DOI: http://doi.org/10.14947/psychono.35.23
時系列ビッグデータの解析と予測
櫻 井 保 志
熊本大学
Mining and forecasting of big time-series data
Yasushi Sakurai
Kumamoto University
Big time-series data have been generated in various applications including sensor networks, financial systems, online documents, medical information, web access records, social networking services, etc. How can we efficiently and effectively find typical patterns? How can we statistically summarize all the sequences, and achieve a meaningful segmentation? What are the major tools for forecasting and outlier detection? This paper summarizes our recent work, which includes: SpikeM that analyzes the rise and fall patterns of influence propagation in social networking services, TriMine for fast mining and forecasting of complex time-stamped events, AutoPlait for automatic mining of co-evolving multidimensional time sequences, EcoWeb as ecology-inspired nonlinear dynamical systems for pat-tern extraction from online activities, FUNNEL for automatic mining of spatially co-evolving epidemics, CompCube for non-linear mining of competing local activities, and RegimeCast for real-time forecasting of data streams.
Keywords: big time-series data, data mining, forecasting
1. は じ め に 時系列シーケンスは,センサネットワーク監視,金 融,オンライン文書,医療情報,Webアクセス履歴や ソーシャルネットワーク等,様々なアプリケーションに おいて大量に生成されている。このような時間発展を伴 う大規模なデータ,すなわち時系列ビッグデータの解析 技術は自然現象や社会現象の特徴をとらえることがで き,特定のビジネスのみならず,社会経済の活性化,環 境,防災やエネルギーなど,重要な社会問題を解決する ための効果的なアプローチとして期待されている。 計算機科学の中でも時系列解析は,計算理論,データ ベース,データマイニングなど幅広い分野において数十 年にわたって取り組みが行われている,いわゆる「よく 知られた」研究課題である。しかし,Web情報やセンサ データストリームなど,近年のデータは大規模かつ多様 化しており,そのような複雑な時系列ビッグデータを解 析し,将来予測のような高度な処理を行うため,著者ら は従来の研究とは異なる新たな方向性を示し,研究開発 をすすめている(Sakurai, Matsubara, & Faloutsos, 2015)。 大規模テンソル解析 時間発展の情報を含むようなデータの多くはテンソル として表現することができる。そしてテンソル解析技術 はセンサデータストリーム,医療情報,ソーシャルネッ トワークなど,様々なアプリケーションにおいて用いる ことができる。例えば,Webのアクセス履歴イベント (timestamp, URL, User ID, access devices, http referrer,…)
というm個の属性からなるレコード群,すなわち複合 イベントデータはm階のテンソルとして表現すること ができる。大規模な複合イベントデータを扱うための時 系列ビッグデータテンソルの解析技術は今後重要な要素 技術の一つとなる。 非線形時系列解析 非線形モデルは,疫学,生物学,物理,経済など, 様々な分野で用いられている。一方で,データマイニン グ分野においては,ソーシャルメディアやオンライン Copyright 2017. The Japanese Psychonomic Society. All rights reserved. Corresponding address. Department of Computer Science
and Electrical Engineering, Kumamoto University, 2–39–1 Kurokami, Kumamoto 860–8555, Japan. E-mail: yasushi@ cs.kumamoto-u.ac.jp
130 基礎心理学研究 第35巻 第2号 ユーザアクテビティの分析が盛んであり,一部の研究で はソーシャルメディアのダイナミクスをとらえるために 非線形モデルが用いられている。特に,著者らは非線形 モデルとテンソルを統合した非線形テンソル解析技術を 考案した。非線形テンソル解析は計算機科学において世 界で初めての取り組みであり,各時系列データに対し 個々の独立したモデルを当てはめるのではなく,時系列 ビッグデータを多角的に,かつ非線形性を考慮しながら 分析することにより,各シーケンス間の潜在的な関係性 をとらえることが可能となる。 自動特徴抽出 実用的な技術やシステムの開発を考えた際,最も重要 である課題が特徴抽出の完全自動化である。例えば,自 己回帰やフーリエ変換,特異値分解をはじめとする従来 の時系列処理技術では,使用する係数の個数や閾値等の パラメータの設定が必要である。しかし,解析するデー タが膨大になるほど,専門のエンジニアによる細やかな パラメータチューニングには時間的,金銭的コストが多 くなり,重大なボトルネックとなる。このように,ビッ グデータの解析においては,解析技術の自動化は極めて 重要な課題である。 2. 時系列ビッグデータ解析技術 著者らの研究室では,主にWeb情報,センサデータ, 医療情報を対象として,情報抽出,パターン検出,モデ ル学習,将来予測などの研究を行っている。特に,上記 に示した新たな3つの方向性に焦点を合わせて,次のよ うな研究に取り組んでいる。 (1) SpikeM: ソーシャルネットワーク上の情報拡散過程 と非線形解析
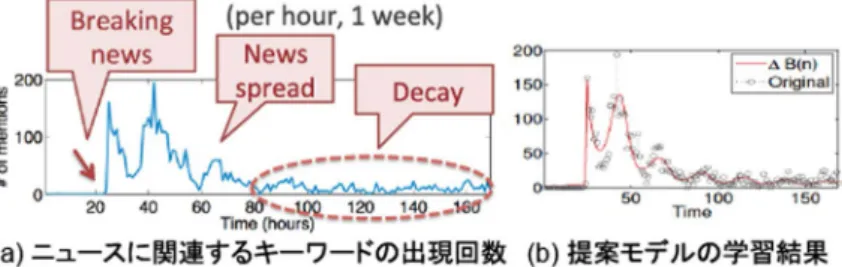
SpikeM (Matsubara, Sakurai, Prakash, Li, & Faloutsos, 2015) は,BlogやTwitterを始めとするソーシャルネット ワーク上において,噂やニュース等の情報が,時間が経 過するごとに,どのように拡散し減衰していくかを表現 する (Figure 1参照)。提案手法は,ユーザ間のグラフ構 造に基づく情報拡散過程をパワー則に基づく非線形モデ ルで表現する。SpikeMは,ニュース記事や噂の拡散過 程をパラメータ学習し,そのニュースの重要度や影響力 等の潜在的な情報を自動抽出する。さらに,抽出された 情報に基づき,将来の情報拡散過程を予測することがで きる。 (2) TriMine: 複合イベントデータのためのテンソル解析 と将来イベント予測
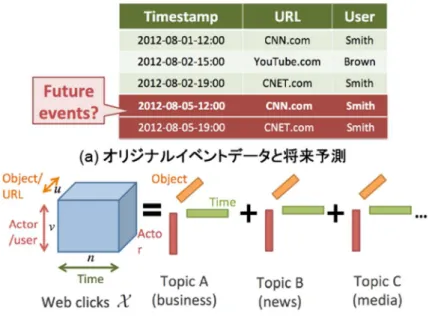
TriMine (Matsubara, Sakurai, Faloutsos, Iwata, & Yoshikawa, 2014)は複数の属性で構成される複合イベントデータが 与えられたとき,イベントの中から重要な要素(トピッ ク)を抽出し,潜在的なトピックの時間的な推移を把握 することにより,将来のイベントを予測するアルゴリズ ムである。 Figure 2 は Web アクセス履歴データの解析例を示す。 アクセス履歴イベントは,(timestamp, URL, User ID)と
いう3個の属性からなるレコード群として表現され,こ れらのデータは3 階のテンソル(URL×user×time)と して表現することができる。TriMineはこれらの3要素 に対して潜在的なトピックを発見し,テンソルを3つの ベクトル集合に分解することで,スパースなテンソルの 中から重要な時系列パターンを発見し,将来のイベント を予測する. (3) AutoPlait: 大規模時系列シーケンスからの特徴自動 抽出
AutoPlait (Sakurai, Matsubara, & Faloutsos, 2014) は大規 模な多次元時系列シーケンスの中から重要なパターンを 自動抽出するアルゴリズムである。Figure 3はモーショ ンキャプチャ (加速度センサ)に対する特徴抽出例であ る。上段がオリジナルシーケンス,下段が AutoPlaitの 出力結果である。提案手法は,パラメータ設定や事前知
識無しに適切なパターンの個数と各パターンの変化点の 位置を完全自動で抽出する。
(4) EcoWeb: 生態系モデルに基づくオンライン活動上の 競合関係自動抽出
EcoWeb (Matsubara, Sakurai, & Faloutsos, 2015)は生態 系における種間競争モデルに基づき,Web上のユーザ活 動の中から潜在的な競合関係や季節性等の重要パターン を自動抽出する非線形モデルである。
Figure 4(a)は,Google検索におけるゲームに関する 4つのキーワード (Xbox, Play Station, Wii, Android) の検 索数の推移を2004年から2015年まで示している。具体 的には,Figure 4(a)はオリジナルシーケンスとEcoWeb によるフィッティング結果,自動抽出された (b)各キー ワ ー ド間 の 競 合 関 係 ネ ッ ト ワ ー ク (例: Wii vs. An-droid),そして(c) 季節性パターン(例: クリスマス セール,ブラックフライデー)を示す。Wiiは多くの ユーザをAndroidに取られており,またXboxはPlaySta-tionとWiiから大きな影響を受けている。EcoWebは,こ のような潜在的な情報を,完全自動で抽出するととも に,その潜在的な情報に基づきユーザの活動パターンの 将来予測を行うことができる.
Figure 2. Analysis of complex event data.
132 基礎心理学研究 第35巻 第2号
(5) FUNNEL: 大規模疫病テンソルデータのための非線 形解析モデル
FUNNEL (Matsubara, Sakurai, van Panhuis, & Faloutsos, 2014)は大規模な疫病感染データ (timestamp, disease, lo-cation) に対し,非線形モデル学習とテンソル解析技術 を融合し,疫病の感染力,季節性,地域性,ワクチン効 果等の重要なパターンを自動抽出する統合モデルであ る。Figure 5は,FUNNELの出力結果例を示している。 これは,アメリカ合衆国で過去 100年の間に報告され た,50種を超える疫病の感染者数のデータに対する解 析結果の様子である。 より具体的には,Figure 5(a)において灰色の丸印は 1928年から1982年までの,はしかの感染者数を示して おり,実線は考案手法の学習結果を示している.シーケ ンスは年の周期性があり,そして数年ごとに大規模な感 染と小さな波が現れている。また,感染者数は 1965年 において急激に減少しており,これはワクチン接種が 1963 年に開始されたことによるものである。FUNNEL はこのようなパターンを高精度で表現することができ る。Figure 5(b)は各州のはしかに関する感受性保持者 の潜在人口を示している.Figure 5(c)は各疫病の季節 性の強さ(半径) とそのピークの時期(角度)を示した ものである.例えば,1月と2月にインフルエンザの流 行のピークがあり,はしかのような小児呼吸器疾患は 春,ライム病のようなダニ媒介疾患は夏がピークとなっ ている.また,淋病のような性感染症(STD)には周期 性がないことわかる. 提案手法は疫病データのみならず,コンピュータウィ ルスの感染パターンも学習することができる。Figure 5 (d)はIPA ITセキュリティセンターにおいて,日本国内 の企業から報告されたウィルス件数の推移のデータに対 する提案手法の学習結果である。例えば,Badtransや KlezといったMicrosoft社のOutlookのセキュリティホー ルを狙ったウィルス感染過程や,Netskyのようなメール 添付型,Mytobのような社内ネットワーク感染型のウィ ルス等,様々なタイプの感染パターンを柔軟に表現する ことができる。 (6) CompCube: 大規模複合データの非線形テンソル解 析
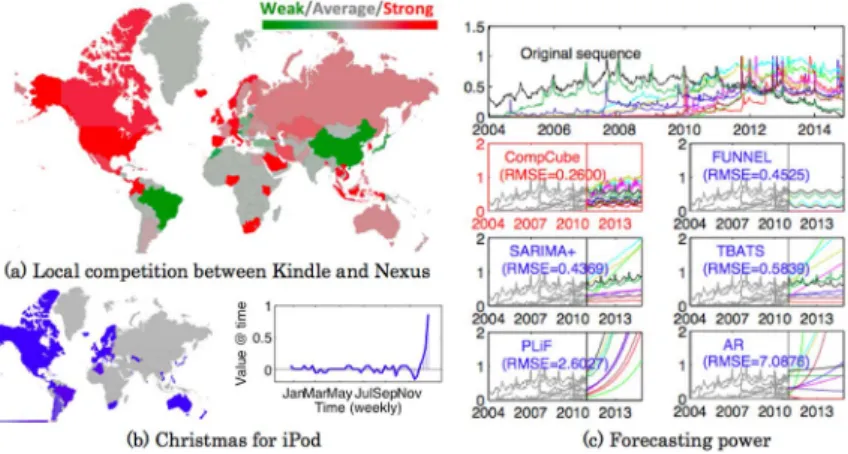
CompCube (Matsubara, Sakurai, & Faloutsos, 2016)は複 数の属性から構成される複合データをテンソルに基づい て解析する手法であり,FUNNELの技術を発展させるこ とにより,精度のさらなる向上を達成している。Comp-Figure 4. Activity patterns on Google and automatic feature extraction.
Cube は,Web 上のユーザの地域別の活動データ(time, activity, location) の中から基本情報,競合関係,季節性, 外れ値の 4つの情報を,Global/Local両視点から抽出す る統合モデルである。例えば,各国におけるGoogleの 検索件数のデータが与えられたとき,Figure 6のように CompCubeは,競合関係(Kindle vs. Nexus等),地域別季
節性(Christmas, Chinese New Year等)の情報を完全自動 で抽出し,各地域における今後のユーザ行動の予測を行 うことができる。
(7) RegimeCast: リアルタイムデータストリーム予測 時系列データの中には複数の時系列パターンが含まれ Figure 5. Automatic mining of spatially coevolving epidemics.
134 基礎心理学研究 第35巻 第2号
ており,それらのパターンは不規則的に出現および推移 し て い く。 そ こ で RegimeCast (Matsubara, & Sakurai, 2016) は,(a) 時系列ストリームデータの中から事前知 識なしに現時刻の状況に応じて多様なパターンをモデル 学習し, さらに,(b) ストリーム内の突発的な変化点を 検出し,現時刻の時系列パターンを瞬時に探索,認識す ることで,未来のイベントを柔軟に予測する。 Figure 7はRegimeCastに基づいて開発したリアルタイ ム予測システムの出力結果である。実験データとして モーションセンサデータを用いており,Figure 7(a)の 上段はオリジナルのデータストリーム,Figure 7(a)下 段は100から120時刻先をリアルタイムかつ継続的に予 測した結果である。事前学習なしに様々なパターンを高 精度に予測していることが分かる。Figure 7(b-1)から (b-4)まではリアルタイムに時系列データをパターン分 けし,オンライン学習した結果である。4つのパターン は非線形解析に基づき少ない誤差でモデル化し,これら 4つのモデルパターンを使い分けながらリアルタイムに 予測値を推定する。 3. お わ り に 著者らの研究では実用性を重視し,企業連携,技術導 入,オープンソース化などを通じた実用的な基盤技術の 開発を目指している。国産企業との連携を意識し,研究 活動の最終目標として,国内の経済と産業を支える基盤 技術の確立を目指している。 参考文献
Matsubara, Y., & Sakurai, Y. (2016) Regime shifts in streams: Real-time forecasting of co-evolving time sequences. Pro-ceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1045–1054. Figure 7. Real-time forecasting of data streams.
Matsubara, Y., Sakurai, Y., Faloutsos, C., Iwata, T., & Yoshika-wa, M. (2012) Fast mining and forecasting of complex time-stamped events. Proceedings of the 18th ACM SIGKDD In-ternational Conference on Knowledge Discovery and Data Mining, 271–279.
Matsubara, Y., Sakurai, Y., & Faloutsos, C. (2014) Autoplait: Automatic mining of co-evolving time sequences. Proceed-ings of the 2014 ACM SIGMOD International Conference on Management of Data, 193–204.
Matsubara, Y., Sakurai, Y., & Faloutsos. C. (2016) Non-linear mining of competing local activities. Proceedings of the 25th International Conference on World Wide Web, 737–747. Matsubara, Y., Sakurai, Y., & Faloutsos, C. (2015) The web as a
jungle: Nlinear dynamical systems for co-evolving on-line activities. Proceedings of the 24th International
Confer-ence on World Wide Web, 721–731.
Matsubara, Y., Sakurai, Y., Prakash, B. A., Li, L., & Faloutsos, C. (2012) Rise and fall patterns of information diffusion: Model and implications. Proceedings of the 18th ACM SIG-KDD International Conference on Knowledge Discovery and Data Mining, 6–14.
Matsubara, Y., Sakurai, Y., van Panhuis, W.G., & Faloutsos, C. (2014) FUNNEL: Automatic mining of spatially coevolving epidemics. Proceedings of the 20th ACM SIGKDD Interna-tional Conference on Knowledge Discovery and Data Mining, 105–114.
Sakurai, Y., Matsubara, Y., & Faloutsos, C. (2015) Mining and forecasting of big time-series data. Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, 919–922.