Chang Peng (
48
0
0
全文
(2)
(3)
(4)
(5)
(6)
(8)
(10)
(11)
(12)
(13)
(14)
(18)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
(29)
(30)
(31)
(32)
(33)
(35)
(36)
(38)
(39)
(40)
(41)
(43)
(45)
(46)
(47)
(48)
図
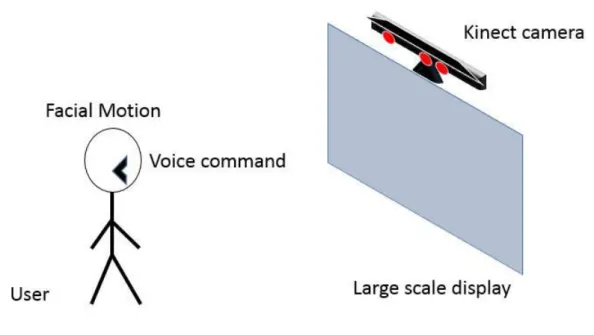
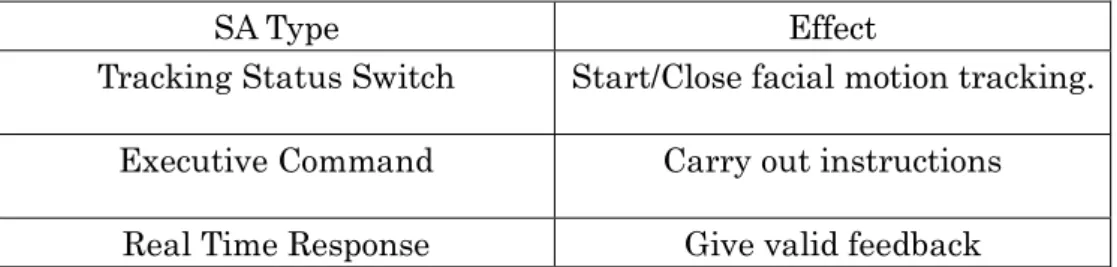


+7
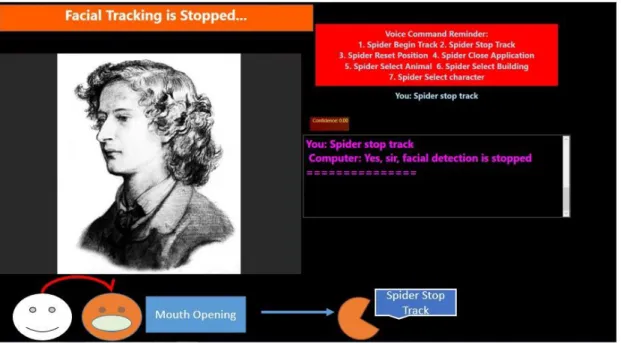
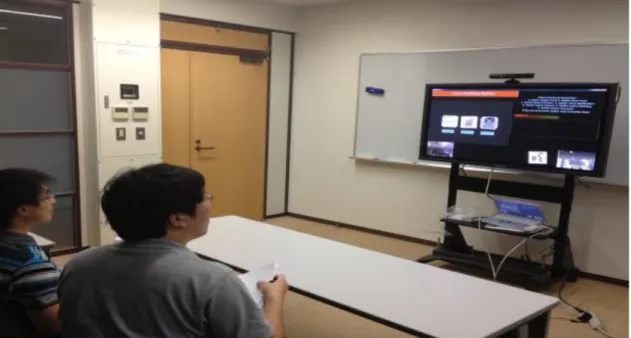



関連したドキュメント
And then we present a compensatory approach to solve Multiobjective Linear Transportation Problem with fuzzy cost coefficients by using Werner’s μ and operator.. Our approach
Zaslavski, Generic existence of solutions of minimization problems with an increas- ing cost function, to appear in Nonlinear
In [10, 12], it was established the generic existence of solutions of problem (1.2) for certain classes of increasing lower semicontinuous functions f.. Note that the
S.; On the Solvability of Boundary Value Problems with a Nonlocal Boundary Condition of Integral Form for Multidimentional Hyperbolic Equations, Differential Equations, 2006, vol..
Infinite systems of stochastic differential equations for randomly perturbed particle systems in with pairwise interacting are considered.. For gradient systems these equations are
More precisely, suppose that we want to solve a certain optimization problem, for example, minimization of a convex function under constraints (for an approach which considers
In this work, we present an asymptotic analysis of a coupled sys- tem of two advection-diffusion-reaction equations with Danckwerts boundary conditions, which models the
GENERAL p-CURL SYSTEMS AND DUALITY MAPPINGS ON SOBOLEV SPACES FOR MAXWELL EQUATIONS..
