こ の ホ ワ イ ト ペーパーでは、 TSMC 28nm high-k メ タ ル ゲー ト (HKMG) 、高性能、低消費電力 (28nm HPL ま た は 28 HPL) プ ロ セ ス の 選択 を 含 め、 ザ イ リ ン ク ス 28nm 7 シ リ ーズ FPGA の消費電力に関す る 事項につい て さ ま ざ ま な観点で論 じ ます。
28 HPL プ ロ セ ス に よ っ て得 ら れ る 消費電力の利点やザ イ リ ン ク ス製品すべてが も た ら す有用性だけでな く 、 革 新的な アーキ テ ク チ ャ やス タ テ ィ ッ ク 電力、 ダ イ ナ ミ ッ
ク 電力、 お よ び I/O 電力を削減す る ための機能について も 説明 し てい ます。
ホワ イ ト ペーパー : 7 シ リ ーズ FPGA
WP389 (v1.1) 2011 年 6 月 13 日
28nm プ ロ セス を採用 し た
7 シ リ ーズ FPGA で消費電力を削減
著者 : Jameel Hussein、Matt Klein、Michael Hart
は じ めに
は じ めに
FPGA の消費電力は FPGA 選定におけ る 重要な要素 と な っ てい ます。 絶対的な消費電力、 使用可能なパ フ ォーマ ン ス、 バ ッ テ リ ー寿命、 熱課題、 あ る いは信頼性の どれを考慮 し て選択す る 場合で も 、 その中 心であ る のが消費電力です。 ザ イ リ ン ク ス は、 こ れま で何年に も わた っ て消費電力削減に注力 し てお り 、 Virtex®-4 FPGA の開発では ト リ プルオキサ イ ド を使用す る こ と で、 ス タ テ ィ ッ ク 電力の飛躍的な削減 に成功 し ま し た。 さ ら に、Virtex-4 デバ イ ス では、FPGA の ス タ テ ィ ッ ク 電力の温度変動を モデル化 し て提供 し てい ます (WP221 『ス タ テ ィ ッ ク 電力お よ び現実的なジ ャ ン ク シ ョ ン温度解析の重要性』 を参 照)。 ザ イ リ ン ク ス は、 プ ロ セ ス の変更や改善、 アーキ テ ク チ ャ の変更、 電圧ス ケー リ ン グ製品、 ソ フ ト ウ ェ アでの消費電力最適化な ど、 さ ま ざ ま消費電力削減方法についての検討 と 実装を継続的に行っ てい ます。
ザ イ リ ン ク ス の 7 シ リ ーズ FPGA (Artix™-7、Kintex™-7、 お よ び Virtex-7) では、 ス タ テ ィ ッ ク 電力、
ダ イ ナ ミ ッ ク 電力、I/O 電力に対す る 電力削減方法の効果がすべて評価 さ れてい ます。 ま た、 新 し いテ ク ノ ロ ジの導入、 製品化ま での時間、 パフ ォーマ ン ス、 ソ フ ト ウ ェ ア、 ダ イ 面積への影響な ど の リ ス ク お よ びその コ ス ト についての追加調査 も 実施 し てい ます。 こ のホ ワ イ ト ペーパーでは、 ザ イ リ ン ク ス の 最新 28nm 7 シ リ ーズ FPGA の消費電力に関わ る 事項について さ ま ざ ま な観点で論 じ る と 共に、28 HPL プ ロ セ ス の選択、 すべてのザ イ リ ン ク ス製品におけ る 消費電力 と 有用性の利点、 ス タ テ ィ ッ ク 電力、 ダ イ ナ ミ ッ ク 電力、I/O 電力を削減す る ための革新的な アーキ テ ク チ ャ や機能について も 説明 し てい き ま す。
適切な プ ロ セス技術の選択
ザ イ リ ン ク ス では、 各プ ロ セ ス ノ ー ド におけ る 製品 リ リ ース に先立っ て、 革新的なプ ロ セ ス技術の調査 や さ ま ざ ま なオプシ ョ ン を ど の よ う に FPGA アーキ テ ク チ ャ で適合 さ せ る かの決定 ま でに数年を かけ て い ま す。 そ し て、 そ の調査ではパ フ ォ ーマ ン ス、 消費電力、 製造の容易 さ に重点 を 置い て い ま す。
TSMC は 28nm に対 し て、28 LP、28 HP、28 HPL の 3 つのプ ロ セ ス を提供 し てい ます。 ザ イ リ ン ク ス 7 シ リ ーズ FPGA での最適な選択は 28 HPL プ ロ セ ス で、消費電力 と パフ ォーマ ン ス が重要な決定要 素 と な り ま し た (ザ イ リ ン ク スプ レ ス リ リ ース、「ザ イ リ ン ク ス、 高性能かつ低消費電力の 28nm プ ロ セ ス を採用」 を参照)。
ザ イ リ ン ク ス は、7 シ リ ーズ FPGA の製品決定段階で実現可能な あ ら ゆ る 28nm プ ロ セ ス技術について 検討 し ま し た。 そ し て非常に早い段階で、FPGAアプ リ ケーシ ョ ン におけ る HKMG ト ラ ン ジ ス タ 技術 の優位性を認識 し 、 フ ァ ウ ン ド リ パー ト ナー と 密接に協力 し て、 こ の技術の確立 と 開発を行い ま し た。
HKMG は (40nm お よ び従来の Poly/SiON (ポ リ シ リ コ ン/シ リ コ ンオキ シナ イ ト ラ イ ド)と 比較 し て) パ フ ォーマ ン ス の飛躍的な向上を可能 と し 、高性能で低価格な FPGA を実現す る 統一アーキ テ ク チ ャ を採 用す る 機会を生み出 し ま し た。 低消費電力のためのパフ ォーマ ン ス に関す る い く つかの ト レー ド オ フ に よ り 、 他社 40nm 製品において報告 さ れてい る ス タ テ ィ ッ ク 電力の問題を軽減 し てい ます。
適切な プ ロ セス技術の選択
統一アーキテ ク チ ャ
7 シ リ ーズ FPGA におけ る 統一アーキ テ ク チ ャ は、 高性能な領域を備えつつ、 飛躍的な消費電力削減を 可能 と す る 28 HPL プ ロ セ ス をベース と し てい ます。(HP プ ロ セ ス と 比較 し て) リ ー ク 電流の低い HPL プ ロ セ ス を採用す る こ と で、FPGA デザ イ ンにおけ る 複雑で高 コ ス ト の ス タ テ ィ ッ ク 電力の管理が不要 と な り 、 予定通 り の市場出荷、 新たな製品機能、 し っか り と し た設計、 性能強化に集中す る こ と が可能 と な り ます。 量産かつ高性能な FPGA 全体でアーキ テ ク チ ャ が統一 さ れてい る こ と は、FPGA 業界でほ かにな く 、 次の よ う な利点を も た ら し ます。
• 異な る FPGA デバ イ ス間お よ びフ ァ ミ リ 間の移行が容易
• お客様の コ ー ド や IP が再利用可能
• 共通ブ ロ ッ ク (ブ ロ ッ ク RAM、DSP、I/O、 ク ロ ッ キ ン グ、 相互接続 ロ ジ ッ ク 、 メ モ リ イ ン タ ーフ ェ イ ス)
28 HPL プ ロ セスの利点
28 HPL プ ロ セ ス技術は、28 HP プ ロ セ ス で使用 さ れ る SiGe 埋め込みプ ロ セ ス に見 ら れ る 歩留 ま り や リ ー ク 問題を回避 し 、 よ り コ ス ト 効率の良いプ ロ セ ス ソ リ ュ ーシ ョ ン を提供 し ます。HPL プ ロ セ ス の 大規模デザ イ ン のマージ ン (電圧マージ ン) は、 よ り 広い VCC 動作範囲の選択を許容 し て、28 HPプ ロ セ ス では不可能な、 電力/性能の柔軟な組み合わせを可能 と し ます。28 HPL には次に示す よ う な利点が あ り ます。
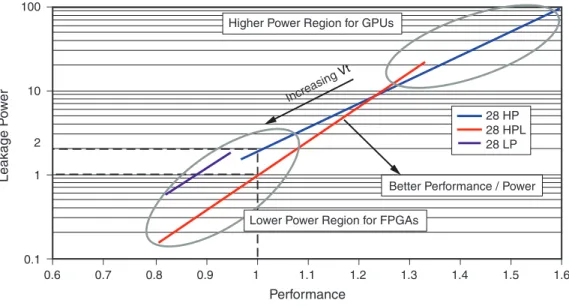
• 高性能モー ド (VCC = 1.0V) : 28 HPL は FPGA の タ ーゲ ッ ト 性能範囲で、 ス タ テ ィ ッ ク 電力を低 く 抑えた状態の 28 HP よ り も 高い性能を提供 し ます (図1 参照)。
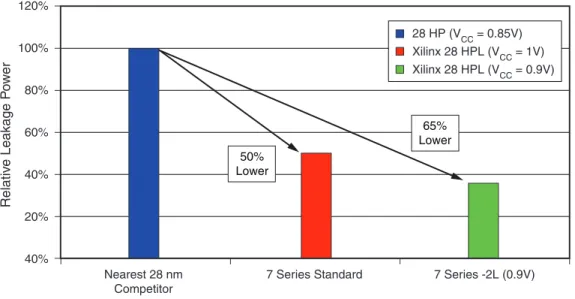
• 低消費電力モー ド (VCC= 0.9V) : 28 HPL は 28 HP よ り も 65% 低い ス タ テ ィ ッ ク 電力を実現 し ま す。28 HPL での電圧マージ ンは Vcc = 0.9V において も 、 良好な性能分布を示 し ます (図1 参照)。 ま た、 ダ イ ナ ミ ッ ク 電力 も こ の低い電圧に よ り ~20% 削減 さ れます。
• Adaptive Voltage Scaling (AVS) ま たは Voltage ID (VID) モー ド : こ れ ら のモー ド は VCC を制御す る こ と で電力削減を可能 と し 、 一部のデバ イ ス では さ ら な る 性能向上に活用 さ れてい ます。VID で は特にデバ イ ス ご と に電圧 ID が格納 さ れてい ます。 読み出 し 可能な電圧 ID は、 必要な性能を満足 す る 最小電圧を示 し ます。
低消費電力モー ド の優位点は、28 HPL プ ロ セ ス におけ る 電圧マージ ンに よ っ て も た ら さ れてい ます。
適切な プ ロ セス技術の選択
ス タ テ ィ ッ ク 消費電力が重要ではない場合、28 HP 技術は高性能製品に良い選択肢 と な り ます。 歴史的 には MPU や GPU ク ラ ス製品では、65nm お よ び 40nm ノ ー ド において HP (G) タ イ プのプ ロ セ ス が使 用 さ れて き ま し たが、 こ れ ら の製品の電力は複雑な ヒ ー ト シ ン ク を必要 と す る よ う な非常に高い レベル に達 し ま し た。FPGA は電力レベルの許容範囲での性能低下を引 き 替えに し つつ も 、 こ れに追従 し ま し た。 し か し 、 28nm HP (G) プ ロ セ ス では、MPU や GPU 製品では ま だ許容可能であ っ て も 、FPGA で は受け入れ る こ と ので き ない、 さ ら に高い電力レベルに達 し ます。
こ の よ う な電力レベルは FPGA には適 し てい ません。 あいに く 、28 HP では高い ス タ テ ィ ッ ク 電力レベ ルで高性能を提供 し よ う と い う 傾向が続いてい ます。FPGA の場合、28 HP 技術で妥当な ス タ テ ィ ッ ク 電力レベルを使用す る と 、主に こ のプ ロ セ ス では VCC 動作電圧が低い こ と に関連 し て電圧マージ ンが低 いために、 大 き な性能低下を引 き 起 こ し ます。 こ の よ う な性能低下は温度お よ びプ ロ セ ス の厳 し い部分 では機能的な障害が発生す る な ど、 顕著 と な り ま す。 電圧マージ ン は VCC - VTで求め ら れ ま す (VCC
=コ ア電圧、VT = し き い値電圧)。
28 HPL は、 リ ー ク 電流の低いポ イ ン ト で、 28 HP よ り も 良好な性能/電力特性を提供 し 、 よ り 低い リ ー ク 電流領域へ拡張 し ます。 低 リ ー ク 電流領域へ拡張す る こ と で、 ザ イ リ ン ク ス はま っ た く 異な る プ ロ セ ス技術に乗 り 換え る こ と な く 、 低電力な Artix-7 フ ァ ミ リ の製造を可能に し ま し た。
最終的な結果 と し て、28 HP プ ロ セ ス で製造 さ れ る 競合 FPGA で、Virtex-7 FPGA を超え る 性能は実現 で き てい ま せん。 あ る 競合 FPGA 製品では ス タ テ ィ ッ ク 電力が 2 倍以上 と い う 大 き な代償を伴っ てお
り 、 リ ー ク 電流を削減す る こ と が課題 と な っ てい ます (表1 参照)。
X-Ref Target - Figure 1
図 1 : 28 HPL、28 HP、 および 28 LP プ ロ セスにおける性能 と リ ー ク 電流の比較 100
10
1 2
0.1
Leakage Power
0.9 0.8
0.7
0.6 1 1.1 1.2 1.3 1.4 1.5 1.6
WP389_01_060911
Performance
28 HP 28 HPL 28 LP
Better Performance / Power Increasing
Vt Higher Power Region for GPUs
Lower Power Region for FPGAs
適切な プ ロ セス技術の選択
28 HPL ではプ ロ セ ス のば ら つ き 、 電圧、 お よ び温度へのセ ン シ テ ィ ビ テ ィ が、 主に設計マージ ンが大 き く な っ た こ と に よ り 、28 HPよ り も 大 き く 改善 さ れてい ます。図2 に、28 HPL お よ び 28 HP の各プ ロ セ ス での ト ラ ン ジ ス タ の し き い値電圧 (V) におけ る 電圧マージ ン対性能を示 し ます。
HPL プ ロ セ ス では、 こ の よ う なすべての要素が HP プ ロ セ ス よ り も 容易に電力 と 性能の タ ーゲ ッ ト を満 たすのに役立ち ます。HP プ ロ セ ス と HPL プ ロ セ ス のデバ イ ス上で同 じ デザ イ ン を動作 さ せた場合、 前 者の方がずっ と 早い段階でシ ス テ ムの温度 も し く は電力が上限に到達す る で し ょ う 。 こ の周波数マージ ンは、HPL プ ロ セ ス と ザ イ リ ン ク ス の最適化 さ れた ト ラ ン ジ ス タ 構成の必然的な結果です。 電圧ス ケー リ ン グは HPLプ ロ セ ス の も う 1 つの利点で、 電力、 温度条件が等 し い同一デザ イ ンの消費電力マージ ン を増加 さ せます。図3 に、 こ の概念を図示 し ます。
表 1 : 28 HP における電力削減かつ性能向上のためのプ ロ セステ ク ニ ッ ク Options Other FPGA Vendors 28 HP
Process to Reduce Leakage Xilinx 28 HPL Low Leakage
Low leakage transistors Custom Standard
Low bulk leakage transistors Custom Standard
Judicious use of mixed gate lengths
New
Used by Xilinx since 65 nm (Virtex-5 FPGAs and earlier):
See WP246, Power Consumption in 65 nm FPGAs and WP298, Power Consumption at 40 and 45 nm.
Capacitance 1X 1X
Ability to operate at two different VCC voltages for different power modes
No, due to
lack of headroom Yes
X-Ref Target - Figure 2
図 2 : 28 HPL と 28 HP プ ロ セスにおける性能対電圧マージ ン 0.8
0.7
0.5 0.6
0.4 Headroom (V CC - V T) Volts
0.9 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7
WP389_02_021511
Performance Less Sensitive to VCC and Process
Unusable Region (Too Leaky) Increasing
VT
28 HP 28 HPL Increasing
Headroom
適切な プ ロ セス技術の選択
7 シ リ ーズ FPGA の -3 お よ び -2L デバ イ ス には拡張 (E) 温度範囲 (0 ~ 100°C) のオプシ ョ ンがあ り ま す。28 HPL プ ロ セ ス では設計マージ ンが確保 さ れてい る ため、-2LE デバ イ ス は 1.0V ま たは 0.9V で 動作可能です。 こ のホ ワ イ ト ペーパーでは、 こ れ ら のデバ イ ス を -2L (1.0V) お よ び -2L (0.9V) と 記載 し ます。1.0V で動作す る -2L デバ イ ス は ス ピー ド グ レー ド では -2I お よ び -2C デバ イ ス と 同 じ 性能を 持ち ますが、 ス タ テ ィ ッ ク 電力が大 き く 削減 さ れてい ます。 ま た、0.9V で動作す る -2L デバ イ ス も -1I お よ び-1C デバ イ ス と ほぼ同等の能力を持ちなが ら 、 ス タ テ ィ ッ ク 電力 と ダ イ ナ ミ ッ ク 電力が低 く な っ てい ます。「改善 さ れた電圧ス ケー リ ン グ オプシ ョ ン」を参照 し て く だ さ い。
28 HPL プ ロ セ ス の電圧ス ケー リ ン グデバ イ ス は、HPプ ロ セ ス のデバ イ ス と 比べ、 かつてない レベルで の ス タ テ ィ ッ ク 電力削減を実現 し ます。図4 は、28 HPL と 電圧ス ケー リ ン グに よ っ て リ ー ク 電流が さ
ら に削減 さ れ る こ と を示 し てい ます。
X-Ref Target - Figure 3
図 3 : カ ス タ マーデザイ ンにおける 28nm でのプ ロ セス別の性能マージ ン
X-Ref Target - Figure 4
図 4 : 28 HP と 28 HPL プ ロ セスの リ ー ク電流 Frequency in MHz
WP389_03_060711
Power Headroom from 28 HPL Process
and Voltage Scaling Frequency Headroom
from HPL Process
Additional Frequency Headroom from Voltage Scaling
-2L (0.9V)
28 HP 28 HPL 28 HPL at 0.9V Power/Thermal Limit
Power in Watts
120%
100%
60%
80%
40%
40%
20%
Relative Leakage Power
Nearest 28 nm Competitor
7 Series Standard 7 Series -2L (0.9V)
WP389_04_060711
28 HP (V
CC = 0.85V) Xilinx 28 HPL (V
CC = 1V) Xilinx 28 HPL (V
CC = 0.9V)
50%
Lower
65%
Lower
適切な プ ロ セス技術の選択
HP プ ロ セス と LP プ ロ セス
HPL プ ロ セ ス が低価格、 高性能、 低電力、 そ し て フ ァ ミ リ 間での簡単な移行を提供す る 、 世界 ク ラ ス の FPGA フ ァ ミ リ に と っ て正 し い選択であ る こ と は明 ら かです。 ザ イ リ ン ク スは、HPL プ ロ セ ス に よ り 、 最適な電力範囲内で、2 倍の ロ ジ ッ ク セルを集積で き ま し た。 高集積の 28nm で一層高性能な製品を提 供す る こ と で、 マルチ コ アプ ロ セ ッ サに よ っ て CPU の性能が向上す る の と 同様に、 ユーザーは並列処 理を有効に活用 し て、同 じ 熱お よ び電力要件内で 2 倍のデザ イ ン量を持つ こ と がで き る よ う にな り ます。
HPL プ ロ セ ス に よ っ てザ イ リ ン ク ス は さ ら に、 さ ま ざ ま な コ ス ト と 性能の組み合わせを可能 と す る 統一 アーキ テ ク チ ャ を提供 し てい ます。
HP プ ロ セ ス は 100W 程度で動作す る GPU お よ び CPU を タ ーゲ ッ ト と し 、 その う ち最大 40% が リ ー ク 電力 (~40W) で消費 さ れます。 ダ イ サ イ ズは GPU や CPU と ほぼ同等ですが、40W 程度を総電力 (リ ー ク 電力 と ダ イ ナ ミ ッ ク 電力) の最大値 と す る FPGA では、 こ の リ ー ク 電力量は許容で き ません。
FPGA の許容範囲内に HP プ ロ セ ス での リ ー ク 電力が削減 さ れた と し て も 、 性能は著 し く 減少す る こ と にな り 、 結果的にそのプ ロ セ ス は、 同等の性能の HPL プ ロ セ ス よ り も 非常に高価で複雑な も の と な り ます。
LP プ ロ セ ス は、それほ ど性能を必要 と し ないアプ リ ケーシ ョ ン を タ ーゲ ッ ト と す る 従来の PolySiON プ ロ セ ス で、FPGA には不向 き です。 妥当な性能を得 る には、28 LP は VCC=1.1V で動作 さ せなければな ら ず、HKMG 28nm プ ロ セ ス と 比べ る と 非常に高いダ イ ナ ミ ッ ク 電力にな っ て し ま い ます。 こ のプ ロ セ ス は、 性能の低い携帯電話な ど を タ ーゲ ッ ト と し てい ます (表2 参照)。
HPL プ ロ セ ス の選択は、FPGA 業界で 28G SerDes を リ ー ド す る ザ イ リ ン ク ス の可能性 も 拡げ ま す。
Virtex-7 HT FPGA は業界最高のバン ド 幅 (28G の ト ラ ン シーバーを 16 本、 他社 FPGA ベン ダーの 4 倍) を提供 し ます。
表 2 : 28nm プ ロ セスの比較 Process Normalized
FPGA Speed
Normalized Leakage
Current
Technology
Features Targeted
Applications
28 LP 87% 250%
Legacy PolySiON:
Complex embedded SiGe strain
Legacy low performance cell phones
28 HPL 100% 100% HKMG: Simple rotated
substrate strain
FPGAs, ASICs, and ASSPs
28 HP 100% 220% H K M G : C o m p l e x
embedded SiGe strain GPUs and CPUs
ス タ テ ィ ッ ク、 ダ イ ナ ミ ッ ク、I/O の電力削減
ス タ テ ィ ッ ク 、 ダ イ ナ ミ ッ ク 、 I/O の電力削減
FPGA に正 し い低電力プ ロ セ ス を決定す る には、 おびただ し い技術や調査が必要 と さ れ ます。 し か し 、 プ ロ セ ス レベルでの低電力化が止ま る こ と はあ り ません。ザ イ リ ン ク ス は 28nm ノ ー ド であ ら ゆ る 角度 か ら 電力効率を高め る こ と に力を注ぎ ま し た。 ザ イ リ ン ク ス の電力に対す る 取 り 組みは、 プ ロ セ ス改善、
革新的な アーキ テ ク チ ャ 、 電圧ス ケー リ ン グ、 ソ フ ト ウ ェ アに よ る 最適化な ど広範囲にわた り ます。 ス タ テ ィ ッ ク 、 ダ イ ナ ミ ッ ク 、 あ る いは I/O の電力削減率並びに歩留ま り 、 イ ンプ リ メ ン テーシ ョ ンに伴 う リ ス ク や時間な ど を基準に多数のオプシ ョ ンが評価 さ れま し た。 さ ら に こ れま で と 同様に、 各電力削 減手法は性能、 コ ス ト 、 デザ イ ン フ ロ ーや全体的な ス ケ ジ ュ ールへの影響な ど の点での評価 も 行い ま し た。数多 く の手法が 28nm 7 シ リ ーズ FPGA に適用 さ れ、かつ統一アーキ テ ク チ ャ が採用 さ れた こ と で、
すべての製品フ ァ ミ リ で低電力機能が利用で き る よ う にな っ てい ます。
ス タ テ ィ ッ ク 電力の削減
28nm ノ ー ド におけ る ス タ テ ィ ッ ク 電力削減の最 も 大 き な要素は TSMC か ら の HPL プ ロ セ ス で、HP プ ロ セ ス よ り も 電力が 50% 低 く な っ てい ます。 それに加え、 ザ イ リ ン ク ス は電力を抑え る ための総合的 な アプ ロ ーチをプ ロ セ スレベルを超え て行い、28nm で改善あ る いは導入 さ れた ス タ テ ィ ッ ク 電力の低 減機能を多数組み込みま し た。(表3 参照)。
表 3 : 7 シ リ ーズ FPGA で使用 さ れている ス タ テ ィ ッ ク 電力削減手法
Reduction Technique Power Savings Reason for Xilinx Choice Use 28 HPL Process 50% savings compared to HP
process
Xilinx co-developed this low-power, high-performance process specifically for FPGAs Transistor Distribution
Optimizations in Integrated Blocks and Core Logic
40–80% reduction compared to previous generation, depending on block, with new high threshold voltage transistors
Xilinx’s investment at design time provides great reduction in leakage for customer applications
Stacked Silicon Interconnect Technology
Saves 40% static power compared to monolithic device of same density
Offers unprecedented power savings in the largest devices ever made
Integrated Blocks Up to 90% reduction in static power compared to soft-IP implementations through reducing the number of transistors
Selecting a set of common blocks needed by many customers allows Xilinx to offer better performance and lower static power. Also, see 表5 for dynamic power benefits.
Power Gating of Unused Blocks Eliminates up to 100% of block RAM leakage depending on utilization
Allows customers to power blocks instead of forcing them to pay a power penalty for blocks they are not using Partial Reconfiguration 80% static power savings if
several sections of logic are swapped in and out of the active design
Unique Xilinx benefit; great static power savings
ス タ テ ィ ッ ク 、 ダ イ ナ ミ ッ ク 、I/O の電力削減
最適な ト ラ ン ジ ス タ 構成
Virtex-6 FPGA ( WP298 『40nm お よ び 45 nm におけ る 消費電力』 参照) で初めて導入 さ れてい ますが、
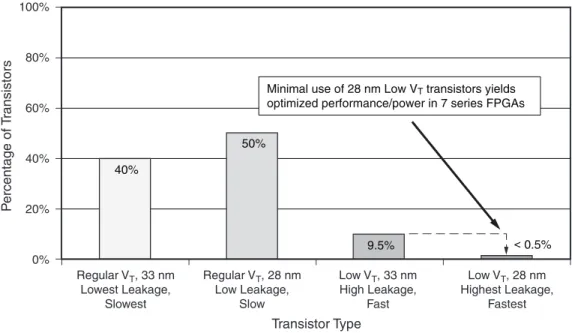
すべての 7 シ リ ーズ FPGA において も ト ラ ン ジ ス タ の選択や前世代 よ り も 優れた ト ラ ン ジ ス タ 構成に よ る 利点を得てい ます。IC 設計者は、 高/標準/低の し き い値電圧お よ びゲー ト 長、 幅の異な る ト ラ ン ジ ス タ を使用で き ます。 各 ト ラ ン ジ ス タ にはそれ自身の リ ー ク 電流 と 性能の特性があ り ます。 高速な ト ラ ン ジ ス タ と 低速な ト ラ ン ジ ス タ の リ ー ク 電流差は、15~20 倍に も な り 得 る こ と に注意す る こ と が重要で す。 可能な限 り リ ー ク 電流を低 く す る ためにザ イ リ ン ク スは、 各ブ ロ ッ ク を設計す る 際に最 も リ ー ク 電 流の低い ト ラ ン ジ ス タ だけ を使用 し て設計を開始 し ま し た。 そ し て、 ブ ロ ッ ク の性能目標を達成す る た めに必要な部分だけ高速 ト ラ ン ジ ス タ に移行 し ま し た。 こ の手法は各ブ ロ ッ ク におけ る 高 リ ー ク 電流の ト ラ ン ジ ス タ を減少 さ せ る ために非常に有効で、標準 (Typical) と 最大 (Maximum) の間のば ら つ き を減 ら し ま し た。HPL プ ロ セ ス と 上手 く 組み合わせ る こ と で、 ザ イ リ ン ク ス は前世代 と 比較 し て 65% の ス タ テ ィ ッ ク 電力の削減を実現 し てい ます (図5 参照)。
Voltage Scaling
-2L Devices Operated at 0.9V
Static power from leakage is approximately proportional to VCCINT3 (i.e., ~30% reduction for 10% lower VCCINT)
Up front IC design verification and implementation of process screen at manufacturing test allows lower power option for users
Lower VCCAUX Voltage from 2.5V to 1.8V
30% savings compared to previous generation on PLL, IDELAY, and other parts of the I/O block
Significantly reduces expensive DC power in the FPGA
表 3 : 7 シ リ ーズ FPGA で使用 さ れている ス タ テ ィ ッ ク 電力削減手法 (続き)
Reduction Technique Power Savings Reason for Xilinx Choice
X-Ref Target - Figure 5
図 5 : 7 シ リ ーズ FPGA の コ ア ロ ジ ッ ク での ト ラ ン ジ ス タ の タ イ プ比率 100%
80%
40%
60%
0%
Percentage of Transistors 20%
Regular VT, 33 nm Lowest Leakage,
Slowest
Regular VT, 28 nm Low Leakage,
Slow
Low VT, 33 nm High Leakage,
Fast
Low VT, 28 nm Highest Leakage,
Fastest Minimal use of 28 nm Low VT transistors yields optimized performance/power in 7 series FPGAs
40%
50%
9.5% < 0.5%
WP389_06_021511
Transistor Type
ス タ テ ィ ッ ク、 ダ イ ナ ミ ッ ク、I/O の電力削減
改善 さ れた電圧スケー リ ン グ オプ シ ョ ン
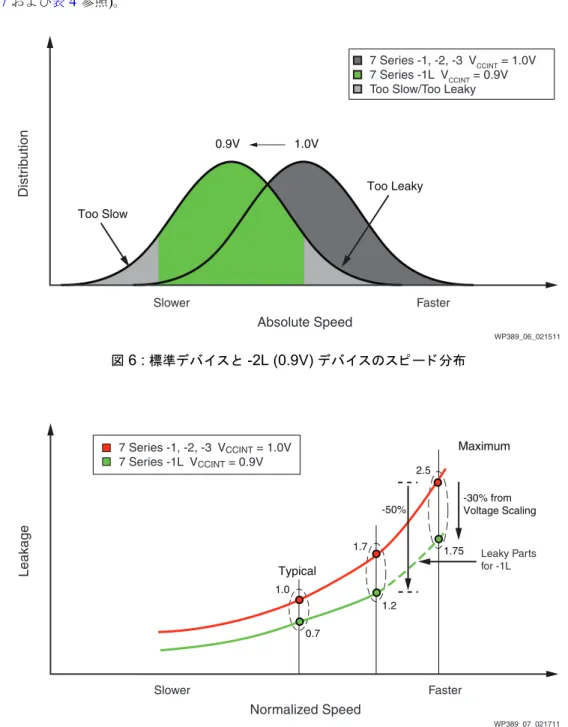
ザ イ リ ン ク ス は、28 HPL プ ロ セ ス のマージ ン増加に よ る も う 1 つの有効な利点であ る 電圧ス ケー リ ン グオプシ ョ ン を提供 し てい ます。7 シ リ ーズ FPGA は 1.0V と 0.9V の 2 つの コ ア電圧で動作 さ せ る こ と が可能です。 こ れは Virtex-6 と Spartan-6 で初めて導入 し た消費電力への取 り 組み と 同様です。1.0V ま たは 0.9V で動作可能なデバ イ ス は、1.0V での ス ピー ド グ レー ド に基づいて 「-2L」 と 位置付け ら れ ま し た。 その性能は 1.0V で -2 ス ピー ド グ レー ド と 等 し く で、0.9V では -1 ス ピー ド グ レー ド と ほぼ同 等ですが、 「L」 は低ス タ テ ィ ッ ク 電力 と 低電圧で動作可能であ る こ と を示 し てい ます。0.9V でデバ イ ス の電圧を下げ る だけで も ~30% の ス タ テ ィ ッ ク 電力が削減 さ れます。電圧を下げ る こ と に よ っ て性能 も 低下 し て し ま い ますが、ザ イ リ ン ク ス は こ の -2L (0.9V) デバ イ ス を ス ピー ド お よ び標準デバ イ ス よ り も 厳 し い リ ー ク 電流の条件で選別 し てい ます。図6 に示す よ う に、-2L (0.9V) デバ イ ス にな り 得 る 低い リ ー ク 電流お よ び高い性能のデバ イ ス のみを選択 し てい ます。こ の選別手法を用い る こ と で、標準ス ピー ド グ レー ド のデバ イ ス と 比較 し て ワース ト ケースプ ロ セ ス で 55% の電力削減を可能 と し てい ます (図7 お よ び表4参照)。
X-Ref Target - Figure 6
図 6 : 標準デバイ ス と -2L (0.9V) デバイ スのス ピー ド 分布
X-Ref Target - Figure 7
図 7 : 標準デバイ ス と -2L (0.9V) デバイ スの リ ー ク 電流
Distribution
Slower Faster
WP389_06_021511
Absolute Speed
Too Leaky Too Slow
7 Series -1, -2, -3 VCCINT = 1.0V 7 Series -1L VCCINT = 0.9V Too Slow/Too Leaky
1.0V 0.9V
Leakage
Slower Faster
WP389_07_021711
Normalized Speed
Maximum
Typical
-30% from Voltage Scaling 2.5
1.7 1.75
1.2 1.0
0.7
-50%
7 Series -1, -2, -3 VCCINT = 1.0V 7 Series -1L VCCINT = 0.9V
Leaky Parts for -1L
ス タ テ ィ ッ ク 、 ダ イ ナ ミ ッ ク 、I/O の電力削減
PDS (電力分配シ ス テ ム) は、 電源が最悪条件下で正常動作 し 、 供給で き る こ と を保証す る ために ワース ト ケース (最大) での電力要求に追従す る 必要があ り ます。 こ のため、 ザ イ リ ン ク スは ワース ト ケース プ ロ セ ス での ス タ テ ィ ッ ク 電力を削減す る ための取 り 組みに も 非常に注力 し ま し た。
ス タ ッ ク ド シ リ コ ン イ ン タ ー コ ネ ク ト テ ク ノ ロ ジ
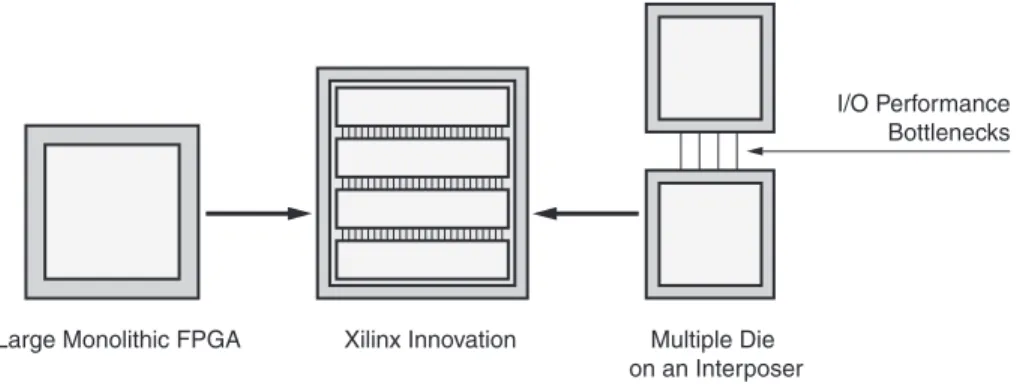
ワ ー ス ト ケース での リ ー ク 電流は FPGA において深刻な問題にな っ てい ます。 それは各 ト ラ ン ジ ス タ が リ ー ク 要素を持つだけでな く 、 大規模デバ イ ス では 1 兆個を超え る ト ラ ン ジ ス タ が使用 さ れ る こ と も あ る ためです。XC7V1500T や XC7V2000T の よ う な大規模な 7 シ リ ーズ FPGA は、 ザ イ リ ン ク ス の ス タ ッ ク ド シ リ コ ン イ ン タ ー コ ネ ク ト テ ク ノ ロ ジ を使用 し て製造 さ れます。 単純に言えば、 こ のテ ク ノ ロ ジは 1 つの大 き なデバ イ ス を作 る ために複数のダ イ を用い ます。 ス タ ッ ク ド シ リ コ ン イ ン タ ー コ ネ ク ト テ ク ノ ロ ジの利点の 1 つは、1 つのダ イ で製造 さ れたほぼ同 じ サ イ ズのデバ イ ス に比べて、 最大 ス タ テ ィ ッ ク 電力が削減で き る こ と です (図8 参照)。
た と えば、1 つのダ イ で構成 さ れた 500K ロ ジ ッ クセルで ワース ト ケース の リ ー ク 電流が標準的な リ ー ク 電流に対 し て 2 倍の場合、 ス タ ッ ク ド シ リ コ ン イ ン タ ー コ ネ ク ト テ ク ノ ロ ジ を 使用 し て い な い 1,500K ロ ジ ッ ク セルのデバ イ ス の ワース ト ケース リ ー ク 電流は約 6 倍にな り ます。 こ れに対 し て、 ス タ ッ ク ド シ リ コ ン イ ン タ ー コ ネ ク ト テ ク ノ ロ ジ を使用 し 、 かつザ イ リ ン ク ス の低電力手法を適用 し た 場合は、1,500K ロ ジ ッ ク セルデバ イ ス の ワ ース ト ケース の リ ー ク 電流は 3.6 倍で、40% 削減 さ れます。
ザ イ リ ン ク ス は 1 つのデバ イ ス 内のダ イ すべての リ ー ク 電流が ワ ー ス ト ケー ス と な ら ない よ う に し ま し た。 ダ イ の 1 つが ワ ース ト ケース の リ ー ク 電流に近い場合は、 デバ イ ス内のその他のダ イ は標準に近 い も のを選択 し ます。 その結果、 同 じ 集積度の 1 つのダ イ と 比べ る と ワース ト ケース の リ ー ク 電流は非 常に小 さ く な り ま し た。
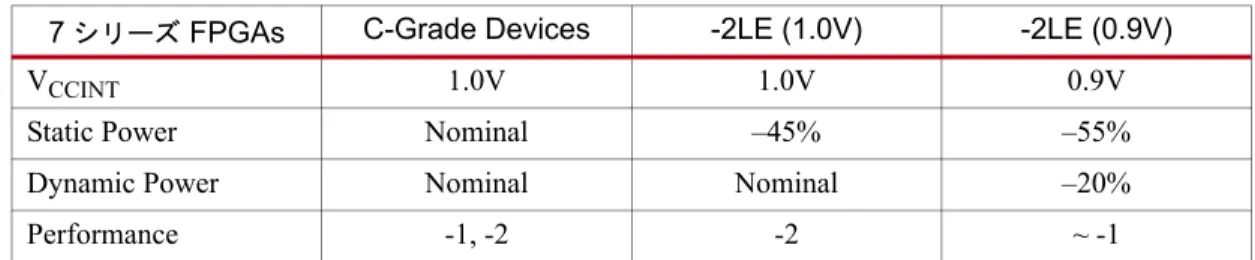
表 4 : ス タ テ ィ ッ ク 電力、 ダ イ ナ ミ ッ ク電力、 性能の比較
7 シ リ ーズ FPGAs C-Grade Devices -2LE (1.0V) -2LE (0.9V)
VCCINT 1.0V 1.0V 0.9V
Static Power Nominal –45% –55%
Dynamic Power Nominal Nominal –20%
Performance -1, -2 -2 ~ -1
X-Ref Target - Figure 8
図 8 : Virtex-7 FPGA の最大 (Maximum) プ ロ セスでのス タ テ ィ ッ ク電力 と ロ ジ ッ ク セル
Maximum Static Power
0 500 1,000 1,500 2,000
WP389_08_021711
28 nm FPGA Slice 28 nm FPGA Slice 28 nm FPGA Slice 28 nm FPGA Slice
Stacked Silicon Interconnect Technology with 28 nm FPGA Slices
Virtex-7 Monolithic FPGA Virtex-7 Multi-Slice FPGA Extrapolated
Virtex-7 Monolithic FPGA
ス タ テ ィ ッ ク、 ダ イ ナ ミ ッ ク、I/O の電力削減
を用いれば、I/O イ ン タ ー コ ネ ク ト 電力は I/O と ト ラ ン シーバーで構成 し た同等の イ ン タ ーフ ェ イ ス よ り も 100 倍 (帯域/W) 小 さ く な り ます。 信号を オ フチ ッ プで駆動す る のではな く 、 すべての接続を オン チ ッ プで構成す る こ と に よ り 、 非常に高速かつ低電力 と な る 、 こ の劇的な削減が可能 と な っ てい ます (図9 参照)。
V
CCAUXの低電圧化
ス タ テ ィ ッ ク 電力はアーキ テ ク チ ャ レベルで も 削減 さ れま し た。ザ イ リ ン ク ス は VCCAUX を 2.5V か ら 1.8V に低減 し ま し た。 こ れに よ り 、PLL、IDELAY、 入出力バ ッ フ ァ ー、 コ ン フ ィ ギ ュ レーシ ョ ン回路 な ど VCCAUXに よ っ て電力供給 さ れ る すべてのブ ロ ッ ク の消費電力が~30% 抑え ら れます。
未使用ブ ロ ッ ク の電力ゲーテ ィ ン グ
こ れ ま での世代のザ イ リ ン ク ス FPGA で も 、 未使用の ト ラ ン シーバー、PLL、DCM、 お よ び I/O の電 力を遮断で き ま し た。 こ れに さ ら に 7 シ リ ーズデバ イ ス では、 未使用ブ ロ ッ ク RAM への電力ゲーテ ィ ン グが追加 さ れてい ます。
前世代のザ イ リ ン ク ス FPGA を分析 し た と こ ろ、 リ ー ク 電流の約 30% がブ ロ ッ ク RAM に よ る も ので し た。 ザ イ リ ン ク ス は こ の リ ー ク 電流 を削減す る た めに積極的に改善に取 り 組み ま し た。7 シ リ ーズ FPGA では、 デバ イ ス上のすべてのブ ロ ッ ク RAM ではな く 、 そのデザ イ ン で使用 さ れてい る ブ ロ ッ ク RAM でのみ リ ー ク 電流が発生 し ま す。 ソ フ ト ウ ェ アはブ ロ ッ ク RAM が イ ン ス タ ン ス さ れてい る か、
さ れていないか を認識 し 、 デザ イ ンが ロ ー ド さ れ る と き に イ ン ス タ ン ス さ れてい る ブ ロ ッ ク RAM にの み電力を供給 し ます。 反対に、 未使用のブ ロ ッ ク RAM に対 し ては電力を供給 し ません (図10 参照)。
X-Ref Target - Figure 9
図 9 : ス タ ッ ク ド シ リ コ ン イ ン タ ー コ ネ ク ト テ ク ノ ロ ジによ る I/O イ ン タ ー コ ネ ク ト 電力削減
I/O Performance Bottlenecks
Large Monolithic FPGA Multiple Die
on an Interposer Xilinx Innovation
WP389_09_021011
X-Ref Target - Figure 10
図 10 : 未使用ブ ロ ッ ク RAM の電力ゲーテ ィ ング
WP389_10_021011
Unused Block RAM Power Savings
Block RAM
ス タ テ ィ ッ ク 、 ダ イ ナ ミ ッ ク 、I/O の電力削減
パーシ ャ ル リ コ ン フ ィ ギ ュ レーシ ョ ン と ス タ テ ィ ッ ク 電力の低減
い く つかの例外 (ス タ ッ ク ド シ リ コ ン イ ン タ ー コ ネ ク ト テ ク ノ ロ ジ を使用 し たデバ イ ス な ど) を除い て、 ス タ テ ィ ッ ク 電力はデバ イ ス のサ イ ズに直接関係 し ます。 ス タ テ ィ ッ ク 電力を削減す る 手段の 1 つ は、 簡単に言 う と 小 さ なデバ イ ス を使 う こ と です。 し か し 、 こ れま で多 く のデザ イ ンは小 さ なダ イ に適 合で き ませんで し た。 こ れが、Virtex-6 FPGA で主流デザ イ ンにおけ る パーシ ャ ル リ コ ン フ ィ ギ ュ レー シ ョ ン を推進す る 変化の始ま り で し た。 そ し て、 こ れは 7 シ リ ーズ FPGA において も 継続 し 、 改善 さ れ て き てい ます。 ザ イ リ ン ク ス はすでにパーシ ャ ル リ コ ン フ ィ ギ ュ レーシ ョ ン技術を持っ てい ま し たが、
こ の機能は最近の ソ フ ト ウ ェ アの改善に よ り 、従来 よ り も さ ま ざ ま な FPGA デザ イ ンに適用で き る も の と な り ま し た。 パーシ ャ ル リ コ ン フ ィ ギ ュ レーシ ョ ン では、 カ ス タ マーは原則的に FPGA を時分割で 処理 さ せ、 デザ イ ンの各部を個別に動作 さ せます。 デザ イ ンの全部分が常に必要 と はな ら ないため、 よ
り 小 さ なデバ イ ス が使用で き ます。
ま た、 パーシ ャ ル リ コ ン フ ィ ギ ュ レーシ ョ ンは ス タ テ ィ ッ ク 電力だけでな く 、 動作電力を削減で き る 可 能性 も 持っ てい ます。 た と えば、 多 く のカ ス タ マーデザ イ ンは非常に高速で動作 し なければな り ません が、その最高性能が必要 と さ れてい る 時間の割合は と て も 低い も のです。電力を抑え る ため、常時 100%
高性能なデザ イ ンではな く 、パーシ ャ ル リ コ ン フ ィ ギ ュ レーシ ョ ン を使用 し て低電力バージ ョ ンに置 き 換え る こ と が可能です。 その後、 必要な と き に高性能デザ イ ンに戻す こ と がで き ます (図11 参照)。
ま た、 こ の原理は I/O 規格に対 し て も 適用可能で、 消費電力の高い イ ン タ ーフ ェ イ ス が随時必要 と さ れ ない場合に有効です。LVDS は直流動作であ る ため、 動作率に関わ ら ず消費電力の高い イ ン タ ーフ ェ イ ス です。 こ こ でパーシ ャ ル リ コ ン フ ィ ギ ュ レーシ ョ ン を用いて、最高速が必要のない と き には LVDS か ら LVCMOS の よ う な消費電力の低い I/O 規格に変更で き ます。 そ し て、 再び高速伝送が要求 さ れた と き に LVDS に戻す こ と が可能です。
パーシ ャ ル リ コ ン フ ィ ギ ュ レ ーシ ョ ン に関す る 詳細は、 WP374 『ISE 12 を使用 し た Virtex FPGA の パーシ ャ ル リ コ ン フ ィ ギ ュ レーシ ョ ン』 を ご参照 く だ さ い。
X-Ref Target - Figure 11
図 11 : パーシ ャル リ コ ン フ ィ ギ ュ レーシ ョ ン によ る機能的な変更 と サイ ズの削減
WP389_11_021011
ス タ テ ィ ッ ク、 ダ イ ナ ミ ッ ク、I/O の電力削減
ダ イ ナ ミ ッ ク 電力の削減
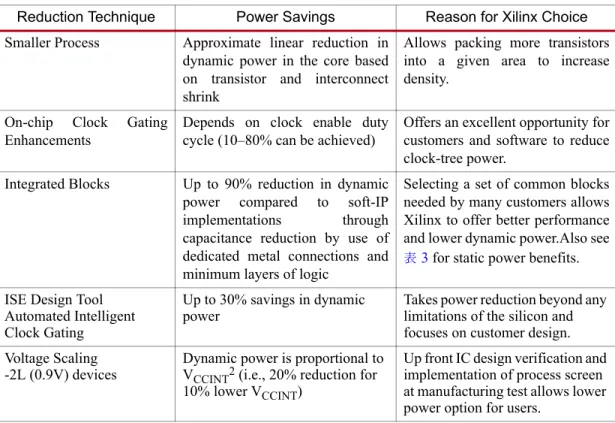
ダ イ ナ ミ ッ ク 電力は、CV2f (=動作率、 C =容量、 V =電圧、 f =ク ロ ッ ク 周波数) で得 ら れます。 ザ イ リ ン ク ス は 7 シ リ ーズ FPGA におけ る ダ イ ナ ミ ッ ク 電力に関わ る 全要素を検討 し ま し た。プ ロ セ ス ノ ー ド が継続的に微細化 し てい る のに伴い、 ダ イ ナ ミ ッ ク 電力の削減は難 し い課題 と な っ てい ます。 それに も 関わ ら ずザ イ リ ン ク スは、 多 く の改善 と 新たな機能に よ っ て、7 シ リ ーズ FPGA においてダ イ ナ ミ ッ ク 電力を さ ら に低減 さ せてい ます (表5 参照)。
7 シ リ ーズ FPGA では、 プ ロ セ ス の微細化をは じ め と し て、 寄生容量お よ び配線容量の削減に よ っ てダ イ ナ ミ ッ ク 電力が 25% 以上低減 さ れます (図12 参照)。
28 HPL お よ び製造中のテ ス ト を通 し て得 ら れたマージ ン に よ り 、 ザ イ リ ン ク ス は設計者へ選択肢を提 供 し ます。 設計レベルでは、-2L (0.9V) 電圧ス ケー リ ン グデバ イ ス を使用す る だけで、 標準の 7 シ リ ー ズ FPGA に比べて 20% の電力を節約で き ます。
表 5 : 7 シ リ ーズ FPGA における ダ イ ナ ミ ッ ク 電力の削減
Reduction Technique Power Savings Reason for Xilinx Choice Smaller Process Approximate linear reduction in
dynamic power in the core based on transistor and interconnect shrink
Allows packing more transistors into a given area to increase density.
On-chip Clock Gating Enhancements
Depends on clock enable duty cycle (10–80% can be achieved)
Offers an excellent opportunity for customers and software to reduce clock-tree power.
Integrated Blocks Up to 90% reduction in dynamic power compared to soft-IP implementations through capacitance reduction by use of dedicated metal connections and minimum layers of logic
Selecting a set of common blocks needed by many customers allows Xilinx to offer better performance and lower dynamic power.Also see 表3 for static power benefits.
ISE Design Tool Automated Intelligent Clock Gating
Up to 30% savings in dynamic
power Takes power reduction beyond any
limitations of the silicon and focuses on customer design.
Voltage Scaling -2L (0.9V) devices
Dynamic power is proportional to VCCINT2 (i.e., 20% reduction for 10% lower VCCINT)
Up front IC design verification and implementation of process screen at manufacturing test allows lower power option for users.
X-Ref Target - Figure 12
図 12 : プ ロ セス微細化によ る容量 と ダ イ ナ ミ ッ ク電力の削減
WP389_12_021411
L
POLY Transistor
Interconnect
Drain Via
Source
W
Metal Plate
ス タ テ ィ ッ ク 、 ダ イ ナ ミ ッ ク 、I/O の電力削減
FPGA その も ので比較す る 場合、 コ ア電圧が低減す る と 、 常に電圧の二乗の割合でダ イ ナ ミ ッ ク 電力 も 削減 さ れます。 し か し 、 複数の FPGA を比較す る 場合は、 一部の FPGA 製造者が提案 し てい る よ う に 単純に コ ア電圧のみの問題ではあ り ません。 ザ イ リ ン ク ス FPGA では、 高い コ ア電圧を使用 し てい る に も 関わ ら ず、 似た よ う な機能を持つい く つかのブ ロ ッ ク で実際、 ダ イ ナ ミ ッ ク 電力が よ り 低 く にな っ て い ます。 こ れは容量を最小化す る ために内部で ク ロ ッ ク ゲーテ ィ ン グ な ど を使用 し 、 非常に効率の良い ブ ロ ッ ク 設計が施 さ れてい る ためです。
ザ イ リ ン ク ス はい く つかの方法で容量に対処 し てい ます。 アーキ テ ク チ ャ レベルでは、 ザ イ リ ン ク ス の エ ン ジ ニ アは LUT6 や メ モ リ サブシ ス テ ム ブ ロ ッ ク の統合な ど の よ う な機能的な革新に注力 し てい ま す。 ク ロ ッ ク ゲーテ ィ ン グの よ う な機能、 ク ロ ッ ク ツ リ ーの電力削減お よ び高フ ァ ン ア ウ ト の削減な ど Virtex-6 FPGA におけ る 改善はすべての 7 シ リ ーズデバ イ ス に適用 さ れてい ます。LUT6 は高性能、
小領域、 少配線を継続 し て提供 し 、 容量を小 さ く 、 電力を節約す る こ と がで き ます。7 シ リ ーズデバ イ ス では、PCIe の よ う な統合 さ れたブ ロ ッ ク に よ っ て、 ソ フ ト IP を実装す る 場合に比べて、 ス タ テ ィ ッ ク 電力を最大 90% 下げ ら れ る こ と があ り ます。
周波数は よ く デザ イ ン目標 と し てかかげ ら れますが、 それを緩和す る こ と でダ イ ナ ミ ッ ク 電力を削減す る こ と が可能です。 多 く の場合、 デザ イ ンのい く つかの部分は 100% は動作 し てい ません。 し たがっ て 設計者は、 ク ロ ッ ク バ ッ フ ァ ーを使用 し て、 その部分に接続 さ れ る ク ロ ッ ク を止め る こ と がで き ます。
周波数を 0 に落 と す こ と は、 デザ イ ンの一部のダ イ ナ ミ ッ ク 消費電力を本質的に抑え ます。
動作率はダ イ ナ ミ ッ ク 電力計算式の最後の部分で、 最大で ど の程度 ト グル し てい る か を示 し 、 周波数は ト グル し てい る 速度にな り ます。 ザ イ リ ン ク スは こ のダ イ ナ ミ ッ ク 電力計算式の動作率の部分 と 挑戦す る ために ソ フ ト ウ ェ アに よ る 最適化を用い ます。 こ の最適化は Virtex-6 FPGA で初めて導入 し た も ので す ( 「ISE デザ イ ン ツールでの自動 ク ロ ッ ク ゲーテ ィ ン グ」を参照)。
ス タ テ ィ ッ ク、 ダ イ ナ ミ ッ ク、I/O の電力削減
内蔵ク ロ ッ ク ゲーテ ィ ン グ
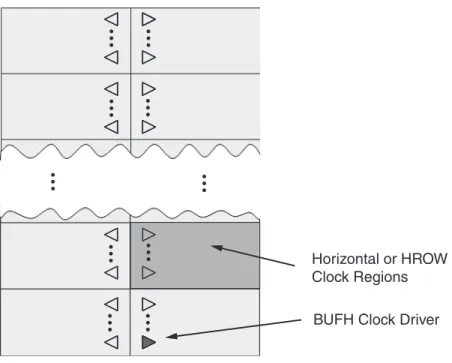
内蔵 ク ロ ッ ク ゲーテ ィ ン グは、 ダ イ ナ ミ ッ ク 電力削減のための優れた手法を提供 し ます。 ク ロ ッ ク ゲー テ ィ ン グに よ り 、 ク ロ ッ ク ド ラ イ バーは ロ ジ ッ ク が使用 さ れていない と き に動的に停止 さ れます。 こ れ は、 あ る 時間基準で動作/停止す る 必要があ る 部分に対 し て静的に、 ま たは 1 ク ロ ッ ク サ イ ク ルの精度で 動的に動かす こ と がで き ます。 以前の Virtex お よ び Spartan デバ イ ス には、 デバ イ スサ イ ズに関わ ら ず、16~32 個の静的あ る いは イ ネーブル付 き のグ ロ ーバルバ ッ フ ァ ー (それぞれ BUFG と BUFGCE) があ り ます。図13 は、多 く の世代の FPGA に共通す る ク ロ ッ ク 領域 と 次の レベルの横方向のバ ッ フ ァ ー (BUFH) を示 し てい ます。BUFG は割愛 し てい ますが、図13の中に階層的に存在 し ます。
各 HROW 領域は 32 個の ク ロ ッ ク バ ッ フ ァ ーすべてに接続で き ます。 各 HROW ク ロ ッ ク 領域の中に は選択 さ れた 8~12 本の ク ロ ッ ク が BUFH と 呼ばれ る ブ ロ ッ ク を通 し てバ ッ フ ァ ー さ れます。図14 に 示す よ う に、 各 HROW 領域あ た り 12 の BUFH を動的あ る いは静的にゲー ト 制御で き ます。 つ ま り 、 固定数のゲー ト 付 き ク ロ ッ ク (16~32 個) ではな く 、Virtex-6 お よ びすべての 7 シ リ ーズ FPGA ではデ バ イ ス サ イ ズに よ っ て異な る 数の ク ロ ッ ク が使用で き ます。3 段階の階層レベルの ク ロ ッ ク ゲーテ ィ ン グお よ び さ ま ざ ま な ク ロ ッ ク イ ネーブル (CE) を使用 し たブ ロ ッ ク の イ ネーブルは電力削減に大 き な柔 軟性を与え ます。 最 も 大 き な 7 シ リ ーズ FPGA には、 ゲー ト 制御可能な グ ロ ーバル ク ロ ッ ク に加え て、
数百のゲー ト 制御可能な リ ージ ョ ナル ク ロ ッ ク があ り ます (図14 参照)。
X-Ref Target - Figure 13
図 13 : HROW ク ロ ッ ク領域 と BUFH ク ロ ッ ク ド ラ イバー
WP389_13_021611
Horizontal or HROW Clock Regions BUFH Clock Driver
ス タ テ ィ ッ ク 、 ダ イ ナ ミ ッ ク 、I/O の電力削減
ク ロ ッ ク ツ リ ー電力 (CV2f) のほ と ん どは、BUFH お よ びその上位か ら き てい ます。 それは、 何千本 も の負荷 (キ ャ パシ タ ン ス) が駆動す る ために必要 と な る か ら です。 こ の レベルでのゲーテ ィ ン グが許容で き ればダ イ ナ ミ ッ ク 電力を大幅に削減で き ます。 数千個の フ リ ッ プ フ ロ ッ プ も し く はその他の リ ソ ース を制御す る フ ァ ン ア ウ ト の多い CE は複数あ る いは 1 つの BUFH に移行 さ せ る こ と がで き ます (図14 内の CEY (1-y) を参照 )。 フ ァ ン ア ウ ト を減 ら す こ と は、CE が数本だけの負荷にな り 、 さ ら に
ク ロ ッ ク ツ リ ーの電力を削減す る ため、CE の電力削減につなが り ます。 非常に多数のゲー ト 制御可能 な ク ロ ッ ク に よ り 、 デザ イ ンに よ っ ては (イ ネーブル率に も 依存 し ますが) ク ロ ッ ク ツ リ ー電力を 30~ 80% 節約で き ます。 こ の ク ロ ッ ク ゲーテ ィ ン グは、 デザ イ ン に フ ァ ン ア ウ ト の多い CE が含 ま れてい る 場合に有効です。
統合 さ れたブ ロ ッ ク
統合 さ れたブ ロ ッ ク は、 ト ラ ン ジ ス タ 数を最少にで き る ため ス タ テ ィ ッ ク 電力を削減 し ますが、 ダ イ ナ ミ ッ ク 電力に対 し て も 大 き な効果があ り ます。 統合 さ れたブ ロ ッ ク はプ ロ グ ラ マブルな配線を必要 と せ ず、配線長や ロ ジ ッ ク 段数を減 ら す こ と がで き る ため、 エ リ アお よ びダ イ ナ ミ ッ ク 電力が削減 さ れます。
すべてにおいて、 ソ フ ト IP を統合ブ ロ ッ ク で置 き 換えれば電力を最大で 10 分の 1 ま で削減可能です。
ザ イ リ ン ク ス は、 特徴的な機能の統合ブ ロ ッ ク を豊富に構築 し ま し た。7 シ リ ーズでの特に注目すべ き 統合ブ ロ ッ ク は、PCI Express® Gen1/Gen2 お よ び ト ラ ン シーバー (最大 28Gbps) です。
X-Ref Target - Figure 14
図 14 : ク ロ ッ ク ゲーテ ィ ングの概要 BUFG
(32 Clocks)
1 2
32
BUFH
(Clocks = 12 x Number of Regions) 1
2
12 1 2
12
1 2
12 32
Flip-Flops, DSP, Block RAM, etc.
12
12
12
WP389_14_021011
CEX (1-x)
CEY (1-y)
CEZ (1-z)
Flip-Flops, DSP, Block RAM, etc.
Flip-Flops, DSP, Block RAM, etc.
ス タ テ ィ ッ ク、 ダ イ ナ ミ ッ ク、I/O の電力削減
ISE デザイ ン ツールでの自動ク ロ ッ ク ゲーテ ィ ン グ
デザ イ ン ツ ールでの電力最適化の点で、 ザ イ リ ン ク ス は FPGA デザ イ ン で ダ イ ナ ミ ッ ク 電力 を 最大 30% 削減で き る 初の自動化、 フ ァ イ ング レーン ク ロ ッ ク ゲーテ ィ ン グ ソ リ ュ ーシ ョ ン を取 り 入れま し た。 こ れは Virtex-6 お よ び Spartan-6 FPGAで初めて導入 さ れた重要な機能です。 ザ イ リ ン ク ス の高度 な ク ロ ッ ク ゲーテ ィ ン グに よ る 最適化は、 新たな ツールやフ ロ ーへの追加手順を必要 と せず、 さ ら に既 存 ロ ジ ッ ク や ク ロ ッ ク に対 し てデザ イ ンの挙動を変え る こ と な く 、 デザ イ ン全体に対 し て自動的に実行
さ れます。 そ し て ま た、 ほ と ん ど の場合で タ イ ミ ン グに影響を与え ません。
ISE® Design Suite 12 デザ イ ン ツールの リ リ ー ス に よ り 、 ザ イ リ ン ク ス はデザ イ ン全体 (従来の IP や サー ド パーテ ィ の IP を含む) を解析す る 革新的な アルゴ リ ズ ム を用いて、標準の FPGA デザ イ ンフ ロ ー の配置配線の部分に自動化機能を取 り 入れま し た。 ソ フ ト ウ ェ アは、 各 ク ロ ッ ク サ イ ク ルの結果に影響 を与え ない、 レ ジ ス タ に接続 さ れ る 前段の ロ ジ ッ ク を解析 し て、7 シ リ ーズ FPGA が豊富に備え る CE を利用 し ます。 ソ フ ト ウ ェ アは、図15 に示 し た よ う に、 必要以上の ス イ ッ チン グ を抑制す る ための フ ァ イ ング レーン ク ロ ッ ク ゲーテ ィ ン グ も し く は ロ ジ ッ クゲーテ ィ ン グ信号を生成 し ます。 さ ら に フ リ ッ プ フ ロ ッ プレベルでは、CE は対象 と な る FF の D 入力 と Q 出力ではな く 、 実際には ク ロ ッ ク を ゲー ト 制御 し ます。 こ れは CE の性能を上げ る だけではな く 、 ク ロ ッ ク の電力 も 削減 し ます。 こ れは Virtex-6 FPGA に も 言え る こ と ですが、7 シ リ ーズ FPGA では さ ら に改善 さ れてい ます。
高度な ク ロ ッ ク ゲーテ ィ ン グに よ る 最適化に よ り 、 専用ブ ロ ッ ク RAM (シ ンプル、 デ ュ アルポー ト の 両モー ド で利用可能) の電力 も 削減で き ます。 こ れ ら のブ ロ ッ ク は数本の イ ネーブル、 ア レ イ イ ネーブ ル、 ラ イ ト イ ネーブルお よ び出力レ ジ ス タ の ク ロ ッ ク イ ネーブルを備え てい ま す。 電力節約のほ と ん どはア レ イ イ ネーブルに よ る も のです。 そ し て、 ソ フ ト ウ ェ アはデー タ が書 き 込み さ れていない と き や 出力が未使用の と き に電力を削減す る ための機能を実装 し ます (図16 を参照)。
7 シ リ ーズ FPGA においては、 さ ら に多 く のデザ イ ン で電力が一層削減 さ れ る よ う ソ フ ト ウ ェ アの改善 が続け ら れてい ます。 WP370『高度な ク ロ ッ クゲーテ ィ ン グに よ る ス イ ッ チ電力の削減』 を参照 し て く だ さ い。
X-Ref Target - Figure 15
図 15 : 高度な ク ロ ッ クゲーテ ィ ング
X-Ref Target - Figure 16
図 16 : ブ ロ ッ ク RAMイ ネーブルを活用 し た高度な ク ロ ッ ク ゲーテ ィ ングによ る最適化
WP389_15_021011
Before
sig
Power Consumption
Power Consumption
After
sig
CE
address address
data in
data in
ce
data out data out
Before After
WP389_16_021011
I/O の電力削減
I/O の電力削減
I/O の電力は、 総電力の中で も 極めて大 き な要素の 1 つにな っ て き てい ます。FPGA の進化に よ り 、 コ ア電力は大 き く 削減 さ れ ま し たが、I/O 電力はそれほ ど削減 さ れてい ません。 メ モ リ を集約す る よ う な デザ イ ンでは総電力の 50% 程度が I/O に よ る も のです。ザ イ リ ン ク ス は前世代の FPGA で積極的に I/O 電力の削減に取 り 組み、 改善の余地を見ま し た。 そ し て、7 シ リ ーズ FPGA に電力削減技術を実装 し ま
し た (表6 参照)。
変更可能な スルーレー ト や ド ラ イ ブ能力に加えて、FPGA 間や低速な メ モ リ イ ン タ ーフ ェ イ ス の電力を 大 き く 減 ら す こ と がで き る HSLVDCI の よ う な特別な規格 も 用意 し てい ます。7 シ リ ーズ FPGA でザ イ リ ン ク ス は、 高速 メ モ リ イ ン タ ーフ ェ イ ス での電力削減に注力 し ま し た。 その利点は、 そ こ での電力削 減がほかの タ イ プの イ ン タ ーフ ェ イ ス に も 適用で き る こ と です。
すべての 7 シ リ ーズデバ イ スは変更可能な スルーレー ト や ド ラ イ ブ能力を兼ね備え てい ます。ザ イ リ ン 表 6 : 7 シ リ ーズ FPGA における I/O 電力の削減
Reduction Technique Power Savings Reason for ザイ リ ン ク ス Choice
Programmable Slew Rate and Drive Strength
Lowers dynamic power in I/O drive.
Gives the user the ability to choose various edge rates for signal integrity vs. I/O dynamic power.
Lowest slew/power should be used.
3-State DCI Dynamically assertable
termination during memory read removes termination power during memory write.
Eliminates unnecessary termination power when I/O input is not being used.
Stacked Silicon Interconnect Technology
Saves 100X I/O connection power needed to bridge multiple devices together to get an equivalently sized device.
Offers unprecedented power savings compared to a multi-device equivalent.
HSLVDCI Series Termination 50% input power reduction for FPGA inputs driven by HSLVDCI vs. split termination plus IODELAY and input buffer power
Offers users the ability to gain a high-performance, single-ended I/O standard and lower power without the need for a parallel termination.
Programmable IODELAY Power
70% input power reduction vs.
high performance.
Offers the ability to selectively reduce IODELAY power for small reduction in performance.
Programmable Reference Receiver Power (HSTL, SSTL, LVDS)
50% input power reduction vs.
high performance.
Offers the ability to selectively reduce power for the input receiver for a small reduction in performance.
IBUF and DCI Termination Disable
Eliminates power on IBUF and DCI termination when bus is in IDLE state.
Cuts power when the bus is not in use.The customer only pays for DC power in I/O during inputs to the device.
I/O の電力削減
ま た、ザ イ リ ン ク ス は HSLVDCI と い う 基本的に直列終端の I/O 規格を持っ てい ます。 こ れは FPGA 間 の接続に有効なだけでな く 、RLDRAM の よ う な外部 メ モ リ の DQ ピ ンか ら デー タ を キ ャ プチ ャ す る 場 合な ど に も 有効です。7 シ リ ーズデバ イ ス には、HSTL お よ び SSTL のためのユーザ変更可能な リ フ ァ レ ン ス レ シーバー電力モー ド も あ り ます。 そ し て、 ザ イ リ ン ク ス は 7 シ リ ーズデバ イ ス において も 変 更可能な電力モー ド を持つ IODELAY ブ ロ ッ ク を継続的に提供 し ます。こ れ ら の 2 つの変更可能な電力 モー ド は I/O 単位で制御可能であ る ため、 設計者は電力 と 性能の ト レー ド オ フ を考慮 し なが ら DC 電力 を削減で き ます。
メ モ リ イ ン タ ー フ ェ イ スの電力
メ モ リ イ ン タ ーフ ェ イ ス の I/O 電力には 3 つの主要素があ り ます。1 つは PCB 配線の イ ン ピーダ ン ス 整合のための DCI、 次に I/O 電圧か ら コ ア電圧への リ フ ァ レ ン ス入力レ シーバー、 最後に信号を ク ロ ッ ク に同期 さ せ る ための IDELAY です。 こ れ ら の要素は相当量の電力を消費 し ます。Virtex-6 FPGA で は、 ト ラ イ ス テー ト DCI に よ っ て メ モ リ 書 き 込み動作中は自動的に終端を切 り 離す こ と で終端電力を 50% 節約で き ま し た。 ザ イ リ ン ク ス は高性能モー ド と 比較 し て 70% 節約可能な リ フ ァ レ ン ス レ シー バーお よ び 50% 節約可能な IDELAY の低電力モー ド を提供 し ます。 こ れ ら の機能に よ り 、 前世代では 同等 イ ン タ ーフ ェ イ ス で消費 さ れていた電力の 50% 以上を節約で き ます。7 シ リ ーズ FPGA でザ イ リ ン ク ス はその基盤を構築 し 、 最大限の電力削減を行 う ために各機能の微調整を行っ てい ます。
設計面で第一歩 と し て、VCCAUXを 2.5V か ら 1.8V へ下げ る こ と で VCCAUXに よ っ て電源供給 さ れ る すべてのア イ テ ム (IDELAY や入出力バ ッ フ ァ ーな ど) の 30% が節約で き ます (図17 参照)。
X-Ref Target - Figure 17
図 17 : VCCAUXの電圧変更
WP389_17_021511
Input
PAD OBUF
IBUF IOB
Output
VCCO
1.8V 2.5
VCCAUX
VCCAUX
1.8V 2.5
I/O の電力削減
7 シ リ ーズ FPGA での新 し い機能は、 動作中に入力バ ッ フ ァ ーを無効にで き る こ と です。 こ れは動的な ト ラ イ ス テー ト DCI 回路の改良 と 拡張に よ っ て実現 し ま し た。 ト ラ イ ス テー ト DCI 機能は、 メ モ リ へ の書 き 込み動作中に終端が未使用の と き は切 り 離す、 も し く は無効にす る 機能か ら 派生 し た も のです。
し か し 、 前世代では、 入力バ ッ フ ァ ーは出力 も し く は メ モ リ への書 き 込み動作中に も 電力を消費 し てい ま し た。7 シ リ ーズ FPGA では、 入力バ ッ フ ァ ー も メ モ リ への書 き 込み動作 (出力) 中に無効にで き ま す。こ れに よ り 書 き 込み と 読み出 し が 50% の比率の場合には、50% の電力削減が可能にな り ます (図18 参照)。
X-Ref Target - Figure 18
図 18 : 入力バ ッ フ ァ ー と DCI 終端の無効化
WP389_18_021011
Tristate
TERMINATION OFF
Input
OBUF
IBUF IOB
IBUF OFF
Output
OE
VCCO
PAD
Memory Write
Tristate
TERMINATION OFF
Input
OBUF
IBUF IOB
IBUF OFF
Output
OE
VCCO
PAD
Memory Read
I/O の電力削減
こ の よ う な機能を活用す る こ と で、 メ モ リ 書 き 込み中の電力の多 く を削減で き ますが、 メ モ リ イ ン タ ー フ ェ イ ス が読み出 し あ る いは書 き 込みを行っ ていない場合 も 考え ら れます。 こ れはア イ ド ル状態 と 考え ら れ、 以前は DCI 終端お よ び入力バ ッ フ ァ ーの両方が こ の状態で も 電力を消費 し てい ま し た。こ れを受 けて、7 シ リ ーズ FPGA では、DCI と 入力バ ッ フ ァ ーの一方ま たは両方を無効にす る 新機能が追加 さ れ てい ます (図19 参照)。
7 シ リ ーズ FPGA の場合、I/O は メ モ リ か ら の読み出 し 動作の よ う な必ず必要な場合にのみ電力を消費 し 、 書 き 込み動作中 も し く はア イ ド ル状態の場合には電力を節約 し ます。 その結果、 前世代の製品 と 比 べて 50% の電力削減 と な り 、 以前の同等の イ ン タ ーフ ェ イ ス と 比較す る と 75% 以上の電力削減 と な り ます (図20 参照)。
X-Ref Target - Figure 19
図 19 : バスがア イ ド ル状態の場合は、 入出力バ ッ フ ァ ーおよび DCI 終端を無効化
X-Ref Target - Figure 20
図 20 : 7 シ リ ーズ FPGA の入力電力削減
WP389_19_021011
Tristate
TERMINATION OFF
Input
OBUF
IBUF IOB
IBUF_OFF
Output
VCCO OE
PAD
BUS IDLE
35 30 25 20 15 10 5 0
Power (mW)
DDR2 1.8V DDR3 1.5V T_DCI (50% R/W)
Low Power Ref Receiver
Low Power IODELAY
IBUF and DCI Disable
WP389_20_021511
> 75% Reduction IDELAY
Referenced Receiver DCI
ト ラ ン シーバーの電力削減
ト ラ ン シーバーの電力削減
7 シ リ ーズ FPGA の ト ラ ン シーバーは、 高性能 と 低ジ ッ タ を共に実現す る よ う 最適化 さ れてお り 、 低消 費電力動作用の機能を備えてい ます。 各フ ァ ミ リ の ト ラ ン シーバーは次の と お り です。
• Artix-7 FPGA GTP : 最大 6.6Gb/s
• Kintex-7 FPGA GTX : 最大 12.5Gb/s
• Virtex-7 FPGA GTH お よ び GTZ : それぞれ最大 13.1Gb/s お よ び 28Gb/s
それぞれの ト ラ ン シーバーには、 設計者がその動作を柔軟にカ ス タ マ イ ズ し 、 消費電力 と 性能のバ ラ ン ス を調整で き る よ う にす る 機能があ り ます。
7 シ リ ーズの GTP お よ び GTH ト ラ ン シーバーのアーキ テ ク チ ャ は再設計 さ れてお り 、Spartan-6 LXT と Virtex-6 HXT FPGA そ れぞれの GTP お よ び GTH ト ラ ン シ ーバー と 比較す る と 、 総消費電力が
>60% 削減 さ れてい ます。
Artix-7 フ ァ ミ リ に搭載 さ れてい る GTP ト ラ ン シーバーは最大 6.6Gb/s のデー タ レー ト をサポー ト し 、 コ ス ト と 消費電力を重視す る アプ リ ケーシ ョ ンにおいて、 最 も 低い消費電力を実現す る よ う 最適化 さ れ てい ます。1 つの GTP ク ワ ッ ド にあ る 4 つの ト ラ ン シーバーを 3.125Gb/s の同一レー ト で動作 さ せた 場合の PMA の消費電力はた っ た 80mW です。
Virtex-7 XT お よ び HT デバ イ ス が備え る GTH ト ラ ン シーバーは、400G の ラ イ ンカー ド な どチ ャ ネル 数が非常に多 く 、かつ高性能な アプ リ ケーシ ョ ンにおけ る 消費電力を低減す る よ う 最適化 さ れてい ます。
低 ジ ッ タ LC タ ン ク と 共有 PLL を 使用 し 、1 つ の GTH ク ワ ッ ド に あ る 4 つ の ト ラ ン シ ーバー を 12.5Gb/s の同一 レ ー ト で動作 さ せた場合の PMA の消費電力は 148mW です。 さ ら に、Virtex-7 HT FPGA の GTZ ト ラ ン シーバーは 28Gb/s のデー タ レー ト で、 チ ャ ネルあ た り 250mW の消費電力であ
り なが ら 、 十分 き れいなデー タ ア イ を実現 し ます。
7 シ リ ーズ ト ラ ン シーバーのアーキ テ ク チ ャ には、LC タ ン ク の電力を抑え た状態で、各 ト ラ ン シーバー の リ ン グオシ レー タ ーを使用で き る 高い柔軟性があ り ます。 ま た、LC タ ン ク と リ ン グオシ レー タ ーの 両方を使用す る こ と で、1 つの ト ラ ン シーバーの TX と RX それぞれを異な る ス ピー ド/プ ロ ト コ ルで動 作 さ せ る こ と がで き ます。 つま り 、1 つの ク ワ ッ ド で複数の レー ト の ト ラ ン シーバーを混在 さ せて使用 す る こ と が可能です。
表7 で説明 し てい る 手法を用いて ト ラ ン シーバー全体の消費電力を低減 さ せ る こ と がで き ます。
表 7 : 7 シ リ ーズ FPGA における ト ラ ン シーバーの消費電力の削減
Reduction Technique Power Savings Reason for Xilinx Choice Bypassable DFE Turns off the decision feedback
equalizer (DFE) circuitry when not needed and uses the linear equalizer. The linear equalizer is much lower power than the DFE because of lower RX gain and minimal circuity. This is the Low Power Mode (LPM) of the receiver.
Many non-backplane applications do not need DFE, which burns extra power, so Xilinx gives designers a choice when servicing other applications.
Power Efficient Mode Source all four transceivers’
high-speed clocks from one LC tank in a quad since ring oscillators of the quad are powered down.
Reduces power for multi-lane protocols when all four transceivers of a quad are running at the same rate or division of that rate by 1, 2, 4, or