最小二乗法のストリーム処理における桁あふれ回避方法
今木 常之
†1 概要:オンライントレード,SNS,IoT などで大量に生成する,時系列データの予測値を算出する基本技術として, 最小二乗法のストリーム処理方法を検討した.処理が長期間継続すると,近似対象であるグラフの横軸にあたる時刻 の値が増大し,桁あふれが発生する.この課題の解決策として,スライディングウィンドウに伴って時刻原点を移動 するように変形した最小二乗法を,再帰型の継続クエリを用いて差分処理で実現する方法を提案した.近似精度と計 算スループットの評価実験に基づき,提案手法が前記のような桁溢れを解消すること,およびスライディングウィン ドウ上に保持する近似対象点の個数に依存しない処理性能を実現することを確認した.このことから,無停止のリア ルタイム時系列監視の実現可能性を示した. キーワード:リアルタイム, ストリーム, 最小二乗法, 継続クエリSuppression of Overflow in Stream Processing of Least Squares Method
TSUNEYUKI IMAKI
†1Abstract: We investigated a stream processing technique of least squares method, as a basic tool for prediction of time series
data produced by online trading, SNS, and IoT. When the process continues for a long period, timestamp value which corresponds to the horizontal axis of the target data becomes enlarged and causes overflow. As a solution to this problem, we proposed an incremental processing technique which calculates least squares method modified so as to move the origin of time axis along with a sliding window in a recursive continuous query. Evaluation of computational accuracy and throughput shows that the proposed method resolves the overflow described above, and the processing performance is independent of the number of the target data in the sliding window. It showed the feasibility of real-time and non-stop monitoring of time series data.
Keywords: Real-time, Stream, Least Squares Method, Continuous Query
1. はじめに
IoT,金融取引,通信ログ,システムログ,SNS,クリッ クストリーム,車両の走行データなどの,社会活動で継続 的に発生する様々なストリームデータを分析し,ビジネス やサービスの改善にリアルタイムにフィードバックする技 術であるストリームデータ処理(以下,ストリーム処理)の 分野では,商用のミドルウェア製品群やクラウドサービス のほか,OSS の開発者コミュニティの発展や機械学習との 連携も進んでおり,ストリーム処理はビッグデータの一技 術分野として定着しつつある. ストリーム処理による時系列データ分析の期待される 活用方法の一つとして,データの時間推移の予測処理が挙 げられる.金融取引における価格変動予測,センサ情報に 基づく機器故障の予兆検知,渋滞予測など,予測処理はリ アルタイムに処理することによる恩恵が最も得られる領域 の一つである.リアルタイム予測においては,遠い過去の データによる影響を抑えて,直近のデータに重みをおいて 分析する必要がある.この要件に対して,多くのストリー ム処理技術では,スライディングウィンドウを備えた継続 クエリ言語が用意されている. †1 (株)日立製作所 Hitachi Ltd. 本 稿 で は , 継 続 ク エ リ 言 語 と し て Continuous Query Language(CQL)1)2)を前提としている.CQL は RDBMS の 標準クエリ言語である SQL の意味論に直交する形でスラ イディングウィンドウ演算と再ストリーム化演算を加えた 簡潔な仕様でありながら,他のストリーム処理の意味論も 包含する汎用的な記述能力を備える.ここでは,CQL のタ イムスタンプを離散値ではなく連続値,即ち無限解像度の 時刻として扱うように変更し7),遅延演算による再帰処理 を導入したもの8)を想定する. 時系列データの観測値から近未来の時間推移を予測する 回帰分析の基本的な方法の一つとして最小二乗法が挙げら れる.特に,分析対象をスライディングウィンドウ上に乗 っているデータに絞り込むことで,効果的なリアルタイム 予測の実現が期待される.本稿では,この機能実現におい て課題となった計算桁溢れの解消方法,およびその評価に ついて報告する.より具体的には次の通りである.時系列 データの近似において,近似曲線の横軸は時間である.一 方,ストリーム処理では計算をリアルタイムかつ継続して 実行するため,長時間のノンストップ運用では横軸が非常 に大きな値となり,近似計算における桁溢れの原因となる. 本稿では,この桁溢れを回避するための最小二乗法の変形, および CQL の再帰クエリによるその計算の実現方法を提 案する.2. 最小二乗法のストリーム処理と課題
2.1 継続クエリにおける最小二乗法 ここでは,時系列データの変動予測を,既に観測された 系列を上手く近似するようなモデル式を算出して,その式 を時間軸方向に外挿すること,と想定する.最小二乗法は, この近似に利用される代表的な方法の一つである. ここでは,縦軸 を観測値,横軸 を時間軸とする平面 上にプロットした観測値の系列が近似対象となる.この場 合,時間が独立変数,観測値がその従属変数となり,時刻 における観測値を と表す.ここで,近似モデルとし て直線 を想定した場合,最小二乗法では観測 値と近似値の残差の平方和 が最小と なるような係数 と を求める. ストリーム処理においては,近似対象点が時刻を追って 逐次的に追加されるため,その都度,近似係数を更新する ような計算が必要となる.また,過去の観測点全てを近似 対象にとると,近似結果が過去の履歴に大きく影響されて 直近の傾向変化を表すことができないため,スライディン グウィンドウを利用して,近似範囲をずらしながら計算す る必要がある. 最小二乗法で多項式へ近似する場合,その係数は一般に 以下のような連立一次方程式の解として得られる(一次式 への近似(1)と二次式への近似(2)の場合). 三次式以上も同様で,N 次式については の 0~2N 乗の 和,および の 0~N 乗と の積の和を求めることで,方 程式の係数行列を構成することが可能である. なお,一次式への近似の場合,方程式の解は式(3),(4)の ようになる.但し,n は和の対象となる要素数とする. 二次式以上の場合,式(2)から式(5)への変更のように,行 の順番を反転することにより,係数行列をToeplitz 行列(左 から右の各下降対角線に沿って要素が一定である,即ち行 列の各要素について となる行列)とする ことができる.Toeplitz 行列を係数とする連立一次方程式 はLevinson 再帰アルゴリズム 4)で効率的に解くことが可能 である.一般的な連立方程式の解法であるGauss の消去法 の計算コストが次元数 N の三乗オーダであるのに対し, Levinson 再帰は Toeplitz 行列の特徴を利用することで,N の二乗オーダの計算コストを実現する. ストリーム処理ではスライディングウィンドウを利用 して近似範囲をずらしながら最小二乗法を適用する.この 処理はCQL の集計演算 SUM を利用することで,図 1 のよ うに簡潔に記述することが可能である.クエリ in_window にて,スライディングウィンドウを適用して近似対象点を 直近の100 点に絞り,クエリ next_sum にて,連立方程式の 各係数を集計演算 SUM で算出し,クエリ factor にて,式 (3)(4)に基づいて近似式の係数を算出する.CQL の SUM 演 算は差分処理であるため,個々のデータについての計算オ ーダは,クエリnext_sum における SUM の個数と,クエリ factor の式の計算オーダで決まる.近似式の次元数を N と した場合,前者は O(N),後者は Levinson 再帰を用いるこ とでO(N2)となる. 図 1 最小二乗法のシンプルな CQL クエリ Figure 1 Simple query of Least Squares Method in CQL.REGISTER STREAM data_input
(id VARCHAR(10), x BIGINT, y DOUBLE); REGISTER QUERY in_window
SELECT *
FROM data_input[PARTITION
BY id ROWS 100]; REGISTER QUERY next_sum
ISTREAM(
SELECT id, MAX(x) AS last_x , COUNT(*) AS x0, SUM(x) AS x1 , SUM(x*x) AS x2
, SUM(y) AS yx0, SUM(y*x) AS yx1 FROM in_window
GROUP BY id); REGISTER QUERY factor
ISTREAM(
SELECT id, last_x , (x0*yx1 - x1*yx0) / (x0*x2 - x1*x1) AS a , (x2*yx0 - yx1*x1) / (x0*x2 - x1*x1) AS b FROM next_sum[NOW] WHERE x0 >= 2); (5) (4) (1) (2) (3) (4) (5)
2.2 時刻値の増加による桁あふれ ここで,係数行列の が時間軸であることに注意すると, 図 1 の計算方法には次のような問題がある.いま,スライ ディングウィンドウ上の最小の時刻値(クエリ処理の継続 時間)を X とすると,式(3)(4)の分母の二つの項は,n2 X 2の オーダとなる(但し,n はスライディングウィンドウ上の点 の個数,即ちウィンドウサイズ).n = 100 として,X が十 進数で9 桁まで増えれば n2 X 2は21 桁の数になり,時刻値 のデータ型を 64bit 整数で表現しても桁溢れが発生する. 時刻の解像度をミリ秒単位とした場合,1 日と 4 時間ほど で9 桁に達する.桁溢れを回避するために倍精度の浮動小 数点数(64bit)を利用した場合は,逆に桁落ちが発生し,時 刻の精度が失われる. 対策案の一つとして,時刻を表現するデータの型に, DECIMAL 型(任意精度の整数)を利用することが挙げられ る.但し,DECIMAL 型は,十進数の個々の桁を要素とす る整数の配列によって数値を表現するため,その計算には 大量のCPU リソースとメモリリソースを必要とし,性能劣 化を引き起こす. 他の案として,ウィンドウがスライドする度に,ウィン ドウ上のデータ集合における時刻の最小/最大/平均値な どが原点となるように,ウィンドウ上の全データの時刻を 変更した後で,近似処理を適用する方法が挙げられる.但 し,個々のデータが到来する度に,ウィンドウ上の全点の 計算を処理し直すことになるため,一データ当たりの計算 オーダがウィンドウサイズに比例することになり,性能劣 化を引き起こす.
3. 時間軸のスライドを伴う最小二乗法
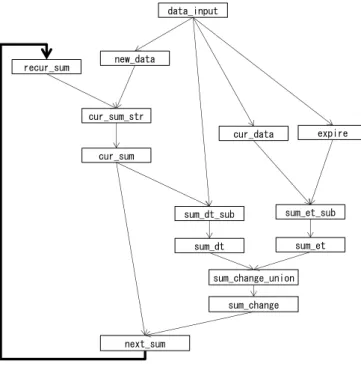
3.1 最小二乗法の再帰的な計算方法 2.2 節では,時刻の値の増加に伴う桁溢れの発生を回避 しつつ,差分計算で実行可能な方法が必要であることを示 した.ここでは,その解決策として,時刻原点のスライド を伴う最小二乗法の差分計算方法を提案する.即ち,デー タが到来する度に,その最新データの時刻が0 となるよう に時間軸を移動させ,方程式の係数行列の要素となる の 累乗の和,およびその観測値 の積との和を,移動後の時 間軸に基づく値として算出する.桁溢れ解消の方針として は,2.2 節の最後に示した案と共通する.但し,個々のデ ータの時刻を変更するのではなく,和のみを差分更新する ことによって,ウィンドウサイズによらない計算コストを 実現する.以下に,提案する計算方法を示す. 処理の開始から 番目のデータについて,その時刻を ,観測値を としたとき, 番目データ到来時点にお ける,時刻 の 乗の和 は式(6)のように表される. 但し, はスライディングウィンドウのサイズである.こ のと き ,一 つ 前の 番目データ到来時点における和 は式(7)のように表される.ここで,式(7)を用い て 式(6) を 式 (8) の よ う に 変 形 す る こ と で , を (k = 0~m)で表現可能となる.即ち,新しいデー タが到来した際に,一つ前のデータ到来時における和から, インクリメンタルに和の更新値を算出可能であることを意 味している. 同様の変形により,時刻 の 乗と観測値 の積の和 は式(9)のように, (k = 0~m)によって表 現可能となる. 但し, , である.なお,前者 は時刻原点の移動量,後者はウィンドウの時間幅と意味付 けることができる.また,便宜的に0 の 0 乗を 1 とおけば, 式(8)および(9)は m = 0 の場合にも成り立つ. と は,それぞれ (= n) と を表す. (6) (7) (8) (9) (6) (7) (8) (9)N 次式に近似するケースでは,データが到来する度に, 式(8)を m=0~2N,式(9)を m=0~N について計算する必要が あり,これらの式の計算のオーダが O(m) であるため, 個々のデータに関する計算オーダは O(N2)となる.これは Levinson 再帰の計算オーダと一致しているため,ナイーブ な SUM 演算を適用する場合と比較しても,近似計算全体 の計算性能は変わらないと言える.また,式(8)(9)の中にス ライディングウィンドウのサイズ は現れていない.即ち, ウィンドウサイズに依存しない計算コストを実現すること を意味している. 3.2 再帰型の継続クエリによる最小二乗法 ストリーム処理のデータ処理定義言語CQL による,3.1 節に示した計算の実現方法を示す.この計算は,各種の和 および を逐次的に更新する処理であるた め,一つ前の過去における和の値を記憶しておく必要があ る.CQL では,再帰クエリを利用することにより,このよ うな計算のステートを表現することが可能である. 図 2 に CQL クエリ間のデータフロー図を,図 3 に CQL クエリ定義本体を示す. 図 3 のクエリは二次式への近似 の例であるのに対し,図 2 に示したデータフローは,次元 数によらず同一の構成となる.また,表 1 に,各クエリの 役割を示す.クエリcur_sum が計算ステートの表現に相当 する. 図 2 再帰クエリのクエリグラフ Figure 2 Query graph of recursive continuous query.
図 2 の太線で示した矢印によって再帰ループが形成さ れており,クエリnew_data,cur_sum_str,cur_sum,next_sum, および recur_sum から構成される部分グラフは,再帰クエ リでステートを表現する際の一般的な形を成している.各 クエリは,ステートの初期値生成,初期値と更新値の合流, ステートの保持,更新値の算出,および遅延させた更新値 のフィードバックを,それぞれ役割として担っている.こ こ で , 更 新 値 を フ ィ ー ド バ ッ ク す る 際 の 遅 延( ク エ リ recur_sum)は,再帰処理における因果関係の論理矛盾を解 消するために必要となる8). 図 3 再帰クエリによる最小二乗法
Figure 3 Lest Squares Method in recursive continuous query.
recur_sum data_input expire cur_data new_data sum_dt_sub cur_sum_str cur_sum sum_dt sum_et_sub sum_et sum_change_union next_sum sum_change
REGISTER STREAM data_input
(id VARCHAR(10), x BIGINT, y DOUBLE); REGISTER QUERY new_data
ISTREAM(
SELECT id FROM data_input[PARTITION BY id ROWS 1]); REGISTER QUERY cur_data
SELECT * FROM data_input[PARTITION BY id ROWS 1]; REGISTER QUERY recur_sum
ISTREAM(SELECT * FROM next_sum)<NOW>; REGISTER QUERY cur_sum_str
ISTREAM(
SELECT d.id, 0L AS last_x
, 0 AS x0, 0L AS x1, 0L AS x2, 0L AS x3, 0L AS x4 , 0.0 AS yx0, 0.0 AS yx1, 0.0 AS yx2
FROM new_data[UNBOUNDED] AS d UNION ALL
SELECT * FROM recur_sum[UNBOUNDED]); REGISTER QUERY cur_sum
SELECT * FROM cur_sum_str[PARTITION BY id ROWS 1]; REGISTER QUERY expire
DSTREAM(
SELECT * FROM data_input[PARTITION BY id ROWS 100]); REGISTER QUERY sum_dt_sub
SELECT d.id, s.last_x - d.x AS dt, d.y, d.x AS last_x , s.x0, s.x1, s.x2, s.x3, s.x4, s.yx0, s.yx1, s.yx2 FROM data_input[NOW] AS d, cur_sum AS s
WHERE d.id = s.id; REGISTER QUERY sum_dt SELECT s.id, s.last_x
, 1 AS x0, s.dt*s.x0 AS x1 , s.dt*(s.dt*s.x0 + 2*s.x1) AS x2
, s.dt*(s.dt*(s.dt*s.x0 + 3*s.x1) + 3*s.x2) AS x3 , s.dt*(s.dt*(s.dt*(s.dt*s.x0
+ 4*s.x1) + 6*s.x2) + 4*s.x3) AS x4 , s.y AS yx0, s.dt*s.yx0 AS yx1
, s.dt*(s.dt*s.yx0 + 2*s.yx1) AS yx2 FROM sum_dt_sub AS s;
REGISTER QUERY sum_et_sub
SELECT d.id, e.x - d.x AS et, e.y, d.x AS last_x FROM cur_data AS d, expire[NOW] AS e
WHERE d.id = e.id; REGISTER QUERY sum_et SELECT s.id, s.last_x
, -1 AS x0, -s.et AS x1, -s.et*s.et AS x2
, -s.et*s.et*s.et AS x3, -s.et*s.et*s.et*s.et AS x4 , -s.y AS yx0, -s.y*s.et AS yx1
, -s.y*s.et*s.et AS yx2 FROM sum_et_sub AS s; REGISTER QUERY sum_change_union
SELECT * FROM sum_dt UNION ALL
SELECT * FROM sum_et; REGISTER QUERY sum_change
SELECT s.id, MAX(s.last_x) AS last_x
, SUM(s.x0) AS x0, SUM(s.x1) AS x1, SUM(s.x2) AS x2 , SUM(s.x3) AS x3, SUM(s.x4) AS x4
, SUM(s.yx0) AS yx0, SUM(s.yx1) AS yx1 , SUM(s.yx2) AS yx2
FROM sum_change_union AS s GROUP BY s.id;
REGISTER QUERY next_sum SELECT s.id, c.last_x
, s.x0+c.x0 AS x0, s.x1+c.x1 AS x1, s.x2+c.x2 AS x2 , s.x3+c.x3 AS x3, s.x4+c.x4 AS x4
, s.yx0+c.yx0 AS yx0, s.yx1+c.yx1 AS yx1 , s.yx2+c.yx2 AS yx2
FROM cur_sum AS s, sum_change AS c WHERE s.id = c.id;
表 1 クエリグラフにおける各クエリの役割 Table 1 Role of queries in the query graph. # クエリ名 役割 1 data_input 入力ストリーム(id: 系列名,x: 時刻値,y: 観測値) 2 new_data 新規系列の到来を検知 3 cur_data 最新の入力値を保持(#10 で利 用) 4 recur_sum ステート(各和)の更新値#14 を 微小時間遅延させて#5 にフィ ードバック 5 cur_sum_str 新規系列到来時の初期ステー ト(各和の初期値 0)を生成し,#4 とマージ 6 cur_sum ステートの最新値を保持 7 expire スライディングウィンドウか ら溢れたデータを出力 8 sum_dt_sub を算出 9 sum_dt 式(8)(9)における第 1 項(から および を 除いたもの)と第 2 項( および )を算出 10 sum_et_sub を算出 11 sum_et 式(8)(9)における第 3 項( お よび )を算出 12 sum_change_union #9 と#12 の和集合 13 sum_change #9 と#12 を加算( およ び に対する変化値) 14 next_sum #13 の変化値を直前のステート および に 加算し,ステートの更新値 および を算出
4. 評価
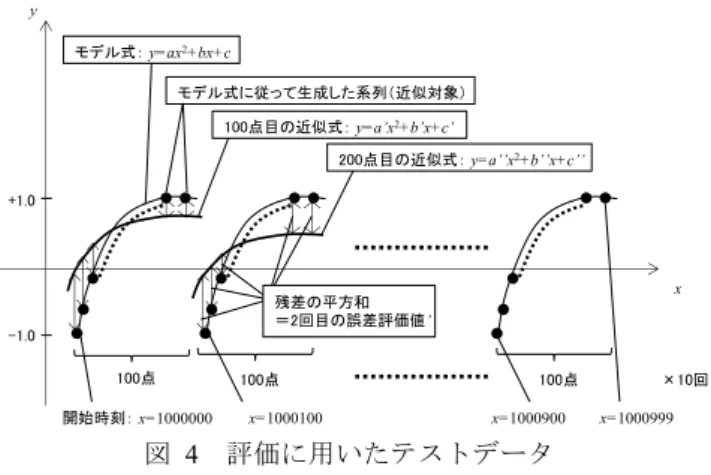
4.1 近似精度の評価 本提案方式の評価として,時刻値の大きさと近似精度と の関係を調査した.近似モデルを一次式から四次式まで変 化させ,2.1 節に示した SUM 演算によるナイーブな計算方 法と比較した.各次元についてモデル式を定め,そのモデ ルに従って生成した系列と,その系列について求めた近似 式との残差の平方和を誤差として評価した.生成系列は 100 点からなる系列の繰り返しとし,観測値がほぼ-1.0~1.0 の範囲に収まるようにした.誤差の計算は100 点の処理が 終わる毎に実施し,10 回の計算の平均を評価値とした(図 4).時刻の値は,生成系列の開始時刻から 1 ずつインクリ メントする整数とした.なお,誤差の評価には Java の BigDecimal クラスを利用した. 図 4 評価に用いたテストデータ Figure 4 Test data for evaluation.評価結果を図 5 に示す.縦軸は誤差,横軸は生成系列の 開 始 時 刻 を 表 す . グラ フ の系 列 は 以 下 の 通 り であ る . simple_... が naive な方式であるのに対して,move_... が本 稿の提案に相当する.
simple_BIGINT: 和 および の計算を,2.1 節
に示したクエリnext_sum で実施.data_input におけるカ ラムx の型に BIGINT(64 ビット整数)を指定
simple_DOULE: simple_BIGINT において,data_input にお けるカラム x の型に DOUBLE(倍精度浮動小数点型)を 指定
simple_DECIMAL: simple_BIGINT において,data_input におけるカラムx の型に DECIMAL を指定 move_BIGINT:和 および の計算を,3.2 節に 示したクエリ群で実施.data_input におけるカラム x の 型にBIGINT を指定 move_DOUBLE:move_BIGINT において,data_input にお けるカラム x の型に DOUBLE(倍精度浮動小数点型)を 指定 なお,一次式への近似では式(3)(4)を利用し,二次式以上 ではLevinson 再帰を利用した.また,simple_DECIMAL に おける精度(桁数)を 64 桁とした.但し,三次式への近似に おいて開始時刻を1E+12 としたケース,および四次式にお いて開始時刻を 1E+6 以上にしたケースでは,桁落ちによ るゼロ割りが発生したため,これらのケースでは精度を 100 桁に変更した. simple_...では,開始時刻のオーダが増大するにつれて精 度が悪化することを確認した.simple_DOUBLE では評価不 可のケースが一部存在した.これは,近似結果として得ら れた多項式の係数が NaN あるいは無限大などの不正な値 となり,誤差計算のためにBigDecimal へ変換する際に,実 行時例外が発生したことによる.simple_DECIMAL では, 精度桁数を大きく取ることで近似精度向上が可能であるも のの,性能が劣化することとなる. モデル式:y=ax2+bx+c モデル式に従って生成した系列(近似対象) 100点目の近似式:y=a’x2+b’x+c’ 200点目の近似式:y=a’’x2+b’’x+c’’ 100点 100点 100点 y x 残差の平方和 =2回目の誤差評価値’ +1.0 -1.0 開始時刻:x=1000000 x=1000100 x=1000900 x=1000999 ×10回
一方,提案手法では,開始時刻の大小に関わらず,安定 した精度を維持することを確認した. [一次式] [二次式] [三次式] [四次式] 図 5 精度の評価結果 Figure 5 Results of evaluation on accuracy.
4.2 性能の評価 性能評価としてスループットを計測した.0~1.0 の間で ランダムな値をとる400,000 点の系列を生成し処理時間を 計測して,その逆数としてスループットを求めた(相対値). 比較対象,およびDECIMAL 型の桁数は 4.1 節と同じ設定 と し , 開 始 時 刻 2 の ケ ー ス の み を 掲 載 し た . な お , simple_DECIMAL 以外のスループット性能は,開始時刻の 大 小 に よ ら な い こ と を 確 認 済 で あ る . ま た , simple_DECIMAL では,桁数を大きく取ることで精度が向 上する一方,スループットは劣化する,というトレードオ フ関係にある.本節では評価項目をスループットのみに絞 り,simple_DECIMAL において最大の性能が出るケースと して,開始時刻が最小の場合のみを評価した. 図 6 は,近似式の次数と性能の関係を示している. simple_BIGIINT,および simple_DOUBLE では,クエリが 簡潔であるため高スループットを達成する.一方,提案手 法であるmove_BIGINT,および move_DOUBLE の性能は, その1.5~3 分の 1 程度にとどまる.但し,simple_BIGIINT, simple_DOUBLE には,4.1 節に示したような精度劣化が存 在するため,実運用への適用は困難である. こ れ ら と 比 較 し て simple_DECIMAL の ク エ リ は , simle_BIGINT,simple_DOUBLE と同様に簡潔であるもの の,性能は大きく下回り,特に二次式以上での劣化が顕著 である.これは,一次式と二次式以上での近似係数算出方 法の違いに起因していると考えられる.一次式では,式 (3)(4)を利用して一つのクエリで係数を算出可能であるの に対し,二次式以上では,Levinson 再帰アルゴリズムの実 現のために,複数のクエリを連結する必要がある. 図 7 は,一次式の近似に Levinson 再帰を利用した場合の 性能を示している.左側は式(3)(4)の性能(図 6 の再掲),右 側は Levinson 再帰の性能である.何れの方法においても, アルゴリズムの違いによる性能劣化が確認された.但し, move_...における劣化は相対的に軽微である.これは,和 および の計算自体のコストが simple_...に比 較して大きく,後半のLevinson 再帰による劣化が目立たな いためである.一方,simple_DECIMAL における性能劣化 は 顕 著 で あ る . こ れは , アル ゴ リ ズ ム の 複 雑 化に よ る DECIMAL 型演算の増加のためと考えられる.時刻値 x の 型にDECIMAL を選択した場合,和の算出のみならず,そ の後の係数算出も DECIIMAL 型で計算することになるた め,性能劣化の大きな要因となり得る. 図 8 は,Levinson 再帰における係数行列の次元と性能の 関係を示している.係数行列の次元は,近似式の次数N に 1 を加えた数となるため,横軸には N+1 をとっている.ま た,縦軸,横軸共に対数表示の両対数平面にプロットして いる.Levinson 再帰の計算コストは(N+1)2であり,スルー プットはその逆数となるため,各方法の性能曲線は,両対 数平面上では傾き-2 の直線になると考えられる.実際, 1.00E-30 1.00E-20 1.00E-10 1.00E+00 1.00E+10 1.00E+20 1.00E+30 1.00E+40 1.00E+50 1.00E+60
1 1000 1000000 1E+09 1E+12 1E+15
1.00E-30 1.00E-20 1.00E-10 1.00E+00 1.00E+10 1.00E+20 1.00E+30 1.00E+40 1.00E+50 1.00E+60 1.00E+70 1.00E+80 1.00E+90
1 1000 1000000 1E+09 1E+12 1E+15
1E-30 1E-20 1E-10 1 1E+10 1E+20 1E+30 1E+40 1E+50 1E+60 1E+70 1E+80 1E+90 1E+100 1E+110 1E+120 1E+130 1E+140
1 1000 1000000 1E+09 1E+12 1E+15
1E-30 1E-20 1E-10 1 1E+10 1E+20 1E+30 1E+40 1E+50 1E+60 1E+70 1E+80 1E+90 1E+100 1E+110 1E+120 1E+130 1E+140 1E+150 1E+160 1E+170 1E+180 1E+190 1E+200
1 1000 1000000 1E+09 1E+12 1E+15
simple_BIGINT simple_DOUBLE simple_DECIMAL move_BIGINT move_DOUBLE
図 8 より,各方法の性能が傾き-2 の直線(破線)とほぼ平 行になることを確認できる.
図 6 性能の評価結果
Figure 6 Result of performance evaluation.
図 7 一次式の係数算出の性能
Figure 7 Performance of coefficients calculation for linear expression.
図 8 Levinson 再帰の性能
Figure 8 Performance of coefficients calculation by Levinson recursion for high order expression.
以上,本節に示した評価結果により,近似精度と性能を 両立する方法として,提案方式が妥当であることを確認し た.
5. 関連研究
最 小 二 乗 法 の イ ン ク リ メ ン タ ル な 計 算 法 と し て , RLS(Recursive Least Squares)アルゴリズムが広く知られて いる5).これは,最小二乗法における共分散行列(本稿にお ける連立一次方程式の係数行列)を,逐次的に更新する方法 である.即ち,最新データが到来する度に,それ以前にお ける近似式の係数,共分散行列,および新データの値から, 最新の係数と共分散行列を求める方法を提供する. 本稿との本質的な違いとして,以下の二点が挙げられる. (1) 時刻値をスライドさせることは考慮されていない (2) 近似結果に対する古いデータの影響を減じる目的で は,忘却パラメータを利用する (1)のため,本稿で課題とした時刻値の増加による近似 精度劣化の解消には適用できない.また(2)のため,本稿の 前提である,スライディングウィンドウを対象としたスト リーム処理には適用できない. ストリームデータの再帰処理に関する研究として3)が関 連する.再帰処理中の二項演算でpunctuation の伝搬が永久 にブロックするという課題に対し,閉ループ内に特殊なオ ペレータ(Flying Fixed-Point)を設け,投機的な punctuation(以 下sp)をループ内で発生させる方式を提案している.但し, ループ内には同時に一つの sp しか流さないことを前提と するため,ループ中に分岐を含むクエリは対象外と推定さ れ,3.2 節に示したデータフローの実行は不可である.こ れに対し,本稿で利用した方法8)にはクエリグラフの構造 に関する制約は存在しないため,より広範囲な応用に適用 可能である. SQL をデータマイニングやストリームデータ処理に適 用するための拡張案として,6)では SQL の Insert 文や Delete 文などのデータ操作命令で構成するユーザ定義の 集約演算 UDA(User-Defined Aggregates)を導入する方針を 提案している.また,UDA によるチューリングマシンの 模倣が可能であることに基づき,計算完備であることを示 している.但し,同方式ではテーブルに保存するテープや ヘッドの状態を排他的に変更するため,CQL の意味論にお ける個数ウィンドウと同様の動作となり,計算ステートの 振動に繋がる 8).従って,CQL の再帰クエリを実現する 目的では利用不可である.これに対し,本稿では遅延演算 によって振動を回避することで,CQL の意味論を保存しつ つ再帰クエリを実現する.また,CQL はデータ照会命令 (SELECT 文) のみで構成されるため宣言的であり,クエリ 定義の容易性が高いと考える. 0 5000 10000 15000 20000 25000 30000 35000 1 2 3 4 simple_BIGINT simple_DOUBLE simple_DECIMAL move_BIGINT move_DOUBLE 0 5000 10000 15000 20000 25000 30000 35000 100 1000 10000 100000 1000000 1 10 simple_BIGINT simple_DOUBLE simple_DECIMAL move_BIGINT move_DOUBLE (N+1)^(-2)
6. まとめ
ストリーム処理における時系列データの近似方法とし て,その基本方式である最小二乗法について,ストリーム 処理として実現する際の課題を検討した.その結果,処理 の継続による時刻値の増大が,近似計算における桁溢れに 繋がるという問題を指摘し,その回避策として,時刻原点 のスライドを伴う最小二乗法の計算方法,およびCQL の再 帰クエリによる同計算の実現方法を提案した. 更に,近似精度と計算性能について,ナイーブな計算方 法との比較評価を実施し,提案手法が上記の桁溢れを回避 すること,および精度と性能を両立する点で,提案手法が 優位であることを確認した. 以上の検討結果から,ストリーム処理による時系列デー タの近似方法,およびその外挿による変動予測の方法とし て,提案手法が有効であるとの結論を得た. 提案した近似計算方法に基づく予測処理においては,ス ライディングウィンドウのサイズ,および近似式の外挿期 間といったパラメータを,案件毎にチューニングする必要 がある.今後は,パラメータ設定の自動最適化,機械学習, 動的設定変更方式などを検討する必要がある.参考文献
1) P. Buneman, M. Grohe, and J. Widom: “CQL: A Language for Continuous Queries over Streams and Relations,” In Proc. of DBPL 2003, pp. 1-19 (2003).
2) A. Arasu, B. Babcock, S. Babu, J. Cieslewicz, M. Datar, K. Ito, R. Motwani, U. Srivastava, and J. Widom: “STREAM: The Stanford Data Stream Management System,” Technical Report, Stanford University (2004).
3) B. Chandramouli, J. Goldstein, and D. Maier: “On-the-fly Progress Detection in Iterative Stream Queries,” In Proc. of VLDB 2009, pp.241-252 (2009).
4) “Levinson recursion”,
http://en.wikipedia.org/wiki/Levinson_recursion 5) “Recursive least squares filter”,
http://en.wikipedia.org/wiki/Recursive_least_squares_filter 6) Y-N. Law, H. Wang, and C.Zaniolo: “Query languages and data models for database sequences and data streams,” In: Proc. of VLDB, pp. 492–503 (2004).
7) 今木常之,西澤格: “ストリームデータ処理におけるデータ生 存期間管理方式”, 日本データベース学会 Letters Vol.5, No.2, pp.65-68 (2006).
8) 今木常之,西澤格:“遅延演算を利用した再帰的ストリームデー タ処理の計算完備性”, 日本データベース学会論文誌 Vol.9, No.3, pp.25-30 (2011).