田村 晃裕
†・渡辺 太郎
††・隅田英一郎
†本論文では,隠れ層の再帰的な構造により,過去のアラインメント履歴全体を活用 するリカレントニューラルネットワーク (RNN) による単語アラインメントモデルを 提案する.ニューラルネットワークに基づくモデルでは,従来,教師あり学習が行 われてきたが,本論文では,本モデルの学習法として,Dyer らの教師なし単語アラ インメント (Dyer, Clark, Lavie, and Smith 2011) を拡張して人工的に作成した負例 を利用する教師なし学習法を提案する.提案モデルは,IBM モデル (Brown, Pietra, Pietra, and Mercer 1993) などの多くの従来手法と同様に,各方向で独立にアライン メントを学習するため,両方向を考慮した大域的な学習を行うことができない.そ こで,各方向のモデルの合意を取るように同時に学習することで,アラインメント の精度向上を目指す.具体的には,各方向のモデルの word embedding の差を表すペ ナルティ項を目的関数に導入し,両方向で word embedding を一致させるようにモ デルを学習する.日英及び仏英単語アラインメント実験を通じて,RNN に基づくモ デルは,フィードフォワードニューラルネットワークによるモデル (Yang, Liu, Li, Zhou, and Yu 2013) や IBM モデル 4 よりも単語アラインメント精度が高いことを示 す.さらに,日英及び中英翻訳実験を通じて,これらのベースラインと同等かそれ 以上の翻訳精度を達成できることを示す.
キーワード:単語アラインメント,リカレントニューラルネットワーク,教師なし学習, 合意制約
Recurrent Neural Networks for Word Alignment
Akihiro Tamura†, Taro Watanabe†† and Eiichiro Sumita†This paper proposes a novel word alignment model based on a recurrent neural net-work (RNN), in which an unlimited alignment history is represented by recurrently connected hidden layers. In addition, we perform unsupervised learning inspired by (Dyer et al. 2011), which utilizes artificially generated negative samples. Our align-ment model is directional, like the generative IBM models (Brown et al. 1993). To overcome this limitation, we encourage an agreement between the two directional models by introducing a penalty function, which ensures word embedding consistency across two directional models during training. The RNN-based model outperforms both the feed-forward NN-based model (Yang et al. 2013) and the IBM Model 4 under Japanese-English and French-English word alignment tasks, and achieves compara-ble translation performance to those baselines under Japanese-English and Chinese-English translation tasks.
† 国立研究開発法人情報通信研究機構, National Institute of Information and Communications Technology †† グーグル株式会社, Google
Key Words: Word Alignment, Recurrent Neural Network, Unsupervised Learning,
Agree-ment Constraint
1
はじめに
対訳文中の単語の対応関係を解析する単語アラインメントは,統計的機械翻訳に欠かせない重 要な処理の一つであり,研究が盛んに行われている.その中で,生成モデルである IBM モデル 1-5 (Brown et al. 1993) や HMM に基づくモデル (Vogel, Ney, and Tillmann 1996) は最も有名な手法 であり,それらを拡張した手法が数多く提案されている (Och and Ney 2003; Berg-Kirkpatrick, Bouchard-Cˆot´e, DeNero, and Klein 2010).近年では,Yang らが,フィードフォワードニュー ラルネットワーク (FFNN) の一種である「Context-Dependent Deep Neural Network for HMM (CD-DNN-HMM)」(Dahl, Yu, Deng, and Acero 2012) を HMM に基づくモデルに適用した手法 を提案し,中英アラインメントタスクにおいて IBM モデル 4 や HMM に基づくモデルよりも高 い精度を達成している (Yang et al. 2013).この FFNN-HMM アラインメントモデルは,単語ア ラインメントに単純マルコフ性を仮定したモデルであり,アラインメント履歴として,一つ前 の単語アラインメント結果を考慮する. 一方で,ニューラルネットワーク (NN) の一種にフィードバック結合を持つリカレントニュー ラルネットワーク (RNN) がある.RNN の隠れ層は再帰的な構造を持ち,自身の信号を次のス テップの隠れ層へと伝達する.この再帰的な構造により,過去の入力データの情報を隠れ層で 保持できるため,入力データに内在する長距離の依存関係を捉えることができる.このような 特長を持つ RNN に基づくモデルは,近年,多くのタスクで成果をあげており,FFNN に基づく モデルの性能を凌駕している.例えば,言語モデル (Mikolov, Karafi´at, Burget, Cernock´y, and Khudanpur 2010; Mikolov and Zweig 2012; Sundermeyer, Oparin, Gauvain, Freiberg, Schl¨uter, and Ney 2013) や翻訳モデル (Auli, Galley, Quirk, and Zweig 2013; Kalchbrenner and Blunsom 2013) の構築で効果を発揮している.一方で,単語アラインメントタスクにおいて RNN を活用 したモデルは提案されていない.本論文では,単語アラインメントにおいて,過去のアライン メントの情報を保持して活用することは有効であると考え,RNN に基づく単語アラインメント モデルを提案する.前述の通り,従来の FFNN に基づくモデルは,直前のアラインメント履歴 しか考慮しない.一方で,RNN に基づくモデルは,隠れ層の再帰的な構造としてアラインメン トの情報を埋め込むことで,FFNN に基づくモデルよりも長い,文頭から直前の単語アライン メントの情報,つまり過去のアラインメント履歴全体を考慮できる. NN に基づくモデルの学習には,通常,教師データが必要である.しかし,単語単位の対応関 係が付与された対訳文を大量に用意することは容易ではない.この状況に対して,Yang らは, 従来の教師なし単語アラインメントモデル(IBM モデル,HMM に基づくモデル)により生成
した単語アラインメントを疑似の正解データとして使い,モデルを学習した (Yang et al. 2013). しかし,この方法では,疑似正解データの作成段階で生み出された,誤った単語アラインメント が正しいアラインメントとして学習されてしまう可能性がある.これらの状況を踏まえて,本 論文では,正解の単語アラインメントや疑似の正解データを用意せずに RNN に基づくモデル を学習する教師なし学習法を提案する.本学習法では,Dyer らの教師なし単語アラインメント (Dyer et al. 2011) を拡張し,正しい対訳文における単語対と語彙空間全体における単語対を識 別するようにモデルを学習する.具体的には,まず,語彙空間全体からのサンプリングにより偽 の対訳文を人工的に生成する.その後,正しい対訳文におけるアラインメントスコアの期待値 が,偽の対訳文におけるアラインメントスコアの期待値より高くなるようにモデルを学習する. RNN に基づくモデルは,多くのアラインメントモデルと同様に,方向性(「原言語 f → 目的 言語 e」又は「e→ f」)を持ち,各方向のモデルは独立に学習,使用される.ここで,学習され る特徴は方向毎に異なり,それらは相補的であるとの考えに基づき,各方向の合意を取るよう にモデルを学習することによりアラインメント精度が向上することが示されている (Matusov, Zens, and Ney 2004; Liang, Taskar, and Klein 2006; Gra¸ca, Ganchev, and Taskar 2008; Ganchev, Gra¸ca, and Taskar 2008).そこで,提案手法においても,「f → e」と「e → f」の 2 つの RNN に基づくモデルの合意を取るようにそれらのモデルを同時に学習する.両方向の合意は,各方 向のモデルの word embedding が一致するようにモデルを学習することで実現する.具体的に は,各方向の word embedding の差を表すペナルティ項を目的関数に導入し,その目的関数に したがってモデルを学習する.この制約により,それぞれのモデルの特定方向への過学習を防 ぎ,双方で大域的な最適化が可能となる. 提案手法の評価は,日英及び仏英単語アラインメント実験と日英及び中英翻訳実験で行う. 評価実験を通じて,前記提案全てを含む「合意制約付き教師なし学習法で学習した RNN に基 づくモデル」は,FFNN に基づくモデルや IBM モデル 4 よりも単語アラインメント精度が高い ことを示す.また,機械翻訳実験を通じて,学習データ量が同じ場合には,FFNN に基づくモ デルや IBM モデル 4 を用いた場合よりも高い翻訳精度を実現できることを示す1.具体的には, アラインメント精度は FFNN に基づくモデルより最大 0.0792(F1 値),IBM モデル 4 より最大 0.0703(F1 値),翻訳精度は FFNN に基づくモデルより最大 0.74% (BLEU),IBM モデル 4 よ り最大 0.58% (BLEU) 上回った.また,各提案(RNN の利用,教師なし学習法,合意制約)個 別の有効性も検証し,機械翻訳においては一部の設定における精度改善にとどまるが,単語ア ラインメントにおいては各提案により精度が改善できることを示す. 以降,2 節で従来の単語アラインメントモデルを説明し,3 節で RNN に基づく単語アライン 1 実験では,NN に基づくモデルの学習時の計算量を削減するため,学習データの一部を用いた.全学習データから 学習した IBM モデル 4 を用いた場合とは同等の翻訳能であった.
メントモデルを提案する.そして,4 節で RNN に基づくモデルの学習法を提案する.5 節では 提案手法の評価実験を行い,6 節で提案手法の効果や性質についての考察を行う.最後に,7 節 で本論文のまとめを行う.
2
従来の単語アラインメントモデル
今まで数多くの単語アラインメント手法が提案されてきており,それらは,生成モデル(例 えば (Brown et al. 1993; Vogel et al. 1996; Och and Ney 2003))と識別モデル(例えば (Taskar, Lacoste-Julien, and Klein 2005; Moore 2005; Blunsom and Cohn 2006))に大別できる.2.1 節 では生成モデルを概観し,2.2 節では識別モデルの一例として,提案手法のベースラインとなる FFNN に基づくモデル (Yang et al. 2013) を説明する.
2.1
生成モデル
生成モデルでは,J 単語から構成される原言語の文を fJ 1 = f1, . . . , fJ,それに対応する I 単語で 構成される目的言語の文を eI 1= e1, . . . , eIとすると,f1Jは e I 1からアラインメント a J 1 = a1, . . . , aJ を通じて生成されると考える.ここで,各 ajは,原言語の単語 fjが目的言語の単語 eaj に対応 する事を示す隠れ変数である.通常,目的言語の文には単語「null」 (e0) が加えられ,fjが目 的言語のどの単語にも対応しない場合,aj = 0 となる.そして,f1Jが eI1から生成される生成 確率は,次の通り,eI 1が生成する全アラインメントとの生成確率の総和で定義される: p(f1J|e I 1) = ∑ aJ 1 p(f1J, a J 1|e I 1). (1) IBM モデル 1,2 や HMM に基づくモデルでは,式 (1) 中の特定アラインメント aJ 1 との生成確 率 p(fJ 1, aJ1|eI1) をアラインメント確率 paと語彙翻訳確率 ptで定義する2: p(f1J, aJ1|eI1) = J ∏ j=1 pa(aj|aj−1, j)pt(fj|eaj). (2) この 3 つのモデルでは,アラインメント確率の定義が異なる.例えば,HMM に基づくモデルで は単純マルコフ性を持つアラインメント確率を用いる:pa(aj|aj− aj−1).また,目的言語の各単語に対する稔性 (fertility) や歪み (distortion) を考慮する IBM モデル 3-5 も提案されている. これらのモデルは,EM アルゴリズム (Dempster, Laird, and Rubin 1977) により,単語単位 のアラインメントが付与されていない対訳文の集合(ラベルなし学習データ)から学習される.
2 アラインメント確率 p
また,ある対訳文 (fJ 1, eI1) の単語アラインメントを解析する際は,学習したモデルを用いて, 次式 (3) を満たすアラインメント(ビタビアラインメント)ˆaJ 1 を求める: ˆ aJ1 = argmax aJ 1 p(f1J, aJ1|eI1). (3) 例えば,HMM に基づくモデルは,ビタビアルゴリズム (Viterbi 1967) によりビタビアラインメ ントを求めることができる.
2.2
FFNN に基づく単語アラインメントモデル
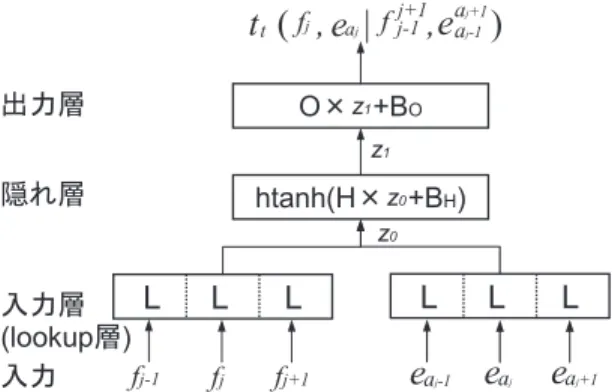
FFNN は,非線形関数を持つ隠れ層を備えることにより,入力データから多層的に非線形な 素性を自動的に学習することができ,入力データの複雑な特徴を捉えることができる.近年, その特長を活かし,音声認識 (Dahl et al. 2012),統計的機械翻訳 (Le, Allauzen, and Yvon 2012; Vaswani, Zhao, Fossum, and Chiang 2013) やその他の自然言語処理 (Collobert and Weston 2008; Collobert, Weston, Bottou, Karlen, Kavukcuoglu, and Kuksa 2011) 等,多くの分野で成果をあ げている.Yang らは,FFNN の一種である CD-DNN-HMM (Dahl et al. 2012) を HMM に基づ くアラインメントモデルに適用したモデルを提案した (Yang et al. 2013).本節では,提案手法 のベースラインとなる,この FFNN に基づく単語アラインメントモデルを説明する. FFNN に基づくモデルは,式 (2) のアラインメント確率 pa及び語彙翻訳確率 ptを FFNN に より計算する: sN N(aJ1|f J 1, e I 1) = J ∏ j=1 ta(aj− aj−1|c(eaj−1))· tt(fj, eaj|c(fj), c(eaj)). (4) ただし,全単語にわたる正規化は計算量が膨大となるため,確率の代わりにスコアを用いる.ta と ttは,それぞれ,アラインメントスコアと語彙翻訳スコアであり,paと ptに対応する.ま た,sN Nはアラインメント aJ1 のスコアであり,「c(単語 w)」は単語 w の文脈を表す.ビタビア ラインメントは,典型的な HMM に基づくアラインメントモデル同様,ビタビアルゴリズムに より求める.アラインメントスコアは直前のアラインメント aj−1に依存しているため,FFNN に基づくモデルも単純マルコフ過程に従う. 図 1 に,語彙翻訳スコア tt(fj, eaj|c(fj), c(eaj)) を計算するネットワーク構造(語彙翻訳モデ ル)を示す.このネットワークは,lookup 層(入力層),1 層の隠れ層,出力層から構成され, 各層は,それぞれ,重み行列 L,{H, BH},{O, BO} を持つ.L は word embedding 行列であり,各単語を特徴付ける低次元の実ベクトルとして,単語の統語的,意味的特性を表す (Bengio, Ducharme, Vincent, and Janvin 2003).原言語の単語集合を Vf,目的言語の単語集合を Ve,word
embedding の長さを M とすると,L は M× (|Vf| + |Ve|) 行列である.ただし,Vfと Veには,
図 1 FFNN に基づくモデルにおける語彙翻訳スコア tt(fj, eaj|c(fj), c(eaj)) 計算用ネットワーク この語彙翻訳モデルは,入力として,計算対象である原言語の単語 fjと目的言語の単語 eaj と共に,それらの文脈単語を受け付ける.文脈単語とは,予め定めたサイズの窓内に存在する 単語であり,図 1 は窓幅が 3 の場合を示している.まず,lookup 層が,入力の各単語に対して 行列 L から対応する列を見つけ,word embedding を割り当てる.そして,それらを結合させた 実ベクトル z0を隠れ層に送る.次に,隠れ層が lookup 層の出力 z0を受け取り,z0の非線形な 特徴を捉える.最後に,出力層が隠れ層の出力 z1を受け取り,語彙翻訳スコアを計算して出力 する.隠れ層,出力層が行う具体的な計算は次の通りである3: z1= f (H× z0+ BH), (5) tt= O× z1+ BO. (6) ここで,H,BH,O,BOは,それぞれ,|z1| × |z0|,|z1| × 1,1 × |z1|,1 × 1 行列である.また,
f (x) は非線形活性化関数であり,本論文の実験では,(Yang et al. 2013) に倣い,htanh(x)4を用
いた.
アラインメントスコア ta(aj− aj−1|c(eaj−1)) を計算するアラインメントモデルも,語彙翻訳
モデルと同様に構成できる.語彙翻訳モデル及びアラインメントモデルの学習では,次式 (7) の ランキング損失を最小化するように,各層の重み行列を最適化する.最適化は,サンプル毎に
勾配を計算してパラメータを更新する確率的勾配降下法 (SGD)5で行い,各重みの勾配は,誤
差逆伝播法 (Rumelhart, Hinton, and Williams 1986) で計算する.
loss(θ) = ∑
(f ,e)∈T
max{0, 1 − sθ(a+|f, e) + sθ(a−|f, e)}. (7)
3 本論文では,実験コストを削減するため,NN(FFNN 及び RNN)に基づくモデルの隠れ層は 1 層としたが,連続
した l 層の隠れ層を用いる事もできる:zl= f (Hl× zl−1+ BHl).複数の隠れ層を用いた実験は今後の課題とする.
4 x <−1 の時は htanh(x) = −1,x > 1 の時は htanh(x) = 1,それ以外の時は htanh(x) = x である.
ここで,θ は最適化するパラメータ(重み行列の重み),T は学習データ,sθはパラメータ θ の モデルによる aJ 1 のスコア(式 (4) 参照),a+は正解アラインメント,a−はパラメータ θ のモ デルでスコアが最も高い不正解アラインメントである.
3
RNN に基づく単語アラインメントモデル
本節では,アラインメント aJ 1のスコアを RNN により計算する単語アラインメントモデルを 提案する: sN N(aJ1|f1J, eI1) = J ∏ j=1 tRN N(aj|aj1−1, fj, eaj). (8) ここで,tRN N はアラインメント ajのスコアであり,FFNN に基づくモデルと異なり,直前の アラインメント aj−1だけでなく,j− 1 個の全てのアラインメントの履歴 a j−1 1 に依存している. また,本モデルにおいても,FFNN に基づくモデルと同様,確率ではなくスコアを用いる. 図 2 に RNN に基づくモデルのネットワーク構造を示す.このネットワークは,lookup 層(入力 層),隠れ層,出力層から構成され,各層は,それぞれ,重み行列 L,{Hd, Rd, Bd H},{O, BO} を持 つ.隠れ層の重み行列 Hd,Rd,Bd Hは,直前のアラインメント aj−1からの距離 d (d = aj−aj−1) 毎に定義される.本論文の実験では,8 より大きい距離及び−8 より小さい距離は,それぞれ, 「≥ 8」と「≤ −8」にまとめた.つまり,隠れ層は,直前のアラインメントからの距離 d に対 応した重み行列{H≤−8, H−7,· · · , H7, H≥8, R≤−8, R−7,· · · , R7, R≥8, B≤−8 H , BH−7,· · · , B 7 H, BH≥8} を用いて yjを算出する. ビタビアラインメントは,FFNN に基づくモデルと同様に,図 2 のモデルを f1から fJに順 番に適用して求める.ただし,アラインメント ajのスコアは,yiを通じて a1から aj−1の全て 図 2 RNN に基づくアラインメントモデルに依存しているため,動的計画法に基づくビタビアルゴリズムは適用できない.そこで,実験 では,ビームサーチにより近似的にビタビアラインメントを求める.
図 2 のモデルにより fjと eajのアラインメントのスコアを計算する流れを説明する.まず,fj
と eajの 2 単語が lookup 層へ入力される.そして,lookup 層が 2 単語それぞれを word embedding
に変換し,その word embedding を結合させた実ベクトル xj を隠れ層に送る.この lookup 層
が行う処理は,FFNN に基づくモデルの lookup 層と同じである.次に,隠れ層は,lookup 層 の出力 xjと直前のステップ j− 1 の隠れ層の出力 yj−1を受け取り,それらの間の非線形な特 徴を捉える.この時に用いる重み行列 Hd,Rd,Bd Hは,直前のアラインメント aj−1との距離 d により区別されている.隠れ層の出力 yjは,出力層と次のステップ j + 1 の隠れ層に送られ る.そして最後に,出力層が,隠れ層の出力 yjに基づいて fjと eaj のアラインメントのスコ ア tRNN(aj|a j−1 1 , fj, eaj) を計算して出力する.隠れ層,出力層が行う具体的な計算は次の通りで ある6: yj = f (Hd× xj+ Rd× yj−1+ BdH), (9) tRNN = O× yj+ BO. (10) ここで,Hd,Rd,Bd
H,O,BOは,それぞれ,|yj| × |xj|,|yj| × |yj−1|,|yj| × 1,1 × |yj|,1 × 1
行列である.ただし,|yj−1| = |yj| である.また,f(x) は非線形活性化関数であり,(Yang et al. 2013) と同様に,本論文では htanh(x) を用いる. 前述の通り,FFNN に基づくモデルは,語彙翻訳スコア用とアラインメントスコア用の 2 つ のモデルから構成される.一方で,RNN に基づくモデルは,直前のアラインメントとの距離 d に依存した重み行列を隠れ層で使うことで,アラインメントと語彙翻訳の両者を考慮する 1 つ のモデルで単語アラインメントをモデル化する.また,RNN に基づくモデルは再帰的な構造を した隠れ層を持つ.このため,過去のアラインメント履歴全体をこの隠れ層の入出力 yiにコン パクトに埋め込むことで,直前のアラインメント履歴のみに依存する従来の FFNN に基づくモ デルよりも長いアラインメント履歴を活用して単語アラインメントを行うことができる.
4
モデルの学習
提案モデルの学習では,特定の目的関数に従い,各層の重み行列(つまり,L,Hd,Rd,Bd H, O,BO)を最適化する.最適化は,単純な SGD(バッチサイズ D = 1)よりも収束が早いミニ バッチ SGD により行う.また,各重みの勾配は,通時的誤差逆伝播法 (Rumelhart et al. 1986) で計算する.通時的誤差逆伝播法は,時系列(提案モデルにおける j)でネットワークを展開 6 j = 1 の時の隠れ層では,a 0は 0 とし,直前ステップの隠れ層からの出力 y0は考慮しない:y1= f (Hd× x1+ BHd).し,時間ステップ上で誤差逆伝播法により勾配を計算する手法である. 提案モデルは,FFNN に基づくモデル同様,式 (7) で定義されるランキング損失に基づいて 教師あり学習することができる(2.2 節参照).しかし,この学習法は正解の単語アラインメン トが必要であるという問題がある.この問題を解決するため,次の 4.1 節で,ラベルなし学習 データから提案モデルを学習する教師なし学習法を提案する.
4.1
教師なし学習
本節で提案する教師なし学習は,Dyer らにより提案された contrastive estimation (CE) (Smith and Eisner 2005) に基づく教師なし単語アラインメントモデル (Dyer et al. 2011) を拡張した手 法である.CE とは,観測データの近傍データを疑似負例と捉え,観測データとその近傍データ を識別するモデルを学習する手法である.Dyer らは,ラベルなし学習データ中の対訳文 T にお いて考えられる全ての単語アラインメントを観測データ,目的言語側を単語空間 Ve全体とした 単語アラインメント,つまり,対訳文 T 中の原言語の各単語と Ve中の各単語との全単語対を近 傍データとして CE を適用した.提案する学習法は,この考え方を目的関数のランキング損失 に導入する: loss(θ) = max { 0, 1− ∑ (f+,e+)∈T EΦ[sθ(a|f+, e+)] + ∑ (f+,e−)∈Ω EΦ[sθ(a|f+, e−)] } . (11) ここで,Φ は対訳文 (f , e) に対する全ての単語アラインメントの集合,EΦ[sθ] は Φ におけるス コア sθの期待値を表す.Ω は対訳文 T 中の目的言語の各単語を Ve全体とした対訳対集合であ る.したがって,e+は学習データ T 中の目的言語の文であり,e−は|e+| 個の目的言語の単語 で構成される疑似の文である (e−∈ V|e+| e ).一つ目の期待値が観測データ,二つ目の期待値が 近傍データに関する項である. しかしながら,式 (11) 中の Ω に対する期待値の計算量は膨大となる.そこで,計算量を削減 するため,Noise Contrastive Estimation (Gutmann and Hyv¨arinen 2010; Mnih and Teh 2012) に基づく Negative Sampling (Mikolov, Sutskever, Chen, Corrado, and Dean 2013) のように,近
傍データ空間からサンプリングした空間を用いる.つまり,各原言語の文 f+に対する e−とし て,|e+| 個の目的言語の単語で構成される全ての文ではなく,サンプリングした N 文を使う. さらに,ビーム幅 W のビームサーチにより期待値を計算することで,スコアが低いアラインメ ントを切り捨て計算量を削減する: loss(θ) = ∑ f+∈T max { 0, 1− EGEN[sθ(a|f+, e+)] + 1 N ∑ e− EGEN[sθ(a|f+, e−)] } . (12) 式 (12) において,e+は学習データ内で f+の対訳となっている目的言語の文 ((f+, e+)∈ T ) であり,e−は無作為に抽出された長さ|e+| の疑似の目的言語の文である.つまり,|e+| = |e−|
である.そして,N は,各原言語の文 f+ に対して抽出する疑似の目的言語の文の数である. GEN は,ビームサーチにより探索される単語アラインメント空間であり,全ての単語アライン メント空間 Φ の部分集合である. 各 e−は,無作為に抽出した|e+| 個の目的言語の単語を順番に並べることで生成する.学習 に効果的な負例を生成するために,e−の各単語は,V eから抽出する代わりに,l0正則化付き
IBM モデル 1 (Vaswani, Huang, and Chiang 2012) によって対訳文中で fi∈ f+との共起確率が
C 以上と判定された目的言語の単語集合から抽出する.l0正則化付き IBM モデル 1 は,単純な IBM モデル 1 と比較して,より疎なアラインメントを生成するため,疑似翻訳 e−の候補の範 囲を制限することが可能となる.
4.2
両方向の合意制約
FFNN に基づくモデルと RNN に基づくモデルは,共に方向性を持つモデルである.すなわ ち,f に対する e のアラインメントモデルにより,単語 fjに対して e との 1 対多アラインメン トを表す.通常,方向性を持つモデルは方向毎に独立に学習され,両方向のアラインメント結 果をヒューリスティックに結合し決定される.Yang らの研究においても,FFNN に基づくモデ ルは独立に学習されている (Yang et al. 2013). 一方で,各方向のモデルの合意を取るように同時に学習することで,アラインメント精度を 改善できることが示されている.例えば,Matusov らや Liang らは,目的関数を「f → e」と「e→ f」の 2 つのモデルのパラメータで定義し,2 つのモデルを同時に学習している (Matusov
et al. 2004; Liang et al. 2006).また,Ganchev らや Gra¸ca らは,EM アルゴリズムの E ステッ プ内で,各方向のモデルが合意するような制約をモデルパラメータの事後分布に課している (Ganchev et al. 2008; Gra¸ca et al. 2008).そこで,提案モデルの学習においても両方向の合意制 約を導入し,それぞれのモデルの特定方向への過学習を防ぎ,双方で大域的な最適化を可能と する.具体的には,各方向の word embedding が一致するようにモデルを学習する.これを実 現するために,各方向の word embedding の差を表すペナルティ項を目的関数に導入し,その目 的関数に基づいて各方向のモデルを同時に学習する: argmin θF E, θEF { loss(θF E) + loss(θEF) + α∥θLEF − θLF E∥ } . (13) ここで,θF Eと θEF は,それぞれ,f→ e と e → f のアラインメントモデルのパラメータ,θL
は lookup 層のパラメータ(L の重みであり word embedding を表す),α は合意制約の強さを制
御するパラメータ,∥θ∥ は θ のノルムである.実験では 2-ノルムを用いた.この合意制約は,教
師あり学習と教師なし学習の両方に導入可能である.教師あり学習の場合は,式 (13) の loss(θ) として式 (7) を用い,教師なし学習の場合は式 (12) を用いる.
Algorithm 1 学習アルゴリズム 入力: θ1 F E, θ 1 EF, 学習データ T , MaxIter, D, N , C, IBM 1, W , α
1: for all t such that 1≤ t ≤ MaxIter do 2: {(f+, e+)D} ← sample(D, T ) 3-1: {(f+,{e−}N)D} ← nege({(f + , e+)D}, N, C, IBM 1) 3-2: {(e+,{f−}N)D} ← negf({(f + , e+)D}, N, C, IBM 1) 4-1: θt+1 F E ← update({f +, e+,{e−}N)D, θt FE, θtEF, W, α) 4-2: θt+1EF ← update({e+, f+,{f−}N)D, θEFt , θ t FE, W, α) 5: end for 出力: θMaxIter +1 EF , θ MaxIter +1 FE は,学習データ T からバッチサイズ分の D 個の対訳文 (f+, e+)Dを無作為に抽出する.ステッ プ 3-1 と 3-2 では,それぞれ,各 f+と e+に対して,l 0正則化付き IBM モデル 1 (IBM 1) が特 定した翻訳候補の単語集合から無作為に単語をサンプリングすることにより,負例となる対訳 文を N 個 ({e−}N と{f−}N) 生成する(4.1 節参照).ステップ 4-1 と 4-2 では,特定の目的関数 に従い,SGD により各層の重み行列を更新する(4.1 節と 4.2 参照).このステップでは,θF E と θEF の更新は同時に行われ,各方向の word embedding を一致させるために,θEF は θF Eの 更新に,θF Eは θEF の更新に制約を課している7.
5
評価実験
5.1
実験データ
提案手法の有効性を検証するため,単語アラインメントの精度及び翻訳精度の評価実験を行っ た.単語アラインメントの評価実験は,NAACL 2003 の shared task (Mihalcea and Pedersen 2003) で使われた Hansards データにおける仏英のタスク (Hansards) と,Basic Travel Expression Corpus (BTEC) (Takezawa, Sumita, Sugaya, Yamamoto, and Yamamoto 2002) における日英の タスク (IWSLTa) で実施した.翻訳精度の評価実験は,IWSLT2007 における日英翻訳タスク(Fordyce 2007) (IWSLT),新聞データから作成された FBIS コーパスにおける中英翻訳タスク (FBIS),NTCIR-9 及び NTCIR-10 における日英特許翻訳タスク (Goto, Lu, Chow, Sumita, and Tsou 2011; Goto, Chow, Lu, Sumita, and Tsou 2013) (NTCIR-9, NTCIR-10) で行った.
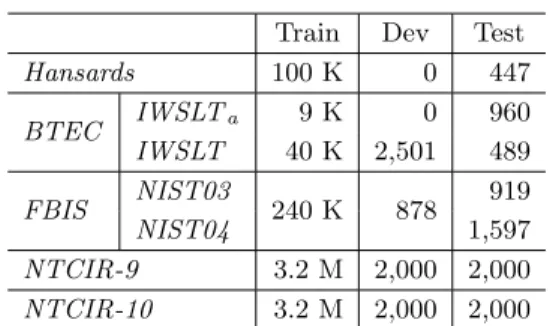
表 1 に各タスクで使用する対訳文の数を示す.「Train」は学習データ,「Dev」はディベロップ
メントデータ,「Test」はテストデータを表す.IWSLTa及び IWSLT の実験データは共に BTEC
7 t 回目の θt EF,θ t F Eの更新の際には,それぞれ,t− 1 回目に更新された θ t−1 F E と θ t−1 EF が制約として使われ,更新 中の θt EF,θ t F Eはお互いに依存しないことに注意されたい.θ t EF と θ t F E をお互いに依存させて同時に最適化す る学習もあり得るが,今後の課題としたい.
表 1 実験データのサイズ(対訳文数) Train Dev Test
Hansards 100 K 0 447 BTEC IWSLTa 9 K 0 960 IWSLT 40 K 2,501 489 FBIS NIST03 240 K 878 919 NIST04 1,597 NTCIR-9 3.2 M 2,000 2,000 NTCIR-10 3.2 M 2,000 2,000 のデータであり,IWSLTaの実験データは,IWSLT の学習データのうち,単語アラインメント
が人手で付与された 9,960 対訳文である (Goh, Watanabe, Yamamoto, and Sumita 2010).9,960 の対訳文の最初の 9,000 を学習データ,残りの 960 をテストデータとした.IWSLTaの学習デー
タは単語アラインメントが付与されているラベルあり学習データであるのに対し,Hansards の 学習データは単語アラインメントが付与されてないラベルなし学習データである.Hansards 及
び IWSLTaのアラインメントタスクでは,各アラインメントモデルのハイパーパラメータは学
習データの一部を用いた 2 分割交差検証により予め決定し,ディベロップメントデータは使わ なかった8.また,NAACL 2003 の shared task オリジナルの学習データの総数は約 110 万文対
あるが,今回の Hansards の実験では,学習時の計算量を削減するため,無作為にサンプリング した 10 万文対を学習データとして用いた.大規模データの実験は今後の課題とする.FBIS で は,NIST02 の評価データをディベロップメントデータとして使い,NIST03 と NIST04 の各評 価データでテストした.
5.2
実験対象
評価実験では,提案手法である RNN に基づくモデルに加え,ベースラインとして,IBM モデ ル 4 と FFNN に基づくモデルを評価した.また,単語アラインメントタスクにおける合意制約 の有効性を考察するため,ベースラインとして,典型的な HMM に基づくアラインメントモデル である Vogel らのモデル (Vogel et al. 1996) (HMMindep) とこの Vogel らのモデルに Liang らの
両方向の合意制約 (Liang et al. 2006) を導入したモデル (HMMjoint) も評価した.IBM モデル
4 は,IBM モデル 1-4 と HMM に基づくモデルを順番に適用して学習した (Och and Ney 2003). 具体的には,IBM モデル 1,HMM に基づくモデル,IBM モデル 2,3,4 をこの順で 5 回ずつ繰 り返した (15H53545) .これは,GIZA++のデフォルトの設定である (IBM4).HMM indep及び 8 IWSLT aの学習データの最初の 2,000 文を用いた 2 分割交差検証で最適なパラメータを用いた.IWSLTa以外の データに対してもこの検証により得られたパラメータを使った.ディベロップメントデータを使った各タスクでの パラメータ調整は今後の課題としたい.
HMMjointは BerkleyAligner9を用いた.Liang らの通り,IBM モデル 1,HMM に基づくモデル を順番に 5 回ずつ繰り返し,各モデルを学習した (Liang et al. 2006).FFNN に基づくモデルで は,word embedding の長さ M を 30,文脈の窓幅を 5 とした.したがって,|z0| は 300 = 30×5×2 である.また,隠れ層として,ユニット数|z1| が 100 の層を 1 層使用した.この FFNN に基づ くモデルは,(Yang et al. 2013) に倣って 2.2 節の教師あり手法により学習したモデル FFNNsに 加えて,4.1 節と 4.2 節で提案した教師なし学習や合意制約の効果を確かめるため,FFNNs+c, FFNNu,FFNNu+cのモデルを評価した.「s」は教師ありモデル,「u」は教師なしモデル,「+c」 は学習時に合意制約を使うことを意味する.RNN に基づくモデルでは,word embedding の長 さ M を 30,再帰的に連結している隠れ層のユニット数|yj| を 100 とした.したがって,|xj| は 60 = 30× 2 である.また,提案の学習法の効果を検証するため,FFNN に基づくモデル同様, RNNs,RNNs+c,RNNu,RNNu+cの 4 種類を評価した.FFNN に基づくモデル及び RNN に 基づくモデルの各層のユニット数や M などのパラメータは,学習データの一部を用いた 2 分割 交差検証により予め設定した. NN に基づくモデルの学習について説明する.まず,各層の重み行列を初期化する.具体的 には,lookup 層の重み行列 L は,局所解への収束を避けるため,学習データの原言語側と目的 言語側からそれぞれ予め学習した word embedding に初期化する.その他の重みは,[−0.1, 0.1]
のランダムな値に初期化する.word embedding の学習には,Mikolov らの手法 (Mikolov et al. 2010) を基にした RNNLM ツールキット10(デフォルトの設定)を用いる.その際,コーパスで の出現数が 5 回以下の単語は⟨unk⟩ に置き換える.各重みの初期化後は,ミニバッチ SGD によ り特定の目的関数に従って各重みを最適化する.本実験では,バッチサイズ D を 100,学習率 を 0.01 とし,50 エポックで学習を終えた.また,学習データへの過学習を避けるため,目的関 数には l2 正則化項(正則化の比率は 0.1)を加えた.教師なし学習におけるパラメータ W ,N , C は,それぞれ,100,50,0.001 とし,合意制約に関するパラメータ α は 0.1 とした.
翻訳タスクでは,フレーズベース機械翻訳 (SMT) システム Moses (Koehn, Hoang, Birch, Callison-Burch, Federico, Bertoldi, Cowan, Shen, Moran, Zens, Dyer, Bojar, Constrantin, and Herbst 2007) を用いた.日本語の各文は ChaSen11,中国語の各文は Stanford Chinese segmenter12に
より単語へ分割した.その後,40 単語以上の文は学習データから除いた.言語モデルは,SRILM ツールキット (Stolcke 2002) により,modified Kneser-Ney スムージング (Kneser and Ney 1995; Chen and Goodman 1996) を行い学習した.IWSLT,NTCIR-9 及び NTCIR-10 では,学習デー タの英語側コーパスから構築した 5 グラム言語モデル,FBIS では,English Gigaword の Xinhua
9 https://code.google.com/p/berkeleyaligner/ 10http://rnnlm.org/
11http://chasen-legacy.sourceforge.jp/
部分のデータから構築した 5 グラム言語モデルを使用した.翻訳モデルは,各単語アラインメ ント手法により特定されたアラインメント結果に基づいて学習した.SMT システムの各パラ メータは,ディベロップメントデータを用いて MERT (Och 2003) によりチューニングした.
5.3
実験結果(単語アラインメント)
表 2 に各手法の単語アラインメントの精度を F1 値で示す.NN に基づく教師ありモデルに 対しては,学習データに付与されている正しい単語アラインメントを学習したモデル (REF) と,IBM4 で特定した単語アラインメントを学習したモデル (IBM4) の 2 種類の精度を示す. Hansards の学習データには正しい単語アラインメントが付与されていないため,REF に対する 実験は実施していない. 評価手順は,まず,各アラインメントモデルにより,f → e と e → f のアラインメントをそれぞれ生成する.その後,「grow-diag-final-and」ヒューリスティックス (Koehn, Och, and Marcu 2003) により,両方向のアラインメントを結合する.そして,その結合したアラインメント結 果を F1 値で評価する.有意差検定は,有意差水準 5%の符号検定で行った.具体的には,テス トデータの各単語に対して,他方の手法では不正解だが正しく判定したものを +,他方の手法 では正解だが誤って判定したものを − として,2 手法の評価に有意な差があるかどうかを片 側検定の符号検定で判定した.表 2 中の「+」は,ベースラインとなる FFNN に基づくモデル FFNNs(REF/IBM4) との精度差が有意であることを示し,「++」は,ベースラインの FFNN に 表 2 単語アラインメント精度 アラインメントモデル IWSLTa Hansards HMMindep 0.4366 0.8979 HMMjoint 0.5411 0.9013 IBM4 0.4859 0.9029 FFNNs(IBM4 ) 0.4770 0.9020 FFNNs+c(IBM4 ) 0.4854+ 0.9085+ RNNs(IBM4 ) 0.5053++ 0.9068 RNNs+c(IBM4 ) 0.5174++ 0.9202++ FFNNu 0.5105++ 0.9026 FFNNu+c 0.5313++ 0.9144++ RNNu 0.5307++ 0.9037 RNNu+c 0.5562++ 0.9275++ FFNNs(REF ) 0.8224 − FFNNs+c(REF ) 0.8367++ − RNNs(REF ) 0.8798++ − RNNs+c(REF ) 0.8921++ − 数値:F1 値
基づくモデル FFNNs(REF/IBM4) に加えて IBM4 との精度差も有意であることを示す.また, 正しい教師ラベルを使用するモデル (REF) と使用しないモデル(REF 以外)のそれぞれで最 高の精度を太字で示す. 表 2 より,IWSLTaと Hansards の両タスクにおいて,本論文の提案手法(RNN に基づくモ デル,教師なし学習,合意制約)RNNu+cが最もアラインメント精度が高いことが分かる.特 に,ベースラインとの精度差は有意であることから,本論文の提案を組み合わせることにより, 従来手法より高いアラインメント精度を達成できることが実験的に確認できる. 次に,本論文の各提案の個別の有効性について確認する.表 2 より,IWSLTaと Hansards の両タ
スクにおいて,RNNs/s+c/u/u+c(IBM4),RNNs/s+c(REF) は,それぞれ,,FFNNs/s+c/u/u+c(IBM4),
FFNNs/s+c(REF) よりも精度が良い.特に,IWSLTa では,RNNs(REF),RNNs(IBM4) と
FFNNs(REF),FFNNs(IBM4) とのそれぞれの性能差は有意であることが分かる.これは,RNN
に基づくモデルにより長いアラインメント履歴を捉えることで,アラインメント精度が向上す ることを示しており,RNN を利用したモデルの有効性を確認できる.ただし,Hansards にお いては,RNN の効果が少ない.この言語対による効果の違いについては 6.1 節で考察する.
IWSLTaと Hansards の両タスクにおいて,RNNs+c(REF/IBM4),RNNu+cのアラインメン
ト精度は,それぞれ,RNNs(REF/IBM4),RNNuを上回っており,これらの精度差は有意であっ
た.さらに,FFNNs+c(REF/IBM4),FFNNu+cは,それぞれ,FFNNs(REF/IBM4),FFNNu
より有意にアラインメント精度が良い.この結果より,教師ありと教師なしの両方の学習にお いて,両方向の合意制約を導入することで FFNN に基づくモデル及び RNN に基づくモデルの アラインメント精度を改善できることが分かる.一方で,HMMjointの方が HMMindepよりも 精度が良いことから,提案の合意制約に限らず,両方向の合意をとるようにモデルを学習する ことは有効であることが確認できる.HMM に基づくモデルに導入した Liang らの両方向の合 意制約と提案の合意制約の傾向の違いは,6.2 節で考察する.
IWSLTaでは,RNNuと RNNu+cは,それぞれ,RNNs(IBM4) と RNNs+c(IBM4) より有意
にアラインメント精度が良い.一方で,Hansards では,これらの精度は同等である.この傾向 は FFNN に基づくモデルでも同様である.これは,学習データの質(IBM4 の精度)が悪い場 合,教師あり学習は IBM4 による疑似学習データに含まれる誤りの悪影響を受けるのに対し,提 案の教師なし学習は学習データの質に依らずに精度の良い FFNN や RNN に基づくモデルを学 習できることを示している.
5.4
実験結果(機械翻訳)
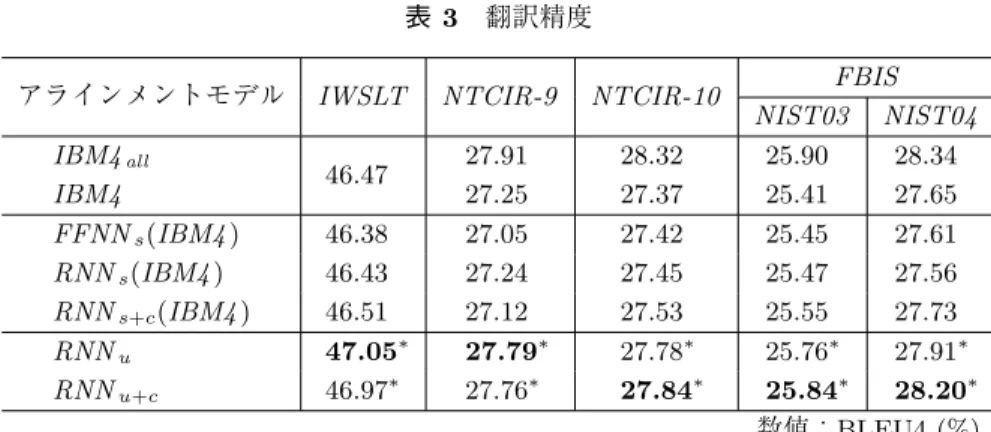
表 3 に各手法により付与されたアラインメントを用いた SMT システムの翻訳精度を示す.評 価尺度は,大文字と小文字を区別した BLEU413(Papineni, Roukos, Ward, and Zhu 2002) を用
いた.MERT の不安定な振る舞いの影響を緩和するため,MERT によるチューニングは 3 回行 い,その平均値を表 3 に示す (Utiyama, Yamamoto, and Sumita 2009).
IWSLT では,アラインメントモデル及び翻訳モデルの学習には学習データ全てを用いた.一
方で,NTCIR-9,NTCIR-10 と FBIS では,アラインメントモデルの学習における計算量を削 減するため,学習データから無作為にサンプリングした 10 万文対からアラインメントモデルを 学習した.その後,学習したアラインメントモデルにより学習データ全ての単語アラインメン トを自動的に付与し,翻訳モデルを学習した.また,詳細な比較を行うため,全学習データか ら学習した IBM モデル 4 に基づく SMT システムの精度を IBM4allとして示す.翻訳精度の有
意差検定は,有意差水準 5%でブートストラップによる検定手法 (Koehn 2004) により行った. 表 3 の「*」は,ベースライン(IBM4 及び FFNNs(IBM4))との精度差が有意であることを示 す.また,各タスクで最高精度(IBM4allを除く)を太字で示す. 表 2 と表 3 より,単語アラインメント精度を改善しても,必ずしも翻訳精度が向上するとは限 らないことが分かる.この事は従来より知られており,例えば,(Yang et al. 2013) においても同 様の現象が確認されている.しかしながら,表 3 より,全ての翻訳タスクで,RNNuと RNNu+c は FFNNs(IBM4) と IBM4 よりも有意に翻訳精度がよいことが分かる.この結果から,提案手 法は翻訳精度の改善にも寄与することが実験的に確認できる.また,NTCIR-9 と FBIS では, 提案モデルは学習データの一部から学習したが,学習データ全てから学習した IBM4all と同等 の精度を達成している.学習データ量の影響は 6.2 節で考察する. 表 3 翻訳精度
アラインメントモデル IWSLT NTCIR-9 NTCIR-10 FBIS
NIST03 NIST04 IBM4all 46.47 27.91 28.32 25.90 28.34 IBM4 27.25 27.37 25.41 27.65 FFNNs(IBM4 ) 46.38 27.05 27.42 25.45 27.61 RNNs(IBM4 ) 46.43 27.24 27.45 25.47 27.56 RNNs+c(IBM4 ) 46.51 27.12 27.53 25.55 27.73 RNNu 47.05∗ 27.79∗ 27.78∗ 25.76∗ 27.91∗ RNNu+c 46.97∗ 27.76∗ 27.84∗ 25.84∗ 28.20∗ 数値:BLEU4 (%) 13評価ツールとして mteval-v13a.pl (http://www.itl.nist.gov/iad/mig/tests/mt/2009/) を用いた.
6
考察
6.1
RNN に基づくモデルの効果
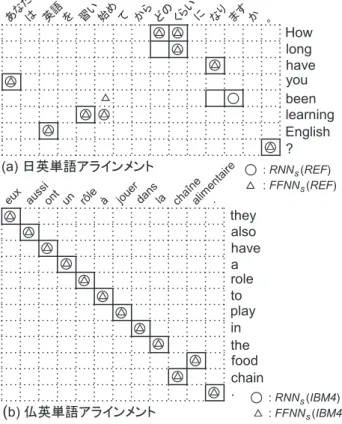
図 3 に FFNNs及び RNNsで解析した単語アラインメントの具体例を示す.三角が FFNNsの
解析結果,丸が RNNsの解析結果,四角が正しい単語アラインメントを表す.図 3 より,RNNs
は FFNNsと比較して,複雑なアラインメント(例えば,図 3(a) 中の「have you been」に対す
るギザギザのアラインメント)を特定できていることが分かる.これは,FFNNsは直前のアラ インメント履歴しか利用しないが,RNNsは長いアラインメント履歴に基づいてアラインメン トのパス(例えば,フレーズ単位のアラインメント)を捉えられることを示唆している. 5.3 節で述べた通り,RNN に基づくモデルの効果は,日英アラインメント (IWSLTa) と比べ て仏英アラインメント (Hansards) に対して少ない.これは,英語とフランス語は語順が似てい て,日英に比べて 1 対 1 アラインメントが多く(図 3 参照),仏英単語アラインメントは局所的 な手がかりで捉えられる場合が多いためであると考えられる.図 3(b) は,このような単純な単 語アラインメントは,FFNNsと RNNsの両モデルで正しく解析できることを示している. 図 3 単語アラインメントの解析結果例
6.2
学習データ量の影響
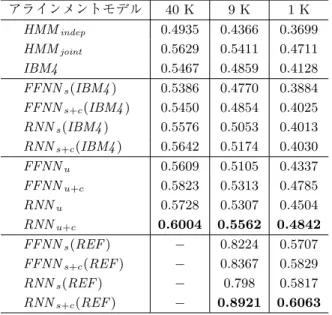
BTEC における日英アラインメントタスクにおいて様々なサイズの学習データを使った時の アラインメント精度を表 4 に示す.「40 K」,「9 K」,「1 K」は,それぞれ,IWSLT の全学習デー タ,IWSLTaの全学習データ,IWSLTaの全学習データから無作為に抽出した 1,000 文対を学 習データとした時の,IWSLTaのテストデータに対するアラインメント精度である.「9 K」及 び「1 K」はラベルあり学習データ,「40 K」はラベルなし学習データである.そのため,教師 ありモデル (REF) の「40 K」に対する実験は実施していない.表 4 より,「1 K」の RNNs+c(REF) と「9 K」の RNNu+cは「40 K」の IBM4 より性能がよいこ
とが分かる.すなわち,RNN に基づくモデルは,IBM4 の学習データの 22.5%以下 (9,000/40,000) のデータから同等の精度を持つモデルを学習できたことが分かる.その結果,表 3 が示す通り, 学習データの一部を使った RNNu+cに基づく SMT システムが,全学習データを用いた IBM4all
に基づく SMT システムと同等の精度を達成できる場合がある. 表 4 より,HMM に基づくモデルに導入した Liang らの両方向の合意制約は学習データが小 規模なほど効果があることが分かる.一方で,提案の合意制約は,Liang らの合意制約と比較す ると精度の改善幅は小さいが,どのテータサイズにおいても同等の効果を発揮することが確認 できる. また,各データサイズで 5.3 節と同様の手法の比較を行うと,教師ラベルを使わない場合は 表 4 学習データ量による単語アラインメント精度の比較 アラインメントモデル 40 K 9 K 1 K HMMindep 0.4935 0.4366 0.3699 HMMjoint 0.5629 0.5411 0.4711 IBM4 0.5467 0.4859 0.4128 FFNNs(IBM4 ) 0.5386 0.4770 0.3884 FFNNs+c(IBM4 ) 0.5450 0.4854 0.4025 RNNs(IBM4 ) 0.5576 0.5053 0.4013 RNNs+c(IBM4 ) 0.5642 0.5174 0.4030 FFNNu 0.5609 0.5105 0.4337 FFNNu+c 0.5823 0.5313 0.4785 RNNu 0.5728 0.5307 0.4504 RNNu+c 0.6004 0.5562 0.4842 FFNNs(REF ) − 0.8224 0.5707 FFNNs+c(REF ) − 0.8367 0.5829 RNNs(REF ) − 0.798 0.5817 RNNs+c(REF ) − 0.8921 0.6063 数値:F1 値
RNNu+c,使う場合は RNNs+c(REF) が最も性能が良い.そして,本論文で提案した,RNN の 利用,教師なし学習,合意制約の個別の有効性も確認できることから,データサイズに依らず 提案手法が有効であることが分かる.
7
まとめ
本論文では,RNN に基づく単語アラインメントモデルを提案した.提案モデルは,隠れ層の 再帰的な構造を利用し,長いアラインメント履歴に基づいてアラインメントのパス(例えば,フ レーズ単位のアラインメント)を捉えることができる.また,RNN に基づくモデルの学習法と して,Dyer らの教師なし単語アラインメント (Dyer et al. 2011) を拡張して人工的に作成した負 例を利用する教師なし学習法を提案した.そして,更なる精度向上のために,学習過程に各方 向の word embedding を一致させる合意制約を導入した.複数の単語アラインメントタスクと 翻訳タスクの実験を通じて,RNN に基づくモデルは従来の FFNN に基づくモデル (Yang et al. 2013) よりアラインメント精度及び翻訳精度が良いことを示した.また,提案した教師なし学 習や合意制約により,アラインメント精度を更に改善できることを確認した. 提案モデルでは,アラインメント対象の文脈をアラインメント履歴 (yi) に暗示的に埋め込み 利用しているが,今後は,FFNN に基づくモデルのように周辺単語の入力(c(fj) や c(eaj))と して明示的に利用することも検討したい.また,Yang らは複数の隠れ層を用いることで FFNN に基づくモデルの精度を改善している (Yang et al. 2013).これに倣って提案モデルでも各隠れ 層を複数にするなど,提案モデルの改良を行う予定である.さらに,本論文では提案モデルに より特定したアラインメントに基づいて翻訳モデルを学習したが,翻訳モデル学習時の素性と してアラインメントモデルが算出するスコアを使用したり,Watanabe ら (Watanabe, Suzuki, Tsukada, and Isozaki 2006) のように翻訳候補のリランキングの中で使ったりするなど,提案モ デルの SMT システムへの効果的な組み込み方に関しても検討したい.謝 辞
本論文は国際会議 The 52nd Annual Meeting of the Association for Computational Linguistics で発表した論文 (Tamura, Watanabe, and Sumita 2014) に基づいて日本語で書き直し,説明や 評価を追加したものである.
参考文献
Auli, M., Galley, M., Quirk, C., and Zweig, G. (2013). “Joint Language and Translation Modeling with Recurrent Neural Networks.” In Proceedings of EMNLP 2013, pp. 1044–1054.
Bengio, Y., Ducharme, R., Vincent, P., and Janvin, C. (2003). “A Neural Probabilistic Language Model.” Journal of Machine Learning Research, 3, pp. 1137–1155.
Berg-Kirkpatrick, T., Bouchard-Cˆot´e, A., DeNero, J., and Klein, D. (2010). “Painless Unsuper-vised Learning with Features.” In Proceedings of HLT:NAACL 2010, pp. 582–590.
Blunsom, P. and Cohn, T. (2006). “Discriminative Word Alignment with Conditional Random Fields.” In Proceedings of Coling/ACL 2006, pp. 65–72.
Brown, P. F., Pietra, S. A. D., Pietra, V. J. D., and Mercer, R. L. (1993). “The Mathematics of Statistical Machine Translation: Parameter Estimation.” Computational Linguistics, 19 (2), pp. 263–311.
Chen, S. F. and Goodman, J. (1996). “An Empirical Study of Smoothing Techniques for Language Modeling.” In Proceedings of ACL 1996, pp. 310–318.
Collobert, R. and Weston, J. (2008). “A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning.” In Proceedings of ICML 2008, pp. 160–167. Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., and Kuksa, P. (2011). “Nat-ural Language Processing (Almost) from Scratch.” Journal of Machine Learning Research,
12, pp. 2493–2537.
Dahl, G. E., Yu, D., Deng, L., and Acero, A. (2012). “Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition.” IEEE Transactions on Audio,
Speech, and Language Processing, 20 (1), pp. 30–42.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). “Maximum Likelihood from Incomplete Data via the EM Algorithm.” Journal of the Royal Statistical Society, Series B, 39 (1), pp. 1–38.
Dyer, C., Clark, J., Lavie, A., and Smith, N. A. (2011). “Unsupervised Word Alignment with Arbitrary Features.” In Proceedings of ACL/HLT 2011, pp. 409–419.
Fordyce, C. S. (2007). “Overview of the IWSLT 2007 Evaluation Campaign.” In Proceedings of
IWSLT 2007, pp. 1–12.
Ganchev, K., Gra¸ca, J. V., and Taskar, B. (2008). “Better Alignments = Better Translations?” In Proceedings of ACL/HLT 2008, pp. 986–993.
Goh, C.-L., Watanabe, T., Yamamoto, H., and Sumita, E. (2010). “Constraining a Genera-tive Word Alignment Model with DiscriminaGenera-tive Output.” IEICE Transactions, 93-D (7),
pp. 1976–1983.
Goto, I., Chow, K. P., Lu, B., Sumita, E., and Tsou, B. K. (2013). “Overview of the Patent Machine Translation Task at the NTCIR-10 Workshop.” In Proceedings of 10th NTCIR
Conference, pp. 260–286.
Goto, I., Lu, B., Chow, K. P., Sumita, E., and Tsou, B. K. (2011). “Overview of the Patent Machine Translation Task at the NTCIR-9 Workshop.” In Proceedings of 9th NTCIR
Con-ference, pp. 559–578.
Gra¸ca, J. V., Ganchev, K., and Taskar, B. (2008). “Expectation Maximization and Posterior Constraints.” In Proceedings of NIPS 2008, pp. 569–576.
Gutmann, M. and Hyv¨arinen, A. (2010). “Noise-Contrastive Estimation: A New Estimation Prin-ciple for Unnormalized Statistical Models.” In Proceedings of AISTATS 2010, pp. 297–304. Kalchbrenner, N. and Blunsom, P. (2013). “Recurrent Continuous Translation Models.” In
Proceedings of EMNLP 2013, pp. 1700–1709.
Kneser, R. and Ney, H. (1995). “Improved Backing-off for M-gram Language Modeling.” In
Proceedings of ICASSP 1995, pp. 181–184.
Koehn, P. (2004). “Statistical Significance Tests for Machine Translation Evaluation.” In
Pro-ceedings of EMNLP 2004, pp. 388–395.
Koehn, P., Hoang, H., Birch, A., Callison-Burch, C., Federico, M., Bertoldi, N., Cowan, B., Shen, W., Moran, C., Zens, R., Dyer, C., Bojar, O., Constrantin, A., and Herbst, E. (2007). “Moses: Open Source Toolkit for Statistical Machine Translation.” In Proceedings of ACL
2007, pp. 177–180.
Koehn, P., Och, F. J., and Marcu, D. (2003). “Statistical Phrase-Based Translation.” In
Pro-ceedings of HLT/NAACL 2003, pp. 48–54.
Le, H.-S., Allauzen, A., and Yvon, F. (2012). “Continuous Space Translation Models with Neural Networks.” In Proceedings of NAACL/HLT 2012, pp. 39–48.
Liang, P., Taskar, B., and Klein, D. (2006). “Alignment by Agreement.” In Proceedings of
HLT/NAACL 2006, pp. 104–111.
Matusov, E., Zens, R., and Ney, H. (2004). “Symmetric Word Alignments for Statistical Machine Translation.” In Proceedings of Coling 2004, pp. 219–225.
Mihalcea, R. and Pedersen, T. (2003). “An Evaluation Exercise for Word Alignment.” In
Pro-ceedings of the HLT-NAACL 2003 Workshop on Building and Using Parallel Texts: Data Driven Machine Translation and Beyond, pp. 1–10.
Mikolov, T., Karafi´at, M., Burget, L., Cernock´y, J., and Khudanpur, S. (2010). “Recurrent Neural Network based Language Model.” In Proceedings of INTERSPEECH 2010, pp. 1045–1048.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., and Dean, J. (2013). “Distributed Represen-tations of Words and Phrases and their Compositionality.” In Proceedings of NIPS 2013, pp. 3111–3119.
Mikolov, T. and Zweig, G. (2012). “Context Dependent Recurrent Neural Network Language Model.” In Proceedings of SLT 2012, pp. 234–239.
Mnih, A. and Teh, Y. W. (2012). “A Fast and Simple Algorithm for Training Neural Probabilistic Language Models.” In Proceedings of ICML 2012, pp. 1751–1758.
Moore, R. C. (2005). “A Discriminative Framework for Bilingual Word Alignment.” In
Proceed-ings of HLT/EMNLP 2005, pp. 81–88.
Och, F. J. (2003). “Minimum Error Rate Training in Statistical Machine Translation.” In
Proceedings of ACL 2003, pp. 160–167.
Och, F. J. and Ney, H. (2003). “A Systematic Comparison of Various Statistical Alignment Models.” Computational Linguistics, 29, pp. 19–51.
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). “BLEU: a Method for Automatic Evaluation of Machine Translation.” In Proceedings of ACL 2002, pp. 311–318.
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). “Learning Internal Representa-tions by Error Propagation.” In Rumelhart, D. E. and McClelland, J. L. (Eds.), Parallel
Distributed Processing, pp. 318–362. MIT Press.
Smith, N. A. and Eisner, J. (2005). “Contrastive Estimation: Training Log-Linear Models on Unlabeled Data.” In Proceedings of ACL 2005, pp. 354–362.
Stolcke, A. (2002). “SRILM - An Extensible Language Modeling Toolkit.” In Proceedings of
ICSLP 2002, pp. 901–904.
Sundermeyer, M., Oparin, I., Gauvain, J.-L., Freiberg, B., Schl¨uter, R., and Ney, H. (2013). “Comparison of Feedforward and Recurrent Neural Network Language Models.” In
Proceed-ings of ICASSP 2013, pp. 8430–8434.
Takezawa, T., Sumita, E., Sugaya, F., Yamamoto, H., and Yamamoto, S. (2002). “Toward a Broad-coverage Bilingual Corpus for Speech Translation of Travel Conversations in the Real World.” In Proceedings of LREC 2002, pp. 147–152.
Tamura, A., Watanabe, T., and Sumita, E. (2014). “Recurrent Neural Networks for Word Alignment Model.” In Proceedings of ACL 2014, pp. 1470–1480.
Taskar, B., Lacoste-Julien, S., and Klein, D. (2005). “A Discriminative Matching Approach to Word Alignment.” In Proceedings of HLT/EMNLP 2005, pp. 73–80.
Utiyama, M., Yamamoto, H., and Sumita, E. (2009). “Two Methods for Stabilizing MERT: NICT at IWSLT 2009.” In Proceedings of IWSLT 2009, pp. 79–82.
Vaswani, A., Huang, L., and Chiang, D. (2012). “Smaller Alignment Models for Better Trans-lations: Unsupervised Word Alignment with the l0-norm.” In Proceedings of ACL 2012,
pp. 311–319.
Vaswani, A., Zhao, Y., Fossum, V., and Chiang, D. (2013). “Decoding with Large-Scale Neural Language Models Improves Translation.” In Proceedings of EMNLP 2013, pp. 1387–1392. Viterbi, A. J. (1967). “Error Bounds for Convolutional Codes and an Asymptotically Optimum
Decoding Algorithm.” IEEE Transactions on Information Theory, 13 (2), pp. 260–269. Vogel, S., Ney, H., and Tillmann, C. (1996). “Hmm-based Word Alignment in Statistical
Trans-lation.” In Proceedings of Coling 1996, pp. 836–841.
Watanabe, T., Suzuki, J., Tsukada, H., and Isozaki, H. (2006). “NTT Statistical Machine Trans-lation for IWSLT 2006.” In Proceedings of IWSLT 2006, pp. 95–102.
Yang, N., Liu, S., Li, M., Zhou, M., and Yu, N. (2013). “Word Alignment Modeling with Context Dependent Deep Neural Network.” In Proceedings of ACL 2013, pp. 166–175.
略歴
田村 晃裕:2005 年東京工業大学工学部情報工学科卒業.2007 年同大学院総 合理工学研究科修士課程修了.2007 年から 2011 年まで日本電気株式会社に て自然言語処理,特にテキストマイニングに関する研究に従事.2011 年から 2014 年まで情報通信研究機構にて統計的機械翻訳に関する研究に従事.2013 年東京工業大学大学院総合理工学研究科博士課程修了.2014 年から 2015 年 まで日本電気株式会社にてテキスト分類に関する研究に従事.2015 年から情 報通信研究機構の研究員,現在に至る.工学博士.情報処理学会,言語処理 学会,ACL 各会員. 渡辺 太郎:1994 年京都大学工学部情報工学科卒業.1997 年京都大学大学院 工学研究科情報工学専攻修士課程修了.2000 年 Language and Information Technologies, School of Computer Science, Carnegie Mellon University, Master of Science 取得.2004 年京都大学博士(情報学).ATR,NTT および NICT に て研究員として務めた後,現在,グーグル株式会社ソフトウェアエンジニア. 隅田英一郎:1982 年電気通信大学大学院修士課程修了.1999 年京都大学大学院 博士(工学).日本アイ・ビー・エム東京基礎研究所,国際電気通信基礎技術 研究所を経て,2007 年より国立研究開発法人情報通信研究機構に勤務,現在, ユニバーサルコミュニケーション研究所副所長.自動翻訳,e ラーニングに関 する研究開発に従事.2007,2014 年アジア太平洋機械翻訳協会長尾賞,2007 年情報処理学会喜安記念業績賞,2010 年文部科学大臣表彰・科学技術賞(開発部門),2013 年第 11 回産学官連携功労者表彰・総務大臣賞.情報処理学会, 電子情報通信学会,ACL,日本音響学会,ACM 各会員.
(2015 年 6 月 16 日 受付) (2015 年 8 月 12 日 再受付) (2015 年 8 月 28 日 採録)