AltPS:原子局所環境の類似性に基づくタンパク質表面の構造アライメントツール
6
0
0
全文
(2) Vol.2010-BIO-20 No.6 2010/3/4. 情報処理学会研究報告 IPSJ SIG Technical Report. radius of less than 5 ˚ A are grouped into a “local area.”. 2. Methods. (3). Two local areas lqi and ltj are selected, in which the central atoms of lqi and. 2.1 Definition of Similarities in Local Atomic Environments. ltj are surface atom i on protein q and surface atom j on protein t, respectively.. タンパク質表面領域の特徴を簡潔に記述する方法として、我々の以前の研究13) における. If there is a strong similarity between the feature vectors of atoms i and j (s3ij. 特徴ベクトルを採用した。これは、タンパク質の任意の表面原子 (溶媒露出原子)i について、. ≥ 0.8), the 3D structure of lqi will be superposed on ltj , and the similarity is. その原子局所環境をベクトルで表現したものとなっていて、以下に示されるように、物理化. calculated as follows.. 学的性質の成分ごとに近傍の表面原子 j の個数 (相対距離により換算した値) を加算するこ. a. The similarities, s1ab , are calculated for each atom pair, where a is an atom. とで得られる。. Ci (k) =. ∑(. 1 2 6 hAT (k), hAT (k), ..., hAT (k) ij ij ij. ). of lqi and b is an atom of ltj . (k = 1, 2, 3). b. A pair of similar atom triads (s1ab ≥ 0.85) is taken from local areas lqi and. (1). ltj .. j∈V i. ここで、V i は原子 i の近傍原子の集合である。AT 1 から AT 6 は、原子 j の物理化学的性. c. The 3D coordinates of the atoms of lqi are transformed by translation and. 質 (cation (AT1), anion (AT2), hydrogen-bond donor (AT3), hydrogen-bond acceptor. rotation that best superpose its atom triad onto the atom triad of ltj , by. (AT4), hydrophobic (AT5), and none of these (AT6)) を示し、PATTY アルゴリズム14). applying the Kabsch algorithm15) .. x により定義される。また、hAT (k) は、|dij − (k − 1)dc |/dc ≤ 1 かつ原子 j の属性が AT x ij. のとき. x hAT (k) ij. = a (1 − |dij − (k − 1)dc |/dc ). x その他の場合、hAT (k) ij. d. The similarity between superposed local areas lqi and ltj , S local =. ∑. = 0 である。また、. s1kl /N , are calculated. Here, k is an atom of lqi , l is the atom ˚, and of ltj and is selected as a counterpart of k if it is located within 2.5 A k∈lqi. 原子 j がドナーとアクセプターの両方の性質を持つ場合 a = 0.5、その他の場合 a = 1 とす ˚) なお、k の値が小 る。dij は原子 i と j の距離、dc は基準距離 (デフォルトで dc = 3.2 A. N is the number of constituent atoms in lqi . e. If S local is greater than or equal to 0.8, the pair lqi and ltj is defined as a. さいほど、Ci (k) は原子 i に近い距離の特徴を保持することとなる。 さらに、原子 i, j 間の類似度として、 Ci (k) と Cj (k) 間の Tanimoto coefficients. (T c) を 利 用 し 、次 の 2 つ を 定 義 し た 。s1ij. ∑3. k=1. =. T c (Ci (1), Cj (1)) and s3ij. “similar local area pair” and proceed to step (4).. =. f. Another pair of similar atom triads is selected and repeat from step (c).. T c (Ci (k), Cj (k)) /3. なお、s3 は s1 よりも広範囲の周辺環境の類似性を示して. (4). いる。ここで、2 つのベクトル A,B 間の Tanimoto coefficients は次式で計算される。. {. Select another two local areas and repeat (3). Repeat this process until there are no more new pairs.. }. T c (A, B) = A · B/ |A|2 + |B|2 − A · B .. (5). 2.2 Algorithm. Since the “similar local area pairs” in (3) and (4) are obtained as isolated fragments, they are subjected to the following clustering procedure.. 2 つのタンパク質 q, t の 3D 構造データ (PDB 形式) を AltPS に入力すると、以下に示す. When local areas lq1 and lq2 of protein q are selected from members of “similar. 手順で q, t の類似表面が計算される。. local area pairs,” they are clustered by imposing the following conditions.. (1). and then solvent-accessible atoms (ASA > 0) are extracted as surface atoms.. a. The distance between the central atoms of lq1 and lq2 should be less than ˚. 10 A. Moreover, the feature vectors, Ci (k), of these atoms are calculated by using. b. When the (virtual) local areas lq1 and lq2 separately superposed onto each. (2). The solvent-accessible surface area (ASA) of each protein atom is calculated. equation (1).. counterpart (designated as the “similar local area pair”) on protein t by the. By considering individual surface atoms as central atoms, surface atoms with a. method described in (3) are defined as lq1′ and lq2′ , respectively, the distance. 2. c 2010 Information Processing Society of Japan ⃝.
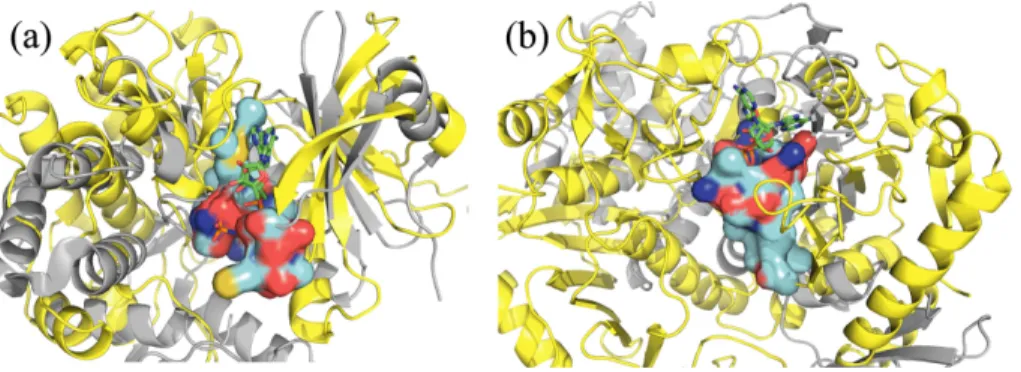
(3) Vol.2010-BIO-20 No.6 2010/3/4. 情報処理学会研究報告 IPSJ SIG Technical Report. between the central atoms of lq1′ and lq2′ should be less than 10 ˚ A. c. The difference between the interatomic distance of the central atoms in lq1 and lq2 and the interatomic distance of the central atoms in lq1′ and lq2′ should ˚. be less than 4 A d. The difference between the angle formed by the normal vectors of lq1 and lq2 and the angle formed by the normal vectors of lq1′ and lq2′ should be less than 30◦ . Here, the direction of the normal vector is directed outward (toward the solvent region) from the central atom of the local area (which is defined as the origin). e. When a merged region of lq1 and lq2 and a merged region of the counterparts 図 1 検出された類似表面。(a) insulin receptor (PDB code 1ir3), (b) insulin-like growth factor 1 receptor (PDB code 1k3a) の表面。配列相同性は 79.3%である。検出された類似表面を赤で表示した。図中の A は 表面構造の違いが大きい領域を示している。. of protein t are hypothetically superposed, the similarity S local between these merged regions should be more than 0.7. When lq1 and lq2 are clustered, the crossover of atoms between lq1 and lq2 is eliminated.. indicating the highest similarity.. This process is repeated for all pairs in the local area of protein q that are. 3. Results. the members of the “similar local area pairs,” and they are clustered by single. AltPS を、配列ホモロジーを有するペア、配列類似性は低いがフォールドが同じペア、. linkage clustering. In this manner, several surface regions, which are formed by the union of local areas of protein q, are. q obtained:{R1q , R2q , · · · , RN }.. フォールドが異なるペアのタンパク質について適用した結果を以下に示す。なお、計算には. Athlon 64 1CPU(2.2GHz) の linux マシンを使用した。. Since each local area of protein q (if these areas are members of “similar local area pairs”) has a counterpart local area in protein t, clusters of lo-. 3.1 ATP-binding Protein ATP は配列やフォールドの異なる数多くのタンパク質と結合するため、ATP-binding. cal areas of protein t are obtained by merging the counterpart local areas for q each of {R1q , R2q , · · · , RN }.. {. (6). }. protein は表面構造類似性を調べる良いサンプルとなる。まず、insulin receptor (PDB code. As a result, the surface regions of protein t are. t obtained: R1t , R2t , · · · , RN .. 1ir3) と insulin-like growth factor 1 (IGF1) receptor (PDB code 1k3a) について類似表. Each surface area Rkq (k = 1, · · · , N ), which was obtained in (5), is super-. 面を計算した。これらのタンパク質は、配列相同性が 79.3%と高く、SCOP16) の分類では. posed onto Rkt by the same process as in (3), and the final similarity score. 同じファミリー (protein kinases, catalytic subunit) に属している。計算の結果、ほぼ全表. s1ij /Nk∗ for the pair of Rkq and Rkt is calculated. Here, i and (i,j)∈Ak. 面を覆う一つの大きなクラスターが検出された (図 1 の赤で示す領域)。Z-score = 65.2 で. j denote atoms of Rkq and Rkt , respectively; Ak denotes aligned atom pairs be-. あり、計算時間は 8 分 41 秒であった。この例のように構造類似性の高いタンパク質ペアに. tween Rkq and Rkt (i and j are defined as an aligned atom pair when i and j are ˚ from each other and are of the same atom types acwithin a distance of 2.5 A. ついては、違いが大きい領域を自動的に抽出することにも利用できる (図中の A)。. Sk =. ∑. Nk∗. 配列類似性の低いケースの計算結果を図 2 に示す。図 2(a) は insulin receptor (PDB code. is the smaller of the numbers of constituent atoms. 1ir3) と aminoglycoside 3’-phosphotransferase (PDB code 2b0q) の検出された類似表面で. between Rkq and Rkt . Here, the range of S values is between 0 and 1, with 1. ある。互いに異なる SCOP 分類のファミリーに属するが、スーパーファミリーは共に protein. cording to PATTY); and. 3. c 2010 Information Processing Society of Japan ⃝.
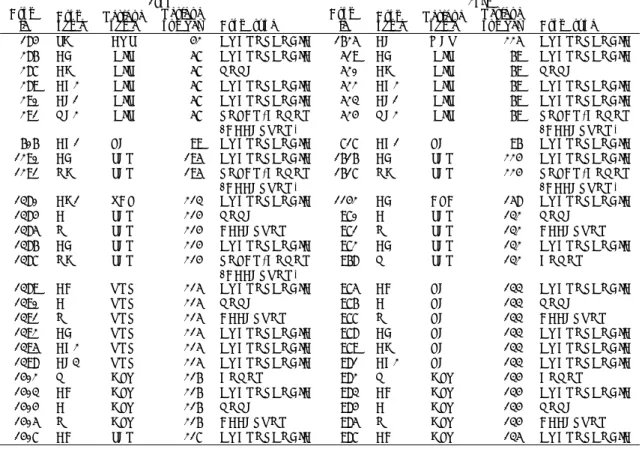
(4) Vol.2010-BIO-20 No.6 2010/3/4. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 2 ATP 結合部位の検出。(a) insulin receptor (PDB code 1ir3, 黄色リボン) と aminoglycoside 3’phosphotransferase (PDB code 2b0q, 灰色リボン) の検出された類似表面。それぞれのリガンド (ANP と ADP) をスティック形式で示す。(b) phosphoenolpyruvate carboxykinase (PDB code 1k3c, 黄色 リボン) と ABC transporter (PDB code 1oxu c-chain, 灰色リボン) の検出された類似表面。リガンド (ADP) をスティック形式で示す。AltPS によりスーパーポーズされた類似表面をコノリー表面で表示した。 図 3 触媒活性部位の検出。trypsin (PDB code 1tpo, シアン) と subtilisin(PDB code 2prk, 黄色) において 検出された類似表面をスーパーポーズした図。catalytic triad を構成する残基が検出された (Ser195-Ser224 と His57-His69)。. kinase-like である。Z-score が 4.2 で検出されたクラスターが図示されている。図 2(b) は phosphoenolpyruvate carboxykinase (PDB code 1k3c) と ABC transporter (PDB code 1oxu c-chain) における類似表面であり、互いに異なる SCOP のフォールドに属している。. 較対象をポケット領域などの “機能が予測される部位” に絞り込む必要が無いため、重要な. Z-score は 5.5 であった。それぞれの計算時間は (a)7 分 38 秒、(b)8 分 13 秒である。共に. 類似領域が前処理 (機能部位予測) の段階で見落とされるリスクを軽減できる。. ATP 結合部位周辺 (特にリン酸基結合領域) が類似部分として検出された。. AltPS は、局所領域の幾何学的および物理化学的性質を特徴ベクトルに変換し、初期段. 3.2 Proteins Having Different Folds. 階での比較領域の絞込みを効率的に行うことで計算量を削減している。さらに、タンパク質. trypsin と subtilisin は共にセリンプロテアーゼであり、全体のフォールド構造は異なる. 表面形状の記述に溶媒露出原子の中心座標のみを利用した事も、計算量の大幅な削減に貢. が、共通の機能 (catalytic triad, Ser, His, Asp) を持つことが知られている。そこで、AltPS. 献している。これは、タンパク質表面の局所的な凹凸形状を正確には表現できないものの、. を用いて trypsin (PDB code 1tpo) と subtilisin (PDB code 2prk) の表面を比較した。図 3. 表面原子のアラインメントを効率的に得るには充分であった。. に検出した類似表面領域を示す。Z-score は 5.3、計算時間は 2 分 32 秒であった。表 1 に. また、AltPS は検出した各類似領域の統計スコア (Z-score) を算出する。類似領域のサイ. 図 3 の結果に対応する原子アラインメントを示す。catalytic triad の内 2 残基のアライン. ズ (構成原子数) が大きいほど類似スコア S が小さくなる傾向があることから、これを補正. メント (Ser195-Ser224 and His57-His69) が得られた。これは Schmitt らの結果10) と良く. するために導入した。Z-score が高いほど重要な類似箇所である可能性が高いため、研究対. 一致している。なお、AltPS により Z-score ≥ 3 のクラスターが全部で 4 つ検出されたが、. 象として注目する表面領域の絞り込みに有効である。実際に、RESULTS で示した例では. 図 3 で示した領域の Z-score が最も高かった。. Z-score の高い領域 (≥ 4) は数箇所∼10 箇所程度と少なく、さらに、その上位にリガンド 結合部位などが検出されている。. 4. Discussion. 本バージョンの AltPS は pirewise 計算に特化したものとなっているが、今後は、多数の. AltPS は、タンパク質の表面全体を隈なく比較して類似領域を検出するツールである。比. PDB を含むデータセットに対して効率的な検索ができるように改良していきたい。. 4. c 2010 Information Processing Society of Japan ⃝.
(5) Vol.2010-BIO-20 No.6 2010/3/4. 情報処理学会研究報告 IPSJ SIG Technical Report 表 1 AltPS により検出した trypsin (1tpo) と subtilisin (2prk) の類似表面領域 (図 3) についての原子アラインメント。 1tpo 2prk Atom Residue Atom Residue Atom Residue Atom Residue id name name number Atom type id name name number Atom type. 参. 184 286 287 289 290 291. SG CB CG CD2 CE1 NE2. CYS HIS HIS HIS HIS HIS. 42 57 57 57 57 57. 606 1290 1291. CD1 CB OG. LEU SER SER. 99 195 195. 1380 1384 1385 1386 1387. CG1 C O CB OG. VAL SER SER SER SER. 213 214 214 214 214. 1389 1390 1391 1392 1395 1398 1402 1403 1404 1405 1407. CA C O CB CD2 CE3 N CA C O CA. TRP TRP TRP TRP TRP TRP GLY GLY GLY GLY SER. 215 215 215 215 215 215 216 216 216 216 217. 考. 文. HYDROPHOBIC HYDROPHOBIC NONE HYDROPHOBIC HYDROPHOBIC POLAR(DONOR /ACCEPTOR) HYDROPHOBIC HYDROPHOBIC POLAR(DONOR /ACCEPTOR) HYDROPHOBIC NONE ACCEPTOR HYDROPHOBIC POLAR(DONOR /ACCEPTOR) HYDROPHOBIC NONE ACCEPTOR HYDROPHOBIC HYDROPHOBIC HYDROPHOBIC DONOR HYDROPHOBIC NONE ACCEPTOR HYDROPHOBIC. 1625 519 520 522 523 524. CE CB CG CD2 CE1 NE2. MET HIS HIS HIS HIS HIS. 225 69 69 69 69 69. 717 1616 1617. CD1 CB OG. LEU SER SER. 96 224 224. 1142 970 971 972 968. CB C O CB N. ALA SER SER SER SER. 158 132 132 132 132. HYDROPHOBIC HYDROPHOBIC NONE HYDROPHOBIC HYDROPHOBIC POLAR(DONOR /ACCEPTOR) HYDROPHOBIC HYDROPHOBIC POLAR(DONOR /ACCEPTOR) HYDROPHOBIC NONE ACCEPTOR HYDROPHOBIC DONOR. CA C O CB CG CD2 N CA C O CA. LEU LEU LEU LEU LEU LEU GLY GLY GLY GLY GLY. 133 133 133 133 133 133 134 134 134 134 135. HYDROPHOBIC NONE ACCEPTOR HYDROPHOBIC HYDROPHOBIC HYDROPHOBIC DONOR HYDROPHOBIC NONE ACCEPTOR HYDROPHOBIC. 975 976 977 978 979 981 982 983 984 985 987. binatorial extension (CE) of the optimal path, Protein Eng, Vol. 11, pp. 739–747 (1998). 5) Weber, A., Casini, A., Heine, A., Kuhn, D., Supuran, C., Scozzafava, A. and Klebe, G.: Unexpected nanomolar inhibition of carbonic anhydrase by COX-2-selective celecoxib: new pharmacological opportunities due to related binding site recognition, J Med Chem, Vol.47, pp.550–557 (2004). 6) Kinoshita, K., Sadanami, K., Kidera, A. and Go, N.: Structural motif of phosphatebinding site common to various protein superfamilies: all-against-all structural comparison of protein-mononucleotide complexes, Protein Eng, Vol.12, pp.11–14 (1999).. 献. 1) Holm, L. and Sander, C.: Dali: a network tool for protein structure comparison, Trends Biochem Sci, Vol.20, pp.478–480 (1995). 2) Orengo, C. and Taylor, W.: SSAP: sequential structure alignment program for protein structure comparison, Methods Enzymol, Vol.266, pp.617–635 (1996). 3) Gibrat, J., Madej, T. and Bryant, S.: Surprising similarities in structure comparison, Curr Opin Struct Biol, Vol.6, pp.377–385 (1996). 4) Shindyalov, I. and Bourne, P.: Protein structure alignment by incremental com-. 5. c 2010 Information Processing Society of Japan ⃝.
(6) Vol.2010-BIO-20 No.6 2010/3/4. 情報処理学会研究報告 IPSJ SIG Technical Report. 7) Brakoulias, A. and Jackson, R.: Towards a structural classification of phosphate binding sites in protein-nucleotide complexes: an automated all-against-all structural comparison using geometric matching, Proteins, Vol.56, pp.250–260 (2004). 8) Sael, L., La, D., Li, B., Rustamov, R. and Kihara, D.: Rapid comparison of properties on protein surface, Proteins, Vol.73, pp.1–10 (2008). 9) Kinoshita, K., Murakami, Y. and Nakamura, H.: eF-seek: prediction of the functional sites of proteins by searching for similar electrostatic potential and molecular surface shape, Nucleic Acids Res, Vol.35, pp.W398–W402 (2007). 10) Schmitt, S., Kuhn, D. and Klebe, G.: A new method to detect related function among proteins independent of sequence and fold homology, J Mol Biol, Vol.323, pp.387–406 (2002). 11) Angaran, S., Bock, M., Garutti, C. and Guerra, C.: MolLoc: a web tool for the local structural alignment of molecular surfaces, Nucleic Acids Res, Vol. 37, pp. W565–W570 (2009). 12) Shrestha, N. L., Kawaguchi, Y. and Ohkawa, T.: SUMOMO: A Protein Surface Motif Mining Module, International Journal of Computational Intelligence and Applications, Vol.4, No.4, pp.431–450 (2004). 13) Minai, R., Matsuo, Y., Onuki, H. and Hirota, H.: Method for comparing the structures of protein ligand-binding sites and application for predicting protein-drug interactions, Proteins, Vol.72, pp.367–381 (2008). 14) Bruce, L.B. and Sheridan, R.P.: PATTY: a programmable atom typer and language for automatic classification of atoms in molecular databases, J Chem Inf Comput Sci, Vol.33, pp.756–762 (1993). 15) Kabsch, W.: A solution for the best rotation to relate two sets of vectors, Acta Crystallographica Section A, Vol.32, No.5, pp.922–923 (1976). 16) Murzin, A., Brenner, S., Hubbard, T. and Chothia, C.: SCOP: a structural classification of proteins database for the investigation of sequences and structures, J Mol Biol, Vol.247, pp.536–540 (1995).. 6. c 2010 Information Processing Society of Japan ⃝.
(7)
図

関連したドキュメント
Yamasaki : Formation of Step-Free Surfaces on Diamond (111) Mesas by Homoepitaxial Lateral Growth, Jpn. Inokuma : Anisotropic Lateral Growth of Homoepitaxial Diamond (111) Films
▶原子力をめぐる各領域の関心 環境: 汚染,リスク 医学: 被ばく.
Wach 加群のモジュライを考えることでクリスタリン表現の局所普遍変形環を構 成し, 最後に一章の計算結果を用いて, 中間重みクリスタリン表現の局所普遍変形
つの表が報告されているが︑その表題を示すと次のとおりである︒ 森秀雄 ︵北海道大学 ・当時︶によって発表されている ︒そこでは ︑五
■鉛等の含有率基準値について は、JIS C 0950(電気・電子機器 の特定の化学物質の含有表示方
点検方法を策定するにあたり、原子力発電所耐震設計技術指針における機
表2 試験の種類と条件 試験の 種類 標準 温冷 試験 乾湿 試験... 基盤の表面を水湿しした後に,断面修復材を厚 さ 1cm で塗布した。
仕上の構成 仕上の構成は、表面処理、主仕上、仕上下地及び附合物よりなるものとする。 ア「 表面処理 」とは 、仕上表面の保護又は意匠
