Deep Q-Network による
RC カー運転制御学習のための報酬設計
Reward Design for RC Car Operation Control by Deep Q-Network
小川一太郎
1横山想一郎
2川村秀憲
2酒徳哲
3柳原正
3田中英明
3Ichitaro Ogawa
1, Soichiro Yokoyama
2,Hidenori Kawamura
2, Akira Sakatoku
3,
Tadashi Yanagihara
3, Hideaki Tanaka
3 1北海道大学工学部
1
Hokkaido University School of Engineering.
2
北海道大学大学院情報科学研究科
2
Graduate School of information Science and Technology, Hokkaido University.
3KDDI 総合研究所
3
KDDI Research, Inc.
Abstract: Acquisition of autonomous driving of multiple RC cars is performed by Deep Q-Network. This
research aims to acquire the behavior of RC cars where they do not get out of the track, do not collide with other vehicles and turn to the specified direction at intersections. Two cameras under the ceiling take a picture of RC cars on the track and this system recognize location and directions of each RC cars. From these information, the system calculates inputs of Neural Network and decides actions based on outputs. For creating expected behavior, adjustment of reward used in Q learning was made using experimental design method.
1 はじめに
近年,様々なロボットが機械学習を用いて動作を 学習している. 実環境中のロボットが複雑な環境を 認識し, 動作を決定することをニューラルネットで 行う研究がなされている. Deep Q-Network[1]は状態を評価して行動を決定す るという面で, エージェントに行動をさせて学習さ せることに適している.例えば,ビデオゲームを学 習させて人間の操作よりも大きくスコアを獲得した 例[1]や,自動車の交通の整理[2]など様々な研究がされ ている. 一方で,Deep Q-Network を用いた際にロボットの 行動価値を評価する報酬の設計は,期待している動 作をさせるには,どんな行動に対してどれだけの報 酬を与えればよいのか判断することが難しい. また, 複数のエージェントに適応する場合には特に問題と なり,エージェント同士での行動を認識し,報酬の 設計を正確に行う必要がある. 本研究では、RC カーを制御する複数エージェント を対象とした自律走行の自律習得を目的とする。具 体的には、コースアウトをせずに走行が可能である こと、他車と接触をしないこと、外部より与えられ る方向指示に従って曲がるような走行を目指す。 RC カーの動作に必要な入力はアクセルとステア リングの二つとする.また,RC カーが走行するため に環境を認識する必要がある.モデル化が行い易く, ニューラルネットのサイズが大きくなりすぎないよ うにするために,コースの情報だけを環境となる設 定にした. RC カーの運転制御学習を行うため,走行に必要 な要素に対して Deep Q-Network の報酬を設定し,最 適な走行に必要な報酬設定や学習のパラメータを調 査する. 実験計画法によって直交表を作り,そこに調整す るべき学習パラメータや報酬の値を割り振ることで, 要素ごとに適切な値を選択する. 本研究ではパラメータ探索を行った際, カリキュ ラム学習ごとに同一のパラメータを使用することを 想定しており, 単機での走行と複数の走行で学習時に違いが現れた. 中でも単機での自律走行が可能鵜 であることが確認できた.カリキュラムごとにパラ メータの調整が必要になることが考えられる.
2 関連研究
Deep Q-Network[1]ではエージェントの行動を行っ た結果の状態に対して報酬を与えることができるた め,目的に対して最適な行動をとることを学習する ことに長けている.ここではその Deep Q-Network に ついて説明する.2.1 Deep Q-Network
まず Q 学習とはエージェントの行動結果の状態に 対して報酬を与えることで,その累積報酬を予測し て行動を決定するものである.時刻 t において状態 s,行動 a に対する価値は Q(st,at)で表される. 最適 化された場合の Q*(s,a)は報酬 r を用い式(1)のよう に表される. 𝑄∗(𝑠 𝑡,𝑎𝑡) = 𝑚𝑎𝑥E[𝑟𝑡+ 𝛾𝑟𝑡+1+ 𝛾2𝑟𝑡+2+ ⋯ ] (1) ここでγは割引率と呼ばれ,未来の報酬が行動に どの程度影響するか調整するパラメータである.式 (1)を変形すると式(2)のようになる, 𝑄∗(𝑠 𝑡,𝑎𝑡) = 𝑟𝑡+ 𝛾𝑄∗(𝑠𝑡+1,𝑎𝑡+1) (2) 式(2)より,行動 a をとったときの状態遷移を学習 するとき,更新式は式(3)のようになる.Q(s,a) ← Q(s,a) + α(𝑟 + 𝛾 max
𝑎′ Q(s ′,a′) − Q(s,a))(3) Deep Q-Network には学習を成功させるための方策 が多く存在している. Target Network と呼ばれる方策は,教師信号である 𝑟 + 𝛾 max 𝑎′ Q(s′,a′)の Q 値を出力する専用のニュー ラルネットを作成するものである.これは,学習時 に教師信号を計算するニューラルネットの重みを固 定することで学習を安定化させることができる.こ の target network は通常の Q 値を出力するニューラ ルネットから一定回数の学習ごとにコピーをするこ とで更新する. Preferred Networks も RC カーを用いた自動運転の 研究[3]を行っており,こちらでは走行コースに沿っ た走行を実現している.本研究では外部からの命令 によって交差点内の進路を決定するため,新規性が あるといえる.
3 実験システムの解説
複数のエージェントが実機で行動を学習する環境 を作成するため,RC カーの学習環境を作成する.学 習環境を説明するにあたって,大きく分けて 3 つの 構成に分けることができる.走行部,走行制御部, 学習部の 3 つをそれぞれについて説明する.3.1 走行部
3.1.1 RC カーの動作制御 使用する RC カーは市販のものを使用した(株式会 社タミヤ トヨタ 86(TT-01 シャーシ TYPE-E))(図 1). RC カーにはマイコン(ラズベリーパイ 3)を搭載し, 制御を行う.この RC カーはコントローラーからの 無線の受信機から,2つのサーボモーターにパルス 信号が送られる.そのため,この受信機ではなくマ イコンからパルス信号を送るようにすることでシス テムによる制御を可能とした.ステアリング制御用 のモーターに用いているものが 1.1 ミリ秒幅から 1.9 ミリ秒幅,アクセル用のモーターに用いているもの が 1.46 ミリ秒幅から 1.61 ミリ秒幅である. 屋内での実験で学習を行い走行させるにあたり, ハンドル角を増加させるように改造を施した.前輪 に左右方向の力を与える接続部を短くすることで, 小さな動きで大きく曲がるように変更した.更にス トッパーも切断し,可動域を広げた.改良後のタイ ヤの角度は 30 度になった. 改造後は最小の旋回半 径は 400mm である. 適正な電圧を供給できるため,電源供給は同梱の ニカドバッテリーを使用する. RC カーのモーターは PWM による出力に個体差 があるため,走行速度は最大で 1.5m/s になるように RC カーごとに PWM の出力を調整している.PWM の出力内容は,ラズベリーパイで計算はしておらず, 図 1 RC カーとマーカー制御部から wifi 通信で送られたものを出力する. 3.1.2 RC カーの認識方法 RC カーの位置と方向を素早く推定し,加えてそれ ぞれの機体が判別するため,RC カーの屋根部分に三 つのマーカーを取り付けた.(図 1)RC カー進行方向 に一点,反対側に二点の小円のシールを貼り付け, それぞれの距離を 8cm,8cm,6.5cm とした.三点の 重心が RC カーの中心であり,三角形の頂点のうち ほかの頂点から距離が離れている点を求めることで 方向を判別できる.また,緑と黄の二色用意し,RC カーの判別がつくようになっている. 3.1.3 走行用コースの作成 走行用のコースは 0.91m×1.82m の石膏ボードを 24 枚敷き詰めた,5.46m×7.28m の領域を用意した. システムで RC カーの位置を認識するために四方に は壁を設置し,RC カーが外に出てしまうことを防い だ. RC カーが走行するべきコースを決めるコースの 境界は様々なコースを走行させることを想定し,処 理部で仮想的に作成する.また,RC カーの走行に無 理が生じないサイズにするため,RC カーの全長の 1/80 以下である 5mm を 1px,全体で 1092px×1456px のコースになるように設定した. コース走行中は RC カーが無理なくすれ違いがで きることと,コーナーでの旋回に無理がないように するため,最小旋回半径である 0.4m を元に,走行可 能なコース幅を 1m,コーナー内側の半径を 0.405m.
3.2 走行制御部
走行制御部は RC カーの位置や状態の推定,RC カ ーの行動を計算する. Deep Q-Network の計算を遅延なく行い,同時に複 数のエージェントを制御するためにマイコンとは別 にノート PC で RC カーの状態認識,行動決定,行動 の送信を行うこととした. 3.2.1 位置の推定 RC カーの位置を推定するため,固定されたカラー カメラよりマーカーを認識する.処理速度を保つた めカメラは二台,コースの対角に俯瞰するように設 置した.カメラから距離が遠いほど認識に誤差が生 まれやすいため,二つの撮影領域が,コースの中心 付近で重なるようにしている. カメラの画像を取り込んだ後,マーカーを認識す るために画像の編集を行う.マーカーの2色(緑,黄) で閾値処理を行い,それぞれの色に応じた二値化画 像を2つ作成する. マーカーは RC カーの天井に存在しているため, 天井の高さである地上 13cm の平面で,カメラ画像 を射影変換する.これによって,マーカーを斜めか ら撮影してもコース上のどこに存在しているかが求 められる. マーカーの位置と色を元に RC カーの位置と機体 番号を判別する. RC カーの検知にはパーティクルフィルタ[4] [5]を 導入しており,検知されない瞬間があったとしても 位置を推定できるようになっている. 3.2.2 状態の推定 RC カーの運転を適切に行うためには、RC カーの 走行状態と周囲のコース状態について認識する必要 がある. まず,RC カーが未来の状態を予測するためには現 在の速さが必要不可欠である.速さに準ずる状態と して,加速度,角速度,角加速度などが考えられる. また,過去の行動を入力に加えることで同様の働き が得られると考えられる.そのためステアリング, アクセルの出力の履歴から 3 ステップ分入力に用い た. 次に,RC カーにとっての環境とはコース,または 他の RC カーである.それらを検知するために,自 動車などで用いられているライダーを使用すること とした(図 2).光線を発して障害物までの距離を求め られるので,仮想的に車の中心から発しているとし た時に,全方位のコースの形や他の RC カーの位置 を認識することができる. コースと他の RC カーとの認識を分けるためライ ダーを二種類用意した.一つはコースのみ障害物と みなし,コースの形を認識するためのもの,もう一 つはコースと他の RC カーの両方を障害物としてみ なし,RC カーの位置を認識するためのものである. 図 2 RC カーの中心から発する ライダーの表示 実際のライダーよりも少なく表示した表 1 ニューラルネットに用いる入力内容 種類 入力数 入力内容 単位 過去の行動 6 直前 3 ステップのステアリング 対応した入力 直前 3 ステップのアクセル 対応した入力 方向指示 1 目標ルートと現在の RC カーの向いている方向との差 rad 走行状態 4 速さ m/s 加速度 m/s2 角速度 rad/s 角加速度 rad/s2 ライダー 112 RC カーの中心から各角度ごとのコース境界との距離 m RC カーの中心から各角度ごとのコース境界またはほかの車との距離 m 表 2 出力に対応する RC カーの動作 出力 ステアリング ステアリング角 アクセル 0 左(大) 約 30° 前進 1 左(中) 約 22° 前進 2 左(小) 約 7° 前進 3 直進 0° 前進 4 右(小) 約 7° 前進 5 右(中) 約 22° 前進 6 右(大) 約 30° 前進 7 直進 0° 停止 それぞれのライダーは 56 方向に発している.しか し,走行中であれば RC カー同士の衝突やコースア ウトは進行方向で起こるはずなので,進行方向情報 を重視するため,ライダーのうち 32 方向が前方 90 度に密集する形で配置してある. ここで,RC カーをただランダムに走行させるだけ でなく,走行ルートの制御を行うために方向指示も 環境からの入力に加えた.RC カーが交差点または T 字路に侵入したときに直進,左,右の選ばれた方向 と RC カーの向いている方向との差を入力として与 えることで走行ルートを制御する. ただし,T 字路などで支持された方向が通行不可 の時,または一本道で選択肢がない場合は 0 を入力 として自由に走行するようにした. 3.2.3 ニューラルネットによる制御 RC カーの行動を決定するためにニューラルネッ トを用いる.Deep Q-Network では与えられた入力に 対し,出力の値が最大となるノードに対応した行動 を取ることになる. ここで,RC カー走行ルートを制御するために方向 指示用の入力を追加する.ランダムに走行ルートを 決定するだけでなく,命令された走行ルートを走行 することを目的としている. 走行ルートを変更するためには交差点において進 むべきコースを認識する必要がある.報酬を線形に 与えることができるため,RC カーの進行方向と進む べきコースの方向との差を入力に用いる. 次に出力に関して述べる.RC カーがコースを無理 なく走行できるよう,ハンドル角に左右それぞれ 3 通り定めた.左右の中間のハンドル角はコーナーに 適した軌道で旋回でき,他 2 つのハンドル角で調整 をする.また,通常走行用の直進と,交差点での他 の RC カーとの衝突を回避するための停止も行動の 選択肢の中にある.よって今回の研究では 8 つの出 力を定めた. Deep Q-Network では複数ある出力のうち最大のも のと対応した行動を取る.本研究ではニューラルネ ットに合計 123 の入力をし,8 つの出力から行動を 決定する. この出力の内容を RC カー内のマイコン に送ることで RC カーの制御を行う.ただし,学習 時は探索のため,εグリーディに従って行動を決定 する. 入力と,出力の内訳は表 1,表 2 にまとめた. システムのループごとに以上までの,カメラの画 像から RC カーの位置と方向を推定する,位置と方 向から現在の RC カーの状態を推定する,ニューラ ルネットで行動を求める,RC カーのマイコンに出力 内容を送信するといった内容を行う.現在のシステ ムでは一度のループは 150ms で行われており,約
6.67fps で動作している.
3.3 学習部
学習部にはデータベースの一つである MySQL で 走行データが保存されている. 走行データ一つにつき,走行の開始からコースア ウト,他 RC カーとの衝突または一定時間経過まで の入力出力データが保存される.tensorflow を用いて Deep Q-Network を実装した.
4 報酬設定
4.1 報酬の設定
ここでは行動価値を求める際の報酬の設計につい て説明する.実際の値は実験によって求めたため次 の章で示すため,計算方法や実装方法を説明する. 4.1.1 報酬の計算 RC カーの運転制御を学習するための報酬として, 次の 5 つを設定した. ・コースアウトによる減点 Rcourse out ・速さによる加点 Rspeed ・ライダーの長さによる減点 Rlidar ・ハンドルの切り替えによる減点 Rhandle ・方向指示による加点 Rorder それぞれの内容は以降で説明する.報酬の合計 Rsumの計算は ・次のステップでコースアウトまたはほかの RC カーと衝突する場合(式(4)) 𝑅𝑠𝑢𝑚= 𝑅𝑐𝑜𝑢𝑟𝑠𝑒 𝑜𝑢𝑡 (4) ・次のステップも走行が続いている場合(式(5)) 𝑅𝑠𝑢𝑚= 𝑅𝑠𝑝𝑒𝑒𝑑+ 𝑅𝑙𝑖𝑑𝑎𝑟+ 𝑅ℎ𝑎𝑛𝑑𝑙𝑒+ 𝑅𝑜𝑟𝑑𝑒𝑟 (5) の二通りで計算する. 4.1.2 コースアウトによる減点 まず,コースアウトによる減点に説明する. これはコースアウトをした時,または他の車と衝突 した時に与える定数の罰則である. これにより,コース内を走行するように学習させ る意図がある. 4.1.3 速さによる加点 次に,速さによる加点について説明する. これは行動のうち,'停止'を率先して行わないよう にする狙いがある. 具体的にはコースアウトしない走行を学習するため に停止し続け,動かなくなる可能性がある.そのた め,速さの定数倍を加点させることで走行を行うよ うにする.加算する報酬の値𝑅𝑠𝑝𝑒𝑒𝑑は変数𝑎𝑠𝑝𝑒𝑒𝑑を用 いて式(6)のように表される. 𝑅𝑠𝑝𝑒𝑒𝑑= v[m/s] × 𝑎𝑠𝑝𝑒𝑒𝑑 (6) 4.1.4 ライダーの長さによる減点 ライダーの長さによる加点について. コースアウトの防止を目的として,定められたラ イダーが設定した最大長 maxL 以下になると減点を 行うようにする.同時に, 最大長 maxL を RC カー 左側は短く,一方で右側を長くすることで左寄りの 走行を学習することを狙った.ライダーの長さは RC カーの中心から楕円を描いたとき,中心から周まで の距離とする. RC カーの右側は16𝑥2 9 + 𝑦 2= 1, 左側は16𝑥2+ 𝑦2= 1の式で表される楕円で定めて おり,それぞれ長辺が RC カーの進行方向と重なる. 計算を簡略化するため,用いるライダーは前方 180 度中の 15 度ずつ,計 9 本とした. 一つのライダーに対して加算する報酬の値𝑅𝑙𝑖𝑑𝑎𝑟 は変数𝑎𝑙𝑖𝑑𝑎𝑟とそれぞれのライダーの最大長 maxL, それぞれのライダーの長さ lidar len を用いて式(7)の ように表される. 𝑅𝑙𝑖𝑑𝑎𝑟= ∑ 𝑎𝑙𝑖𝑑𝑎𝑟 9 9 𝑖=1 × min(𝑚𝑎𝑥𝐿𝑖, 𝑙𝑖𝑑𝑎𝑟 𝑙𝑒𝑛𝑖) /𝑚𝑎𝑥𝐿𝑖 (7) 4.1.5 ハンドルの切り替えによる減点 ハンドル切り替えによる減点は,入力データにあ る直前 3 ステップのハンドル角から求められる. ステップが進むごとにハンドル角が変更されるたび に-3 ずつ減点する. このことで直線やコーナーなどを蛇行せずに滑ら かに走行させる狙いがある. 4.1.6 方向指示による加点 3.2.2 節で説明した通り,RC カーの走行ルートを 制御するために目標ルートとの誤差の入力に対して 報酬を与える. 方向指示は交差点や T 字路にて指定された方向に 道が存在しているときにのみ計算をする.よって T 字路にて道が存在していない時や一本道などでは, その方向が選択された場合はどこへ向かっても最大 の加点を行うこととした. RC カーの進行方向と方向指示の方向との差が大 きくなるほどに報酬は減少し,差が 0 になると最大 の報酬を与えるようにする. ただし,差が左右 20 度までは猶予とみなし,報酬の変化を小さくしてい る.表 3 直交表 実験 γ 𝑎𝑜𝑟𝑑𝑒𝑟 Rcourse out 𝑎𝑠𝑝𝑒𝑒𝑑 𝑎𝑙𝑖𝑑𝑎𝑟 1 0.8 50 -1 30 0 2 0.8 80 -20 50 -30 3 0.8 100 -50 60 -50 4 0.8 150 -100 80 -70 5 0.85 50 -20 60 -70 6 0.85 80 -1 80 -50 7 0.85 100 -100 30 -30 8 0.85 150 -50 50 0 9 0.9 50 -50 80 -30 10 0.9 80 -100 60 0 11 0.9 100 -1 50 -70 12 0.9 150 -20 30 -50 13 0.99 50 -100 50 -50 14 0.99 80 -50 30 -70 15 0.99 100 -20 80 0 16 0.99 150 -1 60 -30 加算する報酬の値𝑅𝑜𝑟𝑑𝑒𝑟は変数𝑎𝑜𝑟𝑑𝑒𝑟と角度差θ° を用いて式(8)のように表される.
𝑅
𝑜𝑟𝑑𝑒𝑟={
𝑎
𝑜𝑟𝑑𝑒𝑟(1 −
𝜃 20×
1 15) (𝜃 < 20°)
𝑎
𝑜𝑟𝑑𝑒𝑟14 15(1 −
𝜃−20 160) (𝜃 ≥ 20°)
(8)
5 調査実験
5.1 実験目的
本研究の目標は複数の RC カーの運転制御を学習 することである. その実現のため, パラメータの調 査を行った.さらに求められたパラメータや報酬の 値を実際に導入した学習を行い,その性能を評価す る.5.2 実験内容
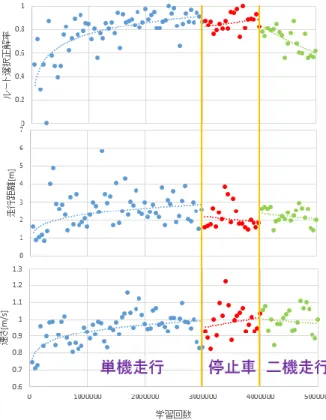
5.2.1 報酬設計パラメータ探索実験 走行行動を学習するために,パラメータや報酬の 値を設定するための実験を行う.パラメータの探索 をするための走行であるので,一台での走行で実験 する. 実験計画法で用いられている直交表を使用する. 直交表を用いることで少ない実験回数で幅広い探索 が行える. パラメータと報酬は ・割引率 ・方向指示による報酬 ・コースアウトによる報酬 ・速さによる報酬 ・ライダーの長さによる報酬 の五つについて調査した. L16 直交表に表 3 のように割り当てることでパラ メータや報酬の重みの探索を行うこととする. 各パラメータや報酬の組み合わせごとの性能評価 については,それぞれの組み合わせで図 3 のコース を走行しながら 100 万回学習を行い,そのニューラ ルネットを用いて 20 回走行させる.1 回の走行はコ ースアウトするまで,もしくは 90 秒が経過するまで とした.20 回の走行は交差点と T 時路の三方向の計 箇所からそれぞれ 5 回の走行とする. 今回の実験ではコースアウトしない走行と,方向 指示による制御に従う走行に報酬が多く与えられる ため,評価するデータはルート選択の正解率と走行 距離, 速度の三つとする. それぞれの要素にわけ,水準ごとに走行距離とル ート選択の正解率, 速度を平均しグラフに出力する. そのグラフから最も良いと思われる各パラメータや 報酬の値を,RC カーの運転制御に適しているものと して採択する. 学習に用いるそのほかのパラメータについて,ε グリーディのεは 0.1, 活性化関数は Relu, 最適化 関数は RMSprop, 学習係数は 0.000025, ターゲ ットネットワークの更新頻度は 5000 学習に一度と した.ニューラルネットの中間層は 5 層用意し,入 力側から順に 500,400,300,200,75,のサイズで ある. また,性能評価のテスト走行では,εグリーディ のεを 0.001 にした. 5.2.2 性能評価実験 採択されたパラメータや報酬を用いたニューラル ネットの性能を評価するため図 4 のコースで再度学 図 3 報酬設計パラメータ探索実験 のコース習を行い,得られた行動の変遷を調査した. 複数台での走行を目指すため,カリキュラム学習 [6]を導入して学習を進める.カリキュラム学習とは, 簡単な内容から難しい内容に段階をつけて学習させ る手法である.段階の付け方に絶対的な基準がない が,適切な難易度で学習させることで効果的に学習 ができるとされている. 本研究では,一台での走行から複数台の走行へと 学習を進めるように設定する.それぞれの段階で, 学習が収束した時に,次の段階に移るようにする. ・phase1 一台での走行 基本的な走行を学習する ・phase2 停止車を設置した一台での走行 基本的な走行からだけでなく, 他の車を認識することを学習する ・phase3 二台での同時走行 他の車が走行している中での走行を学習する それぞれの段階で走行距離とルート選択正解率, 速 度に関する変遷をグラフにして出力し,評価する. 学習に用いるそのほかのパラメータは報酬設計パ ラメータ探索実験で用いたものと同じである.
5.3 実験結果
5.3.1 パラメータ探索実験 それぞれの要素ごとにグラフをつくり,水準ごと に平均を取って出力した.(図 5) 走行距離とルート選択の正解率を用いて判定する. 方向指示,速さ,ライダーの長さの報酬は両方の最 大値を出した値で決定した.従って,方向指示に関 する報酬は 0~150,速さに関する報酬は RC カーの 速さの 50 倍,ライダーに関する報酬は-70~0 とした 最大値が別れてしまった変数に関しては,割引率は 方向指示を重視して 0.9,コースアウトによる減点は 走行距離を重視して-100 とした. 5.3.2 性能評価実験(図 6) Phase1 一台での走行 300 万回まで学習を行い,走行距離や方向指示の 正答率が収束したと判断したため学習を終了した. Phase2 一台での走行 停止車有り コース上に停止車を追加して学習を行った.停止 車の配置は 20 通り用意し,コースアウトや停止車と の衝突ごとに切り替えるようにした.停止車との衝 突による減点はコースアウトによる減点の 2 倍とな る 200 とした. Phase1 から追加して 100 万回の学習を行った. ル ート選択正解率や速度が上昇しているのに対し, 走 行距離は減少している. Phase3 二台での走行 Phase2 から追加して 100 万回の学習,合計で 500 万回の学習を行った. 走行距離は減少してきており,学習が上手に進ん でいないことが読み取れる. このパラメータの評価として,一台での自律走行 は可能であることを確認した.また,停止車の追加 や,2 台での走行とした時に学習がよく進んでいな い. パラメータを求めた際に探索範囲内の最大の水準 が採択されることが多くあったため,探索が不十分 であった可能性が考えられる.最大の水準を採択し た報酬は方向指示,コースアウトとライダーに関す るものである.これらの報酬は速さよりも優先して 値を大きくすべきことがわかった. 図 5 報酬設定のパラメータ探索実験 図 4 性能評価実験時のコース6 おわりに
今回の研究では複数の RC カーによる運転制御の 獲得を目的とし,Deep Q-Network を用いて行動を学 習させた.RC カーの運転制御が可能になるように報 酬の値を,実験計画法を用いて探索した.今回の手 法では複数台での走行に対する効果的なパラメータ を得ることはできなかった.カリキュラム学習の段 階ごとにパラメータを調査する必要がある他, 設定 していた報酬設計のパラメータの探索範囲が狭かっ たことや, 個々のパラメータの性能だけでなく決定 した組み合わせから得られる行動を考慮していなか ったことが原因として考えられる.パラメータの探 索の幅を増やすとともに,ほかの探索方式でのパラ メータ調整することが求められる.参考文献
[1] Volodymyr Mnih., Koray Kavukcoglu., David Silver.: Human-level control through deep reinforcement learning, Nature, Vol. 518, issue 7540, pp. 529-533, (2015) [2] Li Li., Yisheng Lv., Fei-Yue Wang. : Traffic Signal Timing via Deep Reinforcement Learning, IEEE/CAA
JOURNAL OF AUTOMATICA SINICA, Vol. 3, No. 3, (2016)
[3] Preferred Networks : CES2016 でロボットカーのデモ を 展 示 し て き ま し た , Preferred Reserch, https://research.preferred.jp/2016/01/ces2016/, 参 照 日 2016/2/28(2016) [4] 北川源四郎 : モンテカルロ・フィルタ及び平滑化に ついて,統計数理, 第 44 巻, 第 1 号, pp.31--48, (1996). [5] 矢野浩一 :粒子フィルタの基礎と応用:フィルタ・平 滑化・パラメータ推定, 日本統計学会誌, 第 44 巻, 第 1 号, pp.189--216, (2014).
[6] Yoshua Bengio., Jérôme Louradour., Ronan Collobert., Jason Weston. :Curriculum Learning, ICML'09 Proceedings of the 26th Annual International Conference on Machine Learning, pp. 41--48