INVITED PAPER
Special Section on Security, Privacy and Anonymity in Computation, Communication and Storage SystemsFraud Analysis and Detection for Real-Time Messaging Communications on Social Networks
Liang-Chun CHEN†, Chien-Lung HSU††, Nai-Wei LO†††,Nonmembers, Kuo-Hui YEH††††a),Member, andPing-Hsien LIN†††,Nonmember
SUMMARY With the successful development and rapid advancement of social networking technology, people tend to exchange and share infor- mation via online social networks, such as Facebook and LINE.Massive amounts of information are aggregated promptly and circulated quickly among people. However, with the enormous volume of human-interactions, various types of swindles via online social networks have been launched in recent years. Effectively detecting fraudulent activities on social networks has taken on increased importance, and is a topic of ongoing interest. In this paper, we develop a fraud analysis and detection system based on real- time messaging communications, which constitute one of the most com- mon human-interacted services of online social networks. An integrated platform consisting of various text-mining techniques, such as natural lan- guage processing, matrix processing and content analysis via a latent se- mantic model, is proposed. In the system implementation, we first collect a series of fraud events, all of which happened in Taiwan, to construct analy- sis modules for detecting such fraud events. An Android-based application is then built for alert notification when dubious logs and fraud events hap- pen.
key words: Facebook, fraud analysis, latent semantic analysis, natural language processing, social networks
1. Introduction
With the universality of smartphones and the rapid develop- ment of mobile communication technology, a variety of so- cial applications, such as Facebook, Line, Twitter, WeChat and WhatsApp, have been designed for smartphones in re- cent years.All of these social applications are able to sig- nificantly reduce the cost of communication among people, and make daily life more convenient than before. How- ever, while taking advantage of the convenience afforded by social applications in life, many potential risks may arise. Generally speaking, two kinds of application risks exist with smartphones, i.e. mobile application risks and human behavior risks. In the first categorization, for ex- ample, many mobile applications ask users to agree to grant some high-risk permissions, such as “INTERNET”
Manuscript received January 15, 2017.
Manuscript revised June 12, 2017.
Manuscript publicized July 21, 2017.
†The author is with the Department of Management, Fo Guang University, Yilan County 26247, Taiwan.
††The author is with the Department of Information Manage- ment, Chang Gung University, Taoyuan 33302, Taiwan.
†††The authors are with the Department of Information Man- agement, National Taiwan University of Science and Technology, Taipei 10607, Taiwan.
††††The author is with the Department of Information Manage- ment, National Dong Hwa University, Hualien 97401, Taiwan.
a) E-mail: [email protected] (Corresponding author) DOI: 10.1587/transinf.2016INI0003
and “READ CONTACTS”, and then perform these permit- ted privileges in the background without users’ scrutiny. A possible consequence of this is sensitive personal informa- tion being revealed via the Internet. On the other hand, from the perspective of human behavior risk, fraudsters may use tricks on social media to communicate with victims for specific fraudulent purposes. For instance, fraudsters may pretend to a friend of a victim and chat with him/her via Facebook or Line for the purpose of tricking the victim into offering fraudsters some virtual currency, i.e. online game points, or even to steal his/her credit card’s serial number and card security code. Huge losses may be incurred by victims who fall for such ruses. In 2015, according to the Taiwan government’s official report provided by the Crimi- nal Investigation Bureau[15], more than 8 thousand fraud events were reported and around 670 million NT dollars was lost in Taiwan. It is thus vitally important to heighten awareness of personal information protection, including the required know-how to prevent falling victim to fraud. In the literature, adaptive fraud detection[6], signature-based systems[2] and host-based intrusion detection systems[3]
have all been proposed to detect and prevent suspicious events and fraudulent behaviors via network monitoring and packet flow analysis. Unfortunately, these methods may not provide accurate discernment when it comes to protecting against fraud events launched by a legitimate but malicious fraudster. For example, a fraudster may register a legiti- mate account and then exploit social engineering tricks dur- ing real-time messaging communications operated on smart- phones to cheat victims. In this case, network-level monitor- ing is not enough to detect a fraud event, and a content-based analysis is required.
Frauds perpetrated on social networks usually happen on smartphones and involve a series of malicious steps of social engineering being launched. Well-known examples involve bogus insurance claims, tax return claims, credit card transactions and online purchases. To effectively detect and predict fraud events on social networks, data analysis techniques are vitally important. In general, analysis tech- niques for fraud detection can be classified into two major classes: statistical-based techniques and machine learning- based techniques. Examples of statistical data analysis tech- niques are data pre-processing, analysis on statistical pa- rameters, and prediction and detection via operation pat- terns against activities and user profiles, all of which are intended to estimate risks and predict fraud. On the other Copyright c2017 The Institute of Electronics, Information and Communication Engineers
hand, machine learning-based analysis techniques are ones such as data mining, expert systems, pattern recognition and neural networks. As it stands, data analysis techniques have been widely used to detect fraud events on social net- works[5], [7]–[13]. However, it is difficult to effectively and efficiently detect and prevent fraud on social networks since fraud is a complicated and adaptive crime process which involves various areas of knowledge, such as biol- ogy, financial and business operation. In addition, to de- tect fraud events on social networks, individuals (or orga- nizations) usually need to monitor and analyze transactions against critical system parameters and data analysis patterns.
This requires complex and time-consuming investigations involving the analysis of enormous transaction logs.
In this paper, we would like to introduce a novel anal- ysis method for fraud identification on social networks. In contrast to existing methods, we present a fraud detection method in which the fraudulent features are extracted from a chat log via text mining analysis. We utilize natural lan- guage processing (NLP) to filter out the meaningless data and further adopt latent semantic analysis (LSA) to elimi- nate the noise signal from the analyzed data set. The fraud- ulent feature is then extracted and used to identify the fraud event. In brief, the main contributions of this study are as follows: (1) an integrated platform with text-mining tech- niques is developed to prevent the deceptive fraud events in the real world; (2) the proposed method is efficient for real- time fraud detection on social networks and possesses high accuracy of fraud detection as well. The rest of the paper is organized as follows. Section 2 introduces the state of the art of fraud detection on social networks. In Sect. 3, we present the proposed fraud detection system with detailed explana- tions of each data analysis module. Then, we demonstrate the results of the tested scenarios and the findings gathered during the evaluation in Sect. 4. Finally, we give a conclud- ing remark in Sect. 5.
2. Related Works
In this section, we introduce the state of the art of fraud de- tection. In 2009, Yu and Wang[13]proposed a fraud detec- tion model via an outlier judgement process. A distance sum between the target record and other object records is com- puted by the Euclidean distance against the infrequency and unconventionality of the fraud observed in a historic credit card transaction dataset.
According to a higher degree of unexpectedness and a longer time interval, suspicious records can be identi- fied. The authors claimed that outlier mining is superior to clustering-based anomaly detection for credit card fraud analysis and identification. Zhu et al.[11]observed that the buyer-feedback mechanism is not sufficiently effective when it comes to seller reputation verification, and accordingly provides weak fraudulent behavior prevention. A fraud analysis and detection scheme was constructed via the re- lationships in social networks during transactions. In more detailed terms, the relationships between users in an online
auction system were investigated to verify whether credit speculation happened or not. The authors examined the fea- sibility of the proposed scheme via the evaluation of real data from a famous electronic commerce platform in China, i.e. Taobao. Next, Ying et al.[12]demonstrated a spectrum based analysis method to detect the launching of a malicious attack, called random link attacks. In the attack scenario, a malicious user may create multiple fake identities and then launch malicious tricks targeting regular members of the network via interactions disguised as legitimate user behav- iors, while using those fake identities. The authors then pre- sented an analysis scheme which exploits the spectral space of the underlying network topology to identify frauds or at- tacks. The spectral characteristics of a potential attacker are determined by the regular users.
In 2012, Jamshidi and Hashemi[5]proposed a data en- richment mechanism embedded within social network anal- ysis to detect fraud scenarios. The presented method con- centrates on the efficiency of update procedures when new users (or new transactions) emerge. The probability of a fraud is calculated based on the relations between the tested event and known frauds. Next, Sylla et al.[8]combined sev- eral methods and tools to solve the problems of linking in- formation spread across different heterogeneous data repos- itories for detecting fraud and other crimes targeting bank- ing and consumption on social networks. Later, Nandhini et al.[7]proposed a methodology to identify fraudulent ac- tivities and suspicious profiles on social networks. Their proposed method can help online users to safely communi- cate with each other by preventing particular malicious ac- tivities, such as profile hacking and phishing attacks. Then, Agrawal et al.[1] combined several techniques, such as a genetic algorithm, a behavior based technique and a hidden Markov model, to detect fraud events during the processes of registration, login, banking and proceeding with shop- ping. After that, Wu et al.[10]introduced a continuous au- thentication scheme to detect in-situ identity fraud, in which an attacker operates as a legal user with the victim’s account information, and even, in some instances, with the victim’s own devices. The presented method analyzes and detects the in-situ fraud via patterns constructed from users’ brows- ing behaviors, such as habits of photo viewing and page switching. The authors demonstrated that their method can provide greater than 80% detection accuracy within 2 min- utes, and 90% after 7 minutes of observation time on the Facebook platform. In the same year, Vlasselaer et al.[9]
introduced a fraud detection approach, called active fraud investigation and detection, which uses active inference to effectively detect fraud in time-varying social networks. In active inference on social networks, a set of unlabeled events is considered and marked as fraud by inspectors. All of the marker labels will then be used in the inference process by the trained classifiers. In the proposed method, fraudulent and non-fraudulent events are first classified and then the analysis is performed via intrinsic features and neighbor- hood features extracted from a time-varying network.
3. The Proposed Fraud Detection System
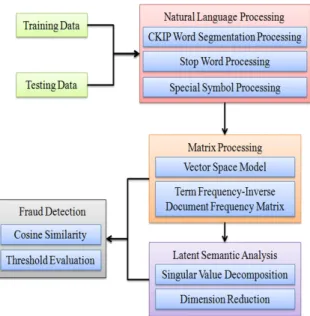
The goal of this study is to develop a fraud analysis sys- tem which can efficiently and effectively detect fraud events during real-time messaging communications on social net- works. In this section, we describe the details of the pro- posed system consisting of five modules, i.e. data collec- tion, NLP, matrix processing, semantic models and similar- ity evaluation. The system architecture is shown in Fig. 1.
First, we collect the existing fraud events in Taiwan as the fraud templates for the purpose of data analysis. Note that all of these data are real fraud scripts which happened in Taiwan. Next, we perform the NLP technique on the test- ing data, in which word segmentation and the elimination of stop words and special symbols are executed. Then, we put the processed data into the matrix processing and trans- form it into a VSM (Vector Space Model) and TF-IDF (Term Frequency-Inverse Document Frequency). Finally, based on the LSA (Latent Semantic Analysis) model and similarity evaluation, the results of fraud detection are presented.
3.1 Data Collection
In the data collection phase, we first collect the relevant news about fraud events via search engines, i.e. Google and Bing. In addition, we obtain data on real cases of fraud event through the Taiwan government’s anti-fraud center website[15]. The two kinds of source data are integrated to make up the fraud templates during our implementation.
Next, in order to transform the original testing data from the search engine into predefined tested-format data, we per- form a series of NLP techniques.
Fig. 1 The proposed fraud detection system
3.2 Natural Language Processing (NLP)
This section is divided into three steps, i.e. Chinese word segmentation and the elimination of stop words and spe- cial symbols. First, the system performs a Chinese word segmentation operation via CKIP service[14]. CKIP word segmentation can be exploited to retrieve information and, in particular, to retrieve critical keywords appearing in the testing data. Second, in general, stop words usually refer to the most common words in a language such as particles, adverbs and conjunctions. It is thus suggested to remove stop words from the testing data to prevent deviation in the analysis results. Hence, we adopt the stop word lists pro- vided by Academia Sinica of Taiwan to remove stop words from the testing data. Third, since Chinese sentences are al- ways composed with punctuation marks, such as commas, periods, quotation marks, and brackets, we establish a list of special symbols for removing punctuation marks and special symbols from the testing data.
3.3 Matrix Processing
Before performing the LSA technique, we have to trans- form the processed testing data, which is the result of the NLP phase, as shown in Sect. 3.2, into VSM matrix form.
We present the fraud templates adopted in this study in Ta- ble 1 and the VSM matrix of the fraud templates and the pre-defined fraud keywords in Table 2. Based on the VSM matrix, a TF-IDF matrix is then generated. The TF-IDF fre- quency increases proportionally with the number of times a word appears in the testing data. However, the word’s im- portance is offset by its frequency in the corpus, so it will be adjusted.
Term Frequency (TF): The importance of term ti in the testing data can be presented as Eq. (1).
T Fi,j= ni,j
knk,j
(1) Note thatni,jis the number of times the termtiappears in the testing datadj, while
knk,j is the total number of times the term appearstiin the testing datadj.
Inverse Document Frequency (IDF): The IDF is able to measure the amount of information provided by the word.
It is the logarithmic scale of the testing data containing the keyword, which is obtained by dividing the total number of documents by the number of documents containing the
Table 1 The fraud templates adopted in this study
Table 2 The VSM matrix of the fraud templates and the pre-defined fraud keywords
term, and then taking the logarithm of the quotient in Eq. (2), where Nmeans the total number of the testing data in the corpus.
IDF(t,D)=log N
| {d∈D:t∈d} | (2) Note that| {d∈D:t∈d} |is the number of the testing data where the term t appears (i.e. tf(t,d)0).
Term Frequency-Inverse Document Frequency (TF- IDF): Finally, TF-IDF is calculated as Eq. (3).
T FIDFi,j=T Fi,j×IDFi (3)
3.4 Latent Semantic Analysis (LSA)
LSA is a model based on mathematical statistics combin- ing singular value decomposition (SVD) with dimension- ality reduction. LSA can not only depict the information about the testing data, but can also derive the relation- ships between latent semantics and information. In this section,given a real matrix A (m×n) and supposing m≥n;
rank(A)=r, r means the quantity of singular values, and rep- resents the rank size of the matrix as well. Operating singu- lar value decomposition for A (m×n) can be expressed as a formula, as shown in Eq. (4). Table 4 shows the result matrix
Table 3 Matrix ¯A
A¯of the LSA operation.
A=US VT (4)
U: Term vector matrix.
S: Retaining singular value matrix.
VT: Vector matrix.
3.5 Cosine Similarity
In this section, the relevance of the testing data and the fraud templates is evaluated via cosine similarity. Cosine similar- ity is always adopted in positive space, where the outcome is bounded between [0, 1]. In the area of information re- trieval and text mining, each term is notionally assigned a different dimension, and a document is characterized by a vector where the value of each dimension corresponds to the number of times that term appears in the document. Cosine similarity is able to provide a useful measure of how simi- lar two documents are likely to be, in terms of their subject matter. The cosine of two vectors can be derived by using the Euclidean dot product formula as presented in Eq. (5).
a·b=abcosθ (5)
In that case, given two vectors of attributes, A and B, the cosine similarity, cos(θ), is represented as in Eq. (6).
similarity
=cos(θ)= A·B ab=
n i=1Ai×Bi
n
i=1(Ai)2×n i=1(Bi)2
(6)
The resulting similarity ranges from −1 meaning ex- actly opposite, to 1 meaning exactly the same, with 0 indi- cating orthogonality (decorrelation), and in-between values
indicating intermediate similarity or dissimilarity.
4. Implementation: Scenario Testing
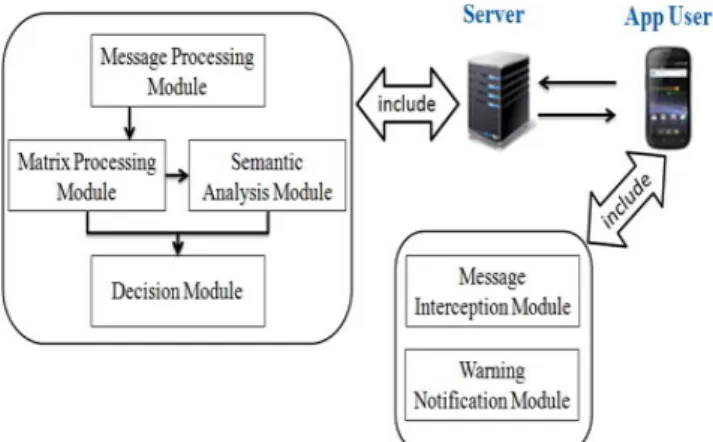
In this section, we develop a demo-system to present the practicability of the proposed fraud detection method. Fig- ure 2 shows the implementation of the proposed fraud detec- tion system. An Android-based application is implemented on a NEXUS 9 tablet to support chat log retrieval and alert notification, while the backend server is operated on a desk- top computer and responsible for data pre-processing, ma- trix processing and data analysis. The normal procedure of our proposed system is as follows. First, the message inter- ception module in the Android-based application is used for retrieving the real-time chat logs from Facebook Messenger, and the chat logs are then forwarded to the backend server.
Next, the server performs NLP procedure on the chat logs via the message processing module and converts the results into a TFIDF matrix via the matrix processing module. Af- ter that, LSA is operated at the semantic analysis module to eliminate the noise signal during the data analysis phase. Fi- nally, the decision module computes the relevance between the testing data and pre-defined fraud scripts, and returns the fraud detection result to the Android-based application.
The warning notification module then sends a notification to inform the user whether a fraud event is happening (or has been correctly identified) or not.
In our experiment, we investigate fraud information from a search engine and anti-fraud website to simulate two kinds of real fraud tricks: one group (including d1 to d6) in- volves a game-point based fraud event, and the other group (including d7 to d9) involves a micro-payment based fraud event. Note that in our experiment d1-d9 are adopted as fraud templates which really happened in Taiwan. Regard- ing the testing data, we simulate three kinds of groups: (1) one group consists of fraud events, i.e. t1 to t5; (2) one group consists of non-fraud events with fraud keywords, i.e. t6 to t8; and (3) the others are non-fraud events without any fraud keywords, i.e. t9 and t10.
Figures 3 and 4 present the snapshot of our developed Android-based application on a NEXUS 9 tablet. In Fig. 3,
Fig. 2 The implementation of the proposed fraud detection system
a smartphone user opens our fraud detection application and clicks the icon to monitor (and retrieve) chat logs from Face- book Messenger, as shown in Fig. 4. Next, the applica- tions sends retrieved real-time messaging (i.e. a chat log) to the backend sever, which then executes the NLP and LSA techniques on the chat log for fraud analysis and detection.
Then, the application receives the analysis result from the backend sever and sends a notification to the user (such as that shown in Fig. 5).
In our experiment, we set up two processes to judge whether an instance of testing data is fraud or not. First, we calculate the cosine similarity between the TF-IDF matrices derived from the testing data and the pre-defined fraud tem- plate, respectively. The TF-IDF similarity ranges from zero (irrelevant) to one (totally relevant). Next, we further calcu- late the cosine similarity between LSA-performed matrices, which is based on the TF-IDF matrices in the first step. If the LSA similarity is greater than the TF-IDF similarity and a pre-defined threshold, it means that the testing data is prob- ably a fraud event. We present the following two scenarios to test the performance of the proposed system.
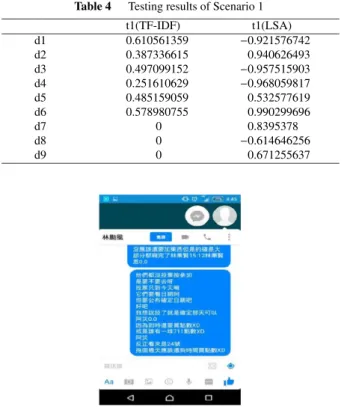
Scenario 1 (fraud-event): In scenario 1, we input a real fraud event as the testing data. Given an input data t1 as shown in Fig. 5, we can derive the TF-IDF similarity be- tween t1 and the fraud templates (i.e. d1-d6 and d7-d9) as shown in Table 4. In addition, the LSA similarity between t1 and d2, d5 and d6, respectively, is greater than the TF-IDF similarity and the pre-defined threshold. This means that the input data t1 is probably a fraud event.
Scenario 2 (non-fraud event with fraud keyword): In scenario 2, we input a testing data which is a non-fraud event
Fig. 3 Starting pages of fraud detection application
Fig. 4 Capturing Facebook chat logs process
Fig. 5 Fraud warning notification of Scenario 1
Table 4 Testing results of Scenario 1
t1(TF-IDF) t1(LSA)
d1 0.610561359 −0.921576742
d2 0.387336615 0.940626493
d3 0.497099152 −0.957515903
d4 0.251610629 −0.968059817
d5 0.485159059 0.532577619
d6 0.578980755 0.990299696
d7 0 0.8395378
d8 0 −0.614646256
d9 0 0.671255637
Fig. 6 Fraud warning notification of Scenario 2
with a fraud keyword. Given an input data t2 as shown in Fig. 5, we can derive the TF-IDF similarity between t2 and the fraud template, i.e. d1-d9, as shown in Table 5. Nev- ertheless, the LSA similarity of t2 between the fraud tem- plates (i.e. d1-d6) is less than the TF-IDF similarity and the predefined threshold. This means that the input data t2 is probably not a fraud event and an alert notification is shown as appears at the top of Fig. 4.
Finally, we summarize the performance results in Ta- ble 6, in which ten testing data are adopted. We can see that the results of testing data (t1-t5, t9, t10) are judged accu- rately, as expected. Nevertheless, the result of testing data (t6, t7) is not as expected. We observe that there are many negative values between terms and data in the matrix pro- duced by LSA. The negative values certainly affect the re- sult. Thus, we need to consider both the TF-IDF similarity
Table 5 Testing results of Scenario 2
t2(TF-IDF) t2(LSA)
d1 0.242878105 0.192613904
d2 0.48462316 −0.24393336
d3 0.393627993 −0.771613234
d4 0.314807156 −0.333108654
d5 0.38417323 −0.403889652
d6 0.23655327 0.664691936
d7 0 −0.020377966
d8 0 −0.997602794
d9 0 0.237544749
Table 6 Performance evaluation Expected Result Tested Result
t1 fraud fraud
t2 fraud fraud
t3 fraud fraud
t4 fraud fraud
t5 fraud fraud
t6 Non-fraud fraud
t7 Non-fraud fraud
t8 Non-fraud Non-fraud
t9 Non-fraud Non-fraud
t10 Non-fraud Non-fraud
Accurate Rate 80%
and the LSA similarity to help us judge whether the testing data is a fraud event or not.
5. Conclusion
Nowadays, people spend much of their time on social net- works in which real-time messaging applications are used for communication. In this study, we focus on fraud anal- ysis and detection during real-time messaging communica- tions. The natural language processing and semantic anal- ysis model is integrated and utilized to increase the effec- tiveness of fraud detection. We then build a demo-system to present the practicability of the proposed idea. To the best of our knowledge, we are among the pioneers when it comes to investigating fraud analysis and detection via user conversations. In the future, different semantic models, such as probabilistic latent semantic analysis (PLSA) and latent dirichlet allocation (LDA), may be adopted to enhance the effectiveness of fraud detection.
Acknowledgments
This work was supported in part by the Academia Sinica, in part by the Taiwan Information Security Center, and in part by the Ministry of Science and Technology, Taiwan un- der Grant MOST 105-2221-E-259-014-MY3, Grant MOST 105-2221-E-011-070-MY3, Grant MOST 105-2923-E-182- 001-MY3, Grant MOST 105-2218-E-001-001 and MOST 106-3114-E-011-003.
References
[1] A. Agrawal, S. Kumar, and A.K. Mishra, “Credit card fraud detec- tion: A case study,” International Conference on Computing for Sus- tainable Global Development, pp.5–7, 2015.
[2] M.H. Cahill, D. Lambert, J.C. Pinheiro, and D.X. Sun, “Detecting fraud in the real world,” Handbook of Massive Data Sets, vol.4, pp.911–929, 2002.
[3] S. Freeman, A. Bivens, J. Branch, and B. Szymanski, “Host-Based Intrusion Detection Using User Signatures,” Graduate Research Conference, 2002. http://citeseerx.ist.psu.edu/viewdoc/download?
doi=10.1.1.113.3217&rep=rep1&type=pdf, accessed August 22.
2017.
[4] P.-Y. Hui and H.Y. Meng, “Latent semantic analysis for multimodal user input with speech and gestures,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol.22, no.2, pp.417–429, 2014.
[5] S. Jamshidi and M.R. Hashemi, “An efficient data enrichment scheme for fraud detection using social network analysis,” 6th Inter- national Symposium on Telecommunications (IST), pp.1082–1087, 2012.
[6] W. Lee and K.W. Mok, “Adaptive intrusion detection: a data mining approach,” Artificial Intelligence Review, vol.14, no.6, pp.533–567, 2000.
[7] M. Nandhini and B.B. Das, “An assessment and methodology for fraud detection in online social network,” The 2nd International Conference on Science Technology Engineering and Management (ICONSTEM), pp.104–108, 2016.
[8] Y. Sylla and P. Morizet-Mahoudeaux, “Fraud detection on large scale social networks,” 2013 IEEE International Congress on Big Data, pp.413–414, 2013.
[9] V.V. Vlasselaer, T. Eliassi-Rad, L. Akoglu, M. Snoeck, and B.
Baesens, “AFRAID: Fraud detection via active inference in time- evolving social networks,” 2015 IEEE/ACM International Con- ference on Advances in Social Networks Analysis and Mining (ASONAM), pp.659–666, 2015.
[10] S.-H. Wu, M.-J. Chou, C.-H. Tseng, Y.-J. Lee, and K.-T. Chen, “De- tectingin situidentity fraud on social network services: A case study with facebook,” IEEE Systems Journal, 2015.
DOI:10.1109/JSYST.2015.2504102
[11] Z. Yanchun, Z. Wei, and Y. Changhai, “Detection of feedback rep- utation fraud in taobao using social network theory,” 2011 Interna- tional Joint Conference on Service Sciences, pp.188–192, 2011.
[12] X. Ying, X. Wu, and D. Barbar´a, “Spectrum based fraud detection in social networks,” IEEE 27th International Conference on Data Engineering, pp.912–923, 2011.
[13] W.-F. Yu and N. Wang, “Research on credit card fraud detection model based on distance sum,” International Joint Conference on Artificial Intelligence (JCAI ’09), pp.353–356, 2009.
[14] CKIP word segmentation, http://ckipsvr.iis.sinica.edu.tw/, accessed April 24. 2017.
[15] Criminal Investigation Bureau, Taiwan,
http://www.cib.gov.tw/english/, accessed Dec. 14. 2016.
Liang-Chun Chen received the M.S. degree in institute of learning technology from the Na- tional Hualien University of Education, Hualien, Taiwan, in 2006, and the Ph.D. degree in infor- mation management from the National Taiwan University of Science and Technology, Taipei, Taiwan, in 2013. He is currently an Assistant Professor with the Department of Management, Fo Guang University, Yilan, Taiwan. His re- search interests include wireless protocol and power saving algorithm design in broadband ac- cess networks, social networks, and e-learning.
Chien-Lung Hsu is a Professor of Informa- tion Management Department at Chang Gung University (CGU), in Taiwan, R.O.C. He re- ceived a B.S. degree in business administration, an M.S. degree in information management, and a Ph.D. degree in information management from the National Taiwan University of Science and Technology, Taiwan in 1995, 1997, and 2002, respectively. Currently, he is the director of the Ubiquitous Security and Applications Lab and his research expertise includes cryptography, in- formation security, mobile commerce, digital forensics, healthcare, big data, internet of things, etc. He is also the director of Chinese Cryptology
& Information Security Association (CCISA, Taiwan), the chair of Mem- bership Committee of CCISA, the director of Taiwan Association for Med- ical Informatics, and a senior researcher of Taiwan Information Security Center (TWISC) in Taiwan, R.O.C. He is also the director of Program of Information Security with Medical Applications, the director of Program of Data Science with Industrical Applications for Big Data, the director of Program of Internet of Things with Industrial Innovative Applications, a researcher of Healthy Aging Research Center (HARC), and a researcher of Elder Industry Development and Research Center (EIDRC) at CGU. Dr.
Hsu received research awards from Taiwan Ministry of Science & Tech- nology, CGU, and Chang Gung Memorial Hospital. He published more than 80 international journal articles and received best paper awards from eCASE 2010, CISC 2010, JCMIT 2015, MMHS 2015, and SDPS 2016 in- ternational conferences in the information security and healthcare research fields.
Nai-Wei Lo received the B.S. degree in engineering science from National Cheng Kung University, Tainan, Taiwan, in 1988 and the M.S. and Ph.D. degrees in computer science and electrical engineering from the State University of New York at Stony Brook, Stony Brook, NY, USA, in 1992 and 1998, respectively. He is currently a Professor with the Department of Information Management, National Taiwan University of Science and Technology, Taipei, Taiwan, and the Director of Taiwan Informa- tion Security Center, National Taiwan University of Science and Technol- ogy (TWISC@NTUST). His research interests include smart grid security, IoT/IoV security, web technology, and cloud security. He is an IEEE senior member.
Kuo-Hui Yeh received the B.S. degree in mathematics from Fu Jen Catholic University, New Taipei City, Taiwan, in 2000, and the M.S.
and Ph.D. degrees in information management from the National Taiwan University of Science and Technology, Taipei, Taiwan, in 2005 and 2010, respectively. He is currently an Asso- ciate Professor with the Department of Informa- tion Management, National Dong Hwa Univer- sity, Hualien, Taiwan. He has authored over 80 articles in international journals and conference proceedings. His research interests include Internet of Things security, an- droid security and privacy, NFC/RFID security, digital signature, network security, and big data and cloud computing.
Ping-Hsien Lin received the B.S. and M.S.
degrees in information management from Na- tional Taiwan University of Science and Tech- nology, Taipei, Taiwan, in 2013 and 2015, re- spectively. He is currently a software engineer and works on Wistron Information Technology
& Services, Taipei, Taiwan. His master’s thesis is “A fraud detection system for real-time mes- saging communication on Android Facebook messenger”. His research interests include an- droid mobile application security and website development of E-commerce.