1
2009 年度夏学期大学院輪講資料 2010 年 4 月 30 日
ウェブテキスト分析における固有表現の曖昧性解消
Word sense disambiguation of named entities for Web text analysis
情報理工学系研究科 電子情報学専攻 喜連川・豊田研究室 修士課程
2 年 村本 英明
Abstract
Sense ambiguity of polysemous named entities is a critical problem of text analysis. Generally, sense dis-ambiguation is formalized as the classification problem classifying each appearance of ambiguous word into the predefined categories. Most methods are based on su-pervised machine learning techniques using huge amount of manually labeled data. So, these methods aren’t flexible for category change, because preparation of a huge amount of manually labeled data is needed whenever category design changes.
We investigate the framework which can disambi-guate named entities without manually labeled data, and evaluate it. We mention the experimental result, and problems of our framework for our future work.
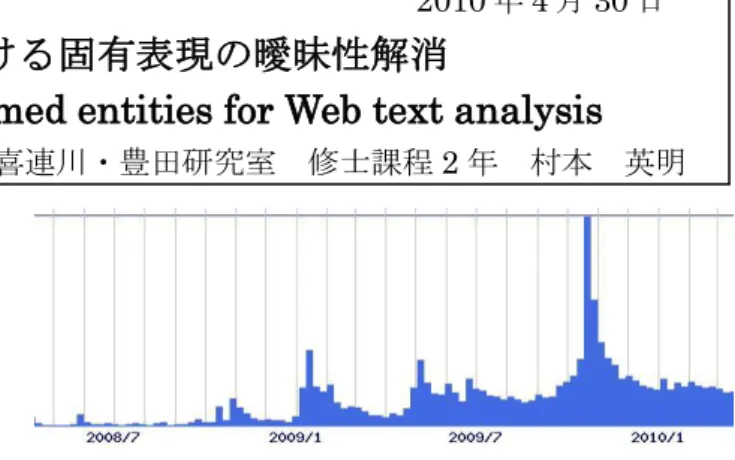
1. はじめに 今日,ブログやtwitter1等のソーシャルメディアを通じ て,多くのテキスト情報がウェブに発せられている.総務 省の調べによると1カ月に約4千万のブログ記事が日本 だけでポストされたことが分かっている[1].こうしたソー シャルメディアを通じて発せられるテキスト情報は,人々 の意見や考えを含んでいる.そのため,ウェブのテキスト 分析は,社会動向を知るために有用である. 例えば,Fig. 1 は,”Windows7”という単語を含むフィー ドの件数を週次で図示したものである.この図から,2009 年10 月頃に”Windows7”という単語を含むフィードの件数 が急増していることが分かる.これは,”Windows7”の発 売日の前後で,人々の”Windows7”に対する関心が急に高 まっていることの現れである.この例は,ウェブのテキス ト情報は,人々の関心を知る手掛かりになることを示して いる.
1 Twitter, http://twitter.com/
Fig. 1 Number of feeds that contain “Windows7” また,Fig. 2 は,”tiger”という単語を含むフィードの件 数を図示したグラフである.この図からはオペレーティン グシステムの”tiger”に関する,人々の関心は知ることがで きない.これは,”tiger”が多義語(トラとしての”tiger”や人 名の”Tiger”)であり,それぞれの語義で用いられた”tiger” という単語を区別せずに,フィード件数を集計したことが 原因である.
Fig. 2 Number of feeds that contains “tiger” “tiger”のような多義語が持つ言葉の意味の曖昧性のこ とを,語義の曖昧性と呼ぶ.上の例からも分かるように, 多義語はウェブのテキスト分析の結果に悪影響を及ぼす. そのため,語義の曖昧性を扱う研究が,数多くなされてき た. 語義の曖昧性を扱った研究として,語義の曖昧性解消 (word sense disambiguation, WSD)[2]や,固有表現抽出 (named entity recognition, NER)[3][4]が挙げられる.こ れらは,新聞記事を対象とした古典的な枞組みであるため, 製品名や映画や音楽を始めとする作品名等の新語が絶え ず出現するウェブテキストの分析には適さない. そこで,我々はウェブテキストの分析に適した語義の曖 昧性の解消のための新しい枞組みの提案を目標として研 究を行う.本報告会では,そのための予備実験を行ったの で,その結果を報告する.
2
本論文の構成は以下の通りである.まず2章で先行研究, 及びその問題点について述べる.次に3章で我々の研究の 目的及びアプローチについて説明する.そして4章で予備 実験の方法,及びその結果について述べ,5章で今後の課 題について述べ,6章で本稿のまとめを述べる. 2. 先行研究 固有表現の語義の曖昧性を扱った研究としては,語義の 曖昧性解消(word sense disambiguation, WSD)と,固有表 現抽出(named entity recognition, NER)が挙げられる.ま ず,2.1 で語義を扱うために必要となる基本的な考え方に ついて説明し,2.2 で WSD について,2.3 で NER につい て説明する. 2.1. 語義の扱い方 語義の扱い方として,辞書・シソーラスを用いる手法と, 分布類似度を用いる手法がある.それらについてそれぞれ 説明する. 2.1.1. 辞書・シソーラスを用いた手法 語句の意味を扱う方法の一つとして,辞書やシソーラス を用いる方法があげられる.ここでは,広く用いられてい るWordNet[5]を例に説明する. WordNet とは,synset と呼ばれる語義が,各単語につい て振られているシソーラスのようなものである.単語”plant”についての WordNet での記載は Table 1 の ようになっている.”plant”については,4 つの語義が定義 されている.また,”tiger”については Table 2 のようにな る.”tiger”については 2 つの語義が定義されているが,人 名や製品名という語義の定義は記載されていない.このこ とから分かるように,WordNet にはすべての語義が網羅的 に記載されているわけではない.これは,辞書やシソーラ スといった言語資源が人手で作成されていることによる 限界の一例である. こうした不完全性に対処するために,シソーラスの語義 をコーパスを用いて自動的に拡張する取り組みである word sense induction(WSI)という研究がなされている [6][7].
Table 1 Definitions for plant in WordNet synset-id Definition
00017222-n a living organism lacking the power of locomotion
05906080-n something planted secretly for dis-covery by another
03956922-n buildings for carrying on industrial labor
10438470-n an actor situated in the audience whose acting is rehearsed but seems spontaneous to the audience
Table 2 Definition for tiger in WordNet synset-id Definition
02129604-n large feline of forests in most of Asia having a tawny coat with black stripes; endangered
10710632-n a fierce or audacious person
2.1.2. 分布類似度による手法 上で示したように,人手で作成された辞書やシソーラス には,網羅できる語義の数に限界がある.そのため,自動 的に語義を扱える手法として分布類似度が考案されてき た.分布類似度とは,語句の意味の類似度を,コーパスを 用いて自動で計算する手法のことである. 分布類似度は,「似た意味の語句は似た文脈で出現する」 という分布仮説[8]に基づいて計算される語句の類似度で ある.例えば,次のような英文を考える.
(1)・A bottle of tezguino is on the table. ・Everyone likes tezguino.
・Tezguino makes you drunk.
・We make tezguino out of corn.
(2)・I drank two bottles of Heineken , and got drunk. ・A bottle of Heineken is in the refrigerator.
(1)の例文から,tezguino の単語の意味を我々はアルコー ル飲料の一種だと,文脈から推測することができる.これ は,文脈と語句の意味が密接に関係していることを表して いる.また,(1)と(2)の tezguino と Heineken の近傍の文 脈を比較すると文脈が類似していることが分かる.このよ
3
うに,「似た意味を持つ語句は似た文脈で出現する」こと が(1),(2)の例から見てとれる. 分布類似度計算において,文脈は近傍にある単語を特徴 量とするベクトルで表現される.例えば,tezguino と Heineken の 2 つの単語をベクトルで表現すると次のよう になる.なお,各値は各近傍の単語の出現頻度を表してい る.Table 3 Example of feature vectors Feature … bottle like drink … Tezguino … 1 1 2 … Heineken … 2 0 1 … 各語句がベクトル表記されると容易に類似度を計算す ることができる.分布類似度計算において用いられる代表 的な類似度としてコサイン関数があげられる.コサイン関 数は,以下で定義される.なお,v1, v2とは,語句をベクト ル表現したベクトルのことである. cos v1, v2 = 𝑣𝑣1∙𝑣2 1 𝑣2 このようにして,各語句間の類似度を計算することができ る. 2.2. 語義の曖昧性解消
語義の曖昧性解消(word sense disambiguation, WSD) とは,対象単語をWordNet 等で,あらかじめ定義された 語義に割り振る問題である[2].例えば,”plant”について は,文章中に出現する,各”plant”に対して,Table 1 の4 つの synset の中から,1つを選び,割り当てる.そのた め,”tiger”の例のように,WordNet に記載されていない, 語義は扱うことができない.そのため,WSI と WSD を組 み合わせた取り組みである,WSID(word sense induction and discrimination)という研究がなされているが[9],分類 する語義の粒度が細かいため,十分な精度が得られないと いう問題点が指摘されている[10].
2.3. 固有表現認識 2.3.1. 固有表現認識の概要
固有表現認識(named entity recognition, 以下 NER)とは テキスト中から人名,組織名,地名等の固有表現の認識を 行う処理で,情報抽出等に用いられる.日本語のNER の
研究では,一般にIREX ワークショップ[4]の定義を用いる ことが多い.IREX では固有表現を,ARTIFACT, DATE, LOCATION, MONEY, ORGANIZATION, PERCENT, PERSON, TIME の 8 つのカテゴリで定義している.Table 4 に8つのカテゴリとその例を説明する。
Table 4 Categories of named entity recognition
カテゴリ 例 PERSON 田中,木村庄之助 LOCATION 太平洋,東京都 ORGANIZATION 松下電器,自民党 ARTIFACT PL 法案,カローラ DATE 21 世紀,昨年春 TIME 午前7 時,正午 MONEY 500 億円,100 ドル PERCENT 20%,3 割 NER の枞組みを用いることによって,例えば,次の2つ の例文中の “ホンダ”は,それぞれ,ORGANIZATION とPERSON のカテゴリが割り振られるため,多義性を解 消することができる. (3)・ホンダが F1 から撤退した. ・先日,ホンダさんと食事をした. NER においては,人手で作成した訓練データを用いた 機会学習による手法が用いられるのが一般的である.代表 的 に は 機 会 学 習 ア ル ゴ リ ズ ム の conditional random field[11]を用いて,ラベル付きデータを用いて学習する手 法が用いられる[3][12]. 2.3.2. 固有表現抽出の課題 NER は,Table 4 の8つのカテゴリに固有表現を分類す るため,次の例のような問題点が生じる. (4)・ニュートンの先月号の特集は面白かった. ・ニュートンは17世紀から18世紀にかけて活躍した イギリスの物理学者である. 上の1つめの例は,人名の「ニュートン」,2 つめの例は, 雑誌名の「ニュートン」を示しているが.こうしたカテゴ リはNER のカテゴリには存在しない.そのため,NER の カテゴリでは,製品名や,雑誌や映画等の作品名が絶えず 出現し,ウェブテキストに含まれる単語の曖昧性解消に用
4
いるのには,カテゴリ数が少ないと言える. こうしたNER のカテゴリが持つ問題点を解決するため に,関根らは拡張固有表現[13]を提案している.拡張固有 表現では,200種類以上のカテゴリに固有表現を分類し ている.拡張固有表現は,NER の持つカテゴリの少なさ による問題点を解消しているが,分類対象となるカテゴリ 数が増えたことにより,NER と比較して,ラベル付きデ ータの準備に人手がかかることや,分類器の精度が低下す ることが報告されている[14]. 3. 研究の目的と提案手法 3.1. 研究の目的 上で述べたように,NER は,カテゴリがウェブのテキ スト分析には適さないという問題点がある.そのため, 我々は,ウェブテキストの分析に適したカテゴリの設計を 行う. 加えて,人手でラベル付けした訓練データが不要な手法 の提案を目標にして研究を行う.これは,カテゴリの設計 は,アプリケーションに依存することが多いため,カテゴ リの設計が変わる度に,訓練データのラベリングを人手で 行うことは不可能であるためである. 3.2. 提案手法 3.2.1. 概要 上で説明したように,NER ではウェブテキストの解析 には十分ではない.そこで,不足しているカテゴリを拡張 する.カテゴリの拡張は関根の拡張固有表現を参考にして 行う. カテゴリセット毎に,訓練データを人手で作成すること は困難である.そのため,人手で作成した訓練データによ らない手法を提案することを目的とする. そこで,我々はPERSON や LOCATION といった単語 の下位語集合を辞書等の言語資源を用いて抽出し,その下 位語集合と対象とする単語との類似度を用いて,曖昧性を 解消する手法を提案する.我々の手法は次の4つのステッ プからなる. ① カテゴリの設計 アプリケーション等に応じてカテゴリを設計する.例え ば,本報告会の実験においては,関根の拡張表現を参考に NER のカテゴリを修正し,11個のカテゴリを準備した. ② 各カテゴリの下位語集合の準備 辞書やシソーラス等の言語資源から,名詞の下位語集合 を抽出することができる.得られた下位語集合と①で定義 したカテゴリとの対応関係のルールを記述することで,各 カテゴリの下位語集合を準備することができる.本稿では, 岩波国語辞典[15]を用いて下位語集合を作成する手法につ いて述べる. ③ 候補カテゴリの選択 各カテゴリの下位語集合の各単語と,対象とする単語の ウェブのコーパス上での分布類似度を計算し,類似度の高 いカテゴリを候補カテゴリとして抽出する.これは,分類 対象となるカテゴリ数の増加に伴い,各出現に対して,一 度で,分類を行うのは困難なので[14],まず,対象となる カテゴリを絞り込むことで精度の向上を試みたいという 理由からである.例えば,”tiger”の場合は,PRODUCT, PERSON,LIVING_THING といったカテゴリが候補とし て,選ばれることが期待される. ④ 各出現を該当するカテゴリへ分類 各文に出現する各単語の語義が,③で選択された候補カ テゴリの中から一つ選ばれる.例えば,”tiger”という単語 はPRODUCT,PERSON,LIVING_THING というカテ ゴリの中から,一つが選択され,それに分類される.なお, 本報告会の段階では,手法の詳細については,検討中であ る. 本報告会では,①~③の手法についての検討を行ったの で, 以下,①~③の各ステップの詳細について説明する. 3.2.2. カテゴリの設計方法 分析する対象に応じてカテゴリの設計を行う.我々が本 報告会までに行った,カテゴリの設計を例に,説明をする.我々は,Fig. 1 や Fig. 2 の”Windows7”や”tiger”の例で 示したように,固有名の曖昧性解消を研究の目的としてい る.そのため,NER が対象としている時間の表記等のカ テゴリは,削除して考えることとする.NER のカテゴリ から,数値表現等のカテゴリを削除すると,PERSON, ARTIFACT,LOCATION の3つのカテゴリしか残らない.
5
これは,ウェブのテキスト分析の多義性解消を目的とした 場合に,少なすぎる.そこで関根の拡張固有表現を参考に し,カテゴリの拡張を行った.我々は,以下の11のカテ ゴリを準備した.これは,我々の研究は,製品や作品に対 する評判や関心を知るという目的が反映された設計にな っている.LOCATION, PERSON, ARTIFACT, FOOD, LIV-ING_THING, ART_AND_PRINTIINGS, CLOTH-ING, DISEASE, VEHICLE, PRODUCT, EVENT ただし,このカテゴリは本報告会での予備実験のために用 意した暫定的なものである. 3.2.3. 下位語集合の作成方法 下位語集合の作成には,辞書を用いて行う.まず,上位 下位関係にある単語を辞書から自動で抽出する手法につ いて説明し,次に,得られた上位下位関係を用いて,辞書 の見出し語とPERSON 等のカテゴリの対応関係を記述す ることで,NER のラベル付き訓練データを作成する場合 と比較して,ごくわずかな労力でカテゴリの下位語集合が 作成できることを示す. 3.2.3.1. 上位下位関係の抽出 上位下位の関係にある単語の組み合わせは国語辞典の 定義文から抽出することができる.定義文の一例として, 表に,岩波国語辞典の見出し語とその定義文のをしめす. Table 5 Definition sentences of the dictionary
例 見出し語 定義文 得られる上 位語 1 教師 学業を教える人. 人 2 公務員 国 ま た は 地 方公 共 団 体 の 職 務 を 担当 す る 者. 者 3 遊園地 遊覧・娯楽などのため の設備をした,公園風 の土地. 土地 4 公園 公 衆 の た め に設 け ら れた庭園や遊園地. 遊園地 5 シューマイ 中華料理の一種. 中華料理 1~4 の例から,定義文の文末に位置する名詞が,見出し 語の上位語になっていること分かる.ただし,5 の例のよ うに,「一種」で定義文は終わる場合など,例外的な場合 も存在する. また,5 の例から,「の一種」の前の「中華料理」が「シ ューマイ」の上位語になっていることが分かる.この例か ら分かるように,「の一種」の前に位置する名詞は,見出 し語の上位語を表している.同様のパターンとして,「の 一つ」や,「の一網」や「の一類」が挙げられる. 上で述べた2つのパターンによって得られる上位下位 関係は,単語をノード,上位下位の関係を枝と考えると木 構造をなしている.岩波国語辞典から得られる木構造の一 例を.Fig. 3 に示す.
Fig. 3 Tree structure of the dictionary
Fig. 3 から分かるように,ある単語をルートとする木構 造から,その単語の下位語集合を抽出することができる. 例えば,Fig. 3 の例では,「人」の下位語集合は,{「教師」, 「友達」,「幼馴染」,「旧友」,「選手」,} となる. 3.2.3.2. 人手によるカテゴリと上位語の対応付け 上記により得られた,見出し語とその下位語集合を用い て.カテゴリの下位語集合を作成する手法について説明す る.各々のカテゴリに,国語辞典から得られた見出し語を 割り当てるという作業を行う. 例として,我々が準備した 11 のカテゴリに対して行っ た全対応関係を示す.
人
教師
友達
幼馴染
旧友
選手
…
者
公務員
…
6
Table 6 Example of mapping rule Category 見出し語 PERSON 人,者,子供,女性,男,女 LOCATION 場所,部屋,土地,国,山 FACILITY 店,施設,建物 FOOD 食品,食べ物,料理 LIVINGTHING 木,鳥,動物,昆虫,魚,生物,犬,花, 植物 ART_AND_PRINTTIN G 書物,本,作品,詩,絵,歌,文書,曲 CLOTHING 衣服 DISEASE 病気,症状 VEHICLE 車 ORGANIZATION 人々,機関,集団,会 PRODUCT_OTHER 道具,品,装置,機械,容器,楽器 EVENT 現象 この表から分かるように,我々の手法において,人手が必 要となる作業は,わずか49個の国語辞典の見出し語と, カテゴリの対応関係を人手で記述するだけである.これは, NER のラベル付き訓練データを準備する場合と比較して, 極わずかな作業であることに注意されたい. 3.2.4. 候補カテゴリの選択 分布類似度を用いて,候補カテゴリの選択を行う.対象 とする固有表現と,各カテゴリとの類似度の定義について 述べる.対象とする固有表現と,各カテゴリ間の類似度は, カテゴリの下位語集合に含まれる分布類似度との平均で 定義される.対象とする固有表現を w,カテゴリCi(i = 1,2,…,n)の下位語集合をSi= {hi1, hi2, … , hin}とすると,カ テゴリCiと,対象とする固有表現w との類似度は,分布類 似度を計算する関数distributionalSimilarity とすると, 次のように定義できる. similarity w, Ci = 1 m distributionalSimilarity(w, hik) m k=1 上式で得られた類似度が,閾値以上のカテゴリを選択す る. 4. 予備実験 4.1. 予備実験の目的 我々の提案手法は,上で説明したように,①~④の4 つ のステップからなる.本報告会では,④を除く,①~③に ついての評価実験を行った. ①~③のステップを行い,選択された候補カテゴリの妥 当性の評価を行うことで,提案手法の有効性,及び,問題 点を確認することを目的として予備実験を行った. 4.2. 実験方法 提案手法の,①~③の各ステップについて,実験の設定 について簡単に説明する.「①カテゴリの設計方法」につ いては,3.2.2,「②下位語集合の準備」については,3.2.3 の例の通り行った.また,「③候補カテゴリ」の選択方法 について,分布類似度を用いる.分布類似度を計算する際 に使用するコーパスには,我々の研究で蓄えているブログ アーカイブを用いた.その中から,2006 年にポストされ たブログ記事約300万記事を用いて行った.分布類似度 計算においては,係り受け先にある「格助詞+動詞」を特 徴量として扱った.なお係り受け解析には,Mecab[16]を 用いた. 4.3. 予備実験の結果 “ニュートン”,“タイガー”,“オリンピック”の3つの 多義語に対して,11個のカテゴリの各下位語集合との分 布類似度を計算した結果を示す.
Fig. 4 Similarity between “ニュートン” and each cate-gories
7
Fig. 5 Similarity between “タイガー” and each category
Fig. 6 Similarity between “オリンピック” and each cat-egory “ ニ ュ ー ト ン ” の 結 果 に つ い て は , ART_AND_PRINTING,PERSON の2つのカテゴリの類 似度が上位となっている.これは,我々の手法で正しくカ テゴリの選択ができている例である. “ タ イ ガ ー ” の 結 果 に つ い て は ,PERSON , ART_AND_PRINTING , PRODUCT_OTHER , LIVINGTHING との類似度が上位となっている.タイガ ーは前述の通り,人名,製品名,動物の3つの語義を持っ ている.そのため,ART_AND_PRINTING が上位となっ ているのは,選択が正しく行われていないといえる.これ は,“タイガー”とART_AND_PRINTING が,「タイガー を見る」と「映画を見る」のように,同じ動詞に係ること が多いことが原因だと考えられる.これは,分布類似度の 計算に用いる特徴量を増やすことで改善できると考えら れる. “オリンピック”の結果については,LOCATION, ART_AND_PRINTING との類似度が高くなっている.こ れは,スーパーの“オリンピック”が「オリンピックに行 く。」や「オリンピックで待ち合わせをする。」等,場所と して用いられることが多いことが原因だと考えられる.ま た,スポーツの大会の“オリンピック”については,テレ ビ 番 組 等 と 同 等 の 文 脈 で 出 現 す る こ と が 多 い た め , ART_AND_PRINTING との類似度が高くなったと考えら れる.今回, 定義した11個のカテゴリには,店名や, 催し物の名前といったカテゴリは準備しなかったが,こう したカテゴリを準備する必要があるかどうかは,今後検討 が必要だといえる. 5. 今後の課題 予備実験の結果で,我々の提案手法では,わずかなルー ルを準備するだけで,人手でラベル付けした大量の訓練デ ータを用いずとも,語義カテゴリの候補を選択することが できることを確認できた.一方で今後の課題としては,カ テゴリ設計の更なる検討,下位語集合準備において他の言 語資源を用いることの検討,候補カテゴリ選択時の分布類 似度計算の高度化,定量的評価方法の検討の4点が挙げら れる. カテゴリ設計の更なる検討については,予備実験の“オ リンピック”の例から分かる必要であるといえる.拡張固 有表現等の既存のシソーラスを参考にしながら,カテゴリ の設計を改善していきたい. 下位語集合の準備において,店名や催し物の名前は岩波 国語辞典からは得ることができなかった.そのため, Wikipedia2等の他の言語資源から,下位語集合の準備を行 うことも検討していきたい. カテゴリ選択においては,“タイガー”の例で見られた ように,分布類似度計算時における特徴量の不十分さが原 因と考えられる誤判断が生じた.今後は,係り受け関係に ある格助詞と動詞に加えて,対象単語の周辺の名詞を特徴 量に加えることを検討していきたい. 最後に,今回の報告では定量的な評価を行うことができ なかった.今後,ベンチマークとなるデータセットを我々 で作成し,定量的な評価を行いたいと考えている. 6. まとめ 固有表現の曖昧性解消のための既存研究を調査し,ウェ
2 http://ja.wikipedia.org/
8
ブのテキスト分析に応用するには,語義カテゴリの不適切 さ,及び,ラベル付きデータ作成のコストという2つの問 題点があることを指摘した.それらの問題点を改善する手 法として,カテゴリ設計の修正,及び,大量のラベル付き データが不要な手法の提案を行った.提案手法の評価実験 を行い,我々の提案手法が,大筋,うまく機能することを 確認した.一方で,カテゴリの設計の更なる検討の必要性, 分布類似度計算手法の改善の必要性があることが分かっ た.これらは,今後検討すべき課題である. また,今回は提案手法の①~③までの評価実験しか行わ なかったが,今後は④の評価実験を進めることで,更なる 手法の高度化に努めたい. 7. 参考文献 [1] 総務省 情報通信政策研究所, "ブログの実態に関する 調査研究 ~ ブログコンテンツ量の推計とブログの 開設要因等の分析 ~," 2008.[2] George Miller, Claudia Leocock, Randee Tengi, and Ross Bunker, "A semantic concordance ," In Proceedings of the ARPA Workshop on Human Language Technology, 1993.
[3] Dekang Lin and Xiaoyun Wu, "Phrase Clustering for Discriminative Learing," 2009.
[4] IREX Committee, "Proceedings of IREX Workshop," 1999.
[5] Christiance Fellbaum, "WordNet, an electronix lexical database," Cambridge, MA: The MIT Oress, 1998.
[6] Pantel Pattrick and Lin Dekang, "Discovering word senses from text," In Proceedings of ACM SIGMOD Conference on Knowledge Discovery and Data Mining, 2002.
[7] Bordag Stefan, "Word Sense Induction : Triplet-Based Clustering and Aytomatic Evaluation," In Proceedings of EACL-06, 2006. [8] J.R.Firth, "Studies in Linguistic Analysis," Oxford,
1957.
[9] Agirre Eneko and Soroa Aitor, "Semeval-2007 Task 02: Evaluating Word Sense Induction and Discrimination Systems," In Proceedings of the 4th International Workshop on Semantioc Evaluations, 2007.
[10] Izuquierdo Ruben, Suarez Armando, and Rigau German, "An Empirical Study on Class-based Word Sense Disambiguation," Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, 2009. [11] John Lafferty, Andrew McCallum, and Fernando
Pereira, "Comditiomal Random Field: Probabilistic Models for Segmenting and Labeling Sequence Data," 2001.
[12] Junichi Kazama and Torisawa Kentaro, "Inducing Gazetteers for Named Entity Recognition by Large-scale Clustering of Dependency Relations," ACL-08, 2008.
[13] Satoshi Sekine, Kiyoshi Sato, and Chikashi Nobata, "Extended Named Entity Hierarch," 3rd international conference on Language resournce and evaluation(LREC-2002), 2002. [14] 新納 宏幸 and 関根 聡, "拡張固有表現タガーの作成 とその問題点の考察," 言語処理学会第 12 回年次大 会, 2006. [15] 西尾 実, 岩淵 悦太郎, and 水谷 静夫, "岩波国語辞 典 第六版," 岩波書店, 2001.
[16] Taku Kudo, Kaoru Yamamoto, and Yuji Matsumoto, "Applying Conditional Random Fields to Japanese Morphological Analysis," Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, 2004.