統計的検定における多重比較に関する一考察
名古屋大学 古橋 武A Study on Multiple Comparisons in Statistical Test
Nagoya University Takeshi Furuhashi
1 はじめに 多重比較は研究者にとって間違いやすく,いさ さかならずややこしい問題である.本稿は統計的 検定における多重性の問題について,全て Excel のシミュレーションによる具体例を紹介しながら, 多重比較法の基本的な考え方を解説する.シミュ レーションは Excel2007 を用いている.本稿中の Excel ファイルは全て次の URL よりダウンロード できる. http://www.echo.nuee.nagoya-u.ac.jp/~furuhasi/educat ion/multiple_comparison/index.html 多重比較法の進展は,各手法が提案された順序 を無視すれば,FWER = αを確保しながら,いかに して閾値を緩めるか,という観点から見ることが できる.シダックの方法は事象間が独立であると して閾値を決定している.テューキーの方法は, 事象間に相関がある検定において,閾値を緩めて いる.下位検定法(ヘイター・フィッシャー方法)は上位検定 法(分散分析)よりもデータ群数を1 つ減らして 閾値を決定でき,閾値を緩められる.ホルムの方 法では,この考えを推し進めて,データ群数を 1 つずつ減らしながら下位検定を繰り返すことで, 閾値のさらなる緩和を実現している.FDR は FWER とは異なる新しい発想で,閾値の大幅緩和 に成功している.本稿では,これらの手法をシミュレ ーション例を付して紹介する.本稿の最後では,多重 比較法を深く理解するための課題を提示する. 2 多重性の問題 帰無仮説が正しかったのに棄却してしまう過誤 は第 1 種の過誤と呼ばれる.逆に対立仮説が正し かったのに帰無仮説を棄却しない確率は第 2 種の 過誤と呼ばれる.通常,統計的検定は第1 種の過 誤の確率を有意水準以下とする. 図 2.1は1 つの組の中でステューデントの t 検 定を2 回繰り返すことを 1000 組について実施する シ ミ ュ レ ー シ ョ ン 画 面 の 抜 粋 で あ る . 図 説 の xxx.xlsm はこのシミュレーション用の Excel のフ ァイル名である.多重比較とは1 つの組の中で検 定を複数回繰り返すことである.図の例では,独 立な事象X1,X2の母分散をそれぞれµ1,µ2とする と,帰無仮説H1, H2を 𝐻𝐻1: 𝜇𝜇1= 𝜇𝜇0 𝐻𝐻2: 𝜇𝜇2= 𝜇𝜇0 (2.1) としている.ここで,帰無仮説H1, H2はファミリ ーと呼ばれる.多重比較におけるFamily-wise Error Rate (FWER)は FWER = 𝑃𝑃𝑃𝑃 {𝑉𝑉 ≥ 1} (2.2) と定義される.V は帰無仮説のファミリーの中で 図2.1 ステューデントのt 検定を2回繰り返 すことを1000組実施するシミュレー ションの画面 (t検定(2事象)のシミュレーション .xlsm)
る確率である. 各事象のサンプルサイズn = 9 である.セル B7 ~B15 に事象 X1の第1 組のサンプル値が計算され ている.各サンプル値はNORMDIST(RAND(), µ0, σ0)関数により平均µ0,標準偏差σ0の正規乱数が生 成されている.µ0とσ0はセルB4, C4 にてそれぞれ 1 に指定されている.セル B16 で平均値 𝑥𝑥̅1が,セ ルB17 で不偏分散𝑣𝑣𝑒𝑒2が計算されている.セルB18 では 𝑡𝑡1= 𝑥𝑥̅1− 𝜇𝜇0 �𝑣𝑣𝑒𝑒2/𝑛𝑛 (2.3) により検定統計量が計算されている.この t 値は 自由度8 (= n - 1)の t 分布に従うことが知られてい る.また,セルB19 では TDIST(t, n-1, 2)関数によ り両側検定の場合のp 値が求められている.ここ で,3 番目の引数の 2 は両側検定の指定である. セルB20 では p 値がセル F4 の有意水準を下回っ た場合に1 が出力される.この例では,セル B20 が1 であるので,第 1 組の事象 X1の帰無仮説H1 は棄却されている.サンプルはµ0とσ0に従った正 規乱数であるので,正しい帰無仮説が棄却された ので,ここで第1 種の過誤が起きている. C 列のセル C6~C20 では事象 X2の 9 個のサン プルに対して t 検定が実施されている.セル B21 ではB20,C20 の少なくともいずれかで 1 となっ た場合に1 が出力される.これが 1 であれば,帰 無仮説のファミリーの中で第1 種の過誤が起きた ことを意味する. この Excel ファイルではセル B5~C21 を横に 1000 組コピーしてある.セル B23 では第 21 行目 の中の1 の数を数えて,全体の組数 1000 で割り, 第1 種の過誤の起きた頻度が求められている.そ れぞれの検定における閾値をαとすると 2 重の検 定の場合のFWER は FWER = 1 − (1 − α)2 (2.4) となる.セルF4 にてα = 0.05と設定されているの ンでは確率的ゆらぎが大きいので,この1000 組の シミュレーションを100 回繰り返すマクロを作成 して,第1 種の過誤の確率の平均値を求め,その 95%信頼区間を計算した.マクロは当該 Excel フ ァイルのメニューバーの「開発」→「マクロ」→ 「実行」とクリックすることで実行できる.マク ロの中身は「実行」の代わりに「編集」をクリッ クすることで見ることができる.結果を第26 行目 に示す.第1 種の過誤の確率の真値が 95%の確率 で0.0959~0.1003 の範囲内にあることが分かる. 図 2.2は,独立な事象X1, X2の場合のt 分布の 結合確率密度関数の鳥瞰図(同図(a))と等高線を 描いた平面図(同図(b))である.ステューデント のt 検定において,両側検定の場合,p 値 = 0.05 に対応する検定統計量t = 2.306 である.図 2.3は 図2.2 において,|t| > 2.306 の領域を示す.鳥瞰図 では|t| < 2.306 の領域の値を 0 としている.|t| > 2.306 の領域は小さな山として残っている.平面図 図2.2 独立な事象X1, X2の 場合のt 分布の 結合確率密度関数 (a) 鳥瞰図 (b) 平面図 t1 t2
図2_2では|t| > 2.306 の領域を黒く塗ってある.第 1 種の過誤の確率は|t| > 2.306 の領域の体積で与え られる.この体積が0.0975 である. このように1 つの組の中で検定を複数回繰り返 すことで,第 1 種の過誤が有意水準αを超えてし まう問題が多重性の問題と呼ばれる. 3 多重比較法[1, 2, 3] 多重比較法は,有意水準をαとすると FWER ≤ α (3.1) とする手法である. 3.1 シダックの方法[4] 同じ組の中で検定を 2 回繰り返す例を取りあげ る.事象X1, X2は独立とする.帰無仮説のファミ リーは 𝐻𝐻𝑖𝑖:𝜇𝜇𝑖𝑖 = 𝜇𝜇0 𝑖𝑖 = 1, 2 (3.2) である.(2.4)式において,FWER = 0.05 とする閾 値をα'とすると α′= 1 − (1 − FWER)12 = 0.0253 (3.3) と求められる.α' は名義水準と呼ばれる.シダッ クの方法は,各検定のp 値が名義水準 α' を下回 った場合に帰無仮説を棄却する.この方法は, FWER = α を保証する. 図 3.1 はシダックの方法により 2 重の検定を 1000 組実施するシミュレーション画面の抜粋で ある.図2.1 との違いは,各検定における p 値の 閾値をセルG4 にて名義水準 α' = 0.0253 としてい る点だけである.第20 行目の各セルでは,p 値が α' を下回った場合に 1 が出力されている.第 26 行目より,FWER = 0.05 となる結果が得られてい る. 図 3.2は図2.3 と比較すると,閾値 ta' = 2.743 と して,黒塗りの部分を狭くしてある.この|t| > |ta'| の領域が,事象X1, X2の少なくとも一方において 検定統計量の|t|値が閾値を超えた場合に,対応す る帰無仮説を棄却する領域である.この領域の体 積を0.05 (= FWER) としている. なお,ボンフェローニの方法はシダックの方法 の簡略法である.同じ組の中でN 回検定を繰り返 す場合は α′= FWER/𝑁𝑁 (3.4) とする.ボンフェローニの方法は(3.3)式をN 回検 定を繰り返す場合に拡張した場合と較べて 図2.3 t 検定を2重に繰り返す場合の第1 種の過誤の領域(tα= 2.306) tα -tα tα -tα (a) 鳥瞰図 (b) 平面図 t1 t2 図3.1 シダックの方法による 検定を1000 組実施するシミュレーションの画 面 (シダックの方法(2事象)のシミュレーション.xlsm)
FWER/𝑁𝑁 < 1 − (1 − 𝐹𝐹𝐹𝐹𝐹𝐹𝐹𝐹)1/𝑁𝑁 (3.5) が常に成立する.計算機が身近になかった時代に は便利な方法であった. 3.2 テューキーの方法[5] 前節の例では,検定対象である事象X1, X2の平 均値は独立であった.検定の課題には各事象の母 平均の差の検定がある.帰無仮説のファミリーを 𝐻𝐻12:𝜇𝜇1= 𝜇𝜇2 𝐻𝐻13:𝜇𝜇1= 𝜇𝜇3 𝐻𝐻23:𝜇𝜇2= 𝜇𝜇3 (3.6) とする.事象X1, X2, X3が互いに独立であっても, 平均値の差𝑋𝑋�1− 𝑋𝑋�2, 𝑋𝑋�1− 𝑋𝑋�3, 𝑋𝑋�2− 𝑋𝑋�3には従属関係 がある. の平均値の差についてt 検定を 3 回繰り返すこと を,1000 組実施した場合のシミュレーション結果 で あ る . セ ル B19, C19, D19 でそれぞれ𝑥𝑥̅1− 𝑥𝑥̅2, 𝑥𝑥̅1− 𝑥𝑥̅3, 𝑥𝑥̅2− 𝑥𝑥̅3が計算されている.セル B20, C20, D20 の検定統計量 qij (i, j = 1, 2, 3, 𝑖𝑖 ≠ 𝑗𝑗)は次 式による. 𝑞𝑞𝑖𝑖𝑖𝑖= �𝑥𝑥� − 𝑥𝑥𝚤𝚤 ��/�2𝑣𝑣𝚥𝚥 𝐸𝐸2/𝑛𝑛 (3.7) ただし,𝑣𝑣𝐸𝐸2は各事象の不偏分散の平均値であり, 平均平方と呼ばれる.検定統計量qijは,データ群 数(事象の数)をN, 各事象のサンプルサイズを n とすると,自由度 ν = 𝑁𝑁(𝑛𝑛 − 1) (3.8) のt 分布に従う.図 3.3 の例では N = 3, n = 9 であ る.セルF4 の閾値 q0は,TINV(α, N(n-1)) (ただし, α = 0.05)によって求められた値である.もし,平 均値の差𝑋𝑋�1− 𝑋𝑋�2, 𝑋𝑋�1− 𝑋𝑋�3, 𝑋𝑋�2− 𝑋𝑋�3が互いに独立で あれば,(2.4)式を参考に,FWER=0.143 となると 期待されるが,これらには従属関係があるため, FWER の 95%信頼区間は 0.1152~0.1198 と得られ ている. 図 3.4はN = 3, n = 9 のデータを 1 千万組生成し て,q12値とq13値の分布を求めた結果である.q12値 と q13値の結合確率密度関数の鳥瞰図と平面図であ る.図中の縞模様は等高線である.q12と q13は独立 ではないため結合確率分布は楕円形状となっている. テューキーの方法は,検定統計量 |qij| の最大値 qmax の確率分布から, FWER = 𝑃𝑃{𝑞𝑞𝑚𝑚𝑚𝑚𝑚𝑚≥ 𝑞𝑞𝑚𝑚𝑚𝑚𝑚𝑚0} = 𝛼𝛼 (3.9) とする閾値qmax0を与える.α = 0.05 のとき qmax0 はステューデント化された範囲の 5%点と呼ばれ る.qmax0 は解析的には求められないため[1][3],数 値計算により求められた数表が作成されている. このステューデント化された範囲の 5%点の数表 よりN = 3, ν =24 のとき 𝑞𝑞𝑚𝑚𝑚𝑚𝑚𝑚0= 3.532/√2 = 2.498 (3.10) と与えられる.図 3.5はこの閾値により第1 種の 過誤が起きる領域を黒く塗りつぶして示す.実際 にはq23値の軸を加えた 4 次元空間内の黒色部分の 図3.2 シダックの方法(tα’= 2.743) tα’ - tα’ tα’ - tα’ t1 図3.3 平均値の差の検定(3事象,多重比較を 考慮せず)を1000組実施するシミュレーション (平均値の差の検定(3事象)シミュレーション.xlxm)
超体積が 0.05 (=FWER)となる.なお,数表の値を 1/√2倍して用いるのは,数表が作られた歴史的経 緯によるようである. 図 3.6 はテューキーの方法による検定を 1000 組実施するシミュレーション結果である.図 3.3 との違いは,セルF4 に qmax0の値が与えられた点 だけである.第21 行目にて(3.7)式のqijの絶対値 がqmax0の値を超えた場合に,その平均値の差に有 意差有りとしている.27 行目に求められているよ うに,FWER ≈ 0.05 が得られている. 4 上位検定と下位検定 N 重比較の FWER = αとする閾値は,N が大き くなるとともに厳しくなり,仮説の有意差が出に くくなる.上位検定・下位検定と呼ばれる手法が あるが,これを閾値緩和の視点で見ていく. 4.1 分散分析(上位検定)[6] 一元配置の分散分析について紹介する.帰無仮 説のファミリーを 𝐻𝐻123:𝜇𝜇1= 𝜇𝜇2= 𝜇𝜇3 (4.1) とする.このとき対立仮説は 対立仮説:𝜇𝜇1≠ 𝜇𝜇2 or 𝜇𝜇1≠ 𝜇𝜇3 or 𝜇𝜇2≠ 𝜇𝜇3 (4.2) である.帰無仮説H123を棄却できる場合,対立仮 説のいずれかが有意であることが分かるが,どれ であるかは下位検定を実施しなければ分からない. 分散分析の検定統計量F は,データ群数が N, 各群のサンプルサイズが等しくn である場合 𝐹𝐹 =𝑆𝑆𝑆𝑆𝐴𝐴/(𝑁𝑁 − 1) 𝐸𝐸/(𝑛𝑛(𝑁𝑁 − 1)) (4.3) により与えられる.このF 値は自由度 N -1, n (N - 1)の F 分布に従う.ここで, 𝑆𝑆𝐴𝐴= � 𝑛𝑛(𝑥𝑥̅𝑖𝑖− 𝑥𝑥̅)2 𝑁𝑁 𝑖𝑖=1 𝑆𝑆𝐸𝐸= � ��𝑥𝑥𝑖𝑖𝑖𝑖− 𝑥𝑥̅𝑖𝑖�2 𝑛𝑛 𝑖𝑖=1 𝑁𝑁 𝑖𝑖=1 (4.4) 図3.4 平均値の差の q 値の結合確率密度関数 q q (a) 鳥瞰図 (b) 平面図 q12 q13 図3.5 テューキーの方法(qmax0= 2.498) qmax0 - qmax0 qmax0 - qmax0 q12 q13 図3.6 テューキーの方法(3事象)を1000組実 施するシミュレーション (テューキーの方法(3事象)のシミュレーション.xlsm)
であり,SA, SEはそれぞれ水準間変動,水準内変動 と呼ばれる.𝑥𝑥̅は全体の平均値,𝑥𝑥̅𝑖𝑖はデータ群i の平 均値である. 図 4.1は分散分析による検定を1000組実施する シミュレーションの画面の抜粋である.N = 3,帰 無仮説が(4.1)式の場合である.セル B18, B19 で (4.4)式のSA, SEがそれぞれ計算され,セルB20 で (4.3)式のF 値が求められている.セル B21 では, このF 値から FDIST()関数により求められる p 値 がセル F4 に入力された有意水準を下回った場合 に1 が出力される.このとき帰無仮説 H123が棄却 される.第26 行目の 95%信頼区間より,FWER ≈ 0.05 であることが分かる. 4.2 ヘイター・フィッシャーの方法(下位検定)[7,8] 分散分析の結果,帰無仮説が棄却された場合, どの対立仮説が有意であるかを調べるのが下位検 定である.下位検定法にヘイター・フィッシャー の方法[7]がある.これは,データ群数がN で,各 群のサンプルサイズが等しい場合,データ群数N' = N - 1 と 1 つ減らしてテューキーの方法を適用す る方法である.元のデータ群数N = 3 の場合にの み適用できる下位検定法にフィッシャーの PLSD 法[8]があるが,ヘイター・フィッシャーの方法は 理由は次のように説明される.例えば4 群の場合 で各群の母平均がµ1 >> µ2, µ3, µ4であったとする. これらの平均値の差により,上位検定では有意差 有りとなる.このとき注意すべきは,µ2 - µ3, µ2 - µ4, µ3 - µ4については「検定されずに」下位検定に渡 されることである.そこで,下位検定ではデータ 群数N' = 4 ではなく,N' = 3 として,µ2 - µ3, µ2 - µ4, µ3 - µ4について多重性を考慮した検定を行えば十 分である.なお,µ1 - µ2, µ1 - µ3, µ1 - µ4に関しては 検定により有意差有りと出るが,これは正しい結 論であり,第1 種の過誤ではない. N = 4 とする.分散分析の帰無仮説は 𝐻𝐻1234:𝜇𝜇1= 𝜇𝜇2= 𝜇𝜇3= 𝜇𝜇4 (4.5) である.下位検定の帰無仮説のファミリーは 𝐻𝐻12:𝜇𝜇1= 𝜇𝜇2 𝐻𝐻13:𝜇𝜇1= 𝜇𝜇3 𝐻𝐻14:𝜇𝜇1= 𝜇𝜇4 𝐻𝐻23:𝜇𝜇2= 𝜇𝜇3 𝐻𝐻24:𝜇𝜇2= 𝜇𝜇4 𝐻𝐻34:𝜇𝜇3= 𝜇𝜇4 (4.6) である. 図 4.2は4 群の場合の上位検定を分散分析,下 位検定をヘイター・フィッシャーの方法として, 1000 組の検定を実施するシミュレーション画面 の抜粋である.第22 行目までで図 4.1 と同様の分 散分析がなされている.セルB26~E26, B27, C27 にて(3.7)式のq12, q13, q14, q23, q24, q34の値(サンプ ルサイズn = 9, 自由度ν = N(n - 1)= 32)が求められ, セルB28~E28, B29, C29 にてそれぞれセル E24 に 入力されている閾値qmax0 = 2.457 との比較がなさ れている.閾値 qmax0 はステューデント化された 範囲の数表より,データ群数N' = N - 1= 3, 自由度 ν = N(n - 1) = 32 のとき qmax0 =3.475/√2 = 2.457で ある.FWER ≈ 0.05 が達成されている. もし,上位検定を介さずに,4 群に対してテュ ーキーの方法を適用する場合は,数表よりN = 4, ν = 32 のとき qmax0 =3.832/√2 = 2.710であるので, ヘイター・フィッシャーの方法により閾値の緩和 が実現されている. 図4.1 分散分析(3事象)を1000組実施するシ ミュレーション (分散分析(3事象)のシミュレーション.slxm)
4.3 ホルムの方法[9] ホルムの方法は下位検定法として位置づけられ ているわけではないが,前節までの下位検定にお ける閾値緩和の考え方を発展させた方法として位 置づけることができる.すなわち,最も検定統計 量の絶対値の大きいものに多重比較法を適用し, 対応する帰無仮説を棄却できれば,データ群を 1 つ削減して閾値を緩和し,以降同様にして,多重 比較法の適用,対応する帰無仮説の棄却,閾値緩 和を繰り返す方法である. 簡単のため,帰無仮説のファミリーを 𝐻𝐻𝑖𝑖:𝜇𝜇𝑖𝑖= 𝜇𝜇0 𝑖𝑖 = 1, 2, ⋯ , 𝑁𝑁 (4.7) とする.3.1 節に記したボンフェローニの方法に対 して,以下の手順で閾値(名義水準)αth を緩和 する. (1) 帰無仮説 Hiをp 値の小さな順に並べる. 𝑝𝑝𝑖𝑖 ≤ 𝑝𝑝𝑘𝑘≤ ⋯ ≤ 𝑝𝑝𝑙𝑙 1 ≤ 𝑗𝑗, 𝑘𝑘, ⋯ , 𝑙𝑙 ≤ N (4.8) であったとする.i = j, t = N とする. (2) 名義水準αth = α/t とし,𝑝𝑝𝑖𝑖 < 𝛼𝛼𝑡𝑡ℎであれば,Hi を棄却し,(3)へ進む.𝑝𝑝𝑖𝑖 ≥ α𝑡𝑡ℎであれば,(4)へ 進む. (3) t ← t -1 とする.t = 0 であれば,(4)へ進む.(4.8) 式の順に,次に大きいp 値の添え字を i に代入 し,(2)へもどる. (4) 検定を終了する. 図 4.3はデータ群数N = 5, サンプルサイズ n = 9 の場合にホルムの方法を適用して,1000 組の検 定を繰り返すシミュレーション画面の抜粋である. 帰無仮説の数N = 5 である.セル D4 にて,FWER の有意水準 α = 0.05 が入力されている.第 23 行 目にて第21 行目の p 値が小さい順に並べ替えられ ている.セルB24 では,セル B23 の p 値がセル H4 の有意水準α5 = α/5 = 0.05/5 = 0.01 を下回った ので,有意差有りとして1 が出力されている.対 応する帰無仮説H3が棄却されている.もともと帰 無仮説が正しい設定であるので,ここで第1 種の 過誤が起きている.セルC24 ではセル C23 の p 値 がセルG4 の有意水準α4 = α/4 = 0.0125 より大きか ったので,0 が出力されている.結果として帰無 仮説H1, H2, H4, H5は棄却されず,検定が終了して いる.セルB25 では B24~F24 にて 1 回以上 1 が あるときに 1 が出力される.セル B27 では 1000 組の検定において第1 種の過誤が起きた頻度が求 められている.図の例では43 組で第 1 種の過誤が 起きていた. 図4.2 ヘイターフィッシャーの方法(4事象) を1000組実施するシミュレーション (ヘイター・フィッシャーの方法(4事象)のシミュレーション.xlsm) 図4.3 ホルムの方法(5事象)を1000組実施す るシミュレーション (ホルム(5事象)によるシミュレーション.xlsm)
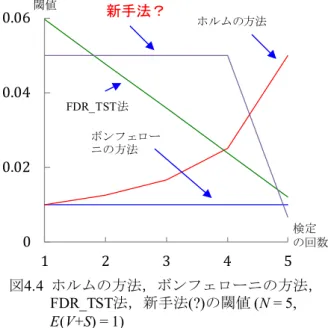
マクロにより,この1000 組の検定を 100 回繰り 返して,第1 種の過誤の確率の 95%信頼区間を求 めた結果が第29 行目に表示されている.FWER ≈ 0.05 である. 図 4.4はホルムの方法とボンフェローニの方法 の閾値αthと検定の回数の関係を示す.ホルムの方 法により,検定の回数とともに閾値が緩和されて いく様子が分かる.他の方法の閾値は後述する. 5 FDR_TST 法[10, 11] 帰無仮説の数が増えると,検定の閾値が厳しく なり,有意差は出にくくなる.FWER を抑えると いう観点では問題ないのであるが,対立仮説の中 に真のものが含まれていても有意差なしとされる 第2 種の過誤の確率が高くなってしまう.ゲノム 解析などでは仮説の数に対してサンプルサイズが 小さく,有意差が出にくいことが問題となってい た.そこで,FWER そのものを見直す考え方とし
てFDR(False Discovery Rate)が提唱されている.
表 5.1は帰無仮説の棄却/保留と第1 種/第 2 種 の過誤の関係を表す.帰無仮説の数N の検定にお いて,帰無仮説が真である場合に帰無仮説を保留 した数が U,棄却した数が V,帰無仮説が偽であ る場合に帰無仮説を保留した数が T,棄却した数 がS である.V は第 1 種の過誤が起きた数であり, T は 第 2 種 の 過 誤 が 起 き た 数 で あ る . N = U+V+T+S の関係がある.また,帰無仮説を棄却 した総数がV+S である.FDR は FDR = 𝐹𝐹(𝑉𝑉/(𝑉𝑉 + 𝑆𝑆)) (5.1) と定義される.E(x)は x の期待値である.FDR は 採択した対立仮説の中に含まれる間違った対立仮 説の比率の期待値である.FDR に基づく検定では FDR ≤ 𝛼𝛼 (5.2) となるように,検定の閾値を緩和し, FWER > α (5.3) となることは許容する.FWER が上式のようであ っても,採択された対立仮説に含まれる誤った対 立仮説の比率が一定値以下であればそれでよしと する,新しい考えに基づく多重検定法である. 5.2 BH 法[10] FDR に基づく検定法の基本的方法は BH 法と呼 ばれる.簡単のため,帰無仮説のファミリーを 𝐻𝐻𝑖𝑖:𝜇𝜇𝑖𝑖= 𝜇𝜇0 𝑖𝑖 = 1, 2, ⋯ , 𝑁𝑁 (5.4) とする.以下の手順で検定を行う.なお,α' は次 節のTST 法では𝛼𝛼1′, 𝛼𝛼2′として与えられる. (BH1) 帰無仮説 Hiをp 値の大きな順に並べる. 𝑝𝑝𝑖𝑖 ≥ 𝑝𝑝𝑘𝑘≥ ⋯ ≥ 𝑝𝑝𝑙𝑙 1 ≤ 𝑗𝑗, 𝑘𝑘, ⋯ , 𝑙𝑙 ≤ 𝑁𝑁 (5.5) であったとする.i = j, t = N とする. (BH2) 名義水準αthを 𝛼𝛼𝑡𝑡ℎ= 𝛼𝛼′𝑡𝑡/𝑁𝑁 (5.6) とし,𝑝𝑝𝑖𝑖 < 𝛼𝛼𝑡𝑡ℎであれば,HiおよびHiよりp 値 の小さな帰無仮説を全て棄却し,(BH4)へ進む. 𝑝𝑝𝑖𝑖≥ α𝑡𝑡ℎであれば,Hiを保留して(BH3)へ進む. (BH3) t ← t - 1 とする.t = 0 であれば,(BH4)へ 進む.(5.5)式の順に,次に小さいp 値の添え字 をi に代入し,(BH2)へもどる. (BH4) 検定を終了する. 図4.4 ホルムの方法,ボンフェローニの方法, FDR_TST法,新手法(?)の閾値 (N = 5, E(V+S) = 1) 0 0.02 0.04 1 2 3 4 5 ボンフェロー ニの方法 FDR_TST法 検定 の回数 帰無仮説を保留 帰無仮説を棄却 計 帰無仮説 真 U 第1種の過誤 V U + V 帰無仮説 偽 第2種の過誤 T S T + S 計 U + T V + S N 表5.1 帰無仮説の保留/棄却と第1/2種の過誤
5.3 TST (Two-stage linear step-up procedure)法[11] BH 法を 2 段階(Two-stage)で適用する方法(TST 法)が提案されている.TST 法は,1 段階目では BH 法をE(V + S)の推定に適用し,2 段階目で FDR ≈ αとする検定を行う.TST 法の手順は以下の通り である. (TST1) 𝛼𝛼1′ = α /(1 + α),として,BH 法を適用する. 棄却された帰無仮説の数をV + S とする.V + S = 0 であれば,(TST4)へ進む.V + S = N であれ ば,全ての帰無仮説を棄却して(TST4)へ進む. 0 < V + S < N であれば,(TST2)へ進む. (TST2) 𝐹𝐹�(𝑉𝑉 + 𝑆𝑆) = V + S として(TST3)へ進む. (TST3) 次式により𝛼𝛼2′を決定し,BH 法を適用する. 𝛼𝛼2′ = 𝛼𝛼1′× 𝑁𝑁/(𝑁𝑁 − 𝐹𝐹�(𝑉𝑉 + 𝑆𝑆)) (5.7) 終了したら(TST4)へ進む. (TST4) 検定を終了する. , 図 5.1はTST 法によるシミュレーション画面の 抜粋である.帰無仮説のファミリーは(5.4)式で, N = 10 である.ただし,10 のデータ群の内,事象 X8, X9, X10はセルD4 の平均値µ1を用いて正規乱数 が生成されている.表5.1 において S = 3 となる設 定である.第24 行目までが(TST1)の計算である. 第 23 行目で(BH1)の並べ替えがなされ,セル F4 にてα = 0.05 と与えられているので,セル G4~K6 にて(5.6)式によりαthが計算されている.第 24 行 目で(BH2), (BH3)の比較がなされ,セル B26 に V + S が得られている.(TST2)にてこの V + S を 𝐹𝐹�(𝑉𝑉 + 𝑆𝑆)としている.セル D26 と第 28, 29 行目で (TST3)が実行されている.セル D26 にて(5.7)式の 計算がなされ,第28 行目で(5.6)式の閾値が求めら れている.第 29 行目で各帰無仮説の p 値と閾値 αthの比較がなされている.第30 行目では,偽の 帰無仮説の数S = 3が分かっているとして,V/(V+S) が計算されている.図の例では1/4 = 0.25 である. 第35 行目の FDR の 95%信頼区間より,少し小さ めではあるがFDR≈ 𝛼𝛼の値が得られている. 図 4.4に帰無仮説のファミリーにおいてN = 5, 𝐹𝐹�(𝑉𝑉 + 𝑆𝑆) = 1 の場合の閾値と検定の回数の関係を 示してある.FDR_TST 法では,ホルムの方法より もさらに閾値の緩和が実現されている. 6 課題 以下のアルゴリズムを考えてみた.帰無仮説のフ ァミリーを 𝐻𝐻𝑖𝑖:𝜇𝜇𝑖𝑖= 𝜇𝜇0 𝑖𝑖 = 1, 2, ⋯ , 𝑁𝑁 (6.1) とする. (1) 帰無仮説 Hiをp 値の大きな順に並べる. 𝑝𝑝𝑖𝑖 ≥ 𝑝𝑝𝑘𝑘≥ ⋯ ≥ 𝑝𝑝𝑙𝑙 1 ≤ 𝑗𝑗, 𝑘𝑘, ⋯ , 𝑙𝑙 ≤ 𝑁𝑁 (6.2) であったとする.i = j, t = N とする. (2) 名義水準αthを 𝛼𝛼𝑡𝑡ℎ= 𝛼𝛼 (6.3) とし,𝑝𝑝𝑖𝑖 < 𝛼𝛼𝑡𝑡ℎであれば,HiおよびHiよりp 値 の小さな帰無仮説を全て棄却し,(5)へ進む. 𝑝𝑝𝑖𝑖≥ α𝑡𝑡ℎであれば,Hiを保留して(3)へ進む. (3) t ← t - 1 とする.t = 1であれば,(4)へ進む. (6.2)式の順に,次に小さいp 値の添え字を i に 代入し,(2)へもどる. (4) 名義水準αth1を 𝛼𝛼𝑡𝑡ℎ1= 𝑁𝑁(1 − 𝛼𝛼) 𝑁𝑁−1𝛼𝛼 + (1 − 𝛼𝛼)𝑁𝑁− (1 − 𝛼𝛼) 𝑁𝑁(1 − 𝛼𝛼)𝑁𝑁−1 (6.4) とする.𝑝𝑝𝑙𝑙 < 𝛼𝛼𝑡𝑡ℎ1であれば,Hlを棄却し,𝑝𝑝𝑙𝑙≥ α𝑡𝑡ℎ1であれば,Hlを保留して(5)へ進む. (5) 検定を終了する. 図5.1 FDR_TST法(N = 10, 1000組)のシミュレー ション (FDR_TST(10群)によるシミュレーション.xlsm)
ステップ(4)は FWER = αとなるように最後の段 階で調整している. 図 6.1はこの新手法(?)により,N = 5 の帰無 仮説のファミリーに対して,1000 組について検定 を実施するシミュレーション画面の抜粋である. セルF6 にてαth1の値が(6.4)式により計算されてい る.ただし,α = 0.05 である.このシミュレーシ ョンでは帰無仮説は全て正しい設定である.第30 行目においてFWER ≈ 0.05 である. 図 4.4にこの新手法(?)の閾値の変化の様子を 書き加えて示す.この手法は,FWER ≈ 0.05 を保 ちながら,閾値の大幅な緩和を実現している??? この手法は致命的な間違いを犯している.理由 は,本稿を前章まで読まれた方にはお分かりいた だけると思いますが,いかがでしょうか? 7 結論 本稿では Excel を用いたシミュレーションによ り多重性の問題を例示し,基本的な多重比較法の 解説を,閾値の緩和の観点から展開した. もとより,本稿ではカバーできなかった多重比 較法がたくさんある.別の機会に報告したい. [1] 広津千尋:「実験データの解析-分散分析を 超えて-」共立出版(1992) [2] 永田・吉田:「統計的多重比較法の基礎」サ イエンティスト社(1997) [3] 古橋武編:「統計・多変量解析とソフトコン ピューティング(改訂版)」共立出版(2014)
[4] N. Salkind(Ed.): BonferroniTest, Encyclopedia of Measurement and Statistics, Vol.1, pp.103-107 (2007)
[5] H. I. Braun(Ed.): The Collected Works of John W. Tukey, Vol. III Multiple Comparisons: 1948--1983, Chapman & Hall (1994)
[6] 石村貞夫:「分散分析のはなし」東京図書 (1992)
[7] A. J. Hayter: The Maximum Familywise Error Rate of Fisher's least Significant Difference Test, J. of American Statistical Association, Vol. 81, No. 396, pp.1000-1004 (1986)
[8] N. Salkind(Ed.): Fisher's LSD, Encyclopedia of Measurement and Statistics, Vol.1, pp.359-360 (2007)
[9] S. Holm: A Simple Sequentially Rejective Multiple Test procedure, Scandinavian J. of Statistics, Vol. 6, No. 2, pp.65-70 (1979)
[10] Y. Benjamini and Y. Hochberg: Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing, J. of the Royal Statistical Society. Series B(Methodological), Vol. 57, No. 1, pp.289-300 (1995)
[11] Y. Benjamini, A. M. Krieger and D. Yekutieli: Adaptive Linear Step-up Procedures that Control the False Discovery Rate, Biometrika, Vol. 93, No. 3, pp. 491-507 (2006) 図6.1新手法(?)(N = 5, 1000組)のシミュレー
ション