修士論文
制限された環境下における学習型行動 プランニング
―状況に特化したプランナー選択に基づく手法―
平成
25
年度修了 三重大学 工学研究科博士前期課程 電気電子工学専攻
篠原 駿介
目 次
第
1
章 はじめに1
第
2
章 研究で使用するアルゴリズム4
2.1 A*アルゴリズム . . . . 4
2.2 Q
学習. . . . 5
第
3
章 題材とする環境8 3.1
ゲームベンチマーク. . . . 8
3.2 Infinite Tux . . . . 9
3.3
優勝アルゴリズムの問題点. . . . 11
第
4
章 提案15 4.1
提案手法. . . . 15
4.2 A*
アルゴリズムとQ
学習の組合せ. . . . 16
4.3
行動のために得られるデータが限られた環境における提案手法の有 効性. . . . 22
第
5
章 実験24 5.1
各プランナーの性能の評価尺度. . . . 24
5.2
実験1:提案手法の性能に関する実験 . . . . 24
5.2.1
実験1:実験条件 . . . . 25
5.2.2
実験1
:実験結果と考察. . . . 26
5.3
実験2:他手法との比較 . . . . 28
5.3.1
実験2
:実験条件. . . . 28
5.3.2
実験2:実験結果と考察 . . . . 29
第
6
章 まとめと今後の課題30
謝辞
32
参考文献
33
発表論文
35
第 1 章 はじめに
近年,PCの性能の向上に伴い,その性能を活かした知的システムの研究が盛ん に行われている.知的システムとは,機械やコンピュータの持つ特徴を生かし,さ らに人間などの生物がもつ,適応,学習などの優れた機能を取り込んだシステムの ことである
[1].近年では,プロの棋士に勝利したコンピュータプログラム「GPS
将 棋」[2]
,「ツツカナ」[3]
,「ponanza
」[4]
などが話題となっている.また,アメリカに おいては,クイズに挑戦した「Watson」[5]という質問応答システムが話題となっ た.これら「GPS
将棋」や「Watson
」等は複数台のPC
を利用し,並列クラスタ 処理を行うことにより,成果を挙げている[6][7].更に, GPGPU(General-purpose computing on graphics processing units)
といわれる技術も注目されている[8][9].
この技術は,コンピュータを構成するものの1つである
GPU(Graphics Processing
Unit)
を用いて並列に計算を行うものである.これもPC
の性能向上に伴って生まれた技術であり,
GPGPU
を用いたニューラルネットワーク学習の高速化といった 知的システムへの応用も近年報告されている[10].
しかし,計算リソース等が少ない,計算のための時間が短いなど,計算コスト が制限された場合においては,これらのような高性能化した
PC
の機能を活用し た知的システムを構築することは難しい.そのような場合の例として,組み込み システムがある.組み込みシステムには一般的に,厳しいリソース制約の下,リ アルタイム性や,即応性が求められている.例えば,カーナビゲーションにおい て経路探索などでは,運転中に目的地を変更する可能性がある.そのようなとき に,経路探索に数十分もかかってしまうことはあってはならない.そのため,専 用LSI
のような専用演算器を開発し,利用することで高速化等が図られているが,そのような専用
LSI
は一般的に,価格や消費電力等のコストが高くなる.組み込 みシステムは低コストで開発が要求されるため,高性能LSI
を多用することは難 しい[11]
.そのため,前述したような高性能なプロセッサによる並列計算処理を利 用することは難しい.そのため,使用できる計算リソースや計算時間といった計算コストが限られて
いる環境でも,効果的な知的システムの開発が求められている.そこで本研究で は,計算コストが限られた環境下で,効率よく目的を達成することが可能なアル ゴリズムの開発を目指す.
制限された環境としては,組み込みシステム以外にもさまざまな環境が考えら れる.特に,本研究ではそのような環境として「ビデオゲーム」に着目した.近 年盛んに開催されているビデオゲームを題材とした
AI
コンペティションは,さま ざまな制限がかけられている.特に,プラットホームゲームベンチマークを題材 としたPlatformer AI Competition[12]
では,ベンチマークそのものが,他の問題 よりも複雑であり,コンペティションにおける制限も厳しく定められている.そ こで,本研究では,制限された複雑な環境として,Platformer AI Competitionで 使用された「Infinite Tux
」[13]
を使用する.複雑な環境下において目的を達成するために,プランニングという方法がしば しば用いられる.これは,目的達成のための行動方針,つまりプランを立てるこ とにより,効率よく目的を達成するという方法である.例えば,単純にある状況 から行動を直接決定するエージェント(意思決定・行動を行うもの)の場合,その 行動後の状況まで考慮していない.その結果,全体で見ると効率のよい行動がで きない場合がある.そのような場合において,プランニングを行うことで,一つ 一つの行動は最適でなくても,全体で見ると結果として効率の良い行動となるこ とができる.プランニングは,ロボットの行動やナビゲーションの経路探索等様々 な分野で用いられている
[14][15].プランニングを利用する手法においては,プラ
ンナー(
プランニングを行うもの)
の性能を向上させれば,システム全体の性能も 向上する.しかしながら,制限された環境下において,計算リソース等のコスト の問題から,1つのプランナーで考えられるすべての状況に対して適切なプラン ニングを行うことは難しい.そこで,本研究では,特定の状況において適切なプランニングを行うプランナー を複数用意し,状況に合わせて適切なプランナーを選択することにより,効率よ くプランニングを行う手法を提案する.提案の実装として
A*アルゴリズムと Q
学 習の組合せ手法を作成した.本手法は,実際の行動選択はA*
アルゴリズムで探索 することによって行い,プランナーはQ
学習によりA*アルゴリズムの目標節点の
位置をプランニングするものを複数用意する.各プランナーには,特定の状況に おいてのみプランニングを行うようにし,限られた計算リソースの下でも効果的 にプランニングできるようにする.提案手法の性能は,各プランナーの性能と,選 択可能なプランナー数に大きく依存する.これらの要因とプランニング性能との関係を実験により調査し,検討する.また,提案手法の有効性を他手法との比較 することで確かめる.
本論文の構成を以下に示す.2章では,本研究で使用する
A*アルゴリズムと Q
学習の2
つのアルゴリズムについて説明する.3
章では,題材とするプラットホー ムゲームベンチマーク「Infinite Tux」について説明し,更にInfinite Tux
を使用 したコンペティションにおいて優秀な成績を収めたアルゴリズムとその問題につ いて述べる.4
章では,効率よくプランニングを行うための手法を提案し,実装として
A*アルゴリズムと Q
学習の組合せについて述べる.5章では,提案手法の有効性を実験によって確認し,最後に
6
章で本研究をまとめる.第 2 章 研究で使用するアルゴリズム
本章では,本研究で使用する
A*アルゴリズムと,Q
学習について説明する.2.1 A*
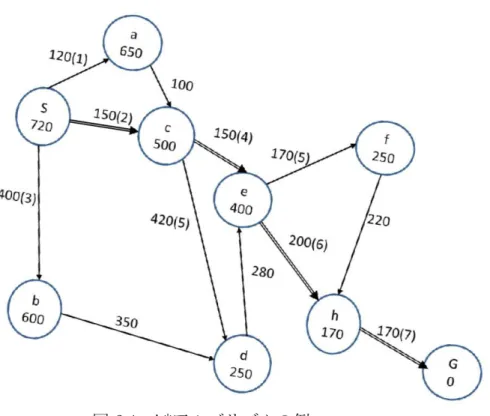
アルゴリズムA*アルゴリズムは探索アルゴリズムの代表的な手法の一つである [16].ある節
点から次の節点に移動するときのコストが定められた状態空間を考える.根節点 からある節点
n
を通って,目標節点までたどり着くときのコストが最小となる経 路を考えた時,根節点から節点n
までの最小コストをg(n)
,節点n
から目標節点 までの最小コストをh(n)
とすると,この経路のコストf(n)
は式2.1
で与えられる.f (n) = g(n) + h(n) (2.1)
この時,実際に根節点
n
までの最小コストg(n)
は探索中に求めることが可能であ る.目標節点までの最小コストh(n)
が不明な場合,h(n)
の推定をh
∗(n)
とすると,ある節点
n
を通る最短経路のコストf
∗(n)
は式2.2
で見積もることができる.f
∗(n) = g(n) + h
∗(n)
(2.2)
式2.2
において,節点n
を根節点から目標節点まで近づけながら,コストを小さく するn
を順に決定することで,最終的に根節点から目標節点までの最短経路を探索 することが可能となる.この時のh
∗(n)
をヒューリスティック関数といい,ヒュー リスティック関数h
∗(n)
が,目標までの実際のコストを決して超えない見積もりに なるように選ぶとき,最適(いくつかの解があるとき,最も良いの解を見つける)
であり,完全(解が一つ存在するときに,それを見つけることが保証されている)
である[16]
.このようなアルゴリズムをA*
アルゴリズムという.図2.1
に,A*
ア ルゴリズムの例を示す.図中の丸印が節点,節点内の数字が,その節点から目標 節点までの推定コスト,矢印がその節点から展開可能な枝,枝に書かれている数 字が実際のコストである.図2.1
の例で,根接点S
から目標節点G
までの最短経路図
2.1: A*
アルゴリズムの例を探索する.まず,根接点
S
から,節点a
を通る最短経路を考えるとき,式2.2
よ り,f
∗(a) = 120 + 650 = 770
となる.同様に,f
∗(b) = 1000
,f
∗(c) = 650
となる ため,まず節点c
を通る経路が最小コストの経路となる.これを,図2.1
内のカッ コつき数字の順で評価していくことで探索を行う.結果として,図2.1
では,二重 矢印が根接点S
から目標節点G
まで経路探索した結果の解となる.A*アルゴリズムの問題点として,生成したすべての節点をメモリに記憶してお
くために,探索範囲が広くなると膨大なメモリが必要となることと,ヒューリス ティック関数の誤差が実際の経路コストの対数より早く増加する,つまり式2.3
に あてはまる場合,計算量の指数的爆発が起こることがあげれらる.| h(n) − h
∗(n) | > O(log h
∗(n)) (2.3)
2.2 Q
学習Q
学習は,強化学習における代表的な学習手法の一つである[17].強化学習は,
意思決定を行うエージェントが環境と以下のやり取りを行うことで,学習する
(
図2.2).ここで,Q
学習における環境とはエージェントが相互作用を行う対象のことを示す.
図
2.2:
強化学習の枠組み1.
エージェントは環境から状態s
を観測する.2.
エージェントは観測した状態s
に基づいて行動a
を選択,実行する.3.
エージェントは,その行動a
の結果,行動a
に対する価値に応じた報酬r
を 環境から与えられる.4. 1〜3
を繰り返す.Q
学習において,エージェントは環境から報酬を受け取り, 式(2.4)
の更新式を 用い,図2.3
の手順に従いQ(s, a)
を更新する.Q(s
t, a
t) ← Q(s
t, a
t) + α(r
t+1+ γ max
at+1
Q(s
t+1, a
t+1) − Q(s
t, a
t))
(2.4)
ここで,
α
は学習率(
行動価値観数の更新の度合い)
,γ
は割引率(
将来に得られる と期待される報酬が現在においてどれだけの価値があるかの度合い),sは状態,a
は行動,r
は報酬,添字のt
は時刻を表す.行動価値関数Q(s
t, a
t)
の集合をQ
表と 呼ぶ.エージェントはQ
表を参照することにより,規則に従い行動を選択する.そ のため,環境に合わせたQ
表の作成が必要となる.そこで,行動価値観数Q(s
t, a
t)
を最大の報酬を得られるような最適行動価値関数Q
∗(s
t, a
t)
の集合であるQ
表を学 習によって作成する.Q学習においては,学習率α
に関する通常の確率近似の条 件のもとで,確率1
でQ
はQ
∗に収束することが示されている[18]
.エージェント
状態
5 I
報酬r I
行動Q│ 環境
図
2.3: Q
学習の手順行動選択規則には,現在の状態
s
tにおけるQ(s
t, a
t)
から,常にmax
atQ(s
t, a
t)
となるような行動を選択するgreedy
行動選択規則,少ない確率で現在の状態s
tに おけるQ(s
t, a
t)
からランダムに選択し,残りの確率でmax
atQ(s
t, a
t)
を選択するϵ-greedy
行動選択規則,現在の状態s
tにおけるQ(s
t, a
t)
から確率的に選択するソフトマックス行動選択規則等がある.本研究では,行動選択手法にはソフトマック ス手法を用いる.ソフトマックス行動選択規則は,推定価値を等級付けした関数 によって,行動確率を変化させる
[17].すなわち,価値が最も高い行動には最も高
い選択確率が与えられ,他のすべての行動は,その推定価値に従って重みをかけ られ,ランク付けさせられる.具体的には,t
回目の行動a
を次の確率で選択する.e
Qt(a)/τ∑
nb=1
e
Qt(b)/τ(2.5)
ここで,τは温度パラメータである.温度が高い場合,すべての行動がほぼ同程度 に起こる.逆に低い場合は,価値の推定が異なる動作の選択確率の差がより大き く異なるように設定される.
Q ( s
,α )
を任意に初期化各エピソードに対して繰り返し:
Sを初期化
エピソード、の各ステップに対して繰り返し.
Q
から導かれる方策(例えばQに対するソフトマックス行動選択規則) を使って,s
での行動α
を選択する行動
α
を取り,報酬r
,次の状態どを観測するQ ( s
,α )← Q ( s
,α)+α [ r + Y m a X a ' Q ( s '
,a ' ) ‑ Q ( s
,α ) ] s
←‑s '
s
が終端状態なら繰り返し終了第 3 章 題材とする環境
本章では,まず制限された環境の代表的な1つとして,ゲームベンチマークに ついて説明する.次に,本研究で題材とする制限された環境であるプラットホー ムゲームベンチマーク「Infinite Tux」と,IEEEで開催されたコンペティション
「Platformer AI Competition」において優秀な成績を得たアルゴリズムについて説 明する.
3.1
ゲームベンチマーク知的システムの性能を測る場合,しばしばゲームを題材としたゲームベンチマー クが利用される.例えば,IEEEの学術コンペティションとして,プラットホーム ゲームを題材とした「
Platformer AI Competition
」,リアルタイムストラテジー ゲームを題材とした「StarCraft RTS AI Competition」,巡回セールスマン問題を 題材とした「Physical Travelling Salesman Problem(PTST)
」等,様々なゲームを 題材としたコンペティションが開催されている.これらのゲームベンチマークは,基本的に以下のような特徴を持っている.
1.
複雑な環境である2.
様々な制限がある3.
基本的に一般配布されている本研究では,プラットホームゲームの特徴と,コンペティションの制限の観点 から,「
Platformer AI Competition
」に着目する.次節では,本コンペティション において使用されているプラットホームベームベンチマークについて説明する.3.2 Infinite Tux
本研究では,様々な制限が課せられている環境として,プラットホームゲーム ベンチマーク「Infinite Tux」(図
3.1)
を題材とする.IEEEの学術コンペティショ ンとして,2009年から「Platformer AI Competition」が開催されている.本コン ペティションでは,プラットホームゲーム「Infinite Tux」が題材として利用され ている.プラットホームゲームとは,キャラクターを操作することで台(プラット ホーム)を飛び移り,敵キャラクターや障害物を避けながらゴールを目指すゲー ムの総称のことである.例えば,任天堂株式会社によって発売された「スーパー マリオブラザーズ」等がこれに該当する.「Infinite Tux」ベンチマークは,意思決定行動を行うエージェントと,ブロッ クや壁などの障害物,動き回る敵キャラクター,様々なアイテムなどで構成され ている.エージェントは,障害物や敵キャラクターを左右移動やジャンプ等で避 けつつ,右端にあるゴール地点まで進むことを目的としており,これらに基づい たスコアーによりその性能が評価される.本ベンチマークにおいてエージェント が観測する状態は,エージェントのステータスと位置情報,画面に表示されてい るブロックなどの障害物の位置情報や種類,動き回る敵キャラクターの位置情報 や種類である.エージェントの行動は上下左右移動,ダッシュ,ジャンプ,飛び道 具での攻撃の計
7
種類の行動の組合せである.本ベンチマークにおいて,1つの ステージは,図3.1
に表示されている画面の16
倍の長さであり,エージェントが 移動することにより図3.1
の画面がスクロールする.エージェントは,図3.1
に表 示されている範囲内の情報しか取得できない.エージェントは刻一刻と変化する 周囲の状況に合わせて行動する必要が有るため,単純な迷路問題や他のゲームベ ンチマークと比べ,非常に複雑な環境であるといえる.更に,本ベンチマークを使用したコンペティションでは,以下の3つの制限が 課せられている.
1.
エージェントの一回の行動を決定するまでの計算時間は,約40[ms]
まで2.
意思決定を行うために,事前に得ることができるデータは,最大10000
ステージ分のプレイ情報
3.
エージェントの行動を決定する際に使用できる計算機は1
台のみ(スペック は指定)そのため,本ベンチマークにおいては,これらの制限を考慮したアルゴリズムの 開発が必要となる.具体的には,以下の二つの条件を満たすアルゴリズムである 必要がある.
1.
少ない計算リソースで動作する(
計算時間や,使用メモリの制限) 2.
少ない情報量でも適切な行動選択が可能である(データ量の制限)
実際に「
Platformer AI Competition
」において,優秀な成績を収めたアルゴリ ズムを表3.1
に示す.次節では,各アルゴリズムについての簡単な説明と,その問 題点を述べる.図
3.1: Infinite Tux[julian togelius, 2009]
表
3.1: Platformer AI Competition
における優勝アルゴリズム[20]
開催年度
2009
年2010
年優勝アルゴリズム
A*アルゴリズム
[Robin Baumgarten, 2009]
ルールベースシステム
+
遺伝アルゴリズム
+
A*アルゴリズム
[Slawomir Bojarski, 2010]
3.3
優勝アルゴリズムの問題点3.2
節で述べたとおり,Infinite Tux
は非常に複雑な環境である.そのため,単純 な機械学習や深さ優先探索といった系統的探索アルゴリズムのみを使用する手法で は,エージェントを効率よく行動させることは難しい.A*アルゴリズムは,ヒュー
リスティックを用いた発見的探索アルゴリズムであり,2.1
節で述べたように効率 よく最適な行動を探索することが可能である.そのため,複雑な環境下においてA*
アルゴリズムは有効なアルゴリズムといえる.実際,表3.1
を見ると,両年とも
A*アルゴリズムを用いた手法が優秀な成績を収めていることがわかる.
しかしながら,
Infinite Tux
に単純にA*アルゴリズムを用いるのには大きな問題
がある.それは,Infinite Tux
の持つ制限の1つである,エージェントの一回の行 動を決定するまでの計算時間により引き起こされる.2009
年度に使用されたA*ア
ルゴリズムは,表示されているInfinite Tux
の画面右端をA*
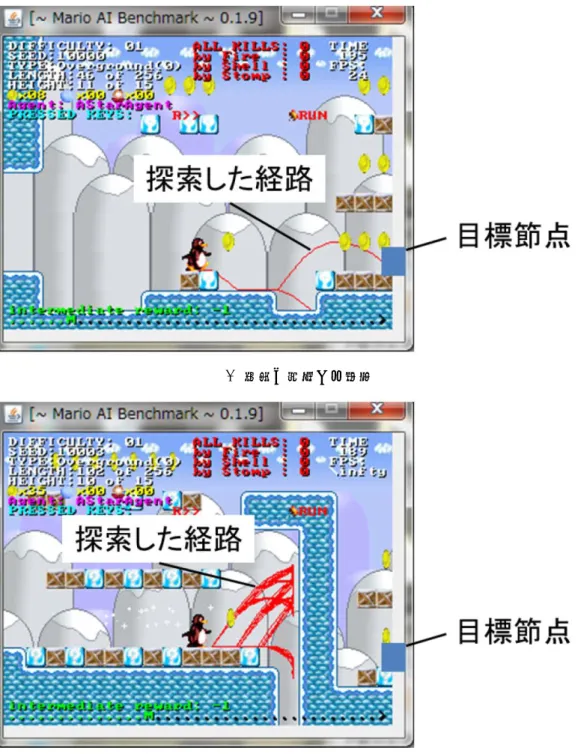
アルゴリズムの目標 節点として固定し,表示される画面が切り替わる度に経路探索を行っている[21].
図
3.3(a)
のように目標節点までの移動距離が短い場合,Infinite Tux
の計算時間の 制限内に探索が可能である.しかしながら,図3.3(b)
のように,目標節点までの 移動距離が長い場合,Infinite Tuxの計算時間の制限を超過してしまい,適切な行 動ができなくなってしまう.2009
年度Platformer AI Competition
は図3.3(a)
の ようなステージ構成がほとんであったが,2010年度からは図3.3(b)
のような状況 が出現するステージ構成が追加された.そのため,2010
年度にA*
アルゴリズム単 体を用いた手法は優勝できなかった.2010
年度の優勝アルゴリズムは単純なA*アルゴリズムでなく,それにルール
ベースシステムを加え,遺伝的アルゴリズムによってルールの調整を行っている[22]
.こうすることで,大雑把なプランニングをルールベースで行い,その方針に したがってA*アルゴリズムで実際の行動を探索している.そのため,本手法は計
算時間の問題を解決している.しかしながら,ルールの作成自体は開発者が行う 必要がある.これは,アルゴリズム開発者にとって大きな負担となる.論文[23]
で は,Infinite TuxにDeep Boltzman Machine[24]
を適用した結果,ほとんどのシー ンが異なったものであったことが報告されている.そのため,大量のシーンを考 慮したルール作成が必要となる.さらに,コンペティションで勝利するためにはInfinite Tux
に最適なルールのキャリブレーションを必要とするため,ルールベースシステムを使用する手法は
Infinite Tux
に特化してしまう可能性がある.本手法 は,2010年度コンペティションでは優勝しているが,本手法の解説をしている論 文において,2009
年度のA*
アルゴリズム単体には勝利することができなかったこ とが述べられている.2009
年度の手法をフローチャートで表すと,図3.2(a)
のようになる.このよう な手法は,状況の変化に対応することができない.具体的には,先程述べたよう に,目標節点までの移動距離が長い場合,A*アルゴリズムでは膨大な計算時間を 必要とする.そのため,3.2
節で述べた,少ない計算リソースで動作するという条 件を満たすことができていない.このようなアルゴリズムで性能を向上させるた めには,CPU
の性能の向上や並列計算処理といったことが必要となるが,これは 計算リソースを増やすことに繋がるため,本環境下ではこの問題を解決するため,2010
年度では,ルールベースシステムをプランナーとしてプランニングしている.これは,図
3.2(b)
のように行動決定の前に大域的な意志決定であるプランニング を行うことで,先の問題を解決しているといえる.しかしながら,単一のプラン ナーによるプランニングは,そのプランナーのみがすべての状況に対応する必要 があるため,このようなアルゴリズムで適切な行動選択をしようとすると,プラ ンナーが必要とする情報量は膨大なものとなることが予測される.このようなア ルゴリズムは,3.2
節で述べた,少ない情報量でも適切な行動選択が可能であると いう条件を満たすことができていない.更に,一つのプランナーが複雑な計算を 行う必要がある可能性があるため,プランナーのプランニングの仕方によっては,少ない計算リソースで動作する条件も満たすことができない可能性がある.
そこで,本研究では複数のプランナーを状況に応じて切り替えることで,これ らの問題を解決することができる手法を提案する.次章では,提案手法について 詳しく説明する.
(a)
反射的な行動選択(b)
単一プランナーによるプラ ンニング図
3.2:
従来の主な手法のフローチャート状態の入力 状態の入力
プランニング
行動選択 行動選択
(a)
探索に成功する場合(b)
探索が成功しない場合図
3.3: A*アルゴリズムで探索が成功する場合と成功しない場合
目標節点
目標節点
第 4 章 提案
本章では,Infinite Tuxにおける計算時間や計算リソースといった制限を満たし つつ,
3.3
節で述べたアルゴリズムの問題点を解決するアルゴリズムについて説明 する.4.1
提案手法本研究では,エージェントが遭遇する状況に合わせて学習型のプランナーそのも のを選択することにより,全体の行動をプランニングするアルゴリズムを提案す る.提案手法のフローチャートを図
4.1
に示す.図4.1
のフローチャートにおいて,状態とはエージェントがその周囲を観測することによって得る情報とし,状態を 入力した結果エージェントが判断するものを状況とする.本手法において,エー ジェントは状況に合わせて,その状況を担当する学習型プランナーを選択する.選 択されたプランナーは,学習によって得られた結果より,その状況において目標 達成のためのプランニングを行う.最後に,プランニング結果に従い,実際に行 動を行う.例えば,図
4.1
において,エージェントが状況A
に遭遇した場合,プラ ンナーA
を選択する.選択されたプランナーA
は,その状況に対応したプランニ ングを行う.その結果に従い,行動を行う.このような手順をとることで,前章で述べた計算リソースの問題を解消するこ とが期待できる.各プランナーではそれぞれが限定された状況下でのプランニン グを行えばよいので,すべての状況に対応しなければならないルールベースシス テムをベースとした従来手法と比べ,一回の行動決定のための計算時間を大幅に 短縮できることが期待される.更に,複数のプランナーが同時にプランニングを 行う必要もなく,複数台
PC
をつなげた並列計算処理も行う必要がないため,計算 リソースの増加も必要としない.つまり,提案手法は少ない計算リソース下でも 動作可能となることが期待される.また,複数のプランナーを用意することはア ルゴリズム設計者の負担を増すが,各プランナーに学習により機能を獲得するものを用いることで,設計者はプランナー選択部分のみを設計するれば良くなる.
次節では,提案手法の実装として,A*アルゴリズムと
Q
学習を組み合わせた手 法について説明する.図
4.1:
提案手法のフローチャート4.2 A*
アルゴリズムとQ
学習の組合せ3.1
節で述べたとおり,A*
アルゴリズムはInfinite Tux
において有効である.特 に,文献[25]
を見ると,コンペティションではルールベースシステムや遺伝的ア ルゴリズムを使用するエージェントも参加しているが,A*
アルゴリズムを使用し たエージェントが上位を独占していることがわかる.このことからも,A*アルゴリズムは
Infinite Tux
の制限下でも,目標節点までの移動距離が十分短い場合には,有効であることがわかる.そこで,本手法において,行動選択には
A*
アルゴ リズムを利用し,目標節点の位置の調整をプランナーによるプランニングによっ て行う.4
犬!I!の入力グ
ン コ
ニ 包
w p
舵ブグ
ン対 ン ニ宛 丸‑
ヲパ 刊
吋 プ
ナ市
HH
U 一 グ
ト ド .
一ンH吋
: ‑
一 そ 肌
一 フ パ 刊
ブ
行 動
• • •
各プランナーは,
A*
アルゴリズムの目標節点を学習により選択する.本手法で は,学習アルゴリズムとしてQ
学習を使用する.Q学習は解を開発者が示す必要 なしに,目的を効果的に達成する(報酬を最大にする)行動を自律的に獲得でき る.そのため,人手によるルールベースシステムにおけるルールの作成やキャリ ブレーションといった手間を必要としない.図
4.2
にA*
アルゴリズムとQ
学習の組合せ手法のフローチャートを示す.本手 法において,図3.3(a)
のような状況を状況A,図 3.3(b)
のような状況を場合に応 じて状況B,状況 C,・
・・とする.各状況には,その状況に特化されたプランナー が存在する.本手法において,状況A
においては,表示されている画面右端にA*
アルゴリズムの目標節点を固定するようにプランニングするプランナーとし,状 況
B
以降ではA*
アルゴリズムの目標節点の位置をQ
学習によって選択すること によってプランニングするプランナーとする.例えば,図
3.3(b)
のように前方に大きな壁がある状況を状況B
とする.この時,エージェントの周囲
10
×10
格子の内,足場がある格子をQ
学習で選択可能なA*
アルゴリズムの目標節点の位置とする.図
4.3(a),図 4.3(b)
のエージェント周囲 の格子が,Q
学習で選択可能な範囲であり,図中の丸印が実際に選択可能な目標 節点の位置を示している.これらの図のように,選択可能な目標節点は,エージェ ントを中心とし,相対位置を扱う.こうすることで,A*
アルゴリズムで探索しな ければならない行動数が少なくなるため,3.3節で述べた計算時間の問題の解決が 期待できる.プランナーの選択方法には,さまざまに考えることが可能である.具体的には,
敵との距離や袋小路の有無によって,プランナーを変える方法などがあげられる.
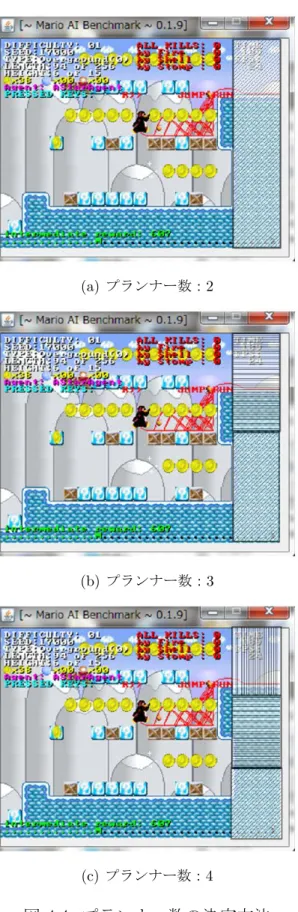
本稿では,隆起している壁の高さに応じて,プランナーを選択するようにしてい る.図
4.4
に,プランナーの選択方法を示す.図中の塗りつぶされている範囲は,エージェントが隆起している壁の高さを判別する際に,どの程度細かく判断する かを表す.例えば,図
4.4(a)
のように,画面右側の範囲で大きな壁があるかどう かで見る場合,プランナー数は,1.
画面右端に目標節点を固定2.
画面右側に大きな壁がある場合にQ
学習により目標節点を選択の2種類となる.また,図
4.4(b)
のように,画面右下半分と,画面右上半分の2 つの領域に分け,画面右側に出現する壁の高さがどちらの領域まで到達している かによって判断することで,プランナー数は,1.
画面右端に目標節点を固定2.
画面右下半分までの高さの壁がある場合にQ
学習により目標節点を選択3.
画面右上半分までの高さの壁がある場合にQ
学習により目標節点を選択 の3
種類となる.同様に,図4.4(c)
の場合は4
種類となり,更に分解能を上げるこ とでプランナー数は増加し,最大16
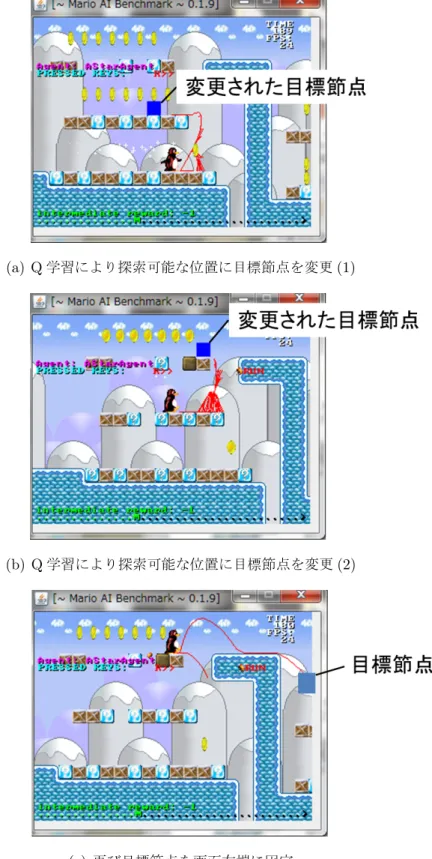
種類のプランナーを使用することができる.具体的に,提案手法の動作を説明する.まずエージェントは,図
4.5(a)
のよう に,Q学習によりA*アルゴリズムの目標節点を選択する.次に, A*アルゴリズム
を用いて,その目標節点までの経路を探索し,実際に行動する.エージェントが 目標節点に到達したとき,再び画面右端を目標節点とし,探索を試みる.この時,探索が成功しなければ,図
4.5(b)
のように到達した地点を新たな探索開始地点と し,Q
学習により目標節点を選択する.この動作を繰り返し,図4.5(c)
のように 画面右端までの経路が探索可能となった時,再びプランナーA
が目標節点を固定 し,探索を続ける.こうすることで,ステージ全体の行動をプランニングする.図
4.2: A*アルゴリズムと Q
学習の組合せ手法のフローチャート(a)
選択可能な目標節点(1)
(b)
選択可能な目標節点(2)
図
4.3: Q
学習により選択可能な目標節点の位置•
(a)
プランナー数:2(b)
プランナー数:3(c)
プランナー数:4図
4.4:
プランナー数の決定方法(a) Q
学習により探索可能な位置に目標節点を変更(1)
(b) Q
学習により探索可能な位置に目標節点を変更(2)
(c)
再び目標節点を画面右端に固定図
4.5:
プランナーによる目標節点の変更の様子4.3
行動のために得られるデータが限られた環境におけ る提案手法の有効性4.1
,4.2
節において,コンペティションにおける制限のうち,計算時間と計算リ ソースに対する提案を行った.予備実験(論文 [c])
より,A*アルゴリズム単体で計
算時間の問題から探索不可能な状況においても,A*アルゴリズムとQ
学習の組合 せ手法においては,十分に短い時間で探索し,行動できていることが確認できた.このことから,提案手法は,コンペティションの計算リソースの制限を満たして いることがわかる.
コンペティションでは,この他に学習に用いることのできるステージ数といっ たデータ量も限られている.本手法は,状況に特化したプランナーを複数用意し,
それらを学習する必要がある.したがって,各プランナーは元々限られた学習用の データをさらに分け合って利用することとなる.そのため,この点について検討 する必要がある.予備実験
(
論文[d])
より,Q
学習を行動選択に使用したアルゴリ ズムで3000
ステージ学習しても,複雑なステージでは目標達成できていなかった が,プランナー数が3
の場合の提案手法は,100
ステージ分の学習により,約60%
のステージにおいて有効的なプランニングを行うことができたことが確認できた.
このことからも,提案手法は制限された環境下においてもある程度有効的にプラ ンニングできることがわかる.しかし,プランナー数を変更できる場合,提案手 法の性能はプランナー数によって変化することが予測される.仮に,全てのプラ ンナーが大量の学習データを持つことが可能ならば,プランナー数は多ければ多 いほど,あらゆる状況において適切なプランニングが可能となる.しかし,得ら れるデータ量に制限がある環境下においては,限られたデータを各プランナーで 分け合うため,十分に学習できないプランナーができる可能性がある.そのため,
単純にプランナー数を増加させても,全てのプランナーがそれぞれの対応する状 況で適切なプランニングを行うことが可能とはならない.
用いることのできるデータ量の制限が制限された環境下における提案手法の性 能については,主に以下の二つの要素が関係している.
1.
各プランナーそれぞれの性能2.
プランナー数項目
1
における性能とは,各プランナーが担当する状況おいて,持っているデー タ量に対して正しくプランニングができるかどうかを表す.仮に各プランナーの性能が低い場合,そのプランナーが担当する状況に対して正しくプランニングで きず,結果として全体の行動プランニングの性能も低下する.
また,与えられるデータ量が制限されている本環境において,項目
2
のプラン ナー数も関係する.仮に,エージェントが得たデータを各プランナーに均等に配 分するとする.プランナー数が少なすぎると,それぞれのプランナーが得られる データ量は多くなるが,それぞれのプランナーが担当しなければならない状況が 増えるため,各プランナーにかかる負担が大きくなり,結果としてそれぞれのプ ランナーが性能を発揮できなくなる可能性がある.しかし,逆に多すぎるとそれ ぞれのプランナーに与えられるデータ量が少なくなりすぎ,各プランナーの性能 が悪くなる可能性がある.次章では,これらの要素と,提案手法の性能に関して実際に実験を行い調査す る.更に他の手法と比較実験を行い,提案手法が実際に有効であるかどうかを実 験により確認する.
第 5 章 実験
本章では,提案法の有効性を実験を通じ確認する.まず
5.1
節で,提案手法が効 率よくプランニングできる時の条件を実験により調査し,次に5.2
節で他の手法と 比較することで,提案手法の有効性を示す.5.1
各プランナーの性能の評価尺度本手法において,Q学習によるプランナーは学習時に獲得した
Q
表に従って行 動を選択する.Q
表は学習開始時,全て‘0’
であり,学習を繰り返すことでその値 が増減する.学習終了時にQ
表の‘0’
を選択するのは,以下の様な場合である.1.
学習時にその状況に遭遇していない2.
その状況に有効な行動を学習できていない(‘0’以外の行動が負)3.
ソフトマックス行動選択規則により確率的に選択されるこの中で,項目
3
のランダム選択を行う確率は小さなものであるため,‘0’
を選択 する原因は主に項目1,項目 2
となる.この2
つの項目は,学習が不十分,つまりQ
学習を用いるプランナーにおいては,その性能が十分でないことを示している.このことから,本手法において各プランナーの性能は
Q
表の‘0’
を選択する回数に 関係すると考え,これも各プランナーの性能の尺度として,実験により評価する.5.2
実験1
:提案手法の性能に関する実験5.1
節で定義した各プランナーの性能,プランナー数とプランニング手法の性能 についての関係について,実験により調査する.5.2.1
実験1
:実験条件今回の実験では,学習に用いたデータ量,プランナー数は,表
5.1
とした.Q
学 習のパラメータとして,学習率,割引率はそれぞれ,本研究室でよく利用される[26]0.05
,0.95
とする.報酬は表5.2
の通りとする.行動選択にはソフトマックス 手法を使用し,温度係数は1.0
とした.Q学習の状態はエージェントの現在の高さ とし,行動は目標節点を選択する範囲の決定とした.エージェントは決定された 範囲のうち,着地可能な位置を抽出し,ランダムで1つの目標節点を決定する.A*アルゴリズムは,目標節点に到達するまでの時間が最小となるような経路を
探索し,敵キャラクターからダメージを受ける,穴に落ちるといった経路にペナ ルティとして大きなコストを与えた.提示する実験結果は,乱数系列を変えて行った
5
回の実験の平均である.実験 に使用するステージは表5.3
のとおりである.表
5.1:
提案手法の性能に関する項目学習に用いたデータ量
[ステージ数] 50,100,1000,または 2000
プランナー数
2,3,4,5,6,8,
または16
個 内訳:
目標節点右端固定1
個+
目標節点学習1,2,3,4,5,6,7,
または15
個表
5.2: Q
学習の報酬条件 報酬
選択した目標節点まで探索不可
-10.0
選択した目標節点まで探索可能 その目標節点から画面右端まで探索可能10.0
その目標節点から画面右端まで探索不可
-1.0
表
5.3:
実験に使用するステージlevel seed
値 オプション学習フェーズ
1 0
〜最大1999
敵出現:
無し,大きな壁:
有り プランニングフェーズ1 10000
〜10499
敵出現:
無し,大きな壁:
有り5.2.2
実験1
:実験結果と考察実験の結果を図
5.1
,図5.2
に示す.図5.1
において,縦軸は500
ステージでプラ ンニングした際のQ
表の‘0’
を選択した回数,横軸はプランナー数を示す.図5.2
において,縦軸は500
ステージでプランニングした際のクリアステージ数,横軸 はプランナー数を示す.また,それぞれのグラフのエラーバーは標準偏差である.図
5.1
より,Q
表と各プランナーの性能について考察する.学習に用いたデータ 量が少ない場合,プランナーの数が増えるにつれ‘0’
を選択する回数が増加してい ることがわかる.プランナー数が増加するにつれ,各プランナーが獲得できる情 報量は減少する.そのため,学習に用いたデータ量が少ない場合,各プランナー が十分なデータを獲得できず,結果としてQ
表の‘0’
を選択しなければならない状 況に多数陥っている.逆に,学習に用いたデータ量が十分に多い場合,プランナー 数がある程度まではQ
表の‘0’
を選択した回数はほぼ0
回である.また,プラン ナー数が最大の16
種類の場合は,少し‘0’
を選択した回数が増加しているが,学 習に用いたデータ量が少ない場合と比べて非常に少ない回数に収まっている.こ れは,各プランナーが十分に学習できているためである.つまり,Q表の‘0’
を選 択する回数は学習に用いたデータ量に大きく依存しており,データ量が十分多け れば,各プランナーの性能も十分なものとなる可能性が高い.ここで示した結果は,学習に用いたデータ量は最大でも
2000
ステージ分の結果 であり,Platformer AI Competition
における制限内には十分に収まっている.そ のため,プランナー数をこの程度に増やしても,コンペティションの制約には全 く抵触せずに,十分に学習できるといえる.次に,図
5.2
より,プランナー数と手法の有効性について考察する.図5.2
を見 ると,学習に用いたデータ量が少ない場合,プランナー数が少ない場合と多い場 合でクリア回数に大きな差が出ていない.このような状況下では,先に示したと おり各プランナーの学習が十分ではなく,各プランナーが状況に合わせたプラン ニングを行うことができず,Q
表の‘0’
を選択しランダムに行動した結果だと考え られる.次に,学習に用いたデータ量が多い場合については,以下に示す傾向が 現れた.プランナー数が少ない場合はデータ量が少ないときと比べてもより少な いクリア回数となっている.逆に,プランナー数がある程度多い場合は,データ 量が少ないときと比べてクリア回数が多くなっている.これは,プランナー数が 少なすぎる場合,各プランナーが学習した時に,環境のエイリアス問題が発生し てしまい,Q表の値が次々に変更され続け,結果として各プランナーが担当する状況に有効なプランナーでなくなっていたためだと考える.プランナー数がある 程度多い場合,各プランナーが担当する各状況に対して十分に学習ができており,
結果として良いプランニングができているということである.しかしながら,プ ランナー数が過剰な場合,各プランナーが取得できるデータが少なくなり,結果 として各プランナーの性能が悪くなり,プランニングの性能も悪くなっている.
今回の結果から,提案手法は環境に合わせて学習に用いるデータ量とプランナー 数を調整するだけで,プランニングの性能を調整することが可能である事がわか る.特に,今回の条件においては,学習に用いるデータ量は
2000
ステージ,プラ ンナー数8
の場合が最もプランニング性能が良いことがわかる.図
5.1:
実験結果:Q表の‘0’
を使用した回数図
5.2:
実験結果:プランニングの有効性5.3
実験2
:他手法との比較5.2
節で確認した最も良い性能となる条件における提案手法と,他の手法とを実 験により比較し,有効性を確認する.5.3.1
実験2
:実験条件比較対象として,本家
Platformer AI Competition
優勝アルゴリズム,2012年度 に開催された国内Platformer AI Competition
優勝アルゴリズムを使用する.2010
年度優勝アルゴリズムについては,それを解説した論文内において,A*アルゴリ ズ ム単体と比べスコアが劣っていると述べられていることから,今回は2009
年 度優勝アルゴリズムであるA*
アルゴリズム単体と比較する.国内Platformer AI
Competition
優勝アルゴリズムは遺伝アルゴリズムであり,学習は10000
ステージ分とした.提案手法は,学習に使用したステージ数が
2000
,プランナー数8
のも のを使用する.実験に使用するステージは,表
5.3
のプランニングフェーズに用いたものと同 様とする.手法の優劣として,500ステージの内のクリア回数と,2012年度国内Platformer AI Competition
で使用されたスコア計算方法(
エージェントの進んだ 合計距離)の二通りで比較する.5.3.2
実験2
:実験結果と考察実験結果を図
5.4
に示す.まず,FSS2012で優勝したアルゴリズムである遺伝ア ルゴリズムは,学習のみで行動している.Infinite Tux
において,1つのステージ をクリアするためには,非常に多くの行動の組合せから選択する必要がある.そ のため,学習のみでそれらを取得しようとする場合,10000
ステージ分のデータ 量でも十分ではない.そのため,スコア基準ではある程度の点数を得ることはで きたが,大きな壁が出現するようなステージではクリアするまでには至らなかっ た.対して,提案手法の学習は先程も述べたとおり,プランの学習であり,2000 ステージ分という少ないデータ量でも十分に学習ができた.結果として,遺伝ア ルゴリズムとは大きな差がついたことがわかる.更に,A*アルゴリズムと提案手法を比較すると,クリア回数では約
29.9%
,ス コアでは約11.4%
の性能向上が見られた.これから,提案手法は2009
年度優勝ア ルゴリズムとくらべても有効であることがわかる.これは,A*アルゴリズム単体 で進むことができない状況においても,Q学習によりプランニングすることでそ の状況を突破することが可能となったためである.クリア回数とスコアで性能に 変化があった理由としては,A*アルゴリズム単体で進む場合,ステージ中に大き な壁が出現するまでは,提案手法と同じように進むことが可能であるため,クリ アできないステージでもある程度のスコアを得ることができたからである.これらの結果から,プランナー数と学習に用いるデータ量を適切に調節するこ とができれば,制限された環境下において有効であることがわかる.
表
5.4:
提案手法と他手法の比較クリアステージ数 コンペティションスコア
提案手法


![図 3.1: Infinite Tux[julian togelius, 2009]](https://thumb-ap.123doks.com/thumbv2/123deta/5927872.2056252/13.892.197.743.448.921/図-infinite-tux-julian-togelius.webp)
![表 3.1: Platformer AI Competition における優勝アルゴリズム [20] 開催年度 2009 年 2010 年 優勝アルゴリズム A*アルゴリズム [Robin Baumgarten, 2009] ルールベースシステム+遺伝アルゴリズム+A*アルゴリズム [Slawomir Bojarski, 2010] 3.3 優勝アルゴリズムの問題点 3.2 節で述べたとおり, Infinite Tux は非常に複雑な環境である.そのため,単純 な機械学習や深さ優先探索といった系統的探索](https://thumb-ap.123doks.com/thumbv2/123deta/5927872.2056252/14.892.173.801.216.375/アルゴリズムアルゴリズムAアルゴリズムルールベースシステム.webp)