コミュニティの影響力を考慮した
Collective Learning
の提案と
スモールワールドネットワーク上でのノルムの収束について
渋澤亮介
1∗菅原俊治
21
早稲田大学基幹理工学部情報理工学科
2
早稲田大学基幹理工学研究科情報理工学専攻
Abstract: 本稿では,影響力を考慮した Collective Learning を提案し,ネットワーク上のエージェ
ントが協調ゲームの繰り返しから学習する事で,ノルムが全体に伝播し,収束する様子を調査する. 人間社会では協調や調整を行う際に,情報交換によって合意するだけでなく,それまでのインタラク ションの経験から適切な行動をノルムとして同定し,直接的な会話が無くても適切な行動をとる.同 様に,マルチエージェントシステムへノルムを導入し,明確な情報交換やそれに伴う推論が無くて も,システムの各所で適切な協調を実現できると考えられる.このため,学習を通じてノルムが広 がる仕組みとその様子を調査することが重要となる.本研究では,人間社会において周辺を観測し, そこから自分の行動を決定する過程を再現した Collective Learning (CL) という学習の枠組みに,各 エージェントのネットワーク上の位置に基づく影響力を導入し,ノルムを伝搬させる仕組みを提案す る.スモールワールドネットワーク上で評価実験を行い,高い確率でノルムの収束に成功すること, またネットワーク生成の各パラメータが与える収束への影響を調べた.
1
はじめに
近年,マルチエージェントシステムの分野において, ノルムはエージェントの協調や調整を効率的に実現す るメカニズムとして注目されている.人間社会におい ても,我々は明確な情報交換することなくノルムにし たがって自らの振る舞いを決定することは多い.具体 的には,車の右側・左側通行,列に並んでいる時に割り 込みをせず一列に並ぶなどが挙げられる.同様にエー ジェントも人工社会でノルムを遵守させることで競合 を避け,行動を効率化できる.そのようなノルムは,法 律のようにオーソリティが導入することもあるが,効 果的なノルムは環境に依存し,適切なものを与えるこ とは容易ではない.したがって,エージェントが相互 のインタラクションを介して自らノルムを学習し,そ れと整合する行動がコミュニティ内に伝搬することが 望ましい.しかし,ノルムは全エージェントがそれに 従うことで意味を持つ.よって,人間社会においてノ ルムが社会全体に伝播し,収束するメカニズムを解明 し,人工社会にそのメカニズムを実装することでノル ムの収束を促進できる.そのためノルムの収束に貢献 するメカニズムを解明することはマルチエージェント システムの分野において着目されている. このような観点からエージェントシミュレーション を用いたノルムの収束 (拡散) の研究が多数行われて ∗連絡先:早稲田大学基幹理工学部情報理工学科 〒 169-8555 新宿区大久保 3-4-1 E-mail: [email protected] いる.例えば [3] では,Social Leraning という学習の 枠組みを提案し,囚人のジレンマや協調ゲームを用い てノルムをエージェント全体に収束させている.しか し,この研究では完全グラフを想定しているため,現 実の社会構造や計算機システムによるエージェントの つながりを再現しているとは言えない.[2] では,囚人 のジレンマゲームを用いて共通の戦略を持つエージェ ントでグループを構成しているためノルムの収束に類 似している.この研究では,全てのエージェントが周囲 エージェントの総利得の情報と Coupling Strength と いう値を保持し,それの基づいてグループを構成する. Coupling Strength は同じグループに属す仲間の多い人 の方が大きくなるように定義され,他人をグループに 取り込みやすくなる.[1] では,[2] と同様にエージェン トを一つのグループにまとめることを目標としている が,Coupling Strength の代わりにグループを抜けた場 合ペナルティを与える仕組みを導入し,グループ化と その安定化を実現している.また,[4] では,自分とあ るエージェントが繋がっているリンクを他のエージェン トに繋ぎ換える rewiring と,ネットワーク上で自分と 直接繋がっていないエージェントの状態を知ることが できる observation を導入している.大多数の人が採用 しているノルムと整合しない小規模なノルムが局所的 に発生し,全体が一つのノルムに収束しない場合にこ れらの仕組みが有効であることを示した.[5] では,各 エージェントが過去のインタラクションを記憶し,そ の記憶の容量やネットワーク構造の違いがノルムの収束に与える影響を調査している.[7] では,Collective Learning (CL) という学習の枠組みを提案している.こ れはネットワーク上で自分の近くにいるエージェントの 行動から多数決によって自分の振る舞いを決定するも ので,現実の人間関係をよく再現している.しかし,こ れらの研究においてこれまで人間社会やシステムの連 携構造と類似した性質を持つスモールワールドネット ワーク上でノルムの収束を高い確率で実現した研究は ない.また,[7] では Watts と Strogatz のスモールワー ルドモデル (WS モデル) の weak ties の確率 p が 0.8 と大きく,ランダムネットワークに近く,クラスター 性が失われたネットワークでの検証となっている [8]. そこで本研究では,[7] の CL を拡張し,コミュニティ における影響力を導入した CL (influence-baced collec-tive learning, 以下 ICL) を提案し,スモールワールド ネットワーク上でも高い確率でノルムを収束させるこ とを実現する.また,WS モデルのエージェント数,平 均次数,weak ties の確率などのパラメータがノルムの 収束に与える影響についても調査する. 本書の構成は以下の通りである.まず,次節で準備 として協調ゲームとスモールワールドモデルについて 述べる.第 3 節では,提案する ICL について説明する. 第 4 節では,評価実験を行いその結果について考察し, 第 5 節で,結論と今後の課題について述べる.
2
準備
2.1
協調ゲーム
エージェントの集合を N ={1, …, n} とおく.本研究 で協調ゲームは 2 人ゲームで 2 種類の行動 A ={L, R} に対し,図 1 に示す利得行列で定義する.たとえばエー ジェントが右側通行 (R) か左側通行 (L) の行動に相当 し,同じ行動をとるとき高い利得を得られ,その他で はペナルティを受ける. L R L 1, 1 -1, -1 R -1, -1 1, 1 図 1: 協調ゲームの利得行列2.2
スモールワールドモデル
本研究では,エージェント同士を結ぶネットワーク として,WS モデルを採用する [6].WS モデルは現実 社会や実システムで現れるネットワークが持つ 3 つの 特徴,スモールワールド性,クラスター性,スケール フリー性のうち,スモールワールド性とクラスター性 を持つ.このモデルは,パラメータによって小さい平 均頂点間距離と大きいクラスター係数を持つスモール ワールドにならない場合があるので,一般に WS モデ ルと呼ばれる.WS モデルが持つパラメータには,エー ジェント数 n,平均次数 (友人の数)k,weak ties の確 率 p の 3 つがある. ここで,WS モデルの構成方法を説明する [8]. 1. エージェントを輪になるように配置し,各エー ジェントについて k/2 個先までの両側の隣り合 うエージェントとエッジを繋ぐ. 2. グラフ中の枝の合計 (kn/2) を求め,weak ties の 本数 (pkn/2) を決定する.そして,決定した本数 分の weak ties をランダムに選択する. 3. weak ties のエッジをどちらかのエージェントか ら 1/2 の確率で切り離す. 4. 切り離した枝をランダムに繋ぎ換える.ただし, 初期状態でエッジが繋がっていたエージェントは 選択しない. このように WS モデルは単純なモデルのため,次数分 布のベキ則 (スケールフリー性) のように説明できない 現象はあるが,その単純さゆえに数学的な解析が容易 というメリットもある.なお,エージェント i の次数 を ki,i の隣接エージェントの集合を Niと表す.3
提案手法
3.1
ICL の流れ
ここでは,ネットワーク構造上の影響力を CL に導 入した ICL を提案する.そのプロセスの流れは以下の 通りである. 1. 隣接するエージェント i それぞれに対する行動 をそれまでの学習結果である Q 値を用いて決定 する. 2. 影響力を考慮したアンサンブル法を用いて手順 1 で決定した行動から一つを選択し,自らの行動と する. 3. 手順 2 で選択した行動をもって i と隣接する全エー ジェント Niと協調ゲームを行い,報酬を得る. 4. 報酬値を用いて隣接するエージェントそれぞれに ついて Q 値を更新する. 5. 手順 1∼4 を繰り返すことで学習を進める.1 単位時間に手順 1∼手順 4 を全エージェントが行い, 各隣接エージェントと 1 回ずつゲームを行う.以下具 体的に説明する.
3.2
隣接エージェントに対する行動決定
隣接する全てのエージェントに対してそれぞれ行動 を決める.たとえば5つのエージェントと隣接してい たら5つの行動が決まる.ここでは,ε-greedy 戦略を 用い,(1− ε) の確率で大きな Q 値を持つ行動を選択 し,ε の確率でランダムに行動を選択する.ここでエー ジェント i が j∈ Niに対して選択した行動を aij ∈ A とおく.3.3
影響力
影響力の初期値を w0,i = kiとする.ここで,kiは エージェント i の次数である.時刻 t におけるエージェ ント i∈ N の影響力 wt,iは各ゲームごとに以下の式で 更新する.wt,i = (1− β)wt,i+ S(ai, aj)βrt,jwt,j (1)
ここで j は i と直前にゲームをしたエージェントで,rt,j はそのゲームでの報酬である.また ai,ajは i と j の 直前の行動であり,S(ai, aj) は一致を表す符号関数で, S(ai, aj) = { +1 if ai= aj −1 otherwise. (2) とする.また,β は影響力更新の学習率とする.隣接 するエージェント全てとこの更新を行うが,その順番 はゲーム毎でランダムとなる.
3.4
影響力を考慮したアンサンブル法
アンサンブル法は,時刻 t において 3.2 節の方法で 各隣接エージェントに対して決めた行動から一つの行 動を選択するために使う.最終的に選ばれる行動 ai tは 以下に定義する優先度 pi t(a) を用いて ait= arg max a∈A pit(a) (3) とする.本研究では pi t(a) を影響力を考慮した多数決 で決定する. pit(a) = n ∑ j∈Ni wt,jδ(a, at,j) (4) 表 1: 収束成功率と平均利得 (提案手法),実験 1 エージェント数 (n) Norm(L) Norm(R) 成功率 (%) 利得 50 49 51 100 1.0 100 38 62 100 1.0 200 55 45 100 0.99 400 49 51 100 0.99 600 46 54 100 0.99 1000 48 52 100 0.99 ここで wt,jは j∈ Niの影響力である.また,δ(a1, a2) は δ(a1, a2) = { 1 if a1= a2 0 otherwise. (5) と定義する.但し,ak∈ A である.4
実験と考察
4.1
実験内容
評価実験により提案手法の有効性と,WS モデルの パラメータがノルムの収束に与える影響を調べる.こ こでは 2 種類の行動から適切な行動を Q 学習で求め, エージェントの行動と利得の推移をエージェントシミュ レーションを用いて調査する.Q 学習の学習率 α は 0.1 とし,学習戦略を ε-greedy とし,ε = 0.05 とした.ま た,影響力の学習率 β も 0.1 とする. ここでは [7] に合わせ 9 割のエージェントが Q 値に 基づき同じ行動を適切と判断したときノルムの収束に 成功した(広く伝播した)と判断する.以下で述べる 実験結果は 100 回の試行の平均値である.また以下で 述べる実験において,[7] で提案された既存手法 (CL) と提案手法の結果を比較する. 実験 1 では,全体のエージェント数 n(= |N|) の値 を 50∼1000 で変動させ,時刻 t = 100 までの平均利得 の変化を調査する.このとき,平均次数 k は 12,weak ties の確率 p は 0.1 と固定した.実験 2 では,全体の エージェント数 n は 1000,weak ties の確率 p は 0.1 と 固定し,平均次数 k を 4∼20 で変動させた.最後に実 験 3 では,weak ties の確率 p を 0∼0.1 で変動させた. このときエージェント数 n は 1000,平均次数 k は 12 と固定した.4.2
実験結果
4.2.1 実験 1:エージェント数 n による影響 実験 1 における提案手法を用いた平均利得の推移の グラフを図 2 に,既存手法を用いたときの推移を図 3図 2: 平均利得の推移 (提案手法),実験 1 図 3: 平均利得の推移 (既存手法),実験 1 に示す.また提案手法において 100 回の試行で収束し たノルムの内訳,ノルム収束の成功率,最後の時刻に おける平均利得を表 1 に,既存手法を用いた場合を表 2 に示す. 図 2 から,提案手法ではエージェント数 n の増加に 伴い利得の収束(つまりノルムの収束)は遅くなるが, エージェント数 n が大きくてもノルムの収束に成功し ている (表 1 も参照). 既存手法のグラフ図 3 を見ると,エージェント数 n の変動による収束の速度への影響はあまり見られない が,平均利得は 0.86 程度が上限となっている.表 2 を 見ると,エージェント数 n が大きくなるとノルム収束 表 2: 収束成功率と平均利得 (既存手法),実験 1 エージェント数 (n) Norm(L) Norm(R) 成功率 (%) 利得 50 56 44 59 0.86 100 54 46 34 0.82 200 46 54 3 0.76 400 52 48 1 0.76 600 45 55 0 0.75 1000 55 45 0 0.75 図 4: 平均利得の推移 (提案手法),実験 2 図 5: 平均利得の推移 (既存手法),実験 2 の成功率が急激に低下している. 4.2.2 実験 2 :平均次数 k による影響 実験 2 における提案手法を用いた平均利得の推移の グラフを図 4 に,既存手法を用いたときの推移を図 5 に示す.また提案手法おいて 100 回の試行で収束した ノルムの内訳,ノルム収束の成功率,最後の時刻にお ける平均利得を表 3 に,既存手法を用いた場合を表 4 に示す.図 4 から,提案手法では平均次数 k がの増加に 伴い利得の上昇が早くなったことが分かる.表 3 より, 表 3: 収束成功率と平均利得 (提案手法),実験 2 平均次数 (k) Norm(L) Norm(R) 成功率 (%) 利得 4 46 54 16 0.80 6 50 50 84 0.93 8 50 50 98 0.98 12 48 52 100 0.99 14 46 54 100 0.99 20 46 54 100 1.0
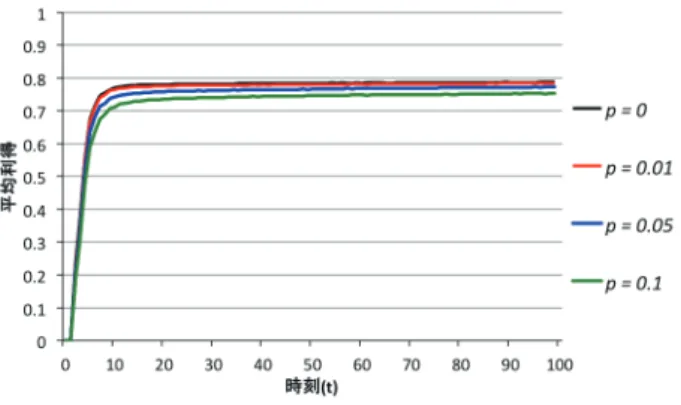
表 4: 収束成功率と平均利得 (既存手法),実験 2 平均次数 (k) Norm(L) Norm(R) 成功率 (%) 利得 4 50 50 0 0.75 6 57 43 0 0.75 8 41 59 0 0.75 12 55 45 0 0.75 14 58 42 0 0.75 20 52 48 0 0.75 図 6: 平均利得の推移 (提案手法),実験 3 平均次数 k が小さいときはノルム収束の成功率は低い が,k が 12 以上ではノルム収束の成功率は 100%であ る.ただし,図 4 から次数 k が小さいときは,依然と して上昇傾向にあり,さらに続ければ成功率も高くな ると考えられる. 既存手法を用いたときのグラフ図 5 を見ると,平均 次数 k の変動による収束の速度への影響はあまり見ら れず,さらに平均利得も 0.75 程度が上限となっている. 表 4 を見ると,平均次数 k に関わらずノルム収束に成 功していない. 4.2.3 実験 3:weak ties の確率 p による影響 実験 3 における提案手法を用いた平均利得の推移の グラフを図 6 に,既存手法を用いたときの推移を図 7 に,提案手法において 100 回の試行で収束したノルム の内訳,ノルム収束の成功率,最後の時刻における平 均利得を表 5 に,既存手法を用いた場合を表 6 に示す. 表 5: 収束成功率と平均利得 (提案手法),実験 3 weak ties の確率 (p) Norm(L) Norm(R) 成功率 (%) 利得
0 43 57 3 0.94 0.01 49 51 49 0.92 0.05 41 59 97 0.98 0.1 48 52 100 0.99 図 7: 平均利得の推移 (既存手法),実験 3 表 6: 収束成功率と平均利得 (既存手法),実験 3 weak ties の確率 (p) Norm(L) Norm(R) 成功率 (%) 利得
0 48 52 0 0.79 0.01 53 47 0 0.78 0.05 51 49 0 0.77 0.1 55 45 0 0.75 図 6 から,始めは weak ties の確率 p が小さい方が利得 の上昇が早いが,最終的には weak tiew の確率 p が大 きい方が利得の収束が早いことが分かる.表 5 を見る と,weak ties の確率 p が小さいときはノルム収束の成 功率は低いが,weak ties の確率 p が大きいと 100%ノ ルムの収束に成功している.ただしこの場合も,平均 利得は上昇傾向にあり継続すればさらに成功率と利得 も上がると予想できる. 既存手法を用いたときのグラフ図 7 を見ると,weak ties の確率 p の変動による収束の速度への影響はあま り見られず,また平均利得も 0.79 程度が上限となって いる.表 6 を見ると,weak ties の確率 p に関わらず一 度もノルムの収束に成功していない.また上昇傾向も 見られない.
4.3
考察
4.3.1 実験 1:エージェント数 n による影響 実験 1 の結果から,既存手法を用いたときは最終的 な利得は低いが,利得の上昇は提案手法より早い.こ れは,既存手法が影響力を考慮せず単純な多数決によ り自らの行動を決めているためと考えられる.一般に 多数決 [7] や近隣エージェントの利得 [2] のみで行動を 選択すると,時間が経ってもきわめて狭い範囲でのみ の影響に限定される.そのため自らと隣接するエージェ ントの中で少数派の行動は無視され,多数派の行動と なる.近くの多数派のみを対象としているため,収束は早い.しかし,ノルムの成功率も上がらず,平均利 得も頭打ちとなる.しかし自らと隣接するエージェン トの中に少数派の行動が存在し,それが行動を変化さ せないという事は,その先に大きなコミュニティが存 在してもこれを無視することになる.他方,提案する ICL では影響力がこれを伝搬させ,収束に導く.結果 として [4] における observation と同様な効果をもたら す.そのため仮に少数派の行動に合わせ一時的に自ら の利得が下がっても全体の整正のために少数派の行動 を選べる.それにより利得の上昇は遅くなるが,最終 的にはノルムの収束に成功する.またこのためエージェ ント数 n が大きくなると利得の収束が遅くなる.これ は伝播の範囲が広くなるためである. 4.3.2 実験 2:平均次数 k による影響 実験 2 の結果を見ると,実験 1 と同様既存手法を用 いたときの方が利得の上昇が早い.この理由は 4.3.1 で 述べたのと同様と考えられる.. 平均次数 k の増加に伴いネットワーク上のリンクの 本数が増え,weak ties の本数も増える.その結果,距 離的に遠いエージェントとインタラクションを行う機 会が増えるため局所的な小規模のノルムの発生を防ぎ, 利得の収束(つまりノルムの収束)が早くなる.また, 平均次数 k が小さいとインタラクションの相手が減る ため隣接エージェントの中での収束は早い.そのため 平均次数 k が小さい方が始めは利得の上昇が早い.し かし距離的に遠いエージェントとインタラクションを 行う機会が少ないため局所的なノルムが発生しやすく, 最終的なノルム収束に時間がかかり,成功率も低い. 4.3.3 実験 3:weak ties の確率 p による影響 実験 3 の結果を見ると,実験 1∼2 と同様既存手法を 用いたときの方が利得の上昇が早い. weak ties の確率 p が小さいと距離的に近いエージェ ント同士でインタラクションを行う機会が増すため局 所的なノルムの収束は早く,その結果利得の上昇が早 い.しかし 4.3.2 で述べた様に,距離的に遠いエージェ ントとインタラクションを行う機会が少なく,局所的な ノルムの発生によりノルム収束の成功率は低い.weak ties の確率 p が大きいと距離的に遠いエージェントと 多くインタラクションを行う事で局所的なノルムの発 生を防ぎ,ノルムの収束が促進される.
5
結論と今後の課題
本研究では,[7] の CL を拡張した ICL を提案し,WS モデル上でのノルムの収束を調査した.また,エージェ ント数や平均次数,weak ties の確率がノルムの収束に 与える影響を調査した.実験から,ICL は既存手法で ある CL よりもよい結果が得られた.さらに,エージェ ント数や平均次数,weak ties の確率がノルムの収束に 与える影響も明らかにし,いずれの場合も既存手法に 比べ,高い成功率を実現した. 今後の課題として,WS モデル以外の複雑ネットワー クのモデル上での実験が必要である.また,より現実 社会の再現性を高めることも必要である.例えば,時 間が進むにつれエージェントの繋がりが変化する仕組 みも考えられる.本研究は科研費 (23650075) の助成を 受けたものです。参考文献
[1] Mohammad Rashedul Hasan and Anita Raja. Emergence of Cooperation using Commitments and Complex Network Dynamics. In Proceedings
of the 2013 IEEE/WIC/ACM International Joint Conference on Intelligent Agent Technology, 2013.
[2] Mohammad Rashedul Hasan and Anita Raja. Emergence of Multiagent Coalition by Leverag-ing Complex Network Dynamics. In ProceedLeverag-ings
of The Fifth International Workshop on Emergent Intelligence on Networked Agents, 2013.
[3] Sandip Sen and Stephane Airiau. Emergence of Norms Through Social Learning. In Proceedings
of IJCAI, 2007.
[4] Daniel Villatoro, Jordi Sabater-Mir, and Sandip Sen. Social Instruments for Robust Convention Emergence. In Proceedings of IJCAI, 2011. [5] Daniel Villatoro, Sandip Sen, and Jordi
Sabater-Mir. Topology and memory effect on
conven-tion emergence. In Proceedings of the 2009
IEEE/WIC/ACM International Joint Conference on Intelligent Agent Technology-Volume 02, 2009.
[6] Duncan J. Watts and Steven H. Strogatz. Collec-tive dynamics of ’small-world’ networks. In
Pro-ceedings of Nature, Vol. 393, pp. 440–442, 1998.
[7] Chao Yu, Minjie Zhang, Fenghui Ren, and
Xudong Luo. Emergence of Social Norms through Collective Learning in Networked Agent Societies. In Proceedings of AAMAS, 2013.
[8] 増田直紀, 今野紀雄. 複雑ネットワークの科学. 産 業図書, 2005.