ストリームデータの時系列予測のための
ストリームデータの時系列予測のための
ストリームデータの時系列予測のための
ストリームデータの時系列予測のための
センサデータベースシステム
センサデータベースシステム
センサデータベースシステム
センサデータベースシステム
荒井健次
†白石陽
††高橋修
†† センサネットワーク技術などの発展によって,データストリームに対する注目 が高まり,ストリームマイニング研究に対する期待が高まってきている.ストリ ームマイニング研究にはデータストリームの過去のデータの周期性を分析し,そ の結果から未来のデータを予測するストリーム予測技術が存在する.しかし,実 際のセンサ環境を想定する場合,センサがもたらす複数のデータストリーム間に は変化の相関が存在する可能性があり,相関を考慮した予測を行うことで精度の 向上が見込まれる.本稿は相関を考慮したデータストリーム予測手法について提 案し,それを実現するシステムの概形を設計する.また,複数のデータストリー ム間の相関が存在すると考えられる実環境について調査し,提案システムの有効 性を検討する.Sensor database system for time series
prediction of stream data
KENJI ARAI
†YOH SHIRAISHI
††OSAMU TAKAHASHI
††By developing sensor network technology, stream mining researches have received much attention and data stream techniques are expected to develop. Stream prediction which predicts future data by analyzing periodicity of past data stream is one of stream mining techniques. However, in real environment of sensor network, data stream from a certain sensor node may relate to that from other one. It is expected to improve the prediction accuracy by considering the correlation between sensor data streams. This paper proposes a method to predict sensor data stream that has correlation and designs a sensor database system with such prediction function. In addition, we study the real environment with multiple sensor data streams and discuss the efficiency of our system.
†公立はこだて未来大学大学院
Graduate School of Future University Hakodate ††公立はこだて未来大学
Future University Hakodate
1.
はじめにはじめにはじめにはじめに 近年,無線技術やセンサ技術の発展により,多くの小型無線センサデバイスが製品 化されている.これらのセンサデバイスはセンサネットワークと呼ばれる独自のアド ホックネットワークを形成する機能を持ち,一定の時間間隔で周囲の情報を計測し, 計測されたセンサデータを送信する.このようなセンサデータは,時々刻々と変化し 蓄積されるデータの流れとして捉えることが可能であり,このようなデータの流れを データストリームと呼ぶ.データストリームはある一定のデータレートで到着するデ ータ列であり,時間の経過と共にデータが増加するためその長さは無限長である. このようなデータストリーム処理についての研究が近年になって注目されており, その中でもストリームマイニングと呼ばれるデータストリームから有用な規則やパタ ーンを見つけるための取り組みが盛んに行われている[1][2][3].例えば,トレンドと 呼ばれるデータストリームの周期性を分析する研究が存在する[4].トレンドは様々な 形で表現されるが,過去から現在までのトレンドの分析結果から未来のデータストリ ームの動きを予測することが可能となる.しかし,従来の研究はあるストリームの予 測を行うためにそのストリームのデータしか利用していない.一般に,室内に複数セ ンサを設置した場合,センサからもたらされる複数のストリームの間には相関が存在 することが考えられる.このため,あるデータストリームの予測を行う場合に,相関 する複数のデータストリームの間の関係を考慮することで予測精度の向上が可能と考 えられる. そこで,本稿では複数のセンサが存在する環境下における,データストリーム間の 相関を考慮した時系列予測を行うセンサデータベースシステムの提案を行い,その有 効性を検討する.2.
関連研究関連研究 関連研究関連研究 2.1 ストリーム相関ストリーム相関ストリーム相関 ストリーム相関 本稿が扱うデータストリーム間の相関の意味について定義する.複数のデータスト リームが同時に計測されている環境を想定する.このとき,あるストリームが変化し た際に,別のストリームがそれと同時,あるいはある一定の遅延の後に変化する場合, この二つのデータストリームの間には相関があるとする[5]. 例えば,室内に CO2センサと温度センサを設置し,それぞれのセンサデータをデー タストリームとして計測しながら温度センサの計測値の予測を行う状況を想定する. その様子を図 1 に示す,このとき,CO2濃度が変化した後に,温度がそれに追従する 形で変化するといった相関がわかっている場合,温度データの予測を行う際も CO2濃 度の変化を参照することで予測精度の向上が見込まれる.しかし,温度データの過去 「マルチメディア,分散,協調とモバイル(DICOMO2010)シンポジウム」 平成22年7月の傾向のみを利用して予測を行った場合,過去の温度データが線形的に上昇している ならば図 1 右の点線のような予測しか得られず,結果として予測精度が低下する可能 性がある. 図 1 データストリーム間の相関の例 また,それぞれのデータストリームの変化の方向は必ずしも同様ではなく,ある一 方の計測値が上昇したのに対し,もう一方の計測値が下降する場合も相関として取り 扱う.図 2 にその例を示す.この中で StreamA と StreamB は全く別の変化をしている が,その変化の契機は時刻 t’であると見られ,この二つのデータストリームの間には 変化のタイミングに相関があると考えられる. 図 2 データストリーム相関の例(逆変化) 2.2 センサデータベースシステムセンサデータベースシステムセンサデータベースシステム センサデータベースシステム センサネットワークから提供されるデータストリームを特にセンサデータストリ ームと呼ぶ.このセンサデータストリームは時間の経過とともにデータ量の増加する 特殊な時系列データであるため,既存のデータベース管理システムで処理することは 難しい.そこで,アプリケーションからセンサデータストリームに対する問い合わせ を行うことに特化したシステムとしてセンサデータベースシステムが提案されている [6].センサデータベースシステムは SQL に類似した問い合わせインターフェースを もち,センサデータストリームに対する継続的な問い合わせ処理が可能である.また, センサデータベースシステムは広義の意味ではセンサデータを扱う機能をもつため, センサデータストリームに対して継続的な処理を行うものと,データベース内に蓄積 されたセンサデータに対して処理を行うものの 2 種類が存在する. 筆者らは,これまでに後者のタイプのセンサデータベースシステムを提案した[7]. この中で筆者らはアプリケーションから任意の時刻におけるセンサデータの問い合わ せに応えるために,センサデータベースシステム側で時系列補間処理を行う手法とそ のためのインターフェースを提案した.しかし,このシステムはリアルタイムに計測 されるセンサデータストリームに対して時系列補間処理を行うことはできないことが 問題となっていた.そこで,センサデータストリームの予測を行うことで時系列補間 処理の問い合わせ範囲を拡張することが可能になると考えられる. 2.3 ストリームマイニストリームマイニストリームマイニングストリームマイニングング ング 2.3.1 既存研究と既存研究と既存研究と既存研究と要素技術要素技術要素技術要素技術 ストリームマイニング研究について説明する.代表的な例として,データストリー ムを受信している時にそのデータストリームから部分シーケンスと呼ばれるデータス トリームの部分列を切り出し,その部分シーケンスが別のデータストリームのどの部 分シーケンスと似ているのかを継続的に調べる類似度探索技術が存在する.櫻井らの SPRING[8]はダイナミックタイムワーピング(DTW)距離に基づいた類似度探索手法 を用いて,アプリケーションからの要求に合わせてデータストリームから継続的に類 似するデータストリームを探索することに成功している.また,豊田ら[9]はダイナミ ックプログラミングを用いることで SPRING より高速に類似度探索を行う手法を示し ている.また,データストリームの部分シーケンスから周波数や周期性を示すトレン ドと呼ばれる情報を継続的に算出するトレンド検出技術が存在する.豊田らは DTW 距離に基づくトレンド検出処理を提案している[10].川島ら[11]はデータストリームの 部 分 シ ー ケ ン ス か ら の ト レ ン ド 検 出 に APCA ( Adaptive Piecewise Constant Approximation)を用いることで次元削減を行い,計算量を減少させることでデータベ ース内のシーケンスとの高速マッチングを行う手法を提案している.菅原ら[12]は加 速度センサから与えられるデータストリームのトレンド検出において,次元削減処理 のために高速フーリエ変換を用いている.しかし,これらの研究はいずれも複数のデ ータストリーム間の相関の検出や予測については言及していない. 次に,ストリーム予測技術が挙げられる.Papadimitriou[13]はトレンドにウェーブレ ット係数を用い,これを自己回帰モデル(Auto Regressive model)のような形で表現する ことで未来のトレンドを予測する手法を実現している.自己回帰モデルおよびウェー ブレット係数の算出はデータが増加する度に実行されるが,前回までの結果を用いて t CO2濃度 現在時刻 t 温度 現在時刻 :実測結果 :予測結果
t
StreamA t’t
StreamB t’最小の計算量でこれらを求めるアルゴリズムが用いられている.しかし,これはあく までも単一のデータストリームの過去のデータを利用したアルゴリズムであり,複数 のデータストリームの相関については触れていない.
さらに,ストリーム間の相関を検出するための技術として BRAID[14]が開発されて いる.また,Zhu らが提案した StatStream[15]は部分シーケンス対して離散フーリエ変 換(Discrete Fourier TransForm,以下,DFT)を用いることで次元減少を行い,DFT 係 数同士を比較することで部分シーケンス間の相関を検出している.しかし,これらの 研究は予測については触れていない. 2.3.2 データマイニングとの関連性データマイニングとの関連性データマイニングとの関連性データマイニングとの関連性 ストリームマイニングと類似した技術として,データベースに蓄積された有限長の 時系列データを対象とするデータマイニング技術が挙げられる.ストリームマイニン グはデータマイニングのある特殊なケースと捉えることが可能であり,対象となる時 系列データをデータストリームに限定していることである.しかし,時系列データの データストリームは一定のデータレートでデータが増加する無限長のデータであるた め,限られたメモリ量,処理時間で分析処理を実現する必要があり,データマイニン グとは異なるアプローチが行われている.精度よりもメモリ量と速度を優先するため に,厳密解ではなく近似解を用いる方法が一般的である.また,計算量の削減のため, インクリメンタルなアルゴリズムが多く用いられる.これはデータを受信する度に全 てのデータを利用して再計算するのではなく,前回までの計算結果を利用して毎回最 低限の計算量で結果を求めるアルゴリズムを指す.
3.
要件要件定義要件要件定義定義 定義 本稿はデータストリーム間の相関に基づいたデータストリーム予測を行うことを 課題とし.提案システムによってこれを解決する.そこで,この課題に対して必要と なる要件について述べる. データストリームの予測は,過去のデータストリームから未来のトレンドを算出す ることで実現される.そこで,まずデータストリームから継続的にトレンドを検出し, トレンド間の相関を発見する手法が必要となる.このとき,相関検出手法については 類似度とは異なるデータストリームの変化に起因する相関を検出できることが求めら れる.さらに検出された相関からデータストリームの未来のトレンドを予測するため の手法が求められる. また,これらの処理はデータストリームのデータの増加と共 にインクリメンタルに行われる必要があると共に,限られたメモリ量で実行可能であ ることが求められる. 本提案システムには提案手法の実現のほか,センサデータベースシステムとしての 基本機能であるセンサデータの蓄積機能と,アプリケーションからの問い合わせ機能 を備えることが要件となる.4.
提案方式提案方式 提案方式提案方式 4.1 提案システム提案システム提案システムの概要提案システムの概要の概要 の概要 本提案方式を実現する提案システムの基本アーキテクチャについて述べる.第 3 章 における提案処理の要件より,提案システムに要求される機能は以下のようになると. (1). データストリームからのトレンド検出 (2). トレンド間の相関検出 (3). 各データの保存・管理 (4). 予測処理 (5). 問い合わせ処理 これらの機能を,データストリームに対して継続的に処理を行うものと,DWT 結 果およびパターンに対して一定時間ごとに行うもの分類し,それぞれデータストリー ム処理を行うデータストリーム管理(Data Stream management System,以下,DSMS) 部と,各種データの保存と検索処理を行うデータベース管理(Database Management System,以下,DBMS)部の 2 つのシステムによって実現する. システム全体図を図 3 に示す.矢印はデータや問い合わせの流れを示す.まず,DSMS 部がデータストリームの受信を行い,トレンドの検出を行う.DBMS 部はセンサデー タと検出されたトレンド情報を受け取り,トレンド間の相関検出とデータの管理を行 う.また,アプリケーションからの問い合わせ機能と,予測処理も DBMS 部が行う. 図 3 提案システムの概要 データストリームの受信 トレンド検出 トレンド間の相関検出 各データの保存・管理 予測処理 問い合わせ処理 DSMS DBMS センサネットワーク センサネットワーク センサネットワーク センサネットワーク データストリーム センサデータ & トレンド情報 予測結果 コンピュータ コンピュータコンピュータ コンピュータ ( (( (アプリケーションアプリケーションアプリケーションアプリケーション)))) 予測問い合わせ4.2 処理手順の概要処理手順の概要処理手順の概要 処理手順の概要 最初に,本提案方式が扱うデータストリーム環境について説明する.データストリ ームは複数同時に計測されていることが前提となる.これらのデータストリームにデ ータの欠損(データ計測・配送ミス)や遅延(データ計測・配送の遅れ)はなく,全 て一定のデータレートによって継続的にデータが蓄積されているものとする. 提案方式の処理手順を以下に示す.まず,データストリームからのパターン検出お よび相関検出処理を以下に示す. Step1:データストリームから部分ストリームを抽出し,トレンドを求める Step2:求められたトレンドから,トレンドを効率的に表現する特徴量を求め, トレンドを特徴量のパターンに変換 Step3:データストリーム毎にクラスタを作成,パターンをクラスタリング Step4:各データストリーム間のクラスタの関係を示す相関マップを作成・更新 Step5:クラスタの更新シーケンスの情報を示すクラスタ更新テーブルを作成・更新 トレンド検出については 4.3 節で説明し,4.4,4.5,4.6 節で検出されたトレンドに 対する相関検出処理について述べる.さらに,4.7,4.8 節で相関を用いたデータスト リーム予測について述べる.また,4.9 節に提案システムの詳細設計について説明す る. 4.3 トレンド検出トレンド検出トレンド検出 トレンド検出 第 2 章に述べたように,トレンドとはデータストリームおよび部分シーケンスの周 期性を表す情報である.データストリームからはデータレート毎にデータが与えられ るが,それぞれのデータは離散的な値であるため,そこからトレンドを検出すること は難しい.そこで,複数のデータを組み合わせて連続的なデータ列を作成し,そこか らトレンドの検出を行う. 最初に,データストリームに対して時間軸方向に一定の長さで分割する.この一定 の長さを持つ区間を窓(window)と呼び,分割されたデータストリームの一部分を部 分シーケンスと呼ぶ.この様子を図 4 に示す.このときの,あるデータストリーム(デ ータ長:n)とデータストリームを形成する個々のデータとの関係を(1)式に示す. また,窓とデータとの関係を(2)式に示し,データストリームと窓の関係を(3)式 に示す.ここで,データを d とし,データストリームを S とし,データストリーム A の x 番目のデータを dAxと表記する.部分シーケンスを w、部分シーケンスの番号を m、 窓の中にあるデータ数を p とする. 図 4 データストリームの部分シーケンス分割 ܵ= ሼ݀ଵ, ݀ଶ, ݀ଷ, … , ݀୬ ሽ
…(1) ܵ. ݓଵ= ൛݀ଵ, ݀ଶ, ݀ଷ, … , ݀ൟ
…(2) ܵ= ൛ܵ. ݓଵ, ܵ. ݓଶ, ܵ. ݓଷ, … , ܵ. ݓ ൟ ただし,݉ = ݊ / …(3) この部分シーケンスからトレンドを検出する手法として,離散ウェーブレット変換 (Discrete Wavelet Transform,以下,DWT)を用いる.離散ウェーブレット変換は離散値 から時間及び周波数の両方の特性を効率的に抽出する手法である.例えば,あるデー タストリームから抽出した部分シーケンスと,ある部分シーケンスに対して離散ウェ ーブレット変換を行った結果を図 5 に示す.それぞれのグラフにおいて,横軸はデー タストリームにおけるデータの順序を表している. 図 5 部分シーケンスの例(左)と DWT 結果の例(右)
t
w1 w2 w3 w4 ウェーブレット 係数値 計測値 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8また,データストリーム A とその離散ウェーブレット係数の集合との関係を(4) 式のように表現する.このとき,DWT 変換処理を function DWT とし,部分シーケン スのウェーブレット係数集合を dwt とする.また,dwt はそれぞれ w と対応する関係 にあり,dwt の要素であるウェーブレット係数を q とする.また,データストリーム A の x 番目のウェーブレット係数値を qA,xとする. ܵ. ݀ݓݐ = function DWTሺܵ. wሻ → ൛ݍ,ሺିଵሻାଵ, ݍ,ሺିଵሻାଶ, … , ݍ,ሺିଵሻା ൟ ただし,1 ≦ ݅ ≦ ݉ …(4) 4.4 特徴量抽出と特徴量抽出と特徴量抽出とクラスタリング特徴量抽出とクラスタリングクラスタリング クラスタリング 一見類似した波形を持つ部分シーケンスでも,そのデータの値が異なっていれば, その DWT 結果であるウェーブレット係数も同様に異なる.そのため,新たな部分シ ーケンスからもたらされたトレンドが,過去のいずれかのトレンドと同値と判断され ることは稀であり,大量の種類のトレンドが検出されることになる.そこで,本提案 方式ではトレンドに対して類似したデータを一つの集合として表現するクラスタリン グ処理を行う.ある程度トレンドの種類の絶対数を減少させる必要がある. クラスタリング処理を行うにあたり,比較するデータ量はなるべく少ないことが望 ましい.そこで,既存研究[11][12]で用いられているようにトレンドを特徴量によって 表現することで計算コストの削減と処理の高速化を図る.例えば,表1のような特徴 量が考えられる.これらの特徴量をまとめて,トレンドを表現するパターンとして扱 う. 表1 算出する特徴量の例 特徴量 備考 最大値 ウェーブレット係数の最大値 最大値のシーケンス番号 最大値のシーケンス番号 合計 ウェーブレット係数の合計値 平均 ウェーブレット係数の平均 分散 ウェーブレット係数の分散 また,ウェーブレット係数の集合とそこから求められたパターンとの関係を(5) 式に示す.ここで,パターンを Pt とし,特徴量そのものを F とする. ܵ. ݀ݓݐ→ ܵ. ܲݐ = ሼܨଵ, ܨଶ, ܨଷ, ܨସ, … ሽ
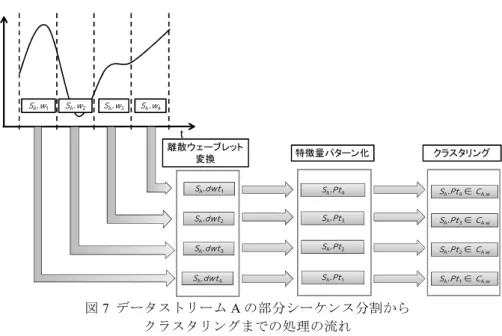
…(5) 特徴量は,トレンドを表現する離散ウェーブレット変換の特徴量を表すデータの性 質に見合ったものを利用する必要があり,その選出は発見的に行う必要がある.また 複数の特徴量を用いることで,元のトレンドに対する高い表現性を得ることができる と考えられる.これによってトレンドをある一定のクラスタによって表現することが 可能になる.データストリーム A におけるクラスタとパターンの関係を(6)式に示 す.また,特徴量の元データとなる離散ウェーブレット係数の集合はクラスタリング 結果と対応付けした形でデータベースに登録し,参照可能とする.また,クラスタ番 号 h のクラスタを CA,hと表記する. ܥ,= ሼܵ. ܲݐଵ, ܵ. ܲݐସ, ܵ. ܲݐଽ, … ሽ …(6) データストリーム A におけるパターンとクラスタの分布関係を図 6 に示す.データ ストリーム A の部分シーケンスとトレンド,パターン及びクラスタの関係を図 7 に示 す. 図 6 クラスタとパターンとの関係
C
A,1C
A,3C
A,2Pt
A,1Pt
A,2Pt
A,4Pt
A,3Pt
A,5Pt
A,6Pt
A,7図 7 データストリーム A の部分シーケンス分割から クラスタリングまでの処理の流れ 4.5 相関の発見相関の発見相関の発見 相関の発見 まず,各データストリームのそれぞれのクラスタを,表 2 のように並べる.これを 相関マップと呼ぶ.例えば,データストリーム A(以下,StreamA)のクラスタ 1 を A1 とし,StreamA にはクラスタが 3 つ存在していることを示している. 表 2 相関マップの例 相関マップはデータストリーム同士の相関を数値化し,統計的に発見可能にするた めに用いられる.初期値として 0 が入力されている.データストリームから部分シー ケンスを抽出し,パターンを検出する時刻のタイミングは一定であるため,複数のデ ータストリームを計測している場合,複数のデータストリームから検出された複数の パターンが同時に出現し,いくつかのクラスタが更新される.このとき,更新された あるクラスタから見て,同時に更新された他のクラスタの更新回数を相関マップによ ってカウントする.例えば,データストリーム A,B,C の計測開始直後,初回のパ ターン検出・クラスタリングの結果,StreamA が A1,StreamB が B3,StreamC が C2 であった場合,表 2 のように各項の値が増加する.このとき,A1 行,B3 列の項を(A1,B3) とし,その値を,cluster correlation(A1,B3)= 1 と表現する. この処理を,StreamA を例にとって説明する.まず A1 の行と,B3,C2 のそれぞれ の列に着目し,それぞれの行と列が重なる項の値に1を加算する.つまり,項の中の 値が大きいものほど,行と列に対応するクラスタ同士の同時更新回数が多く,その相 関が強いことを意味する.この処理をパターンが検出されたデータストリームの本数 分だけ同様に実行する. 4.6 時系列方向の相関時系列方向の相関時系列方向の相関 時系列方向の相関 4.4 節における相関マップによって,データストリーム間の相関をクラスタの同時 更新回数を用いることで表現することはできた.しかし,相関マップはクラスタの更 新順序についての情報を保存することはできない.例えば StreamA において,A1 が 更新された後に A2 が更新されたとしても,相関マップの処理はそれぞれのクラスタ が更新されたタイミングにおいて実行されるため,前後の関係性は失われてしまう. そこで,クラスタの更新シーケンス情報を保存するための試みとして,表 3 のような クラスタ更新テーブルを定義する. 表 3 クラスタ更新テーブル 表 3 は,StreamA にクラスタが 3 種類存在する場合における,クラスタのシーケン ス更新回数の一覧を示している.加算処理は相関マップの更新と同時に行われ,シー ケンス更新クラスタは最近のパターンと比較することによって求められる.例えば, クラスタ1に着目すると,クラスタ 1→3 の遷移回数が最も高いことから,クラスタ 1 が更新された後はクラスタ 3 が更新されることが一般的であると考えられる. ここで, 更新シーケンスが A1→A3 である場合の更新回数の値を,sequence correlation Sq t SA.w1 SA.w2 SA.w3 SA.w4 SA.dwt4 SA.dwt3 SA.dwt2 SA.dwt1 SA.Pt1 SA.Pt2 SA.Pt3 SA.Pt4 離散ウェーブレット 変換 特徴量パターン化 クラスタリング SA.Pt4∈ CA.w SA.Pt3∈ CA.w SA.Pt2∈ CA.w SA.Pt1∈ CA.w
Stream A Stream B Stream C A1 A2 A3 B1 B2 B3 C1 C2 C3 Stream A A1 0 0 1 0 1 0 A2 0 0 0 0 0 0 A3 0 0 0 0 0 0 Stream B B1 0 0 0 0 0 0 B2 0 0 0 0 0 0 B3 1 0 0 0 1 0 Stream C C1 0 0 0 0 0 0 C2 1 0 0 0 0 1 C3 0 0 0 0 0 0 更新シーケンス 更新回数 更新シーケンス 更新回数 更新シーケンス 更新回数 A1→A1 12 A2→A1 19 A3→A1 32 A1→A2 1 A2→A2 11 A3→A2 4 A1→A3 33 A2→A3 4 A3→A3 5
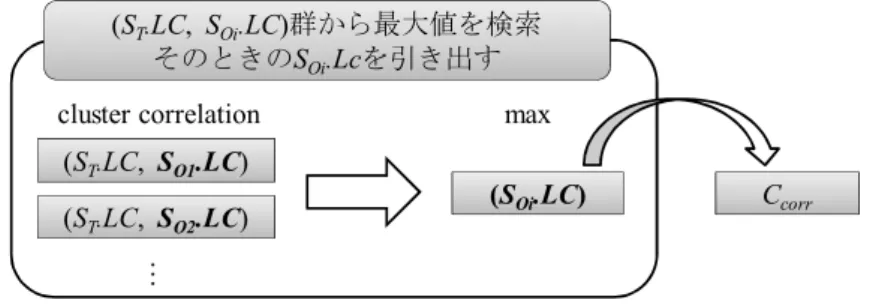
(A1-A3)= 33 と表記する. 4.7 予測処理予測処理予測処理 予測処理 データストリームの予測値を算出する方法について説明する.まず,4.4 節で述べ た相関マップにおいて,複数のデータストリーム間にあるクラスタ同士の相関を把握 することが可能となる.さらに 4.4 節のクラスタ遷移テーブルによって,あるデータ ストリームにおけるクラスタ同士の前後関係について把握することができる.このク ラスタに対する 2 種類の関係性を用いて,複数のデータストリーム間の相関を考慮し, データストリームの予測値を算出する. まず,以下に対象データストリームの予測値を得るための手順を示す. Step1::::相相相相関クラスタ関クラスタ関クラスタの検索関クラスタの検索の検索 の検索 相関マップを参照し,対象ストリームと最も相関の強いクラスタを他の Stream の最近のクラスタから検索する.検索結果を相関クラスタとする. Step2::::更新更新更新更新予想クラスタ予想クラスタ予想クラスタの検索予想クラスタの検索の検索の検索 クラスタ更新テーブルを参照し,相関クラスタからの連続更新回数が最も多い クラスタを検索する.検索結果を更新予測クラスタとする. Step3::::予想クラスタ予想クラスタ予想クラスタ予想クラスタの検索の検索の検索 の検索 相関マップを参照し,対象ストリームのクラスタの中で更新予想クラスタと最 も相関があるクラスタを検索する.これを予測クラスタとする. Step4::::トレンドの検索トレンドの検索トレンドの検索トレンドの検索と予測値の算出と予測値の算出と予測値の算出と予測値の算出 予測クラスタから対応する DWT 結果を検索 それぞれの手順について説明する。前提条件として,StreamA,B,C が計測中であり, その中で StreamA を予想対象とする.それぞれのデータストリームの最新の部分シー ケンスから検出された更新クラスタは表 4 のようになっており,相関マップは表 5 の ようになっている.また,データストリーム C のクラスタ更新テーブル表 6 のように なっている. 表 4 各データストリームの最新の更新クラスタ StreamA Cluster2(A2) StreamB Cluster2(B2) StreamC Cluster3(C3) 表 5 相関マップの前提条件 表 6 データストリーム C のクラスタ更新テーブル 4.7.1 相関パターンの検索相関パターンの検索相関パターンの検索相関パターンの検索 まず,表 5 の相関マップを参照し,表 4 の各クラスタにおける相関値を確認する. 予測対象としたデータストリームの最新の更新クラスタと,他のデータストリームの 最新の更新クラスタとの間の相関値の中で,最も相関値の大きいものを検出する.そ して,その最新の更新クラスタを相関クラスタとする.この様子を図 8 に示す.予測 対象としたデータストリームを ST,それ以外のデータストリームを SOとし,それぞ れ仮に SO1 ,SO2...と表記する.また,表 2 に示した最新の更新クラスタを LC とす
る.また,相関クラスタを Ccorr (Correlation Cluster)と表記する.i はクラスタの番
号を示す,
この場合,予測対象データストリームは StreamA であるため,A2 における, StreamB,C の最新の更新クラスタとの関係性について参照する.A2 行,B2,C3 列の 値を参照し,値が大きい方のクラスタと相関が強いと判断する.cluster correlation (A2,B2)= 20,cluster correlation(A2,C3)= 45 であるため,C3 が相関クラスタとし て選出される.
Stream A Stream B Stream C
A1 A2 A3 B1 B2 B3 C1 C2 C3 Stream A A1 11 29 15 10 10 35 A2 20 20 15 5 5 45 A3 9 8 38 50 1 4 Stream B B1 11 20 9 4 6 45 B2 29 20 8 17 18 20 B3 15 15 38 30 20 5 Stream C C1 10 5 50 4 17 30 C2 10 5 1 6 18 20 C3 35 45 4 45 20 5 更新シーケンス 更新回数 更新シーケンス 更新回数 更新シーケンス 更新回数 C1→C1 21 C2→C1 19 C3→C1 22 C1→C2 1 C2→C2 11 C3→C2 2 C1→C3 1 C2→C3 13 C3→C3 3
図 8 相関クラスタの検索 4.7.2 更新予測更新予測更新予測更新予測クラスタクラスタクラスタクラスタの検索の検索の検索の検索 相関クラスタのデータストリームに対応するクラスタ更新テーブルを参照し,相関 クラスタに対する更新シーケンスの更新回数の中から最も回数の多いものを更新予測 クラスタとして選出する.この様子を図 9 に示す.ここで,更新予測クラスタを Cupdate とする.j はクラスタの番号を示す. 図 9 更新予測クラスタの検索 この場合,C3 が相関クラスタであるため,StreamC のクラスタ更新テーブルである 表 6 を参照する.シーケンス更新回数から,C3 の後は C1 を更新することが一般的で あると考えられる.よって,C1 が更新予測クラスタとして選出される. 4.7.3 予測予測予測予測クラスタクラスタクラスタクラスタの検索の検索の検索の検索 相関マップを参照し,予測対象データストリームの中から更新予測クラスタとの相 関値が最も大きいクラスタを予測クラスタとする.この様子を図 10 に示す.このとき, Cpredictを更新予測クラスタとする.k はクラスタの番号を示す, 図 10 予測クラスタの検索 この場合, StreamA の中から,更新予測クラスタに対して最も相関の強いクラスタ を検索する.(C1,A1)= 10,(C1,A2)= 5,(C1,A3)= 50 であるため,(C1,A3)の項 が最も大きい.そこで,StreamA の予測クラスタは A3 となる. 4.7.4 トレンドの検索と予測値の算出トレンドの検索と予測値の算出トレンドの検索と予測値の算出トレンドの検索と予測値の算出 予想クラスタである A1 の代表パターンを検索し,対応した StreamA.dwt をデータ ベースから検索する.離散ウェーブレット変換は逆変換することによって元のデータ を復元可能であるため,これを用いて実際のデータストリームの予測値を算出する. 4.8 データストリームとデータストリームとデータストリームと予測データストリームと予測予測クラスタの関係予測クラスタの関係クラスタの関係クラスタの関係 本提案方式は 4.7 節のように,単一のデータストリームの更新のために,別のデー タストリームとの相関関係とその前後関係を利用している.この 2 つのデータストリ ームの関係を図 11 に示す. 図 11 StreamA と StreamC の関係 ここで,クラスタそれぞれは部分シーケンスと対応しているものとし,太い点線は 現在時刻を表すとする.予測処理の流れを見ると,StreamA の予測を行うために一度 (ST.LC, SO1.LC) (SOi.LC) Ccorr (ST.LC, SO2.LC) … (ST.LC, SOi.LC)群から最大値を検索 そのときのSOi.Lcを引き出す
cluster correlation max
Sq(Ccorr→C1) Cj Cupdate Sq(Ccorr→C2) … Sq(Ccorr→Ci)群から最大値を検索 そのときのCjを引き出す sequence correlation max
(C
update, S
T.C
1)
S
T.C
kC
predict(C
update, S
T.C
2)
(C
update, S
T.C
k)群から最大値を検索
そのときの, S
T.C
kを引き出す
max
…
cluster correlation
予測クラスタ StreamA StreamC w(m) w(m-1) w(m-2) w(m+1) 相関クラスタ 更新予測クラスタ :予測の流れ 相関マップを検索 クラスタ更新テーブル を検索 相関マップを検索 予測対象に 決定 StreamBStreamC に移動し,そこから再び StreamA に戻っていることがわかる.Stream の移動 には相関マップが利用され,部分シーケンス間の移動にはクラスタ更新テーブルが利 用されている. また,本提案方式で予測するのはデータそのものではなく,クラスタからもたらさ れる部分シーケンスである.StreamA の最新シーケンスである m 番目の部分シーケン スを StreamA.w(m)とすると,予測クラスタからもたらされる部分シーケンスは StreamA.w(m+1)となる.この部分シーケンスが予測する範囲は 4.2 節において説明し た部分シーケンス長 p と同じであり,このシーケンス長とデータレートの関係から, 予測結果の時間範囲が決定される. 4.9 提案システム提案システム提案システムの機能・構成提案システムの機能・構成の機能・構成 の機能・構成 本提案方式を受けた提案システムに求められる機能は以下となる. (1). データストリームの受信 (2). DWT 処理 (3). DWT 用データの一時保存 (4). DWT 結果からの特徴量抽出とクラスタリング (5). DWT 結果の蓄積 (6). パターンの蓄積 (7). 相関マップの作成と更新 (8). クラスタ更新テーブルの作成と更新 (9). 予測処理 (10). アプリケーションからの問い合わせ処理 (11). センサデータの蓄積 これらを反映した結果となるシステム全体図を図 12 に示す.矢印はデータや問い合 わせの流れを示す.白枠は当該処理を行うモジュールを意味し,灰色の枠はデータベ ース機能を利用した保存データを意味する.まず,DSMS 部がデータストリームの受 信を行う.受信したデータは,DWT のために一時データストレージに保存されると 同時に,DBMS 部のデータストレージにも保存される.DWT 処理部は一定時間ごと に一時データストレージに保存されているデータストリームに対して DWT を実行し, その結果を DBMS 部に送信する.DBMS 部は受信した DWT 結果から特徴量を抽出し, クラスタリングを行う.その後,相関マップとクラスタ更新テーブルの更新処理を行 う. アプリケーションがデータストリームの予測結果を利用しようとする場合は DBMS 部に問い合わせを行い,問い合わせを契機として予測処理が実行される.今回はデー タストリームの予測処理についての提案であるため,問い合わせ形式についての設計 は行っていない. 図 12 提案システムの詳細
5.
評価評価 評価評価 5.1 環境基本評価実験環境基本評価実験 環境基本評価実験環境基本評価実験 提案方式によって相関の検出が可能と考えられる実環境について,Sun Microsystems 製の小型無線センサデバイスである SunSPOT[16]を利用して調査した.SunSPOT は温 度と照度,加速度のセンサを持ち,自動的に ZigBee によるセンサネットワークを形成 し,センサデータの計測と配送を行う機能を持つ.大学の構内に SunSPOT を設置し, 10 分間隔で 24 時間に渡って温度と照度の計測を行うよう設定した.図 13 に,あるセ ンサの 5 月 10 日から 11 日の温度と照度の変化を示す.さらに,同日の大学に一番近 いアメダス観測点の気温データを気象庁のサイト[17]から取得し,その結果を図 13 に 示している.左の縦軸が照度値,右の縦軸が温度値を示している.横軸は時刻である. SunSPOT の照度データとアメダスの気温データに着目すると,照度が上昇すると, 気温も同様に上昇する傾向にあることが見て取れる.よってこの 2 つのデータストリ ームの間には相関の関係があると考えられる.逆に,SunSPOT の温度データと照度デ ータを比較すると,5 月 10 日においては気温の上昇と照度の上昇が関係しているよう に見えるが,5 月 11 日のデータを見ると必ずしもその傾向にはないことがわかる. 今回計測したデータストリームは 24 時間の周期性を持っていると考えられるがこ (1).データストリーム 受信処理部 (3).DWT用データの一時保存 (4).パターン抽出 クラスタリング処理部 (2).DWT処理部 (5).DWT結果の蓄積 (6).パターンの蓄積 (7).相関マップ処理部 (8).パターン遷移テーブル 処理部 (9).予測処理部 DSMS DBMS (11).センサデータの蓄積 センサネットワーク センサネットワークセンサネットワーク センサネットワーク データストリーム センサデータ & DWT結果 予測結果 (10).問い合わせ処理部 コンピュータ コンピュータ コンピュータ コンピュータ ( (( (アプリケーションアプリケーションアプリケーションアプリケーション)))) 予測問い合わせのようなデータがある一定周期で計測される環境下の場合,提案システムに数周期間 のデータストリームを蓄積し相関マップを作成することで,これらの相関を把握する ことが可能と考えられる. 図 13 5 月 10~11 日の計測結果 5.2 提案システムの特徴提案システムの特徴 提案システムの特徴提案システムの特徴 本提案方式の長所は,複数データストリーム間の相関を検出可能であることにある. 加えて,相関検出処理を行列の検索によって行うことで,低いコストで処理が可能に なると見込まれる.また,部分シーケンスから検出したパターンに対してクラスタリ ングを行うことで,検索コストの低減を図っている. それに対して本提案方式の課題には, BRAID とは異なり,相関を検出できるデー タストリーム間の遅延時間が固定であることが挙げられる.これはクラスタ更新テー ブル中のパターン遷移数が 1 回で固定であることが原因である.更新シーケンスサイ ズを増加することで対応可能ではあるが,その場合クラスタ更新テーブルのデータサ イズが肥大化することで処理時間に大きな影響が発生するのではないかと考えられる. 実装による調査検討を行い,解決する方針である.
6.
まとめまとめと今後の課題まとめまとめと今後の課題と今後の課題と今後の課題 本稿では複数のセンサからもたらされるデータストリームが存在する環境下にお ける,データストリーム間の相関を考慮した予測処理を行う手法とその実装形態を 示した.また,本提案方式を用いることで相関の検出が可能と考えられる実環境に ついての考察を行った.今後は実際に実装を行い,提案方式の有効性を調査すると 共に,5.2 節で挙げた問題点への対策を行うことが課題となる. 参考文献 参考文献参考文献 参考文献 [1] 櫻井保志, “時系列データのためのストリームマイニング技術”, 情報処理, Vol47, No.7, pp.755-761 (2006). [2] 有村 博紀, 喜田 拓也, “データストリームのためのマイニング技術”, 情報処理, Vol.46, No.1, pp.4-11 (2005). [3] 藤原 靖宏, 櫻井 保志, 山室 雅司, “大量データストリームの類似探索手法”, 日 本データベース学会論文誌, Vol.4, No. 4, pp.13-16 (2006).[4] A.C. Gilbert, Y. Kotidis, S. Muthukrishnan, and M. Strauss, “Surfing Wavelets on Streams: One-Pass Summaries for Approximate Aggregate Queries,” Proceedings of the 27th International Conference on VLDB, pp. 79-88 (2001). [5] 櫻井保志, “データストリームにおける遅延相関の検出”, 情報処理学会 データベ ース・システム研究会報告, Vol.2005, No.68, p.405 (2005). [6] 白石陽 , “センサ ネッ トワ ークの ための データ ベース 技術”, 情 報処理 , Vol.47, No.4,pp.387-393 (2006). [7] 荒井健次, 白石陽, 高橋修, “時系列補間クエリのためのセンサデータベースシス テムの設計と実装”, 第 72 回 情報処理学会全国大会 (2010). [8] 櫻井保志, Faloutsos Christos, 山室 雅司, “ダイナミックタイムワーピング距離に 基づくストリーム処理”, 電子情報通信学会論文誌.D 情報・システム, Vol.J92-D, No.3, pp.338-350 (2009). [9] 豊田 真智子, 櫻井 保志, 市川 俊一, “ダイナミックプログラミングに基づくス トリームマッチング”, 情報処理学会研究報告.データベース・システム研究会報告, Vol.2008, No.88, pp.277-28 (2008). [10] 豊田 真智子, 市川 俊一, 櫻井 保志, “タイムワーピングを考慮したトレンド検 0 5 10 15 20 25 30 35 0 100 200 300 400 500 600 700 800 SunSPOTの気温データ [℃] [lx] アメダスの気温データ SunSPOTの照度データ
出”電子情報通信学会技術研究報告. DE データ工学, Vol.107, No.131, pp.37-4 (2007). [11] 川島英之, 遠山元道, 今井倫太, 安西祐一郎, “波形特徴を用いた類似シーケンス 検索”, 情報処理学会研究報告. データベース・システム研究会報告, Vol.2002, No.67, pp.529-534 (2002). [12] 菅原康太, 白石陽, 高橋修, “3 軸加速度センサと PWM 制御振動モータを用い たユーザ行動と携帯電話接触物体の同時推定”, 第 17 回 マルチメディア通信と分散処 理ワークショップ論文集, pp.25-30 (2009).
[13] S. Papadimitriou, A. Brockwell, and C. Faloutsos, “Adaptive, hands-off stream mining,” Proceedings of the 29th international conference on VLDB, pp.560-571 (2003).
[14] Y. Sakurai, S. Papadimitriou, and C. Faloutsos, “BRAID: stream mining through group lag correlations,” Proceedings of the 2005 ACM SIGMOD, pp.599-610 (2005).
[15] Y. Zhu and D. Shasha, “StatStream: statistical monitoring of thousands of data streams in real time,” Proceedings of the 28th international conference on VLDB, pp.358-369 (2002). [16] Sun Microsystems, “Sun SPOT 無 線セン サーネ ット ワー クデバ イス ”, HTML, Available at “http://jp.sun.com/products/software/sunspot/”
[17] 気 象 庁 , “ 気 象 庁 Japan Meteorological Agency ” , HTML, Available at “http://www.jma.go.jp/jma/menu/report.html”