i-vector に基づく話者照合における非線形帯域 拡張法とその評価に関する研究
A study of non-linear artificial bandwidth extension by using i-vector-based speaker
verification and its evaluation
首都大学東京大学院
システムデザイン研究科 情報通信システム学域
17890512 上西遼大
目 次
i目 次
1
はじめに
12 i-vectorPLDA, x-vector/PLDA
に基づく話者照合
42.1 i-vector [1] . . . 4
2.2 PLDA [2] . . . 6
2.3 x-vector [3] . . . 6
3
非線形帯域拡張法
9 3.1付帯情報を用いない帯域拡張法
. . . 93.2
スペクトルシフティング法
(SHIFT) . . . 93.3
線形予測分析合成法
(LPAS) . . . 93.4
非線形帯域拡張法
(N-BWE) . . . 103.5 PLDA
に基づく話者照合と
N-BWE . . . 123.6
帯域拡張法のスペクトログラムによる比較
. . . 124
日本語データベースにおいての実験
14 4.1共通実験条件
. . . 144.2 clean
音声
. . . 154.2.1
比較手法
(clean音声
) . . . 154.2.2
実験結果
(clean音声
) . . . 164.3
電話音声
. . . 184.3.1
比較手法
(電話音声
) . . . 184.3.2
実験結果
(電話音声
) . . . 205
英語データベースにおいての実験
22 5.1共通実験条件
. . . 225.1.1
英語データベースの詳細
. . . 225.2
共通比較条件
(話者照合実験
) . . . 235.3 i-vector
に基づく話者照合実験
. . . 25目 次
ii5.3.1
実験条件
(i-vector) . . . 255.3.2
実験結果
(i-vector) . . . 265.4 x-vector
に基づく話者照合実験
. . . 285.4.1
実験条件
(x-vector). . . 285.4.2
実験結果
(x-vector). . . 285.5
客観評価実験
. . . 305.5.1
客観評価実験結果
. . . 316
結論
347
謝辞
358
参考文献
36あらまし
iiiあらまし
本論文は
, i-vector / PLDA, x-vector / PLDAに基づく話者照合システ ムを用いて非線形帯域拡張(
N-BWE)法を評価することを目的とし
ている
. N-BWE法とは帯域拡張法の一つで
,モデル学習を行わず
,計
算量が非常に軽い手法として提案された
. N-BWEは単純な非線形関 数とフィルタのみで構成されているにもかかわらず
,GMM-UBMに 基づく話者照合の等価エラー率
(EER)と二乗平均平方根対数スペク トル歪み(
RMS-LSD)において高い性能を得られることが報告され
ている
. PLDAに基づく話者照合は話者とチャネルの依存性を分離す
ることに焦点を当てているが
,帯域制限による劣化音声を用いた場合 については議論されていない
.そこで本論文では
, i-vector / PLDA , x-vector / PLDAに基づく話者照合システムを構築し
, N-Bweや他の 帯域拡張法を用いることでサンプリング周波数の違いによる帯域制 限のかかった音声がシステムに与える影響について調査し
,帯域拡張 を適用した音声の客観評価と
EERの関係を考察した
.実験結果より
,N-Bwe
で生成された音声は低い
RMS-LSDを得られ
,かつアップサ
ンプリングのみを行なった音声と比較して
i-vectorを用いた場合及び
x-vector
を用いた場合の話者照合システムどちらにおいても
EERが
改善したことを報告する
.あらまし
ivSummary
This paper aims to evaluate an effect of a non-linear bandwidth extension (N-Bwe) method by using i-vector/PLDA-based and x-vector/PLDA-based automatic speaker verification (ASV) systems. The N-Bwe method has been reported as a blind, non-learning and light-weight BWE approach.
Although the N-Bwe method consists of a simple non-linear function and lters, it has archived high accuracy in terms of speaker individual- ity and root mean square log-spectral distortion (RMS-LSD). Recently, i-vector/PLDA-based ASV systems become one of the state-of-the-art ASV systems. While the PLDA-based ASV approaches focus on re- moving speaker and channel dependency, there are few discussions about speeches which degraded by band limits. Thus, this paper investigates the infuence of the speech degradation by band limits toward the PLDA- based ASV systems. In the experiments, the N-Bwe and shift-based BWE methods were evaluated by the PLDA-based ASV systems. From the results, the N-Bwe method improved equal error rate (EER) from the simply up-sampled situation.
1.
はじめに
11 はじめに
近年
,端末へのログインやサイトへのアクセス
,入室管理など様々 な場面において本人認証を行う機会が増えている
.これらは主にパ スワードや
IDカードなどを用いることで本人認証が行われている
.しかしこれらの認証方法は
IDカードの携帯やパスワードの記憶など ユーザーへの負担が大きい
.また紛失
,忘却
,盗難などのリスクも常 に存在し
,このリスクもユーザーへの負担につながっている
.これら のユーザーへの負担を軽くする方法として指紋
,虹彩などの個人の身 体的特徴を用いて個人認証を行う生体認証技術が注目を集めている
.特に声を用いた生体認証は発話内容や言語に依存せず
,発生器官の形 状の違いなどの身体的特徴や話し方の癖といった行動的特徴を併せ 持っていることから
,生体認証に用いる特徴量として頑健であると考 える
.声を用いた生体認証技術である話者照合は
i-vector [1, 4, 5]や
probabilistic linear discriminant analysis(PLDA)に基づく手法
[2,6,7]や
x-vector
などと呼ばれる手法
[3,8–10]により非常にその認証精度が向
上していることが報告されている
.これらの手法はアメリカ国立標準
技術研究所
(NIST)から公開されている
speaker recognition evaluation (SRE)シリーズや
Speaker In the Wild(SITW)と呼ばれる世界標準の
データベースを用いて評価され
,高い性能を得られることが示されて
いる
.特に近年ではネットバンキングや携帯電話のセキュリティシス
テムやスマートスピーカーなどの音声対話システムや携帯電話
, PCなどの普及により音声を入力インターフェースとしてシステムを稼
働する機会が増えてきている
.これらのことから
,話者照合システム
のさらなる普及が期待されている
.しかし収録環境によってはシステ
ムが想定しているサンプリング周波数と実際の入力音声のサンプリ
ング周波数が一致しない場合も想定されている
.特に通信を介した
音声は通信速度維持のために
,帯域に制限がかかるため音声の明瞭性
や話者性が大幅に低下してしまい認証システムの性能に大きな影響
を与えてしまうことが知られている
[11, 12].サンプリング周波数の
1.
はじめに
2不一致を解消するために一般的にはサンプリング周波数が高い音声 をダウンサンプリングし低いサンプリング周波数に合わせることが 多い
.しかし入力されるテストデータのサンプリング周波数が低い ため
,学習データをダウンサンプリングさせて話者照合システムを再 び構築し直すには高いコストがかかるという問題点がある
.テスト データのサンプリング周波数が低いため
,アップサンプリングを適用 してサンプリング周波数を学習データに合わせることも可能である が
,アップサンプリングのみだと帯域制限の影響が残るため話者照合 性能が低下してしまうことが知られている
.そこで本論文では帯域制限の問題に対応するため
,帯域拡張法に焦 点を当て
,話者照合実験を行う
.帯域拡張法は帯域制限などにより高 周波数成分が欠落しているデータに対して高周波数を復元する技術 の一である
[13–17].これまでに多くの帯域拡張法が提案されている が大まかには
,付帯情報を用いる手法と用いない手法の二つに分類す ることができる
.付帯情報を用いない手法は低周波数成分のみを用い て高周波数成分を推定するものである
.近年画像信号処理の分野に おいて
,非線形処理による超解像画像処理の手法が 報告された
[18].また
,付帯情報を用いず
,学習を行わないかつ計算量が軽い手法とし て非線形帯域拡張法
N-Bwe(Non-linearbandwidth extension) [11]が提
案された
. N-Bweは単純な非線形関数で構成されているのにもかか
わらず
, GMM-UBM(Gaussian mixture model - Universal backgroundmodel)
に基づく話者照合の等価エラー率
(EER)において高い性能が
得られたことが報告されている
.また近年
,複数の帯域制限が混合し ているデータを用いてモデル学習を行う話者照合システムが報告さ
れている
[12, 19].しかし帯域拡張法を用いた話者照合システムの影
響を調査したものはほとんどない
.そのため本論文では付帯情報を 用いない帯域拡張法に焦点を当て
,最先端の話者照合システムへの影 響を調査する
.実験では
i-vectorに基づく話者照合システムを構築し
,N-Bwe
や他の帯域拡張法を用いた場合にシステムに与える影響につ
いて調査し
,帯域拡張を適用した音声の
EERと客観評価について考
1.
はじめに
3察した
.具体的には帯域制限がかかった
8kHzの音声にアップサンプ リングを適用し
16kHzにした音声と帯域制限がかかった
8kHzの音声 に非線形帯域拡張法を適用して
16kHzにした音声を比較する
.また登 録データ
,学習データ
,テストデータ全てを
N-Bwe法を用いて
16kHzにし話者照合実験を行なった結果とテストデータのみを
N-Bwe法を
用いて
16kHzにし話者照合実験を行なった結果
, 8kHzの音声を用い
て話者照合実験を行なった結果を比較し考察する
.また
N-Bweが日
本語以外の言語
(英語
)でも有効であるか
,実際に使用されているサン
プリング周波数が低く
,帯域制限のかかった固定電話の音声でも有効
であるか
,会話音声
,ノイズがのった音声にも頑健であるかについて
も話者照合実験により合わせて言及する
. N-Bweが有効であること
を確認するために
N-Bweを適用した
16kHzの音声
,アップサンプリ
ングをした
16kHzの音声
, 8kHzの音声
, 16kHzの音声を用いてそれぞ
れ話者照合実験
,客観評価実験を行なった
.実験結果より帯域制限の
かかった音声はアップサンプリングするだけでなく
N-Bwe法を用い
ることで照合性能が改善した
.また全て
8kHzで構築した話者照合シ
ステムの精度と全て
N-Bweを適用し
16kHzで構築した話者照合シス
テムの精度と比較すると
N-Bwe法を用いた場合の話者照合システム
の精度が改善したことを報告する
.同様に他言語
,固定電話の音声
,ノ
イズがのった音声にも
N-Bweを適用することでアップサンプリング
した音声を適用する場合よりも頑健であることを報告する
.2. I-VECTOR PLDA, X-VECTOR/PLDA
に基づく話者照合
42 i-vectorPLDA, x-vector / PLDA に基づく話者照合
話者照合とはユーザーの入力音声を用いて
,入力音声が本人である か否かを判定するシステムである
.一般的に話者照合システムは登録 部と照合部の二つに分けられており
,登録部において照合したい話者 の音声の声を用いて特定話者モデルを作成する
.照合部では入力され た音声の特徴量と登録部で作成された特定話者モデルのスコアを計 算し
,閾値以上であれば受理
,未満であれば棄却するシステムである
.最新の話者照合システムは
i-vectorに基づく手法や
x-vectorに基づく 手法が提案されているが
,本稿では実験に使用する
i-vectorに基づく 話者照合システム及び
x-vectorに基づく話者照合システムについて 言及することにする
.2.1 i-vector [1]
近年
, i-vectorに基づく話者照合システムは最新のシステムの一つ
としてみなされている
[1, 4, 5]. i-vectorにおける話者モデルは式
1に よって定義される
.Mu = mubm+Tωu, (1)
ここで
, mubm ∈ RCDFは大量の不特定話者データで学習した
universalbackground model (UBM)
と呼ばれる
GMMから平均を取り出した
GMM
スーパーベクトル
,T ∈RCDF×DTは話者とチャネル変動をを含む
全変動
(TV)行列である
. Dは音響特徴量の次元数を表す
. ωu ∈RDTは
発話
uの固有ベクトルを表す確率変数であり
,平均ベクトルが
0∈ RDTで共分散行列が単位行列
1 ∈ RDT×DTのガウス分布
N(ω; 0,I)に従う
.この
ωが各発話に対する
i-vectorであり
GMMスーパーベクトル空間
における平均的な話者からの差を次元圧縮し各話者を表現したものと
考えられる
. i-vectorを用いる場合
,識別には主に
cos類似度や
PLDAを用いることが多い
.2. I-VECTOR PLDA, X-VECTOR/PLDA
に基づく話者照合
5登録部 照合部
発話 i-vector抽出 𝑝(𝜔$|𝛿, 𝜁$)
発話 i-vector抽出 𝑝(𝜔$|𝛿, 𝜁$)
UBM TV PLDAmodel 対数尤度⽐
受理 棄却
図
1: i-vectorに基づく話者照合のフロー図
a.
コサイン類似度を用いた評価
登録話者の
i-vectorω1と照合話者の
i-vectorω2のコサイン類似 度によりスコアリングを行う
.cos(ω1, ω2) = ω1ω˙2
||ω1||||ω2|| (2)
この類似度が閾値以上であれば
,照合話者を登録話者とみなし
,閾値以下であれば受理されない
.この時
i-vectorをそのまま用い るのではなく
,話者内変動の影響を補正して得たベクトルを用い ることが有効である
.b. PLDA
に基づく評価
登録話者の
i-vector ω1と照合話者の
i-vector ω2を用いて
ω1, ω2が同一話者モデルから生成されたか
(H1)否か
(H0)に関する仮説 に対して対数尤度比
log p(ω1, ω2|H1)
p(ω1|H0)p(ω2|H0) (3)
を計算することで照合性能を評価する
. PLDAの詳細においては
次節で説明する
.2. I-VECTOR PLDA, X-VECTOR/PLDA
に基づく話者照合
62.2 PLDA [2]
この節では
i-vectorに基づく話者照合のための
PLDAについて説明 する
. PLDAでは
,発話
uから抽出された
i-vectorωuをその生成過程を 無視して式
(4)のように生成されたと考える
.ωu = ω¯ + Φδ+ Γζu +ϵu. (4)
ここで
,Φと
Γは話者とチャネルの部分空間を張る基底行列であり
, δと
ζuは話者及びチャネル因子を表しており
,それぞれ標準正規分布 に従う
. ϵuは残差成分を表し
,平均ベクトル
0 ∈ RCDF,対角共分散行 列
Σ ∈ RCDF×CDFのガウス分布に従う
. ¯ωは
i-vector空間におけるオフ セットである
.式
(4)から確率生成モデルを考える
.p(ωu|δ, ζu) = N( ¯ω+ Φδ+ Γζu,Σ). (5)
式
(5)より登録話者の
i-vectorω1と照合話者の
i-vectorω2を用いて
ω1,ω2が同一話者モデルから生成されたか
(H1)否か
(H0)に関する仮 説に対して対数尤度比
log p(ω1, ω2|H1)
p(ω1|H0)p(ω2|H0) (6)
を計算することで照合性能を評価する
. i-vector/PLDAに基づく話者 照合システムは図
1によって示す
.2.3 x-vector [3]
話者照合において最も
state-of-the-artとされている話者照合の方法
として
x-vectorがある
.これは可変長の発話から固定次元にマッピ
ングする
DNN(Deep Neural Network)を構築することで得られる
. i-vector
に基づく手法よりも話者照合に対して頑健であると報告されて
いるが
,膨大な発話データが必要である
. x-vector/PLDAに基づく話
者照合システムは図
2によって示す
. i-vectorに基づく話者照合シス
テムと同様にあらかじめ登録部において照合話者及び
, DNN, PLDA2. I-VECTOR PLDA, X-VECTOR/PLDA
に基づく話者照合
7登録部 照合部
発話 話者毎の
x-vector抽出 𝑝(𝜔$|𝛿, 𝜁$)
発話 話者毎の
x-vector抽出 𝑝(𝜔$|𝛿, 𝜁$)
DNN PLDAmodel 対数尤度⽐
受理 棄却
図
2: x-vectorに基づく話者照合のフロー図
の構築を行なっている必要がある
. DNNの概要図を図
3に示す
. DNNはネットワークは
7つの層とプーリング層
,活性化関数で構成されて おり
, N人の話者を分類されるように学習される
.図
3において
itsは 発話
s,フレーム
tの特徴
iであり
,これを
DNNの入力として用いる
.プーリング層より前の隠れ層ではフレーム単位で処理を行なってい る
.プーリング層は前の隠れ層の出力を集約し
,対角標準偏差と平均 を計算する
.プーリング層より後の隠れ層は全てセグメント単位で処 理を行なっている
.この結果は全結合である最終層に伝搬され
,発話
sの話者
kのラベルが出力される
.図
3の
enbは埋め込みを示してお
り
,これが
x-vectorと呼ばれる
. DNNを構築する目的はフレーム単位
ではなく発話単位で埋め込みの
enbを抽出することである
. x-vectorを用いる話者照合のスコアを計算するために通常
PLDAを用いる
.2. I-VECTOR PLDA, X-VECTOR/PLDA
に基づく話者照合
8Frame level Segment
level
Static Pooling layer
𝑖"#
𝑒𝑛𝑏
Spkrlabel
𝑃(𝑠𝑝𝑘𝑟-|𝑠)
図
3: DNN構成図
3.
非線形帯域拡張法
93 非線形帯域拡張法
3.1
付帯情報を用いない帯域拡張法
帯域拡張法としてこれまでに多くの手法が報告されている
.これら の手法は付帯情報を用いるか用いないかに分類することができる
.本 論文では付帯情報を用いず
,かつ学習を行わない帯域拡張法に焦点を 当てる
.一般的な帯域拡張ではインターポレータとローパスフィルタ によるアップサンプリングを狭帯域音声に適用し
,高周波域を持たな いアップサンプリング音声を生成する
.付帯情報を用いない帯域拡張 法ではアップサンプリングによりできた空の高周波成分を低周波数 成分のみで補うことを目的としている
.3.2
スペクトルシフティング法
(SHIFT)非学習型の帯域拡張法の一つとしてスペクトルシフティング法が
ある
[20].この手法は
4 kHz未満の周期を変調することによって高周
波成分を生成し
,その成分をアップサンプリングにより空いた周波数 領域にシフトすることで広帯域音声を生成している
.単純な処理のた め処理量が非常に少ないという利点がある.
3.3
線形予測分析合成法
(LPAS)付帯状況を用いない帯域拡張法の一つであり
,シフトベースの手法 の品質を改善するためにシフトに基づく手法を拡張した
LPAS [21]が提案された
. LPASは狭帯域信号からスペクトル包絡線および残留 誤差情報から抽出された高周波数成分を用いて広帯域信号生成する 手法である
.生成された高周波成分は単純にシフトされたものよりも 自然なものになることが報告されている
.LPAS
のフロー図を図
4に示す
.狭帯域音声
xwb[n]から広帯域音声
ˆxswb[n]
を生成するためフレームごとに処理することを考える
.まず
,図
4の
2の高周波数成分生成について説明する
.ここで
awbは線形予
3.
非線形帯域拡張法
10図
4: LPASのフロー図
測係数であり
,これを用いることで周波数応答
H(ω)を求める
.残差 成分
ewb[n]はゼロ挿入をし
, H(ω)と
ˆ(Eswb(ω))をかけ
,ハイパスフィル タを通すことで
,高周波数成分のみを抽出する
.次にまず
,図
4の
3の 低周波数成分について説明する
.ここでは狭帯域音声にアップサンプ リングを適応することで高周波数成分を持たない広帯域音声を生成 する
.最後に 図
4の
2の出力に逆フーリエ変換を適応し
,時間領域の 信号を得る
.時間領域において
,図
4の
3の出力を
sを用いてサンプ リングのずれを考慮し足し合わせることで擬似的に高周波数成分を 持つ広帯域音声を生成する
.フレーム毎に処理を行うため
,フレーム 同士の不連続性を避けるため合成の際には
[22, 23]を用いる
. 3.2の 拡張法のため
,作成された音声は自然性が高いが
,照合を考慮した帯 域拡張法ではない
.3.4
非線形帯域拡張法
(N-BWE)付帯情報を用いない手法でかつ学習を行わない帯域拡張法として非
線形帯域拡張法
(N-BWE)が提案されている
[11].非線形帯域拡張法
の利点として
,学習を行わないため処理が非常に軽く
,任意のサンプ
リング周波数に対応できることである
.図
5は
N-BWE法のブロック
図を示している
.図に示すように
, FS0Hzでサンプリングされた狭帯
域音声
x[n]に対して
,インターポレータ
m,およびローパスフィルタ
3.
非線形帯域拡張法
11Limiter
Narrowband
signal Upsampling Extended
signal LPF
Sampling rate Upsampling rate
Non-linear function +sgn
↑
Hz Hz
図
5: N-BWE法フロー図
を用いたアップサンプリングを適用することで
,高周波数成分を持た ない
yU P[n]を生成する
.ここで
, nは離散時間変数である
.次に
,アッ プサンプリングされた信号に対して式
(7)で表される非線形関数を用 いることで高周波数成分が生成される
.yNLF[n] =sgn(yF(A)[n]) · |yF(A)[n]α| ×β, (7)
ただし
,sgn(a) =
1 (a> 0) 0 (a= 0)
−1 (a< 0)
, (8)
ここで
,αと
βは非線形性制御のための任意のパラメーターであり
, aは実数である
.また
,図
6の
limiterは以下の式で与えられる
.yHB[n] =
yNLF[n], yNLF[n] ≤ Th
M, yNLF[n] > Th , (9)
ここで
,Thは閾値
, Mは定数である
.図
5の
hAと
hBはフィルタを示し
ており
,オールパスフィルタ
,バンドパスフィルタやハイパスフィル
3.
非線形帯域拡張法
12200 400 600 Time (secs) (a) Reference Speech
0 1 2 3 4 5 6 7 8
Frequency (kHz)
200 400 600 Time (secs) (b) Narrowband 0
1 2 3 4 5 6 7 8
Frequency (kHz)
200 400 600 Time (secs)
(c) SHIFT 0
1 2 3 4 5 6 7 8
Frequency (kHz)
200 400 600 Time (secs)
(d) LPA S 0
1 2 3 4 5 6 7 8
Frequency (kHz)
200 400 600 Time (secs)
(e) N-BW E 0
1 2 3 4 5 6 7 8
Frequency (kHz)
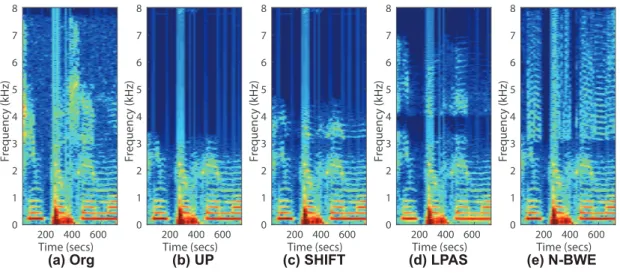
(a) Org (b) UP (c) SHIFT (d) LPAS (e) N-BWE
図
6: Spectrogram examples of speech signals (m= 2;FS0 =8 kHz,FS1 =16kHz)タを想定している
. hAは非線形関数を適用する狙った帯域を選択す るためのフィルタであり
,hBは特に非線形処理を施した音声に生じる 低周波成分へのまわりこみなどによるノイズを取り除く目的がある
.まわりこみを取り除くことで
yN B[n]との足し合わせの際に元の音声 を傷つけないためノイズが低減されると期待できる
.3.5 PLDA
に基づく話者照合と
N-BWE帯域拡張法は帯域制限による高周波成分を補うことを目的として
いる
. PLDAに基づく話者照合システムは話者とチャネル変動を取り
除くことに重点を置いている
.しかし
,これまでに帯域制限によって 失った変動については議論されていない
.そこで本論文では
,帯域制 限により劣化した音声を用い帯域拡張法と
PLDAシステムの性能に ついても調査し
,議論する
.3.6
帯域拡張法のスペクトログラムによる比較
図
6は
,原音声
,アップサンプリング
, SHIFT, LPAS, N-BWEによる
音声信号のスペクトログラムを示している
.まず
, 16kHzでサンプリ
ングされた原音声の信号
(a)は
0 kHzから
8 kHzまでの周波数成分を
3.
非線形帯域拡張法
13有していることがわかる
.次に原音声のサンプリング周波数を
16 kHzから
8 kHzに落とし
,また
8 kHzから
16kHzにアップサンプリング
した音声が図
2の
(b)である
.図からもわかるように
4 kHz以上の高
い周波数成分を含んでいない
.信号
(c)は
SHIFT [20]によって生成さ
れた音声
,信号
(d)は
LPAS [21]によって生成された音声
,信号
(e)は
N-BWEで生成された音声である
. (c), (d), (e)から帯域拡張法によっ
てアップサンプリングではなかった高周波数成分が生成されている
ことがわかる
.4.
日本語データベースにおいての実験
144 日本語データベースにおいての実験
この章ではまず
N-BWE法が
i-vectorに基づく話者照合実験におい て有効かどうかを確認する
.次に
, N-BWEの有効性を評価するため に原音声及び通信音声を用いて
i-vectorに基づく話者照合実験行い
N-BWE
法が通信音声においても有効であるかを確認した
.4.1
共通実験条件
話者照合システムの主な構築条件を
1に示す
. i-vectorを推定する ために必要となる
UBM, TV行列の学習には
JNASデータベース
[24]から女性話者の音声
23657文章を用いた
. GMMの混合数は
1024, i-vector
の次元数は
400次元である
.日本語データベースの実験では評
価のために
VLDデータベース
[25]を用いた
. JNASデータベースで はサンプリング周波数が
16kHzであるが
, VLDデータベースではサ ンプリング周波数は
48kHzで収録されているため
, 16kHzにダウンサ ンプリングしたものを
16kHzの原音声として扱う
.この原音声のう ち
, 70文章
×17名を特定話者モデルの学習データ
, 30文章
×17名をテ ストデータとした
.表
1:共通実験条件
UBM, TV
用データベース
JNAS(女性
) 23657文章
GMM
混合数
1024i-vector
次元数
400次元
UBM
学習回数
30回
TV
学習回数
10回
登録データ
VLDデータベース
(女性
) 17名
x70文章 テストデータ
VLDデータベース
(女性
) 17名
x30文章 フレーム長
/フレームシフト
20ms/10ms特徴量
MFCC19次元
+ ∆ + ∆∆評価尺度
EER(Equal Error Rate)4.
日本語データベースにおいての実験
154.2 clean
音声
この節では
clean音声に対して
N-BWEを適用し
,その有効性につい て確認する
.なお本節の内容は
[26]において発表済みである
.4.2.1 比較手法(clean音声)
比較手法は以下の通りである
.テストデータのみに帯域拡張を適用
した結果
(test)と学習データ
,登録データ及びテストデータ全てに帯
域拡張を適用した場合
(all)の二つについて確認する
. (A) UP (test)狭帯域音声
(8 kHzサンプリング
)に対してアップサンプリング のみを行なった音声
(yU P[n])をテストデータのみに用いた
. (B) N-BWE (test)狭帯域音声に
N-BWE [11]を適用した音声をテストデータとし て用いた
.フィルタ
hA[n]には以下の式
(10)を用いた
.フィルタ
hB[n]は図
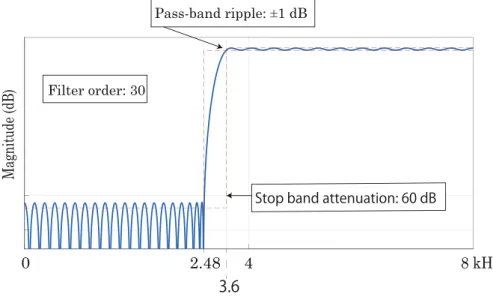
7のように定義した
.hA[n] =
1 (n = 0)
0 (n , 0). (10)
非線形関数
(式
(7))の
αと
βはそれぞれ
2と
100,000とした
. (C) Down (test)16 kHz
の原音声から
8 kHzにダウンサンプリングされた狭帯域
音声
x[n]を登録及びテストデータとして用いた
. (D) N-BWE (all)狭帯域音声に
N-BWE [11]を適用した音声をテストデータとし て用いた
.フィルタ
hA[n]には以下の式
(10)を用いた
.フィルタ
hB[n]は図
7のように定義した
.非線形関数
(式
(7))の
αと
βはそ れぞれ
2と
100,000とした
.(E) Org (all)
全ての音声データは
16 kHzの原音声である
.4.
日本語データベースにおいての実験
16図
7: Filters designed for the N-BWE表
2:比較手法
(clean音声
)Train Enrollment Test
(A)UP
原音声
(16k)原音声
(16k)アップ
サンプリング
(B)N-BWE
原音声
(16k)原音声
(16k) N-BWE(C)Down
ダウン
サンプリング
ダウン サンプリング
ダウン サンプリング
(D)N-BWE N-BWE N-BWE N-BWE
(E)Org
原音声
(16k)原音声
(16k)原音声
(16k)4.2.2 実験結果(clean音声)
図
8に手法ごとの
EERを示す
.まず
(A)UPと
(E)Orgを比較する
. (A)と
(E)の違いはテストデータが帯域制限されているか
,いないか
4.
日本語データベースにおいての実験
176.9 6.67
3.09
2.31
0.76 0
1 2 3 4 5 6 7 8
(A)Up (B)N-BWE (C)Down (D)N-Bwe (E)Org
EER(%)
図
8:話者照合の実験結果
(clean音声
)のみの違いであるが
, (A)の照合性能が大幅に低下している
.このこと により
,音声の帯域制限は話者照合の照合性能に大きく影響を与えて いることが確認できる
.次に
(A)UPと
(B)N-BWEを比較してみると
,(B)N-BWE
の方が精度が高い
.このことにより高帯域成分による影響
もわずかながらではあるが話者照合の性能に影響を与えていること がわかる
.しかし
, (A)UP, (B)N-BWEと
(C)Downをそれぞれ比較する と
,テストデータをアップサンプリング
,帯域拡張をしたものよりも
,ダウンサンプリングで学習しなおしたものの方が性能が良いという ことがわかる
.次に
(C)Downと
(D)N-BWEを比較してみると
, (D)の 方が照合性能が高い
.これらのことより
,話者照合において
N-BWE法が有効であり
,サンプリング周波数を落として学習しなおすよりも
N-BWE
法を適用して学習しなおす方が照合性能が良いということが
確認できた
.4.
日本語データベースにおいての実験
184.3
電話音声
この節では電話音声に対して
N-BWEを適用し
,その有効性につい て確認する
.なお本節の内容は
[27]において発表済みである
.電話音 声に関しては通信を介した音声は様々なパターンがあるが本稿では 固定電話の音声について考える
.本稿では入力音声に対してを
ITU-T勧告
G.712 [28]に基づくフィルタを用い帯域制限をかけたうえでダ
ウンサンプリングを行う
.次に
ITU-T勧告
G.711 [29]によって策定 された
µ− law方式による符号化を用いることで固定電話を介した 音声を摸擬した
.実験において
µは圧縮効率を表しており
,値が小さ いほど強く圧縮されていることを示す
.電話音声作成のフローを図
9示す
.エンコーダは以下の式
11で作成し
,デコーダーは以下の式
12で作 成した
.F(s) = sign(s)in(1+µ|s|)
in(1+µ) (11)
y′ =y∗2−7F−1(y′) = sign(y′)1
µ(1+µ)|y′|−1 (12)
また正規化は次の式
13で表した
.y = sign(F).∗ceil(|F| ∗27) (13)
4.3.1 比較手法(電話音声)
本実験では実際に使用されている圧縮率
µ= 255が
N-BWE法でも 有効であるか確認するため
,他の圧縮率及び
clean音声とも比較し
,そ の有効性を検証する
.(A) 8k
16 kHz
の原音声から
8 kHzにダウンサンプリングされた狭帯域
音声
x[n]を学習
,登録及びテストデータとして用いた
.4.
日本語データベースにおいての実験
19Narrowband signal
図
9:電話音声作成フロー
(B) UP
狭帯域音声
(8 kHzサンプリング
)に対してアップサンプリング のみを行なった音声
(yU P[n])を学習
,登録及びテストデータに用 いた
.(C) N-BWE
狭帯域音声に
N-BWE [11]を適用した音声を学習
,登録及びテ ストデータとして用いた
.フィルタ
hA[n]には式
(10)を用いた
.フィルタ
hB[n]は図
7のように定義した
.非線形関数
(式
(7))の
αと
βはそれぞれ
2と
100,000とした
.(D) 8k (255) (G) 8k (127) (J) 8k (63)
16 kHz
の原音声から
8 kHzにダウンサンプリングされた狭帯域
音声
x[n]に圧縮
,伸長を適用し
,学習
,登録及びテストデータと して用いた
.また圧縮率はそれぞれ
µ = 255, µ = 127, µ = 63と した
.(E) UP (255) (H) UP (127) (K) UP (63)
狭帯域音声
(8 kHzサンプリング
)に対してアップサンプリング のみを行なった音声
(yU P[n])に圧縮
,伸長を適用し
,学習
,登録及 びテストデータに用いた
.また圧縮率はそれぞれ
µ = 255, µ = 127, µ = 63とした
.(F) N-BWE (255) (I) N-BWE(127) (L)N-BWE(63)
狭帯域音声に
N-BWE [11]を適用し
,圧縮
,伸長した音声を学習
,登録及びテストデータとして用いた
.フィルタ
hA[n]には式
(10)を用いた
.フィルタ
hB[n]は図
7のように定義した
.非線形関数
(式
(7))の
αと
βはそれぞれ
2と
100,000とした
.また圧縮率はそ
4.
日本語データベースにおいての実験
20表
3:比較手法
(電話音声)Train Enrollment Test
(A)8k
ダウン
サンプリング
ダウン サンプリング
ダウン サンプリング
(B)UP
アップ
サンプリング
アップ サンプリング
アップ サンプリング
(C)N-BWE N-BWE N-BWE N-BWE
(D)8k (255)
ダウン
サンプリング
(255)ダウン サンプリング
(255)ダウン サンプリング
(255)(E)UP (255)
アップ
サンプリング
(255)アップ サンプリング
(255)アップ サンプリング
(255)(F)N-BWE (255) N-BWE (255) N-BWE (255) N-BWE (255)
(G)8k (127)
ダウン
サンプリング
(127)ダウン サンプリング
(127)ダウン サンプリング
(127)(H)UP (127)
アップ
サンプリング
(127)アップ サンプリング
(127)アップ サンプリング
(127)(I)N-BWE (127) N-BWE (127) N-BWE (127) N-BWE (127)
(J)8k (63)
ダウン
サンプリング
(63)ダウン サンプリング
(63)ダウン サンプリング
(63)(K)UP (63)
アップ
サンプリング
(63)アップ サンプリング
(63)アップ サンプリング
(63)(L)N-BWE (63) N-BWE (63) N-BWE (63) N-BWE (63)
れぞれ
µ = 255, µ = 127, µ =63とした
.4.3.2 実験結果(電話音声)
図
10に手法ごとの
EERを示す
.まず
,クリーン音声における
(A)アップサンプリング
, (B)提案法
, (C)8kを比較すると
, (C)よりもサン
プリング周波数をあげた
(A), (B)の方が
EERが低くなっていること
がわかる
.ここで
(B)が
(A)よよりも
EERが低いため帯域拡張法は
有効であると考えられる
.次に
µ = 255のときの
(D), (E), (F)につい
て比較してみる
.この
3つの手法の中で提案法を用いた
(E)が一番照
合性能が良いことがわかる
. µ = 127,63も同様の傾向が得られた
.圧
4.
日本語データベースにおいての実験
212.66 2.31 3.09
4.52 3.73
4.92 4.41
3.22 4.77
6.05 5.12
5.97
2 2.5 3 3.5 4 4.5 5 5.5 6 6.5
(A) (B) (C) (D) (E) (F) (G) (H) (I) (J) (K) (L)
Equal Error Rate(%)
アップサンプリング 提案法 8k
clean 𝜇 = 255 𝜇 = 127 𝜇 = 63
図
10:話者照合の実験結果
(電話音声
)縮がかかりノイズを含む音声においては非線形帯域拡張法が有効で
あることがわかる
.これは提案法により生成した高周波数成分がノ
イズの影響を受けていても話者性を表現できているからだと考えら
れる
. µ = 255及び
µ = 127の結果を比較するときつい圧縮がかかる
µ = 127の方が
3手法とも
EERが若干低い
. 8kの結果でも
EERが
低いことからノイズが含まれていても話者性を表す部分には悪い影
響を与えておらず
,結果として
(G), (H)の
EERが
(D), (E)よりも低く
なったと考えられる
.5.
英語データベースにおいての実験
225 英語データベースにおいての実験
N-BWE
の有効性を評価するために実環境で収録された音声を用い
て
i-vector/PLDAに基づく話者照合実験
, x-vector/PLDAに基づく話 者照合実験を
N-BWEの音声と他の帯域拡張法を適用した音声で行 い
EERを比較した
.また
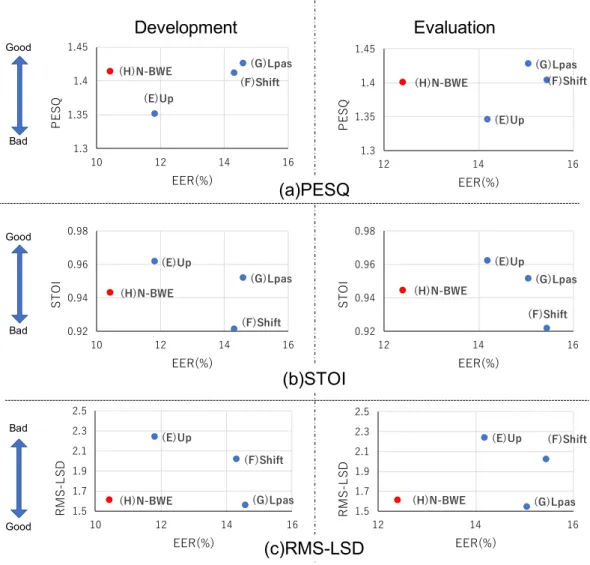
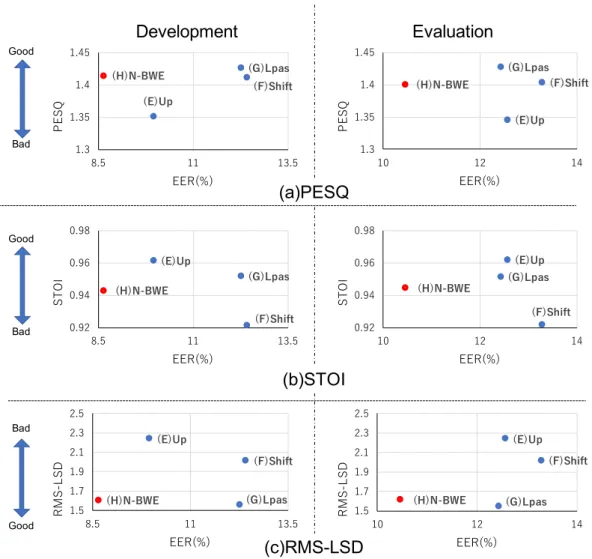
,その
EERと生成した音声を客観評価尺度 で評価したスコアとの関係について調査した
.なお
i-vectorの実験に 関しては
[30], x-vectorの実験に関しては
[31]で発表済みである
.5.1
共通実験条件
5.1.1 英語データベースの詳細
本実験では
Kaldi-toolkit [32]と
SITWデータベース
[33]を用いて
i-vector/PLDAに基づく話者照合システムの構築及び
x-vector/PLDAに基づく話者照合システムの構築を行なった
.その際
, i-vectorに基づ く話者照合実験において必要な
UBM, PLDA, TV行列を推定するた
め
,また
x-vectorに基づく話者照合実験において
DNNを構築するた
めに
Voxcelebデータベースを用いた
. Voxcelebデータベースは二つ
のデータセット
Voxceleb1 [34], Voxceleb2 [35]で構成されており
,ど ちらのデータセットも
Youtubeにアップロードされた著名人のインタ ビュービデオから収集されている
. Voxceleb1は話者数
1251,発話数 は
100,000以上
,Voxceleb2は話者数
6112,発話数は
1,000,000以上と なっている
.これらのデータセットは様々な民族や職業
,年齢
,アクセ ントで構成されている
.登録及びテスト用のデータベースには
SITWを用いた
. SITWは収録状況を制御したデータベースではなく
,本来
の背景ノイズ等を含み
,より実環境に近いデータベースとなっている
.SITW
と
Voxcelebは別々で収集されているが
, 2つのデータベースに
は話者
60名が重複しているため
,学習前に
Voxcelebのデータベース
から削除した
.また
,ノイズ用のデータベースとして
MUSAN [36]と
RIRNOISE [37]を用いた
. MUSANデータベースは
900以上のノイズ
と様々なジャンルの音楽
, 12言語の会話が含まれている
. RIRNOISE5.
英語データベースにおいての実験
23は部屋の残響ノイズである
. PLDAは
Voxcelebデータセットにノイ ズを付与した音声を用いて学習した
.ノイズデータベース以外の全て のデータベースの言語は英語であり
, 16 kHzでサンプリングされて いる
.本実験でサンプリング周波数が
8 kHzとなっている狭帯域音声 は全て原音声の
16 kHzから
8 kHzへのダウンサンプリングしたもの を表す
.5.2
共通比較条件
(話者照合実験
)表
4に比較条件をまとめた
.詳細は以下の通りである
. (A) UP (enroll)狭帯域音声
(8 kHzサンプリング
)に対してアップサンプリング のみを行なった音声
(yU P[n])を登録及びテストデータとして用 いた
.(B) SHIFT (enroll)
狭帯域音声に
SHIFT [20]を適用した音声を登録及びテストデー タとして用いた
.バンドパスフィルタとして
[38]を適用した
. (C) LPAS (enroll)狭帯域音声に
LPAS [21]を適用した音声を登録及びテストデー タとして用いた
.(D) N-BWE (enroll)
狭帯域音声に
N-BWE [11]を適用した音声を登録及びテストデー タとして用いた
.フィルタ
hA[n]には
(10)を用いた
.フィルタ
hB[n]は図
7のように定義した
.非線形関数
(式
(7))の
αと
βはそ れぞれ
2と
100,000とした
.(E) UP (test)
狭帯域音声
(8 kHzサンプリング
)に対してアップサンプリング のみを行なった音声
(yU P[n])をテストデータとして用いた
.登録
データは
16kHzの原音声である
.5.
英語データベースにおいての実験
24表
4: Experimental conditions for each methodTrain Enrollment Test
(A)UP (enroll)
原音声
(16k)アップサンプリング アップサンプリング
(B)SHIFT (enroll)
原音声
(16k) Shift Shift(C)LPAS (enroll)
原音声
(16k) LPAS LPAS(D)N-BWE (enroll)
原音声
(16k)N-BWE N-BWE
(E)UP (test)
原音声
(16k)原音声
(16k)アップサンプリング
(F)SHIFT (test)
原音声
(16k)原音声
(16k) Shift(G)LPAS (test)
原音声
(16k)原音声
(16k) LPAS(H)N-BWE (test)
原音声
(16k)原音声
(16k) N-BWE(I)Down
ダウンサンプリング ダウンサンプリング ダウンサンプリング
(J)Org
原音声
(16k)原音声
(16k)原音声
(16k)(F) SHIFT (test)
狭帯域音声に
SHIFT [20]を適用した音声をテストデータとして 用いた
.バンドパスフィルタとして
[38]を適用した
.登録データ は
16kHzの原音声である
.(G) LPAS (test)
狭帯域音声に
LPAS [21]を適用した音声をテストデータとして 用いた
.登録データは
16kHzの原音声である
.(H) N-BWE (test)
狭帯域音声に
N-BWE [11]を適用した音声をテストデータとし て用いた
.フィルタ
hA[n]には上記の式
(10)を用いた
.フィルタ
hB[n]は図
7のように定義した
.非線形関数
(式
(7))の
αと
βはそ れぞれ
2と
100,000とした
.登録データは
16kHzの原音声である
. (I) Down16 kHz
の原音声から
8 kHzにダウンサンプリングされた狭帯域
音声
x[n]を登録及びテストデータとして用いた
. (J) Org全ての音声データは
16 kHzの原音声である
.5.
英語データベースにおいての実験
25表
5:実験条件
(i-vector)UBM, TV
用データベース
Voxceleb1, Voxceleb2UBM,TV
用発話数
100,000PLDA
用データベース
Voxceleb1, Voxceleb2, musan, RIRnoise PLDA構築用発話数
200,000評価用データベース
SITW(dev, core)特徴量
MFCC24次元
+∆+∆∆フレーム長
/フレームシフト
25ms/20msUBM
混合数
2048TV
行列学習回数
10i-vector
次元数
400PLDA
次元数
150評価尺度
EER5.3 i-vector
に基づく話者照合実験
この節では実環境で収録された音声を用いて
i-vectorに基づく話者 照合実験を行い
N-BWEの有効性を確認する
.5.3.1 実験条件(i-vector)
実験条件を表
5に示す
. Voxcelebデータベースは計
1,000,000以上 の発話を有するデータベースであるが
, UBM, TV行列を学習する上
で
1,000,000以上の発話を学習することは非常に時間を要するため
,1,000,000
のうち
100,000発話を用いて
UBMと
TV行列を学習した
.手法毎に
UBM, TV行列
, PLDAを学習し直すことはコストが非常
にかかってしまうため現実的ではない
.そのため
,本実験では
UBM,TV
行列
, PLDAの推定には
16 kHzでサンプリングされた原音声を
用いた
. (I) Downに関してのみ
UBM, TV行列
, PLDAに用いた音声
データは
8 kHzにダウンサンプリングされたデータを用いた
.本実
験では二つのシナリオを調査した
.一つ目は登録データ
,テストデー
タ共にサンプリング周波数が異なる場合であり
,二つ目はテストデー
タのみがサンプリング周波数が異なる場合である
.比較条件は表
4で
5.
英語データベースにおいての実験
2614.63
15.86
12.44 12.90
11.82
14.32 14.59
10.44 7.54
4.80
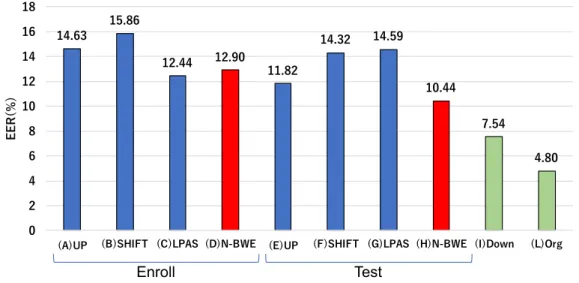
0 2 4 6 8 10 12 14 16 18
(A)UP (B)SHIFT (C)LPAS (D)N-BWE (E)UP (F)SHIFT (G)LPAS (H)N-BWE (I)Down (L)Org
EER(%)
Enroll Test
図
11: I-vector-based speaker verification results by using i-vector (Development task)15.86 16.87
13.91 15.10
14.19
15.45 15.06
12.41
8.58
5.74
0 2 4 6 8 10 12 14 16 18
(A)UP (B)SHIFT (C)LPAS (D)N-BWE (E)UP (F)SHIFT (G)LPAS (H)N-BWE (I)Down (L)Org
EER(%)
Enroll Test
図
12: I-vector-based speaker verification results by using i-vector (Evaluation task)ある
.5.3.2 実験結果(i-vector)
図
11, 12に手法ごとの
EERを示す
.図
11, 12では評価タスクが異 なるものの
,ほぼ同じ傾向が得られた
.そこで図
11を用いて結果を考 察する
.まず
(I) Down (8k)と
(L) Org(16k)を比較すると
EERは
(L)Org (16k)