整形された会議録とその原音声のアラインメント
に基づく整形箇所の自動検出
太
田
健
吾
†1土
屋
雅
稔
†2中
川
聖
一
†1 話し言葉の忠実な書き起こしを含む大規模コーパスは,様々な音声言語処理におい て必要不可欠である.しかし,話し言葉音声の書き起こし作業には極めて高いコスト を必要とすることから,そのようなコーパスが実際に利用できるドメインは稀である. 一方で,速記録や会議録,字幕といった整形された書き起こしは,幅広いドメインに おいて利用が可能である.これらのような整形された書き起こしは,忠実な書き起こ しよりも比較的容易に入手が可能である反面,フィラーや言い直しといった話し言葉 特有の現象が削除されており,また,話し言葉特有の言い回しも文語体に置き換えら れている.このような背景を踏まえ,我々は,整形された書き起こしを忠実な書き起 こしへと半自動的に変換する枠組みの構築について検討している.この枠組みでは, まず整形された書き起こし中の整形箇所を自動検出し,検出された整形箇所を人手で 書き起こすことで,忠実な書き起こしを獲得し,書き言葉から話し言葉への自動変換 のルール抽出を目指す.本稿では,この枠組みのために,整形された書き起こしから 整形箇所を自動検出する方法を提案する.提案手法では,まず整形された書き起こし とその原音声とでアラインメントを行い,このアラインメントによって得られた素性 に基づくサポートベクターマシンを用いて,整形箇所を検出する.国会会議録を用い た評価実験の結果,話者 closed の条件において,実用的な検出精度を達成することが できた.また,この結果の副産物として,音響モデルの教師なし学習用の高精度なラ ベルの生成が可能となった.Automatic Detection of Edited Parts in Inexact
Transcribed Corpora Using Alignment between Edited
Transcription and Corresponding Utterance
Kengo Ohta,
†1Masatoshi Tsuchiya
†2and Seiichi Nakagawa
†1The availability of a large-scale spontaneous speech corpora is crucially im-portant for various domains of spoken language processing. However, the
avail-able corpora are usually limited because of its cost to prepare. On the other hand, inexact transcribed corpora have been widely produced in the form of shorthand notes, meeting records, or closed captions. Although these inexact transcribed corpora are more freely available than faithful/exact ones, these are not faithfully transcribed but contains edited transcriptions. Under this background, we are considering to build an efficient semi-automatic framework for converting inexact transcripts to faithful ones or exact transcriptions. This framework consists of three steps: the first step is to automatically detect posi-tions of edited parts, the second step is to manually transcribe the edited parts, and as the third step, we extract transformation rule from the parallel corpus of written style and spoken style. This paper proposes an automatic detection method of edited parts in edited transcribed corpora for this framework. In our proposed method, an automatic alignment between edited transcription and its corresponding utterance is performed, and then a support vector machine based detector is applied to detect edited parts using some features obtained by the automatic alignment. As a result of evaluation on the Japanese National Diet Record, a reasonable result was obtained in speaker-closed condition. By prod-uct, we obtain reliable transcript for unsupervised learning of acoustic models.
1.
は じ め に
様々な音声言語処理のアプリケーションにおいて,話し言葉の忠実な書き起こしを含む大 規模コーパスが利用できることは非常に重要である.たとえば,話し言葉を対象とした音声 認識システムには,認識対象となる音声とドメインが一致し,かつ,話し言葉特有の言い回 しにも対応した言語モデルが不可欠である.そのような言語モデルを構築する最も単純な方 法は,対象とする音声と同一ドメインの大規模な話し言葉コーパスから言語モデルを学習す るという方法である.しかし,話し言葉を忠実に書き起こす作業は極めて高いコストを必 要とすることから,あらゆるドメインに対してそのようなコーパスが入手できると仮定す ることは非現実的である.我々は書き言葉コーパスから,フィラーとポーズを自動挿入し, 話し言葉コーパスに変換する方法を検討してきた.しかし,書き言葉から話し言葉への言い 回しの変換法については未検討であった. 速記録や会議録,字幕といった整形された書き起こしは忠実な書き起こしと比べて広く作 †1 豊橋技術科学大学 情報・知能工学系Department of Computer Sciences and Engineering, Toyohashi University of Technology
†2 豊橋技術科学大学 情報メディア基盤センター
¶
³
ところ が です ね , えー ,この 資料 ,見 て み ます と 神奈川 県 の 場合 は , け , 結果 と し て 財政 的 に いー 豊か に なっ てる と .µ
´
(i)忠実な書き起こし¶
³
ところ が , この 資料 を 見 て み ます と ,神奈川 県 の 場合 は , 結果 と し て 財政 的 に 豊か に なっ て いる .µ
´
(ii)整形された書き起こし(会議録) 図 1 忠実な書き起こしと整形された書き起こしの例 成されており,比較的容易に入手が可能である.たとえば,国立国会図書館は,1947年以 降のすべての国会の会議録を公開している?1.ただし,これらの会議録は,フィラーや言い 直しといった話し言葉特有の現象が削除されており,また,話し言葉特有の言い回しも文語 体に置き換えられている.例を図1に示す.図1に見られるように,国会会議録では,可 読性を重視するために,フィラー(例.”えー”, ”いー”)や言い直し(例.”け”),および 冗長な言い回し(例.”ですね”, ”と”)はすべて削除されており,また,口語体の言い回し (例.”てる”)は文語体(例.”ている”)に置き換えられている.さらに,助詞の不足が補 われている(例.”を”)ほか,一部の読点は速記者の判断によって追加あるいは削除されて いる. こうした背景を踏まえ,我々は,整形された書き起こしを忠実な書き起こしへと半自動的 に変換する枠組みの構築について検討している.この枠組みでは,まず整形された書き起こ し中の整形箇所を自動検出し,検出された整形箇所を人手で書き起こすことで,忠実な書き 起こしを獲得する.この結果,話し言葉調の言い回しと書き言葉調の言い回しのパラレル コーパスを収集することができる.このパラレルコーパスは,話し言葉調の言い回しと書 き言葉調の言い回しとの変換パターンの構築1)に利用が可能である.最終的には,任意の 書き言葉コーパスに対し,フィラーとポーズの挿入,言い回しの変換によって,音声認識の ための言語モデル作成用の話し言葉コーパスを自動作成することを目標としている.また, 本提案手法により,整形されていない部分,すなわち忠実に書き起こされた部分も同時に検 ?1 http://kokkai.ndl.go.jp/ 出されることから,これらを音響モデルの準教師付き学習2)に用いることも可能である. 本稿では,この枠組みのために,整形された書き起こしから整形箇所を自動検出する方法 を提案する.提案手法では,整形された書き起こしとその原音声とでアラインメントを行 い,このアラインメントによって得られた素性に基づくサポートベクターマシンを用いて, 整形箇所を検出する. テキストと音声とのアラインメントの応用例として,たとえばLamelら2)は,音響モデ ルの準教師付き学習において,信頼できない学習データを除去するためにアラインメント を利用している.また,Royら3)は,アラインメントから得られた音響スコアに基づいて, 対象音声の書き起こし作業の難しさを推定している.さらに,丸山ら4)は,ドキュメンタ リー番組を対象として,字幕の送出タイミングを検出するためにアラインメントを利用して いる.これに対し,我々の提案手法では,整形された書き起こしと原音声とでアラインメン トを行うため,両者の不一致部分(=整形箇所)では,アラインメントにおける音響スコア が低下し,また,各音節の対応区間にばらつきが生じる.この音響スコアの低下や音節区間 のばらつきを手がかりとして,整形箇所を自動検出することが提案手法のねらいである. 本稿の構成は以下の通りである.まず,2節では,整形された会議録とその原音声とのア ラインメントの方法について述べる.続いて,3節では,サポートベクターマシンに基づく 整形箇所の自動検出について詳述する.4節では,国会会議録を用いた実験によって提案手 法を評価する.最後に,5節で本研究のまとめと今後の課題について述べる.2.
整形された書き起こしと原音声とのアラインメント手法
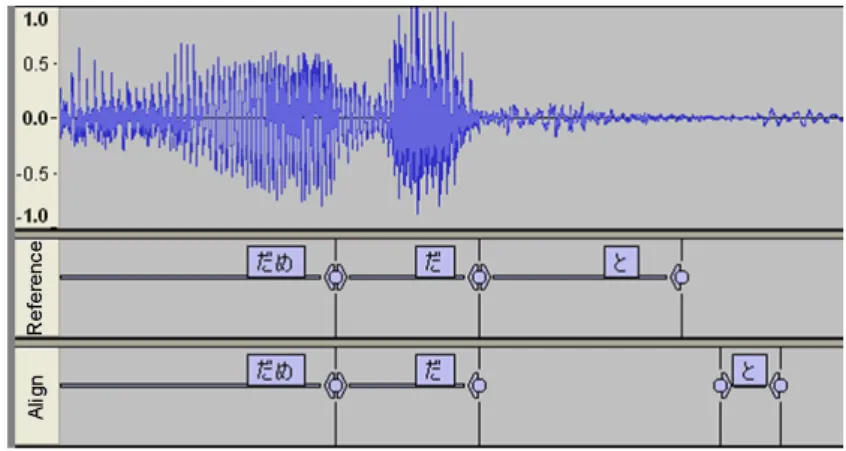
提案手法の第一段階として,整形された書き起こしとその原音声とのアラインメントを行 う.このアラインメントでは,単語間にショートポーズの挿入を許すという制約のもとで, 整形された書き起こしの各単語を原音声に対して対応付ける.このようなアラインメント は,入力音声の書き起こし単語列w1w2· · · wnに対して,図2のような2-gram言語モデル に基づく制約を加えた連続音声認識によって実現される.ここで,wiは書き起こしにおけ るi番目の単語であり,spiはwiの直後に出現するショートポーズである.この制約によ り,音声認識の認識結果は書き起こし通りの単語列に制限される. 忠実な書き起こしおよび整形された書き起こしと,その原音声とのアラインメント結果の 例を図3に示す.図3に見られるように,整形された書き起こしと原音声とのアラインメ ントを行うと,両者の不一致部分(=整形箇所)において,実際の発声とは異なるモデルが 強制的に対応付けられることになる.この結果,周囲の音節の対応区間が歪められ,また,図 2 bigram 言語モデルに基づく制約
図 3 忠実な書き起こし/整形された書き起こしと原音声とのアラインメント結果の例
モデルの不一致によって音響スコアが低下する.図3の例では,音節/si /の区間が不適切 に延びており,また,モデル/te/が音節/ne/に,ショートポーズモデル/sp/が音節/te de
su/にそれぞれ強制的に対応付けられている.よって,音節の区間が極端に長い/短い部分 や,音響スコアが通常よりも低い部分は,整形箇所である可能性が高いといえる. なお,多くの整形された書き起こしにおいて,書き起こし中の各文と原音声中の各発話の 対応に関する情報は付与されていないことが多い.これを考慮し,我々は,連続音節認識結 果の音節数に基づいて,各発話の単語数を推定することにより,両者の対応付けを自動で 行った.この対応付けに基づいて,書き起こし区間に対し,原音声の発話区間を切り出した 上で,書き起こし中の各文とアラインメントを行う.予備実験により,このように各発話の 単語数を自動で推定した場合でも,各発話の単語数が正確に得られた場合と同等の精度でア ラインメントが行えることを確認している.
3.
サポートベクターマシンに基づく整形箇所の自動検出
提案手法の第二段階として,2節のアラインメントによって得られた素性に基づくサポー トベクターマシン(SVM)を用いて,整形された書き起こしから整形箇所を検出する.本 研究では,整形箇所の検出を,書き起こし中の各単語に対する二値分類問題として定式化す る.すなわち,書き起こし中の各単語を,整形された単語かそうでないかの二値に分類す る.SVMの学習には,TinySVM(ver 0.09)5)を用いる.カーネル関数には多項式カーネ ルを採用する. 3.1 素 性 本研究では,以降の節で述べる7種類の素性を用いる.当該単語,直前2単語,および 直後2単語に関するこれらの素性を組み合わせて,各単語の素性とする.素性の選択にあ たっては,Huangらの文献6)を参考にした. 3.1.1 音響スコア アラインメントによって得られた音響スコアを素性に利用する.ただし,この音響スコア (対数尤度)は単語の時間長によって正規化し,さらに,連続音節認識によって得られた音 響スコア(対数尤度)との差分を取る.これは,対数事後確率を素性として用いることに相 当する. 3.1.2 音節時間長の平均 単語に含まれる各音節の時間長の平均を素性として用いる.ただし,周囲の6音節(直前 3音節および直後3音節)に基づいて各音節長を正規化したもの(Local d)と,当該発話の全音節に基づいて各音節長を正規化したもの(Global d)をそれぞれ用いる.それぞれの 定義は以下の通りである. Local d = 1 N N
∑
i=1 dur(si) 1 6∑
i+3j=i−3(j6=i)dur(sj)
(1) ここで,Nは当該単語に含まれる音節の数であり,dur(s)は音節sの時間長である. Global d = 1 N
∑
N i=1dur(si) 1 |U|∑
s∈Udur(s) (2) ここで,Uは当該発話に含まれる音節の集合である. 3.1.3 音節時間長の分散 単語に含まれる各音節の時間長の分散(V ar d)を素性として用いる.ただし,各音節長 を当該発話の全音節に基づいて正規化する. V ar d = 1 N N∑
i=1(
dur(si) 1 |U|∑
s∈Udur(s) − Global d)
2 (3) 3.1.4 音節時間長分布のスコア Loら7)は音素の時間長の分布をガンマ分布でモデル化し,このモデルの尤度に基づいて, 発音トレーニングシステムにおける想定外発話の棄却を行っている.これを参考とし,我々 は,音節の時間長をガンマ分布でモデル化し,このモデルの尤度を素性として用いる.本素 性の定義は次式の通りである. Score d = 1 |W |log(
∏
s∈W P (dur(s)|s) Panti−model(dur(s)))
(4) ここで,W は当該単語に含まれる音節の集合である.P (dur(s)|s)は音節の時間長をモデ ル化したガンマ分布であり,忠実な書き起こしとその原音声とのアラインメントによって得 られた音節時間長から学習を行う.アンチモデルPanti−model(dur(s))は同様にガンマ分布 であり,書き起こしと音声が一致しない場合の音節時間長のばらつきをモデル化する.この アンチモデルは,互いに一致しない書き起こしと音声のアラインメントによって得られた音 節時間長から学習を行う. 3.1.5 単 語 情 報 単語の表層形と品詞の組み合わせの情報を素性として用いる.たとえば,助動詞の”ます” や,助詞の”が”といった単語は整形され易い傾向にあると考えられる. 3.1.6 単語の音節数 単語に含まれる音節の総数を素性として用いる.たとえば,”けれども”は”けど”に整形 され易く,また,”やっぱり”は”やはり”に整形され易いといったように,多数の音節からな る単語は整形され易い傾向にあると考えられる. 3.1.7 単語の時間長 単語の時間長を素性として用いる.一般に,時間長の長い単語は整形を含み易い傾向にあ ると考えられる. 3.2 検出性能の目標値 本研究では,整形箇所の検出性能として,精度33%,再現率50%を目標値とする.ここ で例として,100単語からなる会議録があり,この内の10単語が整形箇所である場合を考 える.この場合,目標値通りの性能が達成できたとすると,15単語が整形箇所として検出 され,この内の5単語が真の整形箇所である.従って,書き起こし作業者は,計30単語の みを確認することで,10単語の整形箇所を見つけることができる.これは,100単語すべ てを確認するのと比べ,約3倍以上の作業効率である. また,本手法を逆に適用して,非整形箇所,すなわち忠実な書き起こし部分を検出するこ とも可能である.上述の場合,100単語の会議録の内,90%が非整形箇所である.これに対 し,本手法を適用すると,85単語が非整形箇所として検出され,この内の80単語,すなわ ち94%が真の非整形箇所である.従って,より忠実な書き起こしを抽出できたことになる. このように忠実な書き起こし部分の抽出に用いることにより,本手法は,音響モデルの準教 師付き学習2)などにも応用できる.4.
評 価 実 験
本節では,国会会議録を用いた評価実験について述べる. 4.1 実 験 条 件 1節で述べたように,国会会議録は大規模な整形された書き起こしであり,フィラーや言 い直しといった話し言葉特有の現象が削除されているほか,話し言葉特有の言い回しも書き 言葉調に置き換えられている.我々の目的はフィラーや言い直しといった話し言葉特有の現 象を復元することではなく,書き言葉調の言い回しを話し言葉調の言い回しに変換することであるため,本実験では,フィラーや言い直しは検出の対象から除くものとした. 話者semi-closedと話者openの2通りの条件で提案手法の評価を行った.話者semi-closed の実験では,同じ会議の一部を2つに分割してそれぞれ学習データおよびテストデータとし て使用しており,2名の話者が学習データとテストデータに共通して含まれる.話者open の実験では,2つの異なった会議を学習データおよびテストデータとして使用しており,そ れぞれに含まれる話者も異なる.各条件における実験データの諸元を表1に示す. アラインメントおよび連続音節認識のためのデコーダには,SPOJUS++8)を用いた.音 響モデルは,CSJ10)から学習した音節モデル(left-to-right型HMM,5状態4出力分布, 全共分散行列からなる単混合ガウス分布/出力分布)を用いた.モデル数は116である.音 響分析条件は表2の通りである 表 1 実験データ諸元 話者 semi-closed 話者 open 学習 テスト 学習 テスト 時間長 (min) 22 20 42 60 話者数 5 4 7 11 総単語数 3.6k 3.6k 7.2k 10.8k 整形箇所の頻度 347 257 604 426 整形箇所の割合(%) 9.6 7.1 8.4 3.9 表 2 音響分析条件 サンプリング周波数 16kHz プリエンファシス 0.98 分析窓 Hamming窓 分析窓長 25ms フレームシフト 10ms
特徴パラメータ MFCC +4MFCC + 44MFCC + 4Pow + 44Pow (38 dimensions)
4.2 実 験 結 果 4.2.1 アラインメントの精度 予備実験として,忠実な書き起こしとその原音声とのアラインメントの精度を評価した. この結果,30msec以内の誤差を許容した場合,97.4%の精度が得られた.アラインメント の誤りのほとんどは,発音が怠けている部分や発声が弱い部分に見られた.このほか,直前 後の雑音や咳,息などの影響でアラインメントが誤る場合も見られた.雑音の影響でアライ ンメントが誤った例を図4に示す.また,パワーの小さい部分ではアラインメントが比較的 誤り易い傾向が見られた.例を図5に示す. 図 4 直前の雑音の影響によってアラインメントが誤る例 4.2.2 話者Semi-closedの実験 全話者(4名),closed話者(2名),およびopen話者(2名)それぞれに対する整形箇 所検出の再現率-精度曲線を図6に示す.図6に見られるように,closed話者とopen話者 とでは検出性能に大きな違いが見られる.すなわち,closed話者に対しては高い性能(再 現率60%,精度30%)が得られたのに比べ,open話者に対する性能は非常に低かった.話 者によって整形のされ方に固有の特徴が存在するか,使用した音響素性に個人性があるの か,あるいは,学習データの量が不十分であったと考えられる.ただし,提案手法の目的は 少量の学習データから学習した検出器を大量のコーパスに適用することであり,大規模な学 習データを利用することは望ましくない. なお,再現率0%∼5%の範囲において,精度が著しく低下する現象が見られた.この現象 は以降の実験でも一貫して観測されたが,これに関する詳細な分析は,今後の課題である. 4.2.3 話者openの実験 話者openの実験の結果得られた再現率-精度曲線を図7に示す.図7に見られるように, 話者semi-closedの実験と比べ,検出性能は大きく低下した.なお,図7の結果と,図6の
図 5 パワーの小さい部分でアラインメントが誤る例 図 6 話者 semi-closed の実験における再現率-精度曲線 open話者に対する結果に一定の差が見られるが,これは,整形箇所の割合が異なること, および録音環境が異なることが原因として考えられる. 図 7 話者 open の実験における再現率-精度曲線 4.2.4 各素性の影響 話者semi-closedの条件において,各素性の与える影響を調査した.ここでは,各素性を 以下の3つのfeature setに分割した. • feature set 1: 音響スコア • feature set 2: 音節時間長の平均・分散,音節時間長分布のスコア • feature set 3: 単語情報,単語の音節数,単語の時間長
各feature setを素性に加えていった結果を図8(全話者)および図9(closed話者)に示 す.図8および図9に見られるように,feature set2を素性に加えても性能に改善は見られ なかった.一方で,feature set3を素性に加えた場合には一貫して性能の改善が見られた. 4.2.5 非整形箇所の検出 提案手法を逆に適用して,非整形箇所,すなわち忠実な書き起こし部分の検出に用いた. 結果を図10(話者semi-closed)および図11(話者open)に示す.図10より,元々の忠 実な書き起こし部分の割合(再現率100%のとき)は93%であったが,提案手法に基づいて 書き起こし全体の60%を検出することにより,この割合が98%に改善された(80%の検出 区間で97%の精度).なお,これを音節単位の精度に換算したところ,88%から97%への
図 8 各 feature set に対する再現率-精度曲線(話者 semi-closed・全話者)
図 9 各 feature set に対する再現率-精度曲線(話者 semi-closed・closed 話者)
改善であった.同様に,図11より,提案手法に基づいて書き起こし全体の60%を検出する ことにより,忠実な書き起こし部分の割合が96%から98%に改善された(80%の検出区間 で97.5%の精度).なお,これを音節単位の精度に換算したところ,95.5%から98.5%への 改善であった(図11参照).このように,提案手法は,忠実な書き起こし部分の抽出に用 いることによって,音響モデルの準教師付き学習2)などにも応用できる. 図 10 非整形箇所の検出における再現率-精度曲線(話者 semi-closed)
5.
お わ り に
本稿では,整形された書き起こしから整形箇所を自動検出する手法を提案した.提案手法 は2段階からなり,まず,整形された書き起こしとその原音声とでアラインメントを行い, 続いて,このアラインメントによって得られた素性に基づくサポートベクターマシンを用い て,整形箇所を検出する.国会会議録を用いた評価実験の結果,話者closedの条件におい て,実用的な検出精度を達成することができた. 今後は,特定話者に対する整形箇所の自動検出器,および不特定話者に対する整形箇所の 自動検出器の構築と評価を行う.また,提案手法によって,忠実な書き起こしの構築作業を どの程度効率化できるかを,被験者実験によって評価する予定である. なお,本提案手法で検出された整形箇所を人手で書き起こすことにより,話し言葉調の言 い回し(忠実な書き起こし)と書き言葉調の言い回し(整形された書き起こし)のパラレル図 11 非整形箇所の検出における再現率-精度曲線(話者 open) コーパスを獲得することが可能である.このパラレルコーパスは,言語モデルのスタイル変 換1)や音響モデルの準教師付き学習11)に利用できる.
謝
辞
本研究は文部科学省グローバルCOEプログラム「インテリジェントセンシングのフロン ティア」の支援を受けた.参 考 文 献
1) G. Neubig, Y. Akita, S. Mori, and T. Kawahara, Improved Statistical Models for SMT-based Speaking Style Transformation, In Proc. of International Conference on Acoustics, Speech, and Signal Processing(ICASSP), pp.5206–5209, 2010. 2) L. Lamel, J.L. Gauvain, G. Adda, Investigating lightly supervised acoustic model
training, in Proc. of International Conference on Acoustics, Speech, and Signal Processing(ICASSP), pp.477–480, 2001.
3) B. C. Roy, S Vosoughi, D Roy, Automatic Estimation of Transcription Accuracy and Difficulty, in Proc. of Interspeech, pp.1902–1905, 2010.
4) 丸山一郎,阿部芳春,江原暉将,白井克彦,ドキュメンタリー番組における字幕送出 タイミング検出の一検討,音響学会秋季講演論文集,3-Q-30,pp.177-178,1999. 5) TinySVM, http://chasen.org/˜taku/software/TinySVM/
6) X. Huang, A. Acero, H. Hon, Spoken Language Processing: A Guide to Theory,
Algorithm and System Development, Prentice Hall, 2001.
7) W. Lo, A.M.Harrison and H.Meng, Statistical Phone Duration Modeling to Fil-ter for Intact UtFil-terances in a CompuFil-ter-Assisted Pronunciation Training System, in Proc. of International Conference on Acoustics, Speech, and Signal Process-ing(ICASSP), pp.5238–5241, 2010.
8) 藤井康寿,山本一公,中川聖一,大語彙連続音声認識システムの改善:SPOJUS++, 第4回音声ドキュメント処理ワークショップ講演論文集,2010.
9) S.Nakagawa, K.Hanai, K.Yamamoto, and N.Minematsu, Comparison of Syllable-Based HMMs and Triphone-Syllable-Based HMMs in Japanese Speech Recognition, in Proc. of International Workshop on Automatic Speech Recognition and Understanding, pp.393-396, 1999.
10) K.Maekawa, Corpus of Spontaneous Japanese: Its Design and Evaluation, In Proc. of the ISCA & IEEE Workshop on Spontaneous Speech Processing and Recognition (SSPR2003), pp.7–12, 2003.
11) T.Kawahara, M.Mimura, and Y.Akita, Language Model Transformation Applied to Lightly Supervised Training of Acoustic Model for Congress Meetings, In Proc. of International Conference on Acoustics, Speech, and Signal Processing(ICASSP), pp.3853–3856, 2009.