二部辺相関クラスタリングとその乱択アルゴリズム
Bipartite Edge Correlation Clustering
and Its Randomized Algorithm
水上幹朗
1∗平田耕一
2久保山哲二
3Mizukami Mikio
1Kouichi Hirata
2Tetsuji Kuboyama
31
九州工業大学大学院情報工学府
1
Graduate School of Computer Science and Systems Engineering,
Kyushu Institute of Technology
2
九州工業大学大学院情報工学研究院
2
Department of Artificial Intelligence, Kyushu Institute of Technology
3
学習院大学 計算機センター
3
Computer Center, Gakushuin University
Abstract: In this paper, first we formulate the problem of a bipartite edge correlation clustering which finds an edge biclique partition with the minimum disagreement from a labeled complete bipartite graph, by extending the bipartite correlation clustering which finds a biclique partition. Then, we design a simple randomized algorithm for bipartite edge correlation clustering, based on the randomized algorithm of bipartite correlation clustering. Finally, we give experimental results to evaluate the algorithms from both artificial data and real data.
1
はじめに
二部クラスタリング (biclustering) [?] とは, 行列で 表現されるデータから行と列の集合を同時にクラスタ リングを行い, 行と列からなる二部クラスタを求める問 題である. この二部クラスタリングの行列を二部グラ フとみなすことで, 二部クラスタリングは二部相関クラ スタリング (bipartite correlation clustering) [?, ?] も しくは二部グラフ編集 (bipartite graph editting) とし ても定式化されている. これらは, 二部グラフから不一 致を最小にする二部クリークの集合を二部クリーク分 割 (bipartite partition) として求める問題である. ここ で, 二部クリークとはそれぞれの左ノードがすべての右 ノードに隣接しているような頂点集合である. また不 一致とは二部クリークを構築するときに増やした辺の 数と 2 つの二部クリークを分割したときに取り除いた 辺の数の和である. Amit [?] は不一致が最小となる二部相関クラスタ リングを求める問題が NP 困難であることを示した. Alion [?] は二部相関クラスタリングに対して不一致 ∗連絡先 : 九州工業大学大学院情報工学府 〒 820-0067 福岡県飯塚市川津 680-4 E-mail:[email protected] の期待値が最適解の 4 倍以内になる乱択アルゴリズム PivotBiCluster を設計した. 本論文では, 二部相関クラスタリングを拡張し, 不一 致が最小となる辺二部クリーク分割 (edge biclique par-tition) を見つける二部辺相関クラスタリング (bipartite edge correlation clustering) を定式化する. そして, アル ゴリズム PivotBiCluster を変更し, 二部辺相関クラ スタリングを解く乱択アルゴリズムの PivotBiClus-terEdge を設計する. さらに, これらのアルゴリズムの 乱択性を除いて, 決定性に変更したアルゴリズム Det-PivotBiCluster と DetDet-PivotBiClusterEdge を 設計する. さらに, これらの 4 つのアルゴリズムの性能 を評価するために人工データと実データに適用し, その 結果について考察する.2
二部相関クラスタリング
二部グラフ G を G = (L, R, E) とする. L は G の 左ノードの集合であり, R は G の右ノードの集合であ る. 二部グラフ G は任意の l ∈ Liと r∈ Riに対して (l, r) ∈ Ei となるとき完全である (complete) という. G の部分グラフ Ci = (Li, Ri, Ei) が完全なとき, すな 人工知能学会研究会資料 SIG-FPAI-B801-05わち任意の l∈ Liと r∈ Riに対して (l, r)∈ Eiとなる とき Ciを G の二部クリーク (biclique) であるという. 二部グラフ G の二部クリークの集合C = {C1, . . . , Ck} に対して Ci= (Li, Ri, Ei) が以下の条件を満たすとき, C を G の二部クリーク分割 (biclique partition) という. 1. k ∪ i=1 Li = L かつ k ∪ i=1 Ri= R. 2. 任意の i, j (1≤ i, j ≤ k, i ̸= j) で Li∩ Lj=∅ か つ Ri∩ Rj=∅. 任意の e∈ E に 1 か −1 の値を取るラベルを付値した 完全二部グラフ G = (L, R, E) をラベル付き完全二部 グラフという. C = {C1, . . . , Ck} を G の二部クリー ク分割とする. また, E+ C = k ∪ i=1 Ei, EC− = E \ EC+と する. このとき G に対するC の不一致 (disagreement) daG(C) は以下のように定義する.
daG(C) = |{e ∈ EC+| l(e) = −1}| + |{e ∈ EC−| l(e) = 1}|.
定義 2.1 (Amit [?]) 二部相関クラスタリング問題 BiC-oClust を以下のように定義する. BiCoClust 例: ラベル付き完全二部グラフ G = (L, R, E). 解: 不一致 daG(C) を最小にする G の二部 クリーク分割C. 問題 BiCoClust はラベルなしで完全でない二部グラ フ G = (L, R, E) でも定式化することができる. そのよ うな G が BiCoClust の入力として与えられた場合, すべての E と (L× R) \ E の要素それぞれに 1 と −1 を付値する. そうすることで二部クリークではない二 部グラフの分割をラベル付き完全グラフの二部クリー ク分割とみなすことができる. そのような二部クリー クではない分割をクラスタまたは二部クラスタと呼ぶ. 定理 2.1 以下の定理が成り立つ. 1. (Amit [?]) BiCoClust は NP 困難である. 2. (Alion et al. [?]) 二部クリーク分割の不一致の 期待値が最適解の 4 倍以内となるように BiCo-Clust を解く乱択アルゴリズムが存在する. アルゴリズム??は定理??の 4 近似アルゴリズム Piv-otBiCluster である.
3
二部辺相関クラスタリング
本論文では, 頂点の集合である二部クリークではなく, 辺の集合である辺二部クリーク (edge biclique) に着目 procedure PivotBiCluster(G) /* G = (L, R, E): 二部グラフ*/ Γ← ∅; /* Γ: クラスタ集合*/ 1 while L̸= ∅ do 2select l1∈ L uniform randomly;
3 C← {l1} ∪ N(l1); /* C: クラスタ*/ L′← L \ {l1}; R′← R \ N(l1); 4 foreach l2∈ L \ {l1} do 5 R1← N(l1)\ N(l2); R2← N(l2)\ N(l1); 6 R1,2← N(l1)∩ N(l2);
With probability min { |R1,2| |R2| , 1 } do 7 begin 8 if |R1,2| ≥ |R1| then C ← C ∪ {l2}; 9 else Γ← Γ ∪ {{l2}}; L′← L′\ {l2}; 10 end 11 Γ← Γ ∪ {C}; L ← L′; R← R′; 12 Γ← Γ ∪ {{r} | r ∈ R}; 13 output Γ; 14 アルゴリズム 1: PivotBiCluster [?]. する. 辺二部クリークの二部相関クラスタリングを二部 辺相関クラスタリング (bipartite edge correlation clus-tering) という. C = {C1, . . . , Ck} を Ci= (Li, Ri, Ei) となる G の二部クリークの集合とする. このとき以下 を満たすC を G の辺二部クリーク分割 (edge biclique partition) という. 1. k ∪ i=1 Ei= E. 2. 任意の i, j (1≤ i, j ≤ k, i ̸= j) で Ei∩ Ej =∅. 二部クリーク分割を辺二部クリーク分割にすることで 問題 BiCoClust を以下のように拡張する. 定義 3.1 二部辺相関クラスタリング問題 BiEgCoClust を以下のように定義する. BiEgCoClust 例: ラベル付き完全二部グラフ G = (L, R, E). 解: 不一致 daG(C) を最小にする G の辺二 部クリーク分割C. BiCoClust と同様に, 問題 BiEgCoClust もラベル なしで完全でない二部グラフで定義することができる. アルゴリズム??の PivotBiCluster を BiEgCo-Clust 問題を扱えるように拡張したアルゴリズムがア ルゴリズム??の PivotBiClusterEdge である. PivotBiCluster はノードを消去しながらクラスタ を作成するが, PivotBiClusterEdge は辺を消去し ながらクラスタを作成する. アルゴリズム??の 2 行目 より PivotBiClusterEdge は E ̸= ∅ の状態でルー プしているが, PivotBiCluster はアルゴリズム??
procedure PivotBiClusterEdge(G) /* G = (L, R, E): 二部グラフ*/ Γ← ∅; /* Γ: クラスタ集合*/ 1 while E̸= ∅ do 2
select l1∈ L uniform randomly;
3 E1← {(l1, r)| r ∈ N(l1)}; C ← E1; 4 E← E \ E1; /* C: クラスタ*/ L′← L \ {l1}; R′← R \ N(l1); 5 foreach l2∈ L \ {l1} do 6 R1← N(l1)\ N(l2); R2← N(l2)\ N(l1); 7 R1,2← N(l1)∩ N(l2);
With probability min { |R1,2| |R2| , 1 } do 8 begin 9 if |R1,2| ≥ |R1| then 10 E1,2← {(l2, r)| r ∈ R1,2}; 11 C← C ∪ E1,2; E← E \ E1,2; if N (l2) =∅ then L′← L′\ {l2}; 12 end 13 Γ← Γ ∪ {C}; L ← L′; R← R′; 14 output Γ; 15 アルゴリズム 2: PivotBiClusterEdge の 2 行目より L ̸= ∅ の状態でループしているアルゴ リズム??の 10 行目より|R1,2| < |R1| の場合は何も 行わず, 12 行目より N (l2) が空の場合に l2を L′から 削除する. R1,2 = ∅ の場合は PivotBiCluster と PivotBiClusterEdge は何も行わない. 例 3.1 図??の G を考える. 図??より l1を⟨1, 5, 6, 3⟩ 1 a 2 b 3 4 d 5 e 6 f g 2 3 4 d 5 e 6 f g 2 3 6 d g 2 3 d G G1 G2 G3 l1= 1 l1= 5 l1= 6 l1= 3 1 a 2 b 4 d 5 e 6 f 6 g 2 3 d C1 C2 C3 C4 図 1: G から構成されるクラスタ Ci (i = 1, 2, 3, 4) と G の変化 Gj (j = 1, 2, 3). の順番で選んだ場合はクラスタ Ciを形成する. クラス タを形成する過程で Giのように G が変形される. こ の場合はクラスタを形成する場合の確率が必ず 0 か 1 になるためクラスタは一意に定まる. アルゴリズムは Γ1 ={C1, C2, C3, C4} のクラスタ集合を出力する. l1 を変えるとアルゴリズムは異なるクラスタ集合を出力 する. 図??は G から出力される異なるクラスタ集合を 表している. Γ1, Γ2, Γ3, Γ4, Γ5 はそれぞれ l1を (1) ⟨1, 5, 6, 3⟩, (2) ⟨2, 1, 4, 6⟩, (3) ⟨6, 3, 1, 2⟩, (4) ⟨6, 2, 1⟩, (5)⟨6, 1, 3⟩ の順番で選んだクラスタ集合である. 1 a 2 b 2 3 d 4 d 5 e 6 f 6 g 1 a 1 b 2 3 d 4 d 5 e 6 f 6 g 1 a b 2 b 2 3 d 4 d 5 e 6 f g 1 a 1 b 2 3 d 4 d 5 e 6 f g 1 a 2 b 2 3 d 4 d 5 e 6 f g Γ1 Γ2 Γ3 Γ4 Γ5 ⟨1, 5, 6, 3⟩ ⟨2, 1, 4, 6⟩ ⟨6, 3, 1, 2⟩ ⟨6, 2, 1⟩ ⟨6, 1, 3⟩ 図 2: クラスタ集合 Γi (1≤ i ≤ 5). PivotBiCluster と PivotBiClusterEdge の乱 択性の効果を評価するために, これらを決定性に変更し たアルゴリズムを作成する. まず, アルゴリズム??と??の 3 行目でランダムに l1∈ L を選択していた処理を以下のように変更する. select l1∈ argmax{|N(l)| | l ∈ L}; 次に, アルゴリズム??において C← C ∪ {l2} の処理 を|R1,2| ≥ |R2| かつ min{|R1,2| |R2|, 1} が 1 となる場合の み行うように変更する. アルゴリズム??の 7 から 11 行 目は以下のようになる. if|R1,2| > 0 and |R1,2| ≥ max{|R1|, |R2|} then C← C ∪ {l2}; L′← L′\ {l2}; このアルゴリズムを DetPivotBiCluster とよぶ. Det-PivotBiCluster は単一ノードクラスタを出力する処 理をアルゴリズム??の 13 行目のみで行う. 一方,PivotBiClusterEdge に対してアルゴリズム ??の 8 から 13 行目は以下のようになる. if|R1,2| > 0 and |R1,2| ≥ max{|R1|, |R2|} then E1,2← {(l2, r)| r ∈ R1,2}; C← C ∪ E1,2; E← E \ E1,2; if N (l2) =∅ then L′← L′\ {l2}; このアルゴリズムを DetPivotBiClusterEdge と よぶ. これを図??の G に適用すると,⟨6, 1, 3⟩ の順番で l1を選択し, 図??の Γ5が出力される. 二部グラフ (L, R, E) において, n =|L|, m = |R| と すると, PivotBiCluster, PivotBiClusterEdge, DetPivotBiCluster, DetPivotBiClusterEdge の計算時間はいずれも O(nm) 時間である.
4
実験
4.1
人工データによる実験
自然数 a, b, c (a < b) とすると, 4 つの点 (a, b), (a + c, b), (a, b + c), (a + c, b + c) で囲まれた四角を [a, b; c] と する. [a, b; c] を L ={a, . . . , a+c} かつ R = {b, . . . , b+
c} の完全二部グラフとみなす. このような 5 つの四角 形の集合で作成された人工データを Da,bとする a, b∈ {e, o} において e は “排他” を示し, o は “重複” を示す. 1. De,e(排他行列バイクラスタ [?]): [1, 1; 100], [101, 101; 100], [201, 201; 100], [301, 301; 100], [401, 401; 100]. 2. De,o (排他行重複列バイクラスタ [?]): [1, 1; 100], [101, 91; 100], [201, 181; 100], [301, 271; 100], [401, 361; 100]. 3. Do,e (重複行排他列バイクラスタ [?]): [1, 1; 100], [91, 101; 100], [181, 201; 100], [271, 301; 100], [361, 401; 100]. 4. Do,o (重複行列バイクラスタ): [1, 1; 100], [91, 91; 100], [181, 181; 100], [271, 271; 100], [361, 361; 100].
PivotBiCluster (PBC), PivotBiClusterEdge (PBCE), DetPivotBiCluster (DPBC), DetPivotBiClusterEdge (DPBCE) を 4 種類の人工データに対してそれぞれ 20 回ずつ適用し, それぞれの不一致, 実行時間の平均を求 める. さらに, 4 種類の人工データの各ノードの間の辺 を 1 から 10 の確率でそれぞれ反転させたデータにも同 様にアルゴリズムを適用する.
図??は Da,b (a, b∈ {e, o}) に k% の確率で辺を反転 させたデータにアルゴリズムを適用した不一致の平均 を表している. x 軸は辺を反転させた確率を表してお り, y 軸は辺を k% の確率で反転させたデータに対して アルゴリズムを適用した場合の不一致の平均を表して いる. 図??は Da,b (a, b∈ {e, o}) に k% の確率で辺を 反転させたデータにアルゴリズムを適用した実行時間 の平均を表している.
図??より, PBCE, DPBC の方が, PBCE, DPBCE よ りも不一致が小さい傾向にある. これは, PBCE, DP-BCE の出力には, クラスタに割り振られない辺が存在 しないためだと考えられる. 確率的アルゴリズムと決定 性のアルゴリズムを比較した場合, PBCE よりも DP-BCE の方が不一致が大きい傾向にある. 一方, PBC と DPBC の不一致数の大小関係は入力データに依存して いる. De,oや Do,oでは DPBC の方が PBC よりも不 一致数が高くなる傾向がある. De,oや Do,oの次数最大 の頂点は 2 つの四角の完全二部グラフが重なっている 箇所の頂点である. この頂点を l1(ピボット) に選んでし 0 10000 20000 30000 40000 50000 60000 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge De,e 0 10000 20000 30000 40000 50000 60000 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge De,o 0 10000 20000 30000 40000 50000 60000 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge Do,e 0 10000 20000 30000 40000 50000 60000 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge Do,o
図 3: Da,b (a, b∈ {e, o}) に k% の確率で辺を反転させ たデータにアルゴリズムを適用した不一致の平均.
まうことで 2 つの四角の完全二部グラフを高確率で 1 つのクラスタとして出力するため, そのときに大きい不 一致が発生するためであると考えられる.
0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge De,e 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge De,o 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge Do,e 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 1 2 3 4 5 6 7 8 9 10 PivotBiCluster PivotBiClusterEdge DetPivotBiCluster DetPivotBiClusterEdge Do,o
図 4: Da,b (a, b∈ {e, o}) に k% の確率で辺を反転させ たデータにアルゴリズムを適用した計算時間の平均.
4.2
実データによる実験
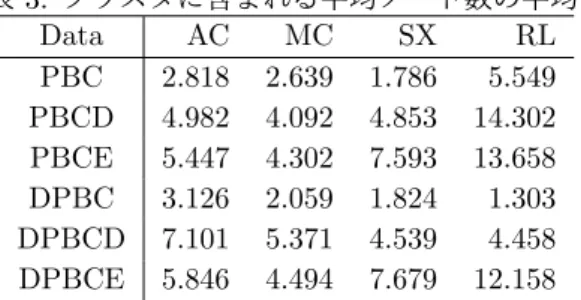
次に, 4 種類の実データに対してそれぞれ 5 回ずつ 適用し, それぞれの不一致, クラスタ数, 一つのクラス タに含まれる平均のノード数, クラスタの半径, ノード の密度, 辺の密度, 実行時間の平均を求める. 実データ は, KONECT から入手した, Crime(MC), Sexual es-corts(SX), Record labels(RL), arXiv cond-mat(AC) を使用する. クラスタの半径 [?] はクラスタの中心ノー ドから, 最も距離が大きいクラスタ内のノードとの距離 とする. クラスタ内の中心のノードは, クラスタ内の他 のノードとの距離の値の合計が最も小さいノードとす る. 距離はノードの間の最短経路の辺の数とする. ノー ドの密度 [?] はクラスタのノード数からクラスタの半 径の 2 乗を割った値とする. 辺の密度は, クラスタ内の ノード間に存在する辺の数から存在する辺と存在しな い辺の和を割った値とする. 表??は各データにアルゴリズムを適用した結果の不 一致である. 表??はクラスタ数の平均である. PBCD と DPBCD は PBC と DPBC で出力したクラスタ集合 から単一ノードクラスタを取り除いた場合を表してい る. ここで, 表??は一つのクラスタに含まれる平均ノー ド数の平均, 表??はクラスタの半径の平均, 表??はクラ スタの密度の平均, 表??はクラスタの辺の密度, 表??は アルゴリズムの平均実行時間をそれぞれ表している. 表 1: 各データをクラスタリングして発生した不一致 の平均. Data AC MC SX RL PBC 31812 670 32730 109805 PBCE 4889 95 4527 42209 DPBC 31932 836 32040 203656 DPBCE 6930 221 5138 164185 表 2: 出力されたクラスタの数の平均. Data AC MC SX RL PBC 13747 523 9371 34321 PBCD 6275 277 1909 11453 PBCE 11559 440 5773 18209 DPBC 12390 670 9170 143263 DPBCD 4319 162 2136 12554 DPBCE 10820 417 5756 18720 表??より単一ノードクラスタを除いた場合, PBCE, DPBCE の出力したクラスタ数の方が PBC, DPBC の 出力したクラスタ数よりも多い. PBC, DPBC を適用 する場合に, ノードを取り除く処理で失われる辺もクラ スタとして出力しているためだと考えられる. DPBC, DPBCE の出力の辺の密度は, PBC, PBCE の出力よりも小さくなると考えられる. 次数が大きい表 3: クラスタに含まれる平均ノード数の平均. Data AC MC SX RL PBC 2.818 2.639 1.786 5.549 PBCD 4.982 4.092 4.853 14.302 PBCE 5.447 4.302 7.593 13.658 DPBC 3.126 2.059 1.824 1.303 DPBCD 7.101 5.371 4.539 4.458 DPBCE 5.846 4.494 7.679 12.158 表 4: クラスタの半径の平均. Data AC MC SX RL PBC 1.253 1.105 1.131 1.065 PBCE 1.218 1.095 1.160 1.092 DPBC 1.350 1.197 1.113 1.127 DPBCE 1.234 1.129 1.165 1.177 表 5: クラスタに含まれるノードの密度の平均. Data AC MC SX RL PBC 3.710 3.653 4.084 11.849 PBCE 4.314 3.901 6.584 11.431 DPBC 5.075 4.543 4.087 3.210 DPBCE 4.586 3.718 6.573 4.487 表 6: クラスターに含まれる辺の密度の平均. Data AC MC SX RL PBC 0.962 0.972 0.964 0.982 PBCE 0.965 0.975 0.957 0.976 DPBC 0.927 0.942 0.966 0.963 DPBCE 0.947 0.950 0.950 0.922 表 7: アルゴリズムの実行時間の平均. Data AC[s] MC[s] SX[s] RL[s] PBC 64.527 0.102 6.659 196.083 PBCE 92.093 0.135 25.977 322.839 DPBC 193.070 0.378 95.770 15195.080 DPBCE 110.510 0.188 40.492 1317.856 左ノードをピボットに選ぶ場合, 他の左ノードとの共通 の隣接右ノードとピボットの隣接右ノードとの割合が 小さくなると考えられるからである. しかし表??より, いくつか DPBC, DPBCE の出力の辺の密度が, PBC, PBCE の出力の辺の密度よりも大きい値となっている.
5
まとめ
本論文では, 二部相関クラスタリングの拡張として, 二部辺相関クラスタリングを定式化し, 二部相関クラス タリングの 4 近似乱択アルゴリズム PivotBiCluster を 修正することで, 二部辺相関クラスタリングの乱択ア ルゴリズム PivotBiClusrerEdge を設計した. また, 乱 択性を決定性に変更したアルゴリズムを設計すると共 に, 人工データと実データに適用し, その結果について 考察した. 今後の課題として, 各アルゴリズムのクラス タを解析すること, および, 二部辺相関クラスタリング の NP 困難性や PivotBiClusterEdge の近似保証可能性 について解明することが挙げられる.参考文献
[1] N. Alion, N. Avigdor-Elgrabli, E. Liberty, A. van Zuylen: Improved approximation algo-rithms for bipartite correlation clustering, SIAM J. Comput. 41, 1110–1121, 2012.
[2] J. Leskovec, A. Rajaraman, J. D. Ullman: Min-ing of Massive Datasets, Cambridge University Press, 2014.
[3] N. Amit: The bicluster graph editing problem, Master Thesis, Tel Aviv University, 2004.
[4] M. Asteris, A. Kyrillidis, D. Papailiopoulos, A. G. Dimakis: Bipartite correlation cluster-ing: Maximizing agreements, Proc. AISTATS’16, 121–129, 2016.
[5] S. C. Madeira, A. L. Oliveira: Biclustering al-gorithms for biological data analysis: A survey, IEEE Trans. Comput. Bio. Bioinfo. 1, 24–45, 2004.