White paper
FUJITSU Supercomputer PRIMEHPC FX100
次世代技術への進化
富士通株式会社
次世代テクニカルコンピューティング開発本部
目次
FUJITSU Supercomputer PRIMEHPC FX100 の概要 2
メニーコアプロセッサ SPARC64™ XIfx 3
HPC 向け命令セット拡張 HPC-ACE2 4
3 次元積層メモリ Hybrid Memory Cube 6
はじめに
富士通は 1977 年に日本初のスーパーコンピュータを開発して 以来、30 年以上にわたり最先端技術を投入したスーパーコンピュ ータを開発してきました。FUJITSU Supercomputer PRIMEHPC FX100(以降、PRIMEHPC FX100 と表記)は、エクサスケールコ ンピューティングに向けた次世代技術によってプロセッサ、メモ リ、インターコネクトを刷新した、最新鋭のスーパーコンピュー タです。 HPC 専用の高性能設計 PRIMEHPC FX100 は富士通が HPC 専用に設計した
SPARC64™ XIfx プロセッサ、Torus Fusion(以降、Tofu と表記) インターコネクト 2 を搭載する超並列計算機です。SPARC64™ XIfx プロセッサは 32 個の計算コアを有し、命令セットは HPC 向けに 拡張されています。主記憶には最先端の 3 次元積層メモリ Hybrid Memory Cube(以降、HMC と表記)を採用し、480 GB/s の高メ モリ帯域とラックあたり 216 ノードの高密度実装を実現しました。 Tofu インターコネクト 2 は 12.5 GB/s の高速リンクでノード間を 接続し、拡張性の高い 6 次元メッシュ/トーラス構成でシステム を構築します。 並列処理の効率を高める専用コア構成 SPARC64™ XIfx プロセッサは計算コアとは別に 2 個のアシスタ ントコアを備えます。計算コアは計算処理に専従し、並列処理の 効率を向上します。PRIMEHPC FX10 ではノードを計算ノードと I/O ノードに分けていましたが、PRIMEHPC FX100 ではアシスタ ントコアが I/O 処理を行うため、全ノードで並列計算を実行でき ます。 高信頼直接水冷 プロセッサ、メモリ、光モジュール、直流電圧変換素子を冷や すコールドプレートに冷却水を循環することにより、半導体温度 の上昇を防ぎます。温度を低く保つことにより素子の故障率を低 く抑え、高信頼性を実現しています。 本体装置およびラック構成 本体装置は 2U サイズと小型です。各本体装置は 3 台のノード を搭載する CPU メモリボード(以降、CMB と表記)を 4 枚、電源 ユニットを 4 台、起動用ディスクを 1 台、システム監視用サービ スプロセッサを 1 台、Low Profile の PCI Express 拡張スロットを 1 つ搭載します。本体装置あたりのノード数は 12 台です。 ラックは標準的な 19 インチサイズです。各ラックは本体装置を 最大 18 台搭載します。ラックあたりの最大ノード数は 216 台で す。 システム構成 PRIMEHPC FX100 は 5 ラックあたり 1 ペタフロップス以上のピ ーク性能を有します。500 ラックを超える構成が可能なため、最 大ピーク性能は 100 ペタフロップスを超えます。 表 1 PRIMEHPC FX100 システム諸元 5 ラック構成 512 ラック構成 本体装置数 90 9,216 ノード数 1,080 110,592 ピーク性能 > 1 Pflops > 110 Pflops メモリ容量 34 TiB 3.4 PiB メモリ帯域 518 TB/s 53 PB/s インターコネクト帯域 108 TB/s 11 PB/s 拡張スロット数 90 9,216 接続トポロジー例 2x5x9x2x3x2 32x32x9x2x3x2
FUJITSU Supercomputer PRIMEHPC FX100 の概要
図 1 PRIMEHPC FX100 CPU メモリボード上の水冷配管
図 2 PRIMEHPC FX100 本体装置
HPC 専用プロセッサ
科学技術計算を高速に実行するため、SPARC64™ X+をベースに 性能を向上させた SPARC64™ XIfx を新たに開発して、PRIMEHPC FX100 に搭載しました。SPARC64™ XIfx では処理性能と消費電力 とのバランスを重視し、高クロック化ではなくコア数を増やし、 さらに Single Instruction Multiple Data(以降、SIMD と表記) 幅を拡張することで、消費電力の増加を最小限に抑えつつ性能向 上を実現しました。
SPARC64™ XIfx の概要
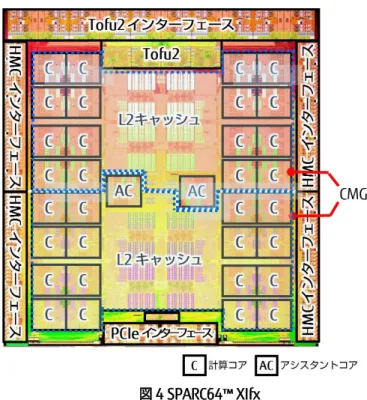
SPARC64™ XIfx は 2 つのコアメモリグループ(以降、CMG と表 記)、Tofu2 コントローラ、PCI Express コントローラなどから構 成されています。1 つの CMG は 16 個の計算コア、1 個のアシス タントコア、17 コア間で共有される 12 MiB の L2 キャッシュ、 メモリコントローラで構成され、2 つの CMG 間ではキャッシュ一 貫性が保たれます。半導体には最先端 20nm テクノロジーを採用 しています。
各コアは Instruction control Unit(以降、IU と表記)、Execution Unit(以降、EU と表記)、Storage Unit(以降、 SU と表記)の 3 つのユニットにわかれます。IU は命令のフェッチ、発行および完 了を制御します。EU は 2 つの整数演算ユニット、2 つの整数演算 兼アドレス計算ユニット、および 8 つの浮動小数点積和演算ユニ ット(Floating-point Multiply and Add、以降、FMA と表記)か ら構成され、整数演算、および浮動小数点演算命令を実行します。 1 つの FMA は 1 サイクルあたり 2 つの倍精度浮動小数点演算(加 算と乗算)を実行可能です。次ページで述べる SIMD 技術により、 1 つの SIMD 演算命令で 4 つの FMA を動作させます。一方、各コ アは 1 サイクルあたり 2 つの SIMD 演算命令を実行します。した がって各コアで 1 サイクルあたり 16 個、32 個の計算コア合計で 512 個の倍精度浮動小数点演算が実行可能となります。また、単 精度浮動小数点の場合は 1 サイクルあたり 2 倍の演算が可能です。 SU はロード・ストア命令を実行します。コアごとに 64KiB のレベ ル 1 命令キャッシュとデータキャッシュを内蔵しています。 アシスタントコア OS、システムソフトウェアによる計算処理の中断は、並列処理 の効率を向上する上で問題です。SPARC64™ XIfx では OS、システ ムソフトウェア用にアシスタントコアを備えました。これにより、 計算コアが計算処理に専従できます。
HPC 向け命令セット拡張 HPC-ACE2
従来の SPARC64™シリーズの命令セット拡張 High Performance Computing - Arithmetic Computational
Extensions(以降、HPC-ACE と表記)を発展させ、演算スループ ットを 2 倍に高めた HPC-ACE2 を導入しました。HPC-ACE2 につ いては次ページで詳しく解説します。 3 次元積層メモリ HMC 近年のプロセッサは処理能力が急激に向上したため、演算に必 要なメモリのデータ供給能力が相対的に不足してきています。こ のため SPARC64™ XIfx では最先端の 3 次元積層メモリ HMC を主 記憶に採用し、ノードあたり 8 個接続します。これによりピーク メモリ帯域 480 GB/s を実現しました。HMC については 6 ページ で詳しく解説します。 Tofu インターコネクト 2 内蔵
SPARC64™ XIfx では、PRIMEHPC FX10 では別チップとなって いたインターコネクト・コントローラを内蔵しました。新たに開 発した Tofu インターコネクト 2(以降、Tofu2 と表記)用に高速 25 Gbps SerDes を 40 レーン搭載し、送受信合計 250 GB/s の帯 域を実現しました。Tofu2 については 7-8 ページで詳しく解説し ます。 表 2 SPARC64™ XIfx 諸元 コア数 32 + 2 コアあたりスレッド数 1 L2 キャッシュ容量 24 MiB ピーク性能 > 1 Tflops メモリ理論帯域 240 GB/s x2 (in/out) インターコネクト理論帯域 125 GB/s x2 (in/out) プロセス・テクノロジー 20 nm CMOS トランジスタ数 約 37 億 5000 万個 信号ピン数 1,001 HMC SerDes 128 レーン Tofu2 SerDes 40 レーン PCIe Gen3 SerDes 16 レーン
メニーコアプロセッサ
SPARC64™ XIfx
HPC-ACE2 の概要 HPC-ACE2 は SPARC-V9 命令セットアーキテクチャーに対する HPC 向け拡張命令セット HPC-ACE の第 2 世代です。 SIMD 演算 SIMD は、1 つの命令で複数のデータに対する演算を実行させる 技術です。HPC-ACE は SIMD 技術を採用し、1 つの命令で 2 つの 倍精度浮動小数点積和演算、もしくは 2 つの単精度浮動小数点積 和演算を実行します。HPC-ACE2 では SIMD 幅を 256 ビットに拡 張し、4 つの倍精度浮動小数点積和演算、もしくは 8 つの単精度 浮動小数点積和演算を実行することが可能になりました。 浮動小数点レジスタ拡張 SPARC-V9 では浮動小数点レジスタの数は 32 本ですが、スーパ ーコンピュータ用アプリケーションの性能を最大限に引き出すた めには必ずしも十分ではありません。前世代の HPC-ACE では、前 置命令 Set eXtended Arithmetic Register(以降、SXAR と表記) を定義して、浮動小数点レジスタを 256 本に拡張しました。 SPARC-V9 では命令長が 32 ビットに固定されており、1 つの命令 中に拡張したレジスタ番号を指定するフィールドはありませんが、 SXAR 命令でレジスタ番号の拡張部分上位 3 ビット、後続の 1~2 命令で従来通りのレジスタ番号 5 ビットを指定することで、合計 8 ビット=256 本のレジスタを指定します。256 本の浮動小数点 レジスタは、SIMD 演算では 128 本の 128 ビット SIMD レジスタ として使えます。HPC-ACE2 では、SIMD 演算で利用可能な SIMD レジスタ本数 128 本を維持しつつ、SIMD 幅を 256 ビットに拡張 しました。コアあたりのレジスタ容量は HPC-ACE の 2 倍に増えて います。 ソフトウェア制御可能キャッシュ(セクタキャッシュ) プロセッサの処理速度とプロセッサにデータを供給する主記憶 の速度の乖離が課題となっています(メモリウォール問題)。 メモリウォール問題の解決方法としては、キャッシュとローカ ルメモリがよく知られています。キャッシュはハードウェアが制 御するのでプログラムを書き換えなくても利用できますが、再利 用頻度の低いデータが再利用頻度の高いデータをキャッシュメモ リから追い出してしまい、性能向上の妨げになる場合があります。 ローカルメモリはソフトウェアでデータアクセスを制御できます が、そのためにはプログラムの大幅な書き換えが必要です。 HPC-ACE では、従来のキャッシュとローカルメモリの長所を兼 ね備えた、ソフトウェア制御可能なキャッシュ(セクタキャッシ ュ)を導入しました。セクタキャッシュではソフトウェアがデー タをセクタ分けし、セクタごとにキャッシュ容量を割り当てるこ とができます。HPC-ACE のセクタ数は各コアの L1 データキャッ シュ、共有の L2 キャッシュとも 2 セクタでしたが、HPC-ACE2 で は各コアの L1 データキャッシュ、各 CMG の共有 L2 キャッシュ とも 4 セクタに拡張しました。これにより、計算コアとアシスタ ントコア間のキャッシュ競合回避など、より柔軟な制御が可能に なります。 数学関数補助命令 HPC アプリケーションは、他の分野のアプリケーションと比較 して、三角関数を始めとする数学関数を高い頻度で利用します。 HPC-ACE では三角関数の sin, cos 関数の近似計算を補助する専用 命令や、除算、平方根を高速化するための逆数近似計算を行う命 令を拡張し、HPC-ACE2 ではさらに指数関数の補助命令、端数処 理命令を追加しました。
HPC 向け命令セット拡張 HPC-ACE2
図 5 前置命令 SXAR による浮動小数点レジスタ拡張 図 6 セクタキャッシュの利用イメージストライド SIMD ロードストア命令 HPC アプリケーションでは、メモリ上に一定の間隔(ストライ ド)を空けて配置されたデータに対して並列処理を行うことがあ ります。ここでストライドが狭いと、1 回のキャッシュアクセス で複数の要素を参照できる場合があります。しかし 1 要素ずつロ ードストア命令で参照する場合、参照している要素以外は利用さ れません。HPC-ACE2 では、1 回のキャッシュアクセスで複数要素 を同時に参照できるように、2 要素間隔から 7 要素間隔のストラ イドを指定して SIMD レジスタへのロードストアを行う命令を追 加しました。 間接 SIMD ロードストア命令 HPC アプリケーションでは、整数配列に格納したインデックス を使用して他の配列を間接参照することがあります。HPC-ACE2 では整数 SIMD 演算と間接 SIMD ロードストア命令を追加し、間 接インデックス参照の SIMD 並列処理を可能にしました。 VISIMPACT 補助機能 PRIMEHPC シリーズのような超並列計算機は総コア数が非常に 多いため、MPI などのプロセス間通信においてオーバーヘッドや メモリ使用量が増加します。この問題の解決には、プロセス並列 とスレッド並列を組み合わせたハイブリッド並列による、プロセ ス並列数の削減が効果的です。
Virtual Single Processor by Integrated Multicore Parallel Architecture(以降、VISIMPACT と表記)は FX1 から導入されて いる、富士通独自の自動マルチスレッド並列化技術です。 VISIMPACT により、PRIMEHPC シリーズではプロセス並列で記述 されたプログラムをハイブリッド並列で実行することができます。 VISIMPACT における SPARC64™プロセッサ側の中核技術は、低 遅延でコアを同期するハードウェアバリア機能です。コンパイラ はコア間の低遅延同期を前提として粒度の小さいマルチスレッド 並列化を行い、スレッド並列実行効率を向上します。 SPARC64™ XIfx のハードウェアバリアは 32 コア間の任意の 8 グループで同期することができ、様々なスレッド数、プロセス数 の組み合わせに対応可能です。 図 7 ストライド数 3 SIMD ロードの例 図 8 間接 SIMD ロードの例 図 9 ハイブリッド並列による、プロセス並列数の削減
PRIMEHPC FX100 では最先端の 3 次元積層メモリである HMC を主記憶に採用し、480 GB/s の高メモリ帯域、2U あたり 12 ノー ドの高密度実装、メモリモジュールの水冷を実現しました。 HMC の概要 HMC は Through-Silicon Via(以降、TSV と表記)技術により複 数の DRAM レイヤーとロジックレイヤーを 3 次元積層したメモリ モジュールです。HMC は複数の DRAM チップを 1 パッケージに 収めることで大幅に部品点数を削減します。またロジックレイヤ ーに論理回路向けプロセス技術を使用できることから、エラー訂 正機能、DRAM セルおよび TSV の故障修復機能、高速シリアル伝 送インターフェースなどの、従来の DRAM 向けプロセス技術では 実装が難しかった高度な機能を搭載します。HMC は高いレベルの メモリ帯域、容量、実装密度、信頼性が求められる HPC 分野に適 したソリューションです。 高速シリアル伝送 HPC ではメモリだけでなくインターコネクトも高い帯域を必要 とするため、メモリとインターコネクトは CPU パッケージのピン 数制約において競合します。高速シリアル伝送で接続する HMC は、 ピン数制約下で高い帯域を得るために最適です。 SPARC64™ XIfx は 128 レーンの 15 Gbps 高速シリアル伝送で 8 つの HMC を接続し、480 GB/s の高メモリ帯域を実現します。メ モリの入出力信号は CPU パッケージの 2 辺から、インターコネク トの入出力信号は 1 辺から引き出されます。 高密度実装 従来の計算機では、DRAM は飛び抜けて部品点数が多い主要部 品でした。そのため複数の DRAM をモジュール基板上に実装した Dual Inline Memory Module(以降、DIMM と表記)が一般的に 使用されています。ボード基板上の DIMM スロットに DIMM を取 り付ける 3 次元実装機構により、限られたボード基板面積に多数 の DRAM を実装します。 HMC は DIMM スロットと比較してもさらに占有面積が小さく、 信号線の引き出し距離も短くなります。PRIMEHPC FX10 ではノー ドあたり 8 つの DIMM スロットを実装し、1U あたり 4 ノードの 実装密度でした。これに対して PRIMEHPC FX100 ではノードあた り 8 つの HMC を実装し、2U あたり 12 ノードと実装密度を 1.5 倍に向上しました。 水冷 メモリ容量が求められるサーバ分野および HPC 分野向けの計算 機では、多数の DIMM スロットをボード基板上に実装していまし た。DIMM の問題点は、機構が複雑になるため水冷の導入におい て大きな障害となることです。PRIMEHPC FX10 ではシステムボー ド上の DIMM 以外の主要部品を水冷しつつ、DIMM のみを空冷す るハイブリッド冷却方式を採用しました。 これに対して PRIMEHPC FX100 では HMC の採用により、メモ リを含めたすべての主要部品がボード基板の表面に実装されるよ うになったため、全面的に水冷を導入しました。 表 3 PRIMEHPC FX100 主記憶諸元 HMC 接続数 8 メモリ容量 32 GiB ピークメモリ帯域 240 GB/s x2 (in/out) 高速シリアル伝送速度 15 Gbps 高速シリアルレーン数 128 入出力信号ピン数 512
3 次元積層メモリ Hybrid Memory Cube
図 11 PRIMEHPC FX100 の高密度実装 CMB
PRIMEHPC FX10 の Tofu インターコネクト(以降、Tofu1 と表 記)をベースに性能、機能を向上させた Tofu インターコネクト 2 を開発し、SPARC64™ XIfx プロセッサに統合しました。 6 次元メッシュ/トーラス・ネットワーク Tofu2 は Tofu1 と同様に、6 次元メッシュ/トーラス・ネット ワークでシステムを構成します。6 次元のうち X, Y, Z 軸の 3 次元 はシステム構成により長さが可変です。残りの A, B, C 軸の 3 次元 は長さが 2, 3, 2 に固定されています。6 次元での相互接続のため、 各ノードは 10 個の接続ポートを備えます。 ユーザービューのネットワークトポロジーは、1 次元/2 次元/ 3 次元の仮想的なトーラスです。ユーザーが指定した次元数、大 きさの仮想トーラス空間は 6 次元メッシュ/トーラス・ネットワ ーク上にマップされ、ランク番号に反映されます。この仮想トー ラス方式により故障ノードを含む領域をトーラスとして利用でき るため、システムの耐故障性、可用性が向上します。
C
B
A
X
Z
Y
25 Gbps 高速シリアル伝送 Tofu1 では 1 リンクあたり 6.25 Gbps の高速シリアル信号を 8 レーン使用しリンク理論帯域は 5.0 GB/s でした。Tofu2 では伝送 速度を 25.78125 Gbps に引き上げ、4 レーンを使用してリンク理 論帯域を 12.5 GB/s と Tofu1 の 2.5 倍に向上しました。 Tofu1 ではすべてのリンクを電気で伝送しましたが、25 Gbps の電気伝送はロスが大きく短い距離しか伝送できないため、Tofu2 では本体装置内のリンクのみ電気伝送とし、本体装置間のリンク はすべて光伝送を採用しました。プロセッサと光モジュール間の 電気伝送ロスを最小化するため、光モジュールは CMB 上でプロセ ッサに近接配置しました。 光リンク主体ネットワーク 本体装置内の 12 ノードは(X,Y,Z,A,B,C) = (1,1,3,2,1,2) の構成 で接続されており、本体装置内の電気伝送リンクは 20 本です(図 14)。すなわち、12 ノードの合計 120 ポートのうち 40 ポートが 本体装置内の電気伝送接続に使用されています。残りの 80 ポート は光伝送で本体装置外と接続されます。 10 Gbps 世代の高速伝送技術を採用している既存の HPC インタ ーコネクトではラック内の距離を電気で伝送できるため、ネット ワーク全体のうち光伝送の比率は 1/3 以下でした(図 15 の A, B,C)。 従来は伝送距離を伸ばす目的で、部分的に光伝送が使用されてい たと言えます。これに対して Tofu2 では光伝送の比率が電気伝送 を大きく上回っており、従来の HPC インターコネクトとは一線を 画しています。Tofu2 は光伝送を主として使用する、次世代の HPC インターコネクトと言えます。Tofu インターコネクト 2
図 12 6 次元メッシュ/トーラスのトポロジーモデル 図 14 本体装置内の接続トポロジー 図 13 光モジュールのプロセッサ近接配置RDMA 通信機能
Tofu2 の RDMA 通信機能は Tofu1 の Put および Get に加えて Atomic Read Modify Write(以降、Atomic RMW と表記)をサポ ートします。Atomic RMW は宛先ノードにおける 4 バイトまたは 8 バイトのデータに対し演算を行います。演算の種類には比較交 換、交換、整数加算、ビット演算があります。 Atomic RMW は宛先ノードにおいてデータ読み出し、演算、書 き戻しを実行している間、別のメモリアクセスによって該当デー タが参照されないこと(Atomicity)を保証します。Atomic RMW は細粒度の排他制御を効率よく実行します。Tofu2 の Atomic RMW は CPU の Atomic 演算に対し、相互に Atomicity を保証しま す。これによりプロセス並列とスレッド並列で資源を共有する処 理において、排他制御オーバーヘッドを削減します。 通信インターフェース RDMA エンジンはコントロールキュー(以降、CQ と表記)と呼 ばれるインターフェースによって通信コマンドの受け付け、実行 結果の通知を行います。CQ の本体は主記憶上に配置されます。CQ 制御レジスタは 1CQ ずつ異なるアドレス空間にマップすることが 可能です。CQ の本体と制御レジスタをユーザープロセスのアドレ ス空間にマップすることで、通信インターフェースは OS カーネル をバイパスします。Tofu2 ではノードあたり CQ 48 組を備えるの で、CQ 数はコア数を上回ります。ユーザープロセスは CQ を占有 できるので、CQ を使用する際は排他制御不要です。 Tofu1 は送信時の遅延削減のため、通信コマンドを CPU レジス タから直接 RDMA エンジンに送る、ダイレクトディスクリプタ機 能を備えていました。Tofu2 ではさらに、受信時の遅延を削減す るため、受信データを L2 キャッシュメモリに直接書き込むキャッ シュインジェクション機能を追加しました。 Tofu2 では集団通信アルゴリズムを自動実行するため、他プロ セスからの通信によって通信コマンドの実行開始を制御可能な、 セッションモードを CQ に追加しました。 表 4 に Tofu2 の通信遅延を論理シミュレーションで評価した結 果を示します。メモリへの Put は Tofu1 の 0.91μ秒とほぼ同等で した。キャッシュインジェクションは遅延を 0.16μ秒削減します。 また Atomic RMW のオーバーヘッドは 0.11μ秒程度と低遅延です。 表 4 通信遅延 通信機能 通信遅延
片道 Put (to memory) 0.87 μ秒 Put (to cache) 0.71 μ秒 往復 Put ping-pong (CPU) 1.42 μ秒 Put ping-pong (Session) 1.41 μ秒 Atomic Read Modify Write 1.53 μ秒 Tofu バリア
Tofu2 は Tofu1 から引き続き Tofu バリアをサポートします。 Tofu バリアは Barrier 集団通信および 1 要素の AllReduce をハー ドウェアで実行するインターフェースです。Tofu バリアはパケッ ト受信、演算、パケット送信を行う専用回路を実装しており、様々 な通信アルゴリズムを実行可能です。また、CPU で同等の処理を 行うよりも低遅延です。さらに、ハードウェアによる集団通信処 理は OS ジッタの影響を受けない利点があります。Tofu バリアは ノードあたりチャネルを 8 個備え、各チャネルは独立に動作します。 表 5 Tofu インターコネクト 2 諸元 データ転送レート 25.78125 Gbps エンコーディング 64b/66b リンクあたりレーン数 4 リンク理論帯域 12.5 GB/s x2 (in/out) ノードあたり接続ポート数 10 ネットワークトポロジー 6 次元メッシュ/トーラス ルーティング方式 拡張次元オーダー 仮想チャネル数 4 最大パケット長 1992 バイト パケット転送方式 バーチャル・カットスルー フローコントロール方式 クレジットベース 送達保証方式 リンクレベル再送信 RDMA 通信機能 Put/Get/Atomic RMW RDMA エンジン数 4 (同時通信可能) RDMA エンジンあたり CQ 数 12 組
アドレス変換方式 Memory Region + Page Table Tofu バリアチャネル数 8 通信保護方式 グローバルプロセス ID 動作周波数 390.625 MHz 参考情報 PRIMEHPC FX100 に関する情報は、当社営業までお問 い合わせいただくか、以下の Web サイトをご参照く ださい。 http://jp.fujitsu.com/solutions/hpc/products/primehpc-fx100/
FUJITSU Supercomputer PRIMEHPC FX100 次世代技術への進化 富士通株式会社
2014 年 11 月 17 日初版 2014-11-17-JP
・ SPARC64 およびすべての SPARC 商標は、米国 SPARC International, Inc.のライセンスを受けて使 用している、同社の米国およびその他の国における商標または登録商標です。
・ その他、会社名と製品名はそれぞれ各社の商標、または登録商標です。
・ 本資料に掲載されているシステム名、製品名などには、必ずしも商標表示(
™
、®
)を付記してお りません。本書を無断で複製・転載しないようにお願いします。 All Rights Reserved, Copyright © 富士通株式会社 2014