートをネタバレか非ネタバレかの2クラスに筆者自身がラベリングを行う. ネタバレと 非ネタバレの判断基準については人によってネタバレか非ネタバレかの境界は違うため,ラベルを つける人次第である. 例えば, 筆者の野球に関する実況ツイートのネタバレ判断基準は,得失点に 関すること(ホームラン, タイムリー,タイムリーエラー等),勝敗,スコア速報, この試合に関係の あるニュース記事はネタバレ扱いとした. チャンスを潰す,ヒットが出る,凡退シーン,誰が何をし たのかわからないツイート,応援ツイート,選手交代,この試合に関係のないニュース記事やツイー トは非ネタバレとした. 筆者が分類した例を表3.1に示す. 「1」がネタバレ, 「0」が非ネタバレ を表している.
1https://twitter.com/search-advanced
2http://hashtagcloud.net/
3http://twport.com/
第3章 提案手法 17
図3.1: 高度な検索の画面
3.4 形態素解析
形態素解析は, MeCab4を使用して行う. 英語では単語と単語の間にスペースが入っているのが 普通なのでこの処理は必要ない. 日本語では単語と単語の間にスペースがないので,形態素解析を 行い,単語を分割する必要がある.
3.5 単語ベクトルの次元の削減
Bag of Wordsモデルで単語ベクトルを作ると非常に高次元のベクトル5が生成されてしまう. こ
のままでは学習時間や計算領域が多くなり,高性能なマシンでしか分類器を作成できない恐れがあ る. そこで, Latent Semantic Indexing(LSI)6 7 により単語ベクトルの次元の削減を行う. 本研究
では1〜128次元の範囲に落として実験を行う.
4http://mecab.googlecode.com/svn/trunk/mecab/doc/index.html
5本研究で使用したデータセット5.2.1節では約2100次元のBoWベクトルになる.
6Latent Semantic Analysis(LSA)とも呼ばれている.
7http://lsa.colorado.edu/
第3章 提案手法 18
表 3.1: ネタバレと非ネタバレの分類例
元ツイート 事実ラベル
2表終了。全セ0‐0全パ#joqr #npb#allstar 1
會澤先制HR!#allstar 1
広島・会沢、球宴初出場の初打席で先制ソロ!守っては黒田を好リード/球宴 http://t.co/XaxQyPPC59#npb
1 田中2点タイムリーで追加点きたあああああああああああああああああああああ
あああ!!!#allstar
1 秋山のホームランきたああああああああああああ#seibulions#npb#AllStarGame 1 筒香タイムリーキタ━(゜∀゜)━! #allstar 1 セリーグ連勝#npballstar#allstar#npb#tvasahi 1 MVPは先制本塁打の會澤。#carp #npb#npballstar#マツダオールスターゲー
ム
1 新井、梶谷、森が敢闘賞#joqr#allstar#npb 1 西武・森、清原以来の10代球宴アーチ!「チャンスがあればと思っていた」/球
宴http://t.co/3APjtraL57 #npb
1
新井さんがんばれ#npballstar#allstar#hanshin#tigers 0 炭谷ゲッツー#joqr#npb#allstar 0 3表、全セP交替。黒田→マエケン#joqr#npb#allstar 0 オリックス・T−岡田、腰痛で抹消も早期復帰の見込みhttp://t.co/i9ThnmfnEM
#npb http://t.co/SkKUZA0hdL
0 きたああああああああああああああああああああああ #AllStarGame #AllStar
#NPB#npballstar
0 入るのこれwwwwwwwwwwwwwwwwww#npb 0
糸井内野安打#allstar#npb 0
タイムリー#allSTAR 0
嶋落球!#allstar 0
角 中 ナ イ ス キャッチ、って ロッテ 勢 が 守 備 で 魅 せ て く れ る なぁ。 #npb
#NpbALLSTAR
0
LSIで次元を削減したとき,ツイートの情報が失われ2クラス分類ができない可能性がある. な ので, LSIで2次元に落とした場合で2クラス分類ができるか検出する必要がある. ジャンルがはっ きりと分かれた2クラスの分類ができるか検証した予備実験を第4章で行った.
3.6 追加要素
上記のベクトルに以下の要素を追加する.
第3章 提案手法 19
3.6.1 URL の有無
2.2節の[2]にもあるように,ニュースサイトのアカウントが発信する速報やユーザが読んだニュー ス記事のツイートには記事のURLが付随するため, ネタバレである可能性が高い. また, Twitter では, ツイートの付随した画像や動画もURLの外部リンクで表される. 番組のキャプチャ画像を ツイートに付加して実況するユーザも少数だが存在する. このようにURLはネタバレ要素を含ん でいるため,分類器のパラメータとして付加する.
3.6.2 ユーザの興奮度
2.5節の[7]では,マイクロブログにおいて単語内に同じ文字が連続したものがあると述べている.
実況ツイートでも,単語内に同じ文字が連続したものがよく見られる. このような文字を検知し,連 続した文字をカウントしたものをユーザの「興奮度」として扱う. 例えば,「タイムリーーー!!!」
の連続した文字を単一に置換すると「タイムリー!」となる. このとき削除された文字数をカウン トすると4となる. これをユーザの興奮度とする.
3.6.3 ツイートの勢い
ある一定時間毎のツイート投稿頻度を計測したものである. 計算式は以下の通りである. 本研究 では, 10分毎に分速を計測した.
ツイートの勢い= 一定時間内のツイート数 一定時間(分)
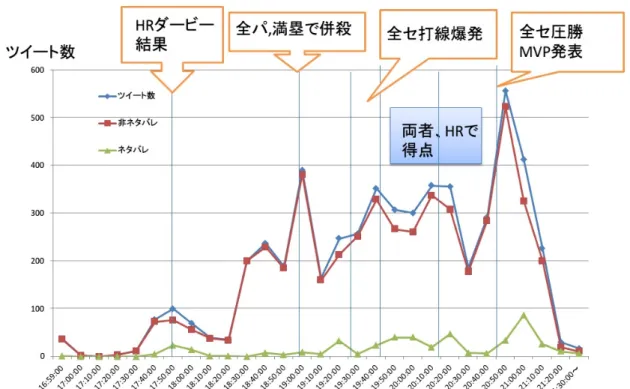
データセットの実況ツイートを時間毎のツイート数のグラフにした結果が図3.2である.
この図からツイートの勢いが上がったとき,全体のツイート数が急激に増え, それと同時にネタ バレツイートの数も急激に増え, ネタバレツイートの割合も上がる. なので, ツイートの勢いを計 測してパラメータとして加えると分類器を良くすることができるのではないかと考えた.
また,図3.2から非ネタバレのツイートに比べて, ネタバレツイートの割合が非常に低いことが わかる. Yuxin Pengらの研究[8]では,不均衡データをSVMで学習させるとうまく2クラス分類 できないので,データ数をサンプリングし各クラス同じ量になるようにする必要があると述べてい る. 本研究では, オーバーサンプリングを行い少ないデータを増やし,データの量を調節すること にした.
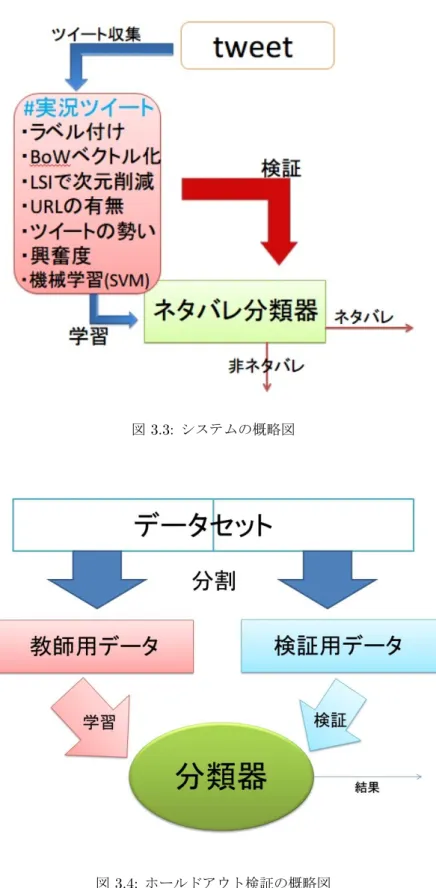
第3章で説明する提案手法の概略図を図3.3に示す.
3.7 分類器の評価方法
得られた分類器は前述した通りホールドアウト検証とK分割交差検証で評価する.
3.7.1 ホールドアウト検証
データセットを教師用データと検証用データとに無作為に分割する. 分割されたデータを用いて 学習と検証を1回行い,評価値を算出し,分類器の評価を行う検証方法である. 図3.4がホールドア ウト検証の概略図である.
本研究では教師用データ:検証用データ=7:3の割合になるように分割し,評価した.
第3章 提案手法 20
図3.2: 時間毎のツイート数と出来事
3.7.2 K 分割交差検証
K分割交差検証とは, データセットをK個に分割し, K-1個を教師用データとして扱い, 残り1 つを検証用データとして扱いモデルの正当性を検証するものである. データセットをK個に分割 し,教師用データと検証用データをK-1:1で機械学習するため, K通りの組ができる. すべての組 について機械学習し,各評価指標の平均を取り,評価する. 図3.5が交差検証のデータ分割の概略図 である.
本研究では,データセットを10個の組に分割し,評価した.
3.8 分類器の評価指標
本研究では評価指標として, Accuracy(正答率), Precision(適合率), Recall(再現率), F1-score(F 値), Area Under the Curve(AUC)を使用した.
表3.2: 事実と予測の関係
事実 真 事実 偽 予測 真 True Positive(TP) False Positive(FP) 予測 偽 False Negative(FN) True Negative(TN)
第3章 提案手法 21
図3.3: システムの概略図
図3.4: ホールドアウト検証の概略図
第3章 提案手法 22
図3.5: 交差検証のデータ分割に関する概略図
3.8.1 Accuracy( 正答率 )
Accuracyは,答えと予測全体がどの程度一致しているかを判断する評価指標である. 計算式は以
下の通りである.
Accuracy= T P +T N
T P+T N+F P +F N
3.8.2 Precision(適合率)
Precisionは,正と予測した中で,実際に答えが正だったものがどの程度あるかを判断する評価指
標である. Web検索で例えると,検索結果のうち,どの程度その通りのWebページがあったかとい
う割合がPrecisionである. 後述のRecallと相関関係にあり, F値の計算に使用される. 計算式は
以下の通りである.
P recision= T P T P+F P
3.8.3 Recall(再現率)
Recallは,答えが正のもののうち, 予測が正だったものがどの程度あるかを判断する評価指標で
ある. Web検索で例えると,実際のWebページのうち,検索結果が実際のWebページをどの程度 表示することができたかという割合がRecallである. 前述のPrecisionとは相関関係にあり,後述 のF値の計算に使用される. 計算式は以下の通りである.
第3章 提案手法 23
Recall= T P T P +F N
3.8.4 F1-score(F 値)
F値は,予測精度を表す評価指標であり, PrecisionとRecallの調和平均から算出される. 計算式 は以下の通りである.
F1−score = 2Recall∗P recision Recall+P recision
= 2T PT P+F N ∗ T P+F PT P
T P
T P+F N +T PT P+F P
= 2T P
2T P +F P +F N
3.8.5 AUC(Area Under the Curve)
Area Under the Curveは,分類器の評価指標であり, ROC(Receiver Operating Characteristic) 曲線の曲線より下の面積から算出される. ROC曲線とは,縦軸にTrue Positive Rate,横軸にFalse
Positeve Rateとして,それらの割合をプロットし,線で連結した曲線のことである. AUCの値が
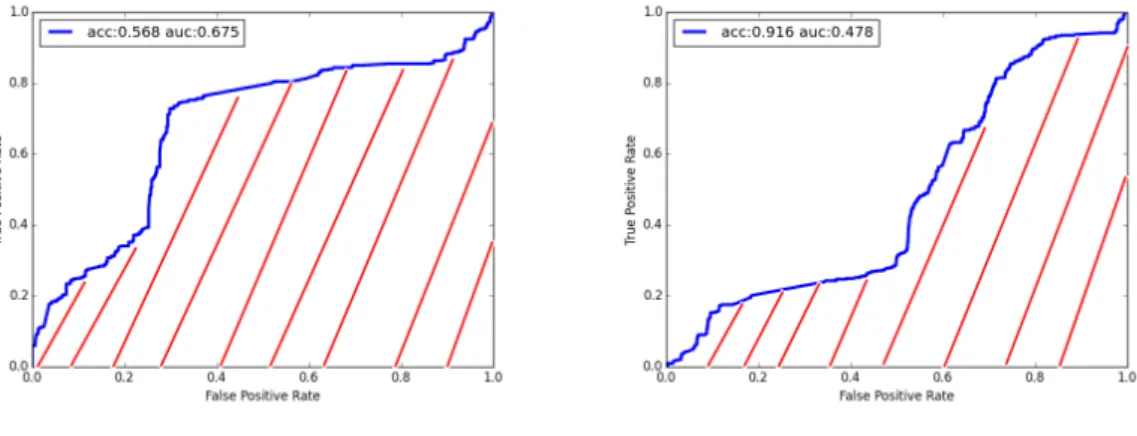
大きいほど良いという評価になる. 図3.6がROC曲線とAUCの例である. 青い曲線がROC曲線 で赤い斜線の領域がAUCである.
2つの図を比較すると, AUCが左図3.6のほうが高い. なので,右図3.6より左図3.6のほうが良 いということがわかる. ROC曲線が左上から上を通るとAUCが大きくなり良い評価となる. 逆に 右下を通るような形になるとAUCが小さくなり悪い評価となる.
図3.6: ROC曲線とAUC
24
第 4 章 予備実験
ここではLSIにより単語ベクトルを2次元に落としたとき,異なる話題の2クラス分類ができる か実験を行う.
4.1 データセット
データセットとして,野球の話題(2014/11/14の日米野球),テニスの話題(2015/7/3のウィンブ ルドンテニス),駅伝の話題(2016/1/2の箱根駅伝)のツイートをそれぞれ約3000件を使用した. 野 球とテニス,テニスと駅伝,野球と駅伝の3通りの組に関して,提案手法にそって2クラス分類器を 作成した. 教師用データと検証用データを7:3に分けたときのホールドアウト検証と10分割交差 検証を行い,各評価値を元に2クラス分類が成功したか評価した.
4.2 結果
4.2.1 ホールドアウト検証の実験結果
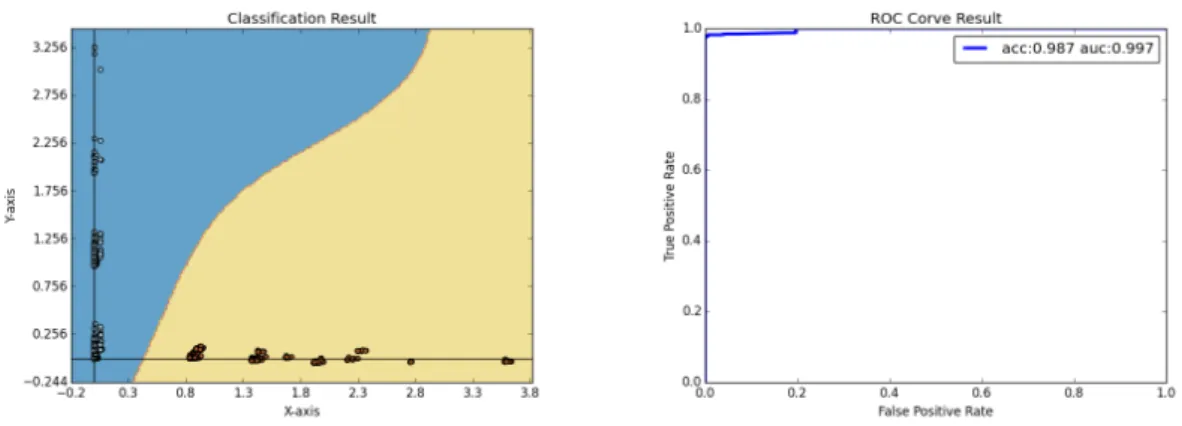
野球とテニス, テニスと駅伝,野球と駅伝の3通りの組に関してホールドアウト検証を行った結 果を以下の表4.1, 4.2に示す. さらに,それぞれの組の分類結果とROC曲線を図4.1,図4.2,図4.3 に示した.
表4.1: ホールドアウト検証の予備実験結果1 野球とテニス Precision Recall F1-score class baseball 0.95 1.00 0.97
class wimbledon 1.00 0.95 0.97
average 0.97 0.97 0.97
テニスと駅伝 Precision Recall F1-score
class wimbledon 0.98 1.00 0.99
class hakone 1.00 0.98 0.99
average 0.99 0.99 0.99
野球と駅伝 Precision Recall F1-score class baseball 0.98 1.00 0.99
class hakone 1.00 0.98 0.99
average 0.99 0.99 0.99
第4章 予備実験 25
図 4.1: 野球とテニスの分類結果とROC曲線
図 4.2: テニスと駅伝の分類結果とROC曲線
図4.3: 野球と駅伝の分類結果とROC曲線
第4章 予備実験 26
表4.2: ホールドアウト検証の予備実験結果2 野球とテニス テニスと駅伝 野球と駅伝
Accuracy 0.971 0.989 0.989
AUC 0.996 0.999 0.999
4.2.2 交差検証の実験結果
ホールドアウト検証のときと同じく, 3つの組について10分割交差検証を行った結果を以下の表 4.3に示す.
表4.3: 交差検証の予備実験結果
野球とテニス テニスと駅伝 野球と駅伝 Accuracy 0.973(+/- 0.012) 0.990(+/- 0.008) 0.990(+/- 0.009) AUC 0.996(+/- 0.003) 0.999(+/- 0.001) 0.998(+/- 0.002) Precision 0.974(+/- 0.011) 0.990(+/- 0.008) 0.990(+/- 0.008) Recall 0.973(+/- 0.012) 0.990(+/- 0.008) 0.990(+/- 0.009) F1-score 0.973(+/- 0.012) 0.990(+/- 0.008) 0.990(+/- 0.009)
4.3 結論
以上の結果から, LSIにより単語ベクトルを2次元に落としたとき,異なる話題の2クラス分類 できることがわかった. 同じ話題のネタバレと非ネタバレの2クラス分類ができるかは後述の実験 により検証する.
27
第 5 章 実装
5.1 開発環境
本研究は,ネタバレツイート分類器作成するにあたって,以下の環境で実装した.
• 言語はPython2.7を使用.
• 形態素解析にはMeCabを使用.
• ツイートのベクトル化(BoWモデル, LSI)はPythonライブラリgensim1を使用.
• 機械学習にはPythonの機械学習ライブラリscikit-learn2を使用.
5.2 分類器の作成
5.2.1 データセット
2015年7月に開催されたプロ野球オールスターゲーム第2戦のTwitter上の実況ツイートをハッ シュタグ検索により,およそ5500件を自分で収集し,データセットとして扱った. これらを自分の 手でネタバレと非ネタバレとにラベル付けを行った. ラベル付けの判断基準は,得失点に関するこ と,勝敗,スコア速報,この試合に関係のあるニュース記事はネタバレ扱いとした. チャンスを潰す, ヒットが出る,凡退シーン,誰が何をしたのかわからないツイート,応援ツイート,選手交代,関係の ないニュース記事やツイート等は非ネタバレとした. その結果,ネタバレと非ネタバレの比率はお よそ1:10であった. 不均衡データではF値での評価が困難である(3.6.3節). 非ネタバレ側のデー タを全て教師データまたは検証用データとして扱いたいため,データセットのネタバレ側のデータ 数にこれらと同じデータを用意し,ネタバレ側のデータ数を10倍に増やして実験を行った.
5.2.2 ツイートのベクトル化
本研究では, SVMで分類器の作成を行うため,各ツイートをベクトルに変換する必要がある. ツ イートのテキストをベクトル化するため, 後述の前処理を行った. テキストの前処理については以 下の通りである. 主に不要な文字列の削除と表記揺れを改善するための処理を行っている.
不要文字の除去
URLやリプライ,非公式リツイート, ハッシュタグの「#」は除去する. URLはツイートに 付随するURLである. 「http://」「https://」から始まる文字列を正規表現で検索し,除去 する.
1https://radimrehurek.com/gensim/
2http://scikit-learn.org/stable/
第5章 実装 28
リプライとは, 他ユーザへの返信を表すもので, @から始まる英数字のことである. @から始 まる英数字で書かれた文字列を正規表現で検索し,除去する.
非公式リツイートとは, 他のツイートを引用して自分のコメントを載せる目的で使われるも ので,「(自分のコメント) RT @… (本文)」といった形で使われる. 「RT」の2文字は不要 なので,除去する.
ハッシュタグを用いるには,頭に「#」をつけてツイートを行う. ハッシュタグの先頭につい た「#」の1文字は不要なので除去する.
品詞の原形を使用
名詞以外の品詞は全て原型に修正する. MeCabを用いて名詞以外の品詞の基本形を取得して いる.
英文字の統一
英文字は全て半角小文字に統一する. 英文字の表記揺れを改善するための処理である.
日本語やその他文字の統一
数字,カタカナ,感嘆符, 疑問符は全て全角大文字に統一する. 英文字の時と同じく表記揺れ を改善するための処理である.
連続した記述の正規化
単語内に同じ文字が連続した記述を単一文字に置換する. これは[5]で提案されている手法で ある. 実況ツイートでは, 単語内, 単語の最後の文字の母音, 感嘆符, 「w」を連続して記述 することが非常に多い. これらを単一の表現にするため連続した記述について正規化を行う.
図5.1に正規化例を示す.
表5.1: 連続した記述の正規化例
元文章 変換後
!!!!! ! お兄様すげえええええ お兄様すげえ ゴーーーーーール!!!!!!11111 ゴール!1 先制ホームランwwwww 先制ホームランw
上記の処理で実際のツイートを変換し,単語を半角スペースで区切った例を表5.1に示す.
次に,上記の前処理により変換されたツイートをベクトルに変換する. 以下のような処理を行う.
単語の出現頻度
単語の出現頻度が高すぎる単語と低すぎる単語は除去する. 出現頻度が高すぎる単語はほと んどのツイートに現れる単語であり,ツイート間の特徴の違いを表現できず,ネタバレと非ネ タバレに分類する上で双方の特徴が出にくいと考えた. ここでの出現頻度が高すぎる単語と いうのは,主に検索に用いたハッシュタグのことである. ハッシュタグは収集したツイートす べてに付加されており,メインのハッシュタグは除去するべきである.
単語の出現頻度が低すぎる単語も出現頻度が高すぎる単語と同じくツイート間の特徴の違い を表せないので, ネタバレと非ネタバレに分類する上で双方の特徴が出にくいと考えた. 出 現頻度が高すぎる単語と同じく除去した.
第5章 実装 29
図 5.1: ツイートの前処理例
単語の出現頻度の下限と上限については, 6.2節の評価実験で得られた結果から最適なものを 選択し使用する.
この処理で残った単語を特徴語として扱う. 後述のBag of Wordsベクトル(BoWベクトル) では,残った特徴語の種類の個数の次元ベクトルが生成される.
Bag of Wordsによるベクトル化
Bag of Wordsによるベクトル化はPythonライブラリのgensimを用いて実装した. 特徴語 の頻度をカウントして, N次元のベクトルが生成される.
BoWベクトルの簡単な例を紹介する. 次の3つの文をベクトル化する.
• ここはホームラン頼むホームラン
• 特大ファール. これは三振前の…
• やっぱり三振…
これらの文で使われた単語を抜き出して特徴語リストを生成すると以下の様になる.
• ここ, は,ホームラン,頼む,特大,ファール, これ,三振,前,の,やっぱり この単語群を元に3つの文章を単語の出現回数で表現すると次のようになる.
• 1, 1, 2, 1, 0, 0, 0, 0, 0, 0, 0
• 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0
• 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1
これがBoWベクトルである. 例の単語群は11個なので, 11次元のBoWベクトルが得ら れる.
次元の削減
得られたBoWベクトルは非常に高次元のベクトルである. 3.5節にそってLSIによる次元の 削減を行い, 1〜128次元ベクトルに簡略化を行う.
第5章 実装 30
追加要素
3.6節で述べた通りURLの有無,ユーザの興奮度,ツイートの勢いのパラメータを追加する.
LSIにより得られたベクトルに3つの追加要素を加える.
5.2.3 機械学習
上記によりベクトル化されたツイートと, 表3.1のようにあらかじめ筆者自身でネタバレと非ネ タバレにラベリングしたラベルを用いる. 教師用データと検証用データに分け,教師用データを使 用し,学習を行い分類器を作成する. 作成された分類器に検証用データ(ベクトル)を与え,予測結
果(ラベル)を得る. 予測結果と人力でラベリングしたラベルから,各評価値を算出し,評価を行う.
31
第 6 章 評価実験
6.1 次元削減を行わない機械学習
ツイートテキストの前処理を形態素解析のみ,出現頻度が高すぎる単語と低すぎる単語の除去な し,単語ベクトルのLSIによる次元削減なしで機械学習を行った.
しかし, 筆者の環境では, 単語ベクトルが巨大すぎたためうまく動作できず, 単語ベクトルの次 元削減を行わずに機械学習した結果が得られなかった. このときの特徴語の数は約2100個だった.
よって,単語ベクトルは2100次元のベクトルであるため,次元削減なしではより高性能なマシンが 必要なのではないかと思われる. このことから単語ベクトルが高次元だと動かせないので,次元を 落として単語ベクトルの簡略化を図る必要がある.
6.2 出現頻度での単語ベクトルの除去
出現頻度が高すぎる単語と低すぎる単語は除去する. ここでは,全体の何%に出現する単語を除 去すれば良いか検証する.
データセットのツイートに対し, 5.2.2節の通りにツイートをベクトル化する. ここでは, LSIで 単語ベクトルを2次元に落とすことにし, 3.6節で述べた追加要素を追加しない. 単語出現頻度が低
いものは0〜5%の範囲で0.5%刻み,単語出現頻度が高いものは75〜100%の範囲で5%刻みで変化
させて除去を行う. 検証方法は5分割交差検証でAccuracyとF値を使用して評価した.
結果はAccuracyが0.570〜0.575, F値が0.543〜0.550の範囲に収まった. F値の標準偏差が小 さい順にソートし, 上位10件と下位5件を示した表6.1を示す.
表6.1を見ると, AccuracyとF値はそれほど大きな変化はない. 各評価値の標準偏差の小さいも のを採用することにする. 下限1.0%上限80%の組は, Accuracyの標準偏差が全体で1番目に低い 値で, F値の標準偏差が全体で3番目に低い値であったため,この組を採用する. 今後の実験では単 語出現頻度が1.0%以下, 80%以上の単語を除去することにする.
第6章 評価実験 32
表6.1: 出現頻度に関する検証結果
下限(%) 上限(%) Accuracy Accuracy標準偏差 F値 F値 標準偏差
1.5 95 0.572 0.011 0.545 0.006
3.0 100 0.571 0.007 0.544 0.007
1.0 80 0.571 0.005 0.545 0.008
5.0 95 0.570 0.010 0.544 0.008
2.5 85 0.573 0.013 0.548 0.008
0.5 75 0.572 0.005 0.547 0.010
3.5 90 0.571 0.007 0.545 0.010
3.5 80 0.571 0.010 0.545 0.010
0.5 100 0.573 0.011 0.548 0.010
3.5 85 0.572 0.012 0.546 0.010
3.0 85 0.571 0.032 0.544 0.033
2.5 90 0.573 0.029 0.548 0.034
0.0 95 0.575 0.036 0.550 0.034
4.0 80 0.571 0.037 0.545 0.036
2.0 95 0.572 0.038 0.546 0.041
6.3 LSI による次元の削減
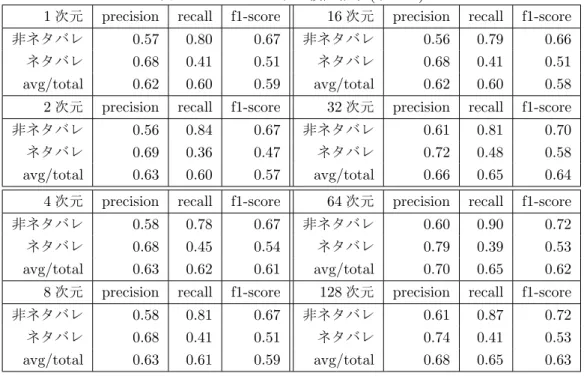
LSIにより単語ベクトルを1〜128次元に削減し,それぞれ機械学習を行った. ここでは,追加要 素は追加せず単語ベクトルのみを使って実験を行った. 追加要素は後述の実験で追加する. ホール ドアウト検証と交差検証で検証し,各評価値を評価した. ホールドアウト検証の結果は表6.2と6.3, 交差検証の結果は表6.4と図6.1に示した.
結果から, Accuracyでは単語ベクトルが32次元以上だと良い結果が得られた. 交差検証では32 次元以上だとほぼ同じ値が得られているので, 32次元頭打ちになっている. また標準偏差は32次 元が一番小さいのでAccuracyで見ると32次元が一番良いという結果が得られた.
AUCで見ると,単語ベクトルの次元が増えるほど良くなる傾向になる結果が得られた. 標準偏差
はAccuracyのときと同様に32次元が一番小さい.
F値で見ると, 32次元のとき一番大きい値が得られたが,それ以降は下降している. 標準偏差も 32次元が一番小さく, F値では32次元が一番良い結果が得られた.
総合的に見ると, 単語ベクトルを32次元に落としたときが一番良い結果が得られた.
第6章 評価実験 33
表 6.2: ホールドアウト検証結果1(単語ベクトルのみ)
1次元 precision recall f1-score 16次元 precision recall f1-score 非ネタバレ 0.53 0.82 0.64 非ネタバレ 0.54 0.85 0.66 ネタバレ 0.65 0.31 0.42 ネタバレ 0.71 0.33 0.45
avg/total 0.59 0.56 0.53 avg/total 0.62 0.58 0.55
2次元 precision recall f1-score 32次元 precision recall f1-score 非ネタバレ 0.55 0.82 0.66 非ネタバレ 0.60 0.83 0.69 ネタバレ 0.66 0.34 0.45 ネタバレ 0.73 0.46 0.56
avg/total 0.61 0.58 0.56 avg/total 0.66 0.64 0.63
4次元 precision recall f1-score 64次元 precision recall f1-score 非ネタバレ 0.57 0.81 0.6 非ネタバレ 0.58 0.93 0.72 ネタバレ 0.66 0.37 0.48 ネタバレ 0.83 0.35 0.50
avg/total 0.61 0.59 0.57 avg/total 0.71 0.64 0.60
8次元 precision recall f1-score 128次元 precision recall f1-score 非ネタバレ 0.56 0.83 0.67 非ネタバレ 0.58 0.93 0.71 ネタバレ 0.67 0.35 0.46 ネタバレ 0.81 0.32 0.46
avg/total 0.62 0.59 0.57 avg/total 0.69 0.62 0.58
表 6.3: ホールドアウト検証結果2(単語ベクトルのみ)
1次元 2次元 4次元 8次元
Accuracy 0.559 0.584 0.592 0.591
AUC 0.569 0.586 0.593 0.611
16次元 32次元 64次元 128次元
Accuracy 0.577 0.641 0.637 0.622
AUC 0.644 0.685 0.710 0.723
表6.4: 交差検証結果(単語ベクトルのみ)
次元 Accuracy AUC Precision Recall f1score
1 0.571 (+/- 0.023) 0.593 (+/- 0.035) 0.596 (+/- 0.029) 0.572 (+/- 0.023) 0.543 (+/- 0.024) 2 0.572 (+/- 0.030) 0.573 (+/- 0.039) 0.595 (+/- 0.031) 0.574 (+/- 0.027) 0.547 (+/- 0.036) 4 0.589 (+/- 0.034) 0.581 (+/- 0.048) 0.609 (+/- 0.038) 0.591 (+/- 0.032) 0.571 (+/- 0.036) 8 0.600 (+/- 0.038) 0.610 (+/- 0.052) 0.622 (+/- 0.040) 0.601 (+/- 0.036) 0.583 (+/- 0.042) 16 0.595 (+/- 0.039) 0.649 (+/- 0.043) 0.627 (+/- 0.050) 0.597 (+/- 0.039) 0.570 (+/- 0.043) 32 0.639 (+/- 0.021) 0.688 (+/- 0.029) 0.661 (+/- 0.027) 0.640 (+/- 0.026) 0.626 (+/- 0.025) 64 0.633 (+/- 0.029) 0.706 (+/- 0.044) 0.701 (+/- 0.037) 0.635 (+/- 0.026) 0.601 (+/- 0.031) 128 0.631 (+/- 0.027) 0.726 (+/- 0.031) 0.698 (+/- 0.013) 0.633 (+/- 0.018) 0.598 (+/- 0.031)
第6章 評価実験 34
6.4 追加要素
6.4.1 URL の有無
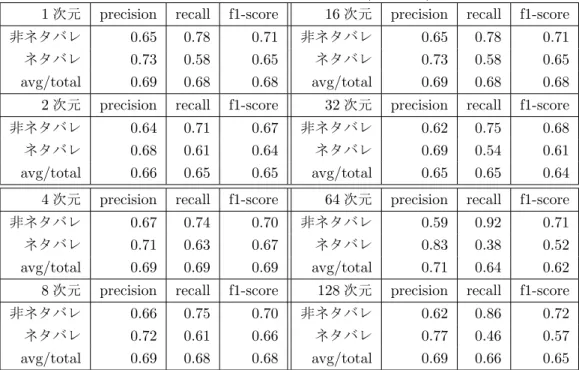
1〜128次元に落とした単語ベクトルにURLの有無の情報を追加して実験を行った. ホールドア
ウト検証と交差検証で検証し, 各評価値を評価した. ホールドアウト検証の結果は表6.5と表6.6, 交差検証の結果は表6.7と図6.2に示した.
結果を見ると, 6.3節のときより全体的に数値が良化した. また,傾向は6.3節のときとほぼ変化 はなく, 32次元のときが一番良いという結果が得られた.
6.4.2 ユーザの興奮度
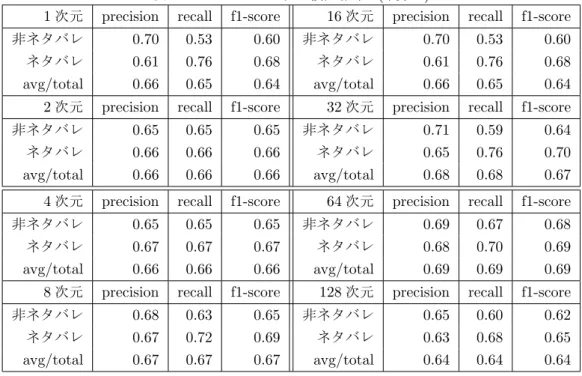
1〜128次元に落とした単語ベクトルにユーザの興奮度の情報を追加して実験を行った. ホール
ドアウト検証と交差検証で検証し,各評価値を評価した. ホールドアウト検証の結果は表6.8と表 6.9, 交差検証の結果は表6.10と図6.3に示した.
結果を見ると, 6.3節と比べて1〜16次元の数値が良化した. 交差検証で, AccuracyとF値では 8次元, AUCでは32次元が一番大きい数値を出し, 6.3節と6.4.1節とは違う傾向が得られた.
興奮度には低次元ベクトルの評価値を大きく良化させる効果があることがわかる.
6.4.3 ツイートの勢い
1〜128次元に落とした単語ベクトルにツイートの勢いの情報を追加して実験を行った. ホール
ドアウト検証と交差検証で検証し,各評価値を評価した. ホールドアウト検証の結果は表6.11と表 6.12,交差検証の結果は表6.13と図6.4に示した.
結果から, 評価値が6.3節のときより全体的に良化した. また, 6.4.2節と同じく1〜16次元の評 価値を大きく引き上げている. 交差検証から, Accuracy, AUC, F値で32次元が一番大きい値を出 しているので, 6.3節と6.4.1節と同じく32次元が一番良いという結果になった.
6.4.4 全ての追加要素
1〜128次元に落とした単語ベクトルに全ての追加要素を追加して実験を行った. ホールドアウ
ト検証と交差検証で検証し,各評価値を評価した. ホールドアウト検証の結果は表6.14と表6.15, 交差検証の結果は表6.16と図6.5に示した.
結果から, 全体的に評価値が6.3節のときより良化した. 特に低次元での評価値が大きく良化し た. これまでの結果とは違い低次元で一番大きい数値を出し,それ以降は下降する傾向にあること がわかった. 2つの検証結果両方で, 4次元が一番良い値が得られた.
第6章 評価実験 35
表6.5: ホールドアウト検証結果(+URL)
1次元 precision recall f1-score 16次元 precision recall f1-score 非ネタバレ 0.57 0.80 0.67 非ネタバレ 0.56 0.79 0.66 ネタバレ 0.68 0.41 0.51 ネタバレ 0.68 0.41 0.51
avg/total 0.62 0.60 0.59 avg/total 0.62 0.60 0.58
2次元 precision recall f1-score 32次元 precision recall f1-score 非ネタバレ 0.56 0.84 0.67 非ネタバレ 0.61 0.81 0.70 ネタバレ 0.69 0.36 0.47 ネタバレ 0.72 0.48 0.58
avg/total 0.63 0.60 0.57 avg/total 0.66 0.65 0.64
4次元 precision recall f1-score 64次元 precision recall f1-score 非ネタバレ 0.58 0.78 0.67 非ネタバレ 0.60 0.90 0.72 ネタバレ 0.68 0.45 0.54 ネタバレ 0.79 0.39 0.53
avg/total 0.63 0.62 0.61 avg/total 0.70 0.65 0.62
8次元 precision recall f1-score 128次元 precision recall f1-score 非ネタバレ 0.58 0.81 0.67 非ネタバレ 0.61 0.87 0.72 ネタバレ 0.68 0.41 0.51 ネタバレ 0.74 0.41 0.53
avg/total 0.63 0.61 0.59 avg/total 0.68 0.65 0.63
表6.6: ホールドアウト検証結果2(+URL)
1次元 2次元 4次元 8次元
Accuracy 0.602 0.597 0.616 0.608
AUC 0.627 0.583 0.624 0.634
16次元 32次元 64次元 128次元
Accuracy 0.597 0.646 0.646 0.647
AUC 0.644 0.698 0.719 0.728
表6.7: 交差検証結果(+URL)
次元 Accuracy AUC Precision Recall f1score
1 0.605 (+/- 0.035) 0.628 (+/- 0.043) 0.626 (+/- 0.034) 0.606 (+/- 0.029) 0.588 (+/- 0.033) 2 0.602 (+/- 0.020) 0.590 (+/- 0.016) 0.630 (+/- 0.015) 0.603 (+/- 0.013) 0.581 (+/- 0.017) 4 0.618 (+/- 0.023) 0.633 (+/- 0.023) 0.638 (+/- 0.022) 0.619 (+/- 0.019) 0.604 (+/- 0.022) 8 0.621 (+/- 0.030) 0.640 (+/- 0.030) 0.638 (+/- 0.032) 0.622 (+/- 0.028) 0.610 (+/- 0.030) 16 0.620 (+/- 0.037) 0.663 (+/- 0.038) 0.644 (+/- 0.037) 0.621 (+/- 0.027) 0.605 (+/- 0.031) 32 0.652 (+/- 0.025) 0.697 (+/- 0.025) 0.668 (+/- 0.031) 0.653 (+/- 0.026) 0.645 (+/- 0.025) 64 0.649 (+/- 0.028) 0.715 (+/- 0.034) 0.695 (+/- 0.033) 0.651 (+/- 0.027) 0.628 (+/- 0.030) 128 0.646 (+/- 0.025) 0.733 (+/- 0.026) 0.694 (+/- 0.023) 0.648 (+/- 0.015) 0.624 (+/- 0.022)
第6章 評価実験 36
表 6.8: ホールドアウト検証結果1(+興奮度)
1次元 precision recall f1-score 16次元 precision recall f1-score 非ネタバレ 0.65 0.78 0.71 非ネタバレ 0.65 0.78 0.71 ネタバレ 0.73 0.58 0.65 ネタバレ 0.73 0.58 0.65
avg/total 0.69 0.68 0.68 avg/total 0.69 0.68 0.68
2次元 precision recall f1-score 32次元 precision recall f1-score 非ネタバレ 0.64 0.71 0.67 非ネタバレ 0.62 0.75 0.68 ネタバレ 0.68 0.61 0.64 ネタバレ 0.69 0.54 0.61
avg/total 0.66 0.65 0.65 avg/total 0.65 0.65 0.64
4次元 precision recall f1-score 64次元 precision recall f1-score 非ネタバレ 0.67 0.74 0.70 非ネタバレ 0.59 0.92 0.71 ネタバレ 0.71 0.63 0.67 ネタバレ 0.83 0.38 0.52
avg/total 0.69 0.69 0.69 avg/total 0.71 0.64 0.62
8次元 precision recall f1-score 128次元 precision recall f1-score 非ネタバレ 0.66 0.75 0.70 非ネタバレ 0.62 0.86 0.72 ネタバレ 0.72 0.61 0.66 ネタバレ 0.77 0.46 0.57
avg/total 0.69 0.68 0.68 avg/total 0.69 0.66 0.65
表 6.9: ホールドアウト検証結果2(+興奮度)
1次元 2次元 4次元 8次元
Accuracy 0.682 0.655 0.686 0.683
AUC 0.732 0.693 0.710 0.701
16次元 32次元 64次元 128次元
Accuracy 0.682 0.647 0.643 0.663
AUC 0.732 0.723 0.727 0.726
表 6.10: 交差検証結果(+興奮度)
次元 Accuracy AUC Precision Recall f1score
1 0.676 (+/- 0.029) 0.728 (+/- 0.023) 0.684 (+/- 0.029) 0.677 (+/- 0.030) 0.673 (+/- 0.031) 2 0.665 (+/- 0.034) 0.701 (+/- 0.029) 0.666 (+/- 0.035) 0.665 (+/- 0.034) 0.664 (+/- 0.034) 4 0.684 (+/- 0.030) 0.711 (+/- 0.043) 0.687 (+/- 0.030) 0.684 (+/- 0.030) 0.683 (+/- 0.030) 8 0.687 (+/- 0.027) 0.714 (+/- 0.038) 0.689 (+/- 0.029) 0.687 (+/- 0.028) 0.686 (+/- 0.027) 16 0.676 (+/- 0.029) 0.728 (+/- 0.023) 0.684 (+/- 0.029) 0.677 (+/- 0.030) 0.673 (+/- 0.031) 32 0.664 (+/- 0.026) 0.740 (+/- 0.032) 0.680 (+/- 0.032) 0.665 (+/- 0.027) 0.656 (+/- 0.025) 64 0.660 (+/- 0.019) 0.726 (+/- 0.011) 0.688 (+/- 0.023) 0.662 (+/- 0.018) 0.648 (+/- 0.021) 128 0.644 (+/- 0.033) 0.723 (+/- 0.028) 0.684 (+/- 0.030) 0.646 (+/- 0.027) 0.625 (+/- 0.036)
![表 2.1: 関連研究 [2] の結果](https://thumb-ap.123doks.com/thumbv2/123deta/7630698.2553601/13.892.261.632.190.310/表21関連研究2の結果.webp)