機械学習を用いたネットワーク異常検知技術の WebAPI 化の研究 *
中野 雄介
†a)池田 泰弘
†松尾 洋一
†渡辺敬志郎
†石橋 圭介
††西松 研
†WebAPI Design for Providing Machine Learning Based Network Anomaly Detection Technology
∗Yuusuke NAKANO
†a), Yasuhiro IKEDA
†, Yoichi MATSUO
†, Keishiro WATANABE
†, Keisuke ISHIBASHI
††, and Ken NISHIMATSU
†あらまし 将来的な労働人口の減少に備えるため,ネットワークの障害対応の自動化が急務である.障害対応 の自動化には,トリガとなる異常検知技術が欠かせない.一方近年,機械学習による異常検知技術の研究が盛 んである.しかし現状,ネットワークでこのような技術は普及していない.原因は次の二つである.(1)ネット ワーク事業者にとって,検知対象に応じて複数の検知技術を導入する場合,技術に応じたデータ収集/前処理等 の開発が必要である.(2)検知技術開発者にとって,検知技術をネットワークで利用可能な技術に仕上げるには,
ネットワークに関する機能/非機能要件も満たす必要がある.本論文ではこれらの障壁を解消する,異常検知技 術のWebAPI化ラッパの構成を提案する.ラッパは(1)ネットワークに対して共通のWebAPIのIFを提供し,
1回の開発で複数技術を導入可能とする.一方(2)ラッパでの実装を肩代わりし,各検知技術の開発の障壁も解 消する.ラッパを実装し,実際の検知技術をWebAPI化することで,少ない工数でネットワークに導入できる ことを確認した.また,検知技術をネットワークに対応させるためのプログラム変更は難易度の低いものであっ た.一方,ラッパによる実行時間のオーバーヘッドは,実測により許容範囲であると確認した.
キーワード 機械学習,異常検知,WebAPI,ラッパ
1.
ま え が きこれまでのネットワークにおける障害対応は人手で 行われることが多かった.しかし,将来的な労働人口 の減少などの社会環境の変化に対応し,ネットワーク 事業者が持続的にネットワークサービスを提供するた め,ネットワーク障害対応の自動化が急務となってい る.ネットワーク障害対応は主に,異常検知,分析,
対処の三つのフェーズから構成され,異常検知がトリ ガとなり,その後の異常箇所を特定するための分析,
分析結果に従った復旧などの対処が実施される.この
†日本電信電話株式会社 NTTネットワーク基盤技術研究所,武蔵 野市
NTT Network Technology Laboratories, NTT Corporation, Musashino-shi, 180–8585 Japan
††国際基督教大学教養学部アーツ・サイエンス学科,三鷹市 College of Liberal Arts, Division of Arts and Sciences, Inter- national Christian University, Mitaka-shi, 181–8585 Japan a) E-mail: [email protected]
*本論文は,システム開発・ソフトウェア開発論文である.
DOI:10.14923/transcomj.2018NSI0001
ため,まず異常検知技術の確立が必要である.
一方近年,機械学習を用いた異常検知技術の研究が 盛んであり,日々新たな技術が公表されている.また,
ネットワーク異常検知への応用も提案されている.し かし,現状のネットワークに最新の技術をタイムリー に適用するには,以下の二つの障壁が存在すると考え られる.
(
1
) 機械学習による異常検知技術は,技術によっ て必要なデータや前処理が異なるため,ネットワーク 事業者が特定の検知技術の導入のためにデータ収集や 前処理を実装したとしても,新たな検知技術を導入す る場合は,新たな実装が必要となり,導入障壁となる.(
2
) 検知技術をネットワークで利用可能な技術に 仕上げるには,ネットワークで利用されるための要件(
長期運用されるネットワークの異常検知に対応する ための可用性確保,早期の障害対応のための検知にか かる時間短縮などの非機能要件を含む)
を満たす必要 があり,これがネットワーク向けに検知技術を実現す る障壁となる.(1)
のネットワーク事業者側の導入障壁解消の一般 的な方法として,WebAPI
の形で検知技術を提供する ことが考えられる.WebAPI
とは遠隔にある機能をHTTP
を介してネットワーク越しに呼び出すための インタフェース(IF)
である.WebAPI
として機能を 提供することで,機能をコンポーネント化できる.こ のようなコンポーネントを組み合わせることで,様々 な人が新たなアプリケーションを簡易に作成できる.近年多様な
WebAPI
が提供され,これらを組み合わ せたアプリケーションも盛んに作成されており,多く の技術者にとってWebAPI
は一般的なIF
となってい る.そこで,WebAPI
を検知技術の共通のIF
として 取り決めることとする.そのうえで,ネットワーク事 業者はこのAPI
に対して,データ収集や前処理など を実装する.こうすることで,ネットワーク事業者は,この
API
をもつ検知技術であればどれでも利用可能 となり,導入障壁である検知技術ごとの実装を解消で きる.一方,検知技術をネットワーク向けに提供したい 検知技術開発者にとって,検知技術に上記のような
WebAPI
のIF
を実装するのは容易ではない.そこで,検知技術を
WebAPI
でラップするラッパが解決方法 として考えられる.このラッパはネットワーク事業者 の環境内のWeb
サーバ上で動作するサービスであり,サーバ内に配置された検知技術のプログラム
(
検知プ ログラム)
をラップし,WebAPI
として検知機能を提 供する.WebAPI
向けのリクエストを受け取ったラッ パは,リクエストを検知プログラムの呼び出しに変 換し,実行する.その後,実行結果をWebAPI
のレ スポンスに変換し,返信する.検知技術開発者はこの ラッパからの呼び出しを受けるIF
を作成すれば,自 身でWebAPI
を実装することなく,検知プログラム をWebAPI
化できる.更に,(2)
の検知技術開発者に 対する障壁解消のため,ラッパ内でネットワークの要 件を満たすための仕組みを一括して実装する方法が考 えられる.これにより,ネットワークの要件を満たす ための仕組みを検知技術開発者が実装する必要はなく,ネットワーク向けの検知技術の実現における障壁が解 消される.
このような検知技術の
WebAPI
化ラッパを実現する ことで,ネットワーク事業者・検知技術開発者双方の障 壁を解消することが求められる.しかし,WebAPI
化 ラッパを普及させ多くのネットワークで多様な機械学習 による検知技術の活用につなげるためには,WebAPI
化ラッパは,ネットワーク事業者にとって使いやすい
WebAPI
を提供すること,且つ,検知技術開発者にとって開発しやすいラッパであることが要求される.
本論文では,まず検知技術の
WebAPI
に対するネッ トワーク事業者の要件と,それらの要件の満たす上で の検知技術の課題を抽出する.更に,検知技術開発者 の障壁解消のため,これらの課題をラッパで解決する ためのラッパの構成を提案する.最後に,この構成を 実現する実装を報告する.また,これまで筆者らが検 討を進めてきたディープラーニングによる異常検知技 術を,ラッパを用いてWebAPI
化することで,ラッパ に本検知技術を対応させるための検知技術開発者に対 する工数と難易度を評価する.加えて,既存のネット ワークオペレーション環境にWebAPI
化された検知 技術を導入することで,ネットワーク事業者による検 知技術導入の工数と難易度を評価する.最後に,ラッ パを介することによる実行時間のオーバーヘッドを実 測することで,オーバーヘッドは許容範囲であること を報告する.2.
関 連 研 究ネットワークの大規模化,複雑化に伴い,従来の異 常検知ルール
(
しきい値など)
を人手で設定すること は困難となってきている.また,あらかじめ設定した ルールでは検知困難なサイレント故障などもネット ワークでは発生する.このような課題に対応するため,様々な機械学習によるネットワーク異常検知技術が提 案されている.このような検知技術を文献
[1]
を参考 に以下のように分類する.なお,ネットワークからは 複数の監視項目に関するデータが一定周期ごとに収集 されているものとし,それを入力データと考える.•
教師なし(
ラベルなし)
/教師あり(
ラベルつ き)
:教師なしの検知では,ネットワークの正常時のみ に収集されたデータを用いて正常状態を学習しておき,現在の値がそれから外れているか否かで異常を検知 する.一方,教師ありの検知では,ネットワークから 収集されたデータに加え,故障対応などの記録
(
トラ ブルチケット)
を教師データとして用いて正常状態/異常状態を学習しておき,現在の値の「正常状態と の乖離」や「異常状態との類似度」で異常を検知す る
[2], [3]
.•
時系列モデル:時系列モデルに基づく検知では,例えばある特定の監視項目
(
あるリンクを流れるトラ ヒック量など)
に関し,過去の時系列データからの予測モデルを構築し,予測値と現在の観測値の乖離によ り異常を検知する
[4], [5]
.•
関係性モデル:関係性モデルに基づく検知では,例えば複数の監視項目間の正常時の関係性モデルを学 習により構築しておき,現在の観測値がそのモデルか ら乖離しているかどうかで異常を検知する
[6]
〜[9]
.以上のような分類で,様々な機械学習によるネット ワーク異常検知技術が検討されている.しかし,実際 のネットワーク障害対応に適用するためには,ネット ワーク事業者は技術ごとに入力データの前処理,定期 的な実行,出力の後処理,表示等の実装が必要となり,
導入の障壁となる.
次に,実際に利用されているネットワークの監視ツー ルとしては,
Zabbix [10]
,Nagios [11]
,Hinemos [12]
などが有名であり,他にも多様なプロダクトを利用可 能である.これらはネットワークからのデータの収集,
収集したデータの可視化,主にしきい値などを用いた 異常検知などを提供し,ネットワークの監視のための 一通りの機能を備えている.また,ネットワークの監 視に特化したツールではないが,多様なデータ分析に 用いられるデータ分析基盤をネットワーク監視に利用 することもできる.有名なプロダクトとしては
Elastic
スタック[13]
やsplunk [14]
などがある.しかし,こ のようなネットワーク監視ツールやデータ解析基盤で 機械学習による異常検知技術を用いるには,連携可能 な形で検知技術を実装する必要があるため,多様な ツールに向けた技術の実装は困難である.一方,近年,機械学習を用いたアプリケーション
を
WebAPI
として提供する基盤が提案されている.Azure Machine Learning Studio [15]
は機械学習の アルゴリズムをGUI
を介して作成でき,作成したアル ゴリズムをWebAPI
として公開できる.公開されたWebAPI
は他のサービスなどに組み込むことができ,様々な応用が容易に実現できる.しかし,それぞれの 検知技術が異なる仕様の
WebAPI
を実装してしまう と,結果としてネットワーク事業者側でそれらを利用 する際に,それぞれの技術のための実装が必要となる.本論文では以上のような課題を解決するため,異 常検知技術をラップすることで,検知技術に共通の
WebAPI
をIF
として付加する,機械学習による異常 検知技術のWebAPI
化ラッパの構成を提案する.3.
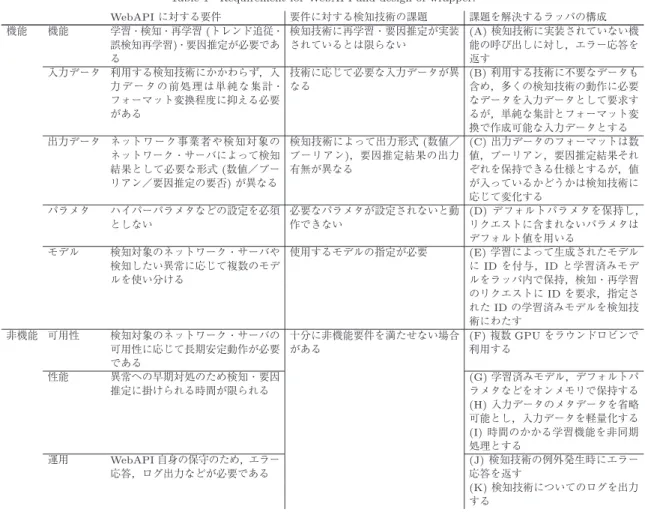
ラッパの概要ラッパの概要を図
1
に示す.ラッパはWebAPI
の図1 ラッパの概要 Fig. 1 Wrapper.
プロトコルと検知プログラムの関数呼び出しのプロト コルとを相互変換するプロトコル変換機能と,ラッパ が提供するネットワーク異常検知
WebAPI (
以降,単 にWebAPI)
に対するネットワーク事業者の要件を満 たすための共通機能から構成され,ネットワーク事業 者の環境内のWeb
サーバで動作する.検知技術開発 者から提供される,具体的な異常検知を行う検知プロ グラムはサーバ内に配置され,ラッパによりWebAPI
のIF
が付加される.まず,ネットワーク事業者から特定の検知プログラ ムへのリクエストを受け取ったプロトコル変換機能は,
リクエストを共通機能の関数呼び出しに変換し,共通 機能を呼び出す.その後,共通機能が対象の検知プロ グラムを呼び出す.その際,ネットワーク事業者の要 件を満たすための処理が共通機能によって実施される.
その後,検知プログラムの実行結果が共通機能に返さ れ,それがプロトコル変換機能によって
WebAPI
の レスポンスに変換され,ネットワーク事業者に返信さ れる.4.
ラッパの構成以上のラッパによって実現される
WebAPI
に対する ネットワーク事業者の要件を満たすために必要なラッ パの構成を以下の手順で明確化し,表1
の各列にまと めた.(
1
) ラッパが提供するWebAPI
に対する,ネッ表1 WebAPIに対する要件とラッパの構成 Table 1 Requirement for WebAPI and design of wrapper.
WebAPIに対する要件 要件に対する検知技術の課題 課題を解決するラッパの構成
機能 機能 学習・検知・再学習(トレンド追従・
誤検知再学習)・要因推定が必要であ る
検知技術に再学習・要因推定が実装 されているとは限らない
(A)検知技術に実装されていない機 能の呼び出しに対し,エラー応答を 返す
入力データ 利用する検知技術にかかわらず,入 力 デ ー タ の 前 処 理 は 単 純 な 集 計・
フォーマット変換程度に抑える必要 がある
技術に応じて必要な入力データが異 なる
(B)利用する技術に不要なデータも 含め,多くの検知技術の動作に必要 なデータを入力データとして要求す るが,単純な集計とフォーマット変 換で作成可能な入力データとする 出力データ ネットワーク事業者や検知対象の
ネットワーク・サーバによって検知 結果として必要な形式(数値/ブー リアン/要因推定の要否)が異なる
検知技術によって出力形式(数値/
ブーリアン),要因推定結果の出力 有無が異なる
(C)出力データのフォーマットは数 値,ブーリアン,要因推定結果それ ぞれを保持できる仕様とするが,値 が入っているかどうかは検知技術に 応じて変化する
パラメタ ハイパーパラメタなどの設定を必須 としない
必要なパラメタが設定されないと動 作できない
(D) デフォルトパラメタを保持し,
リクエストに含まれないパラメタは デフォルト値を用いる
モデル 検知対象のネットワーク・サーバや 検知したい異常に応じて複数のモデ ルを使い分ける
使用するモデルの指定が必要 (E)学習によって生成されたモデル にIDを付与,IDと学習済みモデ ルをラッパ内で保持,検知・再学習 のリクエストにIDを要求,指定さ れたIDの学習済みモデルを検知技 術にわたす
非機能 可用性 検知対象のネットワーク・サーバの 可用性に応じて長期安定動作が必要 である
十分に非機能要件を満たせない場合 がある
(F)複数GPUをラウンドロビンで 利用する
性能 異常への早期対処のため検知・要因 推定に掛けられる時間が限られる
(G)学習済みモデル,デフォルトパ ラメタなどをオンメモリで保持する (H)入力データのメタデータを省略 可能とし,入力データを軽量化する (I)時間のかかる学習機能を非同期 処理とする
運用 WebAPI自身の保守のため,エラー
応答,ログ出力などが必要である
(J)検知技術の例外発生時にエラー 応答を返す
(K)検知技術についてのログを出力 する
トワーク事業者の要件を明確化
(1
列目)
(
2
) これらの要件にラップ対象の検知技術で対応 する場合の課題を抽出(2
列目)
(
3
) 課題を解決するためのラッパの構成を検討(3
列目)
なお,ネットワーク事業者の
WebAPI
に対する要 件は,ネットワークキャリア,アプリケーションプロ バイダ等への異常検知技術の導入のためのヒアリング や,実際の導入作業を通して調査した.また,検知技 術での要件への対応における課題は,既存の異常検知 技術の特性から推測した.4. 1
ラッパが提供するWebAPI
に対するネット ワーク事業者の要件と検知技術で対応する場 合の課題表
1
の1
列目に示すように,ネットワーク事業者のWebAPI
に対する要件を以下のように分類して述べる.•
機能要件:ラッパが提供するWebAPI
の機能 についての要件である.機能そのものの他に,付随す る以下の要件について述べる.–
機能:WebAPI
として提供するべき検知に関す る機能についての要件–
入力データ:機能が学習・検知などを実施する ための入力データ,データの形式などについての要件–
出力データ:機能が学習・検知した結果の出力 データ,データの形式などについての要件–
パラメタ:検知技術に設定するパラメタ,パラ メタの形式などについての要件–
モデル:検知技術が生成する学習済みモデルに ついての要件•
非機能要件:可用性,性能,運用・保守に対す る要件なお,本論文では,
IPA
で定める『非機能要求グレード』
[16]
の大項目となっている非機能要件のうち,上記のように可用性,性能,運用・保守の要件につい て議論する.一方,その他の非機能要件
(
移行性,セ キュリティ,環境・エコロジー)
は,調査の範囲で明 確なものはなく,今後必要に応じて議論することとし,本論文では対象としない.
以降の各項で,表
1
に示すWebAPI
に対する要件,要件に対する検知技術の課題ついて詳しく述べる.
4. 1. 1
機能要件(
機能)
基本的な機能である学習,検知以外に,ネットワー クでは以下の機能も必要である.
•
再学習(
トレンド追従)
:ネットワークは利用者 数の増加,新サービスの提供,ネットワークの構成変 更等により,ネットワークから収集されるデータの傾 向は変化するため,このようなデータのトレンド変化 に追従するための再学習機能が必要である.•
再学習(
誤検知再学習)
:ネットワークではバッ クアップ等による正常なトラヒック急増やCPU
など のリソース使用量の急増がある.このような状況をあ らかじめ学習できていない場合,正常な状況を異常と 検知する,誤検知が発生する.これに対し,それ以降 は誤検知しないよう,誤検知したデータが正常である ことを再学習するための機能が必要である.•
要因推定:ネットワーク事業者にとって,異常 が検知されても,異常の要因が判明しないと次のアク ションに移ることができない.このため,要因推定機 能が必要となる.一方,このような要件に対し,全ての検知技術に再 学習,要因推定が実装されているわけではない.
4. 1. 2
機能要件(
入力データ)
ネットワーク事業者に所属する技術者はネットワー ク関連技術には長けているが,機械学習による異常 検知技術には不慣れな場合が多い.このため,ネット ワーク事業者にとって,自身のネットワーク等から収 集されたデータを,検知技術に応じて前処理すること は困難である.このため,データの前処理は単純な集 計やフォーマット変換程度に抑える必要がある.
一方,異常検知技術は多様であり,それぞれに入力 するデータについても多様となっている.以下に各技 術に対する入力データを整理する.なお,下記のマル チモーダルについて関連研究では述べていないことを 補足する.これは,関係性モデルを用いる技術の効率 的な学習のために,様々な傾向のデータが混在する場 合,
1
種類のベクトルデータとして入力するのではなく,複数種類のベクトルデータに分割して入力する手 法のことである.
•
教師あり:異常なデータと正常なデータとが分 離されたデータ•
関係性モデル:複数次元のベクトルデータ•
時系列モデル:それぞれのベクトルに時刻が付 加されたデータ•
マルチモーダル:複数の種類のベクトルデータ に分離されたデータまた,実際の検知技術の入力データは,上記の掛け合 わせ
(
関係性,且つ,時系列モデルなど)
となるため,入力データの種類も膨大となる.
4. 1. 3
機能要件(
出力データ)
ネットワーク事業者や検知対象によっては,検知結 果を異常度合いの数値で提示されても解釈が困難な場 合があり,検知結果は異常有無のブーリアンで返す必 要がある場合がある.また,ネットワーク事業者が検 知結果の数値を分析して,独自に判断をするため,数 値で返す必要がある場合もある.このように事業者・
検知対象によって検知結果の提示方法に対する要件は 異なる.加えて,要因推定結果の要否についても様々 である.
一方,検知技術によって,検知結果をブーリアンで 返すものと,数値で返すものとがある.また,先の機 能要件で挙げたように,要因推定が可能な技術と不可 能な技術とがあり,技術によって検知結果に要因推定 結果が含まれるかどうかが異なる.
4. 1. 4
機能要件(
パラメタ)
ネットワーク事業者は先に述べたとおり,機械学習 による異常検知技術には不慣れな場合が多いため,検 知技術に設定するハイパーパラメタ等のチューニング が困難な場合が多い.このため,
WebAPI
の入力とし てはハイパーパラメタ等は必須の入力とすることはで きない.一方,検知技術にパラメタの設定は必須である.ま た,検知技術に応じて,設定が必要なパラメタは異 なる.
4. 1. 5
機能要件(
モデル)
ネットワーク事業者は複数のネットワークやサーバ などを運用するため,複数の学習済みモデルを使い分 けて検知・再学習を実施する.また,短期的に発生す る異常
(
バースト的にリソース使用量が変化する異常 等)
や,長期的に発生する異常(
メモリリーク等)
等,検知対象の異常によっても使用する学習済みモデルが
変わる可能性がある.このため,ネットワーク事業者 は
WebAPI
を介し,対象の学習済みモデルを指定し,そのモデルを用いて検知・再学習ができる必要がある.
一般的に検知技術は指定されたモデルを用い検知・再 学習を実施するため,大きな課題はないが,
WebAPI
経由で指定されたモデルを検知技術に指定する必要が ある.4. 1. 6
非機能要件非機能要件のうち,可用性については,検知対象 であるネットワークやサーバの長期安定動作のため,
継続的に異常検知を実施する必要がある.このため,
WebAPI
についても継続的に検知,再学習を実施でき る必要がある.また,ネットワーク事業者では異常に 対し,早期検知,対処する必要がある.このため,検 知・要因推定に掛けられる時間は限られ,一定の性能が 求められる.最後に運用・保守については,WebAPI
自身の保守のために,ログの出力やエラー発生時のエ ラー応答などが必要である.一方,検知技術開発者にとって,このような非機能要 件を満たすための検討や実装を行うことはネットワー ク向けの検知技術開発の障壁となり,それぞれの検知 技術で十分に非機能要件を満たすことは困難である.
4. 2
要件を満たす異常検知技術のWebAPI
化 ラッパの構成の提案本節では以上の課題を解決するラッパの構成を提案 する
(
表1
の右端列)
.なお,文中の記号は表の内容と 対応する.4. 2. 1
機能要件(
機能,出力データ)
機能,出力データについての課題は,検知技術の実 装上,
WebAPI
に対する要件に対応できない場合が あるというものであった.技術に実装されていないも のをラッパで実装することはできないため,ラッパは 次のような構成とする.機能の課題に対しては,再 学習・要因推定が実装されていないにもかかわらず,WebAPI
経由でリクエストがあった場合は,ラッパは エラー応答を返す(A)
.出力データの課題に対しては,出力のデータのフォーマットとしてはブーリアン,数 値,要因推定いずれも保持可能な仕様とするが,各値 の出力を必須としないことで,出力できない値がある 技術を許容する
(C)
.このようにして,IF
としては共 通のものをラッパにより実現する.4. 2. 2
機能要件(
パラメタ)
パラメタに対する課題は,検知技術に必要なパラメ タがリクエストに含まれない可能性があることであっ
た.これに対して,ラッパはデフォルト値をあらかじ め保持し,不足パラメタにはこれを設定する
(D)
.4. 2. 3
機能要件(
入力データ)
入力データに対する課題は,検知技術によって必要 なデータは異なるが,
WebAPI
の入力データとして は技術によらず単純なデータ形式にする必要がある,というものであった.ラッパは先で挙げた全ての技術 が要求するデータを
WebAPI
の入力として要求する が,データ自体は単純な集計とフォーマット変換で作 成可能なものとする.これにより,検知技術によって は,入力された一部のデータは使われない場合がある が,ラップされた検知技術はWebAPI
経由で入力さ れたデータで動作可能とする(B)
.4. 2. 4
機能要件(
モデル)
モデルに対する課題は複数のモデルの使い分けが 必要というものであった.ラッパは学習によって生成 された学習済みモデルに
ID
をつけ,ID
をWebAPI
の学習機能の出力として返信するとともに,ラッパ内 で学習済みモデルをID
とともに保持する.その後,WebAPI
の検知・再学習に対するリクエストには対象 の学習済みモデルのID
を含めることで特定のモデル に対する操作を可能とする(E)
.以上のように,課題を解決するラッパを構成し,共 通の
WebAPI
で複数種類の検知技術をラップ可能と するとともに,ラップされた技術を共通のWebAPI
のIF
経由で実行可能とする.4. 2. 5
非機能要件非機能要件の課題をラッパで解決するための構成を 以下にまとめる.
•
可用性–
複数GPU
を利用可能な場合,特定のGPU
へ の負荷集中による動作不安定化を防ぐため,ラウンド ロビンでGPU
の負荷を分散する(F)
•
性能–
学習済みモデルやデフォルトパラメタなど,読 み込み頻度の高いファイルについては,読み込み時間 の短縮のためオンメモリで保持する(G)
–
入力データの転送時間とラッパ内でのデータ変 換にかかる時間の短縮のため,WebAPI
の利用者側の 判断で入力データのメタデータを省略することによる 入力データの軽量化を可能とする(H)
–
時間のかかる学習機能を非同期処理とする(I)
•
保守・運用–
入力データに誤りがあった場合や,検知技術の例外発生時に,エラーの内容を
WebAPI
の出力とし て返す(J)
–
検知技術のデバッグやエラー時の対応のため,検知技術についてのログを出力する
(K)
5.
実 装以上の構成を実現するラッパを実装した.本章では 実装したラッパの
WebAPI
の仕様と実装方式につい て述べる.なお,文中の記号は表1
の右端列の構成を 実現する実装を示す.5. 1 WebAPI
の仕様WebAPI
は先の要件に対応する,学習,検知(
要因 推定含む)
,再学習(
誤検知再学習,トレンド追従)
の 機能を提供する.なお,学習済みモデルの削除,学習 済みモデルの情報(学習実施日,パラメタ条件,学習 データの情報など)を提供する機能も提供するが,こ れまで述べてきたラッパの構成と直接関連しないため 詳しい説明は割愛する.WebAPI
が提供する機能に共通の仕様は下記のとお りである.•
リクエスト・レスポンスでデータを送受信する 場合は,HTTP
のボディにJSON
形式でデータを保 持する.•
パラメタはURL
のクエリパラメタに保持する.•
利用する検知技術はURL
のパスで指定する.•
対象の学習済みモデルのID
はURL
のパスの 末尾で指定する(E)
.•
ラッパや検知技術自体の異常時にはHTTP
レ スポンスに異常を示すステータスコード(4xx
,5xx
等)
を含め,ボディーにはエラーの内容を示す文言を 含める(J)
.それぞれの機能の
IF
仕様について以下で説明する.説明には,各機能の
URL
例,メソッド,入出力デー タのフォーマットを説明するためのデータ例,機能の 説明を含める.なお,異常検知WebAPI
自身の異常 時の出力については,紙面が限られるため本論文では 割愛する.5. 1. 1
学 習• URL
サンプル(URL
の”machinelearning-a”
までのホスト名・パス,クエリパラメタは例であり,
実際は異なる.以降同様
)
:http
://
api.
dnn.
com/
machinelearning-
a/
traning-
results?
parameter1=100&
parameter2=
true•
メソッド:POST
•
入力データサンプル:{"
training_data": [
{"
data_name": "
MIB", "
time_series_data": [ {"
time": "2015/12/05 15:20", "
data": [{"
value_name
": "
cpu1", "
value": 71.0}, {"
value_name
": "
cpu2", "
value": 79.0},
…{"
time]}, ": "2015/12/05 15:21", "
data": [{"
value_name
": "
cpu1", "
value": 71.0}, {"
value_name
": "
cpu2", "
value": 79.0},
…: ]},
]},
{"
data_name": "
FLOW", "
time_series_data": [ {"
time": "2015/12/05 15:20", "
data": [{"
value_name
": "
TCP_pkt", "
value": 3.0}, {"
value_name": "
TCP_byt", "
value":
212.0},
…{"
time]}, ": "2015/12/05 15:21", "
data": [{"
value_name
": "
TCP_pkt", "
value": 10.0}, {"
value_name": "
TCP_byt", "
value":
923.0},
…: ]},
]}, : ]
"
false_positive_time": [
{
start:"2015/12/05 18:10",
end:"2015/12/05 18:15"},
{
start:"2015/12/06 12:22",
end:"2015/12/06 12:30"},
: ]}
•
出力データサンプル:{"
id": 3}
•
説明:学習データとハイパーパラメタ等を受 け取り,それらに従って学習を実施する機能である.POST
でリクエストを受け付け,その際のボディに学 習データが含まれていることを前提とし,ボディから 学習データを取得する.また,クエリパラメタにはハ イパーパラメタ等を含み,利用者の指定に応じて学習に用いる
(
指定されていない場合はデフォルト値を使 用する(D))
.リクエストを受信し,すぐに学習済みモ デルのID
を返信するが,非同期で学習を実施するこ とで,利用者側の処理をブロックすることを防ぐ(I)
. 学習が終わると,生成された学習済みモデルをラッパ 内で保持する(E)
.入力データの先頭の
training data
のvalue
はar- ray
であり,マルチモーダルな技術への入力を想定 し,複数種類のデータを保持できる.このarray
の各 要素はobject (
連想配列)
であり,データの種類の名 前(
上記の例ではMIB
とFLOW)
と,時系列データ(time series data)
を含む.更に時系列データのvalue
はarray
であり,要素には時系列順にデータが保持さ れている.各時刻のデータには,時刻とその時刻に収集 された複数の値がarray
で含まれる.このようなフォー マットとすることで,時系列モデルへの入力が可能と なるとともに,複数の値のarray
を複数次元のベクト ルデータとして扱うことができ,関係性モデルへの入 力も可能となる.一方,教師あり学習に対応するため,入力データの末尾に,学習データに含まれる異常な時 間帯を示す
array
をfalse positive time
のvalue
とし てもつことができる.array
の要素は異常の開始時刻 と終了時刻を保持し,学習データのうち,この時間帯 に含まれるデータは異常なデータとみなされる(B)
. なお,入力データには三つのメタデータ(
データの 名前,時刻,値の名前)
を含むが,これらのうち,不 要なものを省略することができる.この場合,省略さ れたメタデータを保持するobject
ごと省略される(
下 記に時刻を省略した場合の入力データのサンプルを示 す)
.このようにして,入力データのサイズを削減し,転送/処理にかかる時間を削減する
(H)
.{"
data_name": "
MIB", "
time_series_data": [ [{"
value_name": "
cpu1", "
value": 71.0}, {"
value_name
": "
cpu2", "
value": 79.0},
…[{"
value_name], ": "
cpu1", "
value": 71.0}, {"
value_name
": "
cpu2", "
value": 79.0},
…: ],
]},
5. 1. 2
再 学 習• URL
サンプル:http
://
api.
dnn.
com/
machinelearning-
a/
traning-
results/3?
overwrite=
true&
parameterx=0.1&
parametery=
a•
メソッド:PUT
•
入力データサンプル:学習と同様•
出力データサンプル:学習と同様•
説明:先の学習機能で生成された学習済みモデ ルを再学習するための機能である.PUT
でリクエス トを受け付け,URL
のパスの末尾の学習済みモデルのID
に対応する学習済みモデルを対象に再学習を実施 するが(E)
,ラップ対象の技術に再学習が実装されて いない場合はエラーを返信する(A)
.また,ハイパー パラメタについては再学習特有のものをクエリパラメ タから取得するが,その他のパラメタは学習時に設定 されたものを用いる.なお,クエリパラメタには再学 習結果を既存の学習済みモデルに上書きするかどうか を指定するパラメタと,トレンド追従をするのか,誤 検知再学習をするのかを指定するパラメタも含む.そ の他の仕様は学習機能と同様である.5. 1. 3
検 知• URL
サンプル:http
://
api.
dnn.
com/
machinelearning-
a/
testing-
results/3?
paramete1=100&
parameter2=
true•
メソッド:POST
•
入力データサンプル:ほぼ学習データと共通の 形式であるが,以下の差分がある.–
冒頭のkey
がtraining data
ではなくtest data
となる– false positive time
を含まない•
出力データサンプル:{"
test_results": [
{"
time":"2015/12/05 15:20","
anomaly_degree":
0.0001,"
is_anomaly":
false},
{"
time":"2015/12/05 15:21","
anomaly_degree":
77.2,"
is_anomaly":
true}, :
],
"
cause_analysis_results": [
{"
time": "2015/12/05 15:20","
causes": {"
anomaly_degree
": 0.0001,"
cpu1":
-0.04292,"
cpu2": 0.00965,
…,"
TCP_pkt": 0.000711,"
TCP_byt"-0.000908,
…{"
time}}, ": "2015/12/05 15:20","
causes": {"
anomaly_degree
": 77.2,"
cpu1":
-2.42925328,"
cpu2": 1.00965547,
…,"
TCP_pkt": 1.71820751,"
TCP_byt":
-0.90843786,
…: }}
]}
•
説明:検知データを受け取り,指定されたID
の学習済みモデルを用い,そのデータが異常であるか どうかを検知する機能である.POST
でリクエストを 受け付け,そのボディのデータを検知データとして用 いる.また,クエリパラメタにはハイパーパラメタを 含み,利用者の指定に応じて,検知に用いる(
指定さ れていな場合はデフォルト値を用いる(D))
.利用する 学習済みモデルはURL
のパスの末尾の学習済みモデ ルのID
を参照することで決定される(E)
.通常,検 知は短時間で終了するため,本機能は同期処理となり,検知が終わると検知結果をレスポンスとして返す.
出力データの先頭には
test results
のvalue
として,入力データの各時刻に対する検知結果を
array
として 保持する.このarray
の各要素は入力データの各時刻 に対応する検知結果であり,時刻,異常度の数値,異 常有無のブーリアンから構成される.なお,検知技術 によって,どちらか,若しくは,両方に値が設定され る.値の有無については保証されないが,共通のIF
を ネットワーク事業者に提供できる.また,要因推定結 果はcause analysis results
のvalue
として含めるこ とができ,これも入力データの時刻に対応した要因推 定結果がarray
の各要素に含まれる.このarray
の各 要素は,時刻,要因推定結果から構成され,検知技術 が要因推定を実装していれば,要因に関する値(
一般 的には異常に対する各値の寄与度)
が設定される(C)
.5. 2
実 装 方 式図
2
にラッパの実装方式を示す.ラッパはNginx
,WSGI
,Django
の組み合わせにより,WebAPI
のプ ロトコルとPython
の関数呼び出しとを相互変換する 機能(
プロトコル変換機能)
と,先に提案したラッパ の構成を実現する共通機能で構成される.これにより,検知技術開発者によって作成され,具体的な異常検知 を行うプログラム
(
学習,再学習,検知プログラムを 含む)
をラッパはWebAPI
化する.また,学習済みモ デルや各種コンフィグ(
デフォルトパラメタなど)
をオ ンメモリで取り扱うことで,学習,検知などの際の性 能向上を実現するmemcached (G)
と,学習済みモデ図2 実 装 方 式 Fig. 2 Implementation.
ルの情報
(ID
,学習実施日,パラメタ条件,学習デー タの情報など)
を保持するpostgreSQL
も含まれる.学習のリクエストを受け付けると,プロトコル変 換機能を経て,パラメタと学習データが共通機能の 学習の関数に渡される.共通機能はこれらの形式の チェックを行い,正常なパラメタ,データではない場合 はエラーを返し,プロトコル変換機能がエラーのレス ポンスを返す
(J)
.正常なパラメタ,データの場合は,postgreSQL
から学習済みモデルのID
を新たに払い 出し(E)
,レスポンスとして返信する.一方,学習はレ スポンスとは非同期で実施しており(I)
,必要なパラメ タが不足していれば,共通機能がmemcached
からデ フォルトパラメタを取得する(D)
とともに,JSON
形 式の学習データを学習プログラムで用いる形式に変換 する.その後,共通機能から学習プログラムにこれら のパラメタ,データを渡すことで学習を実施する.な お,GPU
が複数ある場合は,ラウンドロビンでGPU
を割り当てることで,特定のGPU
への負荷の集中を 防止する(F)
.また,必要に応じ,共通機能からログ を出力する(K)
.再学習のリクエストを受け付けた場合,基本的には 学習と同様の流れであるが,再学習プログラムに対し て,再学習対象の学習済みモデルと,その学習済みモ デルを学習したときに設定したパラメタを指定する必 要があるため,共通機能は
memcached
から対象の学 習済みモデルを,postgresql
からパラメタを取得する.これらをデータとともに再学習プログラムに渡し,再 学習を実施する.
検知のリクエストを受け付けた場合,プロトコルの 変換,パラメタ,データのチェック,不足するパラメタ と学習済みモデルの取得を行い,共通機能から検知プ ログラムを呼び出す.その後,検知プログラムからの 検知結果を共通機能が取得し,これを
JSON
形式に変 換し,プロトコル変換機能に返す.最後にプロトコル 変換機能からWebAPI
のレスポンスとして検知結果 が返信される.なお,上記のように検知プログラムが共通機能から 呼び出され,データやパラメタを受け渡しができるよ うに,検知プログラムは
Python
で記述され,特定のIF
を実装する必要がある.また,エラーなどのログの 出力のため,共通機能が提供するログ出力のための機 能を検知プログラムから呼び出すことができる.6.
評 価以上のようにして実装したラッパを用い,これまで 筆者らが検討を進めてきたディープラーニングによる 異常検知技術
[17], [18]
のプログラムをWebAPI
化し,実際のネットワークで異常検知を実施することで,本 ラッパによる検知技術開発者,ネットワーク事業者に 対する工数と難易度について評価した.更に,ラッパ による性能に対するオーバーヘッドを測定した.
6. 1
検知技術開発者にかかる工数と難易度 ラッパは検知技術の開発者がWebAPI
として技術 を提供するための実装と,ネットワークでの利用に関 する要件を満たすための実装を引き受けることで,検 知技術開発者が検知技術をネットワーク対応させる工 数を削減する一方,検知技術をラッパに対応させるた め,検知プログラムに専用のIF
を実装する必要があ る.これが,検知技術の開発者にとってどの程度の障 壁となるか確認した.ラップ対象の技術はオートエンコーダを用いた異常 検知技術とし,関係性モデルを用いた異常検知技術に 分類される.学習時は,正常時のネットワークから収 集される複数の数値
(CPU
使用率やトラヒック量な ど)
をベクトルとし,各時刻のベクトルを学習データ として受け付ける.オートエンコーダはこのような データで正常時の関係性を学習する.その後,検知の 際は,現在のネットワークから収集される同様なデー タを検知データとして受け付け,学習済みモデルを用 いて異常かどうかを判定する.なお,オートエンコー ダを用いた異常検知は要因推定・再学習ができないが,これまでの筆者らの検討により,これらが可能な技術
となっている.
このようなプログラムをラップするための実装の規 模を確認した.この結果,既存のオートエンコーダ による検知プログラムは
33.1KB
であったのに対し,ラッパに対応したプログラムは
51.6KB
であった.つ まり,既存プログラムへのIF
の実装のために20KB
程度,1
行あたり30B
程度と考えると700
行程度の追 加が必要であった.既存のプログラムの規模が小規模 であることも考えられるが,ある程度の量の修正が必 要であると考えられる.また,追加の内容は下記のようなものであった.
•
学習,検知のデータの入力,検知結果の出力を ファイル(CSV)
経由で行っていたものを,引数と戻 り値でやり取りするように修正•
学習済みモデルをファイルで入出力していたも のを,memcached
に入出力するように修正•
パラメタをコンフィグファイルから読み込んで いたものを,引数から読み込むように修正これらは検知技術の開発者が実装するにあたり検討が 必要なものではなく,一意に実装ができるような内容 であるため,難易度は低いと言える.
また,ラッパを用いない場合,
WebAPI
の実装と ネットワークの要件を満たすための実装を,実装方法 の検討からスクラッチで行う必要があるため,ラッパ によるWebAPI
化と比較し,工数・難易度ともに大 幅に上がると考えられる.6. 2
ネットワーク事業者にかかる工数と難易度 ラッパはネットワーク事業者に共通のWebAPI
を提 供し,技術ごとにかかる導入のための実装を削減する.一方,既存のネットワークオペレーションに
WebAPI
の異常検知技術を導入するための実装が必要である.これがネットワーク事業者にとってどの程度の障壁と なるか確認した.
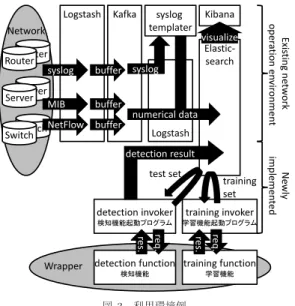
図
3
に実装したラッパの利用環境例を示す.図の 上部に既存のネットワークオペレーション環境を示し ており,この環境では,ネットワークを構成するサー バ・ルータ・スイッチ等からLogstash
でデータを取 得,取得したデータをKafka
にバッファ,バッファさ れたデータをLogstash
で取得し,syslog
などのテキ ストデータをsyslog templater [19]
を用いて数値化,数値データを
Elasticsearch
に保存,保存された数値 データをKibana
で可視化,といった手順で構成され ている.このような環境に検知
WebAPI
を導入するために,図3 利用環境例 Fig. 3 Practical environement.
学習,検知機能の起動プログラムを新たに作成する必 要があった.このプログラムは,
Elasticsearch
から データを取得し,そのデータをJSON
形式に整形し,WebAPI
にリクエストを送り,結果をElasticsearch
に保存する.このプログラムの規模は約80KB
であっ た.この程度の規模であれば数人日程度で実装できる と考えられる.一方,上記プログラムは技術者自身が得意とする言 語で実装できた
(Go
言語を利用)
.また,WebAPI
と 連携するためのライブラリなどは多くのものが公開さ れており,一般的に導入の難易度は低いと考えられる.以上に加えて,一度実装すると他の技術に対しても 使い回せることも考慮すると,ネットワーク事業者に 対する工数と難易度は低いといえる.
6. 3
オーバーヘッドラッパは検知プログラムをラップし,
WebAPI
との プロトコル変換を行う.そこにオーバーヘッドが発生 するため,オーバーヘッドの程度について評価した.評価対象の機能としては,検知+要因推定とし,学 習については非同期処理であるため評価対象外とした.
また,測定項目としては,
WebAPI
のレスポンスタイ ムと,内部の検知プログラムの実行時間とし,これら の差分がラッパによるオーバーヘッドと考える.評価の条件を以下に示す.
•
検知データの次元数:36
次元•
メタデータ省略による入力データの軽量化:なし図4 評 価 環 境 Fig. 4 Experimental condition.
•
リクエスト頻度:2
リクエスト/
秒•
測定時間:300
秒•
評価環境:図4
に示す.検知データの次元数については実際のネットワークで 異常検知に必要であった次元数とした.また,リクエ スト頻度の根拠としては,ネットワーク事業者が抱え る検知対象のネットワークを
10
程度とし,各ネット ワークに対して10
種類のモデル(
トレンド追従の頻度 や前処理の内容を変えたモデル)
を用いて異常検知を 運用することを前提とし,各モデルでの検知間隔を1
回/
分とする.そうすると,全体のリクエスト頻度とし ては100
リクエスト/
分となるが,多少の余裕をもつ ために評価のためのリクエスト頻度としては2
リクエ スト/
秒(120
リクエスト/
分)
とした.なお,評価環境 としてはDocker
コンテナを用いるが,コンテナの異 常検知プログラムからホストのリソースの利用に制限 は加えず,また,コンテナからGPU
にアクセスでき る環境を構築した.更に,ラッパが提供するWebAPI
に負荷をかけるためのトラヒックジェネレータとしてTsung
を用いた.以上の評価の結果,
WebAPI
のレスポンスタイムの 平均は4.29
秒であったのに対し,検知プログラムの実 行時間の平均は3.95
秒であった.この結果,WebAPI
のレスポンスタイムのうち,オーバーヘッドはわずか であると考えられる.また,ネットワークにおいてリ アルタイムな異常検知を実施するにあたり,この程度 のレスポンスタイムであれば問題ないと考えられる.7.
む す び本論文では機械学習によるネットワーク異常検知技 術を
WebAPI
化するラッパの構成を提案した.本ラッ パは様々な検知技術をラップし,共通のWebAPI
を介 して検知機能を提供する.これにより,ネットワーク 事業者は本WebAPI
を利用するための実装をすれば,様々な検知技術を利用可能となり,技術ごとの実装を 削減できる.一方,検知技術開発者は本ラッパを用い ることで,自身で
WebAPI
を実装する必要はなく,更 に,技術のネットワーク対応のための実装をラッパに 肩代わりさせることで容易にネットワーク対応の検知 技術を作成できる.このようなラッパを実装し,ネッ トワーク事業者・検知技術開発者双方に対する工数・難易度は低いことを確認した.加えて,本ラッパによ る検知時間に対するオーバーヘッドが問題ない範囲で あることを実測により確認した.
今後は,ネットワークの障害対応の現場での本ラッ パの普及を進める.これにより,ネットワーク障害対 応で多様な検知技術をタイムリーに利用可能となる.
また,ネットワーク事業者での機械学習による検知技 術の導入コストが下がり,このような技術に対する需 要が高まることで,検知技術開発者によるネットワー ク向けの技術提供の促進も期待される.
また,異常検知以降の分析・対処と本
WebAPI
と の連携による,ネットワークの障害対応の完全自動化 に向けた研究を進めるとともに,ネットワーク以外の 分野でも障害対応の自動化は求められているため,本 ラッパの他分野での活用についても検討を進める.文 献
[1] 川原亮一,渡辺敬志郎,原田薫明,川田丈浩,“ネットワー クオペレーションへのAI活用,”信学通誌,vol.12, no.1, pp.29–38, 2018.
[2] 井手 剛,入門 機械学習による異常検知,コロナ社,
2015.
[3] 井手 剛,杉山 将,異常検知と変化点検知,講談社,
2015.
[4] S. Harada, R. Kawahara, T. Mori, N. Kamiyama, H.
Hasegawa, and H. Yoshino, “A method of detecting network anomalies in cyclic traffic,” IEEE GLOBE- COM 2008 - 2008 IEEE Global Telecommunications Conference, pp.1–5, Nov. 2008.
[5] J. Takeuchi and K. Yamanishi, “A unifying frame- work for detecting outliers and change points from time series,” IEEE Trans. Knowl. Data Eng., vol.18, no.4, pp.482–492, April 2006.
[6] G. Jiang, H. Chen, and K. Yoshihira, “Discover- ing likely invariants of distributed transaction sys- tems for autonomic system management,” 2006 IEEE International Conference on Autonomic Computing, pp.199–208, June 2006.
[7] T. Id´e, A.C. Lozano, N. Abe, and Y. Liu, “Proximity- based anomaly detection using sparse structure learn- ing,” Proc. 2009 SIAM International Conference on Data Mining, pp.97–108, 2009.
[8] 中野雄介,池田泰弘,渡辺敬志郎,石橋圭介,川原亮一,
“オートエンコーダによるネットワーク異常検知,” 2017
信学総大,B-7-33, March 2017.
[9] 池田泰弘,中野雄介,渡辺敬志郎,石橋圭介,川原亮一,
“オートエンコーダを用いたネットワーク異常検知にお ける精度向上に向けた一検討,” 2017信学総大,B-7-34, March 2017.
[10] Zabbix LLC, “Zabbix,” https://www.zabbix.com/, 参照Aug. 31, 2018.
[11] “Nagios,” https://www.nagios.org/, 参 照Aug. 31, 2018.
[12] NTT デ ー タ 先 端 技 術 株 式 会 社 ,“Hinemos,”
http://www.hinemos.info/,参照Aug. 31, 2018.
[13] Elastic, “Elastic,” https://www.elastic.co/,参照Aug.
31, 2018.
[14] Splunk, “Splunk,” https://www.splunk.com/, 参 照 Aug. 31, 2018.
[15] Microsoft, “Azure machine learning studio,”
https://azure.microsoft.com/ja-jp/services/
machine-learning-studio/,参照Aug. 31, 2018.
[16] 情報処理推進機構,“非機能要求の見える化と確認の手段を 実現する「非機能要求グレード」の公開,” https://www.
ipa.go.jp/sec/softwareengineering/reports/
20100416.html,参照Aug. 31, 2018.
[17] 池田泰弘,石橋圭介,中野雄介,渡辺敬志郎,川原亮一,
“オートエンコーダを用いた異常検知におけるスパース最 適化を用いた要因推定手法(情報ネットワーク),”信学技 報,IN2017-18, June 2017.
[18] 池田泰弘,石橋圭介,中野雄介,渡辺敬志郎,川原亮一,
“オートエンコーダを用いた異常検知におけるモデル再学 習手法(情報ネットワーク),”信学技報,IN2017-84, Jan.
2018.
[19] T. Kimura, A. Watanabe, T. Toyono, and K.
Ishibashi, “Proactive failure detection learning gen- eration patterns of large-scale network logs,” 2015 11th International Conference on Network and Ser- vice Management (CNSM), pp.8–14, Nov. 2015.
(2018年8月31日受付,12月11日再受付,
2019年2月1日早期公開)
中野 雄介 (正員)
平成17年和歌山大学大学院システム工 学研究科修了.同年日本電信電話株式会社 入社.以後,NTTネットワークサービス システム研究所,NTTネットワーク基盤 技術研究所勤務.Webスクレイピング,ユ ビキタスコンピューティング,サービスデ リバリープラットホーム,分散データベース,Webパフォー マンス,異常検知技術等の分野の研究に従事.博士(情報科学) (平成23年3月,大阪大学).
池田 泰弘 (正員)
2010年慶應義塾大学大学院基礎理工学 専攻応用物理専修修士課程修了.同年日 本電信電話株式会社に入社.以降インター ネットトラヒック分析,ネットワーク設計,
品質分析等に関する研究に従事.2012年 電子情報通信学会情報ネットワーク研究賞 受賞.
松尾 洋一 (正員)
2015年慶應義塾大学大学院理工学研究 科基礎理工学専攻博士課程修了.同年,日 本電信電話株式会社に入社.以後,通信ネッ トワークのデータ分析を用いた保守運用高 度化に関する研究に従事.
渡辺敬志郎 (正員)
2004年九州大学大学院システム情報科 学府修士課程修了.同年,NTTサービス インテグレーション基盤研究所入社.以降,
映像通信サービスの品質評価・管理技術に 関する研究開発に従事.2012年NTTコ ミュニケーションズに転籍し,メールサー ビスの開発/管理業務に従事.2015年NTTネットワーク基 盤技術研究所に転籍後,現在までAI技術の活用による保守運 用高度化に向けた検討に従事.
石橋 圭介 (正員:シニア会員)
平5東北大・理・数学卒,平7年同大学 院修士課程了,同年,日本電信電話株式会 社に入社.IPネットワークのトラヒック,
品質計測等の研究に従事.平29から国際 基督教大学教養学部アーツ・サイエンス学 科准教授.博士(情報理工学).日本ソフ トウェア科学会,IEEE会員.
西松 研 (正員)
1997年早稲田大学大学院理工学研究科 情報科学専攻修士課程修了.同年,日本電 信電話株式会社に入社.以降,通信トラヒッ クやデータ分析に関する研究に従事.現在 は,NTTネットワーク基盤技術研究所に 所属.情報処理学会,日本オペレーション ズ・リサーチ学会会員.