論文
発話テキストへのキャラクタ性付与のための音変化表現の分類
宮崎 千明
†・佐藤 理史
†「こりゃひでえ」(元の形:「これはひどい」)のような音変化表現は,対話エージェント の発話や小説のセリフの自動生成において,話者であるキャラクタを特徴付けるための 強力な手段となると考えられる.音変化表現を発話のキャラクタ付けに利用するため に,本研究では,(i)キャラクタの発話に現れる音変化表現を収集し,(ii)それらを基に,
音変化表現を人為的に発生させるための知識を整理した.具体的には,収集した音変化 表現を現象と生起環境の観点で分類し,137種類のパターンとして整理した.そして,
これらのパターンが小説やコミックで用いられる音変化表現の80%以上をカバーする ことを確認した.さらに,(iii)音変化表現がキャラクタらしさを特徴付ける手段になる という仮説を検証するために,小説やコミックにおける発話文の話者(キャラクタ)を 推定する実験を行い,音変化表現のパターンの情報を利用することで,推定性能が向上 するキャラクタが存在することを確認した.
キーワード:音変化,キャラクタ,発話テキスト
Classification of Phonological Changes Reflected in Text:
Toward a Characterization of Written Utterances
Chiaki Miyazaki† and Satoshi Sato†
Phonological changes reflected in text can be powerful in characterizing utterances of dialogue agents or characters’ lines in narratives. To use phonological changes to automatically characterize utterances, (i) we collected phonologically changed expres- sions from characters’ written utterances and (ii) formalized the knowledge required to generate phonologically changed expressions. In particular, we categorized the expressions into 137 patterns by analyzing them from the points of the phenomena concerned and the environments of the occurrences. We experimentally confirmed that the patterns cover more than 80% of the phonologically changed expressions used in novels and comics. Furthermore, (iii) to investigate whether phonological change patterns can be effective in characterization, we conducted an experiment that estimated speakers (characters) of the utterances and confirmed that the infor- mation on phonological changes improved the performance of speaker estimation for several characters.
Key Words: Phonological Changes, Characters, Written Utterances
†名古屋大学大学院工学研究科, Nagoya University Graduate School of Engineering
1 はじめに
登場人物(キャラクタ)は小説,コミック,アニメ,ドラマ,映画などの物語世界における重要な 構成要素の一つであり,ライトノベルのように「キャラクタ中心の物語」(メイナード2012)すら 存在する.近年は,ユーザの命令に従ってタスクを実行したり,会話をしたりする対話エージェン トにおいても,エージェントのキャラクタが重視されるようになり,マイクロソフトの「りんな」1 をはじめとして,特定のキャラクタを冠した対話エージェントが数多く作られている2,3,4,5.
物語でも対話エージェントでも,それぞれのキャラクタの発話には,それぞれのキャラクタらし さが表れる.特定の人物像(キャラクタ)と結びついた話し方の類型は役割語(金水2011a)と呼ば れ,「老人語」「幼児語」「お嬢様言葉」など,どのようなキャラクタがどのような表現を使うのか,
文法的な特徴はあるか(金水2011b)などについて,様々な研究が行われてきた.
我々が目指しているのは,キャラクタらしさを表す言語的特徴をうまく捉えて,その特徴を備え た発話テキストを自動生成する仕組みを実現すること,そして,その仕組みを対話エージェントの 発話の自動生成や,小説の自動生成(佐藤2015)に適用することである.我々はこれまで,文末表 現をはじめとする機能語の語彙選択に着目し,例えば,「これはひどいな」という発話を「これはひ どいわね」のように変換する手法(Miyazaki, Hirano, Higashinaka, Makino, and Matsuo 2015;宮 崎,平野,東中,牧野,松尾,佐藤2016)を提案してきた.しかしながら,機能語の語彙選択によ る表現力には限界がある.具体的な課題としては,性別や年代といった大まかなキャラクタらしさ を表現することはできても,それ以上に細かなキャラクタらしさを表現することが難しい点が挙げ られる.例えば,「これはひどいな」の文末表現「な」を「や」に置き換えて「これはひどいや」と すると,「どちらかというと男性らしい」「それほど高齢ではなさそう」という程度のキャラクタら しさは表現できても,これに加えて「もう少し粗野な感じにしたい」といった細かな調整は難しい.
そこで,キャラクタらしさの表現力を高める方策として新たに着目したのが,「こりゃひでえや」
(元の形:「これはひどいや」)のような,発話テキストに文字として現れる音変化である.音変化 を任意の発話テキストに対して人為的に施す仕組みを作れば,これを利用してキャラクタらしさの 表現力を高めることができると考えられる.この仕組み作りに向け,本研究では,テキストに文字 として現れる音変化を音変化表現と名付け,日本語のキャラクタの発話に現れる音変化表現にどの ような種類が存在するのかを調査する.具体的には,音変化表現と呼ぶべき事例を収集し,どのよ うな環境下でどのような音変化が起きるかを示すパターンとして整理する.
音変化表現のパターンを分類する目的は2つある.1つ目は,音変化表現の生成のためである.
1 https://www.rinna.jp/
2 https://www.nttdocomo.co.jp/service/shabette concier/shabette chara/
3 http://line.froma.com/
4 http://mezamane.com/
5 https://narikiri-qa.jp/oreimo-ayase/login.html
具体的には,どのような環境下でどのような音変化が起きるかを示すパターンを作成すれば,「ひ どい」から「ひでえ」や「ひどーい」を生成するなど,音変化のない表現から音変化のある表現を 人為的に生成することができると考えている.人為的に生成された音変化表現は,形態素解析用の 辞書に登録して利用するなどの用途も考えられる.2つ目は,発話テキストに表れるキャラクタら しさの分析,および,発話テキストへのキャラクタらしさの付与のためである.一口に音変化表現 と言っても,「ひでえ」と「ひどーい」とでは,その言葉を発する人物として想像されるキャラク タが大きく違ってくる.音変化表現をパターンとして分類することは,この違いを捉えるうえで非 常に意味がある.小説やコミックの発話テキストの分析においては,発話に現れる音変化表現のパ ターンを調べることで個々のキャラクタの特徴を捉えることができ,対話エージェントの発話や小 説のセリフの自動生成においては,特定のパターンの音変化表現を使用することで,生成する発話 やセリフにキャラクタらしさを付与できるようになると考えている.
音変化は従来より音声学や音韻論の観点から分析されており,『現代言語学入門2日本語の音声』
(窪薗1999)で取り上げられているように,「早う」のようなウ音便が子音+母音の連続から子音が消
えて母音が残る現象(e.g., haya + ku→hayau→hayoo)であること(p. 40),幼児が「何ですか」
を「何でちゅか」と言うのは発音器官が未発達なためにサ行の子音を破擦音の[tʃ]で代用する現象 であること(p. 44),「すごい」と「すげえ」のような丁寧な発音とぞんざいな発音の間に見られる 音変化は母音融合とそれに伴う代償延長で構成される現象であること(pp. 182–183),「書いておこ う」が「書いとこう」に変化するのは母音で始まる音節を避けようとする現象であること(p. 218),
「めえ(目)」のように近畿方言の1モーラ語が2モーラの長さに発音されるのは1モーラの長さの 語を避けようとする制約による現象であること(p. 224)など,様々な現象について既に知られてい る.これに対し,本研究で行いたいのはテキスト処理の観点からの分析であり,テキストに文字と して現れる音変化をテキスト処理で利用しやすい知識として整理するのが本研究の目的である.
本研究では,音変化表現のパターンを提案するとともに,小説やコミックのキャラクタの発話を 対象とした検証実験を通して,本研究で提案するパターンの網羅性を確認する.さらに,発話文の 話者(キャラクタ)を推定する実験を通して,音変化表現のパターンが,発話のキャラクタらしさ を特徴付けるための有効な手段となることを示す.
2 関連研究
話者に応じた発話生成の研究としては,例えば,話者の性格(Mairesse and Walker 2007)や印 象(沈,菊池,太田,三田村2012),年齢・性別などの人物属性(Miyazaki et al. 2015),特定の話 者および聴者との関係性(Li, Galley, Brockett, Spithourakis, Gao, and Dolan 2016)に応じた発話 の生成が行われてきた.これらの研究では,話者らしさを表現するための特徴として,様々な語彙 的・統語的・意味的・語用論的な特徴,および,抽象化された意味的な特徴(単語埋め込み表現)
が利用されている.本研究で扱う音変化表現も,話者らしさを表現するための特徴の一つとなると 考えられる.
日本語の音変化について調査・整理した文献に,「日本語話し言葉コーパスの構築法」の第2章
(小磯,西川,間淵2006)や,「研究社 日本語口語表現辞典」の付録(山根,佐藤,松岡,奥村2013)
がある.前者では,話し言葉コーパスの音声を書き起こすうえで問題となる,様々な音変化の具体 例が列挙・整理されている.後者では,日本語の学習者が利用することを想定して,日常の会話に よく現れる音変化が列挙されている.いずれの文献も,キャラクタの発話で用いられる可能性のあ る音変化表現を把握するための重要な資料である.しかしながら,キャラクタの発話を対象として 調査・整理されたものではないので,そこで挙げられている音変化が,キャラクタの発話に現れる 音変化をどの程度カバーしているのかは明らかでない.
日本語の音変化を工学的に処理する研究としては,既知の語に対して長音記号や小書き文字が挿 入されるなどしてできた非標準的な表記に対する形態素解析(笹野,黒橋,奥村2014;斉藤,貞光,
浅野,松尾2017)があり,例えば,「冷たーーーい」や「冷たぁぁぁい」(笹野 他2014),「うっつら うっつら」や「だいちゅき」(斉藤 他2017)といった表記を形態素として正しく解析するための方 法が提案されている.斉藤ら(斉藤 他2017)は,非標準的な表記(崩れ表記)と標準的な表記(正 規表記)をペアにしたアノテーションデータを用いて,表記の崩れ方に関する多様なパターンを自 動抽出する方法を提案している.これに対し,本研究のように人手でパターンを作成する枠組みで 多様性を追求するのは難しい.しかしながら,キャラクタの発話において頻繁に観察される音変化 表現にはそれほど多くのバリエーションはなく,人手でも主要なパターンは列挙できると考えられ る.本研究では,日本語のキャラクタの発話で観察される音変化表現のパターンを,ある程度の網 羅性を持った知識として予め整理しておくことで,アノテーションデータを用意しなくても,キャ ラクタの発話を対象とした音変化表現の分析や生成が可能となる状態を目指す.
3 音変化表現の種類に関する分析
日本語のキャラクタの発話テキストに現れる音変化表現にどのような種類が存在するのかを把握 するために,小説やコミックに登場するキャラクタなどの発話,および,日本語の口語表現に関す
る文献(小磯 他2006;山根 他 2013)を参照し,音変化が起きている表現(音変化表現)と考えら
れるものを手作業で収集した.本研究では,音変化表現をおおよそ次のようなものと捉える.
音変化表現
元の形から一部の音が変化して派生したと思われる表現.
ここで,元の形とは,小型の国語辞書の見出し語として採用されているような,現代の日本語話者 の間で広く定着した表現を想定する.
音の違いを捉える観点には,音素・モーラ・アクセント・イントネーションなどがあり,どの範 囲での変化を音変化とみなすかを厳密に定義することは難しい.そのため,本研究では,原則とし てかな表記に基づいて音の変化を捉える.すなわち,「元の形とかな表記が異なる場合,音が変化 した」と捉える.ただし,以下の例外がある.
例外a ひらがなとカタカナは同一視する.
例外b 母音を表す小書き文字(ぁ・ぃ・ぅ・ぇ・ぉ)は,通常の文字(あ・い・う・え・お)と 同一視する.
例外c 長音記号は,直前のかな文字(漢字の場合はその読み)の母音部分を表すかな(あ・い・
う・え・お,のいずれか)と同一視する.
例外d エ段の長音を表す「い」と「え」は同一視する.
例外e オ段の長音を表す「う」と「お」は同一視する.
以下に,上記の方針に沿った音変化表現の判定の具体例を示す.
• 「ひでえ」は元の形「ひどい」の音変化表現とみなす.
• 「ひどーい」は元の形「ひどい」の音変化表現とみなす.
• 「ヒドイ」は,国語辞典の見出し語で一般的に用いられる「ひどい」とかな表記が異なるが,
例外aにより,音変化表現とはみなさない.
• 「ひどぃ」は,国語辞典の見出し語で一般的に用いられる「ひどい」とかな表記が異なるが,
例外bにより,音変化表現とはみなさない.
• 「おーきい」は,国語辞典の見出し語で一般的に用いられる「おおきい」とかな表記が異な るが,例外cにより,音変化表現とはみなさない.「おーきー」もこれに同じ.
• 「せんせえ」は,国語辞典の見出し語で一般的に用いられる「せんせい」とかな表記が異な るが,例外dにより,音変化表現とはみなさない.「せんせー」もこれに同じ.
• 「がっこお」は,国語辞典の見出し語で一般的に用いられる「がっこう」とかな表記が異な るが,例外eにより,音変化表現とはみなさない.「がっこー」もこれに同じ.
• 「ぼうっと」の元の形として「ぼうと」あるいは「ぼっと」が考えられるが,これらの語は 現代の日本語話者にとってやや稀だと感じられる表現なので,「ぼうっと」は音変化表現と はみなさない.「ぼーっと」,「ぼおっと」もこれに同じ.
• 「だって」と「でも」は互いに派生関係にないと思われるので,一方を他方の音変化表現で あるとはみなさない.
• 「なんか」と「など」も互いに派生関係にないと思われるので,一方を他方の音変化表現で あるとはみなさない.
なお本研究では,「だって」と「でも」や「なんか」と「など」のような,派生関係にないと思われ
る語同士の交替は,似たような意味を持つ語の集合から一つを選択する問題(以降,語彙選択)で あると捉える.
次に,収集した音変化表現のそれぞれを現象と生起環境の観点から分析し,共通性のある表現同 士を一つのパターンとしてまとめ上げた.本研究では,現象という用語によって「長音挿入」や「撥 音化」のように「音がどのように変化したか」を指す.生起環境という用語は音変化が起きている 環境のことを指す.それがどのような環境であるかは,音変化が起きている語およびその前後に位 置する語の品詞・活用形・活用型・語形,文における位置などに基づいて分析した.また,パター ンとは現象と生起環境の組み合わせのことを指す.なお本稿では,語の境界や品詞・活用形・活用 型にかかわる用語は,基本的には「益岡・田窪文法」(益岡,田窪1992)に従う.ただし,文字単 位での扱いやすさを考え,子音動詞の語幹・語尾の境界を変更した(例えば,本来なら「書く」の 基本形語幹は「kak」,語尾は「u」であるが,語幹を「書」,語尾を「く」とする).加えて,動詞の 未然形を設けた.
3.1 パターンの作成
音変化表現のパターンの作成においては,まず,収集した音変化表現を現象の観点から分析し,
下記の11種類に分類した.
(1)長音挿入 任意の短母音が長母音に交替すること.表記上は,長音記号や小書き文字の挿入と して現れる(e.g.,「嫌だ」→「嫌だー」).
(2)促音挿入 任意の位置に促音「っ」が挿入されること(e.g.,「すごい」→「すっごい」).
(3)撥音挿入 任意の位置に撥音「ん」が挿入されること(e.g.,「すごい」→「すんごい」).
(4)脱落 (連続する)任意の音が消失すること(e.g.,「食べている」→「食べてϕる」).
(5)母音交替 (連続する)任意の母音が(連続する)別の母音に交替すること(e.g.,「おそい」
→「おせえ」).
(6)子音交替 (連続する)任意の子音が(連続する)別の子音に交替すること(e.g.,「ばっちり」
→「ばっちし」).
(7)促音化 任意の音が促音「っ」に交替すること(e.g.,「走るから」→「走っから」). (8)撥音化 任意の音が撥音「ん」に交替すること(e.g.,「嫌になる」→「嫌んなる」).
(9)ウ音便化 動詞やイ形容詞の活用語尾の先頭が「う」に交替すること.また,それに伴う語幹 末尾の変化(e.g.,「言って」→「言うて」).
(10)縮約 任意の音の系列が,部分的な音素の脱落や交替を伴って,より短い系列へと形を変え
ること(e.g.,「食べなければ」→「食べなきゃ」).
(11)その他 上記(1)〜(10)以外の,任意の音同士が交替すること(1対複数,複数対複数の交替
も可).
なお本稿では,かな表記における1文字を指して音と呼ぶ(音の変化の捉え方は3節冒頭を参照 のこと).母音,子音と言う場合には,かな表記における1文字ではなく音素を指す.また,音が 脱落した箇所は記号ϕによって明示する.
次に,11種類の現象を生起環境の観点から細分化することにより,全部で137種類のパターン を作成した.全137種類のパターンを,付録の表12に示す.各パターンは,現象の観点から見た 11種類の分類(大分類)の配下に作成されている.例えば,長音挿入(L1)の配下には,「嫌だー」
のように文末に長音が挿入されるパターン(P1)や,「ばんざーい」「あたたかーい」のように,文 末にあるイ形容詞型の活用語の基本形・子音動詞ラ行イ形の活用語の命令形・感動詞において,末 尾の「い」「し」「ん」の前に長音が挿入されるパターン(P2),文末に位置する「です」の語中に長 音が挿入されて「でーす」となるパターン(P3)などを設けた.これらの例から分かるように,パ ターンの中には,P1やP2のように,多くの語が該当するパターン(生産性のあるパターン)もあ れば,P3のように,特定の語しか該当しないパターンもある.この違いを示すために,表12にお いて,生産性のあるパターンには“*”を付与した.また,生起環境に何らかの共通点があるパター ン同士をまとめ上げるための中分類も用意した.例えば,P2とP3とは,ともに文末に位置する語 の語中で起こる点において共通しているため,文末の語中における長音挿入(M2)という中分類で まとめ上げてある.中分類を用意したのは,音変化を生成する際の使いやすさを念頭に置いて細か く分類されたパターンを,説明のしやすい粒度でまとめて扱うためである.
3.2 パターンの概要
本節では,3.1節で作成した音変化表現のパターンの概要について述べる.具体的には,音変化 の現象(大分類)ごとに,どのようなパターンを設けたかについて,事例を交えて説明する.説明 の中で,キャラクタの発話における各パターンの出現頻度に言及することがあるが,具体的な頻度 を確認したい場合は,後に4.3節で提示する図3を参照されたい.
3.2.1 長音挿入(L1)
長音挿入は,文末への長音挿入(M1),文末の語中における長音挿入(M2),および,その他の長 音挿入(M3)という中分類に区分した.長音挿入の中で特に多く観察されるのは,「嫌だー」(元の 形:「嫌だ」)のような文末への長音挿入(M1; P1と同義)である.「あたたかーい」(元の形:「あ たたかい」)や「でーす」(元の形:「です」)のような,文末にある語の語中(語末以外の位置)に おける長音挿入(M2; P2–P4)が利用される頻度はそれほど高くないが,発話において「あたたか いなー」や「ですよー」のようなM1を使うか「あたたかーい」や「でーす」のようなM2を使う かで,話者がどのような人物であるかに対する印象が違ってくると思われる.
その他の長音挿入(M3)として,文末以外の環境にも現れうるパターン(P5–P8)を用意した.例 えば,「ずーっと」(元の形:「ずっと」)や「ちゃーんと」(元の形:「ちゃんと」)のように,副詞の
語末の「っと」「んと」の前に長音が挿入されるパターン(P5)がある.
なお,ここで言う長音は,「ー」だけでなく「〜」や,ひらがな・カタカナの小書き文字などを 含む.また,文末にある語とは,発話文の末尾にある語だけでなく,引用や伝聞を表す助詞「と」
「って」や「。」「、」「!」などの句読記号の前にある語も含む.
3.2.2 促音挿入(L2)
促音挿入は,文末への促音挿入(M4),イ形容詞・ナ形容詞型の活用語と副詞における促音挿入 (M5),および,その他の促音挿入(M6)という中分類に区分した.促音挿入の中で最も多く観察さ れるパターンは,「走るっ」のように,文末に「っ」が挿入されるパターン(P9)である.P9以外 のパターンがキャラクタの発話において利用される頻度はそれほど高くないが,「すっごい」(元の 形:「すごい」)のように,イ形容詞・ナ形容詞型の活用語や副詞の語頭から二拍目のカ・サ・タ・
パ・ガ・ザ・ダ・バ・ハ行音の前に「っ」が挿入されるパターン(P10)や,「あたたかくって」(元 の形:「あたたかくて」)のように,イ形容詞のテ形の「て(ちゃ)」の前に「っ」が挿入されるパ
ターン(P12),「っという」(元の形:「という」)のように,助詞「と」の語頭に「っ」が挿入され
るパターン(P13)はしばしば観察される.
なお,P10およびP11(語頭から二拍目・三拍目への促音挿入)の生起環境は,日本語の促音は 母音の後のカ・サ・夕・パ行音の前で起こり,外来語や方言の場合は例外的にガ・ザ・ダ・バ行音 およびハ行音の前などでも起こる(浜田1955)とされていることを参考にして設定した.
3.2.3 撥音挿入(L3)
撥音挿入には,「すごい」が「すんごい」に交替するパターン(P15),「おなじだ」が「おんなじ だ」に交替するパターン(P16),「まま」が「まんま」に交替するパターン(P17)の3種が観察され た.ただし,いずれも生産性のあるパターンではない(特定の語しか該当しないパターンである)
ため,これらがキャラクタの発話において観察される頻度は高くない.
3.2.4 脱落(L4)
脱落は,イ形容詞型の活用語における脱落(M8),テ形複合動詞における脱落(M9),語末の「う」
の脱落(M10),および,その他の脱落(M11)という中分類に区分した.脱落の中で最も多く観察さ
れるパターンは,テ形複合動詞における脱落(M9)の一種で,「してϕる」(元の形:「している」)
のように,テ形複合動詞「いる」の語幹の「い」が脱落するパターン(P21)である.その他には,
「けれど」から「れ」が脱落し,「けど」に交替するパターン(P39)や,「だろう(でしょう)」が「だ ろ(でしょ)」に交替するパターン(P25)が多く観察される.
3.2.5 母音交替(L5)
母音交替は,イ形容詞型の活用語における母音交替(M12)と,「せる」「させる」における母音交
替(M13)という中分類に区分した.母音交替の中で最も多く観察されるパターンは,「うるせえ」
(元の形:「うるさい」)のように,イ形容詞型の活用語の基本形の語幹末尾のア段音がエ段音に交 替し,活用語尾の「い」が「え」に交替するパターン(P43)であり,物語作品において特定のキャ ラクタの発話で集中的に用いられる傾向がある.
3.2.6 子音交替(L6)
子音交替は,サ行音と「つ」における子音交替(M14)と,その他の子音交替(M15)という中分類 に区分した.サ行音と「つ」における子音交替(M14)とは,「ちまちた」(元の形:「しました」)や「あ ちゅい」(元の形:「あつい」)のようなもので,幼児風の表現である.このような表現は,クマやイヌ など,人間でない生物のキャラクタの発話では頻繁に観察される(Miyazaki, Hirano, Higashinaka,
and Matsuo 2016)が,小説やコミックに登場する人間のキャラクタの発話においては,それほど
頻繁には観察されない.
3.2.7 促音化(L7)
促音化は,動詞型の活用語における促音化(M16),指示詞における促音化(M17),および,その 他の促音化(M18)という中分類に区分した.促音化は,その他の現象と比べて出現頻度が低いが,
「走っから」(元の形:「走るから」)のように,母音動詞型またはラ行子音動詞型の活用語の基本形 活用語尾の「る」が「っ」に交替するパターン(P53)や,「走ろっか」(元の形:「走ろうか」)のよ うに,動詞型の活用語の意志形活用語尾の「う」が「っ」に交替するパターン(P54)はしばしば観 察される.
3.2.8 撥音化(L8)
撥音化は,ナ行音の撥音化(M19)とラ行音の撥音化(M20)という中分類に区分した.撥音化の 中で最も多く観察されるのは,助動詞「のだ(のです)」が「んだ(んです)」に交替するパターン
(P78)であり,たいていのキャラクタの発話に出現する.次に多く観察されるのは,「走らん」(元
の形:「走らぬ」)のように,助動詞「ぬ」が「ん」に交替するパターンである(P81).ただし,こ のパターンが多く観察されるのは,関西などの方言を話すキャラクタの発話や,物語世界において 支配的な立場にあるキャラクタ(部隊の指揮官など)が話すやや文語調の発話においてである.
撥音化は11種類の現象の中で最も多く観察される現象であり,P78やP81の他にも,様々なパ ターンが多く用いられる.例えば,「走るんは」(元の形:「走るのは」)のように,形式名詞「の」が
「ん」に交替するパターン(P77)や,「走んの」(元の形:「走るの」)のように,母音動詞型または ラ行子音動詞型の活用語において基本形活用語尾の「る」が「ん」に交替するパターン(P86),「な
んも」(元の形:「なにも」)のように,「なに」が「なん」に交替するパターン(P74)は,キャラク タの発話において頻繁に観察される.
3.2.9 ウ音便化(L9)
ウ音便化は,「しもうて」(元の形:「しまって」)や「言うて」(元の形:「言って」)のような,動 詞型の活用語におけるウ音便化(M21)と,「たこうて」(元の形:「たかくて」)や「なつかしゅう て」(元の形:「なつかしくて」)のような,イ形容詞型の活用語におけるウ音便化(M22)の中分類 に区分した.これらは,関西などの方言を話すキャラクタや老人のキャラクタの発話に現れること を想定して作成したものであり,どんなキャラクタの発話にも広く出現するというものではない.
3.2.10 縮約(L10)
縮約は,活用語のテ形と助詞「は」の縮約(M23),指示詞と助詞「は」の縮約(M24),活用語の 基本条件形における縮約(M25),テ形複合動詞における縮約(M26),「という」の縮約(M27),「の うち」の縮約(M28),および,その他の縮約(M29)という中分類に区分した.縮約の中で最も多 く観察されるパターンは,「嫌じゃない」(元の形:「嫌ではない」)のように,ナ形容詞型の活用語 のテ形の「で」と助詞「は」が合わさって「じゃ」に交替するパターン(P93)であり,多くのキャ ラクタの発話に現れる.その他には,「食べちゃう」(元の形:「食べてしまう」)のように,動詞型 の活用語のテ形の「て(で)」と「しまう」が合わさって「ちゃう(じゃう)」に交替するパターン
(P104)や,「食べちゃ」(元の形:「食べては」)のように,動詞型の活用語のテ形の「て(で)」と
助詞「は」が合わさって「ちゃ(じゃ)」に交替するパターン(P94),「食べりゃ」(元の形:「食べ れば」)や「書きゃ」(元の形:「書けば」)のように,動詞型の活用語の基本条件形において,活用 語尾のエ段音とそれに続く「ば」がイ段音と「ゃ」に交替するパターン(P99)などがある.
3.2.11 その他(L11)
L1からL10までのいずれにも当てはまらない音変化表現のパターンが18種類(P120–P137)あ る.その多くが生産性のないパターンであるため,キャラクタの発話において観察される頻度は高 くなく,「気ー使う」(元の形:気を使う)のように,助詞「を」が長音に交替するパターン(P132) や,「そうじゃなければ」(元の形:「そうでなければ」)のように,判定詞「だ」のテ形である「で」
が「じゃ」に交替するパターン(P134),「やはり」が「やっぱ」に交替するパターン(P136)がしば しば見られる程度である.
4 パターンの網羅性の検証
本研究で収集・整理した音変化表現のパターンの網羅性を検証するために,小説・ライトノベル・
コミックの具体的な作品を対象として,表12に示すパターンの他に音変化表現と呼ぶべきものが あるか,どのような表現がどの程度存在するのかを調査した.
4.1 検証用データの作成方法
小説・ライトノベル・コミックの計9作品に含まれるキャラクタの発話1800文(200文×9作 品)に対し,作業者2名で音変化表現へのラベル付けを行った.なお,作業者2名のうち1名は筆 頭著者で,もう1名は著者に含まれない人物である.対象とした作品および発話文の選定は,作者 の異なる9作品において,2名以上のキャラクタの発話が登場する章または話の先頭から順に,発 話部分に含まれる200文を抽出することによって行った.対象とした9作品のうち3作品(『響け!
ユーフォニアム』,『ちはやふる』,『名探偵コナン』)には方言を使用するキャラクタが含まれるが,
これら3作品を利用した理由は,方言の語彙には標準語が音変化した形だとみなせる表現が多く存 在するという仮定に基づき,本研究で提案する音変化表現のパターンの網羅性検証を,より多様な 表現を対象として行いたいと考えたためである.音変化表現に対するラベル付けは,以下の方針に 従って実施した.
音変化表現か否かの判断基準
「元の形から音が変わっていると思われる表現を音変化表現とする.言い換えると,音変化 表現は音が変化する前の元の形を想定できる表現とする」とした.なお,表12に記載のパ ターンはラベル付けの作業者(著者に含まれない人物)には提示しない.
ラベル付けの手順
音変化表現に該当する文字列を“[]”で囲んでマークし,マークした音変化表現の元の形とし て考えられる表現を,音変化表現の右隣に“<>”で囲んだ状態で記入する.
マークする文字列の範囲
どこからどこまでの文字を音変化表現としてマークすべきかについては,厳密な定義をしな い.作業者が「音変化が起きている」と思った文字が含まれていれば,問題ない.
ラベル付けされた結果の例
俺は[知んねえんだ]<知らないのだ>よ
音変化表現としてマークすべき文字列の範囲について厳密な定義をしなかったのは,音変化が起 きている一連の文字列の中から個々の音変化表現を切り出すための基準作りが困難だったためであ る.例えば,「知んねえんだ」をまとめて1つの音変化表現とみなすべきか,「知んねえ」と「んだ」
の2つに分けるべきか,「知ん」「ねえ」「んだ」の3つに分けるべきか,末尾の「だ」は取り除くべ きかなど,あらゆる状況を事前に想定し,基準を作るのは困難であった.明確な基準を設けない代 わりに,マークした文字列の音変化前の形(元の形)を併記することとした.これにより,音変化 表現としてマークされた文字列と元の形として記入された文字列とを比較し,変化した文字を機械
的に抽出できるようにした.例えば,「知んねえんだ」の場合は,元の形として記入された「知ら ないのだ」と比較し,2番目から5番目までの文字(ん,ね,え,ん)が音変化を起こしているこ とが分かる.
以上の理由により,本検証では,音変化を文字単位で扱うこととする.検証用データにおいては,
2名の作業者のうち少なくとも1名のラベル付けの結果から元の形との差分として抽出された文字 を検出対象として利用した.表1に,対象とした作品およびキャラクタの名称,キャラクタごとの 発話文の数,各発話を構成する文字数の平均値,および,元の形との差分として抽出された文字の 数を示す.なお,発話文の数が20に満たないキャラクタは「その他」としてまとめた.
4.2 網羅性の検証方法
元の形との差分として抽出された文字のうち,本研究で提案する137種類の音変化パターンに該 当するものとしないものがどの程度存在するのかを確認する.137種類のパターンに該当するか否 かについて,全ての文字を目視で確認するのは大変な作業であるため,137種類の音変化パターン に該当する文字を自動検出する手段(以降,音変化検出器)を用意し,自動的に検出できなかった 文字に対してのみ目視による確認を行うこととした.
音変化検出器としては,(1)音変化表現辞書との文字列マッチングによる方法と,(2)形態素解 析結果に基づく規則とのマッチングによる方法の2種類を用意した.これは,2種類の方法を併用 することにより,検出性能を高めるためである.(1)を利用するのは,正しく形態素解析されない
(誤った形態素分割や品詞付与が行われた)音変化表現を漏らさず検出するためであり,(2)を利用 するのは,文字列マッチでは扱えない,品詞連接を考慮したマッチングや品詞に付随して出力され る意味的・形態的情報を利用したマッチングを行うためである.
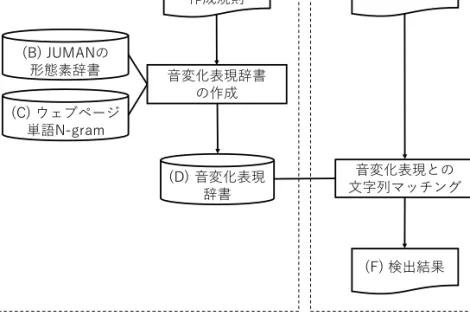
4.2.1 音変化表現辞書との文字列マッチングによる方法
音変化表現辞書との文字列マッチングの処理の流れを図1に示す.まず,検出の事前準備として,
音変化表現辞書を作成する.具体的には,音変化表現作成規則(図1のA;規則の例は表2を参照)
を読み込み,各パターンの音変化表現を作成するための規則を実行するのに必要な語を日本語形態 素解析システムJUMAN version 7.01 (黒橋・河原研究室2012)の形態素辞書(図1のB)から抽 出し,抽出した語に対して規則を適用することで,各パターンに該当する音変化表現を作成する.
このとき,パターンによっては,ウェブページ(2万ページ分)のコーパスを用いて作成された単
語N-gramとその出現頻度6(図1のC)を利用して,出現頻度(つまり,キャラクタの発話にお
いて利用される可能性)が著しく低い語やフレーズを除外したうえで音変化規則を適用する.
表2に音変化表現作成規則および作成される音変化表現の例を示す.音変化表現作成規則は,
6 http://www.ar.media.kyoto-u.ac.jp/member/gologo/lm.html
表1 検証用データに関する統計量
作品名[略称] キャラクタ名[略称] 発話数 平均文字数 音変化文字数 図書館戦争図書館戦争シリーズ(1)
(有川2011)[図書館戦争]
笠原郁 62 15.76 98
堂上淳 45 19.38 30
柴崎麻子 38 21.24 97
小牧幹久 29 20.10 36
その他 26 15.81 30
響け! ユーフォニアム 北宇治高校吹奏楽部 へようこそ(武田2013)
[響け! ユーフォニアム]
加藤葉月 63 11.13 135
黄前久美子 51 12.37 59
川島緑輝 33 17.09 75
その他 53 10.11 43
数学ガールの秘密ノート 微分を追いかけて (結城2015)[数学ガール]
僕 124 20.36 59
ユーリ 76 10.53 83
魔法科高校の劣等生(1)入学編 〈上〉
(佐島2011)[魔法科高校の劣等生]
司波達也 78 14.44 48
司波深雪 39 15.41 8
千葉エリカ 33 15.06 39
七草眞由美 31 19.39 7
その他 19 14.74 15
ソードアートオンライン1アインクラッド
(川原2009)[ソードアートオンライン]
クライン 90 17.24 207
キリト 69 19.70 62
茅場晶彦 29 34.03 0
その他 12 6.25 5
ヘヴィオブジェクト 最も賢明な思考放棄
(鎌池2017)[ヘヴィオブジェクト]
レイス=マティーニ=ベルモッ トスプレー [レイス]
57 34.53 19
ヘイヴィア=ウィンチェル
[ヘイヴィア]
45 22.53 130
アルフレッド=シルバーキング
[シルバーキング]
43 26.81 6
クウェンサー=バーボタージュ
[クウェンサー]
20 25.95 17
その他 35 26.48 17
ちはやふる(1) (末次2008)[ちはやふる] 綾瀬千早 68 9.29 60
綿谷新 44 12.16 34
真島太一 31 10.10 47
その他 57 8.84 52
名探偵コナン(93) (青山2017)[名探偵コナン] 服部平次 39 10.62 64
江戸川コナン 30 8.90 17
高木渉 24 19.38 4
その他 107 12.15 68
ONE PIECE 1, 2 (尾田1997, 1998)
[ワンピース]
ナミ 46 9.13 22
ロロノア・ゾロ [ゾロ] 34 11.47 49 モンキー・D・ルフィ [ルフィ] 30 6.77 24
その他 90 10.00 82
全体 1,800 16.09 1,848
発話数はデータに含まれる発話数,平均文字数は各発話を構成する文字数の平均値,音変化文字数は元の形と の差分として抽出された文字の数を表す.
図 1 音変化表現辞書との文字列マッチングの処理の流れ 表2 音変化表現作成規則および作成される表現の例
パターン 音変化表現作成規則 作成される表現の例
…
P2 イ形容詞型の活用語の基本形,子音動詞ラ行イ形の活用語の命令形,
または,感動詞の末尾の「い,し,ん」の左隣に長音記号,小書き 文字を伴う形を作成
あたたか【ー】い,もし も【ぉ】し,ごめ【〜】ん
…
P10 語頭から二拍目がカ・サ・タ・パ・ガ・ザ・ダ・バ・ハ行音であるイ 形容詞型・ナ形容詞型の活用語および副詞の二拍目に「っ」を挿入
す【っ】ごい,あ【っ】か るい,い【っ】けない
…
P15 「す【ん】ごい」およびその活用形に相当する文字列を作成 す【ん】ごい,す【ん】ご く,す【ん】ごかった
…
P22 品詞が動詞または動詞性接尾辞である語のテ形+「いく」の全活用 形などから「い」を削除した形を作成
書いて【】く,走って【】っ て,読んで【】った
…
【】で囲まれているのは,音変化の起きている文字.
表3 音変化表現との文字列マッチングの結果の例
発話ID 発話 音変化文字位置 パターンID
1 お【ー】い、元気か 1 P2
4 かなり大変らしいぜ【ー】 9 P1
7 大変みたいだけ【】ど一度見てみようってことでさ 7 P39 7 大変みたいだけど一度見てみようって【】ことでさ 17 P30
…
15 あ、【じゃ】あ俺も 2,3 P93
…
【】で囲まれているのは,音変化の起きている文字.
表12に記載の「パターンの説明」を音変化表現を作成するための規則として記載し直したもので ある.作成される表現の例において【】で囲まれているのは,音変化が起きている文字列である.
なお,音変化検出器で利用する音変化表現辞書において音変化表現と呼んでいるものには,音変化 が起きている文字列や,その文字列が属する語だけでなく,その語の左右に隣接する語も含まれて いることがある.これは,マッチング対象の文字列をなるべく長くすることで,音変化表現の誤検 出を防ぐためのものである.
例えばP22のパターンに該当する音変化表現を作成する際は,まず,規則に従ってJUMANの 形態素辞書から品詞が動詞または動詞性接尾辞である語(形態素)を抽出する.次に,抽出した語 のテ形に「いく」の活用形を接続させ,さらにそこから「いく」の語幹である「い」を削除した形 を作成する.このとき,「遭えていく」のように,元の形としても滅多に使われない(単語N-gram の出現頻度が閾値以下である)フレーズは除外したうえで音変化表現を作成する.なお,生産性の ないパターンの場合は,JUMANの形態素辞書から語を抽出せずに音変化表現を作成する.表2の 例では,P15がこれに該当する.また,元の形の出現頻度が閾値以下の語やフレーズを除外するか 否か,および,閾値の設定はパターンによって異なる.
音変化表現を検出する際は,キャラクタ発話(図1のE)を読み込み,事前に作成しておいた音 変化表現辞書(図1のD)を参照して,キャラクタ発話の中から,音変化表現と完全に一致する部 分文字列を検出する.表3に,音変化表現との文字列マッチングの結果(図1のF)の例を示す.
文字列マッチングの結果は,発話ID,発話,音変化が起きているとして検出された文字の位置,ど のパターンの音変化表現とマッチしたかを示すパターンIDで構成される.表3では,分かりやす さのために音変化が起きているとして検出された文字を【】で囲んである.なお,「だけ【】ど」や
「って【】こと」のように文字が脱落している場合は,脱落箇所の次の文字である「ど」や「こ」の 文字位置を音変化文字位置としている.
4.2.2 形態素解析結果に基づく規則とのマッチングによる方法
形態素解析結果に基づく規則とのマッチングの処理の流れを図2に示す.まず,検出対象の発話 を形態素解析にかけ,発話に含まれる形態素の表記および品詞の情報を取得する.形態素解析器と しては,JUMAN version 7.01(黒橋・河原研究室2012)と,UniDic (unidic-mecab ver. 2.1.2) (伝 2009)を辞書として指定したMeCab 0.996(Kudo, Yamamoto, and Matsumoto 2004)を利用した.
次に,それぞれの形態素解析器で使用する形態素辞書の品詞体系に合わせて作成した音変化検出規
則(図2のB,C)と形態素解析結果とを照らし合わせ,音変化の起きている文字列を検出する.
表4にJUMANの品詞体系に合わせて作成した音変化検出規則の例を,表5にUniDicの品詞体
系に合わせて作成した音変化検出規則の例をそれぞれ示す.音変化検出規則はいずれも,音変化が 起きている対象形態素の他に,その左右の形態素に関する条件を持ち,条件にマッチした形態素を 音変化を含むものとして検出する.対象形態素,および,その左右の形態素に関する条件としては,
形態素の表記と品詞(活用型・活用形を含む)を利用した.JUMANの解析結果において,「長音 挿入」や「代表表記:る/る」(語幹の脱落がない場合は「代表表記:いる/いる」)など,音変化が 起きていることを直接的に示す情報(意味情報の欄)が出力される場合は,これも規則に取り入れ た.なお,UniDicの場合は,「連体形-撥音便」(e.g.,走んの)や「仮定形-融合」(e.g.,食べりゃ)
のように,音変化が起きていることを示す情報が活用形の中に組み込まれている.これらの規則を 形態素解析結果と照らし合わせることで,表3と同様の形式の検出結果を出力する.
4.3 検証の結果と考察
4.2.1節および4.2.2節で述べた方法で,元の形との差分として抽出された1,848文字のうち1,241
文字(67%)が検出された.一方で,残り607文字(33%)は自動的には検出されなかったので,こ
れらの文字が本研究で提案する137種類の音変化パターンに該当するものか否かを目視によって確
図2 形態素解析結果に基づく規則とのマッチングの処理の流れ
表4 音変化検出規則の例(JUMANの品詞体系用)
パターン マッチする表現 の例
左形態素の
条件 対象形態素の条件 右形態素の
条件 音変化箇所の例
…
P3 でーす 指定なし 表記が「でーす」で,意 味情報に「長音挿入」を 含む
指定なし で【ー】す
… P21 食べて/ϕる 動詞のタ系
連用テ形で ある
代表表記が「る」「ない」
「ます」である
指定なし 【】る,【】ない,【】
ます
… P35 良い/ϕて/言っ
た
指定なし 表記が「て」である 意味情報に
「補文ト」を 持つ
【】て
…
P92 あたたかくちゃ 指定なし イ形容詞型の活用語のタ 系連用チャ形である
指定なし あたたかく【ちゃ】
…
【】で囲まれているのは,音変化の起きている文字.
表 5 音変化検出規則の例(UniDicの品詞体系用)
パターン マッチする表現 の例
左形態素の
条件 対象形態素の条件 右形態素の
条件 音変化箇所の例
…
P21 食べ/てϕる 指定なし 助動詞の「てる」である 指定なし て【】る
…
P86 走ん/の 指定なし 動詞または助動詞の連体 形-撥音便である
指定なし 走【ん】
… P92 あたたかくちゃ 形容詞型の
活用語の連 用形である
助詞-接続助詞の「ちゃ」
である
指定なし あたたかく【ちゃ】
…
P99 食べりゃ 指定なし 動詞の仮定形-融合である 指定なし 食べ【りゃ】
…
【】で囲まれているのは,音変化の起きている文字.
認し,検出に成功した文字と合わせて,以下に示す5種類に分類した.
(1) 音変化表現に該当しない (2) 音変化表現に該当する
a. 検出成功 音変化検出器で検出された文字
b. 検出器実装不足 137種類のパターンに該当はするが,音変化検出器で使用した音変化 表現辞書や音変化検出規則の実装が不足していたため検出できなかった文字 c. パターン不足 137種類のパターンに該当しない文字
d. 方言 方言と思われる表現に含まれる文字
5種類の内訳は表6に示すとおりである.音変化に該当しないと判断した225文字にどのような ものがあったかは,表7に示す.「っていう」の元の形として「という」が記入された場合など,語 彙選択の問題として捉えたほうが良いと考えられるものは,音変化に該当しない文字とみなした.
また,「だったら」の元の形として「そうだったら」が記入された事例のように,文頭の語が丸ご と消失する場合や,「ない」の元の形として「ないか」が記入された事例のように,文末の語が丸 ごと消失する場合,および,「あ、あたし」のような言い淀みについても,音変化に該当しない文 字とみなした.
方言の一部だと判断した135文字にどのようなものがあったかは,表8に示す.それぞれの表 現について音変化に該当するのかそうでないのかを判断するのは難しいので,ここでは全てまとめ て音変化表現に該当するとみなした.表8を見ると,検証用データ作成時に仮定したとおり,方言 を使用するキャラクタがいる作品を扱うことによって,本研究で提案する137種類のパターンでカ バーされていなかった多様な表現を検証の対象とすることができたと分かる.
パターン不足であった,つまり,本研究で提案する137種類のパターンに該当しない音変化であ る141文字にどのようなものがあったかを表9に示す.表9に記載の表現のほとんどが,現象・生 起環境の面で他の音変化表現との共通性が乏しく生産性のあるパターンが作れないものであり,新
表6 元の形との差分として抽出された文字の内訳
文字数 「音変化に該当す
る」に対する比率 累積比率
「音変化に該当す る」(方言以外)
に対する比率
累積比率
(1)音変化に該当しない 225 NA NA NA NA
(2)音変化に該当する a.検出成功 1,241 76% 76% 83% 83%
b. 検出器実装不足 106 7% 83% 7% 90%
c. パターン不足 141 9% 92% 10% 100%
d. 方言 135 8% 100% NA NA
合計 1,848 100% 100% 100% 100%
表7 音変化に該当しないと判断した文字の内訳 現象 音変化としてマークされた表現/
元の形として記入された表現 文字数
語彙選択 って/と 111
って/とは 26
って/は 23
って/よ 16
って/から 6
って/らしい 4
なんで/なぜ 12
だって/も 6
っけ/かな 4
だって/でも 3
なんか/など 2
いったって/いっても 1
て/と 1
文頭の語の消失 だ/そうだ 1 だったら/そうだったら 1
で/それで 1
となると/そうだとなると 1 なのに/それなのに 1
なら/それなら 1
文末の語の消失 ϕ/か 1
ϕ/の 1
言い淀み あ/ϕ 1
その他 待って/待て 1
合計 225
たに生産性のあるパターンが作れそうな表現は,「置きっぱなし」(元の形:「置きはなし」)と「あ んまり」(元の形:「あまり」)の2つだけであった.前者については,末尾に「はなし(放し)」が 付く様々な語に適用できるパターンを作ることが可能だと考えられ,後者については,生産性のな いパターンとして用意したP16「おんなじだ」やP17「まんま」と合わせて,ナ行・マ行音の前に
「ん」が挿入されるパターンとしてまとめられそうである.その他,「うーむ」(元の形:「うむ」)は 既存のパターンP2において,語末が「い」「し」「ん」だけでなく「む」である感動詞も扱うように 拡張すれば「うーむ」や「ふーむ」がカバーできるようになる.「置きっぱなし」「あんまり」「うー む」以外の表現は全て,生産性のあるパターンが作り難いものであった.つまり,本研究で提案す る137種類のパターンで,生産性のある音変化表現のパターンの多くがカバーできていると言える.
以上の目視確認の結果を受け,音変化に該当しない文字を除外して計算すると,表6に示すとお り,137種類の音変化パターンに該当する文字(検出成功と検出器実装不足の合計)は全体の83%
表8 方言の一部だと判断した文字の内訳
音変化としてマークされた表現/元の形として記入された表現 文字数
や/だ 32
やろ(う)/だろう 11
へん/ない 7
やねん/なのだ 7
ねん/のだ 6
やんけ/ではないか 6
しいひん/しない 4
ねん/の 4
ほんま/ほんとう 4
やってん/だったのだ 4
やで/だよ 4
やん/だよ 4
せや/そうだ 3
で/よ 3
やってんで/だったのよ 3
やん/よ 3
こないな/このような 2
さかい/から 2
ちゃう/ちがう 2
での/からな 2
てんで/たのよ 2
ひん/ない 2
めっちゃ/めちゃ 2
やが/だよ 2
やられてえんくて/やられていなくて 2
やろっさ/やろうよ 2
やん/だね 2
その他 8
合計 135
を占めることが分かる.さらに,方言と思われる表現に含まれる文字を除外して計算すると,137 種類の音変化パターンに該当する文字は全体の90%を占めることが分かる.これにより,本研究で 提案する137種類が,検証の対象としたキャラクタの発話に現れる音変化表現の主要なパターンを カバーすることが確認できた.
なお,音変化に該当しない文字を除外した(方言は含む)状態での音変化検出器の性能は,再現 率0.76,適合率0.85,F値0.80である.再現率(Rec),適合率(P rec),F値 (F)は,音変化が起 きていることを正しく検出できた文字の数をT P,音変化が起きていることを検出できなかった文
字の数をF N,音変化が起きているとして誤って検出してしまった文字の数をF Pとしたとき,下
表9 パターン不足だと判断した文字の内訳
音変化としてマークされた表現/元の形として記入された表現 文字数
じゃん/ではない 36
あたし/わたし 33
やっぱり/やはり 8
んな/そんな 7
てめえ/てまえ 6
こっち/こちら 4
置きっぱなし/置きはなし 2
あんまり/あまり 2
けど/だけど 2
そっち/そちら 2
ちょ/ちょっと 2
ったりめえ/あたりまえ 2
どゆこと/どういうこと 2
なんたって/なんといったって 2
ほんじゃ/それじゃ 2
やた/やった 2
よん/よ 2
わきゃない/わけがない 2
引っこ抜く/引き抜く 2
達ァ/達は 2
あんま/あまり 1
いーや/いや 1
うーむ/うむ 1
おめえ/おまえ 1
かんな/からな 1
こんな/こんなに 1
ぜってえ/ぜったい 1
な/そんな 1
なーに/なに 1
なんちゃら/なんとやら 1
にゃろう/このやろう 1
ピューッ/ピュッ 1
ぶっ殺す/ぶち殺す 1
まぜっかえす/まぜかえす 1
めんどくさい/めんどうくさい 1
やした/ました 1
宙ぶらりん/宙ぶらり 1
突っかかる/突きかかる 1
突っ込む/突き込む 1
合計 141
図3 各パターンの音変化表現辞書,または,音変化検出規則がマッチした回数
記の式で算出する.
Rec= T P
T P +F N, P rec= T P
T P +F P, F =2·Rec·P rec
Rec+P rec (1)
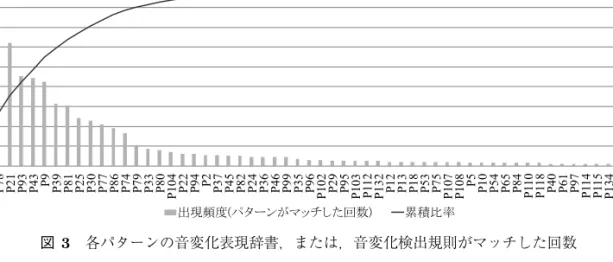
また,各パターンの音変化表現辞書または音変化検出規則がマッチした回数を図3に示す.図3 では,マッチした回数が2以上のパターンについて,マッチした回数を棒グラフで,マッチした回 数の合計に対する比率の累積値を線グラフで表示している.この図から,マッチした回数が2以上 のパターンは全137種類のうち56種しかなく,マッチした回数の多い上位5パターン(P43)まで で全体の約50%を,上位25パターン(P36)までで90%を占めていることが分かる.音変化表現の バリエーションは多岐に渡るが,出現頻度はロングテールの傾向が強く,頻繁に観察されるパター ンはそれほど多くないと言える.
5 発話のキャラクタ付けにおける音変化表現の有用性検証
5.1 検証方法
音変化表現が発話テキストへのキャラクタ付けにおいて有用かどうかを検証する.具体的には,
表1に記載の9作品における「その他」を除く29キャラクタを対象として,各作品200発話の中 から特定のキャラクタの発話を検出する実験を行い,発話にどのような音変化表現が含まれるかと いう情報を用いることで,検出性能が向上するか否かを検証する.音変化表現の情報を用いること で検出性能が向上すれば,小説やコミックにおける発話のキャラクタらしさと,発話における音変 化表現の利用実態との間に何らかの関係性があることが確認できる.
目的のキャラクタの発話の検出には,LIBLINEAR version 2.1(Fan, Chang, Hsieh, Wang, and
Lin 2008)のロジスティック回帰(L2正則化)を用いた.学習と推定は10分割交差検定で行い,目
![表 1 検証用データに関する統計量 作品名[略称] キャラクタ名[略称] 発話数 平均文字数 音変化文字数 図書館戦争図書館戦争シリーズ (1) (有川 2011)[図書館戦争] 笠原郁 62 15.76 98堂上淳4519.3830 柴崎麻子 38 21.24 97 小牧幹久 29 20.10 36 その他 26 15.81 30 響け! ユーフォニアム 北宇治高校吹奏楽部 へようこそ (武田 2013) [響け! ユーフォニアム] 加藤葉月 63 11.13 135黄前久美子5112.3759川島緑輝3](https://thumb-ap.123doks.com/thumbv2/123deta/7566851.2526010/13.892.131.757.238.969/に関するキャラクタシリーズユーフォニアムユーフォニアム.webp)