マルチコアにおけるソフトウェア:1.マルチコア化するマイクロプロセッサ
7
0
0
全文
(2) 1.マルチコア化するマイクロプロセッサ. FR550 VLIW プロセッサコア. FR-Vマルチコアプロセッサ FR550 FR550 core core DMA-I. DMA-E Local BUS IF. 高速接続機構 (クロスバー) FR550 core. 整数演算ユニット. I-cache 32KB. Mem. Cont.. 外部 メモリ. Mem. Cont.. 外部 メモリ. 命令 0 命令 1 命令 2 命令 3. GR. 命令 4 命令 5 命令 6 命令 7. FR. D-cache 32KB. メディア演算ユニット. FR550 core. IO Chip. コア1 コア2. コア1 コア2. ×. スイッチ スイッチ. 高速外部入出力バス •メモリバス:64bit x 2ch / 266MHz •システムバス:64bit / 178MHz (周波数は現FR-Vの2倍). メモリ メモリ. メモリ メモリ. バス接続. クロスバー接続 (本プロセッサ). 図 -1 FR-V マルチコアプロセッサ. SPE. • Power Processor Element (PPE) ‒ Power コアは OS および制御集中 タスクを処理. SP U. SP U. SP U. SP U. SP U. SP U. SP U. SP U. LS. LS. LS. LS. LS. LS. LS. 16B/cycle. ‒ 2-way マルチスレッド • Synergistic Processor Element (SPE). Synergistic Processor Elements for High (Fl)ops / Watt. LS 16B/cycle. ‒ 8 つの SPE が優位な演算性能を提供 ‒ Dual issue の RISC アーキテクチャ ‒ 128bit の SIMD 型 (16‐wayまで) ‒ 128 x 128bit General Registers ‒ 256KB Local Store ‒ 専用 DMA engines. EIB (up to 96B/cycle) 16B/cycle. PPE. 16B/cycle. L2. 16B/cycle (2x). MIC. BIC. 512KB 32B/cycle. PPU L1 32KB+32KB. Dual XDRTM. 16B/cycle. RRAC. I/O. 従来の演算処理のためにVMXを持つ 64bitのPowerArchitecture. 図 -2 Cell プロセッサ. うトランジスタのスイッチング速度と配線遅延の差の増. クロック周波数に比例する.すなわち高クロック周波数. 大といった理由から,チップ上の利用可能なトランジス. 化は高消費電力化を招き,そのためチップの発熱量も増. タ数の増加が命令レベル並列性の向上に結びつきにくく. 大しクロック周波数をあげることができなくなっている.. なっているという状況がある.また,高いクロック周波. 特に最近は,半導体の微細化に伴うリーク電流も増加し. 数を得るためにはプロセッサのパイプラインを細かく区. ており,今後の 65nm,45nm プロセスではリークがさ. 切りパイプラインの段数を増やす必要があるが,このと. らに増大し,消費電力の増加が今後のプロセッサの性能. きパイプラインステージ間に挿入するラッチの数が増え. 向上にとって深刻な問題となっている.. てしまいその分の消費電力が増える.さらに消費電力は. これらの,半導体集積度向上に伴うスケーラブルな性 IPSJ Magazine Vol.47 No.1 Jan. 2006. 11.
(3) 特. 集 マルチコアにおけるソフトウェア Configurable number of hardware interrupt lines. MPCoreTM. Private FIQ lines. Interrupt Distributor Per-CPU aliased peripherals. Timer Wdog. CPU interface. Timer Wdog. CPU interface. CPU interface IRQ. IRQ. CPU/VFP. CPU/VFP. CPU/VFP. L1 Memory. L1 Memory. L1 Memory. L1 Memory. Snoop Control Unit (SCU) Duplicated L1 Tag. TM. Wdog. CPU/VFP. Private Peripheral Bus. 図 -3 MPCore. Timer. CPU interface. IRQ. IRQ. Configurable between 1 and 4 Symmetric CPU. Timer Wdog. I & D Coherence 64bit bus Control bus. Optional 2 nd AXI R/W 64bit bus. Primary AXI R/W 64bit bus. L2 (L220). ブロック図. 能向上,消費電力の増大に対処するための方法としてマ ルチコア化が有力視されている.これは,マルチコアプ. 一般的なマルチプロセッサのアーキテクチャ. ロセッサでは従来プロセッサで使用されていた上述の細. マルチプロセッサの構成方法はメモリの構成方式に着. 粒度命令レベル並列性だけでなく,より並列性の大きい. 目すると,図 -3 に示す MPCore のような共有メモリ型. ループレベル並列性,さらに粒度の粗いループ間,関数. マルチプロセッサと図 -4 に示す BlueGene/L のチップ間. 間の粗粒度タスク並列性も利用でき,より大きな並列性. のような分散メモリ型マルチプロセッサに大別すること. の利用により今後の集積度向上とともにプロセッサコア. ができる .. 数を増やし,性能向上を得ることができる.また消費電. 共有メモリ型マルチプロセッサは全プロセッサがバス. 力的にも,n 台のプロセッサコアを用い同一性能を達成. 等を介して接続されて,1 つの主メモリを共有する構成. するのであれば,クロック周波数を n 分の 1 にし,そ. 方式である.すなわち,全プロセッサが同一のデータを. れに伴い電圧も下げることにより,電圧の 2 乗で増大. 共有することになる.この構成方式はプロセッサからメ. する消費電力を低く抑えることができるようになる.. モリに至るまでの距離が全プロセッサで対等なので,対. また,ソフトウェア面では,通常マルチプロセッサ用の. 称型マルチプロセッサ(Symmetric Multiprocessor: SMP). 並列プログラミングはチューニングに多大な時間を要しア. と呼ばれる.主記憶共有メモリ型マルチプロセッサでは,. プリケーションソフトウェアの開発が大変であるが,比較. 各 CPU がキャッシュを持っている構成が多く,単に各. 的少数のプロセッサを集積する現時点では逐次プログラム. プロセッサを接続しただけでは各キャッシュの持ってい. を自動的に並列化する自動並列化コンパイラにより高性能. るデータの一貫性が損なわれる可能性がある.それで各. を得ることができ,コンパイラにより 4 コア,8 コア,16. キャッシュのデータの一貫性を保持するために MOESI. コアの自動並列化が可能となれば,アプリケーションの質. や MESI 等と呼ばれるキャッシュコヒーレンスプロトコ. と数が市場での競争力を決める情報家電ではそのマルチコ. ルを用い一貫性を保証している.. アは圧倒的に優位となる.さらにマルチコアでは,コンパ. 一方,分散メモリ型マルチプロセッサは,CPU とメ. イラとの協調により,各コアの周波数・電圧を下げダイナ. モリ(ローカルメモリ)を持つノードが相互結合網で接. ミック消費電力を落としたり,ある期間処理を行っていな. 続されている構成方式である.分散メモリ型マルチプロ. いプロセッサは電源を遮断することによりリーク電流によ. セッサでは各々のノードが持つメモリは各プロセッサに. るスタティック電力も削減できる.これらの利点により,. 固有のものであり,プロセッサ間でデータ授受を行う場. 日本ではコンパイラとの協調を行う情報家電用マルチコア. 合には MPI 等の通信ライブラリを用いプログラム中で. プロセッサプロジェクト NEDO“リアルタイム情報家電用マ. 明示的にデータ通信を行う必要がある.分散メモリ型マ. ルチコア”プロジェクトが 2005 年 7 月より開始されている.. ルチプロセッサは多くのプロセッサを比較的簡単に接続. 12. 47 巻 1 号 情報処理 2006 年 1 月.
(4) 1.マルチコア化するマイクロプロセッサ. IBM BlueGene/L 低消費電力チップマルチプロセッサ をベースとしたスパコン. 65,536∼ プロセッサチップ (128Kプロセッサ 360TFLOPS =毎秒360兆回の キャビネットあたり 1,024プロセッサチップ 浮動小数点計算) 1プロセッサチップ上に2プロセッサ集積 図 -4 低消費電力マルチコアベーススーパーコンピュータ. できるため超並列システムの構築が簡単にできるが,共. による対応は難しくなる.. 有メモリ型マルチプロセッサに比べてプロセッサ間通信. 従来よりサーバ上で動作する多くのアプリケーション. 遅延が大きいという問題を持っている.. では,複数プロセスやスレッド処理のスループットが重. 現時点では,マルチコアプロセッサはまだ数プロセッ. 要であり,これらのアプリケーションを動作させるため. サ程度の小規模なものが多いため,プログラミングがしや. に古くから共有メモリ型のマルチプロセッサシステムが. すい SMP 方式のもの,あるいは Cell,FR1000 のようにロ. 利用されてきた.そのため,多くのマルチコアプロセッ. ーカルメモリは有しているが,全プロセッサからアクセス. サが共有メモリ型の構成をとるのは,従来のマルチプロ. できる共有メモリも有している OSCAR タイプ(図 -5). セッサシステムで動作していたアプリケーションを,そ. のマルチプロセッサシステムが多く開発されている.. のままマルチコアのプロセッサを持ったシステムで動作. 11). させることができるため,きわめて自然である.しかし,. コンピューティングエリアと マルチコアプロセッサ. ユーザとのインタラクティブな作業が多いデスクトップ. 前述したとおり,サーバ,デスクトップ,組み込みの. 来のままのシングルプロセッサ用のアプリケーションで. 各分野で,すでに多くのマルチコアのプロセッサが開発. は複数のプロセッサコアを 1 チップ上に集積すること. されている.ここで,各分野のマルチコアプロセッサを. による恩恵を受けることができない.. 先のマルチプロセッサの構成と比較する.. 一方,組み込み用途のマルチコアプロセッサでは,サ. サーバ・デスクトップ用途のマルチコアプロセッサは. ーバ・デスクトップ用のマルチコアとは違い,共有メモ. 共有メモリ型の構成をとっている.特に Pentium D やデ. リ型・分散メモリ型の両方の構成を見ることができる.. ュアルコア Opteron は 2 つのプロセッサコアを 1 チップ. たとえば,MPCore は図 -3 のようにキャッシュの一貫. に搭載したものとなっている.Power4 や UltraSPARC IV. 性を維持する典型的な共有メモリ型マルチプロセッサの. も同様に共有メモリ型の構成だが,2 つのプロセッサコ. 構成となっている.しかしながら,Cell や FR1000 では,. アが L2 キャッシュを共有している.L2 キャッシュを共. チップの外部に共有主記憶と,各プロセッサコアがロー. 有することで,キャッシュ一貫性を維持するハードウェ. カルメモリ(ローカルストレージ)を持つ分散メモリ型. アが不要になる.チップ上に複数のコアを集積すること. に近い構成となっている.これらのローカルメモリは,. による特徴といえるだろう.しかしながら,共有 L2 キャ. SMP では保証しにくい,リアルタイム性の確保のため. ッシュ方式ではプロセッサコアが増加すると,各プロセ. に有利である.. ッサが L2 キャッシュの使用権を取り合うことになり,多. さらに組み込み系のプロセッサでは,Cell,MP211,. 数のプロセッサコアを搭載した場合は L2 キャッシュ共有. UniPhier のように,汎用プロセッサのほかに信号処理用. PC のアプリケーションでは主にターンアラウンドタイ ムが重視される.このようなアプリケーションでは,従. IPSJ Magazine Vol.47 No.1 Jan. 2006. 13.
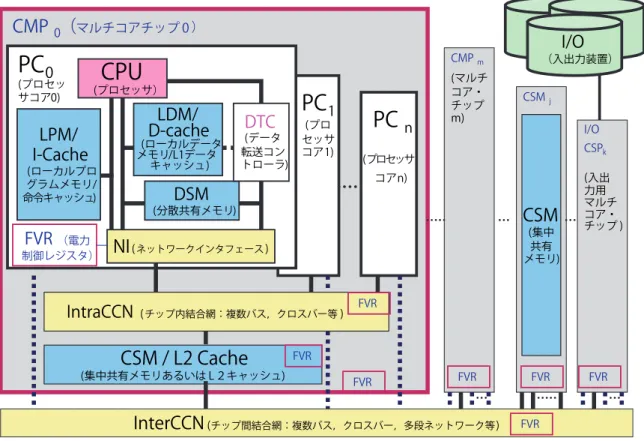
(5) 特. 集 マルチコアにおけるソフトウェア. I/O I/O. CMP 0(マルチコアチップ 0 ). PC 0. CMP. CPU. (プロセッ サコア0). (プロセッサ). LDM/ D-cache. LPM/ I-Cache. (ローカルデータ メモリ/L1データ キャッシュ). (ローカルプロ グラムメモリ/ 命令キャッシュ). FVR (電力. 制御レジスタ). PC 1. DTC. (プロ セッサ コア1). (データ 転送コン トローラ). PC n. (マルチ コア・ チップ m). CSM. j. I/O CSPk. (プロセッサ コアn). DSM. (分散共有メモリ). CSM. (集中 共有 メモリ). NI ( ネットワークインタフェース ). IntraCCN. (入出力装置). m. (入出 力用 マルチ コア・ チップ ). FVR ( チップ内結合網:複数バス,クロスバー等 ) . CSM / L2 Cache. FVR. (集中共有メモリあるいは L 2キャッシュ). FVR. FVR. InterCCN (チップ間結合網:複数バス,クロスバー,多段ネットワーク等 ). FVR. FVR. FVR. 図 -5 コンパイラ協調型 OSCAR(Optimally Scheduled Advanced Multiprocessor)マルチコア. の DSP コアなどを搭載するヘテロジニアスなコア構成. 必須となる(詳しくは本特集「マルチコアにおけるプロ. をとるものも多い.組み込み用アプリケーションで重要. グラミング」を参照).. な画像処理・音声処理などの信号処理をこのような構成. 組み込み用途ではさらに難易度の高い並列化プログラ. で効率よく処理することが目的である.. ミングを要求されるであろう.基本的に,プログラムの 動作中に各々が独立に動作できる処理をスレッドとして. マルチコアにおけるソフトウェア. 切り出す部分までは通常の並列プログラミングと同一で. それでは,これらのマルチコアプロセッサによって,. を実行する場合には,さらにデータをローカルメモリに. アプリケーションのプログラミングの様子はどのように. 収まる単位で分割し,適切なタイミングでプロセッサコ. 変わっていくのだろうか?. ア間,あるいは主メモリとの通信を行う処理を明示的に. サーバ用途でスループットを重視するようなアプリケ. 記述する必要がある.さらにヘテロジニアスなコア構成. ーションを動作させるような場合には,特にこれまでの. をとるマルチコアプロセッサでは,そのようなコア構成. プログラミングスタイルを変える必要はない.逆に,そ. を OS あるいはミドルウェアが関知していない場合,ど. れ以外の分野では並列処理を意識したプログラムを積極. のスレッドをどのコアで実行するのか指定する必要があ. 的に開発しないと,マルチコアによる恩恵を受けること. るかもしれない.いずれにせよ,組み込み用途でマルチ. ができない.プロセッサの性能向上がこれまでのアプリ. コアプロセッサの持つ能力を最大限に引き出すためには,. ケーションの性能向上を自動的にもたらしてくれる時代. アプリケーションとハードウェア構成の両方を熟知して. はひとまず終わってしまった .. いる必要がある. デスクトップ用途では,これまでの開発ツールを使. マルチコア用の並列プログラム作成は,従来のスーパ. うにしても,POSIX thread library などのスレッドライブ. ーコンピュータ用並列アプリケーション作成のように並. ラリや,Java などの言語レベルでマルチスレッドをサ. 列化およびチューニングに数カ月以上をかけるというわ. ポートしているプログラミング言語,あるいは OpenMP. けにはいかない.製品開発サイクルの短い情報家電分野. などの拡張言語によるマルチスレッドプログラミングが. において市場競争力を維持するためには,質の高いアプ. 9). 14. 47 巻 1 号 情報処理 2006 年 1 月. ある.ローカルメモリを持つマルチコア上でプログラム. .. 10).
(6) 1.マルチコア化するマイクロプロセッサ リケーションを多数,短期間で開発していくことが必須で. のマルチコアプロセッサが複数接続され,大規模な並列. ある.そのためには逐次型プログラムを自動的に並列化. システムを構築することも考えられている.現在の組み. し,さらにプロセッサ近接のキャッシュあるいはローカ. 込み用マルチコアは,Cell のように OS を動かすホスト. ルメモリを有効利用しメモリウォール問題に対応するた. プロセッサと演算を行う並列プロセッサからなるプロセ. めのデータの自動分割配置,またサイズの小さいローカ. ッサが共有メモリに接続されたヘテロマルチプロセッサ. ルメモリと共有メモリ間のデータ転送の DMA コントロー. は,オリジナルの OSCAR マルチプロセッサアーキテク. ラを使ったタスク処理とオーバーラップによるデータ転. チャ. 送オーバーヘッドの隠蔽,プロセッサの電圧・クロック. リとローカルメモリを持つホモジニアスなマルチコアは. 周波数制御,あるいは電源シャットダウンの制御を行う. OSCAR マルチコア. ことができる自動並列化コンパイラの開発が重要となる.. 並列化コンパイラが比較的開発しやすいアーキテクチャ. 11). と同種のアーキテクチャであり,また共有メモ 13),15). のサブセットとなっており,. となっている.. マルチコアの今後. この OSCAR チップマルチプロセッサの特徴は OSCAR. 今後身の回りの多くの情報機器にマルチコアプロセッ. うに設計されているところである.2000 年より 3 年間. サが使用される Multicore Everywhere の時代が到来する. の内閣府ミレニアムプロジェクト NEDO“アドバンスト. と予想される.半導体の集積技術の進歩とともに,集積. 並列化コンパイラ”プロジェクトにてその実用性が高め. されるプロセッサコア数も 4 コア 8 コアと増加し 2010. られた OSCAR マルチグレイン並列化コンパイラ. 年頃には 64 コア以上が集積される. プログラム全体にわたる並列性解析により,ソースプロ. マルチグレイン並列化コンパイラの並列化を支援するよ. .. 14). 16). は,. このように身の回りの IT 機器すべてに導入されてい. グラムからループやサブルーチンコール間の粗粒度タス. き,さらに今後の半導体微細化技術の向上とともにさら. ク並列性,従来のループ並列性,基本ブロック内部のス. に重要性が増すマルチコア技術を押さえることは,日本. テートメント間の並列性を表す近細粒度並列性を階層的. の IT 産業の未来を左右する重要なファクタとなる.こ. に自動抽出する.また抽出された複数粒度のタスク間並. のためには,単にハードウェアの性能だけでなく,アプ. 列性はコンパイル時のスタティックスケジューリング,. リケーション生産性,すなわち開発ツールを含めたソフ. 実行時の柔軟なダイナミックスケジューリング方式によ. トウェア開発の容易性が重要となる.特に,アプリケー. りプロセッサに割り当てられ並列実行される.. ション開発者に,並列処理プログラミングの煩わしさを. さらにプロセッサ動作速度に比べて遅いメモリアクセ. 感じさせずに自動的に,高性能,低消費電力を達成する. スオーバーヘッドを最小化するようにデータはキャッ. ことができるコンパイラを開発することができたマルチ. シュあるいはローカルメモリにフィットするように自. コアが大きな市場をとることができると考えられている.. 動分割される.さらに 2005 年 7 月から開始されている. このためには,ハードウェアを開発してからそのハー. NEDO“リアルタイム情報家電用マルチコア”プロジェ. ドを使用するソフトウェアを開発するのではなく,最初. クトでは,サイズの小さいローカルメモリ間あるいはロ. からソフトウェアの最適化を考慮して,その最適化能力. ーカルメモリと共有メモリ間のデータ転送を,DMA を. をうまく活かすことができるハードウェアの設計,すな. 用いタスク処理とオーバーラップして行いデータ転送オ. わちソフトウェア・ハードウェアの協調設計が重要となる.. ーバーヘッドを隠蔽したり,アプリケーション中の並列. このようなコンパイラ協調型マルチプロセッサア. 性が少ない部分でアイドル状態になるプロセッサの電源. ーキテクチャの例としては OSCAR マルチプロセッサ. を遮断したり,負荷の軽いプロセッサのクロック周波数. と OSCAR マルチグレイン並列化コンパイラ,および. および電圧をきめ細かく制御し消費電力を抑える並列化. OSCAR チップマルチプロセッサ(OSCAR マルチコアプ. コンパイラの開発と,その最適化機能を効果的にサポー. ロセッサ)が開発されている. 11)∼ 13),15). .OSCAR チ. トする図 -6 のようなマルチコアアーキテクチャが研究. ップマルチプロセッサを図 -6 に示す.図に示すとおり,. 開発されている.. OSCAR チップマルチプロセッサはプロセッサコアとロ. 今後,ソフトウェア生産性,実効性能が高く,消費電. ーカルデータメモリ(LDM) ,分散共有メモリ(DSM) ,. 力の低いソフトウェア協調型マルチコアを目指した研究. データ転送コントローラ(DTC)を持つプロセッシング. 開発が世界で行われ,淘汰の時代に入っていくと予想さ. エレメント(PE)が相互結合網により接続され 1 チッ. れる.携帯電話,ゲーム,DVD, ディジタルテレビから. プ上に複数搭載された構成を持つマルチコアプロセッサ. スーパーコンピュータ,さらには電子化の著しい自動車. である.またチップ内部,あるいは外部に PE が共有す. までに導入されていくマルチコアの時代を勝ち抜くため. る集中共有メモリ(CSM)が接続されている.これら. には,産官学のさらなる連携が望まれる. IPSJ Magazine Vol.47 No.1 Jan. 2006. 15.
(7) 特. 集 マルチコアにおけるソフトウェア 経済産業省/NEDOリアルタイム情報 家電用マルチコア(2005.7∼2008.3) . 新マルチコア プロセッサ. CMP 0(( 0) 0) マルチコア マルチコアチップ チップ. PC 0. ・高性能. CPU. (プロセッ サコア0)0). (プロセッサ). LDM/ D-cache. LPM/ I-Cache. (ローカルデータ メモリ/L1データ メモリ /L1データ ) ) キャッシュ. (ローカルプロ グラムメモリ グラムメモリ/ / 命令キャッシュ 命令キャッシュ) ). DTC. (データ 転送コン ) トローラ トローラ). PC 1. (プロ セッサ コア1)1). DSM. PC nn (プロセッサ (プロセッサ コアn)n). ) (分散共有メモリ) (分散共有メモリ. ・低消費電力 ・短 HW/SW 開発期間 ・各チップ間で アプリケーション 共用可. NI (ネットワークイン タフェース ターフェイス ) ) IntraCCN (チップ内結合網:複数バス,クロスバー等 (チップ内結合網: 複数バス、クロスバー等 ) ). ・高信頼性. CSM / L2 Cache. ・半導体集積度と ともに性能向上 マルチコア ((チップ間結合網: 複数バス、クロスバー、多段ネットワーク等 InterCCN チップ間結合網: 複数バス, クロスバー, 多段ネットワーク等 ). (集中共有メモリあるいはL2キャッシュ) (集中共有メモリあるいは L2キャッシュ ). 統合ECU. 開発マルチコアチッ 開発マルチコアチップは情報家電へ プは情報家電へ. 図 -6 情報家電競争力強化を目指したマルチコアプロジェクト. 謝辞 本解説の技術的展開に有益なご議論をいただきま した,STARC プログラム研究“並列化コンパイラ協調 型チップマルチプロセッサ技術” ,NEDO“先進ヘテロ ジニアスマルチプロセッサ”プロジェクト,NEDO“リ アルタイム情報家電用マルチコア”プロジェクトメンバ の皆様に厚く御礼申し上げます. 参考文献 1)Diefendorff, K.: Power4 Focuses on Memory Bandwidth, Microprocessor Report, Vol.13, No.13 (1999). 2)UltraSPARC IV Processor Architecture Overview, Technical White Paper, Sun Microsystems (Feb. 2004). 3)Shiota, T. et al.: A 51.2GOPS, 1.0GB/s-DMA Single-Chip Multi-Processor Integrating Quadruple 8-Way VLIW Processors, ISSCC (2005). 4)Pham, D. et al.:The Design and Implementation of a First Generation CELL Processor, ISSCC (2005). 5)Torii, S. et al.: A 600MIPS 120mW 70uA Leakage Triple-CPU Mobile Application Processor Chip, ISSCC (2005). 6)Goodacre, J. et al.: Parallelism and the ARM Instruction Set Architecture, IEEE Computer Magazine, Vol.38, No.7 (July 2005). 7)木村浩三 他:ディジタル家電統合プラットフォーム UniPhier におけ. 16. 47 巻 1 号 情報処理 2006 年 1 月. るメディアプロセッサ , DA シンポジウム (Aug. 2005). 8)Wall, D. W. : Limits of Instruction-Level Parallelism, Proc. of ASPLOS-IV (1991). 9)Sutter, H.:The Free Lunch is Over: A Fundamental Turn Toward Concurrency in Software, Dr. Dobb's Journal, Vol.30, No.3 (Mar. 2005). 10)http://www.research.ibm.com/cellcompiler/compiler.htm, Compiler Technology for Scalable Architectures, IBM Research. 11)笠原博徳 他:OSCAR (Optimally Scheduled Advanced Multiprocessor) のアーキテクチャ , 電子情報通信学会論文誌 , Vol.J71-D, No.8 (Aug. 1988). 12)Kasahara, H. et al.: OSCAR Multi-grain Architecture and Ite Evaluation, Proc. of IWIA (Oct. 1997). 13)Kimura, K. et al.: Multigrain Parallel Processing on Compiler Cooperative Chip Multiprocessor, Proc. of INTERACT-9 (Feb. 2005). 14)NEDO 電 子 情 報 ロ ー ド マ ッ プ( コ ン ピ ュ ー タ 分 野 ) ,http://www. nedo.go.jp/denshi/roadmap/kouen7.pdf 15)木村啓二 他:シングルチップマルチプロセッサ上での近細粒度並列 処理 , 情報処理学会論文誌 , Vol.40, No.5 (May. 1999). 16)笠原博徳:最先端の自動並列化コンパイラ技術,情報処理学会誌, Vol.44, No.4, pp.384-392 (Apr. 2003). (平成 17 年 12 月 12 日受付).
(8)
図
関連したドキュメント
and Nakano, Y., 2002, Middle Miocene ostracods from the Fujina Formation, Shimane Prefecture, South- west Japan and their paleoenvironmental significance. Tansei-maru Cruise KT95-14
Key words: planktonic foraminifera, Helvetoglobotruncana helvetica, bio- stratigraphy, carbon isotope, Cenomanian, Turonian, Cretaceous, Yezo Group, Hobetsu, Hokkaido.. 山本真也
We have investigated rock magnetic properties and remanent mag- netization directions of samples collected from a lava dome of Tomuro Volcano, an andesitic mid-Pleistocene
また,文献 [7] ではGDPの70%を占めるサービス業に おけるIT化を重点的に支援することについて提言して
Max-flow min-cut theorem and faster algorithms in a circular disk failure model, INFOCOM 2014...
administrative behaviors and the usefulness of knowledge and skills after completing the Japanese Nursing Association’s certified nursing administration course and 2) to clarify
Cisco IOS ® XE ソフトウェアを搭載する Cisco ® 1000 シリーズ
[r]
