Parareal法と領域分割法による拡散問題での時空間並列性能評価
7
0
0
全文
(2) Vol.2016-HPC-157 No.19 2016/12/22. 情報処理学会研究報告 IPSJ SIG Technical Report. 実装概要を Algorithm 1 に計算の流れを Fig. 2 に示す.. Serial-in-time integration Time domain. cores. wrkCn, wrkCb, wrkF はワーク領域である.Parareal には. (a) Time domain decomposition. データの通信時間 tcom と通信の待ち時間 twait がある.こ. (b)Temporal Initial value. の 2 つの時間を合わせた通信時間を t′com として数値実験. Parallel-in-time integration. で計測を行う:. (c)Pysycal time integration Domain:n Doman:n-1. (d)Gap. t′com = tcom + twait .. Fine solver. Update. Time domain Coarsening (e)Gap propagation. Algorithm 1 Parareal method Coarse solver. 図 1 Parareal 法の概要. Fig. 1 Overview of Parareal method.. un+1 = F (Tn+1 , Tn , un ). (2). と 表 現 さ れ る .こ こ で Fine solver F(·) は ユ ー ザ ー が 望ましい精度をもつ時間積分をする作用素とする.. U ≡ (u0 , . . . , uNt )⊤ として,(2) を変形する: u0 − u0 u1 − F(T1 , T0 , u0 ) f (U ) = . = 0. .. uNt − F(TNt , TNt −1 , uNt −1 ). (3). f (U ) = 0 となる U を求める Newton 法を用いると,k 反 復目に得られる近似解 U ≡ k. とする.ただ. Ini6al computa6on. Proc. 0 . ・・・. Proc. 1 . ・・・ ・・・. ・・・ ・・・. Coarse solver : Fine solver :. TG Communica6on : TF Wait :. 図 2. tcom twait. t0com. Parareal 法の計算の流れ. Fig. 2 Computation procedure of Parareal method.. 2.1 残差について reskn = ukn − uk−1 n .. F ′ (Tn , Tn−1 , ukn )[F (Tn , Tn−1 , uk+1 n ) (6) −. Kpar=2. Parareal の収束判定では以下の残差式を用いる:. 低い Coarse solver G(·) を用いて近似する:. G(Tn , Tn−1 , uk+1 n ). Kpar=1. Proc. Nt . (5) の 2 式の右辺第 2 項を Fine solver よりも計算コストの. −F(Tn , Tn−1 , ukn )]. Computa6on of Parareal itera6on. (4). (4) の両辺に左から f ′ (U k ) をかけて整理すると, uk0 = u0 U k+1 = F(T , T k n n−1 , un ) n+1 (5) −F ′ (Tn , Tn−1 , ukn )[F(Tn , Tn−1 , uk+1 n ) −F(Tn , Tn−1 , ukn )]. G(Tn , Tn−1 , ukn ).. (9). 残差式 (9) はこれまでに示されていないが文献 [6] の誤差 の式を参照して,以下のように示される.. これにより,よく知られる Parareal アルゴリズムが得られ る [6]:. uk+1 n+1. Computa6on procedure of Parareal method. = u0 とする.. U k+1 = U k − [f ′ (U k )]−1 f (U k ). ≈. Receive u0n−1 from previous time slice [Tn−2 , Tn−1 ] u0n = G(Tn , Tn−1 , u0n−1 ) Send u0n to next time slice [Tn , Tn+1 ] Copy u0n to wrkCn while k < N do wrkF = F(Tn , Tn−1 , ukn−1 ) Copy wrkCn to wrkCb Recieve uk+1 n−1 from previous time slice [Tn−2 , Tn−1 ] wrkCn = G(Tn , Tn−1 , uk+1 n−1 ) Summation vectors uk+1 = wrkCn + wrkF − wrkCb n to next time slice [Tn , Tn+1 ] Send uk+1 n end while. ・・・. し,初期値より. uk0. (uk0 , . . . , ukNt )⊤. (8). reskn. = G · reskn−1 + (F − G)resk−1 n−1. (10). これから,残差は次のように上限を抑えることができる:. = G(Tn+1 , Tn , uk+1 n ) +F(Tn+1 , Tn , ukn ) − G(Tn+1 , Tn , ukn ).. (7). G(Tn , Tn−1 , uk+1 n ) の計算は逐次計算になるが Fine solver よりも低コストに抑えることができ,また,F (Tn , Tn−1 , ukn ). max |reskn | ≤. 1≤n≤Nt. (CT )(k−1) ∆T p(k−1) max |res1n |.(11) 1≤n≤Nt (k − 1)!. ここで,C は定数である.この残差式を使い,. ϵ > res(K par ),. (12). の計算は時間方向の依存性がなく並列計算が可能となって. から,許容誤差 ϵ を下回る残差となる反復数 K par の推定. いる.. が可能となる.. c 2016 Information Processing Society of Japan ⃝. 2.
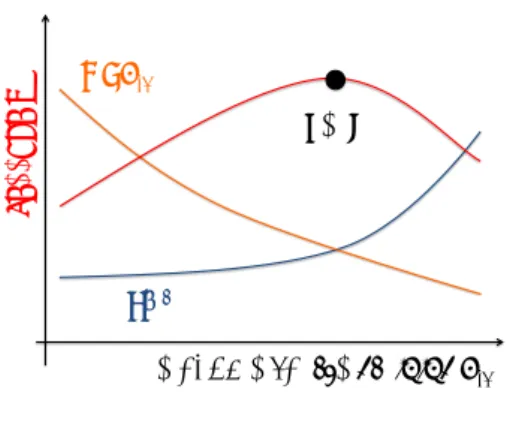
(3) Vol.2016-HPC-157 No.19 2016/12/22. 情報処理学会研究報告 IPSJ SIG Technical Report. 2.2 並列加速率について. するが,その一方で修正計算である Coarse solver の計算. Parareal 法のアルゴリズムから理論的な並列加速率につ. 精度が低下して,並列加速率は低下する.この 2 つの効果. いて説明する [8], [9].Nt を Time slice の数(並列数) ,TG. から,並列加速率は,Rf c に対してピークを持つような挙. と TF を Time slice[Tn−1 , Tn ] での Coarse と Fine solver の. 動を持つと推定できる.その概要を Fig. 3 に示す.. 実行時間とする.並列加速率の基準となる逐次実行時間を. また,Parareal 法の並列加速率の式には,空間並列の影. Fine solver で逐次的に [0, T ] を時間積分するときの実行時. 響は入っていないため,空間並列に関係なく,時間並列の. 間とし,Nt TF と表される.Parareal 法では,まず初期値の. 効果を得ることが出来ると推測される.. 計算に Coarse solver での [0, T ] の時間積分を行う.Coarse. solver の実行時間は通信時間を含めて Nt (TG + tcom ) とな る.また,1 反復に Coarse Solver と Fine solver の実行時 復数とすると Speedup は α(Nt , K par , TG , TF , tcom ) は,. α(Nt , K par , TG , TF , tcom ) = Nt TF , Nt (TG + tcom ) + K par (Nt (TG + tcom ) + TF ). 1 / Rfc. Speedup α. 間が Nt (TG + tcom ) + TF となる.K par を Parareal 法の反. Peak. (13). Kpar. となる.これを変形して. α(Nt , K par , TG , TF , tcom ) = (14) Nt . Nt (TG /TF + tcom /TF ) + K par (Nt TG /TF + 1). Rate of 'me coarse graining Rfc 図 3. Parareal 法の Peak 性能. Fig. 3 Peak performance of Parareal method.. となる.tcom は TF より十分小さいとき無視することがで きる:. 4. 数値実験. α(Nt , K par , TG , TF ) = Nt . par Nt TG /TF + K (Nt TG /TF + 1). (15). (16) と数値実験結果に基づき,拡散問題での Parareal 法の. Speedup モデル (15) から,この上限は Nt /K par [8] とわか るが未知数が多くこのモデルの挙動の検討は難しい.そ のため TG , TF を近似して未知数を減らして検討を行う.. Coarse solver と Fine solver で同じ時間積分法で扱った場 合,それぞれの実行時間の比を時間ステップ幅 δT, δt(< δT ) を使った比 Rf c = TF /TG ≈ δT /δt で近似できるすること で,Speedup モデルを近似する:. α(Nt , K par , Rf c ) = Nt . Nt /Rf c + K par (1 + Nt /Rf c ). 数値実験を行い,前節で説明した並列加速率のモデル 性能評価を行う.. 4.1 拡散問題 今回扱う拡散問題,初期値と境界条件は,. ut (x, t) =. 1 ∆u(x, t), x ∈ Ω = [0, 1]3 , t ∈ [0, T ], (17) 3. u(x, 0) = sin(πx) sin(πy) sin(πx), u(x, t) = 0, (16). x ∈ ∂Ω,. (18). としている [10].離散化は差分法,時間積分法として Coarse,. Fine solver ともに Crank-Nicolson 法を用いており,ま. 時間粗視化率 Rf c はユーザーが指定できるため既知である. た Crank-Nicolson 法から得られる連立一次方程式の線形. が,K par は問題によって収束性が異なるため予測が難しく. solver として Red-Black SOR 前処理付 Bi-CGstab 法を利. 未知数である.そのため数値実験で得られる反復数 K. par. 用している.. を用いた式 (16) により並列加速率を検討する.. 3. 並列加速率の挙動の推定 残差による Parareal 法の計算の打ち切り式 (12) から反 復数 K. par. 4.2 実行環境 京 コ ン ピ ュ ー タ を 使 用 し ,そ の 詳 細 は Table 1 に 示 す .ま た ,計 測 に は 理 研 の Performance Monitor li-. を求め,式 (16) を使うことにより,Parareal 法. brary (PMlib)[11] を 使 用 し て い る .コ ン パ イ ル オ. の並列加速率の挙動を推定できる.正確な式 (12) が得ら. プ シ ョ ン は-Kfast,parallel,ocl,preex,array private,auto -. れていないため,理論的な推定は困難である.しかし,以. Kopenmp,simd=2,uxsimd としている.使用言語は C++. 下のように定性的に並列加速率の挙動は推定できる.Rf c. と Fortran で,プログラムの制御部分と計測を C++で,線. を大きくすると,逐次計算部分が減少し並列加速率が増加. 形 solver などの数値計算の部分は Fortran で実装している.. c 2016 Information Processing Society of Japan ⃝. 3.
(4) Vol.2016-HPC-157 No.19 2016/12/22. 情報処理学会研究報告 IPSJ SIG Technical Report. 空間並列を MPI と OpenMP のハイブリッド並列で実装. からは離れている.各 Time step での Coarse solver の反. し,Parareal 法は MPI で実装している.空間並列は k,j,i. 復数を見るを Tab. 4 に示す.K par = 0 は Parareal の初. の空間三重ループについて,最外側の k ループを MPI で. 期値の計算で扱う Coarse solver の計算を示す.Rf c = 10. 領域分割し,次に k,j の二重ループを OpenMP の Collapse. では,線形 solver の反復数が一定になっている.しかし,. 指示句を用いて一重化しスレッド並列化している.. Rf c = 100 では Time domain の後半部で反復数が増えて おり,また Parareal の反復数の方向にも線形 solver の反復. 表 1. 京コンピュータの詳細. 数が増えている.これによりロードバランスが均一でなく. Table 1 Specification of K computer. SPARC64TM VIIIfx. Archtecture. なっため,モデルとの乖離が見られた.. 128GFLOPS ( 16GFLOPS × 8 core). CPU performance. 14 12. 6MB. Memory band width. 64GB/s. Frequency. 2GHz. ノード間帯域. 5GB/s. Speedup α. L2 cache. 4.3 パラメータ 数値実験で使用したパラメータリストを Table 2 に示す.. 10 8 6 4 2 0. 0. − ukn ||2 のうちの最大値を用いている. の L2 ノルム ||uk+1 n. パラメータリスト. Coarse, Fine solver. Crank-Nicolson 法. の時間積分法 格子数. 1283. 時間領域. [0 : T ] = [0 : 1], [0 : 0.2]. Time Slice の数 Nt. 4,5,10,20,50,100. 領域分割の数 Ns. 1, 2, 4, 8, 16, 32, 64. Rf c (δT ). 500(0.5), 100(0.01),. 14 12 10 8 6 4 2 0. 0.0001. Parareal 法の収束判定. maxn ||uk+1 − ukn ||2 < 10−6 n. 線形 solver. Red-Black SOR 前処理付. 線形 solver の収束判定. ||r||2 /||b||2 < 10−12. 60. 80. 100. Speedup model Numerical result 0. 20. 40. 60. 80. 100. The number of time slices N (b) Rf c = 100(δT = 0.01).. 50(0.05), 10(0.001) δt. 40. (a) Rf c = 10(δT = 0.001).. Speedup α. 表 2. Table 2 Parameter list.. 20. The number of time slices N. なお,Parareal の収束判定は各 Time slice n の端点の残差. 図 4. T = 1 での Time slice の数の変化による Speedup. Fig. 4 Speedup according to the number of time slices at T = 1.. Bi-CGstab 法 (r は残差ベクトル). 表 3. Parareal の反復数 K par. Table 3 The number of iterations of Parareal K par .. T. Rf c. 5. 10. 20. 50. 100. 500. 4. 4. 5. 5. -. -. 100. 3. 3. 3. 3. 3. 3. 50. 2. 3. 3. 3. 3. 3. 10. 2. 2. 2. 2. 2. 2. 100. 3. 3. 3. 3. 3. 3. 4.4 Speedup モデルの性能挙動 ここでは領域分割なし (Ns = 1) の計算条件で,Speedup. 1. モデル (15) の検証を行う.Rf c = 10, 100 のときの Speedup の実験結果を Fig. 4 に,また Parareal 法の反復数を Table. 3 に示す.Speedup モデルの K par は未知数であるので,実 験結果の値を用いて算出している.また実行結果のグラフ. 0.2. The number of time slice N 4. は時間方向に逐次計算した実行時間をもとに示している. まず,Rf c = 10 のときはモデル通りの性能が得られること. Time domain を [0, 0.2] に変えた時の Speedup を Fig. 5. がわかる.次に Rf c = 100 の場合,時間方向に 100 並列す. に示す.Time domain[0, 1] に比べて,[0, 0.2] はモデルに. ることによって,最大 8.5 倍の Speedup が得られることが. 非常に近くなっていることがわかる.このことから,理想. わかる.しかし,Speedup モデルから得られる理想的な値. 的には Speedup モデル通りの加速が期待できる.. c 2016 Information Processing Society of Japan ⃝. 4.
(5) Vol.2016-HPC-157 No.19 2016/12/22. 情報処理学会研究報告 IPSJ SIG Technical Report 表 4. には計算負荷が小さくかつ Rf c が増加しても反復数 K par. Coase solver での線形 solver の反復数. Table 4 The number of iterations of coarse solver.. K. 100. 10. を少なくできるような高精度計算方法が必要とされる.. T 0.2. 0.4. 0.6. 0.8. 1.0. 0. 2. 2. 3. 4. 4. 1. 2. 3. 4. 5. 6. 2. 3. 5. 5. 7. 8. 3. 4. 5. 7. 9. 10. 0. 2. 2. 2. 2. 2. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 100. 80. Rating [%]. Rf c. par. 60. 40. 0. 40. 60. 80. Rfc=100 Rfc=10. 80. 3 2 1. 4. 6. 8. 10. 12. 14. 16. 18. 60. 40. 20. The number of time slices N 図 5. 100. 100. Rating [%]. Speedup α. 4. 20. The number of time slices (a) 通信時間 t′com. Speedup model Result at T=1 Result at T=0.2. 5. Rfc=100 Rfc=10. 20. 20. Time domain による Speedup の変化. 0. Fig. 5 Speedup according to time domain.. よって Speedup の Peak が存在することがわかる.そのた. 40. 60. 80. 100. The number of time slices (b) Fine solver の実行時間 TF. Time Slice の数を 10 で固定し,Rf c を変化させたときの Speedup を Fig. 6 に示す.これから Parareal 法は Rf c に. 20. 図 7. 実行時間のうち通信時間と Fine solver の時間が占める比率. Fig. 7 Rating of communication time and the time of Fine solver in execution time.. め,最適なパラメータを設定する方法が必要となり,K par. 5. Speedup K par. Speedup α. 4.5 4. 5 4. 3.5 3. 3. 2.5 2. 2 500. 100. 50 The rate Rfc. The number of iterations. を予測する式 (12) が必要となる.. 10. 図 6 Rf c による Speedup の変化. Fig. 6 Speedup according to Rf c .. 表 5. Rf c = 100 のときの実行時間と詳細 [sec]. Table 5 Execution time and its details [sec] with Rf c = 100.. Nt. 実行時間. 1. 2.31 × 10. 3. 4. 1.85 × 10. 3. 5. 1.51 × 10. 3. 10. 8.34 × 102. 20. Fine. Coarse. solver. solver. −. t′com. −. 1.38 × 10. 3. −. 2.92 × 10. 1. 8.87 × 101. 2.48 × 10. 1. 9.93 × 101. 6.92 × 102. 1.41 × 101. 1.27 × 102. 5.03 × 102. 3.46 × 102. 7.80 × 100. 1.49 × 102. 50. 3.19 × 10. 1.39 × 10. 3.57 × 10. 0. 1.76 × 102. 100. 2.70 × 102. 1.98 × 100. 1.99 × 102. 2. 1.73 × 10. 3. 2. 6.98 × 101. 次に,実行時間を占める通信時間 t′com と Fine solver の 実行時間 TF の比率を Fig. 7 に示し,また,Tab. 5,6 に実. 4.5 領域分割法との組み合わせ. 行時間と内訳を示している.Time slice の数が増えるほど,. Rf c = 100,Time slice の数 Nt = 10, 100 のときの領. Coarse solver の計算待ちによる通信時間 t′com が増えてい. 域分割との組み合わせによる Speedup を Fig. 8 に示す.. る.また,Rf c が大きいほど,通信時間 t′com の比率が減少. Serial-in-time が示すグラフは領域分割のみによる並列に. し,かつ Fine solver の時間の比率が大きくなっており並列. よって得られた Speedup であり,64 ノードでの並列で 13.5. 性能が上がっていることがわかる.そのため Coarse solver. 倍の Speedup と既に飽和傾向あることがわかる.これは格. c 2016 Information Processing Society of Japan ⃝. 5.
(6) Vol.2016-HPC-157 No.19 2016/12/22. 情報処理学会研究報告 IPSJ SIG Technical Report 表 6. Rf c = 10 のときの実行時間と詳細 [sec]. Table 6 Execution time and its details [sec] with Rf c = 10.. Fine. Coarse. solver. solver. 7. Speedup. 実行時間. Nt. 8. t′com. 6. 4. 1.84 × 103. 1.15 × 103. 1.73 × 102. 5.19 × 102. 5. 1.61 × 103. 9.22 × 102. 1.38 × 102. 5.54 × 102. 10. 1.15 × 103. 4.61 × 102. 6.92 × 101. 6.23 × 102. 4. 20. 9.23 × 10. 2.31 × 10. 3.46 × 10. 1. 6.58 × 102. 7.86 × 102. 9.23 × 101. 1.39 × 101. 6.80 × 102. 3. 50 100. 7.41 × 102. 4.61 × 101. 6.93 × 100. 6.88 × 102. 2. 2. Ns=2 Ns=4 Ns=8 Ns=16 Ns=32 Ns=64. 5. 20. 40. 60. 80. 100. The number of time slices. (a) Rf c = 100(δT = 0.01). 3. 子数が 128 と少ないため,64 分割時には計算量に対して 8. し,そこから Parareal 法による時間方向に 100 並列するこ. 7. とによって,つまり,6400(= 64 × 100) ノードでの並列で. 101 倍の Speedup が得られることがわかる.Parareal 法は 領域分割法ほど計算資源に応じた並列性能がでないが,領 域分割が飽和したあとでも並列性能を得られることがわか. Speedup. 通信の割合が増加し並列性能が低下するためである.しか. 6 5 4 3. る.そのため,exa-scale 級のコア数が多いスパコンを見据 2. えると有用な並列化手法である.. 20. 40. 60. 80. 100. The number of time slices. Speedup. (b) Rf c = 10(δT = 0.001).. Serial-in-time Time slice=10 Time slice=100 Ideal. 100. Ns=64. Ns=64. decomposition Ns .. Ns=2. 10. 図 9 領域分割数 Ns を固定したときの Parareal による Speedup. Fig. 9 Speedup by Parareal with fixed the number of domain. Ns=64. Ns=2. 復数に比べて増加したためである.そのため時間粗視化率 1. Rf c に反比例した Coarse solver の実行時間の短縮を得るこ. Ns=1. 1. 1e+1. 1e+2. 1e+3. 1e+4. The number of nodes. とができなかったためである.粗視化率が小さい Rf c = 10 の場合は性能モデル通りの挙動を確認できた.時空間並列. Rf c = 100 のときの領域分割との組み合わせによる Speedup.. では,性能モデルから予想されるように,時間並列は空間. Fig. 8 Speedup by combination to domain decomposition with. 並列に独立に効果があることを示した.その結果,空間並. 図8. Rf c = 100.. 列性能が飽和後に時間並列によるさらに並列性能が向上す ることが確認できた.. 領域分割による並列後,時間並列による効果について調べ. 今後の課題として,時間粗視化率 Rf c が大きい場合でも. る.領域分割数を固定した場合の時間並列による Speedup. Coarse sovler で扱う線形 solver の反復数の増加がないよう. を Fig. 9 に示す.Rf c = 10 のときは時間並列の効果は領. な対応をする必要がある.その一例として,より高精度な. 域分割数に依存していないが,Rf c = 100 のときは領域分. 4 次精度後退差分法を Coarse solver へ適用し実験する予定. 割数が増えるとともに少し下降傾向にあることがわかる.. である.今回は最も単純で使い易いオリジナルの Parareal. 領域分割による影響が Coarse solver の反復数に影響した. 法を対象に性能評価を実施した.一方で,Parareal 法の. ためと思われる.. 逐次計算部分を短縮するために Pipelined Parareal 法や,. 5. まとめ. SDC 法が提案されており [8],より一層の性能向上が期待 できる状況である.ただし,Pipeleind Parareal 法では並. 拡散方程式を対象に大規模並列と時空間並列での Parareal. 列の制御が複雑であったり,SDC 法ではユーザーアプリの. 法の性能評価を行った.Parareal 法で時間方向に 100 並列. 時間積分法を更新することが必要となるためユーザーの時. した場合,性能モデルでは 14 倍の Speedup が予想された. 間並列計算コードの開発負担は増加する.今後,これらの. が,数値実験では最大 8.5 倍であった.この性能低下の原. 手法を用いた性能評価も実施する予定である.. 因として,Coarse solver での反復数が Fine solver での反. c 2016 Information Processing Society of Japan ⃝. 6.
(7) 情報処理学会研究報告 IPSJ SIG Technical Report. 謝辞. Vol.2016-HPC-157 No.19 2016/12/22. 本研究の成果の一部は,文部科学省科学技術試験. 研究委託事業「近未来型ものづくりを先導する革新的設計・ 製造プロセスの開発」と JSPS26390130 科研費の助成を受 けたものです. 参考文献 [1]. [2]. [3]. [4]. [5]. [6]. [7] [8]. [9]. [10]. [11]. Lions, J.-L., Maday, Y., and Turinici, G.: A “parareal” in time discretization of PDE’s, C. R. Acad. Sci. Paros Ser. I Math., 332 (2001): 661–668. Speck, R., et al.: Integrating an N-Body Problem with SDC and PFASST, Domain Decomposition Methods in Science and Engineering XXI, 98 (2014): 637–645. Falgout, R.D., et al.: Parallel time integration with multigrid, SIAM Journal on Scientific Computing, 36.6 (2014): C635-C661. Kreienbuehl, Andreas, et al.: Numerical simulation of skin transport using Parareal, Computing and visualization in science 17.2 (2015): 99–108. Ruprecht, D., Speck, R. and Krause, R.: Parareal for diffusion problems with space-and time-dependent coefficients, Domain Decomposition Methods in Science and Engineering XXII, (2016): 371–378. Gander, M.J., Vandewalle, S.: Analysis of the parareal time-parallel time-integration method, SIAM J. Sci. Comput., 29 (2007): 556–578. 高見 利也, 西田 晃: 時間方向並列化の線形計算への適用 可能性, 情報処理学会研究報告 HPC-131-6 (2011): 1–8. Minion, M.: A hybrid parareal spectral deferred corrections method, Communications in Applied Mathematics and Computational Science, 5.2 (2010): 265–301. 飯塚 幹夫, 小野謙二, 加藤千幸: Parareal 法による拡散方 程式の時間並列計算, 第 29 回数値流体力学シンポジウム (2015). Minion, M. L., Speck, R., Bolten, M., Emmett, M., and Rupercht, D.: Interweaving PFASST and Paralel Multigrid, SIAM J. Sci. Comput. 37.5 (2015): S244–S263. http://avr-aics-riken.github.io/PMlib/. c 2016 Information Processing Society of Japan ⃝. 7.
(8)
図


+2
![表 6 R f c = 10 のときの実行時間と詳細 [sec]](https://thumb-ap.123doks.com/thumbv2/123deta/6003106.1566796/6.892.489.789.97.565/表6Rfc=1のときの実行時間と詳細sec.webp)
関連したドキュメント
また,この領域では透水性の高い地 質構造に対して効果的にグラウト孔 を配置するために,カバーロックと
道路の交通機能は,通行機能とアクセス・滞留機能に
攻撃者は安定して攻撃を成功させるためにメモリ空間 の固定領域に配置された ROPgadget コードを用いようとす る.2.4 節で示した ASLR が機能している場合は困難とな
チューリング機械の原論文 [14]
ある周波数帯域を時間軸方向で複数に分割し,各時分割された周波数帯域をタイムスロット
はじめに
★分割によりその調査手法や評価が全体を対象とした 場合と変わることがないように調査計画を立案する必要 がある。..
当該 領域から抽出さ れ、又は得ら れる鉱物その他の 天然の物質( から までに 規定するもの
