情報指向ネットワークルータにおける実装を考慮したキャッシュ置換方式
の提案と評価
大岡
睦
†阿多 信吾
††村田 正幸
††
大阪大学 大学院情報科学研究科〒 565-0871 大阪府吹田市山田丘 1-5
††
大阪市立大学 大学院工学研究科〒 558-8585 大阪府大阪市住吉区杉本 3-3-138
E-mail:
†{
a-ooka,murata
}
@ist.osaka-u.ac.jp,
††
[email protected]
あらまし 情報指向ネットワーク (ICN) におけるルータキャッシング技術の実現には,ルータハードウェア実装を考慮
した低オーバーヘッドかつ高キャッシュヒット率を達成可能なキャッシュ置換手法が必要不可欠である.しかし,既存
のキャッシング手法は極めて単純な手法を採用するか,キャッシュ性能向上のために実装不可能なオーバーヘッドを要
するものばかりである.本研究では CAR を参考にして以上の要件を満たすキャッシュ置換手法として Compact CAR
を提案し,単純な手法と同じ性能が 1/10 のキャッシュサイズで達成可能ば場合があることをシミュレーション評価に
よって示す.
キーワード 新世代ネットワーク,情報指向ネットワーク (ICN),コンテンツセントリックネットワーク (CCN),キャッ
シング,キャッシュ置換方式
A Proposal and Evaluation of Cache Replacement Policy for the
Implementation of ICN Router
Atsushi OOKA
†, Shingo ATA
††, and Masayuki MURATA
††
Graduate School of Information Science and Technology, Osaka University
1-5 Yamadaoka, Suita, Osaka, 565-0871, Japan
††
Graduate School of Engineering, Osaka City University
3-3-138 Sugimoto, Sumiyoshi-ku, Osaka-shi, Osaka 558-8585, Japan
E-mail:
†{
a-ooka,murata
}
@ist.osaka-u.ac.jp,
††
[email protected]
Abstract
Information-centric networking (ICN) requires an innovative cache replacement algorithm with performance far
superior to simple policies such as FIFO and computational and memory overheads that are low enough to run on ICN router’s
hardware. We focus on CAR as the suitable policy for an access pattern of workload on the router and propose the cache
replacement policy (called Compact CAR) that satisfies the requirements. We also evaluate our proposed approach and show
that the size of cache memory required to achieve a certain performance can be reduced to 1/10th of that of the simple policy.
Key words
Future Networks, Information-Centric Networking, Content-Centric Networking, Caching, Cache Replacement
Policy
1.
は じ め に
現在のインターネットが直面する課題を解決する将来イン ターネットとしてInformation-Centric Networking (ICN)が注目 されている.現在のインターネットはトラフィック量の急増, 携帯端末普及によるネットワーク接続機器数の爆発的増加,高 度なアプリケーションのための品質・セキュリティ・頑強性の 要請など,様々な問題に直面している.これらの問題を個々に 解決するのではなく,ネットワークアーキテクチャから根本的 な改革を図る試みとしてICNが注目されている.インターネッ トが端末間通信に焦点を当てて端末の在処に対してアドレス を割り振るのに対して,ICNでは,現在の利用形態に即して, IPアドレスの代わりにコンテンツごとにnameと呼ばれる識 別子を割り当て,情報とユーザを結びつける.その有望性か ら,NDN/CCN [1]∼[3], PSIRP/PURSUIT [4], SAIL/NetInf [5]な ど,世界的に多数のプロジェクトが存在している. しかし,ICNは未だに開発初期段階にあり,課題は山積して いる.ICNはclean-slateなアーキテクチャであり,厳密なプロ トコルとそれをサポートするデバイスは策定段階にある.従来 のIPアドレスとは異なり,nameアドレスは位置を指定するも
のではないため,情報とその所在を結びつけるルーティングと フォワーディングが必要である.nameアドレスは中継ルータ におけるキャッシングを可能にするが,限られた資源でネット ワーク負荷を大幅に軽減する方策も求められる.また,nameア ドレスは可変長でIPアドレスよりも長く扱いづらいことが想 定されるため,これをハードウェアで高速にサポートする方法 についても研究されている[6]. ネットワーク内部のルータにおけるキャッシングはICNの有 用な特徴であり,活発に研究が行われている.増大の一途を辿 るネットワークトラフィックはZipf則に従うと言われ,多数の パケットが重複した情報を運ぶ冗長な通信が行われている.観 測期間によっても値は異なるが,2回以上アクセスのあるコン テンツがトラフィック量に対して占める割合は5割を超えると いう結果もある[7].その潜在性からキャッシングに関する研究 は多数行われており,ルータがどのコンテンツをキャッシュす べきか,また,ストレージが溢れた際にどのキャッシュを置換 すべきかを決定する主に2つの観点からアルゴリズムが研究さ れている. 本稿では,ルータにおけるキャッシング実装の問題を解決する ために,実用的かつ高いキャッシュヒット率を達成可能なキャッ シュ置換手法を提案する.ルータでは資源やパケットの処理時 間が限られており,キャッシュ置換手法が要求する計算量・メ モリオーバーヘッドはそれらの制約を満足させるものでなけれ ばならない.しかし,既存研究はキャッシュヒット率を犠牲に する極めて単純な手法を採用したものや,nameアドレスを活 用したきめ細やかな統計情報を用いるために実用時間内の処理 が不可能な手法を提案するものばかりである.また,過去の計 算機領域におけるキャッシング置換手法の研究はプロセス処理 特有のアクセスに特化されており,ネットワークに直接応用で きるかは明らかではない.そこで,本研究ではルータにおける 実現可能性と,ネットワークにおける高い性能の両立を可能と する手法を提案する. 本稿の構成は以下のようになる.2章で,CCNについて述 べ,キャッシングの研究の現状について概観する.3章で,本研 究の背景としてキャッシュに関する知見をまとめ,ICNにおけ る実用的かつ効果的なキャッシュ置換手法とは何かを分析する. その分析に基いて,CARに基づく低オーバーヘッドかつ高ヒッ ト率な提案手法として,Compact CARの設計について4章に 詳述する.5章の評価結果から,提案手法によって単純な手法 と比較して同一のキャッシュヒット率を達成するために10の1 以下のメモリ容量で済む場合があることを明らかにする.最後 に,考察と結論をまとめる.
2.
関 連 研 究
本章では,キャッシングの既存研究を概観する.最初にCCN におけるキャッシングの実現方法を要約し,続いてルータにお けるキャッシュ判断方式と,計算機領域におけるキャッシュ置 換方式についてまとめる. 2. 1 ICN ICNではnameを用いた新しい通信方式を提供する.通信方式 の細部はプロジェクトごとに異なるが,本稿はNDN/CCN [1], [2] に基づく.CCNではコンテンツごとに自然言語で書かれた覚え やすいユニークな識別子が割り当てられる.MTUを超えるよ うなデータサイズのコンテンツはチャンクに分割され,個々の チャンクごとにnameが割り当てられる.要求者はInterestパ ケットとDataパケットの交換を反復してコンテンツの取得を 実現する.また,CCNルータはFIB,PIT,CSの3つのスト レージを持ち,マルチキャスト,ループフリー,キャッシング などの特徴を実現する.特にCSはDataパケットのキャッシュ として機能する.Dataの自己同一性はnameに保証されている ため,キャッシュされたDataはその所在や要求時刻に関わらず 再利用できる. 2. 2 キャッシュ判断方式 ICNの初期設計では全ルータで通過したすべてのコンテンツをキャッシュする方式CE2(Cache Everything Everywhere)が
考えられてきた[1], [2], [4], [5].CE2は人気度の偏りが大きい ネットワークにおいて要求者から遠いルータの資源が十分に活 用できないことが指摘されている[8].ルータごとに一定の確 率dでキャッシングを行うキャッシュ判断方式[9]は,単純な方 式でコンテンツ取得時間を半減できるが,キャッシュ資源の無 駄が発生する.[10]では,経路上のルータからランダムに1つ 選んで確実にキャッシュする方式と,媒介中心性を用いること で効果的なルータを選択してキャッシュする方式を提案・比較 し,少数のルータによるキャッシュ性能向上の可能性を示して いる.[11]では様々な観点から総合的にキャッシュ性能を評価 しており,Leave Copy Down (LCD)と呼ばれる,キャッシュミ スの度に高々1ホップしかキャッシュが下流に伝搬しない低コ ストな方式でもCE2 などとの差が僅少であると述べている. 多くのキャッシュ判断方式が存在する一方で[12],人気度情報 を用いた最適な配置にキャッシングを行う手法も考えられてい る[13].一般的に最適方式は非現実的だが,実現可能性のある 低オーバーヘッドな方式の性能の妥当性を理解するために重要 である. 2. 3 キャッシュ置換方式 ルータハードウェアにおける実現可能性に着目して,アプリ ケーションレベルではなくハードウェアレベルで実装可能な手 法に焦点を当てる. 低オーバーヘッドで性能も低い単純な手法としては,Random
やFirst-In, First Out (FIFO),Not Recently Used (NRU)などがあ
る.Randomは,すべてのチャンクを一様の確率で削除する手
法である.First-In, First Out (FIFO)は現行のIPルータのバッ ファでも採用されているデータ構造で,最初にキャッシュされ たチャンクが最初に置換される.Not Recently Used (NRU)は使
用されたチャンクに参照ビット(以下Rビット)を立て,Rビッ トが0のチャンクを優先的に置換する方式である.いずれも性 能は一般的にLRUに劣るが,状況によってはLRUと同等以上 の性能を発揮しうる[11].
ハードウェア実装の観点からは高オーバーヘッドだが,性能 向上を目指した代表的な手法にはLeast Recently Used (LRU),
Re-cency Set (LIRS) [15],Least Frequently Used (LFU)が挙げられ る.最も代表的な方法であるLRUは,参照の局所性を備えた アクセスに強いが,ネットワークアクセスは局所性が低く,更 に低オーバーヘッドな実装が困難なため,望ましくない.多数 のICNのキャッシングの関連研究でRandomと並んで採用され ているが,LRUはルータハードウェアでの実現が困難であるこ とが指摘されている[11], [16].
ARCはLRUとLFUの長所を兼ね揃えており,LRUよりも キャッシュヒット率が高い.ARCは2つのLRUリストL1と L2を保持し,それぞれ1回だけアクセスされたチャンク,2回 以上アクセスされたチャンクを保持する.Ln(n = 1, 2)は上部 (Tn)と下部(Bn)に分けられ,recentなものがTn,古いものは Bnに含まれる.Bnはghost cacheという,実際のキャッシュ データは保持せずに履歴情報だけを保持する方式を取る.アク セスの局所性の変化や多様性に対応するため,|T1∪ T2| <= cか つ|L1∪ L2| = |T1∪ B1∪ T2∪ B2| <= 2cとなるように適応的 にそれぞれのリスト長の調整を行う.複数のLRUリストで実 装されるため,LRUと同等の処理オーバーヘッドで済む. LIRSはメモリオーバーヘッドは極めて大きいがLRUと同等 の複雑性でloop(3.1節で後述)への耐性を実現している.LFU はチャンクの参照回数に基いてチャンクを置換する.いずれも LRU以上のオーバーヘッドが必要であり,ルータレベルでの実 現は困難である. 高い性能を維持したままオーバーヘッドを妥当な大きさに抑 えるために開発されたLRUの近似手法としてCLOCKが有名 である.CLOCKは前回置換したチャンクの次のアドレスから R = 0のページの探索を開始する.探索中に見つかったR = 1 のチャンクはRビットを0にリセットして無視する仕組みによ り,最近利用されたチャンクを優先的に保持できる.LRUに匹 敵する性能を発揮でき,1チャンクあたり1ビットだけのメモ リオーバーヘッド,および高々数回の探索コストで実現が可能 である.
ARCにCLOCKを適用したキャッシング手法として,Clock
with Adaptive Replacement (CAR) [17]に本稿では注目する.リ
ストT1とT2をCLOCKに変更することで計算量オーバーヘッ ドを削減しつつ,ARCに匹敵した性能を発揮できる.しかし, B1 とB2はLRUのままであり,また,T1 とT2 は可変長の CLOCKとして実装されているので,キャッシュミス時にはキャッ シュリストの任意位置への挿入や削除が必要で,MRU operation と同等の計算量オーバーヘッドが発生する. CLOCKを適応した高性能な近似手法として,LIRSの近似手 法CLOCK-Pro [18]が挙げられ,追加したビットと針のために CLOCKよりメモリ・計算量オーバーヘッドは大きいが,LRU などと比較すると十分に実現可能な範囲である.しかし,loop への耐性はLIRSに劣る. ICNにおける特徴を活かした手法として,チャンクの人気 度に応じたキャッシングを行う手法も存在する[13], [19].LRU やLFUと比較して優れた性能を示すものの,チャンク単位で の人気度の計測と管理が必要であるため,メモリ・計算量オー バーヘッド共に高く,ルータハードウェアにおける実装は困難 である.
3.
背
景
本章では,ネットワークトラフィックに適した低オーバーヘッ ドなキャッシング手法の設計思想を示す.計算機科学領域の知 見から得られた課題について整理した後,これらの知見をネッ トワークに適用してネットワークトラフィック特有の問題を解 決可能かつその特徴を活かすキャッシング手法を議論する. 3. 1 キャッシングの課題 まず,キャッシュヒット率を悪化させる主要な4つのアクセスパターン[20]として,scan, loop, correlated-reference,
frequently-shiftsについて説明する.scanは1度しかアクセスされないチャ ンクの連続的な読み込みである.一般的にはキャッシュサイズを 超える数のユニークチャンクへのアクセスから構成され,LRU の性能を大きく悪化させる.特にnS> cのときにはチャンク されているページすべてが一度もキャッシュヒットしないチャ ンクによって置き換えられるキャッシュ汚染が発生する.loop は,キャッシュサイズを超える長さのscanの繰り返しである. 科学計算の膨大な量のデータに対する繰り返し計算で見られる パターンで,すべてのチャンクの局所性・アクセス頻度が等し いため,基本的な戦略(LRU, LFU, ARCなど)でscanと同様の キャッシュ汚染が連続的に発生してしまう.correlated-reference は,あるチャンクに対するアクセスが短期間に集中するような アクセスパターンである.これらのチャンクは集中アクセスが 終わるとそれ以降全くアクセスされなくなるという特徴を持ち, LFUなどのアクセス頻度に基づく手法は,長期的なキャッシン グが不要なチャンクに高い優先度を付与してしまい,キャッシュ する価値のないチャンクが長期間キャッシュに留まるという問 題が発生する.frequently-shiftsは,アクセスされるチャンク集 合が頻繁に切り替わるアクセスパターンである.LIRSのよう に,チャンクの一部を優遇して長期的に保持する手法では,ア クセス列の切り替わりの際に新しいアクセス列への対応が遅れ てしまい,キャッシュヒット率が低下する. つぎに,キャッシュにおいて注目すべきオーバーヘッドについ てまとめる.第一にデータ構造の維持管理のための計算量オー バーヘッドが挙げられる.キャッシュヒット/ミスに応じてデー タ構造の整合性を保つためのオーバーヘッドで,LRUにおける MRU operationなど,キャッシュへのアクセスがある度に負荷 の大きい処理が必要な手法は,高速環境下では実現できない. 逆に,CLOCKやNRUは維持管理コストは制御ビットの変更 だけで済む.第二に,置換ページを探索するための計算量オー バーヘッドが挙げられる.LFUやLRUは優先度キューを実装 すれば,キューのtailを削除するだけでよい.NRUやCLOCK
はRビットがsetされたページ数が増えるほど探索回数が増え る.第三に,制御用の情報を記憶するためのメモリオーバー ヘッドがある.チャンクごとの置換の優先順位を決定するため の情報を記憶するために必要で,LRU-stackのようにデータ構 造だけで管理が可能な場合を除いて,基本的にはこのオーバー ヘッドはキャッシュサイズに従って増大する.NRUやCLOCK のような単純な手法は1チャンクあたり1bitで済む.ARCや
LIRSなど,ghost cacheを持つ手法は,キャッシュサイズ以上の オーバーヘッドが必要となる.特に,LFUなどの統計情報を用 いる手法は,維持管理コストも含めて実現が困難である. 3. 2 ICNにおけるキャッシング 前節で議論した計算機領域のキャッシングに関する知見に基 いて,ICNにおけるキャッシング手法を考察する. まずアクセスパターンに関して,計算機領域とネットワーク 領域では3つの点で大きく異なる.1点目はアクセスの同時性 で,計算機領域は単一プロセスのページアクセスを対象とした のに対して,ルータは多数のユーザからの要求を同時並列的に 受け付ける.多数同時アクセスによって,scanやloopといっ たアクセスパターンは変則的になる.例えば,多数のユーザか ら独立したアクセスが行われた場合,互いに無関係なワンタイ マーコンテンツ要求はscanを頻繁に生成しうる.また,要求さ れるコンテンツが激しく変動することで,frequently-shiftsが発 生するだろう. 2点目に,コンテンツチャンクの粒度がキャッシュの動作に 甚大な影響を与える.チャンクの粒度がコンテンツサイズと等 しい場合,例えばWebページのような複数のコンテンツから 構成されるコンテンツや,連続的にコンテンツを取得する必要 があるVoIPやストリーミングサービスなどだけがscanやloop
を生成しうる.一方,チャンクの粒度が小さく,イーサネット フレームのMTUと等しい1.5KB程度を想定すると,単一の コンテンツへの要求によってscanやloopが発生しうる.例え ば,100MBの動画コンテンツはルータのキャッシュに対して約 700k回のアクセスを発生させるだろう. 3点目はネットワーク中に複数のキャッシュが存在する点で ある.これは要求がルータによって応答される機会を増やすと 同時に,問題のあるアクセスパターンによる悪影響が多数の ルータに伝搬する可能性を示唆している.要求の満足される確 率を維持しつつこの悪影響を低減するためには,適切な協調的 キャッシング戦略が必要となる.例えば,10個のルータで別々 のコンテンツを協調的にキャッシュすることとすれば,擬似的 に10倍のサイズを持った1つのキャッシュストレージをネット ワーク上に実現することができ,チャンク分割によって顕在化 しやすくなったscanやloopの影響を軽減しうる.当然これを 実現するためには適切なキャッシュ判断・配置アルゴリズムと, 協調キャッシングをサポートするルーティングプロトコルが必 要となる.本稿はルータの実装において必要なキャッシュ置換 アルゴリズムに焦点を当てるため,詳細な議論は省略する. ルータにおけるキャッシングでは,以上のようなネットワー クアクセスの特徴に適したアルゴリズムが必要である.特に
scanやfrequently-shiftsに強く,可能であればloopに強いこと
が望ましい.したがって,ARCやCLOCK-Proが高キャッシュ ヒット率を達成できると考えられる.correlated-referenceが発 生する傾向は弱いと考えられ,統計的情報を利用する手法は高 い性能を発揮することができると予想される.ただし,LFUは loopやfrequtently-shiftsに弱いため不適だろう. 性能だけではなく,アルゴリズムが低オーバーヘッドかつ高 速である必要がある.キャッシュ性能の向上を目指して統計情 報を活用するLFUなどの手法をルータで運用するのはメモリ・ 探索・データ構造管理すべてのオーバーヘッドの観点から困難 である.ARCやLIRSを始めとして,多くのキャッシング手法 はLRU相当のオーバーヘッドを目指して設計されているが, LRUはハードウェア実装においてはオーバーヘッドが大きす ぎる.CLOCKは低オーバーヘッドなメモリ管理方式として実 績がある点が注目されており[17], [18],本稿でもデータ構造管 理と探索コストが抑えられる手法としてCLOCKを採用する. NRUは探索コストが不要に大きくなる可能性があり,性能も CLOCKに劣る. CLOCKと同等の低オーバーヘッドかつネットワークトラ フィックに適したアルゴリズムの候補としては,CLOCK-Proと
CARが挙げられる.CLOCK-Proはその長所であるloopへの耐 性が限定的であるという問題があり,frequently-shiftsに強くな
い点からもCARより性能の面で劣ると考えられる.更に,1つ
のCLOCK上で独立して動作する針を3本持っており,CLOCK
と比較して針の動作回数が多くなる欠点もあり,候補から除外 する.CARはloopに対処できないが,scan,frequently-shifts
に高い耐性を持っている.CARは可変長のCLOCKを採用し ている点,LRUが残っている点から,低オーバーヘッドとは言 えないが,次章でその問題を解決する方法を提示する.
4.
提案方式の設計
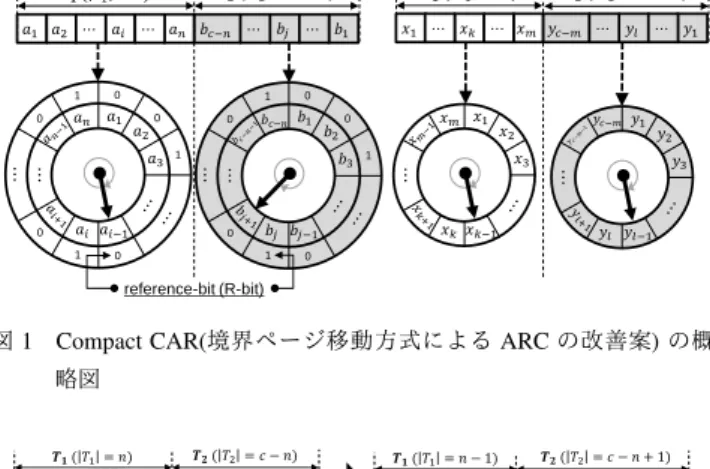
本章では,提案方式Compact CARの具体的なデータ構造と アルゴリズムについて議論する.CARを低オーバーヘッドに改 良することで,低オーバーヘッドかつ高ヒット率なキャッシュ 置換手法を実現する. 4. 1 設 計 方 針 CARはARCの実装コスト削減を図ったものだが,ルータで の実装には2つの課題が残っている.2.3節で述べたように, CARは性質の異なるアクセスに適応的に振る舞うために可変 長のCLOCKを要するが,これに必要なコストはLRU-stackに 匹敵する.可変長のCLOCKを実現するためには,針の位置の チャンクの削除と,針の直前(リストの先頭)へのページの挿入 が必須である.針はキャッシュメモリ上の任意の場所を指す可能 性があるため,メモリ上の任意箇所のチャンクの削除・メモリ上 の任意箇所へのチャンクの挿入が必要となる.このLRU-stack と同等の実装コストは,ルータハードウェアに対しては不適で ある. そこで,本稿では2つのリスト長の総和が一定になること を利用して課題を解決した手法としてCompact CARを提案す る.ARC/CARにおいては,T1, T2, B1, B2はリスト長がそれぞ れ可変で,L1= T1∪ B1, L2= T2∪ B2のリスト長も可変であ る.しかし,T1∪ T2, B1∪ B2は必ず最大長がキャッシュサイ ズc以下に収まり,キャッシュが満杯の状況では常にcと等し くなる.したがって,T∗= T1∪ T2, B∗= B1∪ B2と表記する と,長さcの連続メモリ領域上にT∗とB∗をそれぞれ配置し, チャンクの挿入・削除処理を工夫すれば,固定メモリ領域上で 低オーバーヘッドなCARを実現することができると考えられ る.このようなチャンク挿入・削除処理を実現した方式として,𝑎1 𝑎2 ⋯ 𝑎𝑖 ⋯ 𝑎𝑛 𝑏𝑐−𝑛 ⋯ 𝑏𝑗 reference-bit (R-bit) 𝑻𝟏( 𝑇1= 𝑛) 0 0 1 0 1 0 0 𝑎1 𝑎3 𝑎𝑖−1 𝑎𝑛 𝑎 2 ⋯ ⋯ 𝑏1 ⋯ 𝑥1 ⋯ 𝑥𝑘 ⋯ 𝑥𝑚 𝑦𝑐−𝑚 ⋯ 𝑦𝑙 ⋯ 𝑦1 𝑻𝟐( 𝑇2= 𝑐 − 𝑛) 𝑩𝟏( 𝐵1= 𝑚) 𝑩𝟐( 𝐵2= 𝑐 − 𝑚) 𝑎𝑖 1 0 0 1 0 1 0 0 𝑏1 𝑏3 𝑏𝑗−1 𝑏𝑐−𝑛 𝑏 2 ⋯ ⋯ 𝑏𝑗 1 𝑥1 𝑥3 𝑥𝑘−1 𝑥𝑚 𝑥 2 ⋯ 𝑥𝑘 𝑦1 𝑦3 𝑦𝑙−1 𝑦𝑐−𝑚 𝑦2 ⋯ 𝑦𝑙
図 1 Compact CAR(境界ページ移動方式による ARC の改善案) の概 略図 𝑎1 𝑎2 ⋯ 𝒂𝒊 ⋯ 𝒂𝒏 𝑏𝑐−𝑛 ⋯ 𝑏𝑗 𝑻𝟏( 𝑇1= 𝑛) 0 0 1 0 1 0 0 𝑎1 𝑎3 𝑎𝑖−1 𝒂𝒏 𝑎2 ⋯ ⋯ 𝑏1 ⋯ 𝑻𝟐( 𝑇2= 𝑐 − 𝑛) 𝒂𝒊 1 0 0 1 0 1 0 0 𝑏1 𝑏3 𝑏𝑗−1 𝑏𝑐−𝑛 𝑏2 ⋯ ⋯ 𝑏𝑗 1 𝑎1 ⋯ 𝒂𝒏 ⋯ 𝒂𝒊 𝑏𝑐−𝑛 ⋯ 𝑏𝑗 𝑻𝟏( 𝑇1= 𝑛 − 1) 0 0 1 0 1 0 0 𝑎1 𝑎3 𝑎𝑖−1 𝒂𝒏 𝑎𝑛−1 𝑎2 ⋯ ⋯ 𝑏1 ⋯ 𝑻𝟐( 𝑇2= 𝑐 − 𝑛 + 1) 1 0 0 1 0 0 0 1 𝑏1 𝑏3 𝑏𝑗−1 𝑏2 ⋯ ⋯ 𝑏𝑗 1 𝒂𝒊 +1 𝑎𝑛−1 図 2 境界ページの移動方法の概略図 (T1から T2へページ akを移動)
Algorithm 1Dual-bit/Compact CAR Replacement Algorithm
1: procedureCACHEREPLACEMENT(x) ▷ x is an accessed chunk.
2: if x∈ T∗then ▷ cache hit
3: x.R-bit← 1
4: return
5: else if x∈ B∗then ▷ ghost hit
6: i← 2 ▷ to cache x in T2 7: if x∈ B1then 8: δ← max(1,|B2| |B1|); p← min(c, p + δ) 9: DiscardBtm(1,x) 10: else ▷ x∈ B2 11: δ← max(1,|B1| |B2|); p← max(0, p − δ) 12: DiscardBtm(2,x) 13: end if
14: else ▷ cache miss
15: i← 1 ▷ to cache x in T1
16: if Full(L1) & |B1| > 0 then ReplaceBtm(1)
17: else if Full(L) & |B2| > 0 then ReplaceBtm(2)
18: end if 19: end if
20: if Full(T∗) then
21: if|T1| >= max(p, 1) then st← ReplaceTop(1)
22: else st← ReplaceTop(2)
23: end if
24: else ▷ T∗is not full. 25: st← a free address in Ti
26: end if
27: Ti[st]← x ▷ x is cached as a chunk in Ti.
28: end procedure
Algorithm 2DiscardBtm() for Compact CAR
1: procedureDISCARDBTM(i, x) 2: Swap(x, Bi.EdgeChunk)
3: Discard x (at the edge of Bi)
4: ▷ an address next to the edge of Biis ensured to be free.
5: end procedure
Compact CARを提案する.
4. 2 Compact CARの概要
Compact CARでは,図1のようにT1とT2,B1とB2をそ
Algorithm 3ReplaceBtm() for Compact CAR
1: procedureREPLACEBTM(i)
2: Swap(Bi[HandBi], Bi.EdgeChunk)
3: Discard Bi.EdgeChunk
4: Rotate HandBi
5: ▷ an address next to the edge of Biis ensured to be free.
6: end procedure
Algorithm 4ReplaceTop() for Compact CAR
1: functionREPLACETOP(i) 2: while Ti[HandTi].R-bit= 1 do
3: Ti[HandTi].R-bit← 0
4: ifi=1 then
5: Swap(Ti[HandTi], Ti.EdgeChunk)
6: ▷ Shift the boundary between T1and T2.
7: end if 8: Rotate HandTi
9: end while
10: se← an address next to the edge of Bi
11: Bi[se]← Ti[HandTi]
12: Swap(Ti[HandTi], Ti.EdgeChunk)
13: Discard Ti.EdgeChunk 14: Rotate HandTi 15: return Ti.EdgeAddr 16: end function れぞれメモリ上の連続な位置に配置する.T1は領域の一端,T2 はもう一端からそれぞれ逆方向に針が進むCLOCKとして動作 する.B1とB2も,Rビットが不要なだけで同様である.それ ぞれが独立したCLOCKとして動作するため,単純なページの 置換処理は通常のCLOCKと同様に低オーバーヘッドかつ高速 に実行できる. 問題はリストの大きさが変化するような場合であるが,各 リスト間の境界位置のページと交換することでLRU-stackに 見られるシフト処理を廃する.図2は,キャッシュがいっぱい の場合に,T1 = (a1, a2,· · · , an)からT2 = (b1, b2,· · · , bc−n) へ,ページakを移動する場合の例を示している.LRU-stack であれば,ここでakをT2 の針の位置に挿入するために, (bj+1,· · · , bc−n)のチャンクを左にシフトコピーしなければな らない.その代わりに,Compact CARではakとanの位置を 交換し,リストの境界を1チャンク分だけ移動する.結果と して,交換後はT1 = (a1,· · · ak−1, an, ak+1· · · , an−1),および T2= (b1, b2,· · · , bc−n, ak)となり,T1内のチャンクをT2に移 動することができる.このように,厳密なLRU順序を犠牲に するものの,単純なチャンクの交換でそれぞれのリストの大き さを変更することができる. 4. 3 アルゴリズム Compact CARの具体的なアルゴリズムはアルゴリズム1,2, 3,4に示す.アルゴリズム1では,Compact CARの全体の戦 略,つまり,必要なリストの空き領域を確保してから適切な位 置へキャッシュ情報を移動する方法を示している.まず,キャッ シュヒットした場合はRビットを1に設定して終了する(2–4 行目).キャッシュミスした場合は,5–19行目でB∗の空き領域 を確保する.ghost hit時(5–13行目)には,パラメータpの値 を調整して,ghost hitした領域を元に空き領域を決定する.パ ラメータpはARCの有用な特徴の一つで,リストT1の目標
サイズとして定義され,pの値をヒット状況に応じて動的に変 化させることでアクセスパターンの変化に適切に対応でき,他 の方式のように静的なパラメータを事前に調整する必要がなく なる.完全にキャッシュミスした場合(14–19行目)は,B∗に空 きがなければB1またはB2の履歴情報を置換し,空き領域を 確保する.そうでなければ,パラメータpに従って任意の空き 領域を取得する.実質的にはこの処理はリストの終端のアドレ スを取得するだけで済む.つぎに,20–26行目でキャッシュ置 換処理を行う.置換されたキャッシュの履歴情報をB∗に確保 した領域に記憶しつつ,T∗の空き領域stを確保する.最後に, 27行目でstにキャッシュを行う. アルゴリズム2,3,4は,それぞれ空き領域を確保するため の処理である.HandTiはリストTiの針の位置を示しており, Ti[HandTi]はその針が指し示す領域を表す(Biについても同 様).どの関数でも最終的に空き領域はリストの境界上に確保さ れ,境界上に無いチャンク情報は必ずリスト端部のチャンク情 報(アルゴリズム中のEdgeChunk)と交換される.この理由は, 例えばT∗に空き領域がある場合にGhost hitした場合など,確 保した空き領域が後続の処理で埋められないせいでリストの連 続性が失われることを防ぐためである.端部チャンクはB1と B2の境界線に最も近いBiのチャンクであり,CLOCKの針の 位置とは無関係にリスト端部のチャンクを取得する.これは端 部チャンクであって境界チャンクではない点に注意する.なぜ なら,キャッシュに空き容量がある場合,B1とB2の間には空 き領域が存在し,端部チャンクはリストの境界とならないから である. DiscardBtm関数(アルゴリズム2)はリストBi中のチャン クxの履歴情報を削除する処理で,Ghost hit時に実行される. ReplaceBtm関数(アルゴリズム3)はリストBiの針が指し示す 履歴情報を削除する処理で,キャッシュミス時にB∗が満杯な らば実行される.ReplaceTop関数(アルゴリズム4)はリスト Tiの針が指し示すチャンクを削除する処理で,T∗が満杯の場 合に空き領域を確保するために実行される.置換対象がT1中 のチャンクの場合,Rビットが1のページは図2で示した方法 でT2に移動される.置換されたチャンクは履歴情報として対 応する履歴リストに記憶されるが,この記憶先はその履歴リス トの端部チャンクに隣接する領域のアドレスであり,事前の処 理によって必ず空き領域となっている.B∗に空き領域が存在 した場合は当然リスト端部の隣接アドレスも空いているはずで あり,B∗が満杯の場合はDiscardBtmまたはReplaceBtm関数 の実行時にリストB1とB2の境界上に空き領域が確保されて いるため,どちらのリストから見てもリスト端部に隣接する領 域は解放済みとなっている.
5.
シミュレーション評価
5. 1 概 要 Compact CARの性能を単純な手法と比較して,十分に高い 性能を発揮できることを示す.評価にはコンテンツのアクセス 頻度がZipf分布に従うように人工的に生成した入力列と,阪大 キャンパス内部から外部動画サイトへのアクセスに基いて生成 図 3 阪大の動画アクセス回数の分布 された入力列の2種類を用い,コンテンツ単位とチャンク単位 のアクセスそれぞれの場合についてキャッシュヒット率の評価 を行う. 5. 2 シミュレーション設定 5. 2. 1 アクセス列 シミュレーションに用いる入力列には,Zipf分布に従うもの と,実トラフィックとして阪大のキャンパス内から外部の動画 サイトへのアクセス情報に基いて生成されたものの2種類を用 いる.以降,前者をAZipf(α),後者をAActualと呼称する.ネッ トワークコンテンツへのアクセスは一般的にZipf分布に従う と言われており,提案手法の幅広い状況下における有効性を実 証するためにAZipf(α)のαを変えてシミュレーションを行う. 更に,実トラフィックに対する有効性を実証するために,それ に近いAActualを用いてキャッシュヒット率を評価する. Zipf 則 と は ,コ ン テ ン ツ の 人 気 順 位 r の 関 数 f (r) = cα/rα (c, α は定数)によってその順位のコンテンツのアクセ ス回数が近似できることを指す.[21]の人気度分布に関する 議論によれば,αは0.5から1.2までの値を取るため,今回は α = 0.6, 0.8, 1.0, 1.2の4通りの場合についてシミュレーション を行った.アクセス数は後述のAActualと同様に10 7個程度に 設定した.実トレースデータは,YouTube, nicovideo, dailymotionの3つ の動画サイトに対する,2013年7月26日から2015年2月26日 までのアクセスに基づく.ユニークコンテンツ数は2,428,880個, 2回以上アクセスのあるコンテンツ数はその約半数の918,545 個である.この約1年半の間の全体のアクセス数は13,004,868 アクセスである.アクセス分布は図3のようになっており,Zipf 分布に近い形で,人気が高いコンテンツへの集中が多いことが 確認できる.実際,最もアクセスされたコンテンツのアクセス 数は149,820回である. これらのアクセス列はコンテンツ単位でのアクセスだが,そ こからチャンク単位での入力列も生成した.具体的には,アク セス日時と動画情報を利用し,動画の長さと対応画質の情報 から動画サイズを決定して,予め決定したサイズのチャンクが 再生時間を等分割した時間間隔で要求されるようなアクセス 列を想定する.チャンクサイズLは1500B・1.5KB・60KBを 対象とする.また,動画長1分あたりの通信量は,簡単な事 前調査の結果,表1の規則に従って動画ごとのチャンク数を決
表 1 動画の秒あたりパケット数 [pck/sec] チャンクサイズ 1.5KB 15KB 60KB SD(4.5[MB/min]) 50 5 1.25 HD(9.0[MB/min]) 100 10 2.50 定した.AZipf(α)に関しては,観測された動画の再生時間と画 質の分布に従って,コンテンツごとに再生時間と画質を決定 した.しかし,チャンク単位のアクセスは膨大な量となってシ ミュレーションの実行が困難であるため,107個程度の長さに 収まるように一部分のみを対象としてチャンク単位のアクセ ス列を切り出した.AActualについては,キャッシュの効果を 考慮してアクセスの集中する時間帯を対象とし,2013年7月 29日のトラフィックについて,チャンクサイズ1.5KBに関し ては12:01から12:10まで(約9分間),15KBの場合に関して は13:02から14:08まで(約66分間),60KBの場合に関しては 前日の19:57から14:45まで(約19時間)を対象とした.以降, コンテンツ単位のアクセス列と区別するために,コンテンツ単 位のアクセス列はAC Zipf(α)とA C Actual,チャンク単位のアクセ ス列はAP =LKB Zipf(α) とA P =LKB Actual のように表記する. 5. 2. 2 対 象 方 式 評価対象とするキャッシング手法は提案手法の他に,OPT,
FIFO, CLOCK, CARを用いる.OPTは最適手法であり,同一
キャッシュサイズで実現可能なキャッシュヒット率の上限値が分 かる.それ以外はルータハードウェア実装が実現可能な高速な 方式のみを対象としている.FIFOとCLOCKは単純な手法で あり,提案手法が単純な手法と比較してどれほど改善できてい るかの基準とする.CARは提案手法の基とした既存手法であ り,提案手法がCARよりも性能が悪くないことを示せるのが 望ましい. 5. 2. 3 環 境 設 定 ネットワークトポロジーは単一ノードの場合と単純なトポロ ジーの場合の2通りを考える.単一ノードとは,コンテンツ 供給元とユーザが単一のルータでつながっている場合であり, キャッシュ置換手法の純粋な性能を確認できる.単純なトポロ ジーとしては,10個のルータがコンテンツ供給元とユーザを繋 ぐ直線上のトポロジーを想定し,キャッシュ判断方式にはCE2 を採用する. 評価指標にはキャッシュヒット率を採用する.これは,ユー ザの要求全体(ルータへのアクセス数全体ではない)に対するそ のルータでのキャッシュヒット数の割合である.アクセス列の 長さを107程度に抑えているため,キャッシュサイズCは101 から106[Chunks]の 6通りとする.コンテンツのサイズは考慮 せず,チャンク数に対するキャッシュヒット率を考える. 5. 3 評 価 結 果 5. 3. 1 人工的に生成したトラフィックAZipf(α)に基づく評価 まず,Zipf則に基づき人工的に生成したトラフィックの評価結 果を示す.図4,5,6,7は,単一ルータで,要求がコンテンツ単 位の場合の評価結果である.4通りのαの値ごとに,AC Zipf(0.6) は図4,ACZipf(0.8)は図5,A C Zipf(1.0)は図6,A C Zipf(1.2)は図7 に結果が示されている.また,チャンク単位で要求が行われた 場合の評価結果の一例として,α = 1.0の場合を図8,9,10に 示す. 全体の傾向としては,最も注目すべき点として,提案手法が
CARに匹敵する性能を示している.Compact CARはLRU順序
の不整合による性能の劣化が予想されたが,最大でも0.5%以 下の差しか見られなかった.これらのCAR系の手法は一様に 高い性能を示しており,良い場合には同一のキャッシュヒット 率を達成するためにCLOCKやFIFOの1/10以下で済む.OPT
との差についても,ほぼすべての場合で10%以下に抑えられ ている.αが大きいほどキャッシュヒット率が高く,紙面の制 限上記載していないがチャンク単位のキャッシングでも同じ傾 向が見られる.チャンク単位でのキャッシュでは,チャンクサ イズが小さいほどコンテンツが多数のチャンクに分割される影 響が大きく,キャッシュヒット率が大幅に低下する. 5. 3. 2 実トラフィックAActualに基づく評価 次に,実トラフィックに基づくトラフィックの評価結果を示 す.単一ルータの場合の評価結果は,コンテンツ単位の結果を 図11に,パケット単位の結果を図12,13,14に示している. AC Actualの結果は,OPTを除く手法間で差が出ていない.特 に,CAR系の手法が単純な手法より優れているものの差は小さ い.これは,トレースデータのアクセスの局所性の高さに起因 すると考えられる。人気のコンテンツに対する要求間隔が短い 値に集中するために、単純な手法でもCARに匹敵する性能を 示したと考えられる。実際にAP =1.5KB Actual では104付近でキャッ シュヒット率が急上昇しており、チャンク分割によって要求間 隔が引き伸ばされたものと考えられる。トレースデータは動画 サイトへのアクセスのみを抽出しているため、多様なアプリ ケーションへの要求を扱う現実のルータでは局所性は低くなり、 CARと単純な手法の性能差は大きくなることが予想される。 また,AP =LKB Actual の結果では,CAR系の手法が単純な手法に 大きく勝っている.チャンク単位でのアクセスでは同一チャン ク間のアクセス数が増加して局所性が低下した結果,FIFOや CLOCKの性能が低下したと推測される.一方,CAR系の手法 は高いヒット率を示しており,特にAP =1.5KB Actual とAP =15KBActual で はOPTに近い性能を達成している.注意点として,AP =1.5KB Actual からAP =60KBActual にかけて,チャンクサイズが小さくなっている にも関わらずキャッシュヒット率が低下する傾向が見られるが, これはアクセスの集中度合いが時間帯によって大きく変化する ためである. 5. 3. 3 複数ルータの場合の評価 直線状トポロジーでの評価結果の一部として, ACZipf(α)の一 例を図15に, AP =LKBZipf(α) の評価結果の一部を図17, 18に示す。ま た,AP =15KBActual の結果を図20に示している。グラフの横軸は,左 端がネットワーク全体のキャッシュヒット率を示しており,以降 は1番目から10番目まで要求者に近いルータから順番にアク セス全体に対するヒット数の割合を示している。全体で96通 りの試行を行ったが,そのすべてで記載されている結果とほぼ 同じ傾向が見られた。結果としては,CLOCKやFIFOが2番目 以降のルータではキャッシュヒット率がほぼ0であるのに対し て,提案手法を含むCAR系の手法は2番目以降のルータでも少
0 0.1 0.2 0.3 0.4 0.5 0.6 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 4 AC Zipf(0.6) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 5 AC Zipf(0.8) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 6 AC Zipf(1.0) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 7 AC Zipf(1.2) 0 0.1 0.2 0.3 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 8 AP =1.5KB Zipf(1.0) 0 0.1 0.2 0.3 0.4 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 9 AP =15KB Zipf(1.0) 0 0.1 0.2 0.3 0.4 0.5 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 10 AP =60KB Zipf(1.0) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 11 AC Actual 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 12 AP =1.5KB Actual 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 13 AP =15KB Actual 0 0.1 0.2 0.3 0.4 0.5 0.6 101 102 103 104 105 106
Cache hit rate
Cache size [Chunks] OPT FIFO CLOCK CAR Compact CAR 図 14 AP =60KB Actual 0 0.1 0.2 0.3 0.4 0.5 total 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th
# of Hits / # of total accesses
Node FIFO CLOCK CAR RepelCAR 図 15 AC Zipf(0.8) (c = 105[Chunks]) 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 total 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th
# of Hits / # of total accesses
Node FIFO CLOCK CAR RepelCAR 図 16 AP =60KB Zipf(1.2) (c = 103[Chunks]) 0 0.05 0.1 0.15 0.2 0.25 0.3 total 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th
# of Hits / # of total accesses
Node FIFO CLOCK CAR RepelCAR 図 17 AP =60KB Zipf(1.0) (c = 103[Chunks]) 0 0.05 0.1 0.15 0.2 0.25 0.3 total 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th
# of Hits / # of total accesses
Node FIFO CLOCK CAR RepelCAR 図 18 AP =60KB Zipf(1.0) (c = 104[Chunks]) 0 0.1 0.2 0.3 0.4 0.5 0.6 total 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th
# of Hits / # of total accesses
Node FIFO CLOCK CAR RepelCAR 図 19 AC Actual (C = 103[Chunks]) 0 0.05 0.1 0.15 0.2 0.25 total 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th
# of Hits / # of total accesses
Node FIFO CLOCK CAR RepelCAR 図 20 AP =15KB Actual (C = 103[Chunks]) 量ながら全体のキャッシュヒット率向上に貢献している。
6.
考
察
6. 1 単純な手法からの改善 CARは単純な手法よりも性能が優れており,CARの近似手 法である提案手法はCARとほとんど同等の性能を示した.特 に,低オーバーヘッド化のためにLRUの順序を崩したCompact CARでこのような結果が得られたのは理想的と言える.提案 手法を用いることで同一の性能を達成するために必要なキャッ シュサイズを削減することができ,FIFOやCLOCKと比較し てキャッシュ資源の利用効率を10倍程度に高めることができ る.ほぼすべての場合でOPTとの差は10%以下に抑えられて いるが,AZipf(α)の評価結果から分かるように,αの値が低い,つまり人気度の偏りが低いほどOPTとの差が大きい傾向があ る.現実のトラフィックは様々なアプリケーションの重畳効果 によって人気度の偏りが引き伸ばされていくことが想定される ため,キャッシュ置換アルゴリズムの更なる改良には大きな価 値があるだろう. しかし,OPTとの差は依然として存在している.今回の評価 結果から,アクセスの局所性の多様化が性能の悪化原因と予想 されるため,それに対処可能なキャッシュ置換手法が期待され る.また,CARはloopに弱い手法であるが,チャンク単位の 連続アクセスが直感的にloopを形成しやすいことから,loop への対処が可能な手法について検討すべきと考えられる. 6. 2 ルータの実現可能性 ネットワークトラフィックをキャッシュする場合,キャッシュ 容量とアクセス速度の制約が課題となる.無差別にキャッシュ を行う場合,ルータは自身が送信した全Dataパケットをキャッ シュする.例えば,10Gbpsのトラフィックを扱うラインカー ドは1秒間で最大1.25GBをキャッシュする必要がある.また, Dataパケットサイズが64Bだと仮定すると,最大で約20MSPS の処理速度が必要である.更に,複数のラインカードのトラ フィックを収容するルータ単位では,ラインカード数に比例し た性能を確保しなければならない.現実的には,Interestパケッ トの存在とキャッシュヒットの発生によってこの時間は数十% 程度延長されうると考えられるが,倍以上の改善のためには キャッシュ判断方式の併用が必要だろう. 提案するアルゴリズムはCLOCKと同等の低オーバーヘッド を実現している.記憶容量のオーバーヘッドはエントリあたり 1bit以下であり,上述の20MSPSに合わせて2000万個のエン トリをキャッシュするとした場合,キャッシュへのポインタとし て24bitずつ保持するとしても,容量は63MB以下に抑えられ
る.高速だが集積化困難なSRAMでも2.3Gbit(8× 288Mbit)を 確保可能であり,ラインカード4枚まではルータで集中管理で きる.また,SRAMのアクセス時間が0.45nsとすると[22],最 悪時に数回程度針の回転が必要だとしても,ラインカード4枚 程度であれば十分収容可能と推測される.しかし,キャッシュ データ自体はDRAMやSSDなどの低速なメモリに記憶しなけ ればならない.その読み書きの高速性を保証するために,メモ リの並列化や処理のパイプライン化,メモリ速度に応じた階層 キャッシングなども考察する予定である.最終的には,FPGA を用いた実機評価を視野に,名前検索機構[6]などと組み合わ せることを考慮しつつ,記憶装置を含むキャッシュアルゴリズ ムのハードウェア実装のための最適化を行い,キャッシュ機構 およびルータ全体でのハードウェア実装コストおよび達成可能 な性能を示すことで,ICNルータの実現可能性の実証に貢献し たい.
7.
結
論
ICNにおいては実現可能なICNルータの設計が急務である が,CSにおいて用いるキャッシング手法について,効果的で低 コストな手法はまだ無い.従来研究されてきたWebキャッシン グの多くはソフトウェアレベルでの動作を想定していてルータ での実現は困難であり,同様にICNの特徴を活かしてコンテン ツごとの統計を取る手法もオーバーヘッドが大きすぎる.本研 究では,ネットワーク中を流れるコンテンツのほとんどは1度 しかアクセスされないコンテンツであることに注目し,ワンタ イマーコンテンツを避ける有望な手法としてCAR [17]に注目 した.CARの動作をCLOCKと同等なレベルに置き換え,更 に固定メモリ領域で動作可能なキャッシング手法を提案するこ とで,ワンタイマーコンテンツに耐性を持つ低オーバーヘッド なキャッシュ置換手法の実現を目指した. 可変長のCLOCKをどのようにして低コストに実装するかが 主な実装課題だが,リスト長の相補性に注目して可変長の動 作を無くし,管理・運用コストを最小限に抑える手法Compact CARを提案した.Compact CARは連続したメモリ領域を明確 に二分して,両端ごとに別々のCLOCKを割り当てることで, CLOCKごとのメモリ領域の連続性を維持させる.キャッシュが 溢れた場合は境界線上のエントリを置換することで,領域端か ら境界線上までのキャッシュエントリ連続性を保持する.ただ し,メモリの境界線上のエントリの置換というLRUの特徴を 無視した置換によって,性能が大きく変化する可能性があった. 評価の結果,提案手法はCARと同等の性能を示すという理 想的な結果が確認され,単純な手法と比較して同一の性能を達 成するために必要なキャッシュ容量が1/10で済む場合がある ことが判明した.改善の余地は見られるものの,提案手法が低 オーバーヘッドかつ高性能であることを示し,ICNルータの実 現可能性の実証に貢献した.今後は,ルータ間の協調を考慮に 入れたキャッシングアルゴリズムの考案と,実機を用いたキャッ シングアルゴリズムの実装および評価が研究課題となる. 謝辞 本研究成果の一部は総務省・戦略的情報通信研究開発推進制 度(SCOPE)の支援による. 文 献[1] V. Jacobson, D.K. Smetters, J.D. Thornton, M.F. Plass, N.H. Briggs, and R.L. Braynard, “Networking named content,” Proceedings of the ACM CoNEXT 2009, pp.1–12, Dec. 2009.
[2] L. Zhang, D. Estrin, J. Burke, V. Jacobson, J.D. Thornton, D.K. Smetters, B. Zhang, G. Tsudik, K. Claffy, D. Krioukov, D. Massey, C. Papadopoulos, T. Abdelzaher, L. Wang, P. Crowley, and E. Yeh, “Named data networking (NDN) project,” Oct. 2010.http: //named-data.net/techreport/TR001ndn-proj.pdf
[3] , “CCNx,” 2014.http://www.ccnx.org/
[4] N. Fotiou, P. Nikander, D. Trossen, and G.C. Polyzos, “Developing information networking further: From PSIRP to PURSUIT,” Pro-ceedings of the 7th International ICST Conference on Broadband Communications,Networks, and Systems, pp.1–13, Oct. 2010. [5] T. Lev¨a, J. Gonc¸alves, R.J. Ferreira, et al., “Description of project
wide scenarios and use cases,” Feb. 2011.http://www.sail-project. eu/wp-content/uploads/2011/02/SAIL D21 Project wide Scenarios and Use cases Public Final.pdf
[6] K.I. Atsushi Ooka, Shingo Ata and M. Murata, “High-speed design of conflict-less name lookup and efficient selective cache on CCN router,” IEICE Transactions on Communications, vol.E98-B, no.04, pp.607–620, April 2015.
[7] F. Guillemin, B. Kauffmann, S. Moteau, and A. Simonian, “Exper-imental analysis of caching efficiency for YouTube traffic in an ISP network,” Proceedings of the 25th International Teletraffic Congress, pp.1–9, Sept. 2013.
[8] S.K. Fayazbakhsh, Y. Lin, A. Tootoonchian, A. Ghodsi, T. Koponen, B. Maggs, K.C. Ng, V. Sekar, and S. Shenker, “Less pain, most of the gain: Incrementally deployable ICN,” ACM SIGCOMM Com-puter Communication Review, vol.43, no.4, pp.147–158, Aug. 2013. [9] S. Arianfar, P. Nikander, and J. Ott, “On content-centric router de-sign and implications,” Proceedings of the ACM Re-Architecting the Internet Workshop, pp.1–6, Nov. 2010.
[10] W.K. Chai,D. He,I. Psaras, and G. Pavlou, “Cache “ less for more ” in information-centric networks,” Computer Communica-tions,vol.36,no.7,pp.758–770,2013.
[11] D. Rossi and G. Rossini, “Caching performance of content centric networks under multi-path routing (and more),” Technical report, Telecom ParisTech, July 2011.
[12] A. Ioannou and S. Weber, “A taxonomy of caching approaches in information-centric network architectures,” Technical report, School of Computer Science and Statistics, Trinity College Dublin, Jan. 2015.
[13] L. Wang, S. Bayhan, and J. Kangasharju, “Optimal chunking and partial caching in information-centric networks,” Computer Commu-nications, vol.61, no.1, pp.48–57, May 2015.
[14] N. Megiddo and D.S. Modha, “ARC: a self-tuning, low overhead re-placement cache,” Proceedings of the 2Nd USENIX Conference on File and Storage Technologies, pp.115–130, March 2003.
[15] S. Jiang and X. Zhang, “Making LRU friendly to weak locality work-loads: a novel replacement algorithm to improve buffer cache perfor-mance,” IEEE Transactions on Computers, vol.54, no.8, pp.939–952, Aug. 2005.
[16] S. Arianfar, P. Nikander, and J. Ott, “Packet-level caching for information-centric networking,” Technical report, Finnish ICT SHOK, June 2010.
[17] S. Bansal and D.S. Modha, “CAR: Clock with adaptive replacement,” Proceedings of the 3rd USENIX Conference on File and Storage Technologies, pp.187–200, March 2004.
[18] S. Jiang, F. Chen, and X. Zhang, “CLOCK-Pro: An effective im-provement of the CLOCK replacement,” Proceedings of the USENIX 2005, pp.323–336, April 2005.
[19] J. Ran, N. Lv, D. Zhang, Y. Ma, and Z. Xie, “On performance of cache policies in named data networking,” Proceedings of the Inter-national Conference on Advanced Computer Science and Electronics Information 2013, pp.668–671, July 2013.
[20] A. Jaleel, K.B. Theobald, S.C. Steely, Jr., and J. Emer, “High per-formance cache replacement using re-reference interval prediction (RRIP),” ACM SIGARCH Computer Architecture News, vol.38, no.3, pp.60–71, June 2010.
[21] C. Fricker, P. Robert, J. Roberts, and N. Sbihi, “Impact of traffic mix on caching performance in a content-centric network,” Proceed-ings of the IEEE Conference on Computer Communications 2012, pp.310–315, March 2012.
[22] D. Perino and M. Varvello, “A reality check for Content Centric Networking,” Proceedings of the ACM SIGCOMM workshop on Information-centric networking, pp.44–49, Aug. 2011.