Unsupervised Web Data Extraction
Chia-Hui Chang1, Yen-Ling Lin1, Kuan-Chen Lin1, and Mohammed Kayed2
1 National Central University, Chungli, Taiwan
[email protected],[email protected],[email protected]
2 Faculty of Science, Beni-Suef University, Egypt [email protected]
Abstract. Unsupervised information extraction has been studied a lot in the past decade. However, not much attention has been paid to its wrapper maintenance. In this paper, we study wrapper construction and verification problem based on the given schema and template which is in- duced from unsupervised page-level wrapper induction system. We model the verification problem as a constraint satisfaction problem (CSP) for leaf node label assignment with respect to constraints specified by a finite state machine (FSM) which is constructed from previous learned schema and template. If there exists no solution to the CSP, i.e. no valid label sequence exists, we say the test page fails the verification; otherwise, we rank all valid label sequences by measuring the fitness of each label se- quence for extraction. We evaluate the FSM based approach with XML validation via false positive rate and false negative rate and measure the extraction performance through extraction accuracy. The experimental result shows the proposed method can effectively filter invalid pages (zero false positive rate) and rank the correct label sequence with the highest score with 96.5% accuracy.
Keywords: Unsupervised Information Extraction, Wrapper Induction, Wrapper Verification, Extractor.
1 Introduction
Wrapper Induction (WI) which aims to generate rules for Web data extrac- tion is a key for information integration systems. Many WI approaches have been surveyed in [2] with different extraction targets (field-level, record-level or page-level), with various automation degree (supervised, unsupervised), and with different wrapper representations (HTML tokens, DOM tree paths, etc.). Although many researches focused on WI, the development of tools for wrapper maintenance that following up the correctness of the generated wrapper over time has received less attention.
For supervised WI, wrapper maintenance can be divided into two main tasks: wrapper verification and wrapper re-induction. Wrapper verification remedies the cases when the wrapper seems to work normally but the extracted data are
invalid, while wrapper re-induction repairs the wrapper by gaining new labeled training data in order to learn new extraction rules. Example of such wrapper verification systems are RAPTURE [5] and DataProlog [7].
For unsupervised WI, the first thought is that we do not need wrapper verifier because unsupervised induction can be used to learn new wrappers each time. However, unsupervised web data extraction usually takes longer time (several seconds) than pure extraction module based on the induced schema and tem- plate (several milliseconds). Meanwhile, schema matching is quite challenging for two schemas without labels. If no good schema-matching algorithm is avail- able, we cannot use the extracted data directly. Thus, extraction modules for unsupervised IE systems are still a necessity.
Nevertheless, the construction of an extraction module for page-level WI systems (e.g. RoadRunner [3], EXALG [1] and FivaTech [4]) is not an easy task and is much sophisticated than record-level extraction module (e.g. WIEN [5] and STALKER [8]). For record-level WI systems, the job of the extractor is to repeatedly match all the occurrences of the record template in the input testing page. As for page-level WI systems, the job of the extractor needs to align the whole page with the complete page template that contains sets and optional. The difficulty of matching optional and sets with similar templates in a new page makes the alignment especially complex and requires not just template information but also the data content to assist the comparison.
In this paper, we propose a page-level schema/template verification approach that detects changes of a website and extracts the embedded data from new pages based on existing schema and template induced by the unsupervised WI system FivaTech. Instead of dealing with every node in the DOM tree of a new page, only leaf nodes (with their respective DOM tree paths) are processed to verify if the new page complies with the finite state automata built from the existing schema. That is, there exists a sequence of label assignments for all leaf nodes such that transitions among labels comply with the state transitions of the FSM. Finally, we find the best label sequence by measuring the fitness score of every possible sequence of label assignments such that the data field will be extracted respectively.
The paper is organized as follows. Section 2 presents background of this research. Section 3 introduces some preliminaries for the definitions of page-level wrapper induction. Section 4 describes our proposed wrapper verifier. Section 5 presents the experimental results. Finally, section 6 concludes our work.
2 Background
While WI has been widely studied from various aspects, wrapper maintenance has not been well studied yet. In fact, most wrapper maintenance researches focus on record-level wrappers. Their wrapper verifiers only check the validity of extracted data to remedy the situations when the wrappers work normally while the extracted data are invalid. For example, based on WIEN approach [5], Kushmerick [6] introduced RAPTURE which uses nine features: digit density,
letter density, upper-case density, lower-case density, punctuation density, HTML density, length, word count, and mean word length to measure the similarities between data observed by the wrapper and that expected.
Similarly, Lerman et al. introduced DATAPROG [7] for the verification of STALKER [8]. They use examples of previously extracted data in order to ac- quire semantic descriptions of the data. Two types of features are used to describe the data: extraction patterns learned by DATAPROG and global numeric fea- tures. The wrapper verifier checks the correctness of the data extracted for each data field by statistically comparing two distributions that describe the field in both the training examples and the new test examples. If the distributions are statistically the same, the wrapper is judged to be correct; otherwise, it is failed. For both RAPTURE and DATAPROG, if the extraction process failed due to template change, the verification of the semantic of data is not necessary. There- fore, Pek et al. [9] combine template and content verification for record-level data extraction and verification. The method uses three features for wrapper validation: the extraction path based on HTML tree structure, the number of children per parent node, and the number of possible data nodes that could be extracted by this extraction path. The DOM-tree based feature is considered as a complementary to RAPTURE to advance the verification during extraction.
In spite of these researches for record-level wrappers, there is no literatures or studies on page-level wappers construction or verification to our knowledge. Most wrapper induction focus on record-level extraction, where the wrappers can rely on pattern match for data extraction. As for page-level data extraction, the wrappers need to align the whole test page with the induced page template and schema, which is almost as complex as wrapper induction. In addition, some researchers might consider unsupervised wrapper induction and schema matching as a solution for maintaining the consistency of the extracted data. However, due to limited label information with schema matching, alternative approach based on page-level wrapper is more reliable.
3 Problem Definition
Deep Web pages are generated by a CGI program which embeds a data instance x (taken from a database) into a predefined template T where all data instances conform to a common schema Ω. In this paper, we follow the definition of the structured data used in EXALG [1] where basic data are allocated in leaf nodes while composite data (e.g. tuple, set, option, etc.) are allocated in internal nodes. Fig. 1(a) shows an example schema with 5 basic data and 6 composite data, including 1 set (denoted by {}), 2 options (denoted by ()?) and 3 tuples (denoted by <>).
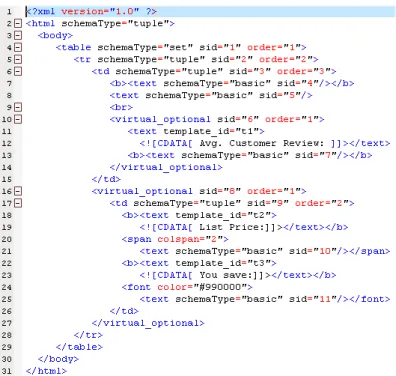
The page generation process can be viewed as an encoding process (denoted by λΩ(T, x)) which embeds a data instance x into the template T , while wrapper induction is a reverse engineering which decodes from the pages to its template and schema. Fig. 2 shows a page template tree with embeded schema informa- tion (e.g. schemaType, virtual optional, sid template id, etc.) from Fig. 1(a) to
Fig. 1. (a) A sample schema and (b) The same schema tree with augmented leaf templates t1, t2and t3 defined by Fig. 2.
Fig. 2.A page template tree with embeded schema from Fig. 1(a).
define the generation of HTML pages. In principle, all HTML tags are template patterns, while leaf text can be either template (embraced by CDATA in Fig. 2; e.g. t1=“Avg. Customer Review:”, t2=“List Price:” and t3=“You save:” at lines 12, 19 and 23, respectively) or data strings (embraced by <text> tags of basic types).
Given a page template tree with embeded schema induced from page-level WI system as shown in Fig. 2, the task of wrapper verification is to decide whether an input page follows the template and schema, and to extract the embedded data if the answer is “yes”.
4 Page-Level Wrapper Verifier
Our page-level template and schema verifier contains three modules: path-guided semantic comparison, finite-state-machine (FSM) construction for structure ver- ification and most possible path selection for extraction. Note that if no path can be found, the test page is considered invalid for the current template and schema. In such a case, wrapper re-induction can then be executed to learn new template and schema.
4.1 Path-Guided Semantic Comparison
To extract data from a test page, we need to match the test page against the template tree. To avoid recursive comparison and backtracking for mismatch, we use a path-guided approach and compare leaf texts in the new page with data items or leaf templates that have identical path in the template tree. To be more specific, each leaf text x with path p is a candidate instance of basic identifiers and leaf template that have the same path p.
For example, given a text string “ A A CD” with path /html/body/table/tr/td, we will compare it with leaf identifiers β5 and t1 according to the template tree in Fig. 2. As another example, for the leaf text “Toddler Favorites” with path /html/body/table/tr/td/b’, we will compare it with basic identifiers β4 and β7
as well as leaf template t2and t3. Note that if a leaf text has no candidate iden- tifiers, it means the test page does not comply with the current page template tree and there is no need to continue the verification process.
We define node similarity between a leaf text in the test page and a candidate leaf template or basic identifier as follows. For leaf template candidate, the node similarity is 1 if the leaf text is identical with the text of the leaf template or 0 otherwise. For basic candidates, we use five features to characterize text strings for similarity measure of the given leaf text and its candidate basic identifier. These features are defined and illustrated with string s = ”Op 123-900” as follows:
– LetterDensity: density of letters in the string; e.g. LetterDensity(s)=0.2. – DigitDensity: density of digits in the string, e.g. DigitDensity(s)=0.6. – PunDensity: density of punctuations in the string, e.g. PunDensity(s)=0.1.
– CapitalStartTokenDensity: density of tokens that begins with upper letter, e.g. CapitalStartDensity(s)=1/2.
– IsHttpStart: whether the string begins with ”http” or not, e.g. IsHttpStart(s)=0. Similar to Rapture, we assume that each instance of a basic identifier βc∈ S follows a multivariate normal distribution with mean vector µc and variance vector σc estimated from training examples. Therefore, we can estimate the probability of a leaf node x = (x1, . . . , xd) to be an instance of this basic identifier as follows:
p(x|βc) = N (x|µc, σc) =q 1 (2π)dΠj=1d σj
exp{−1 2Σ
d
j=1(xj− µj σj
)2} (1)
where d is the number of features. We also use this probability for candidate selection. If the probability is greater than a threshold θ, we consider the basic ID as a candidate for this leaf node; otherwise we remove this basic ID βc from the CandidateSet. The selection of the threshold is studied in the experiment.
Note that instead of finding the best id for each leaf node, we only filter impossible IDs for each leaf node. The reason is that if we choose the id with the maximum probability for each leaf value, we would take only content into consideration; yet the relation between leaf nodes is ignored. Therefore the best id for each leaf node will be decided by the schema as shown next.
4.2 Finite State Machine Construction
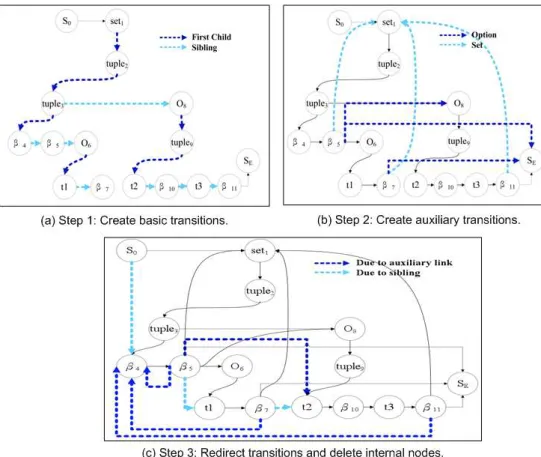
To verify whether a test page complies with the schema induced from the old pages, we need to ensure the occurrence order of assigned identifiers/labels for the leaf nodes follow the schema. Therefore, we make use of the schema tree with augmented template leaf nodes (see Fig. 1(b)) and transform it into a finite state machine (FSM) with only leaf nodes. The FSM can then be used to guide the assignment of identifiers/labels for all leaf texts in the new page. As an example, Fig. 3 is the FSM for the augmented schema tree in Fig. 1(b).
Constructing an FSM from an augmented schema includes 3 main steps: Step 1: Create a directed binary tree of basic transitions where each left link
points to the first child and each right link points to the next sibling (Fig. 4(a)).
Step 2: Create auxiliary transitions from leaf nodes to internal nodes for set and optional data types as follows.
1. For each “option” node x, find the last leaf node before x, denoted by y, and the next node of x ’s right most descendant leaf node, denoted by z. The so called last node and next node is ordered by preorder traversal such that y denotes the right most descendent leaf node of x ’s left sibling or x ’s parent’s left sibling if x is the first child and z denotes the first node following all the leaf nodes in x ’s subtree. For example, the transition
Fig. 3.A finite automata generated from Fig. 1(b).
Fig. 4.Generating a finite automata from the augmented schema tree in Fig. 1(b).
from β5to O8 is added due to optional node O6since β5 is the last leaf before O6 and O8 is the next node of β7, the last descendant leaf of O6. Similarly, the transition from β7 to SE is added since SE is the next of the last descendant leaf β11 (See deep-blue dotted lines in Fig. 4(b)). Note that if z is also optional, then additional transition will be added from y to the next node of z ’s rightmost descendant leaf node until non- optional node is encountered. For example, the transition from β5to SE
is added since O8 is optional.
2. For a “set” type node x, we need to add a transition from the right most leaf node b of x to the set node x to allow repetition. If any ancestor of b is an option type node, an additional transition from l, the last leaf node before the ancestor node, to x needs to be added. The node l denotes the right most leaf node of the option node’s left sibling1. This is similar to the skip link added for option nodes, but this transition is added to allow repetition for set nodes. Again, if any ancestor of l is an option node, we will repeat the process to add proper links from leaf nodes to some internal nodes. For example, the set node in Fig. 4 will generate three transitions from β11, β7 (the last leaf node before O8) and β5(the last leaf node before O6) to set1(See light-blue dotted lines in Fig. 4(b)). Step 3: Delete internal nodes such that only leaf nodes of basic type and tem-
plate nodes are reserved. This will be done as follows.
1. For each node v with auxiliary transitions from some leaf f created at step 2, we create a transition from f to the first leaf under v or v itself if it is leaf. For example, transitions from β5, β7, and β11 to set1 will be directed to β4 (the deep-blue dotted lines in Fig. 4(c)).
2. For each sibling link from v to r : (i) if v is a leaf and t is an internal, we create a transition from v to the first leaf under r ; or (ii) if v is an internal and r is a leaf, we create a transition from r ’s previous node (i.e. the right most leaf under v ) to r ; or (iii) if both are internal, we instead create a transition from r ’s previous node (i.e. the right most leaf under v ) to the first leaf under r. For example, sibling link from β5
to O6 demonstrates case 1 with a new link from β5 to t1, the first child under O6. Also, sibling from tuple3to O8illustrates case 3 with the new link from β7 (the previous node of O8) to t2, the first child under O8. 3. Remove all internal nodes and their transitions. Just keep leaf nodes. Once the FSM is constructed, we then model the task of assigning labels to all leaf nodes as a constrained satisfaction problem where each leaf node is a variable with a set of basic/template identifiers as its domain and the transitions among states in the generated FSM are binary constraints that enumerate possible value pairs for two consecutive variables (leaf nodes). Therefore, we apply constraint propagation to reduce the number of candidate IDs for each node. For example, the only candidate β10 for node 6 with path “/html/body/table/tr/td/span”
1 If the option node is the first child, then l will be the right most leaf node of its parent’s left sibling.
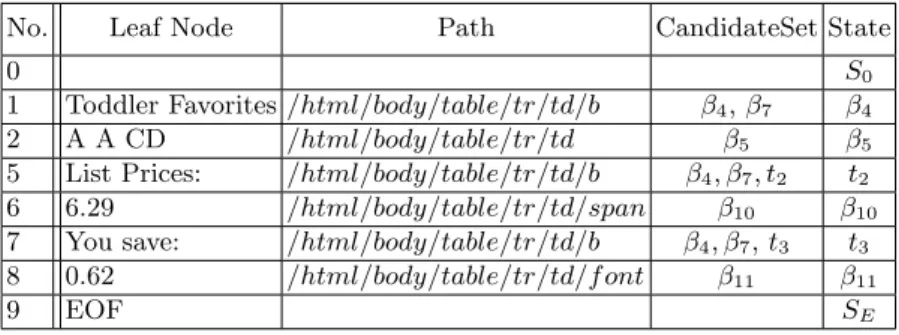
implies the previous label could only be t2 and the next label could be t3. Such arc consistency checking can reduce the number of candidates for each leaf node and improve the efficiency of label sequence enumeration without backtracking. In this particular example, one complete sequence of label assignment after arc consistency checking is β4, β5, t2, β10, t3, β11as shown on the right most column of Table 1.
Table 1.Data extraction and verification for new page
No. Leaf Node Path CandidateSet State
0 S0
1 Toddler Favorites /html/body/table/tr/td/b β4, β7 β4
2 A A CD /html/body/table/tr/td β5 β5
5 List Prices: /html/body/table/tr/td/b β4, β7, t2 t2
6 6.29 /html/body/table/tr/td/span β10 β10
7 You save: /html/body/table/tr/td/b β4, β7, t3 t3 8 0.62 /html/body/table/tr/td/f ont β11 β11
9 EOF SE
4.3 Finding the Most Possible Label Assignment
If there exists more than one label sequence that complies with the generated FSM, we would need to decide which label sequence can be used to extract the data2. Two possible measures are considered here. The first one is based on node similarity as discussed in section 4.1. The second one is based on transition probability between labels. The transition probability can be obtained based on the extracted data at earlier time. For example, given the extracted data sequence:
“β4, β5, t1, β7, β4, β5, t1, β7, β4, β5, t2, β10, t3, β11”,
we could accumulate the transition counts for each state pair. For state pairs without transition occurence, we give a small value η to differentiate it from zero probability which denotes no transition is allowed. For example, β7 has possible transitions to β4, t2, and SE with 2, 0, 0 counts in the above sequence, respetively. By adding a small value η, the transition probabilities are 2/(2+2η), η/(2+2η), η/(2+2η), respectively.
Now to make use of the above transition probabilities and the node similar- ity defined above, we enumerate every possible label and evalute the sequence probability SP (X, L) for a page X with n leaf nodes x1, x2, ..., xn and label assignment L= S0, l1, l2, ..., ln, ln+1(SE) as follows:
log SP (X, L) = log T P (S0, l1) + Σi=1n T P (li, li+1) + Σi=1n log P (xi|βli) (2)
2 If some leaf node of the test page is left with no candidate label, then the schema is considered not complete and needs to be re-induced.
5 Experiments
In the following, we make use of Rapture dataset for the experiment. For each website with n collected pages, we choose two web pages with different keywords to build the schema and template using FivaTech. We then test these n webpages to see if they pass or fail the FSM-based verification, and manually examine each webpage to see if they comply with the induced schema/template (valid) or not (invalid). The process is repeated n/2 times for each website.
We evaluate the performance via false positive rate (i.e. the percentage of invalid pages which pass through the verifier) and false negative rate (i.e. the percentage of valid pages that fail the verification) to compare the proposed method with XML validation as described below.
5.1 Baseline - XML Validation
We use XML validation as the baseline for comparison. XML validation is a module to check whether an XML file conforms to some XML DTD. We first transform the training HTML pages into XML files, and then summarize an XML schema representation, i.e. XSD (XML Schema Description) from these XML files through the XML2XSD function supported by .NET Framework. For validation, the XML validation module takes the XSD file of the template and the XML file of the new page as inputs, and checks whether the XML file is valid with respect to the XSD file.
Note that XSD considers sibling tags with the same tag name as repeated elements even if they contain different subtrees, leading to incorrect schema. In some sense, XML validation only ensures that every path of the test page is a valid one in the old pages. Thus, we might expect a high false positive rate and low false negative rate (≈0) for XML validation.
5.2 Verification Effectiveness Evaluation
We first compare the false positive rate from invalid pages (i.e. type I error) for the proposed methods on Rapture dataset. In our experiment, we did not find any invalid page that can pass through our FSM verification even with a zero threshold θ which is used to control the least probability of a leaf node to be an instance of a basic identifier. All invalid pages would be left with no candidate during arc consistency checking as shown in Fig. 5. Therefore, we obtain zero type I error rate for all possible threshold θ. On the other hand, XML validation has constant type I error 20.2% (i.e. 79.8% specificity) since the parameter θ is used only for FSM verification.
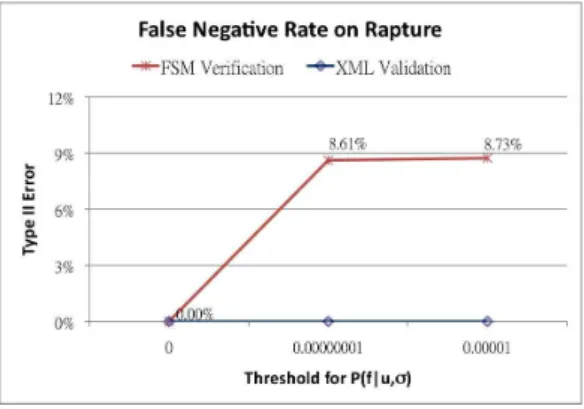
Next, we compare the false negative rate from valid pages (i.e. type II error). The result is shown in Fig. 6. As expected, XML validation has zero type II error, i.e. all valid pages will pass through the validation, while FSM-based approaches also has zero type II error if no threshold θ is set. As the threshold θ increases, type II error increases (around 8.6% to 8.7%) since larger θ will filter more candidate basic identifiers, leaving less chance for valid pages to pass through
Fig. 5.False positive rate for FSM-based and XML-based approaches.
the verification. Since the threshold θ is a mechanism to filter the number of candidates for each leaf node in the DOM-tree, we can ignore this filtering if verification time is not too long.
Fig. 6.False negative rate for FSM-based and XML-based approaches.
5.3 Extraction Effectiveness
Next, we evaluate the effectiveness of data extraction for pages that pass through the FSM verification. This is equivalent to check whether the correct label se- quence can be ranked highest when more than one valid label sequence are available. We compare the proposed label sequence evaluation in Eq. 2 with in- dividual effect based state transition probability (the first two terms of Eq. 2) and leaf node similarity (the last term of Eq. 2). The performance is measured by accuracy, the number of correctly extracted page divided by the total number of test pages.
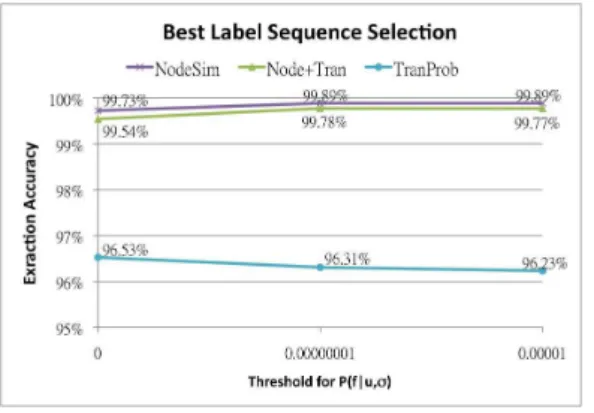
As shown in Fig. 7, leaf node similarity alone performs the best with 99.73% accuracy rate, while state transition probability also has a good performance with 96.53% accuracy. The composite of these two factors has a less accuracy at 99.54%. Meanwhile, when the probability threshold for filtering candidate labels is increased, all accuracy rates increased slightly except for state transition probability. For leaf node similarity, the accuracy is 99.89%, while for state transition probability the accuracy is around 96.23%.
Fig. 7.Best label sequence selection for extraction effectiveness
5.4 Page Selection for Wrapper Induction
With this page-level schema/template verification, we can effectively add more pages that fail the verification to induce a more general schema/template. That is, we can use verifiers to select only essential pages to induce schema/template, reducing the time cost for induction on unnecessary pages. In some situations, the verifier can also be used to detect bugs in the induced schema/template.
To demonstrate this idea, we collect search result pages for nine web sites (as shown in Table 2) by submitting the same query to each search form and obtain an average of 20 pages for each website. We use both randomly selected pages and specific pages for training set, respectively.
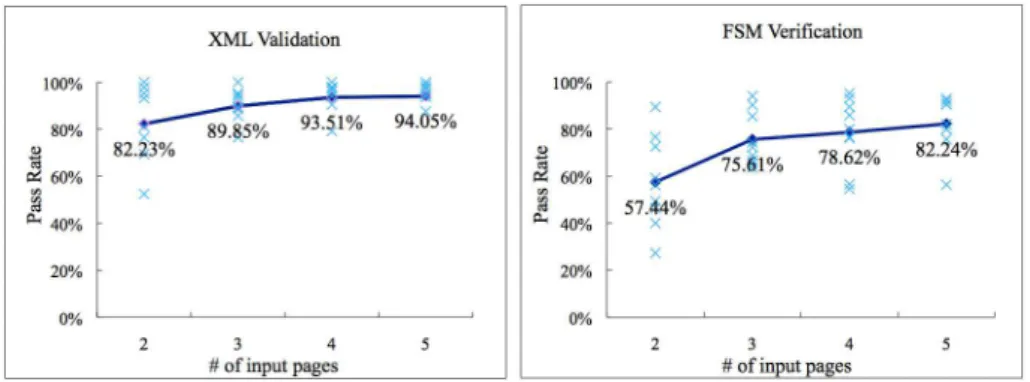
For randomly selected pages, we choose k input pages for each web site for wrapper induction (k=2, 3, 4, 5) and test the generated wrapper to see how many pages from the same website can pass through the generated extractor. The process is repeated five times for each web site for a given k. For XML validation, the coverage is 82% when two pages are used for wrapper induction. The ratio increases to 94% when five pages are used. This shows that although all pages are generated by the same CGI program, there are still many schema variations that are not detected using five pages. Fig. 8 shows the percentage of pages that comply with the induced wrapper for schema verification. If we use only two pages to induce the wrapper, only 57% pages can pass through FSM verification.
The ratio increases to 82% when five pages are used for wrapper induction. This experiment also echos the high false positive rate of XML validation as the XSD schema generated by XML allows more (both valid and invalid) pages to pass the validation.
Fig. 8.Percentage of pages that pass through verification with various training pages for wrapper induction
For specific pages, we try three different combinations of input including {first, second}, {first, midst} and {first, midst, last} for wrapper induction. The first and second pages are commonly chosen for training input since they are the earliest pages one could obtain and often contain additional information than other pages. As shown in Table 2, the percentages of pages that could pass through verification based on two the first and midst pages are higher (72.57%) than average (57.44%). If we use three pages first, midst, last, the average percentage of pages that pass through FSM verification increases to 81.17%. Hence, the wrapper verifier could be used to test whether the induced template and schema are complete or not.
6 Conclusions
In this paper, we solve the problem of page-level wrapper maintenance, which is a problem that has not been studied thoroughly. To solve this problem, we reduce the full schema tree verification to label assignment problem for leaf nodes and exploit finite state machine and constraint satisfaction problem (arc consistency) to verify if the order of label assignments for leaf nodes complies with the schema.
For performance evaluation, we use XML validation which induces a general XSD as a baseline for comparison. The experiments show that the proposed FSM-based approaches have much better effectiveness than XML validation. XML validation, with high pass rate, has zero false negative rate for valid pages but high false positive rate for invalid pages; while the proposed FSM-based
Website # of Pages first+second first+midst first+last first+second+last
BingS 17 16 16 16 16
BookD 23 2 15 15 15
iWatch 18 2 13 13 14
Acm 11 2 3 2 4
YahooS 21 4 10 7 18
CuisineNet 35 32 32 3 34
Dogtoy 17 16 16 2 17
Tradekey 21 3 20 20 20
Tradingpost 19 2 15 15 15
Avg # pages 20.2 8.8 15.6 10.3 17.0
Pass rate N/A 40.1% 72.57% 53.3% 81.17 %
Table 2.Number of valid pages with respect to specific training pages
approaches guarded by leaf node evaluation and transition probability, with low pass rate, has zero false positive rate for invalid pages and acceptable false negative rate for valid pages.
References
1. Arasu, A., Garcia-Molina, H.: Extracting Structured Data from Web Pages. ACM SIGMOD International Conference on Management of Data, pp. 337–348 (2003) 2. Chang, C.-H., Kayed, M., Girgis, M. R., Shaalan, K.F.: A survey of web information
extraction systems. IEEE Trans. on Know. and Data Eng., vol. 18(10), pp. 1411– 1428 (2006)
3. Crescenzi, V., Mecca, G., Merialdo, P.: RoadRunner: Towards Automatic Data Ex- traction from Large Web Sites. Proceedings of the 27th International Conference on Very Large Databases (2001)
4. Kayed, M., Chang, C.-H.: Page-level web data extraction from template pages. IEEE Trans. on Know. and Data Eng., vol. 22(2), pp. 249–263 (2010)
5. Kushmerick, N.: Wrapper induction: Efficiency and expressiveness. Artificial Intel- ligence, vol. 118(1-2), pp. 15–68 (2000)
6. Kushmerick, N.: Wrapper verification. World Wide Web Journal, vol. 3(2), pp. 79– 94 (2000)
7. Lerman, K., Minton, S. N., Knoblock, C.A.: Wrapper maintenance: A machine learn- ing approach. Journal of Artificial Intelligence Research, vol. 18(1), pp. 149–181 (2003)
8. Muslea, I., Minton, S., Knoblock, C. A.: Hierarchical wrapper induction for semistructured information sources. Autonomous Agents and Multi-Agent Systems, vol. 4(1-2), pp. 93–114 (2001)
9. Pek, E.-H., Li, X., Liu, Y.: Web wrapper validation. Proc. of the 5th APWeb, (2003)