テスト項目分析への応用
橋本 貴充
電気通信大学大学院情報システム学研究科 博士(工学)の学位申請論文
2012 年 3 月
博士論文審査委員会
主査 植野 真臣 准教授
委員 岡本 敏雄 教授
委員 大須賀 昭彦 教授
委員 長岡 浩司 教授
委員 渡辺 俊典 教授
委員 繁桝 算男 教授
橋本 貴充
2012 年
Takamitsu Hashimoto
Abstract
Most e-testing systems develop item databases based on item response theory (IRT).
Traditionally, IRT models assume local independence, meaning that when the ability variables influencing the test performance are held constant, an examinee’s responses to any pair of items are statistically independent. However, in many practical settings this assumption is violated. Thus, to develop high quality item databases, local independence (LI) tests are needed. Traditional LI tests marginalize out the latent ability variable and provide independence tests of only the two target items. However, this paper shows that even when the latent variable is marginalized out, items besides the targets affect the LI test. To solve this problem, this paper proposes a latent conditional independence (LCI) test. The unique feature of the LCI test is a conditional independence (CI) test given completely dependent structure of items besides the targets. Therefore the LCI test is not affected by any dependency structure of items. Numerical experiments show that false significance rates are lower and power of dependency detection is higher than those of traditional LI tests.
This paper shows that the proposed LCI test could also be utilized to express relations among test items. Traditional methods for analysis of item structures estimate relations of items through evaluating correlations between items. However, when two items are affected strongly by the latent ability variable, relations can be detected incorrectly, caused by the relation through the latent variable. In contrast, this paper shows that item structure analysis using the LCI test, named the item latent structure (ILS) analysis, can detect conditional independence correctly given a latent ability variable.
Finally, this paper demonstrates practical advantages of ILS analysis by applying it to national center tests (NCT). NCT test items are well designed and therefore are highly correlated with ability, which causes traditional methods to incorrectly detect dependen- cies between the items that are actually conditionally independent given ability. Pro-
posed ILS analysis overcomes this drawback and is able to correctly detect dependencies with respect to ability.
テスト項目分析への応用
橋本 貴充
要旨
近年,TOEFL,CASEC,情報処理技術者試験など,国内外を問わず大規模試験のeテ
スティングによる実施が普及している.eテスティングは,(1)受検者の能力を随時推定し ながら最適な項目を選択出題できる,(2)テスト領域からランダムに項目を抽出しテスト 出題バイアスを減少できる,等の特徴を持つ.一般に,eテスティングは,項目反応理論
(Item Response Theory, 以下,「IRT」)と呼ばれるテスト理論に従い,項目データベース を構築する.IRTとは,項目に対し受検者が正答する確率を,受検者の能力という潜在変 数の関数としてモデル化した数理モデルである.IRTには,(1)異なるテストの受検者の能 力を同一尺度上で評価できる,(2)能力推定の精度を減少させることなくテスト項目を減 らすことができる,(3)テスト構成時に得点分布を予測できる,等の特徴がある.IRTは, 能力潜在変数を所与として,各項目への正答確率が条件付き独立になる「局所独立性」と 呼ばれる仮定を持つ.しかし,現実のテストは局所独立性の仮定が成り立たない場合が多 く,これがパラメータ推定に致命的なバイアスを与えることも報告されている.したがっ て,質の高い項目データベースを構築するために,データベース中の項目集合の局所独立 性を検定し,局所独立性の成り立たない項目を排除することが必要となる.
局所独立性の検定法はこれまでにもいくつか提案されている.特に,Yen(1984)とChen
& Thissen(1997)の局所独立性検定は,能力潜在変数を周辺化しさえすれば2項目間の みで独立性検定を実行可能であることを特徴としており一般的に用いられてきた.これら の手法は暗黙に,局所独立性の検定対象以外のすべての項目が互いに局所独立であること を仮定している.しかし,本論文では,検定対象以外の項目間に従属関係がある場合には,
能力潜在変数を周辺化しても,2項目の関係だけでは局所独立性を検定できないことを明 らかにした.
さらに,本論文では,グラフィカル・モデルの条件付き独立性検定(Conditional Inde-
pendence Test,以下,「CI検定」とする.)のフレームワークを利用し,実際のテスト項
目の構造が未知でも構造に依存しない局所独立性検定である,潜在条件付き独立性検定
(Latent Conditional Independence Test,以下,「LCI検定」とする.)を提案する.いく
つかのシミュレーション実験によりLCI検定が従来手法より優れていることを示した.
LCI検定により,(1)局所独立性の成り立たない項目の出題を回避しIRTのパラメータ 推定精度を維持する,(2)類似した項目および他項目のヒントとなり得る項目の出題を回 避しテスト情報量とテストの妥当性を高める,(3)局所独立性の仮定を緩和したモデルを 用いるシステムでは,互いに従属関係のある項目をセットとして出題する,等のことが可 能となる.
また,本論文では,LCI検定を項目構造分析に応用し,項目潜在構造分析(Item Latent Structure Analysis,以下,「ILS分析」とする.)として提案した.項目構造分析はテスト 項目の従属関係を可視化する方法であるが,従来手法は2項目間の相関関係のみを評価し て構造化するため,能力潜在変数の影響が考慮されていない.本論文では,従来手法が区 別できない,項目同士の従属関係と,能力潜在変数を介した擬似相関とを,ILS分析が区 別し,本質的に意味のある項目間関係を可視化できることを示した.
さらに,ILS分析を大学入試センター試験の問題に適用した結果から,英語のテスト にはテスト全体で測られる「英語力」に加え文法問題特有の能力がある可能性と,数学の テストではテストで測られる能力の他に解答速度が別次元の能力となっている可能性が示 唆された.
目 次
第1章 緒言 1
第2章 IRTと局所独立性 5
2.1 IRTと局所独立性 . . . . 5
2.2 従来の局所独立性検定 . . . . 7
2.2.1 YenのQ3統計量 . . . . 7
2.2.2 Chen and ThissenのIRT利用尤度比検定 . . . . 7
第3章 LCI検定 9 3.1 緒言 . . . . 9
3.2 従来の局所独立性検定の問題. . . . 9
3.2.1 ベイジアン・ネットワークIRT . . . . 10
3.2.2 数値実験の方法 . . . . 12
3.2.3 結果と考察 . . . . 16
3.3 LCI検定 . . . . 18
3.3.1 従来の局所独立性検定のグラフィカル・モデルによる説明 . . . . . 18
3.3.2 グラフィカル・モデルの条件付き独立性検定 . . . . 21
3.3.3 CI検定のアプローチを用いた局所独立性検定 . . . . 22
3.4 LCI検定の評価 . . . . 27
3.4.1 方法と評価基準 . . . . 27
3.4.2 結果と考察 . . . . 30
3.5 結言 . . . . 33
第4章 ILS分析 35 4.1 緒言 . . . . 35
4.2 従来の項目構造分析における誤検出に関する理論的背景 . . . . 35
4.2.1 IRS分析 . . . . 35
4.2.2 ファジィグラフによる項目構造分析 . . . . 36
4.2.3 従来手法の問題点. . . . 38
4.3 ILS分析 . . . . 39
4.4 数値実験 . . . . 41
4.4.1 方法 . . . . 41
4.4.2 結果と考察 . . . . 42
4.5 実データへの適用 . . . . 44
4.5.1 方法 . . . . 44
4.5.2 結果と考察 . . . . 44
4.6 結言 . . . . 46
4.A 分析に用いたテストの問題 . . . . 51
第5章 大学入試センター試験のILS分析 53 5.1 緒言 . . . . 53
5.2 対象 . . . . 53
5.3 結果と考察 . . . . 54
5.3.1 『英語(筆記)』の分析 . . . . 54
5.3.2 『英語(リスニング)』の分析 . . . . 56
5.3.3 『数学I・数学A』の分析 . . . . 65
5.3.4 『数学II・数学B』の分析 . . . . 70
5.4 結言 . . . . 70
第6章 結言 83 6.1 総括 . . . . 83
6.2 今後の展開 . . . . 84
付 録A LCI検定実行ソフトウェア「LCItest.exe」の開発 85 A.1 開発概要 . . . . 85
A.2 使用方法 . . . . 85
A.2.1 必要な環境 . . . . 85
A.2.2 データの形式 . . . . 86
A.2.3 操作方法. . . . 86
引用文献 91
謝辞 97
著者略歴 100
図 目 次
3.1 ベイジアン・ネットワークIRTモデルの構造の例 . . . . 13
3.2 通常のIRTモデルの構造の例 . . . . 13
3.3 数値実験に用いた構造(a)(7項目,完全独立) . . . . 13
3.4 数値実験に用いた構造(b)(7項目, 1対従属) . . . . 13
3.5 数値実験に用いた構造(c)(7項目, 2対従属) . . . . 14
3.6 数値実験に用いた構造(d)(20項目,完全独立) . . . . 14
3.7 数値実験に用いた構造(e)(20項目, 1対従属) . . . . 14
3.8 数値実験に用いた構造(f)(20項目, 9対従属). . . . 15
3.9 局所独立な項目間のQ3統計量の度数分布(項目数: 7) . . . . 17
3.10 局所独立な項目間のQ3統計量の度数分布(項目数: 20) . . . . 17
3.11 局所独立な項目間のG2統計量の度数分布(項目数: 7) . . . . 19
3.12 局所独立な項目間のG2統計量の度数分布(項目数: 20) . . . . 19
3.13 グラフィカル・モデルによる変数Xから変数Y への確率的因果の表現 . . 19
3.14 グラフィカル・モデルを用いたIRTモデルの表現 . . . . 20
3.15 従来の局所独立性検定が暗黙に仮定する構造 . . . . 20
3.16 検定対象以外の項目間に従属関係が存在する構造 . . . . 20
3.17 変数Zを所与とするXとY のCI検定 . . . . 23
3.18 Z-X間およびZ-Y 間にアークがありX-Y 間にアークのない構造 . . . . . 23
3.19 構造gの例 . . . . 23
3.20 検定対象2変数以外のすべての変数が互いに従属である構造(gcとする.) 25 3.21 X¬ii′ =xj¬ii′およびθ= ˆθj を得たときの構造 . . . . 25
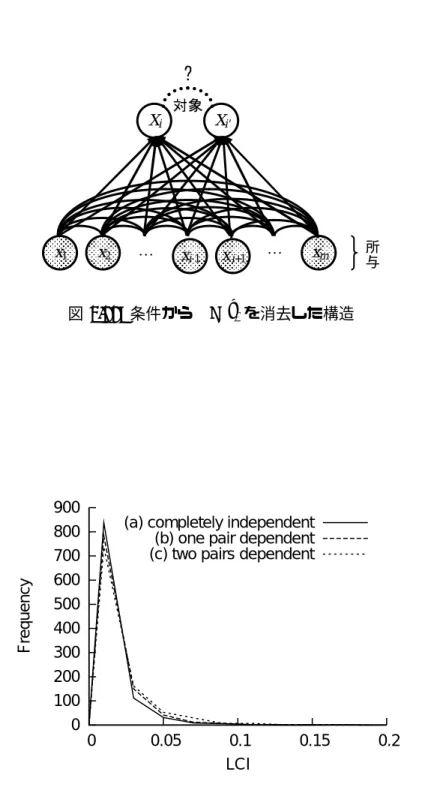
3.22 条件からθ= ˆθj を消去した構造 . . . . 28
3.23 局所独立な項目間のLCI指標の度数分布(項目数7) . . . . 28
3.24 局所独立な項目間のLCI指標の度数分布(項目数20) . . . . 31
4.1 識別力と項目順序性係数の関係 . . . . 40
4.2 識別力とファジィ関連係数の関係 . . . . 40
4.5 IRS分析により推定された実データの構造 . . . . 49
4.6 ファジィグラフにより推定された実データの構造 . . . . 50
5.1 平成20年度『英語(筆記)』の固有値のスクリープロット . . . . 55
5.2 平成21年度『英語(筆記)』の固有値のスクリープロット . . . . 55
5.3 平成22年度『英語(筆記)』の固有値のスクリープロット . . . . 57
5.4 平成20年度『英語(筆記)』のILS分析の結果. . . . 58
5.5 平成21年度『英語(筆記)』のILS分析の結果. . . . 59
5.6 平成22年度『英語(筆記)』のILS分析の結果. . . . 60
5.7 平成20年度『英語(リスニング)』の固有値のスクリープロット . . . . 61
5.8 平成21年度『英語(リスニング)』の固有値のスクリープロット . . . . 61
5.9 平成22年度『英語(リスニング)』の固有値のスクリープロット . . . . 62
5.10 平成20年度『英語(リスニング)』のILS分析の結果 . . . . 62
5.11 平成21年度『英語(リスニング)』のILS分析の結果 . . . . 63
5.12 平成22年度『英語(リスニング)』のILS分析の結果 . . . . 64
5.13 平成20年度『数学I・数学A』の固有値のスクリープロット . . . . 66
5.14 平成21年度『数学I・数学A』の固有値のスクリープロット . . . . 66
5.15 平成22年度『数学I・数学A』の固有値のスクリープロット . . . . 71
5.16 平成20年度『数学I・数学A』のILS分析の結果 . . . . 72
5.17 平成21年度『数学I・数学A』のILS分析の結果 . . . . 73
5.18 平成22年度『数学I・数学A』のILS分析の結果 . . . . 74
5.19 平成20年度『数学II・数学B』の固有値のスクリープロット . . . . 75
5.20 平成21年度『数学II・数学B』の固有値のスクリープロット . . . . 75
5.21 平成22年度『数学II・数学B』の固有値のスクリープロット . . . . 79
5.22 平成20年度『数学II・数学B』のILS分析の結果 . . . . 80
5.23 平成21年度『数学II・数学B』のILS分析の結果 . . . . 81
5.24 平成22年度『数学II・数学B』のILS分析の結果 . . . . 82
A.1 データファイルの例 . . . . 87
A.2 LCItest.exeのウインドウ . . . . 87
A.3 値の記入例 . . . . 89
A.4 計算終了時の画面 . . . . 89
A.5 LCI検定統計量の出力例 . . . . 90 A.6 局所従属な項目の出力例 . . . . 90
表 目 次
3.1 数値実験の設定 . . . . 15
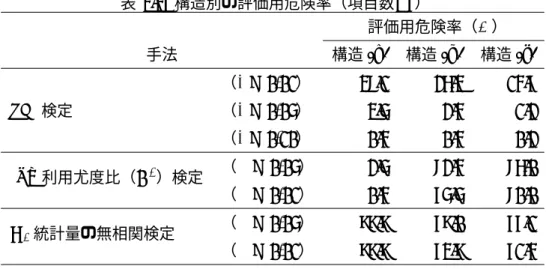
3.2 LCI検定および従来手法の評価用危険率 . . . . 31
3.3 構造別の評価用危険率(項目数: 7) . . . . 32
3.4 構造別の評価用危険率(項目数: 20) . . . . 32
3.5 評価用危険率の値に対応するLCI検定の閾値および従来手法の臨界値 . . . 32
3.6 各手法の評価用検出力 . . . . 34
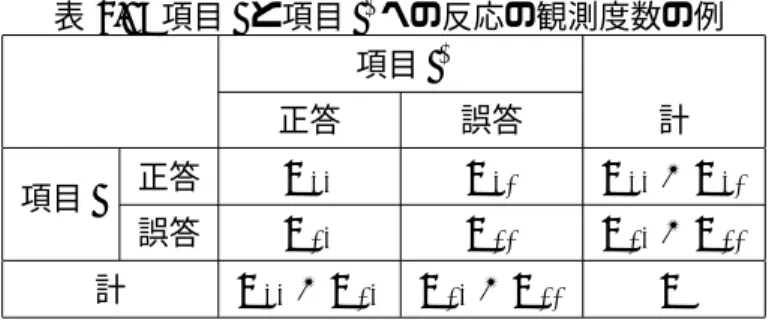
4.1 項目iと項目i′への反応の観測度数の例 . . . . 40
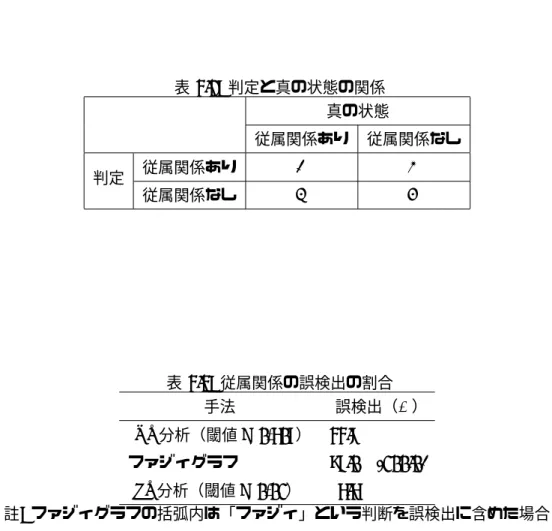
4.2 判定と真の状態の関係 . . . . 43
4.3 従属関係の誤検出の割合 . . . . 43
4.4 従属関係の検出漏れの割合(一般的な閾値の場合) . . . . 43
4.5 従属関係の検出漏れの割合(評価用危険率を5%とした場合) . . . . 45
4.6 検出した従属関係が真である割合(評価用危険率を5%とした場合) . . . . 45
4.7 実データの各項目の正答率 . . . . 45
4.8 実データのLCI指標の値(太字は0.01以上の値) . . . . 47
4.9 実データの項目順序性係数(行から列へ)の値(太字は0.607以上の値) . 48 4.10 実データのファジィ関連係数(行から列へ)の値(太字は0.5以上の値) . 49 5.1 モニター調査の有効受検者数. . . . 55
5.2 平成20年度『英語(リスニング)』各項目の正答率 . . . . 57
5.3 平成21年度『英語(リスニング)』各項目の正答率 . . . . 58
5.4 平成22年度『英語(リスニング)』各項目の正答率 . . . . 59
5.5 平成20年度『数学I・数学A』各項目の無回答率 . . . . 67
5.6 平成21年度『数学I・数学A』各項目の無回答率 . . . . 68
5.7 平成22年度『数学I・数学A』各項目の無回答率 . . . . 69
5.8 平成20年度『数学II・数学B』選択問題の選択人数 . . . . 71
5.9 平成21年度『数学II・数学B』選択問題の選択人数 . . . . 71
5.10 平成22年度『数学II・数学B』選択問題の選択人数 . . . . 71 5.11 平成20年度『数学II・数学B』第1問から第4問の各項目の無回答率 . . . 76 5.12 平成21年度『数学II・数学B』第1問から第4問の各項目の無回答率 . . . 77 5.13 平成22年度『数学II・数学B』第1問から第4問の各項目の無回答率 . . . 78
第 1 章 緒言
近年,TOEFL,TOEIC,情報処理技術者試験など,国内外を問わず大規模試験のeテ
スティングによる実施が普及している.一般にeテスティングは,項目反応理論(Item Response Theory;以下,「IRT」とする.)[16] とよばれるテスト理論に従い,項目データ ベースを構築する.IRTとは,項目に対し受検者が正答する確率を,受検者の能力という 潜在変数の関数として表現した数理モデルである.IRTには,(1)異なるテストの受検者の 能力を同一尺度上で評価できる,(2)能力推定の精度を低下させることなくテスト項目数 を減らすことができる,(3)既存の項目を組み合わせて一つのテストを構成するときに得 点分布を予測できる,(4)受検者の能力に対して情報量を最大化する項目を逐次コンピュー タが出題する適応型テストに利用できる,等の特徴がある.
Lord and Novick [16]が数理統計学的アプローチを用いてIRTの基本構造を定式化して 以来,統計理論,パラメータ推定アルゴリズムなど,様々な視点からIRTの研究が行われ れてきた.IRTには,項目特性を表す関数の形およびパラメータ数が異なる様々なモデル が存在する.たとえば,ラッシュモデル [20],正規累積モデル [16],2パラメータ・ロジ スティック・モデル[2],3パラメータ・ロジスティック・モデル[3] などが挙げられる.よ り一般的なIRTモデルには,段階反応モデル[22],連続反応モデル[23],部分的採点モデ ル[17],名義反応モデル[4] などがある.
これらのIRTモデルは,次の三つの仮定を前提としている.すなわち,(1)項目の正誤 が能力潜在変数で説明・予測できること,(2)項目に正答する確率が能力潜在変数の単調 増加関数(この関数を「項目特性関数」もしくは「項目特性曲線」という.)として記述で きること,(3)能力潜在変数を所与として,各項目への正答確率が条件付き独立になるこ と,である.特に(3)の仮定を「局所独立性」という.
しかし,現実のテストでは局所独立性が成り立たないことが多い[48].この場合,項目 パラメータの推定値が偏る[6] [24],項目の信頼性が過大推定される[32],能力の高い受験 者の能力は過大推定され,低い受験者の能力は過小推定される[21] などの問題が指摘され ている.
したがって,質の高い項目データベースを構築するために,データベース中の項目集合 の局所独立性を検定し,局所独立性の成り立たない項目を排除することが必要となる.し
かし,所与とする変数のない通常の独立性検定に比べ,条件付き独立性検定は難しく[1], 特に潜在変数を所与とする条件付き独立性検定は,顕在変数を所与とする条件付き独立性 検定よりも困難である.能力潜在変数を所与とする条件付き従属性(以下,「局所従属性」
とする.)の強さを測る指標には,Q2統計量[41],Q3統計量[47],AMID(Absolute value of Mutual Information Difference)[36] などがある.この中で,Q3統計量は,局所独立 性を帰無仮説とする標本分布が計算できるため,局所独立性の検定に用いられてきた.Q3
統計量の計算には能力潜在変数の推定値が必要だが,Chen and Thissen [6] は,項目特性 関数を利用して能力潜在変数を周辺化することにより,能力潜在変数の推定値が不要な局 所独立性検定を提案した.[6] の周辺化方法は,Glas and Su´arez Falc´on [10] のS3 検定 でも用いられている.これらの検定は,能力潜在変数を周辺化すれば,二項目間のみの独 立性検定が可能であると暗黙的に仮定している.本論文では,能力潜在変数を周辺化して も,二項目間のみの検定では正しく局所独立性を検定できないことを明らかにし,従来の 方法が誤っていることを示す.さらに,この問題を解決するために,グラフィカル・モデ ルの条件付き独立性検定(Conditional Independence Test;以下,「CI検定」とする.)の フレームワークを利用し,実際のテスト項目の構造が未知でも構造に依存しない局所独立 性検定である,潜在条件付き独立性検定(Latent Conditional Independence Test; 以下,
「LCI検定」とする.)を提案する.
LCI検定には次の二つの特徴がある.第一に,LCI検定は同型性を持つ.すなわち,LCI 検定で条件付き独立と判定された二項目は,能力潜在変数および項目のネットワーク構造 を所与として条件付き独立であり,条件付き従属と判定された二項目はこれらを所与とし て条件付き従属である.第二に,LCI検定は,検定対象以外の全項目間に従属性を仮定す るにもかかわらず,その計算量は従来の方法と同等である.多くの統計量は,全項目間に 従属性を仮定する場合,項目数が増加すると計算量が指数関数的に増加する.しかしLCI 検定は,項目数が増加しても計算量が受検者数のオーダーを上回らない.さらにLCI検定 は従来の方法と異なり,IRTの項目パラメータおよび能力潜在変数の推定が必要ない.こ れらの推定は,計算の反復を伴う複雑なアルゴリズムが必要なため,計算に多大な時間が 必要となる.LCI検定には,これらの推定が不要なため,従来の方法より計算時間が短縮 される.LCI検定により,局所独立性の成立しない項目の出題を回避しIRTパラメータの 推定精度を維持する,類似した項目や他項目のヒントとなり得る項目の出題を回避できる 等,テスト情報量の向上やテスト妥当性の改善が可能となる.
また,本論文ではLCI検定の応用例として,LCI検定を利用して項目どうしの従属関係 を明らかにする項目潜在構造分析(Item Latent Structure Analysis;以下,「ILS分析」と する.)を提案する.加えて,LCI検定を大学入試センター試験に適用し,その項目の持つ
手法は,項目関連構造分析(Item Relational Structure Analysis,以下,「IRS分析」とす る.)[34]であり,他項目との論理和による順序関係が扱えるようにした項目協同関連情報 構造分析(Item Co-Relational Structure Analysis, ICRS分析)[28],項目間の関係の有 無が明確でない「ファジィ」な関係も扱える,ファジィグラフによる項目構造分析[46]が挙 げられる.これらはデータから項目の構造を探索的に推定する手法であるが,教師などの 専門家の事前知識を利用できる場合には,解釈構造モデリング法(Interpretive Structure
Modeling, ISM法) [25] も提案されている.しかし,これらの手法は,二項目間の相関
関係のみを評価して構造化するため,能力潜在変数の影響を考慮していないという問題点 がある.テスト項目は本来,受検者の能力と高い相関を持つため,受検者の能力を強く反 映する項目同士は,たとえ互いに無関係な内容を問うものでも,能力が高い受検者は正答 し,低い受検者は誤答し,二項目間の相関が高くなってしまう.これは受検者の能力を介 した擬似相関であり,これにより項目同士の本来の従属関係が正しく推定できない.つま り,能力との相関が高いという望ましい性質を持つ項目ほど,構造を分析するときに擬似 相関が高くなり,結果として,潜在構造を正しく推定できないという望まれない結果が導 き出されてしまう.
この問題を解決するためには,二項目間の単純相関ではなく,能力潜在変数を所与とす る条件付き従属性,つまり局所従属性を検出する方法が必要である.そこで本論文では,
LCI検定を用いて,項目同士の本来の従属関係の構造を明らかにできるILS分析を提案す る.本論文ではまず,従来の項目構造分析が,受検者の能力を介した擬似相関を項目同士 の従属関係として多く誤検出してしまう問題を,数値実験により明らかにする.加えて,
ILS分析がそのような擬似相関を項目同士の従属関係として検出することなく,本来の従 属関係を検出できることを示す.さらに,実際のテストデータに従来手法とILS分析を適 用し,その結果得られたそれぞれの構造と,専門家がそのテストに対して主観的に判断し た構造とを比較し,ILS分析の持つ特徴を示す.
最後に,大学入試センター試験(以下,「センター試験」とする)の項目の持つ従属関係 を明らかにし,本分析手法の有効性を示す.適用対象は数学と英語のテストである.セン ター試験の数学のテストは,前出の項目の正答を利用して解答する項目が存在するなど,
項目間に従属関係が存在することが明らかな場合が多い.また英語のテストは,各項目が 他項目と局所独立になるように意図されて作成されている.しかし,実施されたテストが 出題者の意図した構造であったかの検証はこれまで行われてこなかった.そこで適用事例 では,センター試験の数学・英語テストにILS分析を適用した結果を報告する.
本論文の構成は次のとおりである.第2章では,局所独立性検定に関わる先行研究を紹 介する.第3章では,従来の局所独立性の検定の問題を解決した方法であるLCI検定を提 案し,その性質を明らかにする.第4章では,LCI検定の応用例として,LCI検定を利用 した項目構造分析であるILS分析を紹介する.第5章では,ILS分析の応用例として,大 学入試センター試験に対して適用した結果を示す.第6章で,総括と今後の展開を述べる.
第 2 章 IRT と局所独立性
本章ではIRTと局所独立性の仮定を示し,従来提案された局所独立性検定を紹介する.
2.1 IRT と局所独立性
IRT [16]は,項目に対する受検者の反応の確率を受検者の能力潜在変数の関数としてモ
デル化する.受検者の反応が正答または誤答の二値である場合,IRTではi番目の項目に 対してXiという確率変数を仮定し,この項目に正答する事象をXi = 1,誤答する事象を Xi= 0で表現する.たとえば,IRTの最もよく用いられるモデルの一つである2パラメー タ・ロジスティック・モデル(2-parameter logistic model; 以下,「2PLモデル」とする.) [2] では,項目iに正答する確率を次のように定式化する.
P(Xi = 1|θ) = 1
1 + exp{−1.7ai(θ−bi)} , (2.1) ただしaiおよびbiは項目パラメータで,θは能力潜在変数である.パラメータaiの値が 大きな項目ほど受検者の能力の変化により正答確率が大きく変化する.つまり項目が受検 者を識別する力が大きくなる.このことよりaiは識別力パラメータとよばれる1.一般に,
識別力パラメータの値が大きな項目ほど良い項目であると考えられている.パラメータbi は値が大きいほど正答確率が低くなり,受検者に困難な項目となる.このことよりbiは困 難度パラメータとよばれる.θを横軸,P(Xi = 1|θ)を縦軸とする曲線を描くと,項目の 識別力および困難度を視覚的に判断できる.この曲線を項目特性曲線という.
式(2.1)より,項目iに誤答する確率は以下のようになる.
P(Xi = 0|θ) = 1−P(Xi= 1|θ)
= 1− 1
1 + exp{−1.7ai(θ−bi)} . (2.2)
1式(2.1)の1.7は正規累積モデル[16]に近似するための定数である.
したがって,2PLモデルの尤度関数は次のようになる.
L(X|θ)
=
∏N h=1
∏m i=1
[ 1
1 + exp{−1.7ai(θh−bi)} ]xhi[
1− 1
1 + exp{−1.7ai(θh−bi)} ]1−xhi
,
(2.3) ただし,それぞれの記号の意味は次のとおりである.
X = { xhi } (h= 1,· · ·, N; i= 1,· · · , m) xhi =
0 受検者hが項目iに誤答
1 受検者hが項目iに正答
θ = { θh } (h= 1,· · ·, N) θh : 受検者hの能力潜在変数の値
N : 受検者数
m: 項目数
式(2.3)の総積記号内に,他項目のパラメータは含まれていない.これは,各項目への
反応が能力潜在変数θを所与として条件付き独立であると仮定されていることを意味する.
つまり,任意の異なる項目i,i′,能力潜在変数θに対して
P(Xi=xi, Xi′ =xi′|θ) = P(Xi=xi|θ)P(Xi′ =xi′|θ) (2.4) が成り立つことが仮定されている.式(2.4)の仮定を「局所独立性」という.ただし,本 論文では,式(2.4)で定義される,任意の二項目間の局所独立性を扱い,三項目以上の間 での局所独立性2は問題としない.
実際のテストで用いられる項目群は局所独立性が成り立たないことが多い.たとえば,
Yen [48]は局所独立性が成り立たない原因として,外的な補助・妨害,解答速度,疲労効
果,練習効果,解答形式,リード文,前問を前提とする項目,前問の答がヒントになる場 合,採点方法,採点者,などを挙げている.
2たとえば,三項目間の局所独立性は,任意の異なる三項目i,i′,i′′, 能力潜在変数θに対してP(Xi = xi, Xi′ =xi′, Xi′′ =xi′′|θ) = P(Xi=xi|θ) P(Xi′ =xi′|θ) P(Xi′′ =xi′′|θ)が成り立つこととして定義さ れる.この関係は,P(Xi=xi, Xi′ =xi′|θ) =P(Xi=xi|θ)P(Xi′ =xi′|θ),P(Xi=xi, Xi′′=xi′′|θ) = P(Xi=xi|θ)P(Xi′′ =xi′′|θ),P(Xi′ =xi′, Xi′′ =xi′′|θ) =P(Xi=xi|θ)P(Xi′′ =xi′′|θ)が成り立つ場 合でも,成り立つとは限らない.
Yen [47]のQ3統計量と,Chen and Thissen [6]のIRT利用尤度比検定が用いられること が多い.次節では,これら二つの手法を説明する.
2.2 従来の局所独立性検定
2.2.1 YenのQ3統計量
Yen [47] は,局所従属性の強さを測る指標としてQ3統計量を提案した.項目iと項目
i′の間のQ3統計量は,以下のdhiとdhi′ の相関係数で定義される.
dhi=xhi−Pˆ(Xi= 1|θˆh) , dhi′ =xhi′−P(Xˆ i′ = 1|θˆh) , (2.5) ただし,xhiは受検者hの項目iへの正誤(1または0),θˆhは受検者hの能力潜在変数θh の推定値で,Pˆ(Xi = 1|θˆh)は項目iのパラメータ推定値および受検者hの能力潜在変数の 推定値が与えられたときの正答確率を表す.
項目iと項目i′が局所独立ならば,Q3統計量は,Fisherのz変換を行うと,平均が0, 分散が1/(N −3)の正規分布に従う [47].ここでN は受検者数である.この性質を利用 し,項目iと項目i′が局所独立であるという帰無仮説を,Q3統計量を用いて検定できる.
Q3統計量の計算には,項目パラメータと能力潜在変数の両方の推定値が必要である.こ れらの推定値は全項目間で局所独立を仮定して得られるため,対象以外の項目間に局所従 属性が存在すると,推定値が偏り,Q3統計量の値も偏る可能性がある.さらに,Q3統計 量は項目パラメータだけでなく全受検者の能力潜在変数の推定値も必要であるため,多大 な計算時間を要し,計算負荷も高くなるという点も問題である.
2.2.2 Chen and ThissenのIRT利用尤度比検定
Chen and Thissen [6]は,局所独立性を検定するために,クロス表の独立性検定で用い
られる期待度数の計算過程で能力潜在変数を周辺化することを提案した.その期待度数の 計算方法は,次のとおりである.
項目iと項目i′にそれぞれxiおよびxi′(xi, xi′ = 0,1)と反応した受検者の数をNxixi′
人とし,全受検者数をN人とする.このとき,項目iと項目i′が局所独立であるという帰
無仮説の下で,項目iと項目i′にそれぞれxiおよびxi′と反応する受検者の期待度数Exixi′
を,次の式で計算する.
Exixi′ = N
∫ +∞
−∞
P(Xˆ i = 1|θ)xiPˆ(Xi′ = 1|θ)xi′ · [
1−Pˆ(Xi = 1|θ) ]1−xi[
1−Pˆ(Xi′ = 1|θ) ]1−xi′
p(θ)dθ , (2.6) ただし,p(θ)は能力潜在変数θの母集団の分布で,通常は標準正規分布を仮定する.Pˆ(Xi = 1|θ)は,項目パラメータの推定値が与えられたときの,項目iの項目特性曲線である.積 分は数値的に近似して行う.
局所独立性の検定をピアソンのχ2検定で行う場合,検定統計量χ2は,式(2.6)のExixi′
を次の式に代入して求める.
χ2 =
∑1 xi=0
∑1 xi′=0
(Nxixi′ −Exixi′)2
Exixi′ . (2.7)
尤度比検定で行う場合,検定統計量G2は,式(2.6)のExixi′を次の式に代入して求める.
G2 = 2
∑1 xi=0
∑1 xi′=0
Nxixi′logeNxixi′
Exixi′
. (2.8)
自由度は通常の独立性検定と同じ1である.したがって,これらの検定統計量が自由度 1のχ2分布の上側5%点を上回った場合,項目iと項目i′が局所独立であるという帰無仮 説を棄却する3.
Q3統計量と異なりG2統計量は能力潜在変数の推定値が必要ない.しかし,Q3統計量 と同様にG2統計量も項目パラメータの推定値が必要である.この推定値は全項目間で局 所独立を仮定して得られるため,Q3統計量と同様に推定値の偏りに起因する問題が起こ り得る.この問題は第3.2節で詳細に議論する.
3なお,ピアソンのχ2検定は尤度比検定の近似であるため,本論文では尤度比検定のみに言及する.
第 3 章 LCI 検定
3.1 緒言
IRTの標準的なモデルが局所独立性を仮定している一方,実際のテストではその仮定が 成り立たないことが多いため,様々な局所独立性検定が提案されてきた.それらの手法で は,能力潜在変数を周辺化すれば,対象二項目だけで局所独立性が検定できると信じられ てきた.しかし,従来手法は検定対象以外の項目間に局所独立性を暗黙に仮定しているた め,実際には能力潜在変数の周辺化が正しく行われず,検定の結果も正しくない.本章で は,従来の局所独立性検定の持つこの問題点を指摘する.さらに,検定対象以外の項目間 に局所従属性が存在するときも局所独立性を正しく検定できるLCI検定を提案し,その有 効性を検証する.
3.2 従来の局所独立性検定の問題
検定対象以外の項目間に局所従属性が存在する場合の従来手法での局所独立性検定への 影響を明らかにするため,乱数を用いてテストデータを人工的に発生させ,これらに従来 手法を適用する数値実験を行った.
局所従属性の存在するデータを発生させるためには,局所従属性を表現できるIRTモデ ルが必要である.そのようなモデルには,能力潜在変数および困難度が多次元であること を仮定したもの[8] [9] [44],互いに類似する項目の束(Wainer and Kiely [42] は「テスト レット」(testlet)と命名した)を仮定したもの[5] [26] [43],ある項目への反応によって 別の項目の困難度が変化するもの[12] [13] [38]などがある.中でも,ベイジアン・ネット
ワークIRT [38] は,局所独立モデルであるIRTの変数間の従属性をベイジアン・ネット
ワークにより拡張したもので,2PLモデルの自然な拡張である.
本章では,ベイジアン・ネットワークIRTのモデルを用いて,局所従属性の存在する人 工データを作成した.
3.2.1 ベイジアン・ネットワークIRT
ベイジアンネットワークIRTモデルは,項目間に任意の従属関係を仮定できるように IRTを拡張したモデルである.たとえば,項目iが項目i′に従属することは,項目iの困 難度パラメータが項目i′の反応によって変化することで表現する.このとき,項目iは項 目i′の子項目であるといい,項目i′は項目iの親項目であるという.
項目の従属関係の構造は,項目をノード,従属関係を親項目から子項目へのアークとし た有向非循環グラフで表現できる.たとえば,図3.1の構造で,項目4の親項目は項目3 であり,項目5の親項目は項目3と項目4である.局所独立性を仮定する通常のIRTモデ ルの構造は図3.2のようになる.
ベイジアン・ネットワークIRTモデルは,最もよく用いられるIRTモデルである2PL モデルを拡張した式になっている.一般に2PLモデルでは,項目数がm個であるとき,全 項目への反応の同時確率を次の式で表す.
P(X1 =x1, X2=x2, . . . , Xi =xi, . . . , Xm =xm|θ)
=
∏m i=1
{ 1
1 + exp[−1.7ai(θ−bi)]
}xi{
1− 1
1 + exp[−1.7ai(θ−bi)]
}1−xi ,
(3.1) ただし,
xi =
1 項目iに正答
0 項目iに誤答
ai : 項目iの識別力パラメータ bi : 項目iの困難度パラメータ とする.
ベイジアン・ネットワークIRTモデルでは,親項目への反応によって異なる困難度パラ メータを仮定する.項目の従属関係の構造をBsで表し,構造Bsを仮定したときの項目i の親項目の数をpi,親項目集合に対応する確率変数をX˜iとする.X˜iはpi次元のベクト ルである.各要素は0または1の値を取り得るため,X˜iは(0,0, . . . ,0)tから(1,1, . . . ,1)t まで2pi通りの値を取り得る.そのj番目(j= 0,1, . . . ,2pi−1)の値x˜ijを「項目iの親 項目へのj番目の反応パターン」とよぶ.このとき,X˜iを所与として,Xi =xiという事
P(Xi =xi|θ,X˜i, Bs)
=
2∏pi−1
j=0
{ 1
1 + exp[−1.7ai(θ−bij)]
}xiuij{
1− 1
1 + exp[−1.7ai(θ−bij)]
}(1−xi)uij
,
(3.2) ただし,
uij =
1 項目iの親項目への反応パターンがj番目のとき 0 項目iの親項目への反応パターンがj番目以外のとき ai : 項目iの識別力パラメータ
bij : 項目iの親項目への反応パターンがj番目のときの項目iの困難度パラメータ とする.
たとえば図3.1の構造でX4 =x4という事象が生起する確率は,項目4の親項目が一つ で,親項目への反応パターンは二通り(j = 0,1)であるため,次のようになる.
P(X4 =x4|θ,X˜4, Bs)
=
∏1 j=0
P(X4 = 1|θ,X˜4= ˜x4j, Bs)x4u4j [
1−P(X4 = 1|θ,X˜4= ˜x4j, Bs) ]x4u4j
=
{ 1
1 + exp[−1.7a4(θ−b40)]
}x4u40{
1− 1
1 + exp[−1.7a4(θ−b40)]
}(1−x4)u40
·
{ 1
1 + exp[−1.7a4(θ−b41)]
}x4u41{
1− 1
1 + exp[−1.7a4(θ−b41)]
}(1−x4)u41
,
(3.3) ただし,
u4j =
1 項目4の親項目への反応パターンがj番目のとき 0 項目4の親項目への反応パターンがj番目以外のとき
a4 : 項目4の識別力パラメータ
b40 : 親項目への反応パターンが0番目のときの項目4の困難度パラメータ b41 : 親項目への反応パターンが1番目のときの項目4の困難度パラメータ である.
ベイジアン・ネットワークIRTモデルにおける,全項目の正誤の同時確率は次のとおり である.
P(X1 =x1, X2=x2, . . . , Xi=xi, . . . , Xm =xm|θ, Bs)
=
∏m i=1
2pi∏−1 j=0
P(Xi= 1|θ,X˜i = ˜xij, Bs)xiuij [
1−P(Xi = 1|θ,X˜i = ˜xij, Bs)
](1−xi)uij
=
∏m i=1
2pi∏−1 j=0
{ 1
1 + exp[−1.7ai(θ−bij)]
}xiuij{
1− 1
1 + exp[−1.7ai(θ−bij)]
}(1−xi)uij
.
(3.4) ここで,対象データセットのすべての項目が互いに局所独立である構造(図3.2)を仮 定すると,すべての項目が親ノードを持たないため,この場合の式(3.4)は2PLモデルの 同時確率の式(3.1)に一致する.つまり,ベイジアン・ネットワークIRTモデルは,2PL モデルを一般化したものになっている.
3.2.2 数値実験の方法
ベイジアン・ネットワークIRTモデルを用い,項目数と局所従属性の数を変化させた6 種類の構造を想定してデータを作成した.
初めの3種類は項目数を7とし,構造は(a)完全独立,(b)1対従属,(c)2対従属,の3 種類を考えた.構造(a)では,すべての項目が互いに局所独立である(図3.3).これは従 来の局所独立性検定が暗黙に前提とする構造である.構造(b)では,1対の項目が局所従 属,それ以外の項目間は局所独立である(図3.4).構造(c)では,2対の項目が局所従属,
それ以外の項目間は局所独立とした(図3.5).
他の3種類は項目数を20とし,構造は(d)完全独立(図3.6),(e)1対従属(図3.7),
(f)9対従属(図3.8),の3種類を考えた.構造(d)が従来手法の前提とする構造である.
以上の設定条件をまとめると表3.1のようになる.
項目パラメータは以下のように設定した.
他項目と局所従属性のない項目の設定 いずれの構造も,他項目との間に局所従属性のな い項目が存在する.そのような項目のパラメータは以下の分布からランダムに発生 させた.
log2ai ∼ N(0, 1) bi ∼ N(0, 1)
X2 X3 X4 X5
θ X1
図3.1: ベイジアン・ネットワークIRTモデルの構造の例
X2 X3 X4 X5
θ X1
図3.2: 通常のIRTモデルの構造の例
X3 X4 X5 X6 X7
θ 対象
X1 X2
図 3.3: 数値実験に用いた構造(a)(7項目,完全独立)
X3 X4 X5 X6 X7
θ 対象
X1 X2
図3.4: 数値実験に用いた構造(b)(7項目, 1対従属)
X3 X4 X5 X6 X7
θ 対象
X1 X2
図3.5: 数値実験に用いた構造(c)(7項目, 2対従属)
X9
X3 X4 X5 X6 X7 X8
X11 X12 X13 X14
X10
X19
X17 X18 X20
X15 X16
θ 対象
X1 X2
図3.6: 数値実験に用いた構造(d)(20項目,完全独立)
X9
X3 X4 X5 X6 X7 X8
X11 X12 X13 X14
X10
X19
X17 X18 X20
X15 X16
θ 対象
X1 X2
図3.7: 数値実験に用いた構造(e)(20項目, 1対従属)
X9
X3 X4 X5 X6 X7 X8
X11 X12 X13 X14
X10
X19
X17 X18 X20
X15 X16
θ 対象
X1 X2
図3.8: 数値実験に用いた構造(f)(20項目, 9対従属)
表3.1: 数値実験の設定 局所従属性
全項目が局所独立 対象項目以外の 対象項目以外の 1対が局所従属 多数が局所従属 項目数 7項目 構造(a) 構造(b) 構造(c)
20項目 構造(d) 構造(e) 構造(f)
他項目と局所従属性のある項目の設定 構造(a), (d)以外は,他項目との間に局所従属性の ある項目の対が存在する.二項目間に局所従属性が存在するとき,出題順が前の項目 を親項目とし,親項目のパラメータは,局所従属性のない項目と同様に発生させた.
子項目のパラメータは以下のように作成した.識別力は局所従属性のない項目と同 様に発生させた.困難度は,親項目への反応に応じて変化するものとし,次の分布 から発生させた乱数を用いて2種類の困難度を作成した.
bi ∼ N(0, 0.25) d ∼ N(1.85, 0.25)
親項目に正答した場合,子項目の困難度はbi−dとした.親項目に誤答した場合,子 項目の困難度はbi+dとした.
このような項目パラメータのテストを10,000人が受検したデータを1セット1とし,各
構造1,000セットずつ,合計6,000セットのデータを作成した.なお,能力潜在変数の値
は標準正規分布から発生させた.
いずれの構造でも,項目1と項目2は局所独立である.この二項目間でQ3統計量およ びChen and ThissenのG2統計量を計算した.
3.2.3 結果と考察
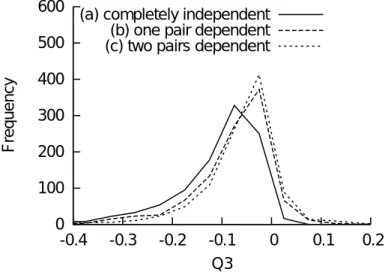
結果を以下に示す.項目数が7の場合のQ3統計量についての度数分布を図3.9に示す.
実線は検定対象以外の項目が他のいかなる項目とも局所独立である場合(構造(a))の度 数分布であり,Q3統計量の暗黙の前提を満たす.構造(a)の分布と比較して,前提を満た さない構造(b)および構造(c)のQ3統計量は値が大きくなった.
項目数が20の場合を図3.10に示す.このとき,構造(d)がQ3統計量の暗黙の前提を満 たしている.項目数が7の場合とは逆に,構造(e)および構造(f)のQ3統計量の値は小さ くなったが,構造(d)とは異なる度数分布となった.
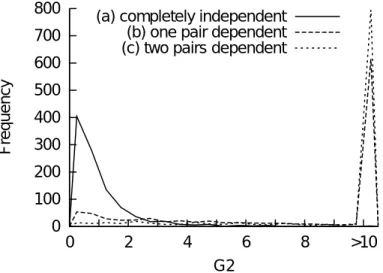
項目数が7の場合のG2統計量の度数分布を図3.11に示す.構造(b)と構造(c)では,10 を超える極端な値が多く得られ,G2統計量の暗黙の前提を満たす構造(a)とは異なる分布 となった.
1つまり,構造(a)〜(c)では1セットにつき7項目×10,000人=70,000個の項目反応データがあり,構 造(d)〜(f)では1セットにつき20項目×10,000人=200,000個の項目反応データがある.
0 100 200 300 400 500 600
-0.4 -0.3 -0.2 -0.1 0 0.1 0.2
Frequency
Q3 (a) completely independent
(b) one pair dependent (c) two pairs dependent
図 3.9: 局所独立な項目間のQ3統計量の度数分布(項目数: 7)
0 100 200 300 400 500 600 700 800 900
-0.4 -0.3 -0.2 -0.1 0 0.1 0.2
Frequency
Q3 (d) completely independent
(e) one pair dependent (f) nine pairs dependent
図3.10: 局所独立な項目間のQ3統計量の度数分布(項目数: 20)
しかし,項目数が20の場合(図3.12),構造(e)の度数分布は,暗黙の前提を満たす構 造(d)の分布と近いものになった.構造(f)の分布は構造(d)と異なるものであった.
以上の結果より,検定対象以外の項目間に局所従属な関係が増えるほど,従来の局所独 立性検定の統計量は偏りが大きくなることがわかった.この偏りは,局所独立性の検出に 影響を及ぼすと考えられる.
3.3 LCI 検定
前節の数値実験により,能力潜在変数を周辺化して二項目だけで独立性を検定する従来 手法では,局所独立な二項目を局所従属と判定する誤りが多くなるという現象が示された.
この現象をグラフィカル・モデル[19]のアプローチを用いて説明する.グラフィカル・モ デルとは,複雑な因果構造における条件付き独立性の推論に用いられるアプローチである.
グラフィカル・モデルは,確率変数をノードで,変数間の確率的因果をアークで表現する.
たとえば,二つの確率変数XとY があり,Xを所与とするY の条件付き確率P(Y|X)が Xの値によって異なるとき,グラフィカル・モデルではXというノードからY というノー ドにアークを引く(図3.13).このとき,XをY の親ノードといい,Y をXの子ノード という.
グラフィカルモデルは,ノードに対する確率変数の型(離散型であるか連続型であるか)
や,アークに対する条件付き確率の関数型に依存しないという好ましい性質がある.本節 では,従来手法の誤りをグラフィカル・モデルを用いて説明し,その上で新しい局所独立 性検定を提案する.
3.3.1 従来の局所独立性検定のグラフィカル・モデルによる説明
グラフィカル・モデルを用いてIRTモデルを表現すると図3.14のようになる(5項目の テストの場合).このグラフで局所独立性は,能力潜在変数θからすべてのXiにアークが 存在することと,任意のiとi′に対してXiとXi′ の間にはアークが存在しないこととし て表現されている.
従来の局所独立性検定は,検定対象以外のすべての項目間に局所独立性を暗黙に仮定し ている(図3.15).そのため,仮定に反し検定対象以外の項目間に従属関係が存在する構 造(図3.16)では,検定が正しく行われない.
0 100 200 300 400 500 600 700
0 2 4 6 8 >10
Frequency
G2
(a) completely independent (b) one pair dependent (c) two pairs dependent
図 3.11: 局所独立な項目間のG2統計量の度数分布(項目数: 7)
0 50 100 150 200 250 300 350 400
0 2 4 6 8 >10
Frequency
G2
(d) completely independent (e) one pair dependent (f) nine pairs dependent
図3.12: 局所独立な項目間のG2統計量の度数分布(項目数: 20)
X Y
図3.13: グラフィカル・モデルによる変数Xから変数Y への確率的因果の表現
X2 X3
θ
X1 X4 X5
図3.14: グラフィカル・モデルを用いたIRTモデルの表現
対象 X2 X3
θ X1
?
X4 X5
図3.15: 従来の局所独立性検定が暗黙に仮定する構造
対象 X2 X3
θ X1
?
X4 X5
図3.16: 検定対象以外の項目間に従属関係が存在する構造