音声入力による図柄パターン検索における未知語処理
6
0
0
全文
(2) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2011-SLP-88 No.2 2011/10/28. 表 1 5 段階評価の内容(複雑さの例) 度合 内容 全く複雑ではない あまり複雑ではない ある程度複雑 かなり複雑 非常に複雑. 1 2 3 4 5. 2.2 クエリと図柄パターンの感性特徴ベクトル比較方法. 今回図柄パターンとクエリの感性ベクトルを比較するのに用いた類似度は、以前の 実験における正解パターンの検出で、最も F 値が高かった確率分布間距離である。今 回は各クエリにおいて図柄パターンとの距離の最も大きいものの値を 1 とし、上位 0.45 に属するパターンを検索結果として抽出した。 表 2 に示す例のようなアンケート調査の結果の頻度分布を確率分布とし、クエリも 複数の検索語から導かれる感性特徴の確率分布が得られているとし、分布間の平均 2 乗距離の期待値を求める方法である。. 感性表現 評価値 図柄パターン □ . 表 2 アンケート調査結果例の頻度分布 丸っこい 角ばった. 複雑. 1. 2. 3. 4. 5. 1. 2. 3. 4. 5. 1. 2. 3. 4. 5. 20 0 0. 0 0 0. 0 5 1. 0 10 3. 0 5 16. 0 10 19. 0 5 1. 0 3 0. 2 2 0. 18 0 0. 19 0 17. 1 0 3. 0 3 0. 0 6 0. 0 11 0. 非常に単純な例としては、アンケート調査結果がある感性表現で 0 0 0 0 1、クエリ の感性表現が、 0 0 1 0 0 であれば、1 の位置が 2 離れているので、距離は 2 の 2 乗。 これに 5 段階のレベルそれぞれに確率が付いているから、期待値はすべてのレベルの 組み合わせの 2 乗距離のアンケート調査結果とクエリの各感性表現レベルの確率が乗 算されたものとなる。 図1. 図柄パターン. 2. ⓒ 2011 Information Processing Society of Japan.
(3) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2011-SLP-88 No.2 2011/10/28. 離散的な 5 段階の評価レベルを用いた計算では、n 番目の図案の k 番目の感性要素 の離散分布を pnk(i) 、pnk(i)における平均値をnk、分散を nk、クエリの k 番目の感性要 素の確率分布を qk(i)、qk(i)における平均値をk、 分散を k とすると、計算式は. 3. クエリ認識方法 この方法では検索語そのものを用いて図柄パターンの検索を行うのではなく、検索 語を感性ベクトルに変換し、それを用いて検索を行う。従って、クエリが未知語であ っても、類似した感性ベクトルが生成できれば、目的の図柄パターンを検索できると 考えられる。 前回のアンケート調査で得られた 150 語のクエリを登録クエリとする。音声入力し たクエリに対して、まず Julius を用いて音声認識を行い、認識結果内の phseq 文を用 いて音素列に変換した。そして入力されたクエリと登録クエリの音素列を照合し、最 も音素列の距離が近いものを認識結果とした。登録語を導いた後に感性ベクトルを得 て、それを用いて同じ感性ベクトル表現をされた図柄パターンを検索する。その際、 第 1 章で述べた類似を用いるというところまで一連の検索アルゴリズムとして記述す る。. L. nk ipnk i i 1 L. k L iq i i 1 L. nk 2 i 2 pnk i nk 2 i 1. L. k i 2 qk i k 2 2. i 1. (1) L. L. d nk p nk i q k j i j . 2. i 1 j 1. . L. p nk i i 2 2i k k k i 1. nk k nk k 2. 2. 2. 2. . 2. (2) となる。 全体としての平均距離は N. d n d nk. 図2. (3). クエリ認識方法のアルゴリズム. k 1. により求められる。なお、ここで、N は感性要素数で 8,、L はレベル数で 5 である。. 音素列の比較は、DP マッチングによって行う。同じ母音同士、同じ子音同士であ る場合は距離 0、異なる分類の子音同士、または母音と子音、異なる母音同士の場合 は距離 1 とした。また、似た音響特徴をもつもの同士でグループを作成し、同じグル ープに属するもの同士の場合は距離 0.5 とした。その分類は表 3 の通りである。DP パ スは図 3 に示す最も基本的なものである。. 3. ⓒ 2011 Information Processing Society of Japan.
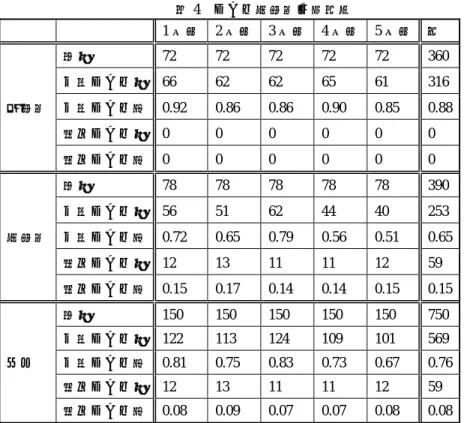
(4) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2011-SLP-88 No.2 2011/10/28. 表3. 音素分類表. 1. a. 2. i,y. 3. u,w. 4. e. 5. o. 6. p, t, k, q. 7. s, h. 8. m, n. 9. b, d, g, z, r. 4. 実験 4.1 実験方法 4.1.1 クエリの未知語処理結果の評価. 前回の実験で得られた 150 語のクエリを音声入力して未知語処理を行い、入力され たクエリと未知語処理結果がどの程度一致するのかを調べた。各クエリについて 5 回 ずつ音声入力を行い、一致する割合を調べた。以下、入力されたクエリと未知語処理 結果が一致するクエリを「一致クエリ」とする。 また一致しなかった場合、その未知語処理結果が入力したクエリと類似した音響特 徴をもち、その語のもつイメージも似ているものについては、これを「類似クエリ」 としてその数を調べた。1 度でも一致クエリまたは類似クエリとなったものは、その クエリを検索において有効であるものとし、その有効クエリの数と割合を調べた。 4.1.2 検出されたパターンに含まれる最適パターン数・適切パターン数の分析. 図3. 前回の実験で得られた 92 語の検索クエリ表現について、それぞれに対して感じた 感性を 8 感性項目 5 段階で被験者に評価してもらうことにより、感性ベクトル値を得 た。残りの 58 語の検索クエリ表現と 100 種類の図柄パターンについての感性ベクトル 値は、前回の実験で得られたものを使用した。クエリ表現と図柄パターンのそれぞれ に対して得られた感性ベクトル値を 3.の計算方法で比較し、類似度の上位 45%以内に 入るものを検索結果とした。 また、各クエリ表現に対し最もふさわしい図柄パターン「最適パターン」と、それ らの次にふさわしい図柄パターン「適切パターン」を設定した。最適パターンは各ク エリにつき一パターンずつ設定し、適切パターンについてはパターン数を制限せずに 設定した。 予めクエリを読み上げた音声を録音しておき、その音声ファイルに対し音声認識・ 未知語処理を行うことで検索クエリを得た。そしてその検索クエリから得られた検索 結果と、設定された「最適パターン」 「適切パターン」を比較し、検索結果内に含まれ る「最適パターン」と「適切パターン」の数を調べた。用いたクエリと図柄パターン は前回のアンケート時に得られたものであり、被験者数は前回実験時と同様に 20 名で ある。. DP パス. 4.2 結果分析 4.2.1 クエリの未知語処理結果. 音声入力したクエリの数と、1~5 回目の実験において入力したクエリと未知語処理 結果が一致したクエリの数、処理結果が類似するクエリとなった数、またそれぞれの 割合は、既知語、未知語、全体のそれぞれにおいて表 4 のようになった。. 4. ⓒ 2011 Information Processing Society of Japan.
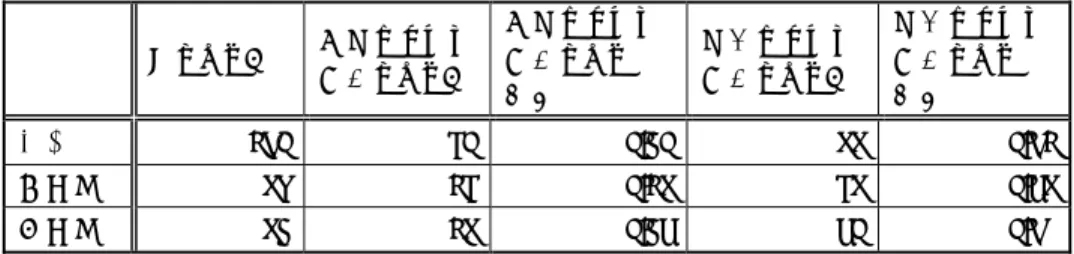
(5) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2011-SLP-88 No.2 2011/10/28. 表4. 既知語. 未知語. 全体. クエリ未知語処理結果. 表 5 クエリ未知語処理結果 2 一致クエリ 類似クエリ 有効クエリ数 種類数 種類数. 1 回目. 2 回目. 3 回目. 4 回目. 5 回目. 計. 総数. 72. 72. 72. 72. 72. 360. 一致クエリ数. 66. 62. 62. 65. 61. 316. 一致クエリ率. 0.92. 0.86. 0.86. 0.90. 0.85. 0.88. 類似クエリ数. 0. 0. 0. 0. 0. 0. 類似クエリ率. 0. 0. 0. 0. 0. 0. 総数. 78. 78. 78. 78. 78. 390. 一致クエリ数. 56. 51. 62. 44. 40. 253. 一致クエリ率. 0.72. 0.65. 0.79. 0.56. 0.51. 0.65. 類似クエリ数. 12. 13. 11. 11. 12. 59. 類似クエリ率. 0.15. 0.17. 0.14. 0.14. 0.15. 0.15. terereN. t e r e: N. 総数. 150. 150. 150. 150. 150. 750. kiraraN. k i r a: N. 一致クエリ数. 122. 113. 124. 109. 101. 569. kiraN. kirakira ch i k u ch i k u. 総数 既知語. 72. 67. 0. 67. 0.93. 未知語. 78. 59. 20. 71. 0.91. 合計. 150. 126. 20. 138. 0.92. 入力したクエリと未知語処理結果クエリが類似した例としては表のようなものが あった。 表6. 類似クエリ例 未知語処理結果 入力クエリ クエリ. 一致クエリ率. 0.81. 0.75. 0.83. 0.73. 0.67. 0.76. ch i k u. 類似クエリ数. 12. 13. 11. 11. 12. 59. pika. pikapika. g u ny a. g u ny a g u ny a. 類似クエリ率. 0.08. 0.09. 0.07. 0.07. 0.08. 有効クエリ率. 0.08. 既知語と未知語において、1 度でも一致クエリとなったクエリの種類数と、1 度で も類似クエリとなったクエリの種類数は表 5 の通りであった。またそれらのクエリを 検索において有効であるクエリとする場合、その有効クエリの数とその割合は同表の ようになった。ただし未知語の有効クエリ数については、一致クエリとなることがで きたものと類似クエリとなることができたものが一部重なっているため、一致クエリ 種類数と類似クエリ種類数の合計と、有効クエリ数は一致していない。. b i sh i. p i sh i. hy o r o. hy o r o hy o r o. 大多数のクエリが有効クエリとなっており、この未知語処理方法は図柄パターンの 検索において、非常に有効であるといえる。. 4.2.2 検出性能の評価. 入力されたクエリに対して設定された「最適パターン」「適切パターン」を検出す ることのできたクエリ数とその割合は、既知語の場合と未知語の場合でそれぞれ表 7 の通りであった。. 5. ⓒ 2011 Information Processing Society of Japan.
(6) 情報処理学会研究報告 IPSJ SIG Technical Report. Vol.2011-SLP-88 No.2 2011/10/28. 表7. 予め設定されたパターンを検出することのできたクエリ数 最適パターン 適切パターン 最適パターン 適切パターン 総クエリ数 検出クエリ 検出クエリ 検出クエリ数 検出クエリ数 割合 割合 全体. 150. 30. 0.20. 77. 0.51. 未知語. 78. 13. 0.17. 37. 0.47. 既知語. 72. 17. 0.24. 40. 0.56. 6. 謝辞 本研究には音声認識に Julius4.1.3 を使わせていただいた。ここに深く感謝する。. 参考文献 [1]鈴木 教子、相川 清明, “音声入力を用いた感性特徴による図柄パターン検索”, 2010-SLP-85, No.4, pp. 1-6, (2011-02) [2]小野寺 悠二、伊藤慶明、小嶋 和徳、石亀 昌明、田中 和世、李時 旭, ”複数のサブワード・ 言語モデルを用いた音声中の検索語検出の高精度化”, SDPWS2010-14, pp. 1-7, (2010-02) [3]高橋将史、藤井 康寿、山本 一公、中川 聖一, “音声ドキュメントに対する頑健な検索方法 の検討”, 日本音響学会講演論文集, 3-Q-35, pp.285-288, (2009-03) [4]嶋田 和孝、遠藤 勉、”対話型ロボットのための複数の音声認識器を利用した発話理解”, 第 60 回 人工知能学会 言語・音声理解と対話処理研究会, SIG-SLUD-B002-06, pp.27-30, (2010-10). [5]笹野 遼平、黒橋 禎夫, “形態素解析における連濁および反復形オノマトペの自動認識”, 言語 処理学会 第 13 回年次大会, pp.819-822 (2007-03) [6]鍛冶 伸裕、喜連川 優, “文脈にもとづく未知語獲得における識別モデルの適用”,言語処理学会 第 15 回全国大会, (2009-03) [7]福岡 知隆、税田 竜一、久保村 千明、服部 峻、亀田 弘之, “文の類似性を用いた未知語処理 手法の提案とそれに基づく円滑な対話応答システムの作成”, 情報処理学会創立 50 周年記念(第 72 回)全国大会 6X-2, pp.619-620, (2010-03) [8]吉野 幸一郎、森 信介、河原 達也, “述語項の類似度に基づく情報推薦を行う音声対話システ ム”,2011-SLP-87, no.11, pp.1-6, (2011-07). 最適パターンを検出することのできたクエリの割合、適切パターンを検出すること のできたクエリの割合は、どちらも未知語と既知語の間で大きな差は見られなかった。 また適切パターン数に最適パターン数を加えたものを「正解数」とし、事前に設定し た正解数、検索で得られた回答数、検出された正解項目数、再現率, 適合率, F 値を求 めたところ、表 8 の通りとなった。 表8. 予め設定されたパターンと検出されたパターンの比較. 総クエリ数 全体. 予め設定 した正解数. 回答数. 検出された 正解項目数. 再現率. 適合率. F値. 150. 2339. 1447. 318. 0.15. 0.24. 0.18. 未知語. 78. 1143. 679. 128. 0.12. 0.21. 0.15. 既知語. 72. 1196. 768. 190. 0.17. 0.27. 0.21. F 値を比較しても既知語と未知語の間にはそれほど大きな値の差はみられなかった。 よって表 7、表 8 より本未知語処理法が効果を有するといえる。. 5. おわりに 本報告では、音声入力による図柄パターン検索において、未知語によるクエリに対 し認識結果の音素列と既知語の音素列から DP マッチングを行い、最も類似したクエ リに変換して未知語処理を行う手法を提案した。それらの動作確認のために小規模な 検索タスクで実験を行い、その結果について提示した。既知語と未知語の間には大き な検索精度の差がみられず、本手法は音声入力による図柄パターン検索における未知 語処理に効果を有するといえる。 6. ⓒ 2011 Information Processing Society of Japan.
(7)
図

関連したドキュメント
Based on the Perron complement P(A=A[ ]) and generalized Perron comple- ment P t (A=A[ ]) of a nonnegative irreducible matrix A, we derive a simple and practical method that
So far as we know, there were no results on random attractors for stochastic p-Laplacian equation with multiplicative noise on unbounded domains.. The second aim of this paper is
In this paper, we generalize the concept of Ducci sequences to sequences of d-dimensional arrays, extend some of the basic results on Ducci sequences to this case, and point out
Beyond proving existence, we can show that the solution given in Theorem 2.2 is of Laplace transform type, modulo an appropriate error, as shown in the next theorem..
It is known that quasi-continuity implies somewhat continuity but there exist somewhat continuous functions which are not quasi-continuous [4].. Thus from Theorem 1 it follows that
This position, presupposing the same structure of the saMskAra-karman as in the previous position, regards the capacity (sAmarthya) or the effect produced through the
Hoekstra, Hyams and Becker (1997) はこの現象を Number 素性の未指定の結果と 捉えている。彼らの分析によると (12a) のように時制辞などの T
The results indicated that (i) Most Recent Filler Strategy (MRFS) is not applied in the Chinese empty subject sentence processing; ( ii ) the control information of the
